
3D Face Recognition Based on an Attention Mechanism and Sparse Loss Function

Abstract
:1. Introduction
- Develop a face recognition model based on 3D scan and deep learning for single 3D scan training data per person;
- Develop an attention layer to the classic CNN to compose ACNN to extract useful information based on the features of faces;
- Use a Siamese network structure to train the network with a sparse loss function to build a distance-based face feature transformer in order to avoid the impact caused by the small size of samples.
2. Materials and Methods
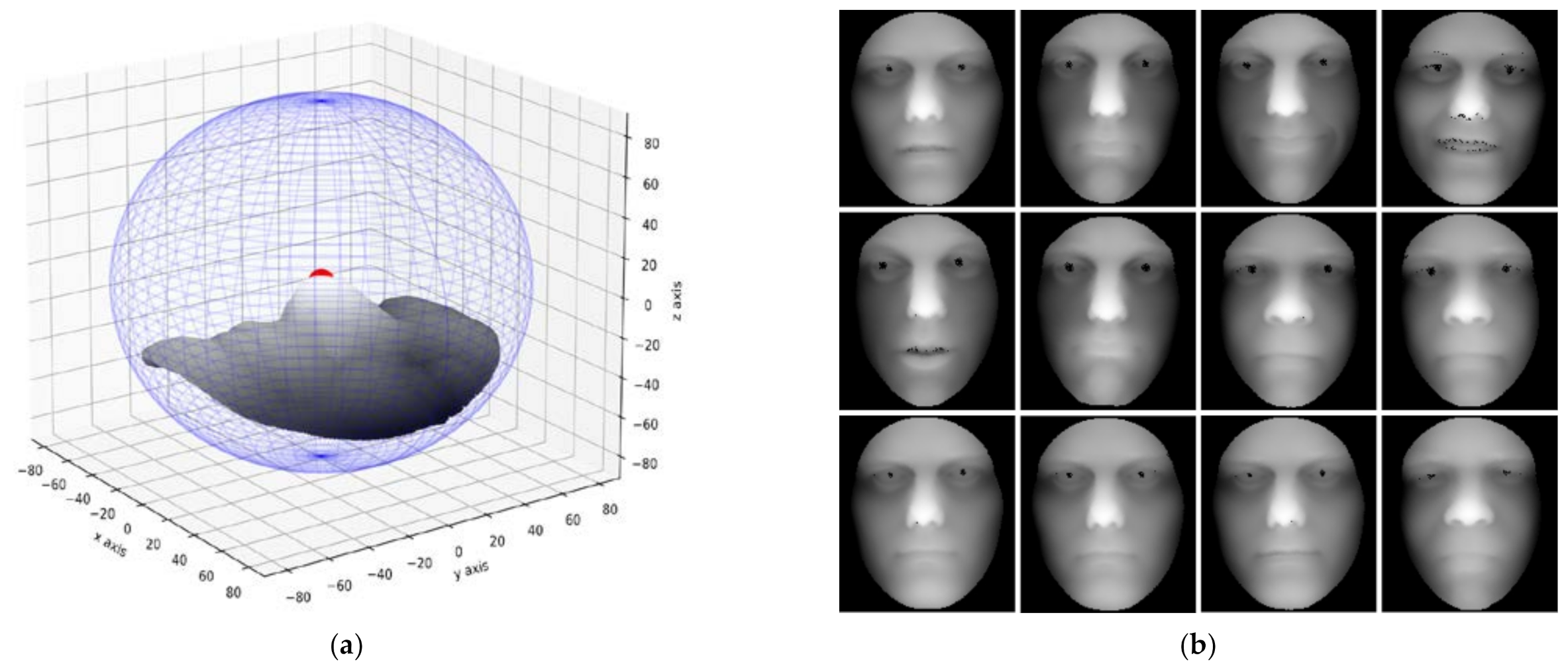
2.1. Introduction of Face Dataset and Preprocessing
- Step 1: Use Equation (1) to calculate and count the corresponding parameters, eliminate outliers in the points set with Equation (2), and decrease the noise caused by the out-of-bounds environment.
- Step 2: Use the S.I. to search the nose candidate area in the point cloud data and utilize the height of the z-axis to confirm the tip of the nose.
- Step 3: Use the tip of the nose found in step 2 to segment the point cloud data. The segmentation used the nose tip point as a sphere center and points in the spherical area with a radius of 90 mm were obtained as the face area.
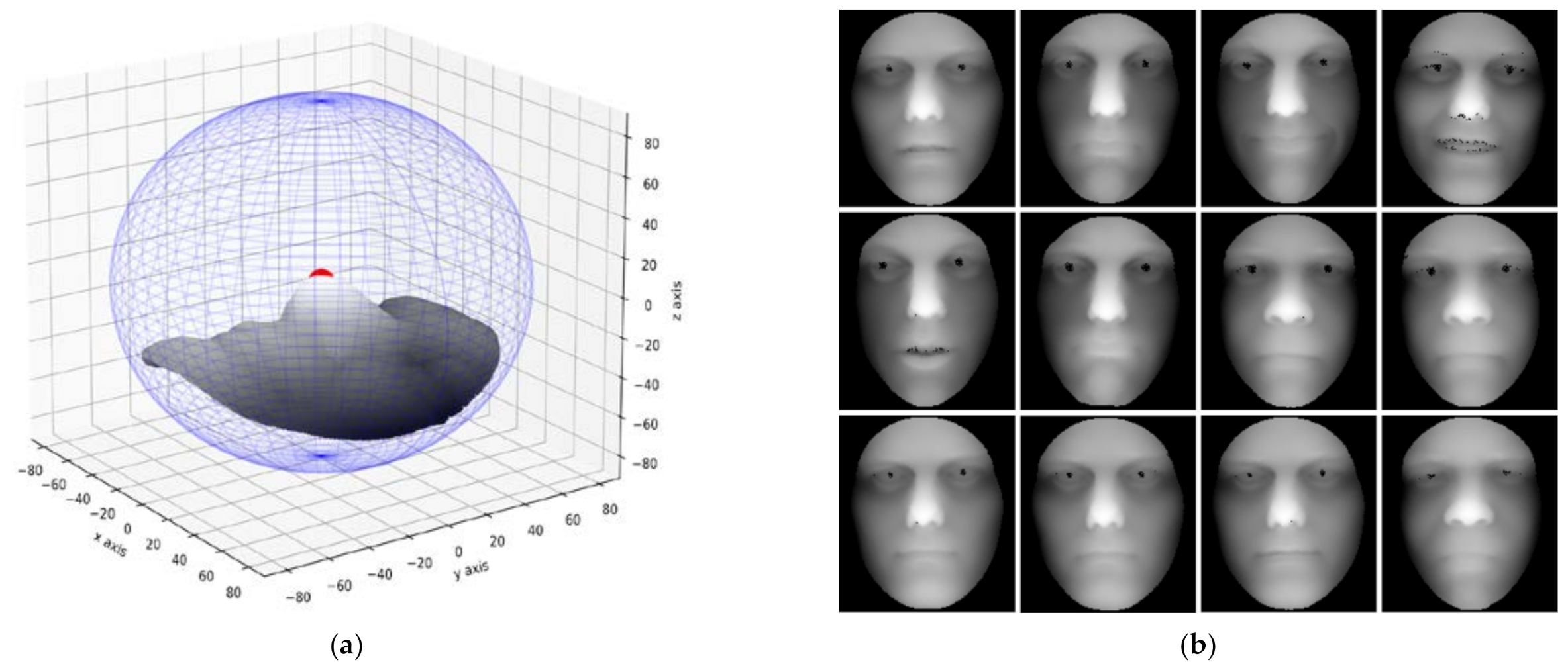
- Step 4: Perform a bicubic interpolation operation on the obtained face area to achieve a smooth surface and the smoothed face area obtained is shown in Figure 1a.
