1. Introduction and Motivation
Natural Language Processing (NLP) is the branch of Artificial Intelligence concerned with automatic processing of text written in natural languages, so as to improve human fruition of its contents. Several NLP tasks are associated to the different, and increasingly complex, levels at which natural languages may be studied and analyzed (morphology, lexicon, grammar, syntax, semantics, and pragmatics). NLP tools typically rely on linguistic resources (lists of words or suffixes, etc.). Since each language is different from the others, specific resources are needed for each language. Manual development of the resources by linguistic experts is time-consuming (it takes much study and refinement), costly (expert time is valuable), and potentially erratic (as all human activities).
While several examples exist for the various NLP tasks, here, we will just provide one that is representative of all of the above issues. A very famous linguistic resource, widely exploited for many tasks, is WordNet, a semantic network/lexical taxonomy (some consider it an ontology) that organizes concepts and English terms according to several syntactic or semantic relationships [
1]. Being manually developed, it is not free of bugs. The problem of cost is evident in the current Webpage of the project (
https://wordnet.princeton.edu/, accessed on 31 August 2021), which states: “Due to funding and staffing issues, […] there are currently no plans for future WordNet releases.” Moreover, the effort had to be duplicated for many other languages, with mixed results. The EuroWordNet project [
2] considered Dutch, Italian, Spanish, German, French, Czech, and Estonian. Its homepage (
https://archive.illc.uva.nl/EuroWordNet/, accessed on 30 July 2021) reports on efforts for Swedish, Norway, Danish, Greek, Portuguese, Basque, Catalan, Romanian, Lithuan, Russian, Bulgarian, and Slovenic. Another work in the same direction is MultiWordNet [
3], that aligns the Italian WordNet with Princeton WordNet and also provides access to the Spanish, Portuguese, Hebrew, Romanian, and Latin WordNets, developed by other research groups. It demonstrates another problem in the building and development of language-specific linguistic resources: the additional work needed to keep them aligned when new versions are available (it is aligned with WordNet v1.6 but subsequent WordNet versions are not backward compatible).
So, it would be desirable to automatically learn the resources from texts in a given language, but finding effective strategies is not trivial, and often relies on statistics that must be drawn from very large amounts of text. In fact, many good resources have been developed for English; some, not always very reliable, resources are available for a few major languages, but nearly nothing exists for the vast majority of non-widespread languages, dialects, and jargons. This prevents application of NLP to the latter, which tampers cultural diversity and might even cause extinction of languages in the long run, with a consequent huge cultural loss.
An NLP task working at the lexical level is Stopword Identification, where “Stopwords are terms that occur most frequently in a document and contain very little information that is usually not necessary” [
4]. Ref. [
5] defines stopwords by contrast to most significant words (‘keywords’) as follows: “Since significance is difficult to predict, it is more practical to isolate it by rejecting all obviously non-significant or ‘common’ words, with the risk of admitting certain words of questionable status. Such words may subsequently be eliminated or tolerated as so much ‘noise’. ” The historical and main application that needs stopwords is Information Retrieval (IR). It aims at indexing a corpus of texts so as to quickly and accurately select those that may best satisfy the information needs of users, usually expressed by queries consisting of sets of terms, e.g., effective IR may foster cultural diversity, and keep alive languages, by making documents in those languages easily retrievable by end-users. IR mostly works at the lexical level, and carries out Stopword Removal to reduce the number of indexed terms. This increases speed, reduces storage requirements, and improves accuracy (by focusing the index on meaningful terms only). Today, a significant trend for IR is based on techniques that avoid text pre-processing and, thus, stopword removal, as well. However, these techniques require very large amounts of data to be applicable, which would not feasible under the small-corpora setting. Additionally, many other applications still exist that rely on Stopword Identification, e.g., it is still relevant or necessary for linguistic studies, or for supporting applications, such as Diachronic Analysis (concerning lexical and semantic changes in language along time) [
6] and Sentiment Analysis (see, e.g., References [
7,
8]).
The linguistic resource used for Stopword Removal is known as ‘stopword list’. It consists of the list of terms to be found and removed from the texts. Quoting, again, Reference [
5], “A list of nonsignificant words would include articles, conjunctions, prepositions, auxiliary verbs, certain adjectives”, known as ‘function words’. This approach requires grammatical knowledge of the language, which might not be available. In addition, additional specific terms might be insignificant in domain-specific contexts (e.g., “words, such as “report”, “analysis”, “theory”, and the like” are considered as irrelevant in the domain indexing of technical literature [
5]). So, each specific domain has its own stopwords, but only generic stopword lists are usually developed. Even worse, an analysis revealed that well-known and widely used stopword lists are not very accurate, which clearly affects their effectiveness [
9].
Motivated by all the considerations above, this paper proposes an integrated approach to automatically learn stopword lists, made up of two components:
a simple yet effective frequency-based approach to rank candidate stopwords, and
a geometric strategy to determine the cutpoint in this ranking.
Importantly and interestingly, our approach can work under the following constraints:
using just plain texts (i.e., no previous linguistic knowledge): so as to deal with languages for which no formal grammar is available;
being language-independent (not tailored to a specific language): so as to provide its benefits to a whole range of languages;
working on very small corpora (in extreme cases, even a single text): so as to deal with languages having limited spread or literature (to the best of our knowledge, this setting is original; all previous works in the literature assumed huge amounts of data to be available, which is not always true in practice); and
being fully automatic: so as to avoid the shortcomings of using linguistic experts.
We ran experiments on several languages of different complexity, and even on mixed languages, proving the effectiveness of our proposal and obtaining interesting insight about the problem in general and how to practically apply our approach.
In the following, after discussing related works, we will describe our approaches, our experimental setting and the datasets used. Then, we will discuss our experimental results on stopword extraction from very small corpora and single texts in different languages, before concluding the paper.
2. Related Work
Since stopword removal is very relevant for IR, proposals for automatic stopword extraction were often evaluated indirectly through the performance of IR based on the extracted stopwords (e.g., Reference [
10]). In this paper, we are mainly interested in the linguistics perspective; thus, we will evaluate the extracted stopword lists based on their contents, rather than on their performance on other tasks.
Some works learn the stopword lists based on external aids, such as labeled texts or extant language-specific tools/resources, e.g., Ref. [
10] uses a Vector Space Model, but previously applies stemming. Ref. [
11] also applies Porter’s algorithm for stemming the text and adopts a supervised learning approach. In addition, Reference [
12] works on labeled corpora. Ref. [
13] focuses on the task of optimizing an existing stopword list, with an approach based on the entropy of words. Ref. [
14] also adopts a supervised approach. Ref. [
15] exploits Part-of-Speech information. These approaches cannot be directly compared to our proposal, in which we purposely start from plain text and avoid any kind of aid or pre-processing.
