
A Novel FPGA-Based Intent Recognition System Utilizing Deep Recurrent Neural Networks



Abstract
:1. Introduction
- A novel FPGA-based intent recognition system to process EEG signals was developed and optimized for Xilinx Alveo U200 high-end FPGA.
- A C++-based RNN intent recognition model was developed eliminating one layer from the original implementation [10].
- The complete design flow with optimizations are analytically presented, while basic modules are distributed as open-source [15]; thus, the proposed design approach can act as a valuable reference for anyone implementing complex RNNs/LSTMs in high-end FPGA devices for mobility difficulty applications; this is very important, since currently there are no FPGA-tailored LSTM implementations freely available.
- A thorough evaluation of the proposed implementation is presented in terms of performance and power efficiency, and the real-world experiments demonstrate that the proposed implementation is an order of magnitude faster (and more energy efficient) than a state-of-the-art Intel CPU, while it is very likely that also outperforms several GPUs.
2. Literature Review
3. Background
4. Materials and Methods
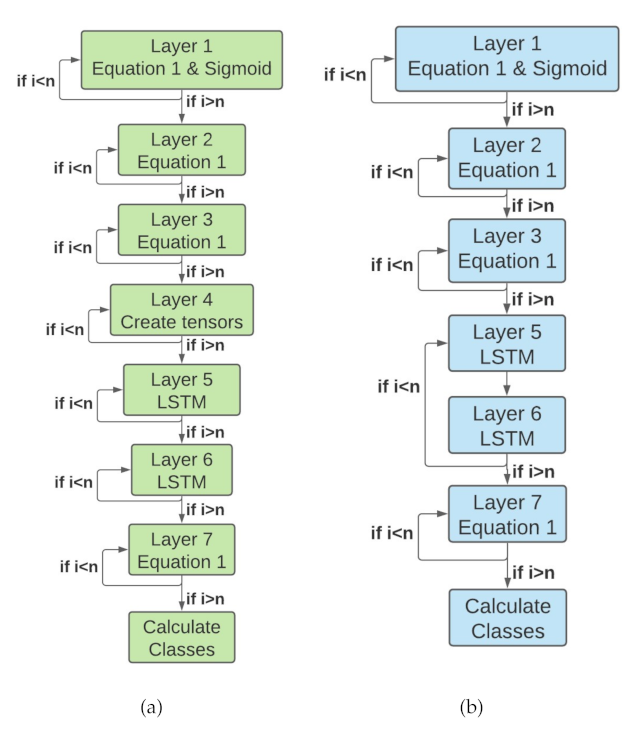
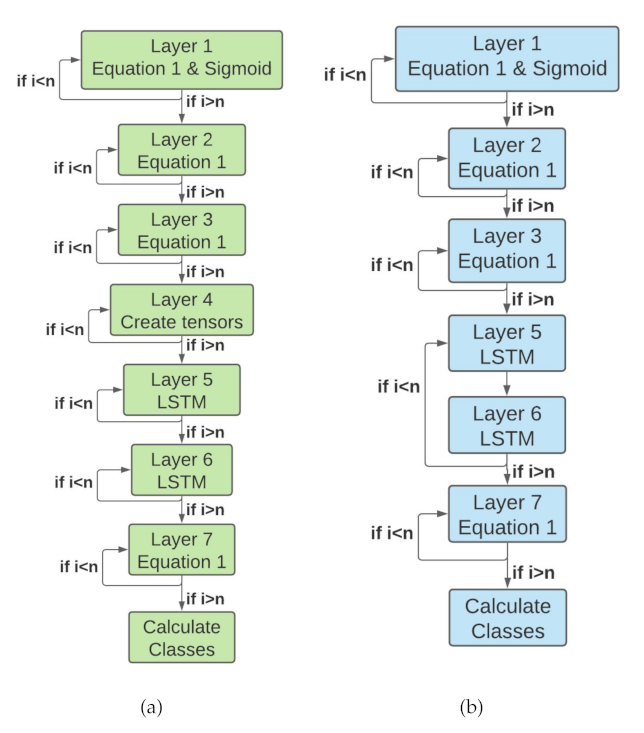
4.1. Design Flow and High-Level Optimizations
4.2. Optimizations for Reconfigurable Implementation
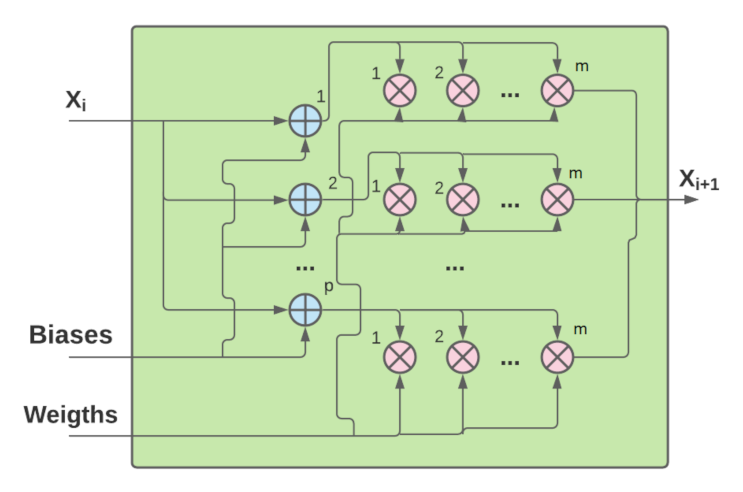
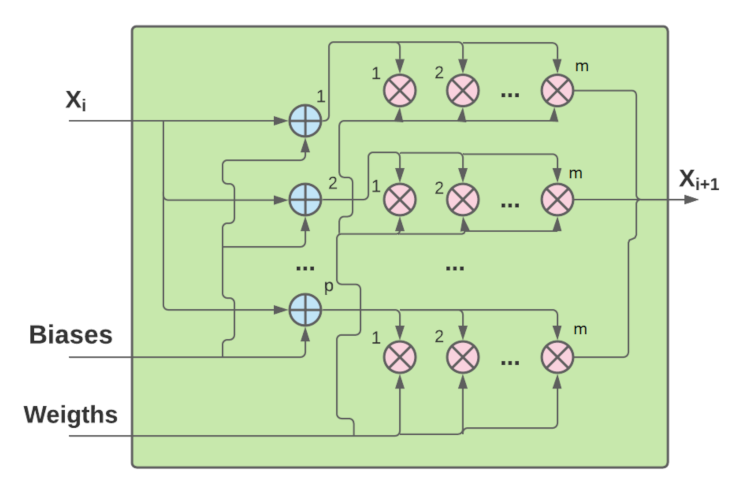
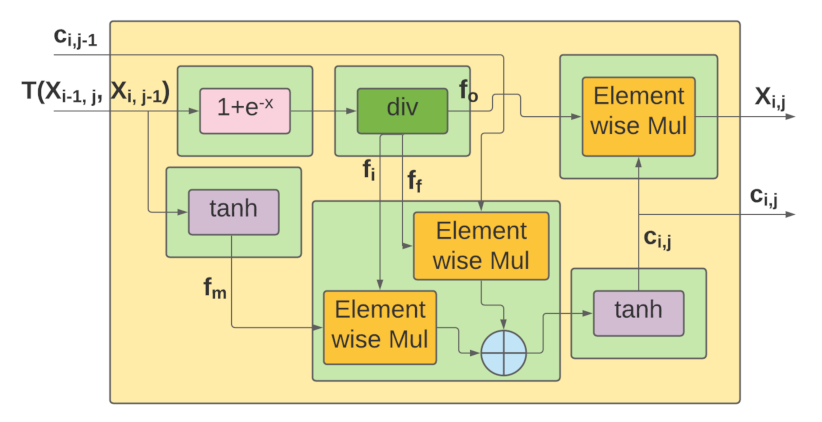
4.2.1. Quantization
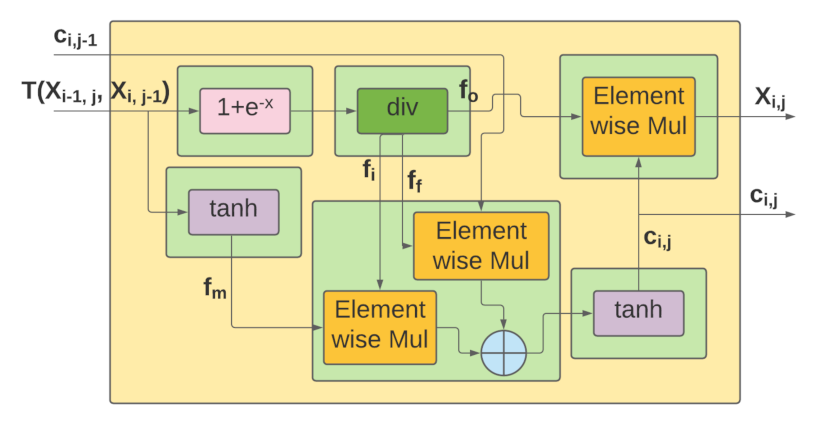
4.2.2. Hardware-Oriented Optimizations
| //gates array for storing all values of LSTM cell’s gates |
| #pragma HLS array_partition variable=gates complete dim=1 |
| #pragma HLS array_partition variable= ff cyclic factor=m dim=1 //forget gate |
