1. Introduction
Promoting the early detection of an outbreak is paramount for the sustainable development of antiviral urban ecosystems. A prerequisite is to build an antiviral intelligent city framework in a multigenerational urban environment relative to the post-COVID-19 era. Humanitarian efforts in the pandemic’s framework deployed novel technological solutions based on the Internet of Things (IoT), machine learning, cloud computing and artificial intelligence (AI). Through our research study, we aim to contribute knowledge-based solutions for the direct control of the exponential promotion of cumulative infectious cases and the cumulative amount of mortality due to COVID-19. We propose an innovative system that could accurately forecast the progress of a virus spread and inform governments to align their policies against the outbreak in real-time. The main objective is to elaborate on the aspects that could construct a sustainable and effective strategy against disease outbreaks and an intelligent urban ecosystem based on technological initiatives.
The novel severe acute respiratory syndrome coronavirus 2, temporarily named SARS-CoV-2 and permanently renamed by WHO on 11 February 2020 as Corona Virus Disease 2019 ‘COVID-19’, caused enormous adverse consequences worldwide. To control spread, countries aligned their policies according to spatial distancing among citizens. However, various technological innovations and response initiatives have been developed to handle the unprecedented situation. It is paramount to establish a reference framework to contribute to effective defences against viruses and reliable urban ecosystems. Therefore, a multigenerational framework will be a significant step in improving digitalization and responding to post-COVID 19 antiviral society [
1]. Fundamental mathematics is paramount to understanding the pandemic’s progress, as we can interpret and forecast cumulative infectious cases [
2]. The development of machine learning techniques to predict the current situation or future outbreaks in conjunction with cloud computing will benefit the timely assessment of the epidemiological portrait. We first interpret the data from cumulative infectious cases and deaths due to COVID-19 and compare their trends. Then, we evaluate the three constructed models, linear, exponential and polynomial, by using R-squared to determine which model best fits. We propose improving the best fit predictive model by using the implementation of machine learning techniques. Real-time data will be driven for evaluation from the cloud repository, which will secure the datasets with the proposed fragmentation scheme [
3,
4]. The objective is to accurately predict the curve’s progress for governments to implement their policy reform from an early stage of the outbreak. We also apply hypothesis testing regarding Italy’s monthly mortality rate. We analyse the cumulative infected cases compared to the daily rate of patients derived from the Polymerase Chain Reaction (PCR) tests during the pandemic’s second wave.
COVID-19, an extremely contagious disease, was first reported in the Wuhan, Hubei Province, China, and affected a vast percentage of the world’s population. After thirteen months, WHO reported that 95,623,389 people have been infected, and 2,042,644 deaths occurred due to the pandemic. The inversely proportional fact of the vast number of infectious cases associated with the limited interval of time interprets the cumulative infectious cases as exponential due to the curve’s rapid increment. Fatality rates statistically prove that mortality occurs mainly in older adults and patients who suffer from chronic diseases with a weakened immune system. Thus, the lack of vaccination has led governments to implement national lockdown rules in order to restrict the spread as much as possible and to respond to healthcare needs. Communities are also taking technological innovation initiatives to deter the pandemic’s waves. Edge computing could contribute several novel ideas to thwart the spread. The development of machine learning, in conjunction with Cloud Computing, is of paramount importance. For instance, the projected alert for the future increase in new infectious cases in the community is a real weapon against the invisible enemy. We can tailor quarantine policies and restrictions accordingly.
The interpretation of cumulative infectious case data through fundamental mathematics includes linear, exponential and polynomial regression models. By generating R-squared by Microsoft Excel, we conclude that sixth-degree polynomial goodness of fit assesses numeric measures accurately as the discrepancy between observed values and the values expected under the model is limited. We calculated the coefficients through the least squares method in order to reduce the variance between the values generated from the sixth-degree polynomial that interprets data and the initial dataset. Therefore, we can forecast the outbreak’s progress by expanding the curve. In addition to that, we can derive the inflexion points by using the second differentiation of the function. They can predict the cavity of the curve and, thus, forecast the increment or decrement of the cases.
Using data driven from a cloud repository called “Our World in Data” [
5], our objective is to develop a novel forecasting model based on fundamental mathematics that can interpret daily reports in real-time. In conjunction with cloud computing, machine learning deployment enables data procurement from a real-time data repository to predict the virus’s course. Accurate predictions of infected cases from the virus will allow governments to adjust their policies because the system will inform them about the maximum number of patients, the number of total infected citizens and the expected period during which the pandemic will last. The mathematical framework will be informed daily, and the polynomial function will be recomputed. The goal is to have an up-to-date curve for accurate forecasts.
One of the most effective cryptographic methods that enable secure data exchange is fragmentation [
6,
7]. During the COVID-19 period, reliability in data acquisition infrastructure was a prerequisite. Therefore, we thoroughly elaborated the fragmentation method by utilizing potential datasets from COVID-19 cases.
Furthermore, the security and reliability of data-sharing infrastructure need a community of trust. Therefore, this paper also introduces an encryption frame based on data fragmentation.
We statistically analysed Italy’s monthly mortality rate to forecast the fatality rate that corresponds to cumulative infectious cases in cumulative cases. Moreover, we studied the contradiction between the cumulative infectious cases’ forecast and the PCR testing rate from the pandemic’s second wave. More specifically, if we interpret cumulative infectious cases and the daily percentage of newly infected patients from the total daily number of examinations, we end up with a different prediction.
2. Literature Review
In order to determine how the Dark Web has been influenced by recent global events, such as the pandemic situation Razaque et al. studied with the usage of a crawler, which scans the network and collects data for further analysis with machine learning [
8]. The pandemic, along with its conservatism measures, has become the new norm for human life. Yaxi et al., based on data acquisition regarding mobile phone positioning of thirty-one million users in Beijing, China, tracked vicissitudes in two rudimentary human daily activities: dwelling and working. They concluded that working concentrations decreased approximately 60% urban wide during the pandemic outbreak while dwelling decreased about 40% [
9]. Andreou and Mavromoustakis et al. proposed a cloud-based framework for accurately identifying truly positive infectious cases. Moreover, they introduced a novel solution aiming to prevent and control the outbreak based on smartphones and initiatives within a Naive Bayesian Network (NBN). In addition, they sought to provide local health authorities with a risk assessment of geolocation risk and early findings to trigger them to increase test rates in high-risk areas [
1]. An approach around economic management orientation to improve the accuracy of the forecast for the pandemic was proposed by Xuan et al. based on a self-correcting intelligent pandemic prediction model [
10]. For the same purpose, Rongbo and Qianao et al. have introduced a real-time warning model that studies the factors of public opinion on the internet and the dynamic characteristics of epidemic incidents. Therefore, they constructed a vector machine and a logistic regression model in order to enhance the prediction based on COVID-19 data [
11]. Following the same motive, Srikanta et al. have analyzed COVID-19 mortality and infectious diseases in Europe using spatial regression models. More specifically, they select thirty-one countries for modelling and consequent analysis [
12]. Elbasi et al., aiming to discover vulnerable groups and to reduce the impact of the disease on particular groups, have deployed machine learning techniques.
Naglaa and Ehab et al. stated that “architecture and urbanism after the COVID19 epidemic will never be the same” and they might be correct [
13]. Their scope was to research the current pandemic situation in order to enhance the response to future similar outbreaks. Chanjuan and Zhiqiang et al., aiming to prevent the spread of corona-virus, elaborated on research fields with respect to spatial distance and indoor ventilation efficiency [
14]. Based on the same research area, Antony, Velraj and Fariborz et al. studied the spread of COVID-19 under several different climates and environmental conditions: indoor and outdoor [
15]. To overcome several lockdown policies’ adverse economic impact due to continually pandemic waves, this paper [
16] proposed a real-time data-driven dynamic clustering framework. Finally, Xing-Yi et al. examined the risk of Coronavirus spreading to health and care ecosystems in order to enhance sustainable work in the hospital environment [
17].
Cities across the EU need to develop supportive environments that provide access to a range of facilities and services to achieve a higher quality of life for their senior citizens in order to improve the future after the Coronavirus pandemic and to confront the fear of a potential upcoming pandemic resurgence. A prerequisite is to identify the areas where cutting-edge technology could be integrated and be beneficial to ageing societies. The three main fields we need to focus on in our research include home services, community services and healthcare services. Hisham et al. presented challenges in the area of knowledge for the pandemic. They concluded with re-entering the norms and standards of social distancing. Moreover, they endorsed the continuation of research after the pandemic recedes, undertaking multidisciplinary methods between fields of knowledge [
18]. Chaudhury et al. explored the difference among multigenerational neighbourhoods in the metropolitan regions, concluding that older people in the higher density neighbourhoods are exposed to more traffic hazards than in the lower density neighbourhoods [
19]. Azzam and Ibrahim et al. investigated the impact of COVID-19 and the global pandemic on energy sector dynamics [
20]. Shiau et al. surveyed older adults to identify KPIs’ importance and their degree of satisfaction relating to age-friendly transportation [
21]. Metz et al. stated that it would be attractive to develop a helpful mobility framework to measure a group of benefits associated with older adults’ travel and transport [
22]. The age-friendly metaphor is multifactorial. For instance, Broome et al. identified that public transport can limit older people’s participation in society. Therefore, focusing on public buses explained the link between bus usability and older people’s health and frames existing evidence on bus usability issues [
23]. COVID-19 research studies are relatively new for apparent reasons. Thus, we also reviewed literature from previous epidemic periods. Liang Fang and Zhi Dong Cao et al. [
24] have constructed a real-time web system by using ArcGIS and Mashup’s technology to collect and display new hotspots according to geographical location. Various models for predicting stability and MERS-CoV infection recovery have been developed by Isra Al-Turaiki et al. [
25] based on Naive Bayes and J48 decision tree classification algorithms. Zhaoyang Zhang et al. [
26] elaborated the epidemiological clusters by using social networking sites, collecting vital signs and social interactions. Based on this approach, we can identify and isolate the optimal bound cluster to reduce dispersion. To forecast and stem Ebola virus disease, Sareen S. Sood, S.K.; and Gupta, S.K. et al. [
27] developed a cloud-based system by deploying Temporal Network Analysis (TNA) and wearable body sensor technology. Sanjay Sareen et al. [
28] developed a cloud-based system for detecting and monitoring Zika virus through IoT technology’s deployment.