Refs. [
16,
17] proposed two approaches purely based on frequency. Both are language-specific (English and French, respectively), and both involve manual adjustment of the list of stopwords extracted automatically. The former was tested on a corpus of broad literature including more than 1 million words, while the latter was applied to two corpora made up of small texts, including more than 4 and more than 6 million words, respectively. In addition, Reference [
12] proposes “automatic generation of domain-specific stopwords from a
large labeled corpus”. We aim at learning stopwords from much less data.
Let us now introduce some notation. We will denote by the training corpus, in a given language, for learning a stopword list for that language, by the number of texts in , and by the vocabulary of , i.e., the set of distinct terms used in . For each term , denotes the number of its occurrences in , the number of texts in which it occurs, and the number of its occurrences in text . So, denotes the total number of tokens (i.e., occurrences of terms) in . In the following, we will consider as fixed and, thus, will ignore it in the notation.
Many techniques proposed in the literature work by ranking all terms in the collection according to their degree of ‘stopwordness’, based on Zipf’s law (the relation
describes very precisely the distribution of frequency of terms rank). Then, they select the top terms in the ranking according to Algorithm 1. Some such techniques are supervised, e.g., Reference [
11]: Information Gain,
Statistic, Odds Ratio, and F-measure Feature Ranking. We assume no information is available except the plain text(s); thus, we cannot exploit such approaches. Instead, we turn to unsupervised approaches in the following. Different functions
used by unsupervised approaches in the literature are:
Term frequency (TF): the number of times a term occurs in the corpus:
Normalized Term Frequency (NTF): TF normalized with respect to the total number of tokens in the corpus:
Inverse Document Frequency (IDF) [
18]: based on the number of texts in the corpus in which the term occurs (assuming that the more texts use a term, the less informative it is):
Normalized IDF (NIDF): IDF normalized with respect to the number of texts that do not contain the term
, with a 0.5 adjustment to mitigate extreme values [
19]:
Entropy (H): based on the distribution of a certain term over the documents collection, i.e., on how (un)evenly distributed it is in the corpus:
where
(we recall that
is the number of occurrences of term
in document
c). The terms having higher entropy contain less information about the documents where they appear, than terms with lower entropy. The maximum entropy value for a given collection of documents is
, obtained for an even distribution.
A different, and more complex, approach is Term-based Random Sampling (TRS) [
20]. It randomly selects
n terms, and, for each, produces a set of candidate stopwords as follows: it samples all the texts containing the term and assesses the relevance of each term
t in the sample using the KL divergence measure [
21]:
to compare its distribution within the sample and in the whole corpus, where:
Then, each set of candidate stopwords is shrunk to m items, and the l least informative candidates overall are returned as stopwords. So, TRS requires 3 input parameters (n, m, l). Note that terms rarely occurring in the collection are likely to yield a small set of terms because few texts contain them. So, the samples obtained by selecting n should improve the estimation of the distribution and relevance of terms. Due to its random nature, the behavior of TRS is very variable and hard to capture.
Ref. [
20] compared the performance of TRS in supporting IR to TF, NTF, IDF, and NIDF, reporting NIDF to be the best technique. However, Ref. [
11] points out the deficiencies of the DF-based approach in general. We further note that, for collections consisting of very few texts, they cannot leverage enough variability and are inapplicable in the case of just one document. Being based on the distribution of terms across texts, H alsosuffers from the same problems and limitations. On the other hand, using TF, Ref. [
9] uncovered some flaws in standard stopword lists in the literature. Inspired by References [
9,
22], Ref. [
23] has shown that TF dramatically outperforms both NIDF and TRS on small corpora, as well as extensively discussed the behavior of these techniques on different types of texts.
Given a training corpus, these approaches will typically yield different stopword lists.
As witnessed by the most recent survey paper available on Stopword Removal, Reference [
4], the literature after Reference [
20] mainly focused on specific and peculiar languages, especially those using non-Latin script. A list of such works (often published in National conferences or journals) includes Arabic [
24,
25,
26], Chinese [
27,
28], Persian [
15], Sanskrit [
29], Gujarati [
30], Punjabi [
31], Hindi [
32,
33,
34], Bengali [
35], Sinhala [
36], and Tamil [
37]. Here, we aim at devising an approach that can be applied to different languages; thus, we will not discuss these works in the following, nor can we compare our proposal to these works, which use very tailored approaches.
Since most approaches to automatic stopword identification work according to Algorithm 1, a relevant problem is how to determine the cutoff threshold
. This is not trivial, due to the typical shape of the
plot providing little hints to determine the cutpoint. While not reporting the value used to obtain the best performance, Ref. [
20] proposed to determine
using the largest frequency difference between adjacent terms in the ranking: if it happens between frequencies
and
, they take
. However, this might be misleading, since the maximum difference typically happens quite early in the ranking, and might cut away too many stopwords. Ref. [
22] used the average-based threshold
, and experimentally found that
yields good results. Again, this solution does not consider the whole shape of the frequency ranking. In other applications facing the same problem, the derivative is used to cut the list, where the plot becomes (almost) flat. This is misleading, too, because the plot is irregular, and (especially in short texts) it often becomes nearly flat for a short time, with no strict relationship to the stopwords.
| Algorithm 1 Ranking-based stopword identification algorithm. |
Require: vocabulary V for
Require: threshold
Ensure: S /* set of identified stopwords */
for all do
if then
end if
end for
return S |
3. Proposed Approach
Based on its very definition, ‘stopwordness’ of a term is proportional to its frequency of occurrence. The most straightforward interpretation of this is considering its term frequency. In addition, indeed, the TF approach, albeit simple, demonstrated great potential, especially in the case of very few training documents [
23]. In another interpretation, the presence of a term in many documents may also be an indication of its being irrelevant to distinguish them. Strangely enough, however, in the literature, the Document Frequency (DF) of a term, i.e., the number of documents in which it appears, has always been used in its inverse form (IDF), possibly normalized (NIDF). Perhaps the inspiration for this came from the usual weighting schemes adopted for the Vector Space Model in IR (e.g., TF*IDF), where the more the spread of a term in the corpus, the less its relevance to a single document. However, using DF in the denominator decreases the weight of a term appearing in many documents, while, in our perspective, a term occurring in many documents should increase the degree of stopwordness for that term. In fact, the classical Vector Space Model expresses the relevance of terms to specific documents, while, here, we are interested in its relevance in the whole collection. In addition, it is unclear why TF, which is the parameter most obviously associated to stopwordness, was ignored by Reference [
20] when using IDF.