- Step 5: Project the smoothed face surface onto a two-dimensional plane with the z-axis value to form a 2D grayscale image.
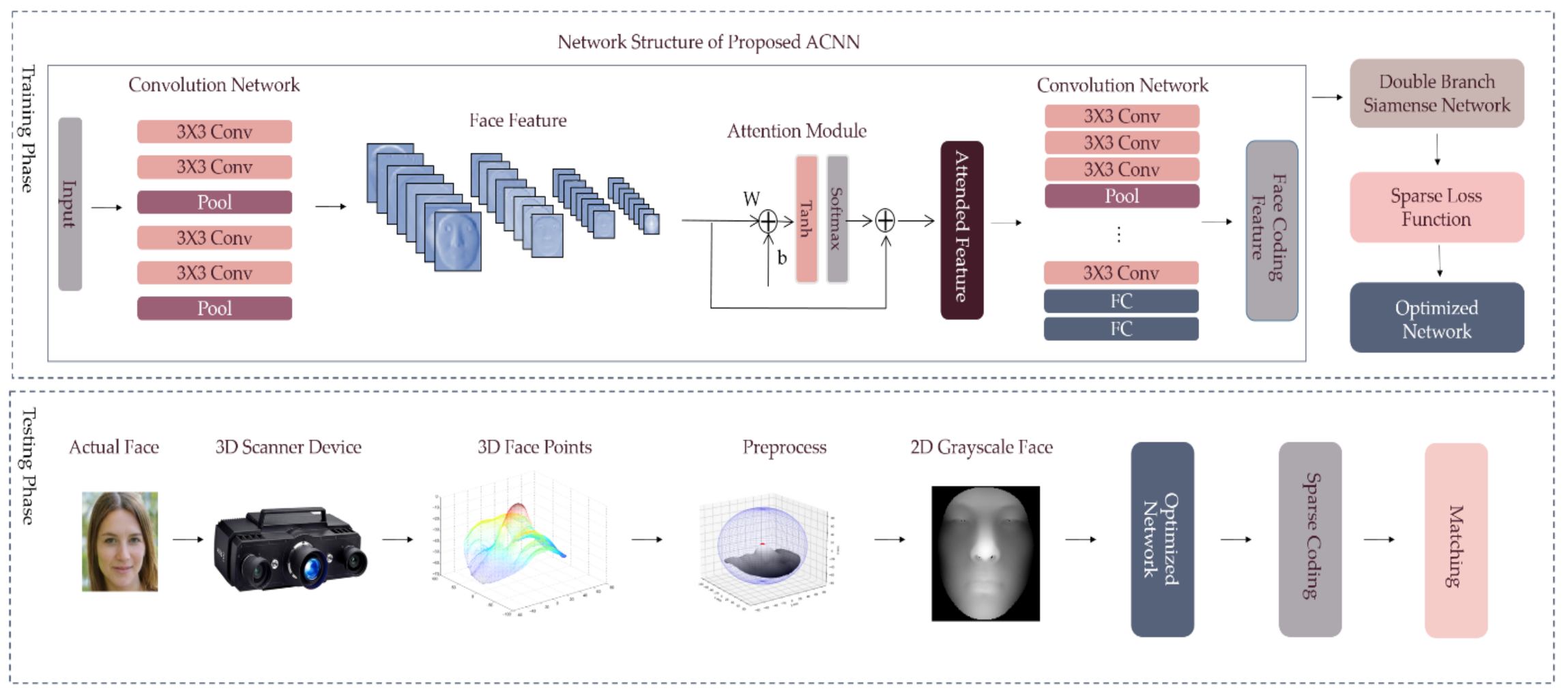
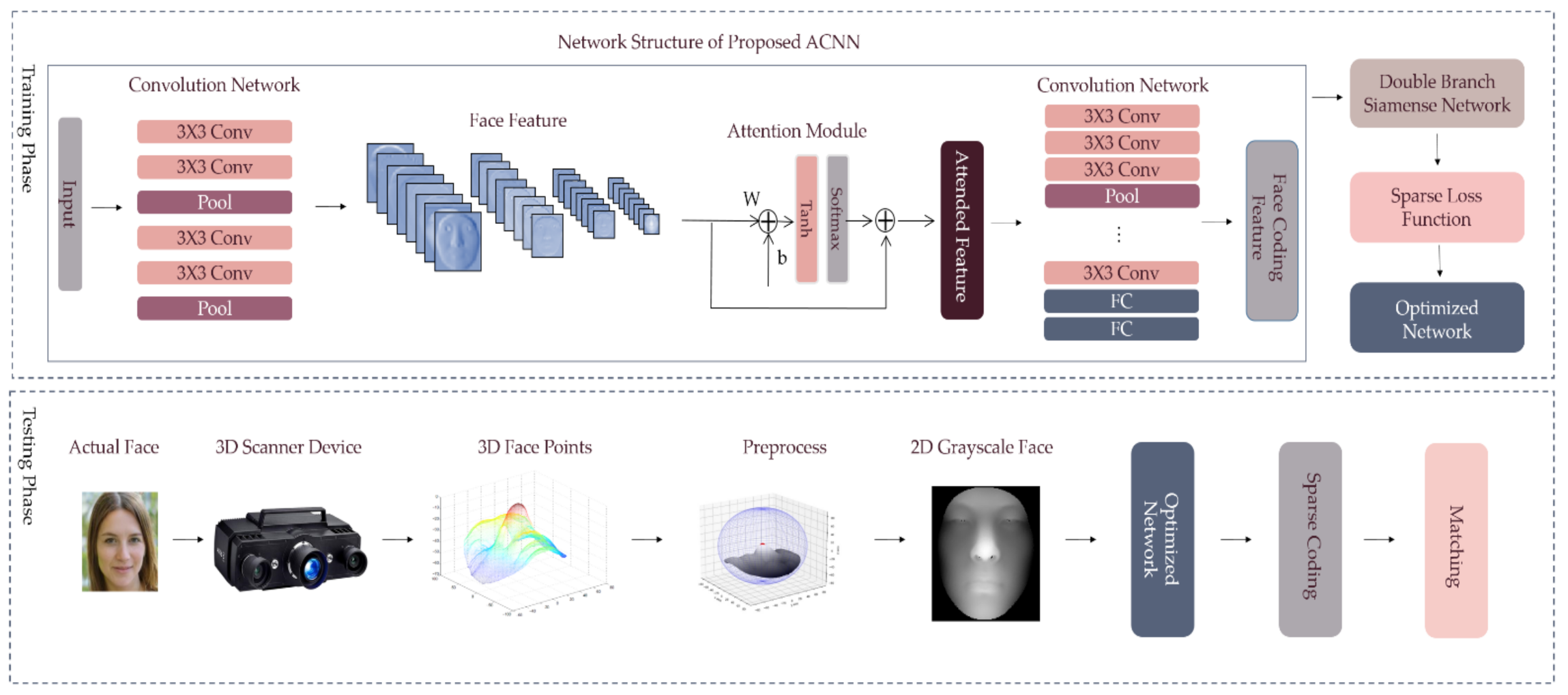
2.2. 3D Face Recognition Based on Deep Learning
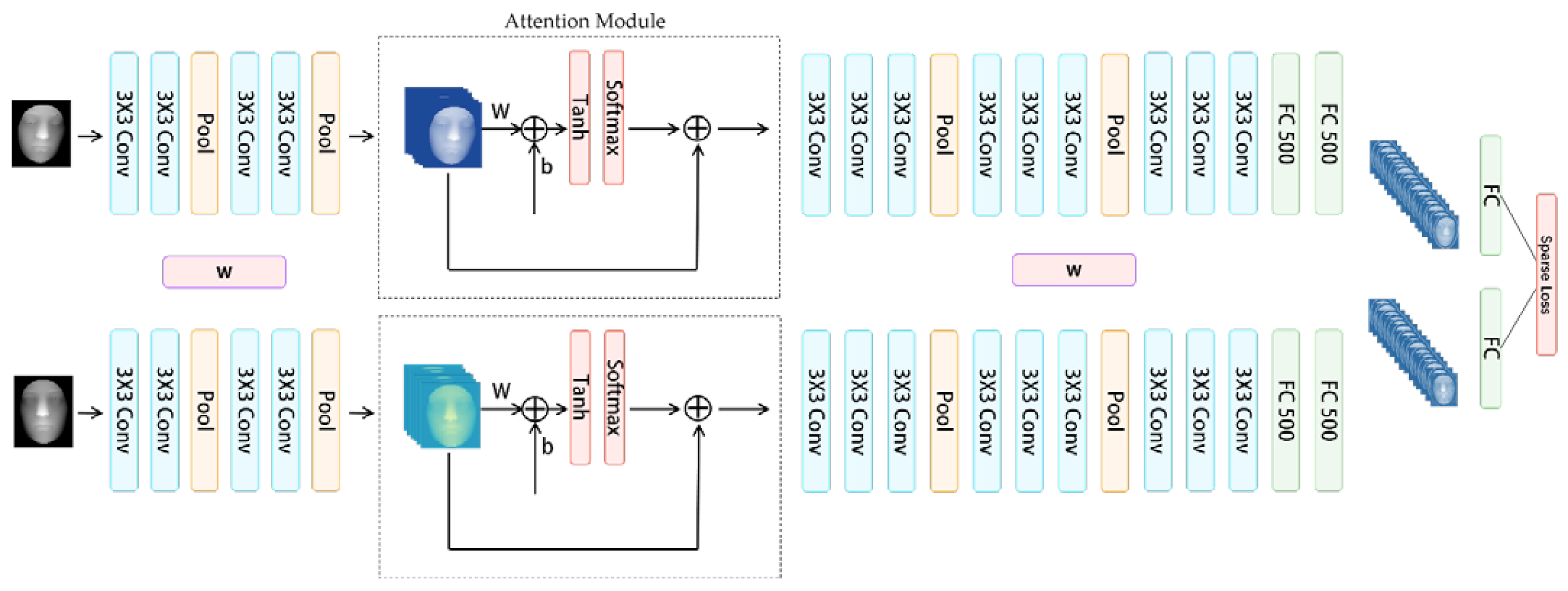
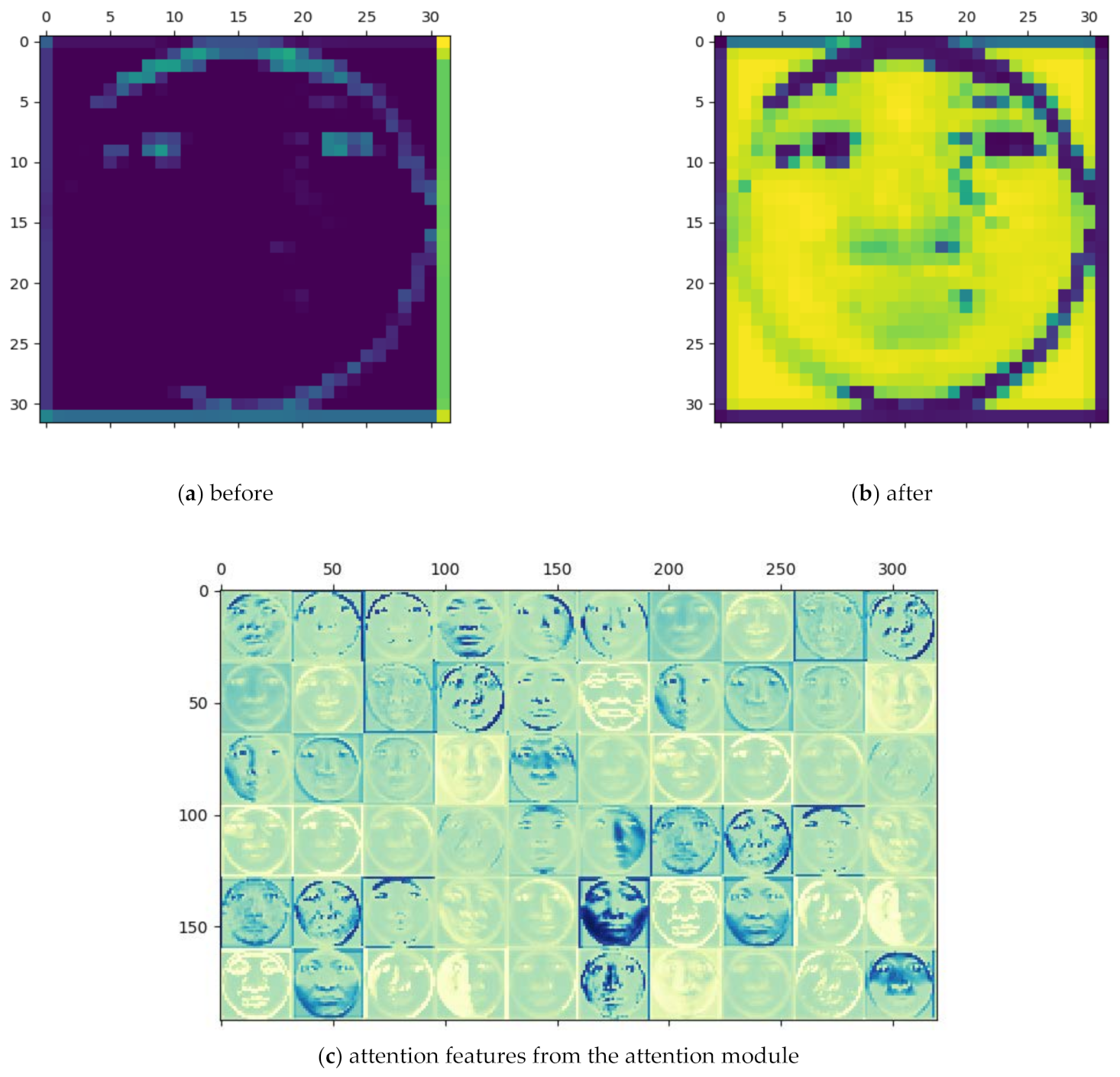
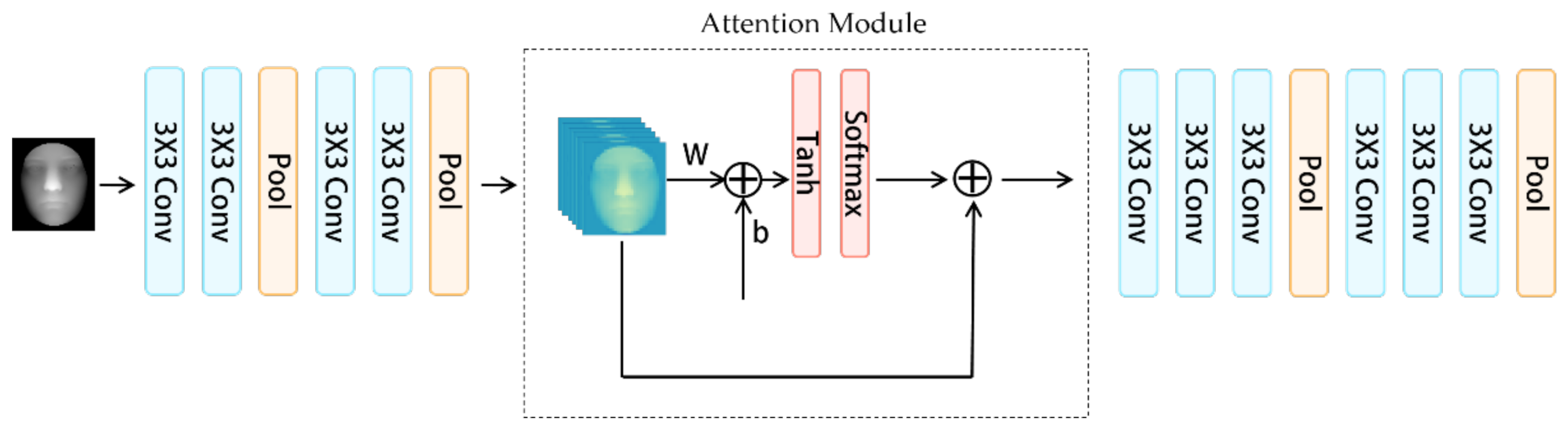
2.2.1. Face Feature Extracting Module based on Attention Mechanism and Convolutional Layers
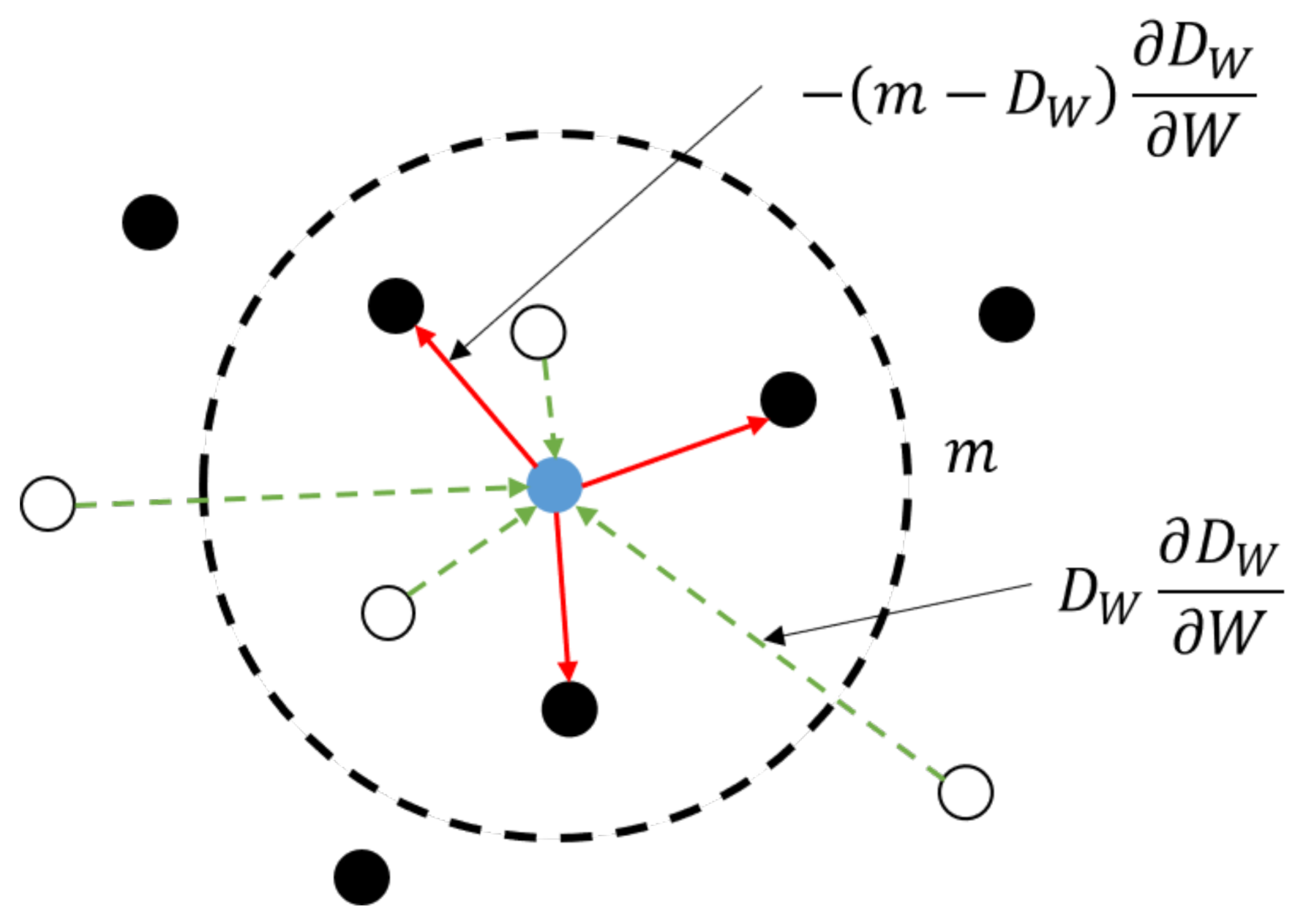
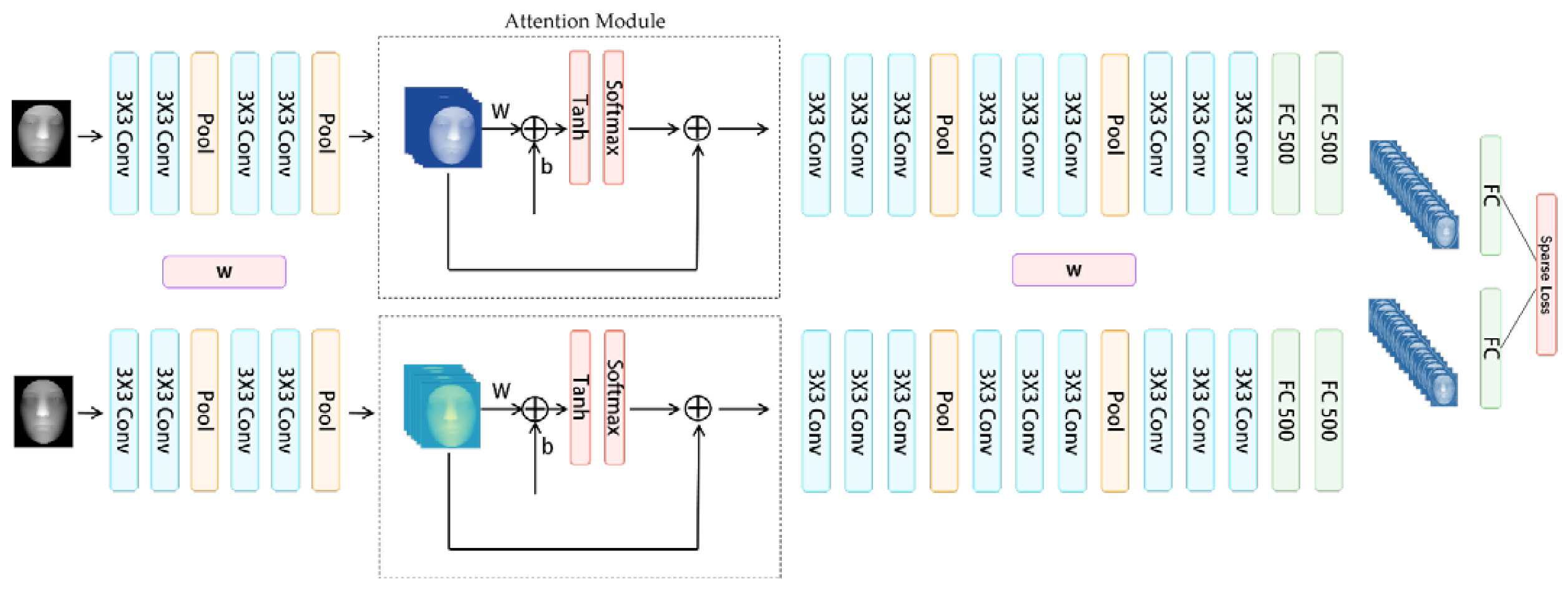
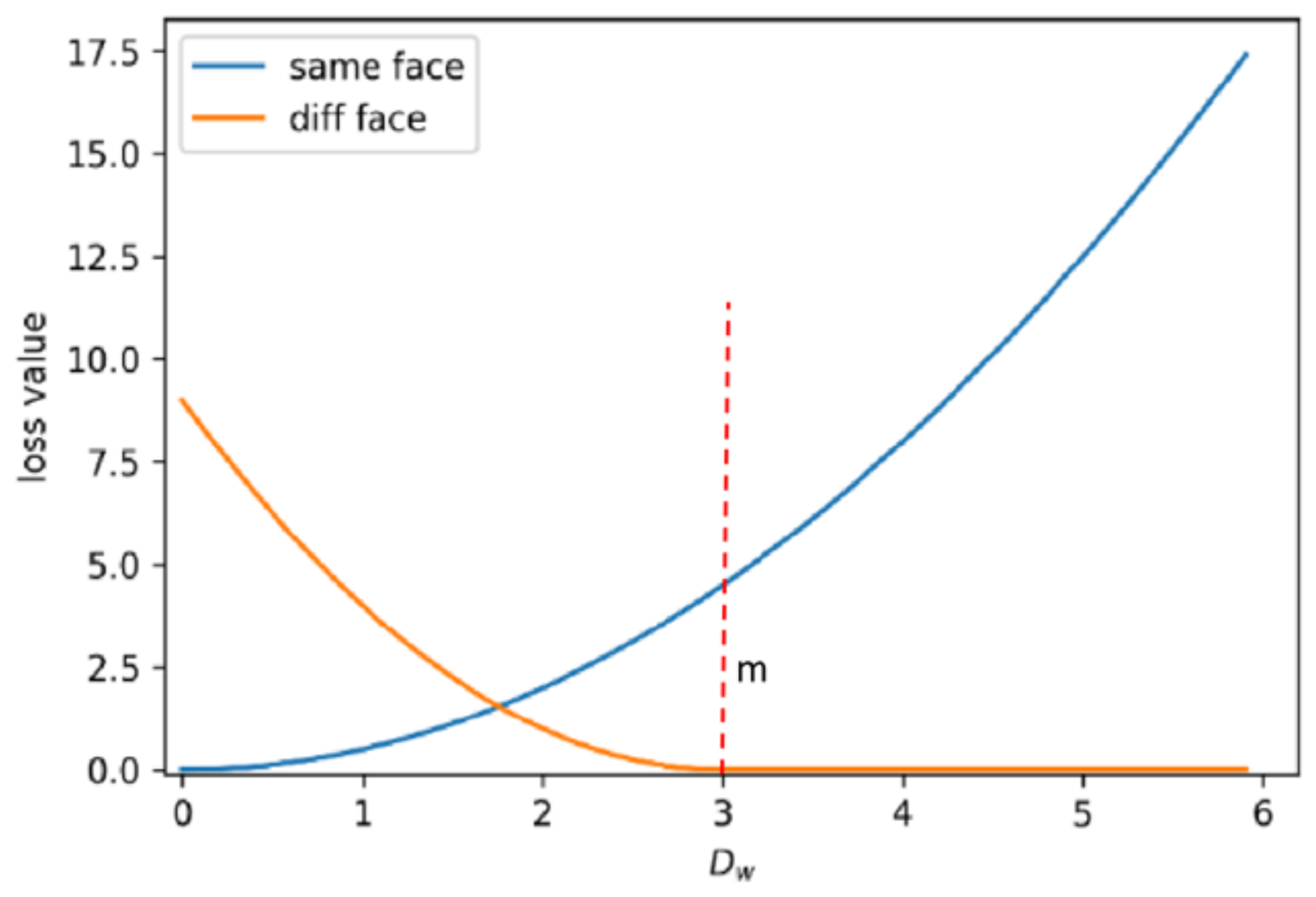
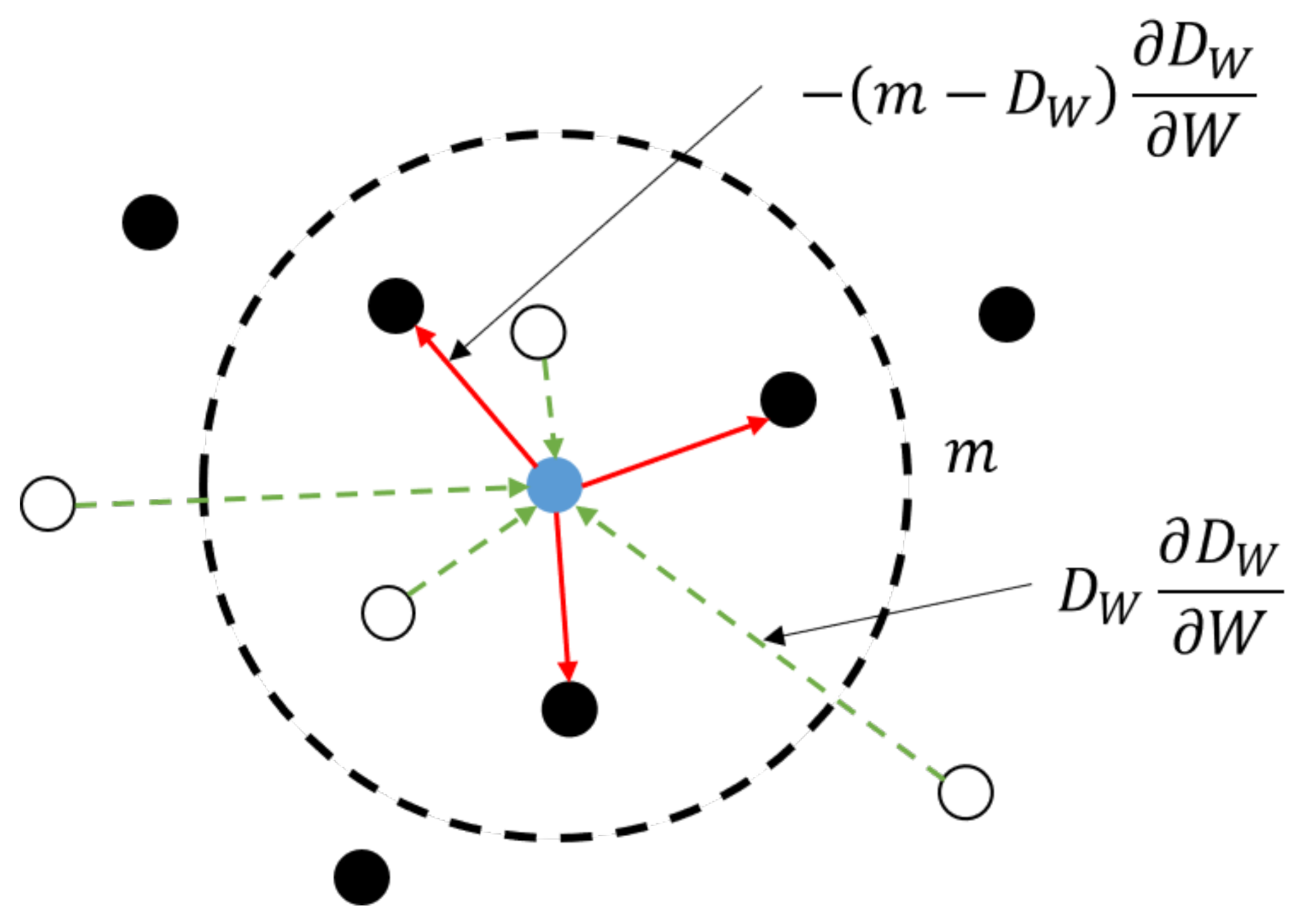
2.2.2. Siamese Network Trained with Sparse Contrastive Loss
3. Results
