
TRIG: Transformer-Based Text Recognizer with Initial Embedding Guidance


Abstract
:1. Introduction
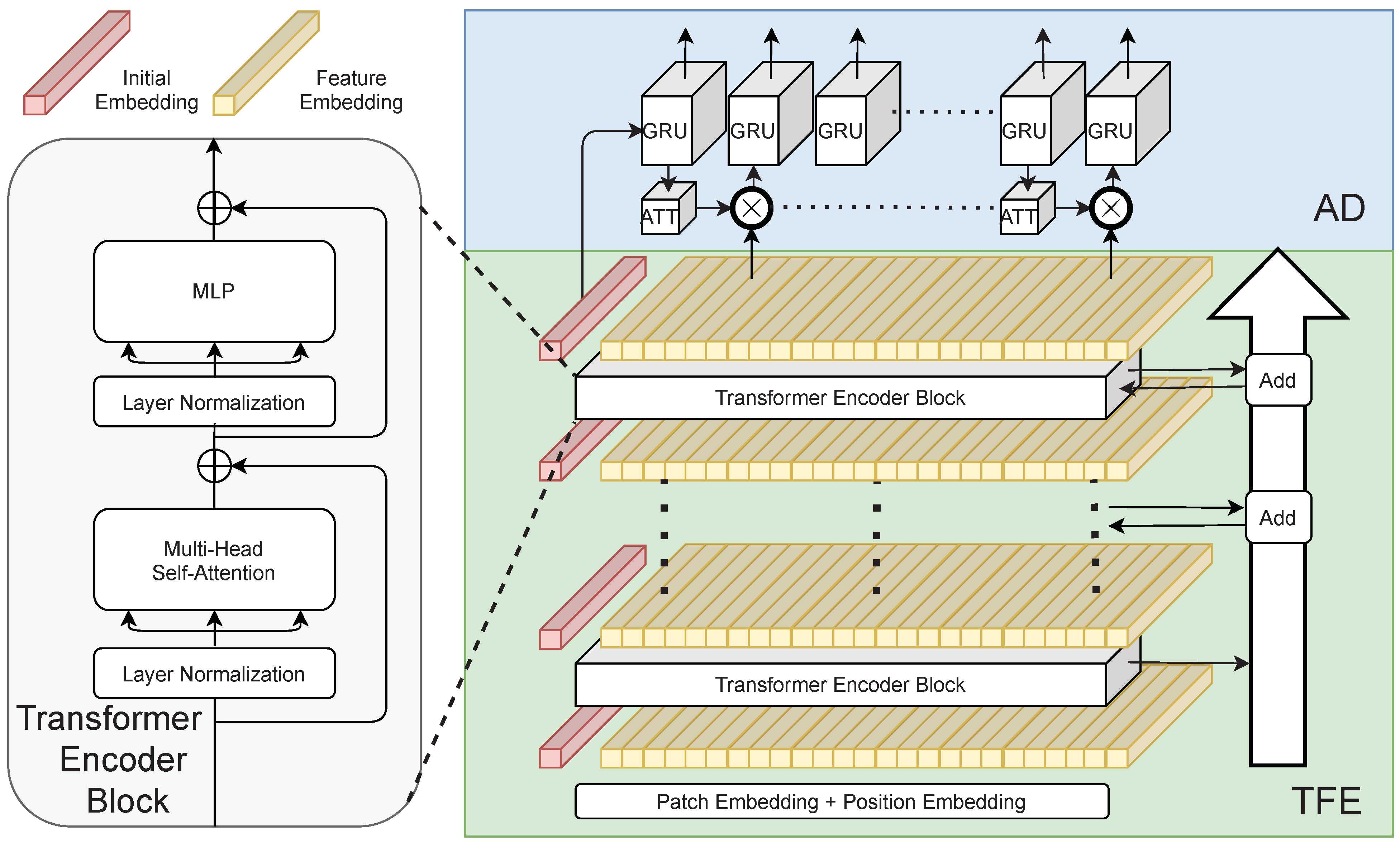
- We propose a novel three-stage architecture for text recognition, TRIG, namely Transformer-based text recognizer with Initial embedding Guidance. TRIG leverages the transformer encoder to extract global context features without an additional context modeling module used in CNN-based text recognizers. Extensive experiments on several public scene text benchmarks demonstrate the proposed framework can achieve state-of-the-art (SOTA) performance.
