
Non-Interactive and Secure Data Aggregation Scheme for Internet of Things


Abstract
1. Introduction
- We design a non-interactive and secure data aggregation scheme that has low communication overheads, which is robust to the exiting users and supports mobile users offline. This scheme uses additive secret sharing to share the original data in two parts, and then masks two shared values with a random number. Finally, the ciphertext is sent to two non-colluding cloud servers separately. Compared with the previous aggregation ones, our scheme reduces the computation and communication costs of users.
- In most of the previous schemes, the server can obtain the final aggregation results, and it is possible for the cloud to misuse the aggregation results for malicious analysis and speculation. However, in our scheme, the two cloud servers perform data aggregation with the ciphertext of the aggregation result, and therefore the true aggregation result is well-protected from the servers.
- This paper designs a set of algorithms so that the final aggregation result can be efficiently verified. Anyone can check the correctness of the aggregation results with a probability of 1, and it is impossible for an incorrect aggregation result to be successfully verified.
2. Related Work
3. Preliminaries
3.1. Secure Multi-Party Computation
3.2. Additive Secret Sharing
3.3. Pseudo-Random Generator
3.4. Bilinear Map
- Bilinearity: For any and we have .
- Computability: There is an efficient algorithm to compute for .
- Non-degeneracy: There exists , such that .
3.5. Verifiable Computation
- KeyGen : The inputs to the key generation algorithm are the secure parameter and function f, and then the outputs are and .
- ProbGen : The inputs to the problem generation algorithm are and x, and the outputs are , where is a public value and is a private value kept by the user.
- Compute : The algorithm takes and as inputs, and the cloud server computes the output value .
- Verify : The user uses and to verify whether is correct; if the verification passes, it will be accepted, otherwise, it will be rejected.
4. System Framework and Non-Interactive and Secure Data Aggregation Scheme
