1. Introduction
The beginnings of transport telecommunication networks date back to the 1960s, when the ARPA (Advanced Research Project Agency) established the first wide area network called ARPANET (ARPA Network). Initially, ARPANET was a simple packet forwarding network connecting only two computers. However, due to its invaluable usefulness and work facilitation, it has been rapidly developed and today it is known as the Internet precursor [
1]. Currently, telecommunication networks are an indispensable part of the society’s everyday life, providing support for plenty of our activities—education, business, health care, finance, social life, entertainment, etc. The extremely relevant role of networks in our life was also revealed and emphasized during the COVID-19 pandemic, when many important human activities (e.g., business, education) could only be realized remotely [
2]. The networks’ immensely relevant position in our society entails the continuous growth of the number of network users and connected devices as well as their increasing requirements regarding the networks [
3]. According to Cisco company, there will be 5.3 billion total Internet users (66% of global population) by 2023, up from 3.9 billion (51% of global population) in 2018, and there will be 29.3 billion networked devices by 2023 up from 18.4 billion in 2018. Moreover, the bandwidth demands of the most popular services (for instance video) will increase up to several times [
3].
Increasing requirements regarding networks and constantly growing traffic trigger the fast development and implementation of new network architectures and technologies [
4]. The new solutions benefit from advance transmission and spectrum management techniques (for instance, adaptive application of complex modulation formats and continuous monitoring of links/paths QoS parameters) [
5]. In turn, they are able to provide superior network performance. However, at the cost of complex network design and operational optimization. Therefore, the adoption of these innovations entails an urgent need for improvement in the field of network design and optimization algorithms, which can be achieved either by revisiting existing methods or by completely new proposals [
4,
6].
The results of recent research in the field of networking have revealed a promising direction in the algorithms improvement—design and implementation of traffic-aware methods [
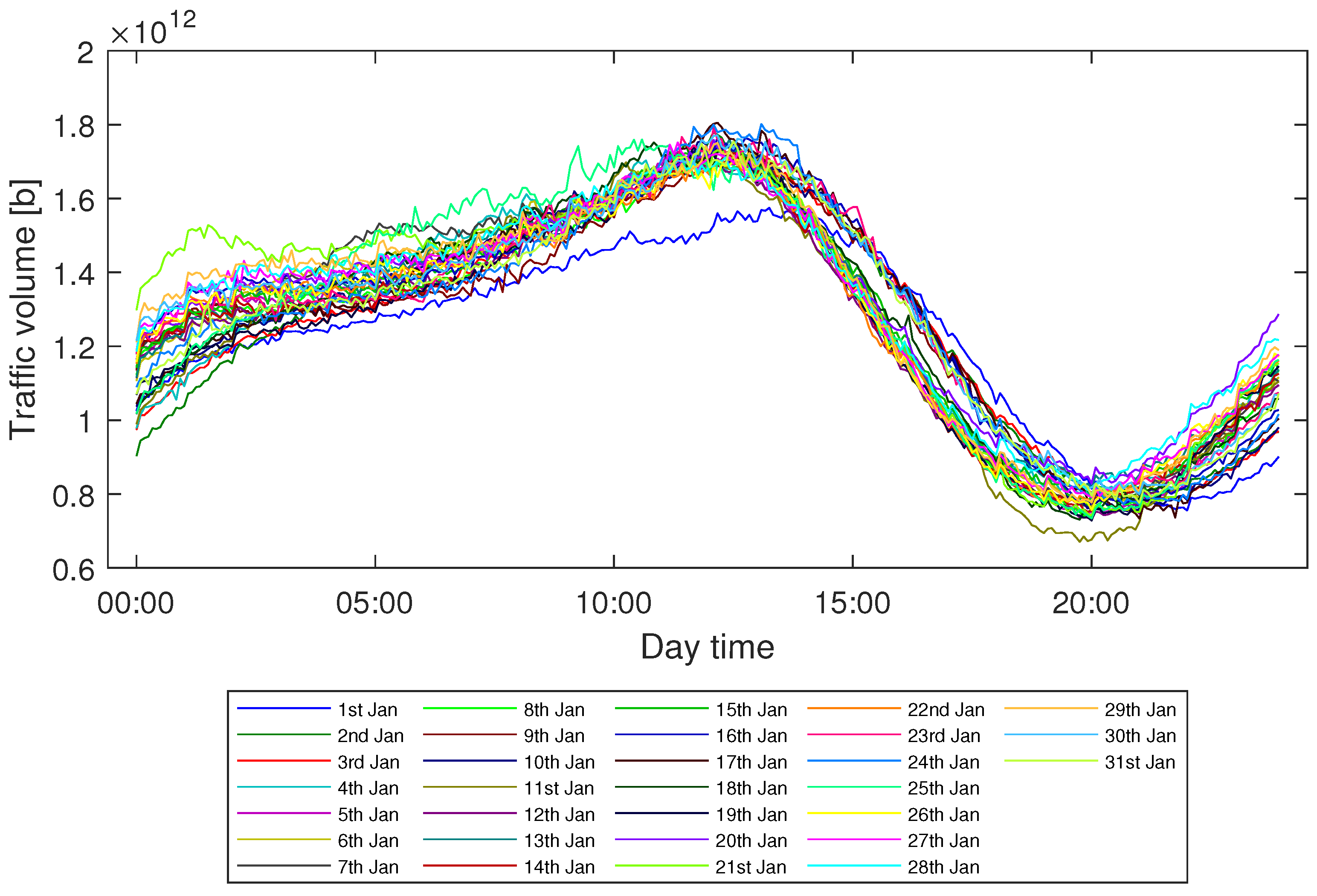
4]. In more detail, the network traffic is not a random process and it follows specific patterns, which come from human behaviours as a result of working habits, weekend activities, and so on [
7,
8,
9]. It was observed that the more aggregated the traffic is (from a higher number of users), the more regular its shape is as a time function and the patterns are more noticeable. The main idea of the traffic-based approach is to collect information regarding observed traffic flows in networks and then to apply various modeling approaches or/and machine learning algorithms to process that data and extract hidden patterns [
4]. The patterns might be then utilized to predict future traffic and use it to design and optimize network performance [
10]. The crucial element of the traffic-aware approach is to collect a vast set of representative data, which might be difficult due to the privacy and security reasons, and properly select a beneficial modeling/prediction method depending on the data characteristics [
4].
The traffic-aware methods might benefit from short-term or the long-term traffic forecasting [
4]. In the short-term prediction, the traffic forecast is made for the near future, i.e., for a period up to several upcoming time stamps (typically only for the next time stamp). That information may be then utilized for instance to plan the routing rules for the approaching traffic demands. By these means, it is possible to increase the ratio of the accepted demands while a demand switching process is realized faster [
11,
12]. In the long-term prediction, which is much more challenging, the forecast is made for a longer period (i.e., several upcoming hours or even days/months). That information might be then used by the network operators to precisely plan the resources’ (i.e., computing and networking infrastructure) assignment process for the forthcoming requests in such a way as to obtain numerous benefits. For instance, in order to: (i) maximize the number of served clients, (ii) maximize their quality of service, (iii) improve the resource utilization, and (iv) reduce the power consumption (which meets the green networking paradigm) [
4,
13,