- A 1-D split is designed to divide the text image as a sequence of rectangle patches with the consideration of efficiency.
- We propose a learnable initial embedding to dynamically learn information from the whole image, which can be adaptive to different input images and precisely guide the decoding process.
2. Related Work
2.1. Transformer-Free Methods
2.2. Transformer-Based Methods
3. Methodology
3.1. Transformation
3.2. Transformer Feature Extractor
3.3. Attention Decoder
3.4. Training Loss
3.5. Efficiency Analysis
4. Experiments
4.1. Dataset
4.2. Implementation Details
4.3. Comparison with State-of-the-Art
4.4. Discussion
4.4.1. Discussion on Training Procedures
4.4.2. Discussion on Long-Range Dependencies
4.4.3. Discussion on Extra Context Modeling Module
4.4.4. Discussion on Patch Size
4.4.5. Discussion on Initial Embedding
4.4.6. Discussion on Attention Visualization
4.4.7. Discussion on Efficiency
4.5. Ablation Study
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Long, S.; He, X.; Yao, C. Scene Text Detection and Recognition: The Deep Learning Era. Int. J. Comput. Vis. 2021, 129, 161–184. [Google Scholar] [CrossRef]
- Zhu, Y.; Yao, C.; Bai, X. Scene text detection and recognition: Recent advances and future trends. Front. Comput. Sci. 2016, 10, 19–36. [Google Scholar] [CrossRef]
- Shi, B.; Yang, M.; Wang, X.; Lyu, P.; Yao, C.; Bai, X. ASTER: An Attentional Scene Text Recognizer with Flexible Rectification. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 2035–2048. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Yu, D.; Li, X.; Zhang, C.; Liu, T.; Han, J.; Liu, J.; Ding, E. Towards Accurate Scene Text Recognition With Semantic Reasoning Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12110–12119. [Google Scholar] [CrossRef]
- Lin, T.; Dollár, P.; Girshick, R.B.; He, K.; Hariharan, B.; Belongie, S.J. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; Neural Information Processing Systems: San Diego, CA, USA, 2017; pp. 5998–6008. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the 9th International Conference on Learning Representations, ICLR 2021, Virtual Event. Vienna, Austria, 3–7 May 2021. [Google Scholar]
- Baek, J.; Kim, G.; Lee, J.; Park, S.; Han, D.; Yun, S.; Oh, S.J.; Lee, H. What Is Wrong with Scene Text Recognition Model Comparisons? Dataset and Model Analysis. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea, 27 October–2 November 2019; pp. 4714–4722. [Google Scholar] [CrossRef] [Green Version]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the 38th International Conference on Machine Learning, ICML 2021; Virtual Event; Austria, 18–24 July 2021, International Conference on Machine Learning: San Diego, CA, USA, 2021; Volume 139, pp. 10347–10357. [Google Scholar]
- Beal, J.; Kim, E.; Tzeng, E.; Park, D.H.; Zhai, A.; Kislyuk, D. Toward Transformer-Based Object Detection. arXiv 2020, arXiv:2012.09958. [Google Scholar]
- Zhao, H.; Jiang, L.; Jia, J.; Torr, P.H.S.; Koltun, V. Point Transformer. arXiv 2020, arXiv:2012.09164. [Google Scholar]
- Valanarasu, J.M.J.; Oza, P.; Hacihaliloglu, I.; Patel, V.M. Medical Transformer: Gated Axial-Attention for Medical Image Segmentation. In Lecture Notes in Computer Science, Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2021-24th International Conference, Strasbourg, France, 27 September–1 October 2021; de Bruijne, M., Cattin, P.C., Cotin, S., Padoy, N., Speidel, S., Zheng, Y., Essert, C., Eds.; Part I; Springer: Berlin/Heidelberg, Germany, 2021; Volume 12901, pp. 36–46. [Google Scholar] [CrossRef]
