3. Methods. Parallel Tiled Code Generation
Using PET and the iscc calculator, we extract dependencies available in the code in
Listing 1; they are presented with the following relation.
where R is the relation name; and n are parameters; ∪ is the union operation of sets (relation R is composed as the set union of simpler relations); the tuple before the sign → of each simpler relation is the left tuple of this relation, for example, for the first simpler relation, the left tuple is presented with variables ; the tuple after the sign → of each simpler relation is the right tuple of this relation, for example, for the first simpler relation, the right tuple is presented with variables ; the expressions after the sign ∣ are the constraints of each simpler relation, each constraint is represented with the conjunctions of inequalities built on tuple variables and parameters; and ∧ is the logical AND operator.
The left tuple of each simpler relation represents dependence sources, whereas the right represents dependence destinations.
Applying the deltas operator of the iscc calculator to relation R, we obtain the three distance vectors presented with set D below.
where the notations used are the same as for relation R above except from the set is represented with a single tuple.
Each conjunct in the set above represents a particular distance vector.
Taking into account the constraints of those distance vectors, we simplify them to the following form.
The time partition constraints created from the resulting distance vectors according to article [
1] are as follows.
where
are the unknowns.
Taking into consideration that
,
,
, we can suppose that to satisfy all the above constraints,
and
should be 0, i.e.,
. Thus, the above constraints can be rewritten as follows.
Hence, we may cease that there exists a single solution to constraints (
1), (
2), and (
3), namely
. This means that all the three loops in the code in
Listing 1 cannot be parallelized and tiled by means of affine transformations.
Next, we try to parallelize and tile only two inner loops
i and
k in the loop nest in
Listing 1. For this purpose, we make the outermost loop
l to be serial and extract dependencies for inner loops
i and
k described with the relation below.
Applying the deltas operator of the iscc calculator to relation R, we obtain the two distance vectors presented with set D below.
Next, we simplify the representation of the distance vectors above to the form.
.
The time partition constraints formed on the basis of the distance vectors above are the following.
where
are the unknowns.
Taking into consideration that , we can deduce that to satisfy constraints (6) and (7), should be 0, i.e., .
So, there exists a single solution to constraints (
6) and (
7), namely
, and we conclude that provided the outermost loop
l is serial, the two inner loops
i and
k cannot be parallelized and tiled by means of affine transformations.
To cope with that problem, we transform the code in
Listing 1 to improve dependence properties. With this goal, we apply the following schedule to each iteration of the code in
Listing 1:
.
This schedule implies that each iteration of the code in
Listing 1, represented with iteration vector
, is mapped to the two-dimensional time
. It means that iterations of loop
l should be executed serially, while for a given value of iterator
l, iteration
should be executed at time
. This time guarantees that each iteration
is executed when all its operands are ready. To justify that fact, let us noting that for iteration
, operand
is input data; hence, its value is ready at time 0, and operand
is ready at time
when an actual value of this operand is already calculated and written in memory. Thus, iteration
can be executed at time
, i.e., at time, which is one more than the time when operand
is ready.
In other words, the schedule above is based on data flow software paradigm [
8].
To generate target serial code, we form the following relation, which maps each statement instance within the iteration space of the code in
Listing 1 to the two-dimensional schedule below.
where the constraints
define the iteration space of the code in
Listing 1. Applying the
iscc codegen operator to the relation above, we get the pseudocode shown in
Listing 2.
Listing 2: Target serial pseudocode.
Listing 2: Target serial pseudocode.
We transform the pseudocode code in
Listing 2 to C code, taking into account that in that pseudocode, variables
, and
correspond to variables
, and
i, respectively, in the tuple of set
; the second variable
in the pseudostatement relates to variable
i, while the third expression
corresponds to variable
k in the tuple of set
. Thus, we replace the pseudostatement in the code in
Listing 2 with the statement
w[i] + = b[k][i] ∗ w[(i − k) − 1];
from
Listing 1 changing variables
i and
k with variable
and the expression
, respectively. As a result, we obtain the compilable program fragment presented in
Listing 3.
Listing 3: Target sequential compilable program fragment.
