
Strong-Weak Feature Alignment for 3D Object Detection

Abstract
:1. Introduction
2. Related Work
2.1. 3D Object Detection
2.2. Domain Adaptation for Object Detection
3. Method
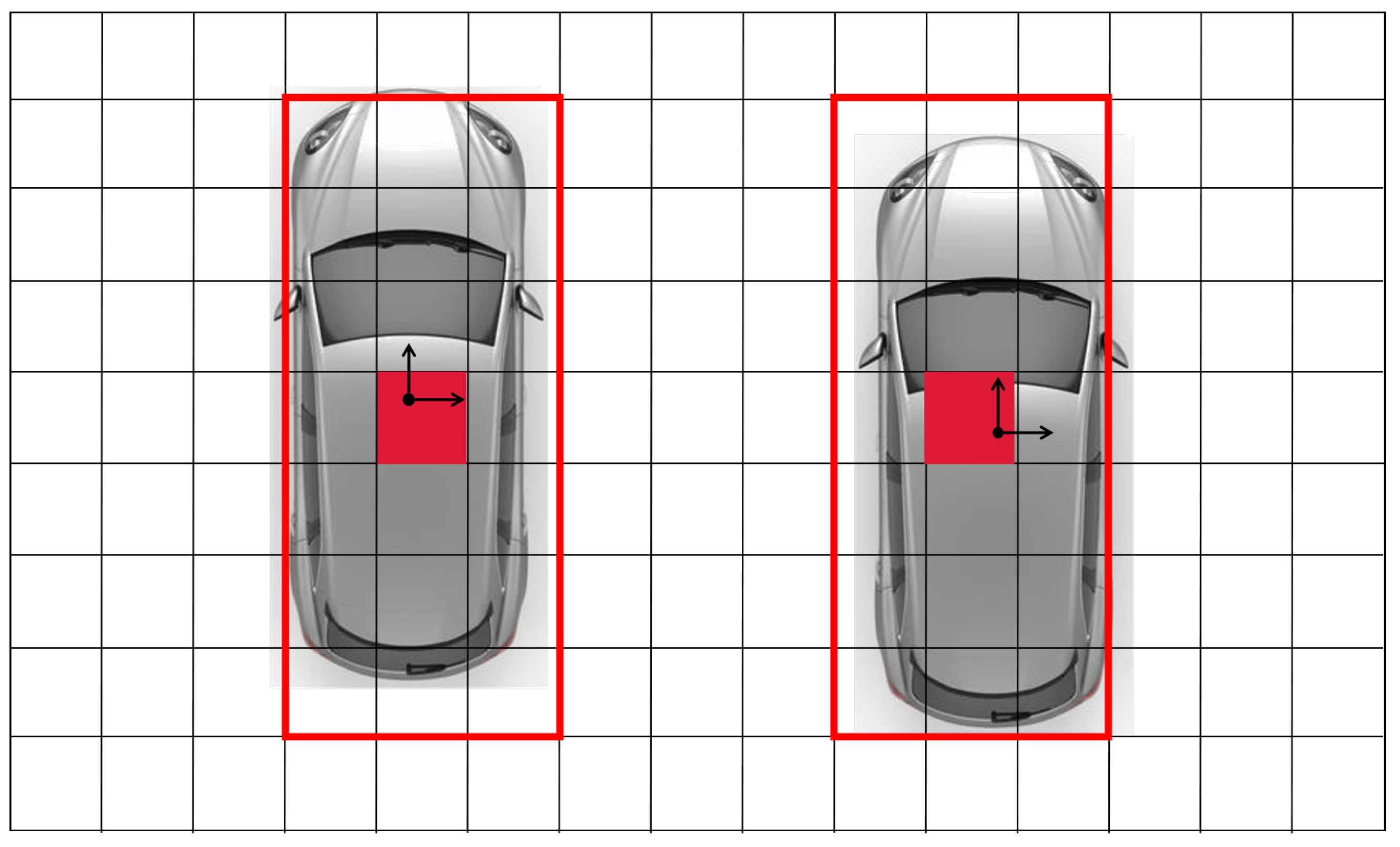
3.1. Complete Object Feature Extractor
3.2. Incomplete Object Feature Generator
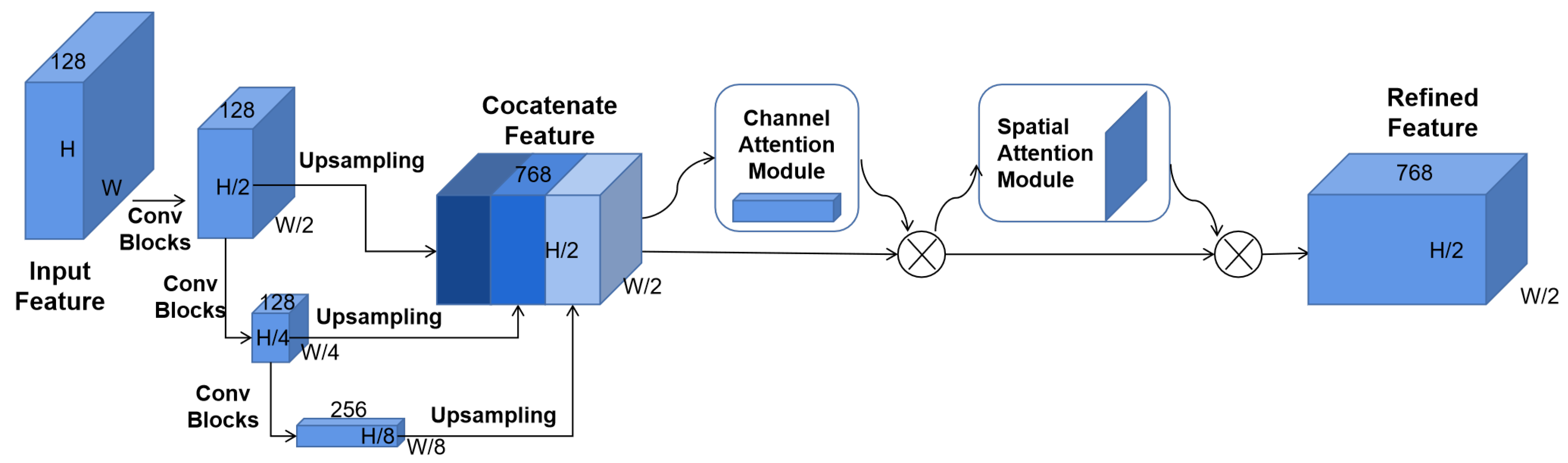
3.3. Strong Feature Alignment Module
3.4. Weak Feature Alignment Module
3.5. Loss
4. Implementation
4.1. Dataset and Metrics
4.2. Implementation Details
5. Experiments
6. Ablation Study
6.1. Hyper-Parameter of Guiding Feature
6.2. Different Strategies for Strong Object Feature Alignment
6.3. Improvement at Different Distances
6.4. Performance of Different Basic Networks
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Yu, T.; Meng, J.; Yuan, J. Multi-view harmonized bilinear network for 3d object recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 186–194. [Google Scholar]
- Du, X.; Ang, M.H.; Karaman, S.; Rus, D. A general pipeline for 3d detection of vehicles. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 3194–3200. [Google Scholar]
- Luo, W.; Yang, B.; Urtasun, R. Fast and furious: Real time end-to-end 3d detection, tracking and motion forecasting with a single convolutional net. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 3569–3577. [Google Scholar]
- Wang, M.; Deng, W. Deep visual domain adaptation: A survey. Neurocomputing 2018, 312, 135–153. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yi, L.; Gong, B.; Funkhouser, T. Complete & label: A domain adaptation approach to semantic segmentation of LiDAR point clouds. arXiv 2020, arXiv:2007.08488. [Google Scholar]
- Wang, Z.; Ding, S.; Li, Y.; Zhao, M.; Roychowdhury, S.; Wallin, A.; Sapiro, G.; Qiu, Q. Range Adaptation for 3D Object Detection in LiDAR. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27–28 October 2019; pp. 2320–2328. [Google Scholar]
- Du, L.; Ye, X.; Tan, X.; Feng, J.; Xu, Z.; Ding, E.; Wen, S. Associate-3ddet: Perceptual-to-conceptual association for 3d point cloud object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13329–13338. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. arXiv 2014, arXiv:1406.2661. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Engelcke, M.; Rao, D.; Wang, D.Z.; Tong, C.H.; Posner, I. Vote3deep: Fast object detection in 3d point clouds using efficient convolutional neural networks. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 1355–1361. [Google Scholar]