A review of the current technological solutions state shows various digital tools to remediate the COVID-19 outbreak. Reshaped implementations of machine learning and cloud computing can contribute to the fight against the virus. Alibaba Cloud 2020 deployed machine learning and deep learning to establish a modified SEIR model to predict the spreading trend of COVID-19 and evaluate the risk of infection increases in a specific region [
29]. This innovative solution can provide a COVID-19 pandemic prediction report with 98% accuracy by submitting primary data such as flight information, number of new cases, number of confirmed cases, number of close contacts, contact date and number of people under quarantine. An innovative biomedical tool that could also contribute to the battle with the invisible enemy is the genomic sequence of machine modelling to forecast possible infectious reactions to various drugs or to control the spread of COVID-19 [
30]. An artificial intelligence frame was also developed to assess computed tomography images identifying COVID-19 pneumonia features relative to screen infected patients [
31].
3. Regression Models and Performance Comparison
By implementing regression analysis, which is explained in the chapter [
32] and further analyzed in the article [
33], we construct linear, exponential and polynomial interpretive models, as shown in
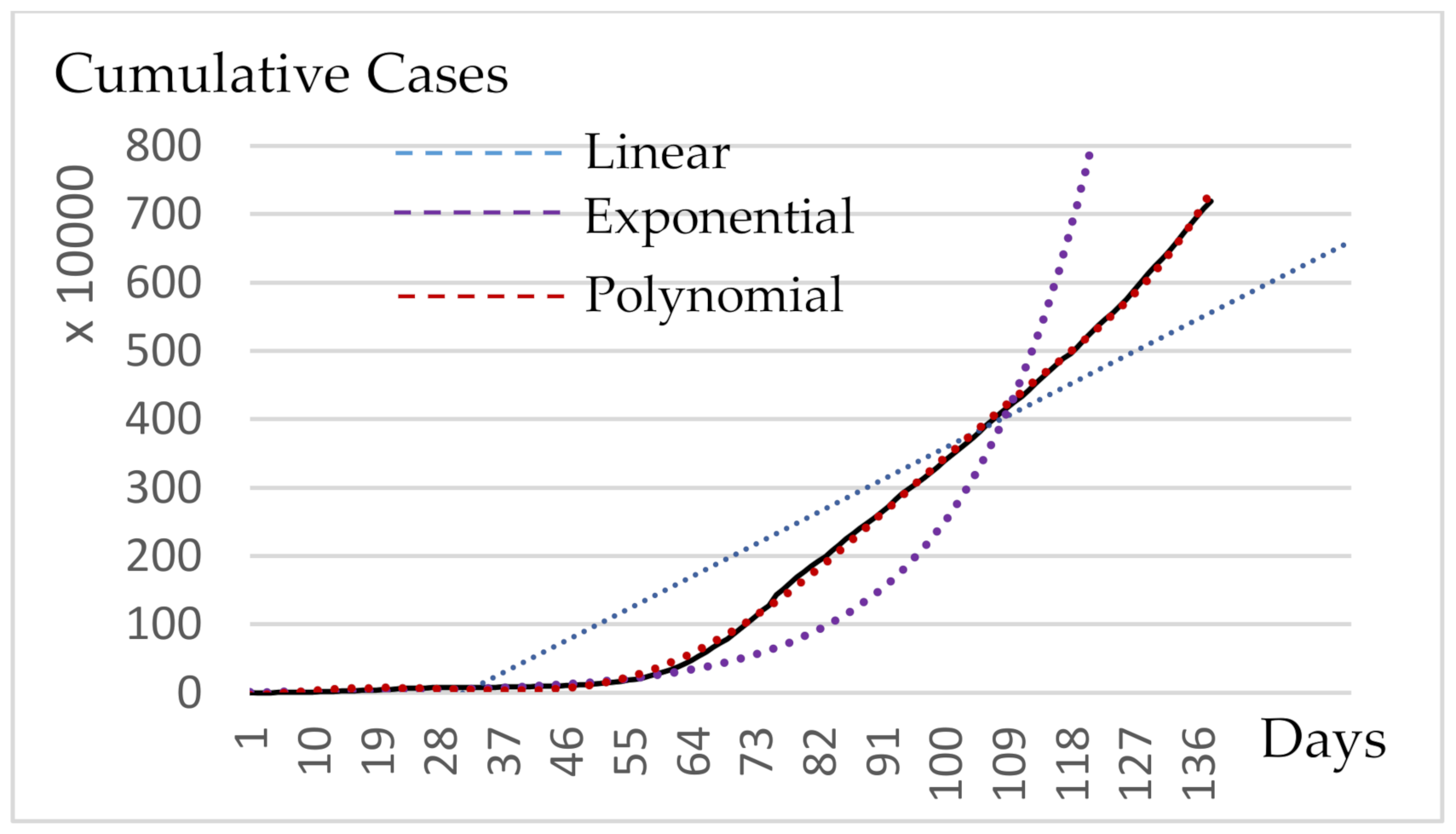
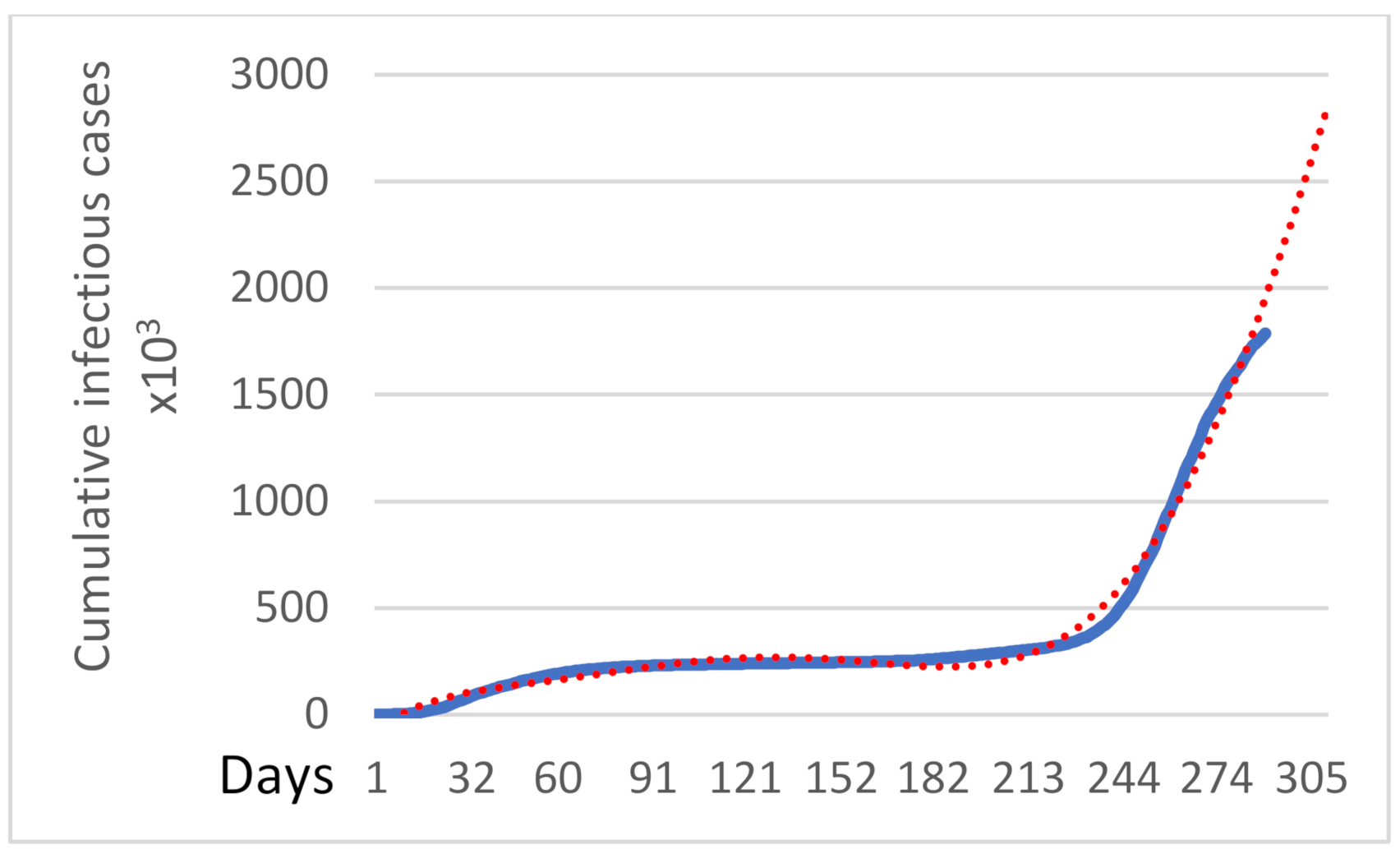
Figure 1, for the cumulative infectious cases of daily reports since 31 January 2020. In addition, the least-squares method enables the calculation of the coefficients for Equations (1)–(3):
where x denotes the days from the initiation of the pandemic, and y denotes the cumulative infectious cases.
