Abstract
Single-image super-resolution (SISR) techniques have been developed rapidly with the remarkable progress of convolutional neural networks (CNNs). The previous CNNs-based SISR techniques mainly focus on the network design while ignoring the interactions and interdependencies between different dimensions of the features in the middle layers, consequently hindering the powerful learning ability of CNNs. In order to address this problem effectively, a residual triplet attention network (RTAN) for efficient interactions of the feature information is proposed. Specifically, we develop an innovative multiple-nested residual group (MNRG) structure to improve the learning ability for extracting the high-frequency information and train a deeper and more stable network. Furthermore, we present a novel lightweight residual triplet attention module (RTAM) to obtain the cross-dimensional attention weights of the features. The RTAM combines two cross-dimensional interaction blocks (CDIBs) and one spatial attention block (SAB) base on the residual module. Therefore, the RTAM is not only capable of capturing the cross-dimensional interactions and interdependencies of the features, but also utilizing the spatial information of the features. The simulation results and analysis show the superiority of the proposed RTAN over the state-of-the-art SISR networks in terms of both evaluation metrics and visual results.
1. Introduction
Single-image super-resolution (SISR) is a well-known technique in computer vision which is used to reconstruct degraded low-resolution (LR) images and convert them into high-resolution (HR) images. However, this is an ill-posed problem, since there are numerous HR outputs for one LR image. In the literature, there are various efficient methods presented to address this issue, such as the interpolation-based method [1], sparse representation methods [2,3], and learning-based methods [4,5,6,7,8,9,10,11,12,13].
With the gradual maturity of deep-learning technologies, image super-resolution has also made a significant breakthrough. The convolutional neural networks (CNNs) possess powerful learning capabilities in different application scenarios [14,15], which enable us to complete end-to-end training of image super-resolution. Dong et al. [5] proposed the Super-Resolution Convolutional Neural Network (SRCNN) which consists of three-layer CNN and learns the non-linear mapping from LR image to its corresponding HR output. Since then, a variety of CNNs-based techniques [16,17,18,19,20,21] were applied to tackle SR tasks by designing deeper or wider networks.
Although impressive results have been achieved in SISR, the existing methods based on CNNs still face several challenges. First, very deep, and very wide networks are usually accompanied by large number of parameters, which is not beneficial to practical applications. Second, most super-resolution models are unable to exploit the advantages of CNNs to further extract the information in the LR image. Third, stacking the complex modules usually ignores the interdependence between different dimensions of the features.
To address these problems effectively, we propose a residual triplet attention network (RTAN), which considers the cross-dimensional interdependence and interaction of the features for more powerful feature representations. Specifically, inspired by the effect of the residual structure which contains the convolution layer, the RELU function and the shortcut connection [6,11,17,22], we propose the multiple nested residual group (MNRG) structure to reduce model degradation and reuse more informative LR features. In MNRG, we adopt the global shortcut connection (GSC) which serves as the first-layer structure to complete the rough learning of LR image. The local shortcut connection (LSC) and the third-layer residual module are further employed to alleviate the training difficulty causing by the network depth and learn abstract residual features. Moreover, motivated by the attention mechanism demonstrated in [23,24,25], a residual triplet attention module (RTAM) is proposed to improve the interactions and interdependencies of the deep residual features. The RTAM mainly contains two cross-dimensional interaction blocks (CDIBs) and one spatial attention block (SAB). The CDIB has the ability to capture the interaction information between the channel dimension C and spatial dimension (W and H) of the features. This mechanism enables the proposed network to acquire more blending cross-dimensional feature information. Meanwhile, the SAB further extracts the spatial information and helps the network to discriminate the spatial locations of the features. The RTAM explores the interdependencies and interactions across the dimensions of the features without introducing too many parameters. By stacking the RTAM, we further bypass most of the low-frequency part in the input LR and fully exploit the feature information from the intermediate layers of the network.
The main contributions of the proposed RTAN are summarized below.
- (1)
- A residual triplet attention network (RTAN) is proposed to make full use the advantages of CNNs and recover clearer and more accurate image details. The comprehensive simulations demonstrate the effectiveness of the proposed RTAN over other chosen SISR models in terms of both evaluation metrics and visual results.
- (2)
- We design the multiple nested residual group (MNRG) structure which reuses more LR features and diminishes the training difficulty of the network.
- (3)
- A residual triplet attention module (RTAM) is proposed to compute the cross-dimensional attention weights by considering the interdependencies and interactions of the features. The RTAM uses the inherent information between the spatial dimension and channel dimension of the features in the intermediate layers, thus achieving sharper SR results and further applying to actual scenes.
This paper is organized as follows. In Section 2, related works on the image-super-resolution and attention mechanism are introduced. In Section 3, the proposed methods are presented. In Section 4, some discussions on RCAN and RTAN are provided. In Section 5, the experimental results and analysis on different benchmark datasets and the ablation study on the proposed network are given. Model complexity comparisons are also included. In Section 6, the conclusions of the paper are drawn.
2. Related Work
In the past few decades, the image super-resolution has made remarkable progress in computer vision. The researchers have proposed numerous of techniques to address the ill-posed issue in single image SR. There are two categories of the proposed solutions, namely, traditional methods and CNN-based techniques. Owing to the effective learning ability of the CNNs, SISR has been developed rapidly. In this section, we firstly present the related techniques considering the SISR based on CNNs. Then, we briefly discuss the attention mechanism, which inspires our work.