Listing 3: Target sequential compilable program fragment.
The target serial code in
Listing 3 is in the scope of reordered transformations. It performs the same computations as those performed with the initial code in
Listing 1 but in a different order. It is well-known that a reordered transformation of a code is correct if it executes the same computations as those executed with the initial one (1) and respects all the dependencies that appear in that code (2) [
1]. The transformed code is correct as it performs the same computations as those executed with the initial one (1) and it respects all the dependencies available in the initial one as explained below (2).
There exist three kinds of dependencies in the code presented in
Listing 3: data flow dependencies (some statement instance first generates a result, then that result is used with another statement instance, those instances belong to different time units represented with the value of iterator counter), antidependencies (some statement instance first reads a result, then that result is updated with another statement instance, and output dependencies (two statement instances write their results to the same memory location).
Data flow dependencies are respected due to the fact that in the target code, the execution of a statement instance being the target of each data dependence starts only when all the arguments (data) of this operation are prepared, i.e., the processing of all the instruction instances generating these arguments has already finished, and the operand values are stored in the shared part of memory. This is guaranteed because the source of each data dependence is executed at a time unit defined with the value of iterator counter that is less than the one when the corresponding target is executed.
Anti- and output dependencies are honored due to the lexicographical order of the execution of dependent statement instances within each time partition represented with the value of iterator var1.
We also experimentally confirmed that the both loop nests presented in
Listing 1 and
Listing 3 generate correct results. The experiments used for input data prepared deterministically and randomly.
Dependencies available in the code in
Listing 3 are represented with the following relation.
where and n are parameters.
Applying the deltas operator of the iscc calculator to relation R, we obtain the three distance vectors presented below.
Taking into account the constraints of those distance vectors, we simplify their representation to the following form.
The time partition constraints constructed according to article [
1] are as follows.
where
are the unknowns.
Taking into account that
,
,
, we can deduce that
and
should be 0, i.e.,
for the constraints (
8), (
9), and (
10) to be compatible. Therefore, these constraints can be written with the following formulas.
Thus, we may conclude that there exists a single solution to constraints (
8), (
9), and (
10), namely
. This means that all thee loops in the code in
Listing 3 cannot be parallelized and tiled by means of affine transformations.
Next, we try to parallelize and tile only two inner loops
and
in the loop nest presented in
Listing 3. For this purpose, we make the outermost loop
to be serial and extract dependencies for inner loops
and
. They are expressed with the relation below.
Applying the deltas operator of the iscc calculator to relation R, we obtain the two distance vectors presented below.
After the simplification of the representation of the distance vector above, we obtain the following vectors.
The time partition constraints created from the distance vectors above are the following:
where
are the unknowns. There are two linear independent solutions to the constraints above:
and
. Applying those solutions, we are able to parallelize and tile the two inner loops of the code in
Listing 3 using the technique presented in paper [
2].
The target parallel tiled code presented by means of the OpenMP C/C++ API is shown in
Listing 4. It is generated for the best tile size equal to 24 × 54; choosing the best tile size is explained in
Section 5.
Listing 4: Transformed parallel loop nest.
Listing 4: Transformed parallel loop nest.
In that code, outermost loop
is serial nontiled, and loops
and
enumerate tile identifiers, while loops
and
enumerate iterations within each tile. Parallelism is extracted with the wavefront technique [
2] and presented with the OpenMP directive
inserted before loop
that means that this loop is parallel.
4. Related Work
Related techniques can be divided into the following two classes: the class of reordering transformations and the one of nonreordering transformations. There are numerous publications concerned with both of the classes. Approaches based on affine transformations [
1,
2,
9,
10,
11] and those based on the transitive closure of dependence graphs [
12,
13,
14,
15,
16] belong to reordering transformations. Reordering techniques are code-independent and are used in optimizing compilers, for example [
17,
18,
19], which automatically generate optimized target code for source code.
Nonreordering transformations are code-dependent, i.e., for a given code, a transformation is fulfilled manually. The following publications within nonreordering transformations concern the problem similar to that implemented with the code in
Listing 1 but not exactly the same problem [
3,
4,
8,
20,
21,
22,
23,
24,
25,
26].