Italy’s cumulative infectious cases appear on the vertical axis according to the daily report (x-axis) from 31 January. Linear (1), exponential (2) and sixth-degree polynomial (3) regression modes in
Figure 1, respectively, are presented by the dashed line. All models interpret 353 days of Italy’s data since 31 January 2020 and are prospectively forecasting 30 days, as we present through the extension of the dashed lines.
The R-square or coefficient of determination is a statistical measure that shows the dependent variable’s variance concerning the independent variable.
meaning that the horizontal axis values can explain 0% to 100% of the vertical axis variation.
While the numerator of (3) represents the unexplained variation, the denominator represents the total variation.
Table 1 present the values of the R-squared evaluation of the three regression models, respectively.
Regression model comparisons by the coefficient of determination
drew the conclusion that sixth-degree polynomial regression best fits the data because the value is closer to one, as shown in
Table 1.
4. Concavity and Points of Inflection
Inflexion points are defined as the change of concavity on the curve’s trajectory. We refer to the intervals where the curve concaves upwards or downwards based on the second derivative sign in terms of concavity. The curve’s symmetrical course around these points motivated us to study Italy’s sigmoid function from cumulative infectious cases. Before the inflexion point curve’s, the orbit is concaved upwards as and concaved downwards as . Therefore, initially, we interpret the data points by the sixth-grade polynomial function (4) that presents the best fitting, and we can calculate the second derivative. Then, the inflexion point coordinates are determined by evaluating the curve’s coordinates, where the second derivative presents its root. That root will be the x-coordinate, and the value that derives from the substitution of the root on the original function will be the y-coordinate of the inflexion point.
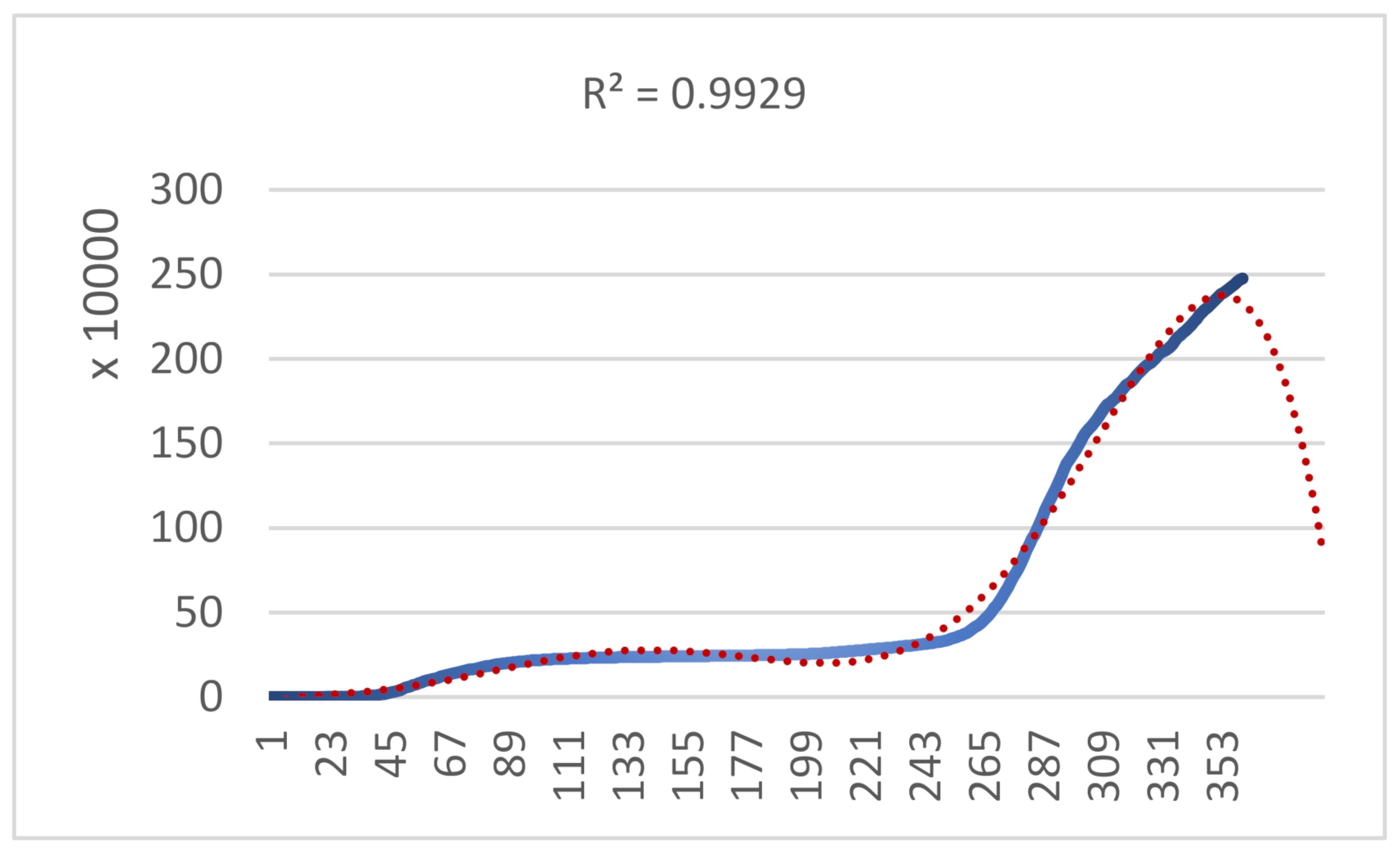
As presented in
Figure 2 we calculated the trendline with the coefficient of determination
, which means a high accuracy of interpretation. After that, we determine the function of the trendline and implement the second derivative, as shown below Equations (5) and (6).
The turning points estimate counts as an additional result that acts as a trademark in the pandemic. Concavity changes which are determined in
Table 2 is essential because it presents the curve’s furtherance until the next turning point and how the infectious cases will progress.
