
Two-Stage Recognition and beyond for Compound Facial Emotion Recognition

 ,
, 
 ,
, 

Abstract
:1. Introduction
- We organized a competition on recognizing compound emotions that require, in addition to performing an effective visual analysis, dealing with recognition of micro emotions. The database includes 31,250 faces with different emotions of 115 subjects whose gender distribution is almost uniform. The challenge was held at the FG2020.
- We introduce the winning method: a two-stage recognition algorithm to recognize compound emotions. In the first stage, coarse recognition, a DCNN was used to extract appearance features, and they are afterward combined with facial-point features. Then, in the second stage, fine recognition is done using a binary classifier. This two-stage recognition method is our first contribution to the proposed method. The second one is multi-modality, using appearance information with facial-point information. Moreover, to improve the performance, a model-ensembling based on the label distribution was used.
2. Related Work
3. Compound Emotion Recognition Challenge
3.1. Compound Emotions Database
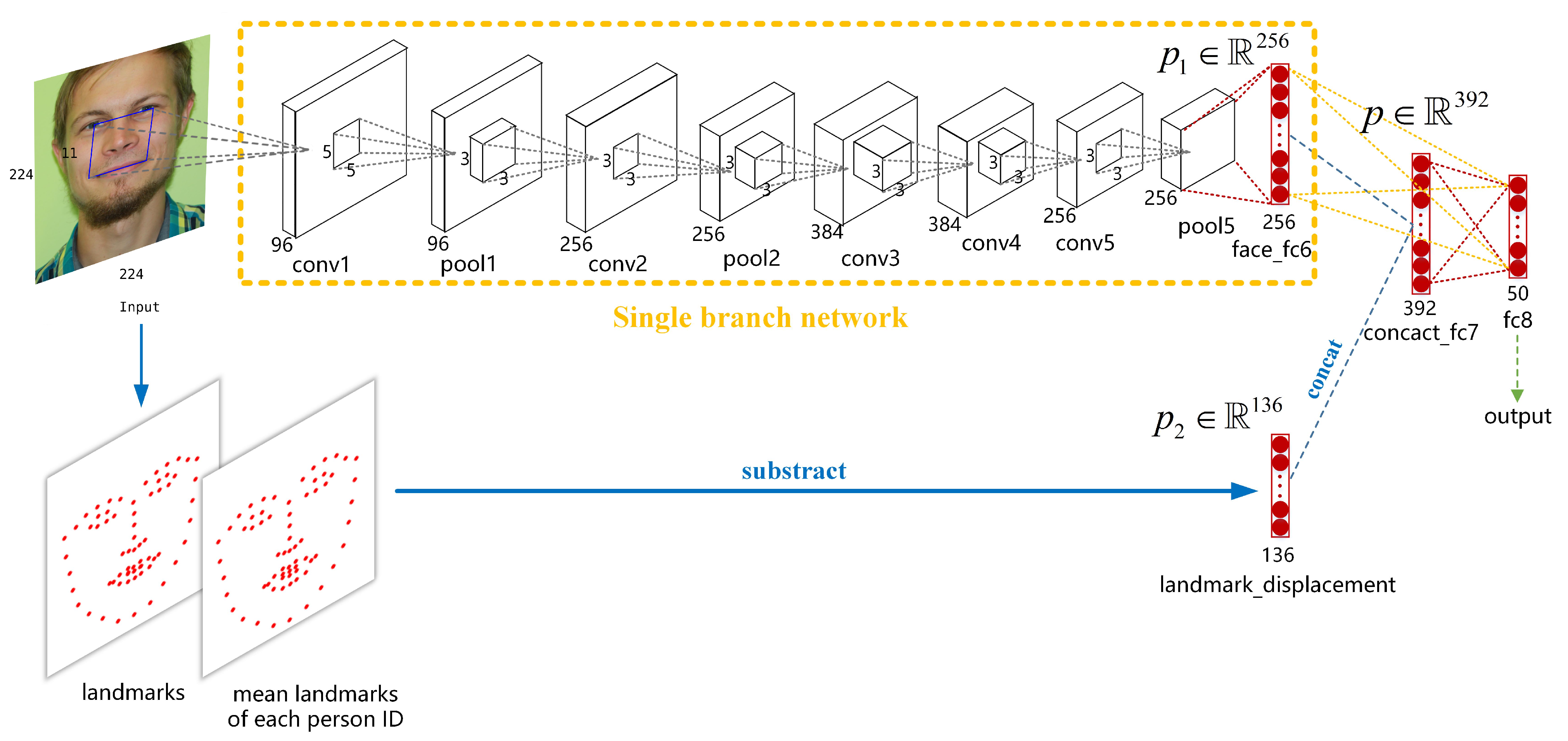
3.2. Baseline–Compound Emotion Recognition Using Multi-Modality Network with Visual and Geometrical Information
3.3. Evaluation Metric
4. The Winning Approach
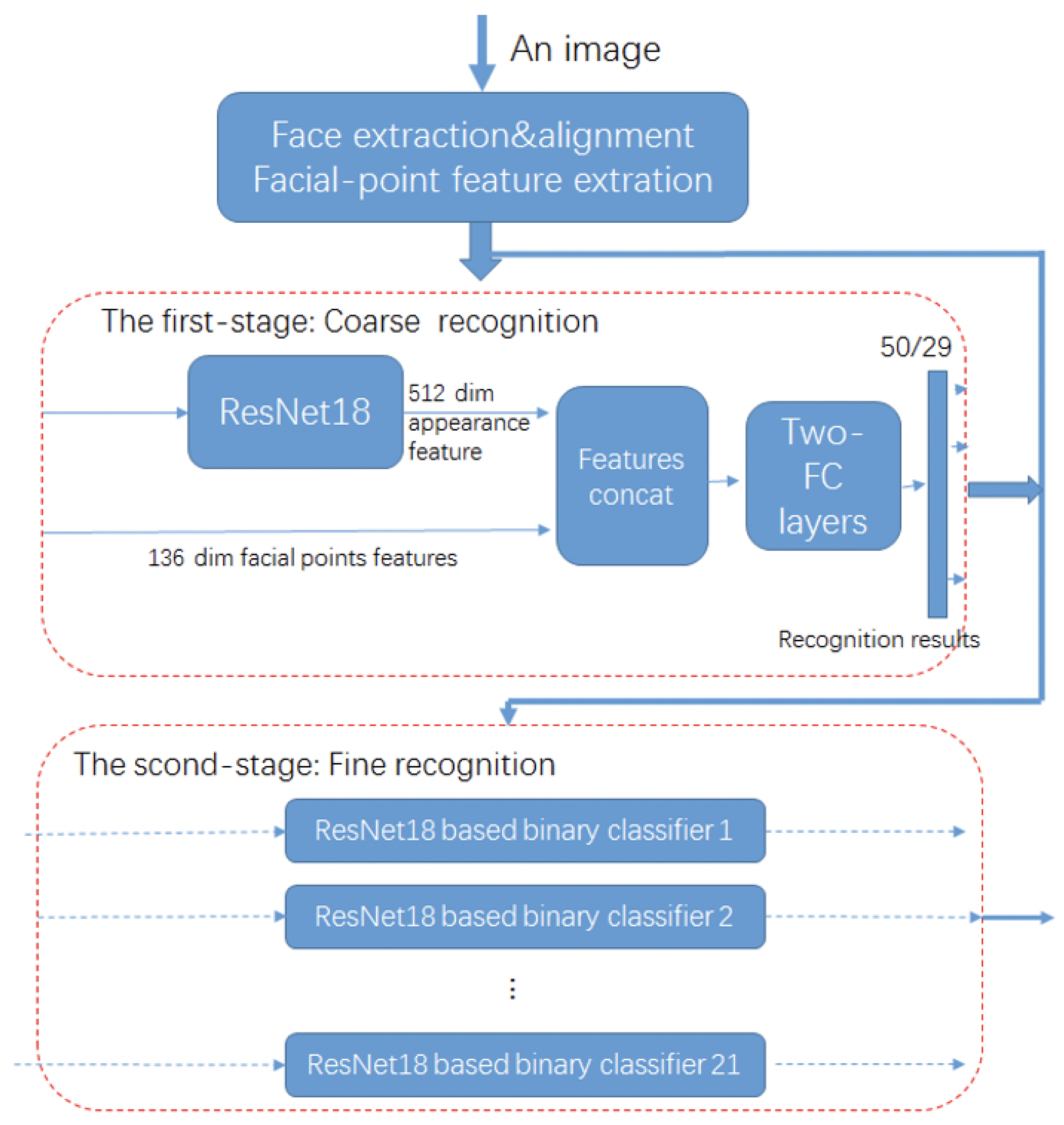
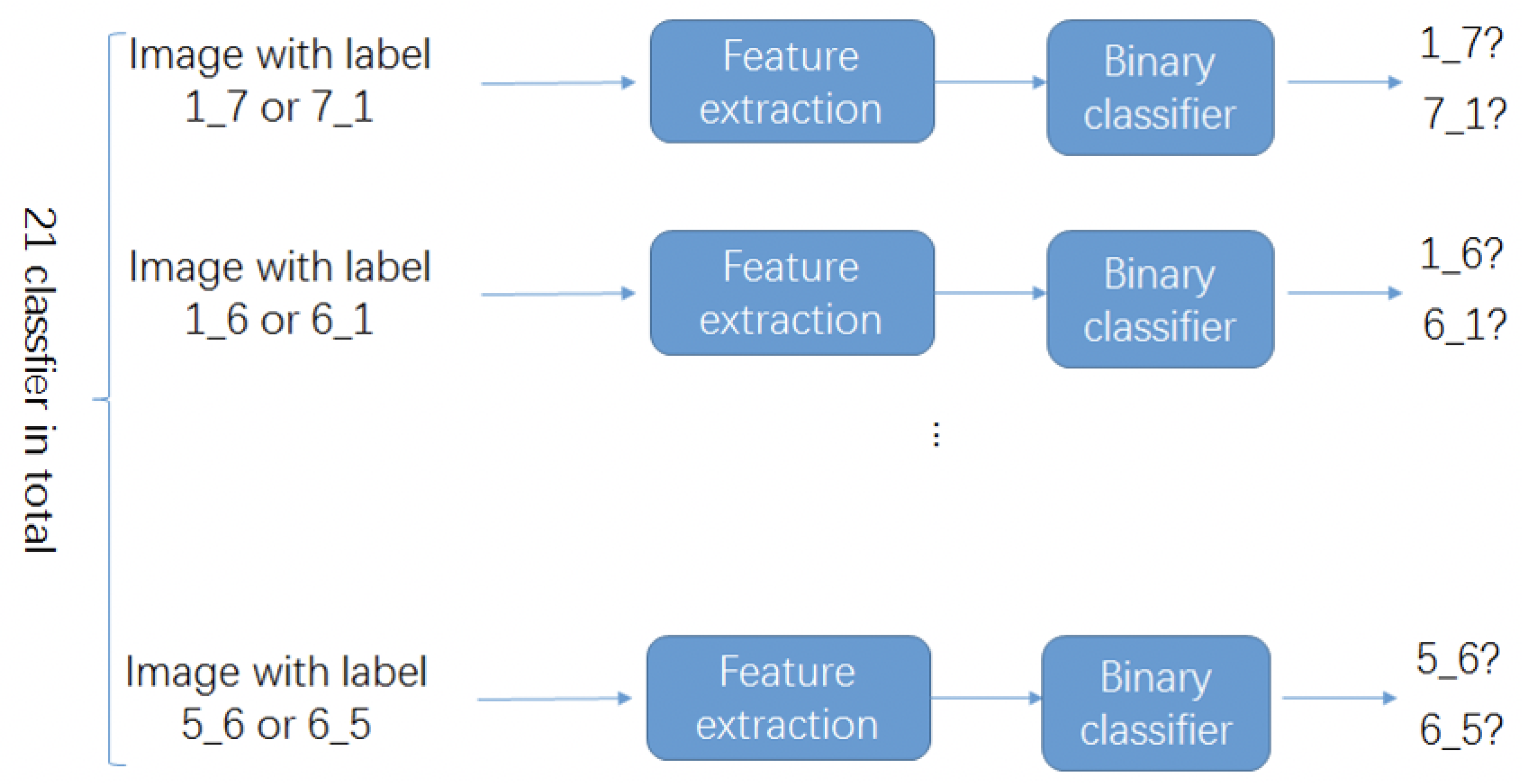
