
Scalable, High-Performance, and Generalized Subtree Data Anonymization Approach for Apache Spark



Abstract
1. Introduction
- We propose a Resilient Distributed Dataset (RDD)-based subtree generalization implementation strategy for Apache Spark. Our novel approach resolves the existing issues and can provide data anonymization outcomes regardless of any specific subtree implementation approaches (e.g., top-down, bottom-up, or hybrid);
- We clearly demonstrate how our proposal can reduce the complexity of operations and improve performance by the use of effective partition, improved memory and cache management for different types of intermediate values, and enhanced iteration support;
- We show that the proposed approach offers high scalability and performance through a better selection of subtree generalization process and data partitioning compared to the state-of-the-art similar approaches. We achieve high privacy and appropriate data utility by taking into account the data distribution and data processing using in-memory computation.
- Our intensive experiments results demonstrate the compatibility and application of our proposal on various datasets for privacy protection and high data utility. Our approach also outperforms the existing Spark-based approaches by providing the same privacy with minimum privacy loss.
2. Related Work
3. Subtree Generalization
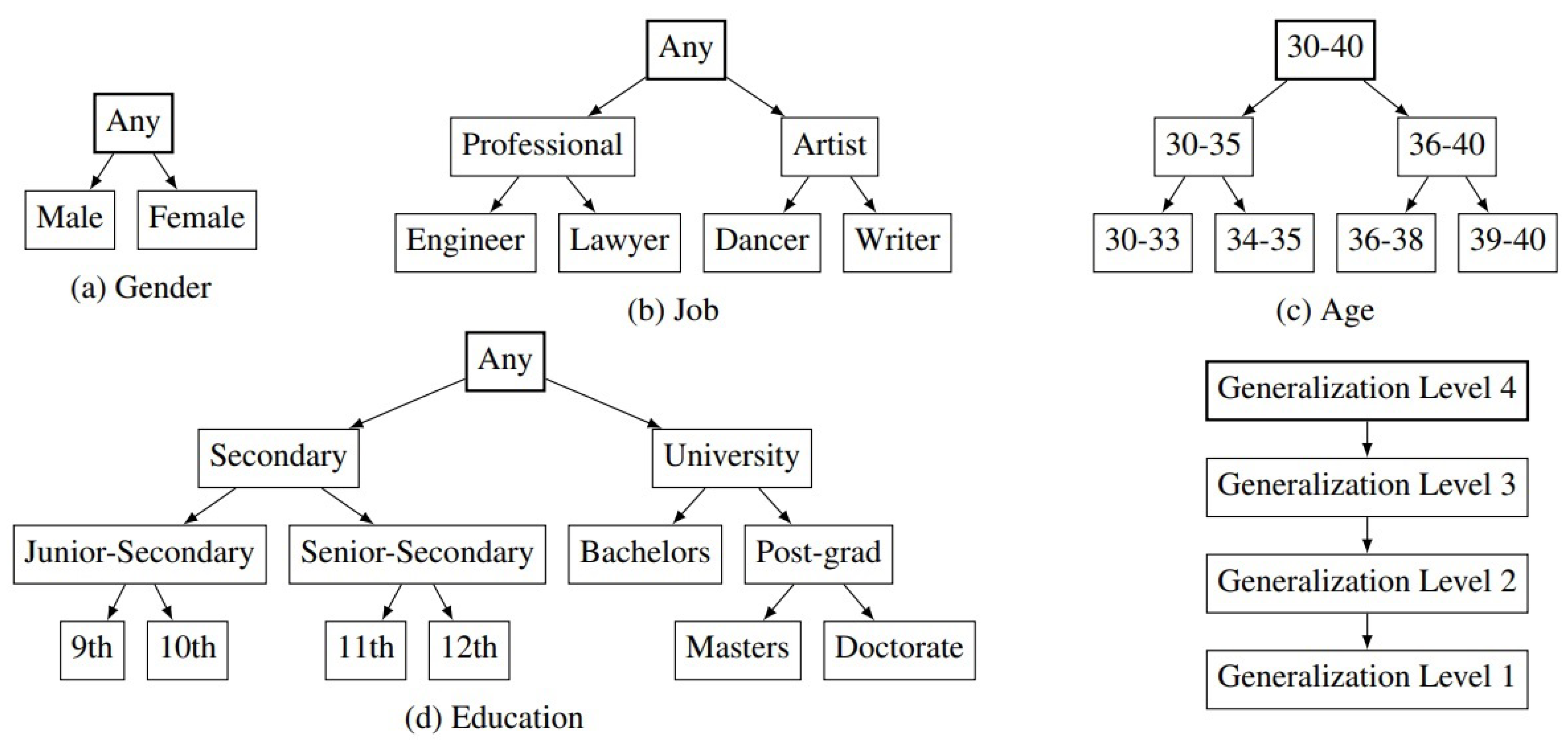
3.1. Preliminaries
3.2. Subtree Generalization Algorithm
| Algorithm 1: Subtree Generalization Algorithm |
 |
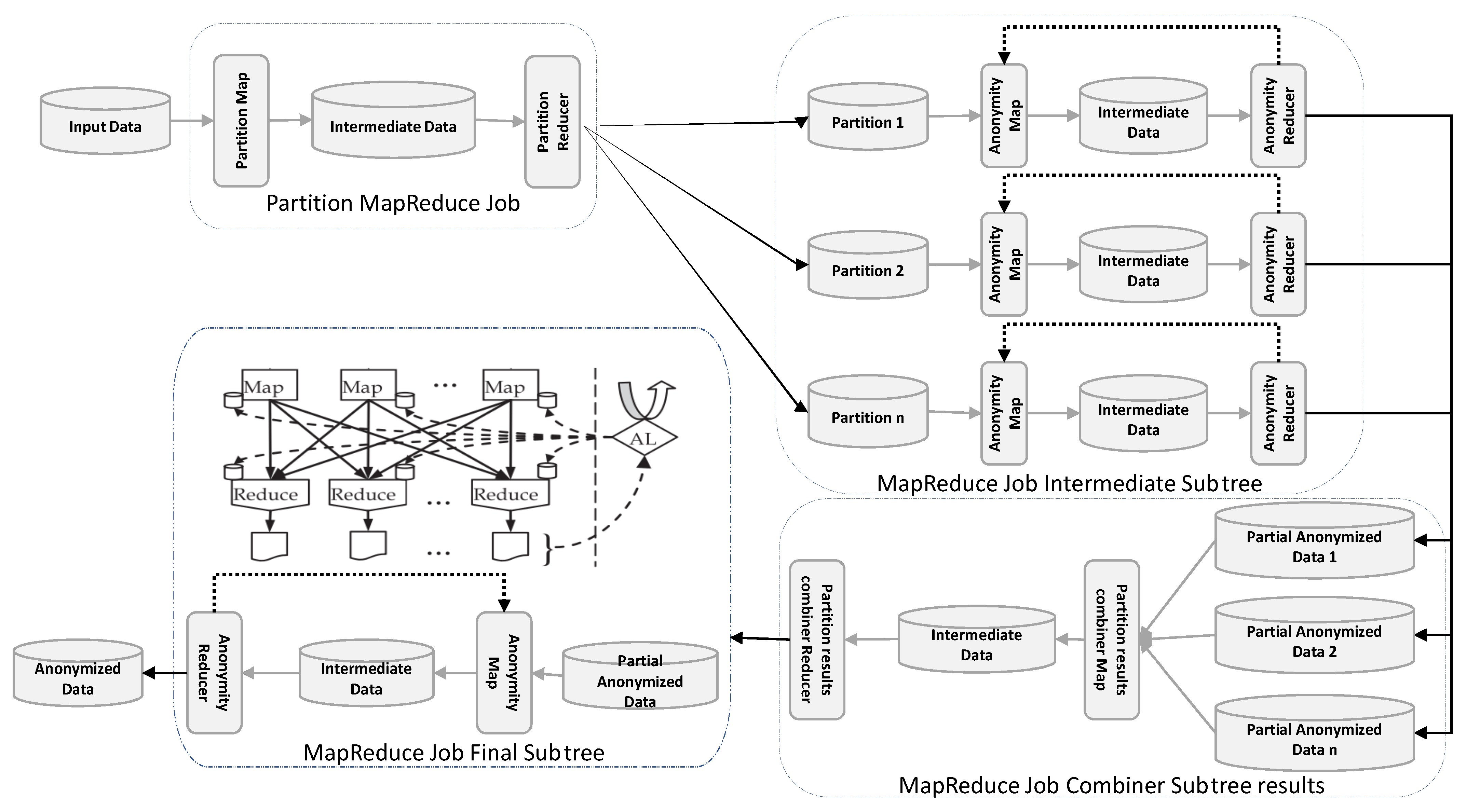
3.3. Review of Subtree Implementation in MapReduce
- (1)
- Partition MapReduce Job: this phase involves dividing the original datasets into multiple chunks (i.e., partitions) in which each chunk contains a smaller portion of the original datasets.
- (2)
- MapReduce Job Intermediate Subtree: This phase applies data anonymization to each chunk in parallel resulting in producing intermediate anonymized results.
- (3)
- MapReduce Job Combiner Subtree Result: In this phase, MapReduce jobs combine all intermediate anonymized results to form an intermediate anonymized dataset.
- (4)
- MapReduce Job Final Subtree: In this phase, the k-anonymity for the complete dataset is validated using the execution of two MapReduce jobs on the intermediate anonymized datas-ets.
