
Lesion Segmentation Framework Based on Convolutional Neural Networks with Dual Attention Mechanism


 , ,
, ,  ,
, 
Abstract
:1. Introduction
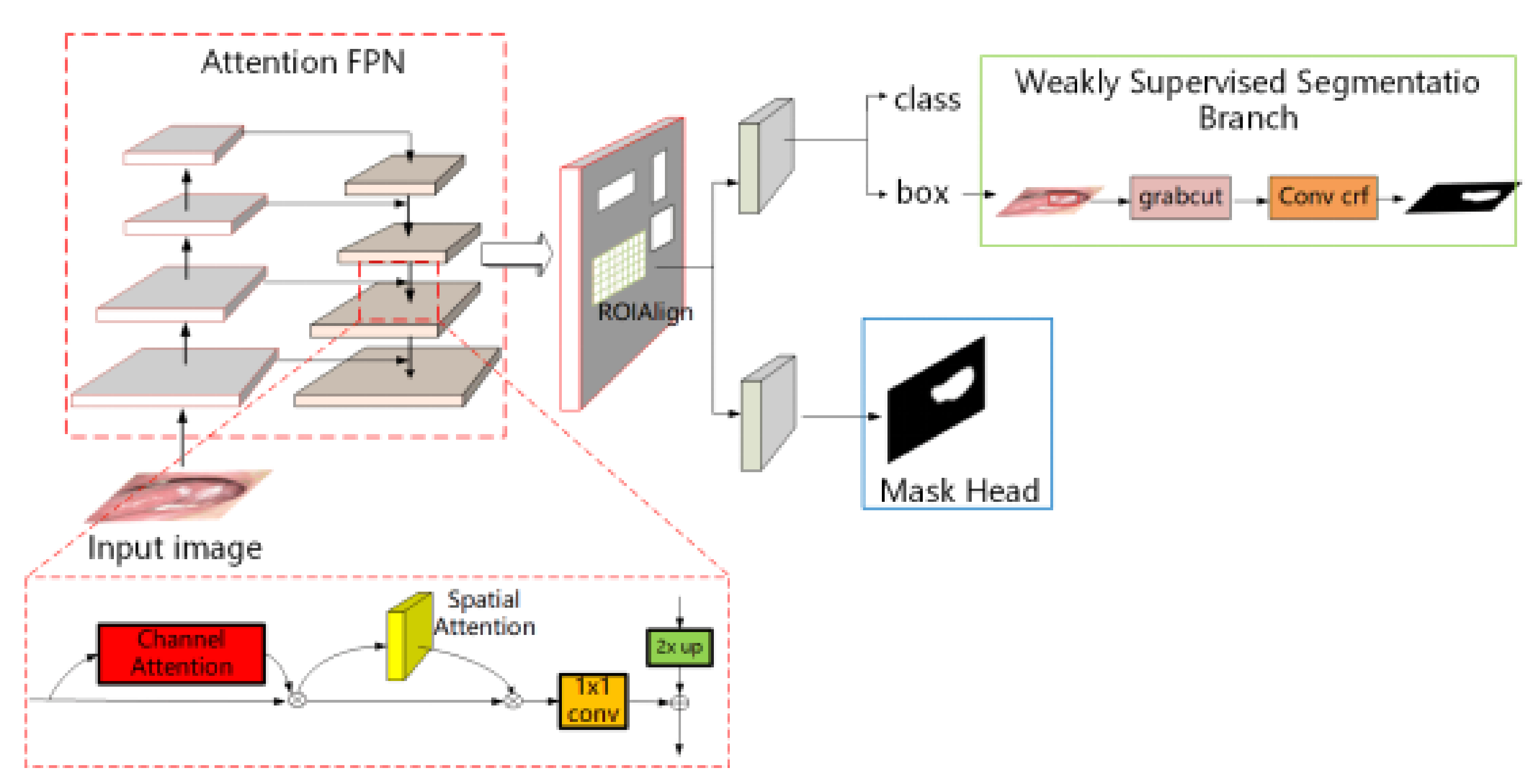
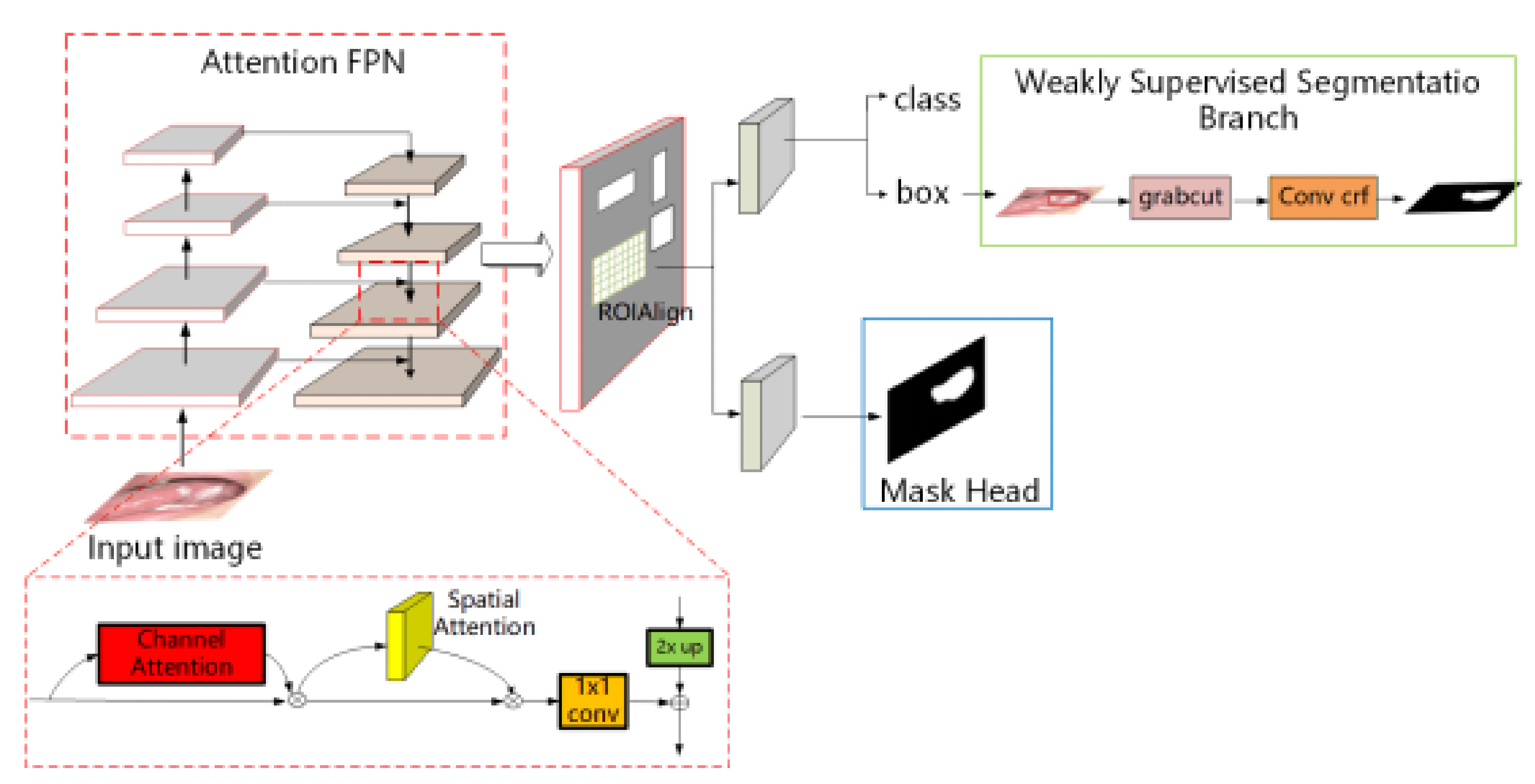
- In this paper, the researchers construct an end-to-end medical lesion segmentation framework, which has both fully supervised segmentation and weakly supervised segmentation branches. If pixel-level labels are used for the images, the fully supervised segmentation branch can be used for lesion segmentation. In the process of experiments if we only have box-level labels similar to the labels for object detection, the researchers can use the weakly supervised segmentation branch to achieve accurate lesion segmentation with comparable results to those obtained by the fully supervised segmentation methods.
