1. Introduction
A generative adversarial network (GAN) [
1] is an unsupervised learning method that learns by letting two neural networks play against each other. This method was proposed by Ian Goodfellow and his colleagues in 2014. With the improvement of the theory, GANs have gradually shown their great potential. Moreover, GANs have produced many fancy computer vision applications, such as image generation, image conversion, style transfer, and image restoration. GANs have made many computer vision achievements, but their development is relatively slow in natural language processing (NLP). There are two main problems:
When a GAN faces discrete data, the discriminator cannot pass the gradient to the generator through backward propagation [
2]. For example, for continuous data, if we will output a picture with a pixel value of 1.0, then we can change this value to 1.0001 through backward propagation. However, if the word “penguin” is output for discrete data, the network cannot change it to “penguin + 0.001” through backward propagation because “penguin + 0.001” is not a word.
The training process for GANs is unstable. We need to balance the generator and the discriminator carefully. Moreover, the generating task is much more complicated than discrimination. Simultaneously, the discriminator’s guidance for the generator is too weak [
3], and the direction contains too little information. For the generator, it can only get a “true or false;’ probability in return. Furthermore, the discriminator may even “cheat”. Since the real sample uses one-hot vectors, the discriminator does not need to judge whether the generated data distribution is closer to the real data. It just needs to identify whether only one item of the current data is 1, and the rest are all 0.
For the first problem, there are currently two effective solutions.
The first solution is the combination of a GAN and reinforcement learning (RL) for sequence generation, such as the Sequence GAN (SeqGAN) [
4] proposed by Yu et al. with the REINFORCE algorithm. This solution focuses on dealing with non-differentiable problems caused by discrete data by considering RL methods or reformulating problems in continuous space [
5]. Using this method will make the GAN more challenging to train and will cause the mode collapse problem.
The second solution is Gumbel–Softmax relaxation [
6,
7]. The most representative network is RelGAN [
5], which was proposed by Nie, W. et al. in 2018. RelGAN can be divided into three parts: a relational-memory-based generator [
8], Gumbel–Softmax relaxation [
6,
7] for training GANs, and multiple representations embedded in the discriminator [
5]. This model performs very well on many datasets. However, RelGAN still has disadvantages in the second problem.
For the second problem, Wasserstein GAN (WGAN) and Wasserstein GAN Gradient Penalty(WGAN-GP), proposed by Martin Arjovsky and Ishaan Gulrajani et al. [
9,
10], respectively, provide a theoretical solution. WGAN converts the discriminator from a binary classification task into an approximately fitting Wasserstein distance. Forcing the discriminator to calculate the distance between the distribution of the generating data and the true data also prevents the discriminator from “cheating”. At the same time, it also provides more accurate guidance information to the generator, not just the probability of being “true or false”. Because the “weight clipping” strategy in WGAN will cause most of the weights to approach two extremes, WGAN-GP was proposed, which uses a “gradient penalty” to replace “weight clipping”. This strategy makes the training more stable and increases the quality of the generated image.
Unfortunately, WGAN is mostly used in computer vision, and there are few applications in text generation. On the other hand, using Wasserstein loss to replace the RSGAN [
11] loss in RelGAN does not perform well for real-world data. We found that the gradient would disappear, and the discriminator loss was almost equal to 0 during training. A detailed description of the performance of RelGAN using Wasserstein loss can be found in
Section 4.2.2.
In this work, we propose a new architecture based on RelGAN and WGAN-GP named WRGAN. The improved model can effectively solve the two issues identified above. We rebuilt the discriminator architecture with a one-dimensional convolution of multiple different kernel sizes and residual modules [
12]. Correspondingly, we also modified the generator and discriminator loss functions of the network with gradient penalty Wasserstein loss. Then, we used the discriminator and the generator with relational memory coordinated by Gumbel–Softmax relaxation to train the GAN model on discrete data. We analyzed and presented the experimental results on multiple datasets and the influence of hyperparameters on the model. The data samples generated from each dataset can be found in
Appendix A. Our experiments demonstrate that our model outperforms most current models on real-world data. The rest of the paper is organized as follows:
Section 3 presents the methodology of the review. The obtained results are presented in
Section 4.
Section 5 presents a discussion of the results and the conclusions.
