
Estimation and Interpretation of Machine Learning Models with Customized Surrogate Model


 , , , ,
, , , ,  and
and
Abstract
1. Introduction
1.1. Scope and Objective
1.2. Problem Statements
1.3. Research Contribution
- We considered different datasets from different resources elaborated in Section 4 in which insights into the datasets are provided. Moreover, these datasets belong to both classification and regression problem domains. With the help of the surrogate model, we were able to perform automatic feature engineering tasks. Then, b was mimicked with the assistance of available global surrogate methods (elaborated in Section 3.6)—also known as white box models—before providing an explanation that is comprehensible for end-users. While mimicking the underlying b, in most cases, our proposed methodology outperforms the b which means that we accomplished our objective of retaining the high accuracy of the model and explaining the inner working of b in a way that simultaneously exposes how b acts when exposed to the specific features of the original dataset.
- There are several areas in which interpretation is necessary because of the legal requirements by target area [32]. Interpretability thus encourages the development of the analysis of interpretable patterns from trained models by allowing one to identify the causes behind poor predictions by machines. If b becomes comprehensible by the end-user, it will surely engender trust in machines and help users detect biasness in machine learning models—as we are doing herein.
- In this work, we propose a technique called enhanced surrogate-assisted feature engineering (ESAFE) for machine learning models, which is an extension of surrogate-assisted feature extraction for model learning (SAFE ML) [33]. It will address all such issues that general interpretable desiderata (explained in Section 3.1), which requires the incorporation of Equations (1) and (2).
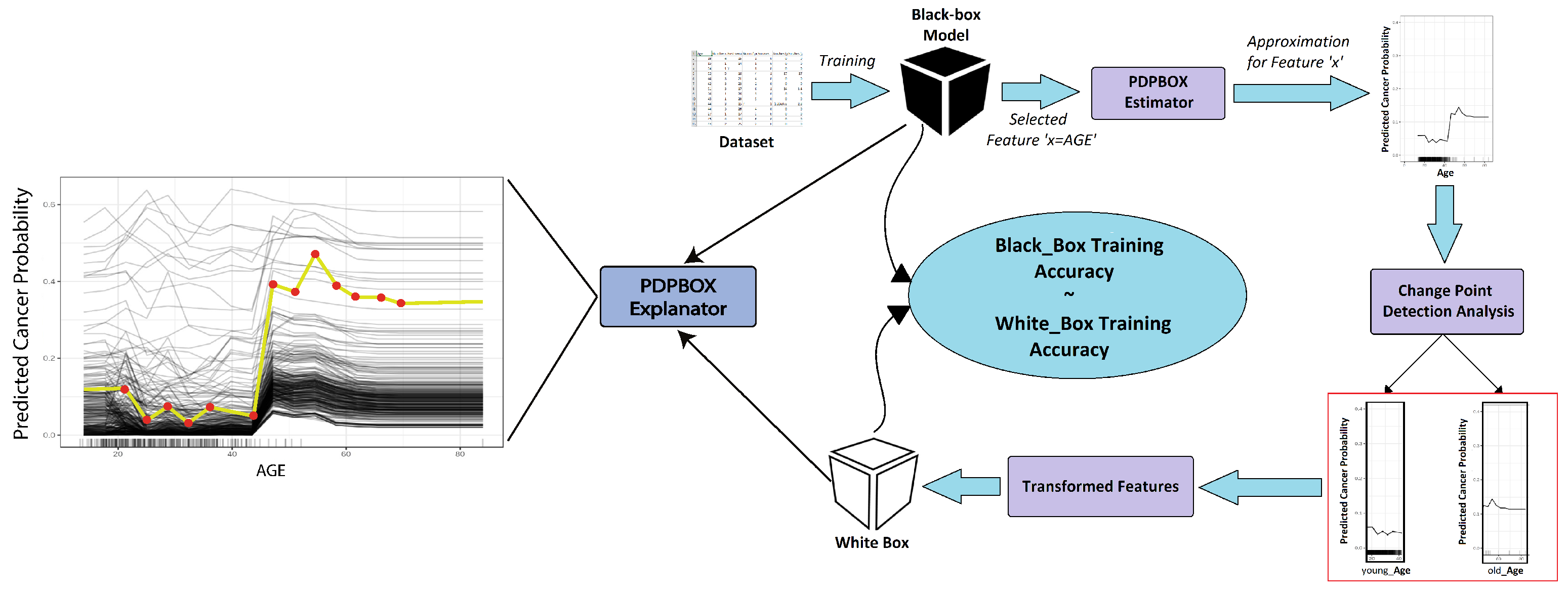
- With the help of technique [34], the proposed methodology achieved a drastic change in terms of computational cost whilst simultaneously respecting all the constraints mentioned in the interpretable desiderata Section 3.1. This technique will help us build . The surrogate model f will assist us in transforming features and thus produce as a result. With enhanced visual interpretability accurately imitating quality and without compromising the accuracy of the machine learning model, we hereby provide a novel technique in the form of the Python package so that the end-user may be satisfied with its results. This will enable the end-user to ascertain different features of the relationships and their effects on the overall prediction of b.
1.4. Paper Orientation
2. Related Work

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Ref | Agnostic | Data Ind | Classification | Regression | Auto Feature Eng | Fast Execution |
|---|---|---|---|---|---|---|---|
| STA | [35] | ✓ | ✓ | ✓ | ✓ | ||
| [37] | ✓ | ✓ | ✓ | ||||
| PALM | [38] | ✓ | ✓ | ✓ | ✓ | ||
| [39] | ✓ | ✓ | ✓ | ||||
| EE | [43] | ✓ | ✓ | ✓ | ✓ | ✓ | |
| SAFE ML | [33] | ✓ | ✓ | ✓ | ✓ | ✓ | |
| MFI | [47] | ✓ | ✓ | ✓ | ✓ | ||
| DTD | [50] | ✓ | ✓ | ✓ | |||
| LORE | [52] | ✓ | ✓ | ✓ | ✓ | ✓ | |
| ESAFE | [53] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
3. Proposed Technique
3.1. The General Desiderata
- Interpretability: Generally, this tells the extent to which the model’s behavior and its predictions are understandable by humans. The most crucial point to debate is how interpretability can be measured. The complexity of the prediction model in terms of model size is one component for determining interpretability [53]. According to our work, this term signifies that the black box model is explainable through a simple glass box model, hence enabling the end-user to audit and understand the factors influencing the prediction of given data. Interpretability comes with different forms, e.g., in the form of natural language, visualization, and mathematical equations which enable the end-user to understand the inner workings and reasoning of the model’s predictions.
- Trust: The degree of trust depends upon the constraints of monotonicity provided by the users which could lead to increased trust in machines [54,55,56]. The user cannot blindly make decisions on a prediction that a machine has made. Nevertheless, the accuracy is very high but interrogation is a subject matter when sensitive cases are at stake as would be the case in the medical field [57,58]. Allowing users to know when the model has probably failed and provided misleading results can increase trust in machines. This factor of trust is directly deduced from interpretability.
- Automaticity: This term has drawn great attention from many researchers who have attempted to conceive more precise and accurate methodologies to achieve efficient results for a problem of interest in an automated way. In this context, by automaticity, we mean a feature engineering task to be automated. This task is usually considered a daunting task in data science and requires excessive effort. This even requires strong statistical knowledge and programming skills. However, machine learning specialists have proposed several techniques to address this issue in the shape of automated machine learning (AutoML) which can target the various stages of the machine learning process [59] and are especially designed to reduce tedious overwork, e.g., feature extraction and feature transformation. Auto-sklearn, autokeras and TPOT are popular packages available for developers to reduce the workflow [60].
