
Performance Improvement of DAG-Aware Task Scheduling Algorithms with Efficient Cache Management in Spark


Abstract
:1. Introduction
2. Background and Motivation
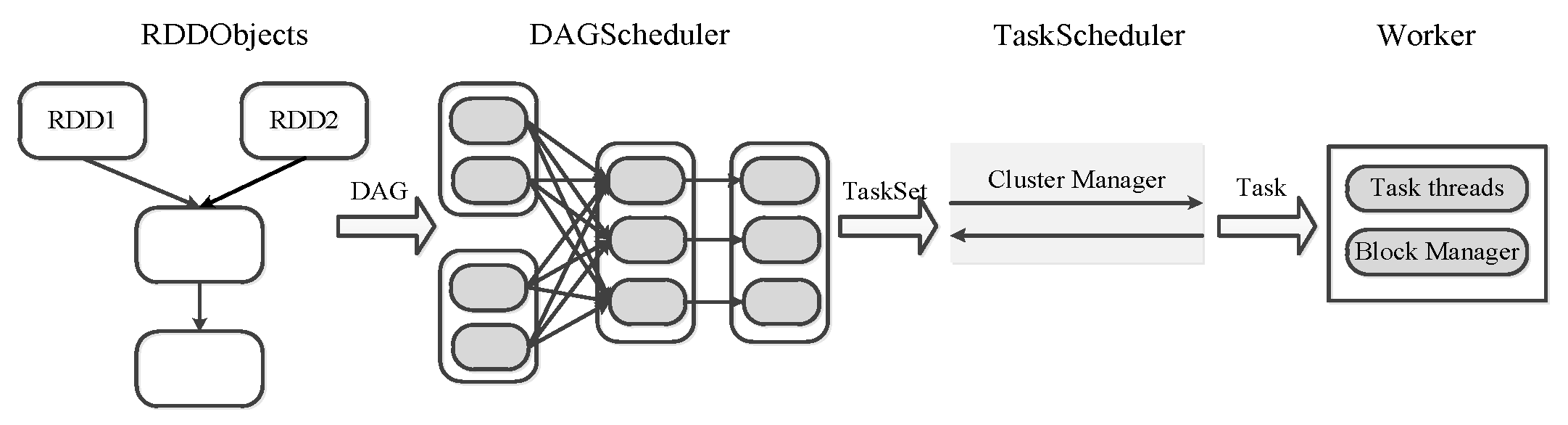
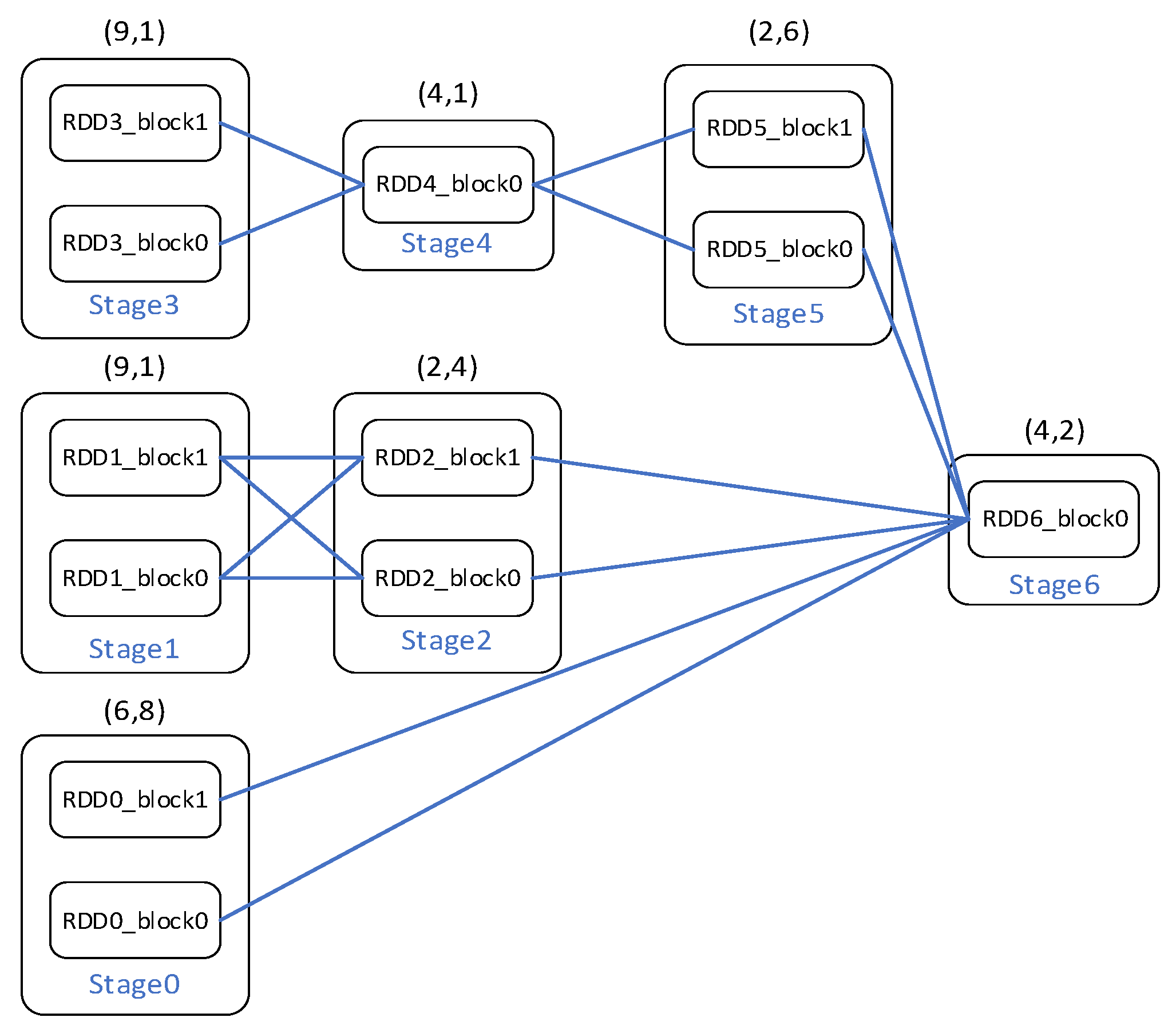
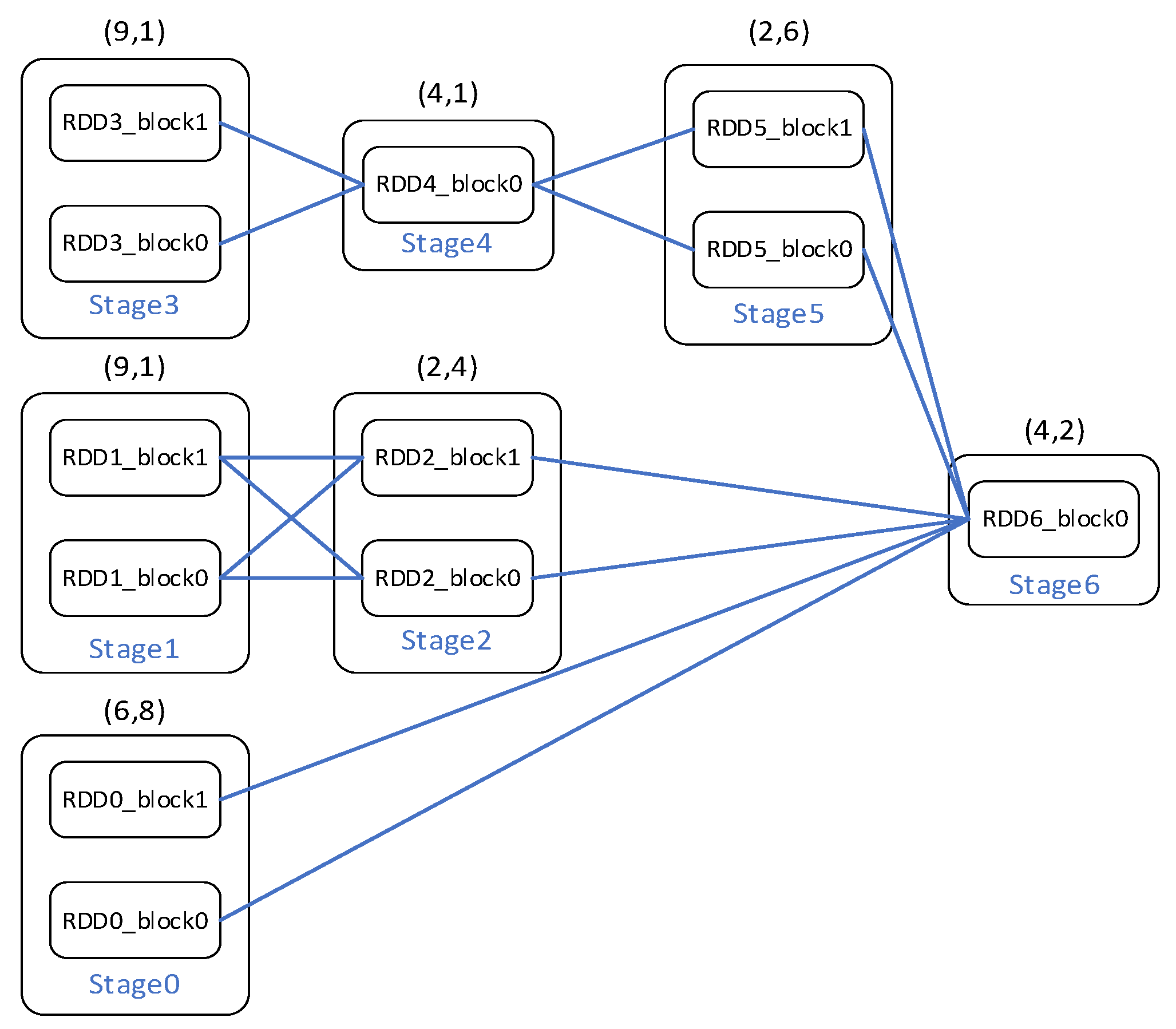
2.1. RDD and Data Dependency
2.2. Inefficient Cache Management in Spark
2.3. Cache-Oblivious Task Scheduling
3. System Design
3.1. Cache Management Policy for DAG-Aware Task Scheduling
| Algorithm 1 LSF cache management policy. |
| Input: DAG of application, stage_set with long_running tasks Candidate_Stage_set: Stage sets overlap long-running stages Candidate_RDD: RDDs ready for prefetching //Computing CU of each RDD 1: for each of DAG do 2: 3: CU_Table <- 4: end for 5: for each including long-running tasks do 6: = 7: end for 8: Candidate_Stage_set <- Stage set with highest RU 9: for each in Candidate_Stage_set do 10: 11: end for 12: for each stage i of SuccPath do 13: update(CU_Table) 14: end for //Eviction policy of cache management 15: if data block size of > free memory then 16: for each cached in memory do 17: <- with lowest cache urgency 18: if( < ) then 19: if() is not 0) then 20: evict() 21: write to disk 22: update(CU_Table) 23: else 24: evict() 25: end if 26: end if 27: end for 28: end if //Prefetch RDD 29: for each stage unprocessed do 30: Candidate RDD <- RDD with highest CU in CU_Table 31: if size of (Candidate RDD) < free memory then 32: prefetch(Candidate RDD) 33: end if 34: end for |