4.1. System Framework
4.1.1. System Model
4.1.2. Threat Model
4.1.3. Design Goals
- Input privacy: The data collected by mobile users are sensitive data. These data should be masked before sending to the server; therefore, in this paper we should ensure that the data input is private.
- Output privacy: Since there are two non-colluding servers, they perform aggregation operations without obtaining the final aggregation result; therefore, in this paper we should ensure the output privacy.
- Verifiability: The verifier can utilize the verification algorithm to verify whether it is correct when all participants execute the protocol correctly.
- Non-interactivity: Our scheme guarantees non-interaction between users, which reduces the communication cost. Due to the non-interactivity between users, it will not affect the normal execution of the protocol even if someone drops out during the aggregation process.
- Efficiency: It is experimentally demonstrated that our aggregation scheme can obtain the aggregation result and verify its correctness with a low computation cost.
4.2. Non-Interactive and Secure Data Aggregation Scheme
4.2.1. Key Generation
4.2.2. Masking of Private Data
| Algorithm 1: Non-Interactive and Secure Data Aggregation Scheme |
|
4.2.3. Data Aggregation
4.2.4. Verification of the Results
5. Analysis
5.1. Input and Output Privacy
5.2. Verification Algorithm Security
5.3. Robustness Analysis
5.4. Limitations
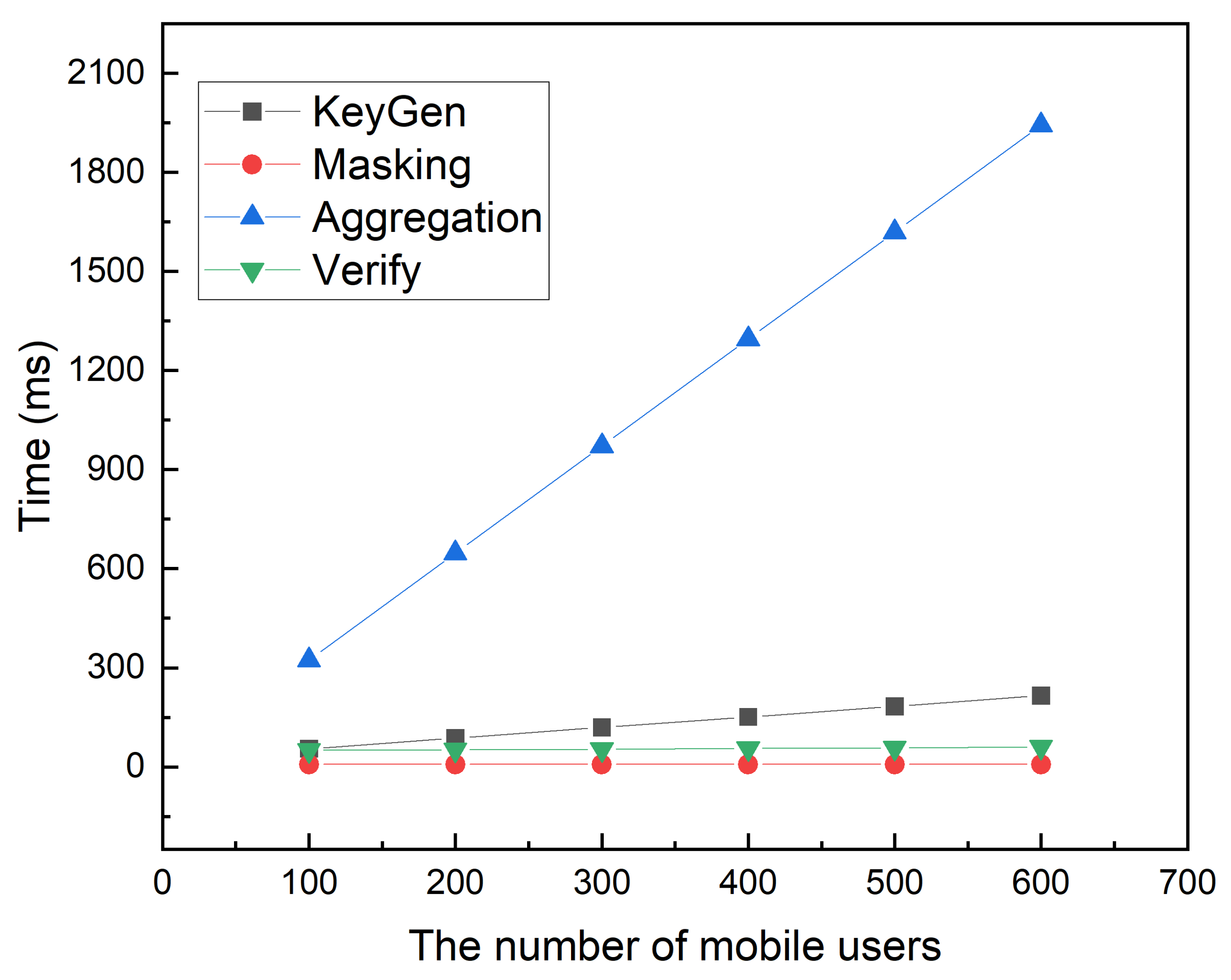
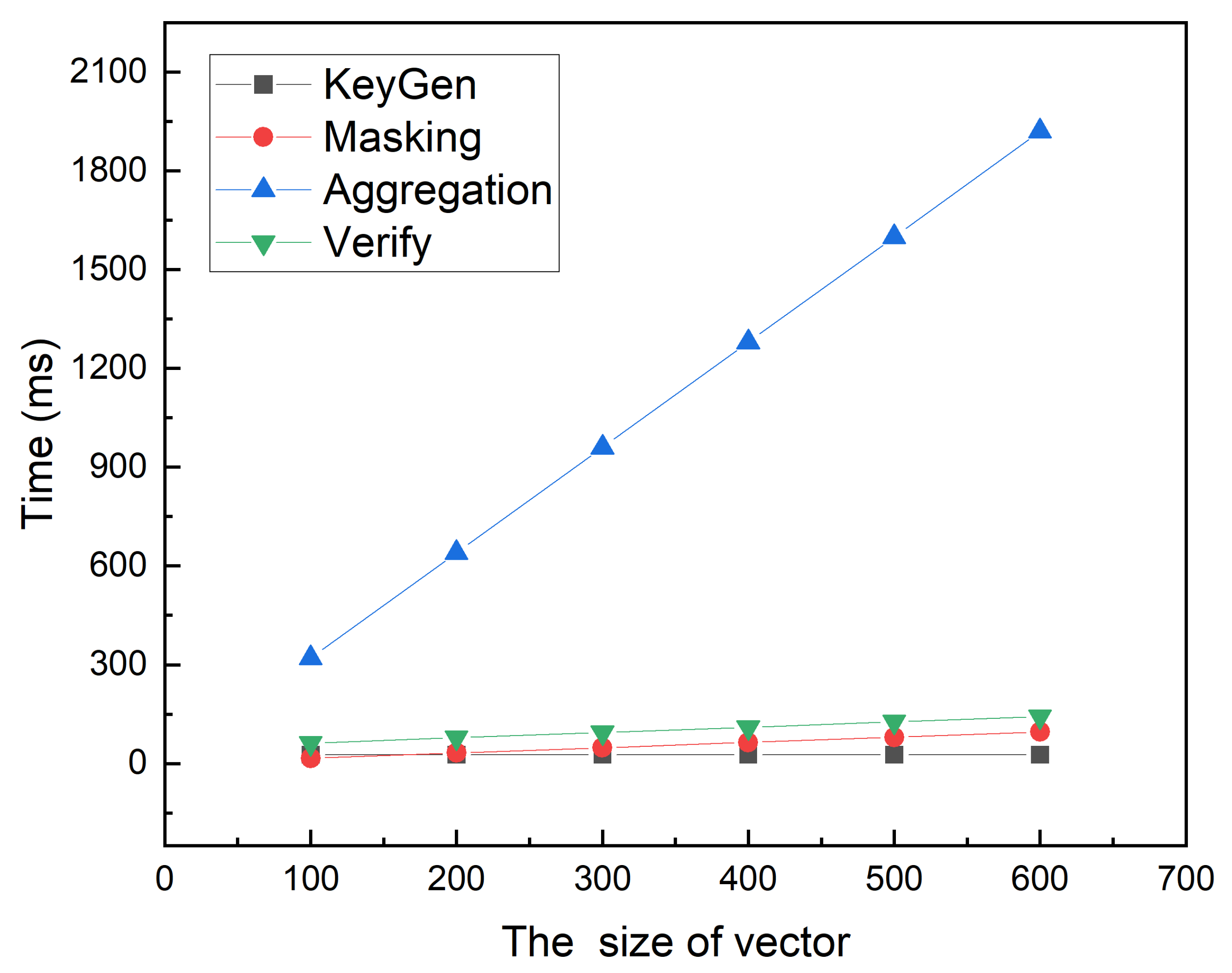
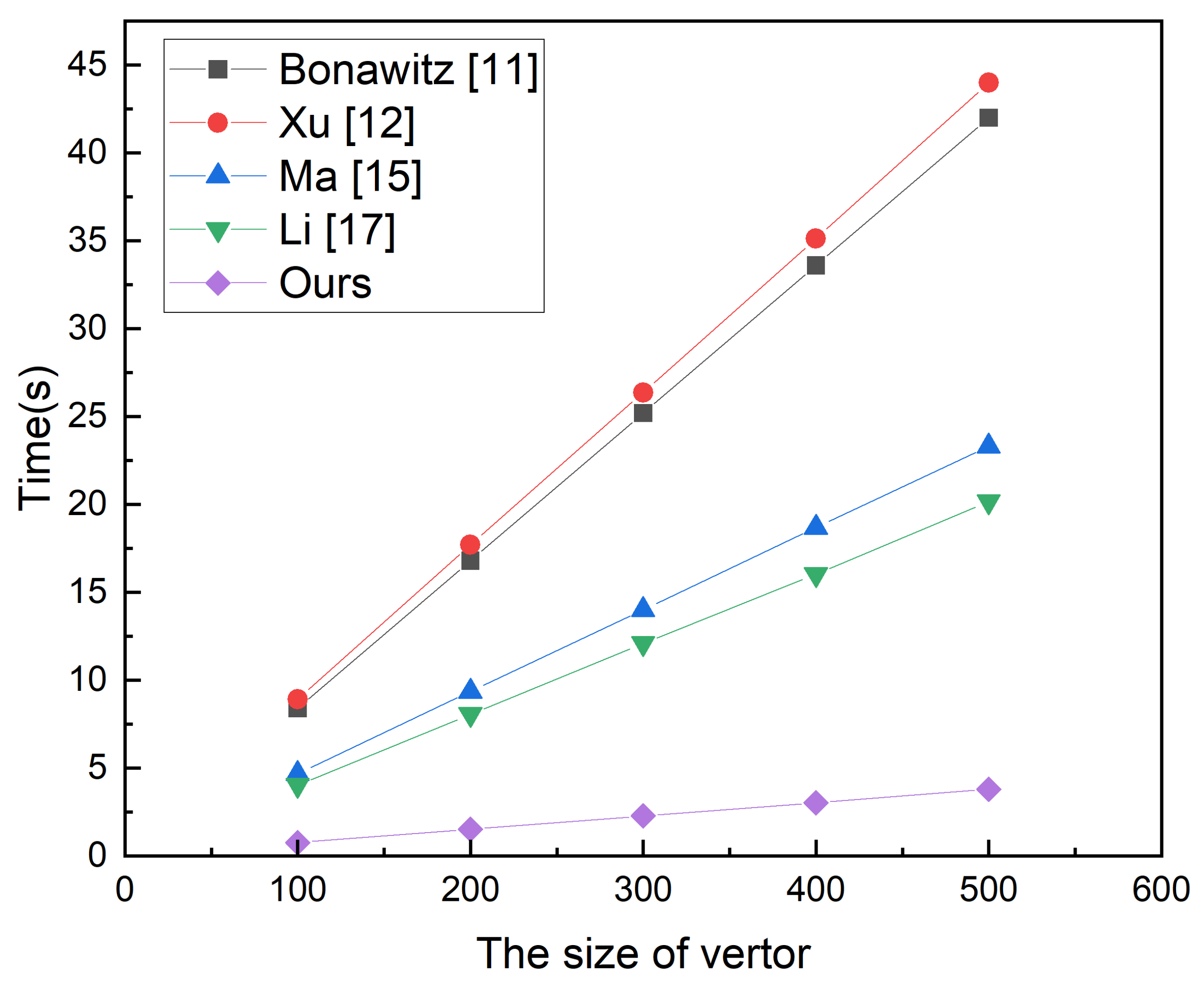
6. Performance Evaluation
6.1. Function Analysis
6.2. Experimental Results
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- The Mobile Economy 2020. Available online: https://www.gsma.com/mobileeconomy/wp-content/uploads/2020/03/GSMA_MobileEconomy2020_Global.pdf (accessed on 5 March 2020).
- Mandal, K.; Gong, G.; Liu, C. Nike-based fast privacy-preserving highdimensional data aggregation for mobile devices. In IEEE T Depend Secure; Technical Report; University of Waterloo: Waterloo, ON, Canada, 2018; pp. 142–149. [Google Scholar]