4.1. The Two-Stage Recognition Model
4.1.1. Preprocessing
4.1.2. The First-Stage: Coarse Recognition
4.1.3. The Second-Stage: Fine Recognition
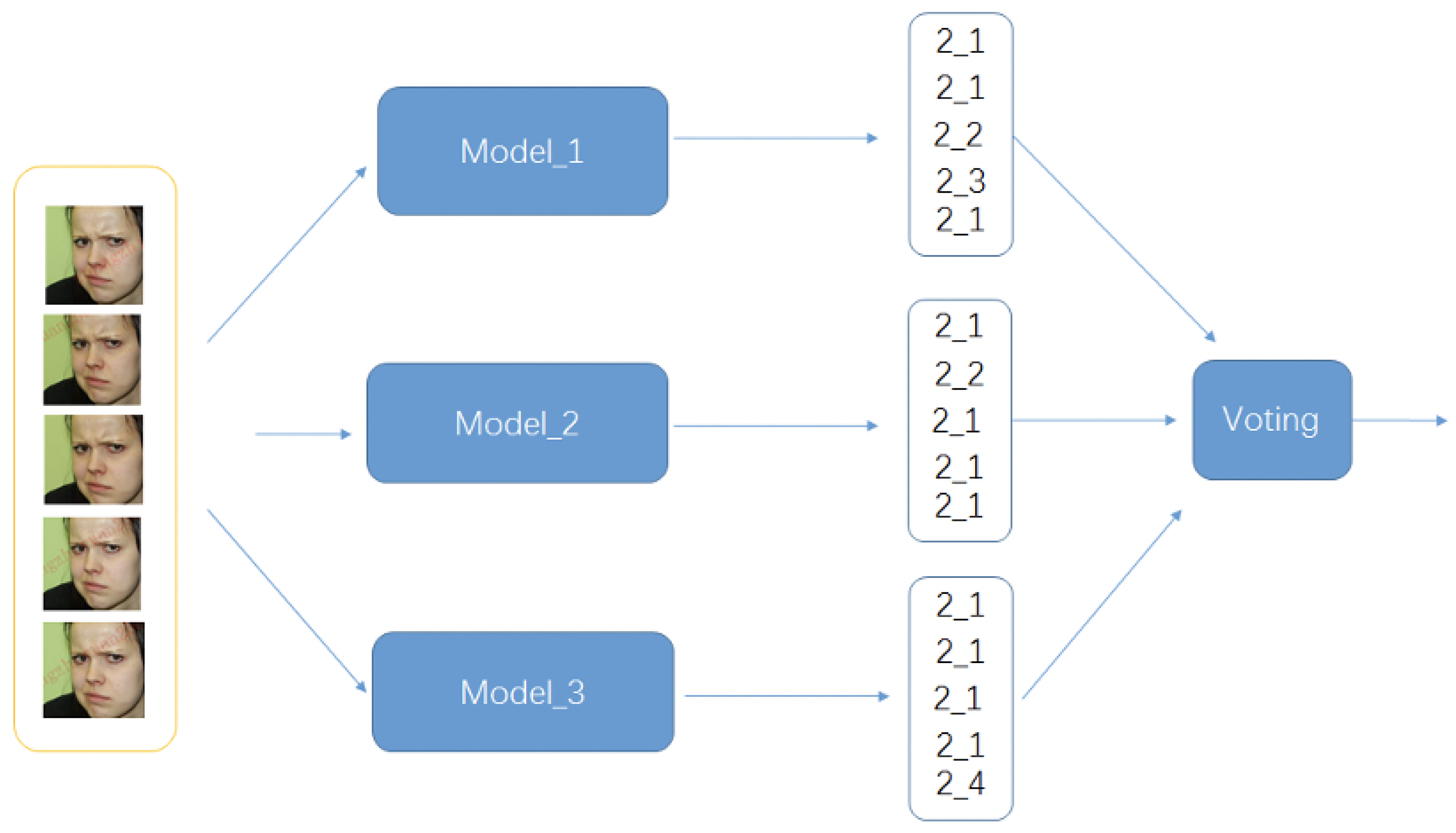
4.1.4. Ensembling and Voting
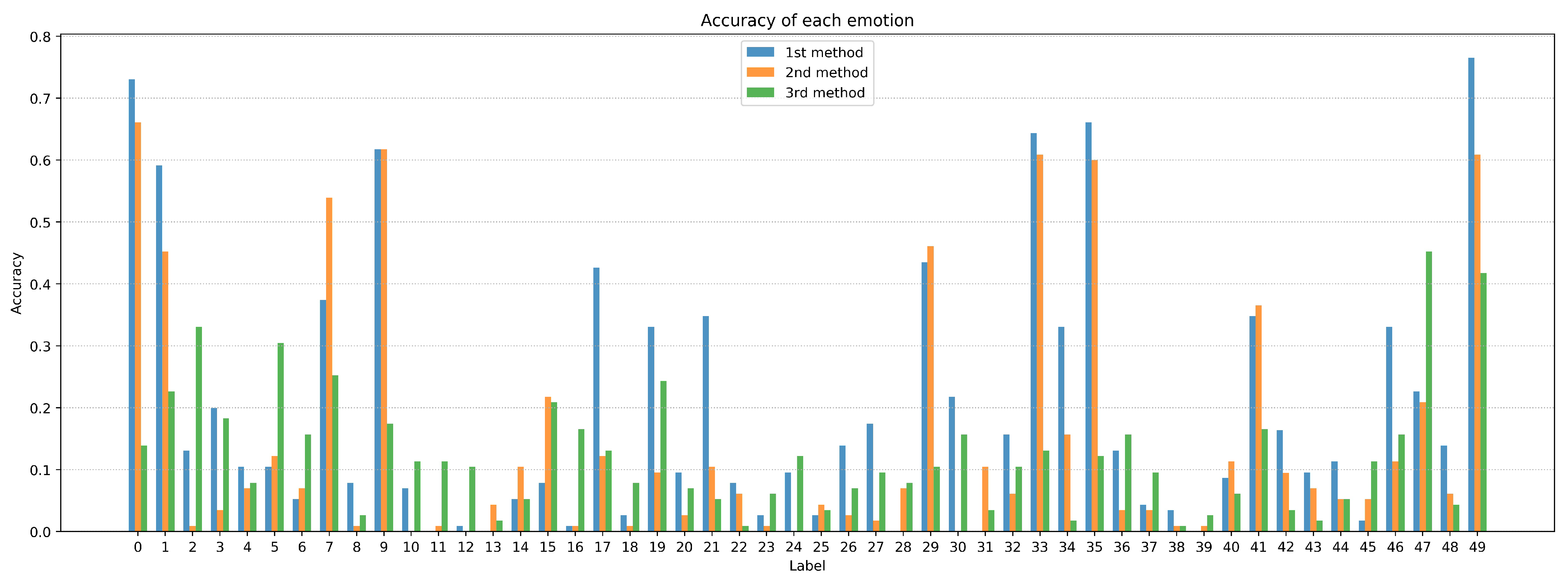
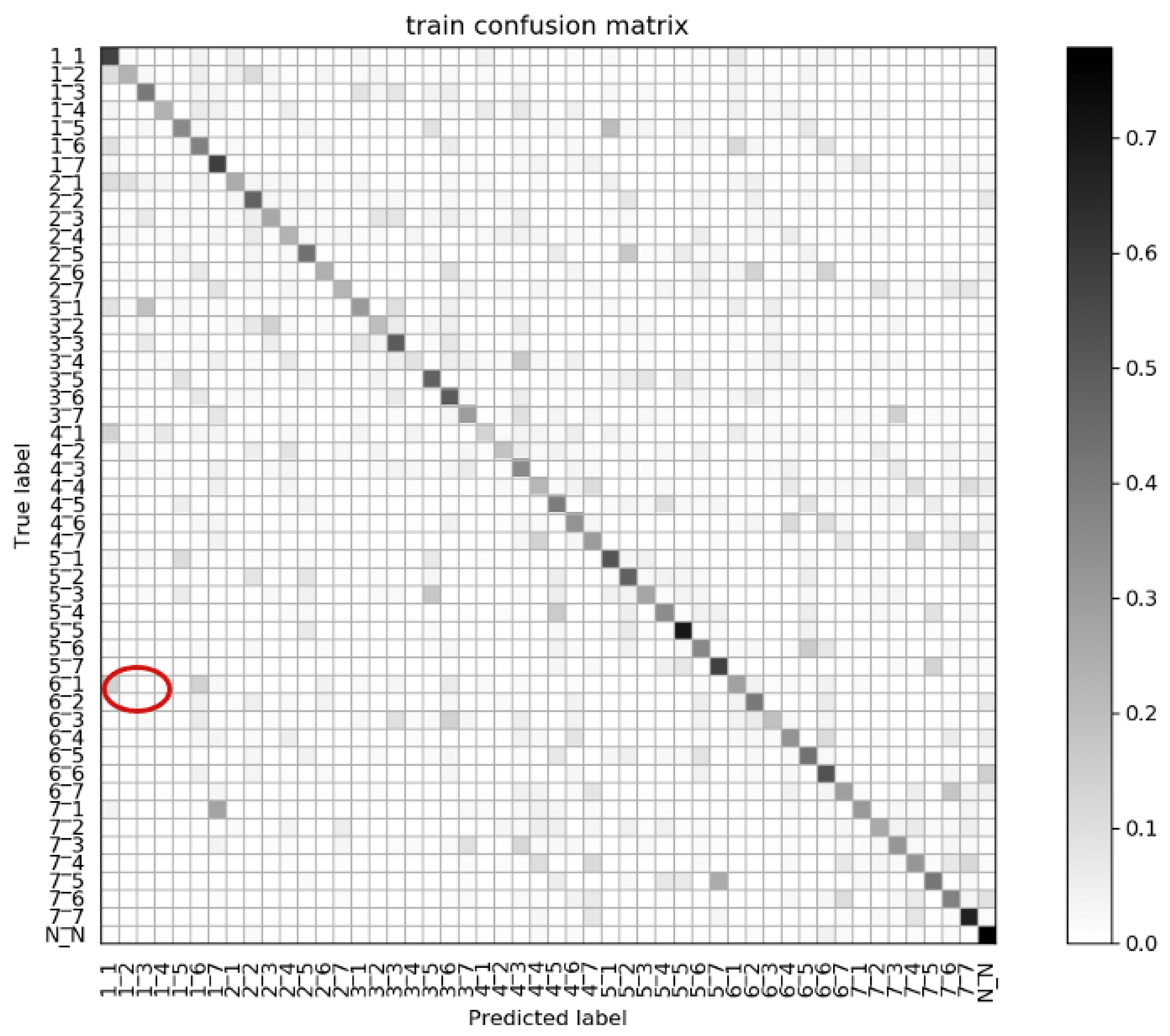
5. Experimental Results
- Dialog tag: we used the same complementary and dominant as a dialog tag to define the label. There are eight dialog tags in this competition such as
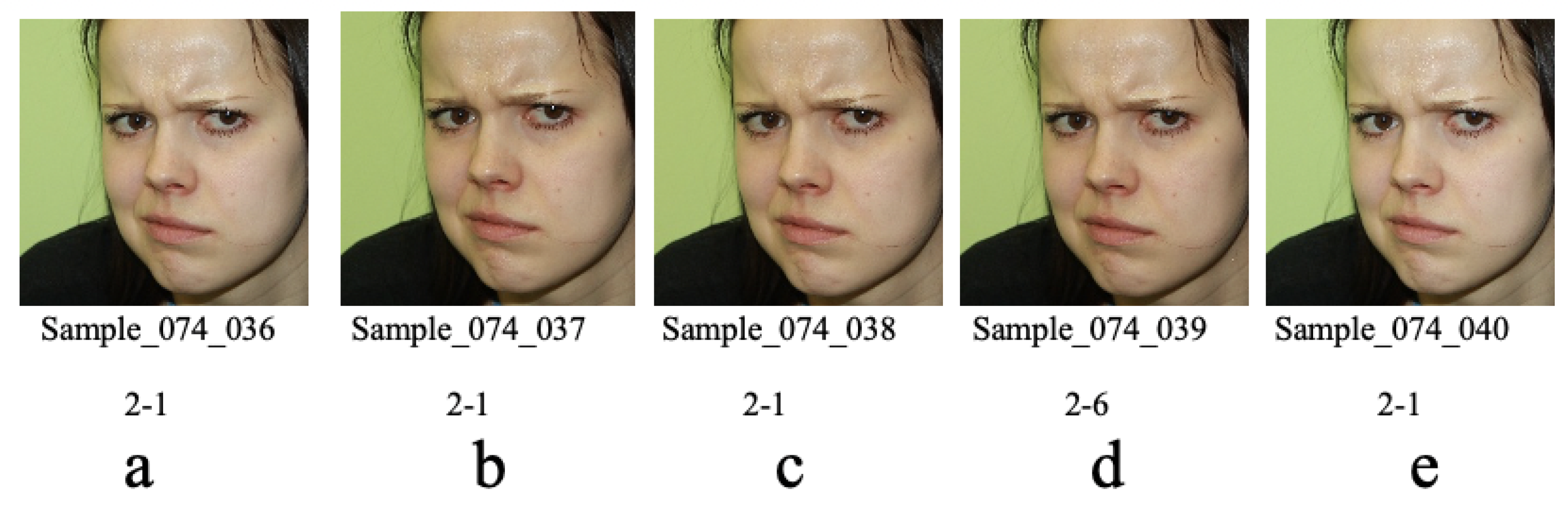