3.2. Cache-Aware Scheduling Algorithm
| Algorithm 2 Cache-aware scheduling. |
| Input: DAG of application, initial schedule sequence init() : stage set of initial job in application : stage set of job suitable for parallel execution : stage set of running jobs Pending_stage: stages pending for scheduling 1: <- initial job of init() 2: for each job of do 3: RAS_Table <- RAS(, ) 4: end for 5: <- job with highest RAS in RAS_Table 6: <- stages in and //Schedule phase 7: Pending_stage <- sort stages of by CU(stage) calculated in LSF 8: Cache_Queue <- RDDs cached in memory 9: for each stage i in do 10: 11: SIT_Table <- 12: end for 13: for stage m in Pending_stage do 14: if stage m is runnable then//Parent stages have been executed 15: for each in Cache_Queue do 16: if then 17: <- 18: end if 19: end for 20: end if 21: If > then 22: Schedule_Queue() <- 23: Schedule_Queue() <- 24: update(Pending_stage) 25: else 26: Schedule_Queue <- 27: end if 28: update(SIT_Table) |
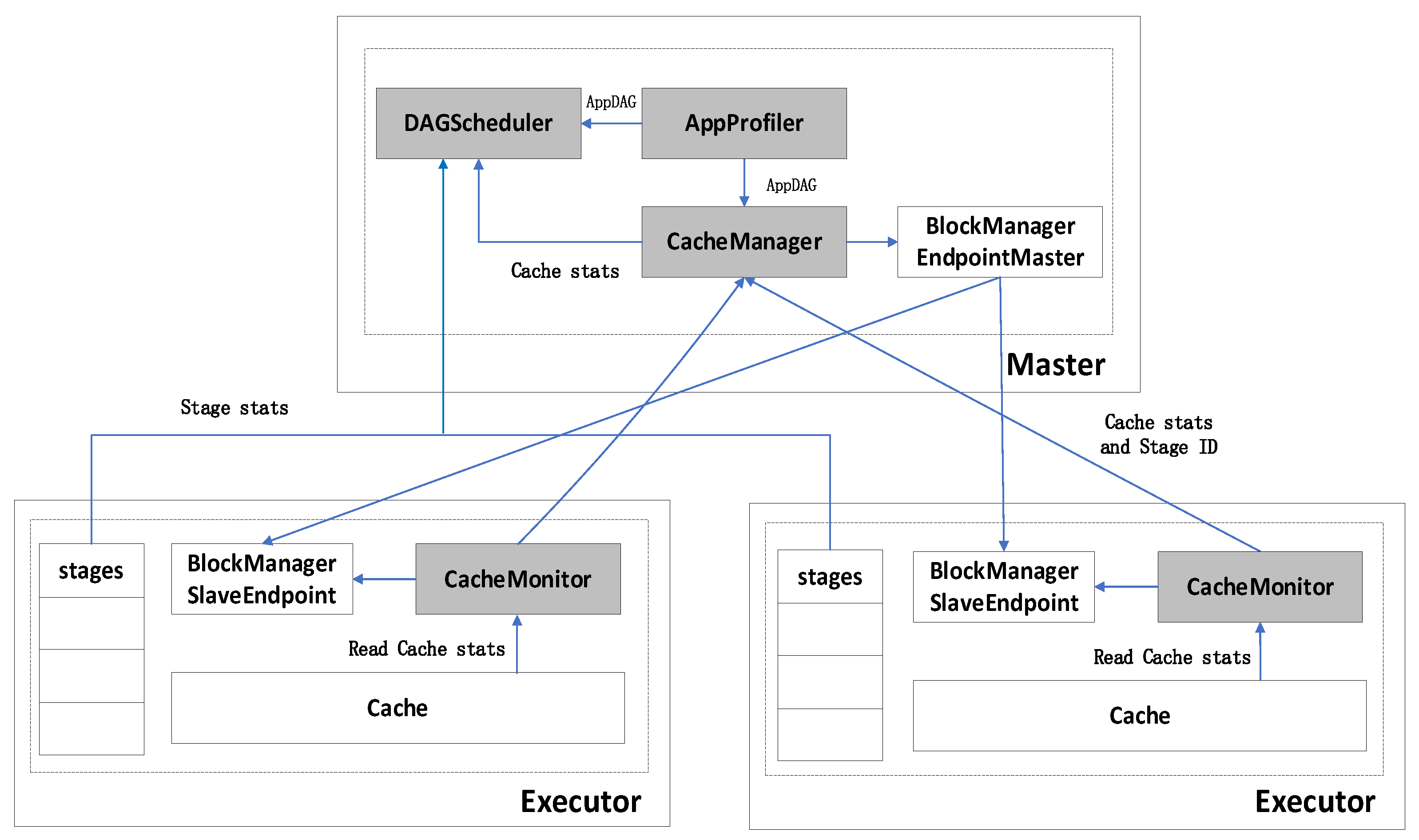
3.3. Spark Implementation
4. Evaluations
4.1. Experimental Environment
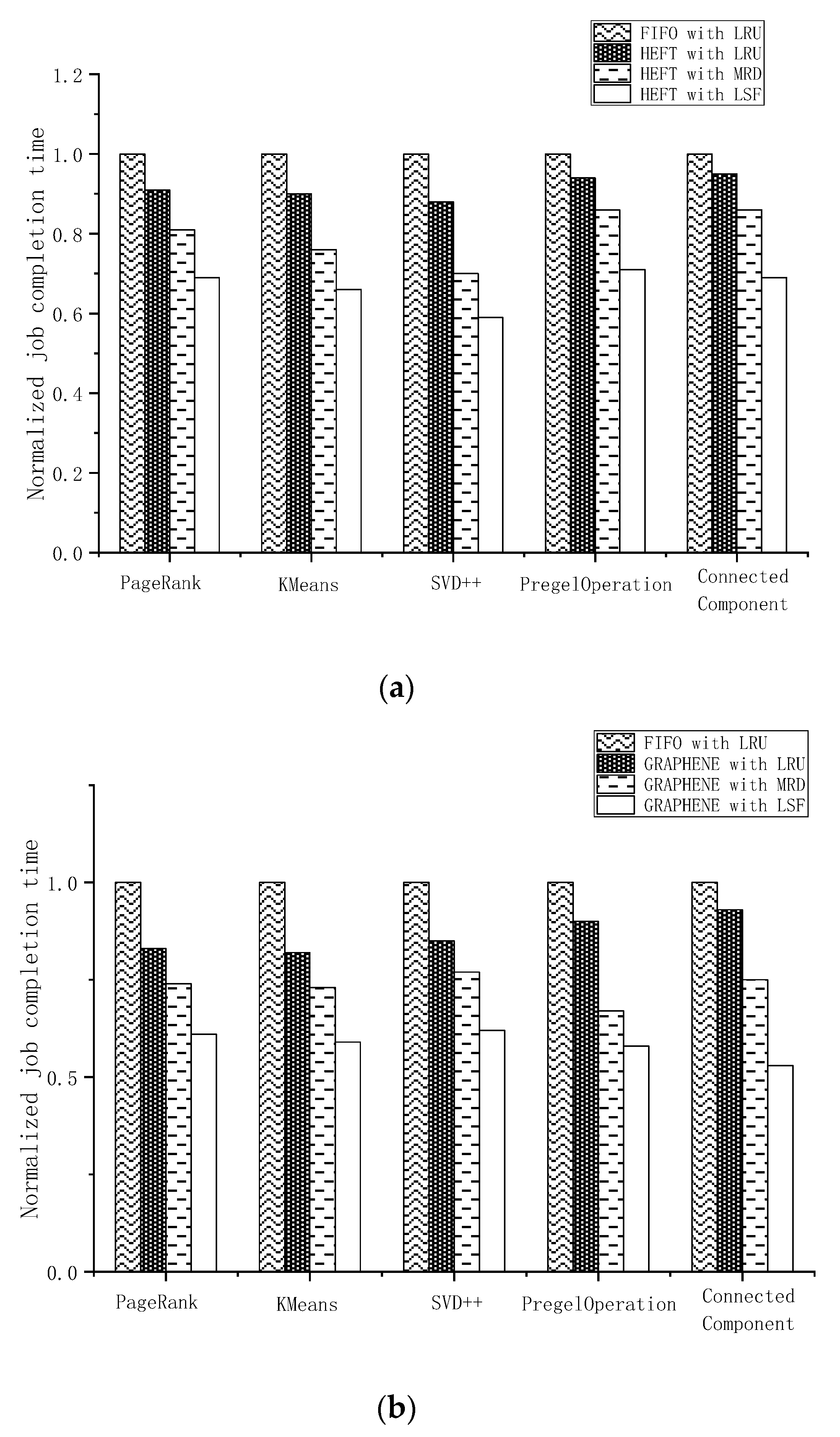
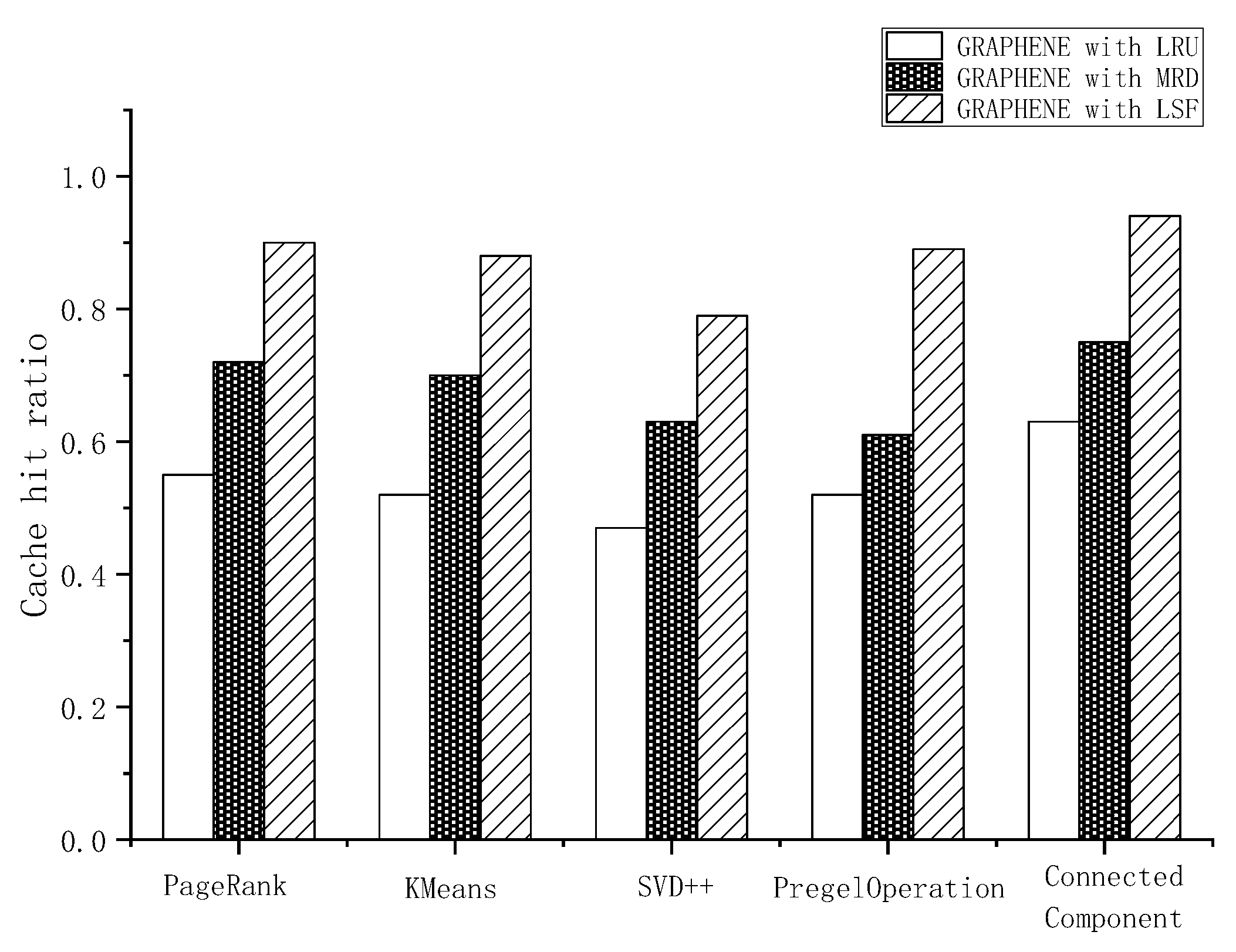
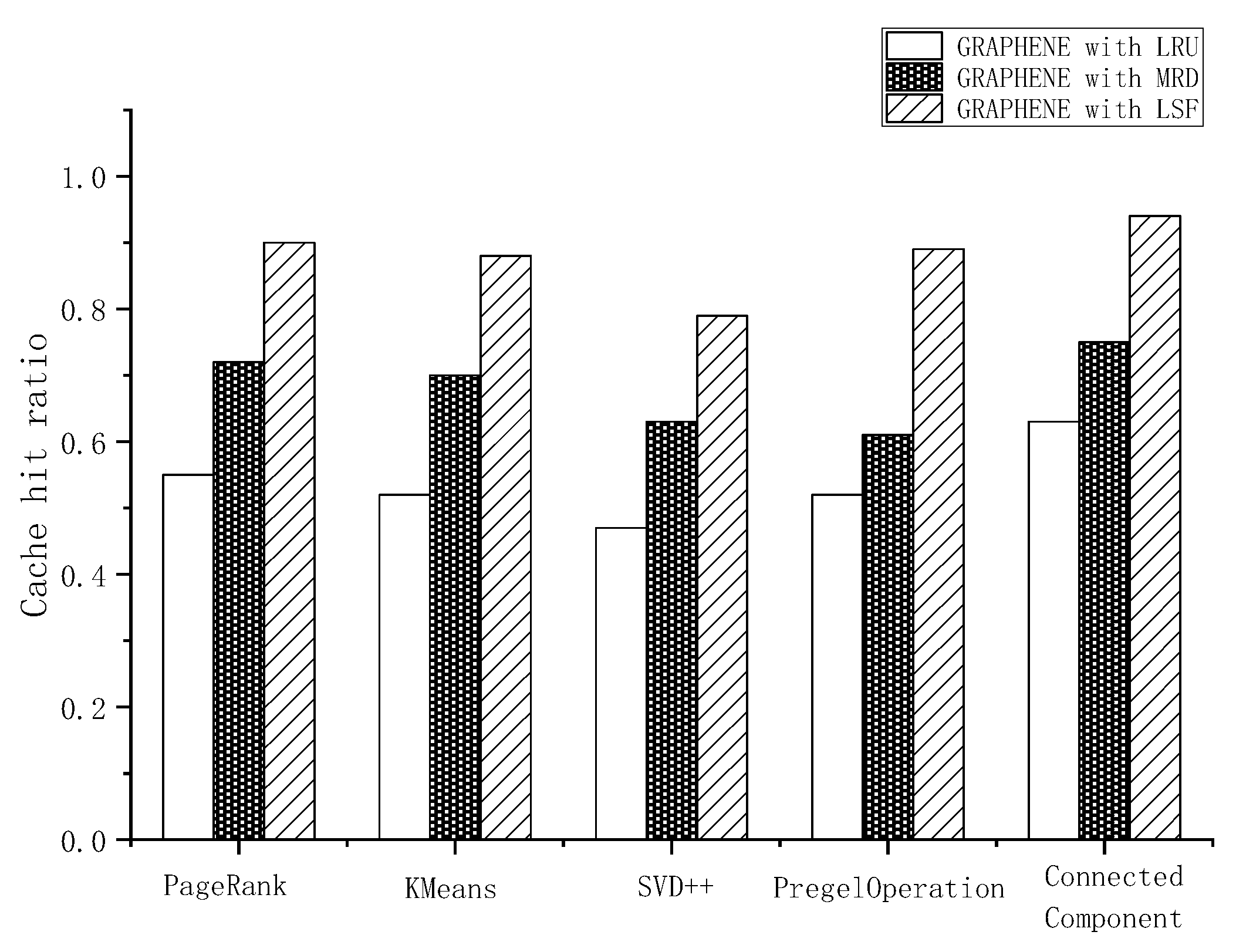
4.2. Performance of LSF
