
A Highly Robust Binary Neural Network Inference Accelerator Based on Binary Memristors



Abstract
:1. Introduction
2. Memristive BNN
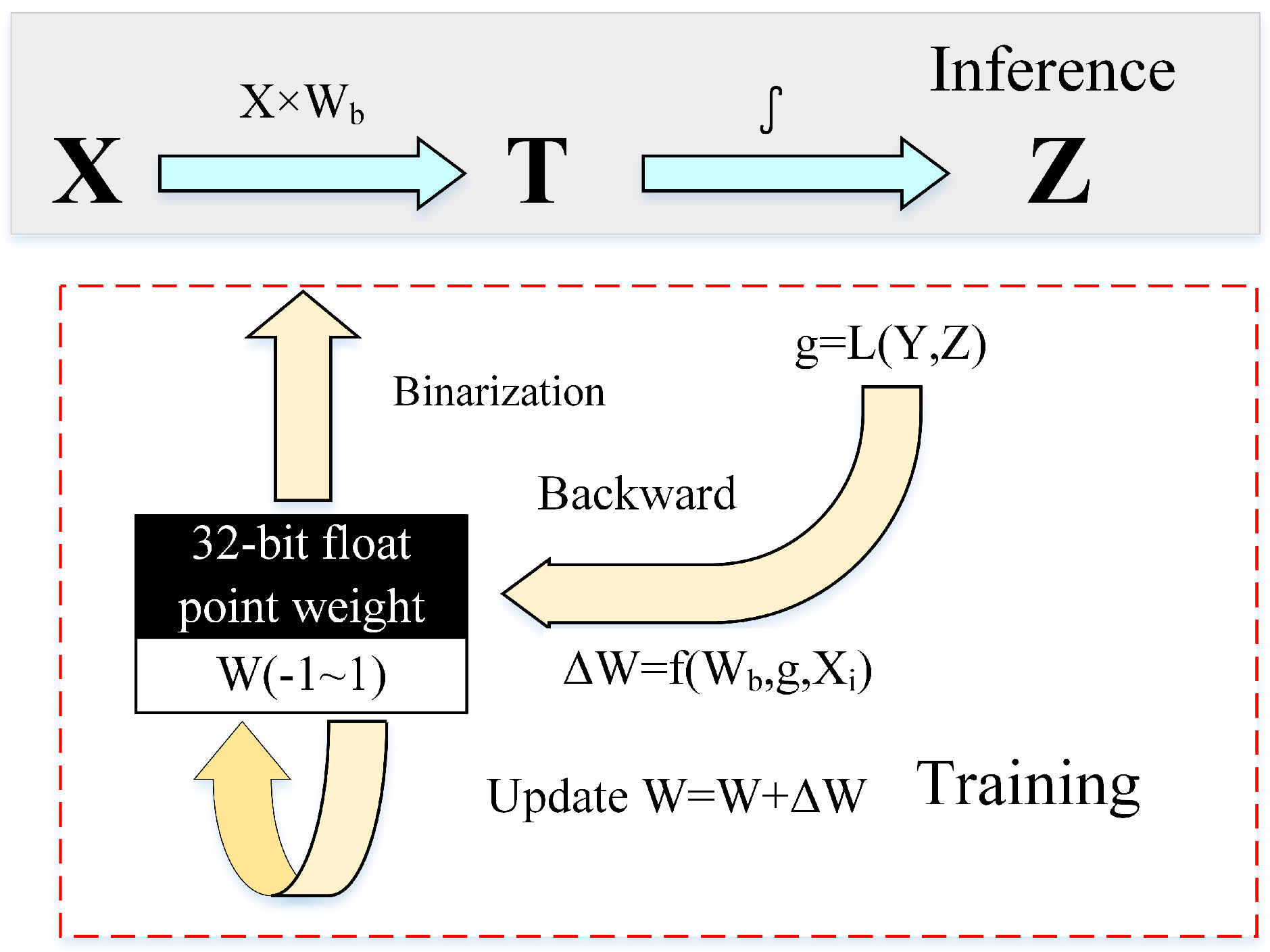
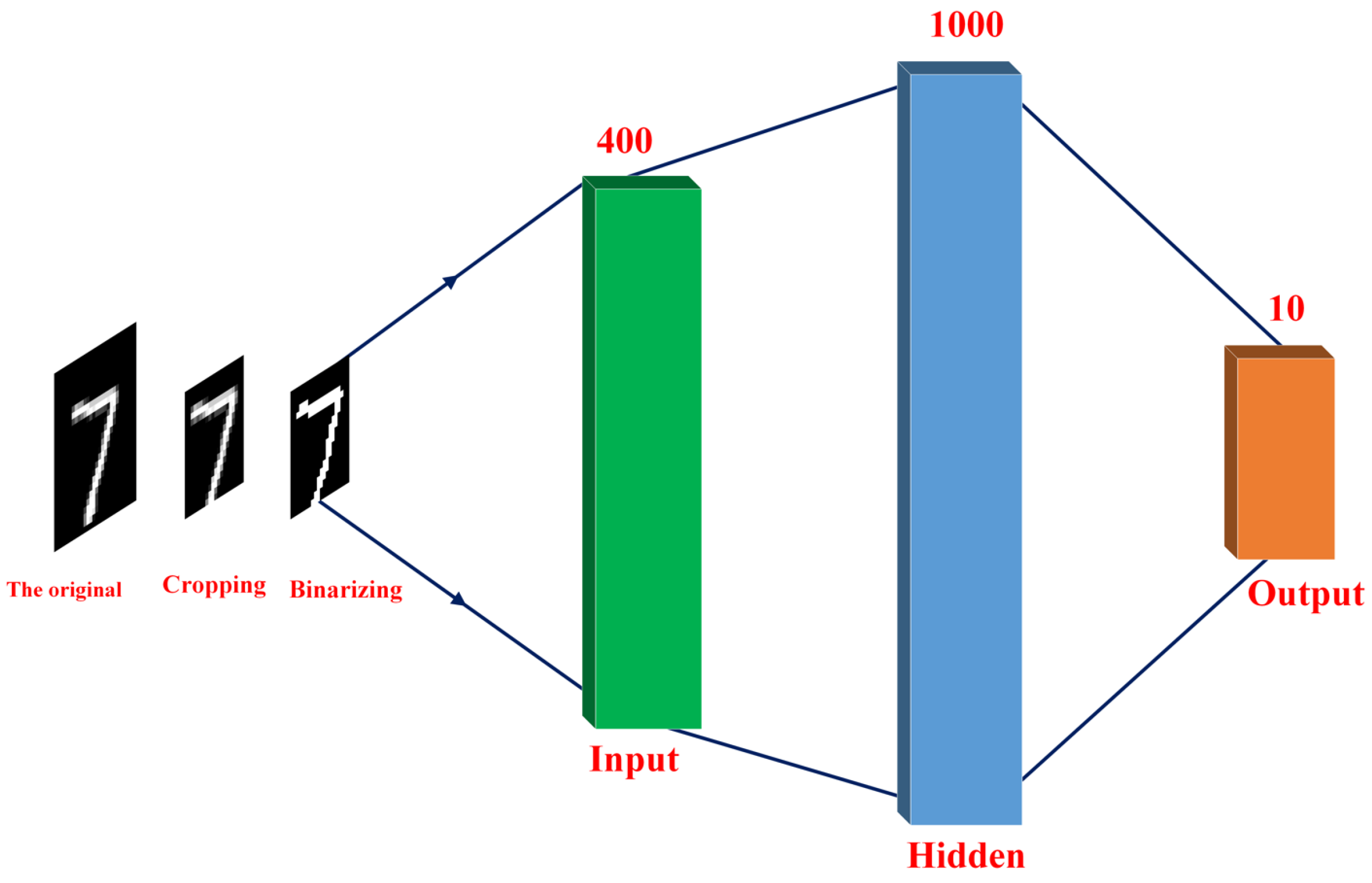
2.1. Binary Neural Network
2.2. Memristor Model
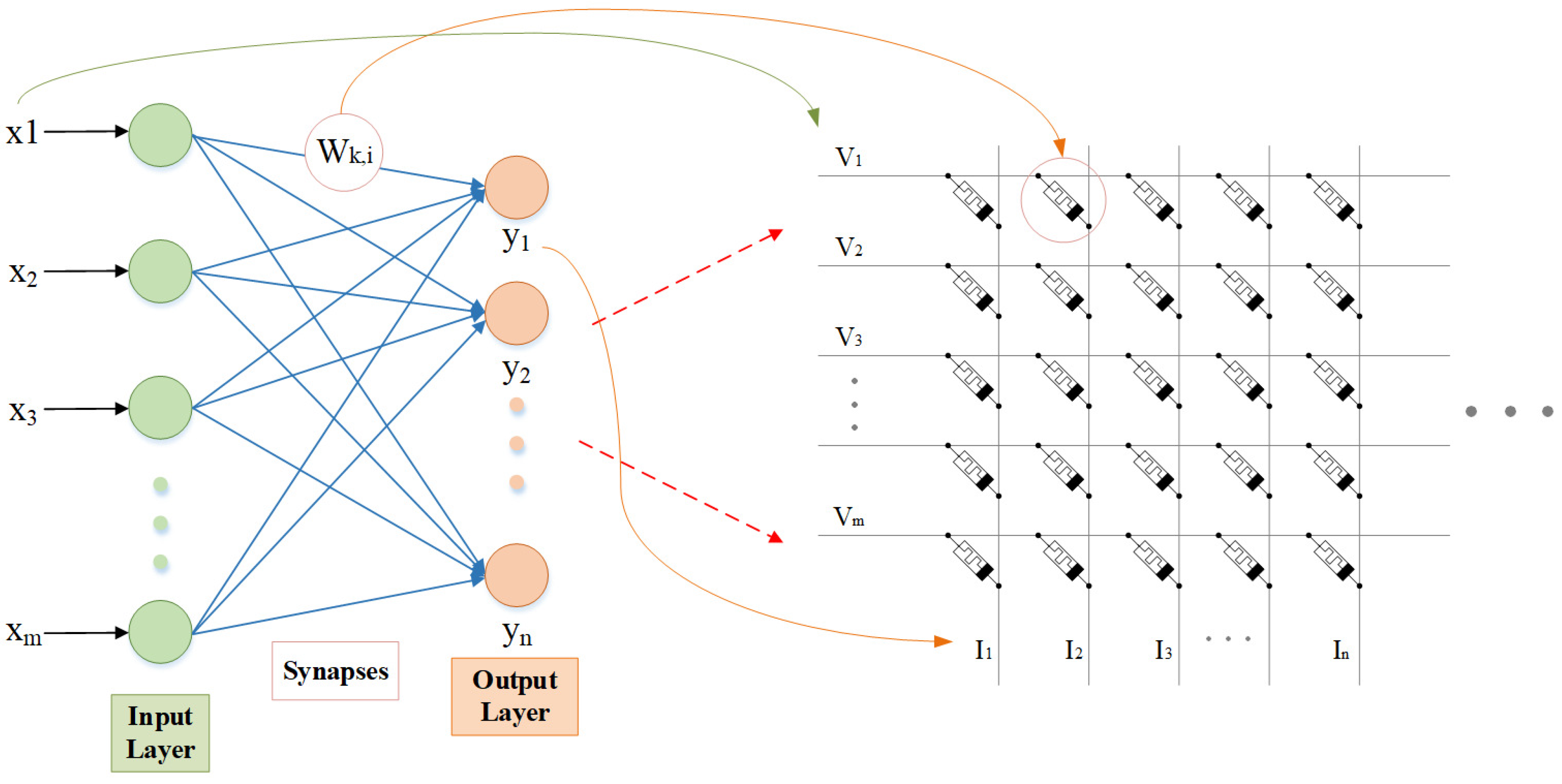
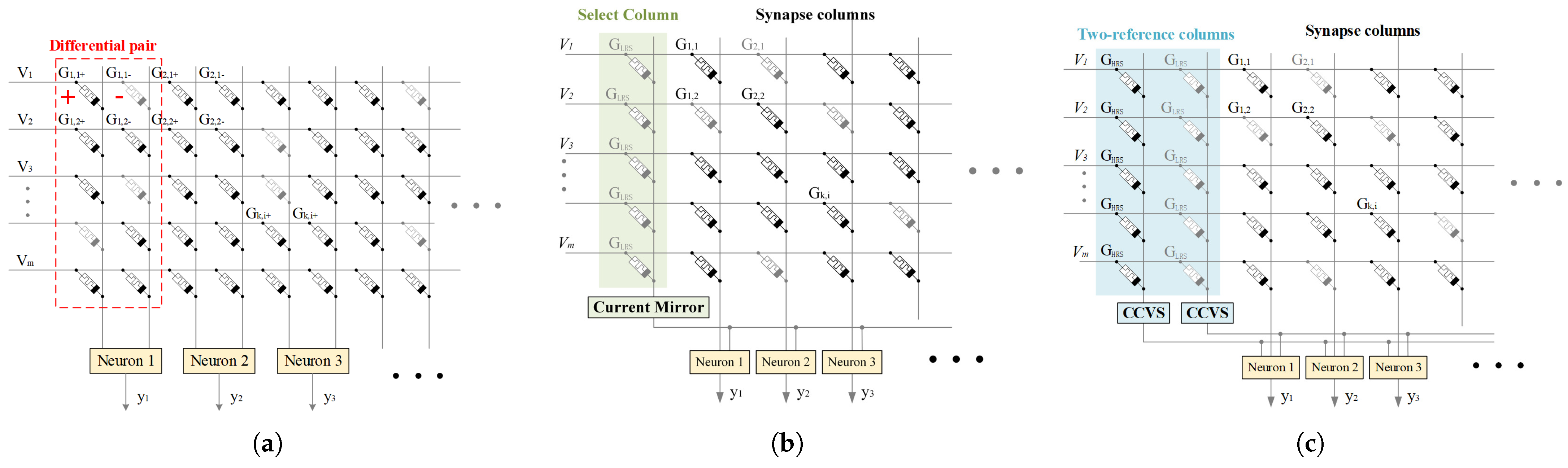
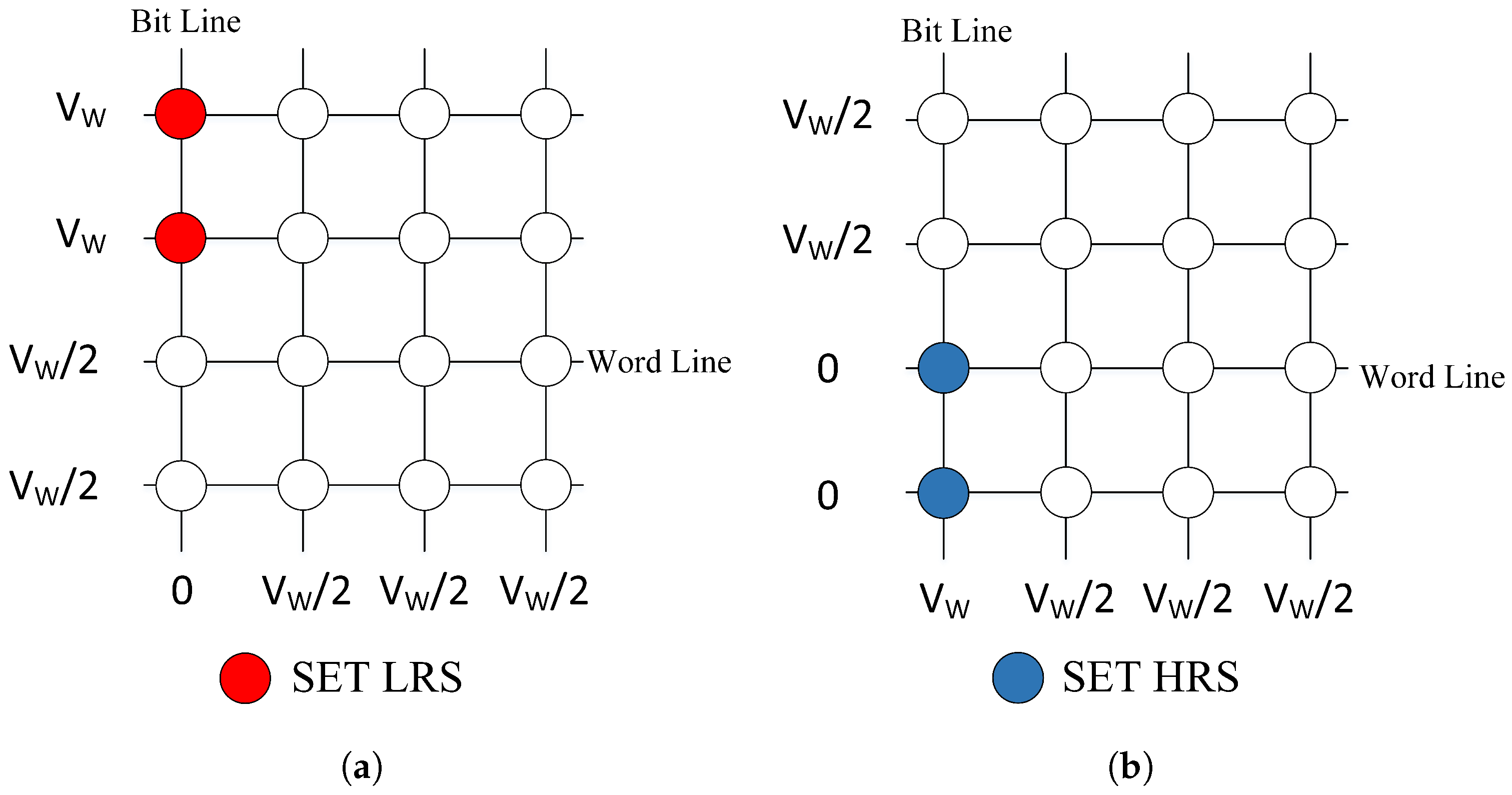
2.3. Implementation of MBNN
3. Results and Analysis
3.1. Simulation Results of the Two Schemes
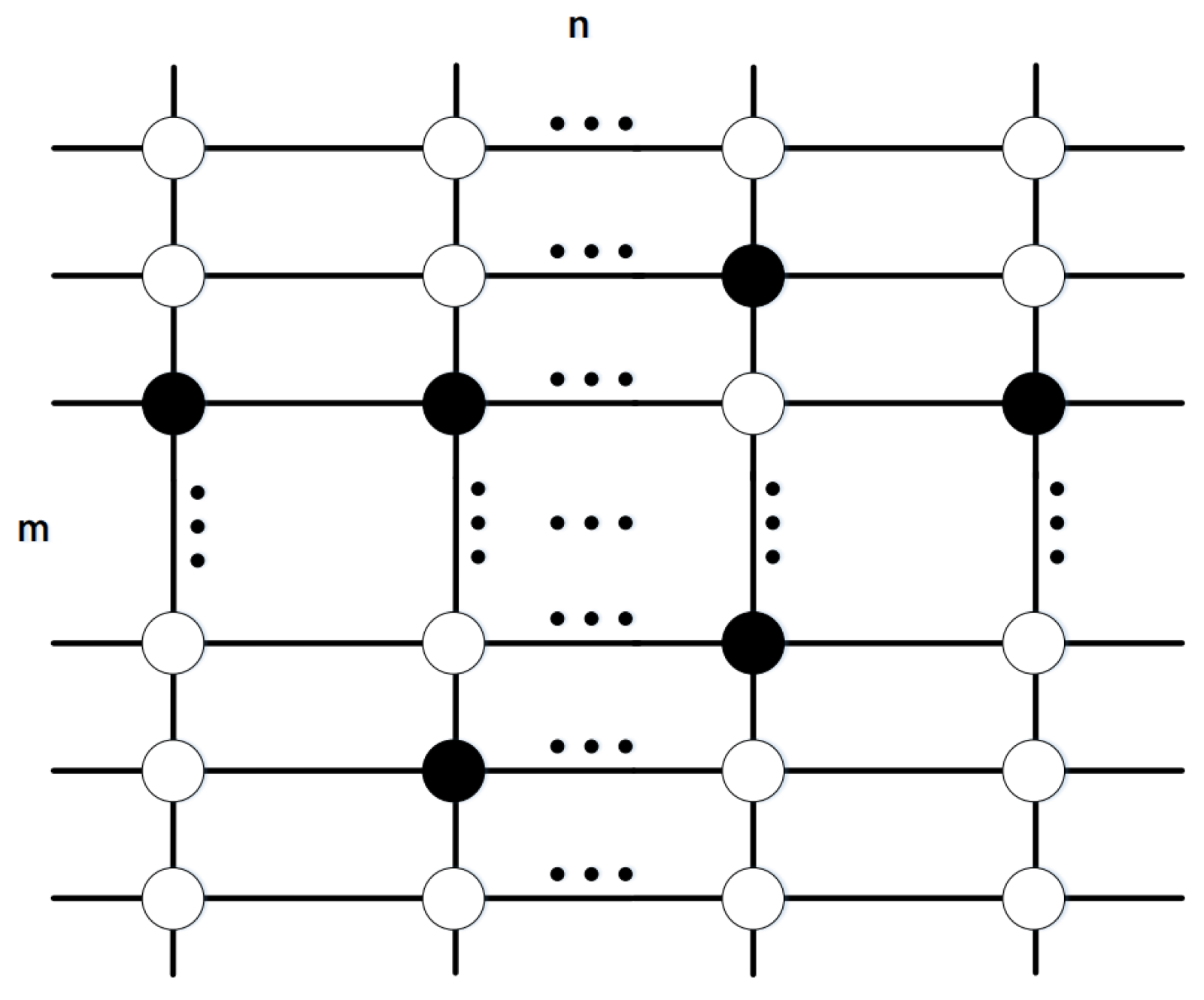
3.2. Non-Ideal Effects on Memristor Crossbar
3.2.1. Yield Rate of Memristor Array
3.2.2. Memristor Resistance Fluctuation
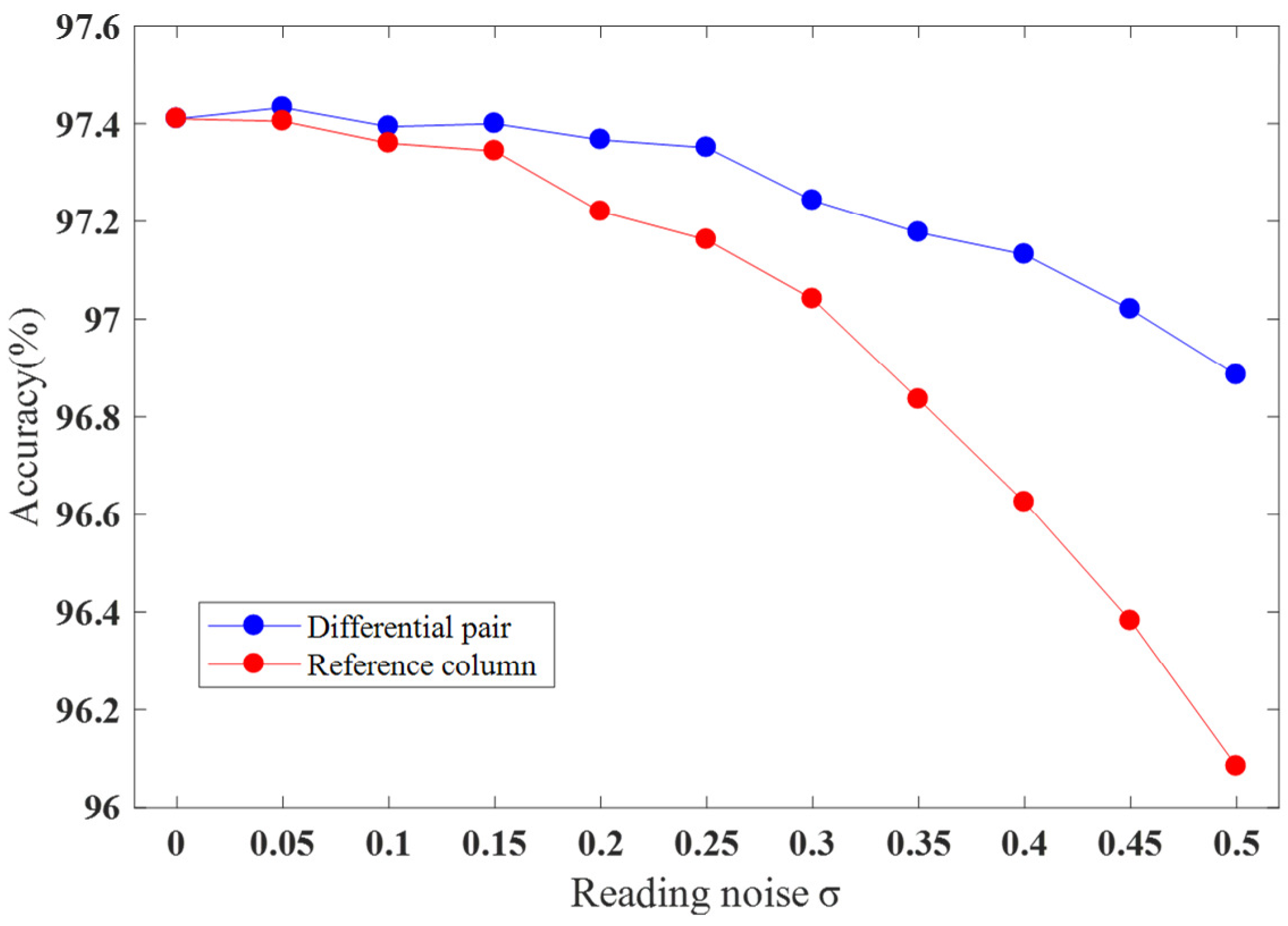
3.2.3. Reading Noise
4. Experiment Environment and Configuration
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| BNN | binary neural network |
| CCVS | current controlled voltage source |
| DNNs | deep neural networks |
| AI | artificial intelligence |
| CPU | Central Processing Unit |
| GPU | Graphic Processing Unit |
| FPGA | Field Programmable Gate Array |
| HP | Hewlett-Packard |
| RRAM | resistive random access memory |
| CMOS | Complementary Metal Oxide Semiconductor |
| MNIST | Mixed National Institute of Standards and Technology database |
| MBNN | memristive binary neural network |
| MOSFET | Metal Oxide Semiconductor Field Effect Transistor |
| VMM | vector-matrix multiplication |
| BN | batch normalization |
| MLP | multi-layer perceptron |
| HRS | high-resistance state |
| LRS | low-resistance state |
| CNN | convolutional neural network |
| RNN | recurrent neural network |
| IoT | Internet of Things |
References
- Klosowski, P. Deep Learning for Natural Language Processing and Language Modelling. In Proceedings of the 2018 Signal Processing: Algorithms, Architectures, Arrangements, and Applications (SPA), Poznan, Poland, 19–21 September 2018; pp. 223–228. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Komar, M.; Yakobchuk, P.; Golovko, V.; Dorosh, V.; Sachenko, A. Deep Neural Network for Image Recognition Based on the Caffe Framework. In Proceedings of the 2018 IEEE Second International Conference on Data Stream Mining & Processing (DSMP), Lviv, Ukraine, 21–25 August 2018; pp. 102–106. [Google Scholar]