- Li, B. 3d fully convolutional network for vehicle detection in point cloud. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 1513–1518. [Google Scholar]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3d object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4490–4499. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. SECOND: Sparsely Embedded Convolutional Detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Graham, B.; van der Maaten, L. Submanifold sparse convolutional networks. arXiv 2017, arXiv:1706.01307. [Google Scholar]
- Wang, Z.; Fu, H.; Wang, L.; Xiao, L.; Dai, B. SCNet: Subdivision coding network for object detection based on 3D point cloud. IEEE Access 2019, 7, 120449–120462. [Google Scholar] [CrossRef]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3D Object Detection Network for Autonomous Driving. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6526–6534. [Google Scholar]
- Ku, J.; Mozifian, M.; Lee, J.; Harakeh, A.; Waslander, S.L. Joint 3d proposal generation and object detection from view aggregation. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1–8. [Google Scholar]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. PointPillars: Fast Encoders for Object Detection From Point Clouds. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 12689–12697. [Google Scholar]
- Yang, B.; Luo, W.; Urtasun, R. PIXOR: Real-Time 3D Object Detection From Point Clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7652–7660. [Google Scholar]
- Charles, R.Q.; Su, H.; Kaichun, M.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 77–85. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. arXiv 2017, arXiv:1706.02413. [Google Scholar]
- Qi, C.R.; Liu, W.; Wu, C.; Su, H.; Guibas, L.J. Frustum pointnets for 3d object detection from rgb-d data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 918–927. [Google Scholar]
- Yang, Z.; Sun, Y.; Liu, S.; Shen, X.; Jia, J. Std: Sparse-to-dense 3d object detector for point cloud. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1951–1960. [Google Scholar]