4.3. Performance of Cache-Aware Scheduling
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, J.; Balazinska, M. Elastic Memory Management for Cloud Data Analytics. In Proceedings of the 2017 USENIX Annual Technical Conference, Santa Clara, CA, USA, 12–14 July 2017; pp. 745–758. [Google Scholar]
- Nasu, A.; Yoneo, K.; Okita, M.; Ino, F. Transparent In-memory Cache Management in Apache Spark based on Post-Mortem Analysis. In Proceedings of the 2019 IEEE International Conference on Big Data, Los Angeles, CA, USA, 9–12 December 2019; pp. 3388–3396. [Google Scholar]
- Sun, G.; Li, F.H.; Jiang, W.D. Brief Talk about Big Data Graph Analysis and Visualization. J. Big Data 2019, 1, 25–38. [Google Scholar] [CrossRef]
- Zaharia, M.; Chowdhury, M.; Franklin, M.J.; Shenker, S.; Stoica, I. Spark: Cluster Computing with Working Sets. HotCloud 2010, 10, 95–101. [Google Scholar]
- Zaharia, M.; Chowdhury, M.; Das, T.; Dave, A.; Stoica, I. Resilient Distributed Datasets: A Fault-tolerant Abstraction for In-memory Cluster Computing. In Proceedings of the 9th USENIX Symposium on Networked Systems Design and Implementation, San Jose, CA, USA, 25–27 April 2012; pp. 15–28. [Google Scholar]
- Bathie, G.; Marchal, L.; Robert, Y.; Thibault, S. Revisiting Dynamic DAG Scheduling under Memory Constraints for Shared-memory Platforms. In Proceedings of the 2020 IEEE international Parallel and Distributed Processing Symposium Workshops, New Orleans, LA, USA, 18–22 May 2020; pp. 597–606. [Google Scholar]