3.3.1. Partition
3.3.2. Memory
3.3.3. Iteration
4. Our Proposal
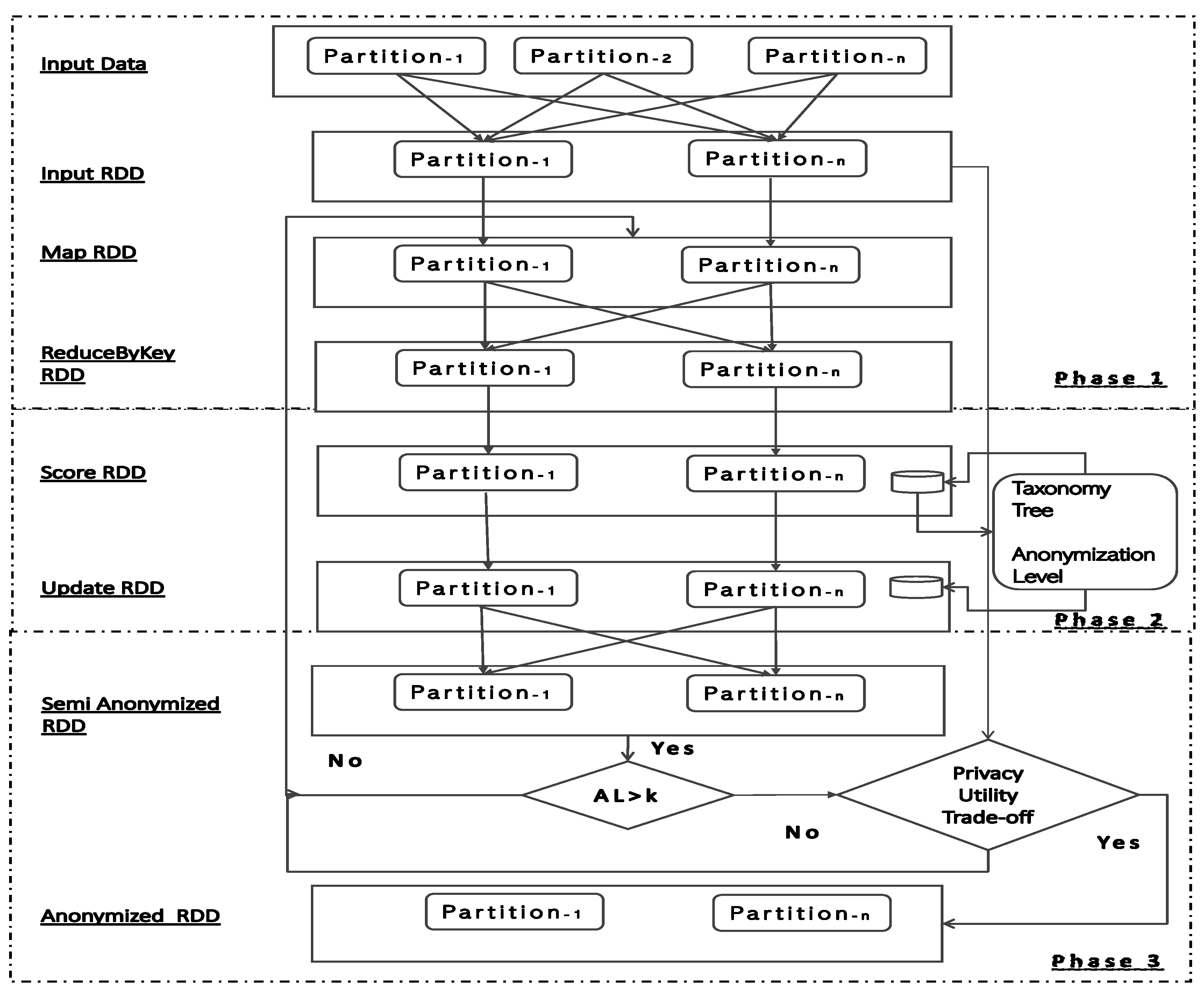
4.1. Phase 1—Initialization
- To avoid the tuple skewness, we first count the total number of records from the input data then divide the records according to the number of partitions so that each partition contains roughly a similar number of records.
- To avoid the key skewness, we count the duplicate records that appear in multiple partitions. Their frequency is recorded in one partition and the duplicated records from other partitions are removed.
- After key skewness is addressed by the above step, we count the number of records from each partition again (as some duplicate records removed) and move the records across partitions so that each partition contains a similar number of records.
| Algorithm 2: Phase 1—Initialization Phase of Spark subtree. |
 |
4.2. Phase 2—Generalization
| Algorithm 3: Phase 2—Generalization Phase of Spark subtree. |
 |
4.3. Phase 3—Validation
| Algorithm 4: Phase 3—Validation Phase of Spark subtree. |
 |
5. Experimental Results
5.1. Datasets
5.2. System Environment Configurations
5.3. Performance and Scalability
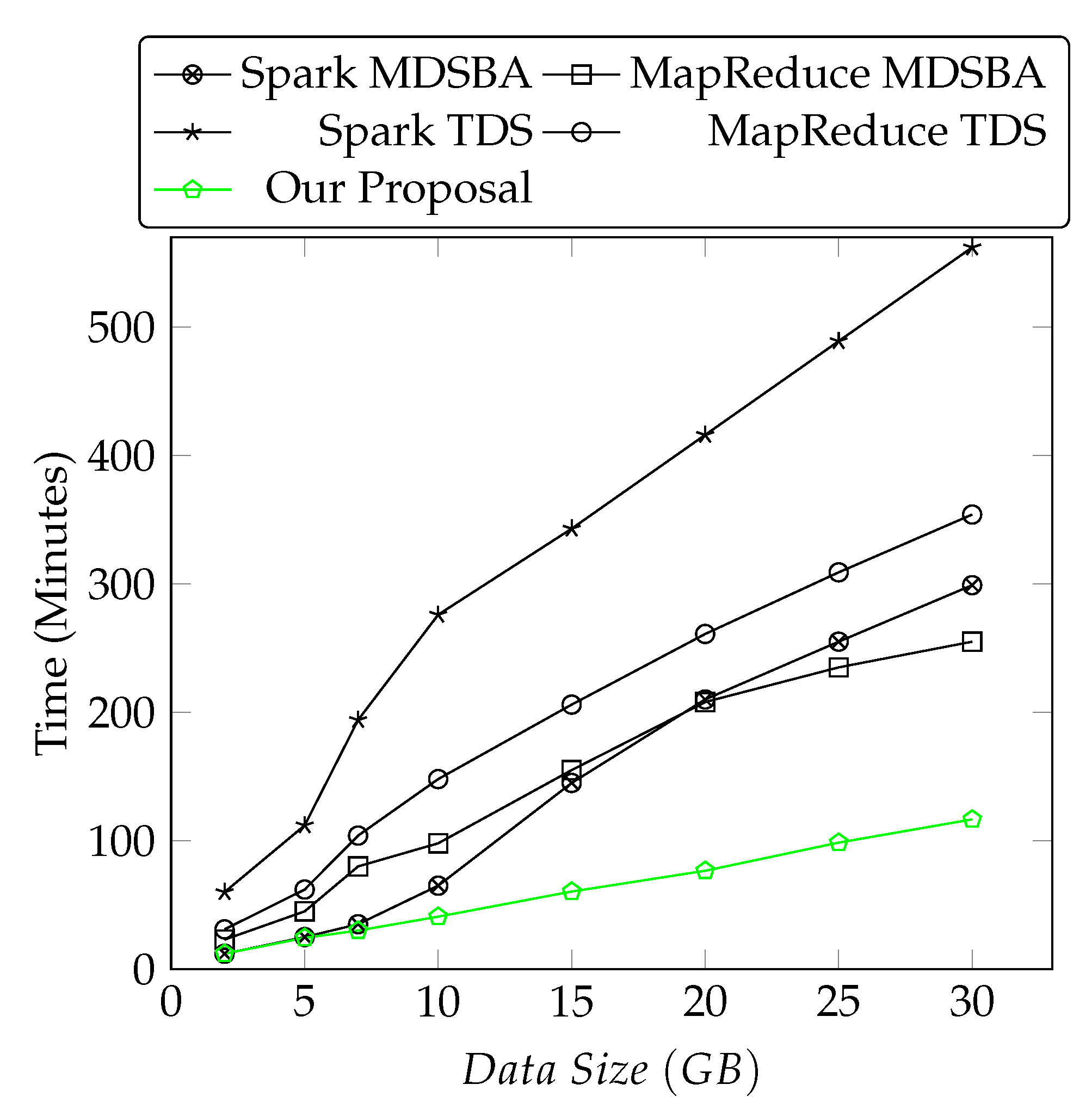
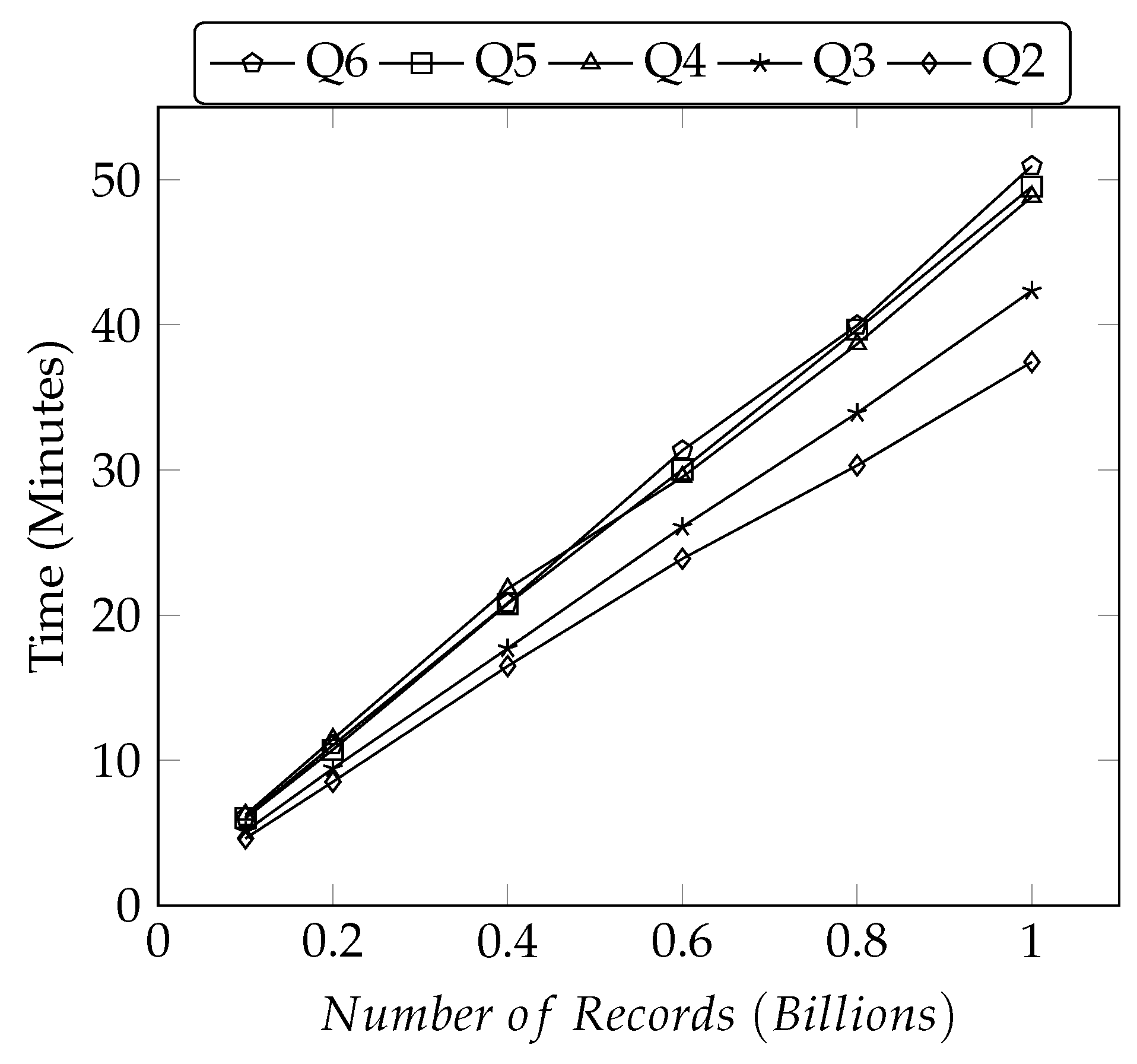
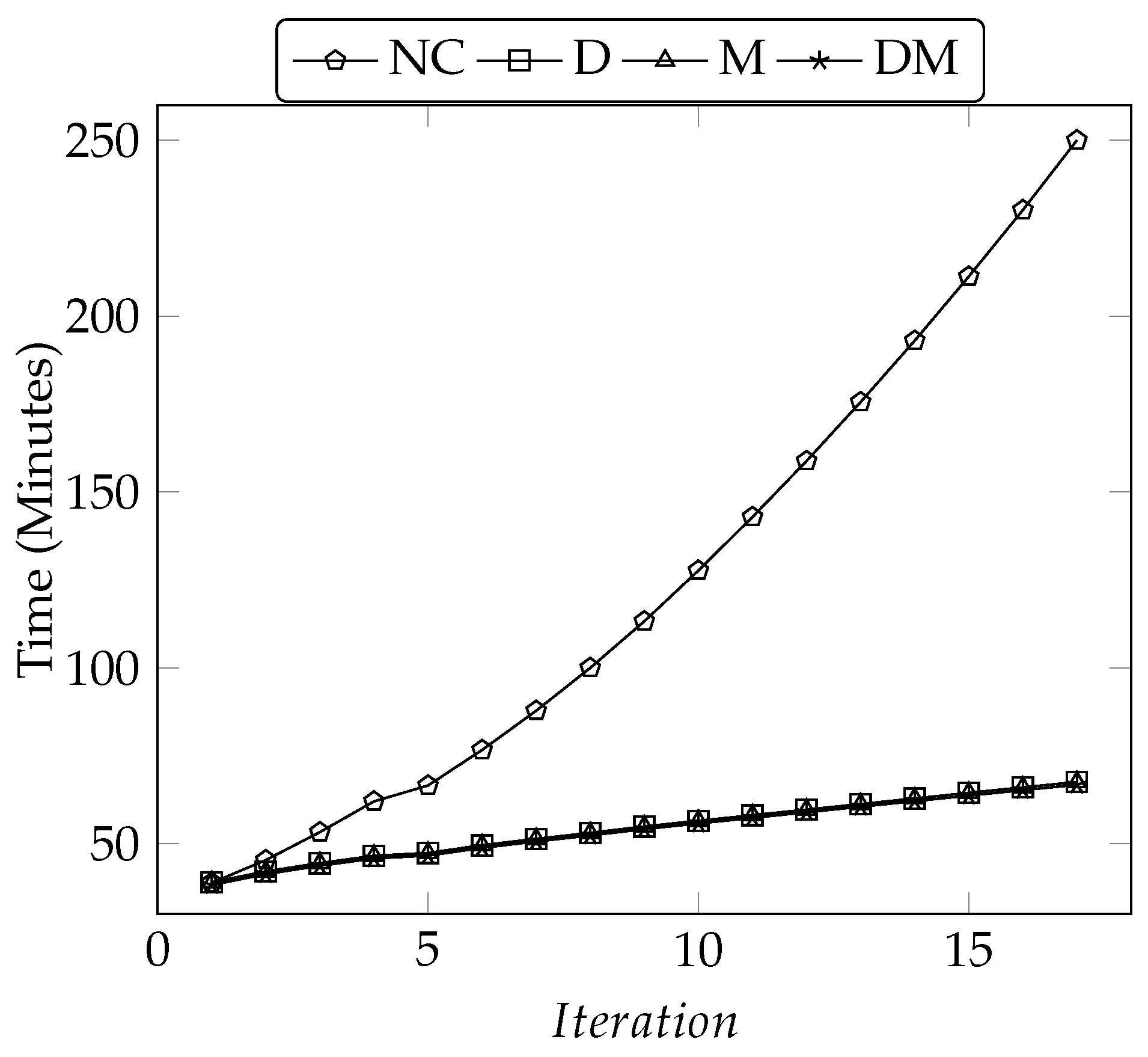
5.3.1. Performance Comparison with Existing Subtree Approaches
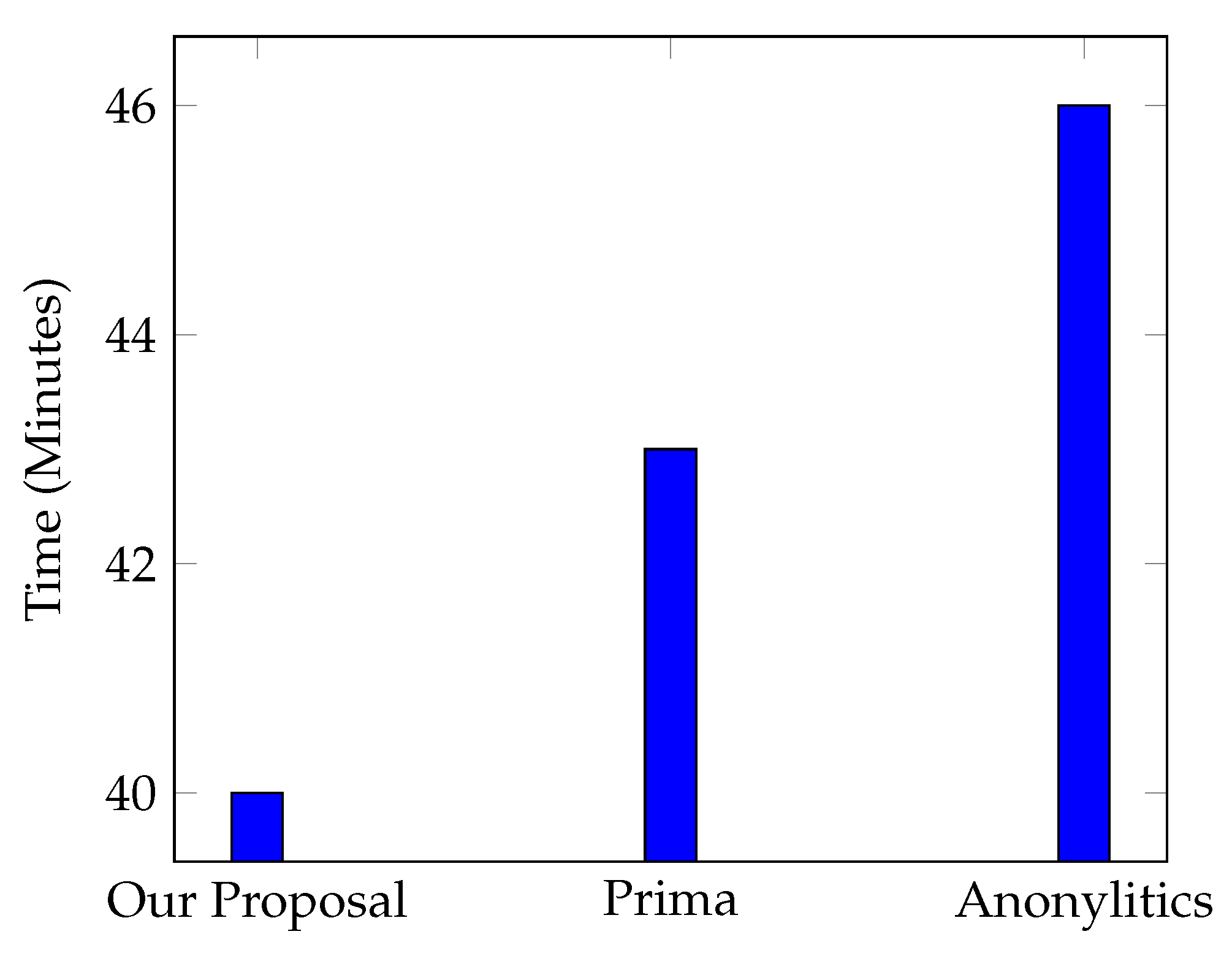
5.3.2. Performance Comparison with Existing Spark-Based k-Anonymity Approaches
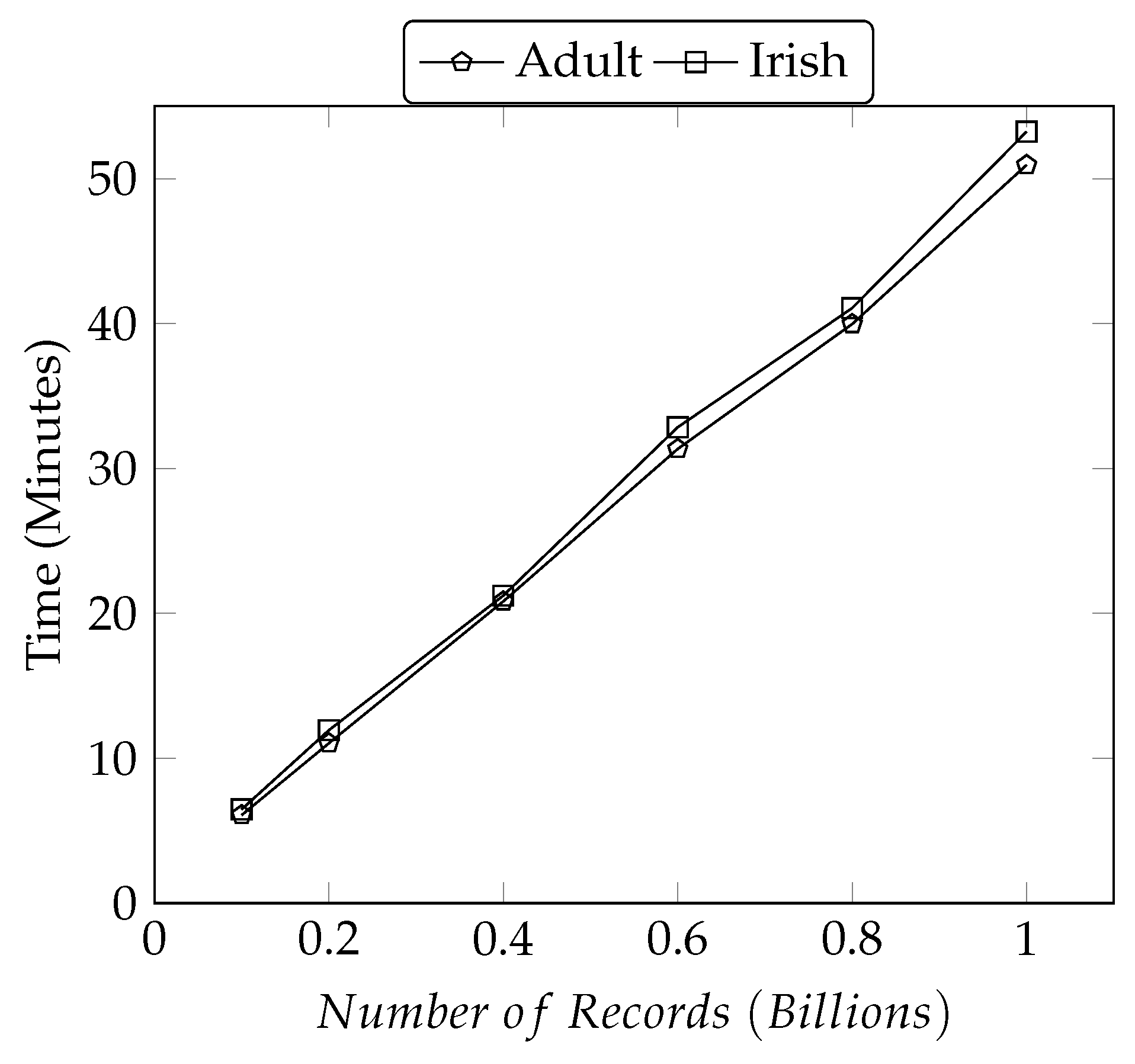
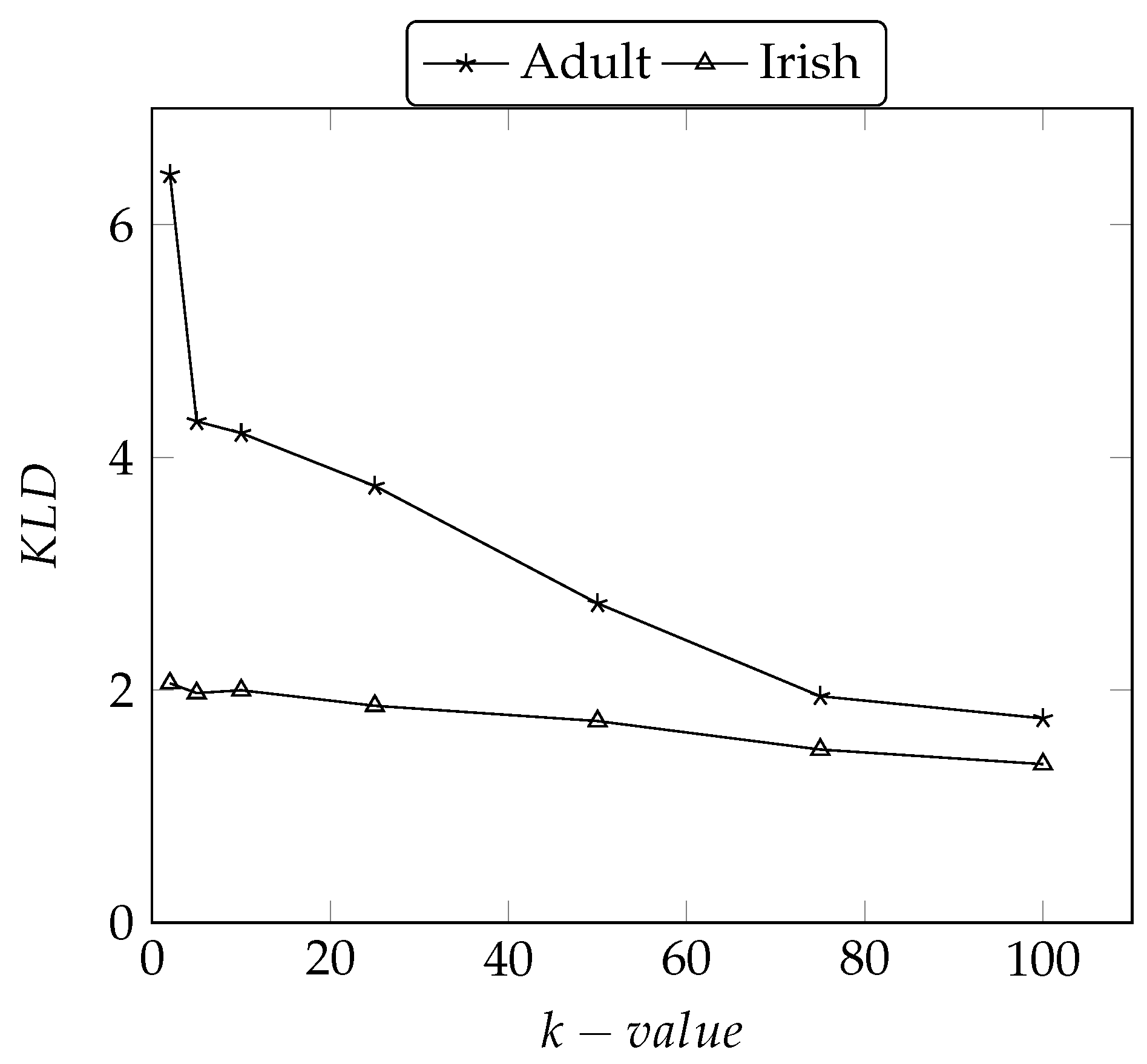
5.3.3. Performance Comparison on Adult and Irish Datasets
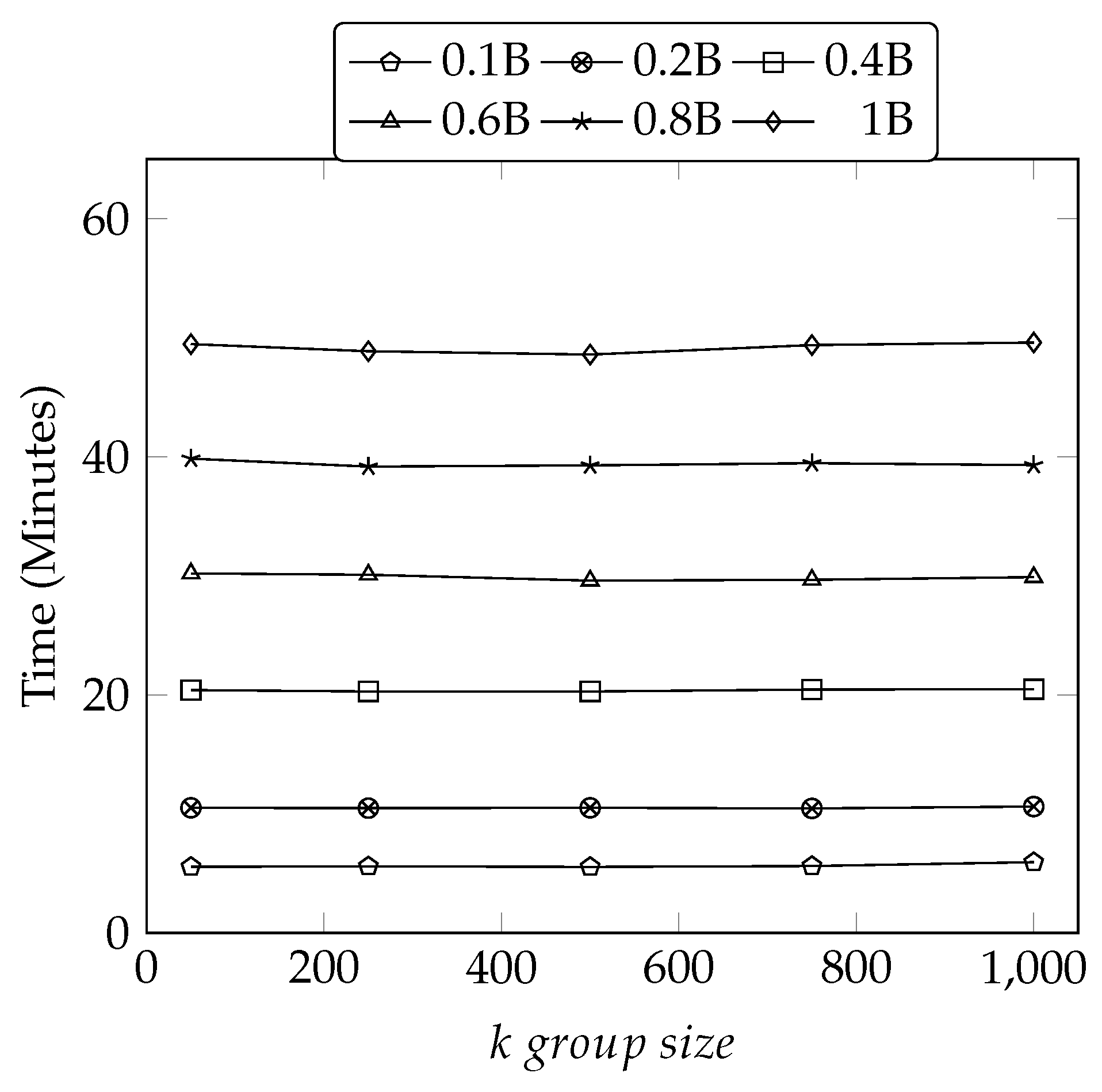
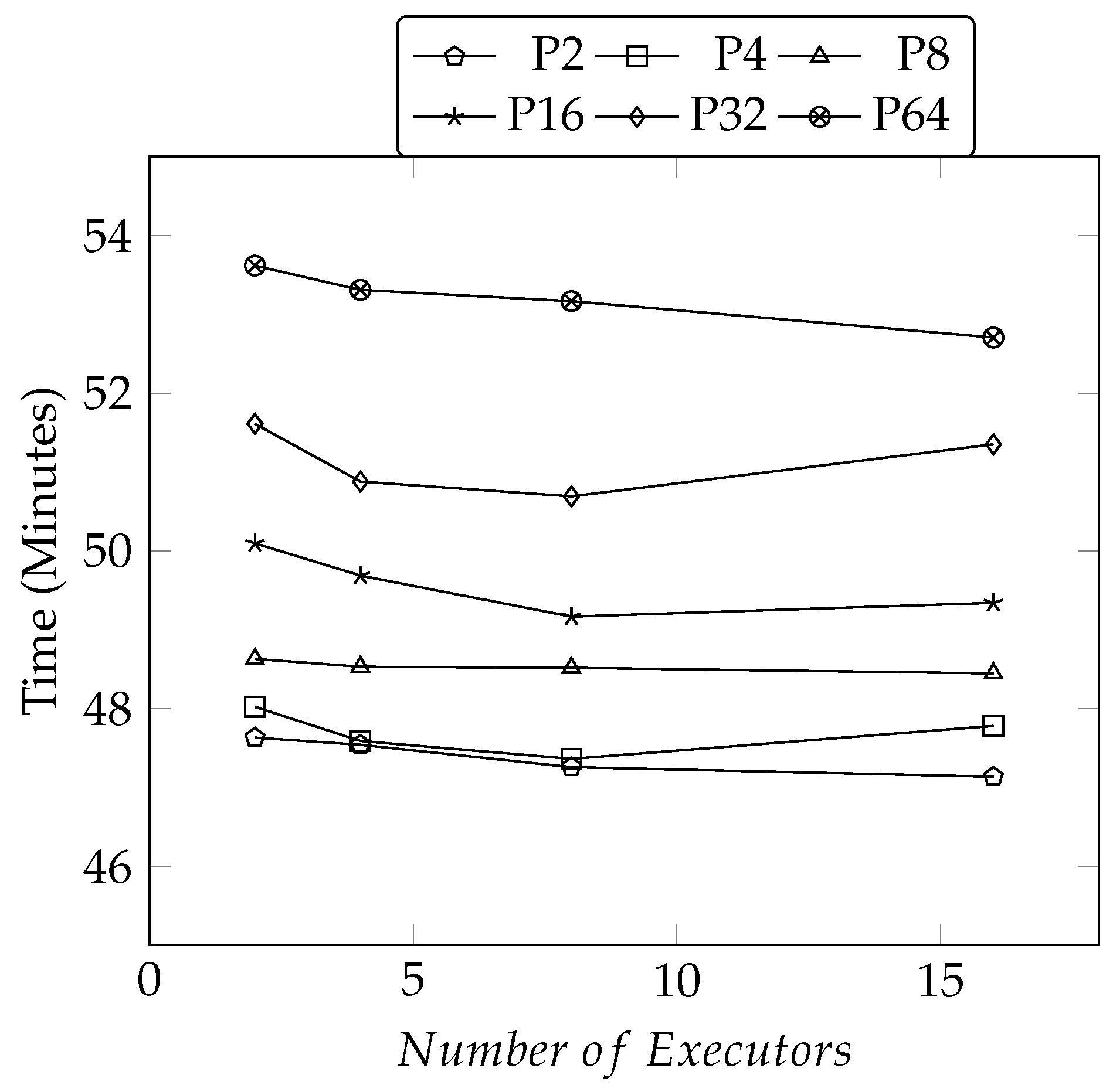