Based on these considerations, we purport that DF and TF can support each other in stopword identification and propose to combine them so that DF is directly, rather than inversely, proportional to ‘stopwordness’. So, each term will be associated with a value equal to the product of TF and DF. We call this extension Term-Document Frequency (TDF), defined by the following function to be used in Algorithm 1:
To the best of our knowledge, no one investigated this approach so far.
As to the choice of the cutpoint for the list of candidate stopwords, we propose a geometric strategy, formally described in Algorithm 2 and graphically shown in
Figure 1, where the
x axis reports the term ranking positions for terms ordered by decreasing stopwordness according to the
f function, and the
y axis reports the stopwordness values. First, all
different values of the stopwordness function
for the terms in the corpus are considered, ordered by decreasing value, and plotted on a Cartesian space where the
x-axis is associated to the set of different frequencies and the
y-axis reports the actual frequencies (plot in
Figure 1). Considering only different values avoids plateaus, yielding a monotonically decreasing plot and a more compact
x-axis, especially on its trailing part. The resulting diagram has an irregular hyperbole-like shape, on which the cut point is determined geometrically as follows. Consider a line
of given (decreasing) slope
a, and height
b on the origin of the Cartesian space such that it is tangent to the plot. Then, the
y coordinate of the tangency point will be our cutpoint frequency. So, our procedure takes the slope parameter
a as the only input. Acting on
a, one may obtain a stricter or looser selection: the more the slope, the earlier the cutpoint; the less the slope, the later the cutpoint. Of course, being the plot on the positive quadrant, we will consider negative slopes. Since the boundaries of the plot depend on the number of words in the vocabulary (
x-axis) and on the maximum word frequency in the corpus (
y-axis), the same line slope will have different effects depending on such boundaries. To reduce the effect of this issue, we propose to normalize the axes ranges, so that the plot becomes square. This has a nice side-effect on the understandability of the slope setting. Indeed, parameter
corresponds to a
slope, which should identify the cutpoint in which the plot slope changes from vertical to horizontal. So, values
[−1, 0] will select the cutpoint on the right-hand side of the elbow, while
will select the cutpoint on the left-hand side of the elbow.
| Algorithm 2 Cutpoint assessment. |
Require:V: vocabulary for
Require:a: slope of the line determining the cutpoint
Ensure:S /* set of identified stopwords */
/* all different stopwordness values */
/* normalization to make the plot square */
list of values in D in decreasing order
list of (normalized) values in in decreasing order
/* index of the cutpoint value */
while do
while /* j-th normalized bar above the line */ do
end while
if then
/* found new candidate cutpoint value */
else
/* all values processed */
end if
end while
for all do
if then
end if
end for
return S |