| #pragma HLS array_partition variable= fi cyclic factor=m dim=1 //input gate |
| #pragma HLS array_partition variable= fo cyclic factor=m dim=1 //output gate |
| #pragma HLS array_partition variable= fm cyclic factor=m dim=1 //input modulation gate |
| loop1:for(int j=0;j<4*m;j=j+1){ |
| #pragma HLS unroll factor=m/4 |
| //gates array is calculated through the four |
| //registers gates_tmp, gates_tmp2, gates_tmp3 and gates_tmp4 |
| dtype gates_tmp = b_all[j]; //first register is initialized with LSTM cell’s biases |
| dtype gates_tmp2 = 0; //the rest are initialized with zero |
| dtype gates_tmp3 = 0; |
| dtype gates_tmp4 = 0; |
| #pragma HLS pipeline II=1 |
| //the values of the previous timestep (inputs) are multiplied with the LSTM |
| //cell’s weights (w_all) and then the biases (b_all) are added through gates_tmp |
| loop2:for(int k=0;k<m/2;k=k+1){ |
| gates_tmp=gates_tmp+inputs[k]*w_all[k][j]; |
| } |
| loop3:for(int k=m/2;k<m;k=k+1){ |
| gates_tmp2=gates_tmp2+inputs[k]*w_all[k][j]; |
| } |
| loop4:for(int k=m;k<3*m/2;k=k+1){ |
| gates_tmp3=gates_tmp3+inputs[k]*w_all[k][j]; |
| } |
| loop5:for(int k=3*m/2;k<2*m;k=k+1){ |
| gates_tmp4=gates_tmp4+inputs[k]*w_all[k][j]; |
| } |
| gates[j] = gates_tmp + gates_tmp2 + gates_tmp3 + gates_tmp4; |
| } |
| //calculate each LSTM cell’s gate utilizing gates array |
| loop6:for(intj=0;j<m;j=j+1){ |
| #pragma HLS unroll factor=m/2 |
| #pragma HLS pipeline II=1 |
| ff[j]= (1+hls::exp((dtype)-(gates[j+2*m]+1))); |
| fi[j]= (1+hls::exp((dtype)-(gates[j]))); |
| fo[j]= (1+hls::exp((dtype)-(gates[j+3*m]))); |
| fm[j]= tanhf((dtype)gates[j+m]); |
| } |
5. Results and Discussion
5.1. Reference Execution Time
5.2. Hardware Execution Time
5.3. Performance over Power Efficiency
6. Conclusions
7. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lee, S.K.; Ahn, J.; Shin, J.; Lee, J. Application of Machine Learning Methods in Nursing Home Research. Int. J. Environ. Res. Public Health 2020, 17, 6234. [Google Scholar] [CrossRef] [PubMed]
- Sak, H.; Senior, A.; Beaufays, F. Long short-term memory recurrent neural network architectures for large scale acoustic modeling. In Proceedings of the 15th Annual Conference of the International Speech Communication Association, INTERSPEECH, Singapore, 14–18 September 2014; pp. 338–342. [Google Scholar]
- Fernández, S.; Graves, A.; Schmidhuber, J. An Application of Recurrent Neural Networks to Discriminative Keyword Spotting. In Artificial Neural Networks—ICANN 2007; de Sá, J.M., Alexandre, L.A., Duch, W., Mandic, D., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 220–229. [Google Scholar]
- Graves, A.; Liwicki, M.; Fernández, S.; Bertolami, R.; Bunke, H.; Schmidhuber, J. A Novel Connectionist System for Unconstrained Handwriting Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 855–868. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bresch, E.; Großekathöfer, U.; Garcia-Molina, G. Recurrent Deep Neural Networks for Real-Time Sleep Stage Classification From Single Channel EEG. Front. Comput. Neurosci. 2018, 12, 85. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tortora, S.; Ghidoni, S.; Chisari, C.; Micera, S.; Artoni, F. Deep learning-based BCI for gait decoding from EEG with LSTM recurrent neural network. J. Neural Eng. 2020, 17, 046011. [Google Scholar] [CrossRef] [PubMed]
- Jeevan, R.K.; S.P., V.M.R.; Shiva Kumar, P.; Srivikas, M. EEG-based emotion recognition using LSTM-RNN machine learning algorithm. In Proceedings of the 1st International Conference on Innovations in Information and Communication Technology (ICIICT), Chennai, India, 25–26 