- Li, H.; Wang, P.; Shen, C.; Zhang, G. Show, Attend and Read: A Simple and Strong Baseline for Irregular Text Recognition. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence, AAAI 2019, Honolulu, HI, USA, 27 January–1 February 2019; AAAI Press: Palo Alto, CA, USA, 2019; pp. 8610–8617. [Google Scholar] [CrossRef] [Green Version]
- Lu, N.; Yu, W.; Qi, X.; Chen, Y.; Gong, P.; Xiao, R.; Bai, X. MASTER: Multi-aspect non-local network for scene text recognition. Pattern Recognit. 2021, 117, 107980. [Google Scholar] [CrossRef]
- Coates, A.; Carpenter, B.; Case, C.; Satheesh, S.; Suresh, B.; Wang, T.; Wu, D.J.; Ng, A.Y. Text Detection and Character Recognition in Scene Images with Unsupervised Feature Learning. In Proceedings of the 2011 International Conference on Document Analysis and Recognition, Beijing, China, 18–21 September 2011; pp. 440–445. [Google Scholar] [CrossRef] [Green Version]
- Wang, K.; Belongie, S.J. Word Spotting in the Wild. In Lecture Notes in Computer Science, Proceedings of the Computer Vision-ECCV 2010, 11th European Conference on Computer Vision, Heraklion, Crete, Greece, 5–11 September 2010; Daniilidis, K., Maragos, P., Paragios, N., Eds.; Part I; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6311, pp. 591–604. [Google Scholar] [CrossRef]
- Lee, C.; Bhardwaj, A.; Di, W.; Jagadeesh, V.; Piramuthu, R. Region-Based Discriminative Feature Pooling for Scene Text Recognition. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2014, Columbus, OH, USA, 23–28 June 2014; IEEE Computer Society: Washington, DC, USA, 2014; pp. 4050–4057. [Google Scholar] [CrossRef]
- Mishra, A.; Alahari, K.; Jawahar, C.V. Top-down and bottom-up cues for scene text recognition. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; IEEE Computer Society: Washington, DC, USA, 2012; pp. 2687–2694. [Google Scholar] [CrossRef] [Green Version]
- Phan, T.Q.; Shivakumara, P.; Tian, S.; Tan, C.L. Recognizing Text with Perspective Distortion in Natural Scenes. In Proceedings of the IEEE International Conference on Computer Vision, ICCV 2013, Sydney, Australia, 1–8 December 2013; IEEE Computer Society: Washington, DC, USA, 2013; pp. 569–576. [Google Scholar] [CrossRef]
- Shi, B.; Bai, X.; Yao, C. An End-to-End Trainable Neural Network for Image-Based Sequence Recognition and Its Application to Scene Text Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2298–2304. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Graves, A.; Fernández, S.; Gomez, F.J.; Schmidhuber, J. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the Twenty-Third International Conference (ICML 2006), Pittsburgh, PA, USA, 25–29 June 2006; Cohen, W.W., Moore, A.W., Eds.; ACM: New York, NY, USA, 2006; Volume 148, pp. 369–376. [Google Scholar] [CrossRef]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial Transformer Networks. In Proceedings of the Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015; Cortes, C., Lawrence, N.D., Lee, D.D., Sugiyama, M., Garnett, R., Eds.; Neural Information Processing Systems: San Diego, CA, USA, 2015; pp. 2017–2025. [Google Scholar]