- Liu, J.; Shen, H. Dependency-Aware and Resource-Efficient Scheduling for Heterogeneous Jobs in Clouds. In Proceedings of the 2016 IEEE International Conference on Cloud Computing Technology and Science, Luxembourg, 12–15 December 2016; pp. 110–117. [Google Scholar]
- Li, Z.; Zhang, Y.; Zhao, Y.; Li, D. Efficient Semantic-Aware Coflow Scheduling for Data-Parallel Jobs. In Proceedings of the 2016 IEEE International Conference on Cluster Computing, Taipei, Taiwan, 12–16 September 2016; pp. 154–155. [Google Scholar]
- Wang, S.; Chen, W.; Zhou, L.; Zhang, L.; Wang, Y. Dependency-Aware Network Adaptive Scheduling of Data-Intensive Parallel Jobs. IEEE Trans. TPDS 2018, 30, 515–529. [Google Scholar] [CrossRef]
- Shao, W.; Xu, F.; Chen, L.; Zheng, H.; Liu, F. Stage Delay Scheduling: Speeding up DAG-style Data Analytics Jobs with Resource Interleaving. In Proceedings of the 48th International Conference on Parallel Processing, Kyoto, Japan, 5–8 August 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 1–11. [Google Scholar]
- Grandl, R.; Chowdhury, M.; Akella, A.; Ananthanarayanan, G. Altruistic Scheduling in Multi-Resource Clusters. In Proceedings of the 12th USENIX Symposium on Networked Systems Design and Implementation, Savannah, GA, USA, 2–4 November 2016; pp. 65–80. [Google Scholar]
