
Analyzing and Visualizing Deep Neural Networks for Speech Recognition with Saliency-Adjusted Neuron Activation Profiles


Abstract
1. Introduction
2. Related Work
2.1. ASR Using Convolutional Neural Networks
2.2. Model Introspection
2.2.1. Feature Visualization
2.2.2. Saliency Maps
2.2.3. Analyzing Data Set Representations
3. Method
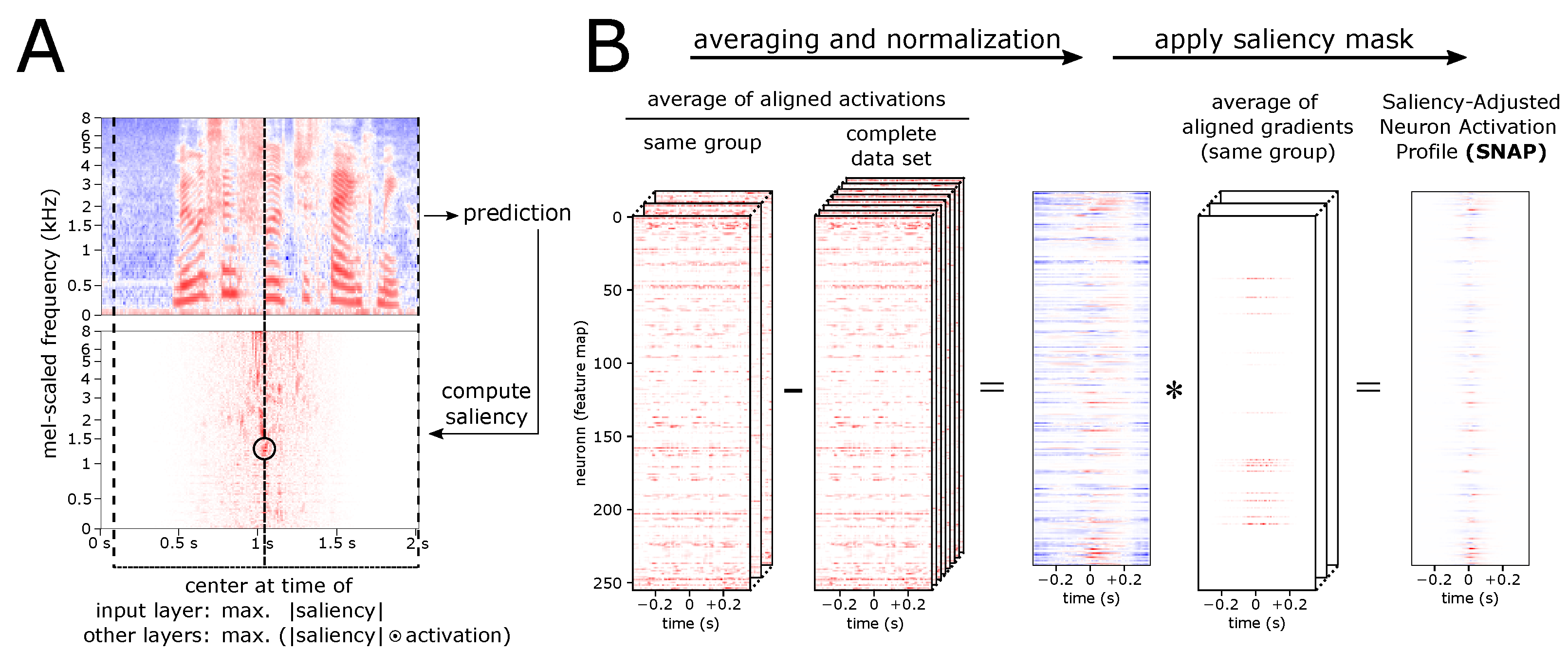
3.1. Normalized Averaging of Aligned Inputs (NAvAI)
3.2. Neuron Activation Profile (NAPs)
3.3. Saliency-Adjusted Neuron Activation Profile (SNAPs)
4. Experimental Setup
4.1. Data
4.2. Model
Model Variations
4.3. Evaluation
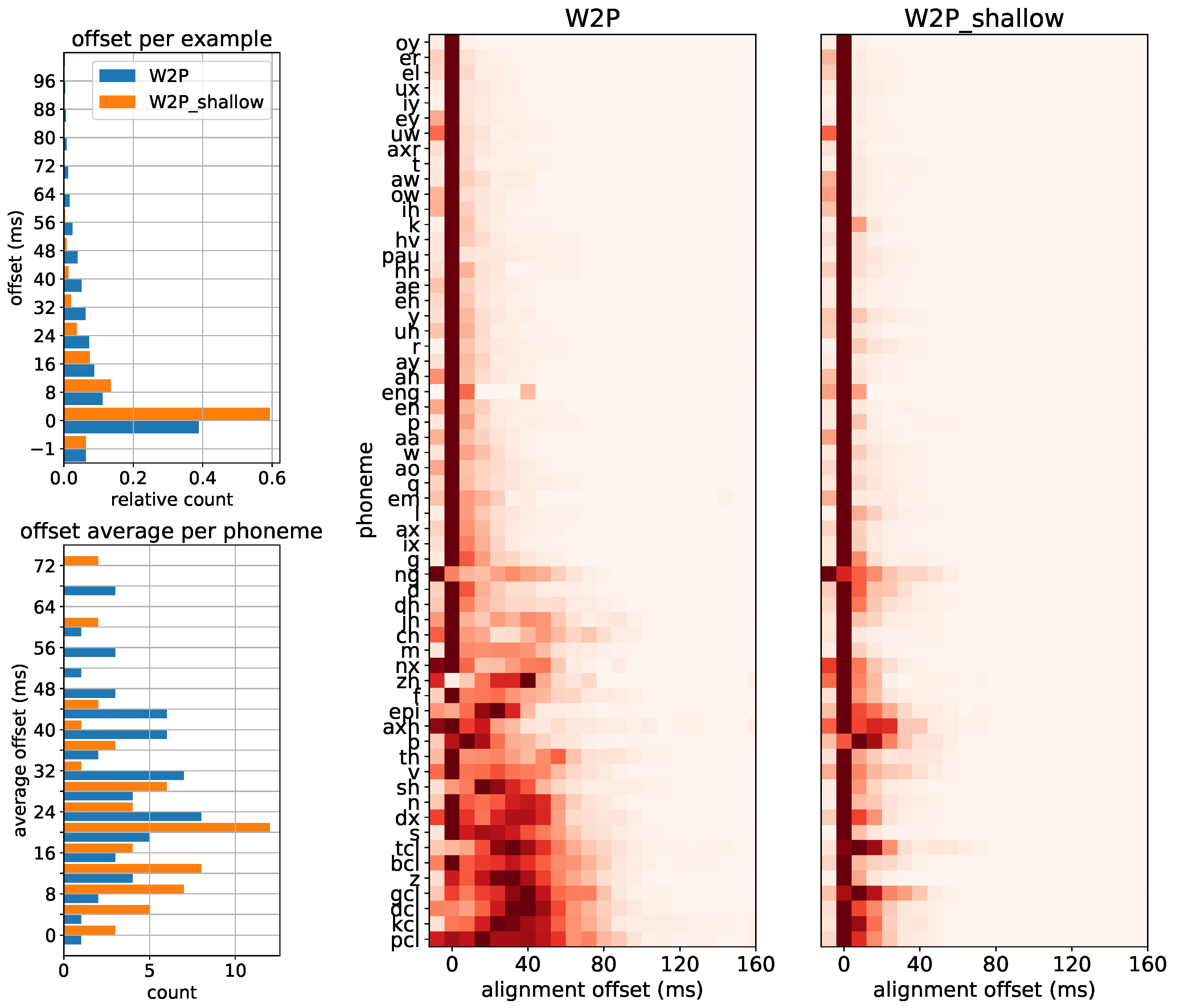
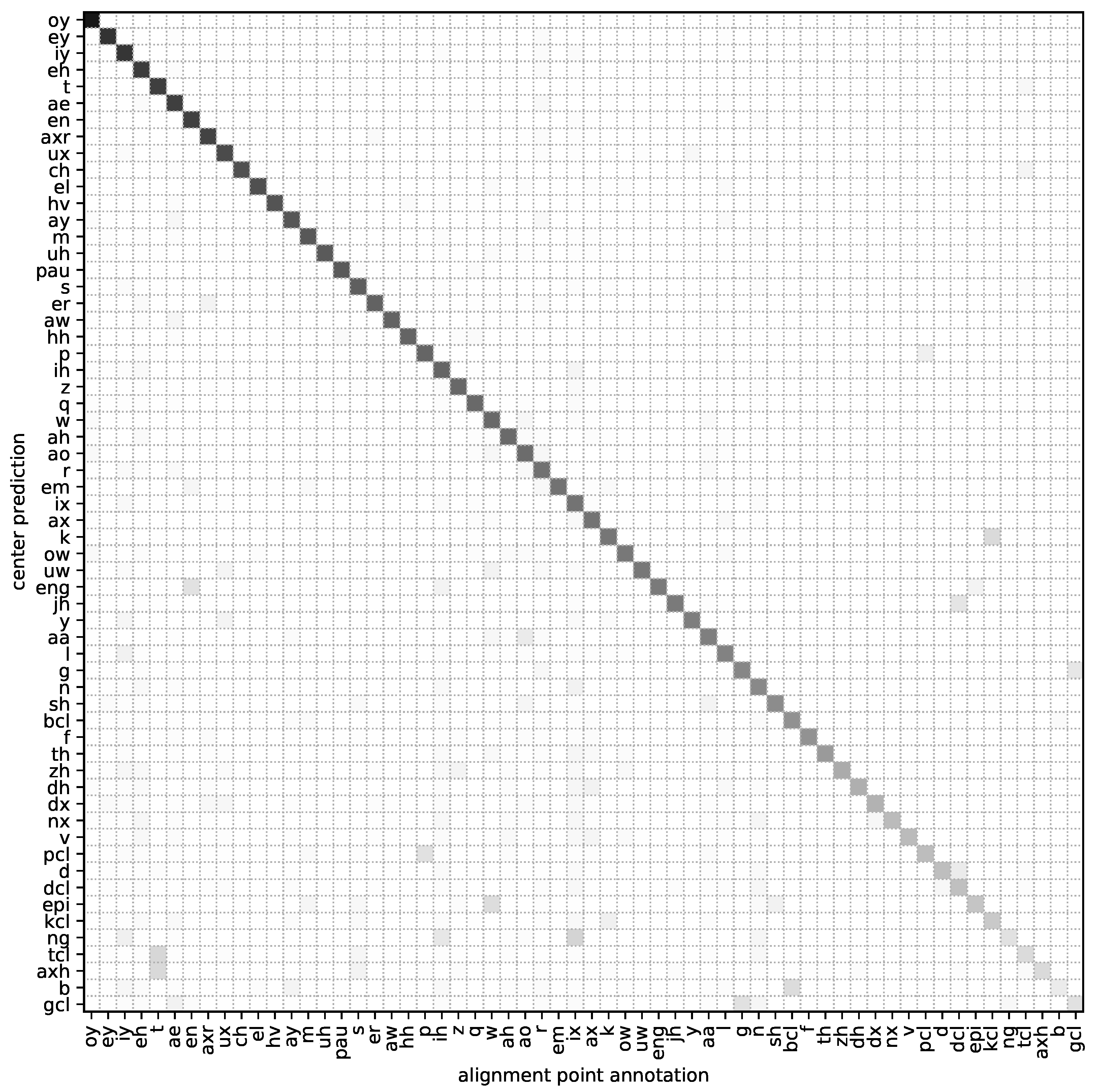
4.3.1. Evaluating the Alignment Step
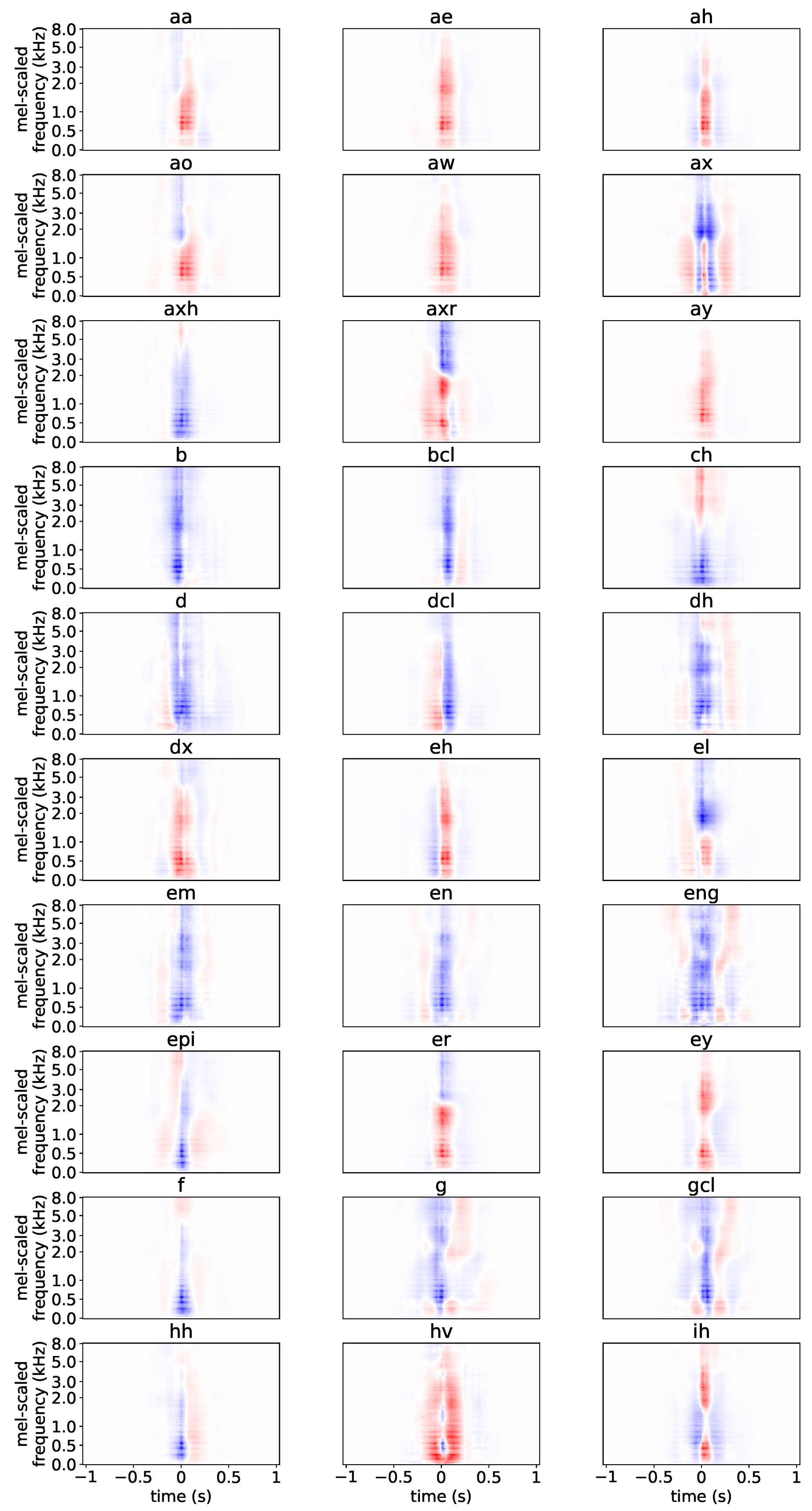
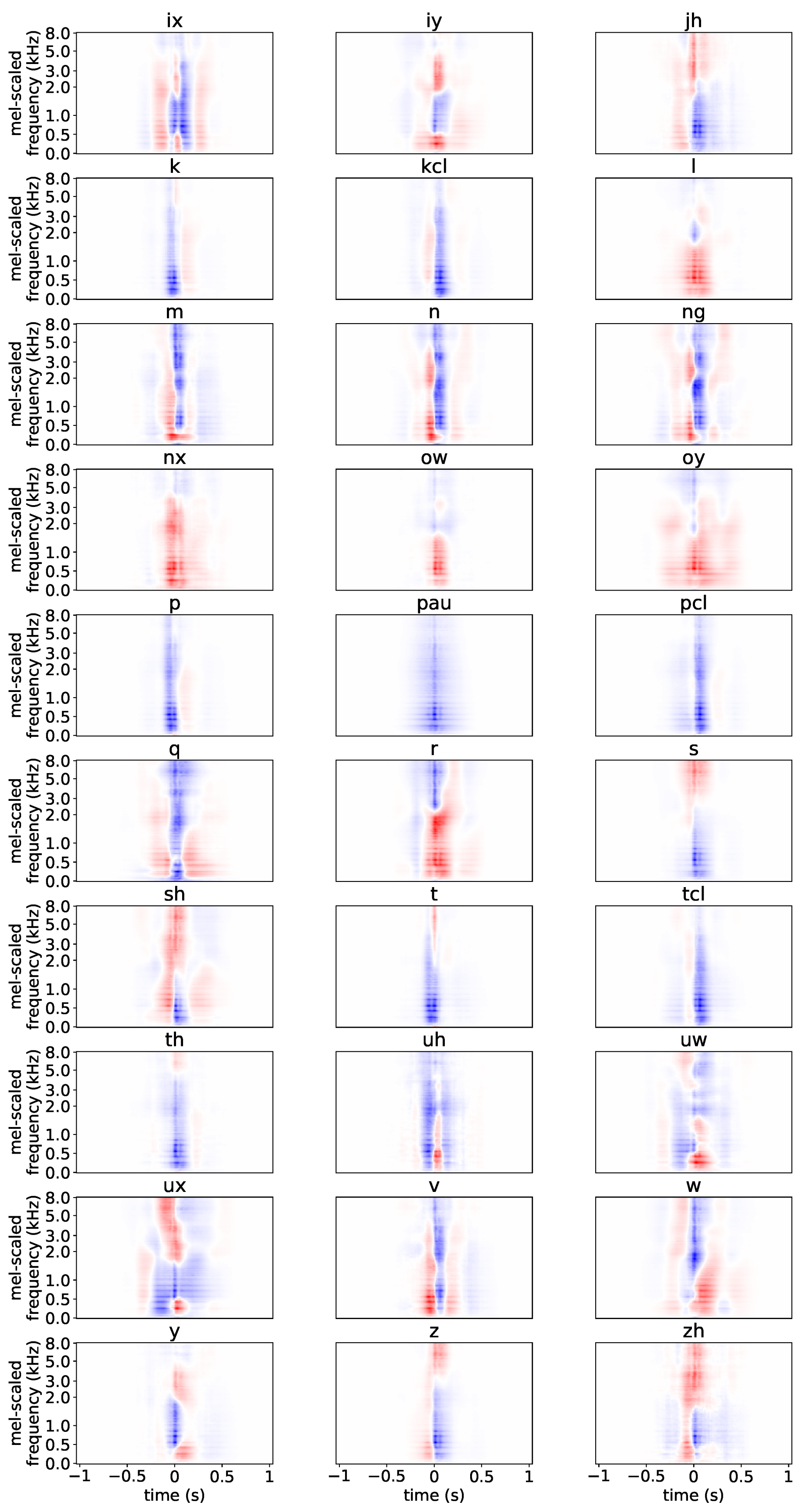
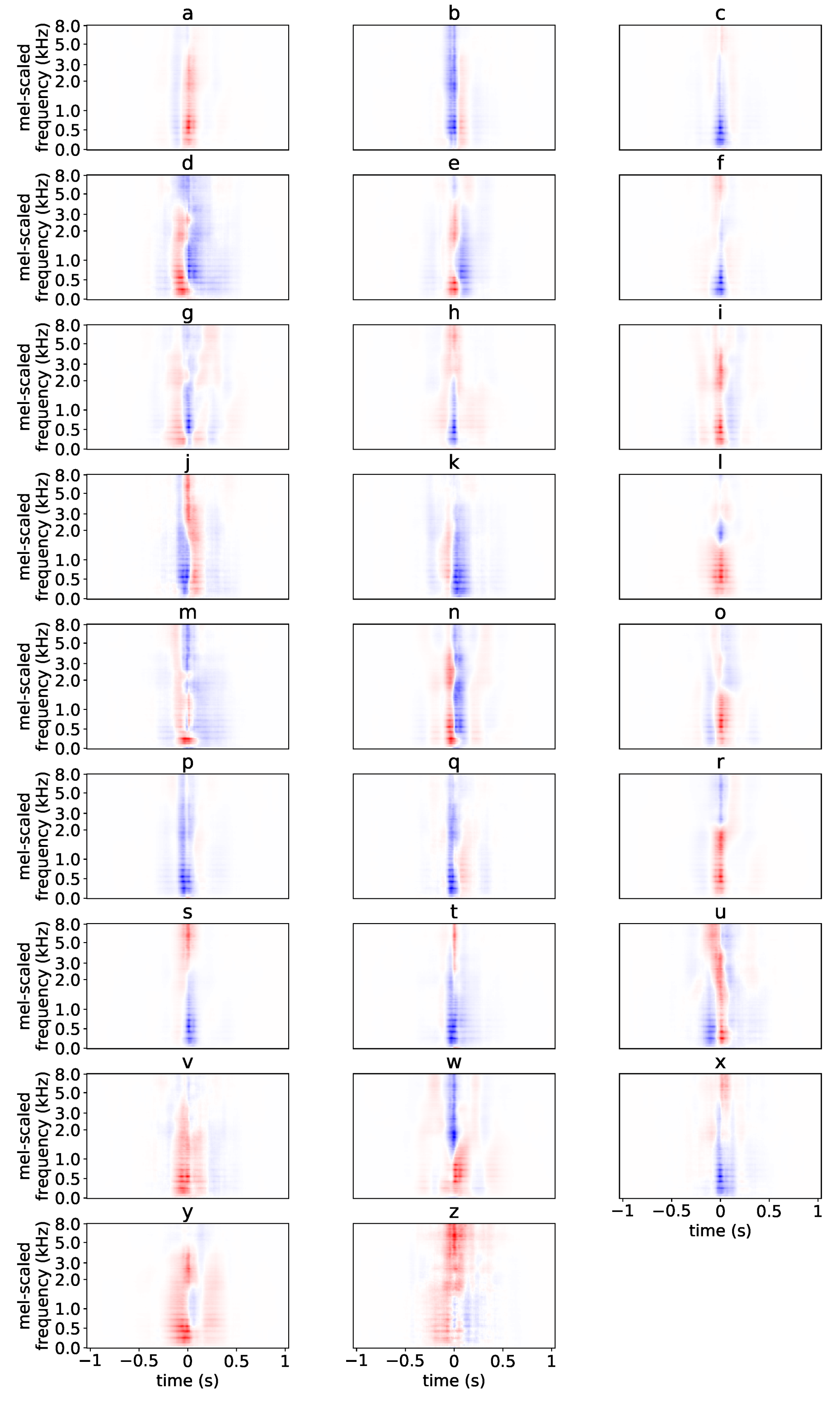
4.3.2. Plotting SNAPs
4.3.3. Representation Power of Layers for Different Groups
5. Results
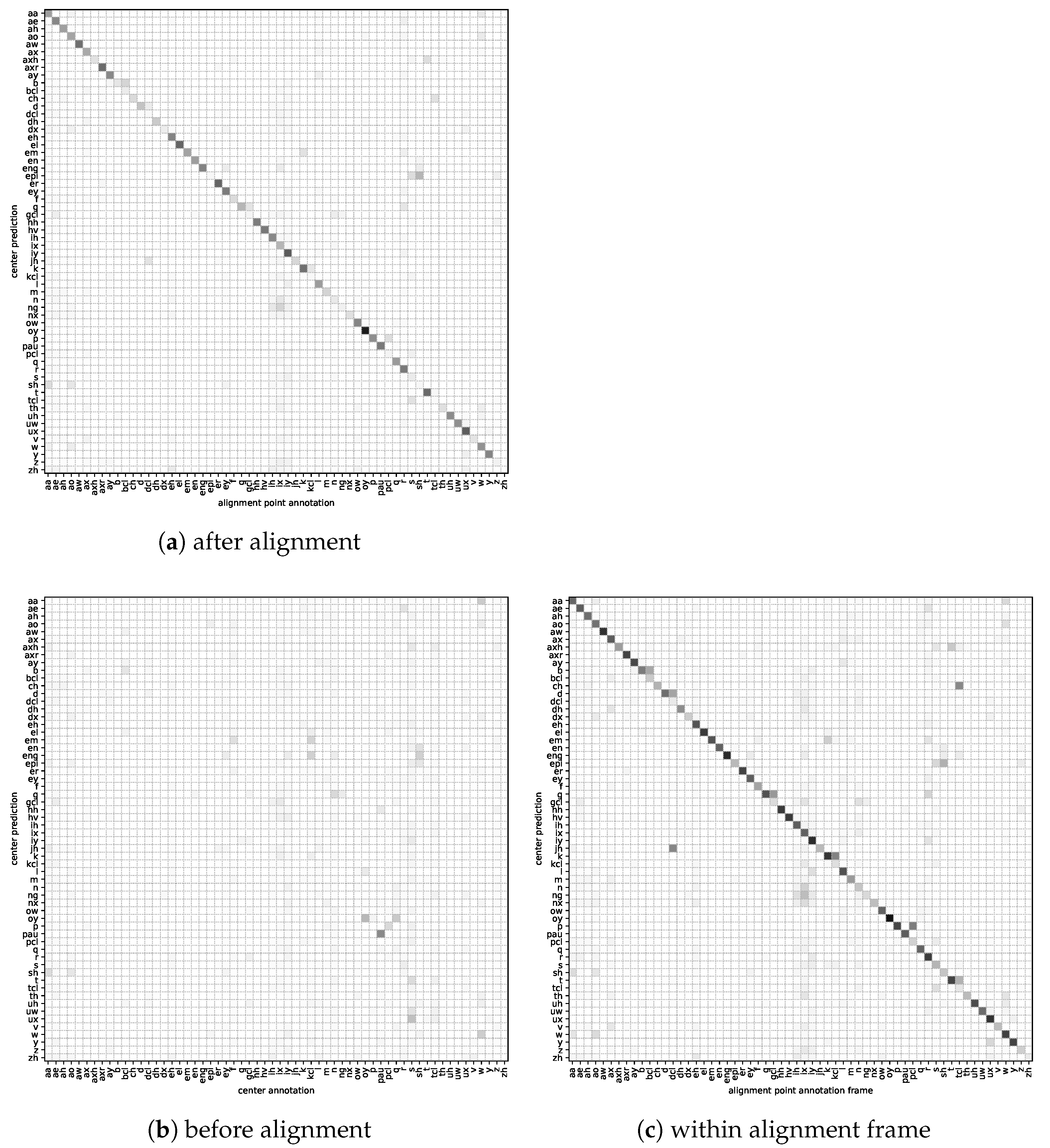
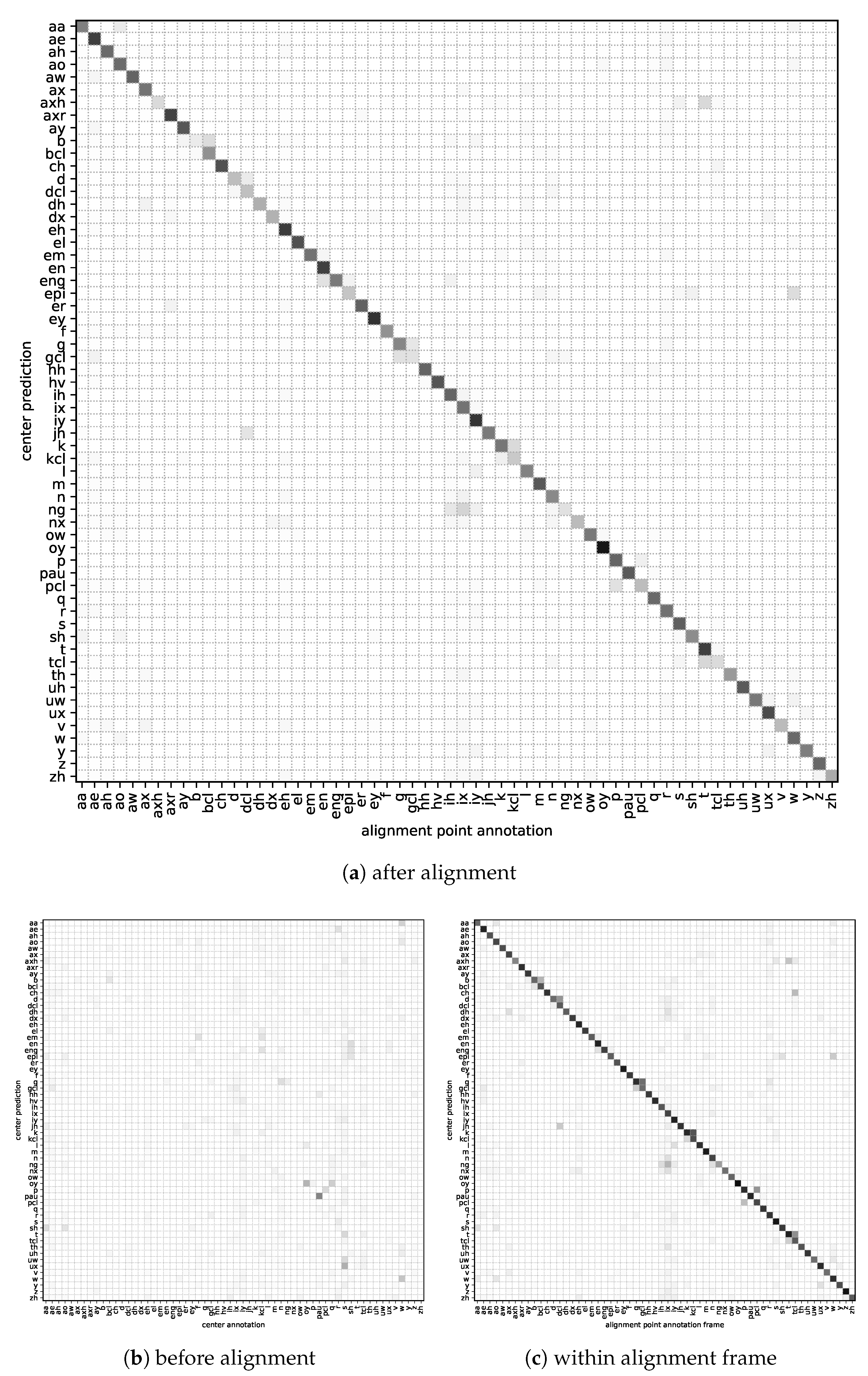
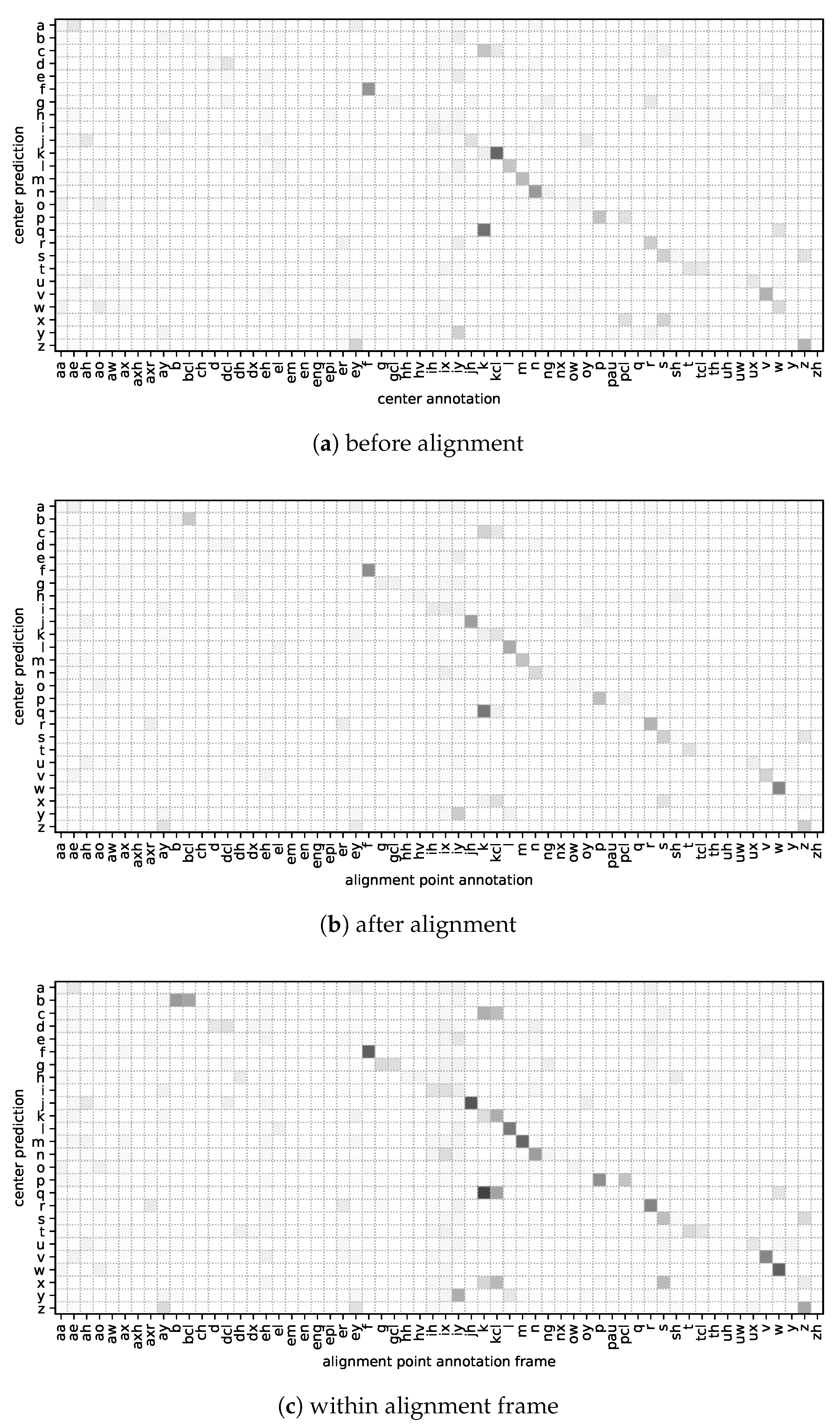
5.1. Alignment Evaluation
5.1.1. Alignment Quality—Model Average
5.1.2. Alignment Quality—Per Phoneme
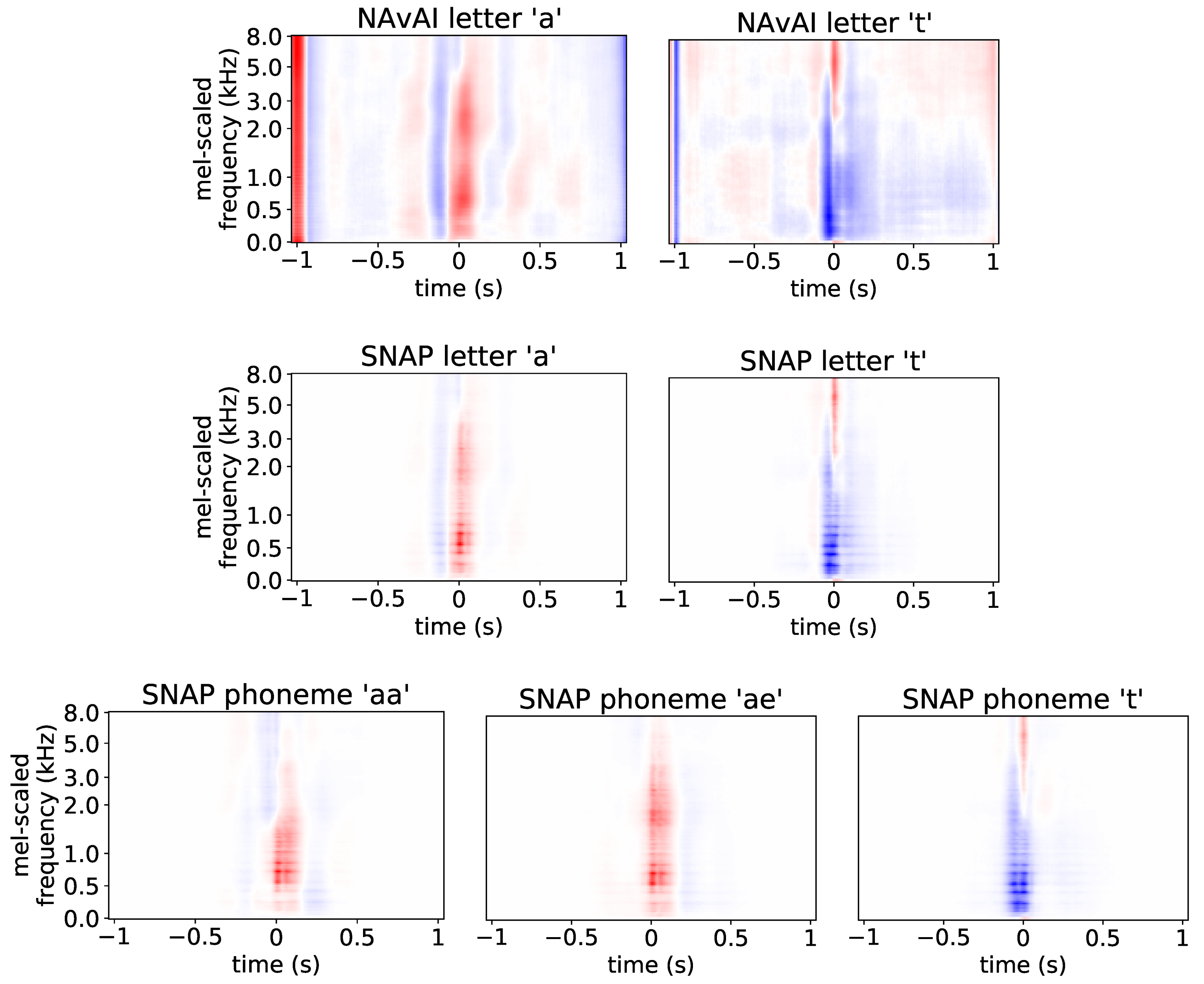
5.1.3. Applicability to Letter Prediction Models
5.2. Per-Layer SNAPs
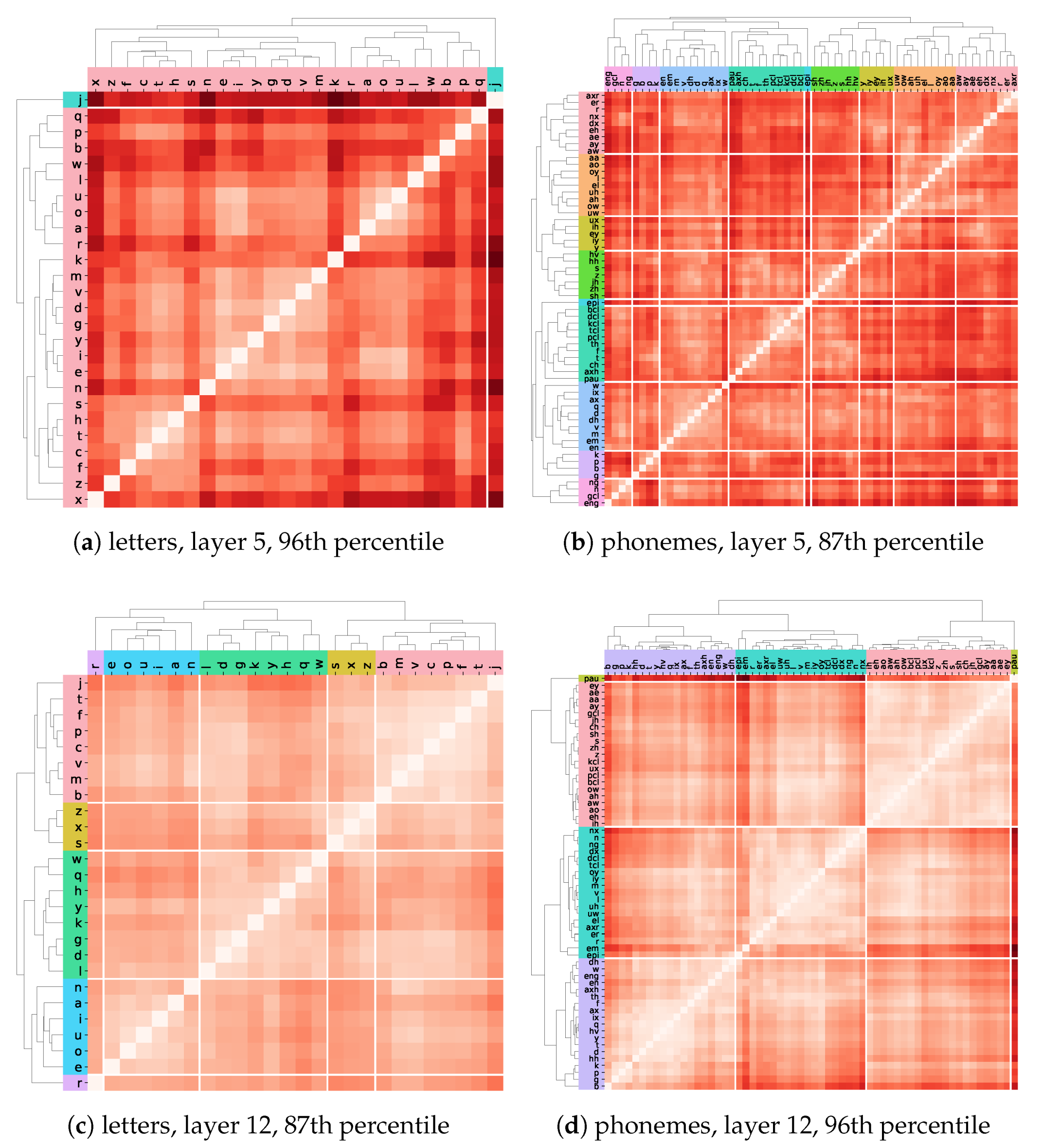
5.3. Evaluation of the Representational Similarity
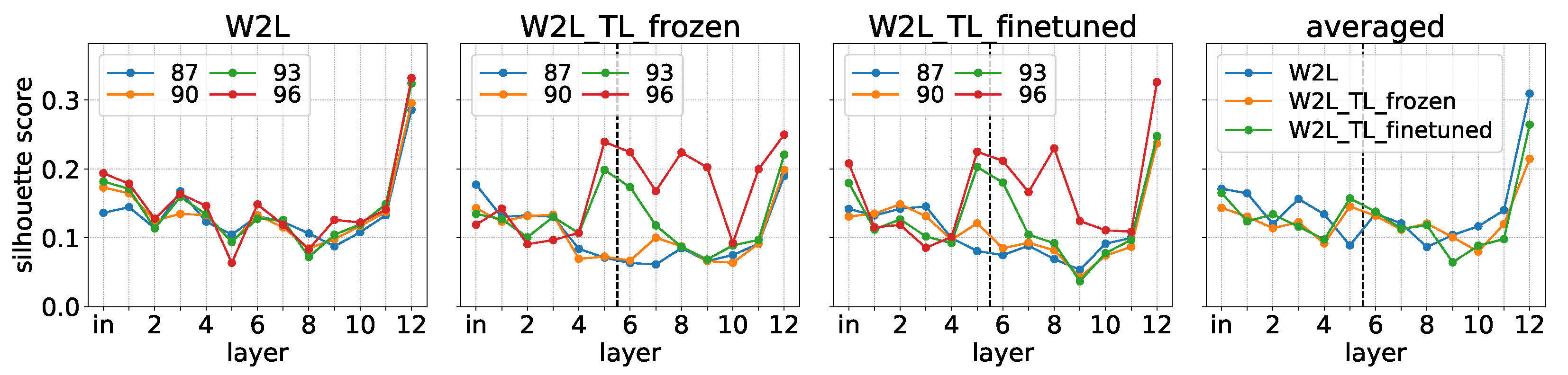
5.3.1. Silhouette Scores
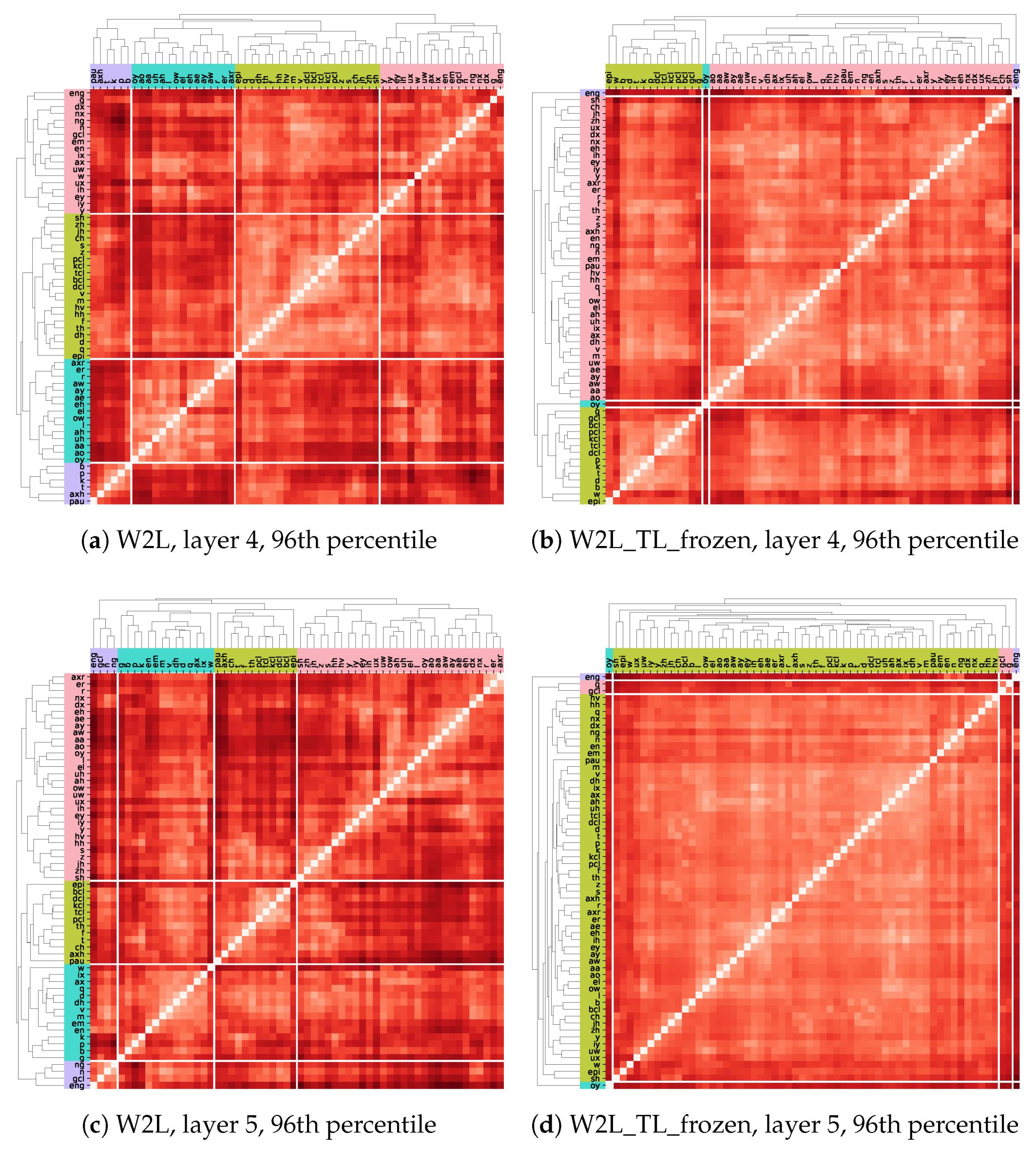
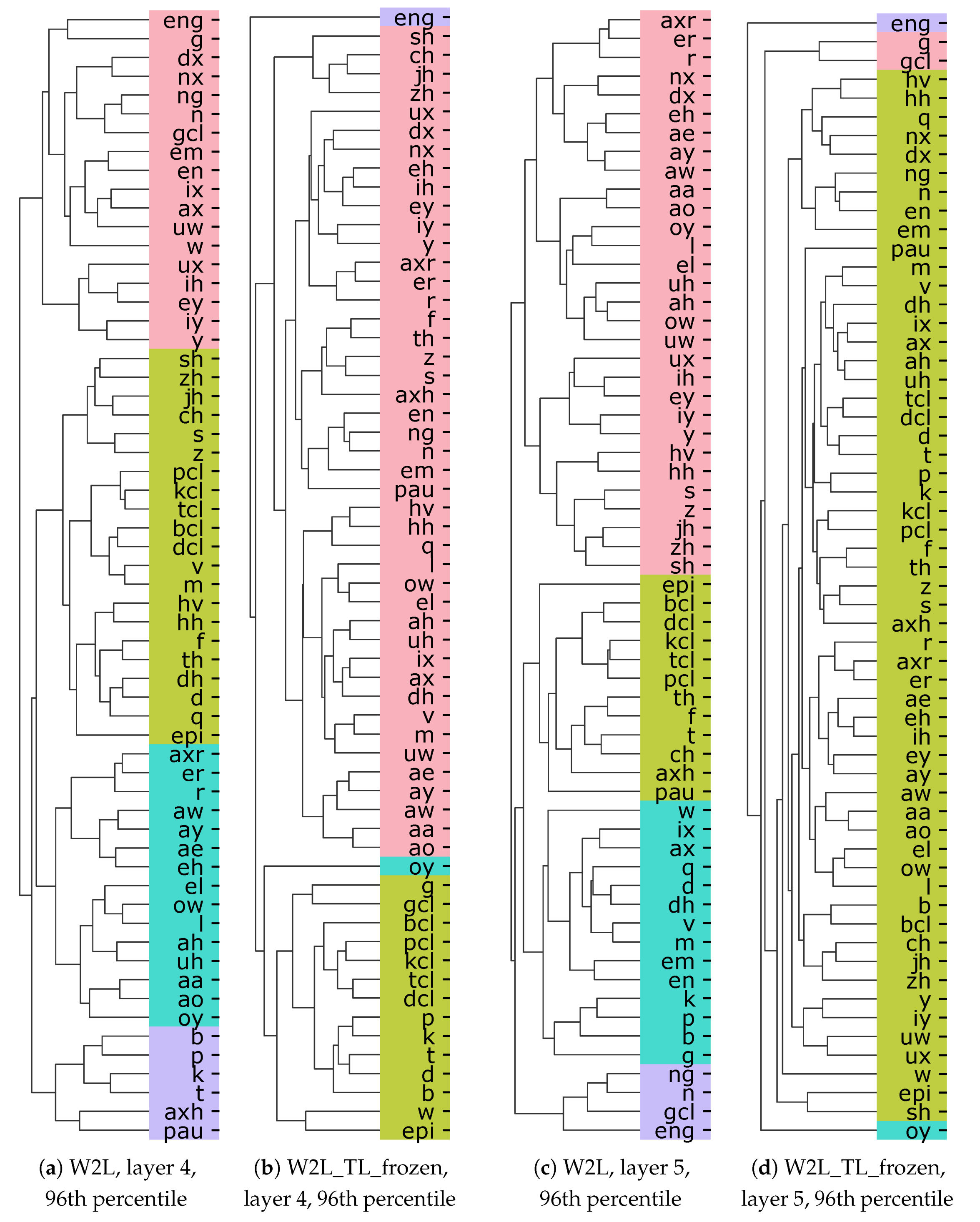
5.3.2. Emerged Clusters
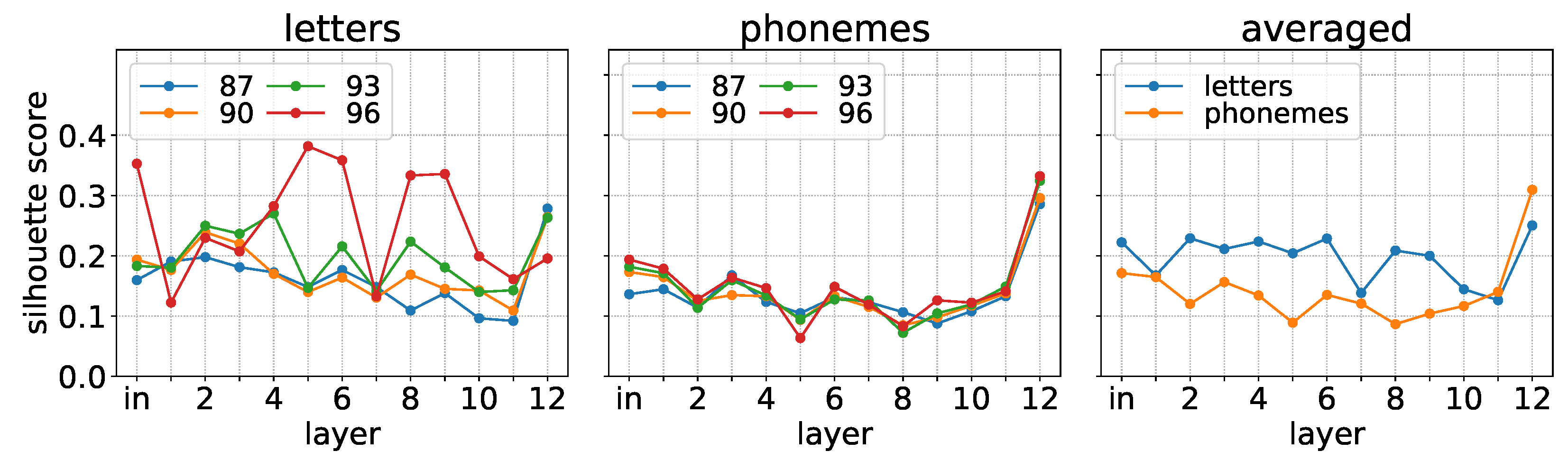
5.4. Comparing Letter and Phoneme Representations in W2L
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A






References