April 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Lee, S.; Hussein, R.; McKeown, M.J. A Deep Convolutional-Recurrent Neural Network Architecture for Parkinson’s Disease EEG Classification. In Proceedings of the 2019 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Ottawa, ON, Canada, 11–14 November 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Zhang, X.; Yao, L.; Huang, C.; Sheng, Q.; Wang, X. Intent recognition in smart living through deep recurrent neural networks. In Lecture Notes in Computer Science, Proceedings of the 24th International Conference on Neural Information Processing (ICONIP 2017); Liu, D., Zhao, D., Xie, S., El-Alfy, E., Li, Y., Eds.; Springer Nature: New York, NY, USA, 2017; Volume 10635, pp. 748–758. [Google Scholar] [CrossRef] [Green Version]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Duarte, J.; Han, S.; Harris, P.; Jindariani, S.; Kreinar, E.; Kreis, B.; Ngadiuba, J.; Pierini, M.; Rivera, R.; Tran, N.; et al. Fast inference of deep neural networks in FPGAs for particle physics. J. Instrum. 2018, 13, P07027. [Google Scholar] [CrossRef]
- Xilinx ML Suite: A Development Stack for ML Inference on Xilinx Hardware Platforms, GitHub Repository. 2019. Available online: https://github.com/Xilinx/ml-suite (accessed on 13 October 2021).
- Kathail, V. Xilinx Vitis Unified Software Platform. In FPGA ’20: Proceedings of the 2020 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays; Association for Computing Machinery: New York, NY, USA, 2020; pp. 173–174. [Google Scholar] [CrossRef] [Green Version]
- Tsantikidou, K. A Novel FPGA-Based Intent Recognition System Utilizing Deep Recurrent Neural Networks, GitHub Repository. 2021. Available online: https://github.com/ntampouratzis/FPGA-based-LSTM (accessed on 13 October 2021).