- Topcuoglu, H.; Hariri, S.; Wu, M.Y. Performance-effective and Low-complexity Task Scheduling for Heterogeneous Computing. IEEE Trans. TPDS 2002, 13, 260–274. [Google Scholar] [CrossRef] [Green Version]
- Grandl, R.; Kandula, S.; Rao, S.; Akella, A.; Kulkarni, J. GRAPHENE: Packing and Dependency-Aware Scheduling for Data-Parallel Clusters. In Proceedings of the 12th USENIX Symposium on Networked Systems Design and Implementation, Savannah, GA, USA, 2–4 November 2016; pp. 81–97. [Google Scholar]
- Hu, Z.; Li, D.; Zhang, Y.; Guo, D.; Li, Z. Branch Scheduling: DAG-Aware Scheduling for Speeding up Data-Parallel Jobs. In Proceedings of the International Symposium on Quality of Service, Phoenix, AZ, USA, 24–25 June 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 1–10. [Google Scholar]
- Dessokey, M.; Saif, S.M.; Salem, S.; Saad, E.; Eldeeb, H. Memory Management Approaches in Apache Spark: A Review. In Proceedings of the International Conference on Advanced Intelligent Systems and Informatics, Cairo, Egypt, 19–21 October 2020; pp. 394–403. [Google Scholar]
- Yu, Y.H.; Wang, W.; Zhang, J.; Letaief, K. LRC: Dependency-Aware Cache Management Policy for Spark. In Proceedings of the 2017 IEEE Conference on Computer Communications, Atlanta, GA, USA, 1–4 May 2017; pp. 1–9. [Google Scholar]
