
Securing Workflows Using Microservices and Metagraphs †


Abstract
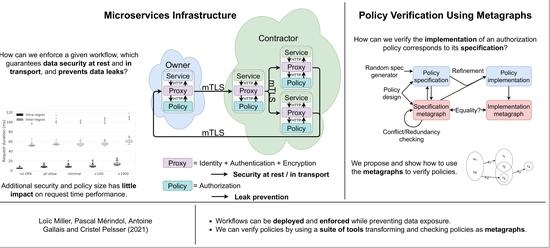
:
1. Introduction
1.1. Basic Concepts
1.2. Approach and Contributions
- First, we develop an infrastructure using the isolation provided by microservices to enforce policy;
- We implement a workflow with our infrastructure in a publicly available proof of concept and verify that our implementation of the specified policy is correctly enforced by testing the deployment for access control violations;
- We measure performance of our infrastructure with policy engines and find the overhead cost of authorization to be reasonable for the benefits;
- Second, we rely on metagraphs to perform the verification of access control policies (to the best of our knowledge we are the first to do so).We argue they represent one of the most appropriate form of policy modeling enabling refinement and verification to finely pinpoint implementation errors;
- We then propose a suite of translation tools enabling policy verification; More specifically, we introduce how to perform such verification on a workflow-like policy specification. We rely on a policy implementation based on Rego, a high-level declarative language built for expressing complex policies;