2.1. CNNs-Based Single Image Super-Resolution Network
Dong et al. [5] applied the CNN to present the pioneering work in image super-resolution. The SRCNN that comprises a three-layer convolutional neural network was firstly proposed by the authors to perform end-to-end learning of image super-resolution. As compared with the traditional solutions, this method shows prominent performance. Kim et al. applied the residual learning strategy to image SR, proposed VDSR by increasing the network depth [12] and DRCN which constructs a very deep recursive layer [26]. Tim et al. presented DRRN by using the recursive learning [27] to control the model parameters and adopted the memory blocks in MemNet [28]. These SR networks first perform interpolation on LR input images to get coarse HR images with the desired size before the feature extraction layer and reduce the learning difficulty, while having relatively large memory and computational overhead. In order to address this issue, Shi et al. [29] designed the sub-pixel layer. This layer is a learnable up-sampling layer and performs the convolution and reshaping operations. Inspired by the technique of sub-pixel layer, an increasing number of excellent SR models were proposed. Lim et al. [17] developed the EDSR which significantly improved SR performance. The authors removed the batch normalization in the original residual blocks and the modified residual module consists of two convolution layers, the ReLU function and the shortcut connection. Other works, such as ESRGAN [30], MemNet [28], and RDN [16], utilize the dense connections by using all the hierarchical features of the convolutional layers. Some recent networks focus on handing the trade-off between performance of the SR and memory consumption. For example, Lai et al. [18] presented LapSRN by reconstructing the sub-band residuals of HR image progressively. Ahn et al. [31] proposed CARN, which uses the group convolution to make the image SR network lightweight and efficient. A few networks further explore the feature correlations in spatial or channel dimensions, such as NLRN [32], and RCAN [6]. Moreover, several works aim to exploit more efficient networks to improve SR performance, such as IMDN [33], OISK [34], NDRCN [35], SMSR [36], FALSR [37] and ACNet [38]. Recently, some researchers adopted the graph convolution network [39] and proposed IGNN [40].
Most of the forementioned techniques only consider the design of architecture of the network to achieve better SR results by making the network deeper or wider. However, most of these methods do not consider the correlation between different dimensions of the features and do not fully utilize the advantages of CNNs, which are good at extracting the inherent features.
2.2. Attention Mechanism
The well-known attention mechanism is an effective means of biasing the distribution of available computing resources to the most useful part of the input signals [23]. The attention mechanism is widely applied in many tasks of computer vision, such as image classification [23,41], semantic segmentation [42], human posture estimation [43], and scene parsing [44]. Some tentative works have been proposed which achieve good performance in high-level computer tasks [45]. Wang et al. [41] exploited an effective bottom-up top-down attention mechanism for image classification. Hu et al. [23] proposed the block by squeezing and exciting to obtain the relationship between feature channels. The squeezing operation is completed by using global average pooling and the exciting operation is finished by adopting the MLP and sigmoid function. This technique improves the performance of the existing CNNs. More recently, Wang et al. [46] proposed a novel non-local block, which computes the response at a position as a weighted sum of the features at all possible positions in the input feature maps. Woo et al. [25] proposed a lightweight module (CBAM) with the channel and spatial attention mechanism.
Recently, some researchers have proposed attention-based models to improve the SR performance. Several works, such as RCAN [6], SAN [21], MCAN [47], A2F [48], LatticeNet [49], and DIN [50], introduce the channel attention (CA) mechanism to SR which makes the network learn more useful features. To learn more discriminative features, some researchers utilize both the channel attention and spatial attention, such as HRAN [51], MIRNet [52], CSFM [53], and BAM [54]. Additionally, SAN [21], NLRN [32], and RNAN [55] use the non-local attention to capture the long-term dependencies between pixels in the image. Mei et al. [56] proposed the CSNLN which combines the recurrent neural network with the cross-scale non-local attention to explore the cross-scale feature correlations. Liu et al. [57] proposed the enhanced spatial attention (ESA) which adopts a strided convolution with a larger stride followed by the max-pooling operation. This method can enlarge the receptive field effectively. Muqeet et al. [58] proposed the efficient MAFFSRN by modifying the ESA with the dilated convolutions to refine the features. Zhao et al. [59] introduced the pixel attention mechanism to SR and designed the effective PAN. Mei et al. [60] designed the pyramid attention network (PANet) to capture multi-scale feature correspondences. Huang et al. [61] proposed the DeFiAN to recover high-frequency details of the images by introducing a detail-fidelity attention mechanism. Wu et al. [62] proposed the multi-grained attention network (MGAN) by measuring the importance of every neuron in a multi-grained way. Chen et al. [63] proposed the attention dropout module in A2N to adjust the attention weights dynamically.
Although this method of computing the channel attention weight is proven to be effective, it results in a major loss of spatial information due to the global average pooling. Other methods usually bring huge computation overhead and complicated operations. In this work, a residual triplet attention network (RTAN) is proposed to exploit the internal relations across different dimensions of the features in an effective way.
3. Proposed Methods
3.1. Network Architecture
The overall architecture of RTAN comprises four parts, namely the shallow feature extraction module, the multiple nested residual deep feature extraction part, the upscale module and reconstruction section, as shown in Figure 1, where and represent the input and output of RTAN, respectively.
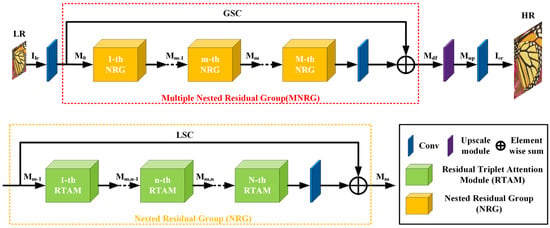
Figure 1.
The overall architecture of the residual triplet attention network (RTAN).
A 3 × 3 convolutional layer of 64 filters is applied to extract the shallow features from the LR input.
where denotes the function of feature extraction. denotes the input of MNRG structure to achieve the deeper feature extraction. Thus,
where denotes the MNRG structure, which is stacked from series of nested residual groups (NRGs). The proposed MNRG structure not only enlarges the size of the receptive field, but also performs substantially by learning the local residuals of the input.
Then, the extracted deep feature is passed to the upscale module. The subsequent procedure is expressed as follows.
where denotes the function of upscale module. denotes the operation of periodic shuffling. and denote the weights and biases of the upscale module, respectively. The symbol “*” denotes the convolution product. L denotes the number of RTAN layers. Please note that denotes the upscaled feature maps. As investigated in [29], we utilize the sub-pixel layer as the upscale module. The mathematical expression is as follows.
where is a periodic shuffling operator which can rearrange the input features maps H × W × r2 × C to the output with the shape of C × rH × rW, r denotes the scale factor. x, y denote the output pixel coordinates in the HR image space. c denotes the number of channels. mod(y,r) and mod(x,r) denotes the different sub-pixel location. T denotes the input tensor. The symbol denotes the rounding-down operation.