- Jian, S.; Chen, W.; Li, T.; Xiao, F.C.; Huang, X.Y.; Zhan, Z.H. Secure data uploading scheme for a smart home system. INS 2018, 453, 186–197. [Google Scholar] [CrossRef]
- Wu, Z.D.; Liang, B.; You, L.; Jian, Z.H.; Li, J. High-dimension space projection-based biometric encryption for fingerprint with fuzzy minutia. Soft Comput. 2016, 20, 4907–4918. [Google Scholar] [CrossRef]
- He, D.B.; Neeraj, K.; Shen, H.; Jong-Hyouk, L. One-to-many authentication for access control in mobile pay-TV systems. Sci. China Inform. Sci. 2016, 59, 1–14. [Google Scholar] [CrossRef][Green Version]
- Xu, C.; Xie, X.; Zhu, L.H. PPLS: A Privacy-Preserving Location-Sharing Scheme in Vehicular Social Networks. Sci. China Inform. Sci. 2020, 063, 163–173. [Google Scholar] [CrossRef]
- Zhang, Y.H.; Zheng, D.; Deng, R.H. Security and privacy in smart health: Efficient policy-hiding attribute-based access control. IEEE Internet Things J. 2018, 5, 2130–2145. [Google Scholar] [CrossRef]
- Sattler, F.; Wiedemann, S.; Müller, K.R.; Samek, W. Robust and communication-efficient federated learning from non-iid data. IEEE Trans. Neural Netw. Learn. 2019, 31, 3400–3413. [Google Scholar] [CrossRef]
- Chen, Y.; Sun, X.Y.; Jin, Y.C. Communication-efficient federated deep learning with layerwise asynchronous model update and temporally weighted aggregation. IEEE Trans. Neural Netw. Learn. 2019, 31, 4229–4238. [Google Scholar] [CrossRef]
- Liu, X.Y.; Li, H.W.; Xu, G.W.; Lu, R.X.; He, M. Adaptive privacy-preserving federated learning. Peer Peer Netw. Appl. 2020, 13, 2356–2366. [Google Scholar] [CrossRef]
- Hao, M.; Li, H.W.; Luo, X.Z.; Xu, G.W.; Yang, H.M.; Liu, S. Efficient and privacy-enhanced federated learning for industrial artificial intelligence. IEEE Trans. Industr. Inform. 2019, 16, 6532–6542. [Google Scholar] [CrossRef]
- Keith, B.; Vladimir, I.; Ben, K.; Antonio, M.; McMahan, H.B.; Patel, S.; Ramage, D.; Segal, A.; Seth, K. Practical secure aggregation for privacy-preserving machine learning. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, New York, NY, USA, 30 October 2017; pp. 1175–1191. [Google Scholar]
