
Two-Branch Attention Learning for Fine-Grained Class Incremental Learning



Abstract
:1. Introduction
2. Related Work
2.1. Class Incremental Learning
2.2. Fine-Grained Visual Categorization
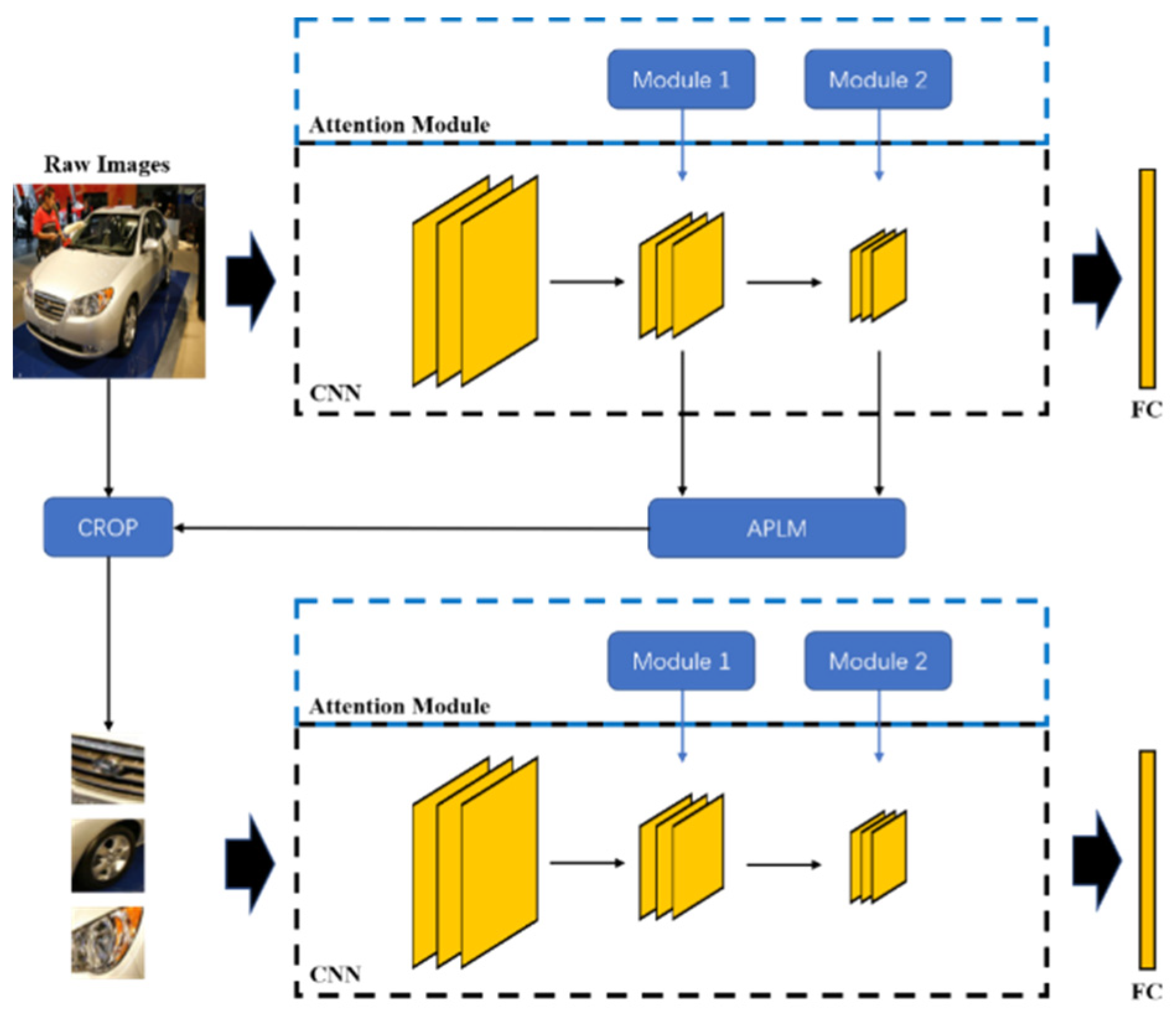
3. Proposed Method
3.1. Network Architecture
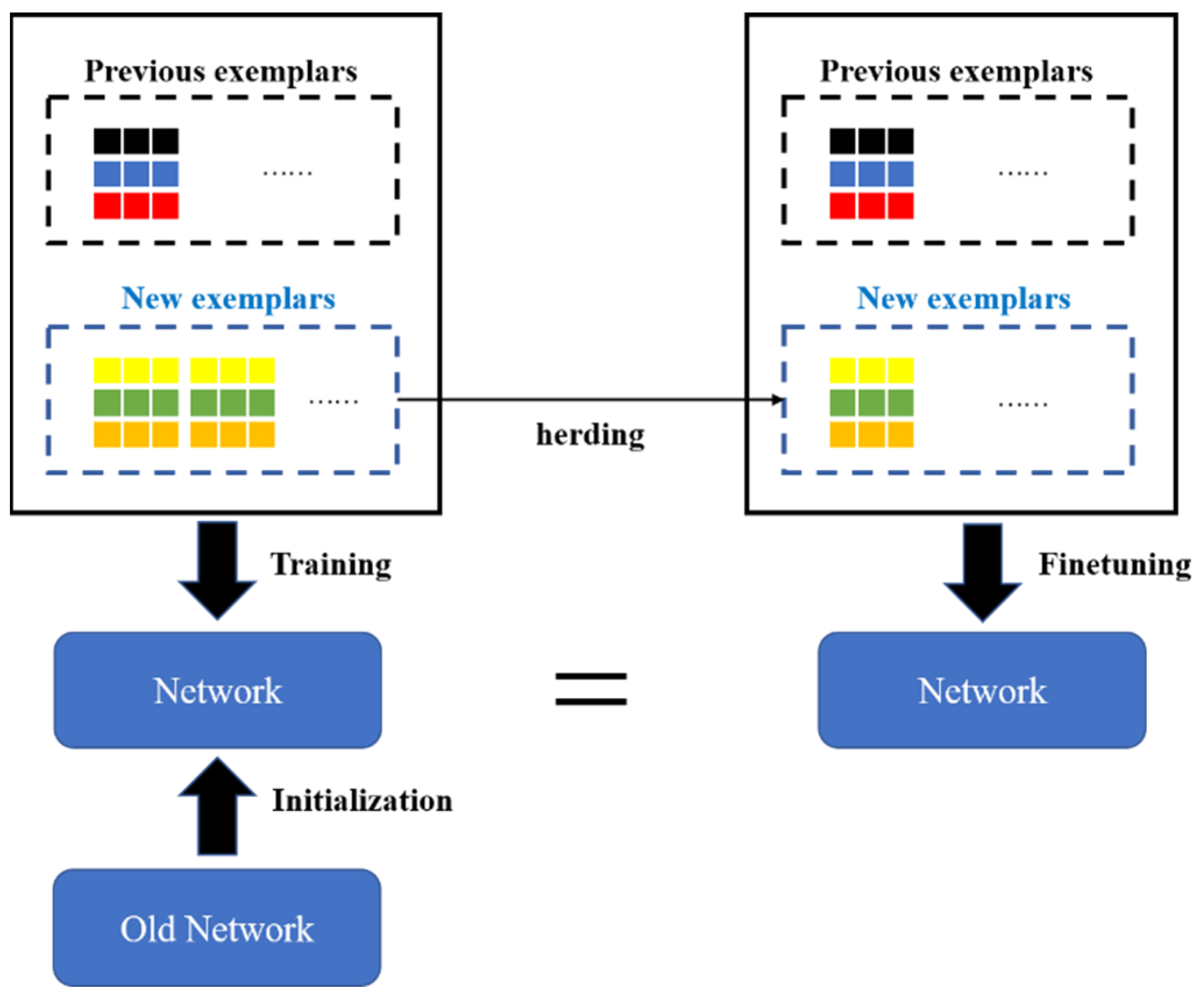
3.2. Class Incremental Learning
4. Experiments
4.1. Datasets
- CUB-200-2011. It is the most widely used fine-grained visual categorization dataset. For each subcategory, about 30 images are used for training and 11–30 images for testing.
- Stanford Car. In this dataset, each subcategory contains 24–84 images for training and 24–83 images for testing.
- FGVC-Aircraft. This dataset is organized into a three-layer label structure. The three layers, from bottom to top, consist of 100 variants, 70 families, and 30 manufacturers, respectively. It is split into 6667 training images and 3333 test images. In the experiments, we considered the case of dividing the images into 70 families.
4.2. Baselines
- ResNet50. As a traditional CNN architecture, ResNet50 [5] pretrained on ImageNet is chosen as a feature extractor. The pretrained FC layer is deleted from the architecture and a new initialized random FC layer is added to the network. Following the experimental setting in [10], when adopting cosine normalization in the last layer, the ReLU in the penultimate layer is removed to allow the features to take both positive and negative values.
