
A Method for Class-Imbalance Learning in Android Malware Detection

Abstract
:1. Introduction
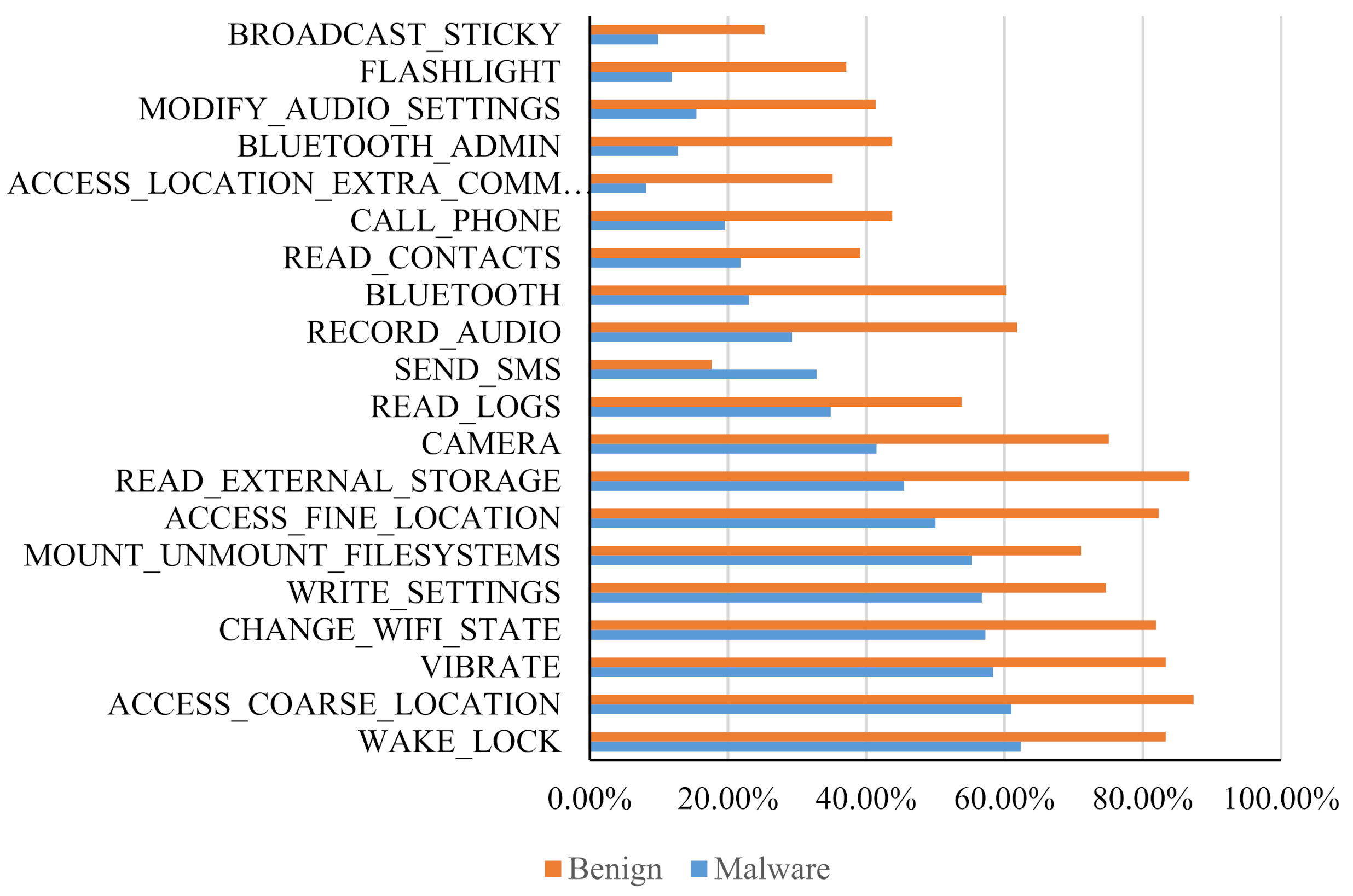
- According to the usage frequency of the same permissions and APIs in benign apps and malware, we selected the features, which represent the difference between malware and benign apps and improve the performance of Android malware detection.
