1. Introduction
In recent years, the use of Deep Learning (DL) has improved the state of the art in many different fields, ranging from computer vision [
1,
2,
3] and text analysis [
4,
5,
6] to bioinformatics [
7,
8]. More specifically, DL-based decision support systems have become increasingly popular in the medical field [
9]—and in particular for application in the Internet of Medical Things—where CNNs have been successfully employed for the classification of radiological, magnetic resonance or CT (Computerized Axial Tomography) images [
10,
11] and for natural images, for instance, in the classification of atypical nevi and melanomas [
12,
13,
14], for the segmentation of bacterial colonies grown on Petri plates [
15,
16] and for retinal images [
17]. In this paper, a DL aortic image semantic segmentation system is presented. The automatic segmentation tool was developed based on a new proprietary dataset, collected at the Department of Medicine, Surgery and Neuroscience of the University of Siena (Italy).
The aorta is the most important arterial vessel in the human body and is responsible for transporting blood from the heart to all other organs. It originates from the left ventricle and extends throughout the abdomen, where it divides into the iliac arteries. The aorta can be classified according to its anatomical location [
18,
19] in the thoracic aorta and the abdominal aorta. Depending on its morphology and on the direction of blood flow, the different parts of the aorta are also classified as ascending/descending and the aortic arch. Normally, the average aortic diameter does not exceed 2.5 cm, but over time it can dilate, stiffen or deform due to various pathologies, such as aneurysms [
20] and dissections [
21]. An aortic aneurysm is a permanent and non-physiological dilation of the aorta, where the vessel diameter exceeds the normal one by more than 1.5 cm. Aortic aneurysms are linked to a high mortality rate and are difficult to treat because they make the vascular wall of the dilated segment thinner and more prone to rupture. In addition, vessel dilation alters the blood flow, promoting abnormal blood clots (emboli) or thrombi. Instead, aortic dissection is a serious condition in which there is a tear in the aortic wall. When the tear extends along the wall, blood can flow between the layers of the aortic wall, resulting in a false lumen. This can lead to rupture of the vessel or a decrease in blood flow to the organs (ischemia).
The automated segmentation of the aorta from CT images helps clinicians speed up the diagnosis of these pathologies, enabling rapid reconstructive surgery, which is critical to saving patients’ lives. The purpose of image segmentation is to divide a digital image into multiple segments based on certain visual features (which characterize the whole segment). In particular, image semantic segmentation can be viewed as a pixel-wise (voxel in 3D images) classification, in which a label is assigned to each pixel/voxel. This is an important step in image understanding, because it provides a complete characterization of the objects present in the image. In recent years, several semantic segmentation models, based on deep neural networks, have been proposed [
22,
23,
24,
25,
26]. DL architectures are usually trained through supervised learning, exploiting large sets of labeled data, which are commonly publicly available. Such datasets are used to train generic semantic segmentation networks, which can later be adapted to specific domains with less data. Unfortunately, no publicly available aortic datasets which can be used for this purpose exist. For this reason, in collaboration with the Department of Medicine, Surgery and Neuroscience of the University of Siena, a dataset of 154 3D CT images was collected. In each image, all pixels belonging to the aorta were labeled using a semi-automatic approach. Labeling images is, in fact, an extremely time consuming task. Therefore, even if labels obtained in a semi-automatic way provide a lower quality information this was a necessary trade-off to obtain enough data in a reasonable amount of time. Subsequently, following an approach inspired by [
10], the segmented images were employed to train three 2D CNN segmentation models, one for each view (coronal, sagittal and axial). Several architectures based on both LinkNet [
27] and U-Net [
28] were employed as segmentation networks and their results were compared. Two-dimensional models were preferred to three-dimensional for computational reasons and also to reduce overfitting—with a small number of images available, in fact, training a 3D model would be difficult due to the large number of parameters required by convolutions. The results obtained are very promising and show that, even with the use of low-quality labeled images, DL architectures can successfully segment the aorta from CT scans.
In particular, the main contributions of this manuscript can be summarized as:
A new approach for 3D CT scan segmentation is proposed for aorta images, based on 2D CNNs;
The model has low computational requirements and can also be employed with limited computational resources;
The approach can be employed on small datasets, possibly with noisy labels;
The method was tested on an original dataset collected at the University of Siena not publicly available due to privacy issues.
The paper is organized as follows. In
Section 2, the related literature is reviewed.
Section 3 presents a description of the proposed approach, and
Section 4 discusses the obtained experimental results. Finally,
Section 5 draws some conclusions and future perspectives.