5.3.4. Memory Effects on Performance and Scalability
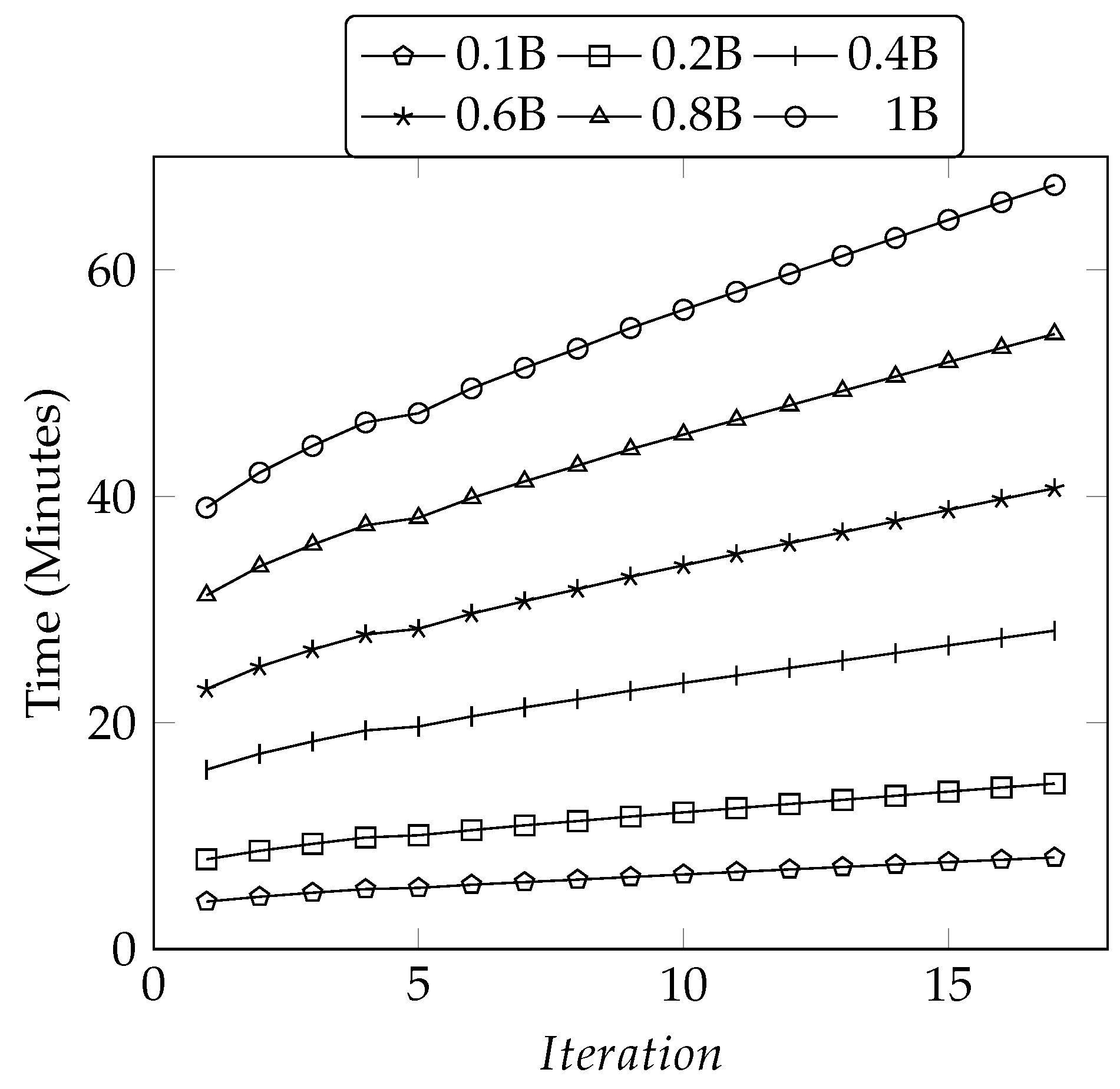
5.3.5. Iteration Effects on Scalability
5.4. Privacy & Utility Trade-Off
5.4.1. Kullback-Leibler-Divergence ()
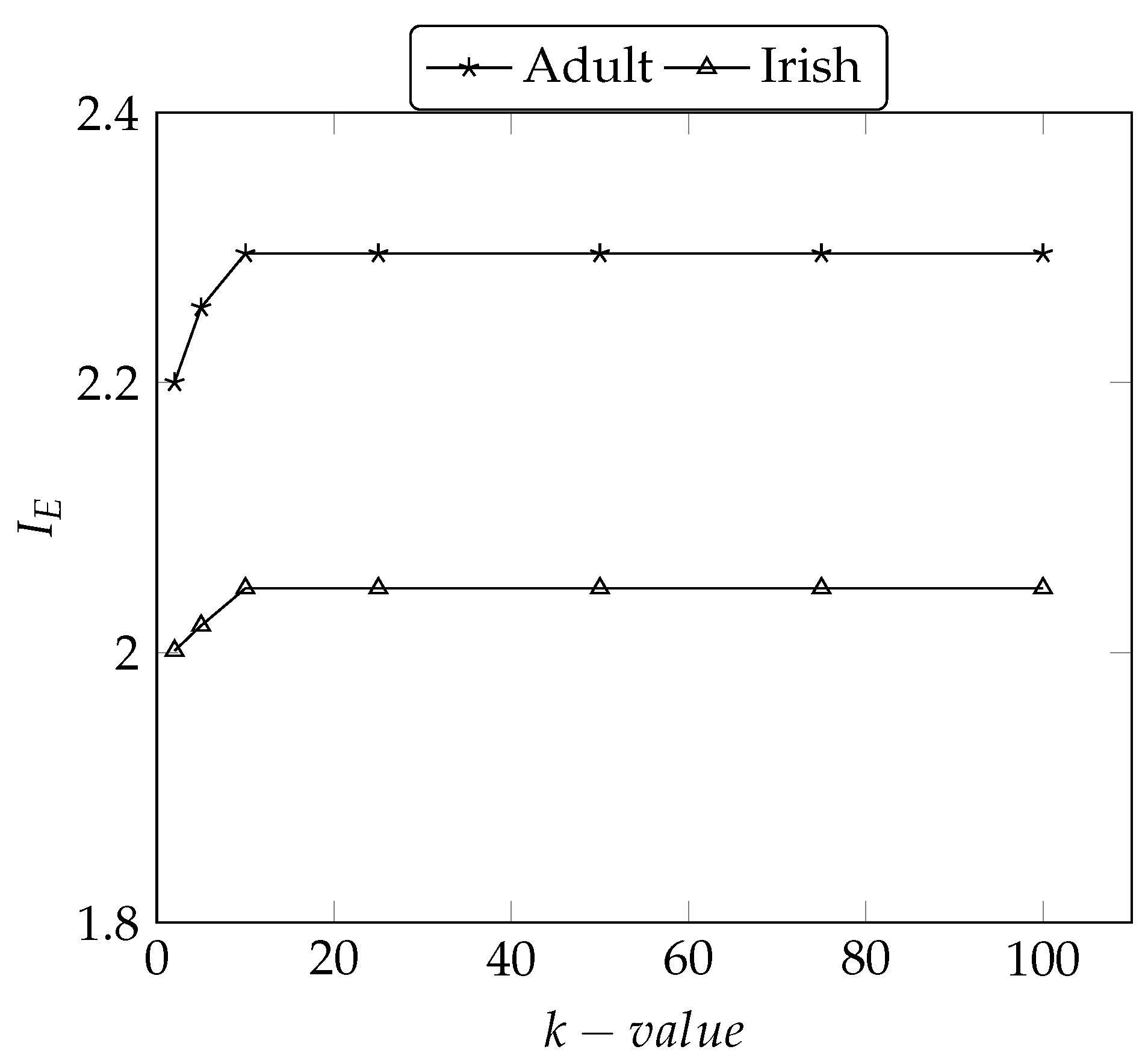
5.4.2. Information Entropy ()
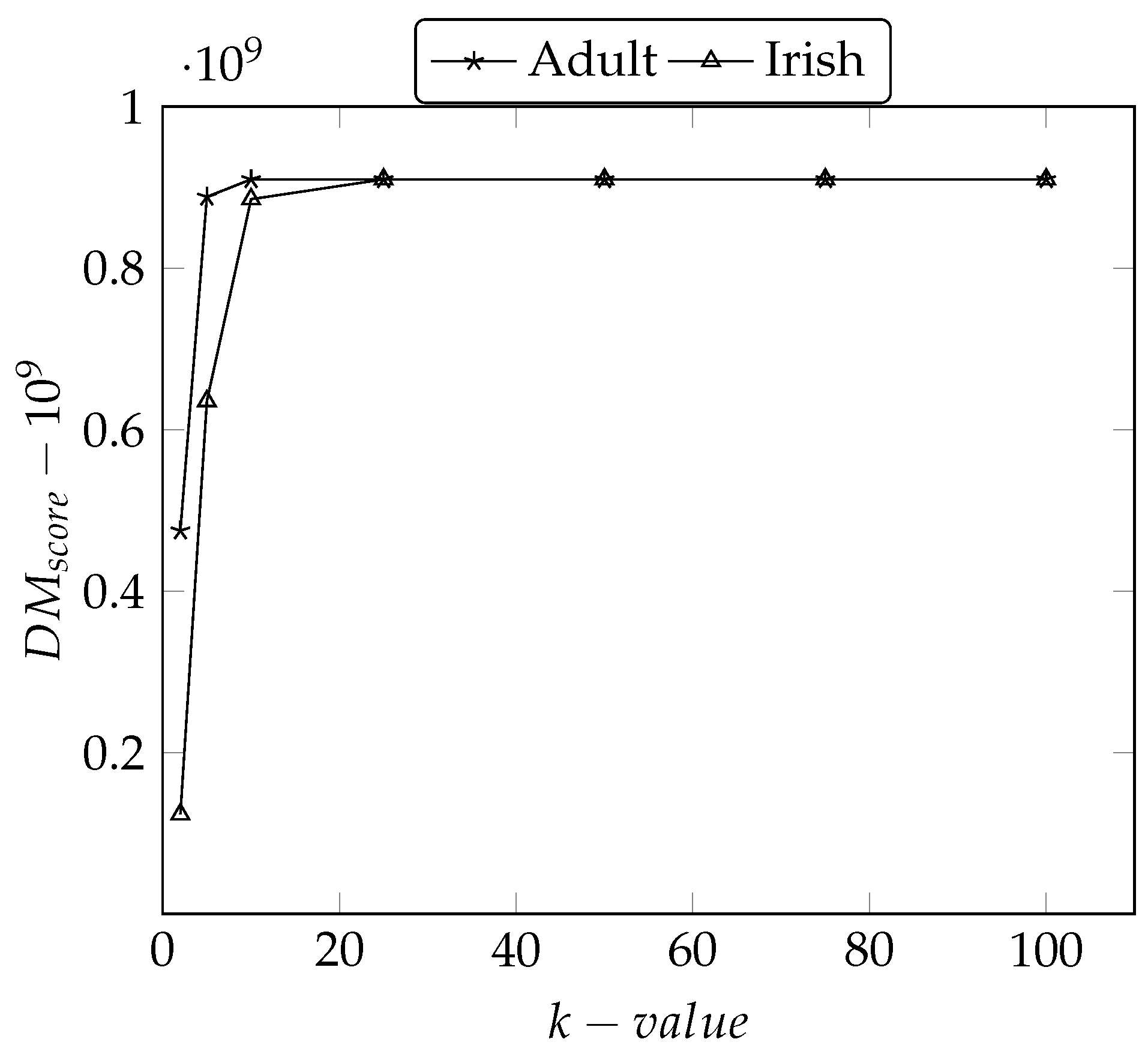
5.4.3. Discernibility Metric ()
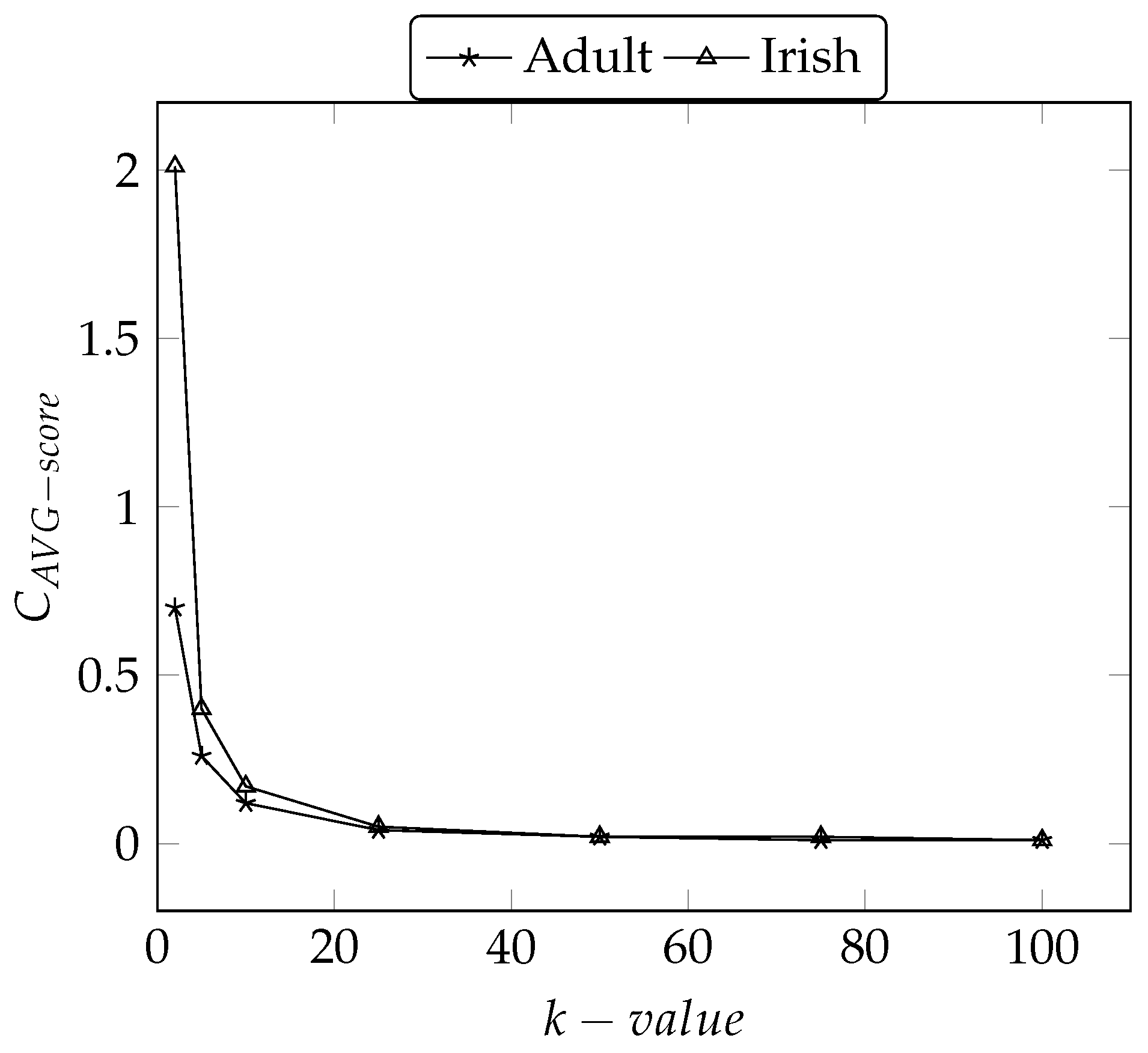
5.4.4. Average Equivalence Class Size Metric ()
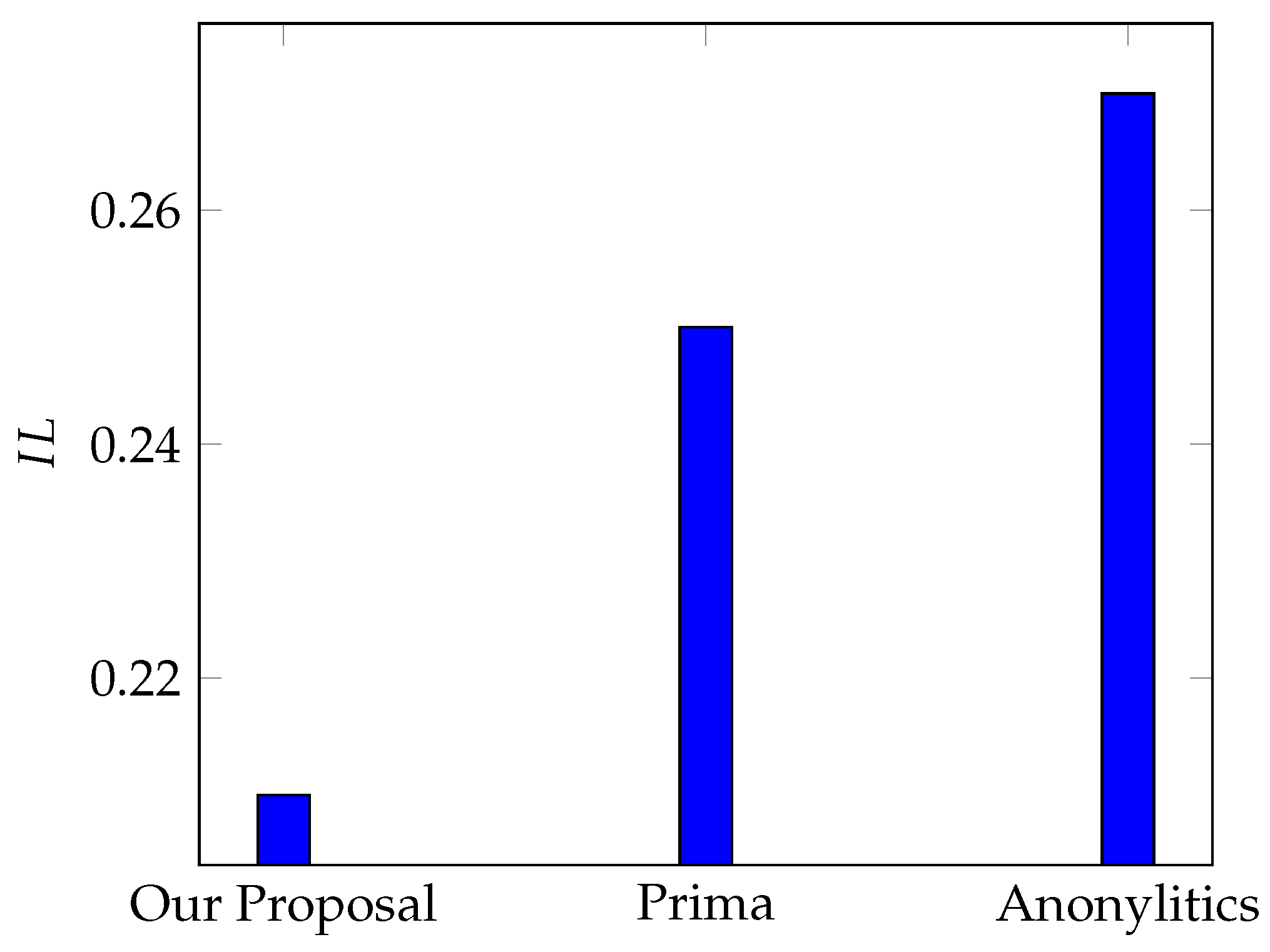
5.4.5. Information Loss ()
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Yu, S. Big privacy: Challenges and opportunities of privacy study in the age of big data. IEEE Access 2016, 4, 2751–2763. [Google Scholar] [CrossRef]
- Jang-Jaccard, J.; Nepal, S. A survey of emerging threats in cybersecurity. J. Comput. Syst. Sci. 2014, 80, 973–993. [Google Scholar] [CrossRef]
- Baryalai, M.; Jang-Jaccard, J.; Liu, D. Towards privacy-preserving classification in neural networks. In Proceedings of the 2016 14th Annual Conference on Privacy, Security and Trust (PST), Auckland, New Zealand, 12–14 December 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 392–399. [Google Scholar]
- Fung, B.C.; Wang, K.; Wang, L.; Hung, P.C. Privacy-preserving data publishing for cluster analysis. Data Knowl. Eng. 2009, 68, 552–575. [Google Scholar] [CrossRef]
- Fung, B.C.; Wang, K.; Wang, L.; Debbabi, M. A framework for privacy-preserving cluster analysis. In Proceedings of the 2008 IEEE International Conference on Intelligence and Security Informatics, Taipei, Taiwan, 17–20 June 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 46–51. [Google Scholar]