Afterwards, we reconstruct the upscaled features via one 3 × 3 convolutional layer. The process of the final module is formulated as
where and denote the reconstruction layer and the function of RTAN, respectively.
Then, the RTAN will be optimized with a certain loss function. There are various loss functions used in previous SR works, such as L1 [5,12], L2 [17,18], perceptual and adversarial losses [11]. We train the proposed RTAN with the L1 loss function. Given the training datasets with N LR images and their HR counterparts , the aim of training RTAN is to minimize the mathematical expression as follows.
where denotes the parameter set of the proposed RTAN.
3.2. Multiple Nested Residual Group (MNRG) Structure
Here, we present the details regarding the proposed multiple nested residual group (MNRG) structure (see Figure 2 and Figure 3), which consists of M nested residual group (NRG) structure with a global shortcut connection (GSC). Each NRG further contains N RTAMs and a local shortcut connection (LSC). Several works [17,22] demonstrate that stacking the residual blocks achieves accuracy gains due to increased depth. However, there is a higher training difficulty as the depth increases. Inspired by previous works presented in [6,11,17], we propose the NRG structure as the fundamental unit. The input and output feature maps , of the m-th NRG satisfy the following expression.
where represents the function of m-th NRG.
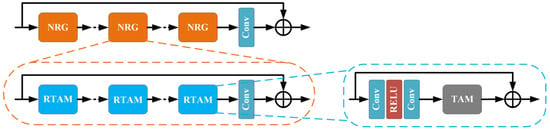
Figure 2.
The framework of the proposed multiple nested residual group (MNRG) structure.
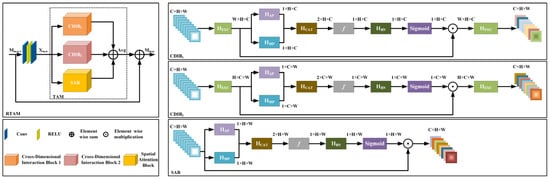
Figure 3.
The framework of the proposed residual triplet attention module (RTAM).
Since the LR and HR image have a highly similar structure, we only need to learn the residual feature mapping to recover the losing high-frequency image information. As discussed in [12], we use global shortcut connection (GSC). Thus, the computation and the learning difficulty of the model are substantially reduced. This procedure is expressed as
where denotes the deep feature maps. represents the set of weight parameters for the convolutional layer at the end of the final NRG in the MNRG structure.
We further present the RTAM to learn more abstract features and reduce the training difficulty. Each NRG structure comprises N stacked RTAMs. The n-th RTAM in the m-th NRG is represented as
where and represent the input and output feature maps of the n-th RTAM in the m-th NRG. denotes the corresponding function.
Image information can be divided into high-frequency components (i.e., edges, texture, and other details.) and low-frequency components (i.e., flat area). Since the residual structure can learn the mapping from LR to HR, it bypasses plenty of redundant low-frequency parts in the input LR image. In order to further improve the learning ability of the representational features and ease the difficulty of training, the local shortcut connection (LSC) is further employed to generate the m-th NRG output via
where represents the weight of the convolutional layer behind the final RTAM.
The GSC along with the LSC encourages the network to learn more residual information which contains more high-frequency features of the LR. In addition, they also alleviate the network degradation caused by the ever-increasing network depths.
3.3. Triplet Attention Module (TAM)
3.3.1. Cross-Dimensional Interaction Block (CDIB)
As discussed in [23,24,25], a CDIB is proposed to compute the attention weights by capturing the cross-dimensional interaction by using a two-branch module. The two branches help the CNNs to make better use of the existing feature information, and fully explore the correlation and dependence between the features. As presented in Figure 3, the input is sent to two CDIBs simultaneously. In CDIB1, the height H and the channel C interact with each other. We exchange dimension C and dimension W of the input feature maps. Then, the exchanged input is denoted as
where denotes the permutation operation, .
We further reduce the dimension W of the to 2 by concatenating the average pooled and max pooled feature maps across that dimension. We obtain the output as follows.
where represents the concatenation of the given input sequences in the specified dimension. and represent the max-pooling and the average-pooling function in the zero-th dimension, respectively.
The pooling layer contributes to preserve the rich information of the original features while reducing the computations. Then, is passed through one convolutional layer with the filter size 7 7 followed by a batch normalization layer.
where denotes the convolutional layer with the filter size 7 × 7. represents the batch normalization.
As discussed in [6,23,24], we use the sigmoid activation function as the gating mechanism to compute the resultant attention weight. The computed attention weight maps are subsequently used to rescale , and then dimension swapping was performed to restore the same dimensional order as the original input . Now, we obtain the final output, i.e.,
Similar to CDIB1, in CDIB2, we create interactions between the channel dimension C and the width dimension W. The input is also exchanged between dimension C and dimension H. The exchanged feature maps are denoted as . Then, is input into the pooling layer. We further get the output . is input into the convolutional layer with the filter size 7 × 7 followed by a batch normalization layer. Then, we also apply the sigmoid function on the output of the last step to obtain the attention weight, which is used for rescaling the feature maps . The dimension order of the rescaled feature maps is exchanged to retain the same shape as input . The final output of second module is .
3.3.2. Spatial Attention Block (SAB)
The previous literature of SR only focuses on the inter-channel relationship of the features. As discussed in [25], we use the spatial attention module (see Figure 3) to complement with CDIB for exploiting the inter-spatial correlations of the features. The spatial attention tells the network which pivotal part should be focused or suppressed. The spatial attention maps are further generated by the following operations. First, we apply the max-pooling and average-pooling operations on the feature maps along the zero-th dimension and concatenate the outputs to generate a useful feature map. The combined output is convolved with the convolutional layer with the filter size 7 × 7. The above output is also passed through a batch normalization layer. In brief, the spatial attention weight is expressed as follows.
where denotes the sigmoid function, denotes the batch normalization, represents the convolutional layer with the filter size 7 × 7, represents the function which concatenates the given input sequences in the specified dimension, and represent the max-pooling and average-pooling function in the zero-th dimension, respectively.