2. Related Works
With the improvement of GAN theory, GANs have also made some progress in text generation. In SeqGAN [
4], the error is regarded as a reward for reinforcement learning by training in a feed-forward manner. An exploration model of reinforcement learning is used to update the generator network. SeqGAN created a mode for GAN in the field of text generation. Many subsequent models also rely on reinforcement learning (RL) algorithms. For example, MaliGAN [
13] proposed a new loss function of the generator to replace the Monte Carlo tree search [
14] and got better results. RankGAN [
15] changed the original discriminator from a binary classification model to a sorting model, and changed from a learning to a ranking problem. LeakGAN [
16] leaked the characteristic information of the high-level discriminator to the manager module to guide the generator to generate long texts. MaskGAN [
17] used the actor–critic algorithm in reinforcement learning to train the generator and used maximum likelihood and stochastic gradient descent to train the discriminator. DP-GAN (Diversity-Promoting GAN) [
18] was proposed with a focus on diversified text generation. The author improved the discriminator based on SeqGAN and proposed a discriminator based on the language model. SentiGAN [
19] has multiple generators and a multi-class discriminator. Multiple generators are trained simultaneously, aiming to generate text with different emotion labels without supervision. Moreover, it establishes a penalty-based goal in the generators to force them to produce diverse examples of a specific emotional label. Matt Kusner [
6] proposed a new method for dealing with discrete data—Gumbel–Softmax—thus solving the “indifferentiable” problem. RelGAN [
5] used relational memory [
20] instead of Long Short-Term Memory(LSTM) [
21] as the generator to obtain more vital expression ability and better model ability for long texts. At the same time, RelGAN used the Gumbel–Softmax relaxation model to simplify the model and replaced the reinforcement learning heuristic algorithm.
For GAN models that were not designed for text generation, we will first introduce a distance measurement method called “Earth-Mover (also called Wasserstein) distance”,
, which is informally defined as the minimum cost of transporting mass in order to transform the distribution q into the distribution p (where the cost is the mass times the transport distance). Under mild assumptions,
is continuous everywhere and differentiable almost everywhere [
10]. The “Earth-Mover distance”
can be defined as:
where
is a probability distribution that satisfies the constraints:
Instead, WGAN was proposed to use the Wasserstein distance as the loss to solve the unstable problem in GAN training. WGAN theoretically points out the defects of the original GAN. WGAN-GP was used to propose another truncation pruning strategy—“gradient penalty”—to make the training process more stable and achieve higher-quality generation results. The f-GAN [
22] used variable dispersion to minimize the training of a generative adversarial network of generative neural samplers. These methods also have reference values for text generation.
Beyond GANs, ARAEs (adversarially regularized autoencoders) [
23] represent a new method that can limit the encoded content information to an autoencoder and prevent the autoencoder from learning the identity function. After training, the generator and encoder parts of the autoencoder can be used as a generative model. The PHVM (planning-based hierarchical variational model) [
24] first plans a sequence of groups and then realizes each sentence depending on the planning result and the previously generated context, thereby decomposing long text generation into dependent sentence generation sub-tasks. These methods provide us with new ideas for text generation.
In general, there have been many excellent variants of GANs in the field of text generation in recent years. Nevertheless, there are still many problems to be solved in text generation, which also means that there is excellent development potential. Based on this point of view, we research GANs in the text generation field and improve the models.
3. WRGAN
With respect to the problem that the discriminator cannot back-propagate the gradient to the generator after experimental testing, we believe that using the Gumbel–Softmax relaxation technology is better than using reinforcement learning (RL). Therefore, we choose Gumbel–Softmax relaxation. On the other hand, since the LSTM-based generator may lack enough expressive power for text generation, relational memory is employed as the generator. Because the discriminator gives too little guidance information to the generator, we choose to use Wasserstein loss to enhance the generator’s guidance. At the same time, in order to make the loss work, we carefully design a discriminator network corresponding to Wasserstein loss. The improved model is named WRGAN, which means that it is an improvement of RelGAN with Wasserstein loss.