- Wan, Z.; Xie, F.; Liu, Y.; Bai, X.; Yao, C. 2D-CTC for Scene Text Recognition. arXiv 2019, arXiv:1907.09705. [Google Scholar]
- Liao, M.; Lyu, P.; He, M.; Yao, C.; Wu, W.; Bai, X. Mask TextSpotter: An End-to-End Trainable Neural Network for Spotting Text with Arbitrary Shapes. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 532–548. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Qiao, Z.; Zhou, Y.; Yang, D.; Zhou, Y.; Wang, W. SEED: Semantics Enhanced Encoder-Decoder Framework for Scene Text Recognition. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13525–13534. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Lecture Notes in Computer Science, Proceedings of the Computer Vision-ECCV 2020-16th European Conference, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J., Eds.; Part I; Springer: Cham, Switzerland, 2020; Volume 12346, pp. 213–229. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lee, J.; Park, S.; Baek, J.; Oh, S.J.; Kim, S.; Lee, H. On Recognizing Texts of Arbitrary Shapes with 2D Self-Attention. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR Workshops 2020, Seattle, WA, USA, 14–19 June 2020; pp. 2326–2335. [Google Scholar] [CrossRef]
- Sheng, F.; Chen, Z.; Xu, B. NRTR: A No-Recurrence Sequence-to-Sequence Model for Scene Text Recognition. In Proceedings of the 2019 International Conference on Document Analysis and Recognition, ICDAR 2019, Sydney, Australia, 20–25 September 2019; pp. 781–786. [Google Scholar] [CrossRef] [Green Version]
- Bookstein, F.L. Principal Warps: Thin-Plate Splines and the Decomposition of Deformations. IEEE Trans. Pattern Anal. Mach. Intell. 1989, 11, 567–585. [Google Scholar] [CrossRef] [Green Version]
- He, R.; Ravula, A.; Kanagal, B.; Ainslie, J. RealFormer: Transformer Likes Residual Attention. In Proceedings of the Findings of the Association for Computational Linguistics: ACL/IJCNLP 2021, Online Event. 1–6 August 2021; Zong, C., Xia, F., Li, W., Navigli, R., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 929–943. [Google Scholar] [CrossRef]
- Cho, K.; van Merrienboer, B.; Gülçehre, Ç.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, EMNLP 2014, Doha, Qatar, 25–29 October 2014; Moschitti, A., Pang, B., Daelemans, W., Eds.; A Meeting of SIGDAT, a Special Interest Group of the ACL. ACL: Stroudsburg, PA, USA, 2014; pp. 1724–1734. [Google Scholar] [CrossRef]
- Jaderberg, M.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Synthetic Data and Artificial Neural Networks for Natural Scene Text Recognition. arXiv 2014, arXiv:1406.2227. [Google Scholar]
- Gupta, A.; Vedaldi, A.; Zisserman, A. Synthetic Data for Text Localisation in Natural Images. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; IEEE Computer Society: Washington, DC, USA, 2016; pp. 2315–2324. [Google Scholar] [CrossRef] [Green Version]
- Mishra, A.; Alahari, K.; Jawahar, C.V. Scene Text Recognition using Higher Order Language Priors. In Proceedings of the British Machine Vision Conference, BMVC 2012, Surrey, UK, 3–7 September 2012; Bowden, R., Collomosse, J.P., Mikolajczyk, K., Eds.; BMVA Press: Durham, UK, 2012; pp. 1–11. [Google Scholar] [CrossRef] [Green Version]
