Urban Water Demand Forecasting: A Comparative Evaluation of Conventional and Soft Computing Techniques


Abstract
1. Introduction
2. Materials and Methods
2.1. Multiple Linear Regression
2.2. Exponential Smoothing
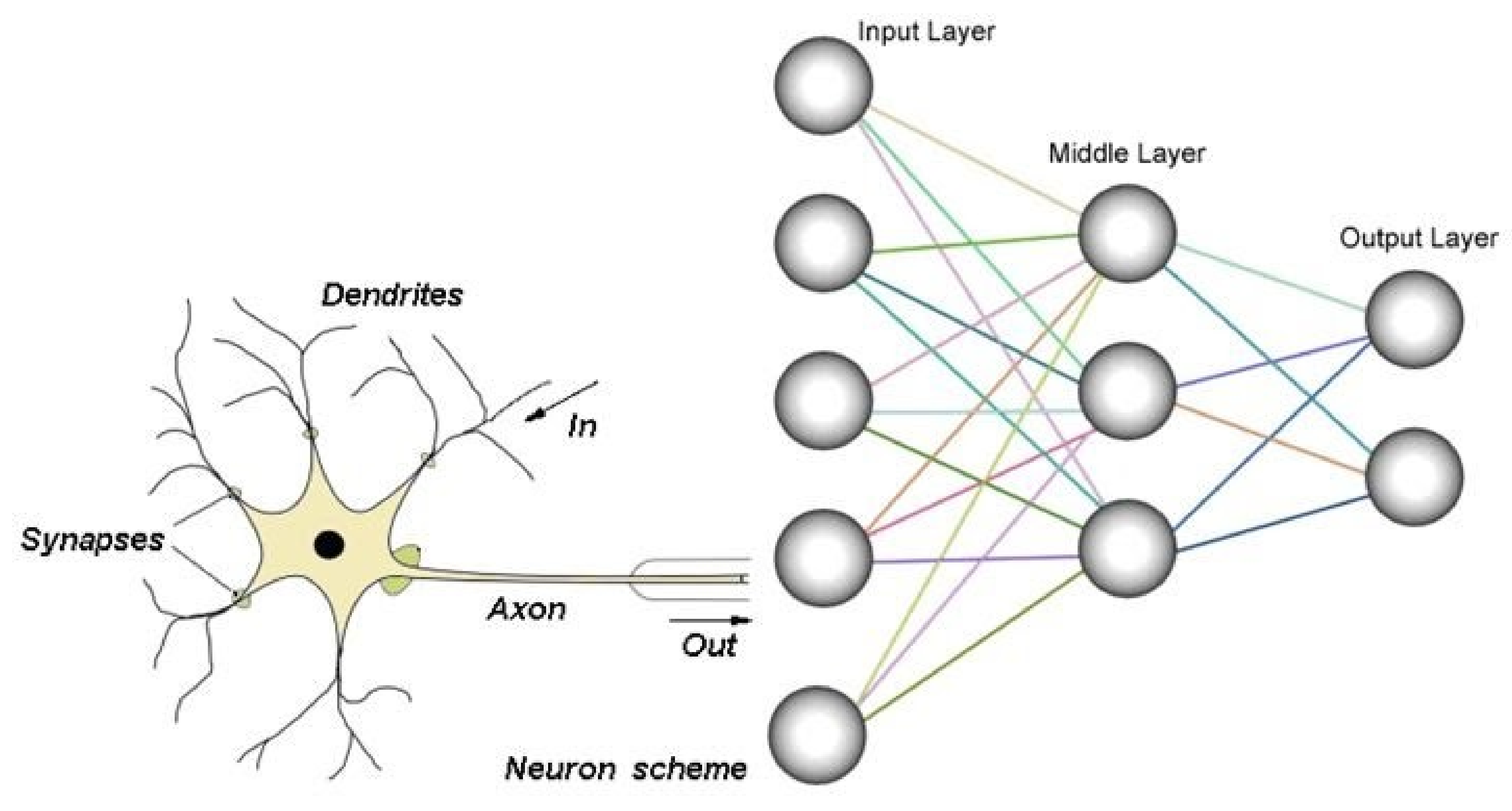
2.3. Artificial Neural Network
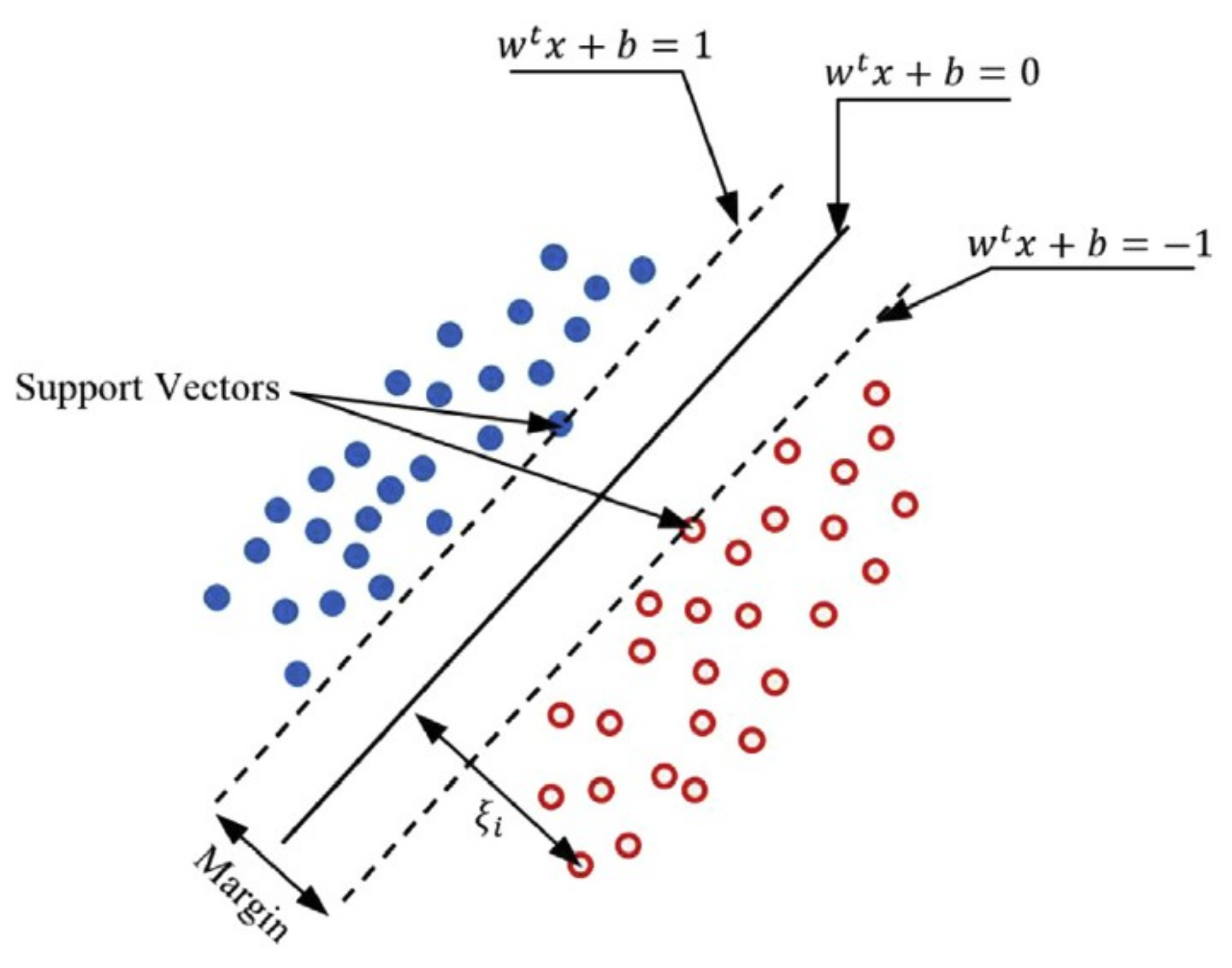
2.4. Support Vector Machine
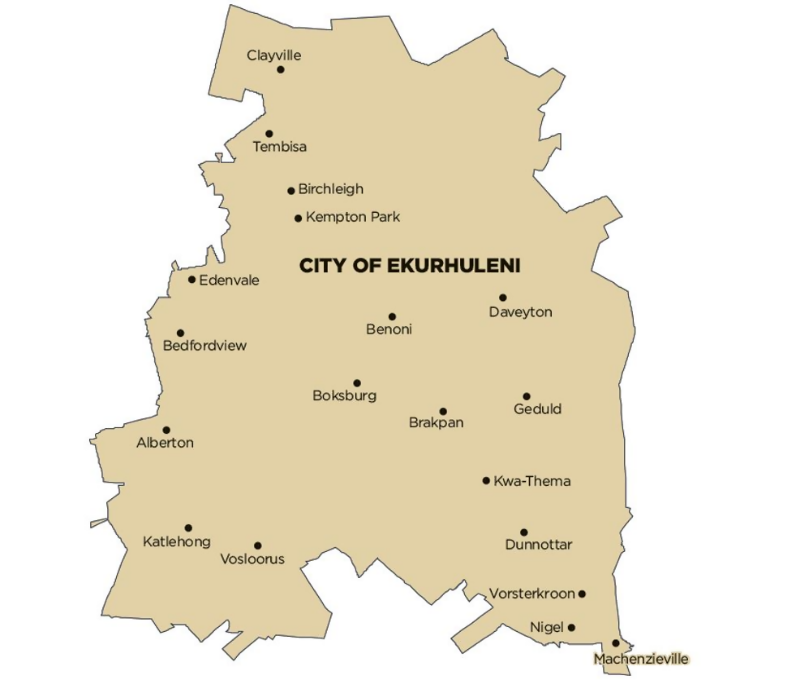
3. Description of Study Area
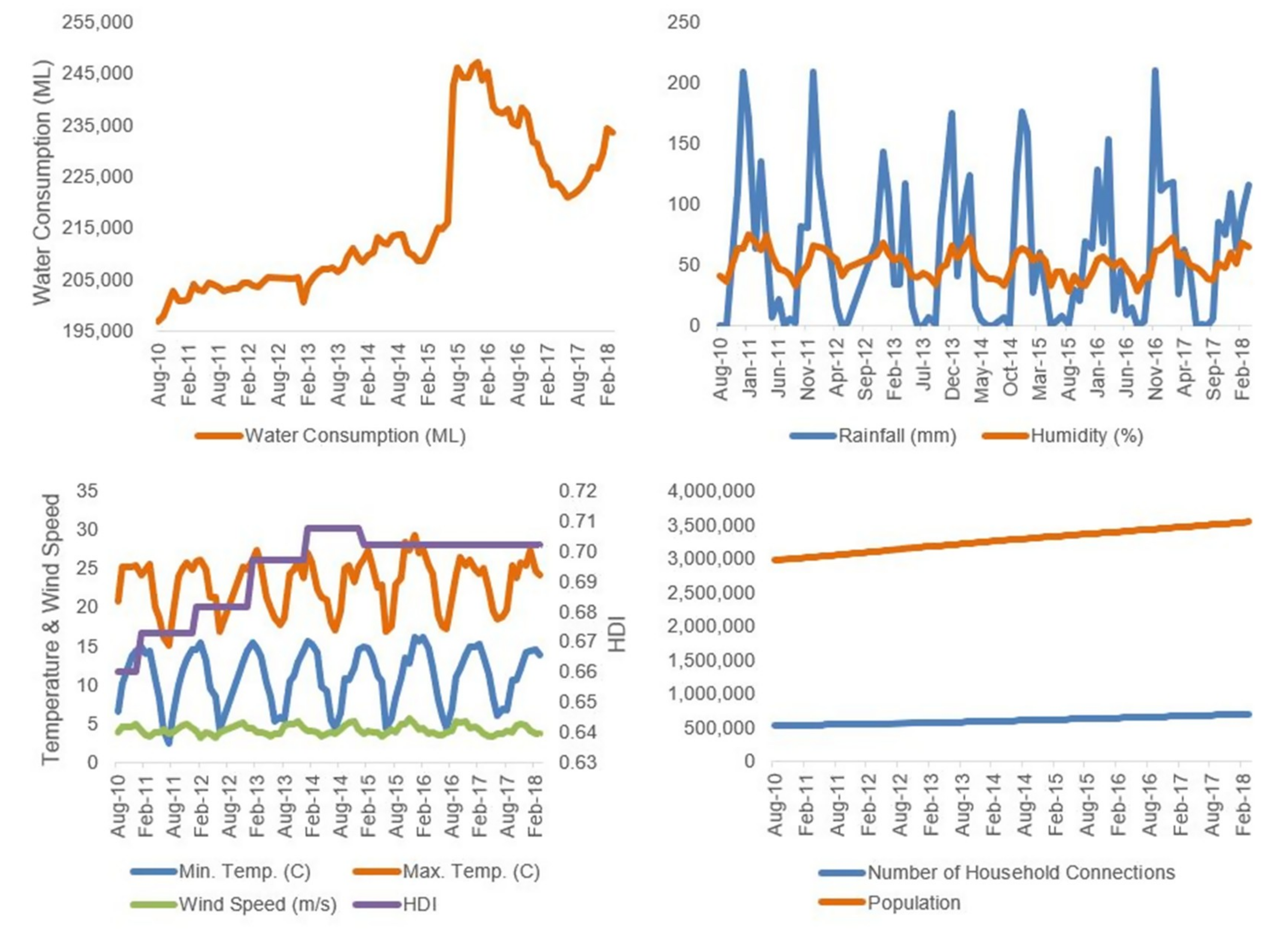
4. Model Development
5. Model Evaluation
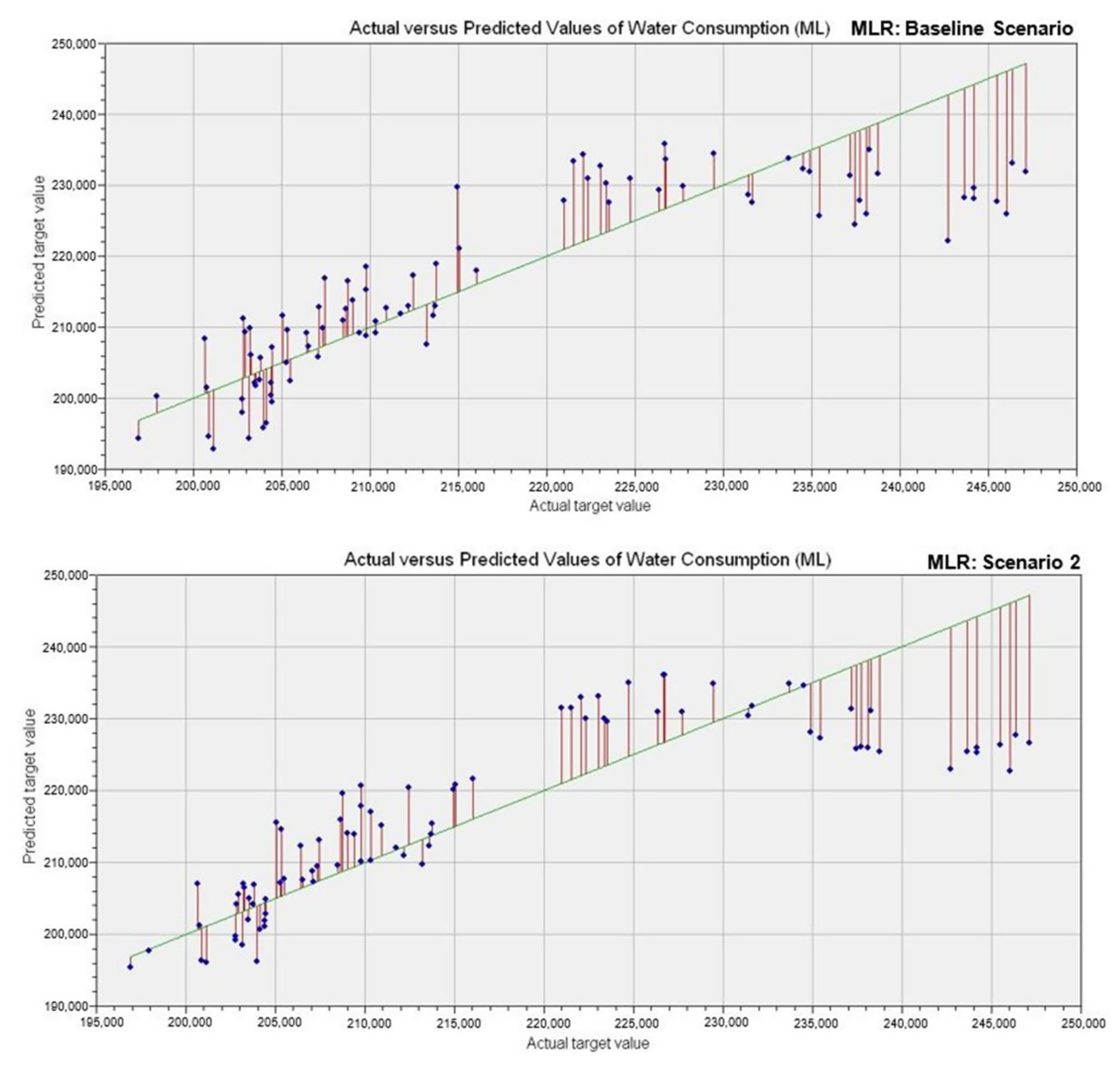
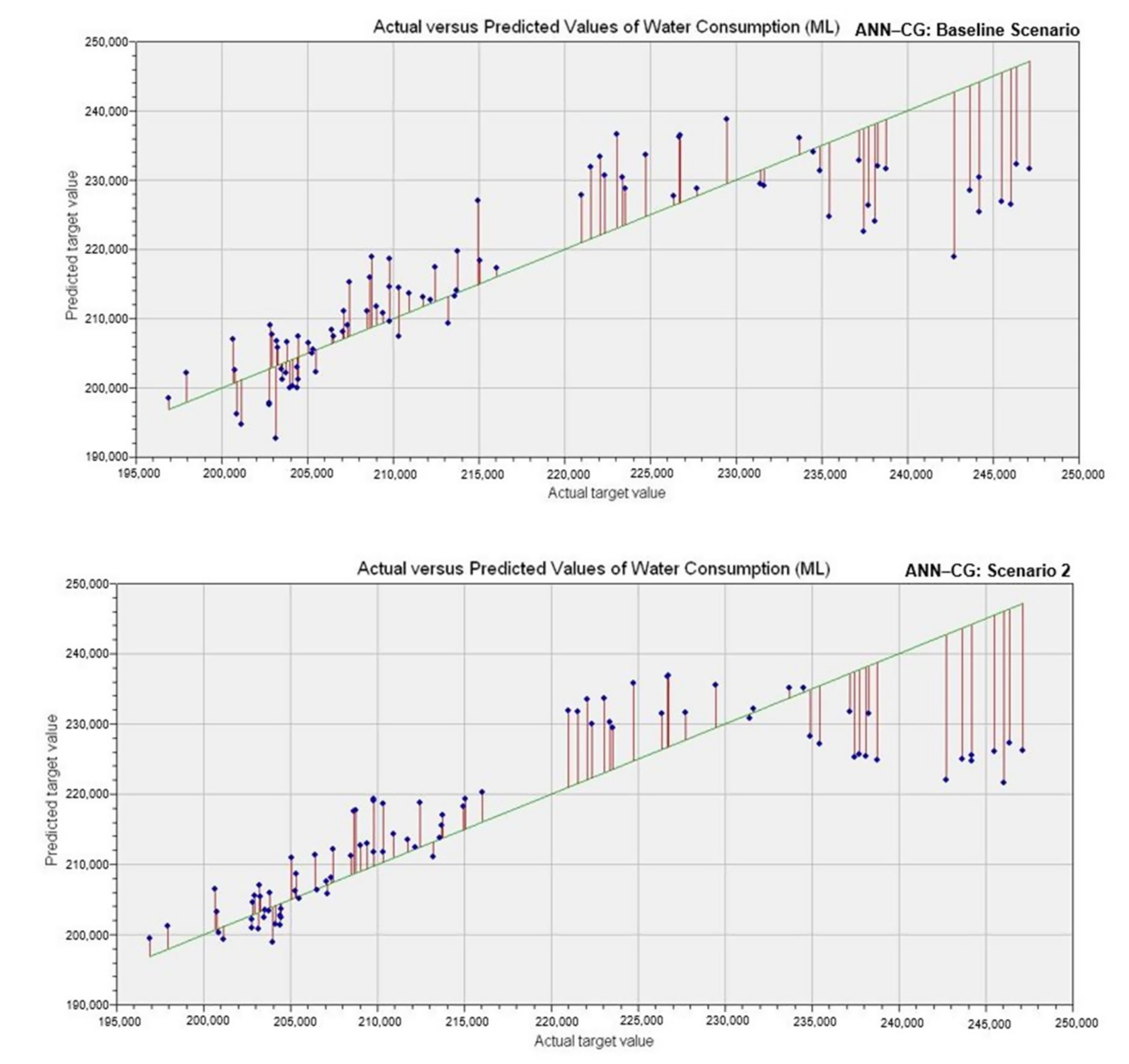
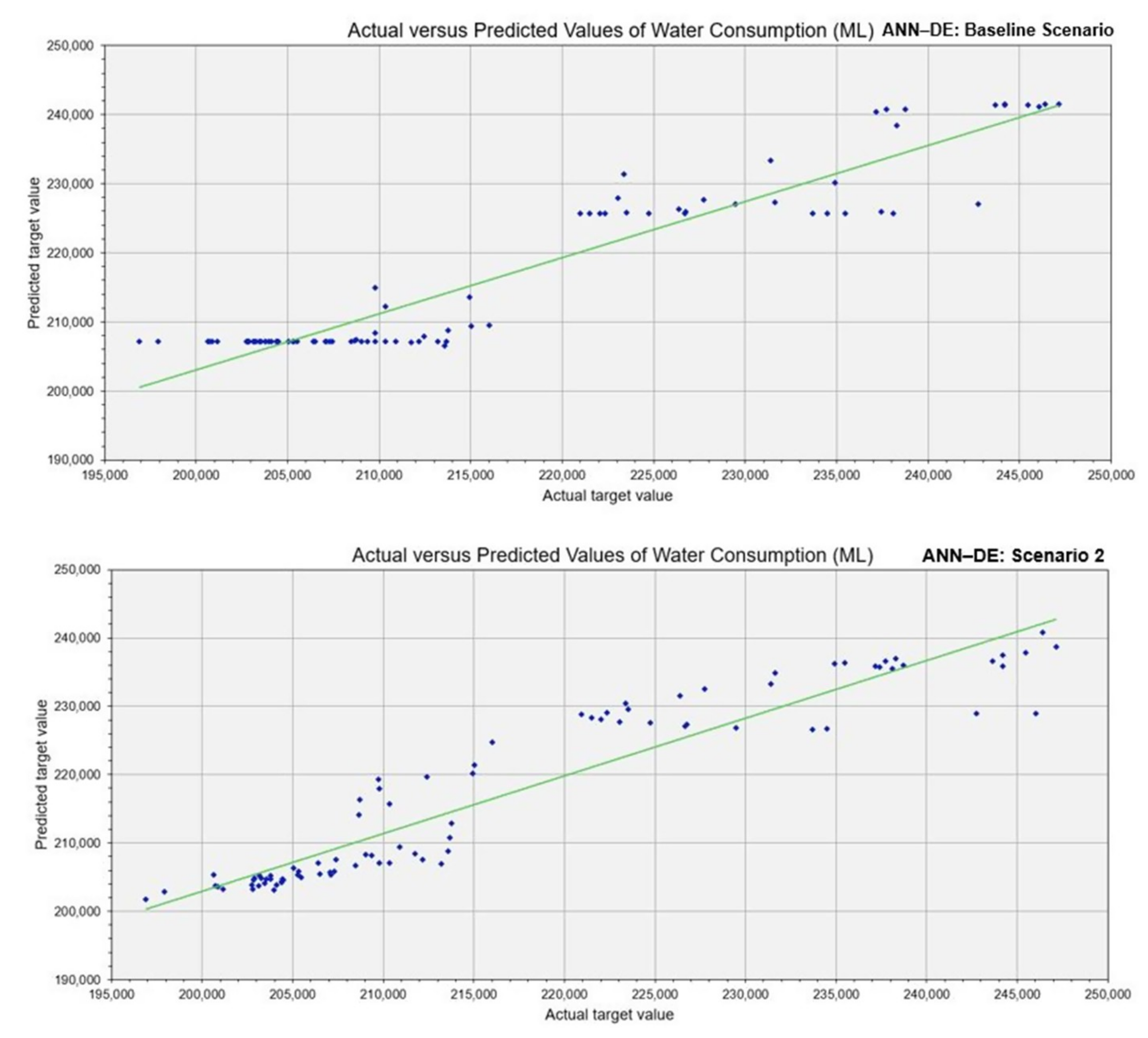
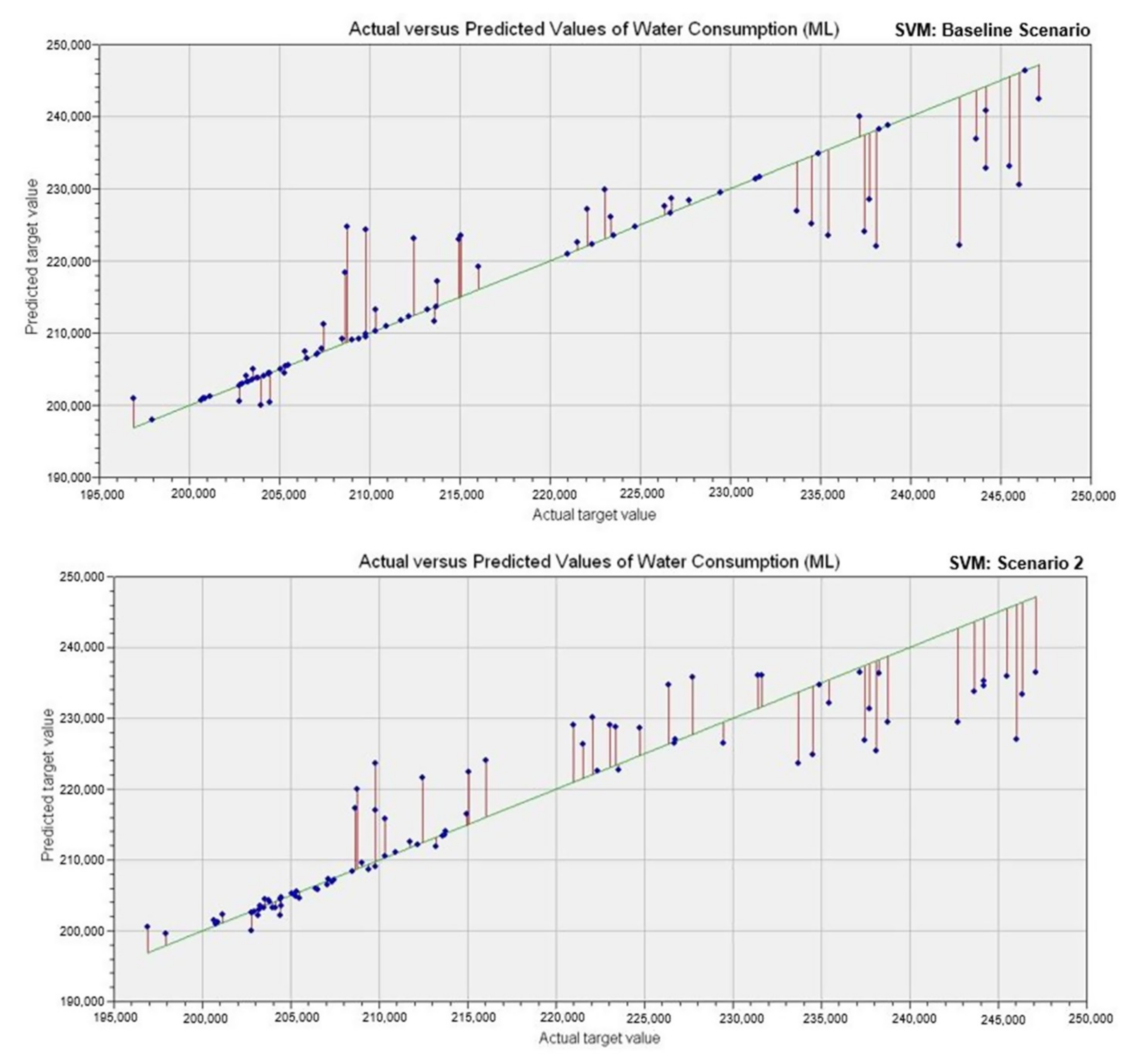
6. Result and Discussions
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- UNESCO. The United Nations World Water Development Report 2015: Water for a Sustainable World; United Nations World Water Assessment Programme—WWAP; 9231000713; UNESCO: Paris, France, 2015. [Google Scholar]
- Pulido-Calvo, I.; Montesinos, P.; Roldán, J.; Ruiz-Navarro, F. Linear regressions and neural approaches to water demand forecasting in irrigation districts with telemetry systems. Biosyst. Eng. 2007, 97, 283–293. [Google Scholar] [CrossRef]