- Guan, Y.; Yuan, Z.; Sun, G.; Cong, J. FPGA-based accelerator for long short-term memory recurrent neural networks. In Proceedings of the 22nd Asia and South Pacific Design Automation Conference (ASP-DAC), Jeju Island, Korea, 22–25 January 2018; pp. 629–634. [Google Scholar] [CrossRef]
- Chang, A.X.M.; Martini, B.; Culurciello, E. Recurrent Neural Networks Hardware Implementation on FPGA. arXiv 2015, arXiv:1511.05552. [Google Scholar]
- Holmes, C.; Mawhirter, D.; He, Y.; Yan, F.; Wu, B. GRNN: Low-Latency and Scalable RNN Inference on GPUs. In EuroSys ’19: Proceedings of the Fourteenth EuroSys Conference 2019; Association for Computing Machinery: New York, NY, USA, 2019. [Google Scholar] [CrossRef]
- Yuxi, S.; Hideharu, A. FiC-RNN: A multi-FPGA acceleration framework for deep recurrent neural networks. IEICE Trans. Inf. Syst. 2020, E103D, 2457–2462. [Google Scholar] [CrossRef]
- Hasib-Al-Rashid; Manjunath, N.K.; Paneliya, H.; Hosseini, M.; Hairston, W.D.; Mohsenin, T. A Low-Power LSTM Processor for Multi-Channel Brain EEG Artifact Detection. In Proceedings of the 21st International Symposium on Quality Electronic Design (ISQED), Santa Clara, CA, USA, 25–26 March 2020; pp. 105–110. [Google Scholar] [CrossRef]
- Chen, Z.; Howe, A.; Blair, H.T.; Cong, J. CLINK: Compact LSTM Inference Kernel for Energy Efficient Neurofeedback Devices. In ISLPED ’18: Proceedings of the International Symposium on Low Power Electronics and Design; Association for Computing Machinery: New York, NY, USA, 2018. [Google Scholar] [CrossRef]
- Mwata-Velu, T.; Ruiz-Pinales, J.; Rostro-Gonzalez, H.; Ibarra-Manzano, M.A.; Cruz-Duarte, J.M.; Avina-Cervantes, J.G. Motor Imagery Classification Based on a Recurrent-Convolutional Architecture to Control a Hexapod Robot. Mathematics 2021, 9, 606. [Google Scholar] [CrossRef]
- Rybalkin, V.; Pappalardo, A.; Ghaffar, M.M.; Gambardella, G.; Wehn, N.; Blott, M. FINN-L: Library Extensions and Design Trade-off Analysis for Variable Precision LSTM Networks on FPGAs. arXiv 2018, arXiv:1807.04093. [Google Scholar]
- Han, S.; Kang, J.; Mao, H.; Hu, Y.; Li, X.; Li, Y.; Xie, D.; Luo, H.; Yao, S.; Wang, Y.; et al. ESE: Efficient Speech Recognition Engine with Compressed LSTM on FPGA. arXiv 2016, arXiv:1612.00694. [Google Scholar]
- Wang, S.; Lin, P.; Hu, R.; Wang, H.; He, J.; Huang, Q.; Chang, S. Acceleration of LSTM With Structured Pruning Method on FPGA. IEEE Access 2019, 7, 62930–62937. [Google Scholar] [CrossRef]
- Mahjoub, A.B.; Atri, M. Implementation of convolutional-LSTM network based on CPU, GPU and pynq-zl board. In Proceedings of the 2019 IEEE International Conference on Design Test of Integrated Micro Nano-Systems (DTS), Gammarth, Tunisia, 28 April–1 May 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Intel Processor Counter Monitor (PCM), GitHub Repository. 2021. Available online: https://github.com/opcm/pcm (accessed on 13 October 2021).