14]. The long-term traffic forecasting improves also the increasingly popular model of the resource outsourcing. In that model, a client who does not have their own computing/networking resources, can outsource it from an external company. To this end, the client must define their requirements, what might be realized by analyzing the long-term traffic forecast.
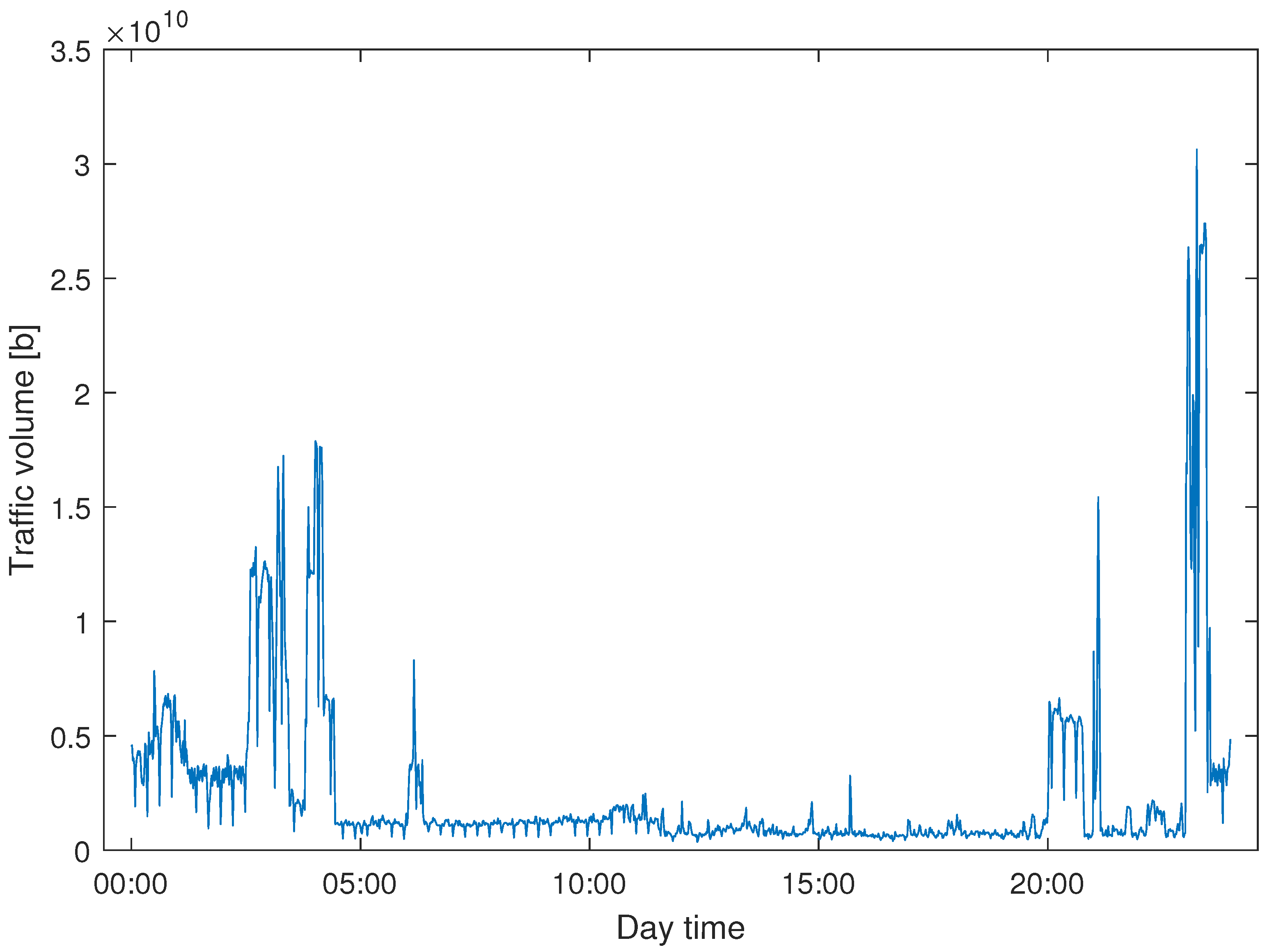
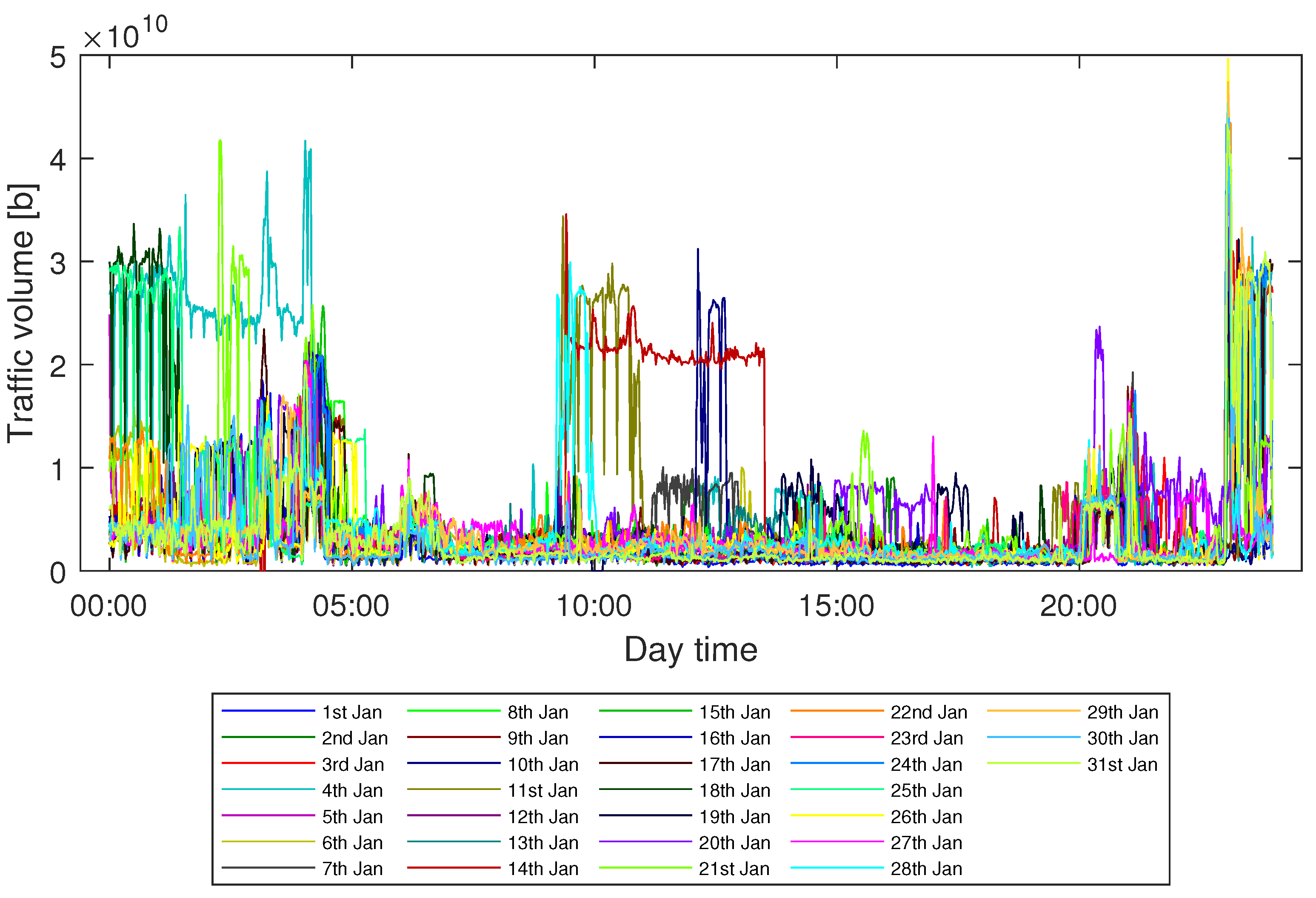
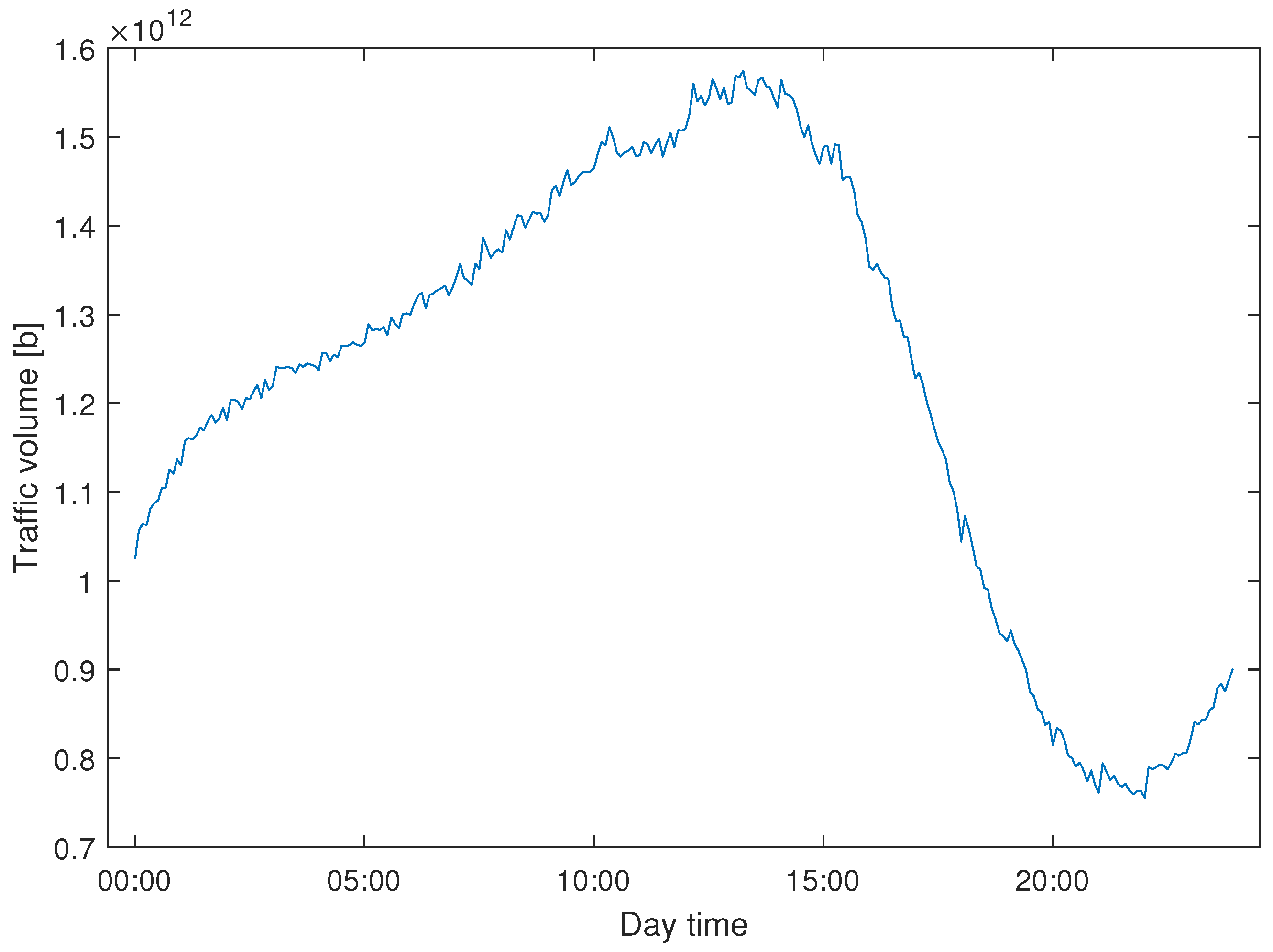
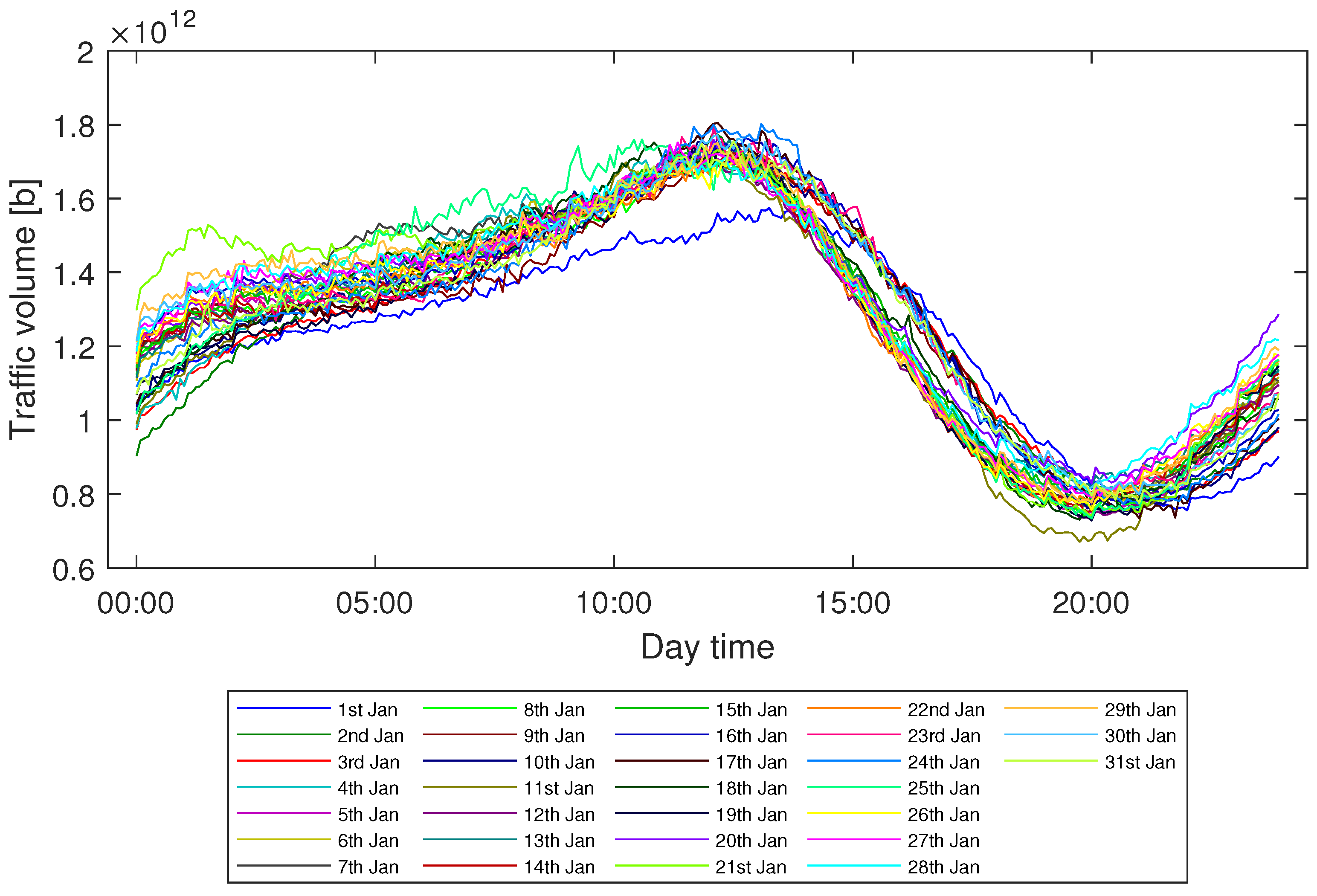
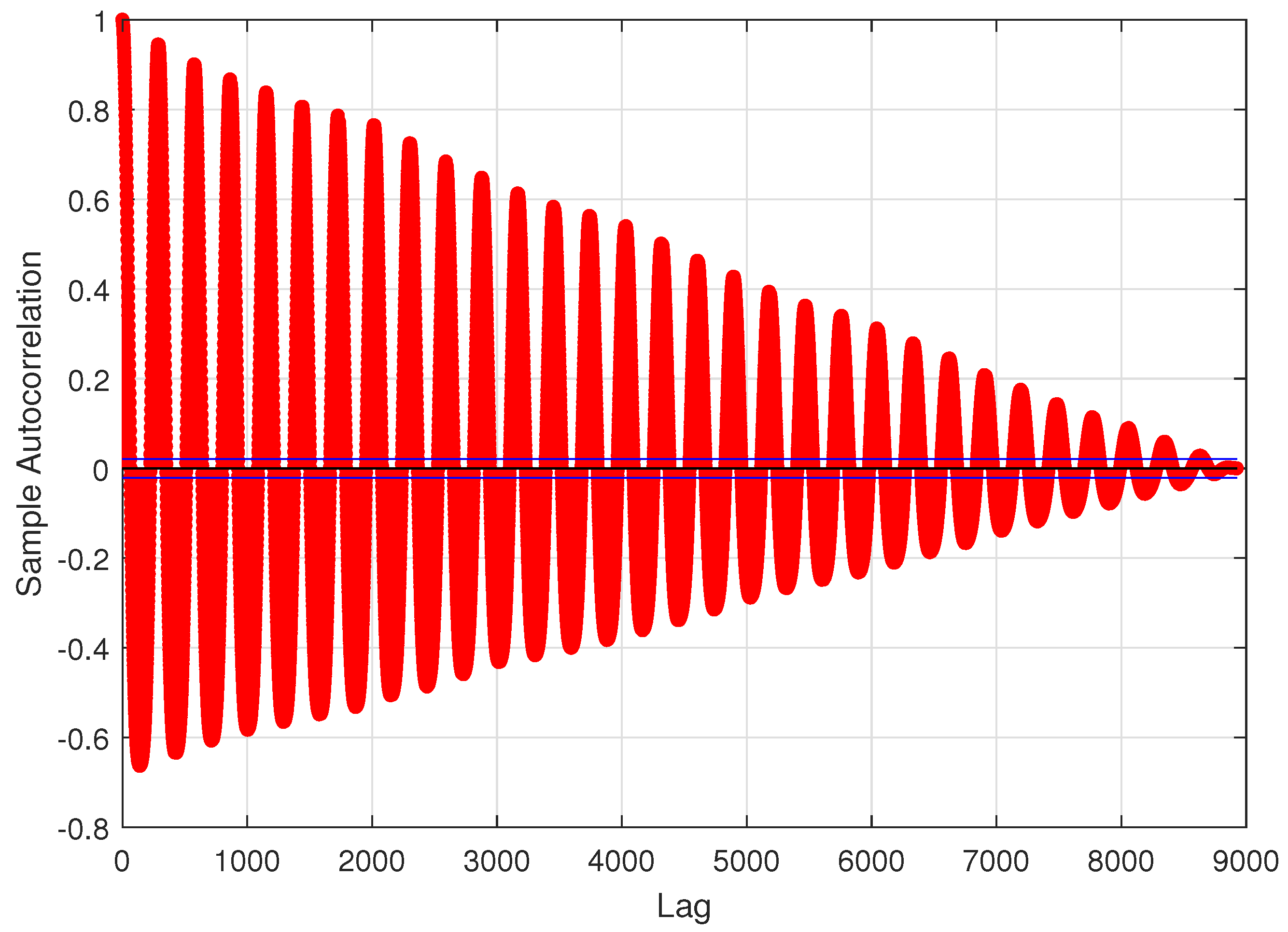
In this paper, we study the problem of efficient modeling and prediction of daily (i.e., long-term) traffic patterns in transport telecommunication networks. In our investigation, we use two historical traffic datasets from January 2021, namely, WASK and SIX. The datasets collect data from edge routers of two transport networks of different sizes, which affect the traffic characteristics and then the modeling/prediction process. It is worth mentioning that WASK is a novel dataset, which is introduced in this paper and has not been analyzed before. For the datasets, we propose long-term modeling and prediction approaches. For modeling, we use Fourier Transform analysis. For prediction, we propose and compare two methodologies: (i) modeling-based prediction (the forecasting model is assessed based on the historical traffic models) and (ii) machine learning-based (the network traffic is handled as a data stream where chunk-based regression methods are applied for prediction). We also perform extensive numerical experiments in order to verify efficiency of the proposed approaches and compare them. Since the datasets significantly differ in characteristics of the traffic, we also study how they influence the modeling and prediction performance.
The rest of the paper is organized as follows.
Section 2 reviews the related works.
Section 3 introduces the analyzed traffic datasets. Then, in
Section 4, we describe the applied traffic modeling and prediction approaches.
Section 5 presents the results of numerical experiments while
Section 6 concludes the work.
2. Related Works
The consideration of historical traffic datasets in research and experiments is able to make the results more valuable and applicable in real networks. In turn, the data acquisition and publication are gaining more and more attention. The task is not trivial due to data privacy and security reasons. Therefore, the number of publicly available traffic datasets is deficient while their content is limited. One of the first publicly available datasets is SNDLIB library [
15], which provides static and dynamic traffic matrices defined for several real network topologies. Unfortunately, the library is not being regularly updated and all the included data was gathered before 2014. Then, Seattle Exchange Point (SIX) [
7] shares history of incoming/outgoing bit-rates (within a given time window) at routers located in the SIX. It is worth mentioning that SIX is currently one of the most popular traffic datasets in the research society, as it shares extensive and diverse statistics. It is especially widely applied for the task of traffic prediction in various configurations [
11,
12]. Similarly, several other platforms publish general information regarding observed traffic at Internet exchange points. However, the published information is usually only in the form of traffic plots, with no detailed numerical data available. For example, the AMS-ix [
8] shares traffic plots from Amsterdam and collaborating locations and the ix.br [
16] shares the graphical statistics from different locations in Brazil. We can also reach data regarding traffic from much smaller network points such as University Campus of AGH University of Science and Technology (Krakow, Poland) [
17].
Due to the numerous limitations of available traffic datasets and the impossibility of their direct application in numerical experiments (lack of numerical data, information from only one network point), traffic modeling becomes increasing popular. The oldest and simultaneously most commonly used traffic model works under the assumption that traffic demands arrive to the network according to a Poisson process while their duration follows a negative exponential distribution [
18,
19,
20]. These assumptions emerge from the traditional telephony networks and do not meet the transmission characteristics of nowadays telecommunication networks supporting a plethora of diversified services. Therefore, the researchers have made a number of attempts to propose more accurate models. For instance, the authors of [