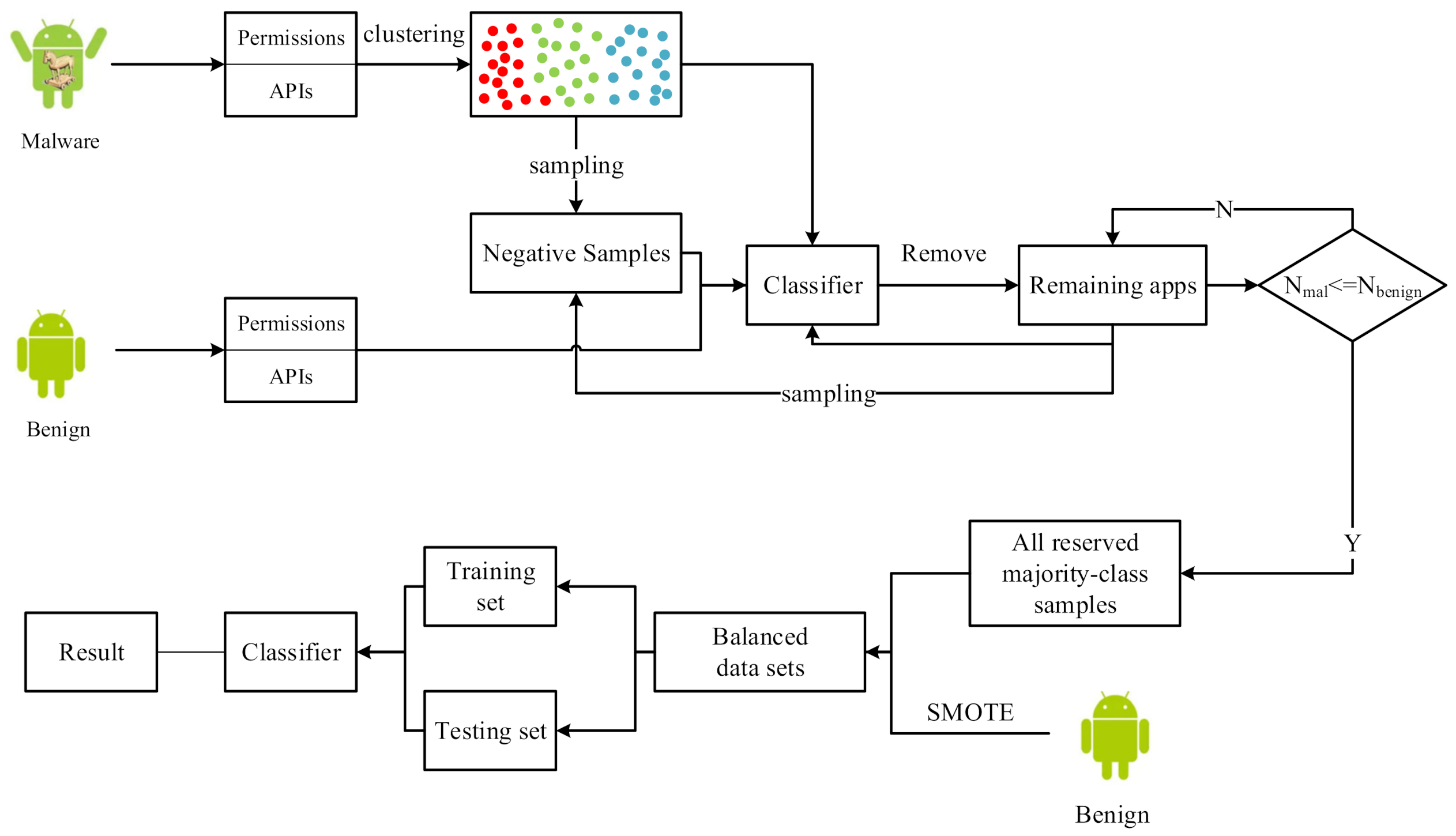
- CIL takes the advantage of the clustering algorithm, under-sampling, and over-sampling. In the process of under-sampling, it focuses on learning malware from different clusters that are not correctly classified to avoid losing important samples and reduce the number of malicious apps. Then, over-sampling is used to generate minority-class samples to construct a balanced training set to improve the performance of the classifier and mitigate the effect of over-fitting. Furthermore, the reduction in the number of training samples helps save the time overhead for machine learning.
- CIL is suitable not only for solving the problem of class imbalance in the field of Android malware detection, but also for unbalanced data sets from UCI. It demonstrates that CIL has generalization capability.
