
Sentiment Analysis in Twitter Based on Knowledge Graph and Deep Learning Classification




Abstract
:1. Introduction
- Intrinsic or post hoc: Intrinsic methods mean simple models that can be interpreted by humans, for example, decision trees or linear models. Nonetheless, the more complex the model is, the more difficult it becomes to interpret it. Post hoc interpretations are those that occur after the model is trained and are not connected to its internal design.
- Model-specific or model agnostic: these are interpretability methods applied to a specific model. All intrinsic methods are model-agnostic, as are post hoc methods, as they do not have access to model structure and weights.
- Local or global: These concepts are related to the scope of the interpretation. Global considers the entire model, while local means focusing on individual predictions.
2. Related Work

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Work | Model | Dataset | Result |
|---|---|---|---|
| Castillo et al., 2015 [51] | Co-occurrence graphs | SemEval 2015 | 76% for positive and 68.04% for neutral classes |
| Violos et al., 2016 [52] | Word-graph model based | Twitter dataset | 75.07% of accuracy. |
| Bijari et al., 2019 [53] | Sentence-level graph-based text representation | IMDB dataset IMDB dataset | 88.31% for negative and 86.60% for positive classes |
| Vizcarra et al., 2021 [54] | Knowledge based graphs | Amazon reviews [57] | 67.0% of precision for joy 79% of precision for trust 75% of precision for sadness 98% of precision for anger |
3. Knowledge Graphs and Neural Nets Models: Preliminaries
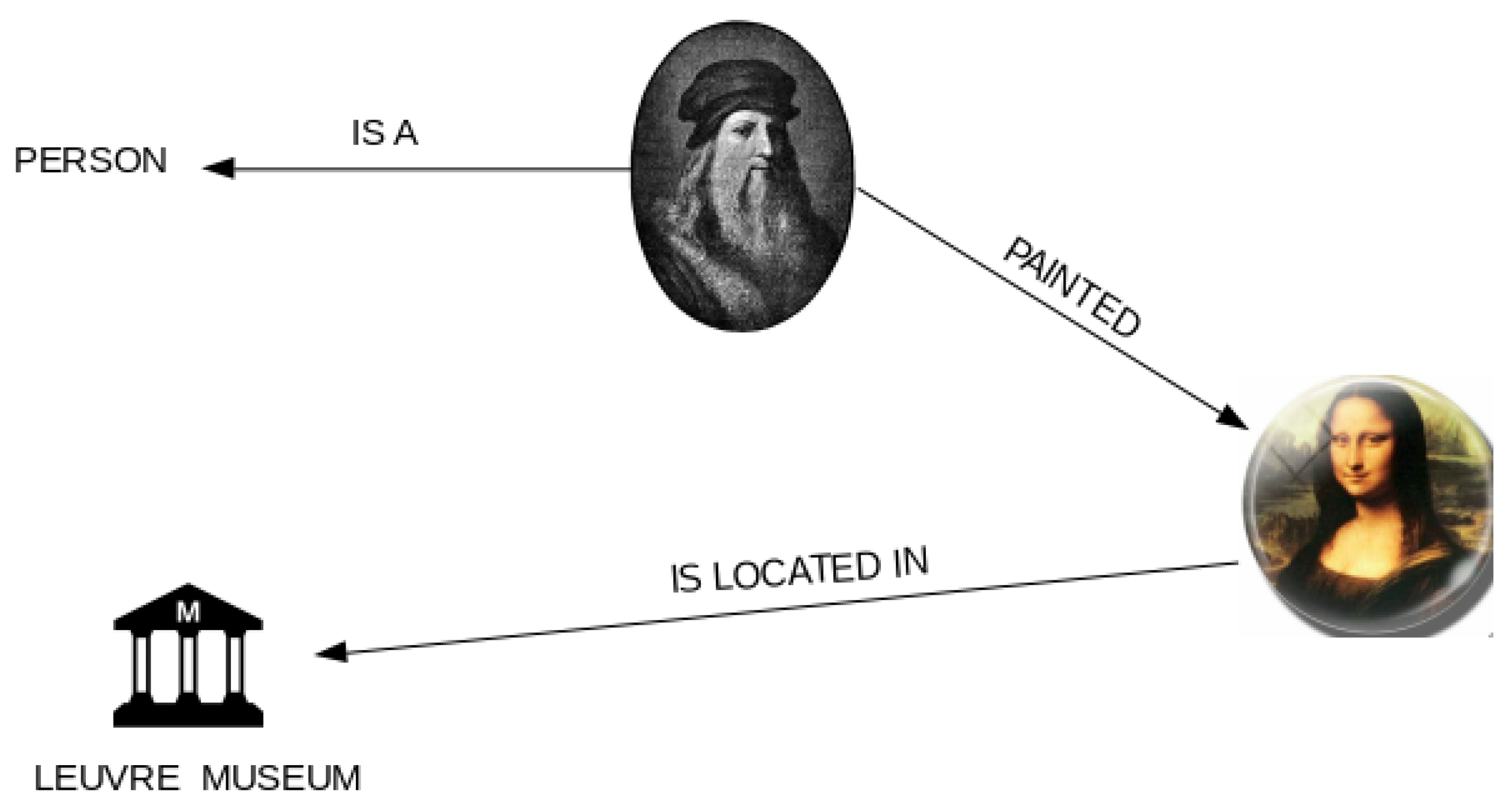
3.1. Knowledge Graphs
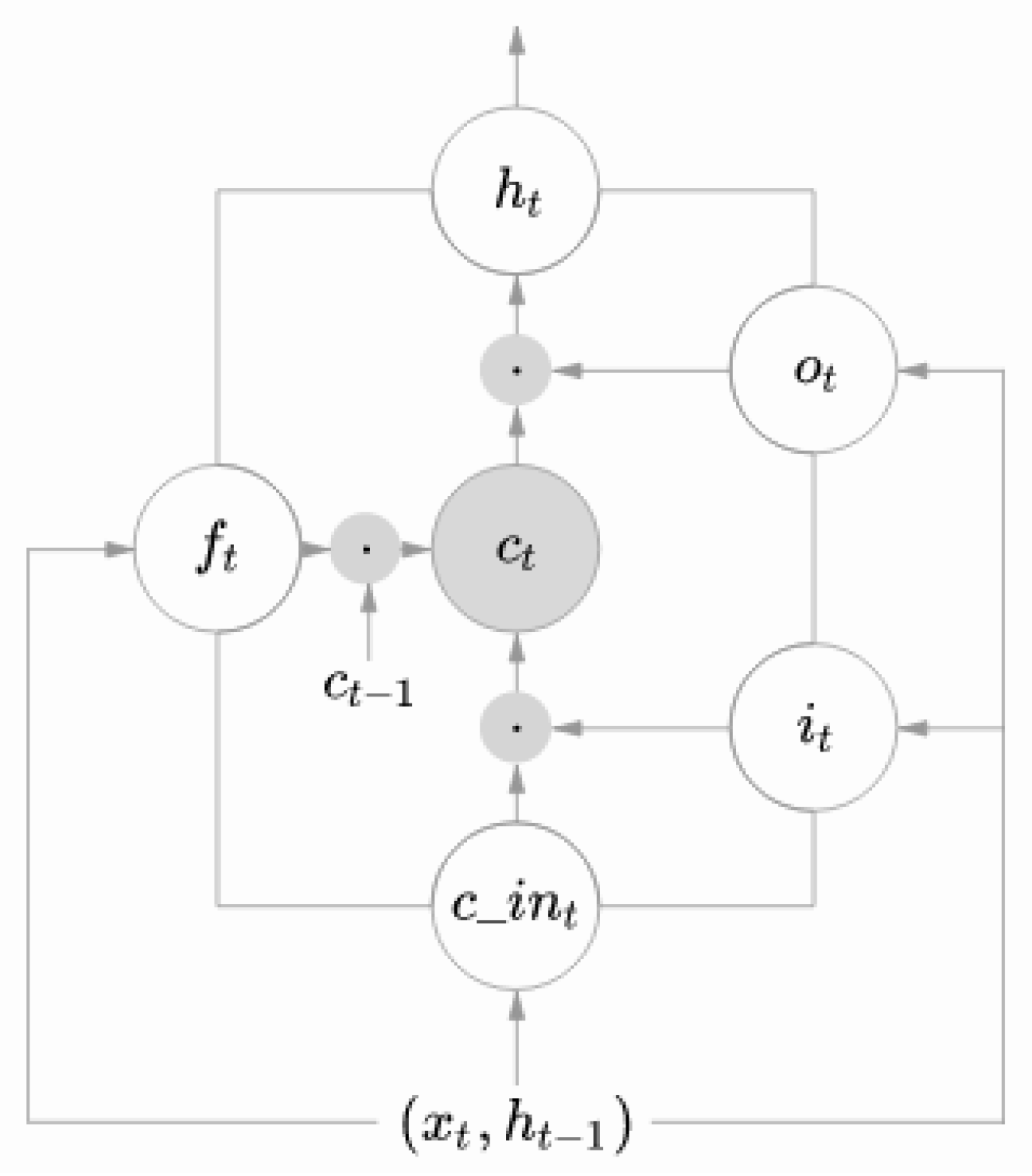
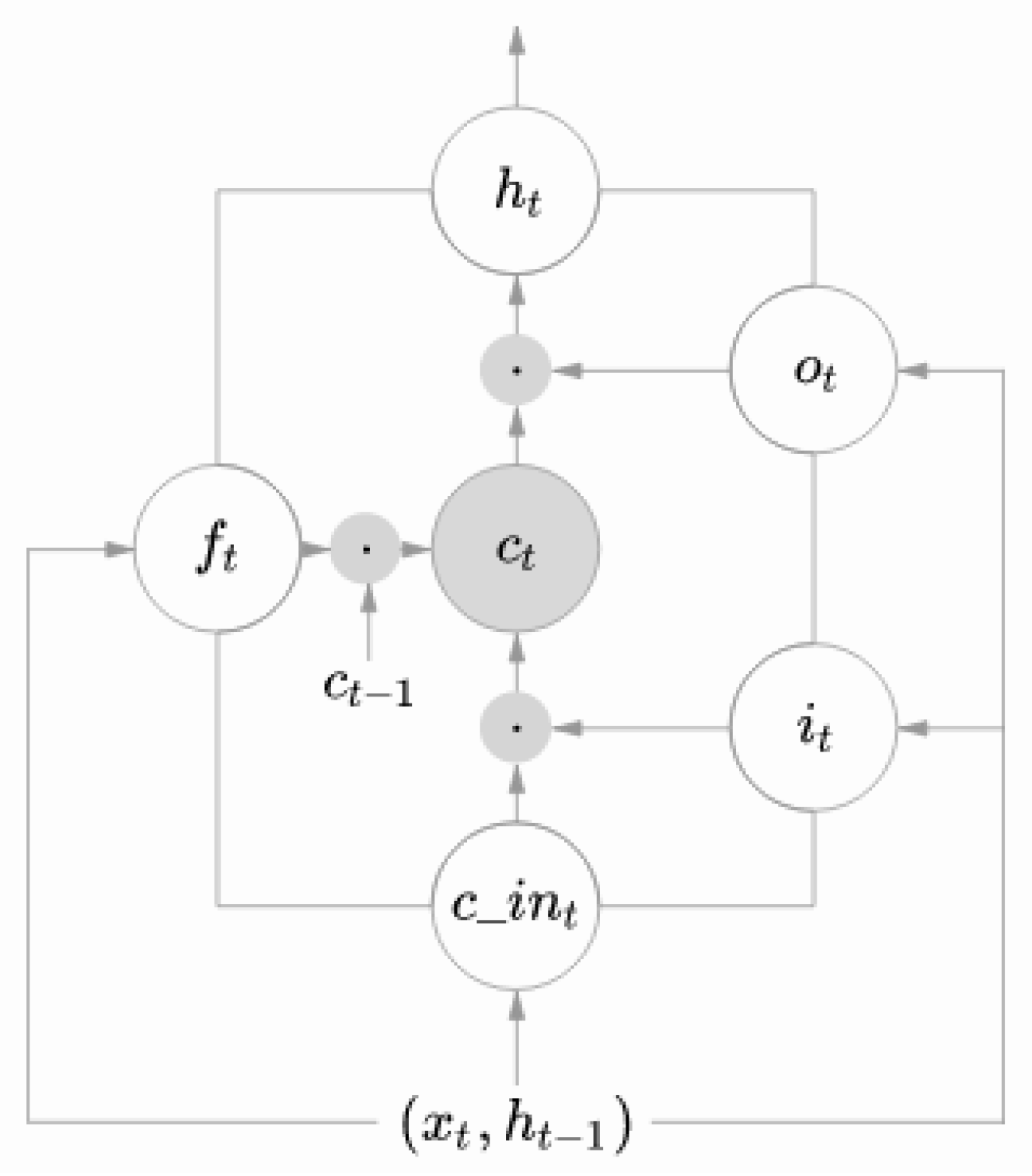
3.2. Long-Short-Term Memory (LSTM)
- The input gate (which tells what new information will be stored in a cell) is defined as:
- The output gate (which provides the activation function with the final output of the LSTM block at a timestamp t) is defined as:
- The forget gate (which tells what information should be forgotten) is defined as:
- : represents a vector of dimension d to the LSTM unit.
- : activation vector of the forget gates.
- : activation vector of input gates.
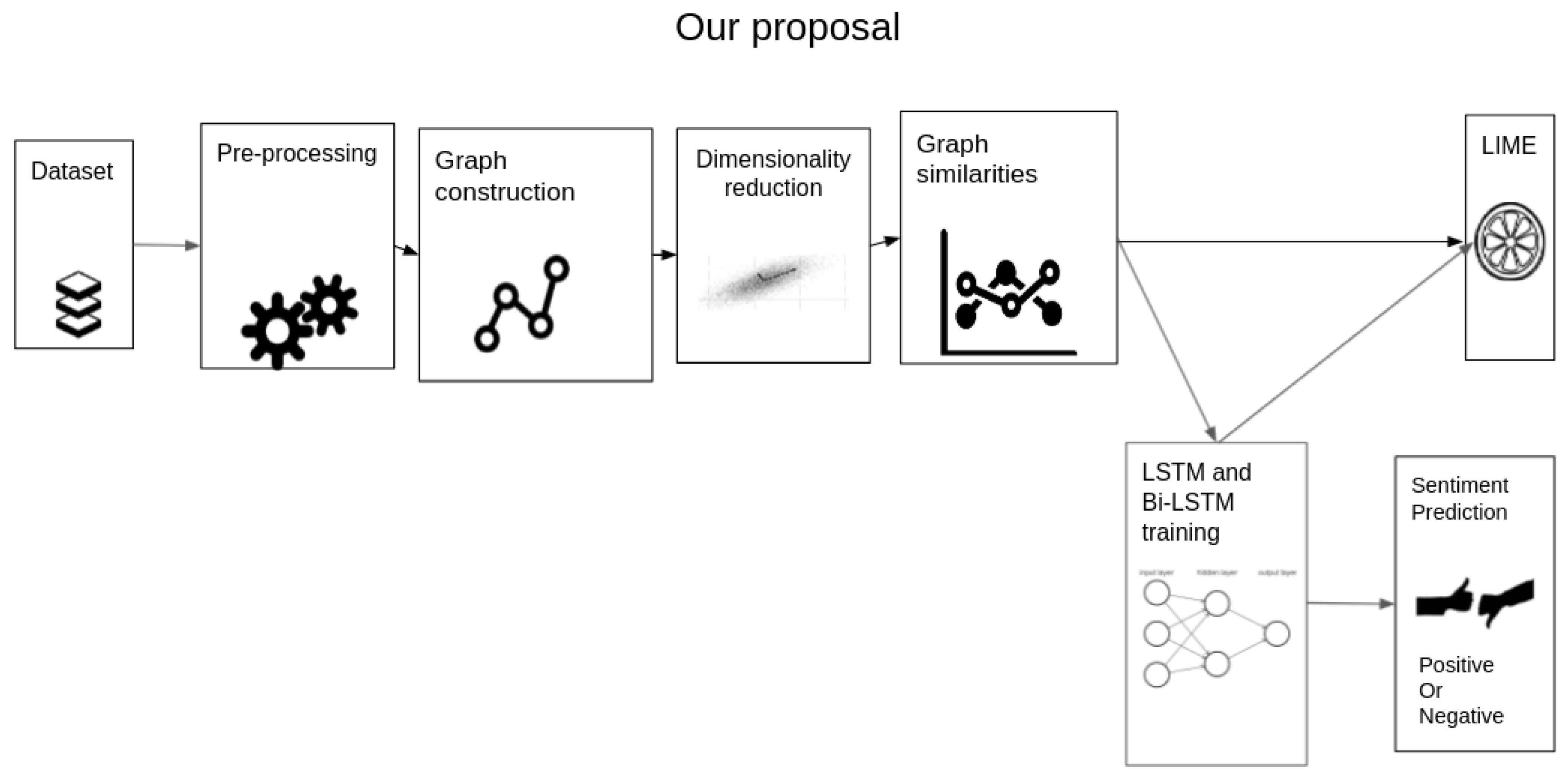
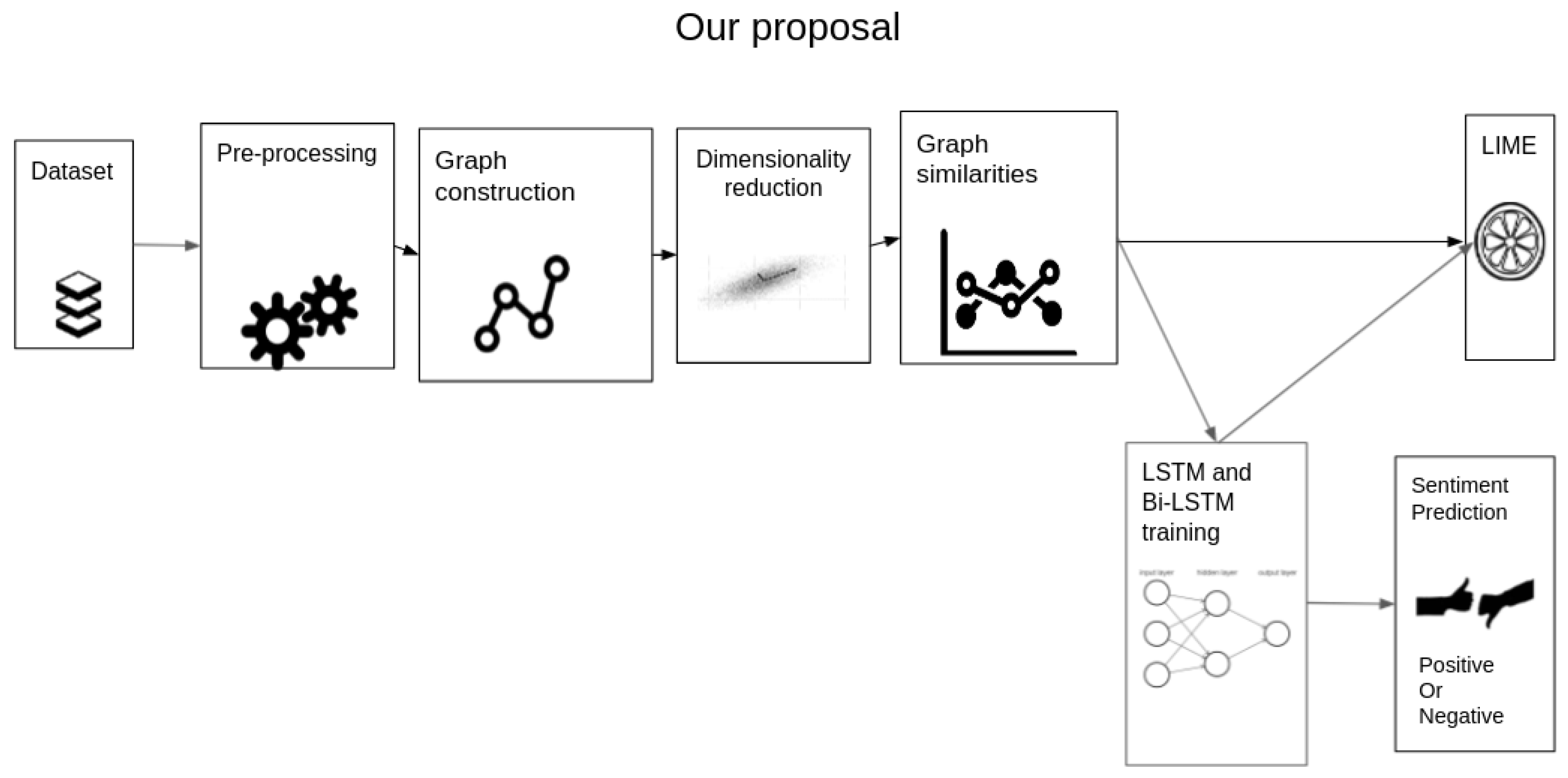
4. Sentiment Analysis Based on KG: The Proposal
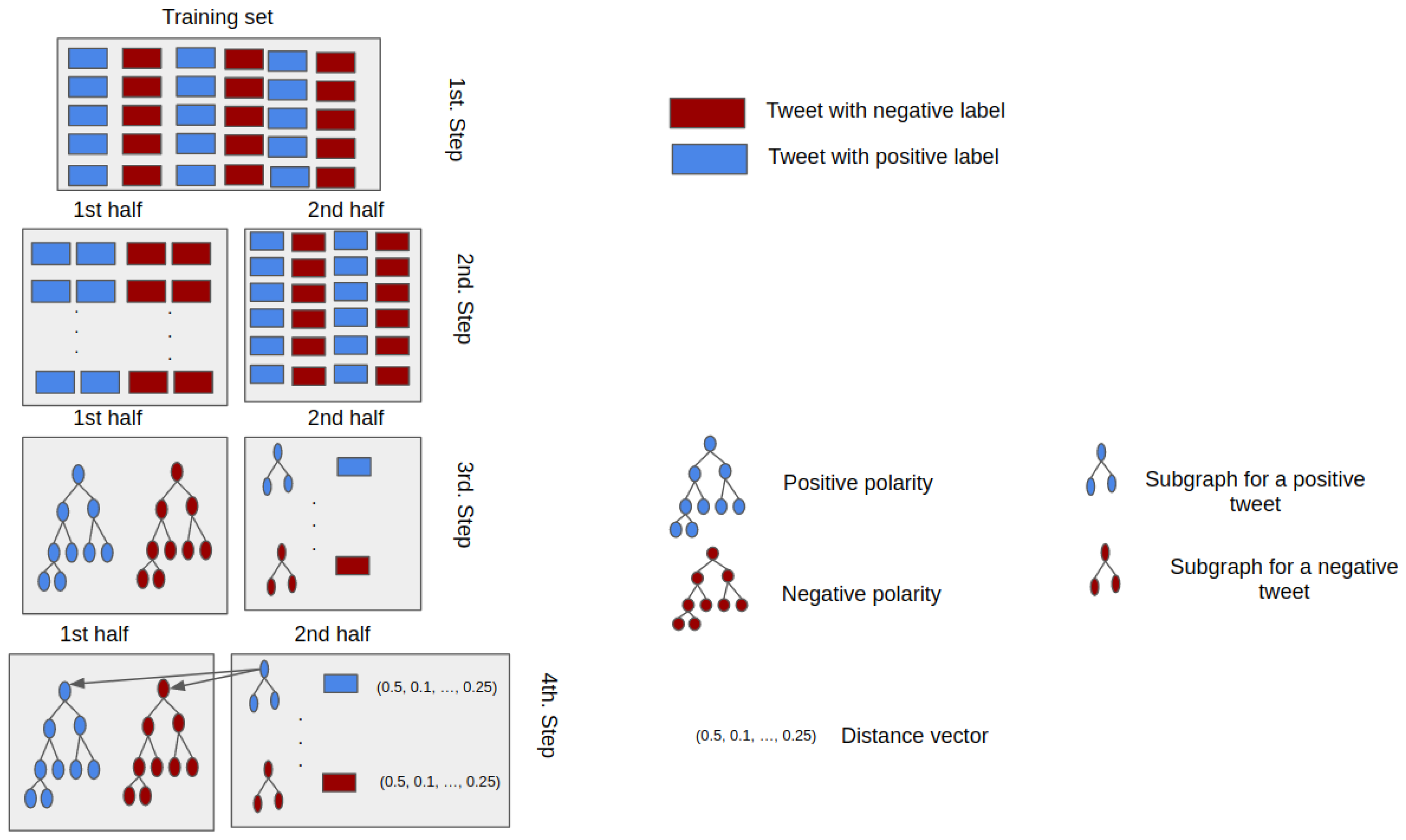
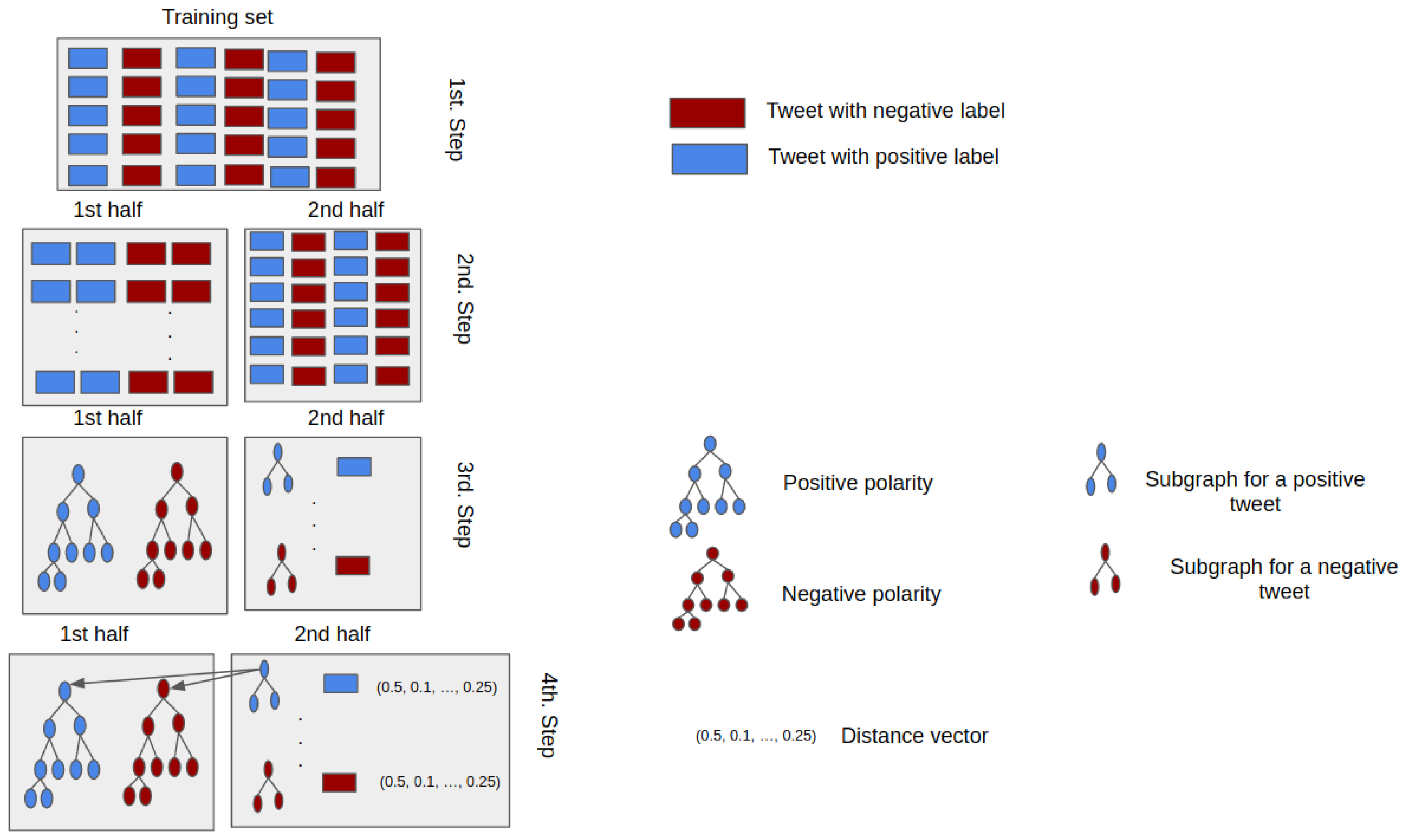
4.1. Dataset
4.2. Pre-Processing
4.3. Graph Construction
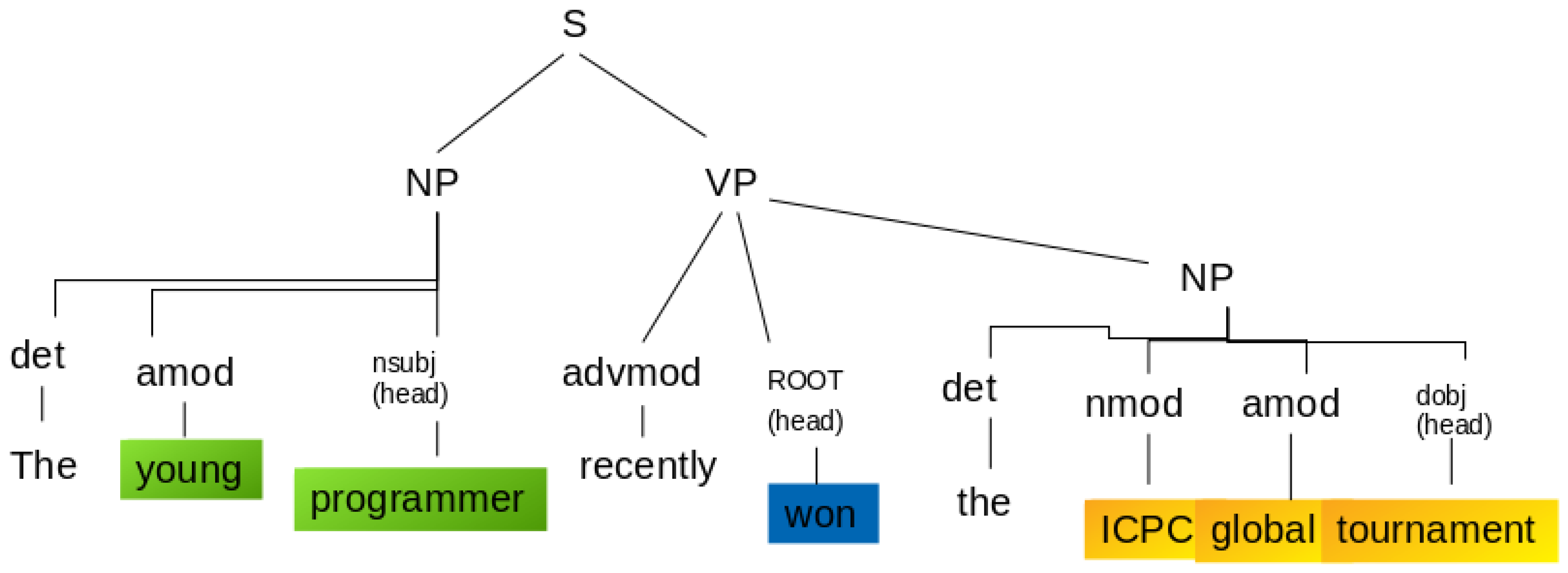
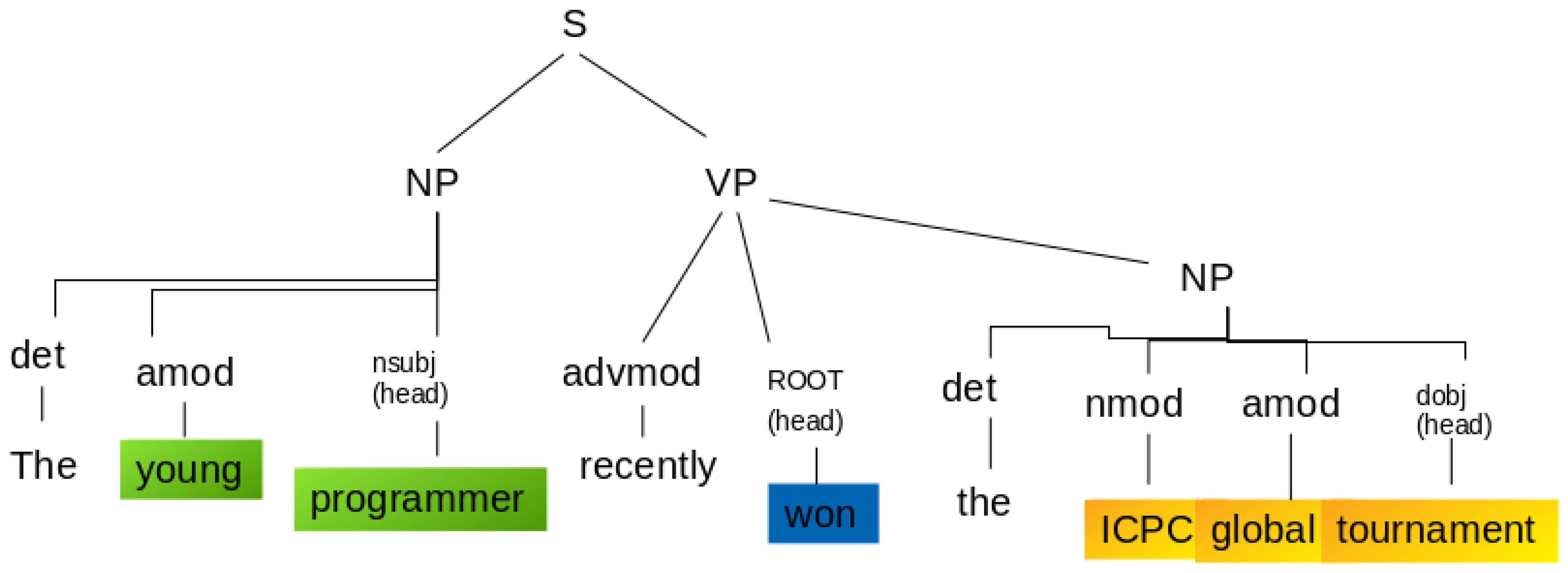
- Sentence segmentation: Split the text (a tweet, in this case) into sentences. Therefore, a sentence has one object and one subject.