- Chen, Y.; Li, W.; Sakaridis, C.; Dai, D.; Van Gool, L. Domain adaptive faster r-cnn for object detection in the wild. In Proceedings of the IEEE conference on computer vision and pattern recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3339–3348. [Google Scholar]
- Ganin, Y.; Lempitsky, V. Unsupervised domain adaptation by backpropagation. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 7–9 July 2015; pp. 1180–1189. [Google Scholar]
- Saito, K.; Ushiku, Y.; Harada, T.; Saenko, K. Strong–weak distribution alignment for adaptive object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6956–6965. [Google Scholar]
- Rist, C.B.; Enzweiler, M.; Gavrila, D.M. Cross-sensor deep domain adaptation for LiDAR detection and segmentation. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 1535–1542. [Google Scholar]
- Wu, B.; Zhou, X.; Zhao, S.; Yue, X.; Keutzer, K. Squeezesegv2: Improved model structure and unsupervised domain adaptation for road-object segmentation from a lidar point cloud. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 4376–4382. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 42, 318–327. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Chen, X.; Kundu, K.; Zhu, Y.; Berneshawi, A.G.; Ma, H.; Fidler, S.; Urtasun, R. 3d object proposals for accurate object class detection. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 424–432. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training | Validation | AP-BEV | AP-3D | ||||
|---|---|---|---|---|---|---|---|
| Easy | Moderate | Hard | Easy | Moderate | Hard | ||
| Complete | Complete | 89.99 | 89.96 | 89.04 | 87.68 | 87.23 | 79.08 |
| Complete | Incomplete | 0 | 48.73 | 48.01 | 0 | 29.41 | 29.34 |
| Incomplete | Incomplete | 1.14 | 62.95 | 60.29 | 1.01 | 40.40 | 37.06 |
| Methods | AP-BEV | AP-3D | ||||
|---|---|---|---|---|---|---|
| Easy | Moderate | Hard | Easy | Moderate | Hard | |
| Baseline | 1.14 | 62.95 | 60.29 | 1.01 | 40.40 | 37.06 |
| IOFG | 1.82 | 63.30 | 61.14 | 1.52 | 40.41 | 38.74 |
| IOFG (S) | 9.09 | 63.31 | 61.69 | 9.09 | 45.33 | 40.65 |
| IOFG (W) | 9.09 | 63.44 | 61.72 | 9.09 | 45.90 | 41.21 |