- Finally, we conduct a thorough performance evaluation of this second contribution. We verify that deployed policies match their specification in a very reasonable time, even for large workflows with a substantial number of rules.
2. Related Works
3. Threat and Security Model
3.1. Trust Model—Actors and Environment
3.2. Attacker Model—External Attackers and Malicious Agents
- External attacker: External to the workflow and the location of the deployed infrastructure. Such attackers try to gain access to the data or the business intelligence from the outside.
- Co-located attacker: External to the workflow, but co-located at the deployment (e.g., an attacker located in one of the third-party clouds). This co-located position opens more exploit options.
- Malicious agent: Internal to the workflow, this attacker tries to leak the data outside.
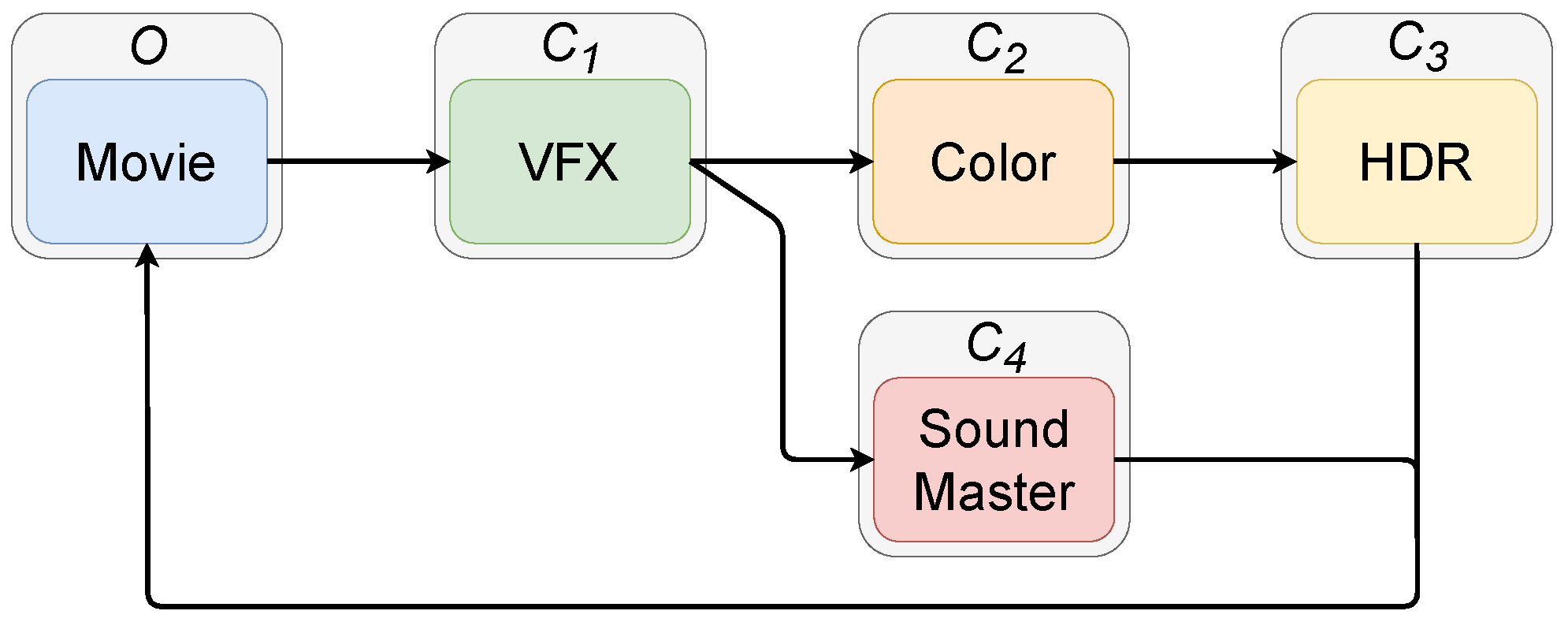
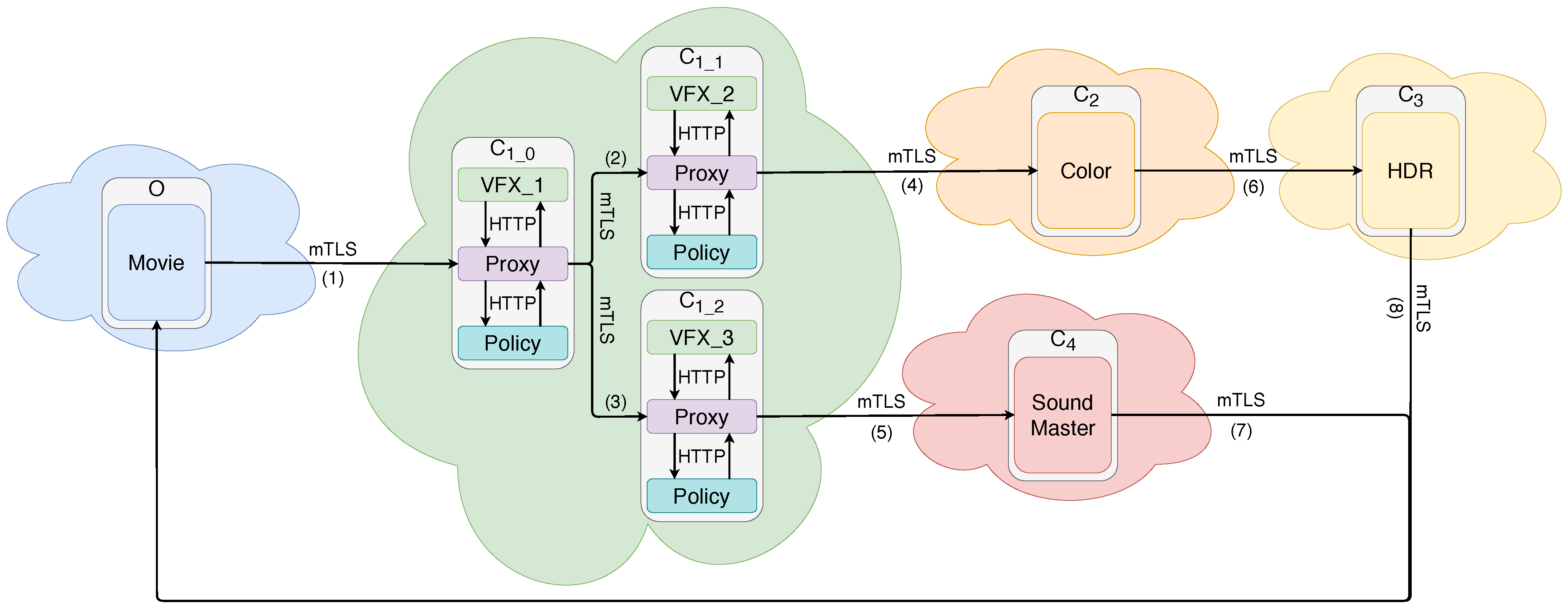
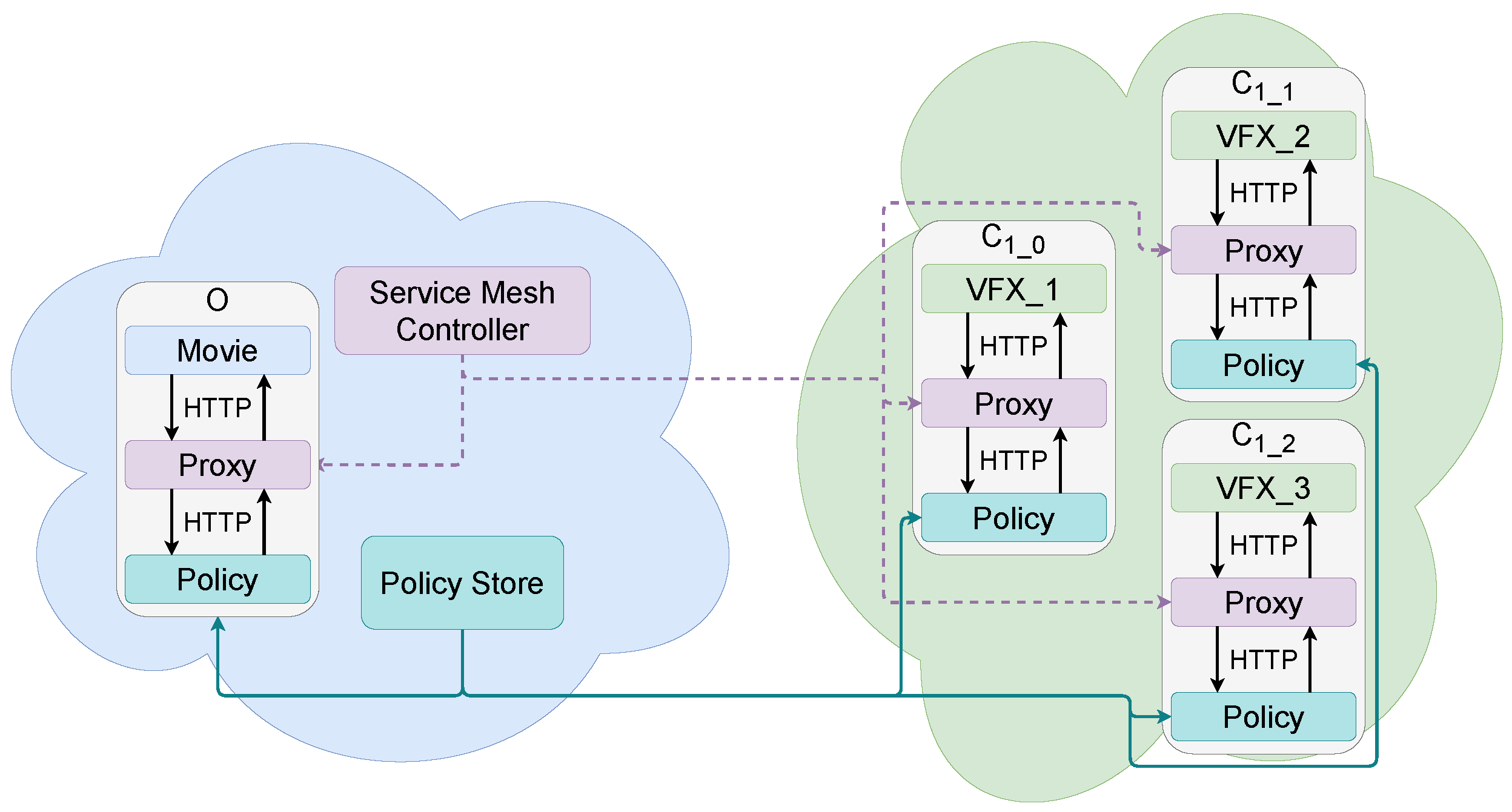
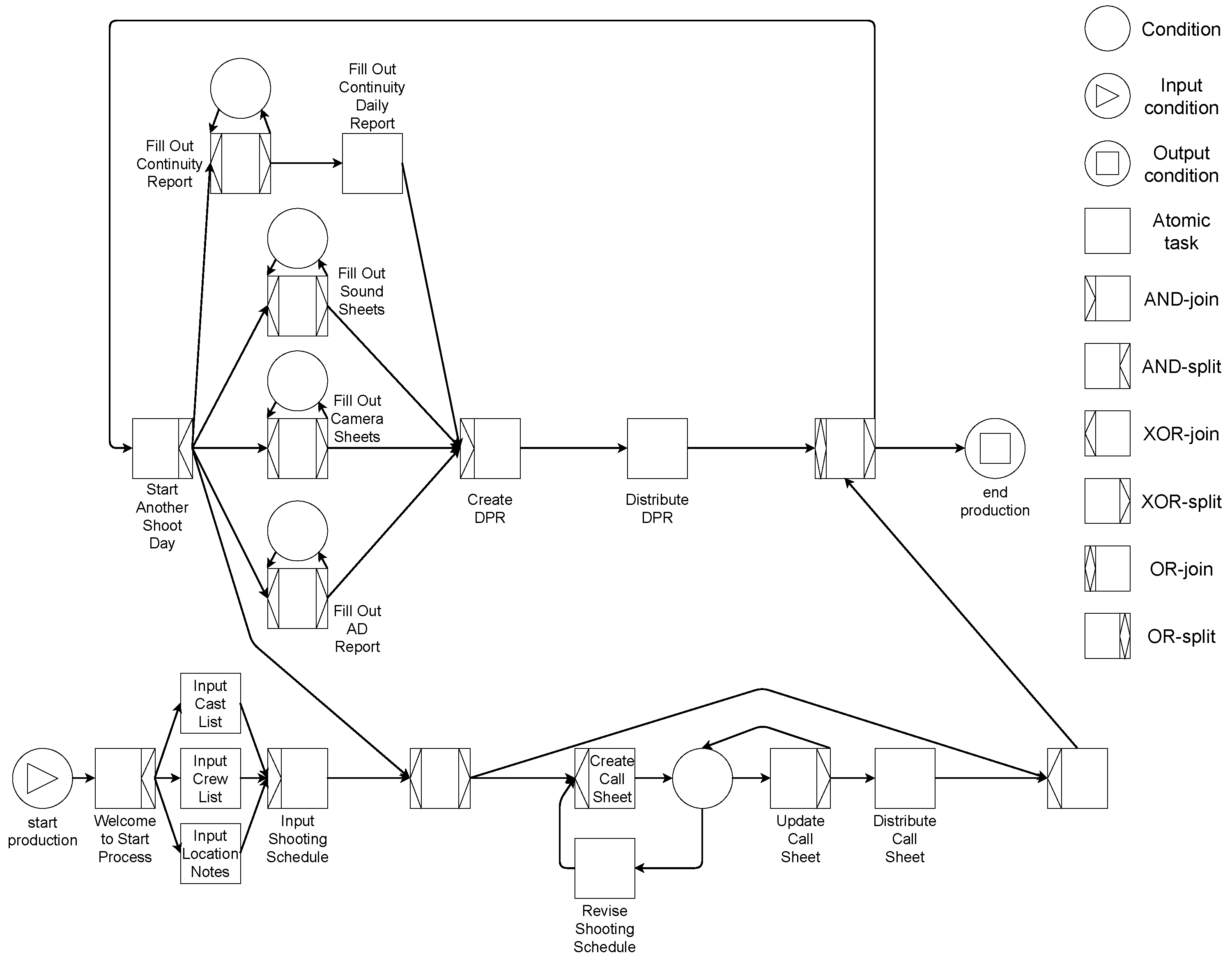
4. Infrastructure and Proof of Concept
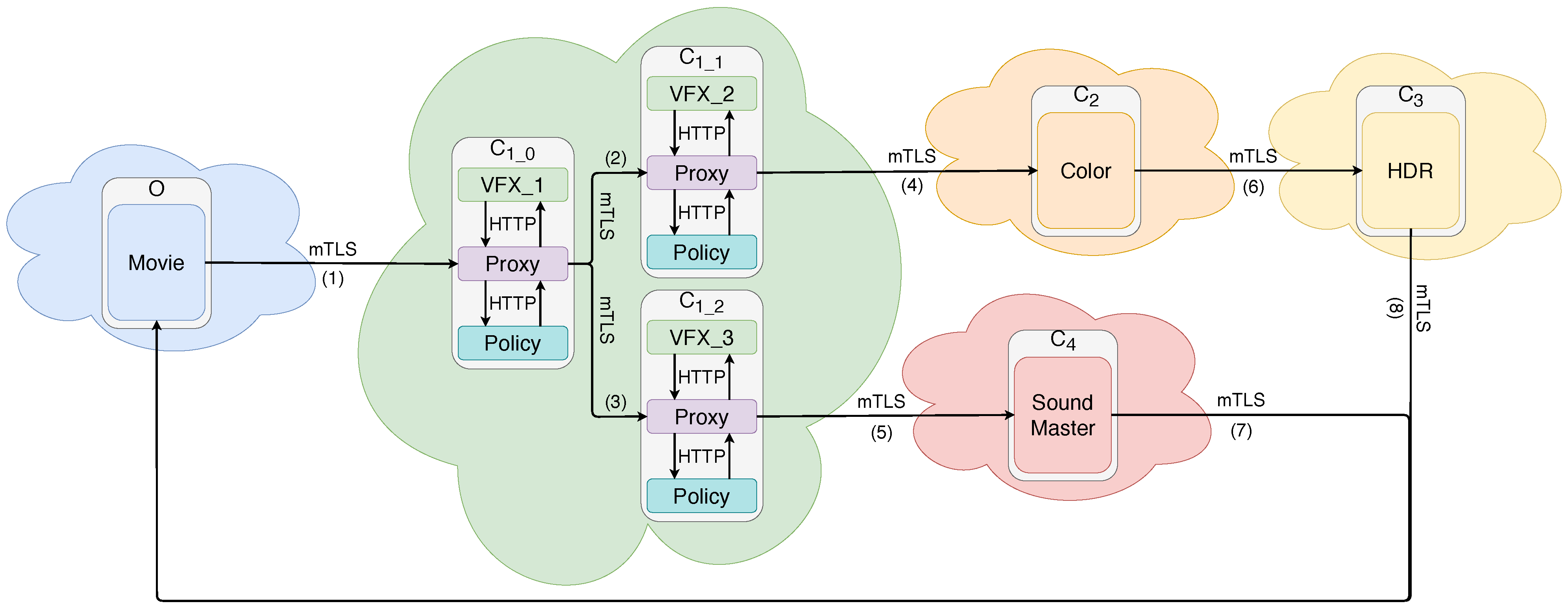
Overall Description of the Infrastructure
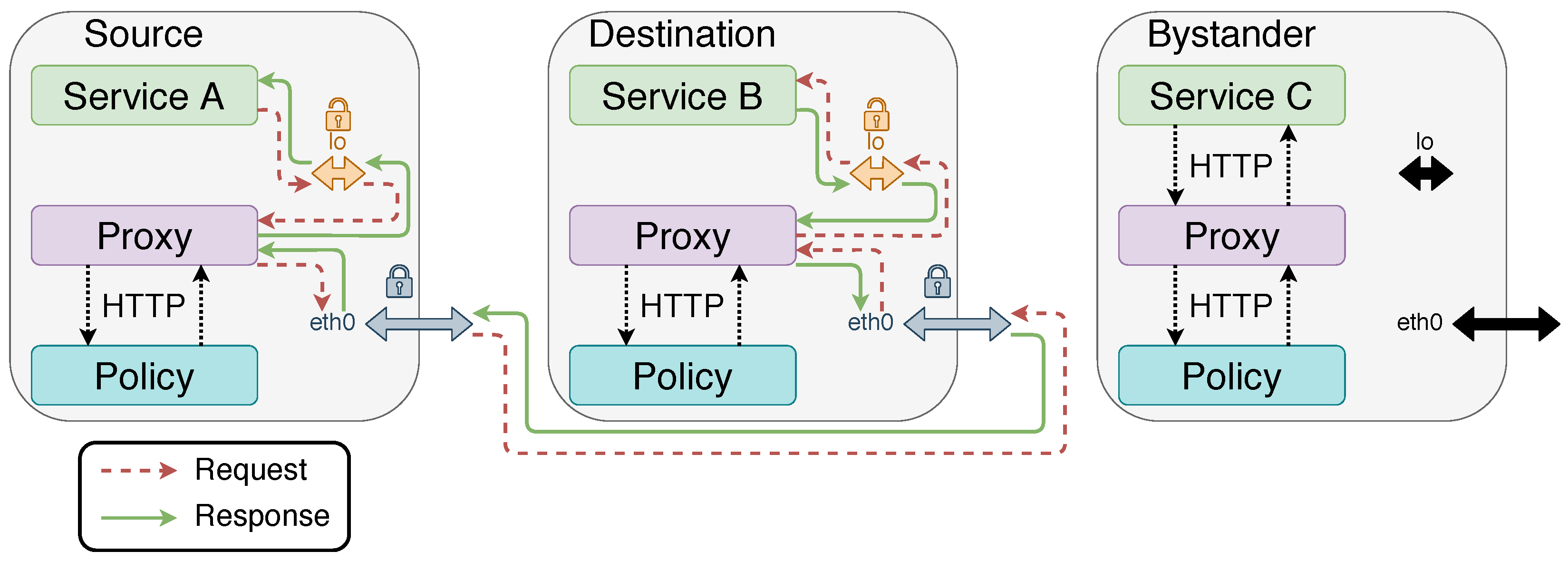
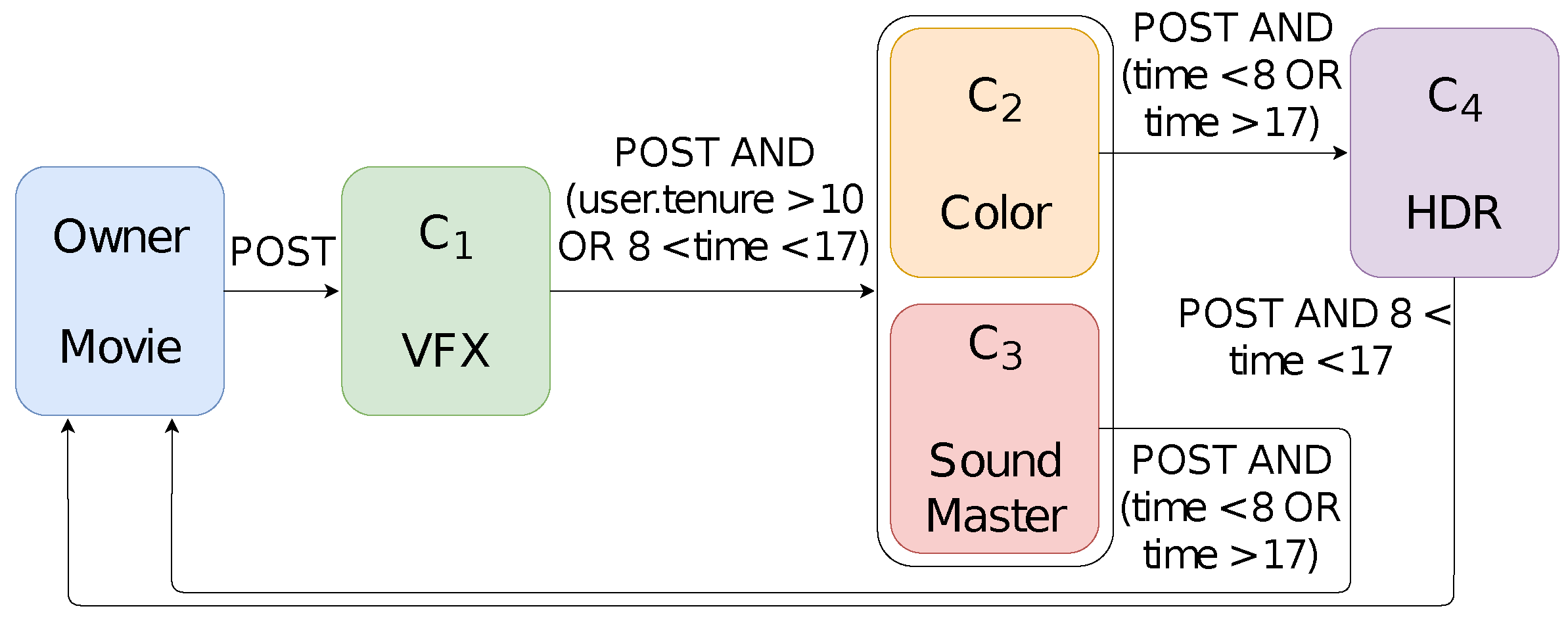
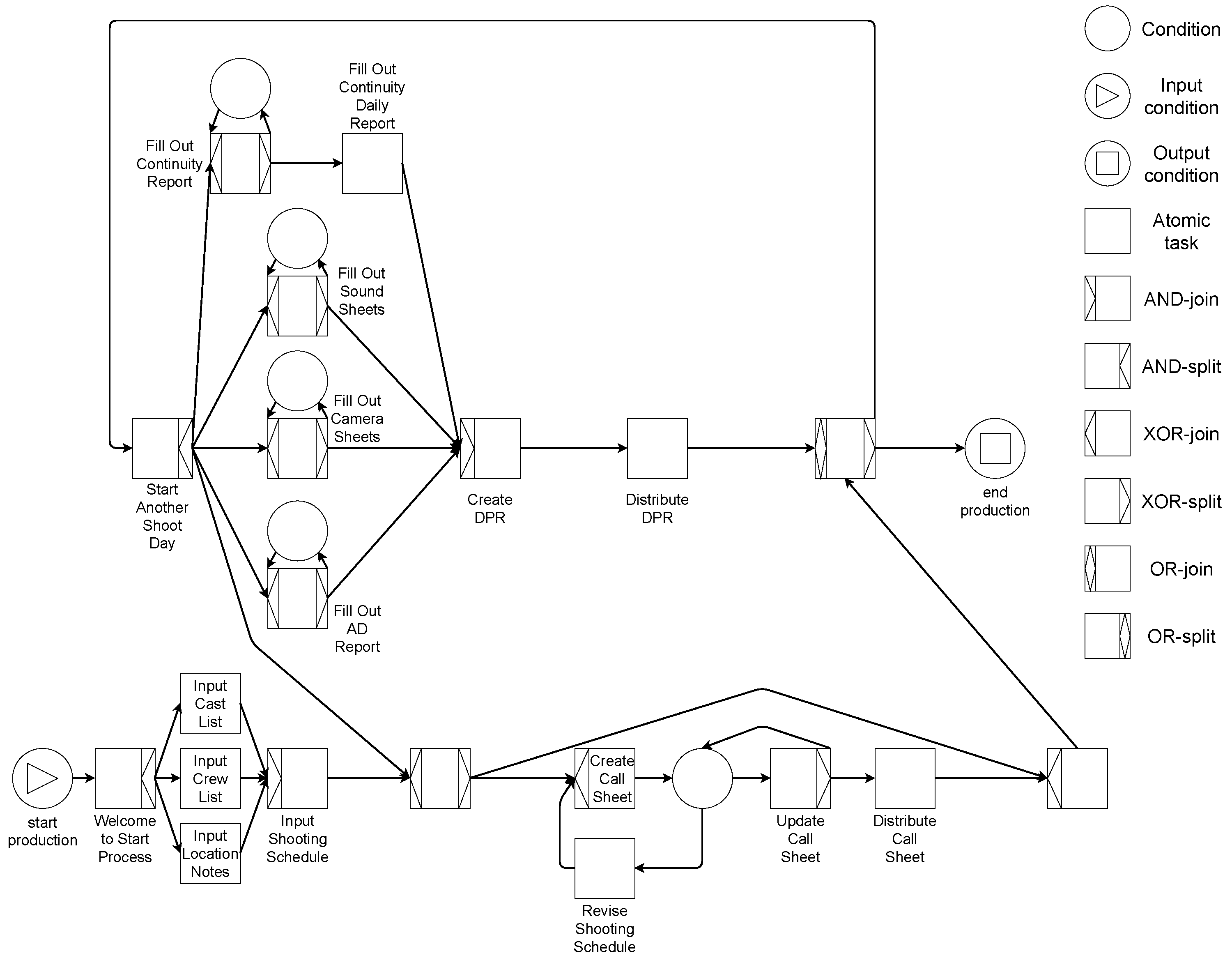
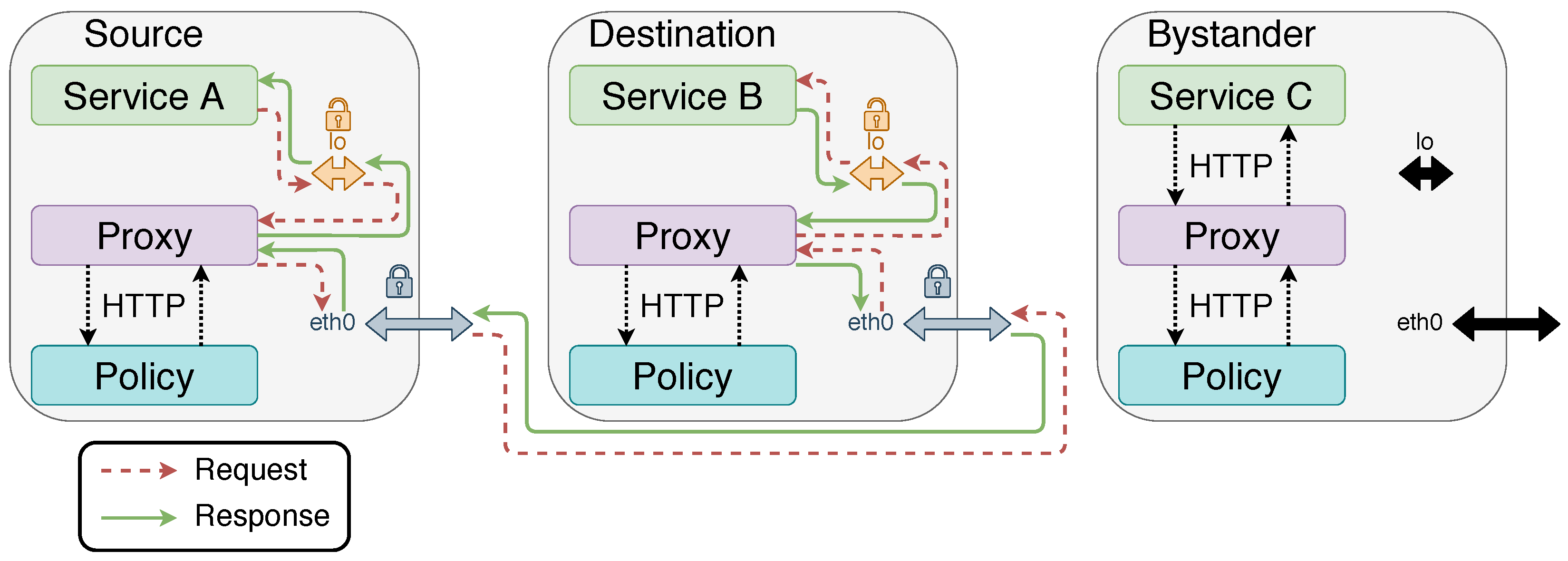
5. Proof of Concept
- Traffic is either encrypted or protected inside a pod by the isolation provided by the pods;