- Wang, B.; Tang, J.; Zhang, R.; Ding, W.; Qi, D. LCRC: A Dependency-Aware Cache Management Policy for Spark. In Proceedings of the Intl Conf on Parallel & Distributed Processing with Applications, Ubiquitous Computing & Communications, Big Data & Cloud Computing, Social Computing & Networking, Sustainable Computing & Communication, Melbourne, Australia, 11–13 December 2018; pp. 956–963. [Google Scholar]
- Perez, T.B.; Zhou, X.; Cheng, D. Reference-distance Eviction and Prefetching for Cache Management in Spark. In Proceedings of the 47th International Conference on Parallel Processing, Eugene, OR, USA, 13–16 August 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 1–10. [Google Scholar]
- Li, M.; Tan, J.; Wang, Y.; Zhang, L.; Salapura, V. SparkBench: A Comprehensive Benchmarking Suite for In-memory Data Analytic Platform Spark. In Proceedings of the 12th ACM International Conference on Computing Frontiers, Ischia, Italy, 18–21 May 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 1–8. [Google Scholar]
- Xu, L.; Li, M.; Zhang, L.; Butt, A.R.; Wang, Y.; Hu, Z.Z. MEMTUNE: Dynamic Memory Management for In-Memory Data Analytic Platforms. In Proceedings of the 2016 IEEE International Parallel and Distributed Processing Symposium, Chicago, IL, USA, 23–27 May 2016; pp. 383–392. [Google Scholar]
