
Domain-Adversarial Based Model with Phonological Knowledge for Cross-Lingual Speech Recognition

 ,
,  and
and
Abstract
:1. Introduction
2. Related Work
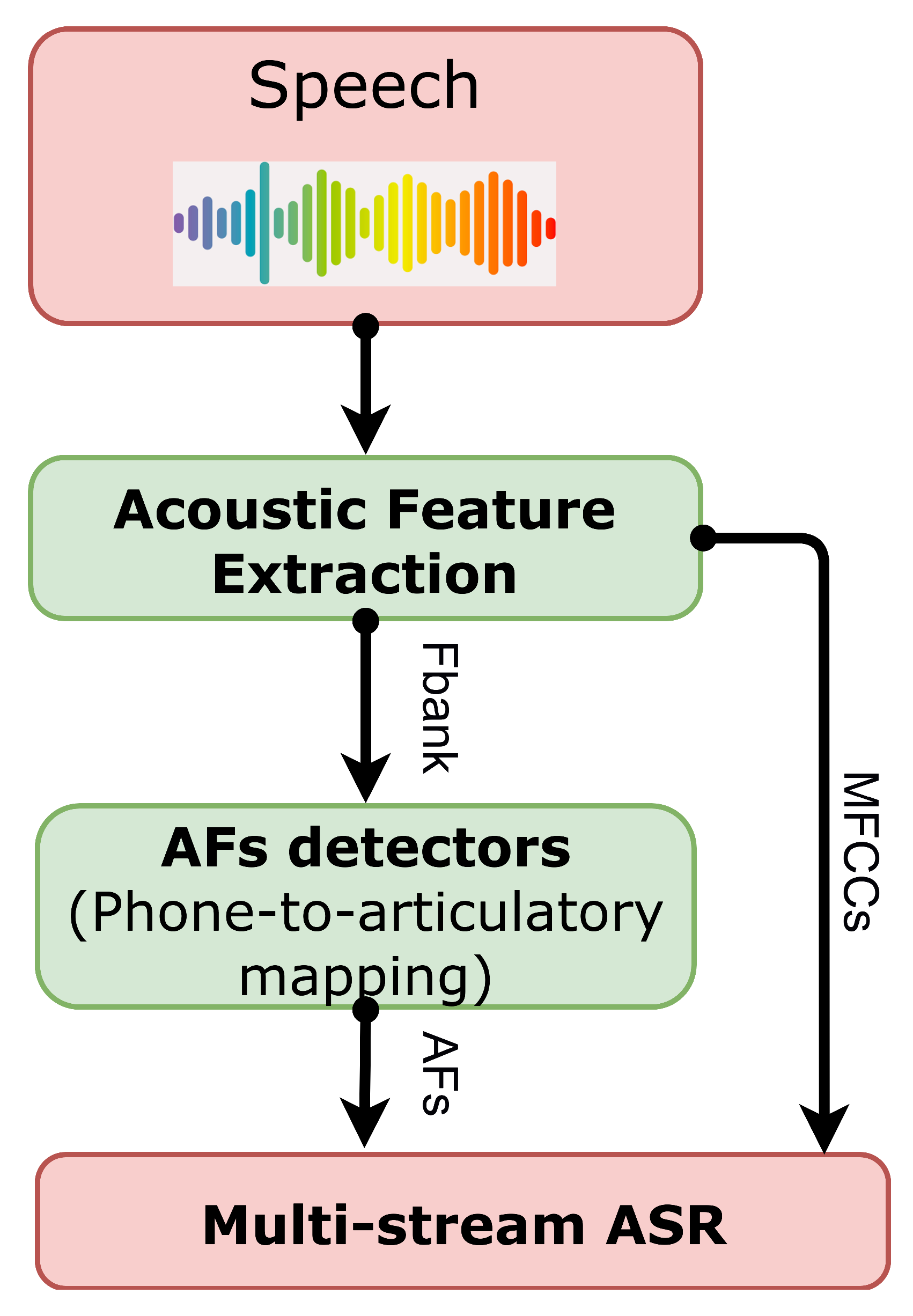
3. AFs Detectors
3.1. Phonological Attributes
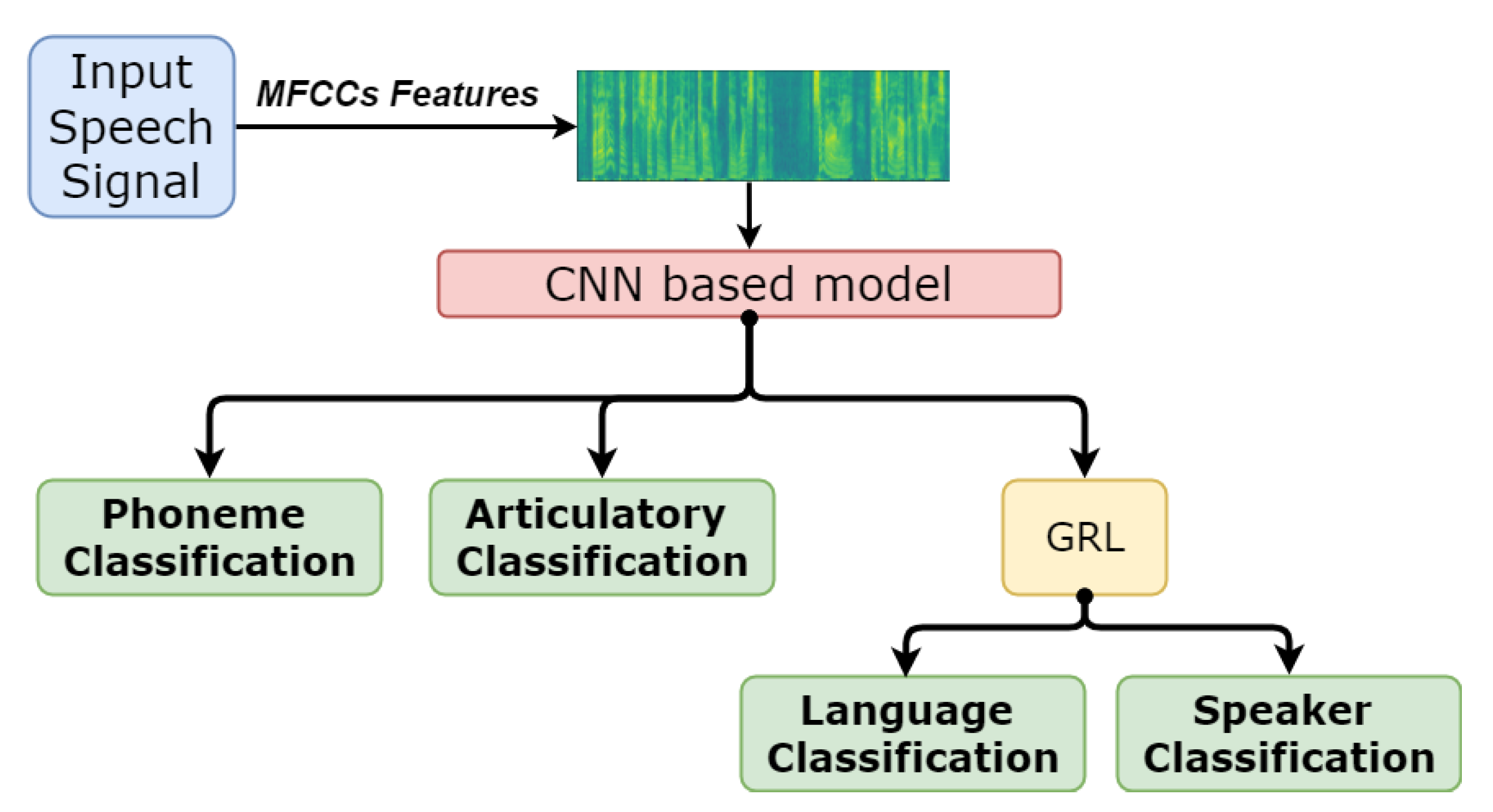
3.2. Domain-Adversarial Modeling: Integrating Phonological Knowledge