- Symmetrical tag: we defined the symmetrical labels pair as a symmetrical tag. There are 21 symmetrical tags in this competition such as
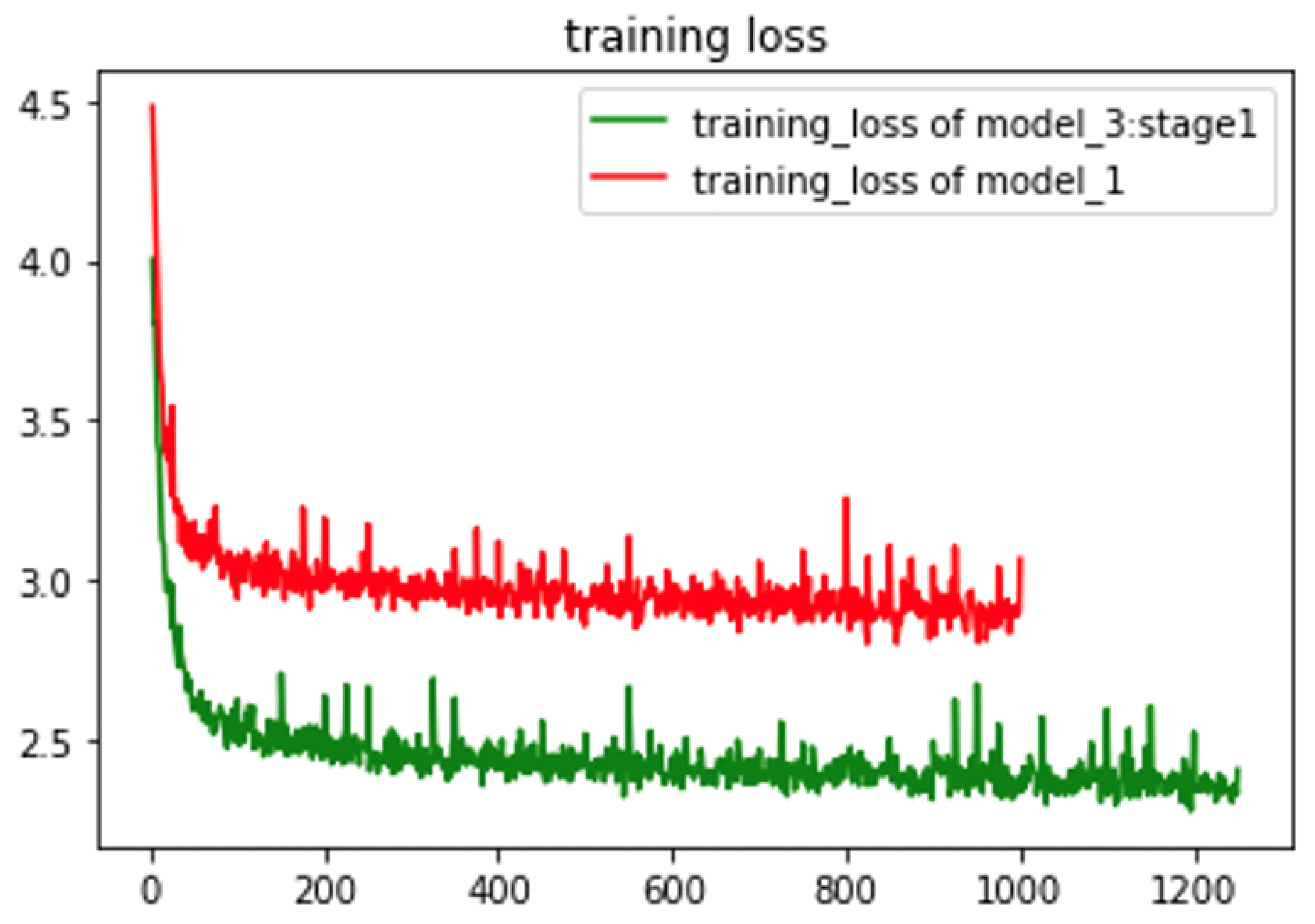
- Model_1: One-stage model: In this model, we used only the first-stage recognition, and the output of this model is the prediction results of all 50 categories. The backbone of this Model is ResNet18-like, where we used both appearance and facial-point features for the classifier.
