
Online Multiple Object Tracking Using a Novel Discriminative Module for Autonomous Driving


Abstract
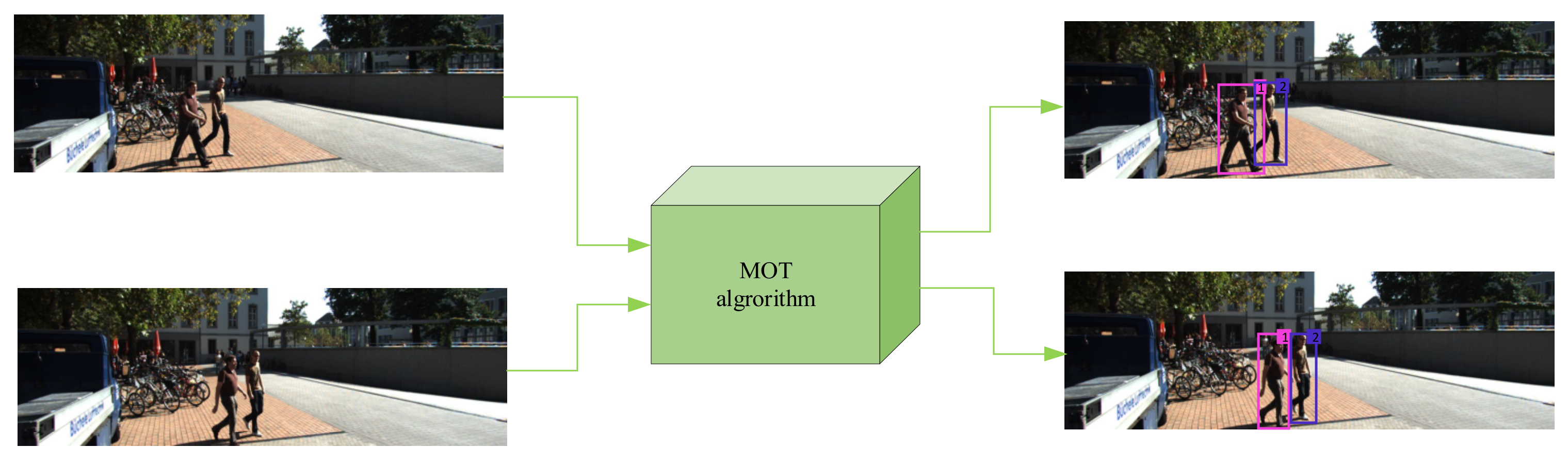
:1. Introduction
- i.
- An online multi-object tracking algorithm suitable for the process of autonomous driving environment perception is proposed.
- ii.
- For the occlusion problem of different objects or overlapping adjacent objects when the object is moving, a discriminative learning model is proposed.
- iii.
2. Our Proposed Tracker
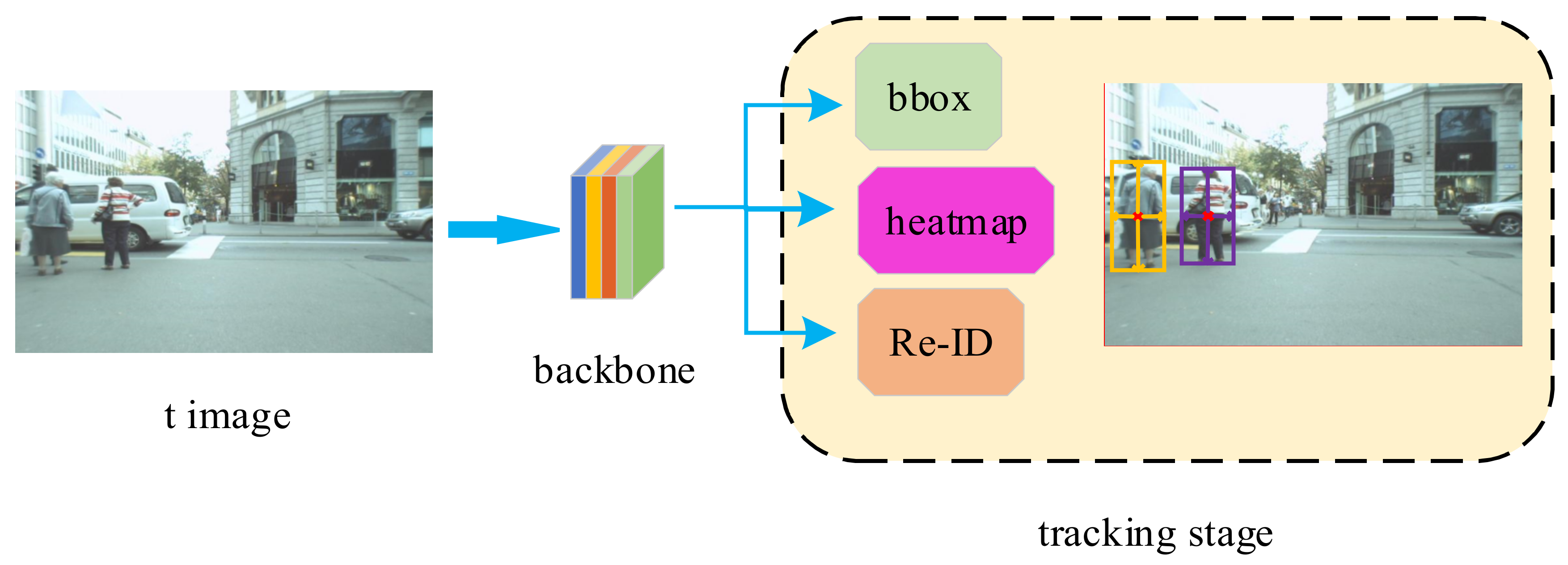
2.1. Baseline FairMOT
2.1.1. Problem Formulation
2.1.2. FairMOT Pipeline
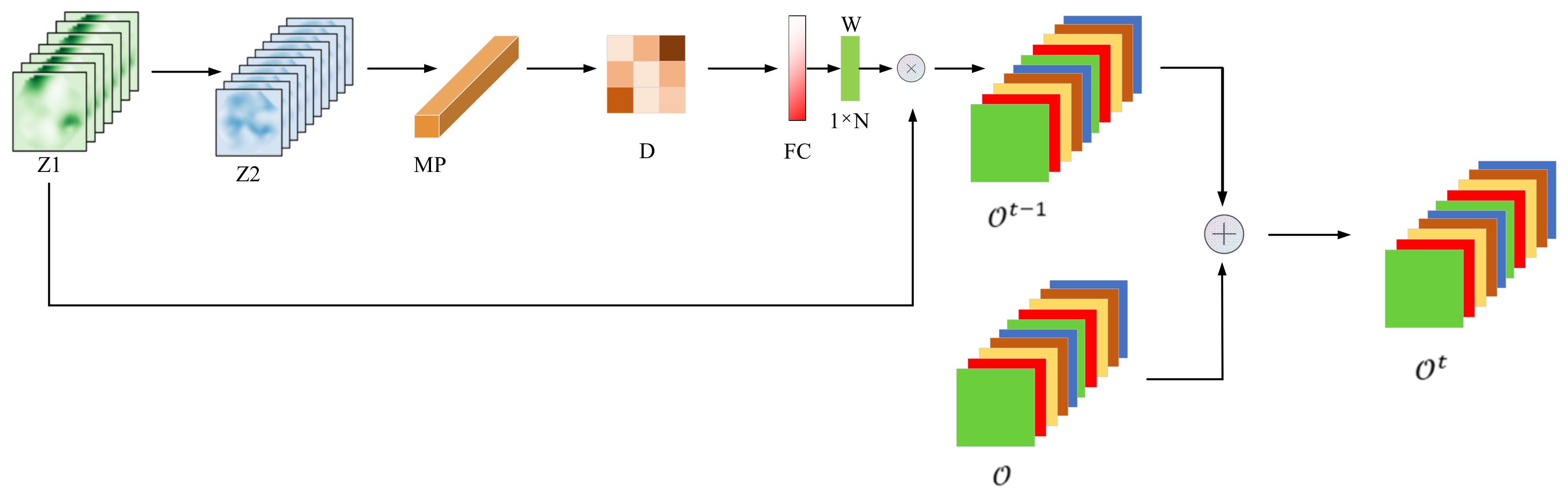
2.2. Discrimination Learning Model
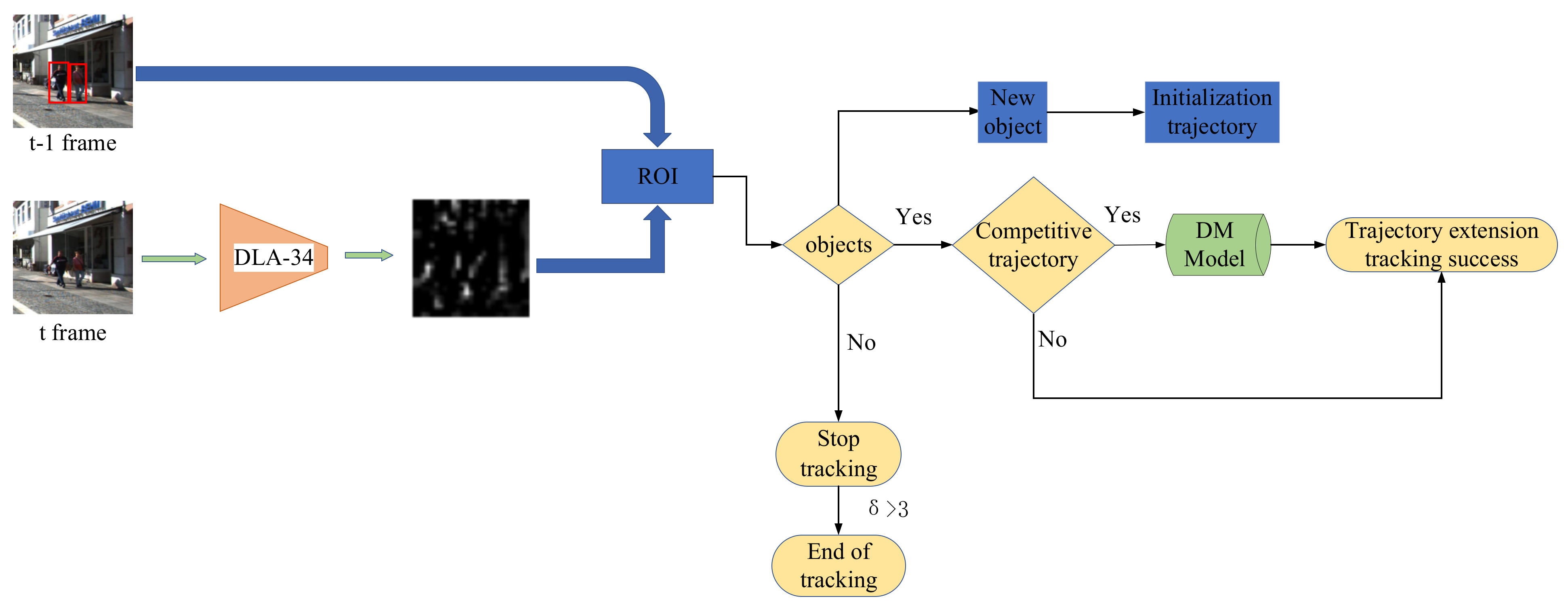
2.3. Trajectory Extension Strategy
2.4. Proposed Online MOT Tracking Network
| Algorithm 1: The proposed Method |
| Input: The pre-trained network model, the first frame, initial obkect location bounding box Output: The object location of the subsequent frames 1. Input the initial frame and initial bounding box 2. for do Get the ROI feature 3. Calculate the correlation matrix using Equation (6) 4. Calculate the maximum response using Equations (4) and (5) 5. Calculate the bounding box 6. end for |
3. Experiments and Evaluation
3.1. Experiment Implementation Details
3.2. Results on MOT16
3.3. Results on MOT17
3.3.1. Quantitative Analysis
3.3.2. Qualitative Analysis
3.4. Results on the Autonomous Driving Dataset KITTI
3.5. Ablation Experiment
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ding, S.; Liu, L.; Park, J.H. A novel adaptive nonsingular terminal sliding mode controller design and its application to active front steering system. Int. J. Robust Nonlinear Control 2019, 29, 4250–4269. [Google Scholar] [CrossRef]
- Norouzi, A.; Masoumi, M.; Barari, A.; Farrokhpour Sani, S. Lateral control of an autonomous vehicle using integrated backstepping and sliding mode controller. Proc. Inst. Mech. Eng. Part K J. Multi-Body Dyn. 2019, 233, 141–151. [Google Scholar] [CrossRef]