We may consider the frequency plot as composed by the top of the bars of a bar diagram where the bar at the i-th position on the x-axis represents the i-th different frequency (in decreasing order). In this representation, the tangent line we are looking for will have the following properties:
passing from a point for some term (i.e., candidate stopword)
being below all bar tops in the diagram:
It can be found by analyzing, in turn, each i, computing the corresponding b, and checking that the bar top of all other i’s is above the line, i.e., . Operationally, we proceed for increasing i’s, starting from . For each i under consideration we scan the subsequent bar tops, and skip them while they are above the line. If we reach the end of the plot, then the current i provides the cutpoint frequency; otherwise, as soon as we find a bar whose top is below the line, the corresponding position becomes our current candidate i, and we go back to the skipping step. In practice, instead of normalizing the axes, we report the normalization on the slope, so as to avoid recomputing all bar values, and also still having all integer values. Consider slope for the case of equal x and y ranges. With different x and y ranges, say and , respectively, the unitary increase of x corresponds to a increase of y; thus, the normalized slope to be used in practice is .
The procedure is shown in
Figure 2 for a sample bar diagram, where the steps are denoted by numbers in circles. The axes in
Figure 2 and
Figure 3 were not labeled because they describe our cutpoint assessment approach in general, for any monotonically decreasing histogram, independent of its interpretation—stopwordness ranking or other (in this work, they are to be interpreted as in
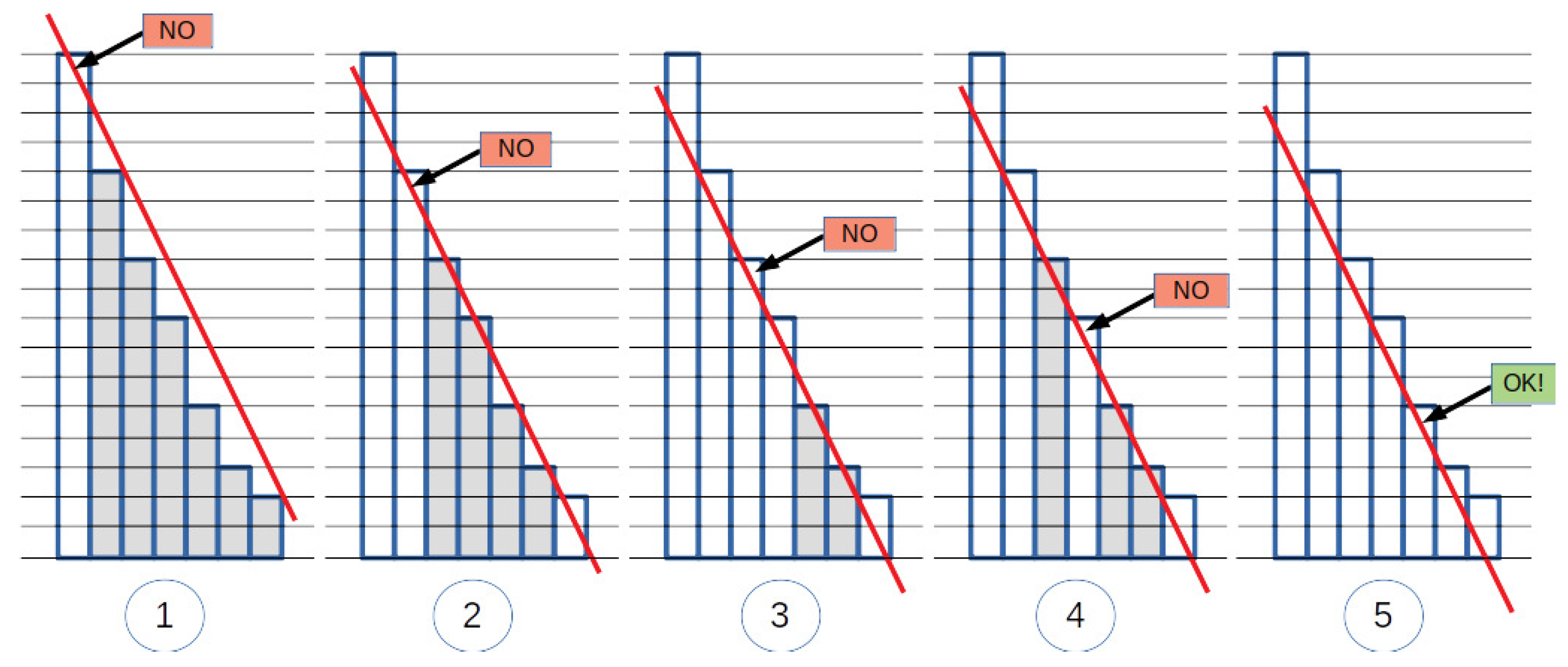
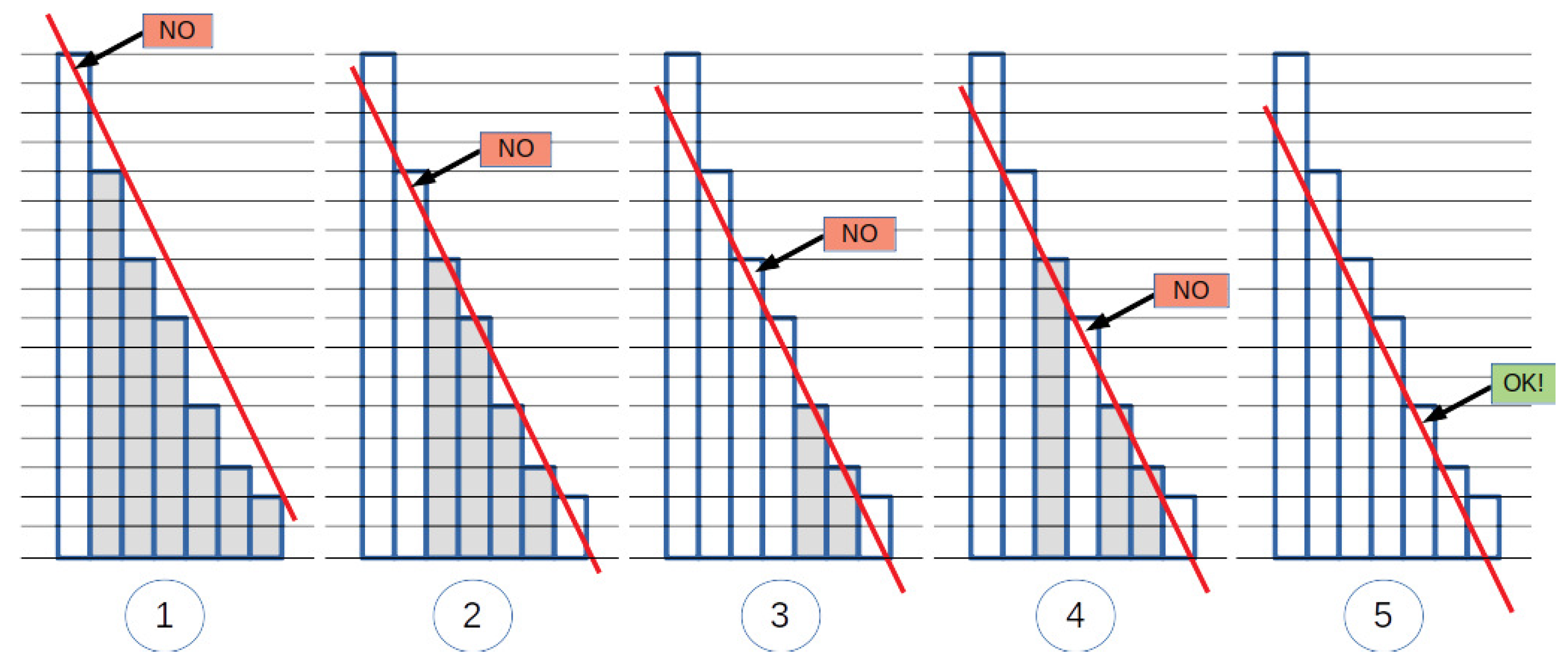
Figure 1). The bars were enlarged for the sake of readability, so that their points become squares; let us consider the centroid of each square as point represented by the square. Circled numbers below the diagrams denote the various steps of the procedure, and, for each step, an arrow shows the candidate cutpoint. Bars whose top point falls below the line are filled with gray in the picture. (1) We start with the first bar, and draw the line passing from its top point (centroid of the top square); we start scanning the subsequent bar tops and see that the second bar top is already below the line. (2) So, the second bar top becomes our new candidate; the line passing from it is drawn, and scanning of subsequent bar tops starts; again, the next (third) bar top is below the line. (3) The line passing from the third bar top is drawn, and scanning starts: the next (fourth) bar top is above the line, so it is skipped, while the fifth bar top is below the line. So, step (4) is not carried out and our new candidate becomes the fifth bar top. (5) The line passing from the fifth bar top is drawn, and scanning starts: all subsequent (sixth and seventh) bars are above the line, and then the bar diagram ends. So, the selected cutpoint corresponds to the height of the fifth bar.
Note that the lines in the various attempts all have the same slope, provided as an input parameter. Of course, changing the slope might return different results.