- Bittencourt, L.F.; Sakellariou, R.; Madeira, E.R.M. DAG Scheduling Using a Lookahead Variant of the Heterogeneous Earliest Finish Time Algorithm. In Proceedings of the 18th Euromicro Conference on Parallel, Distributed and Network-based Processing, Pisa, Italy, 17–19 February 2010; pp. 27–34. [Google Scholar]
- Ferguson, A.D.; Bodik, P.; Kandula, S.; Boutin, E.; Fonseca, R. Jockey: Guaranteed job latency in data parallel clusters. In Proceedings of the 7th ACM European Conference on Computer Systems, Bern, Switzerland, 10–13 April 2012; Association for Computing Machinery: New York, NY, USA, 2012; pp. 99–112. [Google Scholar]
- Zhu, Z.; Shen, Q.; Yang, Y.; Wu, Z. MCS: Memory Constraint Strategy for Unified Memory Manager in Spark. In Proceedings of the 23rd International Conference on Parallel and Distributed Systems, Shenzhen, China, 15–17 December 2017; pp. 437–444. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Scheduling Order (Represented by Stage ID) | Execution Time |
|---|---|---|
| FIFO | 0 -> 1 -> 2 -> 3 -> 4 -> 5 -> 6 | 23 |
| GRAPHENE | 1 -> 3 -> (4, 0) -> (0, 2, 5) | 12 |
| RDD | Stage ID | CU |
|---|---|---|
| 0 | 0 | 56 |
| 1 | 1 | 65 |
| 2 | 2 | 56 |
| 3 | 3 | 69 |
| 4 | 4 | 60 |
| 5 | 5 | 56 |
| 6 | 6 | 8 |
| API | Description |
|---|---|
| DAGProfile | AppProfiler analyze DAG and generates an initial scheduling order |
| updateCachePriority | CacheManager sends a new cache urgency file to CacheMonitor |