- Entities extraction: An entity is a Noun or a Noun Phrase (NP). sentencePart of Speech (PoS) tags help in this case to extract a single-word entity from a sentence. For example, in the sentence “Rafael won the first prize”, the PoS tags classify “Rafael” as a Nominal Subject (nsubj), and “prize” as a Direct Object (dobj); both of them are syntactic dependency tags that contain the information needed for the formation of the KG entities. For most of the sentences, the use of PoS tags alone is almost enough. Nonetheless, for some sentences, the entities span multiple words; therefore, the syntactic dependency tags are not sufficient. For example, in the sentence “The 42-year-old won the prize”, “old” is classified as the nsubj; nonetheless, “42-year-old” would be preferable to extract instead. The “42-year” is classified as adjectival modifier (amod)—i.e., it is a modifier of “old”. Something similar happens with the dobj. In this case, there are no modifiers but there are compound words (collections of words that form a new term with a different meaning); for example, “ICP global tournament” instead of the word “prize”. The PoS tags only retrieve “tournament” as the dobj; however, the extraction of compound words is critical. These words are “ICP” and “global”. Hence, the subjects and objects along with its punctuation marks, modifiers, and also compound words are essential for the extraction. Therefore, parsing the dependency tree of the sentence contributes to this task. To accomplish this, the modifier of the subject is extracted (amod in the dependency tree).
- 3.
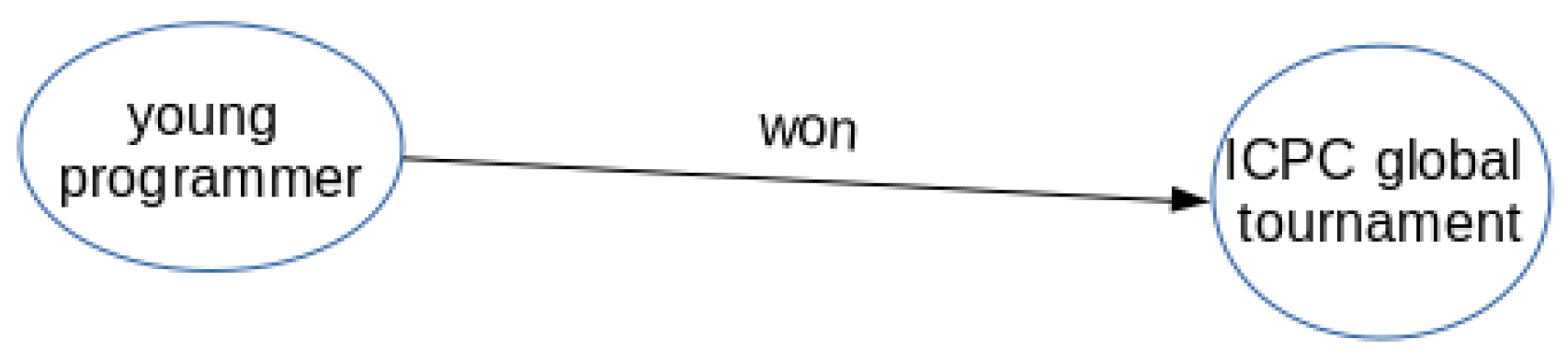
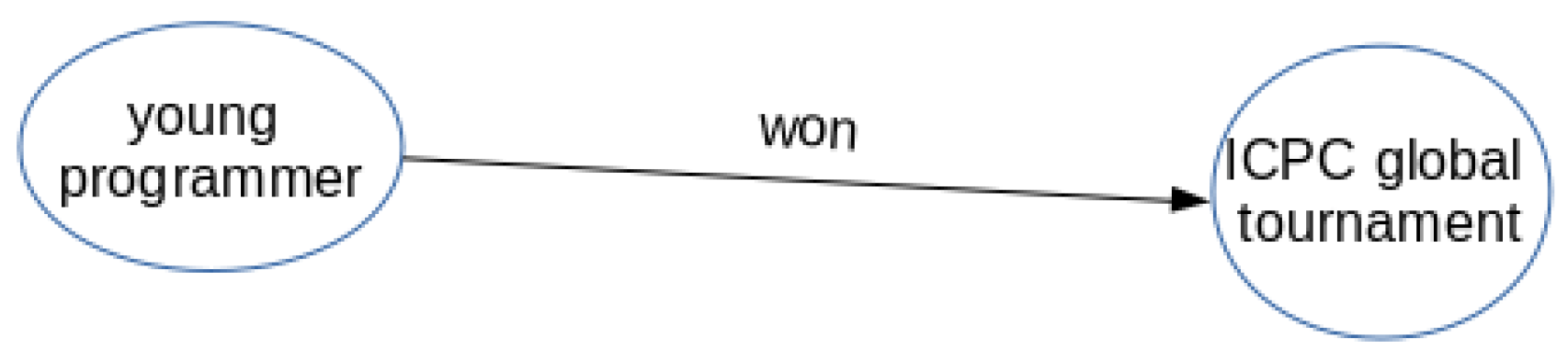
- Relationships extraction: To extract the relations between nodes, it is convenient to assume that it refers to the main verb of the sentence. Therefore, the main verb represents the relationship between two entities. In the sentence in Figure 5, the predicate is “won”, which is also tagged as “ROOT” or main verb.
- 4.
- Building the knowledge graph: In order to build the KG, it is necessary to work with a network in which the nodes are the entities, and the edges between the nodes represent the relations between the entities. It needs to be a directed graph, which means that the relation between two nodes is unidirectional.
4.4. Dimensionality Reduction
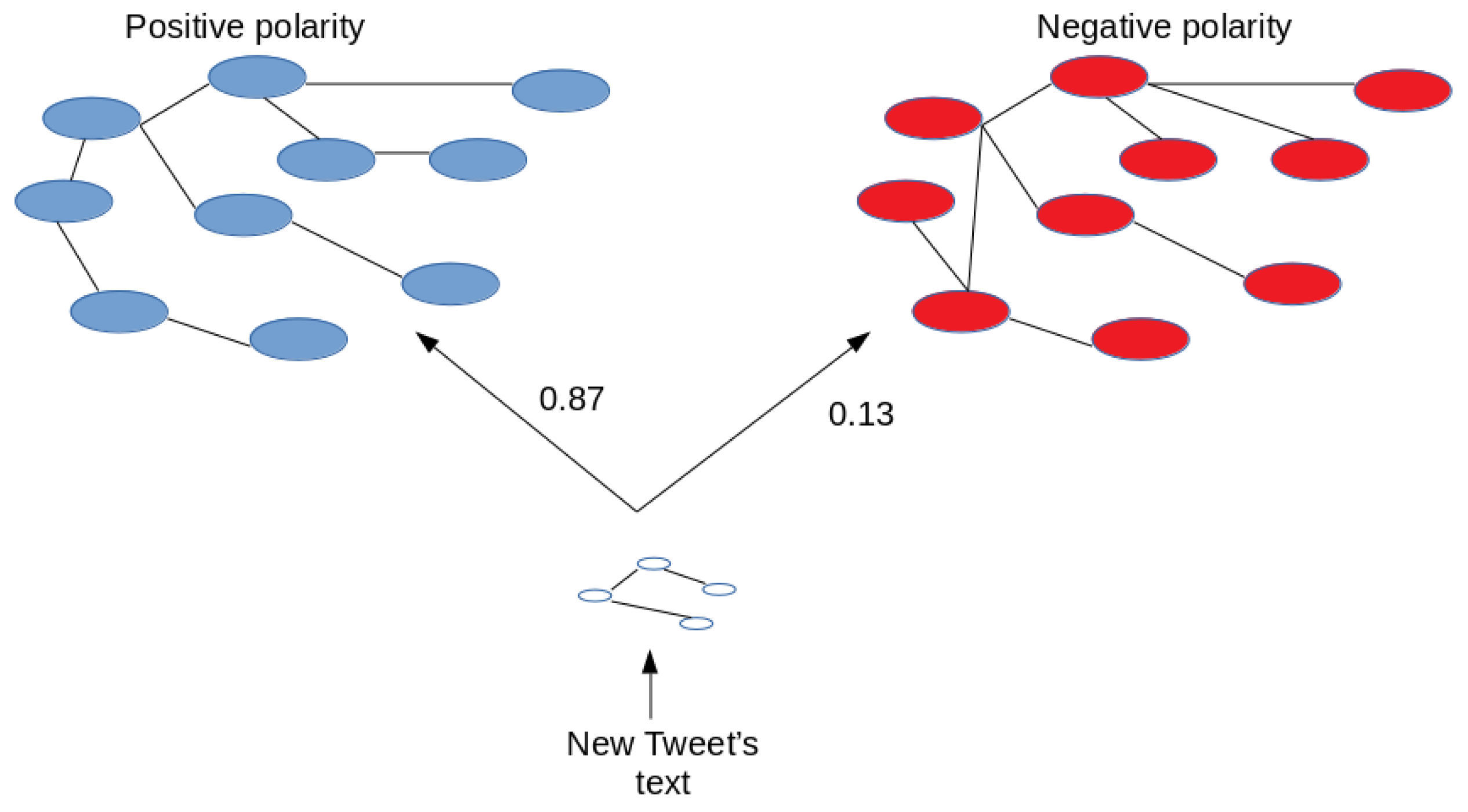
4.5. Graph Similarities
- Containment similarity measurement: This is a graph similarity measurement that expresses the percentage of common edges between the graphs, taking the size of the smaller graph as the factor of this measurement. Given as the knowledge graph of a new document or tweet, and as the knowledge graph of a polarity, Equation (6) calculates the containment similarity measurement between these two graphs, where represents a function that calculates the amount of common edges between the two graphs passed as parameters.