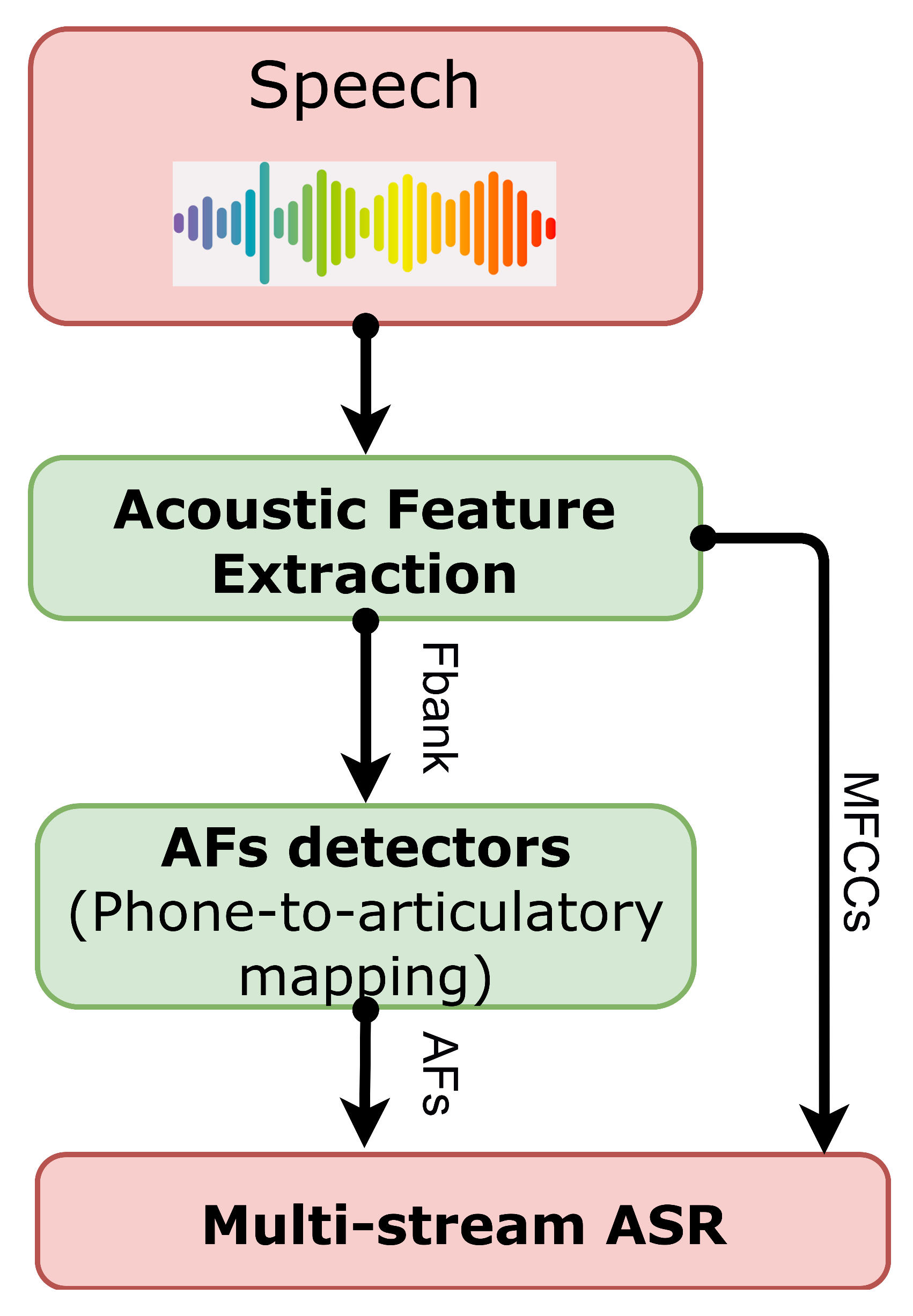
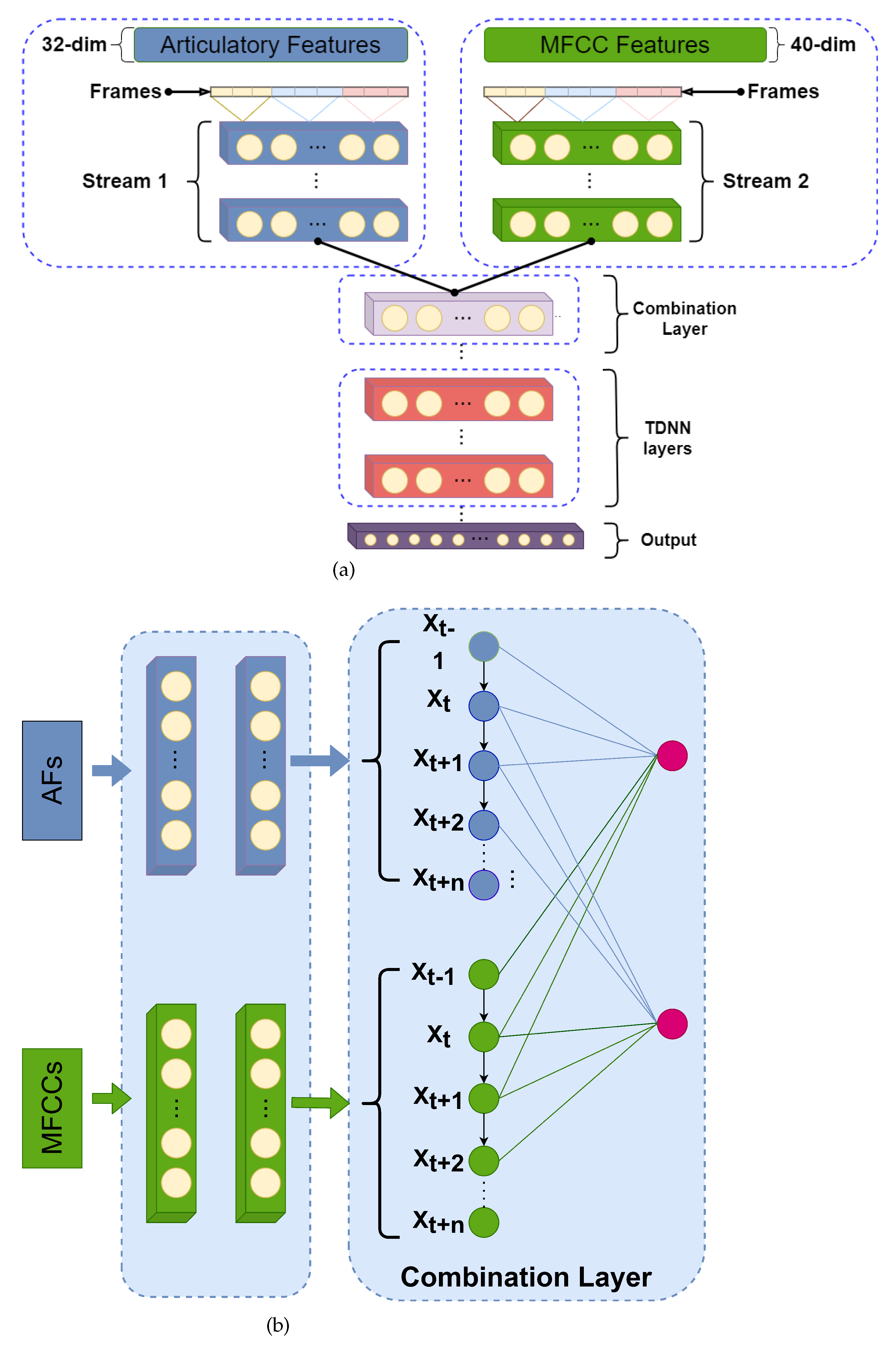
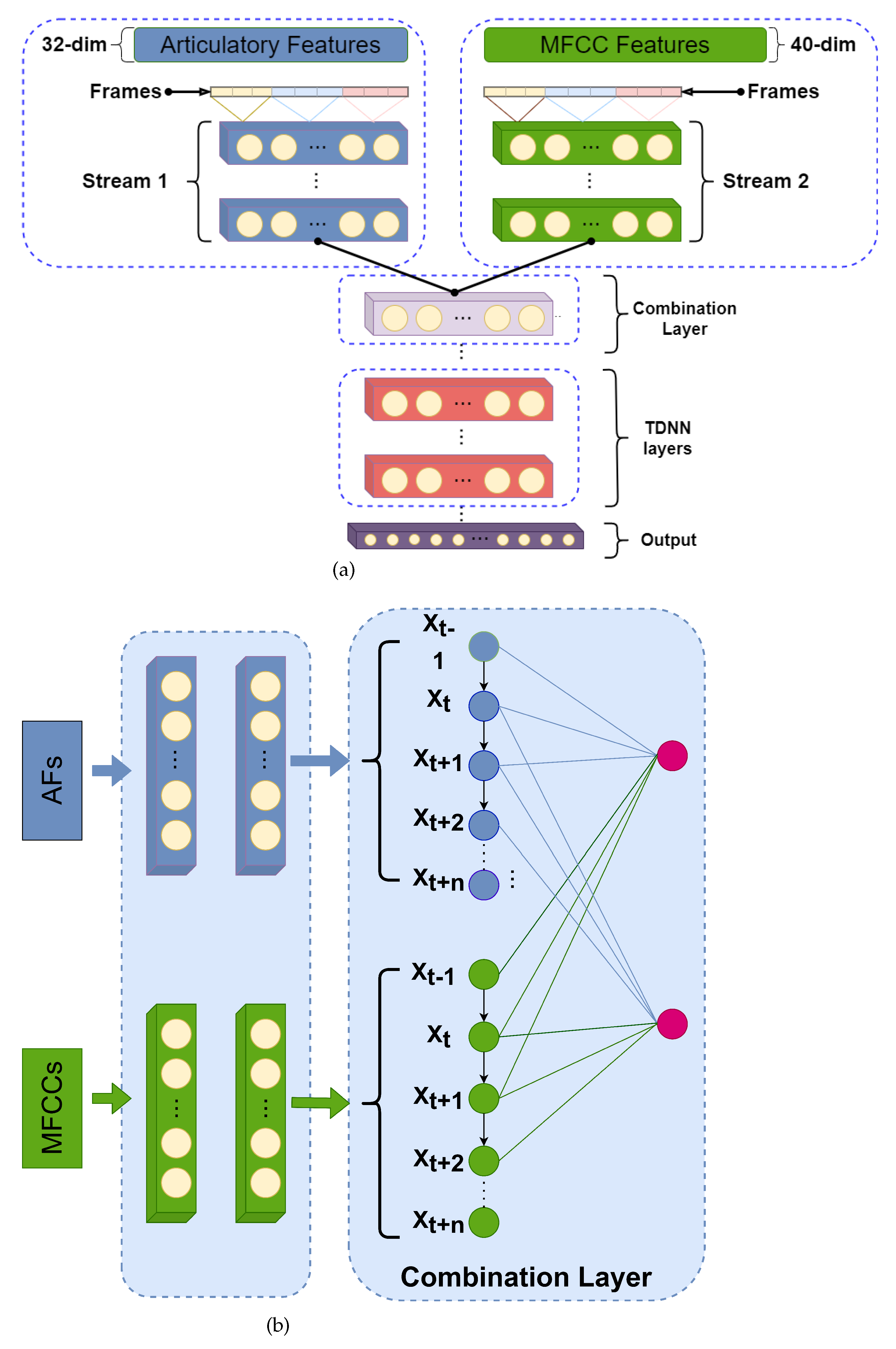
4. Multi-Stream ASR Framework
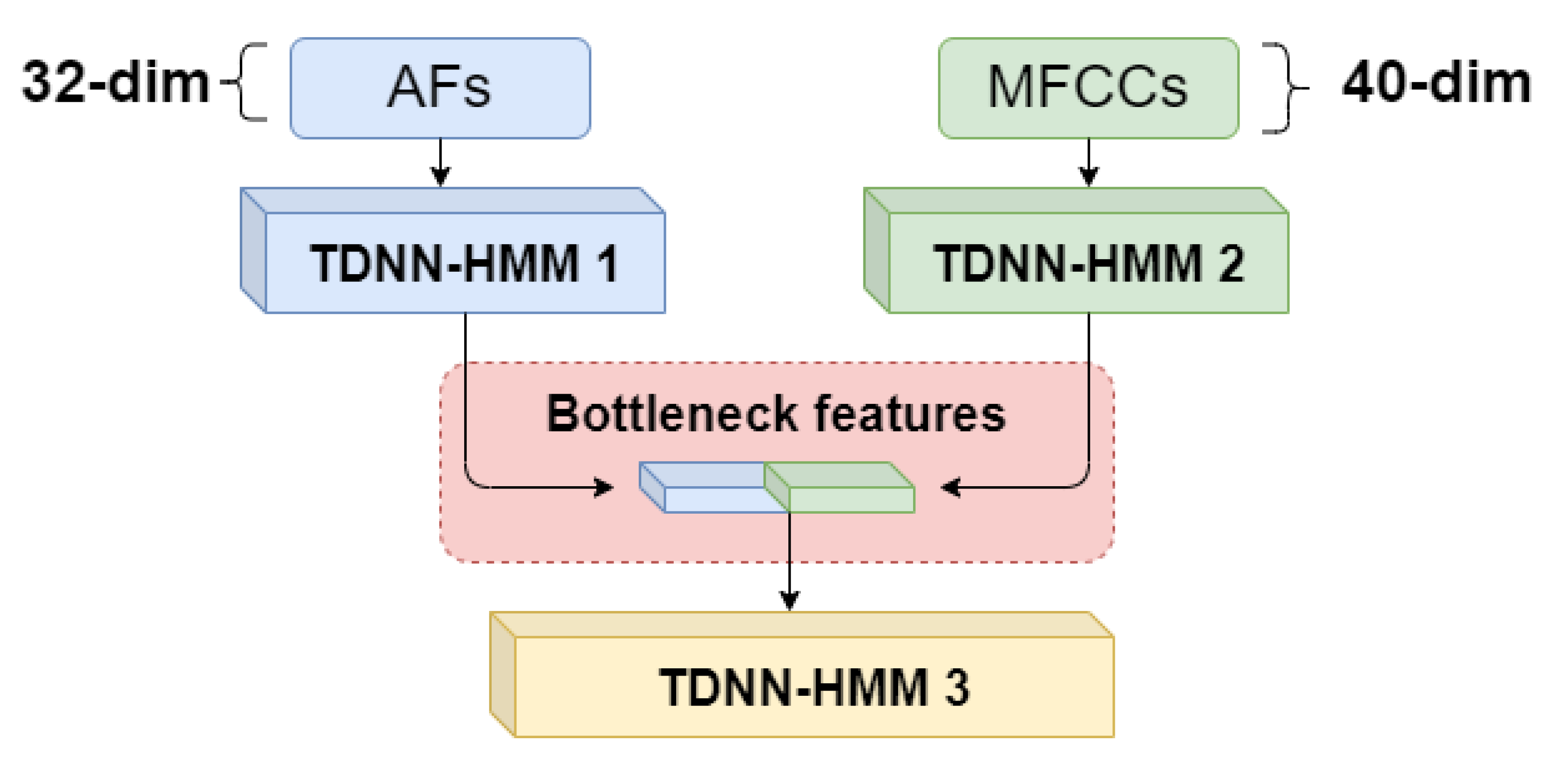
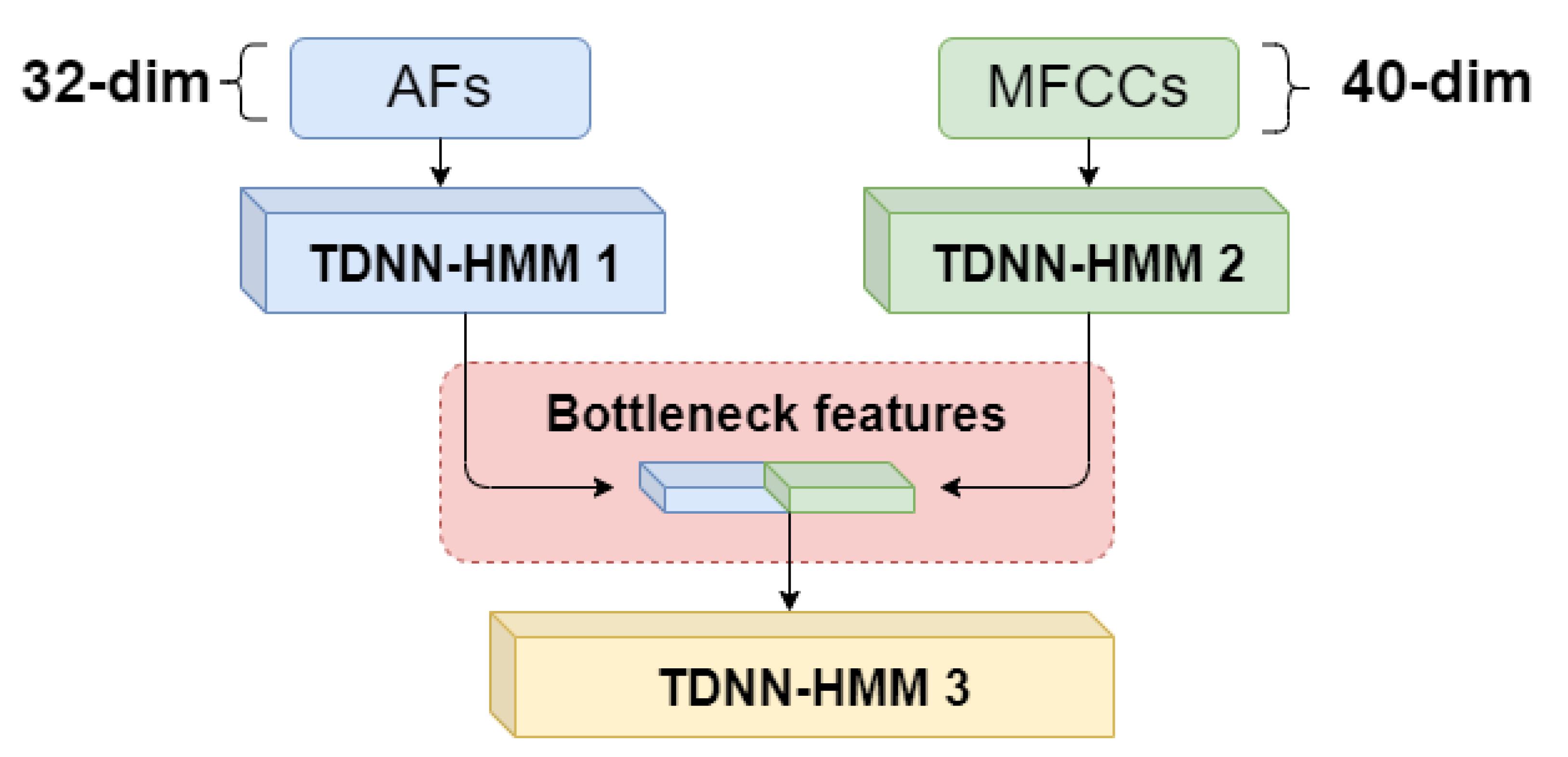
- Parallel-mode: the parallel-mode multi-stream ASR framework is shown in Figure 4. Following the standard Kaldi recipe, The Time Delayed Neutral Network-Hidden Markov Model (TDNN-HMM) is considered the ASR model. First, two TDNN-HMM networks with different features (i.e., MFCCs and AFs) are trained. Then, the bottleneck features from the single TDNN-HMM are taken to concatenate into a later feature vector. This feature vector is used to train the final TDNN-HMM network. The bottleneck features (BNF1 and BNF2) are extracted from the last batch-norm layer following the approach from [27], and the bottleneck dimension is set to a 100 dimension. All the layers in parallel mode are standard TDNN layers.