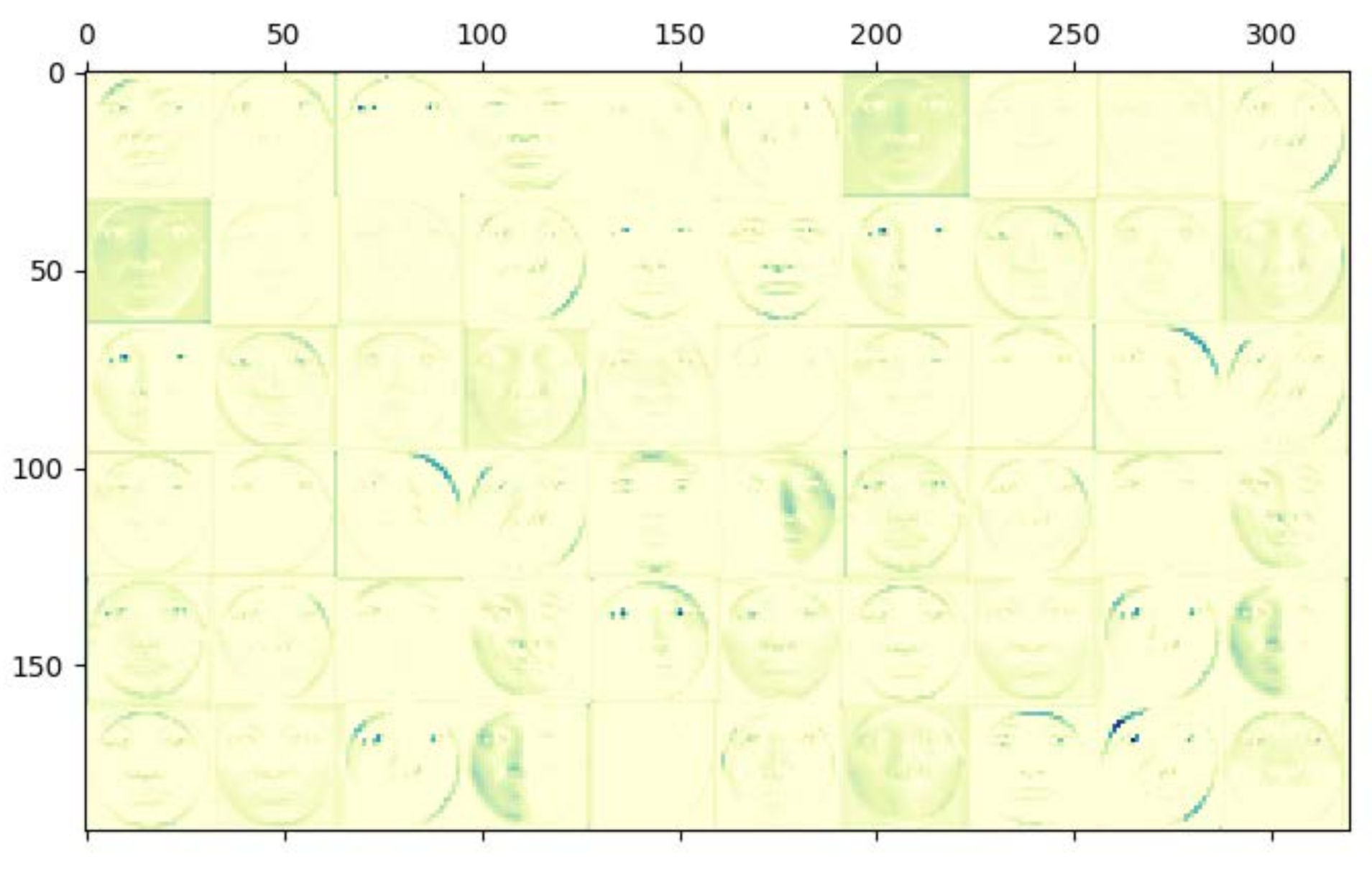
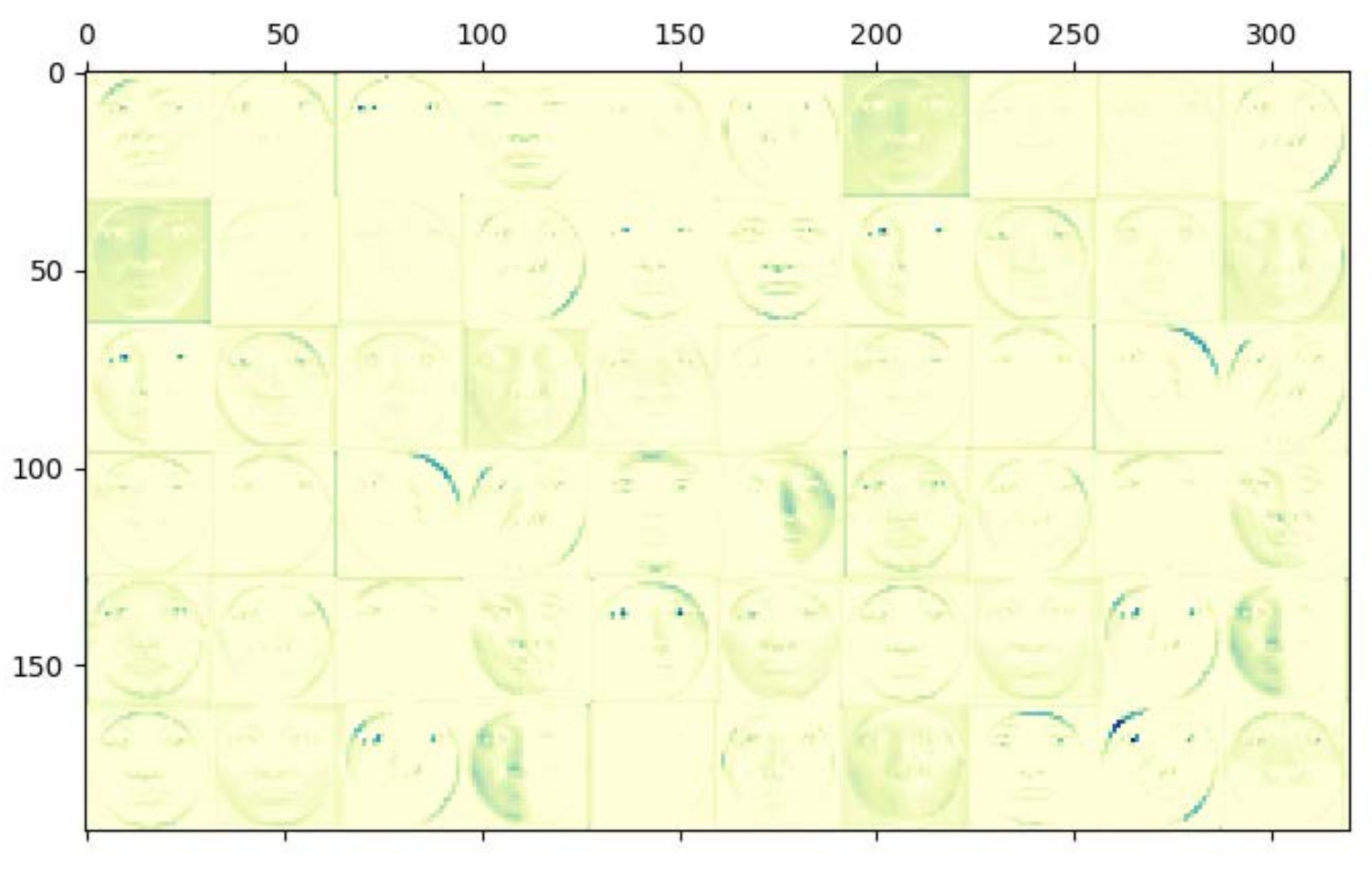
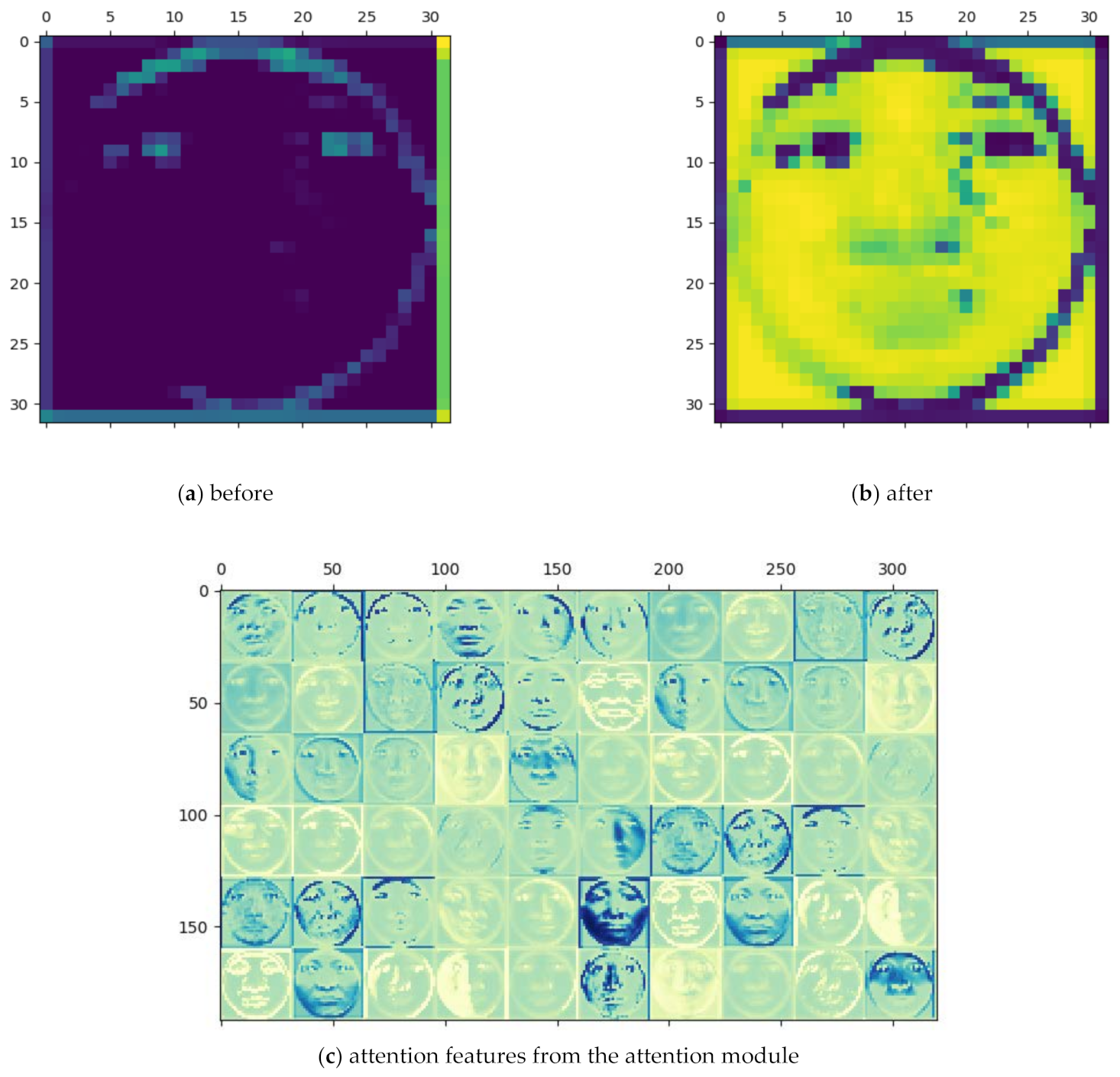
3.1. Performance of Attention Mechanism-Based Convolutional Feature Extractor
3.2. Performance of the Sparse Siamese Neural Network Evaluated
3.3. Sample Size Comparison and Discussion
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Masi, I.; Wu, Y.; Hassner, T.; Natarajan, P. Deep Face Recognition: A Survey. In Proceedings of the 31st SIBGRAPI Conference on Graphics, Patterns and Images, SIBGRAPI 2018, Parana, Brazil, 29 Octorber–1 November 2018; pp. 471–478. [Google Scholar] [CrossRef]
- Gsaxner, C.; Pepe, A.; Li, J.; Ibrahimpasic, U.; Wallner, J.; Schmalstieg, D.; Egger, J. Augmented Reality for Head and