- Wang, K.; Babenko, B.; Belongie, S.J. End-to-end scene text recognition. In Proceedings of the IEEE International Conference on Computer Vision, ICCV 2011, Barcelona, Spain, 6–13 November 2011; Metaxas, D.N., Quan, L., Sanfeliu, A., Gool, L.V., Eds.; IEEE Computer Society: Washington, DC, USA, 2011; pp. 1457–1464. [Google Scholar] [CrossRef]
- Lucas, S.M.; Panaretos, A.; Sosa, L.; Tang, A.; Wong, S.; Young, R.; Ashida, K.; Nagai, H.; Okamoto, M.; Yamamoto, H.; et al. ICDAR 2003 robust reading competitions: Entries, results, and future directions. Int. J. Doc. Anal. Recognit. 2005, 7, 105–122. [Google Scholar] [CrossRef]
- Karatzas, D.; Shafait, F.; Uchida, S.; Iwamura, M.; Bigorda, L.G.; Mestre, S.R.; Mas, J.; Mota, D.F.; Almazán, J.; de las Heras, L. ICDAR 2013 Robust Reading Competition. In Proceedings of the 12th International Conference on Document Analysis and Recognition, ICDAR 2013, Washington, DC, USA, 25–28 August 2013; IEEE Computer Society: Washington, DC, USA, 2013; pp. 1484–1493. [Google Scholar] [CrossRef] [Green Version]
- Karatzas, D.; Gomez-Bigorda, L.; Nicolaou, A.; Ghosh, S.K.; Bagdanov, A.D.; Iwamura, M.; Matas, J.; Neumann, L.; Chandrasekhar, V.R.; Lu, S.; et al. ICDAR 2015 competition on Robust Reading. In Proceedings of the 13th International Conference on Document Analysis and Recognition, ICDAR 2015, Nancy, France, 23–26 August 2015; IEEE Computer Society: Washington, DC, USA, 2015; pp. 1156–1160. [Google Scholar] [CrossRef]
- Risnumawan, A.; Shivakumara, P.; Chan, C.S.; Tan, C.L. A robust arbitrary text detection system for natural scene images. Expert Syst. Appl. 2014, 41, 8027–8048. [Google Scholar] [CrossRef]
- Cheng, Z.; Bai, F.; Xu, Y.; Zheng, G.; Pu, S.; Zhou, S. Focusing Attention: Towards Accurate Text Recognition in Natural Images. In Proceedings of the IEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, 22–29 October 2017; IEEE Computer Society: Washington, DC, USA, 2017; pp. 5086–5094. [Google Scholar] [CrossRef] [Green Version]
- Zhan, F.; Lu, S. ESIR: End-To-End Scene Text Recognition via Iterative Image Rectification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 16–20 June 2019; pp. 2059–2068. [Google Scholar] [CrossRef] [Green Version]
- Luo, C.; Jin, L.; Sun, Z. MORAN: A Multi-Object Rectified Attention Network for scene text recognition. Pattern Recognit. 2019, 90, 109–118. [Google Scholar] [CrossRef]
- Wang, T.; Zhu, Y.; Jin, L.; Luo, C.; Chen, X.; Wu, Y.; Wang, Q.; Cai, M. Decoupled Attention Network for Text Recognition. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, New York, NY, USA, 7–12 February 2020; AAAI Press: Palo Alto, CA, USA, 2020; pp. 12216–12224. [Google Scholar]
- Yue, X.; Kuang, Z.; Lin, C.; Sun, H.; Zhang, W. RobustScanner: Dynamically Enhancing Positional Clues for Robust Text Recognition. In Lecture Notes in Computer Science, Proceedings of the Computer Vision-ECCV 2020-16th European Conference, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J., Eds.; Part XIX; Springer: Cham, Switzerland, 2020; Volume 12364, pp. 135–151. [Google Scholar] [CrossRef]
- Mou, Y.; Tan, L.; Yang, H.; Chen, J.; Liu, L.; Yan, R.; Huang, Y. PlugNet: Degradation Aware Scene Text Recognition Supervised by a Pluggable Super-Resolution Unit. In Lecture Notes in Computer Science, Proceedings of the Computer Vision-ECCV 2020-16th European Conference, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J., Eds.; Part XV; Springer: Cham, Switzerland, 2020; Volume 12360, pp. 158–174. [Google Scholar] [CrossRef]