21] propose to use Pareto process for traffic modeling in wavelength division multiplexing (WDM) networks. Then, authors of. [
22,
23] study network-dedicated models built on the collected traffic flows within a specific time window. The authors of [
24] suggest to model network traffic using mathematical functions such as piecewise linear function with mean value following the Gaussian distribution, sine function, and the combination of two first options. The paper contains only general model assumptions and does not provide a definition of the functions’ parameters. The modeling using trigonometric functions was also studied in [
9,
25]. Another interesting proposal was presented in [
26,
27], where the multivariable gravity model was introduced. It relates the bit-rate exchanged between a pair of nodes with real data related to the populations of the regions served by the network nodes, geographical distance between the nodes, and the economy level expressed by gross domestic product (GDP). It should be noted that each of the proposed models suffers from some limitations and, therefore, none of them was universally approved and applied in the research society.
Besides traffic modeling, the problem of traffic prediction has gained more and more popularity [
4]. The existing literature mainly makes use of the autoregressive integrated moving average (ARIMA) method [
28,
29] and machine learning algorithms [
30,
31,
32]. ARIMA is a statistical model that uses variations and data regressions to find patterns to model data or to predict future data. It was applied, for instance, in [
28], where the authors used the traffic prediction module for the purpose of virtual topology reconfiguration. Similarly, the authors of [
29] applied the provided prediction for the task of the virtual network topology adaptability. In terms of the machine learning-based forecasting, the majority of research makes use of various implementations of neural networks. For example, the authors of [
32,
33] used long short term memory (LSTM) method to predict the network traffic wherein The authors of [
32] used the forecast to determine efficient resource reallocation in the optical data center networks. The authors of [
30] applied the gated recurrent unit recurrent neural network (GRU RNN) enriched with a special evaluation automatic module (EAM), which has the task of automating the learning process and generalizing the prediction model with the best possible performance. The authors of [
31] benefited from a nonlinear autoregressive neural network to design efficient resource allocation procedures for intra-data center networks. It is also worth-mentioning the paper [
11], which compared three regressors (i.e., linear regression (LR), random forest (RF) and k-nearest neighbours (kNN)) used for the task of traffic forecasting. The presented literature reveals that the efficiency of a forecasting method strongly depends on the traffic dataset and there is no universal approach that performs best for all traffic flows.
The above-mentioned papers focus on short-term traffic prediction (i.e., the forecasting traffic volume for a next time stamp). To the best of the authors’ knowledge, long-term traffic prediction (i.e, traffic forecasting for a significantly longer period (several hours or a day)) in telecommunication networks has to yet to be addressed. Moreover, the research is generally deficient in studies covering long-term traffic prediction regardless of the traffic interpretation (network traffic, crowd traffic, cars traffic, etc). The only attempts to address the problem were presented in [
34,
35], where the authors apply neural networks to predict traffic of, respectively, cars in a highway and people in a Chinese city. Therefore, the presented paper fills the literature gaps by studying long-time traffic modeling and prediction in telecommunication networks.
5. Results and Discussion
In this section, we evaluate efficiency of the proposed traffic modeling and prediction approaches applied to WASK and SIX datasets.
5.1. Research Methodology
Before presenting the results of numerical experiments, let us briefly summarize and discuss the general research methodology including data acquisition and processing (if necessary) as well as the efficiency evaluation.
In all studies, the results accuracy is measured using mean absolute percentage error (MAPE) metric. For the sake of simplicity, we refer to this metric as
error in the rest of the paper. Having an
M-elements vector of historical data
y and a vector of corresponding values obtained via modeling/prediction
, MAPE metric is calculated according to Equation (
2).