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Yosinski, J.; Clune, J.; Nguyen, A.; Fuchs, T.; Lipson, H. Understanding Neural Networks Through Deep Visualization. arXiv 2015, arXiv:1506.06579. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations From Deep Networks via Gradient-Based Localization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Krug, A.; Stober, S. Adaptation of the Event-Related Potential Technique for Analyzing Artificial Neural Networks. In Proceedings of the Cognitive Computational Neuroscience (CCN), New York, NY, USA, 6–8 September 2017. [Google Scholar]
- Makeig, S.; Onton, J. ERP features and EEG dynamics: An ICA perspective. In Oxford Handbook of Event-Related Potential Components; Oxford University Press: Oxford, UK, 2011; pp. 51–87. [Google Scholar]
- Luck, S.J. An Introduction to the Event-Related Potential Technique. Monogr. Soc. Res. Child Dev. 2005, 78, 388. [Google Scholar]
- Krug, A.; Stober, S. Introspection for Convolutional Automatic Speech Recognition. In Proceedings of the EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, Brussels, Belgium, 31 October–4 November 2018; pp. 187–199. [Google Scholar]
- Krug, A.; Knaebel, R.; Stober, S. Neuron Activation Profiles for Interpreting Convolutional Speech Recognition Models. In Proceedings of the NeurIPS Workshop IRASL: Interpretability and Robustness for Audio, Speech, and Language, Montréal, QC, Canada, 2–8 December 2018. [Google Scholar]
- Gollapudi, S. Practical Machine Learning; Packt Publishing Ltd.: Birmingham, UK, 2016. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A.; Bengio, Y. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Volume 1. [Google Scholar]
- Dargan, S.; Kumar, M.; Ayyagari, M.R.; Kumar, G. A survey of deep learning and its applications: A new paradigm to machine learning. Arch. Comput. Methods Eng. 2019, 27, 1071–1092. [Google Scholar] [CrossRef]