- Fung, B.C.; Wang, K.; Yu, P.S. Top-down specialization for information and privacy preservation. In Proceedings of the 21st International Conference on Data Engineering (ICDE’05), Tokyo, Japan, 5–8 April 2005; IEEE: Piscataway, NJ, USA, 2005; pp. 205–216. [Google Scholar]
- Zhang, X.; Liu, C.; Nepal, S.; Yang, C.; Dou, W.; Chen, J. SaC-FRAPP: A scalable and cost-effective framework for privacy preservation over big data on cloud. Concurr. Comput. Pract. Exp. 2013, 25, 2561–2576. [Google Scholar] [CrossRef]
- Jain, P.; Gyanchandani, M.; Khare, N. Big data privacy: A technological perspective and review. J. Big Data 2016, 3, 25. [Google Scholar] [CrossRef]
- Bazai, S.U.; Jang-Jaccard, J.; Zhang, X. A privacy preserving platform for mapreduce. In Proceedings of the International Conference on Applications and Techniques in Information Security, Auckland, New Zealand, 6–7 July 2017; Springer: Berlin, Germany, 2017; pp. 88–99. [Google Scholar]
- Bazai, S.U.; Jang-Jaccard, J.; Wang, R. Anonymizing k-NN classification on MapReduce. In Proceedings of the International Conference on Mobile Networks and Management, Melbourne, Australia, 13–15 December 2017; Springer: Berlin, Germany, 2017; pp. 364–377. [Google Scholar]
- Zhang, X.; Yang, L.T.; Liu, C.; Chen, J. A scalable two-phase top-down specialization approach for data anonymization using MapReduce on cloud. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 363–373. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, C.; Nepal, S.; Yang, C.; Dou, W.; Chen, J. Combining top-down and bottom-up: Scalable sub-tree anonymization over big data using MapReduce on cloud. In Proceedings of the 2013 12th IEEE International Conference on Trust, Security and Privacy in Computing and Communications, Melbourne, Australia, 16–18 July 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 501–508. [Google Scholar]