- Accuracy: In general, this term discusses the extent to which the model can accurately predict unseen data. There are several techniques available to measure the accuracy of a model such as the F1 score, receiver operating characteristic curve (ROC), area under the curve (AUC), precision and recall depending on the nature of the problem at hand. Basically, it is a measurement of the models’ prediction that depicts how much our model is efficient in performing a specific task.
- Fidelity: Fidelity is the ability to accurately replicate a black box predictor, which captures the extent to which an interpretable model can accurately imitate the behavior of a black box model. Similarly, fidelity is quantified in terms of accuracy score, F1-score, etc., in terms of the black box outcome.
3.2. The Essentials
- Data consolidation;
- Data preprocessing;
- Analyzing data balancing;
- Implementation of methodology;
- Results verification.
3.3. Components
Global Surrogate Models
- First, select a dataset X which can be the same dataset that was used for training the black box mode. We can also use the subset of that same dataset in the form of grids, depending on the type of application;
- Then, make prediction of X with the help of the black box model b;
- Then, look for the desired interpretable model type, for example, the linear model, decision tree, etc., and then train that on the same dataset X and reveal the prediction;
- Now, our surrogate model is ready. We also need to measure the extent to which the targeted surrogate model accurately replicates the predictions of b using measuring tools such as accuracy, F1 score, mean squared error and area under the curve;
- Now, interpret the surrogate model.
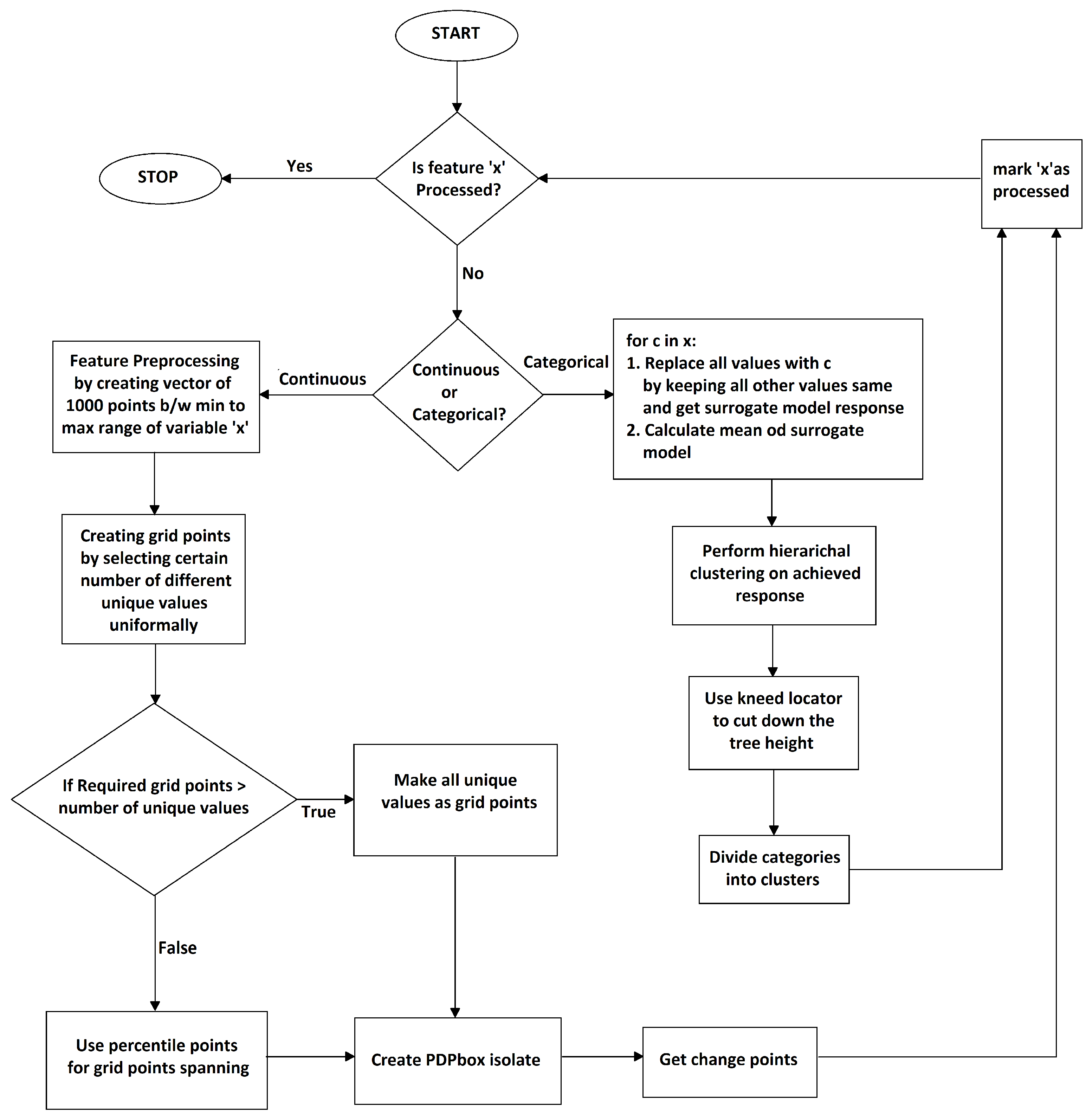
3.4. PDPBOX
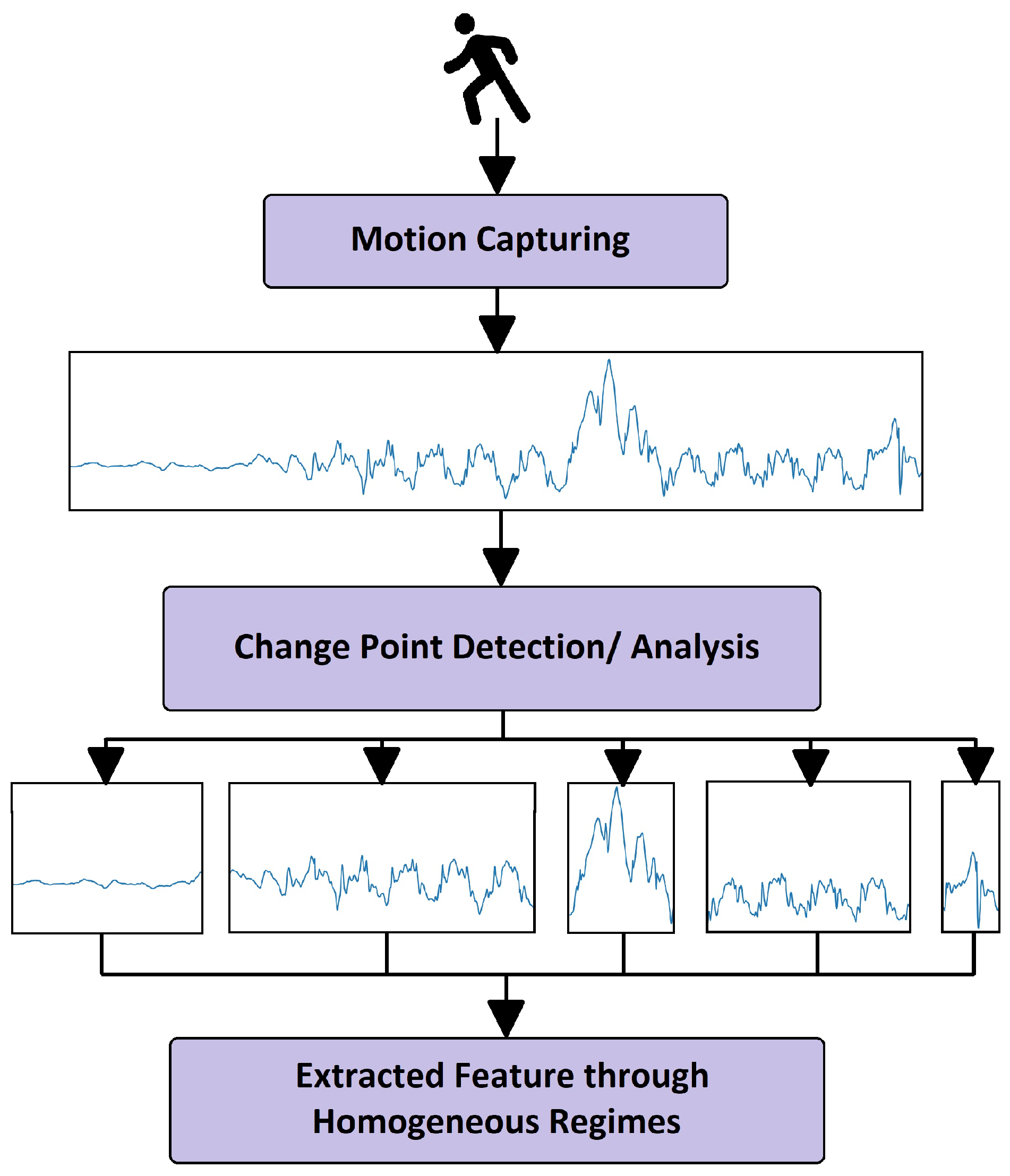
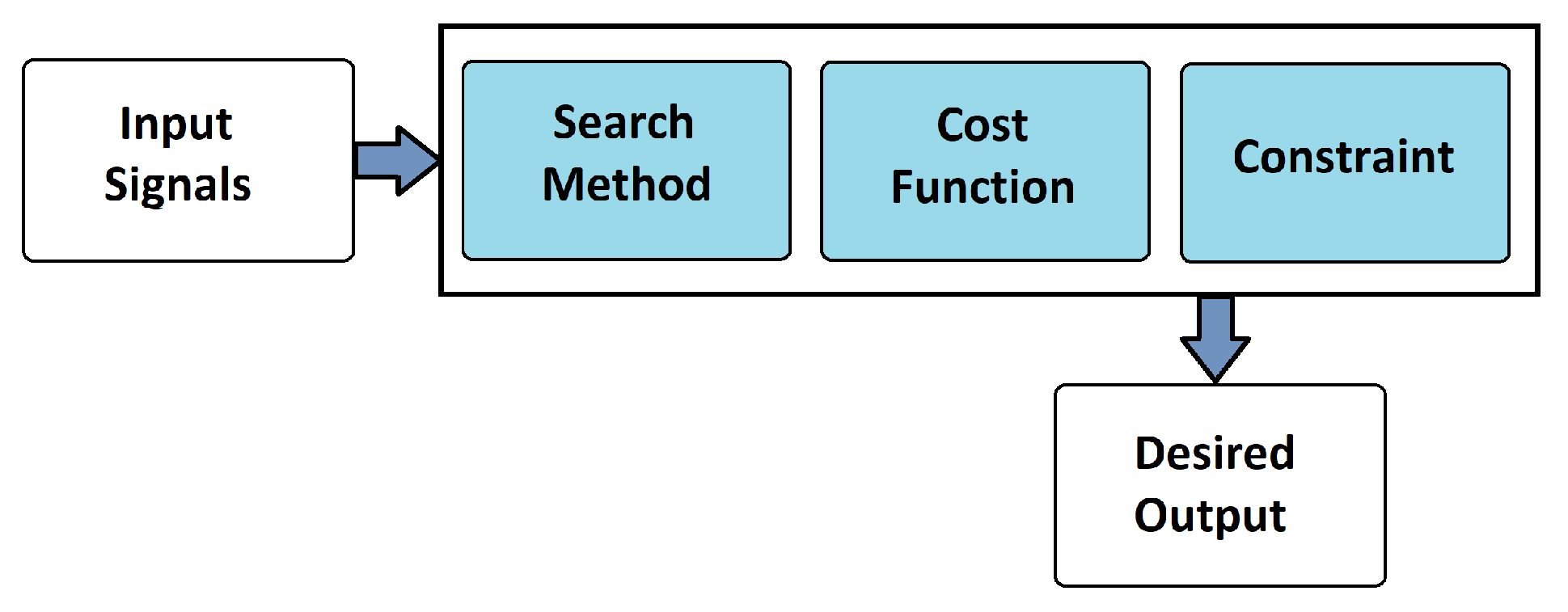
3.5. The Change Point Method
3.5.1. Cost Function
3.5.2. Search Method
3.5.3. Constraint
3.6. Enhanced Surrogate-Assisted Feature Engineering
- PDPBOX estimator approximates b’s behavior for selected feature(s) in the form of signals;
- Then, the approximated signal is further processed for detecting multiple offline change points that are likely to appear in a generated signal;
- Detected change points are then fitted with algorithms e.g., binary segmentation and exact segmentation for the creation of new regimes (features);
- It is then transformed into a new dataset for a selected feature;
- These transformed data are then trained on the white box model to achieve results close to black box model’s predictions.