- NTS-Net. Critical regions with different sizes and aspect ratios are automatically selected by a region proposal network. It could fuse both local and global features for recognition. ResNet50 is the backbone network of NTS-Net. The number of proposal regions is set to 3. In the experiments, the number of learnable parameters in NTS-Net is about 2.8 M. The backbone network in NTS-Net is pretrained on ImageNet dataset. The final feature is obtained through the summation of global and local features. When NTS-Net is trained on the initialized training data, the cosine normalization is also added to the last layer. When facing the new classes, the trainable parameters is added in the FC layer for training.
- MMAL. The backbone of MMAL is also ResNet50, which has been pretrained on the ImageNet dataset. In the attention object location module (AOLM), the outputs of Conv5_b and Conv5_c are used for localization of objects. In the attention part proposal module (APPM), the settings of each dataset are same as the settings used in this paper. In the experiments, the number of learnable parameters in MMAL is about 2.6 M. Similar to the setting in NTS-Net, the final feature in MMAL is also obtained through the summation of global and parts features. The trainable parameters in the FC layer, which is shared by the global and local branch, are also added when facing new classes.
4.3. Implementation
4.4. Ablation Study
- Impact of attention module. Table 2, Table 3 and Table 4 present the top-1 accuracy of models with and without the attention module. Models with the attention module have a suffix -ATT. It is observed that the addition of the attention mechanism leads to consistent performance improvement for all three datasets in all incremental phases, demonstrating a reliable boosting effect.