- The policy, allowing or denying communications between services, is correctly enforced.
- Source/Destination loopback: We need to verify that a communication between the source and the destination is occurring (i.e., correct IP addresses and ports). We need to verify that the request in the capture corresponds to the request we are testing for (GET or POST). The response needs to be in accordance with the policy: in this case, ‘403 Forbidden’ if the policy was ‘deny’ and ‘200 OK’ (GET) or ‘201 OK’ (POST) if the policy was ‘allow’.
- Source/Destination external interface: We need to verify that a communication between the source and the destination is occurring (correct IP addresses and ports). We need to verify that the traffic is encrypted by mTLS, and not passed in clear text.
- Bystander loopback and external interface: We need to verify that no communication between the source and the destination is occurring, whether encrypted or unencrypted.
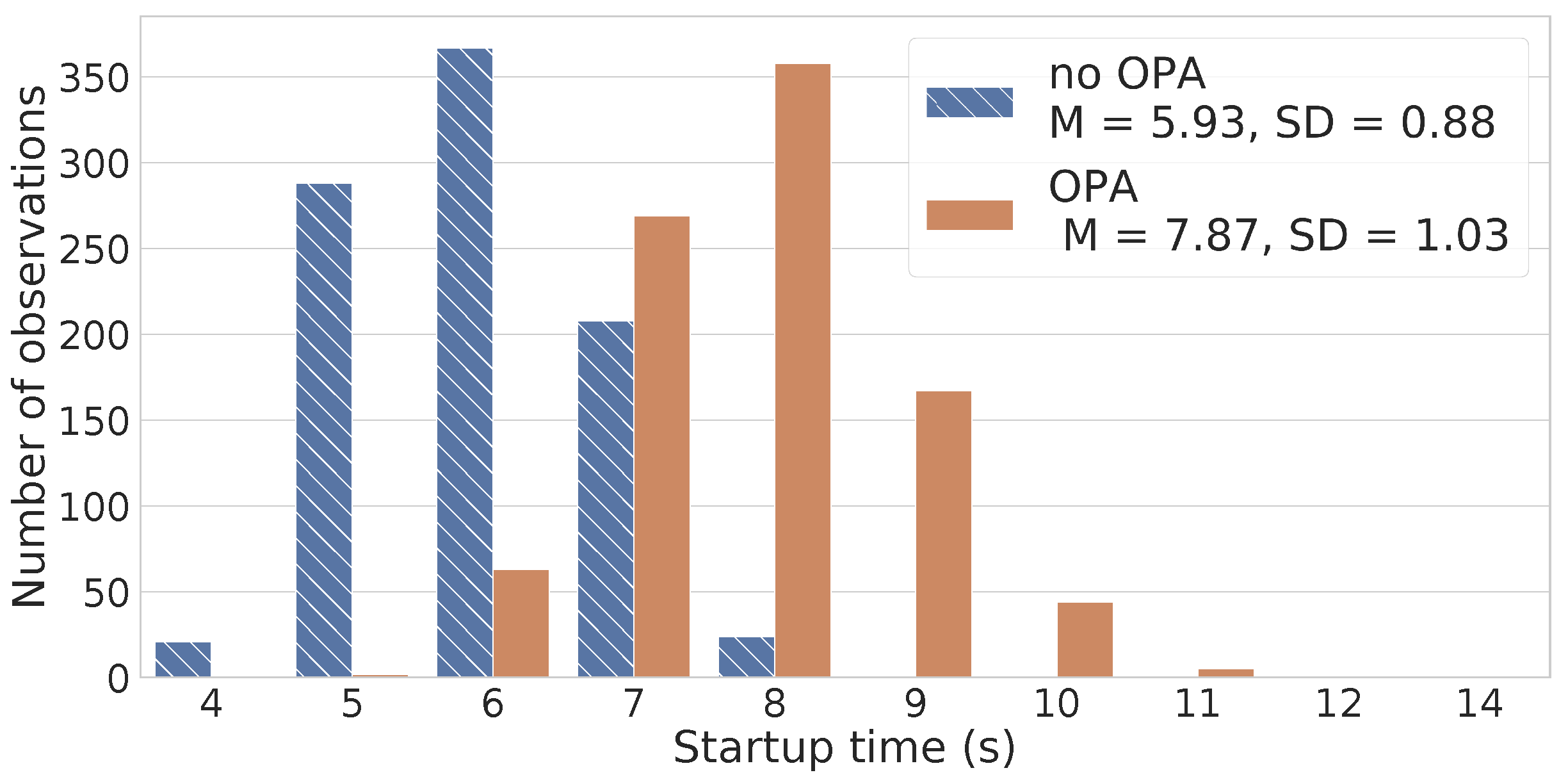
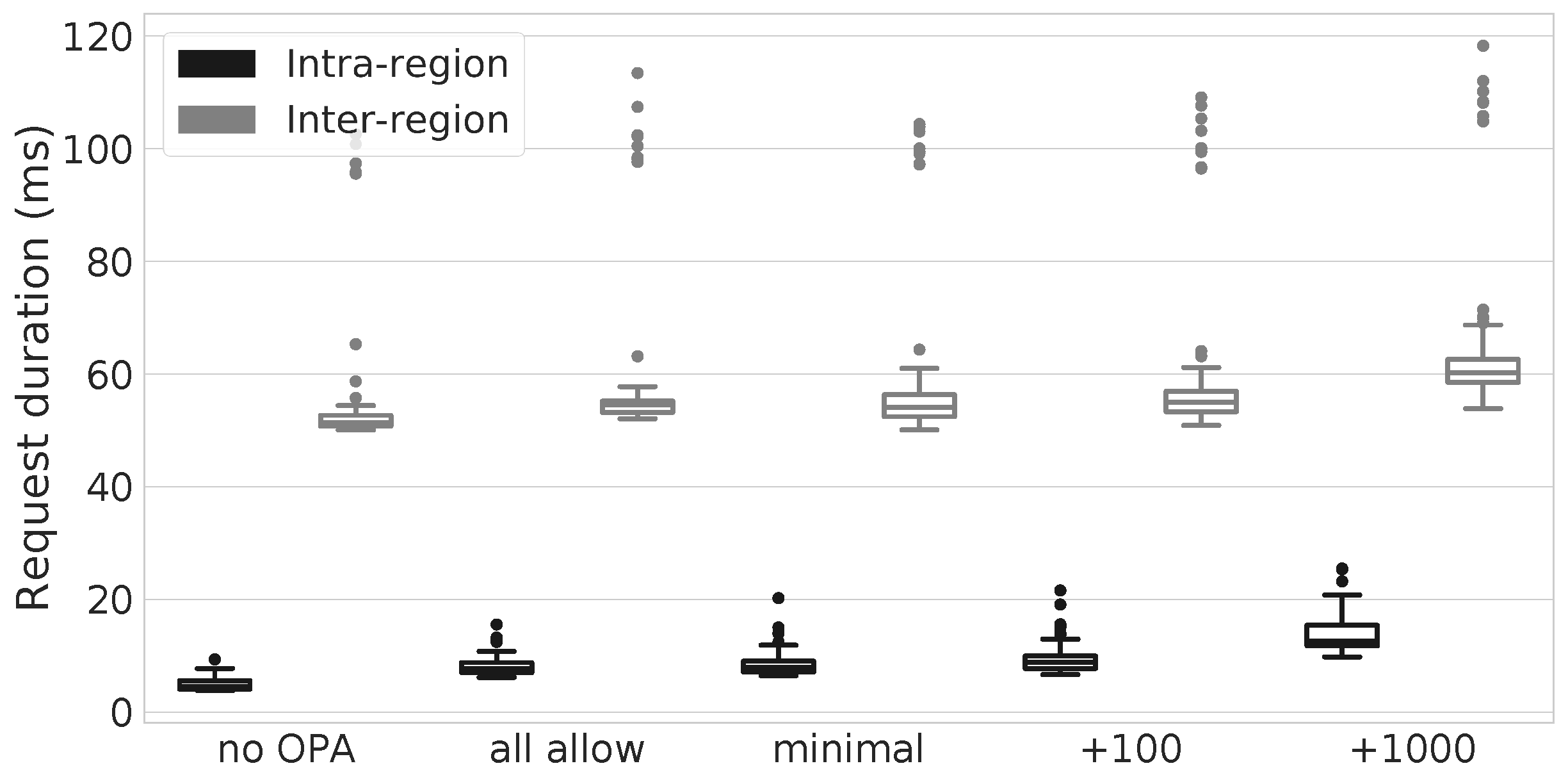
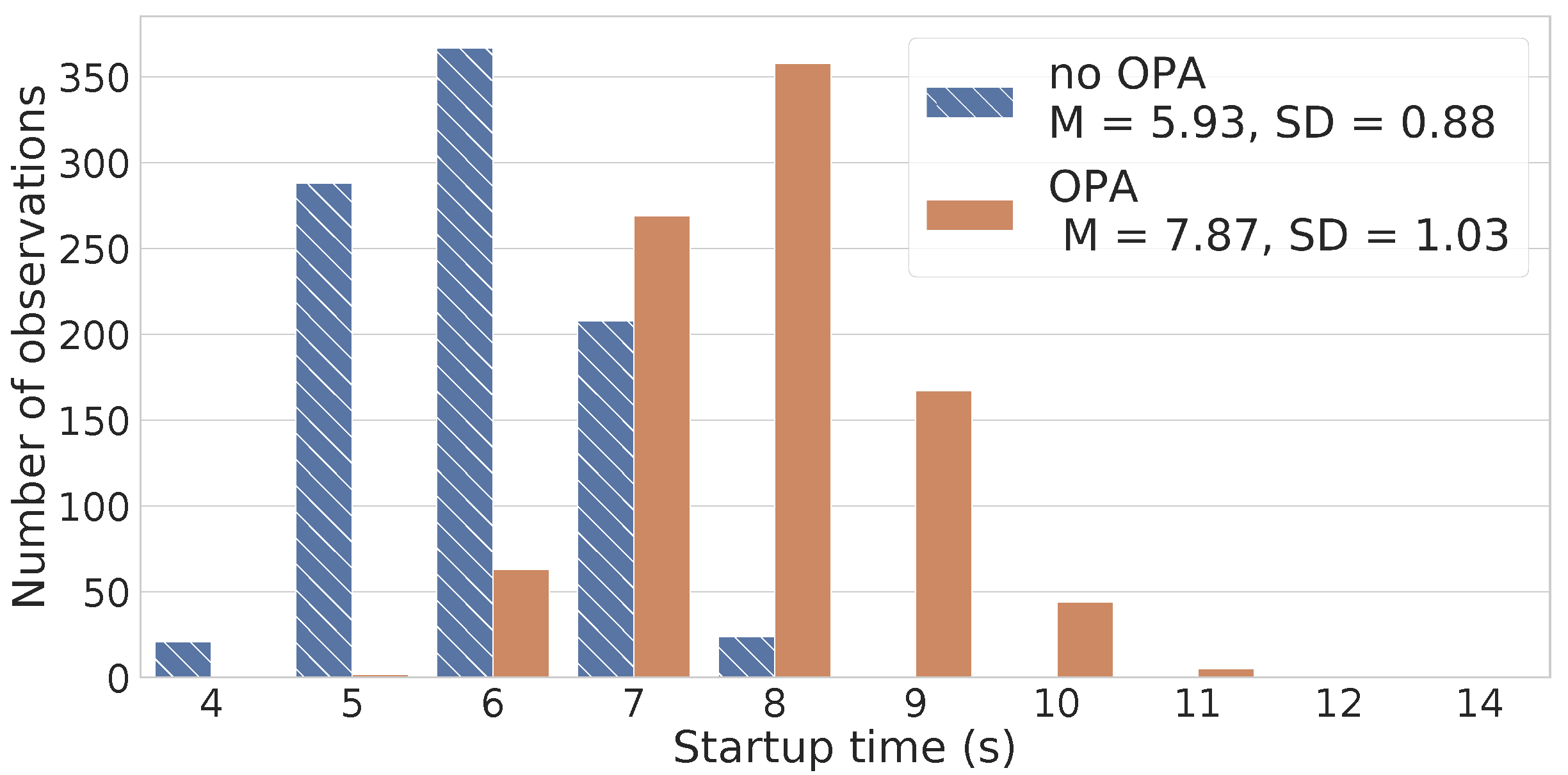
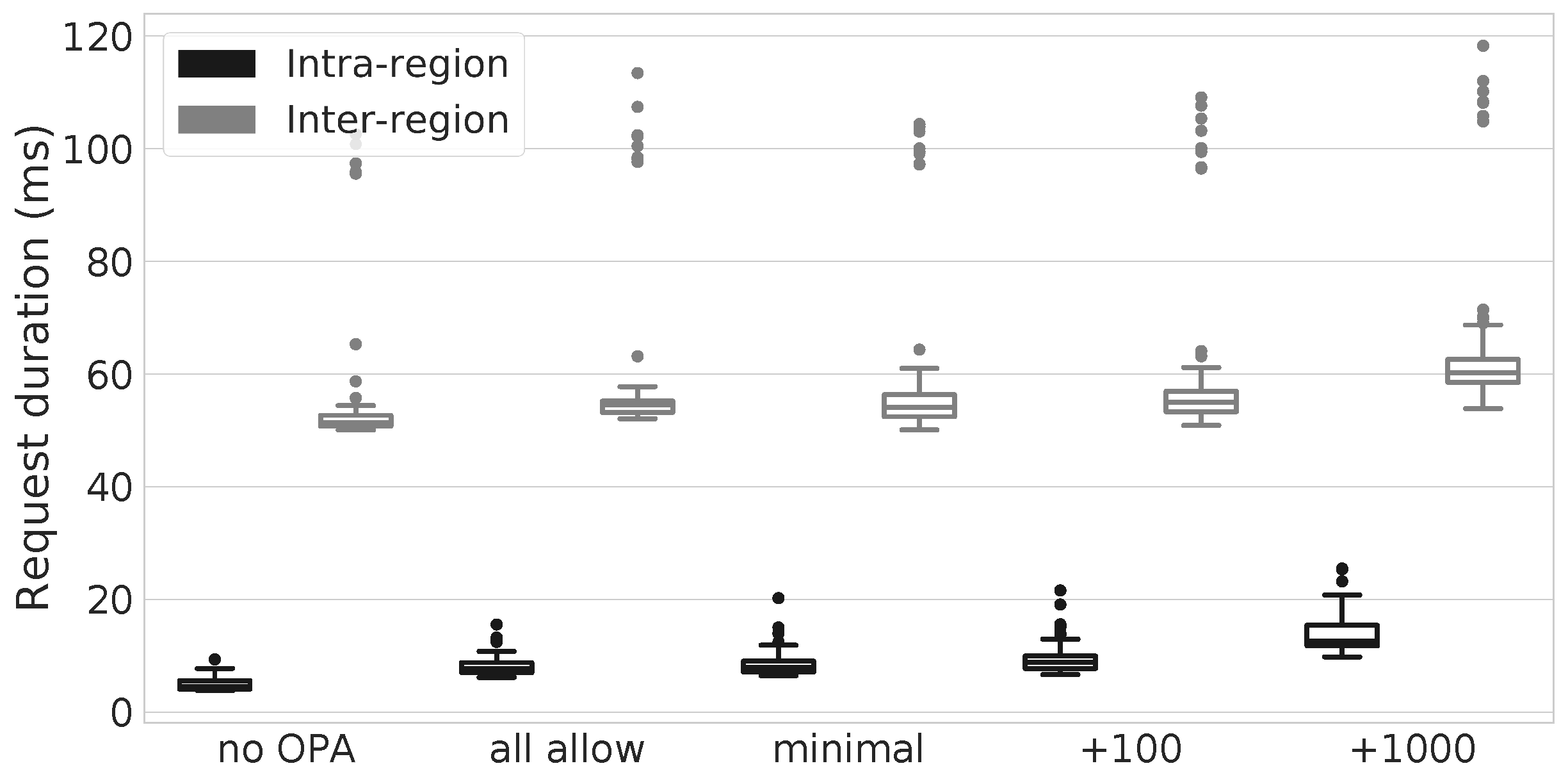
6. The Overhead of Security
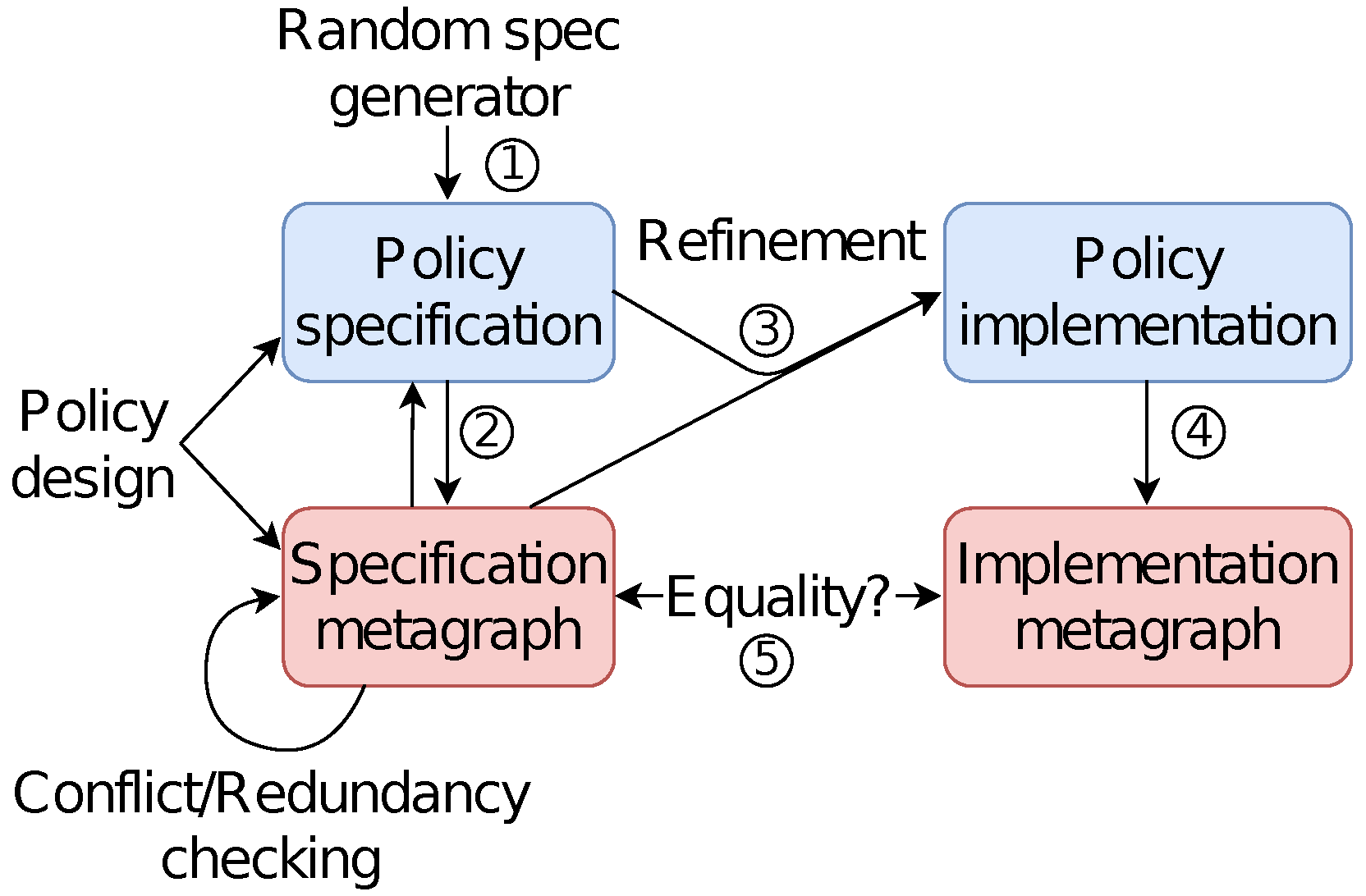
7. Verify the Deployment of the Access Control Policy Using Metagraphs