3.7. Handling Algorithm’s Smoothing Parameter
3.8. Basic Workflow
4. Results and Benchmark
4.1. Regression—Boston Housing Dataset
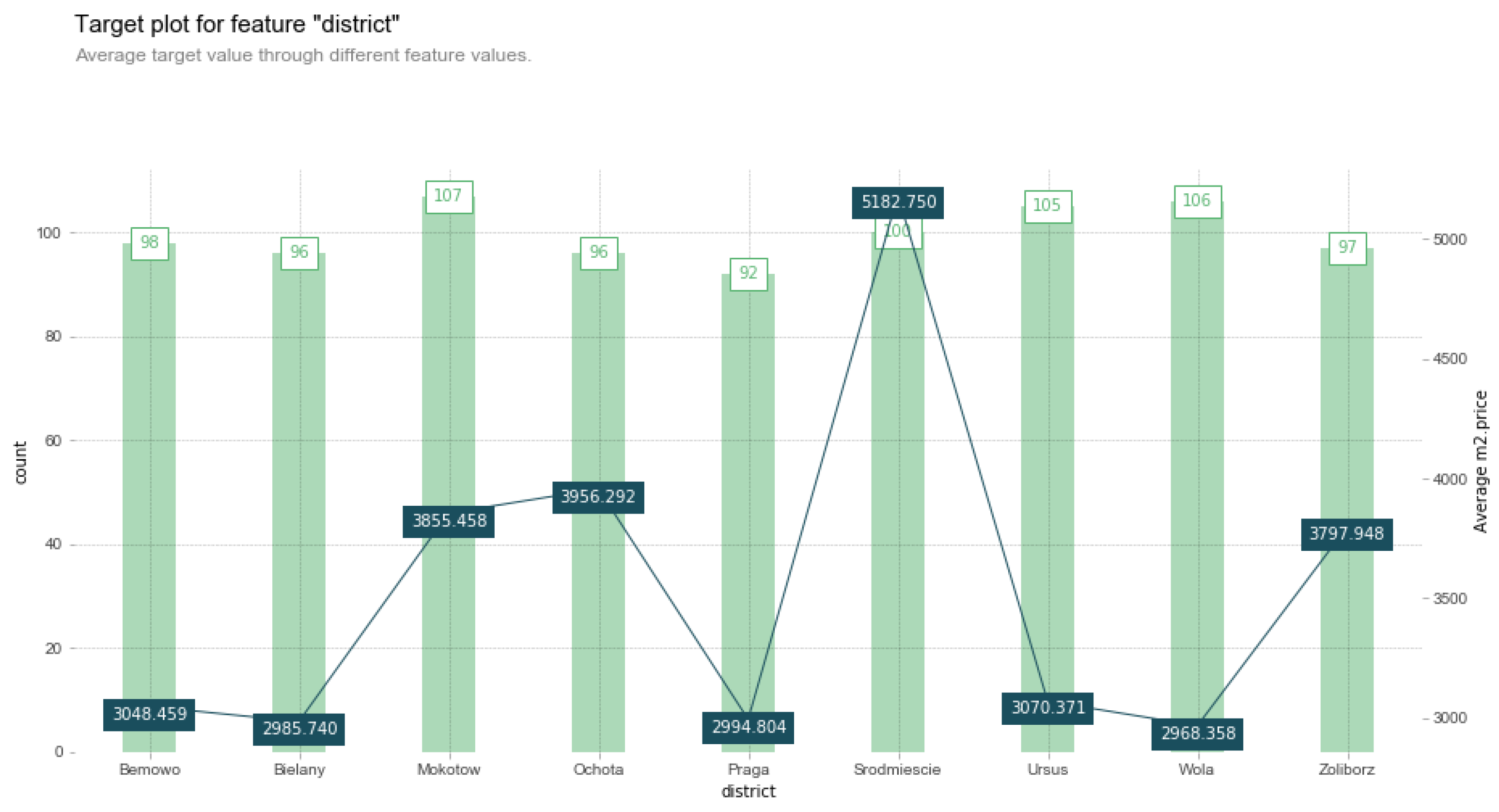
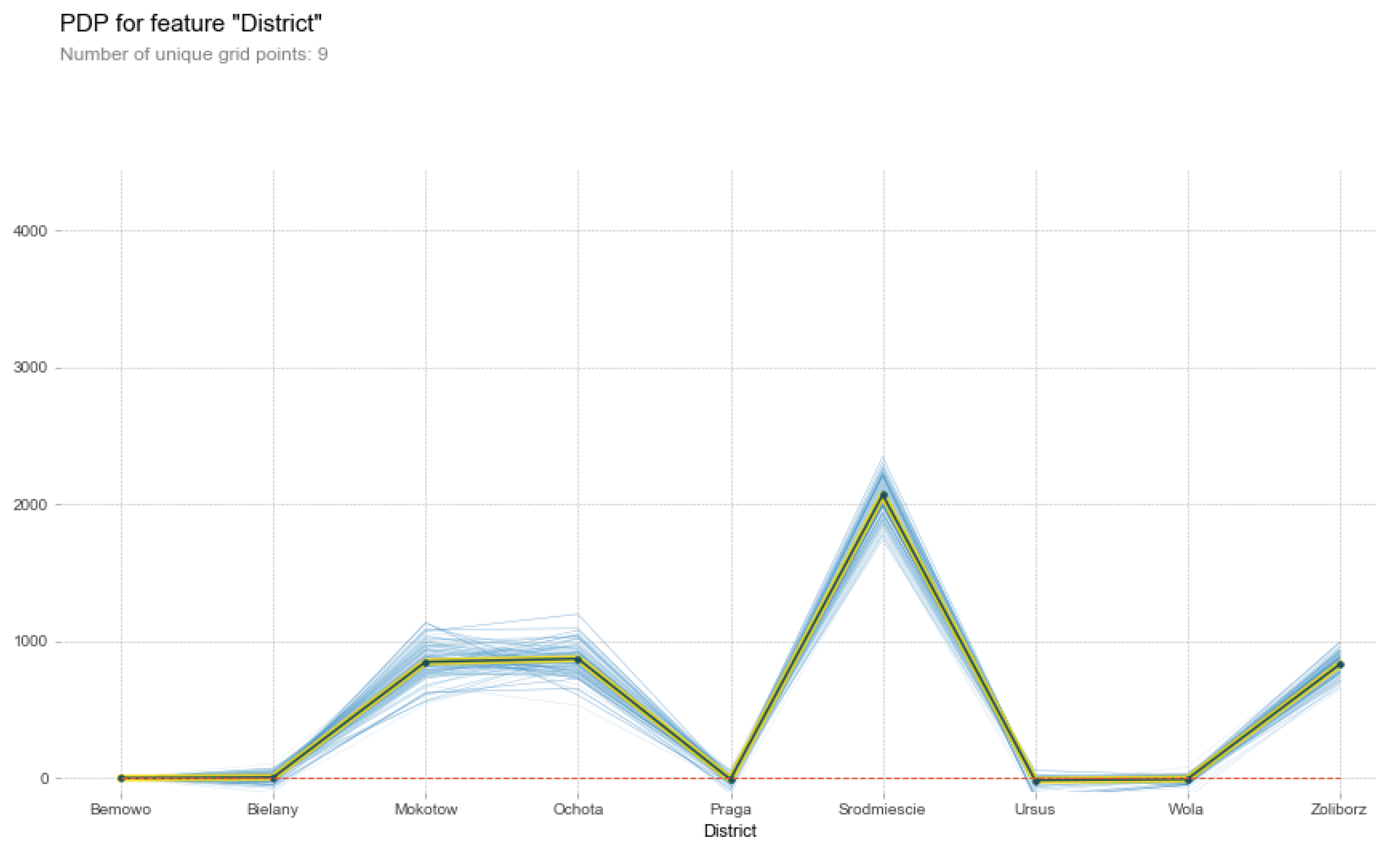
4.2. Regression—Warsaw Apartments Dataset
4.2.1. Data Information
4.2.2. Approximation and Manipulation
4.2.3. Explanation
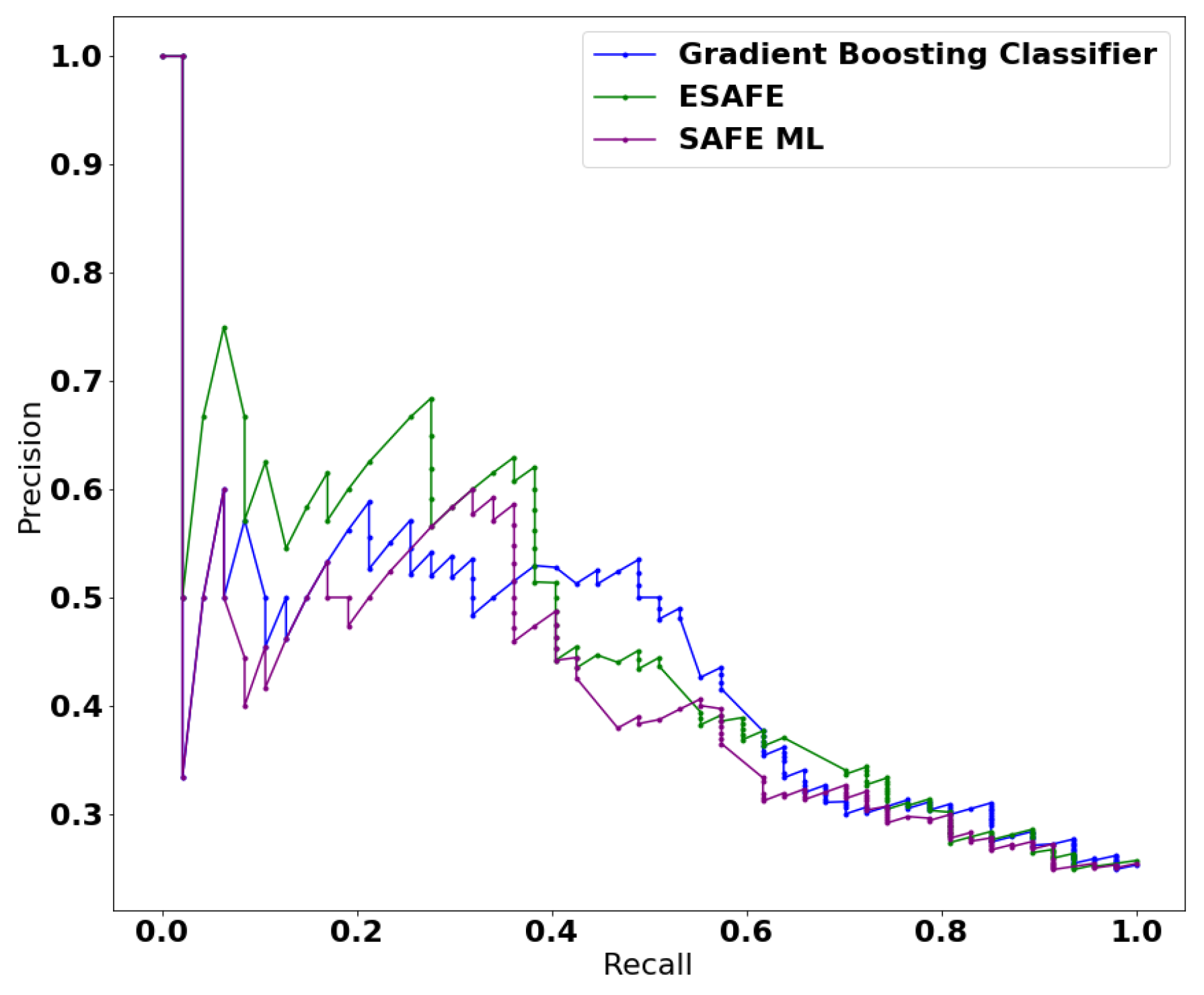
4.3. Classification—Blood Transfusion Dataset
4.3.1. Data Information
4.3.2. Approximation and Manipulation
4.3.3. Explanation
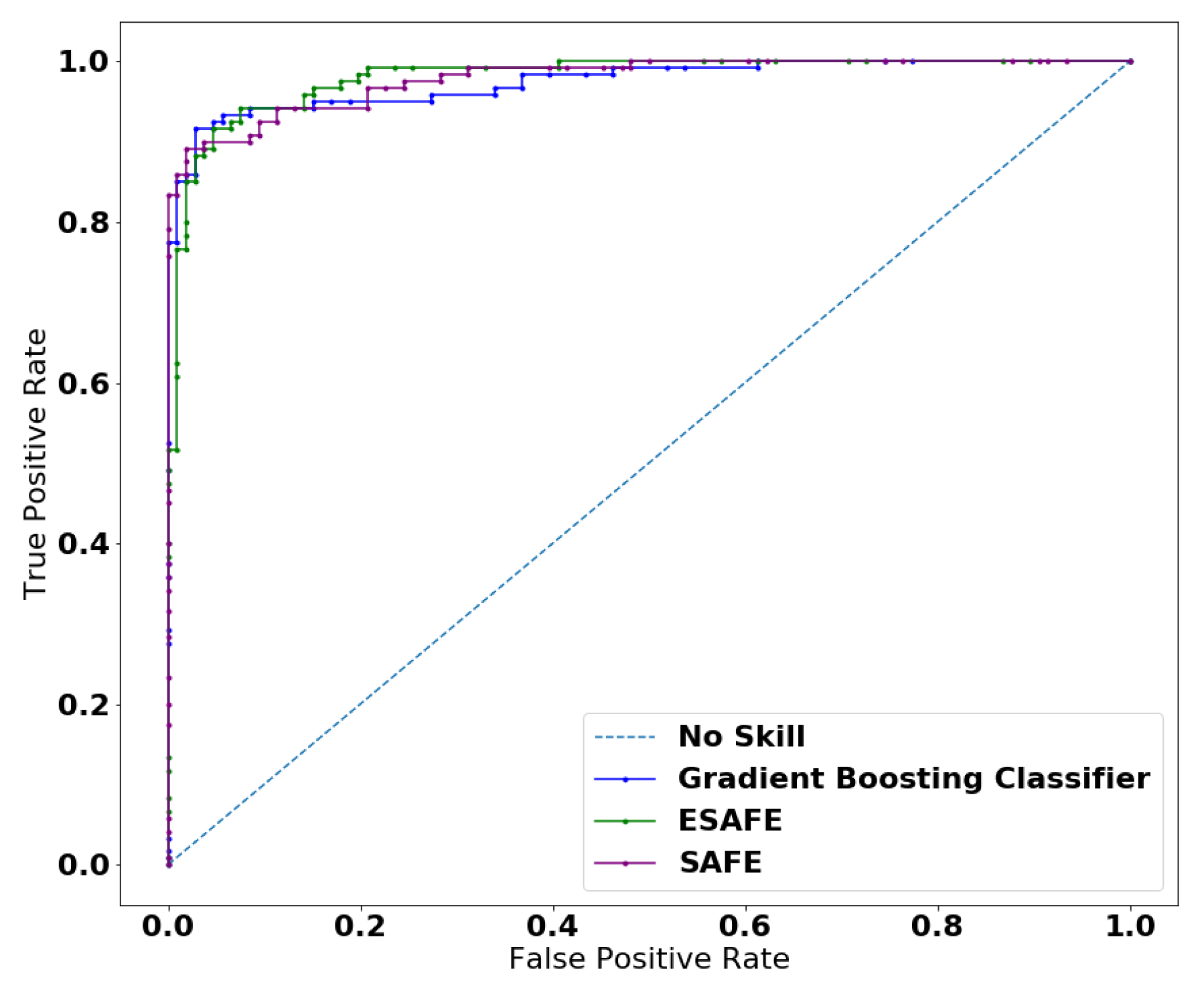
4.4. Classification—Student Performance Dataset
4.4.1. Data Information
4.4.2. Approximation and Manipulation
4.4.3. Explanation
5. Conclusions and Future Extension
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Algorithm for Proposed Extension ESAFE
| Algorithm A1 Feature Engineering. |
|
Appendix B. Algorithm Complexity
References
- Mullainathan, S.; Spiess, J. Machine learning: An applied econometric approach. J. Econ. Perspect. 2017, 31, 87–106. [Google Scholar] [CrossRef]
- Mohammadi, M.; Yazdani, S.; Khanmohammadi, M.H.; Maham, K. Financial Reporting Fraud Detection: An Analysis of Data Mining Algorithms. Int. J. Financ. Manag. Account. 2020, 4, 1–12. [Google Scholar]
- Awoyemi, J.O.; Adetunmbi, A.O.; Oluwadare, S.A. Credit card fraud detection using machine learning techniques: A comparative analysis. In Proceedings of the 2017 International Conference on Computing Networking and Informatics (ICCNI), Lagos, Nigeria, 29–31 October 2017; pp. 1–9. [Google Scholar]
- Raghavan, P.; Gayar, N.E. Fraud Detection using Machine Learning and Deep Learning. In Proceedings of the 2019 International Conference on Computational Intelligence and Knowledge Economy (ICCIKE), Dubai, United Arab Emirates, 11–12 December 2019; pp. 334–339. [Google Scholar]
- Sidiropoulos, N.D.; De Lathauwer, L.; Fu, X.; Huang, K.; Papalexakis, E.E.; Faloutsos, C. Tensor decomposition for signal processing and machine learning. IEEE Trans. Signal Process. 2017, 65, 3551–3582. [Google Scholar] [CrossRef]
- Paulus, M.T. Algorithm for explicit solution to the three parameter linear change-point regression model. Sci. Technol. Built Environ. 2017, 23, 1026–1035. [Google Scholar] [CrossRef]
- Rudin, C. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nat. Mach. Intell. 2019, 1, 206–215. [Google Scholar] [CrossRef]
- Miller, T. Explanation in artificial intelligence: Insights from the social sciences. Artif. Intell. 2019, 267, 1–38. [Google Scholar] [CrossRef]
- Kim, B.; Khanna, R.; Koyejo, O.O. Examples are not enough, learn to criticize! criticism for interpretability. In Proceedings of the 2016 Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 2280–2288. [Google Scholar]
- Azodi, C.B.; Tang, J.; Shiu, S.H. Opening the Black Box: Interpretable Machine Learning for Geneticists. Trends Genet. 2020, 36, 442–455. [Google Scholar] [CrossRef] [PubMed]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Turini, F.; Giannotti, F.; Pedreschi, D. A survey of methods for explaining black box models. ACM Comput. Surv. (CSUR) 2018, 51, 1–42. [Google Scholar] [CrossRef]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer Science & Business Media: New York, NY, USA, 2009. [Google Scholar]
- Shah, A.; Lynch, S.; Niemeijer, M.; Amelon, R.; Clarida, W.; Folk, J.; Russell, S.; Wu, X.; Abràmoff, M.D. Susceptibility to misdiagnosis of adversarial images by deep learning based retinal image analysis algorithms. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; pp. 1454–1457. [Google Scholar]
- Kroll, J.A.; Barocas, S.; Felten, E.W.; Reidenberg, J.R.; Robinson, D.G.; Yu, H. Accountable algorithms. Univ. Pa. Law Rev. 2016, 165, 633. [Google Scholar]
- Danks, D.; London, A.J. Regulating autonomous systems: Beyond standards. IEEE Intell. Syst. 2017, 32, 88–91. [Google Scholar] [CrossRef]
- Kingston, J.K. Artificial intelligence and legal liability. arXiv 2018, arXiv:1802.07782. [Google Scholar]
- Messalas, A.; Kanellopoulos, Y.; Makris, C. Model-Agnostic Interpretability with Shapley Values. In Proceedings of the 2019 10th International Conference on Information, Intelligence, Systems and Applications (IISA), Patras, Greece, 15–17 July 2019; pp. 1–7. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Johansson, U.; Sönströd, C.; Norinder, U.; Boström, H. Trade-off between accuracy and interpretability for predictive in silico modeling. Future Med. Chem. 2011, 3, 647–663. [Google Scholar] [CrossRef]