- Model_2: Two-stage recognition model-version1: The first-stage recognition is the same as Model 1, and the prediction results will go through the second-stage recognition. In this stage, we trained 21 binary classifiers corresponding to 21 Symmetrical tags to classify the final label for each symmetrical tag.
- Model_3: Two-stage recognition model-version2: We transferred the 50 categories into 29 tags for training data in this model and retrained the first stage recognition with 29 output categories. Furthermore, the prediction results would go through the corresponding binary classifier in the second stage of recognition for the final output.
6. Discussion
6.1. Backbone Selection
6.2. Image Resolution
7. Conclusions and Future Work
- A two-stage strategy is used to mitigate the symmetrical label misclassification.
- We benefit from both appearance and facial-point information for compound emotion recognition.
- We ensemble one-stage and two-stage base models to further enhance the performance.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Alarcao, S.M.; Fonseca, M.J. Emotions recognition using EEG signals: A survey. IEEE Trans. Affect. Comput. 2017, 10, 374–393. [Google Scholar] [CrossRef]
- Sapiński, T.; Kamińska, D.; Pelikant, A.; Ozcinar, C.; Avots, E.; Anbarjafari, G. Multimodal database of emotional speech, video and gestures. In International Conference on Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2018; pp. 153–163. [Google Scholar]
- Noroozi, F.; Kaminska, D.; Corneanu, C.; Sapinski, T.; Escalera, S.; Anbarjafari, G. Survey on emotional body gesture recognition. IEEE Trans. Affect. Comput. 2018, 12, 505–523. [Google Scholar] [CrossRef] [Green Version]
- Tammvee, M.; Anbarjafari, G. Human activity recognition-based path planning for autonomous vehicles. Signal Image Video Process. 2021, 15, 809–816. [Google Scholar] [CrossRef]
- Saxena, A.; Khanna, A.; Gupta, D. Emotion recognition and detection methods: A comprehensive survey. J. Artif. Intell. Syst. 2020, 2, 53–79. [Google Scholar] [CrossRef]
- Deng, J.; Ren, F. A Survey of Textual Emotion Recognition and Its Challenges. IEEE Trans. Affect. Comput. 2021. [Google Scholar] [CrossRef]
- Zhou, J.; Zhang, S.; Mei, H.; Wang, D. A method of facial expression recognition based on Gabor and NMF. Pattern Recognit. Image Anal. 2016, 26, 119–124. [Google Scholar] [CrossRef]
- Zeng, J.; Shan, S.; Chen, X. Facial expression recognition with inconsistently annotated datasets. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 222–237. [Google Scholar]
- Cohen, I.; Sebe, N.; Garg, A.; Chen, L.S.; Huang, T.S. Facial expression recognition from video sequences: Temporal and static modeling. Comput. Vis. Image Underst. 2003, 91, 160–187. [Google Scholar] [CrossRef] [Green Version]
- Karnati, M.; Seal, A.; Krejcar, O.; Yazidi, A. FER-net: Facial expression recognition using deep neural net. Neural Comput. Appl. 2021, 33, 9125–9136. [Google Scholar] [CrossRef]
- Wang, W.; Neumann, U. Depth-aware cnn for rgb-d segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 135–150. [Google Scholar]
- Mohan, K.; Seal, A.; Krejcar, O.; Yazidi, A. Facial Expression Recognition Using Local Gravitational Force Descriptor-Based Deep Convolution Neural Networks. IEEE Trans. Instrum. Meas. 2021, 70, 1–12. [Google Scholar] [CrossRef]
- Levi, G.; Hassner, T. Emotion recognition in the wild via convolutional neural networks and mapped binary patterns. In Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, Seattle, DC, USA, 9–13 November 2015; pp. 503–510. [Google Scholar]
- Zhao, X.; Liang, X.; Liu, L.; Li, T.; Han, Y.; Vasconcelos, N.; Yan, S. Peak-piloted deep network for facial expression recognition. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 425–442. [Google Scholar]
- Grobova, J.; Colovic, M.; Marjanovic, M.; Njegus, A.; Demire, H.; Anbarjafari, G. Automatic hidden sadness detection using micro-expressions. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 828–832. [Google Scholar]
- Ekman, P.; Friesen, W.V. Constants across cultures in the face and emotion. J. Personal. Soc. Psychol. 1971, 17, 124. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Alameda-Pineda, X.; Ricci, E.; Sebe, N. Multimodal behavior analysis in the wild: An introduction. In Multimodal Behavior Analysis in the Wild; Elsevier: Amsterdam, The Netherlands, 2019; pp. 1–8. [Google Scholar]
- Izdebski, K. Emotions in the Human Voice, Volume 3: Culture and Perception; Plural Publishing: San Diego, CA, USA, 2008; Volume 3. [Google Scholar]
- Keltner, D.; Sauter, D.; Tracy, J.; Cowen, A. Emotional expression: Advances in basic emotion theory. J. Nonverbal Behav. 2019, 43, 133–160. [Google Scholar] [CrossRef] [PubMed]
- Haamer, R.E.; Rusadze, E.; Lsi, I.; Ahmed, T.; Escalera, S.; Anbarjafari, G. Review on emotion recognition databases. Hum. Robot Interact. Theor. Appl. 2017, 3, 39–63. [Google Scholar]
- Noroozi, F.; Marjanovic, M.; Njegus, A.; Escalera, S.; Anbarjafari, G. Audio-visual emotion recognition in video clips. IEEE Trans. Affect. Comput. 2017, 10, 60–75. [Google Scholar] [CrossRef]