Traffic Modeling
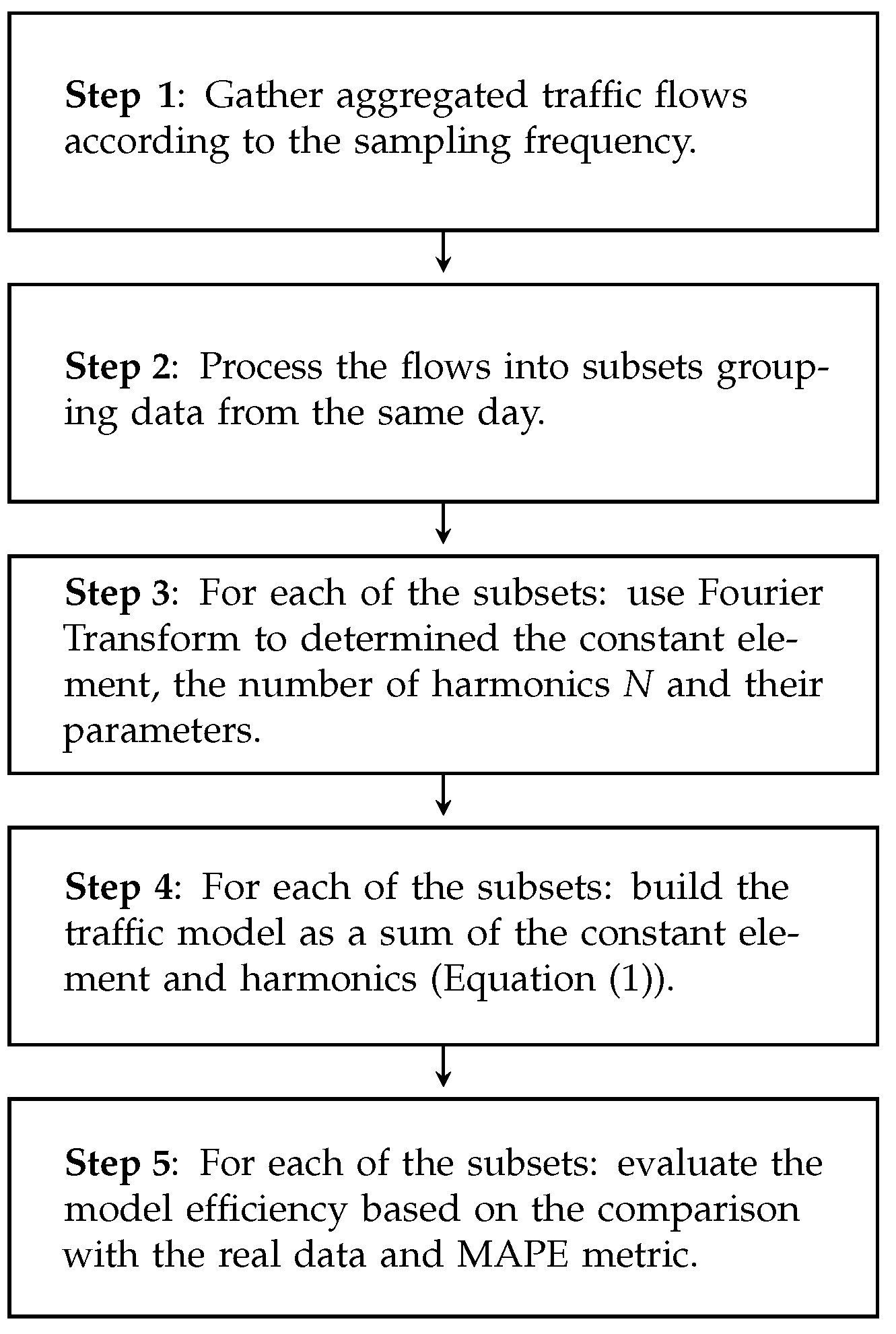
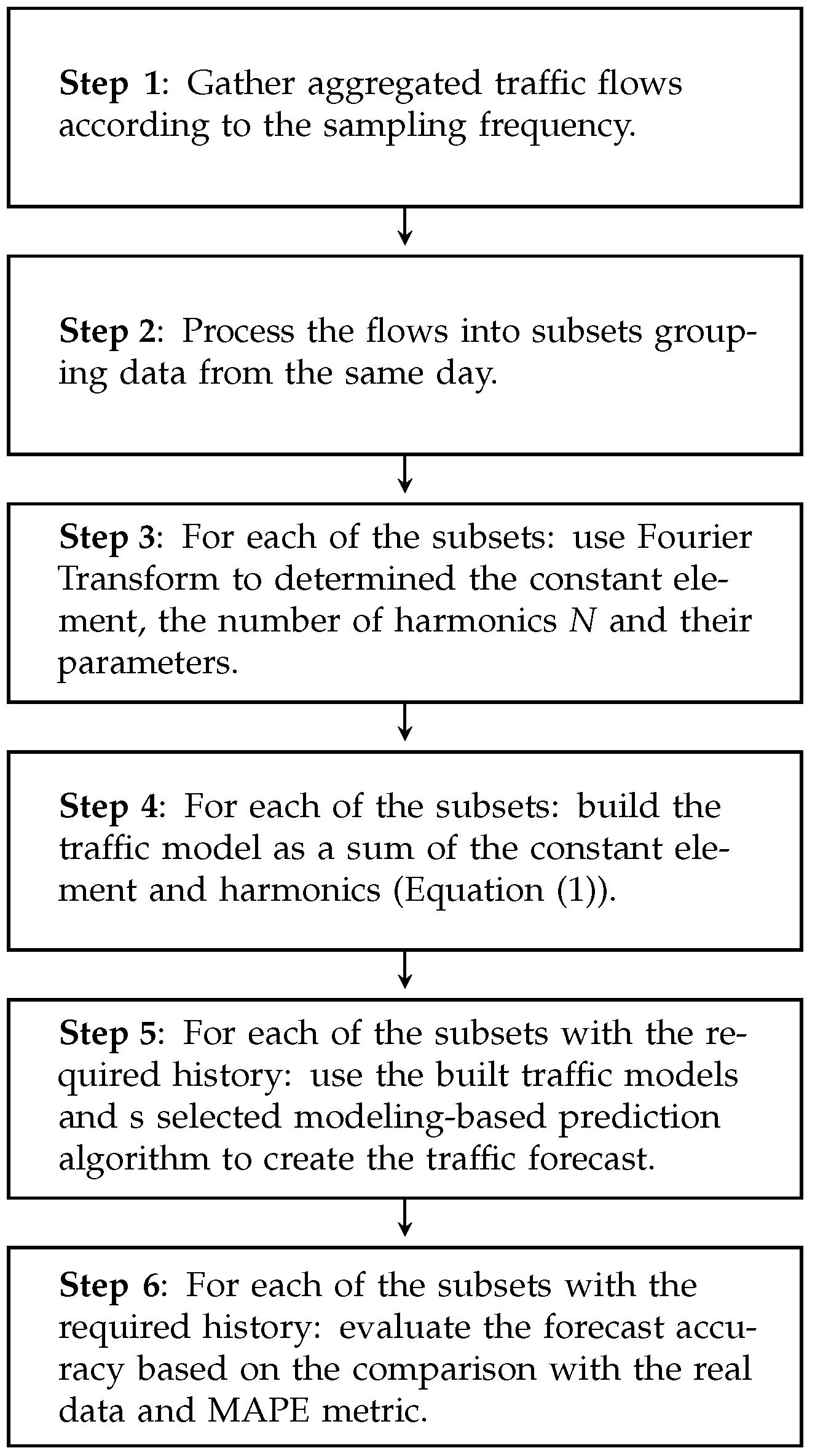
The idea of the traffic modeling and its efficiency evaluation is presented in
Figure 7. At the beginning, it is necessary to create a traffic dataset by gathering traffic flows according to the sampling frequency (i.e., every 1 min for WASK and every 5 min for SIX). Then, the data has to be divided into the subsets grouping flows observed during the same day. In our study, the flows were gathered during January 2021 and 31 subsets were obtained for each dataset. In the next step, out modeling procedure is applied (see
Section 4.1) to create a traffic model for each of the subsets (i.e., a separate traffic model is built for each day). The model efficiency is evaluated separately for each day by calculating average error value according to the MAPE metric. Please note that the results are averaged over 31 days and a number of observations during a single day (1440 for WASK and 288 for SIX).
5.2. Modeling-Based Traffic Prediction
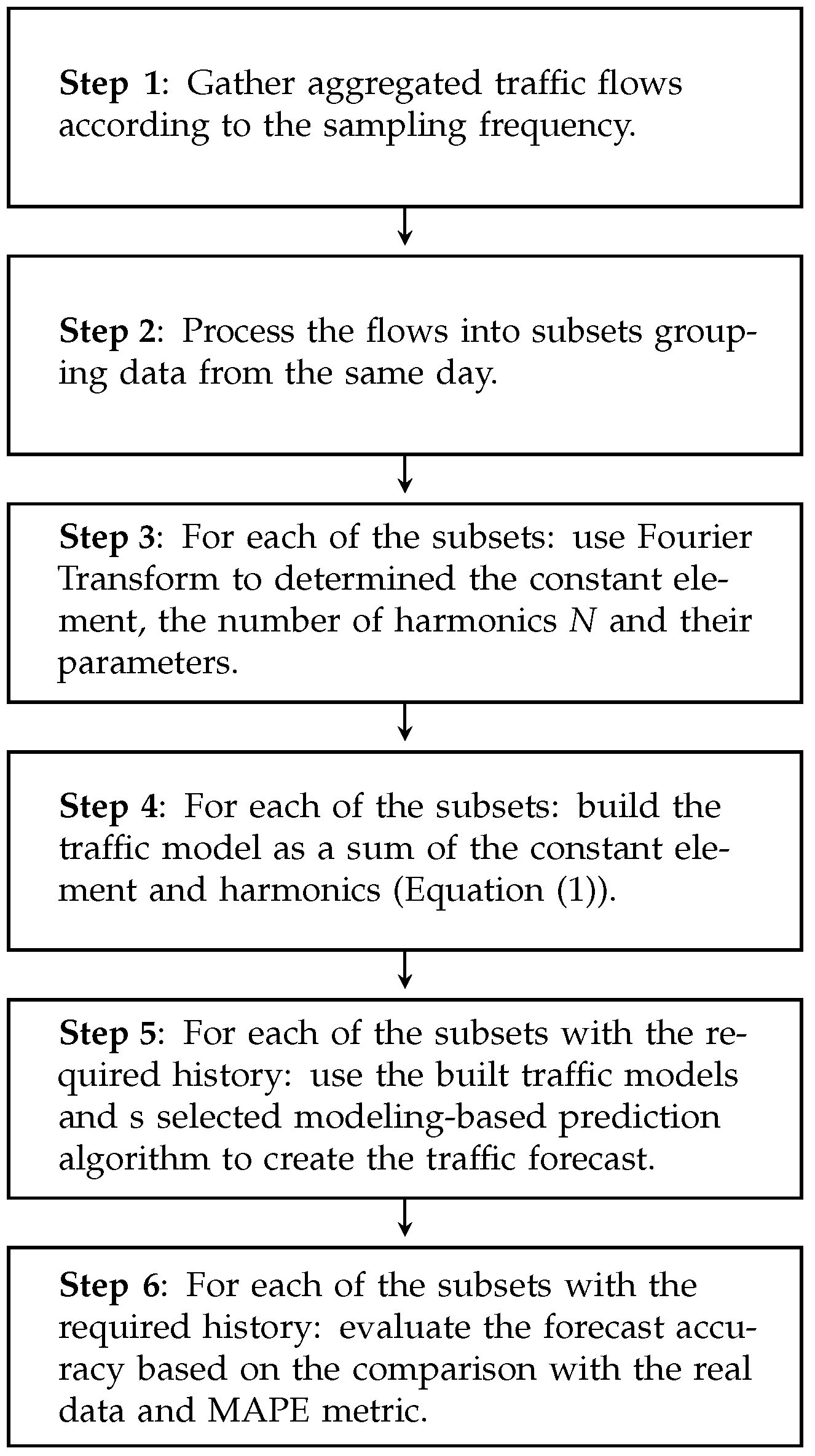
Then, the methodology of the modeling-based traffic prediction is presented in
Figure 8. Since the approach benefits from the traffic modeling, it requires the same first steps as the traffic modeling (i.e., data acquisition, creation of one-day subsets, models creation for each of the days). Next, the approach moves to the creation of the forecasting model based on the selected already built traffic models (the number of including models depends on the selected forecasting algorithm and is described in detail in the next subsections). Please note that a forecasting model can be built only for a day with a history. Then, the accuracy of the forecasting models is evaluated separately for each day by calculating average error value according to the MAPE metric. Please not that the results are averaged over a number of days (with a history) and a number of observations during a single day (1440 for WASK and 288 for SIX).