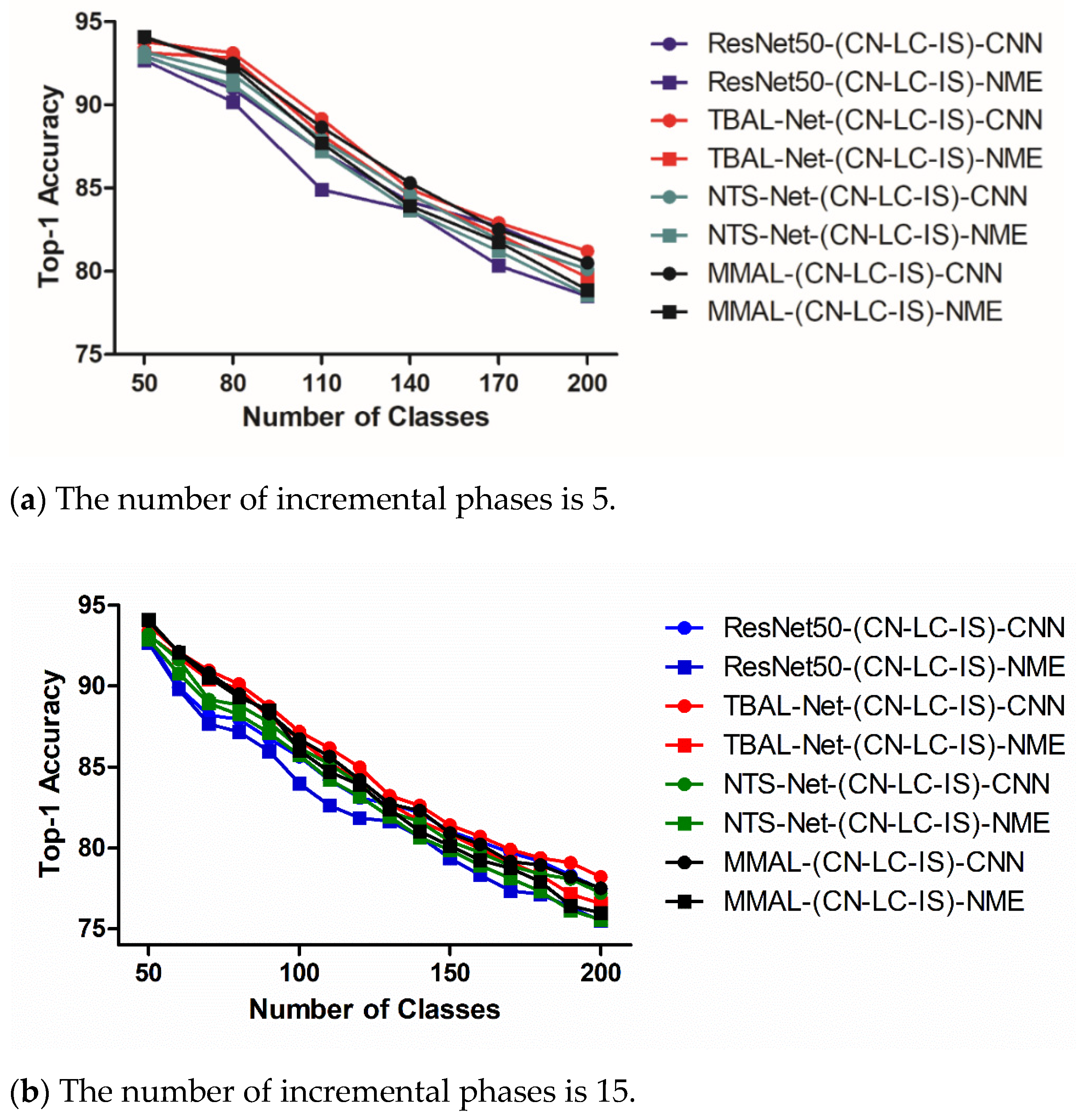
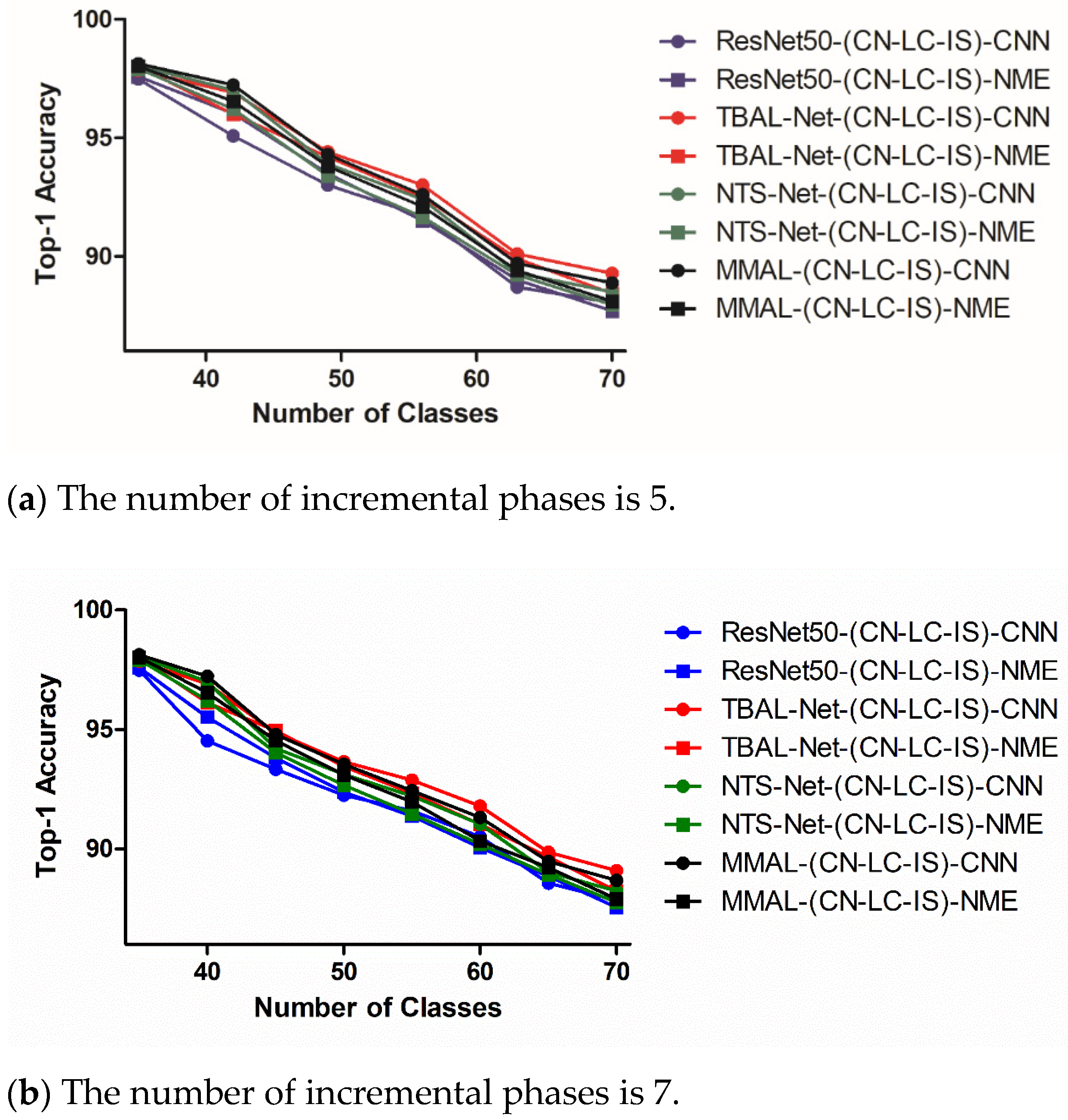
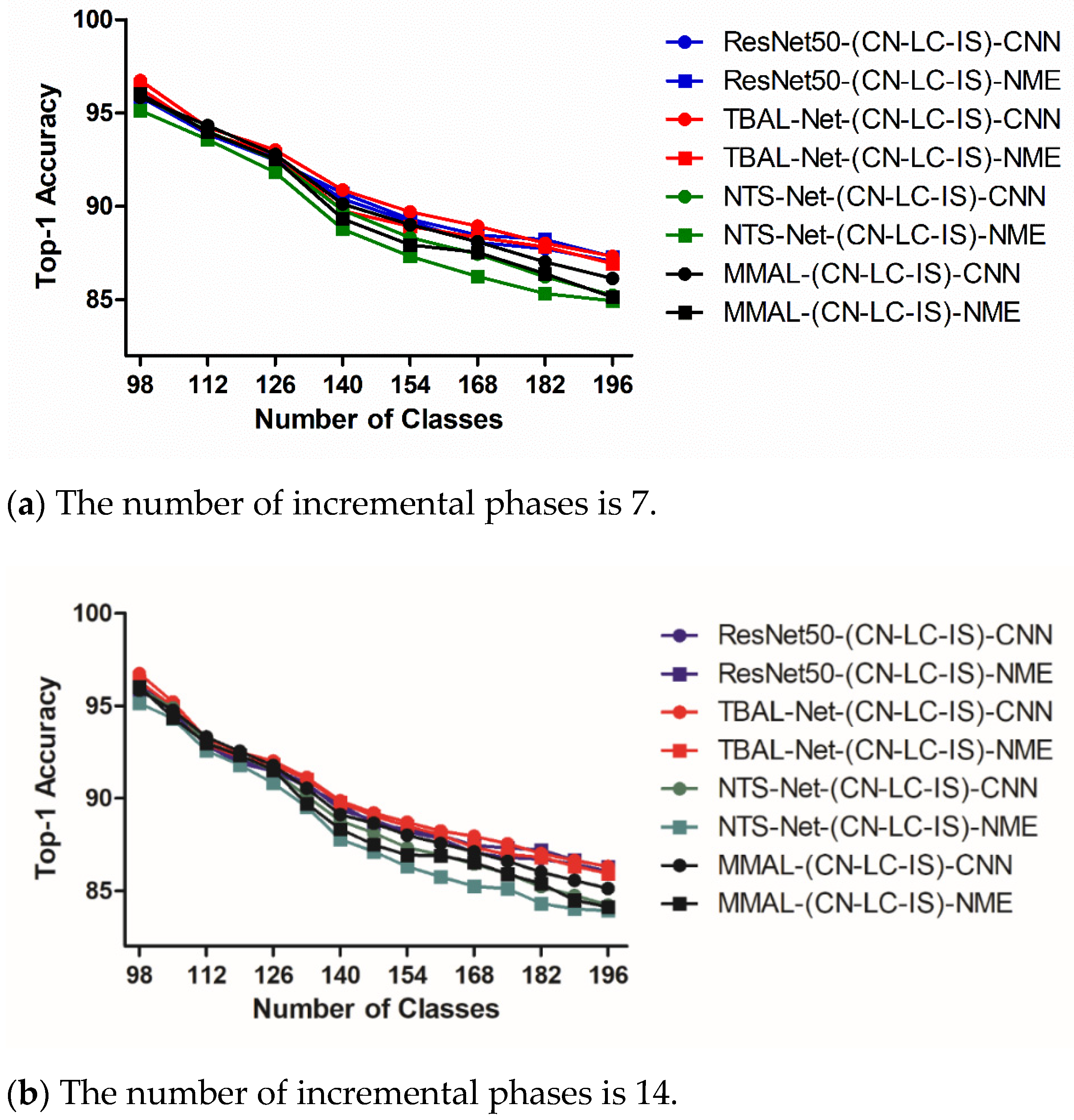
- Impact of incremental phases. Figure 4, Figure 5 and Figure 6 show the experimental results of different choices of incremental phases number. For each dataset, we chose two levels, corresponding to a low level and a high level of the incremental phase number, as shown in subfigures (a) and (b), respectively. It is observed that the models perform better with a lower number of incremental phases in all datasets, which is explainable due to the nature of CIL. Essentially, the more incremental phases we have, the less classes per phase, and the more challenges for models to memorize features and patterns learned from previous phases.
4.5. Results
5. Conclusions
- (1)
- The localization modules designed for FGVC, such as region proposal network (RPN) in NTS-Net, may be not suitable for fine-grained CIL. The RPN is randomly initialized. Due to the limited data size, RPN may not be trained well.
- (2)
- The localization modules in MMAL only increases few parameters. Additionally, MMAL can achieve good performance on FGVC. MMAL does not have enough learning ability in fine-grained CIL.
- (3)