- Zhang, H.; Yao, Q.; Yang, M.; Xu, Y.; Bai, X. AutoSTR: Efficient Backbone Search for Scene Text Recognition. In Lecture Notes in Computer Science, Proceedings of the Computer Vision-ECCV 2020-16th European Conference, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J., Eds.; Part XXIV; Springer: Cham, Switzerland, 2020; Volume 12369, pp. 751–767. [Google Scholar] [CrossRef]
- Zhang, C.; Xu, Y.; Cheng, Z.; Pu, S.; Niu, Y.; Wu, F.; Zou, F. SPIN: Structure-Preserving Inner Offset Network for Scene Text Recognition. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Virtual Event. Vienna, Austria, 2–9 February 2021; AAAI Press: Palo Alto, CA, USA, 2021; pp. 3305–3314. [Google Scholar]
- Hu, W.; Cai, X.; Hou, J.; Yi, S.; Lin, Z. GTC: Guided Training of CTC towards Efficient and Accurate Scene Text Recognition. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, The Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, The Tenth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2020, New York, NY, USA, 7–12 February 2020; AAAI Press: Palo Alto, CA, USA, 2020; pp. 11005–11012. [Google Scholar]
- Litman, R.; Anschel, O.; Tsiper, S.; Litman, R.; Mazor, S.; Manmatha, R. SCATTER: Selective Context Attentional Scene Text Recognizer. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, 13–19 June 2020; pp. 11959–11969. [Google Scholar] [CrossRef]
- Abnar, S.; Zuidema, W.H. Quantifying Attention Flow in Transformers. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online. 5–10 July 2020; Jurafsky, D., Chai, J., Schluter, N., Tetreault, J.R., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 4190–4197. [Google Scholar] [CrossRef]
- Sun, Y.; Liu, J.; Liu, W.; Han, J.; Ding, E.; Liu, J. Chinese Street View Text: Large-Scale Chinese Text Reading With Partially Supervised Learning. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea, 27 October–2 November 2019; pp. 9085–9094. [Google Scholar] [CrossRef] [Green Version]
- Huang, J.; Haq, I.U.; Dai, C.; Khan, S.; Nazir, S.; Imtiaz, M. Isolated Handwritten Pashto Character Recognition Using a K-NN Classification Tool based on Zoning and HOG Feature Extraction Techniques. Complexity 2021, 2021, 5558373. [Google Scholar] [CrossRef]
- Khan, S.; Hafeez, A.; Ali, H.; Nazir, S.; Hussain, A. Pioneer dataset and recognition of Handwritten Pashto characters using Convolution Neural Networks. Meas. Control 2020, 53, 2041–2054. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Training Data | IIIT 3000 | SVT 647 | IC03 867 | IC13 1015 | IC15 1811 | IC15 2077 | SVTP 645 | CUTE 288 | Average |
|---|---|---|---|---|---|---|---|---|---|---|
| CRNN [22] | MJ | 78.2 | 80.8 | - | 86.7 | - | - | - | - | - |
| FAN [43] | MJ + ST | 87.4 | 85.9 | 94.2 | 93.3 | - | 70.6 | - | - | - |
| ASTER [3] | MJ + ST | 93.4 | 89.5 | 94.5 | 91.8 | 76.1 | - | 78.5 | 79.5 | - |
| SAR [15] | MJ + ST | 91.5 | 84.5 | - | 91.0 | - | 69.2 | 76.4 | 83.3 | - |
| ESIR [44] | MJ + ST | 93.3 | 90.2 | - | 91.3 | 76.9 | - | 79.6 | 83.3 | - |
| MORAN [45] | MJ + ST | 91.2 | 88.3 | 95.0 | 92.4 | - | 68.8 | 76.1 | 77.4 | 84.5 |
| SATRN [30] | MJ + ST | 92.8 | 91.3 | 96.7 | 94.1 | - | 79 | 86.5 | 87.8 | 89.2 |
| DAN [46] | MJ + ST | 94.3 | 89.2 | 95.0 | 93.9 | - | 74.5 | 80.0 | 84.4 | 87.7 |
| RobustScanner [47] | MJ + ST | 95.3 | 88.1 | - | 94.8 | - | 77.1 | 79.2 | 90.3 | - |