The spatial attention weight is applied to the input for obtaining the final output.
3.3.3. Feature Aggregation Method
The refined outputs of CDIB1, CDIB2, and SAB are further aggregated by assigning the appropriate scale factor. Then, we get the output of the triplet attention module.
Please note that we adopt the simple averaging aggregation, where .
3.4. Residual Triplet Attention Module (RTAM)
As discussed in Section 3.2, the residual learning and shortcut connections ease the difficulty of learning between the LR and HR image. Similarly, inspired by the successful application of the residual blocks in [22], we use this module in SR. As shown in Figure 3, we embed the TAM in the basic residual module and propose the RTAM. The mathematical expression for the n-th RTAM in m-th NRG is expressed as
where and denote the output and input of the RTAM. denotes the corresponding function of the triplet attention. denotes the residual part which is formulated as
where and denote the weights of the two convolutional layers in RTAM, respectively. RELU denotes the RELU function.
4. Discussion
4.1. Difference between RTAN and RCAN
Zhang et al. [6] proposed the RCAN by introducing the channel attention mechanism, which made a significant improvement in SR performance. The main differences between the RCAN and the proposed RTAN are listed as follows. First, although both RCAN and RTAN adopt residual learning, RCAN builds a very deep network (more than 400 layers), while the network depth of our proposed RTAN is much shallower than that of RCAN (about 240 layers). Second, the most crucial module of the RCAN is the stacked residual channel attention blocks, RCAN only considers the interdependencies among feature channels. While the key part of our RTAN is the residual triplet attention module (RTAM). The RTAM can explicitly model the cross-dimensional feature interdependencies and interactions. Finally, the advantage of RCAN is that it introduces an effective channel attention mechanism and constructs a very deep network to improve the quality of image reconstruction. However, RCAN also has some disadvantages. It is too complex to be used in practice and it only explores feature information in the channel dimension.
4.2. Advantages of the RTAN over RCAN
The advantages of our RTAN over RCAN lie in the following aspects. First, for the real-world image super-resolution, the number of parameters of RTAN is 9.6M, far smaller than 16M in RCAN, which is more conducive to the practical applications. Moreover, the parameter of the channel attention module is about 624 K, while the parameter of the residual triplet attention module is only about 354 K. Second, for RCAN, the operation of global average pooling in the channel attention module leads to the loss of spatial information. While our RTAM uses both the average-pooling and the max-pooling operations to preserve the spatial information. Third, the RTAM utilizes the inherent information of the features by blending different dimensional information with less parameters. In addition, the RTAM introduces the spatial attention auxiliary branch to further enhance the spatial discrimination ability of the network.
5. Experiments and Analysis
5.1. Datasets and Evaluation Metrics
5.1.1. Datasets
In this paper, we use the DIV2K [64] dataset and the real-world [65] SR dataset for training the proposed network. The DIV2K dataset comprises 1000 images for training, validation, and testing. The real-world SR dataset comprises 595 pairs of HR-LR images which are collected by two DSLR cameras. We use the real-world SR dataset version 1. For testing the network performance, we use five commonly used benchmark datasets, namely: Set5 [66], Set14 [67], BSD100 [68], Urban100 [13], and Manga109 [69]. Moreover, we also use the test images which have 30 HR-LR image pairs from the real-world SR dataset. The main characteristics of the datasets are present in Table 1. The bicubic (BI) [7], blur-downscale (BD) [7], and the real-world degradation models [65] are adopted to perform the experiments.

Table 1.
The main characteristics of the public datasets.
5.1.2. Evaluation Metrics
The reconstructed images are transformed to YCbCr space. Then, we evaluate the results with two quantitative metrics, i.e., peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM) [70] on Y channel.
5.2. Implementation and Training Details
During the training process, we perform data augmentation on all the training images. This is accomplished by rotating the images by 90°, 180°, 270° randomly and by flipping them horizontally. The LR and HR images are cropped into appropriate patches with the size of 48 × 48 to enlarge the training datasets. We further set the mini-batch size as 16. The proposed RTAN is trained by adopting the ADAM [71] optimizer with β1 = 0.9, β2 = 0.999, and = 10−8. We initialize the learning rate as and then the learning rate decreases half every 200 epochs. For training the BI and BD degradation model, we set NRG number as M = 10. Within each NRG, we set RTAM number as N = 15. While training the real-world degradation model, we set NRG number as M = 10 and RTAM number N = 12. We set the maximum number of steps to 1 × 106. It takes about 11 days and 10 days to train RTAN on DIV2K and real-world SR datasets, respectively. The models are trained using the PyTorch [72] framework. All the experiments are conducted on an Nvidia 2080Ti GPU.
5.3. Ablation Study
To demonstrate the effect of the RTAN, we perform a series of ablation experiments to compare the effectiveness of different modules, including GSC, LSC, CDIB, and SAB. The performance on Set5 × 4 is shown in Table 1.
5.3.1. GSC and LSC
To prove the effect of the MNRG structure, we remove the GSC or/and LSC from the proposed network. is the base model which only contains over 300 convolutional layers with 10 NRGs and 15 RTAMs in each NRG. As presented in Table 2, the PSNR in is extremely low. This indicates that simply stacking the single-layer residual structure is not sufficient to improve the SR performance effectively. In comparison, the PSNR from to has a sustaining boost without introducing any extra parameters. Specifically, and obtain 0.31 dB and 0.39 dB PSNR gain over , respectively. When both of GSC and LSC are added to , the PSNR increases by 0.41 dB. The results show that the MNRG structure results into a huge improvement in the SR performance and makes the network training easier. This is because the GSC and LSC bypass the redundant low-frequency information and reuse the lower layer information for very deep networks.
Table 2.
The ablation results of the key components (i.e., CDIB1, CDIB2, SAB, GSC, and LSC). The best PSNR (dB) is tested on Set5 (×4) in 100 epochs.