2. Background
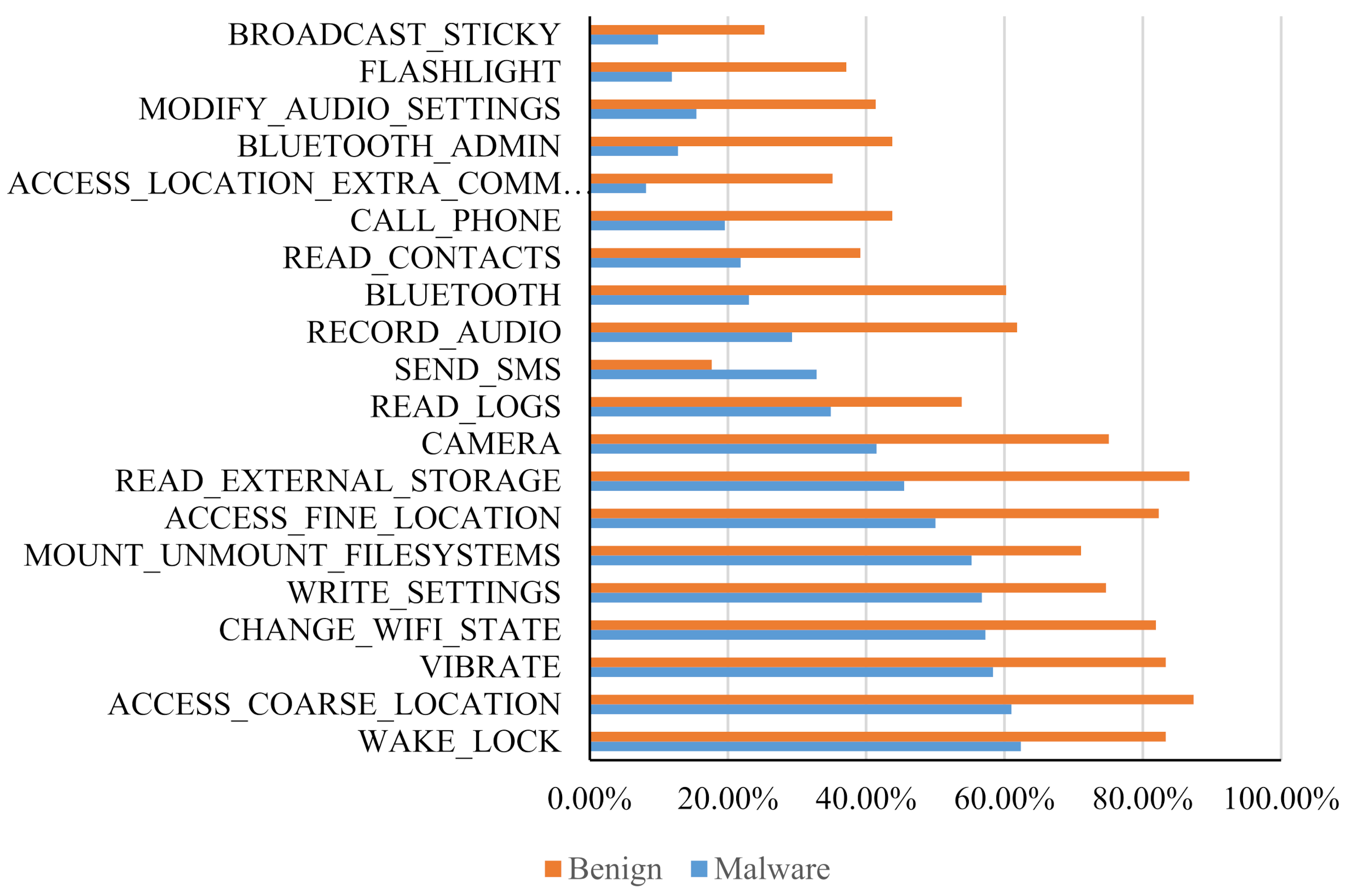
2.1. Feature Extraction and Selection
2.2. Related Work
3. The Proposed Method
| Algorithm 1 Given: Data set, where the minority-class samples are P, and the majority-class samples are N |
Do While
|
4. Experiment
4.1. Experimental Samples and Evaluation Indicators
4.2. The Result of Permissions and APIs as Features