- Wang, T. Hybrid Decision Making: When Interpretable Models Collaborate With Black-Box Models. arXiv 2018, arXiv:1802.04346. Available online: https://arxiv.org/pdf/1802.04346v1.pdf (accessed on 29 August 2021).
- Hu, L.; Chen, J.; Nair, V.N.; Sudjianto, A. Locally interpretable models and effects based on supervised partitioning (LIME-SUP). arXiv 2018, arXiv:1806.00663. [Google Scholar]
- Stiglic, G.; Kocbek, P.; Fijacko, N.; Zitnik, M.; Verbert, K.; Cilar, L. Interpretability of machine learning based prediction models in healthcare. arXiv 2020, arXiv:2002.08596. [Google Scholar] [CrossRef]
- Lakkaraju, H.; Kamar, E.; Caruana, R.; Leskovec, J. Interpretable & Explorable Approximations of Black Box Models. arXiv 2017, arXiv:1707.01154. [Google Scholar]
- Ming, L.; Chao, Y. Mathematical Model and Quantitative Research Method on the Variability of Task Execution-time. In Proceedings of the 2012 International Conference on Computer Distributed Control and Intelligent Environmental Monitoring, Zhangjiajie, China, 5–6 March 2012; pp. 397–402. [Google Scholar]
- Justus, D.; Brennan, J.; Bonner, S.; McGough, A.S. Predicting the Computational Cost of Deep Learning Models. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 3873–3882. [Google Scholar]
- Tunstall, S.L. Models as Weapons: Review of Weapons of Math Destruction: How Big Data Increases Inequality and Threatens Democracy by Cathy O’Neil (2016). Numeracy 2018, 11, 10. [Google Scholar] [CrossRef]
- Gosiewska, A.; Gacek, A.; Lubon, P.; Biecek, P. SAFE ML: Surrogate Assisted Feature Extraction for Model Learning. arXiv 2019, arXiv:1902.11035. [Google Scholar]
- Goldstein, A.; Kapelner, A.; Bleich, J.; Pitkin, E. Peeking inside the black box: Visualizing statistical learning with plots of individual conditional expectation. J. Comput. Graph. Stat. 2015, 24, 44–65. [Google Scholar] [CrossRef]
- Zhou, Y.; Hooker, G. Interpreting models via single tree approximation. arXiv 2016, arXiv:1610.09036. [Google Scholar]
- Gibbons, R.D.; Hooker, G.; Finkelman, M.D.; Weiss, D.J.; Pilkonis, P.A.; Frank, E.; Moore, T.; Kupfer, D.J. The CAD-MDD: A computerized adaptive diagnostic screening tool for depression. J. Clin. Psychiatry 2013, 74, 669. [Google Scholar] [CrossRef]
- Tolomei, G.; Silvestri, F.; Haines, A.; Lalmas, M. Interpretable predictions of tree-based ensembles via actionable feature tweaking. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 465–474. [Google Scholar]
- Krishnan, S.; Wu, E. Palm: Machine learning explanations for iterative debugging. In Proceedings of the 2nd Workshop on Human-In-the-Loop Data Analytics, Chicago, IL, USA, 14–19 May 2017; pp. 1–6. [Google Scholar]
- Hara, S.; Hayashi, K. Making tree ensembles interpretable. arXiv 2016, arXiv:1606.05390. [Google Scholar]
- Cui, Z.; Chen, W.; He, Y.; Chen, Y. Optimal action extraction for random forests and boosted trees. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, NSW, Australia, 10–13 August 2015; pp. 179–188. [Google Scholar]
- Tan, P.N.; Steinbach, M.; Kumar, V. Introduction to Data Mining; Pearson Education Inc.: New Delhi, India, 2006. [Google Scholar]
- Tsanas, A.; Xifara, A. Accurate quantitative estimation of energy performance of residential buildings using statistical machine learning tools. Energy Build. 2012, 49, 560–567. [Google Scholar] [CrossRef]
- Collaris, D.; van Wijk, J.J. ExplainExplore: Visual Exploration of Machine Learning Explanations. In Proceedings of the 2020 IEEE Pacific Visualization Symposium (PacificVis), Tianjin, China, 3–5 June 2020; pp. 26–35. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Natekin, A.; Knoll, A. Gradient boosting machines, a tutorial. Front. Neurorobotics 2013, 7, 21. [Google Scholar] [CrossRef]
- Killick, R.; Fearnhead, P.; Eckley, I.A. Optimal detection of changepoints with a linear computational cost. J. Am. Stat. Assoc. 2012, 107, 1590–1598. [Google Scholar] [CrossRef]