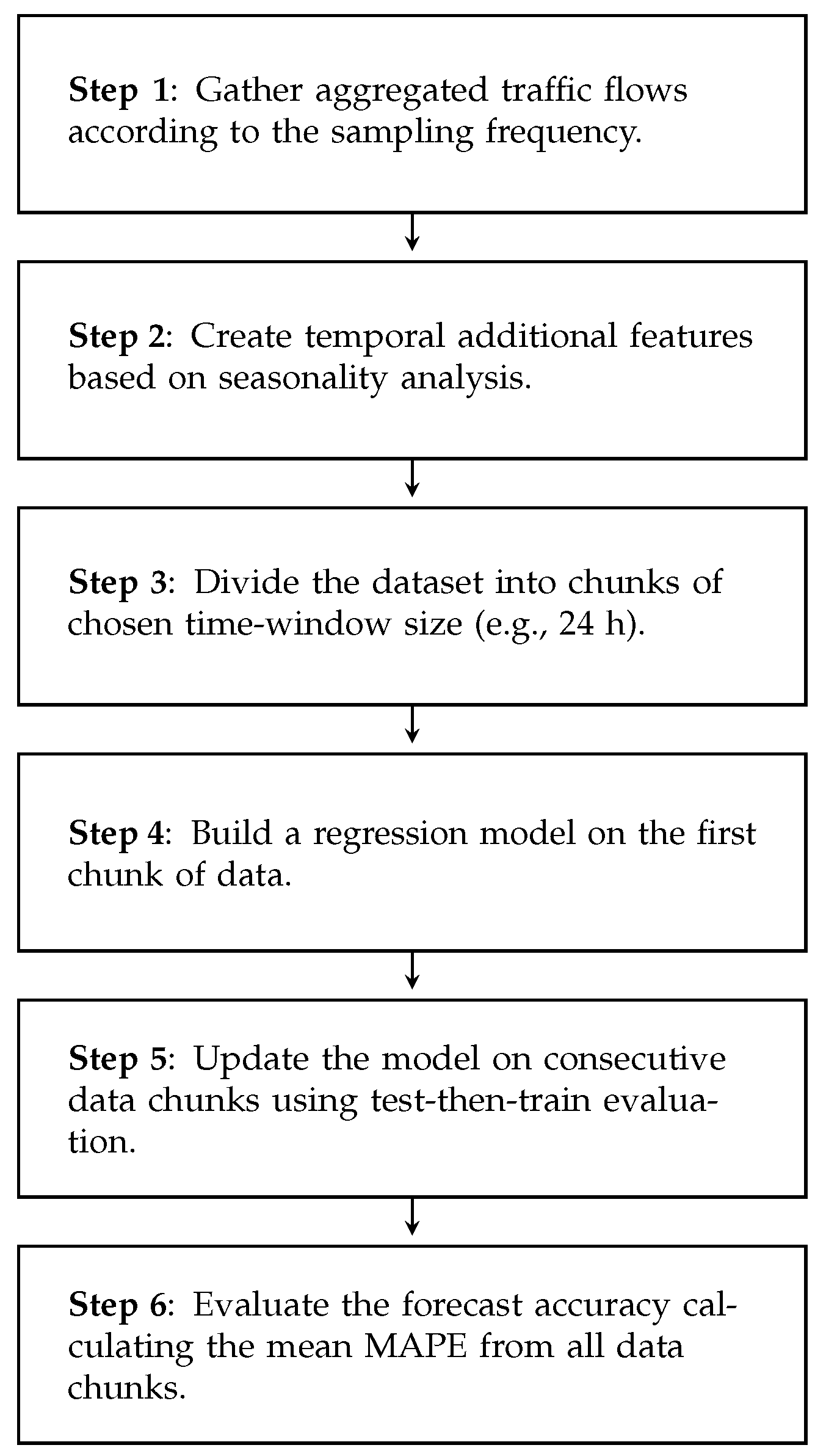
Machine Learning-Based Traffic Prediction
Finally, the methodology of the machine learning-based traffic prediction is presented in
Figure 9. Similarly to traffic modeling and modeling-based prediction, the first step is to create a traffic dataset. In machine-learning based approaches, additional features are needed to make a forecast. In this work, they are created based on the seasonality analysis of considered datasets (see
Section 3) and contain the amounts of traffic in past significant points in time. We use a chunk-based data stream approach, and for that reason, in the third step, the dataset is divided into smaller chunks. In the next step, a regression model is built around the first data chunk. On every consecutive data chunk, the model is continuously updated using test-then-train methodology. That means the model outputs a prediction for all samples in the chunk, which is then compared to real traffic values and the model is updated according to calculated MAPE value. To evaluate the overall forecast accuracy, the mean MAPE metric value is calculated from all the data chunks.
5.3. Traffic Modeling
First, we focus on the performance of the traffic modeling. For each dataset, we build a traffic model separately for each day of the month. Thus, the evaluation is prepared based on the evaluation of 31 models.
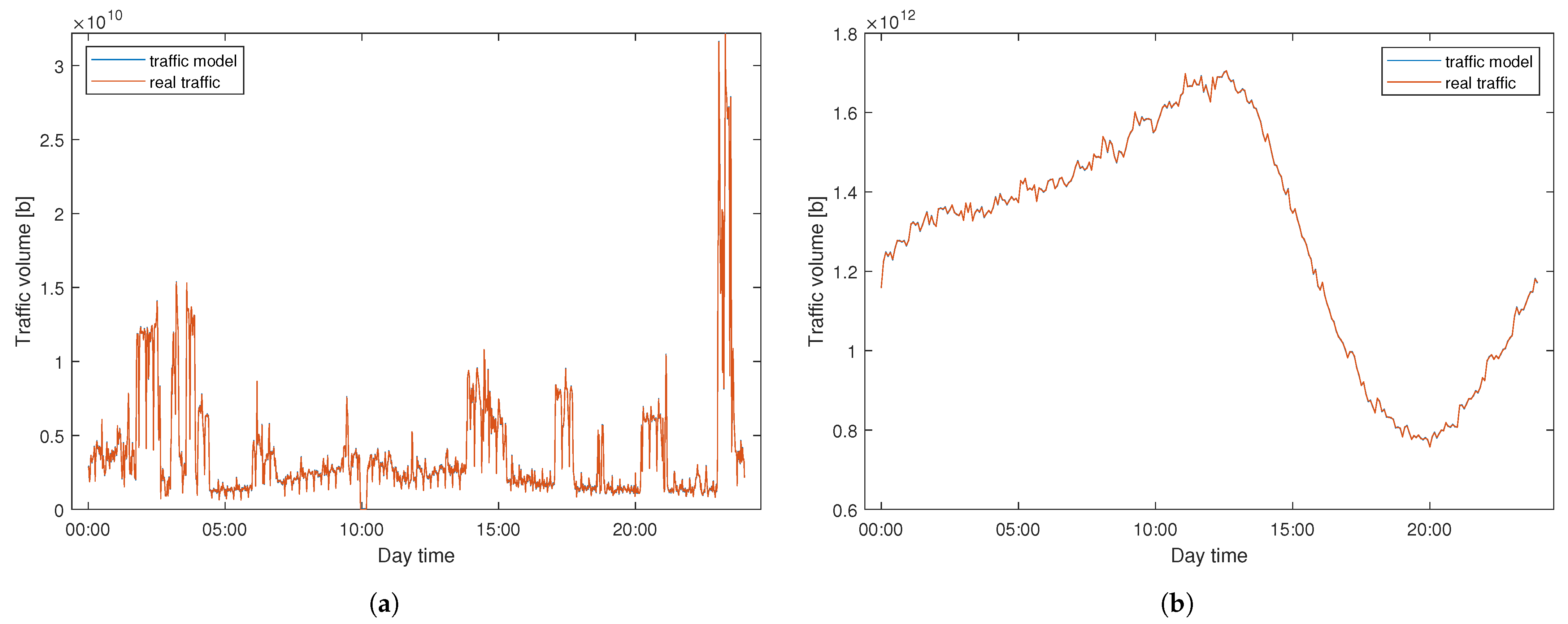
Table 2 reports the efficiency for two considered datasets. Since the results vary between different days of the month, we present a detailed analysis of the obtained errors and the corresponding standard deviation. Firstly, we observe that the quality of results obtained for two datasets differs much and is significantly higher for the SIX (the errors for SIX are smaller than these observed for WASK up to almost several orders of magnitude). For the WASK dataset, the average obtained error was 6.31%. However, the modeling efficiency significantly varies for different observation days. In turn, the minimum error was 0.12% while the highest was equal to 86.05%. It is worth mentioning than there were only two days of observation for which the modeling error was higher than 5%. The noticeable differences between modeling performance for various days are also confirmed by the high value of the standard deviation. Concurrently, the modeling accuracy for the SIX dataset is stable and outstanding—the maximum obtained error was equal to 0.16% while the average error was less than 0.1%. Moreover, the results were stable and characterized by a low standard deviation.
The outstandingly high modeling accuracy observed for SIX dataset proves that the applied sampling frequency (i.e., flows gathered every 5 min) for that traffic was properly selected. Since the modeling precision for WASK dataset was about two ranges of magnitude smaller, we can conclude that the sampling frequency (i.e., flows gathered over 1 min) applied for that traffic was not high enough to accurately project the signal process and variability. Therefore, the modeling accuracy for WASK might be improved by applying a higher sampling frequency.
Figure 10 vizualizes the modeling performance for WASK and SIX datasets. The results are presented for two selected days for which the modeling approach performed the worst (i.e., maximum error obtained). Despite the high error values, the modeled signal properly follows the pattern of real data and the differences between the signal are hardly visible to the naked eye.
It is also worth mentioning that the number of significant harmonics for WASK was 1440 while for the SIX was 720 for each of the considered days. That proves our initial assumptions regarding time shapes of both traffics. WASK flow is determined by significantly more components (i.e., services) than SIX flow due to the different level of users/data aggregation.
Please note that the number of the harmonics influences also the modeling processing time (see
Table 2), which is about six times higher for WASK dataset. Nevertheless, the calculation of a traffic model is a fast process and takes less than a second.
5.4. Traffic Prediction
The efficiency evaluation of traffic prediction is performed separately for modeling-based and machine learning-based approach.
5.5. Modeling-Based Traffic Prediction
In the context of modeling-based traffic prediction, the period for which the modeling is applied (i.e., 24 h) determines the size of a prediction window. The forecasting efficiency is summarized in
Table 3 and
Table 4, accordingly, for WASK and SIX datasets. The analysis comes from 30 days of observations (starting from 02.01.2021) and corresponding predictions. For both datasets the best results were obtained by PSD (all) method. It proves the hypothesis that different traffic patterns are observed for different days of the week. The prediction errors for SIX dataset reached up to almost 10% while keeping its average value on the level about 3–4%. The errors yielded for WASK dataset are much larger (even several orders of magnitude) and characterized by high standard deviation. Therefore, the investigation shows that modeling-based traffic prediction is suitable only for an easy dataset (such as SIX) and does not tackle well with complex data (such as, for instance, WASK traffic). Please note the accuracy of modeling-based traffic prediction is strongly determined by the precision of the built traffic models (see
Table 2), which were outstanding for SIX and significantly weaker for WASK dataset.
The processing time of the modeling-based prediction includes the time required to build the history models and the time required to build a forecasting model. Therefore, it is mostly determined by the number of historical models, which are required. In turn, it is the shortest for PSD (1)/PD (1) and the longest for PD (all). We also observe that the calculations take slightly longer for the SIX dataset; however, they are fast and smaller than a second.