- Maximum common sub-graph similarity measurement: Given two graphs, and , the maximum common sub-graph of them, is a sub-graph of both graphs, such that there is no other sub-graph of and with more nodes [68]. The measurement of maximum common sub-graph is based on the sizes of common sub-graph between the two graphs. Detecting the maximum common sub-graph between two graphs with labeled nodes is a linear problem. Equation (7) is used to calculate the maximum common sub-graph between and , where MCSN is a function that returns the number of nodes that are contained in the maximum common sub-graph of these graphs.
- Maximum common sub-graph number of edges: It takes into account the number of common edges that are contained in the maximum common sub-graph instead of the nodes in common. This is reflected in Equation (8), where the Maximum Common Subgraph of Edges (MCSE) is the number of edges contained in the maximum common sub-graph.
4.6. LSTM and Bi-LSTM
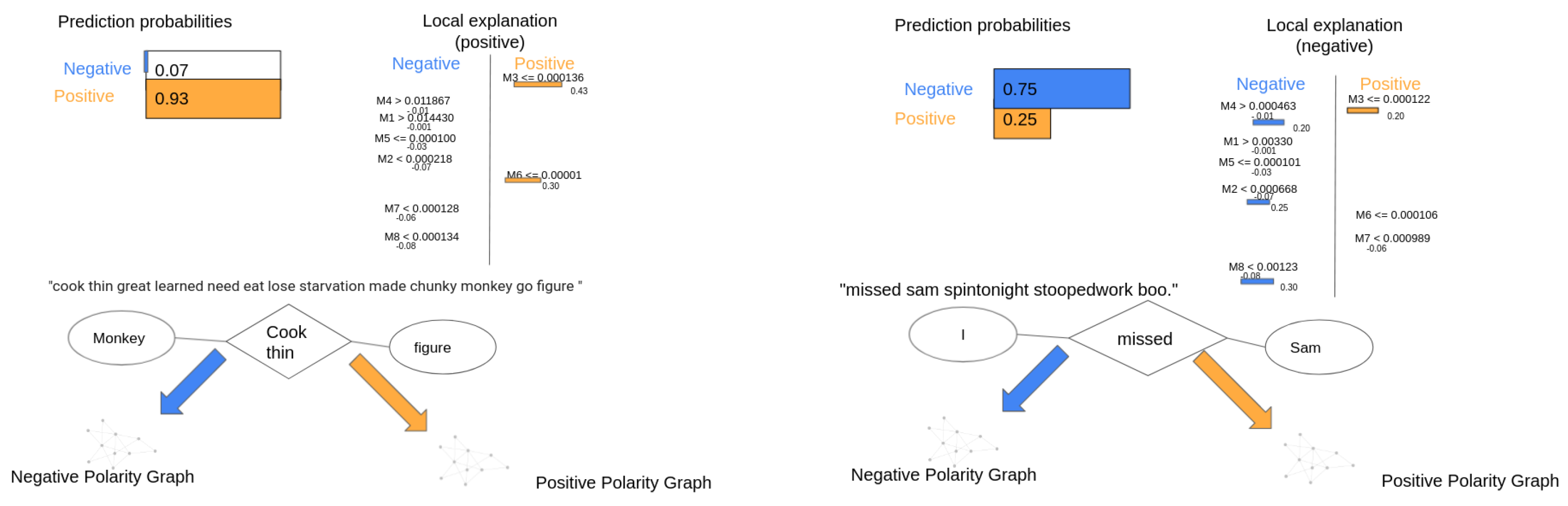
4.7. Lime-Based Interpretability
5. Results
5.1. Performance Evaluation
5.2. Interpretability
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Mostafa, M.M. More than Words: Social Networks’ Text Mining for Consumer Brand Sentiments. Expert Syst. Appl. 2013, 40, 4241–4251. [Google Scholar] [CrossRef]
- Cambria, E.; Das, D.; Bandyopadhyay, S.; Feraco, A. Affective computing and sentiment analysis. In A Practical Guide to Sentiment Analysis; Springer: Cham, Switzerland, 2017; Volume 31, pp. 102–107. [Google Scholar]
- De Albornoz, J.C.; Plaza, L.; Gervás, P.; Díaz, A. A joint model of feature mining and sentiment analysis for product review rating. In European Conference On Information Retrieval; Springer: Berlin/Heidelberg, Germany, 2011; pp. 55–66. [Google Scholar]
- Mirtalaie, M.A.; Hussain, O.K.; Chang, E.; Hussain, F.K. Sentiment analysis of specific product’s features using product tree for application in new product development. In Proceedings of the International Conference on Intelligent Networking and Collaborative Systems, Vancouver, BC, Canada, 24–28 September 2017; pp. 82–95. [Google Scholar]
- Chu, E.; Roy, D. Audio-visual sentiment analysis for learning emotional arcs in movies. In Proceedings of the IEEE International Conference on Data Mining (ICDM), New Orleans, LA, USA, 18–21 November 2017; pp. 829–834. [Google Scholar]
- Oliveira, D.J.S.; Bermejo, P.H.d.S.; dos Santos, P.A. Can social media reveal the preferences of voters? A comparison between sentiment analysis and traditional opinion polls. J. Inf. Technol. Politics 2017, 14, 34–45. [Google Scholar] [CrossRef]
- Agarwal, A.; Xie, B.; Vovsha, I.; Rambow, O.; Passonneau, R.J. Sentiment analysis of twitter data. In Proceedings of the Workshop on Language in Social Media, Portland, OR, USA, 23 June 2011; pp. 30–38. [Google Scholar]
- Rosenthal, S.; Farra, N.; Nakov, P. SemEval-2017 task 4: Sentiment analysis in Twitter. In Proceedings of the 11th International Workshop on Semantic Evaluation, Vancouver, BC, Canada, 3–4 August 2017; pp. 502–518. [Google Scholar]
- Pagolu, V.S.; Reddy, K.N.; Panda, G.; Majhi, B. Sentiment analysis of Twitter data for predicting stock market movements. In Proceedings of the International Conference on Signal Processing, Communication, Power and Embedded System, Odisha, India, 3–5 October 2016; pp. 1345–1350. [Google Scholar]
- Sadegh, M.; Ibrahim, R.; Othman, Z.A. Opinion mining and sentiment analysis: A survey. Int. J. Comput. Technol. 2012, 2, 171–178. [Google Scholar]
- Medhat, W.; Hassan, A.; Korashy, H. Sentiment analysis algorithms and applications: A survey. Ain Shams Eng. J. 2014, 5, 1093–1113. [Google Scholar] [CrossRef] [Green Version]
- Kharde, V.; Sonawane, P. Sentiment analysis of twitter data: A survey of techniques. arXiv 2016, arXiv:1601.06971. [Google Scholar]
- Hussein, D.M.E.D.M. A survey on sentiment analysis challenges. J. King Saud Univ.-Eng. Sci. 2018, 30, 330–338. [Google Scholar] [CrossRef]
- Jianqiang, Z.; Xiaolin, G.; Xuejun, Z. Deep convolution neural networks for twitter sentiment analysis. IEEE Access 2018, 6, 23253–23260. [Google Scholar] [CrossRef]
- Sánchez-Rada, J.F.; Torres, M.; Iglesias, C.A.; Maestre, R.; Peinado, E. A Linked Data Approach to Sentiment and Emotion Analysis of Twitter in the Financial Domain. In Proceedings of the European Semantic Web Conference, Crete, Greece, 25–29 May 2014. [Google Scholar]
- Roshani, S.; Jamshidi, M.B.; Mohebi, F.; Roshani, S. Design and Modeling of a Compact Power Divider with Squared Resonators Using Artificial Intelligence. Wirel. Pers. Commun. 2021, 117, 2085–2096. [Google Scholar] [CrossRef]
- Nazemi, B.; Rafiean, M. Forecasting house prices in Iran using GMDH. Int. J. Hous. Mark. Anal. 2020, 14, 555–568. [Google Scholar] [CrossRef]
- Roshani, M.; Sattari, M.A.; Ali, P.J.M.; Roshani, G.H.; Nazemi, B.; Corniani, E.; Nazemi, E. Application of GMDH neural network technique to improve measuring precision of a simplified photon attenuation based two-phase flowmeter. Flow Meas. Instrum. 2020, 75, 101804. [Google Scholar] [CrossRef]
- Reddy, S.; Allan, S.; Coghlan, S.; Cooper, P. A governance model for the application of AI in health care. J. Am. Med Informatics Assoc. 2020, 27, 491–497. [Google Scholar] [CrossRef] [PubMed]
- Ma, L.; Cheng, S.; Shi, Y. Enhancing Learning Efficiency of Brain Storm Optimization via Orthogonal Learning Design. IEEE Trans. Syst. Man, Cybern. Syst. 2020, 51, 6723–6742. [Google Scholar] [CrossRef]
- Ma, L.; Huang, M.; Yang, S.; Wang, R.; Wang, X. An Adaptive Localized Decision Variable Analysis Approach to Large-Scale Multiobjective and Many-Objective Optimization. IEEE Trans. Cybern. 2021, 1–13. [Google Scholar] [CrossRef]
- Taboada, M. Sentiment Analysis: An Overview from Linguistics. Annu. Rev. Linguist. 2016, 2, 325–347. [Google Scholar]
- Rotmensch, M.; Halpern, Y.; Tlimat, A.; Horng, S.; Sontag, D. Learning a health knowledge graph from electronic medical records. Sci. Rep. 2017, 7, 5994. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; He, X.; Cao, Y.; Liu, M.; Chua, T.S. Knowledge graph attention network for recommendation. In Proceedings of the 5th International Conference Association for Computing Machinery’s Special Interest Group on Knowledge Discovery and Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 950–958. [Google Scholar]