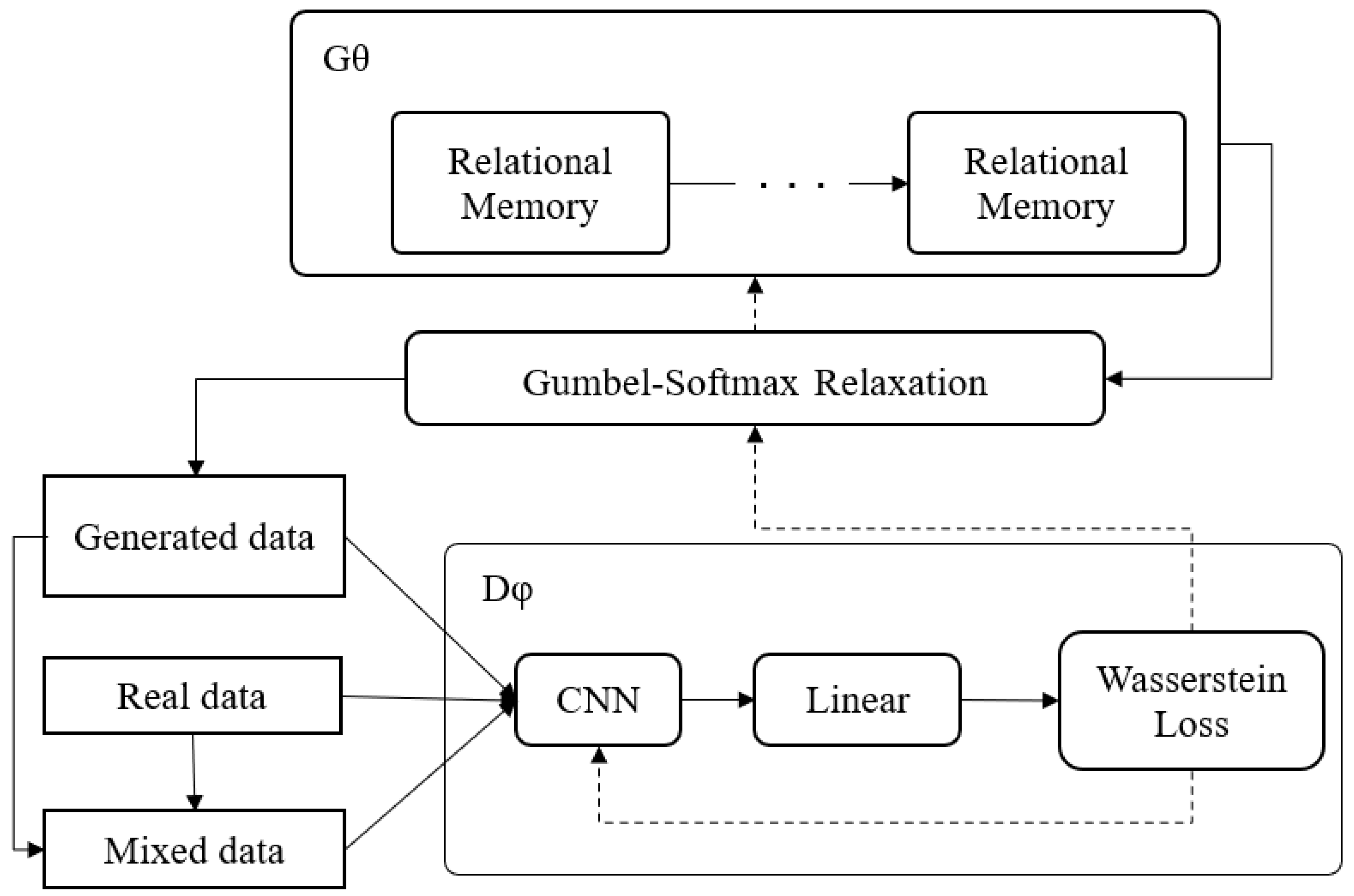
3.1. Overall Framework
The overall framework of WRGAN is shown in
Figure 1. It can be divided into three parts: a relational-memory-based generator, Gumbel–Softmax relaxation, and a one-dimensional convolution-based discriminator. After the generator passes standard maximum likelihood estimation (MLE) training for several epochs, the network starts adversarial training. According to RelGAN, for each
at time
t, we can get the updated memory
:
where
is the Softmax function, and
and
V are the query, key, and value vectors. Then, the output of generator
is given by:
where
is combinations of skip connections, multi-layer perceptron (MLP), gated operations, and/or pre-Softmax linear transformations [
5].
After getting the generator output
, we put
into Gumbel–Softmax; then, we can get the generated data
, defined as:
where
is softmax function, and
is defined as:
and
is a tunable parameter; in this work, we set the value of
as 100.