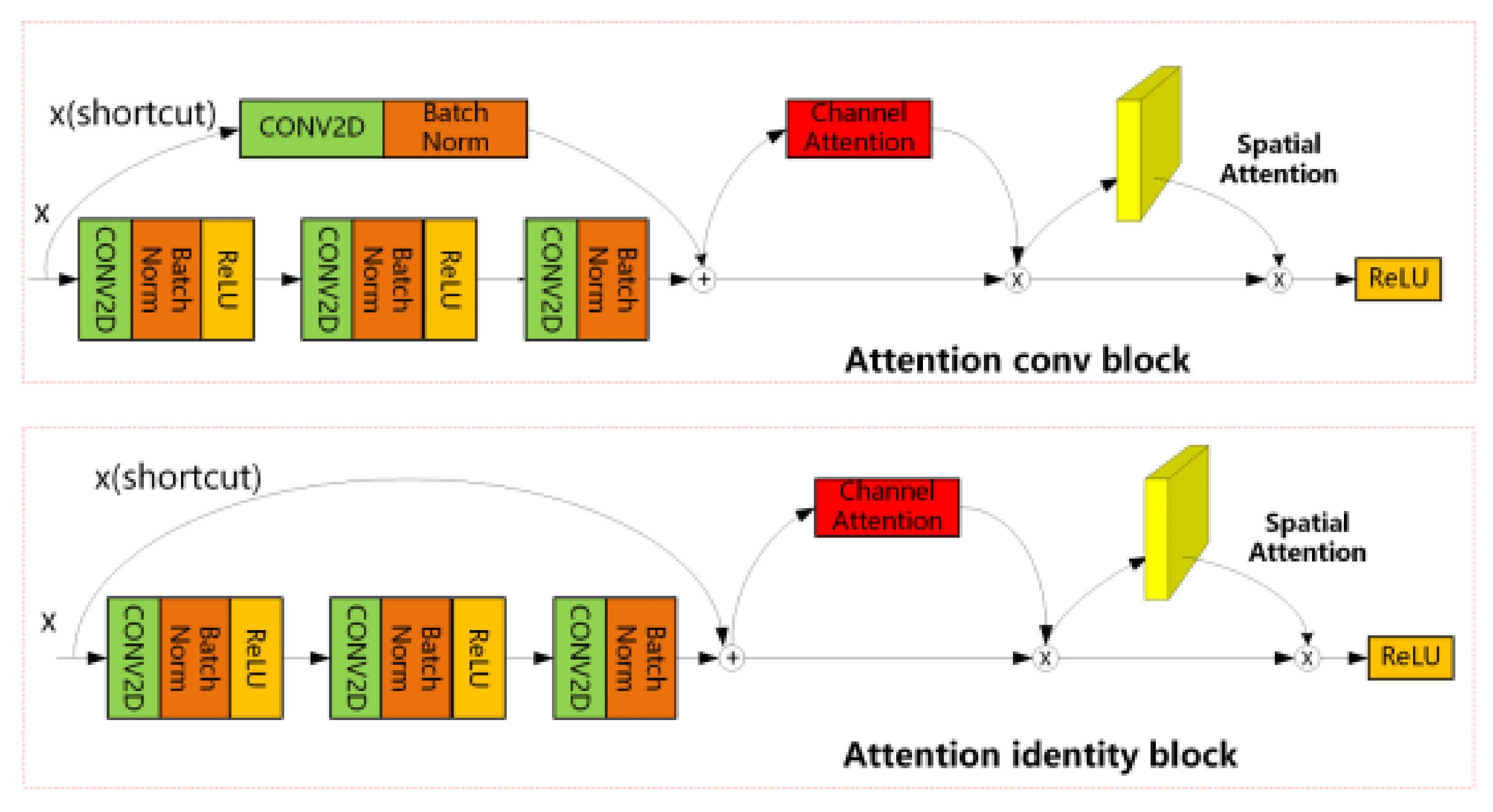
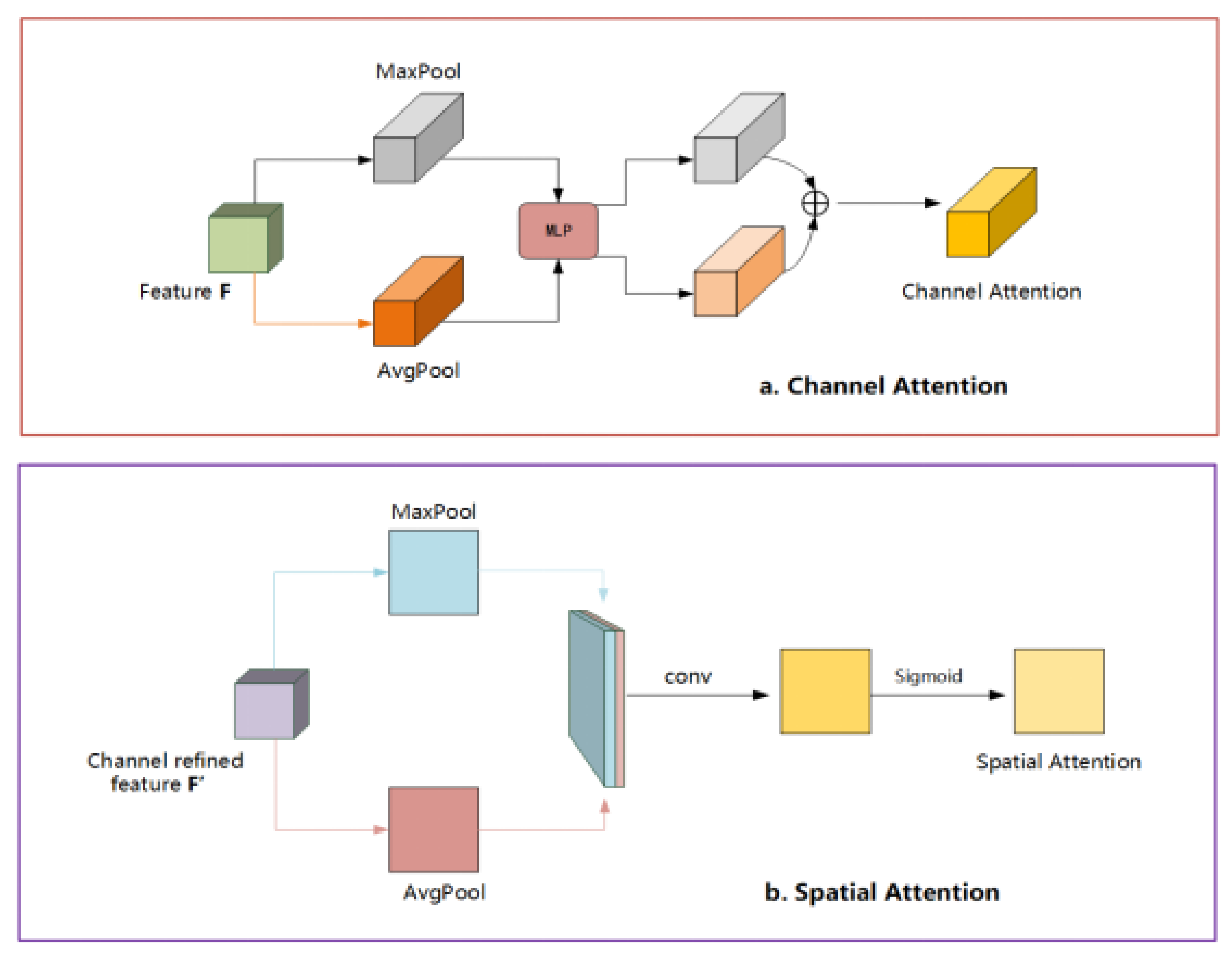
- To solve the problem of inaccurate segmentation of lesion boundaries in the lesion segmentation task, the researchers introduce the CBAM [21] attention mechanism into the Mask R-CNN to help the network pay attention to fine-gain feature learning from the regions of interest. This improvement will be beneficial for the segmentation results, especially for the segmented lesion boundaries.