5.3.2. SAB and CDIB
We further evaluate the effect of the spatial attention block and cross-dimensional interaction block based on the above ablation investigations. The simulation results from to demonstrate the effectiveness of the individual module. We observe that performs better than . Similarly, SAB slightly improves the performance from 32.20 dB to 32.21 dB. Please note that both and achieve 0.01 dB and 0.03 dB PSNR gains, respectively, in comparison with by the introduction of 30 K parameters only. It is worth noting that by using both CDIB1 and CDIB2, the performance of improves significantly as compared to the methods of to . Besides, when all the components are added to the base model (), the proposed RTAN () results in a huge improvement of 0.48 dB in PSNR as compared to . These comparisons firmly indicate that the cross-dimensional interaction and the inter-spatial correlation of the features play a significant role in improving the ability of image reconstruction.
The aforementioned ablation investigations demonstrate the rationality and necessity of the components of the proposed network. The proposed RTAN model shows the superiority in the SR performance.
5.4. Comparison with State-of-the-Art
5.4.1. Results with Bicubic (BI) Degradation Model
The BI degradation model has been widely used to obtain LR images in the image SR tasks. In order to demonstrate the effectiveness of the RTAN, we compared it with 16 state-of-the-art CNN-based SR methods, including SRMDNF [7], NLRN [32], EDSR [17], DBPN [73], NDRCN [35], ACNet [38], FALSR-A [37], OISR-RK2-s [34], MCAN [47], A2F-SD [48], A2N-M [63], DeFiANS [61], IMDN [33], SMSR [36], PAN [59], MGAN [62], RNAN [55].
Table 3 shows all the quantitative results for ×2, ×3, ×4 scaling factors. In general, as compared with all the methods presented in the literature, the proposed model shows the best performance on most of the standard benchmark datasets for various scaling factors. As the scaling factor increases from 2 to 4, the proposed RTAN performs significantly better than other methods. Particularly when compared with MGAN, RTAN exceeds MGAN by a margin of 0.31 dB PSNR on Urban100 × 4, while the number of parameters of the RTAN is similar to that of MGAN. In addition, the PSNR and SSIM are higher than EDSR on most benchmark datasets, while the number of parameters of RTAN (11.6M) is far smaller than that of EDSR (43M). This competitive performance indicates that RTAN makes better use of the limited feature information by employing the efficient network structure. This is mainly because the RTAN adopts the spatial attention and cross-dimensional interaction mechanism to enable the network to exploit the cross-dimensional interactive features and spatial information.
Table 3.
The quantitative comparison (i.e., average PSNR/SSIM) with BI degradation model on datasets Set5, Set14, BSD100, Urban100, and Manga109. The best and second-best results are highlighted and underlined, respectively.
Figure 4 shows the visual comparisons of several recent CNN-based SISR methods. The SR results of the “img_004” from Urban100 are presented. It is evident that the outputs of most of the compared methods are prone to the heavy blurring of artifacts. Additionally, most of these methods are unable to recover the detailed structure of metal holes and green lines. In contrast, the proposed RTAN produces the clearest image, which is more similar to the ground truth. Similar phenomena are evident in image “img_074”, where other SR methods do not replicate the textures of the grids and cannot successfully resolve the aliasing problems. Additionally, it is noteworthy that most of these methods distort the original structures and generate blurred artifacts. However, as compared with other methods, the RTAN alleviates blurred artifacts and achieves sharper results. These results firmly prove the superiority of the RTAN, which not only shows the powerful reconstruction ability, but also achieves better visual SR results with finer structures.

Figure 4.
The visual comparison of ×4 SR with BI model on Urban100 dataset. The best results are highlighted.
5.4.2. Results with Blur-Downscale (BD) Degradation Model
In order to demonstrate the powerful reconstruction ability of the proposed method with BD degradation model, we compare the RTAN with 14 state-of-the-art CNN-based models, i.e., SPMSR [4], SRCNN [5], FSRCNN [74], VDSR [12], SRMD [7], EDSR [17], RDN [16], IRCNN [75], SRFBN [76], RCAN [6], A2F-SD [48], IMDN [33], DeFiANS [61], PAN [59], and MGAN [62].
Considering the work presented in [6,7], we compare the ×3 SR results with blur-downscale (BD) degradation model. As shown in Table 4, in general, the proposed RTAN obtains similar results to RCAN and outperforms other state-of-the-art methods. As compared with RCAN, the proposed RTAN performs better in terms of PSNR for all datasets, while the performance in terms of SSIM for the datasets, e.g., Set5, BSD100, Manga109 is similar. Specially, the proposed RTAN achieves 0.09 dB PSNR gain over RCAN on Urban100 dataset. The simulation results show that the proposed RTAN has a greater ability to deal with more complex degradation models.
Table 4.
The quantitative comparison (i.e., average PSNR/SSIM) with BD degradation model on datasets Set5, Set14, BSD100, Urban100, and Manga109. The best and second-best results are highlighted and underlined, respectively.
We also provide the visual comparisons on ×3 scaling factor with BD degradation model in Figure 5. For reconstructing the detailed textures of zebras in image “253027”, most of the other methods show aliasing effects and significantly blurred artifacts. In contrast, the proposed RTAN recovers information closer to the ground truth. Particularly, the RCAN generates intersecting zebra stripes, while the proposed method restores the texture consistent with the ground truth. These results firmly demonstrate the superiority of the proposed method in alleviating the blurring artifacts.

Figure 5.
The visual comparisons of ×3 SR with BD degradation model on BSD100 dataset. The best results are highlighted.
5.4.3. Results with the Real-World Degradation Model
To further evaluate the performance of the RTAN, we provide the ×4 SR results with the challenging real-world degradation model. Contrary to the simulated degradation model, i.e., BI and BD degradation, which usually deviate from the complex real world, the real-world degradation model is more applicable to the practical applications. We compare the proposed RTAN with eight representative SR models of different sizes, including CARN [31], RCAN [6], EDSR [17], RNAN [55], LP-KPN [65], DeFiANS [61], and MIRNet [52].