- The attention module similar to [36] is effective in fine-grained CIL. Therefore, TBAL-Net can extract a lot of discriminative fine-grained features in the experiments, as shown in the NME predictions.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dang, S.; Cao, Z.; Cui, Z.; Pi, Y.; Liu, N. Class Boundary Exemplar Selection Based Incremental Learning for Automatic Target Recognition. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5782–5792. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the 31st AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Shmelkov, K.; Schmid, C.; Alahari, K. Incremental Learning of Object Detectors without Catastrophic Forgetting. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Zhang, J.; Zhang, J.; Ghosh, S.; Li, D.; Tasci, S.; Heck, L.; Zhang, H.; Kuo, C.-C.J. Class-incremental Learning via Deep Model Consolidation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass, CO, USA, 1–5 March 2020. [Google Scholar]
- Masana, M.; Liu, X.; Twardowski, B.; Menta, M.; Bagdanov, A.D.; van de Weijer, J. Class-incremental learning: Survey and performance evaluation on image classification. arXiv 2020, arXiv:2010.15277. [Google Scholar]
- Rebuffi, S.-A.; Kolesnikov, A.; Sperl, G.; Lampert, C.H. iCaRL: Incremental Classifier and Representation Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Hou, S.; Pan, X.; Loy, C.C.; Wang, Z.; Lin, D. Learning a Unified Classifier Incrementally via Rebalancing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Castro, F.M.; Marín-Jiménez, M.J.; Guil, N.; Schmid, C.; Alahari, K. End-to-End Incremental Learning; Springer: Singapore, 2018. [Google Scholar]