Neck Carcinoma Imaging: Description and Feasibility of an Instant Calibration, Markerless Approach. Comput. Methods Programs Biomed. 2020, 200, 105854. [Google Scholar] [CrossRef] [PubMed]
- Wang, M.; Deng, W. Deep face recognition: A survey. Neurocomputing 2021, 429, 215–244. [Google Scholar] [CrossRef]
- Adjabi, I.; Ouahabi, A.; Benzaoui, A.; Taleb-Ahmed, A. Past, present, and future of face recognition: A review. Electronics 2020, 9, 1188. [Google Scholar] [CrossRef]
- Cootes, T.F.; Edwards, G.J.; Taylor, C.J. Active Appearance Models. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 681–685. [Google Scholar] [CrossRef] [Green Version]
- Xiaofei, H.; Shuicheng, Y.; Yuxiao, H.; Partha, N.; Hong-Jiang, Z. Face Recognition Using Laplacianfaces. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 328–340. [Google Scholar] [CrossRef]
- Ze, L.; Xudong, J.; Alex, K. A novel lbp-based color descriptor for face recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing 2017, New Orleans, LA, USA, 5–9 March 2017; pp. 1857–1861. [Google Scholar]
- Déniz, O.; Bueno, G.; Salido, J.; De La Torre, F. Face recognition using Histograms of Oriented Gradients. Pattern Recognit. Lett. 2011, 32, 1598–1603. [Google Scholar] [CrossRef]
- Li, W.J.; Wang, J.; Huang, Z.H.; Zhang, T.; Du, D.K. LBP-like feature based on Gabor wavelets for face recognition. Int. J. Wavelets Multiresolution Inf. Process. 2017, 15, 1750049. [Google Scholar] [CrossRef]