- House-Peters, L.A.; Chang, H. Urban water demand modeling: Review of concepts, methods, and organizing principles. Water Resour. Res. 2011, 47. [Google Scholar] [CrossRef]
- Donkor, E.A.; Mazzuchi, T.A.; Soyer, R.; Alan Roberson, J. Urban water demand forecasting: Review of methods and models. J. Water Resour. Plan. Manag. 2012, 140, 146–159. [Google Scholar] [CrossRef]
- Shabani, S.; Yousefi, P.; Adamowski, J.; Naser, G. Intelligent soft computing models in water demand forecasting. In Water Stress in Plants; Rahman, I.M.M., Begum, Z.A., Hasegawa, H., Eds.; InTech: Rijeka, Croatia, 2016. [Google Scholar]
- UNESCO. The United Nations World Water Development Report 2016: Water and Jobs—Facts and Figures; United Nations World Water Assessment Programme—WWAP; 9231002015; UNESCO: Paris, France, 2016. [Google Scholar]
- Ghalehkhondabi, I.; Ardjmand, E.; Young, W.A.; Weckman, G.R. Water demand forecasting: Review of soft computing methods. Environ. Monit. Assess. 2017, 189, 313. [Google Scholar] [CrossRef] [PubMed]
- Adeyemo, J.; Oyebode, O.; Stretch, D. River Flow Forecasting Using an Improved Artificial Neural Network. In EVOLVE-A Bridge Between Probability, Set Oriented Numerics, and Evolutionary Computation VI; Tantar, A.-A., Tantar, E., Emmerich, M., Legrand, P., Alboaie, L., Luchian, H., Eds.; Springer: Cham, Switzerland, 2018; pp. 179–193. [Google Scholar]