| IOFG (S + W) | 9.09 | 64.34 | 62.66 | 9.09 | 46.46 | 42.06 |
| Methods | AP-BEV | AP-3D | ||||
|---|---|---|---|---|---|---|
| Easy | Moderate | Hard | Easy | Moderate | Hard | |
| K = 1 | 9.09 | 63.57 | 61.42 | 9.09 | 44.35 | 39.67 |
| K = 5 | 9.09 | 64.34 | 62.66 | 9.09 | 46.46 | 42.06 |
| K = 10 | 9.09 | 62.75 | 61.17 | 9.09 | 45.67 | 40.93 |
| K = 20 | 9.09 | 63.12 | 61.42 | 9.09 | 43.87 | 39.73 |
| Methods | AP-BEV | AP-3D | ||||
|---|---|---|---|---|---|---|
| Easy | Moderate | Hard | Easy | Moderate | Hard | |
| Baseline | 1.14 | 62.95 | 60.29 | 1.01 | 40.40 | 37.06 |
| RANGE [9] | 9.09 | 63.51 | 61.97 | 9.09 | 44.56 | 39.75 |
| Ours | 9.09 | 64.34 | 62.66 | 9.09 | 46.46 | 42.06 |
| Methods | Baseline | Ours | ||||
|---|---|---|---|---|---|---|
| Easy | Moderate | Hard | Easy | Moderate | Hard | |
| 35–40 m | 0.37 | 48.57 | 45.13 | 9.09 | 56.81 | 51.12 |
| 40–45 m | 0.00 | 39.15 | 33.60 | 0.00 | 40.57 | 38.48 |
| 45–50 m | 0.00 | 21.93 | 21.10 | 0.00 | 32.02 | 27.84 |
| 50–55 m | 0.00 | 16.11 | 13.86 | 0.00 | 16.45 | 14.89 |
| Methods | AP-BEV | AP-3D | ||||
|---|---|---|---|---|---|---|
| Easy | Moderate | Hard | Easy | Moderate | Hard | |
| SCNET (w/o) | 1.14 | 62.95 | 60.29 | 1.01 | 40.40 | 37.06 |
| SCNET (w) | 9.09 | 64.34 | 62.66 | 9.09 | 46.46 | 42.06 |
| MV3D (w/o) | 9.09 | 58.93 | 56.76 | 9.09 | 35.66 | 34.04 |
| MV3D (w) | 9.09 | 62.21 | 60.14 | 9.09 | 41.80 | 40.41 |
| PointPillars (w/o) | 4.55 | 61.20 | 59.25 | 0.00 | 39.08 | 37.75 |
| pointPillars (w) | 9.09 | 63.82 | 62.43 | 9.09 | 45.96 | 41.14 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Wang, L.; Dai, B. Strong-Weak Feature Alignment for 3D Object Detection. Electronics 2021, 10, 1205. https://doi.org/10.3390/electronics10101205
Wang Z, Wang L, Dai B. Strong-Weak Feature Alignment for 3D Object Detection. Electronics. 2021; 10(10):1205. https://doi.org/10.3390/electronics10101205
Chicago/Turabian StyleWang, Zhiyu, Li Wang, and Bin Dai. 2021. "Strong-Weak Feature Alignment for 3D Object Detection" Electronics 10, no. 10: 1205. https://doi.org/10.3390/electronics10101205
APA StyleWang, Z., Wang, L., & Dai, B. (2021). Strong-Weak Feature Alignment for 3D Object Detection. Electronics, 10(10), 1205. https://doi.org/10.3390/electronics10101205