- Zhang, X.; Nepal, S.; Yang, C.; Dou, W.; Chen, J. A hybrid approach for scalable sub-tree anonymization over big data using MapReduce on cloud. J. Comput. Syst. Sci. 2014, 80, 1008–1020. [Google Scholar] [CrossRef]
- Shi, J.; Qiu, Y.; Minhas, U.F.; Jiao, L.; Wang, C.; Reinwald, B.; Özcan, F. Clash of the titans: MapReduce vs. spark for large scale data analytics. Proc. Vldb Endow. 2015, 8, 2110–2121. [Google Scholar] [CrossRef]
- Maillo, J.; Ramírez, S.; Triguero, I.; Herrera, F. kNN-IS: An Iterative Spark-based design of the k-Nearest Neighbors classifier for big data. Knowl.-Based Syst. 2017, 117, 3–15. [Google Scholar] [CrossRef]
- Zaharia, M.; Chowdhury, M.; Das, T.; Dave, A.; Ma, J.; McCauley, M.; Franklin, M.J.; Shenker, S.; Stoica, I. Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing. In Proceedings of the 9th USENIX conference on Networked Systems Design and Implementation, San Jose, CA, USA, 25–27 April 2012; USENIX Association: Berkeley, CA, USA, 2012; p. 2. [Google Scholar]
- Bazai, S.U.; Jang-Jaccard, J. SparkDA: RDD-Based High-Performance Data Anonymization Technique for Spark Platform. In Proceedings of the International Conference on Network and System Security, Sapporo, Japan, 15–18 December 2019; Springer: Berlin, Germany, 2019; pp. 646–662. [Google Scholar]
- Ashkouti, F.; Sheikhahmadi, A. DI-Mondrian: Distributed improved Mondrian for satisfaction of the L-diversity privacy model using Apache Spark. Inf. Sci. 2021, 546, 1–24. [Google Scholar] [CrossRef]
- Zaharia, M.; Xin, R.S.; Wendell, P.; Das, T.; Armbrust, M.; Dave, A.; Meng, X.; Rosen, J.; Venkataraman, S.; Franklin, M.J.; et al. Apache spark: A unified engine for big data processing. Commun. Acm 2016, 59, 56–65. [Google Scholar] [CrossRef]