5. Proposed Cloud Framework
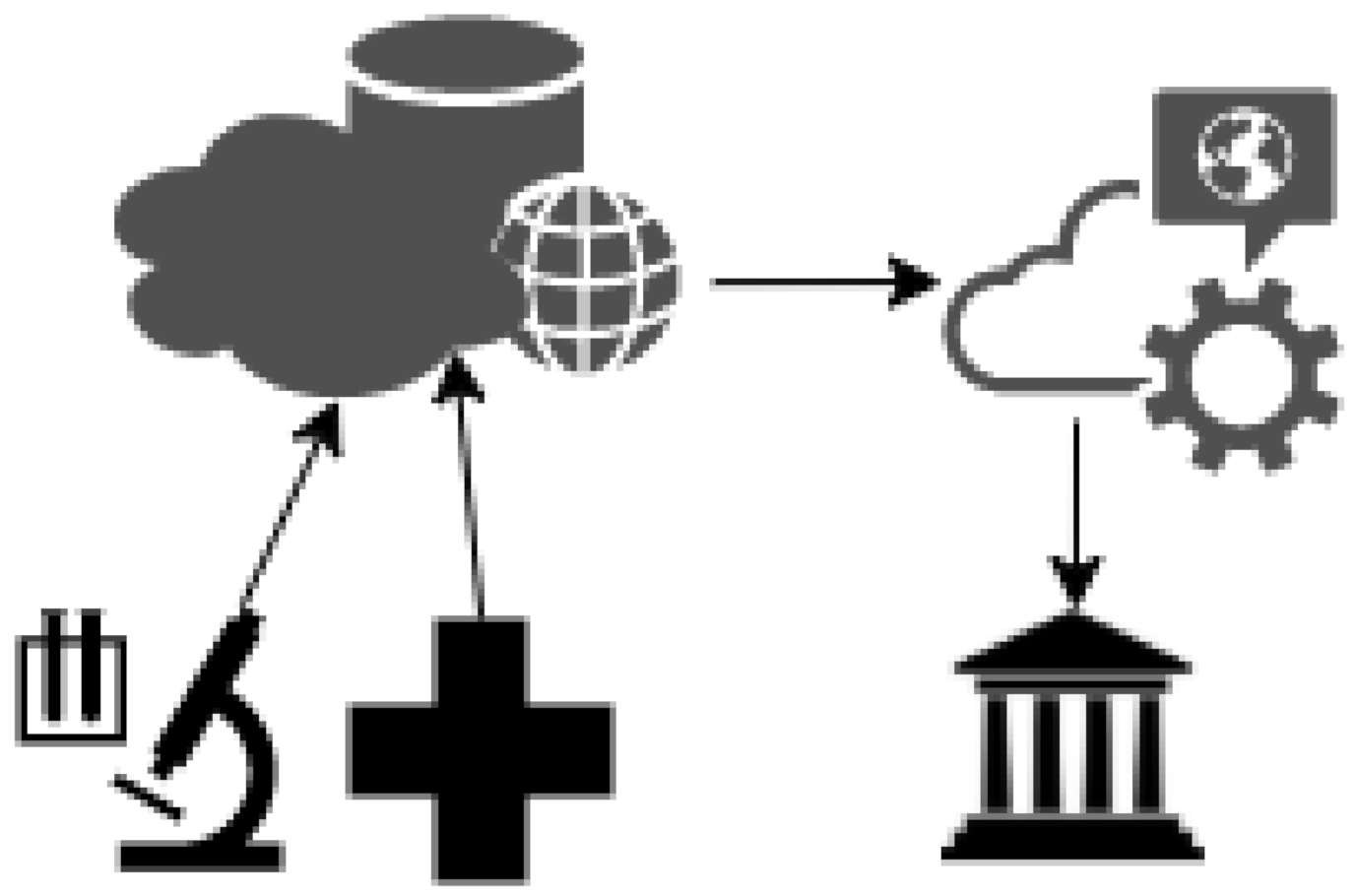
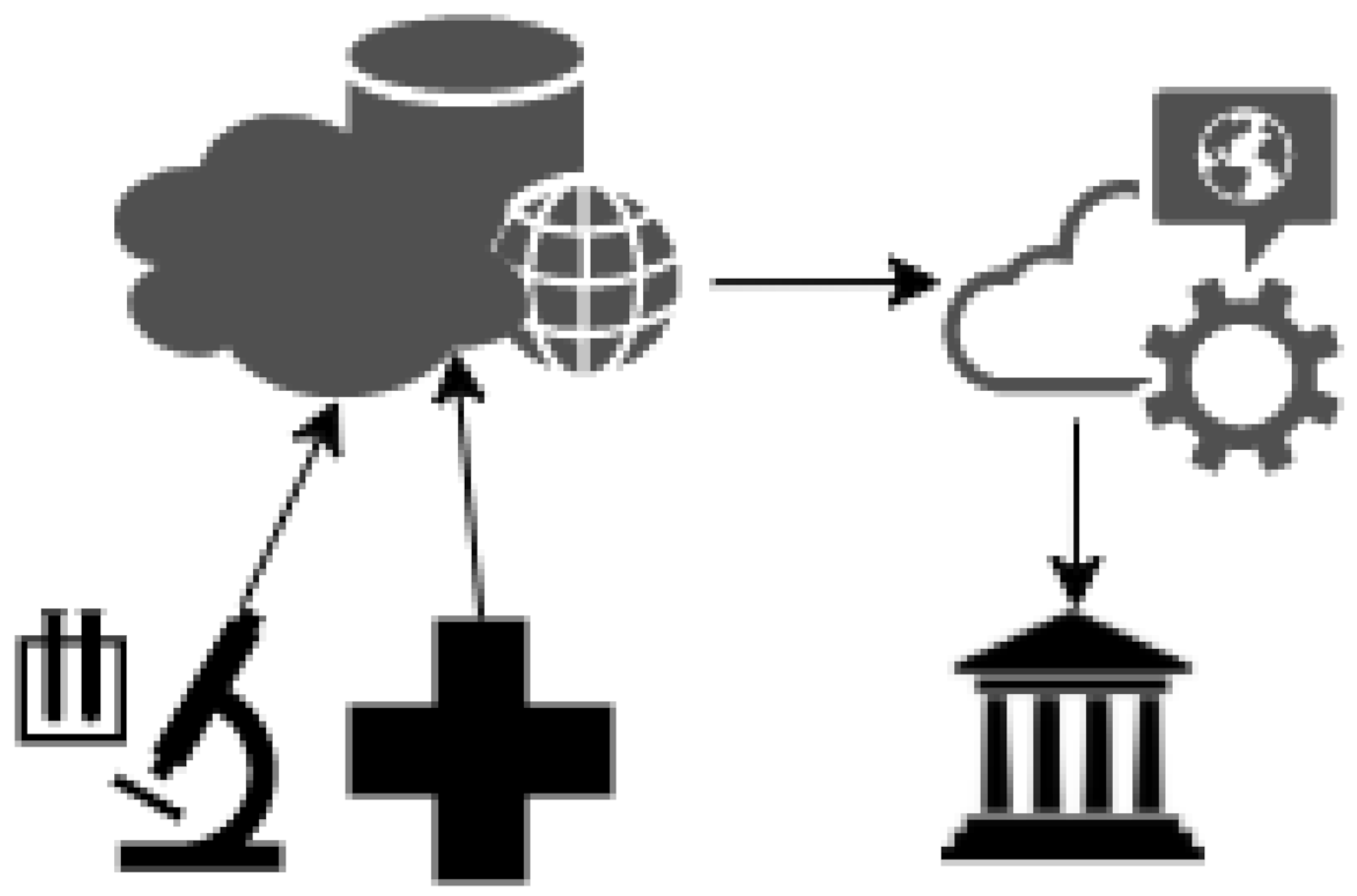
In order to forecast the evolution of the COVID-19 pandemic, we propose modifying a machine learning technique deployed in a cloud-based framework. The regression models we analyzed in Section III can predict the increase and decrease in cumulative infectious cases and any other parameter that could help governments align their policy strategies against the invisible enemy. Furthermore, since late Januarys, several online open data repositories have collected various data regarding the pandemic driven from laboratories worldwide. Therefore, to forecast the progress of the unprecedented situation with accuracy, we propose integrating repositories by using cloud computing to interpret data trends using machine learning methods.
Figure 3 illustrates the proposed model pattern, where raw data from laboratories and hospitals worldwide are routed through the network to data repositories. By modifying the Levenberg–Marquardt algorithm, a machine learning technique, we optimize the accuracy in the trend line that interprets these data sets [
34]. The Levenberg [1944] and Marquardt [1963] algorithm modified the Gauss–Newton method, which provided the solution to the least square determination for nonlinear determination equation coefficients. According to section III, the polynomial that best fits the dataset has coefficients determined by the equation’s minimum values (7), where x denotes the days, m denotes the amount of days from the initial outbreak and
is the aforementioned function.
Extreme values and data noise prompted us to develop an iterative weighting strategy in order to flatten the graph of the curve and to reduce the error for greater accuracy [
35]. In addition, we were reconstructing the regression model to achieve better curve adjustment and reduce outlier data distances. As shown in Equations (8)–(10), we developed three weights by composing the SoftMax function [
23] and the function, which is the difference between the lengths of all the values along the y-axis from the curves of the Sigmoid function, Arc-tangent (
) and Hyperbolic-tangent (
) function in order to optimize the curve fitting process.
We divide the distances denoted by
between the coordinates and the trendline by the maximum value and subtract from one. The SoftMax function standardized the results corresponding to each point. We initially provided three weights denoted by