- Formentin, S.; Garatti, S.; Rallo, G.; Savaresi, S.M. Robust direct data-driven controller tuning with an application to vehicle stability control. Int. J. Robust Nonlinear Control 2018, 28, 3752–3765. [Google Scholar] [CrossRef]
- Chen, J.; Ai, Y.; Qian, Y.; Zhang, W. A novel Siamese Attention Network for visual object tracking of autonomous vehicles. Proc. Inst. Mech. Eng. Part D J. Automob. Eng. 2021. [Google Scholar] [CrossRef]
- Gao, M.; Jin, L.; Jiang, Y.; Guo, B. Manifold Siamese Network: A Novel Visual Tracking ConvNet for Autonomous Vehicles. IEEE Trans. Intell. Transp. Syst. 2020, 21, 1612–1623. [Google Scholar] [CrossRef]
- Zhang, Q.N.; Sun, Y.D.; Yang, J.; Liu, H.B. Real-time multi-class moving target tracking and recognition. IET Intell. Transp. Syst. 2016, 10, 308–317. [Google Scholar] [CrossRef]
- Türetken, E.; Wang, X.; Becker, C.J.; Haubold, C.; Fua, P. Network flow integer programming to track elliptical cells in time-lapse sequences. IEEE Trans. Med. Imaging 2017, 36, 942–951. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yan, X.; Kakadiaris, I.; Shah, A. Modeling local behavior for predicting social interactions towards human tracking. Pattern Recognit. 2014, 47, 1626–1641. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multi box detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; Springer Press: New York, NY, USA, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; IEEE Computer Society Press: Washington, DC, USA, 2015; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE Computer Society Press: Washington, DC, USA, 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; IEEE Computer Society Press: Los Alamices, CA, USA, 2018; pp. 1–6. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, F.; Choi, W.; Lin, Y. Exploit all the layers: Fast and accurate cnn object detector with scale dependent pooling and cascaded rejection classifiers. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2129–2137. [Google Scholar]