- Ch, S.; Anand, N.; Panigrahi, B.K.; Mathur, S. Streamflow forecasting by SVM with quantum behaved particle swarm optimization. Neurocomputing 2013, 101, 18–23. [Google Scholar] [CrossRef]
- Soltani, F.; Kerachian, R.; Shirangi, E. Developing operating rules for reservoirs considering the water quality issues: Application of ANFIS-based surrogate models. Expert Syst. Appl. 2010, 37, 6639–6645. [Google Scholar] [CrossRef]
- Dhungel, R.; Fiedler, F. Price elasticity of water demand in a small college town: An inclusion of system dynamics approach for water demand forecast. Air Soil Water Res. 2014, 7, ASWR-S15395. [Google Scholar] [CrossRef]
- Olofintoye, O.; Otieno, F.; Adeyemo, J. Real-time optimal water allocation for daily hydropower generation from the Vanderkloof dam, South Africa. Appl. Soft Comput. 2016, 47, 119–129. [Google Scholar] [CrossRef]
- Adamowski, J.; Karapataki, C. Comparison of multivariate regression and artificial neural networks for peak urban water-demand forecasting: Evaluation of different ANN learning algorithms. J. Hydrol. Eng. 2010, 15, 729–743. [Google Scholar] [CrossRef]
- Ji, G.; Wang, J.; Ge, Y.; Liu, H. Urban water demand forecasting by LS-SVM with tuning based on elitist teaching-learning-based optimization. In Proceedings of the 26th Chinese Control and Decision Conference (2014 CCDC), Changsha, China, 31 May–2 June 2014; pp. 3997–4002. [Google Scholar]