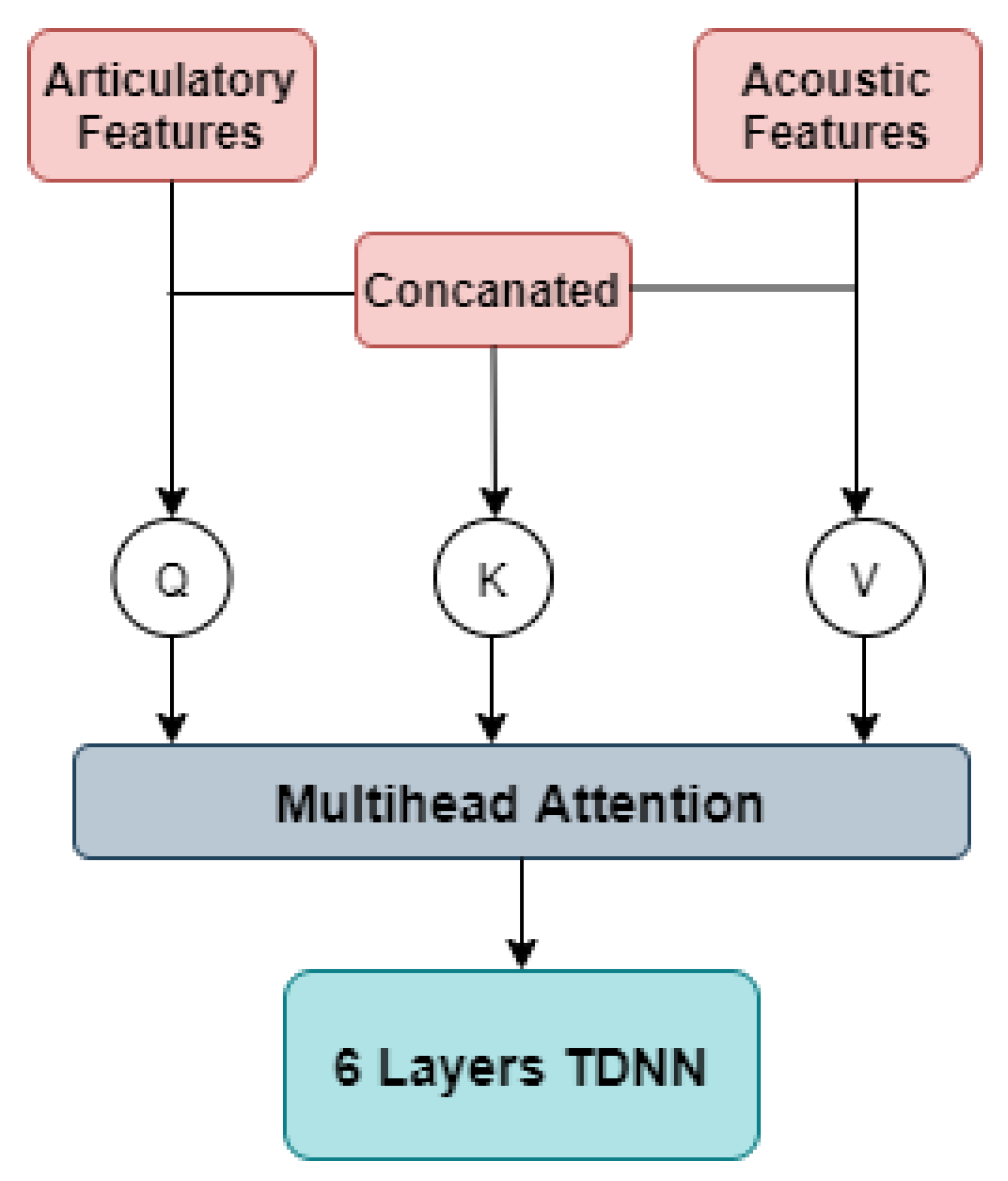
- MHA-mode: Multihead attention (MHA) based fusion method is also used in this paper, which is shown in Figure 6. The attention mechanism allows a neural network to capture speech representation from different inputs. The attention score for each is calculated as:In our experiments, the Q is represented using MFCCs, the K is represented using AFs and the concatenated features are used as V. After fusing those features, a 6-layers TDNN-HMM model is used to train the ASR.
5. Experimental Setup
5.1. Train and Test Data Sets
5.2. AFs Detectors
5.3. Comparison Approaches
- Baseline: the TDNN-HMM with LF-MMI loss function using MFCCs is trained as the baseline.
- TDNN: The parallel-mode uses the feature stream from two TDNN-HMMs. By training a new TDNN-HMM with double parameters (i.e., double number of parameters in hidden layers and units), we want to verify that the improvement of the parallel-mode is not because of the increasing of parameters. To avoid over-fitting, dropout and L1 regularization are applied.
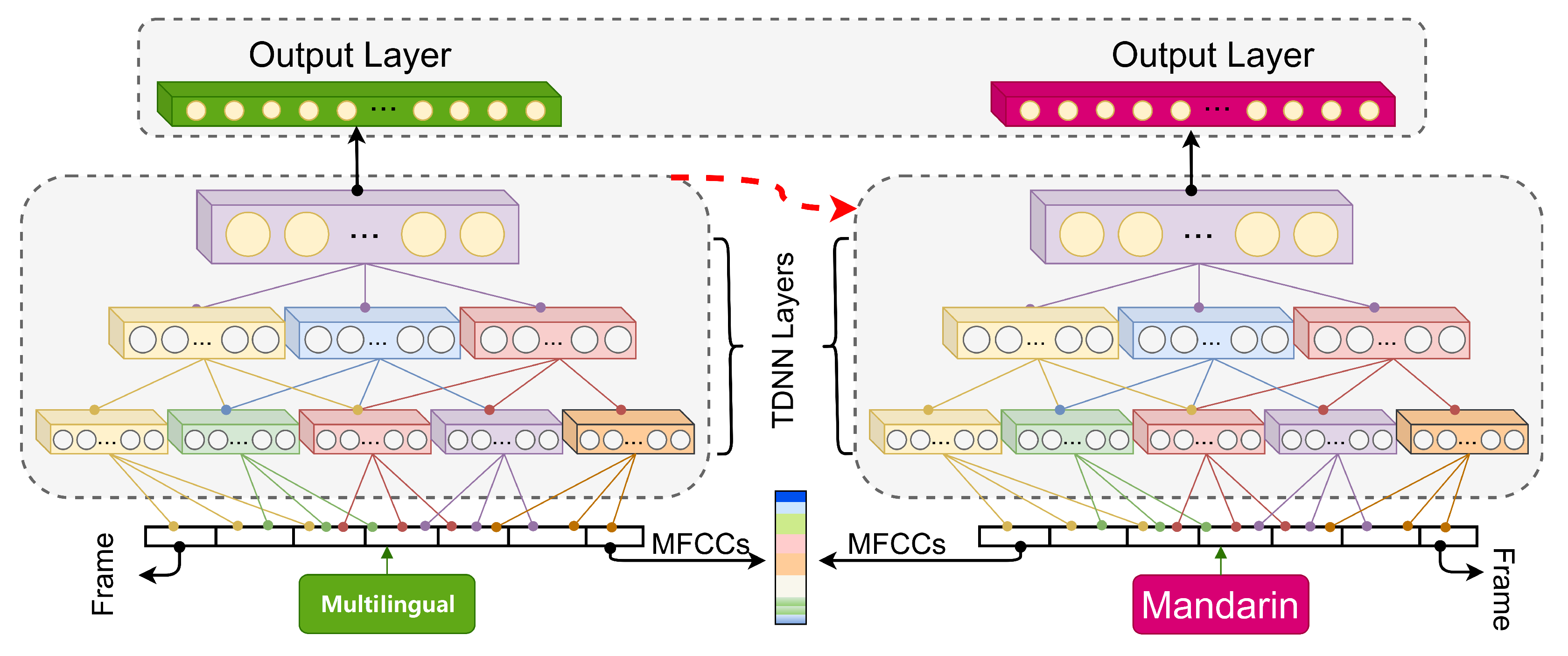
- TDNN-adapted: As shown in Figure 7, a transfer learning-based cross-lingual approach is developed, which is denoted as “TDNN-adapted”. Firstly, an English TDNN-HMM is trained using the LF-MMI loss function, then the output layer is chopped out and replaced by one corresponding to the Mandarin target units. The whole model is retrained by Mandarin while the transferred layer has a smaller learning rate [32].