- Zhang, Y.; Wang, C.; Wang, X.; Zeng, W.; Liu, W. FairMOT: On the Fairness of Detection and Re-Identification in Multiple Object Tracking. Int. J. Comput. Vis. 2020. [Google Scholar] [CrossRef]
- Hu, Y.; Song, R.; Li, Y. Efficient coarse-to-fine patchmatch for large displacement optical flow. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5704–5712. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Milan, A.; Leal-Taixé, L.; Reid, I.; Roth, S.; Schindler, K. MOT16: A benchmark for multi-object tracking. arXiv 2016, arXiv:1603.00831. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Ess, A.; Leibe, B.; Schindler, K.; van Gool, L. A mobile vision system for robust multi-person tracking. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Zhang, S.; Benenson, R.; Schiele, B. Citypersons: A diverse dataset for pedestrian detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3213–3221. [Google Scholar]
- Shao, S.; Zhao, Z.; Li, B.; Xiao, T.; Yu, G.; Zhang, X.; Sun, J. Crowdhuman: A benchmark for detecting human in a crowd. arXiv 2018, arXiv:1805.00123. [Google Scholar]
- Leal-Taixé, L.; Milan, A.; Reid, I.; Roth, S.; Schindler, K. Motchallenge 2015: Towards a benchmark for multi-target tracking. arXiv 2015, arXiv:1504.01942. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Henschel, R.; Leal-Taixé, L.; Cremers, D.; Rosenhahn, B. Fusion of Head and Full-Body Detectors for Multi-Object Tracking. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Peng, J.; Wang, T.; Lin, W.; Wang, J.; See, J.; Wen, S.; Ding, E. TPM: Multiple Object Tracking with Tracklet-Plane Matching. Pattern Recognit. 2020, 107, 107480. [Google Scholar] [CrossRef]