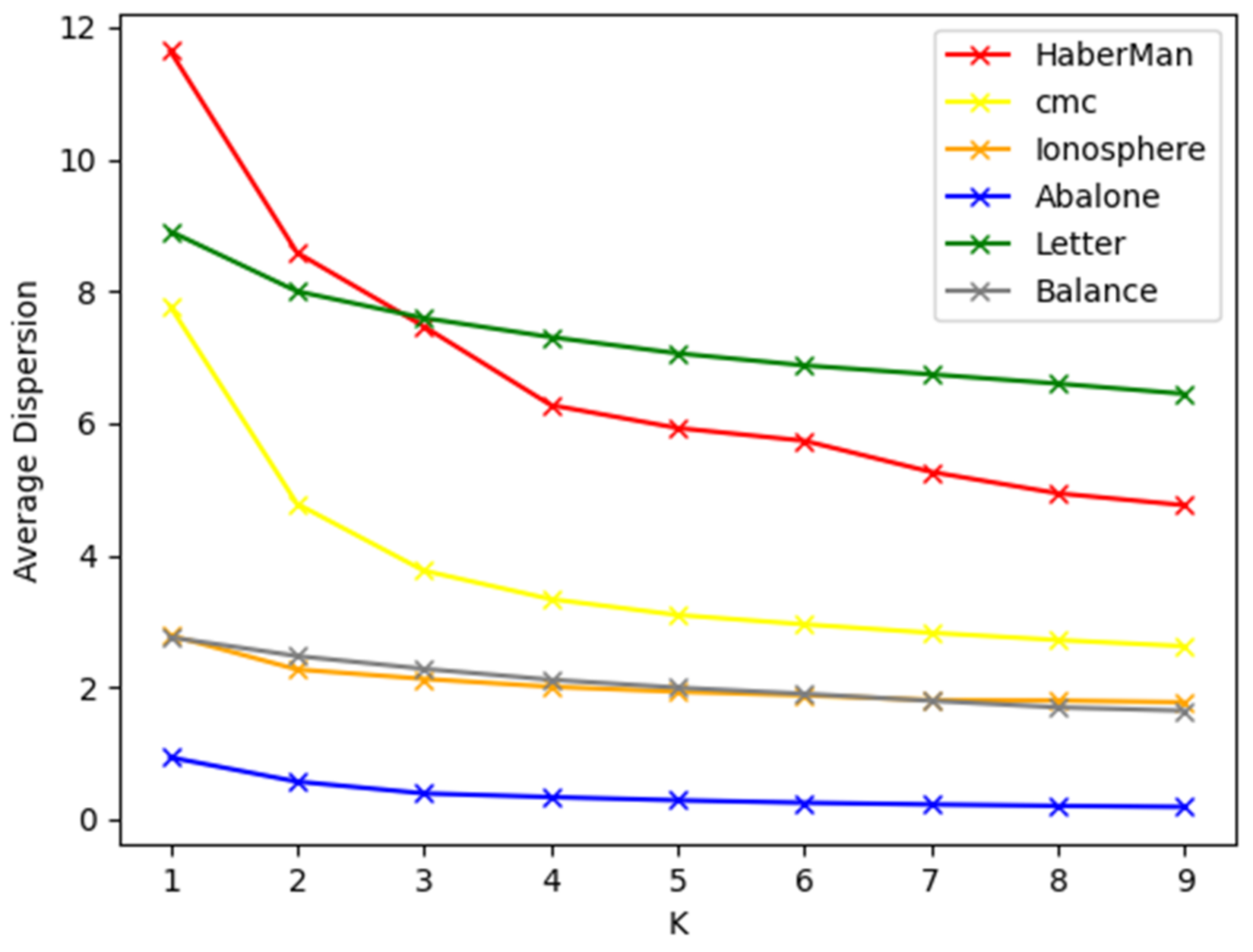
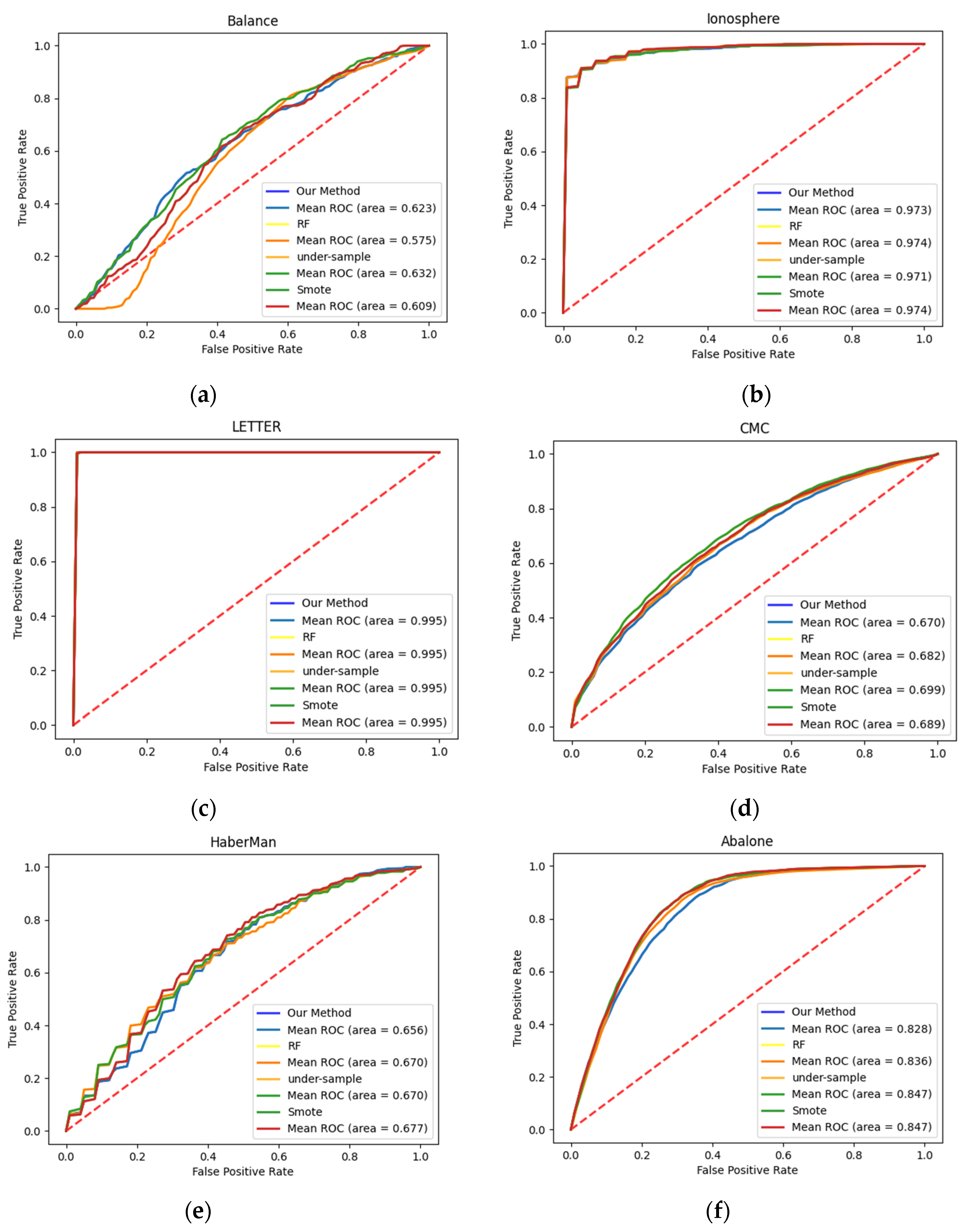
4.3. The Result of the Proposed Method
4.4. Comparisons with Related Work
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Smartphone Market Share. Available online: https://www.idc.com/promo/smartphone-market-share (accessed on 23 January 2021).