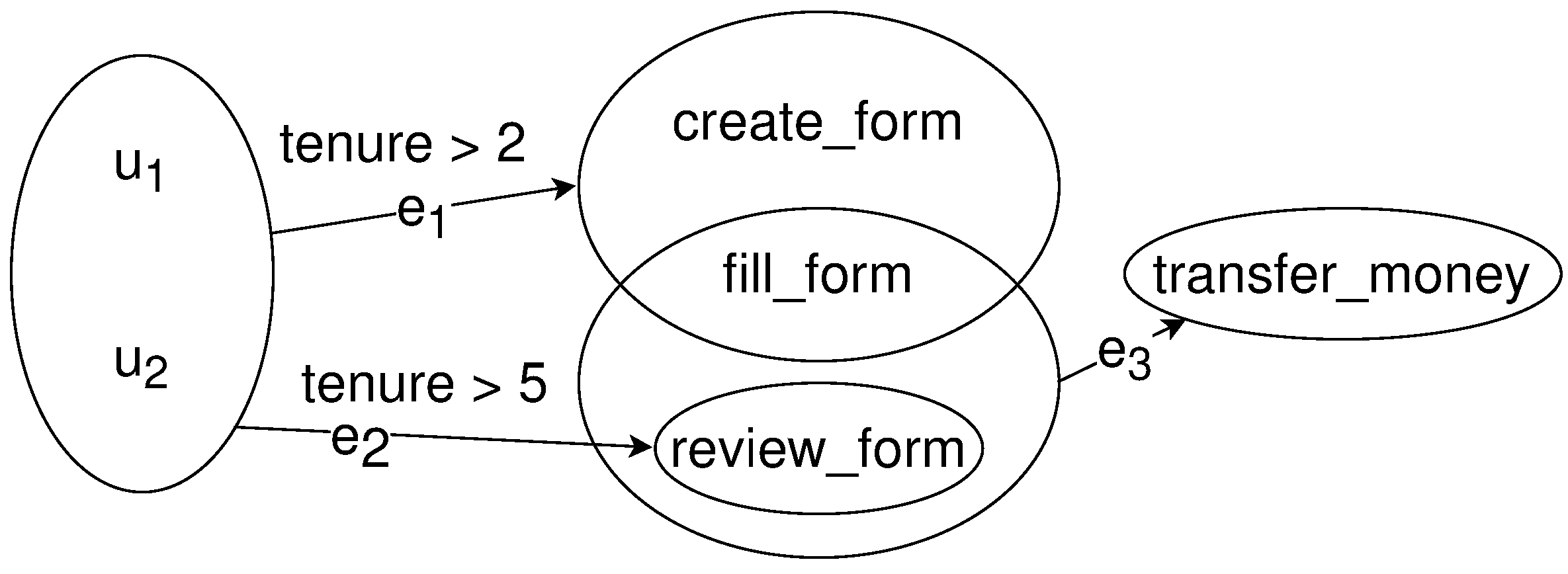
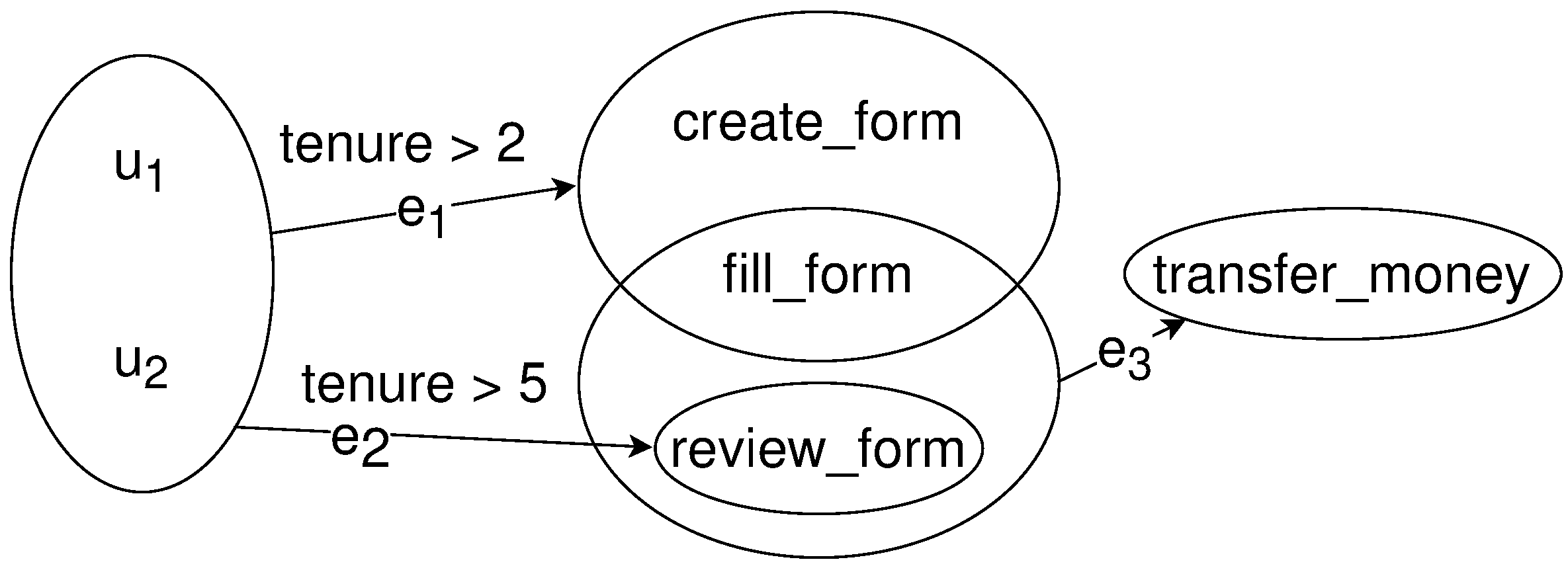
7.1. Background: An Expressive Model
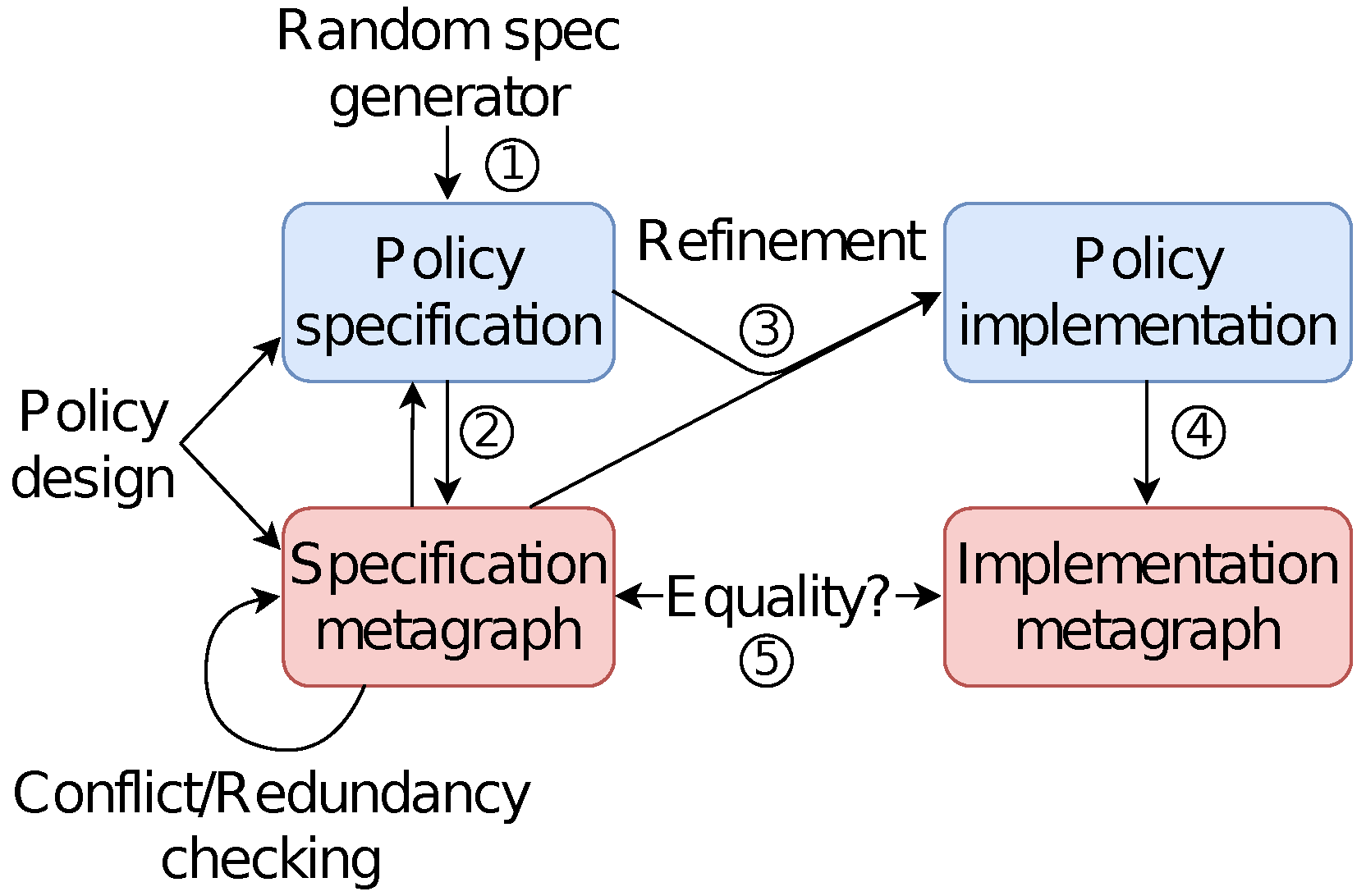
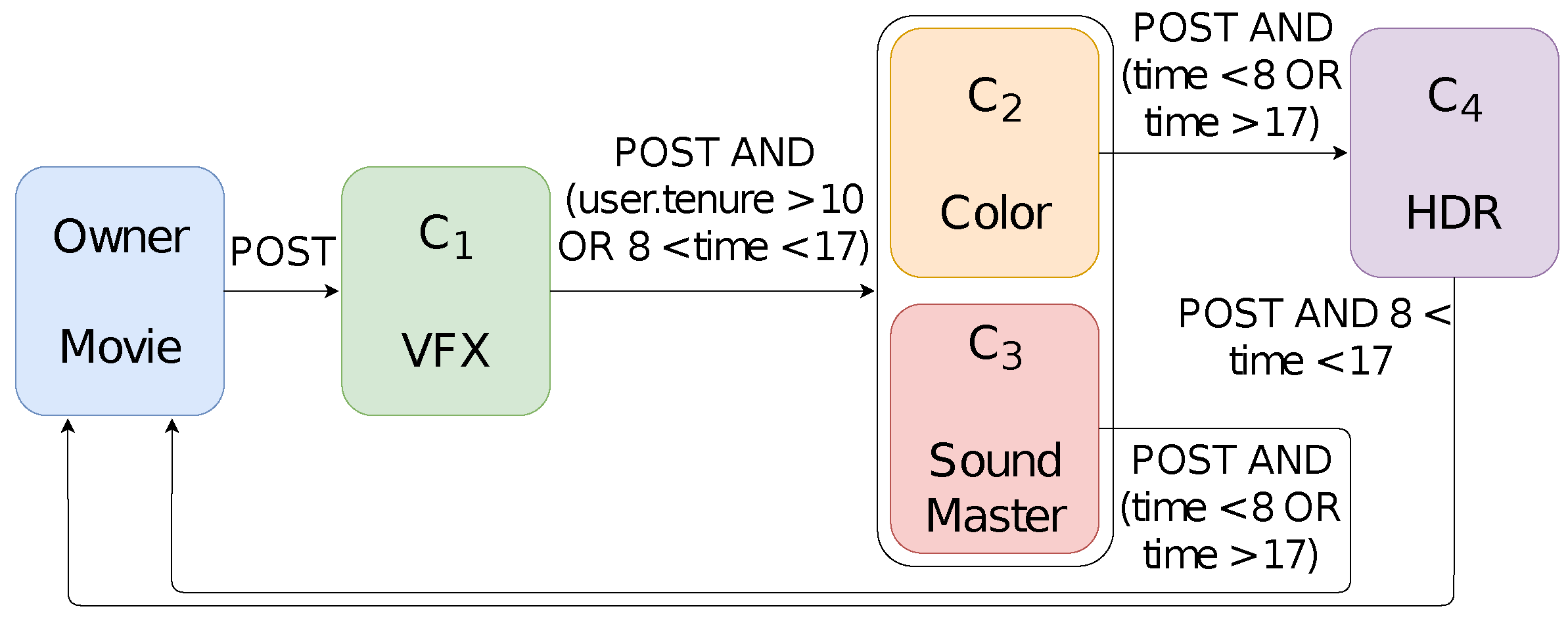
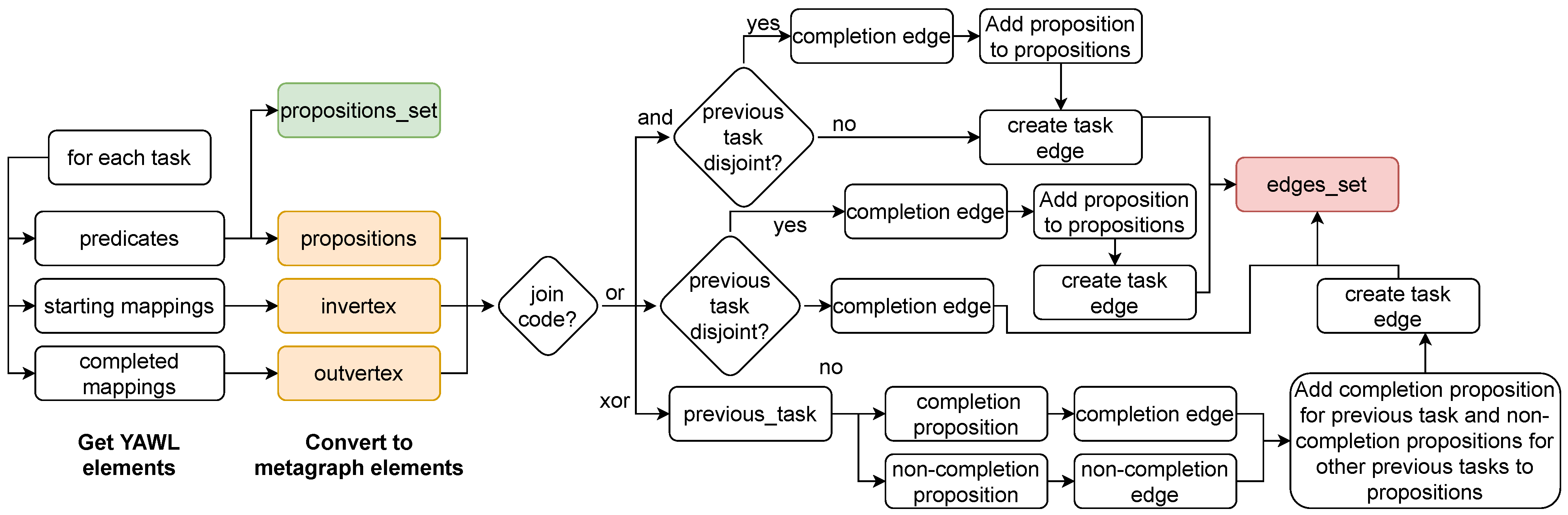
7.2. Comparing the Specification with Its Implementation
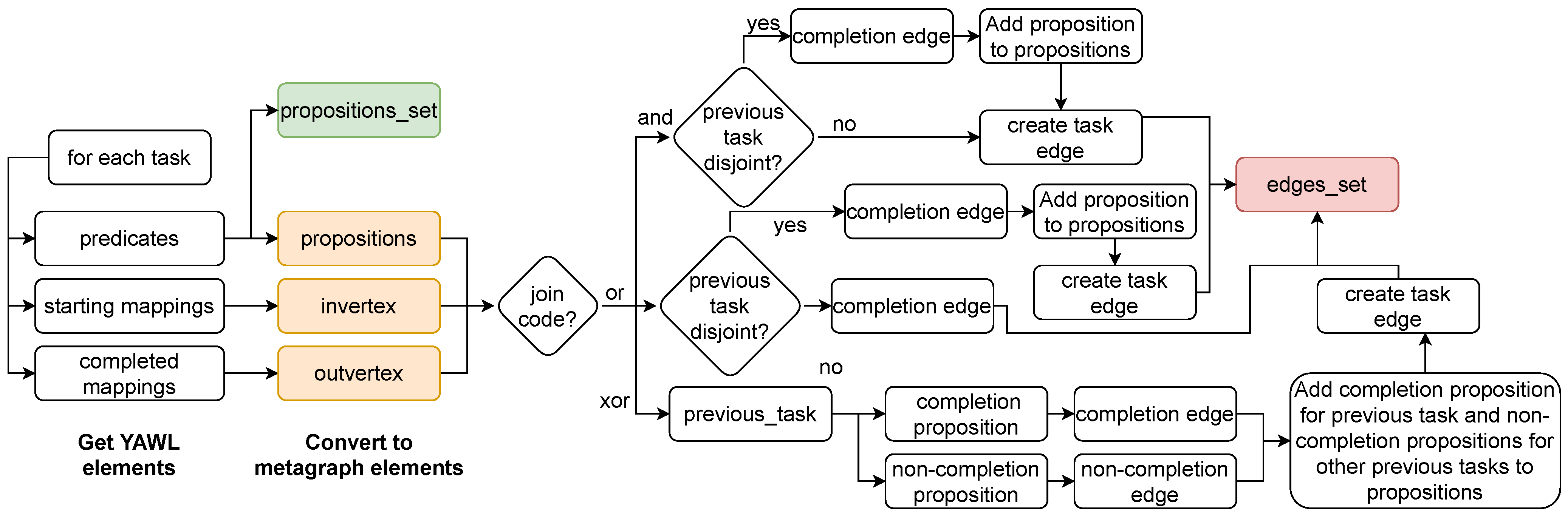
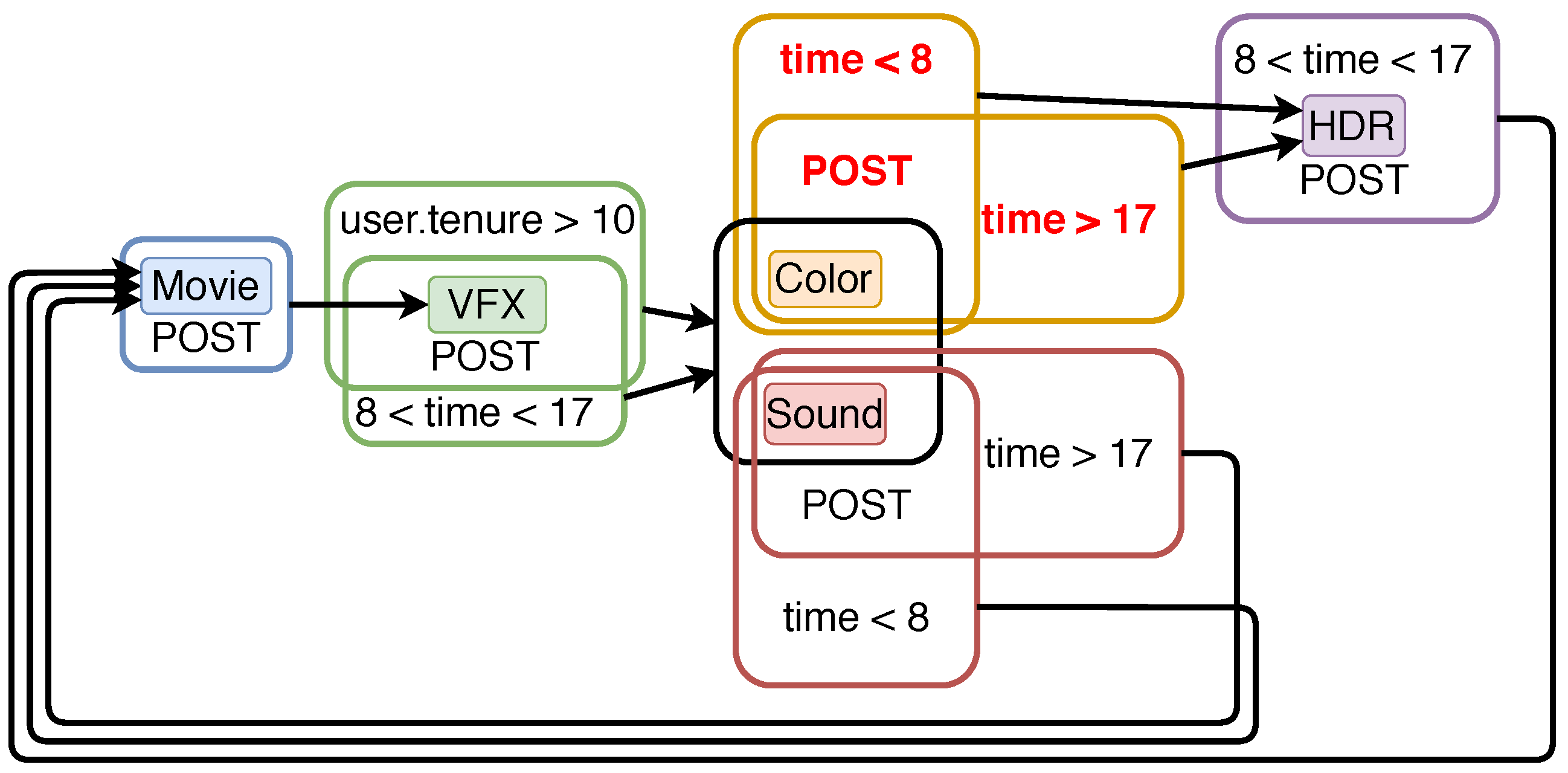
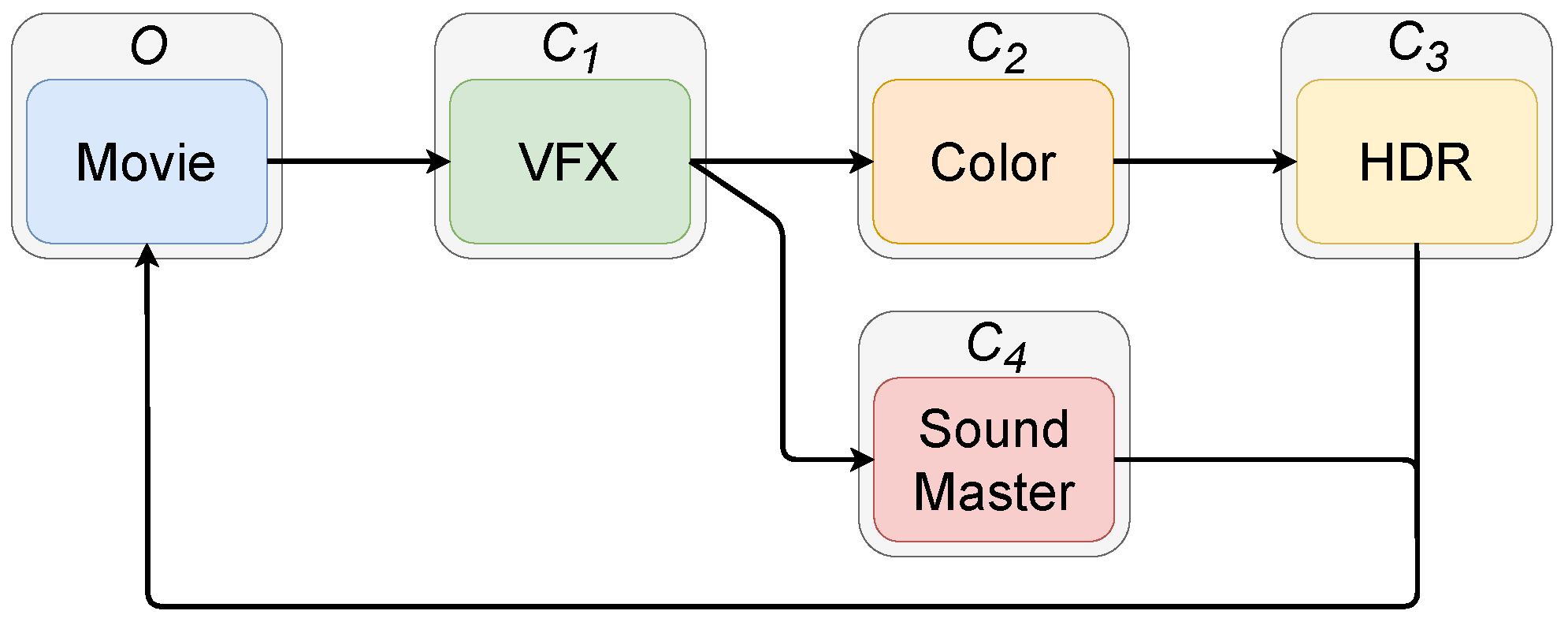
Modeling Workflows and Their Policies
7.3. Roadblocks of Our Model
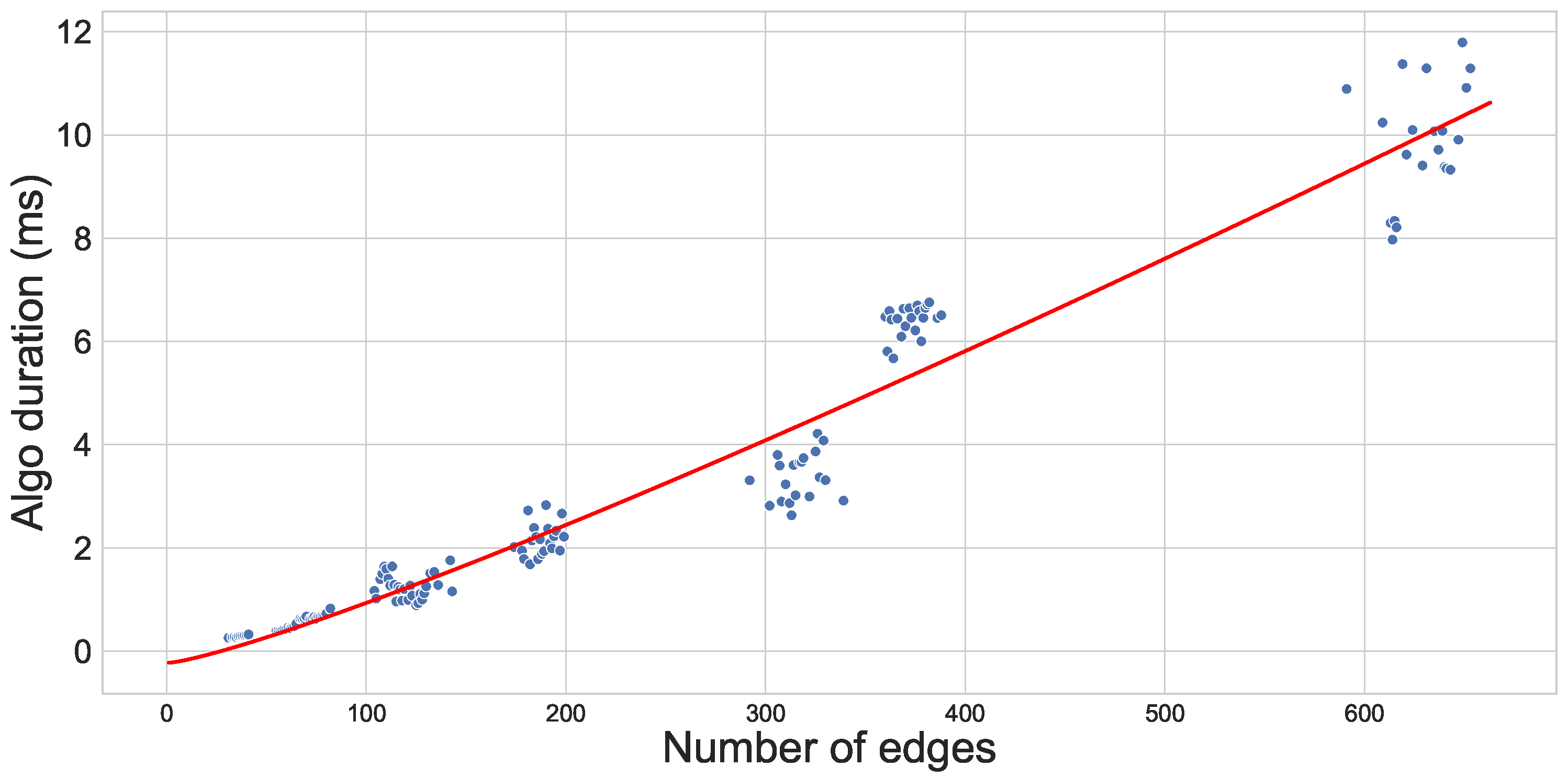
8. Performance Analysis: The Cost of Comparing Random Workflows
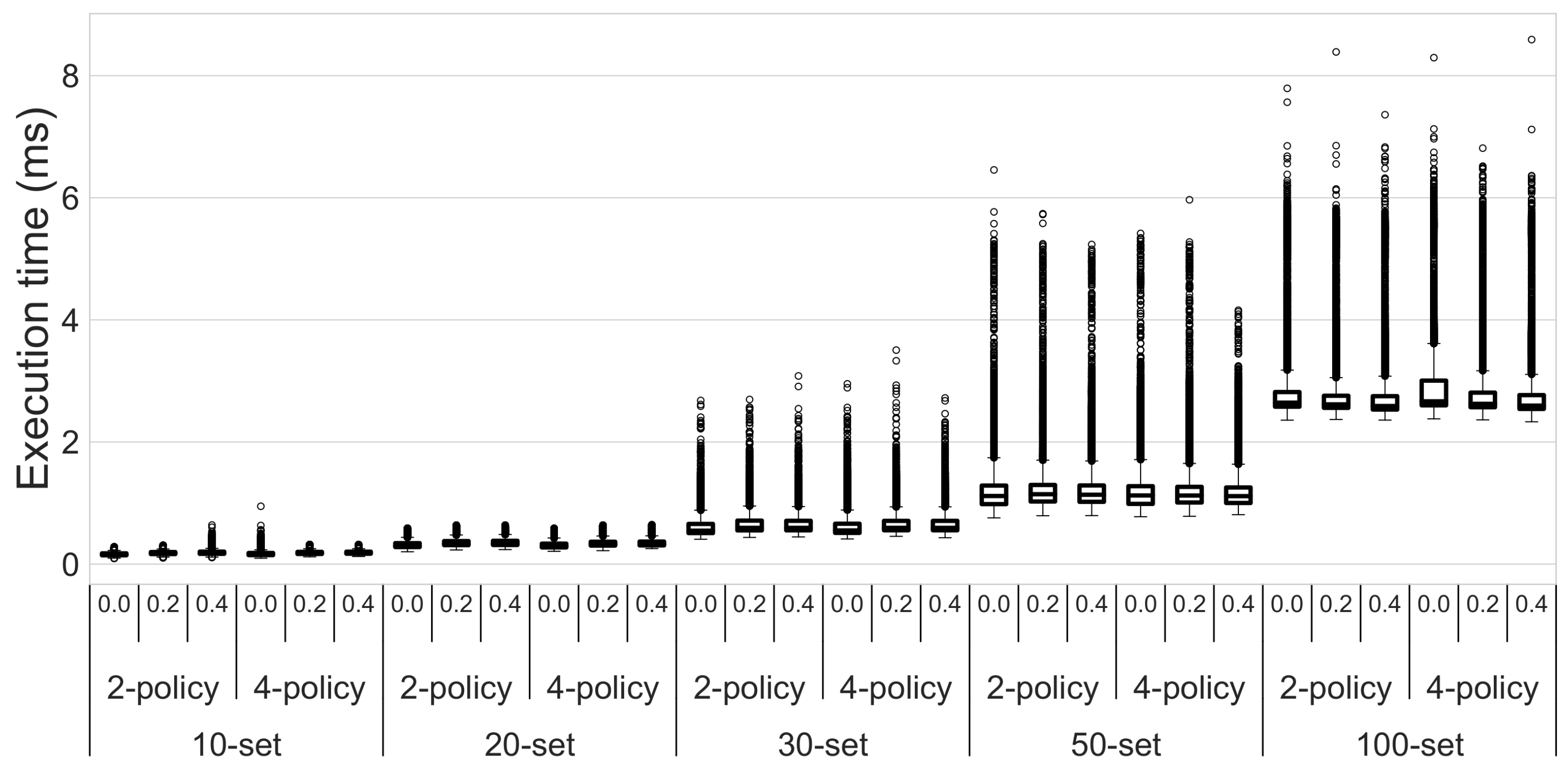
8.1. Methodology to Build Random Workflows
- Size of the workflow, i.e., number of elements in the generating set: 10, 20, 30, 50 or 100. Those correspond to variables which can be used in the input and output of tasks.
- Policy size, i.e., number of conditional propositions on each edge for the policy: 2 or 4.
- Error rate, i.e., fraction of errors in propositions of the metagraph. A value of 0.4 means that 40% of the elements/propositions of the metagraph will be changed to erroneous ones; we consider the following error rates: 0.0, 0.2 and 0.4.
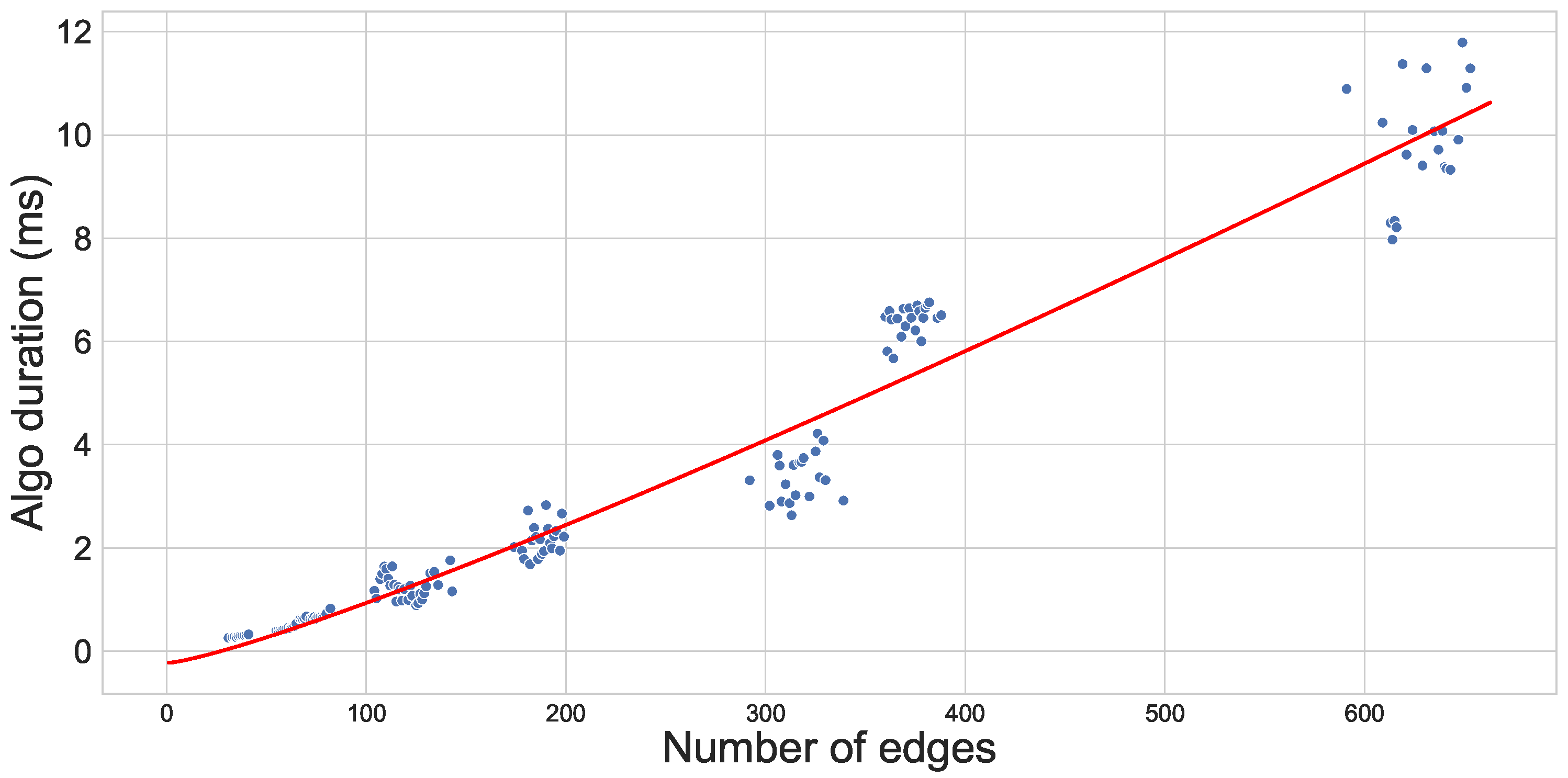
8.2. Evaluation: Sorting Policies and Their Edges Has a Limited Cost of
9. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Galov, N. Cloud Adoption Statistics for 2021. 2021. Available online: https://hostingtribunal.com/blog/cloud-adoption-statistics/ (accessed on 10 December 2021).
- Byers, S.; Cranor, L.; Korman, D.; McDaniel, P.; Cronin, E. Analysis of security vulnerabilities in the movie production and distribution process. In Proceedings of the 3rd ACM Workshop on Digital Rights Management, Washington, DC, USA, 27 October 2003; ACM: New York, NY, USA, 2003; pp. 1–12. [Google Scholar]
- Clearinghouse, P.R. Chronology of Data Breaches. 2021. Available online: https://privacyrights.org/data-breaches (accessed on 10 December 2021).
- Miller, L.; Mérindol, P.; Gallais, A.; Pelsser, C. Towards Secure and Leak-Free Workflows Using Microservice Isolation. In Proceedings of the 2021 IEEE 22nd International Conference on High Performance Switching and Routing (HPSR), Paris, France, 7–10 June 2021; pp. 1–5. [Google Scholar]
- Miller, L.; Mérindol, P.; Gallais, A.; Pelsser, C. Verification of Cloud Security Policies. In Proceedings of the 2021 IEEE 22nd International Conference on High Performance Switching and Routing (HPSR), Paris, France, 7–10 June 2021; pp. 1–5. [Google Scholar]
- Security, R.B. Data Breach Quickview Report 2019 Q3 Trends. 2019. Available online: https://library.cyentia.com/report/report_003207.html (accessed on 10 December 2021).