- Ferlin, M.A.; Grochowski, M.; Kwasigroch, A.; Mikołajczyk, A.; Szurowska, E.; Grzywińska, M.; Sabisz, A. A Comprehensive Analysis of Deep Neural-Based Cerebral Microbleeds Detection System. Electronics 2021, 10, 2208. [Google Scholar] [CrossRef]
- Liu, F.; Ju, X.; Wang, N.; Wang, L.; Lee, W.J. Wind farm macro-siting optimization with insightful bi-criteria identification and relocation mechanism in genetic algorithm. Energy Convers. Manag. 2020, 217, 112964. [Google Scholar] [CrossRef]
- Park, K.; Lee, J.; Kim, Y. Deep Learning-Based Indoor Two-Dimensional Localization Scheme Using a Frequency-Modulated Continuous Wave Radar. Electronics 2021, 10, 2166. [Google Scholar] [CrossRef]
- Rashid, J.; Khan, I.; Ali, G.; Almotiri, S.H.; AlGhamdi, M.A.; Masood, K. Multi-Level Deep Learning Model for Potato Leaf Disease Recognition. Electronics 2021, 10, 2064. [Google Scholar] [CrossRef]
- Ortega-Zamorano, F.; Jerez, J.M.; Gómez, I.; Franco, L. Layer multiplexing FPGA implementation for deep back-propagation learning. Integr. Comput. Aided Eng. 2017, 24, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Shawahna, A.; Sait, S.M.; El-Maleh, A. FPGA-based Accelerators of Deep Learning Networks for Learning and Classification: A Review. IEEE Access 2018, 7, 7823–7859. [Google Scholar] [CrossRef]
- Moore, G.E. Cramming More Components onto Integrated Circuits; Morgan Kaufmann Publishers Inc.: Burlington, MA, USA, 2000. [Google Scholar]
- Strukov, D.B.; Snider, G.S.; Stewart, D.R.; Williams, R.S. The missing memristor found. Nature 2008, 453, 80–83. [Google Scholar] [CrossRef]
- Xia, Q.; Robinett, W.; Cumbie, M.W.; Banerjee, N.; Cardinali, T.J.; Yang, J.J.; Wu, W.; Li, X.; Tong, W.M.; Strukov, D.B. Memristor-CMOS hybrid integrated circuits for reconfigurable logic. Nano Lett. 2009, 9, 3640. [Google Scholar] [CrossRef] [PubMed]
- Amirsoleimani, A.; Ahmadi, M.; Ahmadi, A. Logic Design on Mirrored Memristive Crossbars. IEEE Trans. Circ. Syst. II Express Briefs 2018, 65, 1688–1692. [Google Scholar] [CrossRef]