- Xu, G.W.; Li, H.W.; Liu, S.; Yang, K.; Lin, X.D. Verifynet: Secure and verifiable federated learning. IEEE Trans. Inf. Forensics Secur. 2019, 15, 911–926. [Google Scholar] [CrossRef]
- Yang, W.Q.; Liu, B.; Lu, C.L.; Yu, N.H. Privacy preserving on updated parameters in federated learning. In Proceedings of the ACM Turing Celebration Conference, Hefei, China, 22 May 2020; pp. 27–31. [Google Scholar]
- Kalikinkar, M.; Gong, G. Privfl: Practical privacy-preserving federated regressions on high-dimensional data over mobile networks. In Proceedings of the 2019 ACM SIGSAC Conference on Cloud Computing Security Workshop, London, UK, 11 November 2019; pp. 57–68. [Google Scholar]
- Xu, M.; Ji, C.M.; Zhang, X.Y.; Wang, J.F.; Li, J.; Li, K.C.; Chen, X. Secure multiparty learning from the aggregation of locally trained models. J. Netw. Comput. Appl. 2020, 167, 1084–8045. [Google Scholar] [CrossRef]
- Al-Zubaidie, M.; Zhang, Z.; Zhang, J. REISCH: Incorporating Lightweight and Reliable Algorithms into Healthcare Applications of WSNs. Appl. Sci. 2020, 10, 2007. [Google Scholar] [CrossRef]
- Edemacu, K.; Kim, J.W. Multi-Party Privacy-Preserving Logistic Regression with Poor Quality Data Filtering for IoT Contributors. Electronics 2021, 10, 2049. [Google Scholar] [CrossRef]
- Ming, Y.; Zhang, X.Y.; Shen, X.Q. Efficient privacy-preserving multi-dimensional data aggregation scheme in smart grid. IEEE Access 2019, 7, 32907–32921. [Google Scholar] [CrossRef]
- Li, T.; Gao, C.Z.; Jiang, L.L.; Witold, P.; Shen, J. Publicly verifiable privacy-preserving aggregation and its application in IoT. J. Netw. Comput. Appl. 2019, 126, 39–44. [Google Scholar] [CrossRef]
- Jiang, Y.; Zhao, B.W.; Tang, S.H.; Wu, H.T. A verifiable and privacy-preserving multidimensional data aggregation scheme in mobile crowdsensing. Trans. Emerg. Telecommun. Technol. 2021, 32, e4008. [Google Scholar] [CrossRef]
- Yao, A.C.C. How to generate and exchange secrets. In Proceedings of the 27th Annual Symposium on Foundations of Computer Science (SFCS), Toronto, ON, Canada, 27–29 October 1986; pp. 162–167. [Google Scholar]
- Qiu, S.; Wang, B.Y.; Li, M.; Liu, J.Q.; Shi, Y.F. Toward practical privacy-preserving frequent itemset mining on encrypted cloud data. IEEE Trans. Cloud Comput. 2017, 8, 312–323. [Google Scholar] [CrossRef]