- Liu, Y.; Schiele, B.; Sun, Q. Meta-Aggregating Networks for Class-Incremental Learning. arXiv 2020, arXiv:2010.05063. [Google Scholar]
- Li, Z.; Hoiem, D. Learning without Forgetting. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 2935–2947. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mermillod, M.; Bugaiska, A.; Bonin, P. The stability-plasticity dilemma: Investigating the continuum from catastrophic forgetting to age-limited learning effects. Front. Psychol. 2013, 4, 504. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Krizhevsky, A.; Hinton, G. Learning multiple layers of features from tiny images. In Handbook of Systemic Autoimmune Diseases; Elsevier: Amsterdam, The Netherlands, 2009; Volume 1, p. 4. [Google Scholar]
- Russakovsky, O.; Deng, J.; Karpathy, A.; Ma, S.; Russakovsky, O.; Huang, Z.; Bernstein, M.; Krause, J.; Su, H.; Fei-Fei, L.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Schiele, B.; Sun, Q. Adaptive Aggregation Networks for Class-Incremental Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Wah, C.; Branson, S.; Welinder, P.; Perona, P.; Belongie, S. The Caltech-UCSD Birds200-2011 Dataset. Adv. Water Resour. 2011. Available online: https://authors.library.caltech.edu/27452/ (accessed on 20 November 2021).