- Kiranyaz, S.; Avci, O.; Abdeljaber, O.; Ince, T.; Gabbouj, M.; Inman, D.J. 1D convolutional neural networks and applications: A survey. Mech. Syst. Signal Process. 2021, 151, 107398. [Google Scholar] [CrossRef]
- Kiranyaz, S.; Ince, T.; Abdeljaber, O.; Avci, O.; Gabbouj, M. 1-D Convolutional Neural Networks for Signal Processing Applications. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 8360–8364. [Google Scholar]
- Kriman, S.; Beliaev, S.; Ginsburg, B.; Huang, J.; Kuchaiev, O.; Lavrukhin, V.; Leary, R.; Li, J.; Zhang, Y. Quartznet: Deep Automatic Speech Recognition with 1D Time-Channel Separable Convolutions. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6124–6128. [Google Scholar]
- Smith, J.O., III. Spectral Audio Signal Processing; W3K Publishing: Stanford, CA, USA, 2011. [Google Scholar]
- Khan, M.A.; Kim, J. Toward Developing Efficient Conv-AE-Based Intrusion Detection System Using Heterogeneous Dataset. Electronics 2020, 9, 1771. [Google Scholar] [CrossRef]
- Chen, G.; Na, X.; Wang, Y.; Yan, Z.; Zhang, J.; Ma, S.; Wang, Y. Data Augmentation For Children’s Speech Recognition—The “Ethiopian” System For The SLT 2021 Children Speech Recognition Challenge. arXiv 2020, arXiv:2011.04547. [Google Scholar]
- Abdel-Hamid, O.; Mohamed, A.R.; Jiang, H.; Deng, L.; Penn, G.; Yu, D. Convolutional neural networks for speech recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 1533–1545. [Google Scholar] [CrossRef]
- Senior, A.; Heigold, G.; Ranzato, M.; Yang, K. An empirical study of learning rates in deep neural networks for speech recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013; pp. 6724–6728. [Google Scholar]