- Feature concatenated approach: The MFCCs and AFs are concatenated into one feature vector directly. Then the concatenated features are used to train the TDNN-HMM ASR model.
- Lattice combination approach: Two word-based lattices from two TDNN-HMM systems (i.e., MFCCs ASR system and AFs ASR system) are combined. Then the combined lattices are used to compute the final results.
- Bottleneck features: To better illustrate our AFs, we take the bottleneck features for comparison. First, we train a TDNN-HMM model with LF-MMI loss function using source languages and finally we extracted frame-level embeddings from the well-trained TDNN-HMM model on target language.
5.4. Experiments Configuration
6. Results and Analysis
6.1. Performance on AFs Detectors
6.2. Effectiveness of the Cross-Lingual AFs on ASR
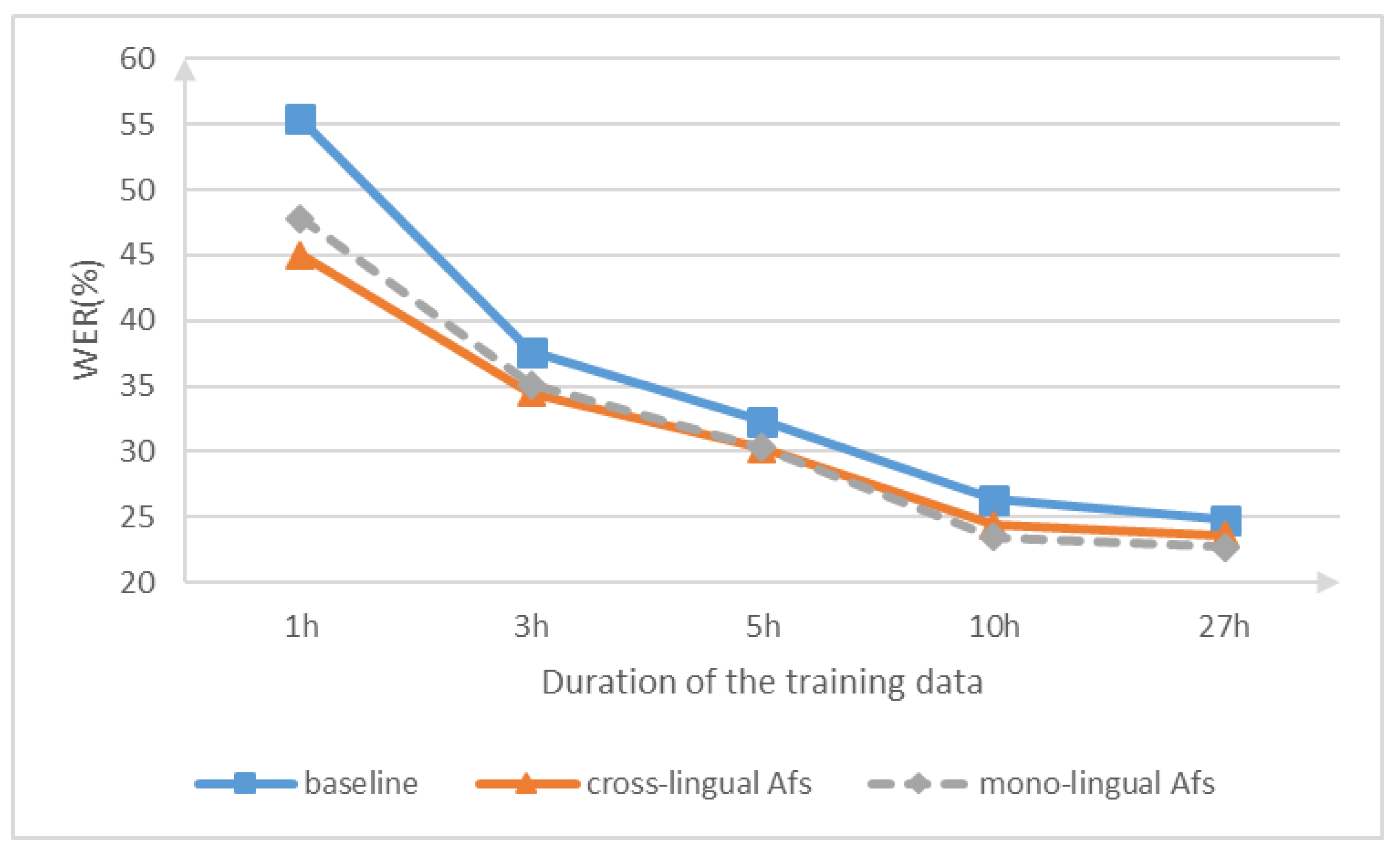
6.3. Performance on Extremely Low-Resource Training Data
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| ASR | Automatic Speech Recognition |
| AFs | Articulatory Features |
| CNN | Convolutional Neural Networks |
| DNN | Deep Neural Networks |
| DANN | Domain adversarial Neural Networks |
| MHA | Multi head Attention |
| WER | Word Error Rate |
| Fbank | Filterbank |
References
- Baevski, A.; Hsu, W.N.; Conneau, A.; Auli, M. Unsupervised Speech Recognition. arXiv 2021, arXiv:2105.11084. [Google Scholar]
- Mitra, V.; Sivaraman, G.; Nam, H.; Espy-Wilson, C.; Saltzman, E. Articulatory features from deep neural networks and their role in speech recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014. [Google Scholar]
- Wang, L.; Chen, H.; Li, S.; Meng, H.M. Phoneme-level articulatory animation in pronunciation training. Speech Commun. 2012, 54, 845–856. [Google Scholar] [CrossRef]
- Lin, Y.; Wang, L.; Dang, J.; Li, S.; Ding, C. End-to-End Articulatory Modeling for Dysarthric Articulatory Attribute Detection. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 7349–7353. [Google Scholar]
- Papcun, G.; Hochberg, J.; Thomas, T.R.; Laroche, F.; Zacks, J.; Levy, S. Inferring articulation and recognizing gestures from acoustics with a neural network trained on X-ray microbeam data. J. Acoust. Soc. Am. 1992, 92, 688–700. [Google Scholar] [CrossRef] [PubMed]
- Schroeter, J.; Sondhi, M.M. Techniques for estimating vocal-tract shapes from the speech signal. IEEE Trans. Speech Audio Process. 1994, 2, 133–150. [Google Scholar] [CrossRef]
- Merkx, D.; Scharenborg, O. Articulatory Feature Classification Using Convolutional Neural Networks. In Proceedings of the Eighth Annual Conference of the International Speech Communication Association (Interspeech), Hyderabad, India, 2–6 September 2018; pp. 2142–2146. [Google Scholar] [CrossRef] [Green Version]
- Manjunath, K.; Rao, K.S. Improvement of phone recognition accuracy using articulatory features. Circuits Syst. Signal Process. 2018, 37, 704–728. [Google Scholar] [CrossRef]
- Wikipedia Contributors. International Phonetic Alphabet—Wikipedia, The Free Encyclopedia. 2020. Available online: https://en.wikipedia.org/w/index.php?title=International_Phonetic_Alphabet&oldid=1060663021 (accessed on 28 October 2020).