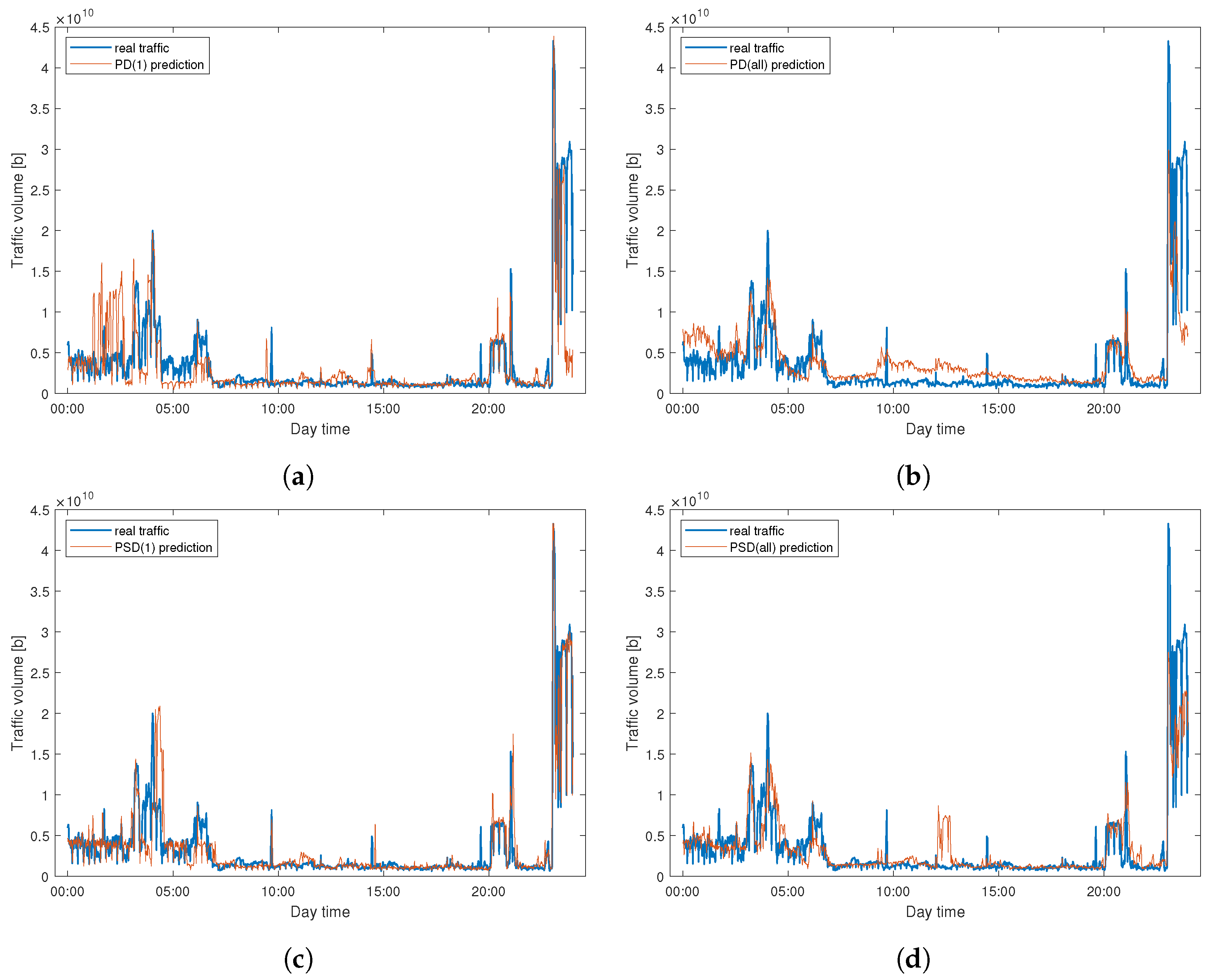
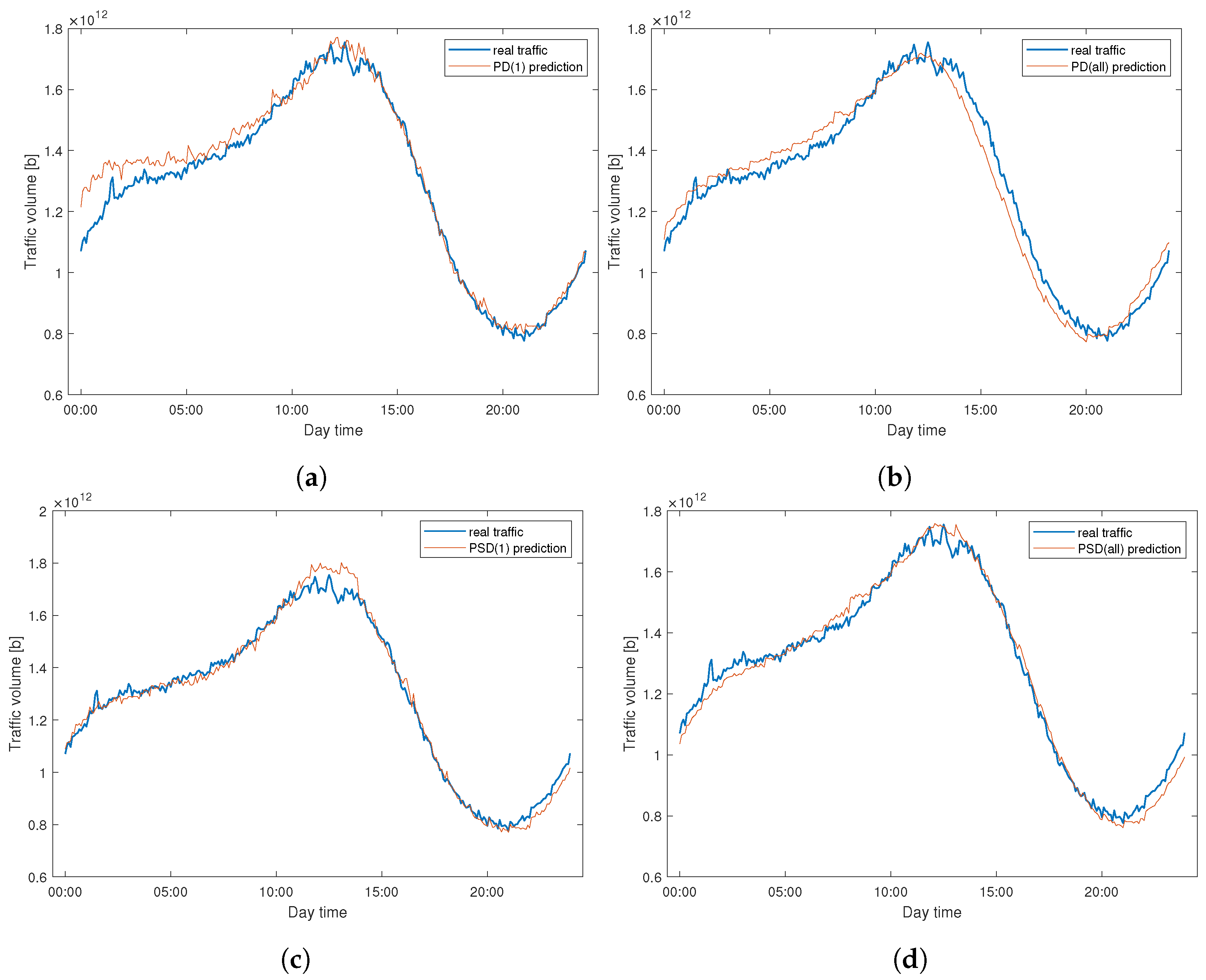
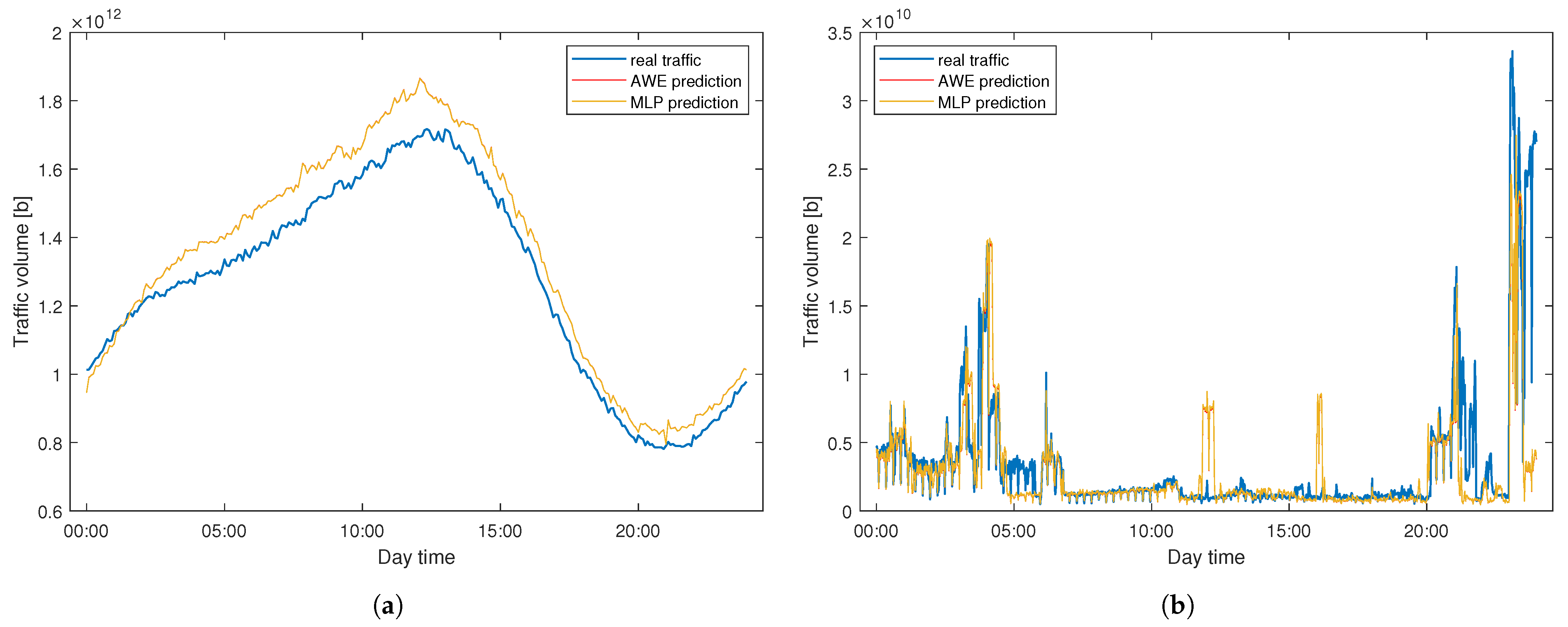
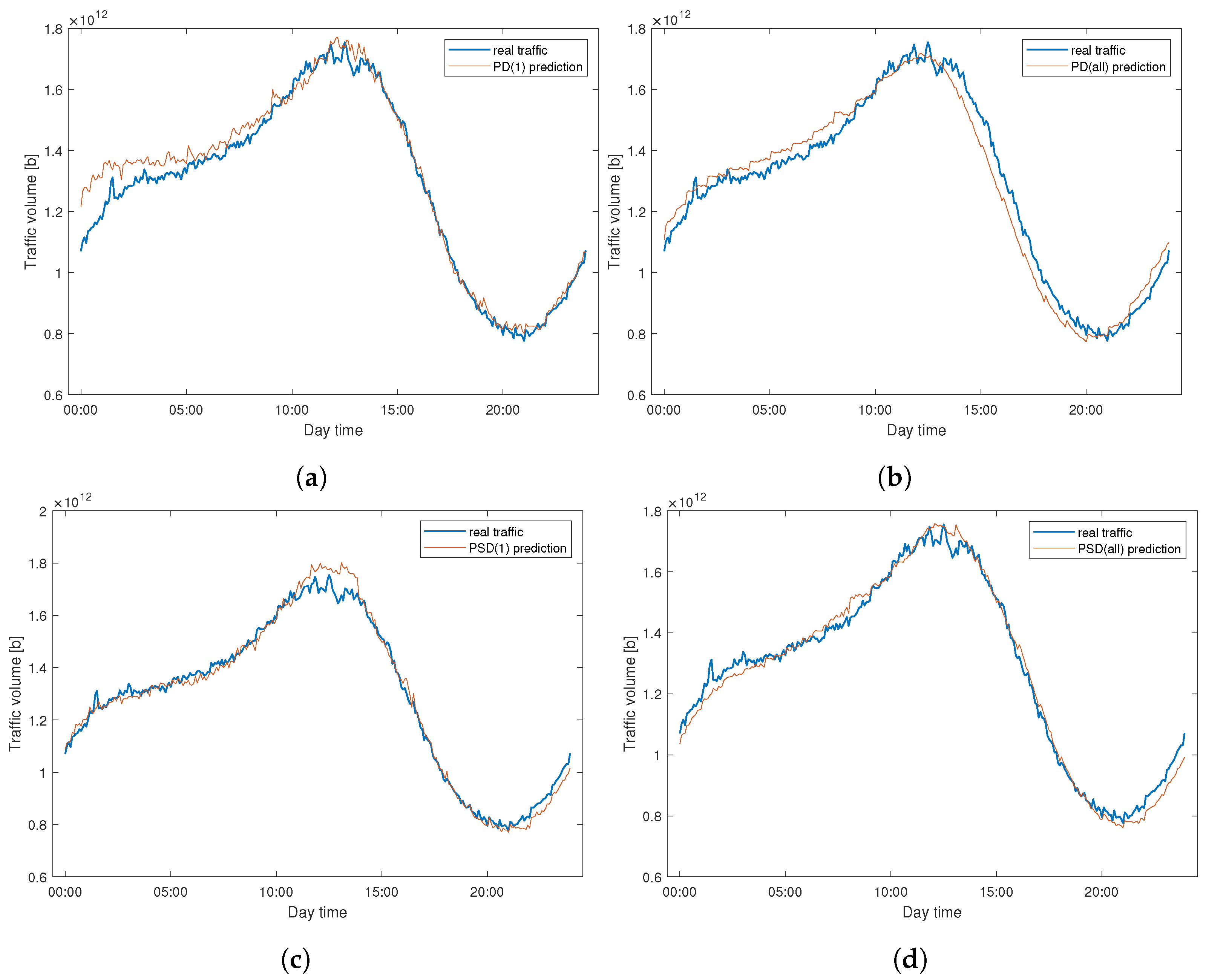
To better visualize method performance,
Figure 11 presents a comparison of the predicted and real traffic for WASK on 31.01.2021. Similarly,
Figure 12 reports the same dependence for SIX dataset. In both cases, we can clearly notice the differences between the real and predicted signal. They are especially significant for WASK dataset, where the trajectories of two signals differ. For the SIX dataset, the predicted signal correctly follows the real signal trajectory while the errors emerge from the amplitude over/under estimation.