- Trigeorgis, G.; Ringeval, F.; Brueckner, R.; Marchi, E.; Nicolaou, M.A.; Schuller, B.; Zafeiriou, S. Adieu features? End-to-end speech emotion recognition using a deep convolutional recurrent network. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 5200–5204. [Google Scholar]
- Cummins, N.; Amiriparian, S.; Hagerer, G.; Batliner, A.; Steidl, S.; Schuller, B.W. An Image-based Deep Spectrum Feature Representation for the Recognition of Emotional Speech. ACM Int. Conf. Multimed. 2017, 478–484. [Google Scholar] [CrossRef]
- Badshah, A.M.; Ahmad, J.; Rahim, N.; Baik, S.W. Speech Emotion Recognition from Spectrograms with Deep Convolutional Neural Network. In Proceedings of the IEEE International Conference on Platform Technology and Service (PlatCon), Busan, Korea, 13–15 February 2017; pp. 1–5. [Google Scholar]
- Bach, S.; Binder, A.; Montavon, G.; Klauschen, F.; Müller, K.R.; Samek, W. On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation. PLoS ONE 2015, 10, e0130140. [Google Scholar] [CrossRef]
- Osindero, S.; Hinton, G.E. Modeling image patches with a directed hierarchy of Markov random fields. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Vancouver, BC, Canada, 8–11 December 2008; pp. 1121–1128. [Google Scholar]
- Erhan, D.; Bengio, Y.; Courville, A.; Vincent, P. Visualizing higher-layer features of a deep network. Univ. Montr. 2009, 1341, 1. [Google Scholar]
- Mordvintsev, A.; Olah, C.; Tyka, M. Inceptionism: Going deeper into neural networks. Google Res. Blog. Retrieved June 2015, 20, 5. [Google Scholar]
- Krug, A.; Stober, S. Visualizing Deep Neural Networks for Speech Recognition with Learned Topographic Filter Maps. arXiv 2019, arXiv:1912.04067. [Google Scholar]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv 2013, arXiv:1312.6034. [Google Scholar]