Then, we put the generated data, the real data, and the mixed data into the discriminator to get the loss. The loss of the discriminator represents the relative distance between the distribution of the generated data and the real data. Finally, the model will adjust the network parameters through loss.
3.2. Rebuilding the Discriminator
The proposed discriminator framework is shown in
Figure 2, and the parameters are shown in
Table 1. We choose one-hot as the input form, and the input shape is [Batch size, Vocabulary size, Max length]. The first layer is a 1D convolutional [
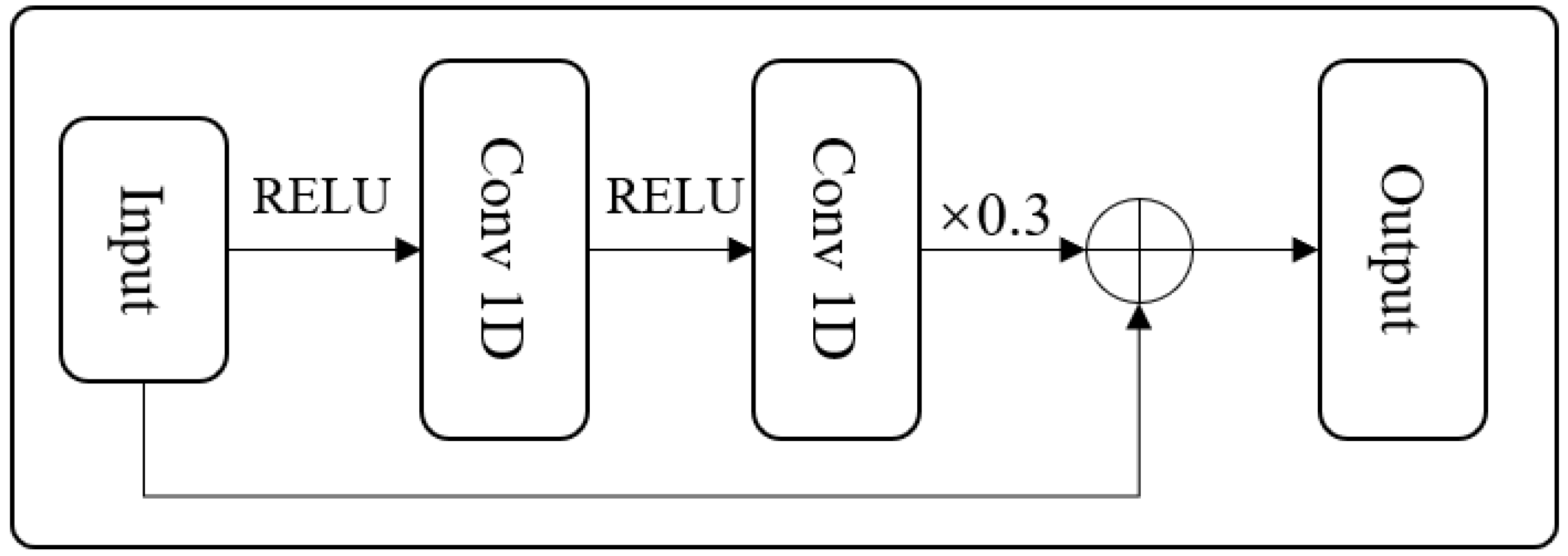
25] layer for dimension conversion. The second layer is three groups of Resblock layers with different one-dimensional convolution kernel sizes. The structure of Resblock [
12] is shown in
Figure 3. The one-dimensional convolution kernel shapes are the same as in the Resblock. The sizes of the three groups of convolution kernels are