- Guo, J.; Lei, Z.; Wan, J.; Avots, E.; Hajarolasvadi, N.; Knyazev, B.; Kuharenko, A.; Junior, J.C.S.J.; Baró, X.; Demirel, H.; et al. Dominant and complementary emotion recognition from still images of faces. IEEE Access 2018, 6, 26391–26403. [Google Scholar] [CrossRef]
- Darwin, C.; Prodger, P. The Expression of the Emotions in Man and Animals; Oxford University Press: Oxford, UK, 1998. [Google Scholar]
- Sown, M. A preliminary note on pattern recognition of facial emotional expression. In Proceedings of the 4th International Joint Conferences on Pattern Recognition, Kyoto, Japan, 7–10 November 1978. [Google Scholar]
- Mase, K. An Application of Optical Flow-Extraction of Facial Expression. In MVA; Tokyo, Japan, 1990; pp. 195–198. Available online: https://www.cvl.iis.u-tokyo.ac.jp/mva/proceedings/CommemorativeDVD/1990/papers/1990195.pdf (accessed on 1 November 2021).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Hasani, B.; Mahoor, M.H. Facial expression recognition using enhanced deep 3D convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 30–40. [Google Scholar]
- Yu, Z.; Liu, G.; Liu, Q.; Deng, J. Spatio-temporal convolutional features with nested LSTM for facial expression recognition. Neurocomputing 2018, 317, 50–57. [Google Scholar] [CrossRef]
- Hu, P.; Cai, D.; Wang, S.; Yao, A.; Chen, Y. Learning supervised scoring ensemble for emotion recognition in the wild. In Proceedings of the 19th ACM International Conference on Multimodal Interaction, Glasgow, UK, 13–17 November 2017; pp. 553–560. [Google Scholar]
- Guo, J.; Zhou, S.; Wu, J.; Wan, J.; Zhu, X.; Lei, Z.; Li, S.Z. Multi-modality network with visual and geometrical information for micro emotion recognition. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 814–819. [Google Scholar]
- Du, S.; Martinez, A.M. Compound facial expressions of emotion: From basic research to clinical applications. Dialogues Clin. Neurosci. 2015, 17, 443. [Google Scholar]
- Loob, C.; Rasti, P.; Lüsi, I.; Jacques, J.C.; Baró, X.; Escalera, S.; Sapinski, T.; Kaminska, D.; Anbarjafari, G. Dominant and complementary multi-emotional facial expression recognition using c-support vector classification. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 833–838. [Google Scholar]
- Lüsi, I.; Junior, J.C.J.; Gorbova, J.; Baró, X.; Escalera, S.; Demirel, H.; Allik, J.; Ozcinar, C.; Anbarjafari, G. Joint challenge on dominant and complementary emotion recognition using micro emotion features and head-pose estimation: Databases. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 809–813. [Google Scholar]
- Martinez, A.; Du, S. A model of the perception of facial expressions of emotion by humans: Research overview and perspectives. J. Mach. Learn. Res. 2012, 13, 1589–1608. [Google Scholar]
- Wan, J.; Escalera, S.; Anbarjafari, G.; Jair Escalante, H.; Baró, X.; Guyon, I.; Madadi, M.; Allik, J.; Gorbova, J.; Lin, C.; et al. Results and analysis of chalearn lap multi-modal isolated and continuous gesture recognition, and real versus fake expressed emotions challenges. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 29 October 2017; pp. 3189–3197. [Google Scholar]
- Kulkarni, K.; Corneanu, C.; Ofodile, I.; Escalera, S.; Baro, X.; Hyniewska, S.; Allik, J.; Anbarjafari, G. Automatic recognition of facial displays of unfelt emotions. IEEE Trans. Affect. Comput. 2018, 12, 377–390. [Google Scholar] [CrossRef] [Green Version]
- Haamer, R.E.; Kulkarni, K.; Imanpour, N.; Haque, M.A.; Avots, E.; Breisch, M.; Nasrollahi, K.; Escalera, S.; Ozcinar, C.; Baro, X.; et al. Changes in facial expression as biometric: A database and benchmarks of identification. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 621–628. [Google Scholar]
- Gorbova, J.; Lusi, I.; Litvin, A.; Anbarjafari, G. Automated screening of job candidate based on multimodal video processing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 26 July 2017; pp. 29–35. [Google Scholar]
- Liliana, D.Y.; Basaruddin, C.; Widyanto, M.R. Mix emotion recognition from facial expression using SVM-CRF sequence classifier. In Proceedings of the International Conference on Algorithms, Computing and Systems, Jeju, Korea, 10–13 August 2017; pp. 27–31. [Google Scholar]
- Zhang, Z.; Yi, M.; Xu, J.; Zhang, R.; Shen, J. Two-stage Recognition and Beyond for Compound Facial Emotion Recognition. In Proceedings of the 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020), Buenos Aires, Argentina, 16–20 November 2020; pp. 900–904. [Google Scholar]
- Li, S.; Deng, W.; Du, J. Reliable crowdsourcing and deep locality-preserving learning for expression recognition in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 26 July 2017; pp. 2852–2861. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Kazemi, V.; Sullivan, J. One millisecond face alignment with an ensemble of regression trees. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23 June 2014; pp. 1867–1874. [Google Scholar]
- Tan, Z.; Zhou, S.; Wan, J.; Lei, Z.; Li, S.Z. Age Estimation Based on a Single Network with Soft Softmax of Aging Modeling. In Asian Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 203–216. [Google Scholar]