Both classes allow for generating the target program that is semantically identical to the original one. However, there are the following differences in target code generated using techniques of those classes.
Reordering transformations do not introduce any additional computations to generated target code in comparison with those of original code; they only reorder loop nest iterations of the original code allowing for tiling and/or parallelism. They are code-independent and are aimed at automatic code generation.
Nonreordering transformations allow us to parallelize and tile code similar to some extent to the code in
Listing 1 but not exactly the same. All of those techniques introduce additional computations to generated target code in comparison with those in the original code. That increases the computational complexity of the algorithm and prevents achieving the maximal target code performance, and it is the main drawback in comparison with reordering transformations.
Each technique is manually created for the code that should be optimized. Adapting such a technique even to a slightly different problem can require additional work that can be time-consuming and not always possible.
After an extensive analysis of many nonreordering techniques mentioned above, we did not find any one that exactly implements the problem presented with the code in
Listing 1. Without extensive research, it is not clear how any of those techniques can be adapted to implement exactly the same problem that implements the code in
Listing 1.
In the class of reordering transformations, we examined the PLUTO [
17] and TRACO compilers [
15]. PLUTO is based on affine transformations and automatically generates tiled and/or parallel code. TRACO uses the transitive closure of dependence graphs to tile and/or parallelize input code. For the code in
Listing 1, both PLUTO and TRACO are unable to generate any tiled and/or parallel code. In
Section 3, we presented the reason why affine transformations fail to generate any parallel and/or tiled code for the serial code in
Listing 1.
Below, we discuss some nonreordering transformations, which allow for generation of code implementing algorithms similar to that realizing with the code in
Listing 1 but not exactly the same. Without extensive research, it is not clear how to adapt any of those techniques to generate target code fulfilling the same calculations as those performed with the code in
Listing 1.
Karp et al. [
20] discussed parallelism in recurrence equations. They proposed a decomposition algorithm that decides if a system of uniform recurrence equations (SURE) is computable or not. If so, multidimensional schedules can be derived and applied to extract parallelism.
Papers [
3,
4] introduced a recursive doubling strategy to compute recurrence equations in parallel. Recursive doubling envisages the splitting of the computation of a function into two subfunctions whose evaluation can be performed simultaneously in two separate processors. Successive splitting of each of these subfunctions allows for the computation over more processors.
Maleki and Burtscher [
21] introduced two phase approach to compute recurrence equations. The first phase iteratively merges pairs of adjacent chunks by correcting the values in the second chunk of each pair. The second phase produces the resulting chunks in a pipelined mode to compute the final solution.
Sung et al. [
22,
23] proposed the idea to divide the input into blocks and decompose the computation over each block. Interblock parallelism is exploited to enhance code performance.
Nehab et al. [
24] also suggested splitting the input data into blocks that are processed in parallel by modern GPU architectures and overlapped the causal, anticausal, row, and column filter processing.
Marongiu and Palazzari [
25] addressed the parallelization of a class of iterative algorithms described as the system of affine recurrence equations (SARE). It introduces an affine timing function and an affine allocation function that perform a space-time transformation of the loop nest iteration space. It considers algorithms dealing with only uniform dependence vectors, while the approach presented in this paper deals with nonuniform vectors.
Ben-Asher and Haber [
26] defined recurrence equations called “simple indexed recurrences” (SIR). In this type of equation, for extending capabilities, ordinary recurrences are generalized to
, where
f and
g are affine functions
is a binary associative operator. In that paper, the authors proposed a parallel solution to the SIR problem. This case of recurrences is simpler than that considered in our paper and any tiled code is not considered.
Summing up, we may conclude that in the class of reordering transformations, there does not exist any technique allowing for parallelizing and/or tiling the code in
Listing 1. In the class of nonordering transformations, to our best knowledge, no technique has been published to generate parallel tiled code implementing the problem addressed in this paper.