2. Materials and Methods
2.1. Fully Supervised Segmentation Methods
2.2. Weakly Supervised Segmentation Methods
2.3. Attention Mechanism
3. Methods
3.1. Segmentation Model Based on Dual Attention Guidance
3.2. Weakly Supervised Segmentation
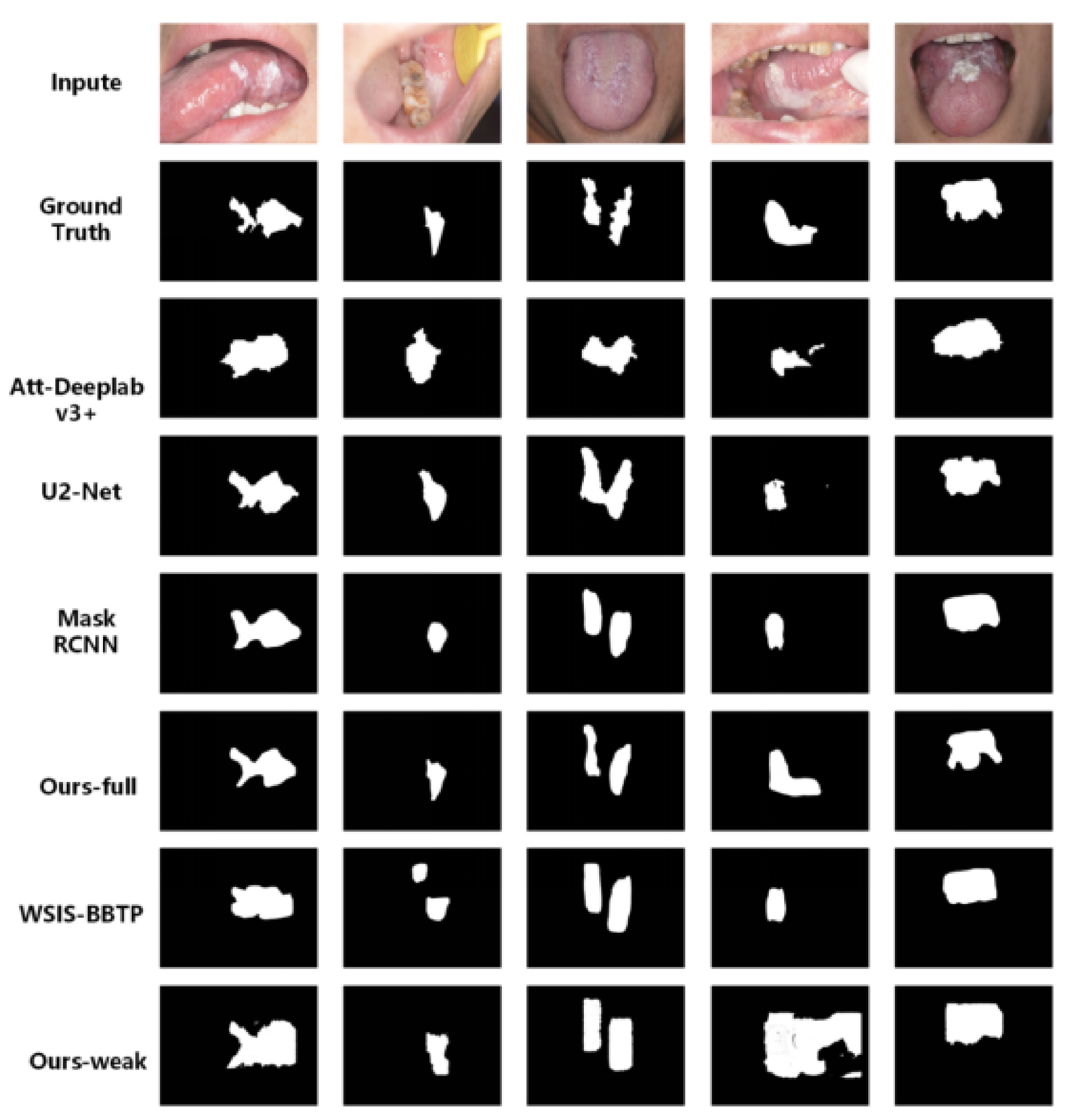
4. Result
4.1. Experimental Details and Evaluation Strategies
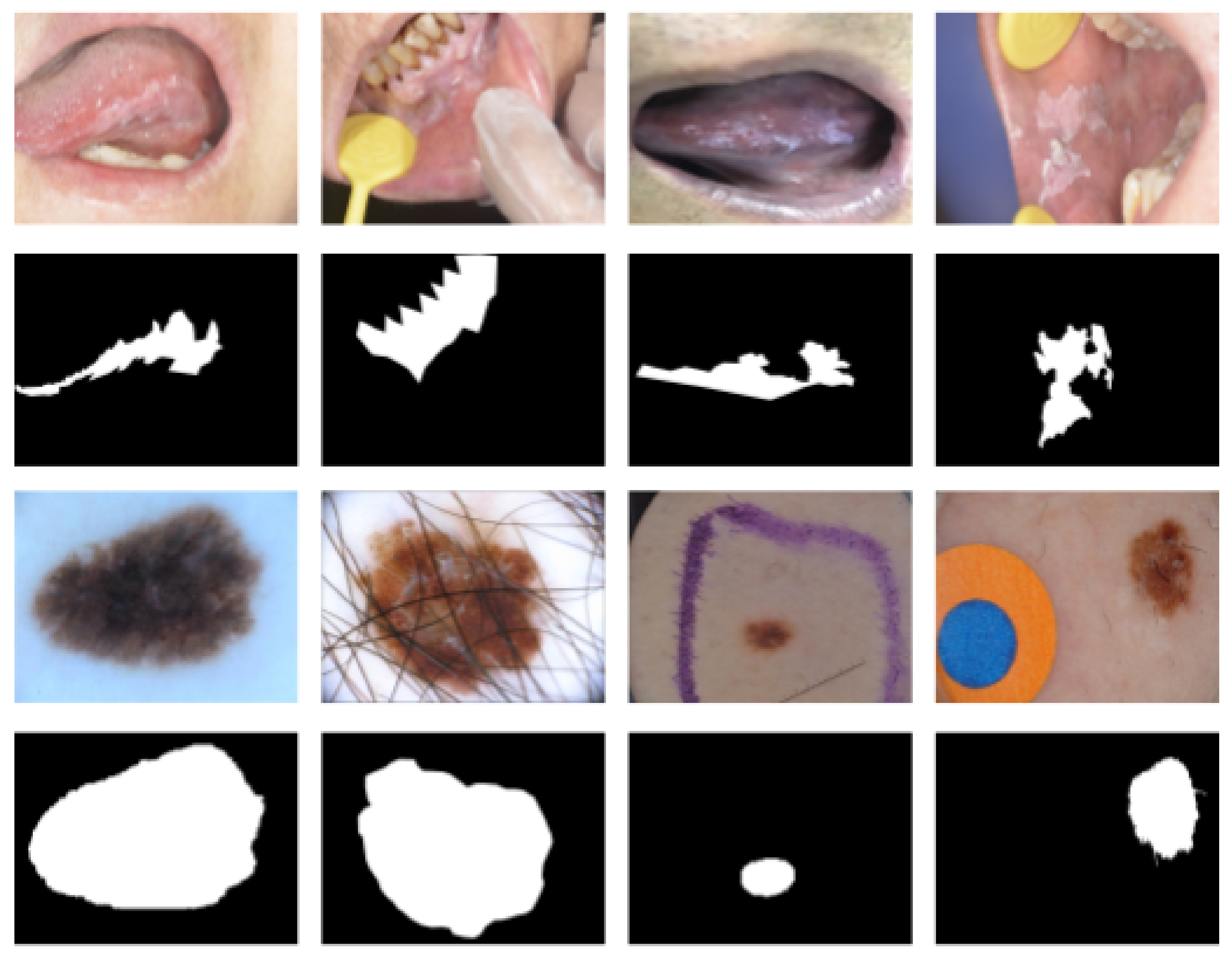
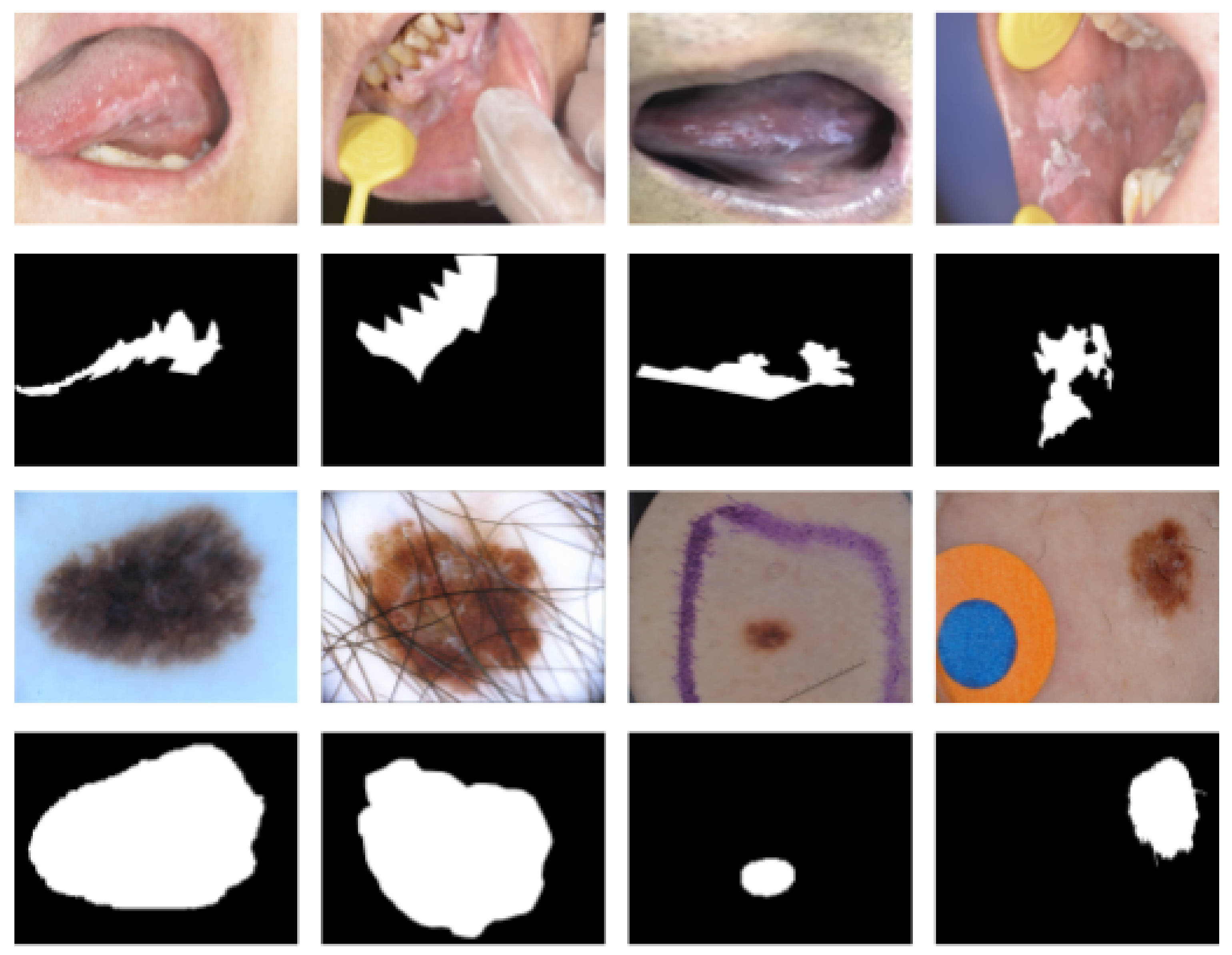
4.2. Oral Leukoplakia Dataset
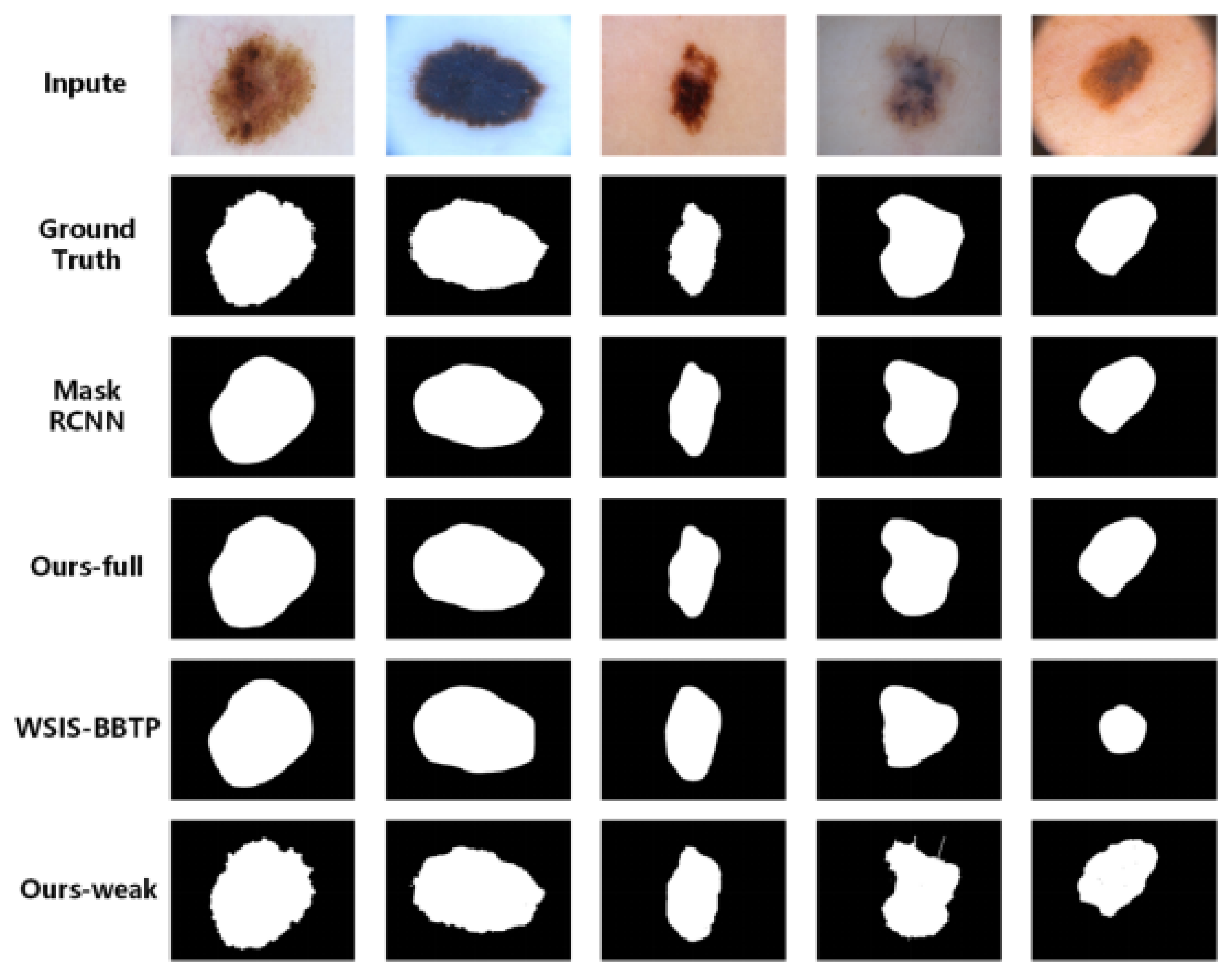
4.3. ISIC
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chang, X.; Yu, Y.L.; Yang, Y.; Xing, E.P. Semantic pooling for complex event analysis in untrimmed videos. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1617–1632. [Google Scholar] [CrossRef]
- Yan, C.; Chang, X.; Li, Z.; Guan, W.; Ge, Z.; Zhu, L.; Zheng, Q. ZeroNAS: Differentiable Generative Adversarial Networks Search for Zero-Shot Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2021. [Google Scholar] [CrossRef] [PubMed]
- Hesamian, M.H.; Jia, W.; He, X.; Kennedy, P. Deep learning techniques for medical image segmentation: Achievements and challenges. J. Digit. Imaging 2019, 32, 582–596. [Google Scholar] [CrossRef] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Xiao, X.; Lian, S.; Luo, Z.; Li, S. Weighted res-unet for high-quality retina vessel segmentation. In Proceedings of the 2018 9th International Conference on Information Technology in Medicine and Education (ITME), Hangzhou, China, 19–21 October 2018; pp. 327–331. [Google Scholar]
- Wang, C.; Zhao, Z.; Ren, Q.; Xu, Y.; Yu, Y. Dense u-net based on patchbased learning for retinal vessel segmentation. Entropy 2019, 21, 168. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ibtehaz, N.; Rahman, M.S. Multiresunet: Rethinking the u-net architecture for multimodal biomedical image segmentation. Neural Netw. 2020, 121, 74–87. [Google Scholar] [CrossRef]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. Unet++: Anested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Cham, Switzerland, 2018; pp. 3–11. [Google Scholar]
- Wang, Z.; Zou, N.; Shen, D.; Ji, S. Non-local u-nets for biomedical image segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 6315–6322. [Google Scholar]
- Codella, N.; Rotemberg, V.; Tschandl, P.; Celebi, M.E.; Dusza, S.; Gutman, D.; Helba, B.; Kalloo, A.; Liopyris, K.; Marchetti, M.; et al. Skin lesion analysis toward melanoma detection 2018: A challenge hosted by the international skin imaging collaboration (ISIC). arXiv 2019, arXiv:1902.03368. [Google Scholar]
- Nie, L.; Zhang, L.; Meng, L.; Song, X.; Chang, X.; Li, X. Modeling disease progression via multisource multitask learners: A case study with Alzheimer’s disease. IEEE Trans. Neural Netw. Learning Syst. 2016, 28, 1508–1519. [Google Scholar] [CrossRef] [PubMed]
- Yuan, D.; Chang, X.; Huang, P.Y.; Liu, Q.; He, Z. Self-supervised deep correlation tracking. IEEE Trans. Image Process. 2020, 30, 976–985. [Google Scholar] [CrossRef]
- Camalan, S.; Mahmood, H.; Binol, H. Convolutional Neural Network-Based Clinical Predictors of Oral Dysplasia: Class Activation Map Analysis of Deep Learning Results. Cancers 2021, 13, 1291. [Google Scholar] [CrossRef]