| PlugNet [48] | MJ + ST | 94.4 | 92.3 | 95.7 | 95.0 | 82.2 | - | 84.3 | 85.0 | - |
| AutoSTR [49] | MJ + ST | 94.7 | 90.9 | 93.3 | 94.2 | 81.8 | - | 81.7 | - | - |
| GA-SPIN [50] | MJ + ST | 95.2 | 90.9 | - | 94.8 | 82.8 | 79.5 | 83.2 | 87.5 | - |
| MASTER [16] | MJ + ST + R | 95 | 90.6 | 96.4 | 95.3 | - | 79.4 | 84.5 | 87.5 | 90.0 |
| GTC [51] | MJ + ST + SA | 95.5 | 92.9 | - | 94.3 | 82.5 | - | 86.2 | 92.3 | - |
| SCATTER [52] | MJ + ST + SA + A | 93.9 | 90.1 | 96.6 | 94.7 | - | 82.8 | 87 | 87.5 | 90.5 |
| RobustScanner [47] | MJ + ST + R | 95.4 | 89.3 | - | 94.1 | - | 79.2 | 82.9 | 92.4 | - |
| SRN [5] | MJ + ST + A | 94.8 | 91.5 | - | 95.5 | 82.7 | - | 85.1 | 87.8 | - |
| TRIG | MJ + ST | 95.1 | 93.8 | 95.3 | 95.2 | 84.8 | 81.1 | 88.1 | 85.1 | 90.8 |
| Mask | Context Modeling | Decoder | IIIT 3000 | SVT 647 | IC03 867 | IC13 2015 | IC15 2077 | SVTP 645 | CUTE 288 |
|---|---|---|---|---|---|---|---|---|---|
| × | ✓ | CTC | 85.0 | 80.4 | 91.7 | 89.6 | 65.8 | 70.5 | 69.4 |
| ✓ | × | CTC | 85.6 | 80.5 | 90.9 | 88.4 | 63.1 | 65.6 | 67.7 |
| × | × | CTC | 86.5 | 82.1 | 92.0 | 89.6 | 65.9 | 71.9 | 71.2 |
| × | ✓ | Attn | 87.9 | 86.7 | 92.3 | 90.8 | 71.9 | 79.4 | 72.9 |
| ✓ | × | Attn | 86.7 | 83.5 | 91.6 | 89.5 | 70.7 | 78.5 | 67.7 |
| × | × | Attn | 89.5 | 88.6 | 93.7 | 92.5 | 74.1 | 79.2 | 76.4 |
| Patch Size | Sequence Length | Average | |
|---|---|---|---|
| 1-D split | 32 × 2 | 1 × 50 | 80.9 |
| 1-D split | 32 × 4 | 1 × 25 | 83.5 |
| 1-D split | 32 × 5 | 1 × 20 | 81.0 |
| 1-D split | 32 × 10 | 1 × 10 | 81.7 |
| 1-D split | 32 × 20 | 1 × 5 | 0.1 * |
| 2-D split | 16 × 4 | 2 × 25 | 81.9 |
| 2-D split | 8 × 4 | 4 × 25 | 73.5 |
| 2-D split | 4 × 4 | 8 × 25 | 76.7 |
| Method | MACs G | #Param. M | GPU Memory (Train) m | GPU Memory (Inference) m | Inference Time ms/Image |
|---|---|---|---|---|---|
| ASTER | 1.6 | 21.0 | 1509 | 3593 | 19.5 |
| TRIG | 2.6 | 68.1 | 2579 | 1855 | 16.2 |
| 2-D split | 18.2 | 68.0 | 8717 | 1929 | 37.6 |
| Blocks | Heads | Embedding Dimension | Initial Guidance | Skip Attention | Average |
|---|---|---|---|---|---|
| 6 | 16 | 512 | × | × | 89.2 |
| 6 | 16 | 512 | × | ✓ | 89.8 (+0.6) |
| 12 | 16 | 256 | × | × | 89.4 (+0.2) |
| 12 | 8 | 256 | × | ✓ | 90.1 (+0.9) |
| 12 | 16 | 256 | × | ✓ | 90.4 (+1.2) |
| 12 | 16 | 512 | × | × | 89.5 (+0.3) |
| 12 | 16 | 512 | ✓ | × | 89.6 (+0.4) |
| 12 | 16 | 512 | × | ✓ | 90.6 (+1.4) |
| 12 | 16 | 512 | ✓ | ✓ | 90.8 (+1.6) * |
| 24 | 16 | 512 | ✓ | ✓ | 90.6 (+1.4) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tao, Y.; Jia, Z.; Ma, R.; Xu, S. TRIG: Transformer-Based Text Recognizer with Initial Embedding Guidance. Electronics 2021, 10, 2780. https://doi.org/10.3390/electronics10222780
Tao Y, Jia Z, Ma R, Xu S. TRIG: Transformer-Based Text Recognizer with Initial Embedding Guidance. Electronics. 2021; 10(22):2780. https://doi.org/10.3390/electronics10222780
Chicago/Turabian StyleTao, Yue, Zhiwei Jia, Runze Ma, and Shugong Xu. 2021. "TRIG: Transformer-Based Text Recognizer with Initial Embedding Guidance" Electronics 10, no. 22: 2780. https://doi.org/10.3390/electronics10222780
APA StyleTao, Y., Jia, Z., Ma, R., & Xu, S. (2021). TRIG: Transformer-Based Text Recognizer with Initial Embedding Guidance. Electronics, 10(22), 2780. https://doi.org/10.3390/electronics10222780