- Knyazev, B.; Barth, E.; Martinetz, T. Recursive autoconvolution for unsupervised learning of convolutional neural networks. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 2486–2493. [Google Scholar]
- Wen, Y.; Zhang, K.; Li, Z.; Qiao, Y. A Discriminative Feature Learning Approach for Deep Face Recognition. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 499–515. [Google Scholar]
- Liu, L.; Jiang, H.; He, P.; Chen, W.; Liu, X.; Gao, J.; Han, J. On the variance of the adaptive learning rate and beyond. arXiv 2019, arXiv:1908.03265. [Google Scholar]
- Liu, S.; Tian, G.; Xu, Y. A novel scene classification model combining ResNet based transfer learning and data augmentation with a filter. Neurocomputing 2019, 338, 191–206. [Google Scholar] [CrossRef]
- McNeely-White, D.; Beveridge, J.R.; Draper, B.A. Inception and ResNet features are (almost) equivalent. Cogn. Syst. Res. 2020, 59, 312–318. [Google Scholar] [CrossRef]
- Sapiński, T.; Kamińska, D.; Pelikant, A.; Anbarjafari, G. Emotion recognition from skeletal movements. Entropy 2019, 21, 646. [Google Scholar] [CrossRef] [PubMed] [Green Version]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Angry | Contempt | Disgust | Fear | Happy | Sadness | Surprise | |
|---|---|---|---|---|---|---|---|
| Angry | angry | contemptly angry | disgustingly angry | fearfully angry | happily angry | sadly angry | surprisingly angry |
| Contempt | angrily contempt | contempt | disgustingly contempt | fearfully contempt | happily contempt | sadly contempt | surprisingly contempt |
| Disgust | angrily disgusted | contemptly disgusted | disgust | fearfully disgusted | happily disgusted | sadly disgusted | surprisingly disgusted |
| Fear | angrily fearful | contemptly fearful | disgustingly fearful | fearful | happily fearful | sadly fearful | surprisingly fearful |
| Happy | angrily happy | contemptly happy | disgustingly happy | fearfully happy | happy | sadly happy | surprisingly happy |
| Sadness | angrily sad | contemptly sad | disgustingly sad | fearfully sad | happily sad | sad | surprisingly sad |
| Surprise | angrily surprised | contemptly surprised | disgustingly surprised | fearfully surprised | happily surprised | sadly surprised | surprised |
| Label | Emotion | Label | Emotion | Label | Emotion | Label | Emotion |
|---|---|---|---|---|---|---|---|
| 0 | neutral | 14 | contemptly surprised | 28 | fearfully surprised | 42 | sadly surprised |
| 1 | angry | 15 | disgustingly angry | 29 | happily angry | 43 | surprisingly angry |
| 2 | angrily contempt | 16 | disgustingly contempt | 30 | happily contempt | 44 | surprisingly contempt |
| 3 | angrily disgusted | 17 | disgust | 31 | happily disgust | 45 | surprisingly disgust |
| 4 | angrily fearful | 18 | disgustingly fearful | 32 | happily fearful | 46 | surprisingly fearful |
| 5 | angrily happy | 19 | disgustingly happy | 33 | happy | 47 | surprisingly happy |
| 6 | angrily sad | 20 | disgustingly sad | 34 | happily sad | 48 | surprisingly sad |
| 7 | angrily surprised | 21 | disgustingly surprised | 35 | happily surprised | 49 | surprised |
| 8 | contemptly angry | 22 | fearfully angry | 36 | sadly angry | ||
| 9 | contempt | 23 | fearfully contempt | 37 | sadly contempt | ||
| 10 | contemptly disgusted | 24 | fearfully disgust | 38 | sadly disgust | ||
| 11 | contemptly fearful | 25 | fearful | 39 | sadly fearful | ||
| 12 | contemptly happy | 26 | fearfully happy | 40 | sadly happy | ||
| 13 | contemptly sad | 27 | fearfully sad | 41 | sad |
| Layer Name | Output Size | Layer |
|---|---|---|
| Input layer | ||
| Layer1 | [] [] | |
| Layer2 | [] [] | |
| Layer3 | [] [] | |
| Layer4 | [] [] |
| Method | Test Set |
|---|---|
| Model_1 | 18.51 |
| Model_2 | 19.71 |
| Model_3 | 19.28 |
| Ensembling | 21.83 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kamińska, D.; Aktas, K.; Rizhinashvili, D.; Kuklyanov, D.; Sham, A.H.; Escalera, S.; Nasrollahi, K.; Moeslund, T.B.; Anbarjafari, G. Two-Stage Recognition and beyond for Compound Facial Emotion Recognition. Electronics 2021, 10, 2847. https://doi.org/10.3390/electronics10222847
Kamińska D, Aktas K, Rizhinashvili D, Kuklyanov D, Sham AH, Escalera S, Nasrollahi K, Moeslund TB, Anbarjafari G. Two-Stage Recognition and beyond for Compound Facial Emotion Recognition. Electronics. 2021; 10(22):2847. https://doi.org/10.3390/electronics10222847
Chicago/Turabian StyleKamińska, Dorota, Kadir Aktas, Davit Rizhinashvili, Danila Kuklyanov, Abdallah Hussein Sham, Sergio Escalera, Kamal Nasrollahi, Thomas B. Moeslund, and Gholamreza Anbarjafari. 2021. "Two-Stage Recognition and beyond for Compound Facial Emotion Recognition" Electronics 10, no. 22: 2847. https://doi.org/10.3390/electronics10222847
APA StyleKamińska, D., Aktas, K., Rizhinashvili, D., Kuklyanov, D., Sham, A. H., Escalera, S., Nasrollahi, K., Moeslund, T. B., & Anbarjafari, G. (2021). Two-Stage Recognition and beyond for Compound Facial Emotion Recognition. Electronics, 10(22), 2847. https://doi.org/10.3390/electronics10222847