The main contribution of our paper is presenting a novel technique, which for the first time allows us to parallelize and tile the examined loop nest implementing computing general linear recurrence equations by means of reordering transformations. The novelty consists in adding an additional phase to classical reordering transformations: to source code, we first apply a reordering schedule that respects all data dependencies; then, we apply classical affine transformations to the serial code obtained in the first phase. This increases target code generation time but does not introduce any additional computations to the source code. Generated target code is still within the class of reordering transformations.
5. Results
The primary reason for writing a parallel program is speed. We strive that the parallel program execution should be completed at a shorter time in comparison with that of the serial one. We need to know what is the benefit from tiling and parallelism. For this purpose, we need to compute the parallel program speedup.
The speedup of a parallel program over a corresponding sequential program is the ratio of the compute time for the sequential program to the time for the parallel program. The value of speedup shows how efficient is a parallel program.
Perfect linear speedup occurs when the value of speedup is the same as the number of threads used for running a parallel program. In practice, perfect linear speedup seldom occurs because of parallel program overhead and the fact that all computations of an original program cannot be parallelized.
According to Amdahl’s law, the parallel code speedup, S, is limited to , where s is the serial fraction of code, i.e., the fraction of code that cannot be parallelized. For example, if , the maximal speedup is 5 regardless of the number of threads used for running a parallel program.
To evaluate the performance of the parallel tiled code presented in
Listing 4, we carried out experiments aimed at measuring the execution time of the original program and parallel one (for the different number of threads) and next calculated the speedup of the parallel program.
Below, we present the results of experiments carried out with the codes shown in
Listing 1 (serial code) and