Table A1 in
Appendix A summarizes the nomenclature used throughout the manuscript.
4. Experiments and Results
The dataset used in our experiments is described in
Section 4.1, while the experimental setup and the obtained results are discussed in
Section 4.2.
4.1. Dataset
The dataset, collected at the Department of Medicine, Surgery and Neuroscience of the University of Siena, is made up of 154 CT scans acquired with contrast medium. The scans were saved in DICOM (Digital Imaging and Communications in Medicine) format, which is the standard for CT images. The DICOM format requires the presence of a set of files, one for each slice, which collectively describe a 3D volume, together with a dictionary of metadata, that contains information on the acquisition setup and on the patient (patient data were anonymized; only details about their age and gender were kept).
Table 1 reports the demographic description of the dataset as well as the number of CT scans available.
Additional metadata, which contain some descriptions of the collected CT scans, namely the orientation and size of the voxels, are available. The orientation is defined for each view: axial (X–Y plane), coronal (X–Z plane) and sagittal (Y–X plane), of the CT scans. Instead, the size of the voxel is defined by two parameters:
The pixel spacing, which indicates the dimension in millimeters of a single pixel in each slice;
The slice thickness, which corresponds to the distance in millimeters between two adjacent slices.
To train the deep segmentation model, the dataset was split into a
training,
validation and
test set, as described in
Table 2.
All the scans were pre-processed as described in
Section 3.1, resulting in a set of slices for each view of the scans.
Table 3 displays the number of slices belonging to the training, validation and test sets, along with their sizes, for each view.
Each slice of the dataset is grayscale, and each pixel has a binary label associated with it, indicating whether the pixel belongs to the aorta or not. Supervision is generated semi-automatically using 3DSlicer. The dataset shows high positional, labeling and contrast variability, mainly caused by the following reasons:
Position of the aorta—not all the scans are centered in the same way;
Presence of errors in the labels—the semi-automatic procedure used to create the labels is sometimes not accurate due to the presence of false positives (voxels which are labeled as aorta but that actually do not belong to it);
Different acquisition systems—the CT scans were collected in different periods and using different acquisition systems.
4.2. Results and Discussion
As described before, different segmentation network architectures were tested. In particular, the following four architectures were used in our experiments:
U-Net with ResNet34—U-Net architecture with ResNet34 used as the encoder;
U-Net with Inception ResNet V2—U-Net architecture with Inception ResNet V2 used as the encoder;
LinkNet with ResNet34—LinkNet architecture with ResNet34 used as the encoder;
LinkNet with Inception ResNet V2—LinkNet architecture with Inception ResNet V2 used as the encoder.
For each of the above architectures, following the training procedure described in
Section 3.2, three models were trained, one for each CT scan view (axial, coronal and sagittal). The results on the validation set of each model for each view are reported in
Table 4 for U-Net and in
Table 5 for LinkNet, respectively.
As can be easily observed, LinkNet obtains a greater MIoU and, in particular, when the ResNet34 is used as the encoder, the difference between LinkNet and U-Net is greater. If, instead, Inception ResNet V2 is used as the encoder, the difference between U-Net and LinkNet is less significant. Furthermore, it can be noted that, even with a small dataset, Inception ResNet V2 outperforms ResNet34 in all the experiments. Only when the model is trained on the coronal view do the two architectures behave quite similarly. Based on these results, the LinkNet architecture with the Inception ResNet V2 encoder was chosen and evaluated on the test set. The results are reported in
Table 6.