equal to one for all data points to fit the Levenberg–Marquardt Algorithm 1 curve. Then, we substitute the value calculated from (8)–(10) corresponding to every point for the next iteration
. Finally, we implemented the Levenberg–Marquardt algorithm with the new weights and evaluated the curve fitting of the three methods. The sum of all weights’ deviation should be lower than a threshold value to converge the algorithm.
| Algorithm 1. Modified Levenberg–Marquardt Algorithm |
| Requirements: |
| : Input sequence of days from first reported case |
| : Input number of cases corresponding to each day in x |
| : Threshold parameter (the earliest time a failure may occur) |
| Process: |
| |
| for iteration n from 0, step 1 do |
| |
|
| Apply one of the following: |
| |
| |
| |
| if then |
| break |
| end for |
| end procedure |
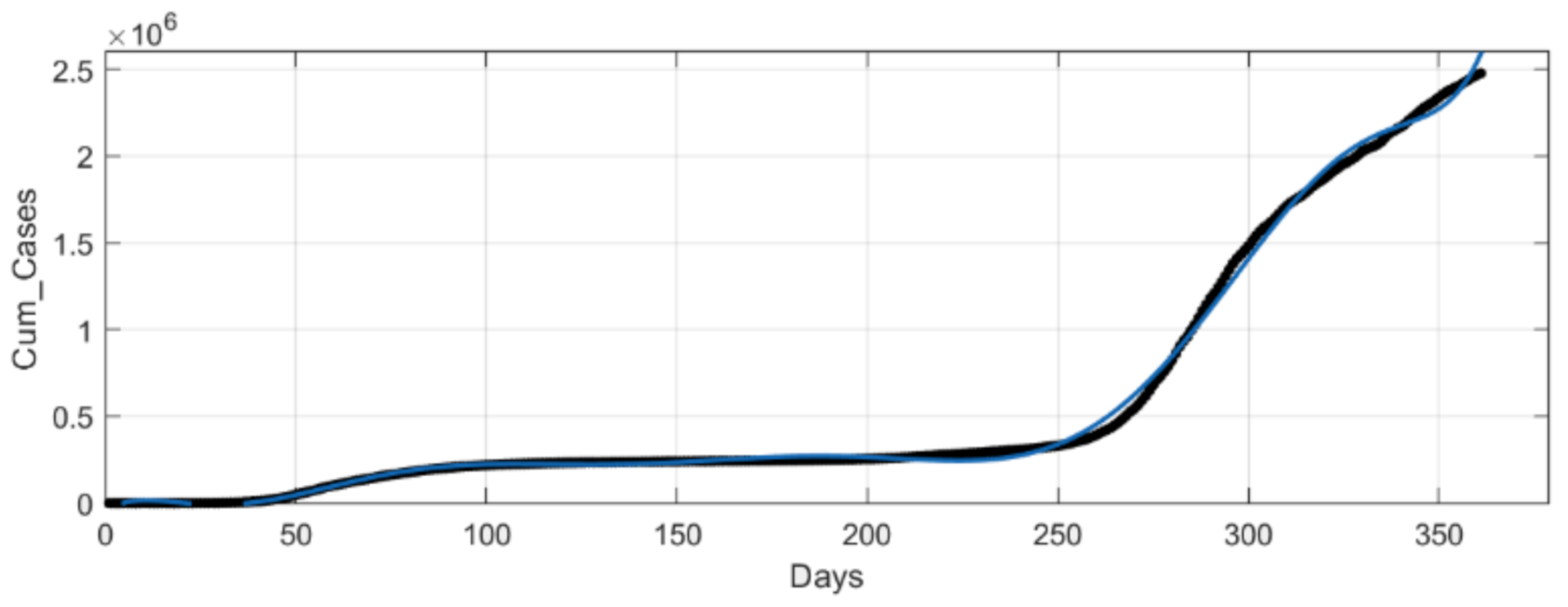
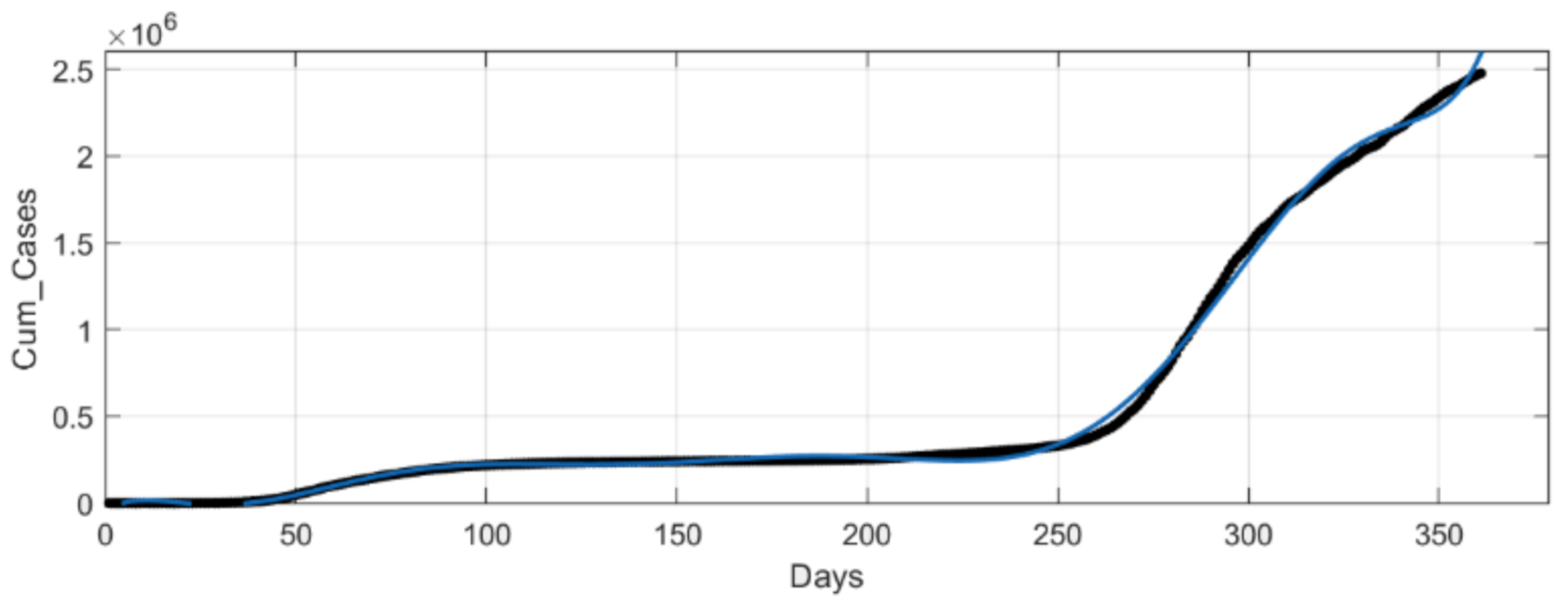
At MATLAB’s Curve Fitting Tool, we implemented a ninth-degree polynomial for curve fitting corresponding to Italy’s cumulative infectious cases. As a result, we generated the curve shown in
Figure 4 interpreted by (11) where x is normalized by mean 181 and std 104.4, and the coefficients’ (with 95% confidence bounds) goodness of fit results are presented in
Table 3.
6. Distribution Fitting
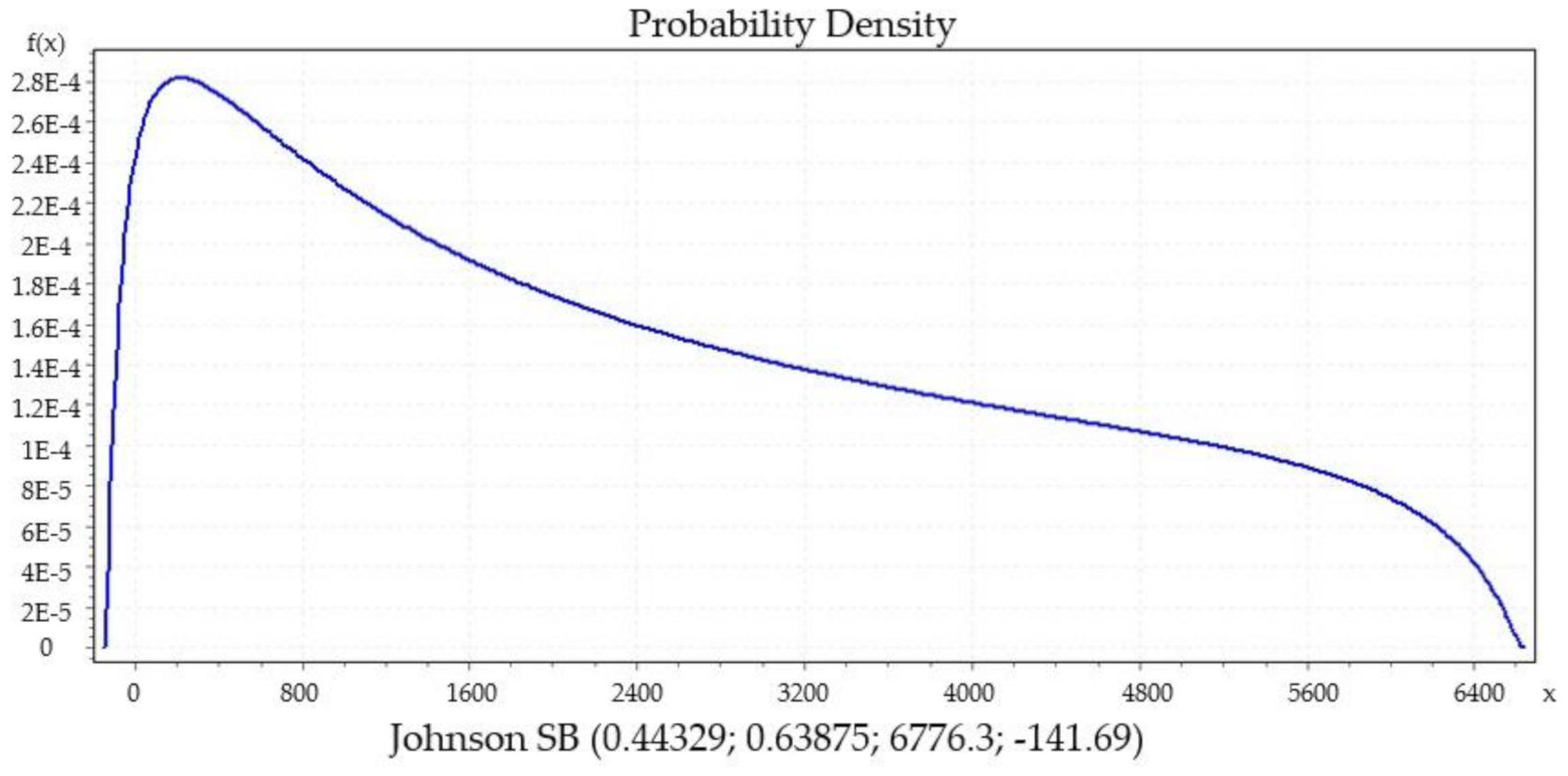
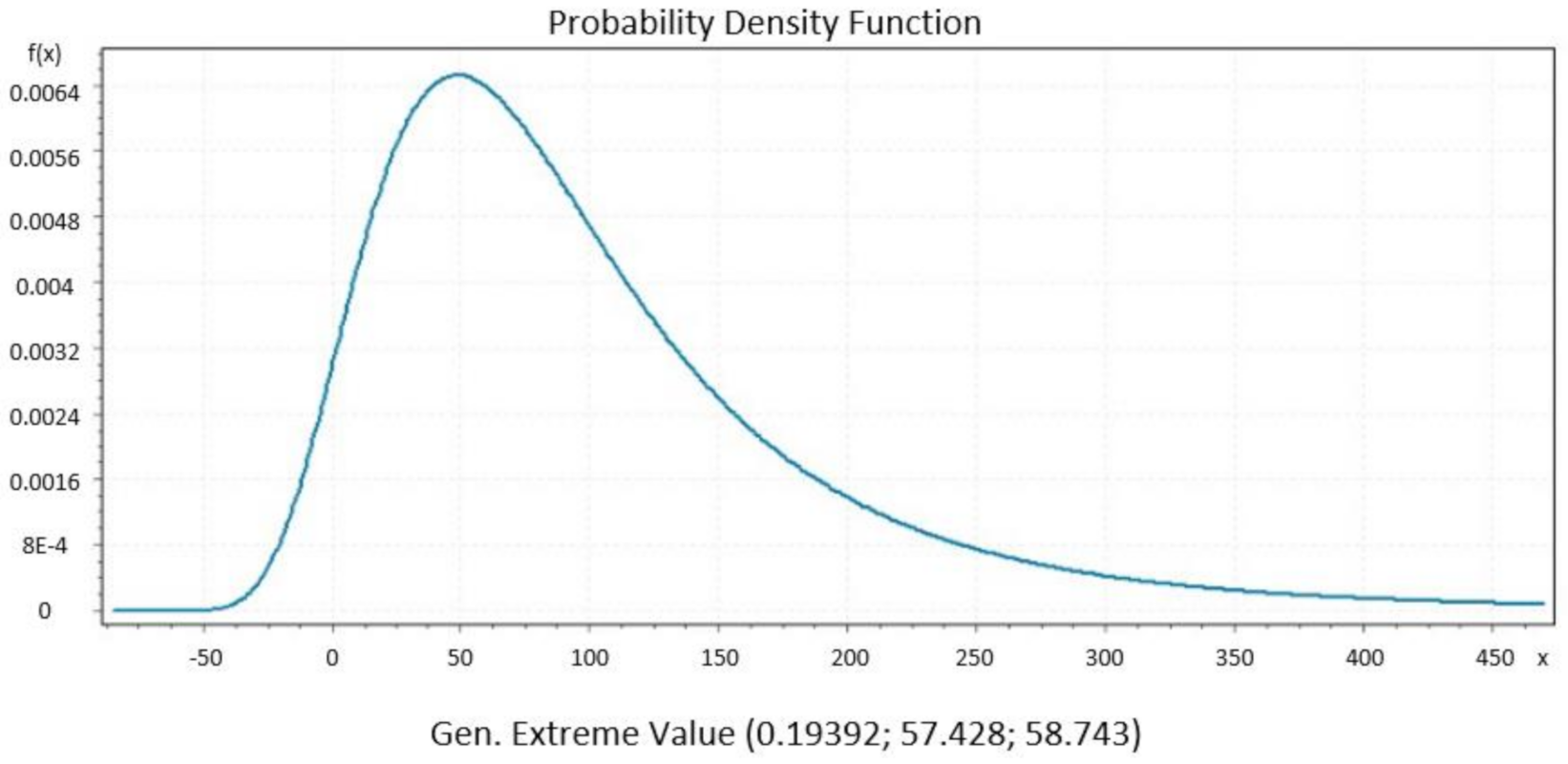
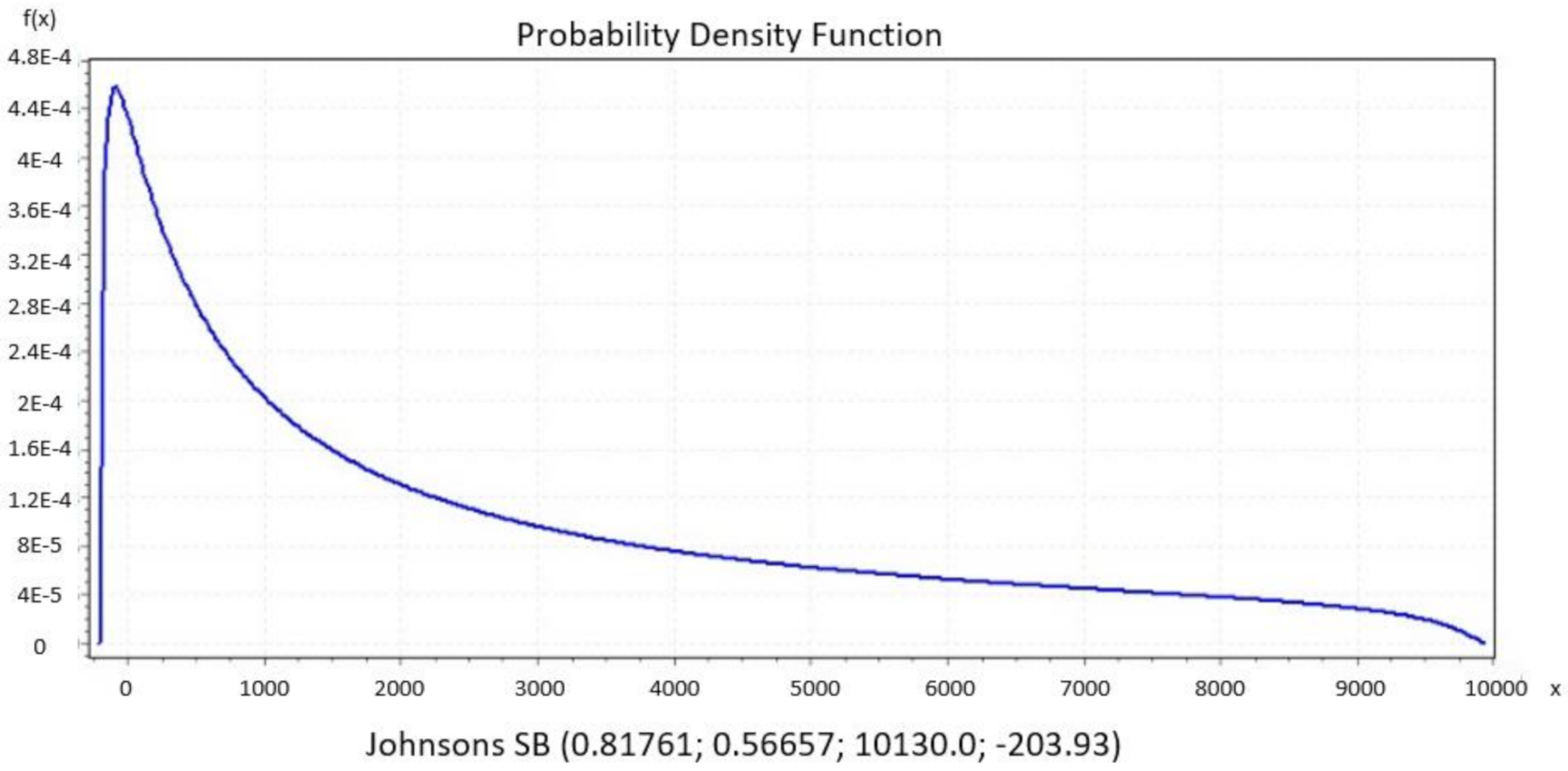
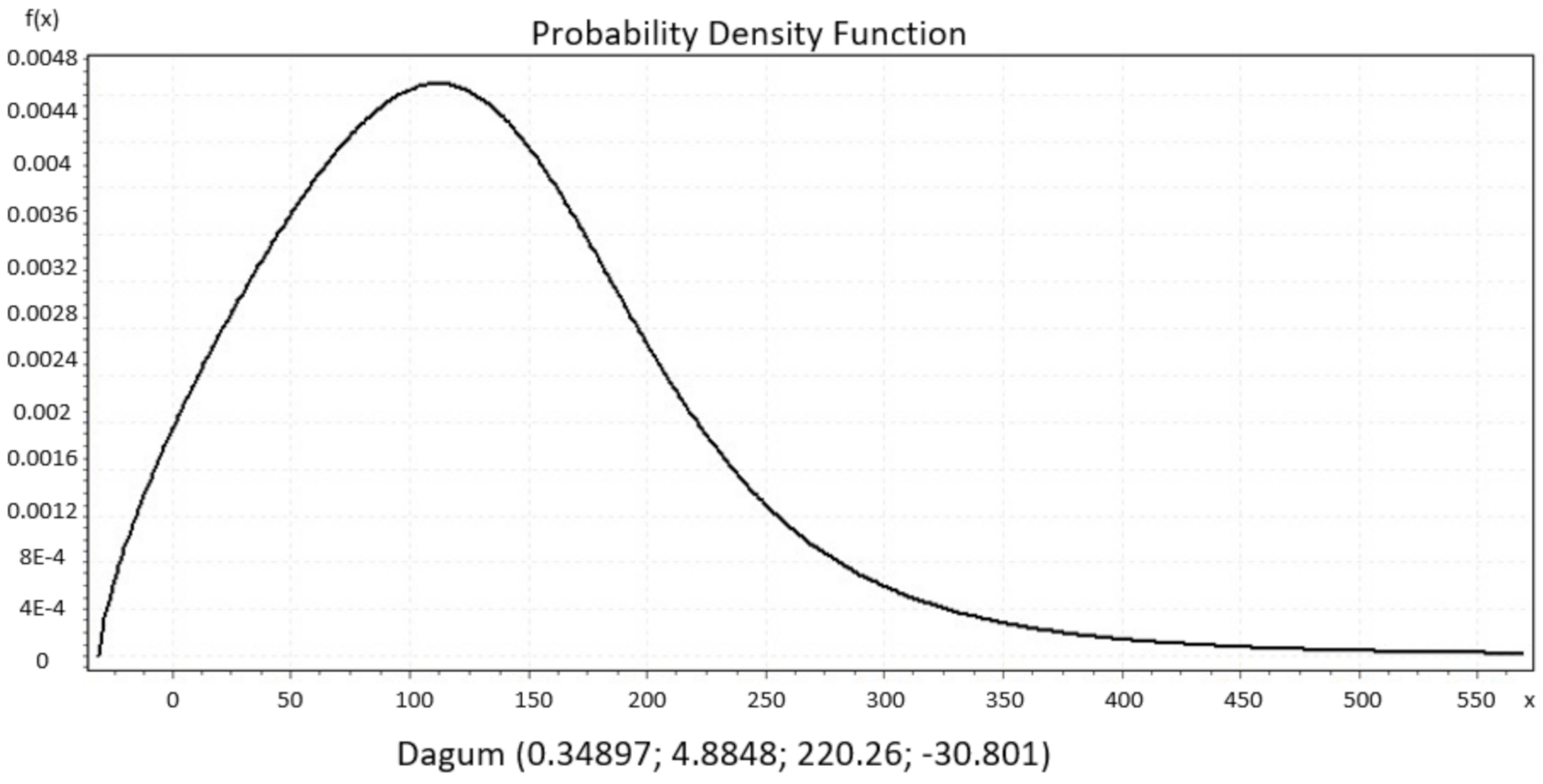
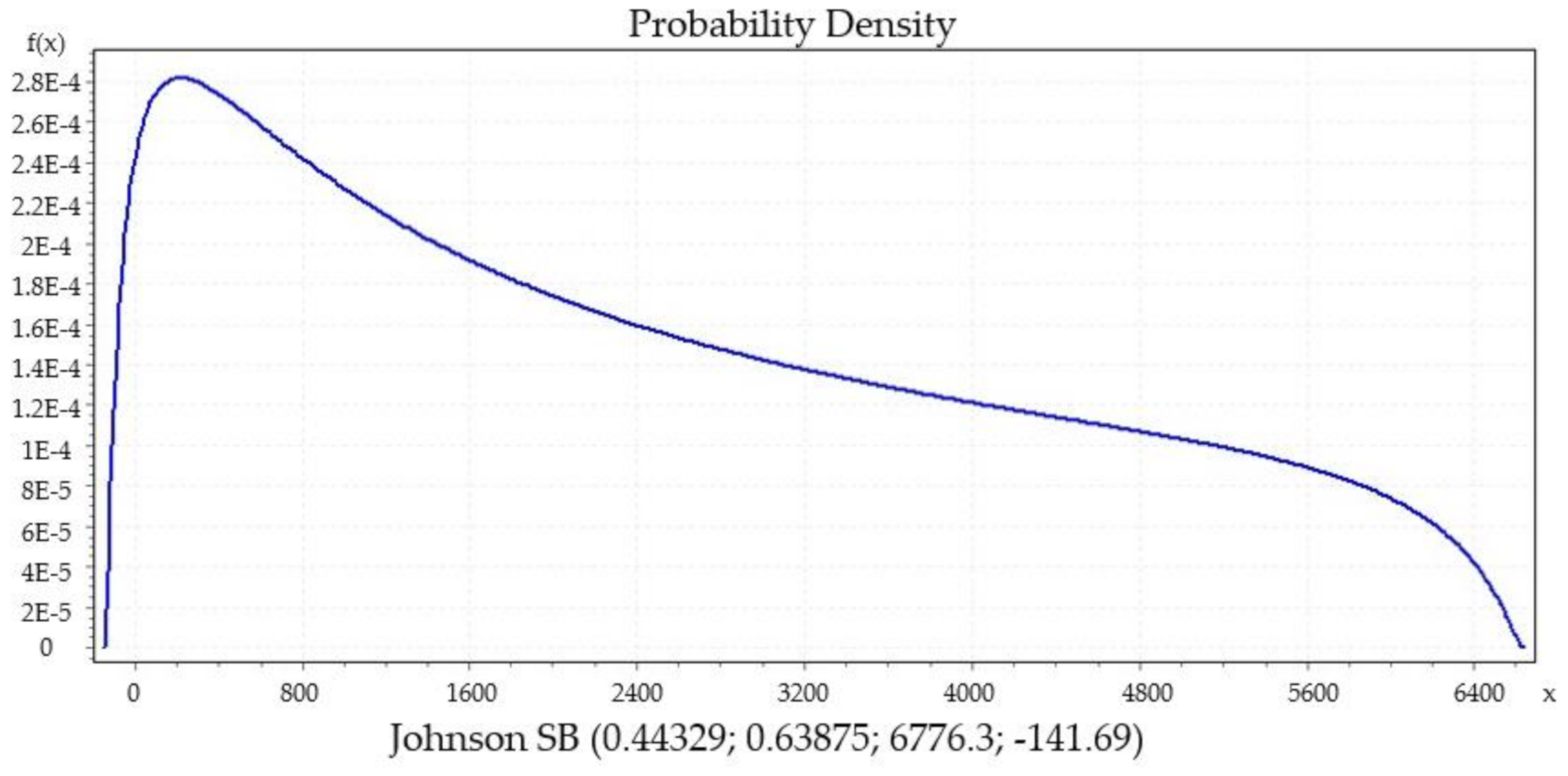
We present significant distribution models regarding daily new COVID-19 cases from datasets of countries that show a decline in their curve’s furtherance, which was preferred. Then, we identified the best performing distributions for each patient using EasyFit Standard version 5.6.
Figure 5,
Figure 6,
Figure 7,
Figure 8 and
Figure 9 present the distributions Johnsons S
B, Gen. Extreme Value, Person 6 and Degum as the best performance of goodness of fit for Italy, Czech Republic, France and Denmark, respectively, and they were evaluated by Kolmogorov Smirnov and Anderson Darling tests. Johnson S
B distribution shows the best fitting performance compared to the other distributions in two countries, Italy (
Figure 5) and Spain (
Figure 8) [
36]. From the iteratively weighted approach in section zero, the distributions fit the curve better than without weight.
7. Personal and Health Information Protection
In order to secure the confidentiality of patients, we propose the implementation of an additional encryption process [
37]. We developed a mathematical model based on data fragmentation to disintegrate the information into several cloud repositories [