- Jubair, F.; Al-karadsheh, O.; Malamos, D. A novel lightweight deep convolutional neural network for early detection of oral cancer. Oral Dis. 2021. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Yao, L.; Chang, X.; Zhan, K.; Sun, J.; Zhang, H. Zero-shot event detection via event-adaptive concept relevance mining. Pattern Recognit. 2019, 88, 595–603. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Luo, M.; Chang, X.; Nie, L.; Yang, Y.; Hauptmann, A.G.; Zheng, Q. An adaptive semisupervised feature analysis for video semantic recognition. IEEE Trans. Cybern. 2017, 48, 648–660. [Google Scholar] [CrossRef] [PubMed]
- Ma, Z.; Chang, X.; Yang, Y.; Sebe, N.; Hauptmann, A.G. The many shades of negativity. IEEE Trans. Multimed. 2017, 19, 1558–1568. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Li, Z.; Nie, F.; Chang, X.; Nie, L.; Zhang, H.; Yang, Y. Rank-constrained spectral clustering with flexible embedding. IEEE Trans. Neural Netw. Learning Syst. 2018, 29, 6073–6082. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Pinheiro, P.O.O.; Collobert, R.; Dollar, P. Learning to segment objec candidates. Adv. Neural Inf. Process. Syst. 2015, 28, 1990–1998. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Zhang, H.; Dana, K.; Shi, J.; Zhang, Z.; Wang, X.; Tyagi, A.; Agrawal, A. Context encoding for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7151–7160. [Google Scholar]
- Ding, H.; Jiang, X.; Shuai, B.; Liu, A.Q.; Wang, G. Context contrasted feature and gated multi-scale aggregation for scene segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2393–2402. [Google Scholar]
- Chen, K.; Pang, J.; Wang, J.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Shi, J.; Ouyang, W.; et al. Hybrid task cascade for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4974–4983. [Google Scholar]
- Xu, D.; Ouyang, W.; Wang, X.; Sebe, N. Pad-net: Multi-tasks guided prediction-and-distillation network for simultaneous depth estimation and scene parsing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 675–684. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Ren, P.; Xiao, Y.; Chang, X.; Huang, P.Y.; Li, Z.; Chen, X.; Wang, X. A comprehensive survey of neural architecture search: Challenges and solutions. ACM Comput. Surv. 2021, 54, 1–34. [Google Scholar] [CrossRef]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1925–1934. [Google Scholar]
- Liu, W.; Rabinovich, A.; Berg, A.C. Parsenet: Looking wider to see better. arXiv 2015, arXiv:1506.04579. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 2, pp. 2169–2178. [Google Scholar]
- Hayder, Z.; He, X.; Salzmann, M. Boundary-aware instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5696–5704. [Google Scholar]
- Dai, J.; He, K.; Sun, J. Instance-aware semantic segmentation via multitask network cascades. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3150–3158. [Google Scholar]
- Li, Y.; Qi, H.; Dai, J.; Ji, X.; Wei, Y. Fully convolutional instance-aware semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2359–2367. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Chen, L.-C.; Hermans, A.; Papandreou, G.; Schroff, F.; Wang, P.; Adam, H. Masklab: Instance segmentation by refining object detection with semantic and direction features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4013–4022. [Google Scholar]