- Li, J.; Dong, Z.; Luo, L.; Duan, S.; Wang, L. A Novel Versatile Window Function for Memristor Model With Application in Spiking Neural Network. Neurocomputing 2020, 405, 239–246. [Google Scholar] [CrossRef]
- Duani, S.; Zhang, Y.; Hu, X.; Wang, L.; Li, C. Memristor-based chaotic neural networks for associative memory. Neural Comput. Appl. 2014, 25, 1437–1445. [Google Scholar] [CrossRef]
- Chen, P.Y.; Peng, X.; Yu, S. NeuroSim+: An integrated device-to-algorithm framework for benchmarking synaptic devices and array architectures. In Proceedings of the IEEE International Electron Devices Meeting, San Francisco, CA, USA, 7–11 December 2019. [Google Scholar]
- Xia, L.; Gu, P.; Li, B.; Tang, T.; Yin, X.; Huangfu, W.; Yu, S.; Cao, Y.; Wang, Y.; Yang, H. Technological Exploration of RRAM Crossbar Array for Matrix-Vector Multiplication. J. Comput. Sci. Technol. 2016, 31, 106–111. [Google Scholar] [CrossRef]
- Lee, M.K.F.; Cui, Y.; Somu, T.; Luo, T.; Zhou, J.; Tang, W.T.; Wong, W.-F.; Goh, R.S.M. A System-Level Simulator for RRAM-Based Neuromorphic Computing Chips. ACM Trans. Archit. Code Optim. 2019, 15, 1–24. [Google Scholar] [CrossRef] [Green Version]
- Song, J.A.; Sp, B.; Yu, W.A. A variation tolerant scheme for memristor crossbar based neural network designs via two-phase weight mapping and memristor programming. Future Gener. Comput. Syst. 2020, 106, 270–276. [Google Scholar]
- The MNIST Database of Handwritten Digits. Available online: http://yann.lecun.com/exdb/mni (accessed on 14 September 2021).
- Hasan, R.; Taha, T.M. Enabling back propagation training of memristor crossbar neuromorphic processors. In Proceedings of the 2014 International Joint Conference on Neural Networks (IJCNN), Beijing, China, 6–11 July 2014. [Google Scholar]
- Courbariaux, M.; Hubara, I.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or −1. arXiv 2016, arXiv:1602.02830. [Google Scholar]
- Pi, S.; Li, C.; Jiang, H.; Xia, W.; Xin, H.L.; Yang, J.J.; Xia, Q. Memristor Crossbars with 4.5 Terabits-per-Inch-Square Density and Two Nanometer Dimension. arXiv 2018, arXiv:1804.09848. [Google Scholar]