38]: fragmentation in terms of features distribution. Thus, their values could only be visible only by a critical enabler. We propose a necessary arithmetical analysis procedure for the decryption process: Newtons’ divided difference interpolation for reconstructing the datasets. The constraints are defined as the rule for distribution among attributes. Consider A as a set of users’ features and c as a set of confidentiality constraints [
39]. Hence, c will be a subset of A,
, and each constraint cannot be a subset of another constraint [
40]. We propose distributing and storing the subsets to database service providers (DSP) with repositories by developing polynomials. The distribution of datasets to k fragments is enable through
coefficients. We denote the constant value as
, which constitutes the sensitive value of the National Identity Number, NIDN. Hence, we construct a
degree polynomial as shown in the Equation (12).
The database management system (DBMS) stores the secret information
, where
, and can computes the values of
by substituting
of the
values from the vector
. By using Newton–Gregory’s divided difference interpolation and by the knowledge of
order pairs
, we can determine
coefficients of the polynomial as well as the original value of National Identity Number NIDN corresponding to the constant
, as shown in Equation (13):
where
will be the first, second and
divided differences, respectively.
Example:
A = {National Identity Number (NIDN), Name, Date of Birth (DoB), Mobile Number (MN), Postal Code (PC), Probability of Infection (PoI)}
An example of fragmenting the attributes which are presented in
Table 4 involved in the constraints so that they are not visible together could be
,
and
. Fragments will be stored in three separate database service providers: database service providers 1, 2 and 3 DSP1, DSP2 and DSP3, respectively. We will develop a second-degree polynomial to share the data among database service providers DSPs, as shown in the Equation (14):
where a
0 represents the NIDN, and the coefficients a
1 = (1,2,5,6,4) and a
2 = (7,3,2,1,9) are randomly selected. Moreover, the secret values of
are randomly selected and correspond to each DSP, respectively; let
.
Table 5 presents the computational results of substitution to each polynomial of the coefficients and the secret values.
The fragments will be distributed as shown within the following tables (
Table 6,
Table 7 and
Table 8) presenting an incorrect value of NIDN for each data from
Table 4.