- Zou, X. A survey on application of knowledge graph. J. Phys. Conf. Ser. 2020, 1487, 012016. [Google Scholar] [CrossRef]
- Richardson, A.; Rosenfeld, A. A survey of interpretability and explainability in human-agent systems. In Proceedings of the eXplainable Artificial Intelligence Workshop, Stockholm, Sweden, 13–19 July 2018; pp. 137–143. [Google Scholar]
- Marcinkevičs, R.; Vogt, J.E. Interpretability and explainability: A machine learning zoo mini-tour. arXiv 2020, arXiv:2012.01805. [Google Scholar]
- Mahajan, A.; Shah, D.; Jafar, G. Explainable AI Approach Towards Toxic Comment Classification. In Emerging Technologies in Data Mining and Information Security; Hassanien, A.E., Bhattacharyya, S., Chakrabati, S., Bhattacharya, A., Dutta, S., Eds.; Springer: Singapore, 2021; pp. 849–858. [Google Scholar]
- Magesh, P.R.; Myloth, R.D.; Tom, R.J. An explainable machine learning model for early detection of Parkinson’s disease using LIME on DaTSCAN imagery. Comput. Biol. Med. 2020, 126, 104041. [Google Scholar] [CrossRef]
- Du, M.; Liu, N.; Hu, X. Techniques for interpretable machine learning. Commun. Assoc. Comput. Mach. 2019, 63, 68–77. [Google Scholar] [CrossRef] [Green Version]
- Monga, V.; Li, Y.; Eldar, Y.C. Algorithm unrolling: Interpretable, efficient deep learning for signal and image processing. IEEE Signal Process. Mag. 2021, 38, 18–44. [Google Scholar] [CrossRef]
- Lovera, F.A.; Cardinale, Y.; Buscaldi, D.; Charnois, T.; Homsi, M.N. Deep Learning Enhanced with Graph Knowledge for Sentiment Analysis. In Proceedings of the 6th International Workshop on Explainable Sentiment Mining and Emotion Detection (X-SENTIMENT), Hersonissos, Greece, 7 June 2021. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Demonstrations, San Diego, CA, USA, 12–17 June 2016; pp. 1135–1144. [Google Scholar]
- Beigi, G.; Hu, X.; Maciejewski, R.; Liu, H. An overview of sentiment analysis in social media and its applications in disaster relief. In Sentiment Analysis and Ontology Engineering; Springer: Cham, Switzerland, 2016; pp. 313–340. [Google Scholar]
- Cieliebak, M.; Dürr, O.; Uzdilli, F. Potential and Limitations of Commercial Sentiment Detection Tools. In Proceedings of the International Conference of the Italian Association for Artificial Intelligence AI* IA, Turin, Italy, 4–6 December 2013; pp. 47–58. [Google Scholar]
- Pang, B.; Lee, L. Opinion mining and sentiment analysis. Found. Trends Inf. Retr. 2008, 2, 1–135. [Google Scholar] [CrossRef] [Green Version]
- Uijlings, J.R.; Smeulders, A.W.; Scha, R.J. Real-time bag of words, approximately. In Proceedings of the Association for Computing Machinery international Conference on Image and Video Retrieval, Kos, Greece, 28 August–2 September 2017; pp. 1–8. [Google Scholar]
- Li, T.; Mei, T.; Kweon, I.S.; Hua, X.S. Contextual bag-of-words for visual categorization. IEEE Trans. Circuits Syst. Video Technol. 2010, 21, 381–392. [Google Scholar] [CrossRef]
- Filliat, D. A visual bag of words method for interactive qualitative localization and mapping. In Proceedings of the IEEE International Conference on Robotics and Automation, Rome, Italy, 10–14 April 2007; pp. 3921–3926. [Google Scholar]
- Sikka, K.; Wu, T.; Susskind, J.; Bartlett, M. Exploring bag of words architectures in the facial expression domain. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 250–259. [Google Scholar]
- Bekkerman, R.; Allan, J. Using Bigrams in Text Categorization; Technical Report, Technical Report IR-408; Center of Intelligent Information Retrieval, UMass: Amherst, MA, USA, 2004. [Google Scholar]
- Krapac, J.; Verbeek, J.; Jurie, F. Modeling spatial layout with fisher vectors for image categorization. In Proceedings of the International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 1487–1494. [Google Scholar]
- Wang, X.; McCallum, A.; Wei, X. Topical n-grams: Phrase and topic discovery, with an application to information retrieval. In Proceedings of the Seventh IEEE International Conference on Data Mining (ICDM), Omaha, Nebraska, 28–31 October 2007; pp. 697–702. [Google Scholar]
- Severyn, A.; Moschitti, A. Twitter sentiment analysis with deep convolutional neural networks. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9–13 August 2015; pp. 959–962. [Google Scholar]
- Yanmei, L.; Yuda, C. Research on Chinese micro-blog sentiment analysis based on deep learning. In Proceedings of the 8th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 12–13 December 2015; pp. 358–361. [Google Scholar]
- Arras, L.; Montavon, G.; Müller, K.R.; Samek, W. Explaining recurrent neural network predictions in sentiment analysis. arXiv 2017, arXiv:1706.07206. [Google Scholar]
- Yanagimoto, H.; Shimada, M.; Yoshimura, A. Document similarity estimation for sentiment analysis using neural network. In Proceedings of the 12th International Conference on Computer and Information Science, Niigata, Japan, 16–20 June 2013; pp. 105–110. [Google Scholar]
- Li, C.; Xu, B.; Wu, G.; He, S.; Tian, G.; Hao, H. Recursive deep learning for sentiment analysis over social data. In Proceedings of the International Joint Conferences on Web Intelligence and Intelligent Agent Technologies, Warsaw, Poland, 11–14 August 2014; pp. 180–185. [Google Scholar]
- Basiri, M.E.; Nemati, S.; Abdar, M.; Cambria, E.; Acharya, U.R. ABCDM: An attention-based bidirectional CNN-RNN deep model for sentiment analysis. Future Gener. Comput. Syst. 2021, 115, 279–294. [Google Scholar] [CrossRef]
- Silhavy, R.; Senkerik, R.; Oplatkova, Z.K.; Silhavy, P.; Prokopova, Z. Artificial intelligence perspectives in intelligent systems. In The 5th Computer Science Online Conference; Springer: Cham, Switzerland, 2016; pp. 249–261. [Google Scholar]
- Castillo, E.; Cervantes, O.; Vilarino, D.; Báez, D.; Sánchez, A. UDLAP: Sentiment analysis using a graph-based representation. In Proceedings of the 9th International Workshop on Semantic Evaluation, Denver, Colorado, 4–5 June 2015; pp. 556–560. [Google Scholar]
- Violos, J.; Tserpes, K.; Psomakelis, E.; Psychas, K.; Varvarigou, T. Sentiment analysis using word-graphs. In Proceedings of the 6th International Conference on Web Intelligence, Mining and Semantics, Nîmes, France, 13–15 June 2016; pp. 1–9. [Google Scholar]