- Choi, B.J.; Torrezan, A.C.; Strachan, J.P.; Kotula, P.G.; Lohn, A.J.; Marinella, M.J.; Li, Z.; Williams, R.S.; Yang, J.J. High-Speed and Low-Energy Nitride Memristors. Adv. Funct. Mater. 2016, 26, 5290–5296. [Google Scholar] [CrossRef] [Green Version]
- Yu, S.; Li, Z.; Chen, P.Y.; Wu, H.; He, Q. Binary neural network with 16 Mb RRAM macro chip for classification and online training. In Proceedings of the 2016 IEEE International Electron Devices Meeting (IEDM), San Francisco, CA, USA, 3–7 December 2016. [Google Scholar]
- Hirtzlin, T.; Bocquet, M.; Penkovsky, B.; Klein, J.O.; Nowak, E.; Vianello, E.; Portal, J.M.; Querlioz, D. Digital Biologically Plausible Implementation of Binarized Neural Networks with Differential Hafnium Oxide Resistive Memory Arrays. Front. Neurosci. 2019, 13, 1383. [Google Scholar] [CrossRef] [Green Version]
- Pham, K.V.; Nguyen, T.V.; Tran, S.B.; Nam, H.K.; Mi, J.L.; Choi, B.J.; Truong, S.N.; Min, K.S. Memristor Binarized Neural Networks. J. Semicond. Technol. Sci. 2018, 18, 568–588. [Google Scholar] [CrossRef]
- Truong, S.N.; Min, K.S. New Memristor-Based Crossbar Array Architecture with 50% Area Reduction and 48% Power Saving for Matrix-Vector Multiplication of Analog Neuromorphic Computing. J. Semiconduct. Technol. Sci. 2014, 14, 356–363. [Google Scholar] [CrossRef] [Green Version]
- Qin, Y.F.; Kuang, R.; Huang, X.D.; Li, Y.; Chen, J.; Miao, X.S. Design of High Robustness BNN Inference Accelerator Based on Binary Memristors. IEEE Trans. Electron. Dev. 2020, 67, 3435–3441. [Google Scholar] [CrossRef]
- Gardner, M.W. Artificial neural networks (the multilayer perceptron)—A review of applications in the atmospheric sciences. Atmos. Environ. 1998, 32, 2627–2636. [Google Scholar] [CrossRef]
- Pershin, Y.V.; Ventra, M. SPICE model of memristive devices with threshold. Radioengineering 2013, 22, 485–489. [Google Scholar]
- Ranjan, R.; Ponce, P.M.; Hellweg, W.L.; Kyrmanidis, A.; Saleh, L.A.; Schroeder, D.; Krautschneider, W.H. Integrated Circuit with Memristor Emulator Array and Neuron Circuits for Biologically Inspired Neuromorphic Pattern Recognition. J. Circ. Syst. Comput. 2017, 26, 1750183. [Google Scholar] [CrossRef] [Green Version]