- Vijayalaksmi, D.; Babu, K.J. Water supply system demand forecasting using adaptive neuro-fuzzy inference system. Aquat. Procedia 2015, 4, 950–956. [Google Scholar] [CrossRef]
- Varahrami, V. Application of genetic algorithm to neural network forecasting of short-term water demand. In Proceedings of the International Conference on Applied Economics—ICOAE, Milan, Italy, 4–6 July 2019; pp. 783–787. [Google Scholar]
- Wu, Z.Y.; Yan, X. Applying genetic programming approaches to short-term water demand forecast for district water system. In Water Distribution Systems Analysis 2010; Lansey, K.E., Choi, C.Y., Ostfeld, A., Pepper, I.L., Eds.; American Society of Civil Engineers (ASCE): Reston, VA, USA, 2010; pp. 1498–1506. [Google Scholar]
- Zhai, C.; Zhang, H.; Zhang, X. Application of system dynamics in the forecasting water resources demand in Tianjin polytechnic university. In Proceedings of the International Conference on Artificial Intelligence and Computational Intelligence (AICI ‘09), Shanghai, China, 7–8 November 2009; pp. 273–276. [Google Scholar]
- Ali, A.M.; Shafiee, M.E.; Berglund, E.Z. Agent-based modeling to simulate the dynamics of urban water supply: Climate, population growth, and water shortages. Sustain. Cities Soc. 2017, 28, 420–434. [Google Scholar]
- Oyebode, O.; Stretch, D. Neural network modeling of hydrological systems: A review of implementation techniques. Nat. Resour. Modeling 2018. [Google Scholar] [CrossRef]
- Oyebode, O.; Babatunde, D.E.; Monyei, C.G.; Babatunde, O.M. Water demand modelling using evolutionary computation techniques: Integrating water equity and justice for realization of the sustainable development goals. Heliyon 2019. in review. [Google Scholar]
- Polebitski, A.S.; Palmer, R.N. Seasonal residential water demand forecasting for census tracts. J. Water Resour. Plan. Manag. 2009, 136, 27–36. [Google Scholar] [CrossRef]
- Toriman, E.; Jaafar, O.; Maru, R.; Arfan, A.; Ahmar, A.S. Daily Suspended Sediment Discharge Prediction Using Multiple Linear Regression and Artificial Neural Network. J. Phys. Conf. Ser. 2018, 954, 012030. [Google Scholar]
- Su, Y.; Gao, W.; Guan, D.; Su, W. Dynamic assessment and forecast of urban water ecological footprint based on exponential smoothing analysis. J. Clean. Prod. 2018, 195, 354–364. [Google Scholar] [CrossRef]