As shown in Table 5, we observe that the RTAN achieves the best performance on the two real-world test datasets. It is evident that the proposed RTAN obtains notable performance gains and has the highest PSRN/SSIM as compared to other methods. Specifically, the PSNR gain of RTAN in comparison with RCAN and EDSR are up to 0.22 dB and 0.51 dB on Nikon dataset, respectively. As compared with the RCAN which introduces the channel attention, the proposed RTAN achieves better results in terms of PSNR and SSIM. Moreover, as compared with the RNAN and MIRNet, our RTAN exceeds them by a margin of 0.25 and 0.23 PSNR on Nikon dataset, respectively. Furthermore, the proposed method outperforms CARN by a large margin of 0.79 dB PSNR on Canon dataset. These comparisons indicate that the proposed method has the ability to generalize for practical applications under the complex real-world degradation.
Table 5.
The quantitative results (i.e., average PSNR/SSIM) with real-world degradation model on datasets Canon and Nikon. The best results are highlighted.
Figure 6 shows the visual SR results of RTAN and other competing methods for the real-world task. For recovering the challenging and tiny texture in image “Canon 006”, it is noteworthy that other methods recover some details of the contours to some degree; however, they still suffer from the serious blurring of artifacts. Contrarily, the proposed RTAN yields more convincing details which are clearer and comprise small number of artifacts than other models. Similar observations are further shown in images “Nikon 014” and “Nikon 015”, where the compared methods fail to recover the minute details from the target patterns. In contrast, the proposed method splits the gap of lines in a clear manner. This indicates that the proposed RTAN has the ability to produce more accurate information and reconstructs the texture which is faithful to the ground truth. Overall, the consistent efficient SR results demonstrate the superiority of the RTAN which has a strong reconstruction ability for the real-world degradation model.


Figure 6.
The visual comparisons for ×4 SR with real-world degradation model on Canon and Nikon datasets. The best results are highlighted.
5.5. Model Complexity Comparison
We also compare the proposed RTAN with other representative models in terms of the SR performance, model size, and computational cost. Considering [6,31], we measure the size of the models with the number of parameters. FLOPs [77] and Mult-Adds are two methods to measure the computational efficiency of the model. Following most works [31,78], for evaluating the models in terms of computational cost, we use the number of composite multiply accumulate operations (Mult-Adds) by assuming the resolution of reconstructed image to be 720p (1280 × 720).
5.5.1. Model Size Analysis
Figure 7a,b show the size of models and SR performance of recent state-of-the-art deep CNN-based SR algorithms under the BI and real-world degradation models, respectively. In order to make comprehensive evaluation, the SR image quality metric is calculated by the average of PSNR on four standard benchmark datasets, i.e., Set5, Set14, B100, Urban100 and two realistic test datasets, i.e., Canon, Nikon, respectively. In Figure 7a, it is obvious that the RTAN outperforms all state-of-the-art models. Especially, the EDSR model which has around 43M parameters has nearly four times more parameters than the proposed RTAN (11.6M). While the PSNR of EDSR is much lower than the proposed RTAN on four benchmark datasets. Similarly, the number of parameters of RTAN is less than RDN (22.1M), but obtains better performance. In addition, the RTAN has similar number of parameters to MGAN (11.7M) but the former achieves much higher PSNR. Considering the importance of practical applications, we further reduce the size of the proposed model for the real-world scenes. As shown in Figure 7b, it not surprising that the CARN and IMDN contain significantly small number of parameters. However, this comes with performance degradation. However, the proposed RTAN has fewer parameters (9.6M) than that of RCAN (16M), MIRNet (31.8M), and EDSR (43M) but achieves much higher PSNR. This implies that the RTAN maintains a better trade-off between model size and performance.
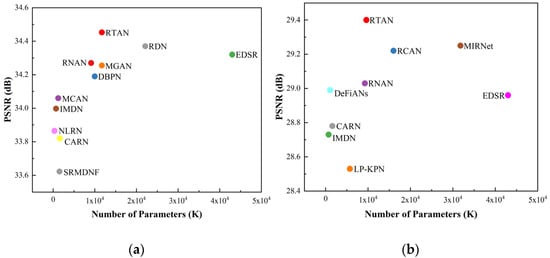
Figure 7.
The performance and number of parameters. The results are evaluated on four standard benchmark datasets (Set5, Set14, BSD100, Urban100) and two real-world test datasets (Canon, Nikon). (a) Results on BI degradation model (×2), (b) Results on real-world degradation model (×4).
5.5.2. Model Computation Cost Analysis
We further measure the computational efficiency of each method for different SR tasks, as shown in Figure 8a,b. From Figure 8a, we observe that the proposed RTAN achieves best performance with less Mult-Adds as compared to DBPN, DRRN, RDN, EDSR, and DRCN. Similar comparisons are further presented in Figure 8b, which shows that the proposed RTAN is more efficient than RCAN, MIRNet, and EDSR. As compared with other larger models, the proposed RTAN attains the balance between the performance and the computational complexity which is considerable from practical applications point of view.
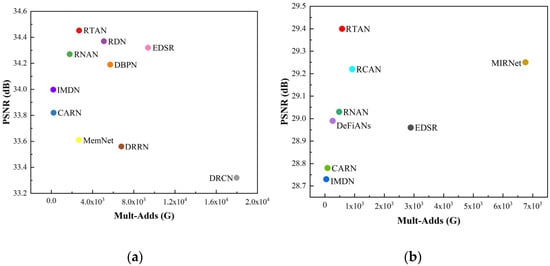
Figure 8.
The performance and number of operations. The results are evaluated on four standard benchmark datasets (Set5, Set14, BSD100, Urban100) and two real-world test datasets (Canon, Nikon). (a) Results on BI degradation model (2), (b) Results on real-world degradation model (×4).