- Cheng, L.; Li, Y.; Yin, K.; Hu, S.; Miao, X. Functional Demonstration of a Memristive Arithmetic Logic Unit (MemALU) for In-Memory Computing. Adv. Funct. Mater. 2019, 29, 1905660. [Google Scholar] [CrossRef]
- Liang, Y.; Lu, Z.; Wang, G.; Yu, D.; Iu, H.C. Threshold-type Binary Memristor Emulator Circuit. IEEE Access 2019, 7, 180181–180193. [Google Scholar] [CrossRef]
- Shukla, A.; Prasad, S.; Lashkare, S.; Ganguly, U. A case for multiple and parallel RRAMs as synaptic model for training SNNs. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018. [Google Scholar]
- Sangwan, V.K.; Lee, H.S.; Bergeron, H.; Balla, I.; Beck, M.E.; Chen, K.S.; Hersam, M.C. Multi-Terminal Memtransistors from Polycrystalline Monolayer MoS2. Nature 2018, 554, 500–504. [Google Scholar] [CrossRef]
- Luo, S.; Liao, K.; Lei, P.; Jiang, T.; Hao, J. Synaptic memristor based on two-dimensional layered WSe2 nanosheets with short- and long-term plasticity. Nanoscale 2021, 13, 6654–6660. [Google Scholar] [CrossRef]
- Zhang, W.; Gao, H.; Deng, C.; Lv, T.; Hu, S.; Wu, H.; Xue, S.; Tao, Y.; Deng, L.; Xiong, W. An ultrathin memristor based on a two-dimensional WS2/MoS2 heterojunction. Nanoscale 2021, 13, 11497–11504. [Google Scholar] [CrossRef] [PubMed]
- Bala, A.; Adeyemo, A.; Yang, X.; Jabir, A. Learning method for ex-situ training of memristor crossbar based multi-layer neural network. In Proceedings of the 2017 9th International Congress on Ultra Modern Telecommunications and Control Systems and Workshops (ICUMT), Munich, Germany, 6–8 November 2017. [Google Scholar]
- Hasan, R.; Taha, T.M.; Yakopcic, C. On-chip training of memristor crossbar based multi-layer neural networks. Microelectron. J. 2017, 66, 31–40. [Google Scholar] [CrossRef]
- Zhou, Z.; Huang, P.; Xiang, Y.C.; Shen, W.S.; Kang, J.F. A new hardware implementation approach of BNNs based on nonlinear 2T2R synaptic cell. In Proceedings of the 2018 IEEE International Electron Devices Meeting (IEDM), San Francisco, CA, USA, 10–18 December 2020. [Google Scholar]