- Yazdani, R.; Ruwase, O.; Zhang, M.; He, Y.; Arnau, J.; González, A. LSTM-Sharp: An Adaptable, Energy-Efficient Hardware Accelerator for Long Short-Term Memory. arXiv 2019, arXiv:1911.01258. [Google Scholar]
- MaliŢa, M.; Popescu, G.V.; Ştefan, G.M. Heterogeneous Computing System for Deep Learning. In Deep Learning: Concepts and Architectures; Pedrycz, W., Chen, S.M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 287–319. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
| 1st | 2nd | 3rd | 4th | 5th | 6th | 7th | 8th |
|---|---|---|---|---|---|---|---|
| <float> <float> <int> | <32,6> <32,2> <10> | <20,6> <20,2> <10> | <16,6> <16,2> <9> | <14,6> <14,2> <9> | <12,5> <12,2> <9> | <10,5> <10,2> <9> | <8,2> <8,1> <9> |
| 1st | 2nd | 3rd | 4th | 5th | 6th | 7th | 8th | |
|---|---|---|---|---|---|---|---|---|
| Accuracy | 96.60% | 94.65% | 94.67% | 93.48% | 91.60% | 63.92% | 30.75% | 23.10% |
| Latency absolute (seconds) | 31.193 | 15.264 | 13.822 | 13.356 | 13.123 | 12.935 | 12.684 | 12.590 |
| 1st | 2nd | 3rd | 4th | 5th | 6th | 7th | 8th | 9th |
|---|---|---|---|---|---|---|---|---|
| <12,5> <12,2> <9> | <12,5> <12,2> <10> | <13,5> <13,2> <9> | <13,5> <13,2> <10> | <13,6> <13,2> <10> | <14,5> <14,2> <9> | <14,6> <14,2> <9> | <15,6> <15,2> <9> | <16,6> <16,2> <9> |
| 1st | 2nd | 3rd | 4th | 5th | 6th | 7th | 8th | 9th | |
|---|---|---|---|---|---|---|---|---|---|
| Accuracy | 63.9% | 64.2% | 75.6% | 75.8% | 80.3% | 77.8% | 91.6% | 93.2% | 93.4% |
| Latency absolute (s) | 12.93 | 12.93 | 13.05 | 13.05 | 13.00 | 13.16 | 13.12 | 13.23 | 13.35 |
| Original Python Model | C/C++ Model | |
|---|---|---|
| Execution Time | 1327 ms | 339.523 ms |
| Throughput | 0.62 GFLOPS/S | 2.45 GFLOPS/S |
| Power Efficiency | 0.017 GFLOPS/W | 0.068 GFLOPS/W |
| 100 MHz | 200 MHz | 300 MHz | |
|---|---|---|---|
| Original C/C++ model (Execution Time) | 12.58 s | 6.31 s | 6.06 s |
| Optimized C/C++ model (Execution Time) | 19.46 ms | 12.25 ms | 8.72 ms |
| Optimized C/C++ model (Throughput) | 42.87 GFLOPS/S | 68.10 GFLOPS/S | 95.68 GFLOPS/S |
| Optimized C/C++ model (Power Efficiency) | 5.29 GFLOPS/W | 4.69 GFLOPS/W | 4.57 GFLOPS/W |
| Logic Utilization | 100 MHz | 200 MHz | 300 MHz |
|---|---|---|---|
| Number of Flip Flops | 18% (441,102) | 27% (660,838) | 30% (722,396) |
| Number of Slice LUTs | 34% (406,863) | 41% (484,837) | 42% (497,795) |
| Number of DSP48E | 83% (5744) | 83% (5744) | 83% (5744) |
| Number of Block RAM 18K | 21% (944) | 21% (944) | 21% (944) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tsantikidou, K.; Tampouratzis, N.; Papaefstathiou, I. A Novel FPGA-Based Intent Recognition System Utilizing Deep Recurrent Neural Networks. Electronics 2021, 10, 2495. https://doi.org/10.3390/electronics10202495
Tsantikidou K, Tampouratzis N, Papaefstathiou I. A Novel FPGA-Based Intent Recognition System Utilizing Deep Recurrent Neural Networks. Electronics. 2021; 10(20):2495. https://doi.org/10.3390/electronics10202495
Chicago/Turabian StyleTsantikidou, Kyriaki, Nikolaos Tampouratzis, and Ioannis Papaefstathiou. 2021. "A Novel FPGA-Based Intent Recognition System Utilizing Deep Recurrent Neural Networks" Electronics 10, no. 20: 2495. https://doi.org/10.3390/electronics10202495
APA StyleTsantikidou, K., Tampouratzis, N., & Papaefstathiou, I. (2021). A Novel FPGA-Based Intent Recognition System Utilizing Deep Recurrent Neural Networks. Electronics, 10(20), 2495. https://doi.org/10.3390/electronics10202495