- Leo, M.J.; Suchitra, S. SVM based expression-invariant 3D face recognition system. Procedia Comput. Sci. 2018, 143, 619–625. [Google Scholar] [CrossRef]
- Sarma, M.S.; Srinivas, Y.; Abhiram, M.; Ullala, L.; Prasanthi, M.S.; Rao, J.R. Insider threat detection with face recognition and KNN user classification. In Proceedings of the 2017 IEEE International Conference on Cloud Computing in Emerging Markets CCEM 2017, Bangalore, India, 1–3 November 2017; pp. 39–44. [Google Scholar] [CrossRef]
- Ding, C.; Tao, D. Trunk-Branch Ensemble Convolutional Neural Networks for Video-Based Face Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1002–1014. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.; Adu, J.; Chen, H.; Zhang, J.; Tang, J. A Facial Expression Recongnition Method Based on Dlib, RI-LBP and ResNet. J. Phys. Conf. Ser. 2020, 1634. [Google Scholar] [CrossRef]
- Almabdy, S.; Elrefaei, L. Deep convolutional neural network-based approaches for face recognition. Appl. Sci. 2019, 9, 4397. [Google Scholar] [CrossRef] [Green Version]
- Xie, S.; Liu, S.; Chen, Z.; Tu, Z. Attentional ShapeContextNet for Point Cloud Recognition. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4606–4615. [Google Scholar] [CrossRef]
- Ghojogh, B.; Ghodsi, A.L.I.; Ca, U. Attention Mechanism, Transformers, BERT, and GPT: Tutorial and Survey. 2020. Available online: https://doi.org/10.31219/osf.io/m6gcn (accessed on 13 October 2021).