- Bijari, K.; Zare, H.; Kebriaei, E.; Veisi, H. Leveraging deep graph-based text representation for sentiment polarity applications. Expert Syst. Appl. 2020, 144, 113090. [Google Scholar] [CrossRef] [Green Version]
- Vizcarra, J.; Kozaki, K.; Ruiz, M.T.; Quintero, R. Knowledge-based sentiment analysis and visualization on social networks. New Gener. Comput. 2021, 39, 199–229. [Google Scholar] [CrossRef]
- Díaz-Rodríguez, N.; Lamas, A.; Sanchez, J.; Franchi, G.; Donadello, I.; Tabik, S.; Filliat, D.; Cruz, P.; Montes, R.; Herrera, F. EXplainable Neural-Symbolic Learning (X-NeSyL) methodology to fusedeep learning representations with expert knowledge graphs: The MonuMAI cultural heritage use case. arXiv 2021, arXiv:2104.11914. [Google Scholar]
- Dieber, J.; Kirrane, S. Why model why? Assessing the strengths and limitations of LIME. arXiv 2020, arXiv:2012.00093. [Google Scholar]
- Sosic, R.; Leskovec, J. Large scale network analytics with SNAP: Tutorial at the World Wide Web 2015 Conference. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 1537–1538. [Google Scholar]
- Huang, X.; Zhang, J.; Li, D.; Li, P. Knowledge graph embedding based question answering. In Proceedings of the Twelfth Association for Computing Machinery International Conference on Web Search and Data Mining, Melbourne, VIC, Australia, 11–15 February 2019; pp. 105–113. [Google Scholar]
- Zhang, Y.; Dai, H.; Kozareva, Z.; Smola, A.J.; Song, L. Variational reasoning for question answering with knowledge graph. In Proceedings of the Thirty-Second Association for the Advancement of Artificial Intelligence Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Teru, K.; Denis, E.; Hamilton, W. Inductive relation prediction by subgraph reasoning. In Proceedings of the International Conference on Machine Learning, 13–18 July 2020; pp. 9448–9457. [Google Scholar]
- Roodschild, M.; Sardiñas, J.G.; Will, A. A new approach for the vanishing gradient problem on sigmoid activation. Prog. Artif. Intell. 2020, 9, 351–360. [Google Scholar] [CrossRef]
- Huang, F.; Li, X.; Yuan, C.; Zhang, S.; Zhang, J.; Qiao, S. Attention-Emotion-Enhanced Convolutional LSTM for Sentiment Analysis. IEEE Trans. Neural Netw. Learn. Syst. 2021, 1–14. [Google Scholar] [CrossRef]
- Ito, Y. Approximation of continuous functions on Rd by linear combinations of shifted rotations of a sigmoid function with and without scaling. Neural Netw. 1992, 5, 105–115. [Google Scholar] [CrossRef]
- Behera, R.; Jena, M.; Rath, S.; Misra, S. Co-LSTM: Convolutional LSTM model for sentiment analysis in social big data. Inf. Process. Manag. 2021, 58, 102435. [Google Scholar] [CrossRef]
- Chagheri, S.; Calabretto, S.; Roussey, C.; Dumoulin, C. Feature vector construction combining structure and content for document classification. In Proceedings of the 6th International Conference on Sciences of Electronics, Technologies of Information and Telecommunications (SETIT), Sousse, Tunisia, 21–24 March 2012; pp. 946–950. [Google Scholar]
- Xu, Y.; Jones, G.J.; Li, J.; Wang, B.; Sun, C. A study on mutual information-based feature selection for text categorization. J. Comput. Inf. Syst. 2007, 3, 1007–1012. [Google Scholar]
- Wang, B.; Liu, W.; Han, G.; He, S. Learning Long-Term Structural Dependencies for Video Salient Object Detection. IEEE Trans. Image Process. 2020, 29, 9017–9031. [Google Scholar] [CrossRef]
- Bunke, H. On a relation between graph edit distance and maximum common subgraph. Pattern Recognit. Lett. 1997, 18, 689–694. [Google Scholar] [CrossRef]
- Quer, S.; Marcelli, A.; Squillero, G. The Maximum Common Subgraph Problem: A Parallel and Multi-Engine Approach. Computation 2020, 8, 48. [Google Scholar] [CrossRef]
- Jin, Z.; Yang, Y.; Liu, Y. Stock closing price prediction based on sentiment analysis and LSTM. Neural Comput. Appl. 2020, 32, 9713–9729. [Google Scholar] [CrossRef]
- Franco-Salvador, M.; Cruz, F.L.; Troyano, J.A.; Rosso, P. Cross-domain polarity classification using a knowledge-enhanced meta-classifier. Knowl.-Based Syst. 2015, 86, 46–56. [Google Scholar] [CrossRef] [Green Version]
- Farías, D.I.H.; Patti, V.; Rosso, P. Irony Detection in Twitter: The Role of Affective Content. Assoc. Comput. Mach. Trans. Internet Technol. 2016, 16, 1–24. [Google Scholar] [CrossRef] [Green Version]



| Work | Model | Dataset | Result |
|---|---|---|---|
| Yanagimoto et al., 2013 [47] | DNN | T&C New | F-score of 90.8% of accuracy |
| Li et al., 2014 [48] | RNDM | 2270 movie reviews from websites | Accuracy of 90.8% |
| Severyn and Moschitti, 2015 [44] | CNN | Semeval-2015 | F-measure score sub-task A: 84.19% and sub-task B: 64.69% |
| Yanmei and Yuda, 2015 [45] | CNN | 1000 micro-blog comments | Statistical model with average of 85.4% of accuracy |
| Silhavy et al., 2016 [50] | HBRNN | 150,175 labeled reviews from 1500 hotels | HBRNN outperformed the rest of the methods. |
| Arras et al., 2017 [46] | RNN | 11,855 single sentences from movies review | Accuracy of 82.9% for binary classification (positive and negative). |
| Basiri et al., 2021 | ABCDM | Five review and Twitter datasets | Accuracy up to 92% |
| Model | Precision | Recall | |
|---|---|---|---|
| LSTM with KG | 0.884 | 0.880 | 0.890 |
| Bi-LSTM with KG | 0.757 | 0.690 | 0.840 |
| Character n-gram based LSTM | 0.849 | 0.840 | 0.860 |
| Character n-gram based Bi-LSTM | 0.852 | 0.851 | 0.856 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lovera, F.A.; Cardinale, Y.C.; Homsi, M.N. Sentiment Analysis in Twitter Based on Knowledge Graph and Deep Learning Classification. Electronics 2021, 10, 2739. https://doi.org/10.3390/electronics10222739
Lovera FA, Cardinale YC, Homsi MN. Sentiment Analysis in Twitter Based on Knowledge Graph and Deep Learning Classification. Electronics. 2021; 10(22):2739. https://doi.org/10.3390/electronics10222739
Chicago/Turabian StyleLovera, Fernando Andres, Yudith Coromoto Cardinale, and Masun Nabhan Homsi. 2021. "Sentiment Analysis in Twitter Based on Knowledge Graph and Deep Learning Classification" Electronics 10, no. 22: 2739. https://doi.org/10.3390/electronics10222739
APA StyleLovera, F. A., Cardinale, Y. C., & Homsi, M. N. (2021). Sentiment Analysis in Twitter Based on Knowledge Graph and Deep Learning Classification. Electronics, 10(22), 2739. https://doi.org/10.3390/electronics10222739