- Hyndman, R.; Koehler, A.B.; Ord, J.K.; Snyder, R.D. Forecasting with Exponential Smoothing: The State Space Approach; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Tomić, A.Š.; Antanasijević, D.; Ristić, M.; Perić-Grujić, A.; Pocajt, V. Application of experimental design for the optimization of artificial neural network-based water quality model: A case study of dissolved oxygen prediction. Environ. Sci. Pollut. Res. 2018, 25, 9360–9370. [Google Scholar] [CrossRef]
- Shahin, M.A.; Jaksa, M.B.; Maier, H.R. State of the art of artificial neural networks in geotechnical engineering. Electron. J. Geotech. Eng. 2008, 8, 1–26. [Google Scholar]
- Mafi, S.; Amirinia, G. Forecasting hurricane wave height in Gulf of Mexico using soft computing methods. Ocean Eng. 2017, 146, 352–362. [Google Scholar] [CrossRef]
- Ilonen, J.; Kamarainen, J.-K.; Lampinen, J. Differential evolution training algorithm for feed-forward neural networks. Neural Process. Lett. 2003, 17, 93–105. [Google Scholar] [CrossRef]
- Hanke, M. Conjugate Gradient Type Methods for Ill-Posed Problems, 1st ed.; Routledge: New York, NY, USA, 2017; p. 144. [Google Scholar]
- Technosoft, M. Artificial Neural Network. Available online: https://msatechnosoft.in/blog/tech-blogs/artificial-neural-network-types-feed-forward-feedback-structure-perceptron-machine-learning-applications (accessed on 20 November 2018).