Listing 4 (parallel code). As we mentioned in the previous section, we cannot find any related parallel code that fulfills exactly the same computations as those executed with the code in
Listing 1. Thus, we limited our experiments to the codes mentioned above.
To carry out experiments, we used a processor Intel Xeon X5570, 2.93 GHz, 2 physical units, 8 (2 × 4) cores, 16 hyper-threads, and an 8 MB cache. Executable parallel tiled code was generated by means of the g++ compiler with the -O3 flag of optimization.
Experiments were carried out for ten different lengths of the problem defined with parameter
N from 1000 to 5000 for the codes presented in
Listing 1 (serial code) and
Listing 4 (parallel code).
All of the source code to perform the experiments and the program to run the tested codes can be found at
https://github.com/piotrbla/livc (accessed on 24 August 2021).
We carried our experiments to choose the optimal size of a tile. The size of a tile is optimal if (i) all data associated with that tile can be held in cache, (ii) those data occupy almost the entire capacity of cache, and (iii) tiled code execution time is minimal provided that the conditions (i) and (ii) above are satisfied.
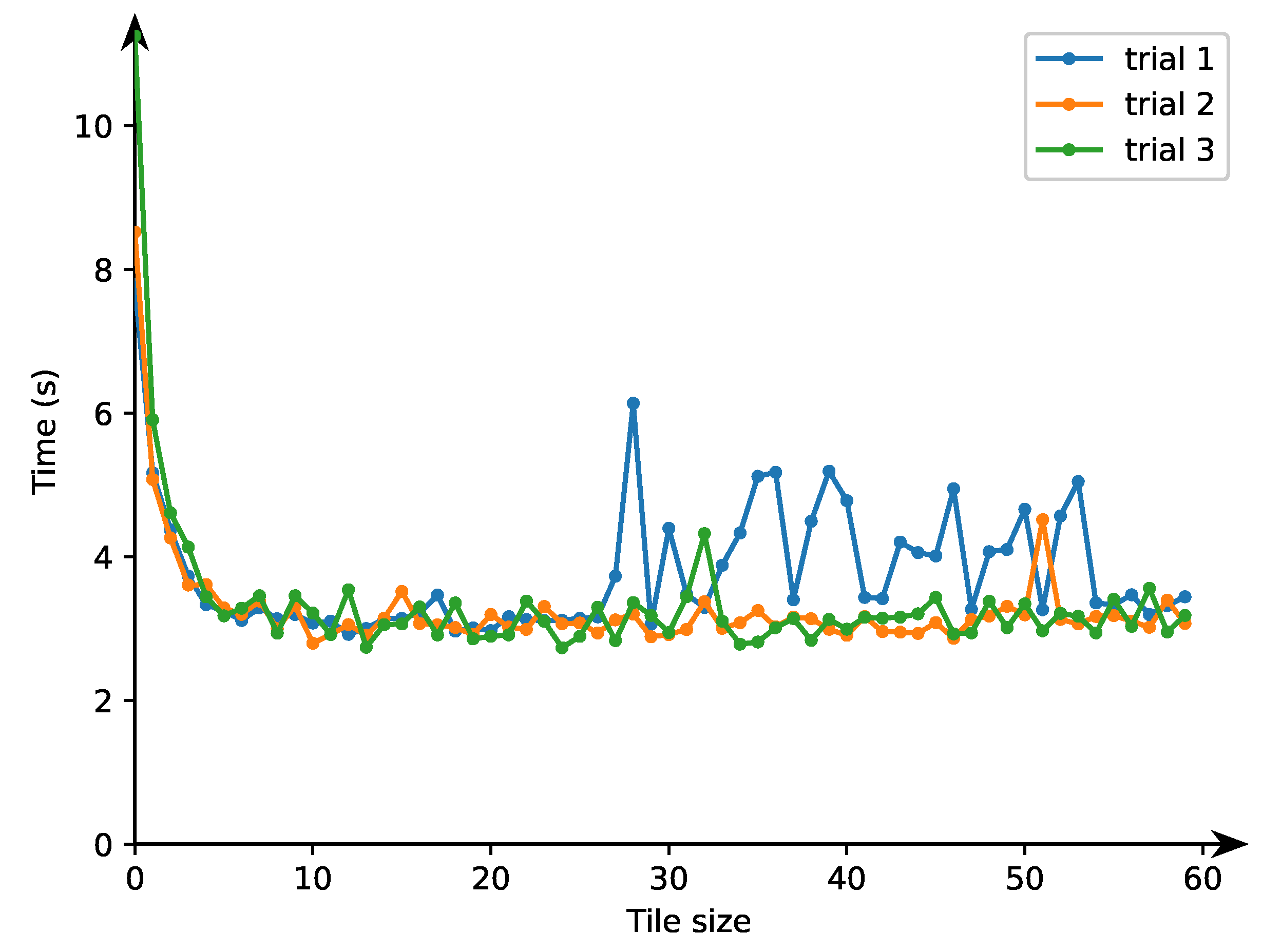
For this purpose, we fulfilled three trials whose results are shown in
Figure 1. The curve “trial1” represents how the time of tiled program execution depends on the block size along axis
when the block size along axis
is fixed equal to 16. After first trial 1, we chose the best size along the
axis equal to 32.
The curve “trial2” demonstrates how the time of tiled program execution depends on the block size along axis when the block size along axis is equal to 32 (the result of trial 1). After trial 2, we chose the best size along axis equal to 24.
The curve “trial3” shows how the time of tiled program execution depends on the block size along axis when the block size along axis is equal to 24 (the result of trial 2). After trial 3, we chose the best tile size along axis equal to 54. Finaly, as the best size of a 2D tile in the parallel tiled code, we chose 24 × 54.
For the best tile size,
Table 1 presents execution times and speedup of the serial program in
Listing 1 and the parallel tiled one presented in
Listing 4 for 32 OpenMP threads used.