- Liu, K.; Xu, S.; Xu, G.; Zhang, M.; Sun, D.; Liu, H. A review of android malware detection approaches based on machine learning. IEEE Access 2020, 8, 124579–124607. [Google Scholar] [CrossRef]
- Gupta, S.; Sethi, S.; Chaudhary, S.; Arora, A. Blockchain based detection of android malware using ranked permissions. Int. J. Eng. Adv. Technol. 2021, 10, 68–75. [Google Scholar] [CrossRef]
- Fan, M.; Wei, W.; Xie, X.; Liu, Y.; Guan, X.; Liu, T. Can we trust your explanations? Sanity checks for interpreters in android malware analysis. IEEE Trans. Inf. Forensics Secur. 2021, 16, 838–853. [Google Scholar] [CrossRef]
- Lopes, J.; Serrão, C.; Nunes, L.; Almeida, A.; Oliveira, J.P. Overview of machine learning methods for Android malware identification. In Proceedings of the 7th International Symposium on Digital Forensics and Security (ISDFS), Barcelos, Portugal, 10–12 June 2019; pp. 1–6. [Google Scholar]
- Liu, X.; Dai, F.; Liu, Y.; Pei, P.; Yan, Z. Experimental investigation of the dynamic tensile properties of naturally saturated rocks using the coupled static—Dynamic flattened Brazilian disc method. Energies 2021, 14, 4784. [Google Scholar] [CrossRef]
- Alswaina, F.; Elleithy, K. Android Malware Family Classification and Analysis: Current Status and Future Directions. Electronics 2020, 9, 942. [Google Scholar] [CrossRef]
- Weiss, G.M.; Provost, F. Learning when training data are costly: The effect of class distribution on tree induction. J. Artif. Intell. Res. 2003, 19, 348–353. [Google Scholar] [CrossRef] [Green Version]
- Nejatian, S.; Parvin, H.; Faraji, E. Using sub-sampling and ensemble clustering techniques to improve performance of imbalanced classification. Neurocomputing 2017, 276, 55–66. [Google Scholar] [CrossRef]
- Chennuru, V.K.; Timmappareddy, S.R. Simulated annealing based undersampling (SAUS): A hybrid multi-objective optimization method to tackle class imbalance. Appl. Intell. 2021. [Google Scholar] [CrossRef]
- Ghori, K.M.; Awais, M.; Khattak, A.S.; Imran, M.; Szathmary, L. Treating class imbalance in non-technical loss detection: An exploratory analysis of a real dataset. IEEE Access 2021, 9, 98928–98938. [Google Scholar] [CrossRef]
- Buda, M.; Maki, A.; Mazurowski, M.A. A systematic study of the class imbalance problem in convolutional neural networks. Neural Netw. 2017, 106, 249–259. [Google Scholar] [CrossRef] [Green Version]
- Sun, C.; Zhang, H.; Qin, S.; Qin, J.; Shi, Y.; Wen, Q. DroidPDF: The obfuscation resilient packer detection framework for android apps. IEEE Access 2020, 8, 167460–167474. [Google Scholar] [CrossRef]
- Duan, Y.; Zhang, M.; Bhaskar, A.V.; Yin, H.; Pan, X.; Li, T.; Wang, X.; Wang, X. Things you may not know about android (Un)packers: A systematic study based on whole-system emulation. In Proceedings of the Network and Distributed System Security Symposium, San Diego, CA, USA, 18–21 February 2018; pp. 18–21. [Google Scholar]
- Lim, K.; Kim, N.Y.; Jeong, Y.; Cho, S.J.; Han, S.; Park, M. Protecting android applications with multiple DEX files against static reverse engineering attacks. Intell. Autom. Soft Comput. 2019, 25, 143–153. [Google Scholar] [CrossRef]
- VirusShare. Available online: http//www.VirusShare.com (accessed on 12 January 2021).