- Sopaoglu, U.; Abul, O. A top-down k-anonymization implementation for apache spark. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2017; pp. 4513–4521. [Google Scholar]
- Al-Zobbi, M.; Shahrestani, S.; Ruan, C. Improving MapReduce privacy by implementing multi-dimensional sensitivity-based anonymization. J. Big Data 2017, 4, 45. [Google Scholar] [CrossRef]
- Al-Zobbi, M.; Shahrestani, S.; Ruan, C. Experimenting sensitivity-based anonymization framework in apache spark. J. Big Data 2018, 5, 38. [Google Scholar] [CrossRef]
- Pomares-Quimbaya, A.; Sierra-Múnera, A.; Mendoza-Mendoza, J.; Malaver-Moreno, J.; Carvajal, H.; Moncayo, V. Anonylitics: From a Small Data to a Big Data Anonymization System for Analytical Projects. In Proceedings of the 21st International Conference on Enterprise Information Systems, Crete, Greece, 3–5 May 2019; pp. 61–71. [Google Scholar]
- Antonatos, S.; Braghin, S.; Holohan, N.; Gkoufas, Y.; Mac Aonghusa, P. PRIMA: An End-to-End Framework for Privacy at Scale. In Proceedings of the 2018 IEEE 34th International Conference on Data Engineering (ICDE), Paris, France, 16–19 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1531–1542. [Google Scholar]
- Bazai, S.U.; Jang-Jaccard, J. In-Memory Data Anonymization Using Scalable and High Performance RDD Design. Electronics 2020, 9, 1732. [Google Scholar] [CrossRef]
- Gao, Z.Q.; Zhang, L.J. DPHKMS: An efficient hybrid clustering preserving differential privacy in spark. In Proceedings of the International Conference on Emerging Internetworking, Data & Web Technologies; Springer: Berlin, Germany, 2017; pp. 367–377. [Google Scholar]