5.6. Machine Learning-Based Traffic Prediction
In this section, we compare the prediction quality of two machine learning (chunk-based data stream) traffic forecasting methods (MLP and AWE) for three chosen time windows. The algorithms output a prediction for the next chunk of data, which is a series of datapoints. The series is then compared with a series of real values of the chunk and an error is calculated. Note that the granularity of gathered samples varies between considered datasets, so the number of points for the same time window is different for WASK and SIX.
Table 5 presents the results of machine learning-based prediction for the WASK dataset. As can be seen, the MLP method achieved lower average error values for all the considered time windows. Furthermore, the results of MLP were more stable among data chunks, as proven by lower values of standard deviation. Comparing the results for different time windows, it can be noted that despite a rather stable average error within each method, the smaller the time window, the higher the value of standard deviation. That means smaller data chunks were generally more precisely predicted. That is visible when analysing the values of minimum error and the 25th and 50th percentiles—they decrease with the decrease in the time window. However, some of the data chunks were extraordinarily difficult to forecast, hence the high values of the maximum error, rising with the decrease in the time window size. It can be concluded that having chosen a smaller time window, one can expect a generally precise forecast, risking rare but high mistakes.
Table 6 presents the results of machine learning-based prediction for the SIX dataset. Comparing to the WASK dataset, the results are outstanding, with the average error being an order of magnitude lower. Similarly to the previously analyzed dataset, MLP achieved lower error values than AWE. Contrary to WASK, there is no clear trend visible in the prediction for different time windows. The lowest average error was obtained for the 6 h window in both methods, with the lowest standard deviation obtained for the 24 h window. However, the standard deviation values for all the time windows are much lower for the SIX dataset when compared to the WASK dataset. That means the prediction error is stable for consecutive data chunks.
Note that machine learning-based prediction outperforms modeling-based prediction for WASK dataset (see
Table 3 vs.
Table 5) regardless of the applied forecasting method (i.e., MLP or AWE). On the contrary, for the SIX dataset, the modeling-based prediction achieves higher efficiency (
Table 4 vs.
Table 6). The results show that none of the prediction approaches is principally better. To obtain high predictions accuracy, the forecasting method should be properly suited to the considered dataset.
The processing time of MLP-based forecasting oscillates around 0.01 seconds while the time of AWE-based forecasting is around 0.1 s (see
Table 5 and
Table 6). It does not vary much between two datasets and different window sizes. Comparing it with the times of the best modeling-based prediction methods (i.e., PSD (1), PSD (all), see
Table 3 and
Table 4), we observe that for WASK, the machine learning-based prediction works faster; however, both methodologies provide fast calculations. In the cast of SIX, MLP runs the fastest, then the modeling-based method, and finally AWE.
Taking into account the prediction accuracy and time of calculations, for the long-term traffic prediction, we recommend the use of a modeling-based approach for SIX (i.e., for more stable and regular traffic) and machine-learning for WASK (i.e., for irregular traffic with a high variability).
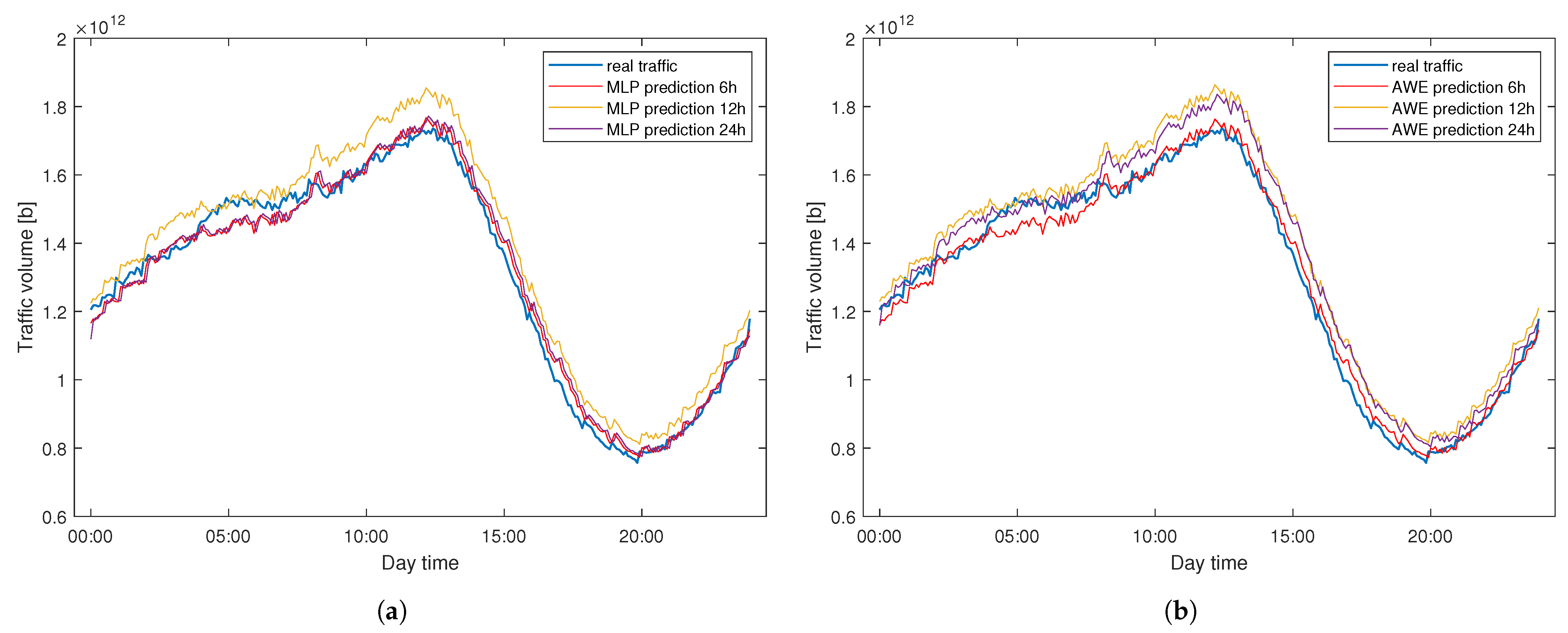
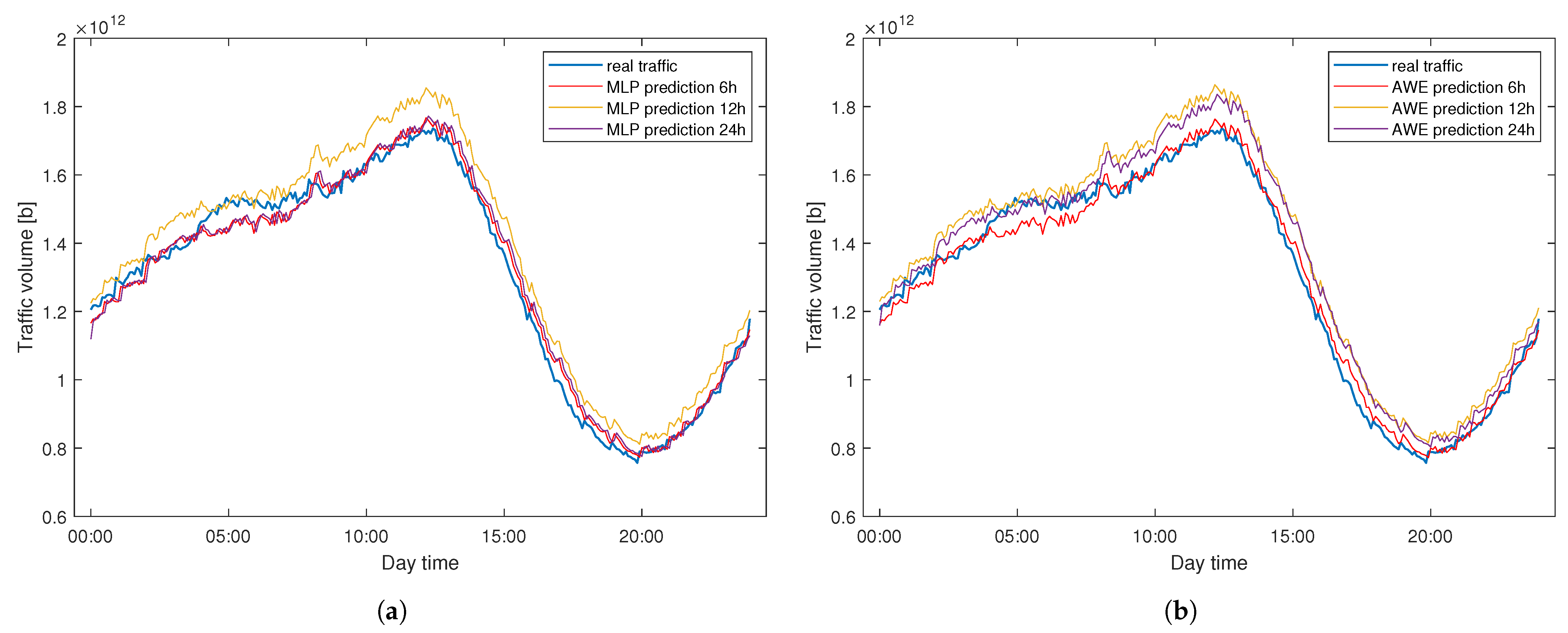
Figure 13 presents the prediction results for the first predicted day in both datasets (2 January 2021) for the 24 h time window. The machine learning models were only trained with one day worth of data at that point. As can be seen, they are able to follow the general pattern and predict the traffic with no substantial mistakes. This proves that the proposed methods do not require previous offline training on large volumes of data, they are ready to use after only one day, even for a difficult dataset like WASK. Interestingly, the predictions made by both models are almost identical in the first day in both datasets. That is due to the fact that in the first predicted chunk of data, the ensemble size in AWE is 1—there is only one estimator trained on the previous portion of data. Since the base estimator for AWE is the MLP regressor itself, the predictions made by both models match almost perfectly and the differences between them are not visible to the naked eye at this point.