- Tang, S.; Andriluka, M.; Andres, B.; Schiele, B. Multiple People Tracking by Lifted Multicut and Person Re-identification. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Xu, Y.; Osep, A.; Ban, Y.; Horaud, R.; Leal-Taixé, L.; Alameda-Pineda, X. How to train your deep multi-object tracker. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 6787–6796. [Google Scholar]
- Bergmann, P.; Meinhardt, T.; Leal-Taixe, L. Tracking without bells and whistles. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Zhu, J.; Yang, H.; Liu, N.; Kim, M.; Zhang, W.; Yang, M.H. Online multi-object tracking with dual matching attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 379–396. [Google Scholar]
- Li, X.; Liu, Y.; Wang, K.; Yan, Y.; Wang, F.Y. Multi-Target Tracking with Trajectory Prediction and Re-Identification. In Proceedings of the 2019 Chinese Automation Congress (CAC), Hangzhou, China, 22–24 November 2019. [Google Scholar]
- Chen, J.; Sheng, H.; Zhang, Y.; Xiong, Z. Enhancing Detection Model for Multiple Hypothesis Tracking. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 2143–2152. [Google Scholar] [CrossRef]
- Zhang, Y.; Sheng, H.; Wu, Y.; Wang, S.; Lyu, W.; Ke, W.; Xiong, Z. Long-Term Tracking With Deep Tracklet Association. IEEE Trans. Image Process. 2020, 29, 6694–6706. [Google Scholar] [CrossRef]
- Lee, S.; Kim, E. Multiple object tracking via feature pyramid Siamese networks. IEEE Access 2019, 7, 8181–8194. [Google Scholar] [CrossRef]
- Chu, P.; Ling, H. FAMNet: Joint Learning of Feature, Affinity and Multi-dimensional Assignment for Online Multiple Object Tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mode | Method | |||||||
|---|---|---|---|---|---|---|---|---|
| Off-line | FWT [29] | 47.8 | 75.5 | 44.3 | 19.1 | 38.2 | 8886 | 85,487 |
| TPM [30] | 51.3 | 75.2 | 47.9 | 18.7 | 40.8 | 2701 | 85,504 | |
| LMP [31] | 48.8 | 79.0 | 51.3 | 18.2 | 40.1 | 6654 | 86,245 | |
| On-line | DeepMOT [32] | 54.8 | 77.5 | 53.4 | 19.1 | 37.0 | 2955 | 78,765 |