- Maji, S.; Rahtu, E.; Kannala, J.; Blaschko, M.; Vedaldi, A. Fine-Grained Visual Classification of Aircraft. arXiv 2013, arXiv:1306.5151. [Google Scholar]
- Krause, J.; Stark, M.; Deng, J.; Fei-Fei, L. 3D Object Representations for Fine-Grained Categorization. In Proceedings of the 2013 IEEE International Conference on Computer Vision Workshops, Sydney, NSW, Australia, 2–8 December 2013. [Google Scholar]
- Kirkpatrick, J.; Pascanu, R.; Rabinowitz, N.; Veness, J.; Desjardins, G.; Rusu, A.A.; Milan, K.; Quan, J.; Ramalho, T.; Grabska-Barwinska, A.; et al. Overcoming catastrophic forgetting in neural networks. Proc. Natl. Acad. Sci. USA 2017, 114, 3521–3526. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kemker, R.; Abitino, A.; McClure, M.; Kanan, C. Measuring Catastrophic Forgetting in Neural Networks. arXiv 2018, arXiv:1708.02072. [Google Scholar]
- Yuan, L.; Tay, F.E.; Li, G.; Wang, T.; Feng, J. Revisiting Knowledge Distillation via Label Smoothing Regularization. arXiv 2020, arXiv:1909.11723. [Google Scholar]
- Shi, Y.; Hwang, M.-Y.; Lei, X.; Sheng, H. Knowledge Distillation for Recurrent Neural Network Language Modeling with Trust Regularization. arXiv 2019, arXiv:1904.04163. [Google Scholar]
- Yun, S.; Park, J.; Lee, K.; Shin, J. Regularizing Class-Wise Predictions via Self-Knowledge Distillation. arXiv 2020, arXiv:2003.13964. [Google Scholar]
- Yuan, L.; Tay, F.E.H.; Li, G.; Wang, T.; Feng, J. Revisit Knowledge Distillation: A Teacher-free Framework. arXiv 2019, arXiv:1909.11723. [Google Scholar]
- Kim, K.; Ji, B.; Yoon, D.; Hwang, S. Self-Knowledge Distillation with Progressive Refinement of Targets. arXiv 2020, arXiv:2006.12000. [Google Scholar]
- Wang, Y.; Li, H.; Chau, L.-P.; Kot, A.C. Embracing the Dark Knowledge: Domain Generalization Using Regularized Knowledge Distillation. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event. 20–24 October 2021. [Google Scholar]
- Zhao, L.; Peng, X.; Chen, Y.; Kapadia, M.; Metaxas, D.N. Knowledge as Priors: Cross-Modal Knowledge Generalization for Datasets Without Superior Knowledge. arXiv 2020, arXiv:2004.00176. [Google Scholar]
- Liu, C.; Xie, H.; Zha, Z.-J.; Ma, L.; Yu, L.; Zhang, Y. Filtration and Distillation: Enhancing Region Attention for Fine-Grained Visual Categorization. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 11555–11562. [Google Scholar]
- Kermany, D.S.; Goldbaum, M.; Cai, W.; Valentim, C.C.; Liang, H.; Baxter, S.; McKeown, A.; Yang, G.; Wu, X.; Yan, F.; et al. Identifying Medical Diagnoses and Treatable Diseases by Image-Based Deep Learning. Cell 2018, 172, 1122–1131.e9. [Google Scholar] [CrossRef] [PubMed]
- Niu, Y.; Jiao, Y.; Shi, G. Attention-shift based deep neural network for fine-grained visual categorization. Pattern Recognit. 2021, 116, 107947. [Google Scholar] [CrossRef]
- Yang, Z.; Luo, T.; Wang, D.; Hu, Z.; Gao, J.; Wang, L. Learning to Navigate for Fine-Grained Classification; Springer: Berlin, Germany, 2018. [Google Scholar]
- Zhang, F.; Li, M.; Zhai, G.; Liu, Y. Multi-branch and Multi-scale Attention Learning for Fine-Grained Visual Categorization. arXiv 2020, arXiv:2003.09150. [Google Scholar]