Figure 14 presents the predictions made by the same methods but with different time windows in a sample day for the SIX dataset. That means that for the 24 h time window, the one-day forecast is composed of one chunk of data, for the 12 h, two chunks, and four chunks for the 6 h window. Separate lines can be spotted by the naked eye, revealing slight differences in prediction efficiency.
Figure 15 presents the predictions made by the same methods with different time windows in a sample day for the WASK dataset. Similarly to SIX, slight differences are visible.
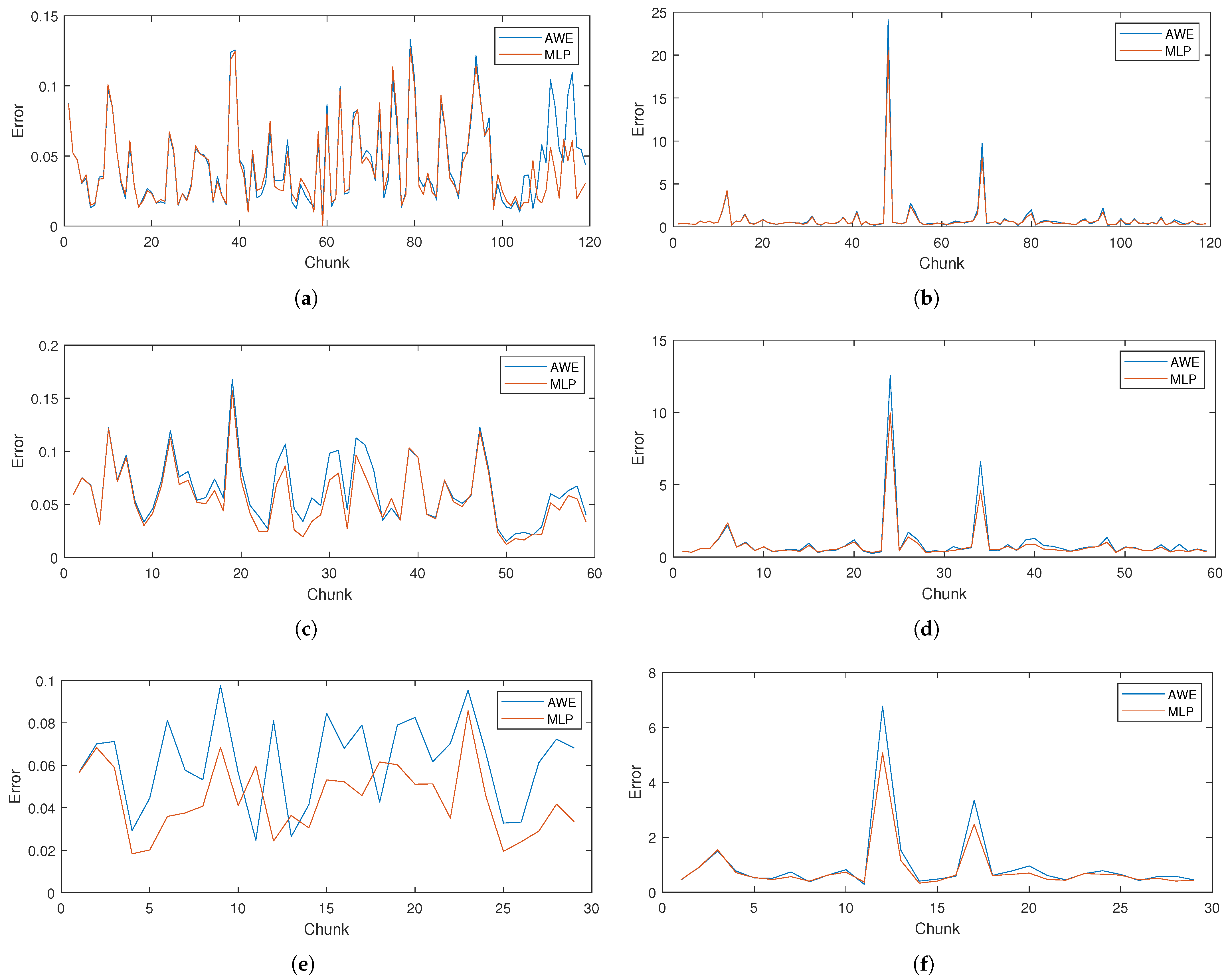
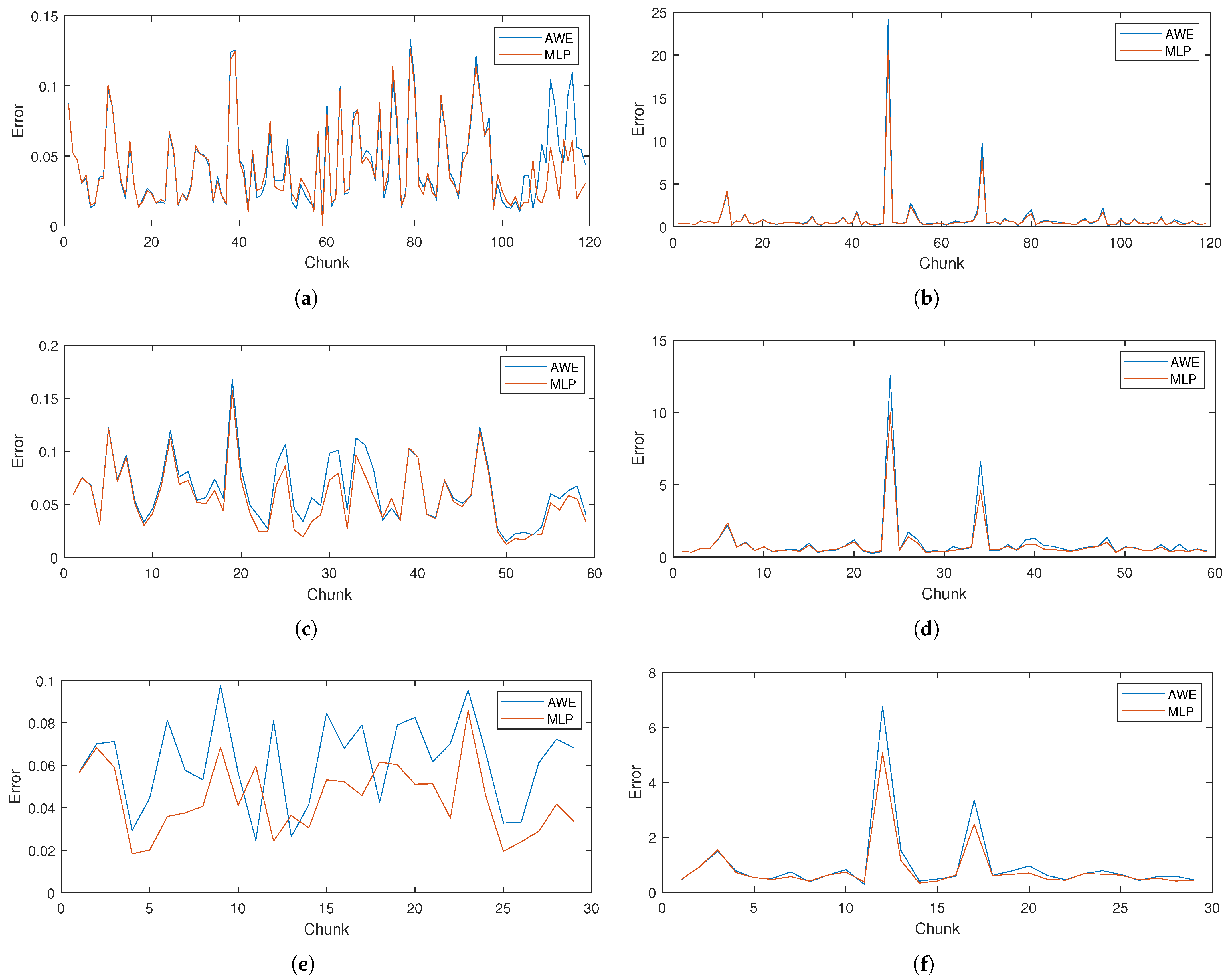
Finally,
Figure 16 presents the error values for consecutive chunks of data for different time windows in both methods for considered datasets. As can be seen, the proposed models are able to react to changes in traffic volume and adapt to current conditions. Moreover, these figures illustrate the span of errors in both datasets. Datapoints exceptionally difficult to predict (with prediction errors much higher than average) are only present in the WASK dataset. The error peaks indicating difficult-to-predict moments in the network traffic time-series are followed by rapid troughs, as models adjust their predictions. The error values are on a stable level for the vast majority of data chunks and both methods follow the same error values patterns. On the other hand, in the SIX dataset, the differences in error patterns between considered methods are much easier to spot. However, their values are generally on a stable level, as pointed out discussing their standard deviations.
6. Conclusions
In this paper, we focused on the efficient modeling and prediction of the daily traffic patterns in the transport telecommunication networks. We used two historical datasets (WASK and SIX), which significantly differ with the characteristics. Since WASK is a completely new dataset, we introduced it and discussed in detail. Then, we proposed modeling and prediction methods. For the modeling, we applied Fourier Transform while for the forecasting we studied two approaches—modeling-based (i.e., PD (1), PD (all), PSD (1), PSD (all)) and machine learning-based (i.e., MLP and AWE).
We evaluated the efficiency of the proposed methods by means of extensive simulations. In the traffic modeling, we achieved the outstanding results of an average error of less than 0.1% in SIX and 6.31% in WASK. In the case of traffic prediction, the modeling-based approach was better for SIX while machine learning-based performed superior for WASK dataset. The average prediction error for SIX was 3.22% (for the best method) while the forecasting for WASK revealed a much more complex nature.
In future work, we are going to further explore WASK dataset by gathering more data and verifying existence of patterns between different months. We plan to use the datasets and proposed models to support network optimization.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}