| Tracktor++ [33] | 54.4 | 78.2 | 52.5 | 19 | 36.9 | 3280 | 79,149 | |
| DMAN [34] | 51.4 | 76.9 | 54 | 16.5 | 34.9 | 21,042 | 251,873 | |
| PV [35] | 50.4 | 77.7 | 50.8 | 14.9 | 38.9 | 2600 | 86,780 | |
| Ours | 56.3 | 79.2 | 55.1 | 20.4 | 35.6 | 3095 | 79,634 |
| Mode | Method | |||||||
|---|---|---|---|---|---|---|---|---|
| Off-line | EDMT [36] | 50.9 | 76.6 | 52.7 | 17.5 | 35.7 | 24,069 | 250,768 |
| TT17 [37] | 54.9 | 77.2 | 63.1 | 24.4 | 38.1 | 20,236 | 233,295 | |
| TPM [30] | 54.2 | 76.7 | 52.6 | 22.8 | 37.5 | 13,739 | 242,730 | |
| On-line | FPSN [38] | 44.9 | 76.6 | 48.4 | 16.5 | 35.8 | 33,757 | 269,952 |
| DeepMOT [32] | 53.7 | 77.2 | 53.8 | 19.4 | 36.6 | 11,731 | 247,447 | |
| FAMNet [39] | 52 | 76.5 | 48.7 | 19.1 | 33.4 | 14,138 | 253,616 | |
| DMAN [34] | 48.2 | 75.7 | 55.7 | 19.3 | 38.3 | 26,218 | 263,6083 | |
| Ours | 55.1 | 78.9 | 54.1 | 20.0 | 35.6 | 8524 | 241,795 |
| Sequence | MOTA() | MOTP() | IDF1() | MT() | ML() | FP() | FN() | IDSW() |
|---|---|---|---|---|---|---|---|---|
| MOT17-01-DPM | 41.7 | 78.4 | 40.3 | 5 | 11 | 23 | 3716 | 21 |
| MOT17-03-DPM | 65.3 | 79.1 | 59.7 | 51 | 19 | 1552 | 34,530 | 216 |
| MOT17-06-DPM | 54.0 | 80.6 | 55.9 | 47 | 86 | 120 | 5227 | 79 |
| MOT17-07-DPM | 41.6 | 79.3 | 45.9 | 5 | 22 | 94 | 9699 | 74 |
| MOT17-08-DPM | 26.6 | 83.5 | 32.7 | 8 | 39 | 68 | 15,375 | 64 |
| MOT17-12-DPM | 45.9 | 82.8 | 53.8 | 16 | 43 | 26 | 4635 | 27 |
| MOT17-14-DPM | 31.7 | 77.3 | 39.5 | 11 | 81 | 218 | 12,263 | 142 |
| average | 43.83 | 80.1 | 56.8 | 20.4 | 43 | 300.1 | 12,206.4 | 89 |
| MOT17-01-FRCNN | 43.6 | 77.9 | 41.1 | 6 | 10 | 107 | 3505 | 24 |
| MOT17-03-FRCNN | 67.7 | 78.7 | 60.3 | 54 | 18 | 1578 | 32,032 | 198 |
| MOT17-06-FRCNN | 57.5 | 80.0 | 58.6 | 55 | 61 | 225 | 4657 | 125 |
| MOT17-07-FRCNN | 41.9 | 79.1 | 46.9 | 6 | 22 | 219 | 9517 | 83 |
| MOT17-08-FRCNN | 26.2 | 83.5 | 32.1 | 8 | 40 | 94 | 15,431 | 60 |