- Vapnik, V.N. An overview of statistical learning theory. IEEE Trans. Neural Netw. 1999, 10, 988–999. [Google Scholar] [CrossRef] [PubMed]
- Elshorbagy, A.; Corzo, G.; Srinivasulu, S.; Solomatine, D. Experimental investigation of the predictive capabilities of data driven modeling techniques in hydrology-Part 1: Concepts and methodology. Hydrol. Earth Syst. Sci. 2010, 14, 1931–1941. [Google Scholar] [CrossRef]
- Oyebode, O.K.; Otieno, F.A.O.; Adeyemo, J. Review of three data-driven modelling techniques for hydrological modelling and forecasting. Fresenius Environ. Bull. 2014, 23, 1443–1454. [Google Scholar]
- Karimi, S.; Shiri, J.; Kisi, O.; Shiri, A.A. Short-term and long-term streamflow prediction by using wavelet–gene expression programming approach. Ish J. Hydraul. Eng. 2016, 22, 148–162. [Google Scholar] [CrossRef]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer Science & Business Media: New York, NY, USA, 2013. [Google Scholar]
- Statistics South Africa—Stats SA. Statistical Release P0302: Mid-Year Population Estimates 2018; Statistics South Africa: Pretoria, South Africa, 2018. [Google Scholar]
- IDP. Integrated Development Plan of City of Ekurhuleni 2017/2018 to 2020/2021; City of Ekurhuleni: Ekurhuleni, South Africa, 2018. [Google Scholar]
- Gubuza, D. Water Conservation and Water Demand Management in the City of Ekurhuleni: On-Site Leak Repair. Presented at Rand Water Services Forum, Johannesburg, South Africa, 24 May 2017. [Google Scholar]
- Bowden, G.J.; Dandy, G.C.; Maier, H.R. Input determination for neural network models in water resources applications. Part 1—background and methodology. J. Hydrol. 2005, 301, 75–92. [Google Scholar] [CrossRef]
- Storn, R.; Price, K. Differential evolution–a simple and efficient heuristic for global optimization over continuous spaces. J. Glob. Optim. 1997, 11, 341–359. [Google Scholar] [CrossRef]
- Wanjawa, B.W.; Muchemi, L. Ann Model to Predict Stock Prices at Stock Exchange Markets. arXiv 2014, arXiv:1502.06434. [Google Scholar]
- Rau, H.H.; Hsu, C.Y.; Lin, Y.A.; Atique, S.; Fuad, A.; Wei, L.M.; Hsu, M.H. Development of a web-based liver cancer prediction model for type II diabetes patients by using an artificial neural network. Comput. Methods Programs Biomed. 2016, 125, 58–65. [Google Scholar] [CrossRef] [PubMed]
- Sherrod, P.H. DTREG Predictive Modeling Software. Available online: http://www.dtreg.com (accessed on 20 November 2018).
- Amaranto, A.; Munoz-Arriola, F.; Corzo, G.; Solomatine, D.P.; Meyer, G. Semi-seasonal groundwater forecast using multiple data-driven models in an irrigated cropland. J. Hydroinformatics 2018. [Google Scholar] [CrossRef]
- Engelbrecht, A.P. Computational Intelligence: An Introduction; John Wiley & Sons: West Sussex, UK, 2007. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Values |
|---|---|
| Number of reservoirs | 73 |
| Number of towers | 32 |
| Number of bulk connections | 186 |
| Pipes (km) | 11,448 |
| Number of distribution zones | 124 |
| Population (million, 2016) | 3.5 |
| Annual population growth | 2.51% |
| Statistical Parameter | (mm) | (°C) | (°C) | (%) | (m/s) | ||||
|---|---|---|---|---|---|---|---|---|---|
| Mean | 59.37 | 11.11 | 23.15 | 51.10 | 4.19 | 607,096 | 3,280,134 | 0.69 | 216,917 |
| Maximum | 210.00 | 16.20 | 29.40 | 75.07 | 5.60 | 698,407 | 3,543,077 | 0.71 | 247,135 |
| Minimum | - | 2.50 | 15.10 | 28.07 | 3.23 | 526,700 | 2,975,216 | 0.66 | 196,908 |
| Standard Deviation | 59.42 | 3.65 | 3.38 | 11.56 | 0.58 | 50,953 | 165,046 | 0.01 | 14,524 |
| Kurtosis coefficient | −0.30 | −0.91 | −0.72 | −0.87 | −0.64 | −1.21 | −1.12 | 0.01 | −0.86 |
| Skewness coefficient | 0.81 | −0.55 | −0.60 | 0.07 | 0.48 | 0.12 | −0.21 | −1.15 | 0.70 |