- Yan, C.; Zheng, Q.; Chang, X.; Luo, M.; Yeh, C.H.; Hauptman, A.G. Semantics-preserving graph propagation for zero-shot object detection. IEEE Trans. Image Process. 2020, 29, 8163–8176. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Compute: Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, X.; You, S.; Li, X.; Ma, H. Weakly-supervised semantic segmentation by iteratively mining common object features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1354–1362. [Google Scholar]
- Wei, Y.; Xiao, H.; Shi, H.; Jie, Z.; Feng, J.; Huang, T.S. Revisiting dilated convolution: A simple approach for weakly-and semi-supervised semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7268–7277. [Google Scholar]
- Huang, Z.; Wang, X.; Wang, J.; Liu, W.; Wang, J. Weakly-supervised semantic segmentation network with deep seeded region growing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7014–7023. [Google Scholar]
- Ahn, J.; Kwak, S. Learning pixel-level semantic affinity with image-level supervision for weakly supervised semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4981–4990. [Google Scholar]
- Ge, W.; Yang, S.; Yu, Y. Multi-evidence filtering and fusion for multilabel classification, object detection and semantic segmentation based on weakly supervised learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1277–1286. [Google Scholar]
- Wei, Y.; Feng, J.; Liang, X.; Cheng, M.-M.; Zhao, Y.; Yan, S. Object region mining with adversarial erasing: A simple classification to semantic segmentation approach. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1568–1576. [Google Scholar]
- Xu, J.; Schwing, A.G.; Urtasun, R. Learning to segment under various forms of weak supervision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3781–3790. [Google Scholar]
- Lin, D.; Dai, J.; Jia, J.; He, K.; Sun, J. Scribblesup: Scribble-supervised convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3159–3167. [Google Scholar]
- Li, Z.; Nie, F.; Chang, X.; Yang, Y. Beyond trace ratio: Weighted harmonic mean of trace ratios for multiclass discriminant analysis. IEEE Trans. Knowl. Data Eng. 2017, 29, 2100–2110. [Google Scholar] [CrossRef]
- Bearman, A.; Russakovsky, O.; Ferrari, V.; Fei-Fei, L. What’s the point: Semantic segmentation with point supervision. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 549–565. [Google Scholar]
- Rother, C.; Kolmogorov, V.; Blake, A. “grabcut” interactive foreground extraction using iterated graph cuts. ACM Trans. Graph. 2004, 23, 309–314. [Google Scholar] [CrossRef]
- Pont-Tuset, J.; Arbelaez, P.; Barron, J.T.; Marques, F.; Malik, J. Multiscale combinatorial grouping for image segmentation and object proposal generation. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 128–140. [Google Scholar] [CrossRef] [Green Version]
- Verbeek, J.; Triggs, W. Scene Segmentation with CRFs Learned from Partially Labeled Images. In Proceedings of the NIPS 2007—Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2007; pp. 1553–1560. [Google Scholar]