Recreating the dataset is a prerequisite for knowing the three ordered pairs
, which corresponds to the three database service providers DSPs. The decryption will be achieved by employing Newton–Gregory’s divided difference interpolation as shown in
Table 9, from which the polynomial after reconstruction will present the original value of NIDN as the constant part of it a
0 [
41]. Finaly, we retrieve the reconstructed
Table 10.
8. Mortality Rate
This section statistically analyzes the mortality rate, aiming to predict the number of deaths due to COVID-19. If we take the quantity of affirmed cases as an independent variable and the number of deaths as a dependent variable, we can find the correlation coefficient between them. We refer to implementing a strategy to evaluate a surmised linear relationship between the two continuous variables by finding the correlation. Measurement can be within the interval
that assess an estimated direct connection between two persistent variables [
42]. To this point, we utilize Student’s t-test to affirm the average number of death rates with the previous quantity of cases [
43]. The T-test is regularly used as a measurable strategy to examine whether the average information from an independent sample following a normal distribution is consistent or deviates from the mean estimate of a null hypothesis or whether the distinction between methods for two independent models following a normal distribution is statistically noteworthy [
44].
Karl Pearson’s correlation coefficient can be calculated using (15) by substituting the results derived from
Table 11. We obtained the data from Italy’s information as n represents the months, x represents the cumulative infectious cases and y represents the number of deaths due to COVID-19. The calculation shows that r(x,y) = 0.869185; thus, we have a high degree of positive correlation. Therefore, the mortality rate denoted by m% will increase by the increment of COVID-19 cumulative cases [
45].
In order to identify whether the data are substantial or not, we implement hypothesis testing where the null hypothesis was what Italy’s average mortality rate could be according to
Table 11, μ = 14.48%. From (16), (17) and
Table 11, we derived |t| = 3.45, which shows a 0.5% level of significance and 11 degrees of freedom, confirming our null hypothesis that Italy’s maximum average fatality rate could be 14.48%, where t denotes the T-test’s variable, m denotes mortality,
denotes the average of the mortality, n is the total amount of the sample, S indicates the Standard deviation, and
denotes the statistical mean.