- Mitra, V.; Wang, W.; Bartels, C.; Franco, H.; Vergyri, D. Articulatory information and multiview features for large vocabulary continuous speech recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5634–5638. [Google Scholar]
- Siniscalchi, S.M.; Reed, J.; Svendsen, T.; Lee, C.H. Universal attribute characterization of spoken languages for automatic spoken language recognition. Comput. Speech Lang. 2013, 27, 209–227. [Google Scholar] [CrossRef]
- Duan, R.; Kawahara, T.; Dantsuji, M.; Zhang, J. Articulatory modeling for pronunciation error detection without non-native training data based on DNN transfer learning. IEICE Trans. Inf. Syst. 2017, 100, 2174–2182. [Google Scholar] [CrossRef] [Green Version]
- Lee, C.H.; Clements, M.A.; Dusan, S.; Fosler-Lussier, E.; Johnson, K.; Juang, B.H.; Rabiner, L.R. An overview on automatic speech attribute transcription (ASAT). In Proceedings of the Eighth Annual Conference of the International Speech Communication Association, Antwerp, Belgium, 27–31 August 2007. [Google Scholar]
- Krishna, H.; Gurugubelli, K.; V, V.V.R.; Vuppala, A.K. An Exploration towards Joint Acoustic Modeling for Indian Languages: IIIT-H Submission for Low Resource Speech Recognition Challenge for Indian Languages. In Proceedings of the Interspeech 2018, Hyderabad, India, 2–6 September 2018; pp. 3192–3196. [Google Scholar] [CrossRef] [Green Version]
- Cetin, O.; Kantor, A.; King, S.; Bartels, C.; Magimai-Doss, M.; Frankel, J.; Livescu, K. An articulatory feature-based tandem approach and factored observation modeling. In Proceedings of the 2007 IEEE International Conference on Acoustics, Speech and Signal Processing, Honolulu, HI, USA, 15–20 April 2007; Volume 4, pp. 4–645. [Google Scholar]
- Li, J.; Zheng, R.; Xu, B. Investigation of cross-lingual bottleneck features in hybrid ASR systems. In Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, Singapore, 14–18 September 2014; pp. 1395–1399. [Google Scholar]
- Sadhu, S.; Li, R.; Hermansky, H. M-vectors: Sub-band Based Energy Modulation Features for Multi-stream Automatic Speech Recognition. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 6545–6549. [Google Scholar] [CrossRef]
- Mallidi, S.H.; Hermansky, H. Novel neural network based fusion for multistream ASR. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 5680–5684. [Google Scholar]
- Yuen, I.; Davis, M.H.; Brysbaert, M.; Rastle, K. Activation of articulatory information in speech perception. Proc. Natl. Acad. Sci. USA 2010, 107, 592–597. [Google Scholar] [CrossRef] [Green Version]
- Browman, C.P.; Goldstein, L. Articulatory phonology: An overview. Phonetica 1992, 49, 155–180. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Association, I.P.; Staff, I.P.A.; Press, C. Handbook of the International Phonetic Association: A Guide to the Use of the International Phonetic Alphabet; Cambridge University Press: Cambridge, UK, 1999. [Google Scholar]
- Qu, L.; Weber, C.; Lakomkin, E.; Twiefel, J.; Wermter, S. Combining Articulatory Features with End-to-End Learning in Speech Recognition. In Proceedings of the International Conference on Artificial Neural Networks, Rhodes, Greece, 4–7 October 2018; pp. 500–510. [Google Scholar]
- Lin, J.; Xie, Y.; Gao, Y.; Zhang, J. Improving Mandarin tone recognition based on DNN by combining acoustic and articulatory features. In Proceedings of the 2016 10th International Symposium on Chinese Spoken Language Processing (ISCSLP), Tianjin, China, 17–20 October 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-Adversarial Training of Neural Networks. J. Mach. Learn. Res. 2016, 17, 1–35. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Kendall, A.; Gal, Y.; Cipolla, R. Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2018, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Veselỳ, K.; Karafiát, M.; Grézl, F.; Janda, M.; Egorova, E. The language-independent bottleneck features. In Proceedings of the 2012 IEEE Spoken Language Technology Workshop (SLT), Miami, FL, USA, 2–5 December 2012; pp. 336–341. [Google Scholar]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An ASR corpus based on public domain audio books. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QLD, Australia, 19–24 April 2015; pp. 5206–5210. [Google Scholar]
- Pratap, V.; Xu, Q.; Sriram, A.; Synnaeve, G.; Collobert, R. MLS: A Large-Scale Multilingual Dataset for Speech Research. In Proceedings of the Interspeech 2020, Shanghai, China, 25–29 October 2020. [Google Scholar] [CrossRef]
- Wang, D.; Zhang, X. Thchs-30: A free chinese speech corpus. arXiv 2015, arXiv:1512.01882. [Google Scholar]
- Povey, D.; Peddinti, V.; Galvez, D.; Ghahremani, P.; Manohar, V.; Na, X.; Wang, Y.; Khudanpur, S. Purely Sequence-Trained Neural Networks for ASR Based on Lattice-Free MMI. In Proceedings of the Interspeech 2016, San Francisco, CA, USA, 8–12 September 2016; pp. 2751–2755. [Google Scholar] [CrossRef] [Green Version]
- Ghahremani, P.; Manohar, V.; Hadian, H.; Povey, D.; Khudanpur, S. Investigation of transfer learning for ASR using LF-MMI trained neural networks. In Proceedings of the 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Okinawa, Japan, 16–20 December 2017; pp. 279–286. [Google Scholar]
- Madikeri, S.; Tong, S.; Zuluaga-Gomez, J.; Vyas, A.; Motlicek, P.; Bourlard, H. Pkwrap: A PyTorch Package for LF-MMI Training of Acoustic Models. arXiv 2020, arXiv:2010.03466. [Google Scholar]