- Fu, J.; Zheng, H.; Mei, T. Look Closer to See Better: Recurrent Attention Convolutional Neural Network for Fine-Grained Image Recognition. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module; Springer: Singapore, 2018. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Number of Classes | Training | Testing |
|---|---|---|---|
| CUB-200-2011 | 200 | 5994 | 5794 |
| FGVC-Aircraft | 70 | 6667 | 3333 |
| Stanford Cars | 196 | 8144 | 8041 |
| Method | 50 | 60 | 70 | 80 | 90 | 100 | 110 | 120 |
|---|---|---|---|---|---|---|---|---|
| TBAL-Net-(CN-LC-IS)-CNN | 92.912 | 91.012 | 89.793 | 88.874 | 87.572 | 86.476 | 85.317 | 84.216 |
| TBAL-Net-(CN-LC-IS)-NME | 92.230 | 90.973 | 89.741 | 89.167 | 87.830 | 86.376 | 84.917 | 83.853 |
| TBAL-Net-(CN-LC-IS)-CNN-ATT | 93.792 | 92.126 | 90.958 | 90.133 | 88.746 | 87.193 | 86.178 | 84.973 |
| TBAL-Net-(CN-LC-IS)-NME-ATT | 93.139 | 91.772 | 90.431 | 89.831 | 88.103 | 86.733 | 85.208 | 84.187 |
| Method | 130 | 140 | 150 | 160 | 170 | 180 | 190 | 200 |
| TBAL-Net-(CN-LC-IS)-CNN | 82.466 | 81.831 | 80.871 | 80.167 | 79.301 | 78.653 | 78.200 | 77.467 |
| TBAL-Net-(CN-LC-IS)-NME | 81.903 | 81.013 | 80.276 | 79.337 | 78.498 | 77.667 | 76.605 | 76.031 |
| TBAL-Net-(CN-LC-IS)-CNN-ATT | 83.240 | 82.617 | 81.420 | 80.707 | 79.910 | 79.379 | 79.088 | 78.210 |
| TBAL-Net-(CN-LC-IS)-NME-ATT | 82.740 | 81.650 | 80.873 | 79.921 | 79.121 | 78.310 | 77.141 | 76.563 |
| Method | 35 | 40 | 45 | 50 | 55 | 60 | 65 | 70 |
|---|---|---|---|---|---|---|---|---|
| TBAL-Net-(CN-LC-IS)-CNN | 97.137 | 96.262 | 94.137 | 92.863 | 92.031 | 91.073 | 89.167 | 88.393 |
| TBAL-Net-(CN-LC-IS)-NME | 97.330 | 95.167 | 94.033 | 89.167 | 88.030 | 86.737 | 85.317 | 83.973 |
| TBAL-Net-(CN-LC-IS)-CNN-ATT | 97.846 | 96.91 | 94.87 | 93.65 | 92.879 | 91.798 | 89.86 | 89.08 |
| TBAL-Net-(CN-LC-IS)-NME-ATT | 98.012 | 96.12 | 94.96 | 93.45 | 92.325 | 91.02 | 89.658 | 88.233 |
| Method | 98 | 112 | 126 | 140 | 154 | 168 | 182 | 196 |
|---|---|---|---|---|---|---|---|---|
| TBAL-Net-(CN-LC-IS)-CNN | 95.863 | 93.317 | 92.073 | 89.915 | 88.767 | 87.876 | 86.717 | 85.916 |
| TBAL-Net-(CN-LC-IS)-NME | 95.315 | 93.073 | 91.930 | 89.390 | 88.130 | 87.176 | 86.527 | 85.353 |
| TBAL-Net-(CN-LC-IS)-CNN-ATT | 96.74 | 94.215 | 93.013 | 90.87 | 89.706 | 88.942 | 88.021 | 87.312 |
| TBAL-Net-(CN-LC-IS)-NME-ATT | 96.317 | 93.915 | 92.813 | 89.77 | 88.916 | 88.342 | 87.821 | 86.93 |
| Method | 50 | 60 | 70 | 80 | 90 | 100 | 110 | 120 |
|---|---|---|---|---|---|---|---|---|
| ResNet50-(CN-LC-IS)-CNN | 92.968 | 89.924 | 88.200 | 87.957 | 86.749 | 85.650 | 84.187 | 83.088 |
| ResNet50-(CN-LC-IS)-NME | 92.686 | 89.807 | 87.650 | 87.174 | 85.978 | 83.986 | 82.616 | 81.847 |
| NTS-Net-(CN-LC-IS)-CNN | 93.192 | 91.626 | 89.158 | 88.833 | 87.746 | 86.193 | 85.178 | 83.973 |
| NTS-Net-(CN-LC-IS)-NME | 92.891 | 90.772 | 88.930 | 88.231 | 87.103 | 85.733 | 84.208 | 83.187 |
| MMAL-(CN-LC-IS)-CNN | 94.018 | 92.130 | 90.810 | 89.502 | 88.310 | 86.730 | 85.653 | 84.210 |
| MMAL-(CN-LC-IS)-NME | 94.107 | 92.070 | 90.531 | 89.312 | 88.512 | 86.037 | 84.702 | 83.903 |
| TBAL-Net-(CN-LC-IS)-CNN | 93.792 | 92.126 | 90.958 | 90.133 | 88.746 | 87.193 | 86.178 | 84.973 |
| TBAL-Net-(CN-LC-IS)-NME | 93.139 | 91.772 | 90.431 | 89.831 | 88.103 | 86.733 | 85.208 | 84.187 |
| Method | 130 | 140 | 150 | 160 | 170 | 180 | 190 | 200 |
|---|---|---|---|---|---|---|---|---|
| ResNet50-(CN-LC-IS)-CNN | 82.716 | 82.176 | 81.032 | 80.390 | 79.707 | 79.179 | 78.319 | 77.477 |