- Prezioso, M.; Merrikh-Bayat, F.; Hoskins, B.D.; Adam, G.C.; Likharev, K.K.; Strukov, D.B. Training and operation of an integrated neuromorphic network based on metal-oxide memristors. Nature 2015, 521, 61–64. [Google Scholar] [CrossRef] [Green Version]
- Jung, C.M.; Choi, J.M.; Min, K.S. Two-Step Write Scheme for Reducing Sneak-Path Leakage in Complementary Memristor Array. IEEE Trans. Nanotechnol. 2012, 11, 611–618. [Google Scholar] [CrossRef]
- Cong, X.; Niu, D.; Muralimanohar, N.; Balasubramonian, R.; Yuan, X. Overcoming the challenges of crossbar resistive memory architectures. In Proceedings of the IEEE International Symposium on High Performance Computer Architecture, Burlingame, CA, USA, 7–11 February 2015. [Google Scholar]
- Frey, P.; O’Riordan, D. Verilog-AMS: Mixed-Signal Simulation and Cross Domain Connect Modules. In Proceedings of the 2000 IEEE/ACM International Workshop on Behavioral Modeling and Simulation, Orlando, FL, USA, 18–20 October 2000; p. 103. [Google Scholar]
- Bidmeshki, M.M.; Antonopoulos, A.; Makris, Y. Proof-Carrying Hardware-Based Information Flow Tracking in Analog/Mixed-Signal Designs. IEEE J. Emerg. Sel. Top. Circuits Syst. 2021, 11, 415–427. [Google Scholar] [CrossRef]
- Liu, C.; Hu, M.; Strachan, J.P.; Li, H. Rescuing Memristor-based Neuromorphic Design with High Defects. In Proceedings of the Design Automation Conference, Austin, TX, USA, 18–22 June 2017; pp. 1–6. [Google Scholar]
- Xu, N.; Liang, F.; Chi, Y.; Chao, Z.; Tang, Z. Resistance uniformity of TiO2 memristor with different thin film thickness. In Proceedings of the 2014 IEEE 14th International Conference on Nanotechnology (IEEE-NANO), Toronto, ON, Canada, 18–21 August 2014. [Google Scholar]
- Veksler, D.; Bersuker, G.; Vandelli, L.; Padovani, A.; Larcher, L.; Muraviev, A.; Chakrabarti, B.; Vogel, E.; Gilmer, D.C.; Kirsch, P.D. Random telegraph noise (RTN) in scaled RRAM devices. In Proceedings of the 2013 IEEE International Reliability Physics Symposium, Monterey, CA, USA, 14–18 April 2013; pp. MY.10.1–MY.10.4. [Google Scholar]