- Springenberg, J.T.; Dosovitskiy, A.; Brox, T.; Riedmiller, M. Striving for simplicity: The all convolutional net. arXiv 2014, arXiv:1412.6806. [Google Scholar]
- Kindermans, P.J.; Schütt, K.T.; Alber, M.; Müller, K.R.; Erhan, D.; Kim, B.; Dähne, S. Learning how to explain neural networks: PatternNet and PatternAttribution. In Proceedings of the International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Schulz, K.; Sixt, L.; Tombari, F.; Landgraf, T. Restricting the Flow: Information Bottlenecks for Attribution. In Proceedings of the International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Becker, S.; Ackermann, M.; Lapuschkin, S.; Müller, K.R.; Samek, W. Interpreting and explaining deep neural networks for classification of audio signals. arXiv 2018, arXiv:1807.03418. [Google Scholar]
- Thuillier, E.; Gamper, H.; Tashev, I.J. Spatial audio feature discovery with convolutional neural networks. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 6797–6801. [Google Scholar]
- Perotin, L.; Serizel, R.; Vincent, E.; Guérin, A. CRNN-based multiple DoA estimation using acoustic intensity features for Ambisonics recordings. IEEE J. Sel. Top. Signal Process. 2019, 13, 22–33. [Google Scholar] [CrossRef]
- Adebayo, J.; Gilmer, J.; Muelly, M.; Goodfellow, I.; Hardt, M.; Kim, B. Sanity checks for saliency maps. In Proceedings of the 32nd Conference on Neural Information Processing Systems (NeurIPS), Montréal, QC, Canada, 2–8 December 2018; pp. 9525–9536. [Google Scholar]
- Nie, W.; Zhang, Y.; Patel, A. A theoretical explanation for perplexing behaviors of backpropagation-based visualizations. In Proceedings of the International Conference on Machine Learning (ICML), Stockholm, Sweden, 10–15 July 2018; pp. 3809–3818. [Google Scholar]