9. Cumulative Cases vs. Daily Case Rate
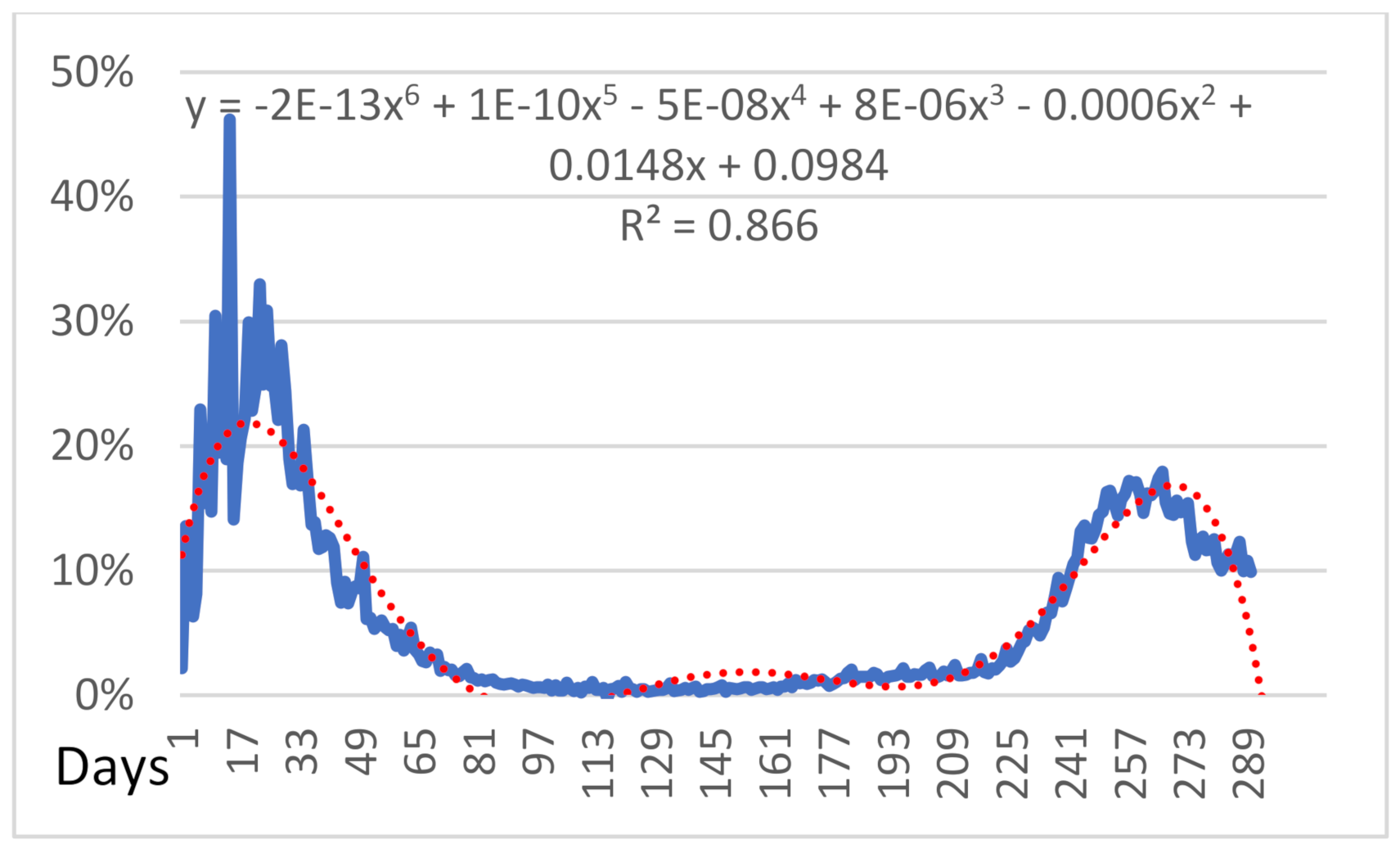
The relaxation of COVID-19 lockdown measures triggered the second wave of the pandemic. As a result, most countries have reassessed, redefined, and revived COVID-19 response activities in readiness to deal with the second and potentially third wave of the outbreak. Unfortunately, in the second wave, an overblown panic occurred as cumulative cases present a contradiction concerning new cases’ positivity per number of tests conducted daily. Based on that, we studied Italy’s number of cumulative cases and the percentage of the PCR testing rate daily since 25 February.
As shown in
Figure 10, since 16 October (day 235), we observed considerable acceleration as the curve displays rapid increasing progression. As observed, the red dashed curve represents (18), which is the trendline that is derived from the implementation of the curve adjustment to predict the extension for 20 days. Evaluation through the coefficient of determination presents that the regression predictions approximate the real data points with a fitting accuracy of R
2 = 0.9885.
We evaluated the percentage of infected cases over the number of daily conducted tests during the same period and presented the generated results graphically in
Figure 11. As shown, the two schemes conclude to dissimilarities due to the curve’s progress and the inferences. The curve in
Figure 10 can be observed, and it changes the concavity from upwards to downwards and presents increasing progress since 06 October, day 225. More specifically, the contradiction occurs due to the rapidly growing growth of the curve in
Figure 11 and the slow acceleration of growth in
Figure 10. The second wave’s maximum point appears to be lower than in the first wave of the pandemic. The forecast for 20 days shows that the trendline’s function (18) with R
2 = 0.866 is decreasing within the interval [273,289] in contrast to the previous
Figure 10 where the rapid increment in the interval [235, ∞) is presented.
10. Discussion and Conclusions
This paper proposes a modified machine learning technique to accurately interpret the data provided by fragmentation techniques by countries worldwide regarding COVID-19. The objective is to inform governments in an early stage of a pandemic situation to regulate their policies with a better strategy based on an accurate forecast model. The corresponding groups among countries utilize models to provide predictions regarding the virus’s progress that could result in a contradiction. Thus, our proposed model’s goal was to implement a technique that fits the regression models as best as possible to the curve. Additionally, the updated data will be driven daily to develop a new polynomial function. The goals are to estimate the upcoming turning points daily. We presented the pandemic progress hallmarks in
Section 4 and forecasted the new curve’s furtherance with the new polynomial. By comparing cumulative infectious cases with the daily rate of PCR testing, we concluded that it is efficient to predict the progression of a pandemic’s second wave by using the daily testing rate as it effectively interprets the outbreak. According to
Section 8, the mortality rate in Italy is 14.48%, as evaluated by Student’s
t-test.
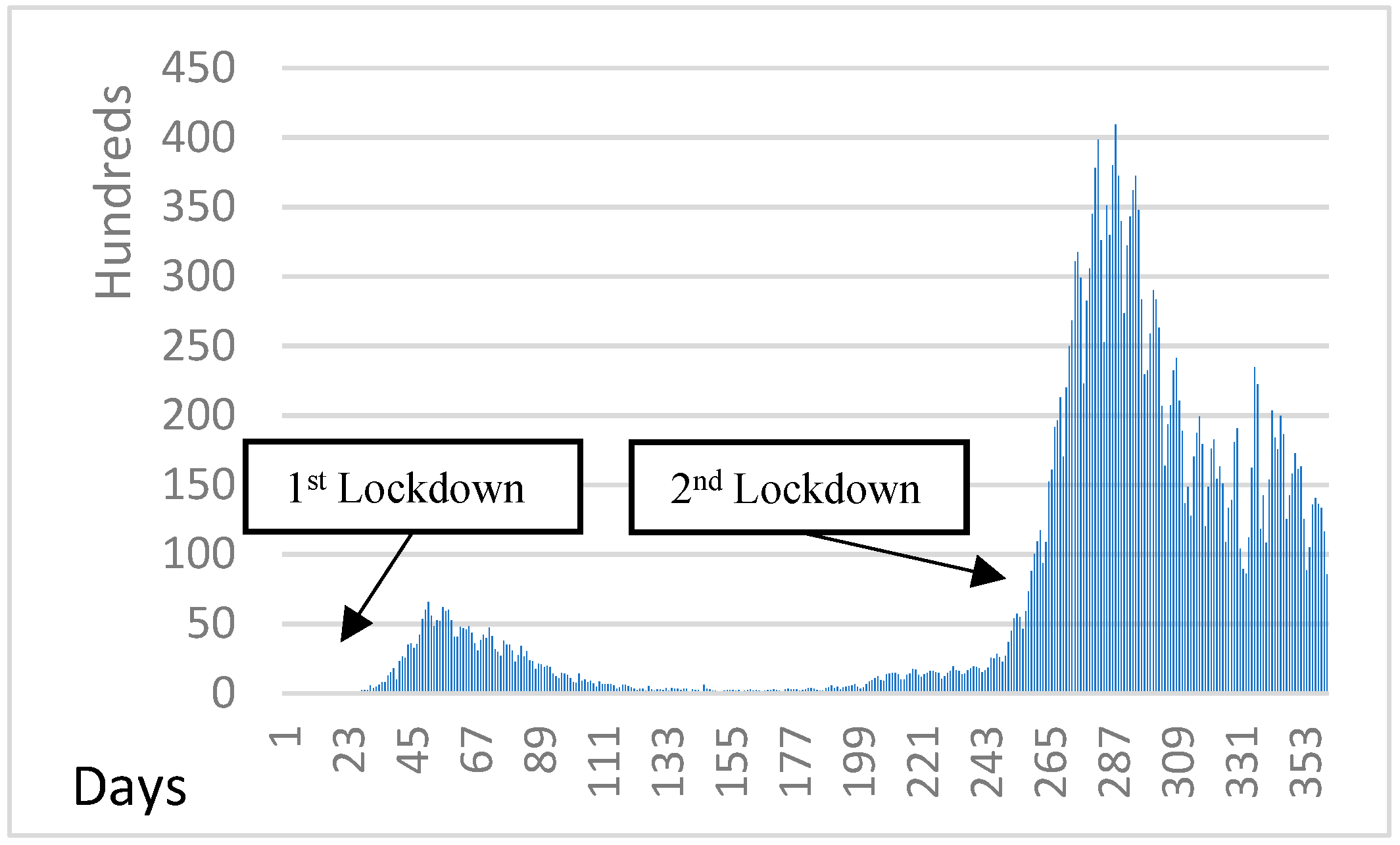
As presented in
Figure 12, the initial stay-at-home orders (enforced and referred to as ‘lockdown’) for Italy’s general population began on 10 March and finished on 4 May. The second lockdown, largo, started on 26 October and was partially completed, as most restrictions were still being implemented on 4 November. Therefore, as the second pandemic wave occurred, there was an increasing trend in new cases. For this reason, if we had early lockdown strategy and if the quarantine measures had been adopted earlier, we would have avoided the unpleasant increment situation of the second wave.
The limitations from our research work include the noise that occurs in datasets due to weekends and public holidays. Due to these occurrences, the real-time data present outliers, resulting in unnecessary concavity points relative to the curves and incorrect gradients for the linear case. Henceforth, we will focus our future orientation to modify the system to exclude the corresponding data that generates this outlier by understanding each country’s weekends and public holidays.


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

