In this chapter, we will evaluate the performance of the MaxAFL. In order to test the proposed deterministic mutation stage of MaxAFL, we evaluated MaxAFL by comparing its performance with the original AFL Fuzzer [
2], AFLFast [
3], and FairFuzz [
4]. The reason why we choose AFLFast and FairFuzz for comparison is that they are also based on the original AFL. We focused on three main metrics for evaluation: line coverage per time, line coverage per total executions, number of unique crashes. Our mutation algorithm is aimed to maximize instruction coverage using MEIC, however instruction coverage is hard to measure. Therefore, we use line coverage because it is easier to measure and instruction coverage and line coverage are not significantly different experimentally.
All experiments were conducted in the Ubuntu 18.04 64 bit environment. The hardware used for the experiments consisted of Intel Xeon Gold 5218 CPU with 32 cores (2.30 GHz) and 64 GB RAM. For the fairness of the experiment, only one core was used per one fuzz test. In addition, in order to increase the reliability of our experiment, the average, maximum, minimum, and variance values were measured by aggregating the results of eight independent experiments.
7.1. Test Targets
We selected simple Linux binaries to test our fuzzer, because original AFL is designed to fuzz Linux binaries. In order to evaluate the generalizability of fuzzer, we prepared various binaries that receive different types of input.
Table 1 demonstrates the list of the tested programs which is used in our experiment.