| Potential Explanatory Variables | Target Variable (WC) |
|---|---|
| −0.06 | |
| 0.07 | |
| 0.15 | |
| −0.23 | |
| 0.50 | |
| 0.79 | |
| 0.79 | |
| 0.59 |
| MLR | ES | ANN–CG | ANN–DE | SVM |
|---|---|---|---|---|
| Confidence interval: 95% | Optimization of damping factor: (0.1, 0.9) Incremental function: 0.1 | Model type: Multilayer Perceptron Number of network layers: 3 (1 hidden) Optimization of hidden layer neurons: (1, 10) Stepping function: 1 Overfitting prevention: Hold out 20% of training rows Hidden layer activation function: Logistic Output layer activation function: Linear CG Parameters: Convergence tries: 4 Maximum iterations: 10,000 Iterations without improvement: 100 Convergence tolerance: 1 × 10−5 Minimum improvement delta: 1 × 10−5 Minimum gradient: 1 × 10−5 Training method: Scaled-conjugate gradient | Model type: Multilayer Perceptron Number of network layers: 3 (1 hidden) Optimization of hidden layer neurons: (1, 10) Stepping function: 1 Overfitting prevention: Yes, Early stopping Hidden layer activation function: Logistic-sigmoidal (0, 1) and re-scaling of inputs: (0.1, 0.9) Output layer activation function: Linear DE Parameters: Pop. Size, where = number of weights and biases Sensitivity analysis: Yes Crossover rate, : (0.5, 0.9) interval Mutation rate, : (0.5, 0.9) interval Stepping value for and : 0.1 Number of generations: 1000 | Model type: Epsilon SVR Kernel function: RBF Stopping criteria: 0.001 Parameter optimization: Grid search: (10, 1) Pattern search: Intervals: 10 Tolerance: 1 × 10−8 % rows to use for search: 100 Cross-validate: 4 folds Model Parameters: C: (0.1, 5000) Gamma: (0.1, 50) P: (0.0001, 100) |
| Baseline | Training | Testing | Training | Testing | Training | Testing |
|---|---|---|---|---|---|---|
| Techniques | R2 | R2 | RMSE | RMSE | MAPE | MAPE |
| MLR | 0.7268 | 0.7030 | 7449 | 8107 | 2.6699 | 2.7181 |
| ANN–CG | 0.7236 | 0.6614 | 7492 | 8655 | 2.5906 | 2.7959 |
| ANN–DE | 0.9038 | 0.8576 | 4766 | 5160 | 1.7892 | 1.8398 |
| SVM | 0.8842 | 0.7568 | 4850 | 7336 | 0.9789 | 2.2359 |
| Optimal Dataset | Training | Testing | Training | Testing | Training | Testing |
|---|---|---|---|---|---|---|
| Techniques | R2 | R2 | RMSE | RMSE | MAPE | MAPE |
| MLR | 0.6765 | 0.7201 | 8106 | 7430 | 2.6823 | 2.4282 |
| ANN–CG | 0.6835 | 0.7122 | 8017 | 7507 | 2.5472 | 2.4490 |
| ANN–DE | 0.8812 | 0.9233 | 5092 | 4172 | 1.6650 | 1.5090 |
| SVM | 0.8609 | 0.8678 | 5315 | 5296 | 1.8775 | 1.6655 |
| Optimal Dataset | Training | Testing | Training | Testing | Training | Testing |
|---|---|---|---|---|---|---|
| Techniques | R2 | R2 | RMSE | RMSE | MAPE | MAPE |
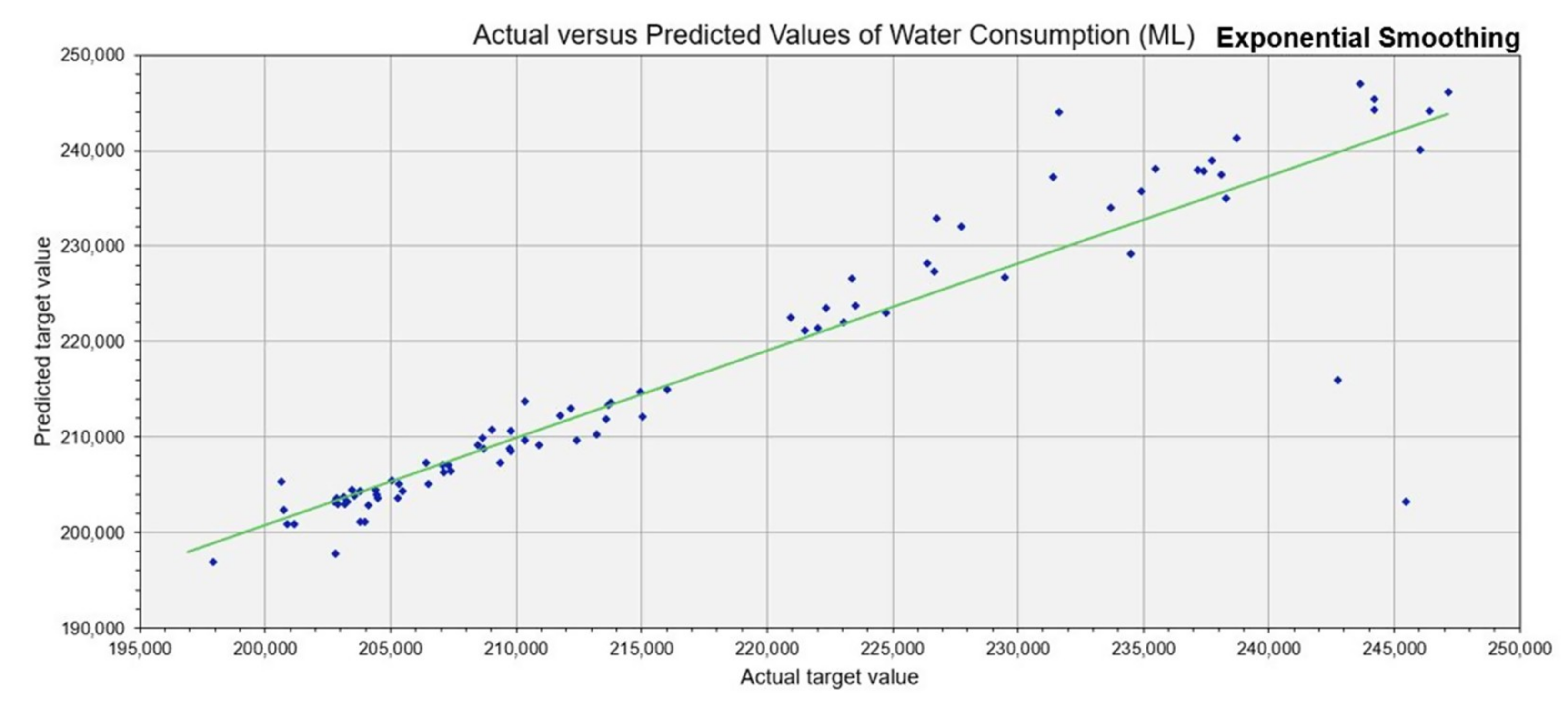
| ES | 0.9038 | 0.6103 | 4348 | 8682 | 0.9458 | 1.3188 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oyebode, O.; Ighravwe, D.E. Urban Water Demand Forecasting: A Comparative Evaluation of Conventional and Soft Computing Techniques. Resources 2019, 8, 156. https://doi.org/10.3390/resources8030156
Oyebode O, Ighravwe DE. Urban Water Demand Forecasting: A Comparative Evaluation of Conventional and Soft Computing Techniques. Resources. 2019; 8(3):156. https://doi.org/10.3390/resources8030156
Chicago/Turabian StyleOyebode, Oluwaseun, and Desmond Eseoghene Ighravwe. 2019. "Urban Water Demand Forecasting: A Comparative Evaluation of Conventional and Soft Computing Techniques" Resources 8, no. 3: 156. https://doi.org/10.3390/resources8030156
APA StyleOyebode, O., & Ighravwe, D. E. (2019). Urban Water Demand Forecasting: A Comparative Evaluation of Conventional and Soft Computing Techniques. Resources, 8(3), 156. https://doi.org/10.3390/resources8030156