- He, X.; Zemel, R. Learning hybrid models for image annotation with partially labeled data. Adv. Neural Inf. Process. Syst. 2008, 21, 625–632. [Google Scholar]
- Luo, M.; Chang, X.; Li, Z.; Nie, L.; Hauptmann, A.G.; Zheng, Q. Simple to complex cross-modal learning to rank. Comput. Vision Image Underst. 2017, 163, 67–77. [Google Scholar] [CrossRef] [Green Version]
- Luo, M.; Nie, F.; Chang, X.; Yang, Y.; Hauptmann, A.G.; Zheng, Q. Adaptive unsupervised feature selection with structure regularization. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 944–956. [Google Scholar] [CrossRef]
- Teichmann, M.T.; Cipolla, R. Convolutional crfs for semantic segmentation. arXiv 2018, arXiv:1805.04777. [Google Scholar]
- Cheng, Z.; Chang, X.; Zhu, L.; Kanjirathinkal, R.C.; Kankanhalli, M. MMALFM: Explainable recommendation by leveraging reviews and images. ACM Trans. Inf. Syst. 2019, 37, 1–28. [Google Scholar] [CrossRef]
- Chang, X.; Nie, F.; Wang, S.; Yang, Y.; Zhou, X.; Zhang, C. Compound rank-k projections for bilinear analysis. IEEE Trans. Neural Netw. Learn. Syst. 2016, 27, 1502–1513. [Google Scholar] [CrossRef] [Green Version]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Wang, X.; Tang, X. Residual attention network for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3156–3164. [Google Scholar]
- Gong, C.; Tao, D.; Chang, X.; Yang, J. Ensemble teaching for hybrid label propagation. IEEE Trans. Cybern. 2017, 49, 388–402. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, D.; Yao, L.; Chen, K.; Wang, S.; Chang, X.; Liu, Y. Making sense of spatio-temporal preserving representations for EEG-based human intention recognition. IEEE Trans. Cybern. 2019, 50, 3033–3044. [Google Scholar] [CrossRef] [PubMed]
- Zhan, K.; Chang, X.; Guan, J.; Chen, L.; Ma, Z.; Yang, Y. Adaptive structure discovery for multimedia analysis using multiple features. IEEE Trans. Cybern. 2018, 49, 1826–1834. [Google Scholar] [CrossRef] [PubMed]
- Ren, P.; Xiao, Y.; Chang, X.; Huang, P.Y.; Li, Z.; Gupta, B.B.; Wang, X. A Survey of Deep Active Learning. ACM Comput. Surv. 2021, 54, 1–40. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Chen, L.; Zhang, H.; Xiao, J.; Nie, L.; Shao, J.; Liu, W.; Chua, T.-S. Scacnn: Spatial and channel-wise attention in convolutional networks for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5659–5667. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. Ccnet: Crisscross attention for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 603–612. [Google Scholar]
- Wang, S.; Chang, X.; Li, X.; Long, G.; Yao, L.; Sheng, Q.Z. Diagnosis code assignment using sparsity-based disease correlation embedding. IEEE Trans. Knowl. Data Eng. 2016, 28, 3191–3202. [Google Scholar] [CrossRef] [Green Version]
- Chen, K.; Yao, L.; Zhang, D.; Wang, X.; Chang, X.; Nie, F. A semisupervised recurrent convolutional attention model for human activity recognition. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 1747–1756. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Yu, E.; Sun, J.; Li, J.; Chang, X.; Han, X.H.; Hauptmann, A.G. Adaptive semi-supervised feature selection for cross-modal retrieval. IEEE Trans. Multimed. 2018, 21, 1276–1288. [Google Scholar] [CrossRef]