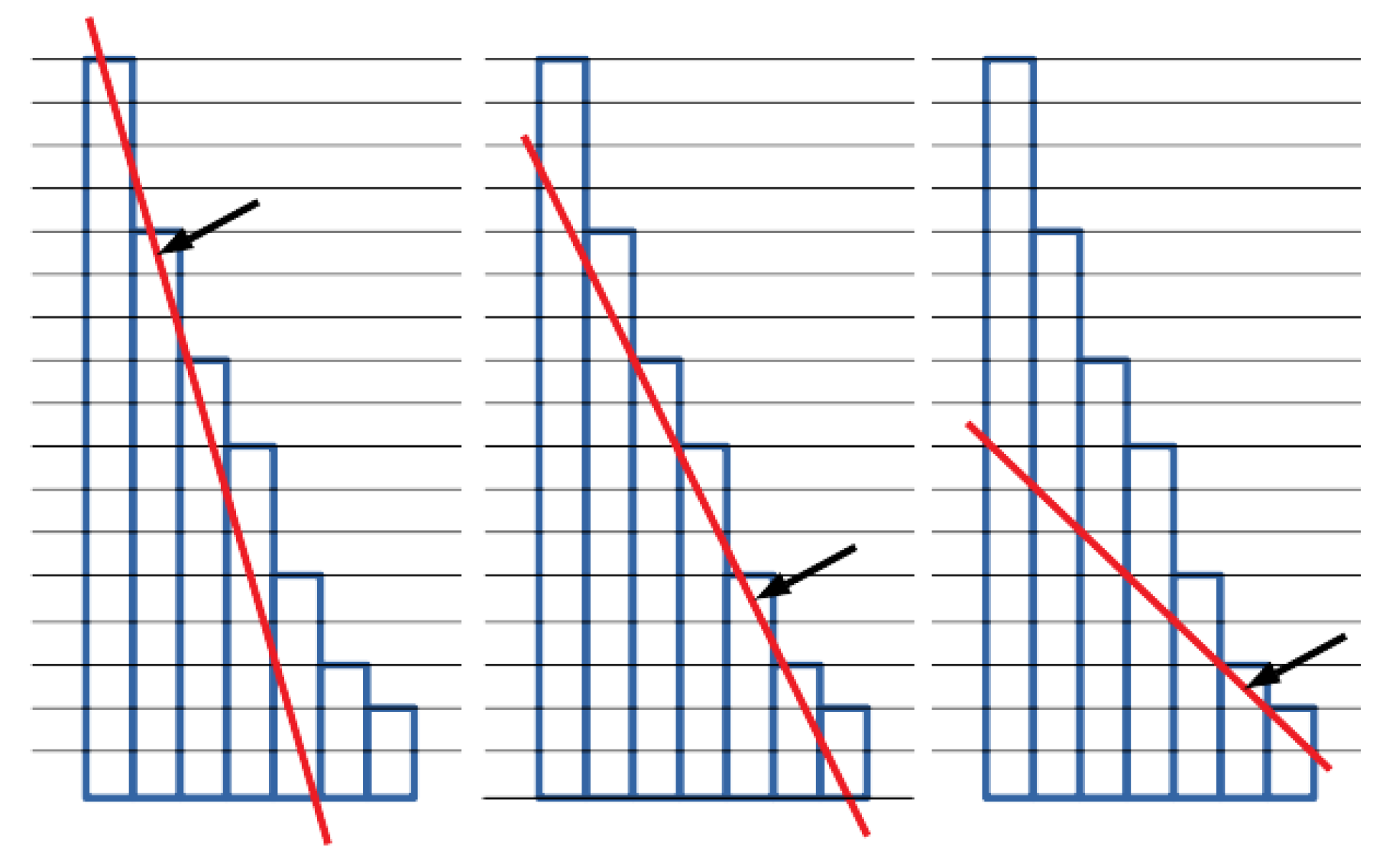
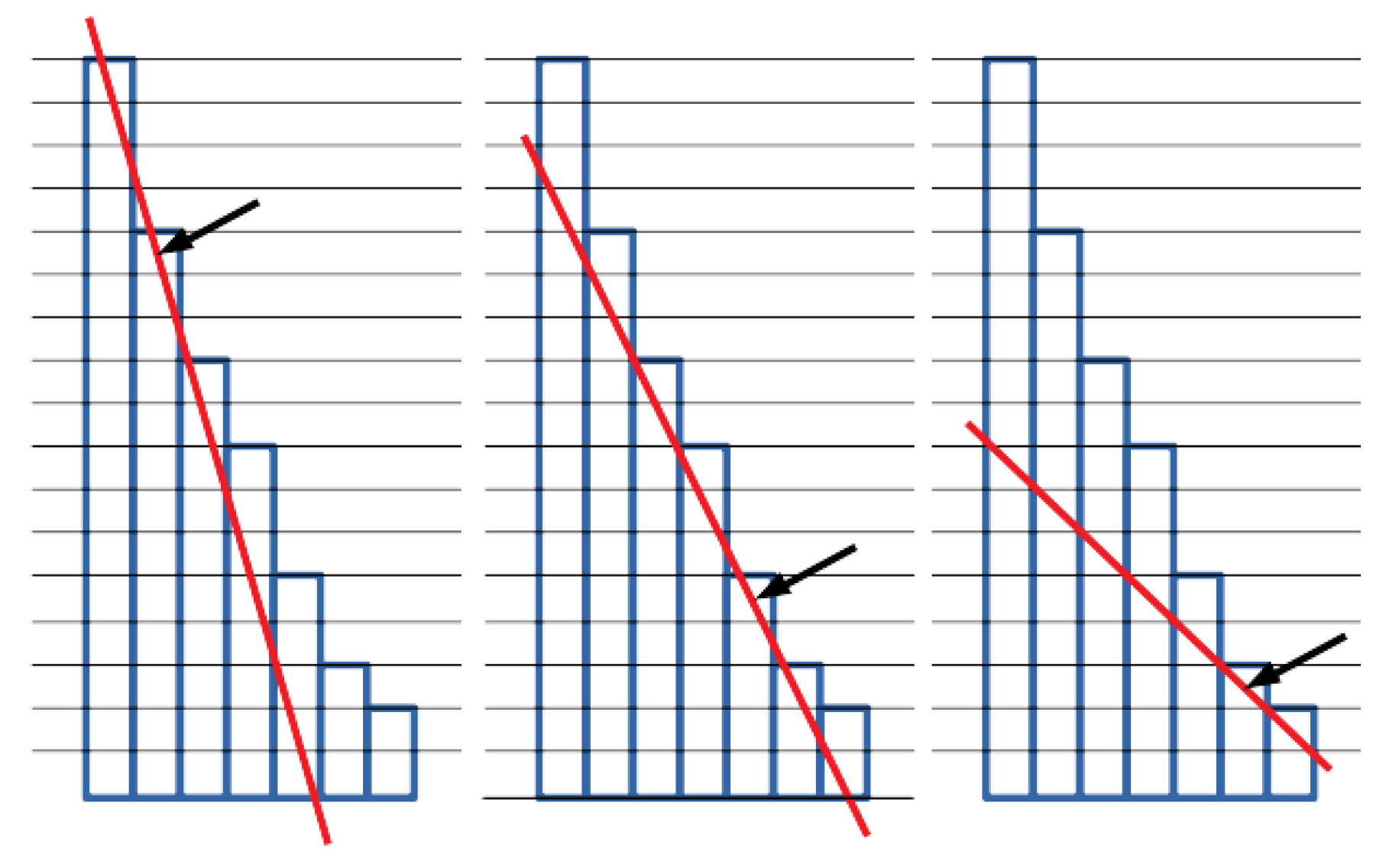
Figure 3 shows the tangent lines for 3 different input slopes, along with the corresponding cutpoints (pointed by the arrows). In addition, it may happen that the line is tangent to the plot in more than one point (e.g., in the rightmost case in
Figure 3, the tangent passes from the top of the sixth and seventh bar). In such a case, different strategies can be applied to determine which of these points should be selected as the cutpoint. Our strategy returns the earliest bar for which the line is below all the bars, which yields the strictest strategy, returning less stopwords. Other possible selection strategies are: the latest (loosest strategy, returning most stopwords), the middle one, etc.