- Verykios, V.S.; Bertino, E.; Fovino, I.N.; Provenza, L.P.; Saygin, Y.; Theodoridis, Y. State-of-the-art in privacy preserving data mining. ACM Sigmod Rec. 2004, 33, 50–57. [Google Scholar] [CrossRef]
- Rakesh, A.; Ramakrishnan, S. Privacy-preserving data mining. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, New York, NY, USA, 16 May 2000; pp. 439–450. [Google Scholar]
- Du, W.; Atallah, M.J. Privacy-preserving cooperative scientific computations. In Proceedings of the 14th IEEE Computer Security Foundations Workshop (CSFW), Cape Breton, NS, Canada, 11–13 June 2001; Volume 1, p. 273. [Google Scholar]
- Liu, L.; Su, J.; Liu, X.; Chen, R.; Huang, K.; Deng, R.H.; Wang, X. Toward highly secure yet efficient KNN classification scheme on outsourced cloud data. IEEE Internet Things J. 2019, 6, 9841–9852. [Google Scholar] [CrossRef]
- Ma, X.; Chen, X.; Zhang, X. Non-interactive privacy-preserving neural network prediction. Inf. Sci. 2019, 481, 507–519. [Google Scholar] [CrossRef]
- Manuel, B.; Silvio, M. How to generate cryptographically strong sequences of pseudorandom bits. SIAM J. Comput. 1984, 13, 850–864. [Google Scholar] [CrossRef]
- Andrew, C.Y. Theory and application of trapdoor functions. In Proceedings of the 23rd Annual Symposium on Foundations of Computer Science (SFCS), Chicago, IL, USA, 3–5 November 1982; pp. 80–91. [Google Scholar] [CrossRef]
- Dan, B.; Craig, G.; Ben, L.; Hovav, S. Aggregate and verifiably encrypted signatures from bilinear maps. In Proceedings of the International Conference on the Theory and Applications of Cryptographic Techniques, Berlin/Heidelberg, Germany, 13 May 2003; pp. 416–432. [Google Scholar]
- Chen, X.F.; Li, J.; Huang, X.Y.; Ma, J.F.; Lou, W.J. New publicly verifiable databases with efficient updates. IEEE Trans. Dependable Secur. Comput. 2014, 12, 546–556. [Google Scholar] [CrossRef]
- Li, J.; Huang, X.Y.; Li, J.W.; Chen, X.F.; Xiang, Y. Securely outsourcing attribute-based encryption with checkability. IEEE Trans. Parallel. Distrib. Syst. 2013, 25, 2201–2210. [Google Scholar] [CrossRef]