- Ma, Z.; Chang, X.; Xu, Z.; Sebe, N.; Hauptmann, A.G. Joint attributes and event analysis for multimedia event detection. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 2921–2930. [Google Scholar] [CrossRef]
- Li, Z.; Nie, F.; Chang, X.; Yang, Y.; Zhang, C.; Sebe, N. Dynamic affinity graph construction for spectral clustering using multiple features. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 6323–6332. [Google Scholar] [CrossRef]
- Azad, R.; Asadi-Aghbolaghi, M.; Fathy, M.; Escalera, S. Attention Deeplabv3+: Multi-level Context Attention Mechanism for Skin Lesion Segmentation. In Lecture Notes in Computer Science, Proceedings of the Computer Vision—ECCV 2020 Workshops, ECCV 2020, Glasgow, UK, 23–28 August 2020; Bartoli, A., Fusiello, A., Eds.; Springer: Cham, Switzerland, 2020. [Google Scholar] [CrossRef]
- Qin, U.; Zhang, Z.; Huang, C.; Dehghan, M.; Osmar, R.Z.; Jagersand, M. U2-Net: Going deeper with nested U-structure for salient object detection. Pattern Recognit. 2020, 106, 107404. [Google Scholar] [CrossRef]
- Alom, M.Z.; Hasan, M.; Yakopcic, C.; Taha, T.M.; Asari, V.K. Recurrent residual convolutional neural network based on U-Net (R2U-Net) for medical image segmentation. arXiv 2018, arXiv:1802.06955. [Google Scholar]
- Azad, R.; Asadi-Aghbolaghi, M.; Fathy, M.; Escalera, S. Bi-directional ConvLSTM U-Net with Densley connected convolutions. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Asadi-Aghbolaghi, M.; Azad, R.; Fathy, M.; Escalera, S. Multi-level context gating of embedded collective knowledge for medical image segmentation. arXiv 2020, arXiv:2003.05056. [Google Scholar]
- Wu, H.; Pan, J.; Li, Z.; Wen, Z.; Qin, J. Automated Skin Lesion Segmentation Via an Adaptive Dual Attention Module. IEEE Trans. Med. Imaging 2021, 40, 357–370. [Google Scholar] [CrossRef]
- Hsu, C.-C.; Hsu, K.-J.; Tsai, C.-C.; Lin, Y.-Y.; Chuang, Y.-Y. Weakly supervised instance segmentation using the bounding box tightness prior. Adv. Neural Inf. Process. Syst. 2019, 32, 6586–6597. [Google Scholar]
- Codella, N.C.; Gutman, D.; Celebi, M.E.; Helba, B.; Marchetti, M.A.; Dusza, S.W.; Kalloo, A.; Liopyris, K.; Mishra, N.; Kittler, H.; et al. Skin lesion analysis toward melanoma detection: A challenge at the 2017 international symposium on biomedical imaging (isbi), hosted by the international skin imaging collaboration (isic). In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; pp. 168–172. [Google Scholar]
- Li, Y.; Shen, L. Skin lesion analysis towards melanoma detection using deep learning network. Sensors 2018, 18, 556. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xie, F.; Yang, J.; Liu, J. Skin lesion segmentation using high-resolution convolutional neural network. Comput. Methods Programs Biomed. 2019, 186, 105241. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
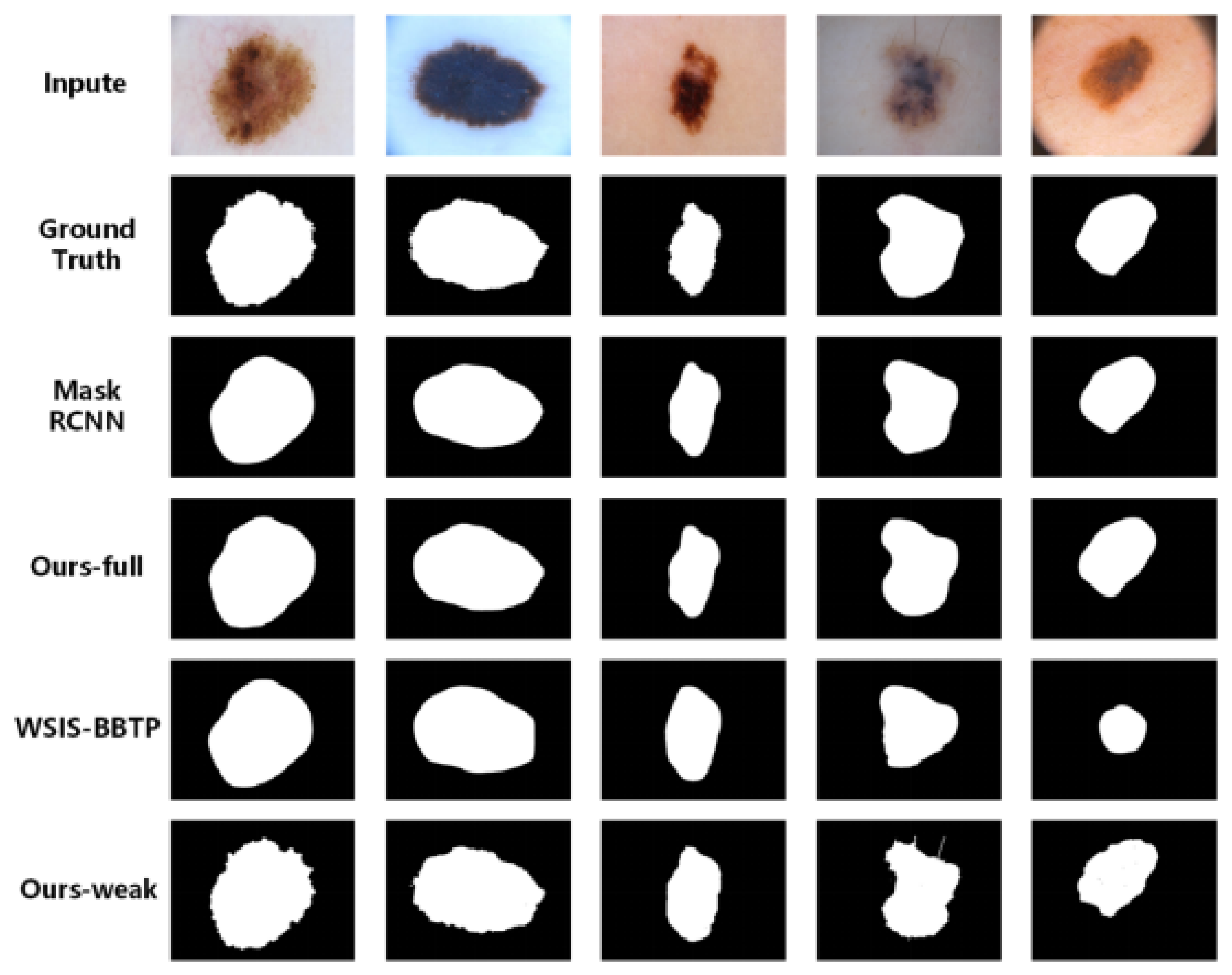{kind=link}
| Method | F1 | SEN | SPE | ACC | Jaccard Similarity | |
|---|---|---|---|---|---|---|
| FS | Att-Deeplab v3+ [79] | 0.514 | 0.521 | 0.953 | 0.935 | 0.935 |