- Peethambaran, G.; Naikodi, C.; Suresh, L. An Ensemble Learning Approach for Privacy–Quality–Efficiency Trade-Off in Data Analytics. In Proceedings of the 2020 International Conference on Smart Electronics and Communication (ICOSEC), Tamilnadu, India, 10–12 September 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 228–235. [Google Scholar]
- Jebali, A.; Sassi, S.; Jemai, A. Secure data outsourcing in presence of the inference problem: Issues and directions. J. Inf. Telecommun. 2020, 5, 16–34. [Google Scholar] [CrossRef]
- Chakravorty, A.; Rong, C.; Jayaram, K.; Tao, S. Scalable, Efficient Anonymization with INCOGNITO-Framework & Algorithm. In Proceedings of the 2017 IEEE International Congress on Big Data (BigData Congress), Honolulu, HI, USA, 25–30 June 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 39–48. [Google Scholar]
- Dwork, C. Differential Privacy. In ICALP LNCS; Bugliesi, M., Preneel, B., Sassone, V., Wegener, I., Eds.; Springer: Berlin, Germany, 2006; pp. 1–12. [Google Scholar]
- Gao, Z.; Sun, Y.; Cui, X.; Wang, Y.; Duan, Y.; Wang, X.A. Privacy-preserving hybrid K-means. Int. J. Data Warehous. Min. (IJDWM) 2018, 14, 1–17. [Google Scholar] [CrossRef]
- Yin, S.L.; Liu, J. A k-means approach for mapreduce model and social network privacy protection. J. Inf. Hiding Multimed. Signal Process. 2016, 7, 1215–1221. [Google Scholar]
- Smith, C.; Albarghouthi, A. Synthesizing differentially private programs. Proc. ACM Program. Lang. 2019, 3, 1–29. [Google Scholar] [CrossRef]
- Asuncion, A.; Newman, D. UCI Machine Learning Repository. 2007. Available online: https://archive.ics.uci.edu/ml/about.html (accessed on 2 March 2021).