- Stempel, J.; Finkle, J. Yahoo Says All Three Billion Accounts Hacked in 2013 Data Theft. 2017. Available online: https://www.reuters.com/article/us-yahoo-cyber/yahoo-says-all-three-billion-accounts-hacked-in-2013-data-theft-idUSKCN1C82O1 (accessed on 10 December 2021).
- Seals, T. Thousands of MikroTik Routers Hijacked for Eavesdropping. 2018. Available online: https://threatpost.com/thousands-of-mikrotik-routers-hijacked-for-eavesdropping/137165/ (accessed on 10 December 2021).
- KrebsonSecurity. First American Financial Corp. Leaked Hundreds of Millions of Title Insurance Records. 2019. Available online: https://krebsonsecurity.com/2019/05/first-american-financial-corp-leaked-hundreds-of-millions-of-title-insurance-records (accessed on 10 December 2021).
- Lecher, C. Google Reportedly Fires Staffer in Media Leak Crackdown. 2019. Available online: https://www.theverge.com/2019/11/12/20962028/google-staff-firing-media-leak-suspension-employee-termination (accessed on 10 December 2021).
- Jin, C.; Srivastava, A.; Zhang, Z.L. Understanding security group usage in a public iaas cloud. In Proceedings of the IEEE INFOCOM 2016—The 35th Annual IEEE International Conference on Computer Communications, San Francisco, CA, USA, 10–14 April 2016; pp. 1–9. [Google Scholar]