, and the padding is
. The Resblock [
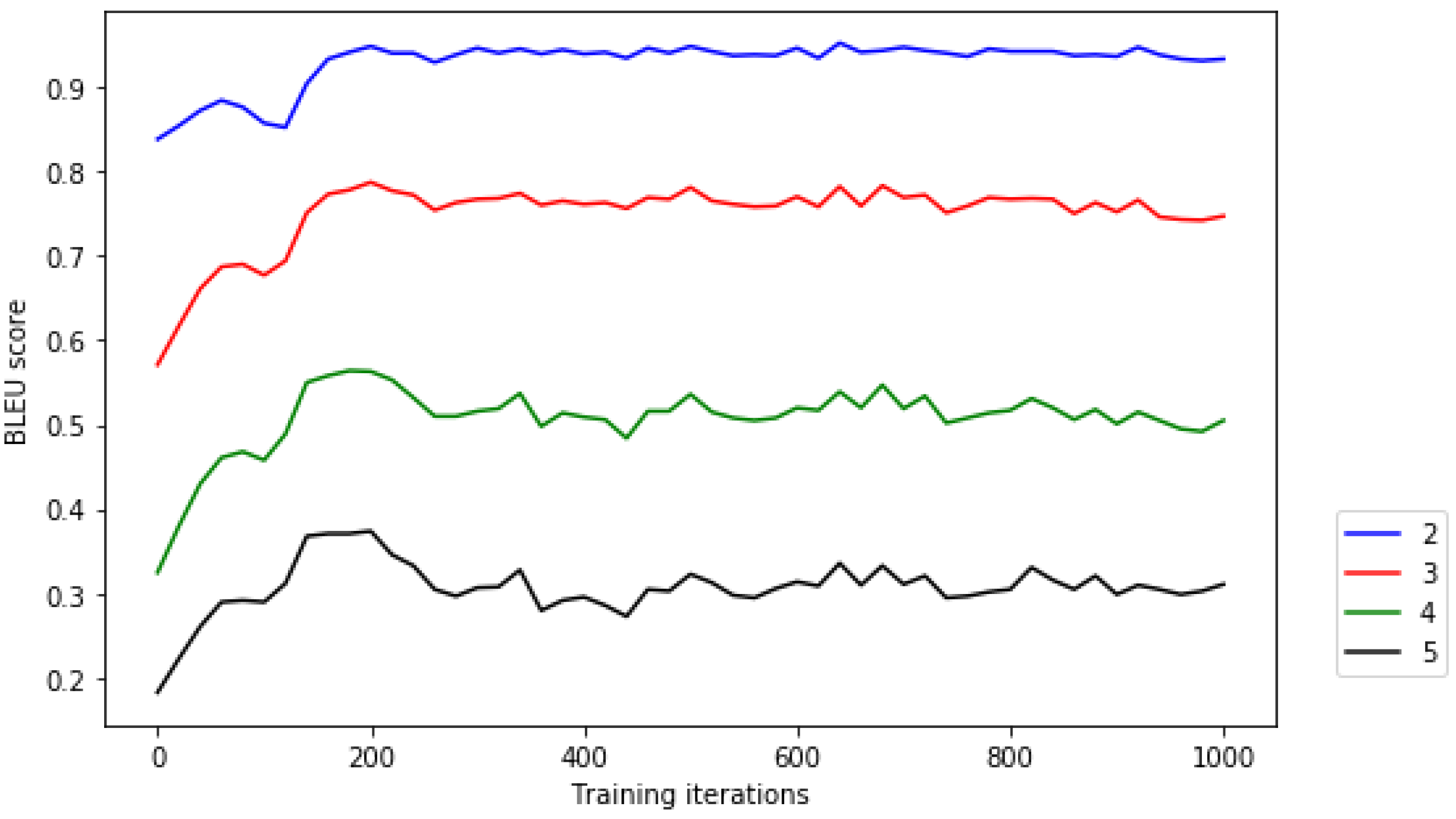
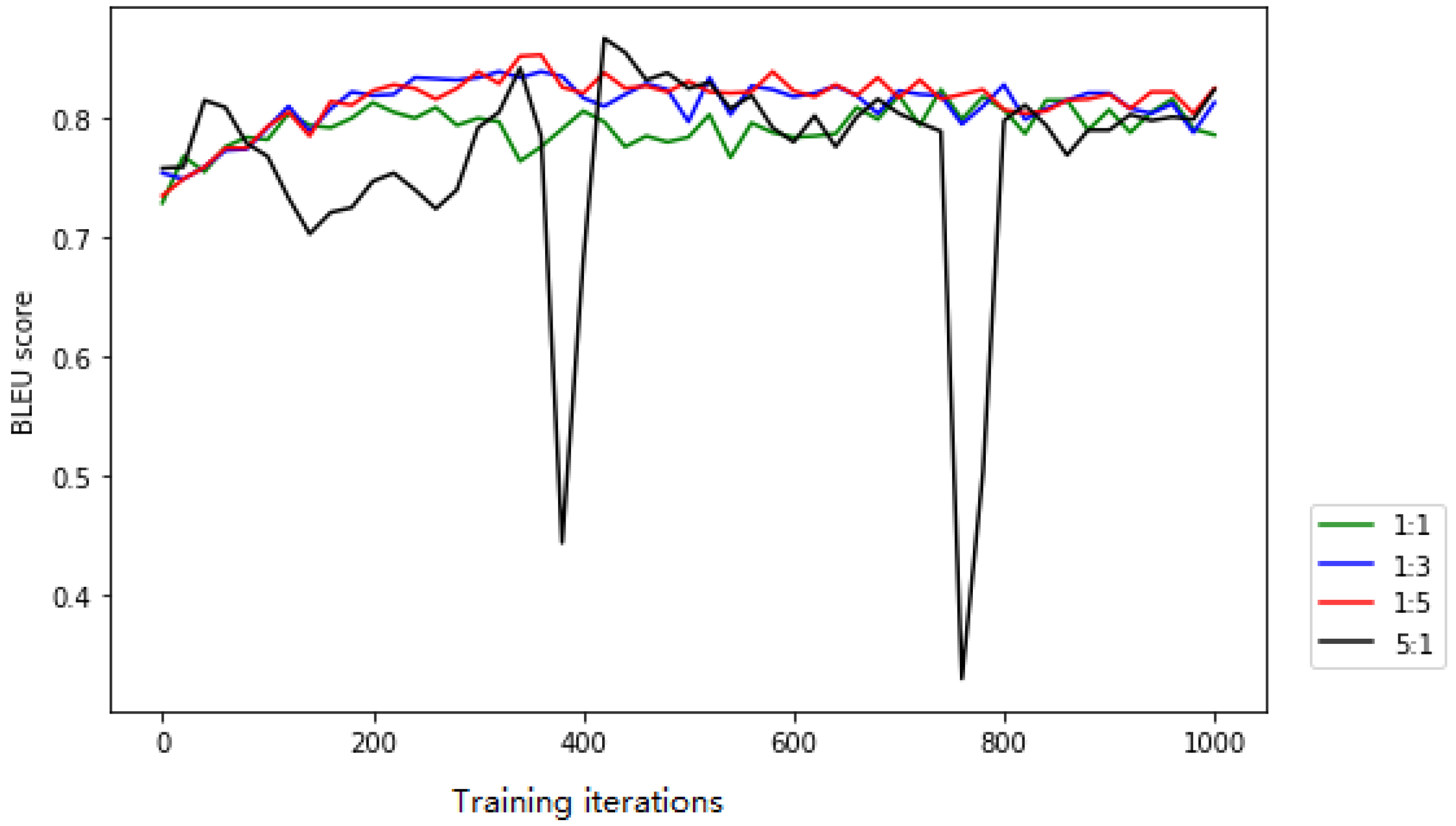
26] also contains a hyperparameter dimension (Dim). Different data sizes correspond to different dimensions; a detailed analysis of the impact of the parameters on the model can be found in
Section 4.6.1. Then, the three channels are concatenated with different convolution kernel sizes. One thing to note is that the two linear layers do not add an activation function.
We assume that the weight of the convolutional layer is
, where
either for the real input
or for the generated input
. For real data, the distributed representation [
27]
is:
The distributed representation of the generated data is:
3.3. Network Training
3.3.1. Loss Function
In this work, we use gradient penalty Wasserstein loss. According to WGAN-GP, adding a gradient penalty will avoid all network parameters approaching two extremes so that the weights can be evenly distributed in a specific interval. The gradient penalty ensures the stability of adversarial training. The discriminator loss can be defined as:
where
is a mixture of the real data and generated data.
is called the penalty coefficient. All experiments in this paper use
. The generator loss is given by:
If we put (6) and (7) into (8) and (9), the
and
will be
where
is obtained by randomly mixing real data and generated data.
3.3.2. Training Parameters
As we were limited by hardware equipment, during the training process, we set the batch size to 64. We used the Adam [
28] optimizer during the adversarial training process, the learning rate of the generator and the discriminator were both 1 × 10
, the L2 regularization weight decay was 0.01 [
29], and the dropout of the discriminator was 0.25. The maximum number of iterations was 2000, and the generator embedding [
30,
31] dimension was 32.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