- Vidovic, M.M.C.; Gornitz, N.; Muller, K.R.; Kloft, M. Feature importance measure for non-linear learning algorithms. arXiv 2016, arXiv:1611.07567. [Google Scholar]
- Sonnenburg, S.; Zien, A.; Philips, P.; Rätsch, G. POIMs: Positional oligomer importance matrices—Understanding support vector machine-based signal detectors. Bioinformatics 2008, 24, i6–i14. [Google Scholar] [CrossRef]
- Zien, A.; Krämer, N.; Sonnenburg, S.; Rätsch, G. The feature importance ranking measure. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases; Springer: Berlin/Heidelberg, Germany, 2009; pp. 694–709. [Google Scholar]
- Montavon, G.; Lapuschkin, S.; Binder, A.; Samek, W.; Müller, K.R. Explaining nonlinear classification decisions with deep taylor decomposition. Pattern Recognit. 2017, 65, 211–222. [Google Scholar] [CrossRef]
- Sturm, I.; Lapuschkin, S.; Samek, W.; Müller, K.R. Interpretable deep neural networks for single-trial EEG classification. J. Neurosci. Methods 2016, 274, 141–145. [Google Scholar] [CrossRef]
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Pedreschi, D.; Turini, F.; Giannotti, F. Local rule-based explanations of black box decision systems. arXiv 2018, arXiv:1805.10820. [Google Scholar]
- Freitas, A.A. Comprehensible classification models: A position paper. ACM SIGKDD Explor. Newsl. 2014, 15, 1–10. [Google Scholar] [CrossRef]
- Martens, D.; Vanthienen, J.; Verbeke, W.; Baesens, B. Performance of classification models from a user perspective. Decis. Support Syst. 2011, 51, 782–793. [Google Scholar] [CrossRef]
- Pazzani, M.J.; Mani, S.; Shankle, W.R. Acceptance of rules generated by machine learning among medical experts. Methods Inf. Med. 2001, 40, 380–385. [Google Scholar]
- Verbeke, W.; Martens, D.; Mues, C.; Baesens, B. Building comprehensible customer churn prediction models with advanced rule induction techniques. Expert Syst. Appl. 2011, 38, 2354–2364. [Google Scholar] [CrossRef]
- Ustun, B.; Rudin, C. Supersparse linear integer models for optimized medical scoring systems. Mach. Learn. 2016, 102, 349–391. [Google Scholar] [CrossRef]
- Ahmad, M.A.; Eckert, C.; Teredesai, A. Interpretable machine learning in healthcare. In Proceedings of the 2018 ACM International Conference on Bioinformatics, Computational Biology, and Health Informatics, Washington, DC, USA, 29 August–1 September 2018; pp. 559–560. [Google Scholar]
- Kotthoff, L.; Thornton, C.; Hoos, H.H.; Hutter, F.; Leyton-Brown, K. Auto-WEKA 2.0: Automatic model selection and hyperparameter optimization in WEKA. J. Mach. Learn. Res. 2017, 18, 826–830. [Google Scholar]
- Jin, H.; Song, Q.; Hu, X. Auto-Keras: An Efficient Neural Architecture Search System. In Proceedings of the KDD ’19: 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 1946–1956. [Google Scholar] [CrossRef]
- Ghorbani, R.; Ghousi, R. Comparing Different Resampling Methods in Predicting Students’ Performance Using Machine Learning Techniques. IEEE Access 2020, 8, 67899–67911. [Google Scholar] [CrossRef]
- Khurana, U.; Turaga, D.; Samulowitz, H.; Parthasrathy, S. Cognito: Automated Feature Engineering for Supervised Learning. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining Workshops (ICDMW), Barcelona, Spain, 12–15 December 2016; pp. 1304–1307. [Google Scholar]
- Bahnsen, A.C.; Aouada, D.; Stojanovic, A.; Ottersten, B. Feature engineering strategies for credit card fraud detection. Expert Syst. Appl. 2016, 51, 134–142. [Google Scholar] [CrossRef]
- Hocking, R.R. A Biometrics invited paper. The analysis and selection of variables in linear regression. Biometrics 1976, 32, 1–49. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Model-agnostic interpretability of machine learning. arXiv 2016, arXiv:1606.05386. [Google Scholar]
- Greenwell, B.M. pdp: An R package for constructing partial dependence plots. R J. 2017, 9, 421–436. [Google Scholar] [CrossRef]
- Bashir, S.; Ali, S.; Ahmed, S.; Kakkar, V. Analog-to-digital converters: A comparative study and performance analysis. In Proceedings of the 2016 International Conference on Computing, Communication and Automation (ICCCA), Greater Noida, India, 29–30 April 2016; pp. 999–1001. [Google Scholar]