6. Conclusions
In this work, we propose a novel residual triplet attention network (RTAN) for image super-resolution. Specifically, the multiple nested residual group (MNRG) structure allows the proposed RTAN to stabilize the training process. Meanwhile, the MNRG structure focuses on the high-frequency information of the input image and reuses low-layer feature maps. Furthermore, in order to effectively utilize the advantages of CNNs and consider the correlation between different dimensions of features, the residual triplet attention module (RTAM) which captures the interactions and interdependencies between different dimensions of features in the intermediate layers by using small number of parameters is proposed. Comprehensive evaluations and ablation investigations on benchmark datasets with BI, BD, and real-world degradation models demonstrate the effectiveness of the proposed RTAN. In future research work, we plan to design a network which is more efficient and lightweight to deal with the more complex degradation models of the images.
Author Contributions
Conceptualization, Y.S.; methodology, F.H. and Z.W.; investigation, Z.W.; writing—original draft preparation, Z.W.; writing—review and editing, Z.W. and Y.S.; validation, J.W., L.C. and Y.S.; formal analysis, J.W., F.H. and Y.S.; supervision, F.H.; project administration, L.C. and Y.S.; funding acquisition, F.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by National Natural Science Foundation of China (62005049).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Zhang, L.; Wu, X. An edge-guided image interpolation algorithm via directional filtering and data fusion. IEEE Trans. Image Process. 2006, 15, 2226–2238. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.; Wright, J.; Huang, T.S.; Ma, Y. Image super-resolution via sparse representation. IEEE Trans. Image Process. 2010, 19, 2861–2873. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Wright, J.; Huang, T.S.; Ma, Y. Image super-resolution as sparse representation of raw image patches. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Anchorage, AK, USA, 23–28 June 2008. [Google Scholar]
- Peleg, T.; Elad, M. A statistical prediction model based on sparse representations for single image super-resolution. IEEE Trans. Image Process. 2014, 23, 2569–2582. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Zhang, K.; Zuo, W.; Zhang, L. Learning a single convolutional super-resolution network for multiple degradations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Wang, S.; Zhang, L.; Liang, Y.; Pan, Q. Semi-coupled dictionary learning with applications to image super-resolution and photo-sketch synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Timofte, R.; De Smet, V.; Van Gool, L. A+: Adjusted anchored neighborhood regression for fast super-resolution. In Proceedings of the Asian Conference on Computer Vision (ACCV), Singapore, 1–5 November 2014. [Google Scholar]
- Timofte, R.; De Smet, V.; Van Gool, L. Anchored neighborhood regression for fast example-based super-resolution. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Sydney, NSW, Australia, 1–8 December 2013. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Huang, J.; Singh, A.; Ahuja, N. Single image super-resolution from transformed self-exemplars. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Ouahabi, A.; Taleb-Ahmed, A. Deep learning for real-time semantic segmentation: Application in ultrasound imaging. Pattern Recognit. Lett. 2021, 144, 27–34. [Google Scholar] [CrossRef]
- Insaf, A.; Ouahabi, A.; Benzaoui, A.; Jacques, S. Multi-block color-binarized statistical images for single sample face recognition. Sensors 2021, 21, 728. [Google Scholar] [CrossRef]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Lai, W.; Huang, J.; Ahuja, N.; Yang, M. Deep laplacian pyramid networks for fast and accurate super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Hu, X.; Mu, H.; Zhang, X.; Wang, Z.; Tan, T.; Sun, J. Meta-sr: A magnification-arbitrary network for super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- He, J.; Dong, C.; Qiao, Y. Modulating image restoration with continual levels via adaptive feature modification layers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Dai, T.; Cai, J.; Zhang, Y.; Xia, S.; Zhang, L. Second-order attention network for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-excitation networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [Green Version]
- Misra, D.; Nalamada, T.; Uppili Arasanipalai, A.; Hou, Q. Rotate to attend: Convolutional triplet attention module. arXiv 2020, arXiv:2010.03045. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-recursive convolutional network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X. Image super-resolution via deep recursive residual network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X.; Xu, C. MemNet: A persistent memory network for image restoration. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Loy, C.C. ESRGAN: Enhanced super-resolution generative adversarial networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Ahn, N.; Kang, B.; Sohn, K.-A. Fast, accurate, and lightweight super-resolution with cascading residual network. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Liu, D.; Wen, B.; Fan, Y.; Change Loy, C.; Huang, T.S. Non-local recurrent network for image restoration. arXiv 2018, arXiv:1806.02919. [Google Scholar]
- Hui, Z.; Gao, X.; Yang, Y.; Wang, X. Lightweight image super-resolution with information multi-distillation network. arXiv 2019, arXiv:1909.11856. [Google Scholar]
- He, X.; Mo, Z.; Wang, P.; Liu, Y.; Yang, M.; Cheng, J. Ode-inspired network design for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Cao, F.; Chen, B. New architecture of deep recursive convolution networks for super-resolution. Knowl. Based Syst. 2019, 178, 98–110. [Google Scholar] [CrossRef]
- Wang, L.; Dong, X.; Wang, Y.; Ying, X.; Lin, Z.; An, W.; Guo, Y. Exploring sparsity in image super-resolution for efficient inference. arXiv 2020, arXiv:2006.09603. [Google Scholar]
- Chu, X.; Zhang, B.; Ma, H.; Xu, R.; Li, Q. Fast, accurate and lightweight super-resolution with neural architecture search. arXiv 2019, arXiv:1901.07261. [Google Scholar]
- Tian, C.; Xu, Y.; Zuo, W.; Lin, C.-W.; Zhang, D. Asymmetric CNN for image super-resolution. arXiv 2021, arXiv:2103.13634. [Google Scholar]