We prepared seed inputs used in each experiment from the public fuzzing corpus available at Github. Almost all seed inputs are from 3 different Github pages: Default testcases of AFL Github [
35], fuzzdata [
39] of Mozilla security, and fuzzing corpus in fuzz-test-suite [
40]. For a smooth experiment, we used the seed inputs as small files as possible in the experiments.
To evaluate a bug finding technique, we used LAVA-M [
41] dataset which is commonly used in comparison of fuzzers. LAVA-M is a data set in which hard-to-find bugs are injected in GNU coreutils [
42]. Types of LAVA dataset include LAVA-1 and LAVA-M. Between them, LAVA-M has injected bugs in 4 binaries (who, uniq, md5sum, base64), and the injected bugs have their own unique numbers. Therefore, we can check what kind of bug we found.
7.3. Experimental Results
Performance evaluation of our proposed approach in this subsection is described and compared with the other fuzzers given the above three questions.
Firstly, we compared the performance of MaxAFL and the other fuzzers within the same time.
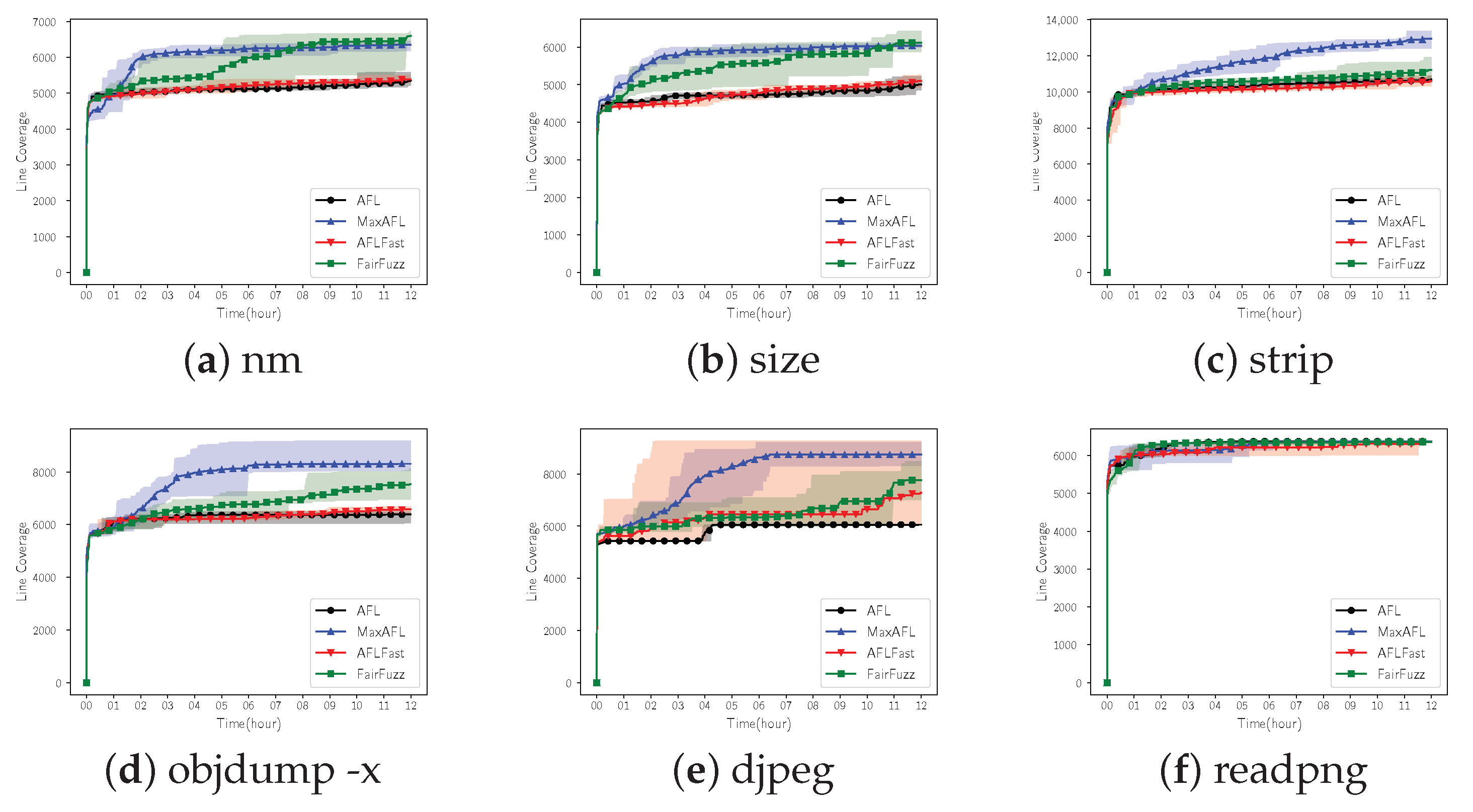
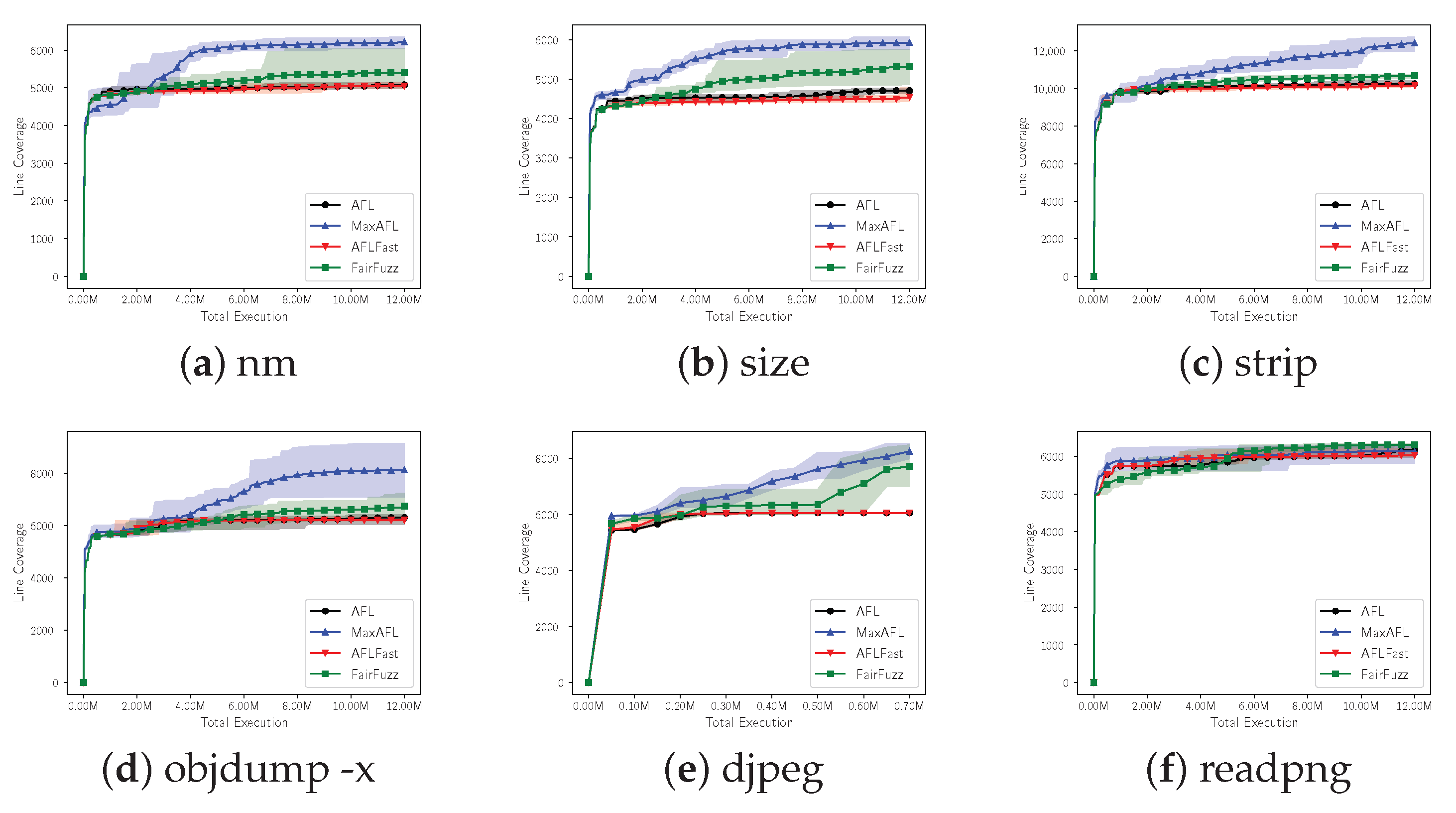
Figure 6 is the result of calculating the average, maximum, and minimum of the line coverage obtained by 8 individual 12 h of fuzzing experiments. The solid line is the average of line coverage of each fuzzer, and we filled a background color between the minimum and maximum line coverage.
Table 2 demonstrates the final result of 12 h fuzzing aiming to provide detailed result.