4. Experimental Setting
To test our TDF and cutoff threshold assessment approaches, we devised an experimental setting compliant with the constraints stated in the Introduction:
We consider plain texts, each associated to one language. Words or phrases from other languages, if any, will act as noise.
We evaluated our proposed methods on 3 languages:
English, as the main language for which NLP solutions have been developed in the literature;
Italian, as an important language with a much more complex morphology than English (its much richer inflection might affect frequency-based stopword identification—thus, if good results are obtained on Italian, one may expect to obtain good results also on many other languages), for which NLP solutions are also available;
Squinzanese, a Southern Italy dialect already investigated in Reference [
22], as an example of a dialect for which no linguistic resources are available, and few texts are available to learn them.
We also tested our approach in a multilingual setting, on a corpus obtained by merging the English and Italian corpora.
We selected very small corpora (including up to 18 texts) for each language. This will make learning more difficult than on a large number of texts, where the frequency of real stopwords should easily dominate that of the other words.
Our approach is fully automatic.
For each language, we used narrative texts of different length from traditional literature. For English and Italian, we also selected additional texts in more specific styles (technical, poetry, drama —these texts were aimed at stressing our approach so as to analyze its behavior under different conditions, inspired by Reference [
23], while mainstream literature typically focused on texts in the same style. Indeed, some are skeptical about the use of mixed styles, especially when the number of texts for each style is so small. For the dialect they were not available. Narrative texts are from the XIX or beginning of the XX century; poetry/drama texts are from the Middle Ages; technical texts are from the late XX century. Many selected texts contain typos because they were extracted using Optical Character Recognition on scanned images of paper documents. This further noise in the data makes our experimental setting more similar to real-world cases.
Due to the different nature of the texts, differently from the dialect, we planned a strategy for progressively incrementing the dataset in the experiment.
Table 1,
Table 2 and
Table 3 report the single texts and the aggregates that were used in the experiments for each language, each associated with an identifier (
ID), to be used for referencing it in the rest of the paper, and with some statistics. Specifically, we reported their length (in number of words as counted by a text editor), the size of their vocabulary
(i.e., the number of different words a
word is defined here as a sequence of alphabetic characters only, preceded and followed by non-alphabetic characters—, as computed by our code), the number of stopwords
they include from the ground truth, and the recall
corresponding to such stopwords (i.e., the maximum recall that any stopword identification technique may reach on such documents). The number of words for each text or group of texts in the training corpus is relevant for relating them to performance.
English texts (see
Table 1) are mostly novels, plus the works of Shakespeare for poetry/drama, and the DOS manual as a technical text. The novels were collected into 2 groups: ‘Dumas’, including all serial stories by Alexandre Dumas, Père; and ‘Novels’ for the rest. Another group (‘Tech’) included the other texts (in more ‘technical’ style): the complete works by Shakespeare and the DOS manual. For Italian (see
Table 2), the selected texts are a subset of those in Reference [
23]. Again, they include mostly narrative texts. Italian texts are generally shorter than English ones, but their vocabulary is generally larger, except for HeG that uses less than 900 distinct words. Again, the narrative texts were collected into two groups: ‘PPI’ includes the 5 volumes of ‘Passeggiate per l’Italia’, a report of travels around Italy by a foreign visitor from the XIX century; ‘Novels’ includes novels and collections of stories from classical Italian literature. Again, another group (‘Tech’) included the other texts (in more ‘technical’ style): Dante’s poem ‘La Divina Commedia’ and the collection of civil norms in the Italian law. Squinzanese texts (see
Table 3) were taken from a tale book [
38] (one of the few available in this language). They are generally much shorter, and with a much smaller vocabulary, than English and Italian ones, which makes this dataset particularly challenging. Since all Squinzanese texts are in the same style, we just collected them in 3 groups consisting of 6 tales each, in the order in which they appear in the book table of contents.
As a baseline for performance evaluation, and to get an idea of its performance on the extreme case of just one training document, the proposed approach was applied separately to each single text. Note that, applied to one text, the TDF approach boils down to TF, since for all terms. Then, the approach was applied to increasingly larger sets of texts, selected so as to investigate the approach behavior on different kinds of texts (i.e., texts with homogeneous or different styles). First, it was applied to the groups specified above, for investigating its approach on texts of homogeneous style. Then, it was applied to further aggregations: all narrative texts for English and Italian, and the first two groups for Squinzanese. Finally, it was applied to the whole corpus for each language.
Concerning the automatic cutpoint identification for the candidate stopwords, we will test the parameter in the range, denoting slopes smaller than or equal to . The underlying rationale is that, for greater slopes, there is still a strong decay in word frequency, while we expect non-stopwords to have a more even frequency distribution. Specifically, we will test 3 values: , as the elbow point that distinguishes more quickly varying frequencies from more smoothly varying ones; , as the middle point in the interval, and , as in between the latter and the horizontal line (, which would take all terms as candidate stopwords).
Many works in the literature, specifically focusing on the IR task, indirectly evaluated the performance of their stopword identification approaches based on the performance of the subsequent IR applications. Since we do not focus exclusively on IR, and we tackle the case of very few texts, we will adopt a content-based evaluation approach, more based on linguistics, and compare the extracted stopwords to those in golden standard stopword lists. As the golden standard for English and Italian, we will use the stopword lists provided by Snowball (
https://snowballstem.org/, accessed on 30 July 2021), which are well-known and currently exploited by many NLP systems. The English list includes 174 stopwords, while the Italian list consists of 279 stopwords. Since no golden standard was available for Squinzanese, we used a list obtained by translating the stopwords in the golden standard for Italian, resulting in 192 stopwords. Performance will be evaluated in terms of number of returned candidate (
) and actual (
) stopwords, precision (
P), recall (
R), and sum of precision and recall (
) with respect to the golden standard. Precision is important to prevent removal of informative words when pre-processing the text. Recall, i.e., how many stopwords from the golden standard are retrieved, allows us to understand whether the results of the automatic technique are comparable to those of human experts. However, we put more emphasis on precision because the very small corpora might not include some stopwords in the golden standard. To have a single number expressing a balance in performance between
P and
R, we use their sum, instead of the traditional
F-measure. This is because
F-measure rewards more cases in which precision and recall are close, while, in our case, they are always very imbalanced and, so, would yield very low values for
F-measure.