- Agarwal, S.; Plimpton, S.J.; Hughart, D.R.; Hsia, A.H.; Marinella, M.J. Resistive memory device requirements for a neural algorithm accelerator. In Proceedings of the International Joint Conference on Neural Networks, Vancouver, BC, Canada, 24–29 July 2016; pp. 929–938. [Google Scholar]
- Ambrogio, S.; Balatti, S.; Mccaffrey, V.; Wang, D.C.; Ielmini, D. Noise-Induced Resistance Broadening in Resistive Switching Memory—Part II: Array Statistics. IEEE Trans. Electron. Dev. 2015, 62, 3812–3819. [Google Scholar] [CrossRef]
- Li, C.; Hu, M.; Li, Y.; Jiang, H.; Ge, N.; Montgomery, E.; Zhang, J.; Song, W.; Dávila, N.; Graves, C.E.; et al. Analogue signal and image processing with large memristor crossbars. Nat. Electron. 2018, 1, 52–59. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Hidden Neurons Per Layer | 1 Hidden Layer | 2 Hidden Layers | 3 Hidden Layers |
|---|---|---|---|
| 100 | 91.8% | 91.83% | 92.3% |
| 400 | 95.89% | 97.1% | 97.15% |
| 700 | 96.88% | 97.82% | 98.05% |
| 1000 | 97.41% | 97.99% | 98.36% |
| 1300 | 97.58% | 98.3% | 98.31% |
| 1600 | 97.78% | 98.25% | 98.27% |
| 1900 | 97.74% | 98.45% | 98.4% |
| 2200 | 97.88% | 98.36% | 98.35% |
| 400 × 100 × 10 MBNN | The Traditional Differential Structure | The Proposed Two-Column Reference Structure |
|---|---|---|
| Total number of memristors | 82,000 | 42,000 |
| Writing time | 40 µs | 20.4 µs |
| Recognition accuracy | 91.8% | 91.8% |
| Device Yield Rate | The Traditional Differential Structure | The Proposed Two-Column Reference Structure |
|---|---|---|
| 100% | 97.41% | 97.41% |
| 99% | 97.4% | 97.28% |
| 98% | 97.37% | 97.33% |
| 97% | 97.3% | 97.26% |
| 96% | 97.26% | 97.12% |
| 95% | 97.17% | 97.04% |
| 94% | 97.23% | 97.11% |
| 93% | 97.26% | 96.97% |
| 92% | 97.08% | 96.98% |
| 91% | 96.99% | 96.77% |
| 90% | 96.98% | 96.89% |
| Device Fluctuation | The Traditional Differential Structure | The Proposed Two-Column Reference Structure |
|---|---|---|
| 0 | 97.41% | 97.41% |
| 0.05 | 97.407% | 94.153% |
| 0.1 | 97.383% | 91.49% |
| 0.15 | 97.209% | 89.69% |
| 0.2 | 97.166% | 90.529% |
| 0.25 | 96.972% | 87.598% |
| 0.3 | 96.968% | 86.593% |
| 0.35 | 96.068% | 85.85% |