- Sixt, L.; Granz, M.; Landgraf, T. When Explanations Lie: Why Many Modified BP Attributions Fail. International Conference on Machine Learning (ICML). In Proceedings of the International Conference on Machine Learning (ICML), Vienna, Austria, 12–18 July 2020; pp. 9046–9057. [Google Scholar]
- Alain, G.; Bengio, Y. Understanding intermediate layers using linear classifier probes. In Proceedings of the International Conference on Learning Representations (ICLR), Workshop Track Proceedings, Toulon, France, 24–26 April 2017. [Google Scholar]
- Kim, B.; Wattenberg, M.; Gilmer, J.; Cai, C.; Wexler, J.; Viegas, F.; Sayres, R. Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (TCAV). In Proceedings of the International Conference on Machine Learning (ICML), Stockholm, Sweden, 10–15 July 2018; pp. 2668–2677. [Google Scholar]
- Fiacco, J.; Choudhary, S.; Rose, C. Deep neural model inspection and comparison via functional neuron pathways. In Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL), Florence, Italy, 28 July–2 August 2019; pp. 5754–5764. [Google Scholar]
- Morcos, A.S.; Raghu, M.; Bengio, S. Insights on representational similarity in neural networks with canonical correlation. arXiv 2018, arXiv:1806.05759. [Google Scholar]
- Nagamine, T.; Seltzer, M.L.; Mesgarani, N. Exploring how deep neural networks form phonemic categories. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association (Interspeech), Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Nagamine, T.; Mesgarani, N. Understanding the representation and computation of multilayer perceptrons: A case study in speech recognition. In Proceedings of the International Conference on Machine Learning (ICML), Sydney, Australia, 6–11 August 2017; pp. 2564–2573. [Google Scholar]