- Kehtarnavaz, N.; Parris, S.; Sehgal, A. Using smartphones as mobile implementation platforms for applied digital signal processing courses. In Proceedings of the 2015 IEEE Signal Processing and Signal Processing Education Workshop (SP/SPE), Salt Lake City, UT, USA, 9–12 August 2015; pp. 313–318. [Google Scholar]
- Jin, T.; Wang, H.; Liu, H. Design of a flexible high-performance real-time SAR signal processing system. In Proceedings of the 2016 IEEE 13th International Conference on Signal Processing (ICSP), Chengdu, China, 6–10 November 2016; pp. 513–517. [Google Scholar]
- Song, T.; Nirmalathas, A.; Lim, C.; Wong, E.; Lee, K.; Hong, Y.; Alameh, K.; Wang, K. Performance Analysis of Repetition-Coding and Space-Time-Block-Coding as Transmitter Diversity Schemes for Indoor Optical Wireless Communications. J. Light. Technol. 2019, 37, 5170–5177. [Google Scholar] [CrossRef]
- Claudio, E.D.D.; Parisi, R.; Jacovitti, G. Space Time MUSIC: Consistent Signal Subspace Estimation for Wideband Sensor Arrays. IEEE Trans. Signal Process. 2018, 66, 2685–2699. [Google Scholar] [CrossRef]
- López, I.; Rodríguez, C.; Gámez, M.; Varga, Z.; Garay, J. Change-Point Method Applied to the Detection of Temporal Variations in Seafloor Bacterial Mat Coverage. J. Environ. Inform. 2017, 29, 122–133. [Google Scholar] [CrossRef]
- Truong, C.; Oudre, L.; Vayatis, N. Selective review of offline change point detection methods. Signal Process. 2019, 167, 107299. [Google Scholar] [CrossRef]
- Barrois, R.P.; Ricard, D.; Oudre, L.; Tlili, L.; Provost, C.; Vienne, A.; Vidal, P.P.; Buffat, S.; Yelnik, A.P. Étude observationnelle du demi-tour à l’aide de capteurs inertiels chez les sujets victimes d’AVC et relation avec le risque de chute. Neurophysiol. Clin. Neurophysiol. 2016, 46, 244. [Google Scholar] [CrossRef]
- Barrois, R.; Oudre, L.; Moreau, T.; Truong, C.; Vayatis, N.; Buffat, S.; Yelnik, A.; de Waele, C.; Gregory, T.; Laporte, S.; et al. Quantify osteoarthritis gait at the doctor’s office: A simple pelvis accelerometer based method independent from footwear and aging. Comput. Methods Biomech. Biomed. Eng. 2015, 18, 1880–1881. [Google Scholar] [CrossRef]
- Yau, C.Y.; Zhao, Z. Inference for multiple change points in time series via likelihood ratio scan statistics. J. R. Stat. Soc. Ser. B Stat. Methodol. 2016, 78, 895–916. [Google Scholar] [CrossRef]
- Haynes, K.; Eckley, I.A.; Fearnhead, P. Computationally efficient changepoint detection for a range of penalties. J. Comput. Graph. Stat. 2017, 26, 134–143. [Google Scholar] [CrossRef]
- Yao, Y.C. Estimating the number of change-points via Schwarz’criterion. Stat. Probab. Lett. 1988, 6, 181–189. [Google Scholar] [CrossRef]
- Yao, Y.C.; Au, S.T. Least-squares estimation of a step function. Sankhyā Indian J. Stat. Ser. A 1989, 51, 370–381. [Google Scholar]
- Fernandes, K.; Cardoso, J.S.; Fernandes, J. Transfer learning with partial observability applied to cervical cancer screening. In Iberian Conference on Pattern Recognition and Image Analysis; Springer: Cham, Switzerland, 2017; pp. 243–250. [Google Scholar]
- Satopaa, V.; Albrecht, J.; Irwin, D.; Raghavan, B. Finding a “kneedle” in a haystack: Detecting knee points in system behavior. In Proceedings of the 2011 31st International Conference on Distributed Computing Systems Workshops, Minneapolis, MN, USA, 20–24 June 2011; pp. 166–171. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Harrison, D.; Rubinfeld, D. Hedonic housing prices and the demand for clean air. J. Environ. Econ. Manag. 1978, 5, 81–102. [Google Scholar] [CrossRef]
- Biecek, P. DALEX: Explainers for complex predictive models in R. J. Mach. Learn. Res. 2018, 19, 3245–3249. [Google Scholar]
- Yeh, I.C.; Yang, K.J.; Ting, T.M. Knowledge discovery on RFM model using Bernoulli sequence. Expert Syst. Appl. 2009, 36, 5866–5871. [Google Scholar] [CrossRef]
- Saito, T.; Rehmsmeier, M. The precision-recall plot is more informative than the ROC plot when evaluating binary classifiers on imbalanced datasets. PLoS ONE 2015, 10, e0118432. [Google Scholar]
- Seliya, N.; Khoshgoftaar, T.M.; Van Hulse, J. A study on the relationships of classifier performance metrics. In Proceedings of the 2009 21st IEEE International Conference on Tools with Artificial Intelligence, Newark, NJ, USA, 2–4 November 2009; pp. 59–66. [Google Scholar]