It is worth noting that the reported results can be actually considered a lower bound on performance, since the golden standard is known to miss many stopwords (e.g., in Italian preposition ‘fra’, an alternate form of ‘tra’, which is in the list; in English, the archaic form ‘thou’ for ‘you’), especially most truncated forms in Italian (LDC is a poem in archaic Italian from the 1300s, so the most frequent terms are often real stopwords, but truncated for poetry; these truncated forms are missing in the golden standard, but are actually very common also in everyday language, so, this is not an issue with the text, rather it further confirms the incompleteness of the golden standard noted in Reference [
9]). Indeed, Reference [
9] showed that, considering some missing stopwords, precision of the first 100 candidate stopwords (
) rises from 0.72 to 0.94 on the entire dataset, and even more for some texts (see
Table 4). Worth noting are the cases LDC and HeG: the former has the best increase in precision, from 0.53 to 0.92, becoming the most effective text in the corpus; in the latter precision also increases by 0.18, up to 0.70, in spite of its being a very short text.
5. Experimental Results
This section reports extensive experimentation showing the effectiveness of our proposals for stopword identification (both the ranking function and the cutoff assessment), on different languages and even on mixed languages.
5.1. Comparison to State of the Art
The obvious competitor for the method we propose is TF for two reasons:
However, for the sake of completeness, and to confirm the findings in Reference [
23], here, we also compare it to all the most recent approaches proposed in the literature and compatible with our constraints, and specifically: IDF, NIDF, TF*IDF, H, TRS, and NTF.
For direct comparison to the latest literature, we used the same dataset as in Reference [
23], concerning Italian language. Since, as already noted, for single documents TDF boils down to TF, and approaches based on document frequency or distribution are not applicable to single documents, this comparison makes sense only on groups of texts. So, from the dataset in Reference [
23], we considered the sets of texts PPI (as in this paper), NTT (Non Technical Texts), and All. We investigated performance for increasingly larger corpora, in the case of both homogeneous (PPI and NTT) and mixed-style (All) texts.
We evaluated performance in terms of Precision (P, the ratio of a set of candidate stopwords for a language that are actually stopwords in that language) and Recall (R, the ratio of actual stopwords for a language that are included in a set of candidate stopwords for a language). Not to make the evaluation dependent on a specific cutpoint, and in order to check whether there is a correlation between the ranking and the actual stopwordness, we actually computed and , meaning that P and R were computed on the top n candidate stopwords in the ranking returned by the algorithms. Values of n were taken as a multiples of 10. We considered up to the first 100 candidate stopwords returned by each competitor (), except IDF, for which performance @100 could not be assessed. Indeed, due to the small number of documents, it was unable to provide a fine-grained ranking: the best score is shared by 2510 terms for PPI, by 382 terms for NTT, and by 160 terms for All.
Table 5 shows the Precision outcomes. We first note that TF*IDF, NIDF, H and TRS (on the All dataset) all show an undesirable non-monotonic behavior. This means that wrong stopwords are included in the very top items of the ranking, spoiling the performance of subsequent thresholds. This also means that the automatic cutoff method could not be applied reliably on these approaches, since it works best with monotonically decreasing performance. As expected, all approaches based on inverse document frequency or distribution (IDF, NIDF, TF*IDF, H) improve for increasingly large datasets. However, possibly due to the small number of texts, they are clearly the worst, with
(and often
) for all datasets and number of candidates, except NIDF on All texts, but only for the very top candidate stopwords (up to
). In particular, albeit considering many more candidate terms, IDF is clearly and by far the worst approach (
always, even on the complete dataset ‘All’). Being based on the distribution of terms across documents, H rewards even terms with very few occurrences, but evenly spread in the corpus. Note also that H is among the most computationally expensive approaches in the comparison, since it needs to count the frequency of each term in each single document. TRS is the non-TF-based approach with closest performance to TF-based ones but still far from them (interestingly, it performs worst on the complete dataset, which was somehow unexpected). NTF and TF have very good performance, and very similar to each other: in some cases, NTF is slightly worse; in some others, it is slightly better, especially when considering more candidate stopwords (
–100). Both show very good performance, always above 0.90 up to
and always above 0.72 up to
(only once TF is below, for
on NTT).
Notwithstanding the very good performance of TF and NTF, TDF is able to further improve over them, usually showing a smoother decay and higher precision. Only in 4 cases out of 30 (on the smallest dataset PPI @60 and @80–100) is it worse, and only @80 significantly (more than 0.02). This is probably due to the smaller number of texts, preventing good contribution from the DF component, and to the fact that, being the texts in PPI similar to each other (they are different volumes of the same work), they include many domain-specific words with very high frequency that are not stopwords. The top-ranked candidate stopwords are almost perfect (precision is 1.00 for all groups @30, and for ‘All’ even @40). A detailed analysis of the wrong stopwords returned by TDF reveals that most of them might be considered, however, domain-dependent stopwords (e.g., the abbreviation ‘art.’ for ‘articolo’—i.e., ‘law article’— in CCI). So, we are confident that it is possible to recognize ‘meaningless’ domain words, to be considered as stopwords for domain-specific applications.
In spite of Recall performance being typically inverse to that of Precision,
Table 6 confirms the same behavior also for Recall (here, we just report
). Again, only NTF and TF are somehow comparable to TDF, with recall values above 0.25. The performance of other approaches, even on all documents, is completely useless in practice. Again, TDF is able to provide significant improvements over TF and NTF. Note that, since the golden standard consists of 279 stopwords, the maximum
for any possible approach on those (collections of) texts is actually
. So, TDF reaching values 0.28 and 0.31, can be considered a really impressive result.
While it is impossible to formally prove in general the superiority of TDF against its competitors, a comparison of its precision with the baseline consisting of random selection of stopwords may give an idea of its discrimination power. Selecting
k terms at random from a vocabulary of
m terms including
n stopwords, the likelihood that all the
k selected terms are actually stopwords is given by
Indeed, we have
chances of selecting a keyword in the first choice, which must be combined in conjunction with the
chances of selecting one of the
remaining stopwords among the
remaining terms in the second choice, and so on until the
k-th choice. Now, let us consider the cases in
Table 5 in which TDF reached 100% precision but its competitors did not, and compute the likelihood of obtaining such precision at random. Specifically, the cases are:
The odds are so small that we may consider it as a practical proof of reliability of the result and, thus, of the superiority of TDF over its competitors.