- Li, W.; Liu, K.; Zhang, L.; Cheng, F. Object detection based on an adaptive attention mechanism. Sci. Rep. 2020, 10, 1–13. [Google Scholar] [CrossRef]
- Li, J.; Jin, K.; Zhou, D.; Kubota, N.; Ju, Z. Attention mechanism-based CNN for facial expression recognition. Neurocomputing 2020, 411, 340–350. [Google Scholar] [CrossRef]
- Liao, M.; Gu, X. Face recognition approach by subspace extended sparse representation and discriminative feature learning. Neurocomputing 2020, 373, 35–49. [Google Scholar] [CrossRef]
- Liu, S.; Li, L.; Jin, M.; Hou, S.; Peng, Y. Optimized coefficient vector and sparse representation-based classification method for face recognition. IEEE Access 2020, 8, 8668–8674. [Google Scholar] [CrossRef]
- Deng, X.; Da, F.; Shao, H.; Jiang, Y. A multi-scale three-dimensional face recognition approach with sparse representation-based classifier and fusion of local covariance descriptors. Comput. Electr. Eng. 2020, 85, 106700. [Google Scholar] [CrossRef]
- Sun, Y.; Wang, Y.; Liu, Z.; Siegel, J.E.; Sarma, S.E. PointGrow: Autoregressively Learned Point Cloud Generation with Self-Attention. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 1–5 March 2020; pp. 61–70. [Google Scholar] [CrossRef]
- Soltanpour, S.; Boufama, B.; Jonathan Wu, Q.M. A survey of local feature methods for 3D face recognition. Pattern Recognit. 2017, 72, 391–406. [Google Scholar] [CrossRef]
- Tang, H.; Yin, B.; Sun, Y.; Hu, Y. 3D face recognition using local binary patterns. Signal Process. 2013, 93, 2190–2198. [Google Scholar] [CrossRef]
- Lei, Y.; Bennamoun, M.; Hayat, M.; Guo, Y. An efficient 3D face recognition approach using local geometrical signatures. Pattern Recognit. 2014, 47, 509–524. [Google Scholar] [CrossRef]
- Liu, F.; Zhao, Q.; Liu, X.; Zeng, D. Joint Face Alignment and 3D Face Reconstruction with Application to Face Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 664–678. [Google Scholar] [CrossRef] [Green Version]
- You, H.; Feng, Y.; Ji, R.; Gao, Y. PVNet: A Joint Convolutional Network of Point Cloud and Multi-View for 3D Shape Recognition. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Korea, 22–26 October 2018; pp. 1310–1318. [Google Scholar]
- Zhang, Z.Y.; Da, F.; Yu, Y. Data-Free Point Cloud Network for 3D Face Recognition. arXiv 2019, arXiv:1911.04731. [Google Scholar]
- Ahmed, N.K.; Hemayed, E.E.; Fayek, M.B. Hybrid siamese network for unconstrained face verification and clustering under limited resources. Big Data Cogn. Comput. 2020, 4, 19. [Google Scholar] [CrossRef]
- Phillips, P.J.; Flynn, P.J.; Scruggs, T.; Bowyer, K.W.; Chang, J.; Hoffman, K.; Marques, J.; Min, J.; Worek, W. Overview of the face recognition grand challenge. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2005, San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 947–954. [Google Scholar] [CrossRef]
- Mian, A.S.; Bennamoun, M.; Owens, R. An efficient multimodal 2D-3D hybrid approach to automatic face recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1927–1943. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Koenderink, J.J.; van Doorn, A.J. Surface shape and curvature scales. Image Vis. Comput. 1992, 10, 557–564. [Google Scholar] [CrossRef]
- Kang, I.G.; Park, F.C. Cubic spline algorithms for orientation interpolation. Int. J. Numer. Methods Eng. 2015, 46, 45–64. [Google Scholar] [CrossRef]
- Huang, Z.; Zhu, T.; Li, Z.; Ni, C. Non-Destructive Testing of Moisture and Nitrogen Content in Pinus Massoniana Seed-ling Leaves with NIRS Based on MS-SC-CNN. Appl. Sci. 2021, 11, 2754. [Google Scholar] [CrossRef]
- Wang, J.; Li, Z.; Chen, Q.; Ding, K.; Zhu, T.; Ni, C. Detection and Classification of Defective Hard Candies Based on Image Processing and Con-volutional Neural Networks. Electronics 2021, 10, 2017. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision in Lecture Notes in Computer Science, Munich, Germany, 8–14 September 2018; Springer International Publishing: Cham, Switzerland, 2018; Volume 11211, pp. 3–19. [Google Scholar] [CrossRef] [Green Version]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Type | Output Size | Branch1 | Branch2 |
|---|---|---|---|
| Conv | , , stride | , , stride | |
| Conv | , 64, stride | , 64, stride | |
| , Max pooling, stride | , Max pooling, stride | ||
| Conv | , 64, stride | , 64, stride | |
| Conv | , 128, stride | , 128, stride | |
| , Max pooling, stride | , Max pooling, stride | ||
| Attention | Tanh, softmax | Tanh, softmax | |
| Conv | , 128, stride | , 128, stride | |
| Conv | , 256, stride | , 256, stride | |
| Conv | , 256, stride | , 256, stride | |
| , Max pooling, stride | , Max pooling, stride | ||
| Conv | , 256, stride | , 256, stride | |
| Conv | , 512, stride | , 512, stride | |
| Conv | , 512, stride | , 512, stride | |
| , Max pooling, stride | , Max pooling, stride | ||
| Conv | , 256, stride | , 256, stride | |
| Conv | , 512, stride | , 512, stride | |
| Conv | , 512, stride | , 512, stride | |
| , Max pooling, stride | , Max pooling, stride | ||
| FC1 | Average pool, 500-d fc | Average pool, 500-d fc | |
| FC2 | Average pool, 1-d fc | ||
| Models | Accuracy |
|---|---|
| Pure CNN with Contrastive Loss | 81.00% |
| Attention CNN with Contrastive Loss | 89.55% |
| Pure Siamese with Contrastive Loss | 94.52% |
| Pure Siamese with Sparse Loss | 94.85% |
| Attention Siamese with Contrastive Loss | 95.24% |
| Attention Siamese with Sparse Loss | 95.33% |
| Number of People in Training Set | End-to-End Model | Ours | ||||
|---|---|---|---|---|---|---|
| 4 | 3 | 2 | 4 | 3 | 2 | |
| 20 | 0.810 | 0.700 | 0.640 | 0.890 | 0.840 | 0.810 |
| 40 | 0.865 | 0.755 | 0.675 | 0.905 | 0.865 | 0.842 |
| 60 | 0.876 | 0.774 | 0.717 | 0.924 | 0.901 | 0.853 |
| 80 | 0.895 | 0.840 | 0.808 | 0.935 | 0.910 | 0.855 |
| 100 | 0.820 | 0.758 | 0.726 | 0.936 | 0.918 | 0.860 |
| 120 | 0.774 | 0.703 | 0.628 | 0.942 | 0.922 | 0.886 |
| 140 | 0.813 | 0.708 | 0.661 | 0.957 | 0.930 | 0.878 |
| 160 | 0.801 | 0.743 | 0.683 | 0.943 | 0.914 | 0.885 |
| 180 | 0.765 | 0.731 | 0.658 | 0.953 | 0.920 | 0.891 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zou, H.; Sun, X. 3D Face Recognition Based on an Attention Mechanism and Sparse Loss Function. Electronics 2021, 10, 2539. https://doi.org/10.3390/electronics10202539
Zou H, Sun X. 3D Face Recognition Based on an Attention Mechanism and Sparse Loss Function. Electronics. 2021; 10(20):2539. https://doi.org/10.3390/electronics10202539
Chicago/Turabian StyleZou, Hongyan, and Xinyan Sun. 2021. "3D Face Recognition Based on an Attention Mechanism and Sparse Loss Function" Electronics 10, no. 20: 2539. https://doi.org/10.3390/electronics10202539
APA StyleZou, H., & Sun, X. (2021). 3D Face Recognition Based on an Attention Mechanism and Sparse Loss Function. Electronics, 10(20), 2539. https://doi.org/10.3390/electronics10202539