- Kirchhoff, K.; Fink, G.A.; Sagerer, G. Combining acoustic and articulatory feature information for robust speech recognition. Speech Commun. 2002, 37, 303–319. [Google Scholar] [CrossRef]
- Wang, B.; Hu, W.; Li, J.; Zhi, Y.; Li, Z.; Hong, Q.; Li, L.; Wang, D.; Song, L.; Yang, C. OLR 2021 Challenge: Datasets, Rules and Baselines. arXiv 2021, arXiv:2107.11113. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Phone | |||||
|---|---|---|---|---|---|
| Mandarin | English | German | French | ||
| Place | alveolar | n l d t | d t s l ng n | b d s z | h l d n z |
| bilabial | b p m | b p m | p | b m | |
| dental | c iy | th dh | t pf ts | N.A | |
| labiodental | f | f v | f v m | f | |
| palatal | aa o u j q a oo i iz ei uu g ee x v e vv ii | y | C | j J | |
| pos-alveolar | zh r sh ix ch | jh z sh ch zh | S Z tS | S Z | |
| retroflection | er | r er | r | N/A | |
| velar | h | k g w | x N k g | w N g R | |
| glottal | N/A | hh | Q | N/A | |
| nil | all_vowel sil | all_vowel sil | all_vowel sil | all_vowel sil | |
| Manner | approximant | N/A | r y w l | r j I | j w h l |
| fricative | f s sh r x h | sh f jh s th z ch zh v dh | S Z | S Z f | |
| lateral | i | N/A | ts tS pf | N/A | |
| nasal | m ng n | ng n m | m n | N/A | |
| stop | t q j b d ch zh c g k p z | d p k t g b hh | p b t d k g Q | g b d p t | |
| nil | sil all_vowels | sil all_vowels | sil all_vowels | sil all_vowels | |
| Voiced | voiced | oo uu o n ng ei ix a er i vv ee ii iz r m e u iy aa i v | d t g at eh ao uh r z l er uw ow iy ah dh aw aa ey ih m v n w ae jh y s oy ng | all_vowels | 2 6 g b @ E J O N 9 9∼ Z a A∼ e d k j m l o u w U∼∼ y v z |
| unvoiced | s ch p zh z x sh b t g q k c h d j f | sh p f k th b ch zh hh | all_constants | S f h p s t | |
| nil | sil | sil | sil | nil | |
| Height | height | iz vv i iy ix v u uu ii | ih uh uw iy | i i: y y: u: u L l Y U | 6 a |
| mid | N/A | ey aw | 2 2: @ | @ | |
| low | aa a | ae aa oy ay ao ow | a∼ a∼: 6 aU aI | i u y | |
| mid-height | ee e o o | er eh | e e: o o: o∼ o∼: E E: 9 | O E 9 ∼U∼ | |
| mid-low | er ei | ah | 0 | o e | |
| nil | all_constant sil | all_constant sil | all_constant sil | all_constant sil | |
| Round | round | u v uu vv o oo | aw oy ao uh uw iw | y y: u u: Y 2 2: o o o∼o∼: 9 0 OY aU | 2 6 @ 9 9∼o u U∼y |
| unround | ix iy a e ee iz i ii aa er ei | ae ih aa ay eh iy er ah | a a: a∼a∼: 6 aI | E a A∼e i ∼o U∼ | |
| nil | all_constant sil | all_constant sil | all_constant | all_constant sil | |
| Front | front | i ei v iy vv iz ii | ae ih ey ay ei iy | i i: y y: u u: l Y e | 2 6 E 9 9∼a e i y |
| central | a aa er ix | er ah | E OY | @ | |
| back | uu e ee oo o u | aw aa oy ao uh uw ow | u u: U o o: o∼ o∼: O aU aI | O U∼u o A∼ | |
| nil | all_constant sil | all_constant sil | all_constant sil | all_constant sil | |
| Layer | 1 | 2 | Combination Layers | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| Context | {−1,1} | {−1,1} | {Stream-MFCC(−1,0,1),Stream-AFs(−1,0,1)} | {−3,3} | {−3,3} | {−3,3} |
| Utterances | Duration (hours) | |||
|---|---|---|---|---|
| Language | Train | Test | Train | Test |
| Mandarin | 10,893 | 2496 | 27.2 | 6.2 |
| English | 28,539 | - | 100.6 | - |
| French | 32,278 | - | 122.5 | - |
| German | 27,148 | - | 104.6 | - |
| AF Classes | DANN-AF |
|---|---|
| Place | 80.3 |
| Manner | 81.4 |
| Voice | 87.6 |
| Round | 85.5 |
| Height | 80.8 |
| Front | 82.0 |
| Average accuracy | 82.9 |
| Combination Layer Configuration | WER[%] |
|---|---|
| ,,,,, | 24.0 |
| ,,,,, | 24.3 |
| Fully connected layer | 24.7 |
| System | Features | Source Languages | WER[%] |
|---|---|---|---|
| Baseline | MFCCs | - | 24.8 |
| TDNN | MFCCs | - | 24.6 |
| TDNN-adapted | MFCCs | - | 24.3 |
| Parallel-mode | MFCCs + multi-lingual AFs | Multilingual | 23.4 |
| Joint-mode | MFCCs + multi-lingual AFs | Multilingual | 24.0 |
| mha-mode | MFCCs + multi-lingual AFs | Multilingual | 22.5 |
| mha-mode | MFCCs + Bottleneck-features | Multilingual | 23.3 |
| Feature concatenated | MFCCs + cross-lingual AFs | Multilingual | 24.7 |
| Lattice combination | MFCCs + cross-lingual AFs | Multilingual | 24.6 |
| Train Set Size | |||||
|---|---|---|---|---|---|
| System | 1 h | 3 h | 5 h | 10 h | 27 h |
| Baseline | 55.4 | 37.6 | 32.3 | 26.3 | 24.8 |
| Monolingual AFs | 47.8 | 35.1 | 30.3 | 23.5 | 22.2 |
| Cross-lingual AFs | 45.0 | 34.5 | 30.2 | 24.4 | 22.5 |
| System | WER(%) |
|---|---|
| Baseline | 32.4 |
| Cross-lingual AFs | 29.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhan, Q.; Xie, X.; Hu, C.; Zuluaga-Gomez, J.; Wang, J.; Cheng, H. Domain-Adversarial Based Model with Phonological Knowledge for Cross-Lingual Speech Recognition. Electronics 2021, 10, 3172. https://doi.org/10.3390/electronics10243172
Zhan Q, Xie X, Hu C, Zuluaga-Gomez J, Wang J, Cheng H. Domain-Adversarial Based Model with Phonological Knowledge for Cross-Lingual Speech Recognition. Electronics. 2021; 10(24):3172. https://doi.org/10.3390/electronics10243172
Chicago/Turabian StyleZhan, Qingran, Xiang Xie, Chenguang Hu, Juan Zuluaga-Gomez, Jing Wang, and Haobo Cheng. 2021. "Domain-Adversarial Based Model with Phonological Knowledge for Cross-Lingual Speech Recognition" Electronics 10, no. 24: 3172. https://doi.org/10.3390/electronics10243172
APA StyleZhan, Q., Xie, X., Hu, C., Zuluaga-Gomez, J., Wang, J., & Cheng, H. (2021). Domain-Adversarial Based Model with Phonological Knowledge for Cross-Lingual Speech Recognition. Electronics, 10(24), 3172. https://doi.org/10.3390/electronics10243172