| 0.4 | 96.313% | 83.982% |
| 0.45 | 92.173% | 79.486% |
| 0.5 | 89.983% | 76.919% |
| Reading Noise | The Traditional Differential Structure | The Proposed Two-Column Reference Structure |
|---|---|---|
| 0 | 97.41% | 97.41% |
| 0.05 | 97.47% | 97.42% |
| 0.1 | 97.32% | 97.46% |
| 0.15 | 97.39% | 97.4% |
| 0.2 | 97.25% | 97.27% |
| 0.25 | 97.3% | 97.25% |
| 0.3 | 97.25% | 96.98% |
| 0.35 | 97.18% | 96.75% |
| 0.4 | 97.09% | 96.63% |
| 0.45 | 97.09% | 96.27% |
| 0.5 | 96.77% | 96.05% |
| Analysis of Non-Ideal Factors | The Traditional Differential Structure | The Proposed Two-Column Reference Structure |
|---|---|---|
| 400 × 1000 × 10 MBNN (Device yield rate) | 62 min | 20 min |
| 400 × 1000 × 10 MBNN (Device fluctuation) | 58 min | 21 min |
| 400 × 1000 × 10 MBNN (Reading noise) | 60 min | 20 min |
| Training Stage | The Traditional Differential Structure | The Proposed Two-Column Reference Structure |
|---|---|---|
| 400 × 100 × 10 MBNN | 10 h | 10 h |
| 400 × 1000 × 10 MBNN | 3 h | 3 h |
| Inference Stage | The Traditional Differential Structure | The Proposed Two-Column Reference Structure |
|---|---|---|
| 400 × 100 × 10 MBNN | 47 h | 18 h |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Y.; Wang, Y.; Wang, R.; Rong, Y.; Jiang, X. A Highly Robust Binary Neural Network Inference Accelerator Based on Binary Memristors. Electronics 2021, 10, 2600. https://doi.org/10.3390/electronics10212600
Zhao Y, Wang Y, Wang R, Rong Y, Jiang X. A Highly Robust Binary Neural Network Inference Accelerator Based on Binary Memristors. Electronics. 2021; 10(21):2600. https://doi.org/10.3390/electronics10212600
Chicago/Turabian StyleZhao, Yiyang, Yongjia Wang, Ruibo Wang, Yuan Rong, and Xianyang Jiang. 2021. "A Highly Robust Binary Neural Network Inference Accelerator Based on Binary Memristors" Electronics 10, no. 21: 2600. https://doi.org/10.3390/electronics10212600
APA StyleZhao, Y., Wang, Y., Wang, R., Rong, Y., & Jiang, X. (2021). A Highly Robust Binary Neural Network Inference Accelerator Based on Binary Memristors. Electronics, 10(21), 2600. https://doi.org/10.3390/electronics10212600