| MOT17-12-FRCNN | 44.8 | 82.5 | 54.7 | 15 | 44 | 34 | 4728 | 18 |
| MOT17-14-FRCNN | 33.0 | 76.2 | 39.9 | 12 | 78 | 457 | 11,734 | 197 |
| average | 45.0 | 79.7 | 47.7 | 22.3 | 39 | 359.1 | 11,657 | 100.7 |
| MOT17-01-SDP | 43.9 | 77.7 | 59.7 | 6 | 10 | 104 | 3488 | 26 |
| MOT17-03-SDP | 71.8 | 78.1 | 62.7 | 62 | 16 | 2380 | 26,774 | 333 |
| MOT17-06-SDP | 58.0 | 80.0 | 56.9 | 58 | 65 | 282 | 4545 | 127 |
| MOT17-07-SDP | 43.9 | 78.7 | 45.8 | 8 | 19 | 222 | 9149 | 98 |
| MOT17-08-SDP | 27.7 | 82.7 | 32.4 | 10 | 37 | 146 | 15,057 | 74 |
| MOT17-12-SDP | 46.3 | 82.2 | 54.4 | 17 | 44 | 97 | 4532 | 26 |
| MOT17-14-SDP | 35.4 | 76.3 | 42.3 | 11 | 70 | 476 | 11,254 | 208 |
| average | 46.7 | 79.4 | 50.6 | 24.6 | 37.3 | 529.6 | 12,114 | 1513.4 |
| Method | |||
|---|---|---|---|
| Anchor-based tracking | 48.7 | 67.8 | 49.2 |
| Anchor-free tracking | 52.3 | 70.1 | 52.4 |
| Anchor-free tracking + trajectory extension strategy (ours) | 56.3 | 79.2 | 55.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.; Wang, F.; Li, C.; Zhang, Y.; Ai, Y.; Zhang, W. Online Multiple Object Tracking Using a Novel Discriminative Module for Autonomous Driving. Electronics 2021, 10, 2479. https://doi.org/10.3390/electronics10202479
Chen J, Wang F, Li C, Zhang Y, Ai Y, Zhang W. Online Multiple Object Tracking Using a Novel Discriminative Module for Autonomous Driving. Electronics. 2021; 10(20):2479. https://doi.org/10.3390/electronics10202479
Chicago/Turabian StyleChen, Jia, Fan Wang, Chunjiang Li, Yingjie Zhang, Yibo Ai, and Weidong Zhang. 2021. "Online Multiple Object Tracking Using a Novel Discriminative Module for Autonomous Driving" Electronics 10, no. 20: 2479. https://doi.org/10.3390/electronics10202479
APA StyleChen, J., Wang, F., Li, C., Zhang, Y., Ai, Y., & Zhang, W. (2021). Online Multiple Object Tracking Using a Novel Discriminative Module for Autonomous Driving. Electronics, 10(20), 2479. https://doi.org/10.3390/electronics10202479