- Sweeney, L. k-anonymity: A model for protecting privacy. Int. J. Uncertain. Fuzziness Knowl. Based Syst. 2002, 10, 557–570. [Google Scholar] [CrossRef]
- Dean, J.; Ghemawat, S. MapReduce: Simplified data processing on large clusters. Commun. Acm 2008, 51, 107–113. [Google Scholar] [CrossRef]
- Gufler, B.; Augsten, N.; Reiser, A.; Kemper, A. Handling Data Skew in MapReduce. Closer 2011, 11, 574–583. [Google Scholar]
- Tao, Y.; Lin, W.; Xiao, X. Minimal mapreduce algorithms. In Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data, New York, NY, USA, 22–27 June 2013; pp. 529–540. [Google Scholar]
- Zhang, X.; Dou, W.; Pei, J.; Nepal, S.; Yang, C.; Liu, C.; Chen, J. Proximity-aware local-recoding anonymization with mapreduce for scalable big data privacy preservation in cloud. IEEE Trans. Comput. 2014, 64, 2293–2307. [Google Scholar] [CrossRef]
- Kang, M.; Lee, J.G. An experimental analysis of limitations of MapReduce for iterative algorithms on Spark. Clust. Comput. 2017, 20, 3593–3604. [Google Scholar] [CrossRef]
- Fung, B.C.; Wang, K.; Philip, S.Y. Anonymizing classification data for privacy preservation. IEEE Trans. Knowl. Data Eng. 2007, 19, 711–725. [Google Scholar] [CrossRef]
- Fung, B.C.; Wang, K.; Chen, R.; Yu, P.S. Privacy-preserving data publishing: A survey of recent developments. ACM Comput. Surv. (Csur) 2010, 42, 1–53. [Google Scholar] [CrossRef]
- Central Statistics Office (Internet). 2011. Available online: https://www.cso.ie/en/census/census2011reports/ (accessed on 2 March 2021).
- Spark Overview. In Overview—Spark 2.1.0 Documentation; Available online: https://spark.apache.org/docs/2.1.0/ (accessed on 2 March 2021).
- Mehta, B.B.; Rao, U.P. Improved l-diversity: Scalable anonymization approach for privacy preserving big data publishing. J. King Saud Univ. Comput. Inf. Sci. 2019. [Google Scholar] [CrossRef]
- Gopalani, S.; Arora, R. Comparing apache spark and map reduce with performance analysis using k-means. Int. J. Comput. Appl. 2015, 113, 8–11. [Google Scholar] [CrossRef]
- Zaharia, M.; Chowdhury, M.; Franklin, M.J.; Shenker, S.; Stoica, I. Spark: Cluster computing with working sets. HotCloud 2010, 10, 95. [Google Scholar]
- Kifer, D.; Gehrke, J. Injecting utility into anonymized datasets. In Proceedings of the 2006 ACM SIGMOD International Conference on Management of Data, Chicago, IL, USA, 27–29 June 2006; ACM: New York, NY, USA, 2006; pp. 217–228. [Google Scholar]
- Ayala-Rivera, V.; McDonagh, P.; Cerqueus, T.; Murphy, L. A systematic comparison and evaluation of k-anonymization algorithms for practitioners. Trans. Data Priv. 2014, 7, 337–370. [Google Scholar]
- Ashwin, M.; Daniel, K.; Johannes, G.; Muthuramakrishnan, V. l-diversity: Privacy beyond k-anonymity. ACM Trans. Knowl. Discov. Data 2007, 1, 1–52. [Google Scholar]
- Niu, B.; Li, Q.; Zhu, X.; Cao, G.; Li, H. Achieving k-anonymity in privacy-aware location-based services. In Proceedings of the IEEE INFOCOM 2014-IEEE Conference on Computer Communications, Toronto, ON, Canada, 27 April–2 May 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 754–762. [Google Scholar]
- Chakravorty, A.; Wlodarczyk, T.W.; Rong, C. A Scalable K-Anonymization solution for preserving privacy in an Aging-in-Place welfare Intercloud. In Proceedings of the 2014 IEEE International Conference on Cloud Engineering, Boston, MA, USA, 11–14 March 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 424–431. [Google Scholar]
- LeFevre, K.; DeWitt, D.J.; Ramakrishnan, R. Mondrian multidimensional k-anonymity. In Proceedings of the 22nd International Conference on Data Engineering (ICDE’06), Atlanta, GA, USA, 3–7 April 2006; IEEE: Piscataway, NJ, USA, 2006; p. 25. [Google Scholar]
- Li, N.; Li, T.; Venkatasubramanian, S. t-Closeness: Privacy Beyond k-Anonymity and l-Diversity. In Proceedings of the 2007 IEEE 23rd International Conference on Data Engineering, Istanbul, Turkey, 11–15 April 2007; pp. 106–115. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description | Reference |
|---|---|---|
| D | Dataset | Algorithm 1 |
| Anonymized Dataset | Algorithm 1 | |
| r | Record | Algorithms 1–4 |
| Sensitive Attributes | Algorithm 1 | |
| Input_RDD | Algorithm 2 | |
| Anonymized_RDD | Algorithm 4 | |
| Total number of Record | Algorithm 4 | |
| n | nth Record | Algorithms 1–4 |
| Anonymized Record | Algorithm 4 | |
| Anonymization Level | Algorithms 3 and 4 | |
| Record count | Algorithms 2 and 3 | |
| Anonymized record count | Algorithm 4 | |
| Attribute Value | Section 4.2 | |
| Taxonomy Tree | Algorithm 3 | |
| k | Anonymity Parameter | Algorithm 4 |
| Quasi-identifiers set | Algorithm 4 | |
| Quasi-identifier | Section 4.2 | |
| Child attribute | Algorithm 3 | |
| Parent attribute | Algorithm 3 | |
| Domain value in | Algorithm 3 |
| Education | Gender | Age | Income | Count |
|---|---|---|---|---|
| 9th | M | 30 | ≤50 k | 3 |
| 10th | M | 32 | ≤50 k | 4 |
| 11th | M | 35 | >50 k | 2 |
| 11th | M | 35 | ≤50 k | 3 |
| 12th | F | 37 | >50 k | 3 |
| 12th | F | 37 | ≤50 k | 1 |
| Bachelors | F | 42 | >50 k | 4 |
| Bachelors | F | 42 | ≤50 k | 2 |
| Bachelors | F | 44 | >50 k | 4 |
| Masters | M | 44 | >50 k | 4 |
| Masters | F | 44 | >50 k | 3 |
| Doctorate | F | 44 | >50 k | 1 |
| Education | Gender | Age | Income | Count |
|---|---|---|---|---|
| Junior-Secondary | M | 30 | ≤50 k | 3 |
| Junior-Secondary | M | 32 | ≤50 k | 4 |
| 11th | M | 35 | >50 k | 2 |
| 11th | M | 35 | ≤50 k | 3 |
| 12th | F | 37 | >50 k | 3 |
| 12th | F | 37 | ≤50 k | 1 |
| Bachelors | F | 42 | >50 k | 4 |
| Bachelors | F | 42 | ≤50 k | 2 |
| Bachelors | F | 44 | >50 k | 4 |
| Post-grad | M | 44 | >50 k | 4 |
| Post-grad | F | 44 | >50 k | 3 |
| Post-grad | F | 44 | >50 k | 1 |
| Education | Gender | Age | Income | Count |
|---|---|---|---|---|
| Junior-Secondary | M | 30–33 | ≤50 k | 7 |
| 11th | M | 35 | >50 k | 5 |
| 12th | F | 37 | >50 k | 4 |
| Bachelors | F | 40–45 | >50 k | 10 |
| Post-grad | Any | 44 | >5 0k | 8 |
| QID | Distinct Qid Value | GL |
|---|---|---|
| Age | 74 | 3 |
| Work Class | 8 | 4 |
| Education | 16 | 4 |
| Race | 5 | 2 |
| Gender | 2 | 1 |
| Native Country | 41 | 3 |
| QID | Distinct Qid Value | GL |
|---|---|---|
| Age | 70 | 4 |
| Economic Status | 9 | 2 |
| Education | 10 | 4 |
| Marital Status | 7 | 3 |
| Gender | 2 | 1 |
| Field of Study | 72 | 2 |
| Spark Setups | Dataset Setups | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Driver Memory | Executor Memory | No of Executors | Executor Cores | No of Partitions | k Group Size | Dataset Sizes/Records | Number of QIDs | Datasets | |
| Figure 4 | 6.5 GB | 2 GB | 10 | 2 | 18–242 | 100 | 2 GB–30 GB | 6 | Adult |
| Figure 5 | 15 GB | 3.5 GB | 8 | 3 | 40 | 100 | 1.2 B | 6 | Adult |
| Figure 6 | 6.5 GB | 4 GB | 12 | 3 | 24 | 1000 | 0.1 B–1 B | 6 | Adult-Irish |
| Figure 7 | 6.5 GB | 4 GB | 12 | 3 | 24 | 50–1000 | 0.1 B–1 B | 6 | Adult |
| Figure 8 | 6.5 GB | 4 GB | 12 | 3 | 24 | 1000 | 0.1 B–1 B | 2–6 | Adult |
| Figure 9 | 6.5 GB | 4 GB | 12 | 3 | 24 | 1000 | 0.1 B | 6 | Adult |
| Figure 10 | 6.5 GB | 4 GB | 12 | 3 | 24 | 10,000 | 0.6 B | 6 | Adult |
| Figure 11 | 6.5 GB | 4 GB | 2–16 | 3 | 2–64 | 1000 | 0.8B | 6 | Adult |
| Figure 12, Figure 13, Figure 14 and Figure 15 | 6.5 GB | 4 GB | 12 | 3 | 24 | 2–100 | 31062 | 6 | Adult-Irish |
| Figure 16 | 6.5 GB | 4 GB | 12 | 3 | 24 | 100 | 31,062 | 6 | Adult |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bazai, S.U.; Jang-Jaccard, J.; Alavizadeh, H. Scalable, High-Performance, and Generalized Subtree Data Anonymization Approach for Apache Spark. Electronics 2021, 10, 589. https://doi.org/10.3390/electronics10050589
Bazai SU, Jang-Jaccard J, Alavizadeh H. Scalable, High-Performance, and Generalized Subtree Data Anonymization Approach for Apache Spark. Electronics. 2021; 10(5):589. https://doi.org/10.3390/electronics10050589
Chicago/Turabian StyleBazai, Sibghat Ullah, Julian Jang-Jaccard, and Hooman Alavizadeh. 2021. "Scalable, High-Performance, and Generalized Subtree Data Anonymization Approach for Apache Spark" Electronics 10, no. 5: 589. https://doi.org/10.3390/electronics10050589
APA StyleBazai, S. U., Jang-Jaccard, J., & Alavizadeh, H. (2021). Scalable, High-Performance, and Generalized Subtree Data Anonymization Approach for Apache Spark. Electronics, 10(5), 589. https://doi.org/10.3390/electronics10050589