- Davis, J.; Goadrich, M. The relationship between Precision-Recall and ROC curves. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 233–240. [Google Scholar]
- Menze, B.H.; Kelm, B.M.; Masuch, R.; Himmelreich, U.; Bachert, P.; Petrich, W.; Hamprecht, F.A. A comparison of random forest and its Gini importance with standard chemometric methods for the feature selection and classification of spectral data. BMC Bioinform. 2009, 10, 213. [Google Scholar] [CrossRef]
- Cortez, P.; Silva, A.M.G. Using Data Mining to Predict Secondary School Student Performance. Available online: http://www3.dsi.uminho.pt/pcortez/student.pdf (accessed on 29 August 2021).
- Japkowicz, N. Classifier evaluation: A need for better education and restructuring. In Proceedings of the 3rd Workshop on Evaluation Methods for Machine Learning(ICML 2008), Helsinki, Finland, 5–9 July 2008; Available online: https://www.site.uottawa.ca/ICML08WS/papers/N_Japkowicz.pdf (accessed on 29 August 2021).
- Sokolova, M.; Japkowicz, N.; Szpakowicz, S. Beyond accuracy, F-score and ROC: A family of discriminant measures for performance evaluation. In Proceedings of the 19th Australasian Joint Conference on Artificial Intelligence, Hobart, Australia, 4–8 December 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 1015–1021. [Google Scholar]
- Longadge, R.; Dongre, S. Class imbalance problem in data mining review. arXiv 2013, arXiv:1305.1707. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Zhang, C.; Liu, C.; Zhang, X.; Almpanidis, G. An up-to-date comparison of state-of-the-art classification algorithms. Expert Syst. Appl. 2017, 82, 128–150. [Google Scholar] [CrossRef]
- Dua, D.; Graff, C. UCI Machine Learning Repository. Available online: https://archive.ics.uci.edu/ml/index.php (accessed on 29 August 2021).
- Yeh, I.C.; Hsu, T.K. Building real estate valuation models with comparative approach through case-based reasoning. Appl. Soft Comput. 2018, 65, 260–271. [Google Scholar] [CrossRef]
- Simonoff, J. The Unusual Episode and a Second Statistics Course. J. Stat. Educ. 1997, 5. [Google Scholar] [CrossRef]














| Models | (MSE) | Process Time (s) |
|---|---|---|
| Linear Regression | 24.72 | 0.010 |
| Gradient Boosting Regressor | 19.58 | 0.511 |
| SAFE ML | 18.72 | 666.3 |
| ESAFE | 19.57 | 137.4 |
| Models | (MSE) | R2 Score | Process Time (s) |
|---|---|---|---|
| Linear Regression | 75,683 | 0.90 | 0.0069 |
| Gradient Boosting Regressor | 13,146 | 0.98 | 0.2293 |
| SAFE ML | 1235.5 | 0.99 | 913.34 |
| ESAFE | 1335.1 | 0.99 | 60.034 |
| Models | ACC (%) | AUC-PR | Process Time (s) |
|---|---|---|---|
| Logistic Regression | 74.86 | 0.431 | 0.028 |
| Gradient Boosting Classifier | 75.40 | 0.435 | 0.339 |
| SAFE ML | 75.93 | 0.373 | 240.0 |
| ESAFE | 75.40 | 0.460 | 18.00 |
| Models | ACC (%) | AUC-ROC | Process Time (s) |
|---|---|---|---|
| Logistic Regression | 92.03 | 0.978 | 0.056 |
| Gradient Boosting Classifier | 93.80 | 0.974 | 0.126 |
| SAFE ML | 93.36 | 0.974 | 1811 |
| ESAFE | 93.36 | 0.978 | 391.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ali, M.; Khattak, A.M.; Ali, Z.; Hayat, B.; Idrees, M.; Pervez, Z.; Rizwan, K.; Sung, T.-E.; Kim, K.-I. Estimation and Interpretation of Machine Learning Models with Customized Surrogate Model. Electronics 2021, 10, 3045. https://doi.org/10.3390/electronics10233045
Ali M, Khattak AM, Ali Z, Hayat B, Idrees M, Pervez Z, Rizwan K, Sung T-E, Kim K-I. Estimation and Interpretation of Machine Learning Models with Customized Surrogate Model. Electronics. 2021; 10(23):3045. https://doi.org/10.3390/electronics10233045
Chicago/Turabian StyleAli, Mudabbir, Asad Masood Khattak, Zain Ali, Bashir Hayat, Muhammad Idrees, Zeeshan Pervez, Kashif Rizwan, Tae-Eung Sung, and Ki-Il Kim. 2021. "Estimation and Interpretation of Machine Learning Models with Customized Surrogate Model" Electronics 10, no. 23: 3045. https://doi.org/10.3390/electronics10233045
APA StyleAli, M., Khattak, A. M., Ali, Z., Hayat, B., Idrees, M., Pervez, Z., Rizwan, K., Sung, T.-E., & Kim, K.-I. (2021). Estimation and Interpretation of Machine Learning Models with Customized Surrogate Model. Electronics, 10(23), 3045. https://doi.org/10.3390/electronics10233045