| ResNet50-(CN-LC-IS)-NME | 81.651 | 80.692 | 79.366 | 78.332 | 77.346 | 77.145 | 76.337 | 75.492 |
| NTS-Net-(CN-LC-IS)-CNN | 82.240 | 81.617 | 80.420 | 79.707 | 78.910 | 78.379 | 78.088 | 77.210 |
| NTS-Net-(CN-LC-IS)-NME | 81.940 | 80.650 | 79.873 | 78.921 | 78.121 | 77.310 | 76.141 | 75.563 |
| MMAL-(CN-LC-IS)-CNN | 82.720 | 82.312 | 80.921 | 80.218 | 79.150 | 78.940 | 78.210 | 77.501 |
| MMAL-(CN-LC-IS)-NME | 82.390 | 81.030 | 80.127 | 79.238 | 78.750 | 77.913 | 76.420 | 75.980 |
| TBAL-Net-(CN-LC-IS)-CNN | 83.240 | 82.617 | 81.420 | 80.707 | 79.910 | 79.379 | 79.088 | 78.210 |
| TBAL-Net-(CN-LC-IS)-NME | 82.740 | 81.650 | 80.873 | 79.921 | 79.121 | 78.310 | 77.141 | 76.563 |
| Method | 35 | 40 | 45 | 50 | 55 | 60 | 65 | 70 |
|---|---|---|---|---|---|---|---|---|
| ResNet50-(CN-LC-IS)-CNN | 97.48 | 94.519 | 93.33 | 92.248 | 91.595 | 90.506 | 88.566 | 87.849 |
| ResNet50-(CN-LC-IS)-NME | 97.587 | 95.52 | 93.816 | 92.37 | 91.37 | 90.052 | 88.85 | 87.549 |
| NTS-Net-(CN-LC-IS)-CNN | 98.04 | 97.012 | 94.21 | 93.12 | 92.21 | 91.031 | 89.012 | 88.233 |
| NTS-Net-(CN-LC-IS)-NME | 97.921 | 96.21 | 94.037 | 92.67 | 91.47 | 90.19 | 88.921 | 87.75 |
| MMAL-(CN-LC-IS)-CNN | 98.127 | 97.23 | 94.796 | 93.545 | 92.439 | 91.32 | 89.47 | 88.676 |
| MMAL-(CN-LC-IS)-NME | 98.021 | 96.543 | 94.539 | 93.098 | 91.97 | 90.33 | 89.215 | 87.901 |
| TBAL-Net-(CN-LC-IS)-CNN | 97.846 | 96.91 | 94.87 | 93.65 | 92.879 | 91.798 | 89.86 | 89.08 |
| TBAL-Net-(CN-LC-IS)-NME | 98.012 | 96.12 | 94.96 | 93.45 | 92.325 | 91.02 | 89.658 | 88.233 |
| Method | 98 | 112 | 126 | 140 | 154 | 168 | 182 | 196 |
|---|---|---|---|---|---|---|---|---|
| ResNet50-(CN-LC-IS)-CNN | 96.053 | 93.965 | 92.620 | 90.392 | 89.182 | 88.069 | 87.716 | 87.054 |
| ResNet50-(CN-LC-IS)-NME | 95.854 | 93.857 | 92.466 | 90.704 | 89.308 | 88.460 | 88.212 | 87.303 |
| NTS-Net-(CN-LC-IS)-CNN | 95.940 | 94.021 | 92.473 | 89.794 | 88.329 | 87.440 | 86.217 | 85.233 |
| NTS-Net-(CN-LC-IS)-NME | 95.137 | 93.566 | 91.815 | 88.779 | 87.316 | 86.242 | 85.321 | 84.930 |
| MMAL-(CN-LC-IS)-CNN | 95.83 | 94.32 | 92.778 | 90.121 | 89.012 | 88.103 | 87.02 | 86.133 |
| MMAL-(CN-LC-IS)-NME | 96.03 | 93.97 | 92.531 | 89.33 | 87.93 | 87.531 | 86.39 | 85.127 |
| TBAL-Net-(CN-LC-IS)-CNN | 96.74 | 94.215 | 93.013 | 90.87 | 89.706 | 88.942 | 88.021 | 87.312 |
| TBAL-Net-(CN-LC-IS)-NME | 96.317 | 93.915 | 92.813 | 89.77 | 88.916 | 88.342 | 87.821 | 86.93 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, J.; Qi, G.; Xie, S.; Li, X. Two-Branch Attention Learning for Fine-Grained Class Incremental Learning. Electronics 2021, 10, 2987. https://doi.org/10.3390/electronics10232987
Guo J, Qi G, Xie S, Li X. Two-Branch Attention Learning for Fine-Grained Class Incremental Learning. Electronics. 2021; 10(23):2987. https://doi.org/10.3390/electronics10232987
Chicago/Turabian StyleGuo, Jiaqi, Guanqiu Qi, Shuiqing Xie, and Xiangyuan Li. 2021. "Two-Branch Attention Learning for Fine-Grained Class Incremental Learning" Electronics 10, no. 23: 2987. https://doi.org/10.3390/electronics10232987
APA StyleGuo, J., Qi, G., Xie, S., & Li, X. (2021). Two-Branch Attention Learning for Fine-Grained Class Incremental Learning. Electronics, 10(23), 2987. https://doi.org/10.3390/electronics10232987