Out of six test binaries, MaxAFL outperformed the original AFL in five binaries. MaxAFL showed improved performance compared with AFLFast in all test binaries. FairFuzz gained more line coverage compared with MaxAFL in just 2 binaries. If we look at the detailed result, in the case of nm, although the line coverage of FairFuzz was 6597 which is the best performance among the fuzzers, the line coverage of MaxAFL was not significantly different which is 6348. However, AFL and AFLFast showed 5351 and 5380 line coverage, respectively. In the case of size, it was found that FairFuzz covered just 76 lines more compared with MaxAFL. If we compare the result of MaxAFL with results of AFL and AFLFast, MaxAFL gained 1000 more line coverage. The result of strip, as shown in
Figure 6c, showed that the line coverage steadily increased throughout the entire fuzzing process, and finally, MaxAFL showed the best performance among four fuzzers. In the case of objdump, which is the largest target among our test targets, the performance is also improved. Performance improvement in objdump was about 30.13% compared with the original AFL, which is the biggest improvement in binutils binaries. MaxAFL covered 781 lines more compared with FairFuzz. Djpeg of libjpeg, which receives a JPEG image as an input file, showed the greatest performance improvement among the test targets. A total of 3719 lines more were tested compared with the original AFL. Finally, in the case of readpng that receives a PNG file as an input, it was found that there is little difference in performance among the tested fuzzers. The performance results were in the order of AFL, MaxAFL, AFLFast, and FairFuzz. However, the difference of line coverage between AFL and MaxAFL was just two; this is statistically negligible.