- Chen, X.F.; Li, J.; Weng, J.; Ma, J.F.; Lou, W.J. Verifiable computation over large database with incremental updates. IEEE Trans. Comput. 2015, 65, 3184–3195. [Google Scholar] [CrossRef]
- Li, J.; Chen, X.F.; Li, M.Q.; Li, J.W.; Lee, P.P.; Lou, W. Secure deduplication with efficient and reliable convergent key management. IEEE Trans. Parallel Distrib. Syst. 2013, 25, 1615–1625. [Google Scholar] [CrossRef]
- Jia, K.; Li, H.W.; Liu, D.X.; Yu, S. Enabling efficient and secure outsourcing of large matrix multiplications. In Proceedings of the 2015 IEEE Global Communications Conference (GLOBECOM), San Diego, CA, USA, 6–10 December 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Zhang, X.Y.; Jiang, T.; Li, K.C.; Castiglione, A.; Chen, X. New publicly verifiable computation for batch matrix multiplication. Inf. Sci. 2019, 479, 664–678. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbols | Definition |
|---|---|
| U | Mobile user dataset |
| The shares of | |
| Random vector of the mask selected by user | |
| , | The ciphertexts of shared value |
| m | Dimension of the private vector |
| h | Verification vectors |
| The public key for verification | |
| Authentication key for verification | |
| Aggregation result | |
| The proof of computation |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, Y.; Ren, Y.; Feng, G.; Zhang, X.; Qin, C. Non-Interactive and Secure Data Aggregation Scheme for Internet of Things. Electronics 2021, 10, 2464. https://doi.org/10.3390/electronics10202464
Fu Y, Ren Y, Feng G, Zhang X, Qin C. Non-Interactive and Secure Data Aggregation Scheme for Internet of Things. Electronics. 2021; 10(20):2464. https://doi.org/10.3390/electronics10202464
Chicago/Turabian StyleFu, Yanxia, Yanli Ren, Guorui Feng, Xinpeng Zhang, and Chuan Qin. 2021. "Non-Interactive and Secure Data Aggregation Scheme for Internet of Things" Electronics 10, no. 20: 2464. https://doi.org/10.3390/electronics10202464
APA StyleFu, Y., Ren, Y., Feng, G., Zhang, X., & Qin, C. (2021). Non-Interactive and Secure Data Aggregation Scheme for Internet of Things. Electronics, 10(20), 2464. https://doi.org/10.3390/electronics10202464