- de Haro-García, A.; Cerruela-García, G.; García-Pedrajas, N. Ensembles of feature selectors for dealing with class-imbalanced datasets: A proposal and comparative study. Inf. Sci. 2020, 540, 89–116. [Google Scholar] [CrossRef]
- Raghuwanshi, B.S.; Shukla, S. Class imbalance learning using underbagging based kernelized extreme learning machine. Neurocomputing 2019, 329, 172–187. [Google Scholar] [CrossRef]
- Khushi, M.; Shaukat, K.; Alam, T.M.; Hameed, I.A.; Uddin, S.; Luo, S.; Yang, X.; Reyes, M.C. A comparative performance analysis of data resampling methods on imbalance medical data. IEEE Access 2021, 9, 109960–109975. [Google Scholar] [CrossRef]
- Alam, T.M.; Shaukat, K.; Hameed, I.A.; Khan, W.A.; Sarwar, M.U.; Iqbal, F.; Luo, S. A novel framework for prognostic factors identification of malignant mesothelioma through association rule mining. Biomed. Signal Process. Control 2021, 68, 102726. [Google Scholar] [CrossRef]
- Batista, G.E.; Prati, R.C.; Monard, M.C. A study of the behavior of several methods for balancing machine learning training data. ACM SIGKDD Explor. Newsl. 2004, 6, 20–29. [Google Scholar] [CrossRef]
- Giffon, L.; Emiya, V.; Kadri, H.; Ralaivola, L. QuicK-means: Accelerating inference for K-means by learning fast transforms. Mach. Learn. 2021, 110, 881–905. [Google Scholar] [CrossRef]
- Yang, Y.; Yeh, H.G.; Zhang, W.; Lee, C.J.; Meese, E.N.; Lowe, C.G. Feature extraction, selection and k-nearest neighbors algorithm for shark behavior classification based on imbalanced dataset. IEEE Sens. J. 2020, 21, 6429–6439. [Google Scholar] [CrossRef]
- Peng, C.; Wu, X.; Yuan, W.; Zhang, X.; Li, Y. MGRFE: Multilayer recursive feature elimination based on an embedded genetic algorithm for cancer classification. IEEE/ACM Trans. Comput. Biol. Bioinform. IEEE ACM 2019, 18, 621–632. [Google Scholar] [CrossRef]
- Almomani, I.M.; Khayer, A.A. A comprehensive analysis of the android permissions system. IEEE Access 2020, 8, 216671–216688. [Google Scholar] [CrossRef]
- Liu, X.Y.; Wu, J.; Zhou, Z.H. Exploratory undersampling for class-imbalance learning. IEEE Trans. Syst. Man Cybern. Part B 2009, 39, 539–550. [Google Scholar]
- Peng, M.; Zhang, Q.; Xing, X.; Gui, T.; Huang, X. Trainable Undersampling for Class-Imbalance Learning. Proc. AAAI Conf. Artif. Intell. 2019, 33, 4707–4714. [Google Scholar] [CrossRef] [Green Version]
- Zheng, M.; Li, T.; Zheng, X.; Yu, Q.; Chen, C.; Zhou, D.; Lv, C.; Yang, W. UFFDFR: Undersampling framework with denoising, fuzzy c-means clustering, and representative sample selection for imbalanced data classification. Inf. Sci. 2021, 576, 658–680. [Google Scholar] [CrossRef]
- Pradipta, G.A.; Wardoyo, R.; Musdholifah, A.; Sanjaya, I.N.H. Radius-SMOTE: A New Oversampling Technique of Minority Samples Based on Radius Distance for Learning from Imbalanced Data. IEEE Access. 2021, 9, 74763–74777. [Google Scholar] [CrossRef]
- Han, H.; Wang, W.-Y.; Mao, B.-H. Borderline-SMOTE: A new over-sampling method in imbalanced data sets learning. In Proceedings of the International Conference on Intelligent Computing, Hefei, China, 23–26 August 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 878–887. [Google Scholar]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; IEEE: Manhattan, NY, USA, 2008; pp. 1322–1328. [Google Scholar]