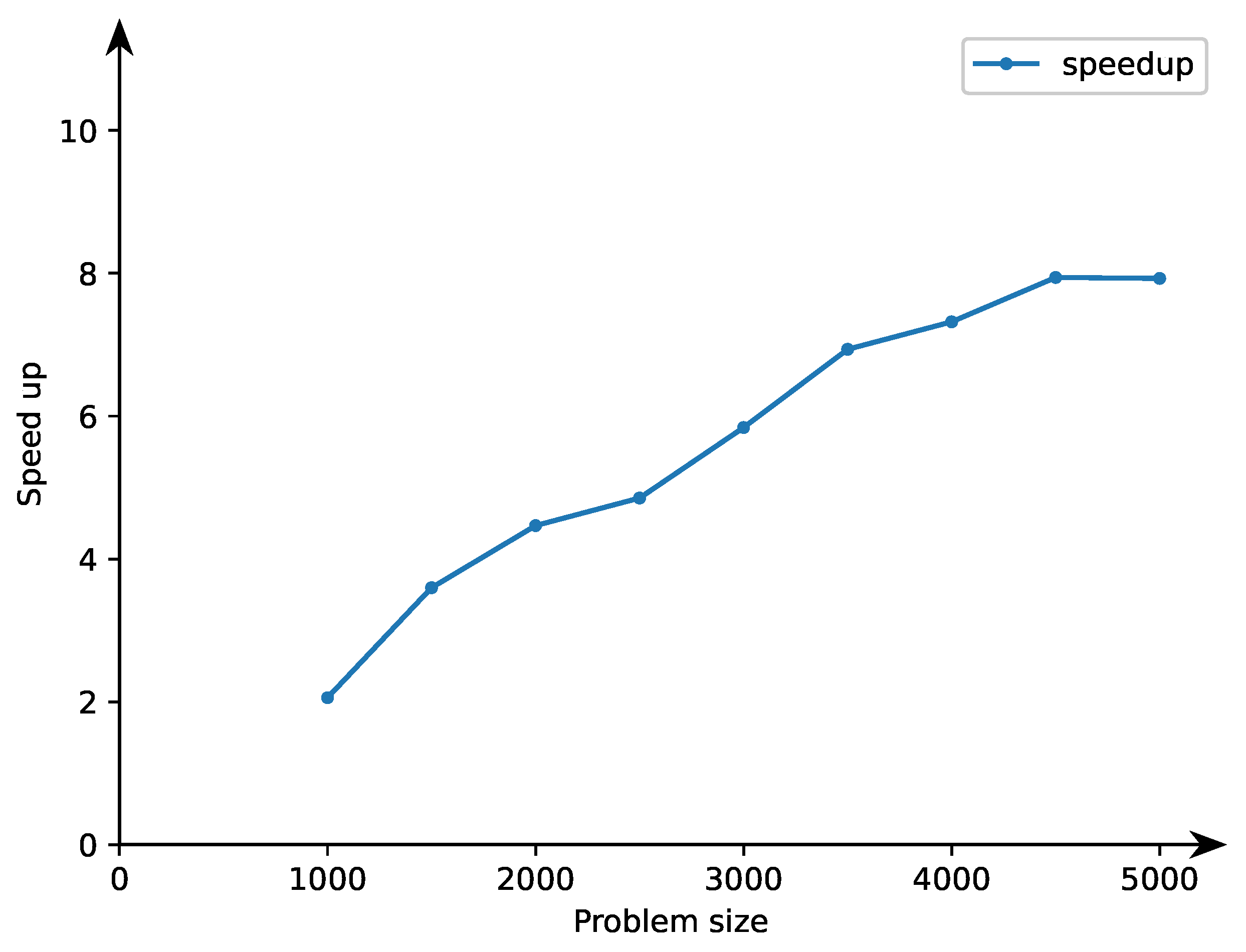
Figure 2 depicts the data presented in
Table 1 in a graphical way. As presented, the execution time of parallel tiled program grows practically in a linear manner exposing considerable speedup (the ratio of the serial program execution time to that of the corresponding parallel one) presented in
Figure 3.
Figure 4 presents how parallel tiled code speedup depends on the thread number for the maximal problem size used for experiments, i.e., for
. The parallel tiled code speedup grows practically linear for the number of threads 1 to 12. Linear speedup for the number of threads
is prevented with the serial fraction of code (Amdahl’s law)—parallel loop initialization fulfilled with a single thread and serial input–output operations. Speedup is also limited with parallel program overhead—there is thread synchronization in the examined parallel code, after each wavefront, barrier synchronization is inserted because the following wavefront can be executed after completing the calculations of the previous wavefront.
We may conclude that the generated parallel tiled code implementing computing-intensive general linear recurrence equations and presented in
Listing 4 can be successfully run on modern multicore machines with a large number of cores.




{kind=link}
{kind=link}
{kind=link}
{kind=link}