- Goodfellow, I.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An ASR corpus based on public domain audio books. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QLD, Australia, 19–24 April 2015; pp. 5206–5210. [Google Scholar]
- Garofolo, J.S.; Lamel, L.F.; Fisher, W.M.; Fiscus, J.G.; Pallett, D.S. DARPA TIMIT acoustic-phonetic continous speech corpus CD-ROM. NIST speech disc 1-1.1. NASA STI/Recon Tech. Rep. 1993, 93, 27403. [Google Scholar]
- McFee, B.; Raffel, C.; Liang, D.; Ellis, D.P.; McVicar, M.; Battenberg, E.; Nieto, O. librosa: Audio and Music Signal Analysis in Python. In Proceedings of the 14th Python in Science Conference, Austin, TX, USA, 6–12 July 2015; Volume 8, pp. 18–25. [Google Scholar]
- Collobert, R.; Puhrsch, C.; Synnaeve, G. Wav2Letter: An End-to-End ConvNet-based Speech Recognition System. arXiv 2016, arXiv:1609.03193. [Google Scholar]
- Rao, K.; Peng, F.; Sak, H.; Beaufays, F. Grapheme-to-phoneme conversion using Long Short-Term Memory recurrent neural networks. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QLD, Australia, 19–24 April 2015; pp. 4225–4229. [Google Scholar]
- Hughes, C.J. Single-Instruction Multiple-Data Execution. Synth. Lect. Comput. Archit. 2015, 10, 1–121. [Google Scholar] [CrossRef]
- Murtagh, F.; Contreras, P. Algorithms for hierarchical clustering: An overview. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2012, 2, 86–97. [Google Scholar] [CrossRef]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Name | Layer | #Convolution Filters | Kernel Size | Stride |
|---|---|---|---|---|
| 1 | 256 | 48 | 2 | |
| W2L | 2–9 | 256 | 7 | 1 |
| W2L_TL_frozen | 10 | 2048 | 32 | 1 |
| W2L_TL_finetuned | 11 | 2048 | 1 | 1 |