- Kaur, P.; Gosain, A. Robust hybrid data-level sampling approach to handle imbalanced data during classification. Soft Comput. 2020, 24, 15715–15732. [Google Scholar] [CrossRef]
- Zhu, Y.; Yan, Y.; Zhang, Y.; Zhang, Y. EHSO: Evolutionary Hybrid Sampling in overlapping scenarios for imbalanced learning. Neurocomputing 2020, 417, 333–346. [Google Scholar] [CrossRef]
- Seiffert, C.; Khoshgoftaar, T.M.; Hulse, J.V.; Napolitano, A. RUSBoost: Improving classification performance when training data is skewed. In Proceedings of the International Conference on Pattern Recognition, Tampa, FL, USA, 8–11 December 2008; IEEE: Manhattan, NY, USA, 2008. [Google Scholar]
- O’Brien, R.; Ishwaran, H. A random forests quantile classifier for class imbalanced data. Pattern Recognit. 2019, 90, 232–249. [Google Scholar] [CrossRef]
- Basu, S.; Söderquist, F.; Wallner, B. Proteus: A random forest classifier to predict disorder-to-order transitioning binding regions in intrinsically disordered proteins. Comput.-Aided Mol. Des. 2017, 31, 453–466. [Google Scholar] [CrossRef]
- Zhu, H.J.; You, Z.H.; Zhu, Z.X.; Shi, W.L.; Chen, X.; Cheng, L. DroidDet: Effective and robust detection of android malware using static analysis along with rotation forest model. Neurocomputing 2018, 272, 638–646. [Google Scholar] [CrossRef]
- Tbarki, K.; Said, S.B.; Ksantini, R.; Lachiri, Z. Landmine detection improvement using one-class SVM for unbalanced data. In Proceedings of the 2017 International Conference on Advanced Technologies for Signal and Image Processing (ATSIP), Fez, Morocco, 22–24 May 2017; IEEE: Manhattan, NY, USA, 2017. [Google Scholar]
- Dar, K.S.; Luo, S.; Chen, S.; Liu, D. Cyber threat detection using machine learning techniques: A performance evaluation perspective. In Proceedings of the IEEE International Conference on Cyber Warfare and Security, Islamabad, Pakistan, 20–21 October 2020; IEEE: Manhattan, NY, USA, 2020; pp. 1–6. [Google Scholar]
- Latif, J.; Xiao, C.; Tu, S.; Rehman, S.U.; Imran, A.; Bilal, A. Implementation and use of disease diagnosis systems for electronic medical records based on machine learning: A complete review. IEEE Access 2020, 8, 150489–150513. [Google Scholar] [CrossRef]
- Chawla, N.V. Data mining for imbalanced datasets: An overview. In Data Mining and Knowledge Discovery Handbook; Springer: Boston, MA, USA, 2009; pp. 875–886. [Google Scholar]
- UCI Machine Learning Repository. Available online: http://archive.ics.uci.edu/ml/index.php (accessed on 23 March 2021).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ratio | Precision | Recall | F1 | |
|---|---|---|---|---|
| NB | 1:10 | 0.268 ± 003 | 0.763 ± 007 | 0.395 ± 005 |
| 1:20 | 0.145 ± 001 | 0.765 ± 008 | 0.244 ± 002 | |
| 1:30 | 0.100 ± 001 | 0.765 ± 007 | 0.178 ± 002 | |
| 1:40 | 0.079 ± 000 | 0.771 ± 004 | 0.144 ± 001 | |
| RF | 1:10 | 0.795 ± 013 | 0.464 ± 014 | 0.576 ± 013 |
| 1:20 | 0.737 ± 027 | 0.218 ± 014 | 0.317 ± 018 | |
| 1:30 | 0.657 ± 071 | 0.216 ± 016 | 0.316 ± 024 | |
| 1:40 | 0.631 ± 061 | 0.192 ± 011 | 0.286 ± 012 | |
| KNN | 1:10 | 0.581 ± 014 | 0.615 ± 015 | 0.592 ± 012 |
| 1:20 | 0.513 ± 027 | 0.551 ± 018 | 0.523 ± 018 | |
| 1:30 | 0.492 ± 015 | 0.461 ± 012 | 0.466 ± 014 | |
| 1:40 | 0.489 ± 022 | 0.381 ± 016 | 0.421 ± 011 | |
| SVM | 1:10 | 0.787 ± 021 | 0.468 ± 010 | 0.574 ± 011 |
| 1:20 | 0.685 ± 081 | 0.163 ± 020 | 0.254 ± 030 | |
| 1:30 | 0 | 0 | 0 | |