5.2. Cut off Assessment Performance on Single Texts
Our second experiment analyzes the behavior of the automatic cutoff strategy on single texts, where TDF = TF. While the reader may analyze the figures in more detail and from different perspectives, here, we will comment on some aspects that we consider more relevant.
Table 7 shows the results of T(D)F on the English corpus. Again, we used Precision
P and Recall
R, computed on the set of candidate stopwords returned by our algorithm using the automatic cutpoint assessment approach. As expected, the worst performance from almost all perspectives is for D33 because it uses a less varied vocabulary and a technical language. So, we will not discuss it further. Note from
Table 1 that basically each single text includes almost all stopwords in the golden standard, which makes the problem quite challenging because the target recall
is very high. As expected, performance is in general proportional to the length of the text, and always very high (
being always ≥1, except for TBA with
and
, where it is slightly below 1.0). Even for shorter texts (the shortest one being DJaMH), precision is very high up to the loosest setting (
): sometimes 1.0, always >0.81. The best performance is obtained on Scw, which is the longest text but, surprisingly, not using a narrative style and in archaic language.
Table 8 shows the performance on Italian texts. Here, with a couple of exceptions (IPS and TlN, which are the longest narrative texts),
is less than 0.61 (see
Table 2). The worst performance, as expected, is obtained on HeG, which is actually extremely short. For this very short text, the effect of reducing the
parameter is much more emphasized than for longer texts. Lower performance is obtained on non-narrative texts, but still with
in all settings. Compared to English, precision is still very high also in the loosest setting (
), but recall is lower than for English (perhaps due to the texts being significantly shorter than those in the English corpus and to the maximum recall reachable being much less than for English texts).
Table 9 reports performance on Squinzanese texts. All the texts in this corpus are quite short (see
Table 3) and include a very small portion of the stopwords in the golden standard, which has clear consequences on performance, and especially on recall. As for HeG in the Italian corpus, for shorter texts taking
causes a significant increase in the number of selected candidate stopwords, with no improvement in the quality of the candidates. Nevertheless, in most of the cases, we may consider performance to be satisfactory, given the very challenging problem.
For the sake of comparison, we may take as a baseline the approach of cutting the list of candidate stopwords at the position where the largest weight gap between adjacent items in the ranking occurs.
Table 10 shows, for each language (first column), which single texts (fourth column) and groups of texts (fifth column) returned the number of stopwords (
) reported in the second column using this method. It is evident that the method is useless: in most cases, it returns just 1 stopword. Only for Italian and Squinzanese does it sometimes return more than 2 stopwords, exceptionally returning more than 3 for some Squinzanese texts. Interestingly, groups of texts do not improve performance over single texts. This behavior is not surprising, since, given the typical weight plots as in
Figure 1, with a very steep decay on the left, the largest difference happens very early in the ranking. Since TDF always places correct stopwords in the top positions of the ranking, Precision is always 1 for these few stopwords. For the reader’s reference, the third column in
Table 10 reports the recall (
R) corresponding to each given number of stopwords for each language.
5.3. Performance on Sets of Texts
Given the good performance of the cutoff threshold assessment and of TDF on Italian compared to the state-of-the-art, reported in previous subsections, we now focus on the joint performance of TDF and of the cutoff threshold assessment on different languages.
Table 11 shows the experimental results for the various languages at various values of the slope parameter
a.
The worst precision in the entire table is
, which ensures applicability of the approach to very different languages and experimental settings. As expected, for all languages, the maximum number of correct stopwords is obtained for the loosest slope (
) and for the complete set of texts (‘All’). It is worth noting that the number of stopword selected for English and Italian in this setting (171 and 122, respectively) is surprisingly close to the number of stopwords of these languages, as assessed in Reference [
39] (174 and 134, respectively). Except for Squinzanese with
on group ‘All’, the number of candidate and correct stopwords retrieved increases for larger groups of texts. Interestingly, for all groups of texts and languages, the rate of increase in number of returned candidate stopwords for smaller
is much more than the corresponding rate of decrease in precision. The most cautious slope setting (
) ensures very high precision, obviously at the expenses of recall. The loosest slope setting (
) doubles recall without dramatically dropping precision. In fact,
is quite stable, and always >1.00, except for some cases in Italian (which is a complex language). English achieves the best results in all metrics for all values of the slope parameter (albeit, of course, the datasets in different languages are not comparable), consistently with its being the easiest case (syntactically simpler and with more text in the dataset). Especially recall is very high (
) on ‘All’ with slope
. Squinzanese retrieved the smallest number of stopwords, but it was the more complex case (dataset with less text and including the smallest percentage of stopwords in the golden standard). Partly unexpected, technical texts (‘Tech’) reach good performance both on English and on Italian, comparable to that of narrative texts or even better (in English for looser slopes), notwithstanding their shorter texts and more peculiar styles.
Very interesting is the multilingual case, run on the merger of all English and all Italian texts (and of their golden standards). For all settings of parameter a, the results of precision and of number of candidate stopwords (overall and correct) retrieved is larger than those of the ‘All’ datasets for the single languages. This was not obvious, since merging different languages might spoil the frequencies of each of them and make their stopwords not recognizable. On the contrary, this result shows that, even for corpora that mix several languages, our proposed approach may be effective. In addition, recall is consistent with what was obtained on the single languages, in spite of the nearly doubled number of stopwords in the golden standard.
6. Conclusions
Many languages lack the linguistic resources needed by Natural Language Processing (NLP) approaches because they are language-specific, and manually building them is difficult. In particular, Stopword lists, i.e., lists of terms not carrying significant information for the texts in a corpus, are fundamental to improve effectiveness and efficiency of many tasks (Information Retrieval or Diachronic Analysis applications, linguistic studies, etc.). This paper concerned the automatic extraction of stopword lists from plain texts, proposing (i) a simple frequency-based approach to assign a degree of ‘stopwordness’ to each term in a corpus, and (ii) a geometric strategy to automatically determine the cutoff point in the ranking of candidate stopwords. Specifically, it focused on the case of very small corpora and of independence from language.
Extensive experiments have shown that both strategies (ranking and cut-off) are effective. Both proved to be effective on different languages and under different experimental settings (amount of training text, different styles, mixed languages). In particular, the approach for cutoff assessment is based on a very intuitive parameter that can be set by the experimenter, instead of the fixed strategies used so far in the literature, that may not be consistent with the frequency values of candidate stopwords. The stopword weighting approach is very simple; still, it significantly outperforms all comparable state-of-the-art solutions. Given these outcomes, we plan to investigate possible applications of the TDF techniques to other NLP tasks that may be carried out statistically, perhaps real-life scenarios of language modeling or machine translation.




{kind=link}
{kind=link}
{kind=link}