| U2-Net [80] | 0.759 | 0.734 | 0.986 | 0.967 | 0.967 | |
| Mask R-CNN [18] | 0.741 | 0.704 | 0.978 | 0.959 | 0.959 | |
| Ours-full | 0.815 | 0.758 | 0.990 | 0.967 | 0.967 | |
| WS | Ours-weak | 0.684 | 0.843 | 0.964 | 0.943 | 0.943 |
| Method | F1 | SEN | SPE | ACC | Jaccard Similarity | |
|---|---|---|---|---|---|---|
| FS | U-net [5] | 0.647 | 0.708 | 0.964 | 0.890 | 0.549 |
| Att U-net [6] | 0.665 | 0.717 | 0.967 | 0.897 | 0.566 | |
| R2U-net [81] | 0.679 | 0.792 | 0.928 | 0.880 | 0.581 | |
| Att R2U-Net [81] | 0.691 | 0.726 | 0.971 | 0.904 | 0.592 | |
| BCDU-Net [82] | 0.851 | 0.785 | 0.982 | 0.937 | 0.937 | |
| MCGU-Net [83] | 0.895 | 0.848 | 0.986 | 0.955 | 0.955 | |
| Deeplab v3+ [25] | 0.882 | 0.856 | 0.977 | 0.951 | 0.951 | |
| Att-Deeplab v3+ [79] | 0.712 | 0.875 | 0.988 | 0.964 | 0.964 | |
| Mask R-CNN [18] | 0.872 | 0.846 | 0.974 | 0.947 | 0.947 | |
| Wu’s Method [84] | - | 0.942 | 0.941 | 0.947 | - | |
| Ours-full | 0.904 | 0.865 | 0.987 | 0.961 | 0.961 | |
| WS | WSIS-BBTP [85] | 0.858 | 0.784 | 0.967 | 0.937 | 0.937 |
| Ours-weak | 0.874 | 0.861 | 0.986 | 0.950 | 0.950 |
| Method | F1 | SEN | SPE | ACC | Jaccard Similarity | |
|---|---|---|---|---|---|---|
| FS | U-net [5] | 0.8682 | 0.9479 | 0.9263 | 0.9314 | 0.9314 |
| Melanoma det [86] | - | - | - | 0.9340 | - | |
| Lesion Analysis [87] | - | 0.8250 | 0.9750 | 0.9340 | - | |
| R2U-net [81] | 0.8920 | 0.9414 | 0.9425 | 0.9424 | 0.9421 | |
| BCDU-Net [82] | 0.8810 | 0.8647 | 0.9751 | 0.9528 | 0.9528 | |
| MCGU-Net [83] | 0.8950 | 0.8480 | 0.9860 | 0.9550 | 0.9550 | |
| HRFB [88] | - | 0.870 | 0.964 | 0.938 | - | |
| Deeplab v3+ [25] | 0.9162 | 0.8733 | 0.9921 | 0.9691 | 0.9691 | |
| Att-Deeplab v3+ [79] | 0.9190 | 0.8851 | 0.9901 | 0.9698 | 0.9698 | |
| Mask R-CNN [18] | 0.9092 | 0.8644 | 0.9794 | 0.9472 | 0.9472 | |
| Wu’s Method [84] | - | 0.9061 | 0.9628 | 0.9570 | - | |
| Ours-full | 0.9145 | 0.8865 | 0.9879 | 0.9635 | 0.9636 | |
| WS | Ours-weak | 0.8845 | 0.8473 | 0.9706 | 0.9384 | 0.9384 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, F.; Zhang, P.; Jiang, T.; She, J.; Shen, X.; Xu, P.; Zhao, W.; Gao, G.; Guan, Z. Lesion Segmentation Framework Based on Convolutional Neural Networks with Dual Attention Mechanism. Electronics 2021, 10, 3103. https://doi.org/10.3390/electronics10243103
Xie F, Zhang P, Jiang T, She J, Shen X, Xu P, Zhao W, Gao G, Guan Z. Lesion Segmentation Framework Based on Convolutional Neural Networks with Dual Attention Mechanism. Electronics. 2021; 10(24):3103. https://doi.org/10.3390/electronics10243103
Chicago/Turabian StyleXie, Fei, Panpan Zhang, Tao Jiang, Jiao She, Xuemin Shen, Pengfei Xu, Wei Zhao, Gang Gao, and Ziyu Guan. 2021. "Lesion Segmentation Framework Based on Convolutional Neural Networks with Dual Attention Mechanism" Electronics 10, no. 24: 3103. https://doi.org/10.3390/electronics10243103
APA StyleXie, F., Zhang, P., Jiang, T., She, J., Shen, X., Xu, P., Zhao, W., Gao, G., & Guan, Z. (2021). Lesion Segmentation Framework Based on Convolutional Neural Networks with Dual Attention Mechanism. Electronics, 10(24), 3103. https://doi.org/10.3390/electronics10243103