| updateRAS | DAGAnalyzer returns a new RAS index when receiving new DAGs |
| BlocksEviction | When the cache is full, data with a low cache urgency will be evicted |
| DataPrefetch | Prefetches specific blocks for use in the next stage |
| Workloads | Data Sizes |
|---|---|
| KMeans | 6 GB |
| PageRank | 9 GB |
| Connected Component | 8 GB |
| PregelOperation | 10 GB |
| SVD++ | 8.3 GB |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Y.; Dong, J.; Liu, H.; Wu, J.; Liu, Y. Performance Improvement of DAG-Aware Task Scheduling Algorithms with Efficient Cache Management in Spark. Electronics 2021, 10, 1874. https://doi.org/10.3390/electronics10161874
Zhao Y, Dong J, Liu H, Wu J, Liu Y. Performance Improvement of DAG-Aware Task Scheduling Algorithms with Efficient Cache Management in Spark. Electronics. 2021; 10(16):1874. https://doi.org/10.3390/electronics10161874
Chicago/Turabian StyleZhao, Yao, Jian Dong, Hongwei Liu, Jin Wu, and Yanxin Liu. 2021. "Performance Improvement of DAG-Aware Task Scheduling Algorithms with Efficient Cache Management in Spark" Electronics 10, no. 16: 1874. https://doi.org/10.3390/electronics10161874
APA StyleZhao, Y., Dong, J., Liu, H., Wu, J., & Liu, Y. (2021). Performance Improvement of DAG-Aware Task Scheduling Algorithms with Efficient Cache Management in Spark. Electronics, 10(16), 1874. https://doi.org/10.3390/electronics10161874