- Chandramouli, R.; Butcher, Z. Building Secure Microservices-Based Applications Using Service-Mesh Architecture; Technical Report; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2020.
- Gilman, E.; Barth, D. Zero Trust Networks; O’Reilly Media, Incorporated: Newton, MA, USA, 2017. [Google Scholar]
- Blog, N.T. Netflix Conductor: A Microservices Orchestrator. 2016. Available online: https://netflixtechblog.com/netflix-conductor-a-microservices-orchestrator-2e8d4771bf40 (accessed on 10 December 2021).
- Blog, N.T. Evolution of Netflix Conductor: v2.0 and beyond. 2019. Available online: https://netflixtechblog.com/evolution-of-netflix-conductor-16600be36bca (accessed on 10 December 2021).
- Valenza, F.; Basile, C.; Canavese, D.; Lioy, A. Classification and analysis of communication protection policy anomalies. IEEE/ACM Trans. Netw. 2017, 25, 2601–2614. [Google Scholar] [CrossRef] [Green Version]
- Moffett, J.D.; Sloman, M.S. Policy hierarchies for distributed systems management. IEEE J. Sel. Areas Commun. 1993, 11, 1404–1414. [Google Scholar] [CrossRef] [Green Version]
- Enterprise, V. Data Breach Investigations Report. 2020. Available online: https://www.verizon.com/business/resources/reports/2020/2020-data-breach-investigations-report.pdf (accessed on 10 December 2021).