| (output) 12 | 29 | 1 | 1 | |
| W2P | 1 | 256 | 48 | 2 |
| 2–9 | 256 | 7 | 1 | |
| 10 | 2048 | 32 | 1 | |
| 11 | 2048 | 1 | 1 | |
| (output) 12 | 62 | 1 | 1 | |
| 1 | 256 | 48 | 2 | |
| W2P_shallow | 2–5 | 256 | 7 | 1 |
| (output) 6 | 62 | 1 | 1 |
| Model Name | #Layers | Output Type | Initializing Weights Using Model | Used in Experiments |
|---|---|---|---|---|
| W2L | 12 | letters | none | PS, RS, LP |
| W2P | 12 | phonemes | none | AE |
| W2P_shallow | 6 | phonemes | none | AE |
| W2L_TL_frozen | 12 | letters | W2P_shallow | RS |
| W2L_TL_finetuned | 12 | letters | W2L_TL_frozen | RS |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Krug, A.; Ebrahimzadeh, M.; Alemann, J.; Johannsmeier, J.; Stober, S. Analyzing and Visualizing Deep Neural Networks for Speech Recognition with Saliency-Adjusted Neuron Activation Profiles. Electronics 2021, 10, 1350. https://doi.org/10.3390/electronics10111350
Krug A, Ebrahimzadeh M, Alemann J, Johannsmeier J, Stober S. Analyzing and Visualizing Deep Neural Networks for Speech Recognition with Saliency-Adjusted Neuron Activation Profiles. Electronics. 2021; 10(11):1350. https://doi.org/10.3390/electronics10111350
Chicago/Turabian StyleKrug, Andreas, Maral Ebrahimzadeh, Jost Alemann, Jens Johannsmeier, and Sebastian Stober. 2021. "Analyzing and Visualizing Deep Neural Networks for Speech Recognition with Saliency-Adjusted Neuron Activation Profiles" Electronics 10, no. 11: 1350. https://doi.org/10.3390/electronics10111350
APA StyleKrug, A., Ebrahimzadeh, M., Alemann, J., Johannsmeier, J., & Stober, S. (2021). Analyzing and Visualizing Deep Neural Networks for Speech Recognition with Saliency-Adjusted Neuron Activation Profiles. Electronics, 10(11), 1350. https://doi.org/10.3390/electronics10111350