- Ullah, I.; Manzo, M.; Shah, M.; Madden, M. Graph convolutional networks: Analysis, improvements and results. arXiv 2019, arXiv:1912.09592. [Google Scholar]
- Zhou, S.; Zhang, J.; Zuo, W.; Change Loy, C. Cross-scale internal graph neural network for image super-resolution. arXiv 2020, arXiv:2006.16673. [Google Scholar]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Wang, X.; Tang, X. Residual attention network for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Li, H.; Xiong, P.; An, J.; Wang, L. Pyramid attention network for semantic segmentation. arXiv 2018, arXiv:1805.10180. [Google Scholar]
- Chu, X.; Yang, W.; Ouyang, W.; Ma, C.; Yuille, A.L.; Wang, X. Multi-context attention for human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Yuan, Y.; Wang, J. OCNet: Object context network for scene parsing. arXiv 2018, arXiv:1809.00916. [Google Scholar]
- Li, K.; Wu, Z.; Peng, K.; Ernst, J.; Fu, Y. Tell me where to look: Guided attention inference network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Ma, H.; Chu, X.; Zhang, B.; Wan, S.; Zhang, B. A matrix-in-matrix neural network for image super resolution. arXiv 2019, arXiv:1903.07949. [Google Scholar]
- Wang, X.; Wang, Q.; Zhao, Y.; Yan, J.; Fan, L.; Chen, L. Lightweight single-image super-resolution network with attentive auxiliary feature learning. arXiv 2020, arXiv:2011.06773. [Google Scholar]
- Luo, X.; Xie, Y.; Zhang, Y.; Qu, Y.; Li, C.; Fu, Y. Latticenet: Towards lightweight image super-resolution with lattice block. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Li, F.; Cong, R.; Bai, H.; He, Y.; Zhao, Y.; Zhu, C. Learning deep interleaved networks with asymmetric co-attention for image restoration. arXiv 2020, arXiv:2010.15689. [Google Scholar]
- Muqeet, A.; Iqbal, M.T.B.; Bae, S.-H. Hybrid residual attention network for single image super resolution. arXiv 2019, arXiv:1907.05514. [Google Scholar] [CrossRef]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.-H.; Shao, L. Learning enriched features for real image restoration and enhancement. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Hu, Y.; Li, J.; Huang, Y.; Gao, X. Channel-wise and spatial feature modulation network for single image super-resolution. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 3911–3927. [Google Scholar] [CrossRef] [Green Version]
- Wang, F.; Hu, H.; Shen, C. Bam: A lightweight and efficient balanced attention mechanism for single image super resolution. arXiv 2021, arXiv:2104.07566. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Zhong, B.; Fu, Y. Residual non-local attention networks for image restoration. arXiv 2019, arXiv:1903.10082. [Google Scholar]
- Mei, Y.; Fan, Y.; Zhou, Y.; Huang, L.; Huang, T.S.; Shi, H. Image super-resolution with cross-scale non-local attention and exhaustive self-exemplars mining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Liu, J.; Zhang, W.; Tang, Y.; Tang, J.; Wu, G. Residual feature aggregation network for image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Muqeet, A.; Hwang, J.; Yang, S.; Heum Kang, J.; Kim, Y.; Bae, S.-H. Multi-attention based ultra lightweight image super-resolution. arXiv 2020, arXiv:2008.12912. [Google Scholar]
- Zhao, H.; Kong, X.; He, J.; Qiao, Y.; Dong, C. Efficient image super-resolution using pixel attention. arXiv 2020, arXiv:2010.01073. [Google Scholar]
- Mei, Y.; Fan, Y.; Zhang, Y.; Yu, J.; Zhou, Y.; Liu, D.; Fu, Y.; Huang, T.S.; Shi, H. Pyramid attention networks for image restoration. arXiv 2020, arXiv:2004.13824. [Google Scholar]
- Huang, Y.; Li, J.; Gao, X.; Hu, Y.; Lu, W. Interpretable detail-fidelity attention network for single image super-resolution. IEEE Trans. Image Process. 2021, 30, 2325–2339. [Google Scholar] [CrossRef]
- Wu, H.; Zou, Z.; Gui, J.; Zeng, W.J.; Ye, J.; Zhang, J.; Liu, H.; Wei, Z. Multi-grained attention networks for single image super-resolution. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 512–522. [Google Scholar] [CrossRef] [Green Version]
- Chen, H.; Gu, J.; Zhang, Z. Attention in attention network for image super-resolution. arXiv 2021, arXiv:2104.09497. [Google Scholar]
- Timofte, R.; Agustsson, E.; Gool, L.V.; Yang, M.; Zhang, L.; Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M.; et al. Ntire 2017 challenge on single image super-resolution: Methods and results. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Cai, J.; Zeng, H.; Yong, H.; Cao, Z.; Zhang, L. Toward real-world single image super-resolution: A new benchmark and a new model. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Alberi-Morel, M.-L. Low-complexity single image super-resolution based on nonnegative neighbor embedding. In Proceedings of the British Machine Vision Conference (BMVC), Guildford, UK, 3–7 September 2012. [Google Scholar]
- Zeyde, R.; Elad, M.; Protter, M. On single image scale-up using sparse-representations. In Proceedings of the International Conference on Curves and Surfaces (ICCS), Avignon, France, 24–30 June 2010. [Google Scholar]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Vancouver, BC, Canada, 7–14 July 2001. [Google Scholar]
- Matsui, Y.; Ito, K.; Aramaki, Y.; Fujimoto, A.; Ogawa, T.; Yamasaki, T.; Aizawa, K. Sketch-based manga retrieval using manga109 dataset. Multimed. Tools Appl. 2017, 76, 21811–21838. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; Devito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in pytorch. In Proceedings of the Neural Information Processing Systems Workshop (NIPSW), Long Beach, CA, USA, 9 December 2017. [Google Scholar]
- Haris, M.; Shakhnarovich, G.; Ukita, N. Deep back-projection networks for super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Zhang, K.; Zuo, W.; Gu, S.; Zhang, L. Learning deep CNN denoiser prior for image restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Li, Z.; Yang, J.; Liu, Z.; Yang, X.; Jeon, G.; Wu, W. Feedback network for image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Molchanov, P.; Tyree, S.; Karras, T.; Aila, T.; Kautz, J. Pruning convolutional neural networks for resource efficient inference. arXiv 2016, arXiv:1611.06440. [Google Scholar]
- Wang, Z.; Chen, J.; Hoi, S.C.H. Deep learning for image super-resolution: A survey. arXiv 2019, arXiv:1902.06068. [Google Scholar] [CrossRef] [Green Version]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).