| 1:40 | 0 | 0 | 0 |
| Ratio | Precision | Recall | F1 | |
|---|---|---|---|---|
| NB | 1:10 | 0.310 ± 015 | 0.751 ± 015 | 0.434 ± 012 |
| 1:20 | 0.161 ± 003 | 0.764 ± 009 | 0.265 ± 005 | |
| 1:30 | 0.109 ± 002 | 0.765 ± 008 | 0.191 ± 003 | |
| 1:40 | 0.087 ± 001 | 0.773 ± 006 | 0.157 ± 002 | |
| RF | 1:10 | 0.758 ± 022 | 0.597 ± 020 | 0.655 ± 020 |
| 1:20 | 0.700 ± 016 | 0.491 ± 004 | 0.565 ± 006 | |
| 1:30 | 0.677 ± 030 | 0.396 ± 016 | 0.485 ± 014 | |
| 1:40 | 0.671 ± 018 | 0.367 ± 020 | 0.463 ± 018 | |
| KNN | 1:10 | 0.215 ± 006 | 0.861 ± 014 | 0.344 ± 009 |
| 1:20 | 0.115 ± 003 | 0.842 ± 015 | 0.202 ± 005 | |
| 1:30 | 0.085 ± 003 | 0.838 ± 018 | 0.155 ± 005 | |
| 1:40 | 0.066 ± 002 | 0.837 ± 020 | 0.123 ± 004 | |
| SVM | 1:10 | 0.618 ± 031 | 0.623 ± 010 | 0.612 ± 017 |
| 1:20 | 0.504 ± 020 | 0.601 ± 019 | 0.539 ± 014 | |
| 1:30 | 0.428 ± 015 | 0.552 ± 016 | 0.474 ± 012 | |
| 1:40 | 0.385 ± 020 | 0.518 ± 006 | 0.437 ± 008 |
| Algorithm | Ratio | Precision | Recall | F1 |
|---|---|---|---|---|
| RUS | 1:10 | 0.338 ± 013 | 0.786 ± 025 | 0.469 ± 014 |
| 1:20 | 0.198 ± 006 | 0.796 ± 022 | 0.316 ± 010 | |
| 1:30 | 0.134 ± 006 | 0.789 ± 014 | 0.228 ± 009 | |
| 1:40 | 0.106 ± 005 | 0.788 ± 016 | 0.187 ± 009 | |
| SMOTE | 1:10 | 0.503 ± 024 | 0.713 ± 014 | 0.584 ± 018 |
| 1:20 | 0.315 ± 017 | 0.728 ± 022 | 0.437 ± 017 | |
| 1:30 | 0.227 ± 008 | 0.726 ± 013 | 0.343 ± 009 | |
| 1:40 | 0.181 ± 008 | 0.722 ± 011 | 0.288 ± 010 |
| Dataset | Attribute | Ratio | Size | Positive |
|---|---|---|---|---|
| Abalone | 8 | 9.7 | 4177 | 7 |
| Cmc | 9 | 3.4 | 1473 | Class 2 |
| Balance | 4 | 11.8 | 625 | Balance |
| Letter | 16 | 24.3 | 20,000 | A |
| Ionosphere | 33 | 1.8 | 351 | bad |
| Haberman | 3 | 2.7 | 306 | Class 2 |
| F-Measure | Balance | Ionosphere | Letter |
|---|---|---|---|
| CIL | 0.146 ± 025 | 0.897 ± 007 | 0.989 ± 002 |
| CIL Without K-means | 0.066 ± 027 | 0.896 ± 007 | 0.988 ± 002 |
| Random Forest | 0.000 ± 000 | 0.903 ± 004 | 0.969 ± 002 |
| Random under-sampling | 0.189 ± 006 | 0.893 ± 006 | 0.909 ± 006 |
| SMOTE | 0.151 ± 019 | 0.906 ± 006 | 0.954 ± 004 |
| BalanceCascade | 0.194 ± 011 | 0.905 ± 003 | 0.976 ± 002 |
| F-Measure | Cmc | HaberMan | Abalone |
| CIL | 0.376 ± 015 | 0.383 ± 039 | 0.364 ± 009 |
| CIL Without K-means | 0.364 ± 012 | 0.354 ± 047 | 0.360 ± 013 |
| Random Forest | 0.351 ± 013 | 0.300 ± 015 | 0.120 ± 014 |
| Random under-sampling | 0.458 ± 007 | 0.468 ± 031 | 0.389 ± 003 |
| SMOTE | 0.427 ± 014 | 0.418 ± 026 | 0.402 ± 006 |
| BalanceCascade | 0.436 ± 009 | 0.438 ± 014 | 0.384 ± 002 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guan, J.; Jiang, X.; Mao, B. A Method for Class-Imbalance Learning in Android Malware Detection. Electronics 2021, 10, 3124. https://doi.org/10.3390/electronics10243124
Guan J, Jiang X, Mao B. A Method for Class-Imbalance Learning in Android Malware Detection. Electronics. 2021; 10(24):3124. https://doi.org/10.3390/electronics10243124
Chicago/Turabian StyleGuan, Jun, Xu Jiang, and Baolei Mao. 2021. "A Method for Class-Imbalance Learning in Android Malware Detection" Electronics 10, no. 24: 3124. https://doi.org/10.3390/electronics10243124
APA StyleGuan, J., Jiang, X., & Mao, B. (2021). A Method for Class-Imbalance Learning in Android Malware Detection. Electronics, 10(24), 3124. https://doi.org/10.3390/electronics10243124