The results obtained are promising but limited by the quality of the annotations. Indeed, the ground truth of the dataset was obtained with a semi-automatic procedure and, in some cases, was not completely accurate. However, the dataset was provided with a reasonable supervision that somehow compensates for the absence of datasets with aortic images labeled at the pixel level. In
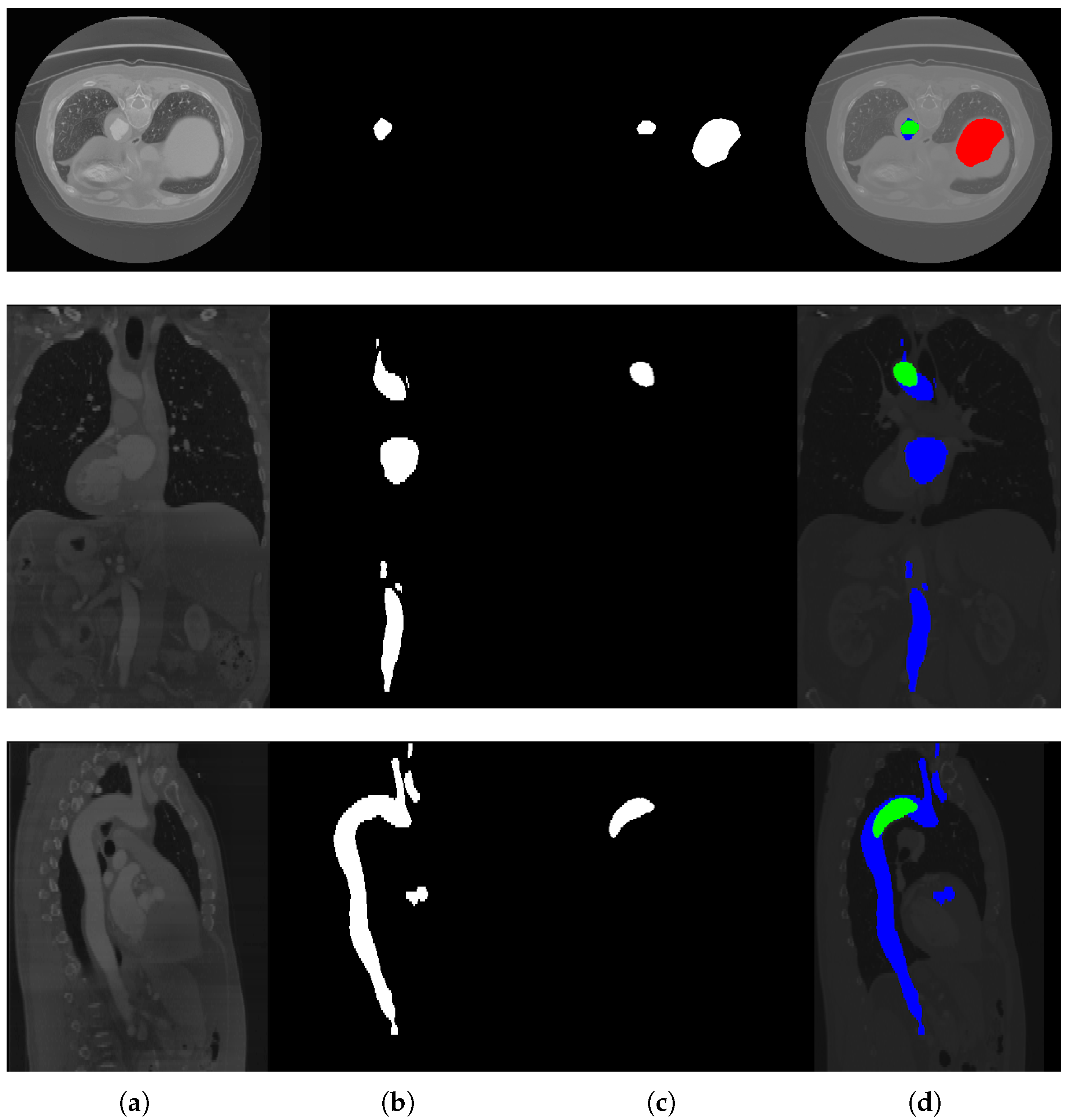
Figure 5, some images are provided, together with their labels and the segmentation generated by the network, for a qualitative evaluation.
Figure 6 shows some slices not correctly segmented by the network. As we can see, in this case, the images are actually difficult to interpret; in the second and third row, in fact, the slices are really dark and, in the first row, the network probably wrongly classified the aorta due to its size.
5. Conclusions
In this paper, some deep convolutional neural networks for aorta segmentation were trained, using a dataset of 154 CT scans collected at the Department of Medicine, Surgery and Neuroscience of the University of Siena. Two types of architectures, U-Net and LinkNet, with different types of encoders, ResNet34 and Inception ResNet V2, were tested as segmentation networks. Despite the fact that network training was based on a small set of training images with a low-quality supervision, obtained with a semi-automatic labeling approach, and there was variability in the acquisition conditions, we demonstrated that it was possible to successfully train three 2D segmentation networks, one for each view (axial, coronal and sagittal). Obtaining a set of high-quality supervised 3D images is costly and time consuming; however, if a larger set of semi-automatically supervised scans become available, it would be possible in principle to further improve the results. Therefore, as a matter of future research, we leave the possibility of employing a semi-supervised approach to enrich the current dataset, based on a set of unlabeled scans, that will hopefully increase the network performance. Another future development currently under investigation entails post-processing on the network output to clean the predictions. In particular, consistency between predictions from adjacent sections and between predictions from different views could be used to improve the segmentation quality.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