- Amazon. AWS Policy Generator. 2020. Available online: https://awspolicygen.s3.amazonaws.com/policygen.html (accessed on 10 December 2021).
- Dohndorf, O.; Kruger, J.; Krumm, H.; Fiehe, C.; Litvina, A.; Luck, I.; Stewing, F.J. Tool-supported refinement of high-level requirements and constraints into low-level policies. In Proceedings of the 2011 IEEE International Symposium on Policies for Distributed Systems and Networks, Pisa, Italy, 6–8 June 2011; pp. 97–104. [Google Scholar]
- Klinbua, K.; Vatanawood, W. Translating tosca into docker-compose yaml file using antlr. In Proceedings of the 2017 8th IEEE International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 24–26 November 2017; pp. 145–148. [Google Scholar]
- Vulners. Razer US: Database Credentials Leak. 2017. Available online: https://vulners.com/hackerone/H1:293470 (accessed on 10 December 2021).
- Cimpanu, C. Steam Bug Could Have Given You Access to All the CD Keys of Any Game. 2018. Available online: https://www.zdnet.com/article/steam-bug-could-have-given-you-access-to-all-the-cd-keys-of-any-game/ (accessed on 10 December 2021).
- Muthiyah, L. Hacking Facebook Pages. 2018. Available online: https://thezerohack.com/hacking-facebook-pages (accessed on 10 December 2021).
- Aboul-Ela, A. Delete Credit Cards from any Twitter Account. 2014. Available online: https://hackerone.com/reports/27404 (accessed on 10 December 2021).
- Miller, L.; Mérindol, P.; Gallais, A.; Pelsser, C. Towards Secure and Leak-Free Workflows Using Microservice Isolation. arXiv 2020, arXiv:2012.06300. [Google Scholar]
- Ter Hofstede, A.H.; Van der Aalst, W.M.; Adams, M.; Russell, N. Modern Business Process Automation: YAWL and Its Support Environment; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Model, B.P. Notation (bpmn) Version 2.0; OMG Specification, Object Management Group: Milford, MA, USA, 2011; pp. 22–31. [Google Scholar]
- Foundation, Y. YAWL4Film. 2010. Available online: http://yawlfoundation.org/pages/casestudies/yawl4film.html (accessed on 10 December 2021).
- Blockchain, V. The Future of Business: Multi-Party Business Networks. 2020. Available online: https://octo.vmware.com/the-future-of-business/ (accessed on 10 December 2021).
- Van Der Aalst, W.M.; Ter Hofstede, A.H. YAWL: Yet another workflow language. Inf. Syst. 2005, 30, 245–275. [Google Scholar] [CrossRef] [Green Version]
- Ranathunga, D.; Roughan, M.; Nguyen, H. Verifiable Policy-Defined Networking using Metagraphs. IEEE Trans. Dependable Secur. Comput. 2020. [Google Scholar] [CrossRef]
- Basu, A.; Blanning, R.W. Metagraphs and Their Applications; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2007; Volume 15. [Google Scholar]
- Chandramouli, R. Security Strategies for Microservices-Based Application Systems; Technical Report; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2019.
- El Malki, A.; Zdun, U. Guiding Architectural Decision Making on Service Mesh Based Microservice Architectures. In European Conference on Software Architecture; Springer: Berlin/Heidelberg, Germany, 2019; pp. 3–19. [Google Scholar]
- Souppaya, M.; Morello, J.; Scarfone, K. Application Container Security Guide (2nd Draft); Technical Report; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2017.
- Chandramouli, R.; Chandramouli, R. Security Assurance Requirements for Linux Application Container Deployments; US Department of Commerce, National Institute of Standards and Technology: Gaithersburg, MD, USA, 2017.
- de Weever, C.; Andreou, M. Zero Trust Network Security Model in Containerized Environments; University of Amsterdam: Amsterdam, The Netherlands, 2020. [Google Scholar]
- Hussain, F.; Li, W.; Noye, B.; Sharieh, S.; Ferworn, A. Intelligent Service Mesh Framework for API Security and Management. In Proceedings of the 2019 IEEE 10th Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), Vancouver, BC, Canada, 17–19 October 2019; pp. 735–742. [Google Scholar]
- Zaheer, Z.; Chang, H.; Mukherjee, S.; Van der Merwe, J. eZTrust: Network-Independent Zero-Trust Perimeterization for Microservices. In Proceedings of the 2019 ACM Symposium on SDN Research, San Jose, CA, USA, 3–4 April 2019; pp. 49–61. [Google Scholar]
- Accorsi, R.; Wonnemann, C. Strong non-leak guarantees for workflow models. In Proceedings of the 2011 ACM Symposium on Applied Computing, TaiChung, Taiwan, 21–24 March 2011; pp. 308–314. [Google Scholar]
- Shu, X.; Yao, D.D. Data leak detection as a service. In International Conference on Security and Privacy in Communication Systems; Springer: Berlin/Heidelberg, Germany, 2012; pp. 222–240. [Google Scholar]
- Farhatullah, M. ALP: An authentication and leak prediction model for Cloud Computing privacy. In Proceedings of the 2013 3rd IEEE International Advance Computing Conference (IACC), Ghaziabad, India, 22–23 February 2013; pp. 48–51. [Google Scholar]
- Shu, X.; Yao, D.; Bertino, E. Privacy-preserving detection of sensitive data exposure. IEEE Trans. Inf. Forensics Secur. 2015, 10, 1092–1103. [Google Scholar] [CrossRef]
- Liu, F.; Shu, X.; Yao, D.; Butt, A.R. Privacy-preserving scanning of big content for sensitive data exposure with MapReduce. In Proceedings of the 5th ACM Conference on Data and Application Security and Privacy, San Antonio, TX, USA, 2–4 March 2015; pp. 195–206. [Google Scholar]
- Shu, X.; Zhang, J.; Yao, D.D.; Feng, W.C. Fast detection of transformed data leaks. IEEE Trans. Inf. Forensics Secur. 2015, 11, 528–542. [Google Scholar]
- Shu, X.; Zhang, J.; Yao, D.; Feng, W.C. Rapid screening of transformed data leaks with efficient algorithms and parallel computing. In Proceedings of the 5th ACM Conference on Data and Application Security and Privacy, San Antonio, TX, USA, 2–4 March 2015; pp. 147–149. [Google Scholar]
- LeVasseur, T.; Richard, P. Data Leak Protection System and Processing Methods Thereof. US Patent 9,754,217, 5 September 2017. [Google Scholar]
- Segarra, C.; Delgado-Gonzalo, R.; Lemay, M.; Aublin, P.L.; Pietzuch, P.; Schiavoni, V. Using trusted execution environments for secure stream processing of medical data. In IFIP International Conference on Distributed Applications and Interoperable Systems; Springer: Berlin/Heidelberg, Germany, 2019; pp. 91–107. [Google Scholar]
- Zuo, C.; Lin, Z.; Zhang, Y. Why does your data leak? Uncovering the data leakage in cloud from mobile apps. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2019; pp. 1296–1310. [Google Scholar]
- Jayaraman, K.; Ganesh, V.; Tripunitara, M.; Rinard, M.; Chapin, S. Automatic error finding in access-control policies. In Proceedings of the 18th ACM Conference on Computer and Communications Security, Chicago, IL, USA, 17–21 October 2011; pp. 163–174. [Google Scholar]
- Khurat, A.; Suntisrivaraporn, B.; Gollmann, D. Privacy policies verification in composite services using OWL. Comput. Secur. 2017, 67, 122–141. [Google Scholar] [CrossRef]
- Hu, H.; Ahn, G.J.; Kulkarni, K. Discovery and resolution of anomalies in web access control policies. IEEE Trans. Dependable Secur. Comput. 2013, 10, 341–354. [Google Scholar] [CrossRef] [Green Version]
- Koch, M.; Mancini, L.V.; Parisi-Presicce, F. Conflict detection and resolution in access control policy specifications. In International Conference on Foundations of Software Science and Computation Structures; Springer: Berlin/Heidelberg, Germany, 2002; pp. 223–238. [Google Scholar]
- Schneider, F.B. Enforceable security policies. ACM Trans. Inf. Syst. Secur. (TISSEC) 2000, 3, 30–50. [Google Scholar] [CrossRef]
- Cheminod, M.; Durante, L.; Valenza, F.; Valenzano, A. Toward attribute-based access control policy in industrial networked systems. In Proceedings of the 2018 14th IEEE International Workshop on Factory Communication Systems (WFCS), Imperia, Italy, 13–15 June 2018; pp. 1–9. [Google Scholar]
- Basile, C.; Canavese, D.; Pitscheider, C.; Lioy, A.; Valenza, F. Assessing network authorization policies via reachability analysis. Comput. Electr. Eng. 2017, 64, 110–131. [Google Scholar] [CrossRef]
- Rezvani, M.; Rajaratnam, D.; Ignjatovic, A.; Pagnucco, M.; Jha, S. Analyzing XACML policies using answer set programming. Int. J. Inf. Secur. 2019, 18, 465–479. [Google Scholar] [CrossRef]
- Attia, H.B.; Kahloul, L.; Benhazrallah, S.; Bourekkache, S. Using Hierarchical Timed Coloured Petri Nets in the formal study of TRBAC security policies. Int. J. Inf. Secur. 2020, 19, 163–187. [Google Scholar] [CrossRef]
- Liu, A.X.; Chen, F.; Hwang, J.; Xie, T. Xengine: A fast and scalable XACML policy evaluation engine. ACM Sigmetrics Perform. Eval. Rev. 2008, 36, 265–276. [Google Scholar] [CrossRef]
- Liu, A.X.; Chen, F.; Hwang, J.; Xie, T. Designing fast and scalable XACML policy evaluation engines. IEEE Trans. Comput. 2010, 60, 1802–1817. [Google Scholar] [CrossRef] [Green Version]
- Hughes, G.; Bultan, T. Automated verification of access control policies using a SAT solver. Int. J. Softw. Tools Technol. Transf. 2008, 10, 503–520. [Google Scholar] [CrossRef] [Green Version]
- Bera, P.; Ghosh, S.K.; Dasgupta, P. Policy based security analysis in enterprise networks: A formal approach. IEEE Trans. Netw. Serv. Manag. 2010, 7, 231–243. [Google Scholar] [CrossRef]
- Ranathunga, D.; Nguyen, H.; Roughan, M. MGtoolkit: A python package for implementing metagraphs. SoftwareX 2017, 6, 91–93. [Google Scholar] [CrossRef]
- Hamza, A.; Ranathunga, D.; Gharakheili, H.H.; Roughan, M.; Sivaraman, V. Clear as MUD: Generating, validating and applying IoT behavioral profiles. In Proceedings of the 2018 Workshop on IoT Security and Privacy, Budapest, Hungary, 20 August 2018; pp. 8–14. [Google Scholar]
- Hamza, A.; Ranathunga, D.; Gharakheili, H.H.; Benson, T.A.; Roughan, M.; Sivaraman, V. Verifying and monitoring iots network behavior using mud profiles. IEEE Trans. Dependable Secur. Comput. 2020. [Google Scholar] [CrossRef]
- Docker. Docker. 2019. Available online: https://www.docker.com/ (accessed on 10 December 2021).
- Kubernetes. Kubernetes. 2020. Available online: https://kubernetes.io/ (accessed on 10 December 2021).
- Istio. Istio. 2020. Available online: https://istio.io/ (accessed on 10 December 2021).
- Envoy. Envoy. 2020. Available online: https://www.envoyproxy.io/ (accessed on 10 December 2021).
- Open Policy Agent. Open Policy Agent. 2020. Available online: https://www.openpolicyagent.org/ (accessed on 10 December 2021).
- Ranathunga, D.; Roughan, M.; Nguyen, H.; Kernick, P.; Falkner, N. Case studies of scada firewall configurations and the implications for best practices. IEEE Trans. Netw. Serv. Manag. 2016, 13, 871–884. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Source | Destination | ||||||
|---|---|---|---|---|---|---|---|
| Owner | Color | Sound | HDR | ||||
| Owner | - | POST | |||||
| - | POST | POST | |||||
| - | POST | ||||||
| - | POST | ||||||
| Color | - | POST | |||||
| Sound | POST | - | |||||
| HDR | POST | - | |||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Miller, L.; Mérindol, P.; Gallais, A.; Pelsser, C. Securing Workflows Using Microservices and Metagraphs. Electronics 2021, 10, 3087. https://doi.org/10.3390/electronics10243087
Miller L, Mérindol P, Gallais A, Pelsser C. Securing Workflows Using Microservices and Metagraphs. Electronics. 2021; 10(24):3087. https://doi.org/10.3390/electronics10243087
Chicago/Turabian StyleMiller, Loïc, Pascal Mérindol, Antoine Gallais, and Cristel Pelsser. 2021. "Securing Workflows Using Microservices and Metagraphs" Electronics 10, no. 24: 3087. https://doi.org/10.3390/electronics10243087
APA StyleMiller, L., Mérindol, P., Gallais, A., & Pelsser, C. (2021). Securing Workflows Using Microservices and Metagraphs. Electronics, 10(24), 3087. https://doi.org/10.3390/electronics10243087