In conclusion, we compared MaxAFL with three other AFL-based fuzzers on six Linux binaries for 12 h and found that MaxAFL showed the best line coverage metric, on average, on three binaries. In the other three binaries, MaxAFL showed second performance among four fuzzers and there was no remarkable performance difference with the fuzzer which showed the best line coverage.
![Electronics 10 00011 i001]()
Secondly, to check the effectiveness of MaxAFL’s mutation using gradient descent, we limited the maximum number of executions of fuzzers and compared the performance of MaxAFL with the other fuzzers: AFL, AFLFast, and FairFuzz. Note that, approximately, one test target execution means one mutation of the input. Therefore, we can say that the mutation action of the fuzzer, which shows better performance in this experiment, is more efficient than the others without considering execution speed. Each experiment was conducted by comparing the line coverage obtained by each fuzzer during 12 million executions. However, in the case of djpeg, the execution speed was extremely slow, so the maximum number of execution was limited to 0.7 million rather than 12 million. In this experiment, a total of eight independent experiments were performed and we aggregated and analyzed all eight results. The results of line coverage per executions are shown in
Figure 7, and the detailed final results are shown in
Table 3.
As a result of the experiment of RQ2, MaxAFL showed better performance than that of RQ1. Out of 6 binaries, MaxAFL showed the best line coverage per program execution on five binares. In the case of nm, a total line coverage increased by 1143 lines on MaxAFL, showing a performance improvement of 22.50% compared with AFL. The difference of line coverage between FairFuzz and MaxAFL is 823 which is meaningful improvement. Compared with the results of RQ1, it showed that there is more performance improvement. In the case of size, MaxAFL tested 613 more lines compared with FairFuzz. In RQ1, FairFuzz outperformed MaxAFL slightly, however, MaxAFL outperformed FairFuzz in RQ2. Next, in the case of strip, MaxAFL showed 21.19% better performance than AFL and it is the greatest result among the tested fuzzers. In the case of objdump, the biggest binary in our tested target, MaxAFL also showed improved performance. AFL, AFLFast and FairFuzz showed less than 7000 line coverage, however, MaxAFL showed 8128 line coverage that is outstanding improvement. Djpeg showed a total increase of 2674 line coverage compared with AFL, which means that the performance of MaxAFL is improved by about 44.15%. Finally, readpng suffered a −0.66% performance drop compared with AFL, worse than the result of RQ1. However, it was just a decrease of 41 line coverage.
In conclusion, as a result of comparing the performance of MaxAFL and the other three fuzzers by limiting the maximum number of binary executions, MaxAFL showed the best results on five binaries. This means that MaxAFL’s mutation process is more efficient than mutation actions of the other fuzzers. The results of RQ2 are much better than the results of RQ1, which means that our fuzzer has a performance advantage in terms of mutation action more than execution speed.
To evaluate the important goal of the fuzzer, bug finding ability, we ran our fuzzer with LAVA-M [
41] dataset and compared the results with the other fuzzers. We checked how many unique bugs were found by fuzzing for 12 h on four bug-injected binaries (who, uniq, md5sum, and base64). A total of eight repeated experiments were conducted and the best results were compared. The experimental results are shown in
Table 4.
As a result of the experiment, in the case of base64, we found 47 more crashes compared with AFL. We found three crashes unlisted by LAVA author because we could trigger injected bugs that LAVA authors could not trigger. In the case of other binaries, there were no significant differences from the other fuzzers.
Table 5 shows a list of all bugs found by MaxAFL.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}