1. Motivation and Need for Analog Abstraction
Although developing abstraction of analog is considered an unlikely dream, this paper shows the first step in analog (and mixed signal) abstraction utilized in large-scale Field Programmable Analog Arrays (FPAA), encoded in the open-source SciLab/Xcos based toolset (
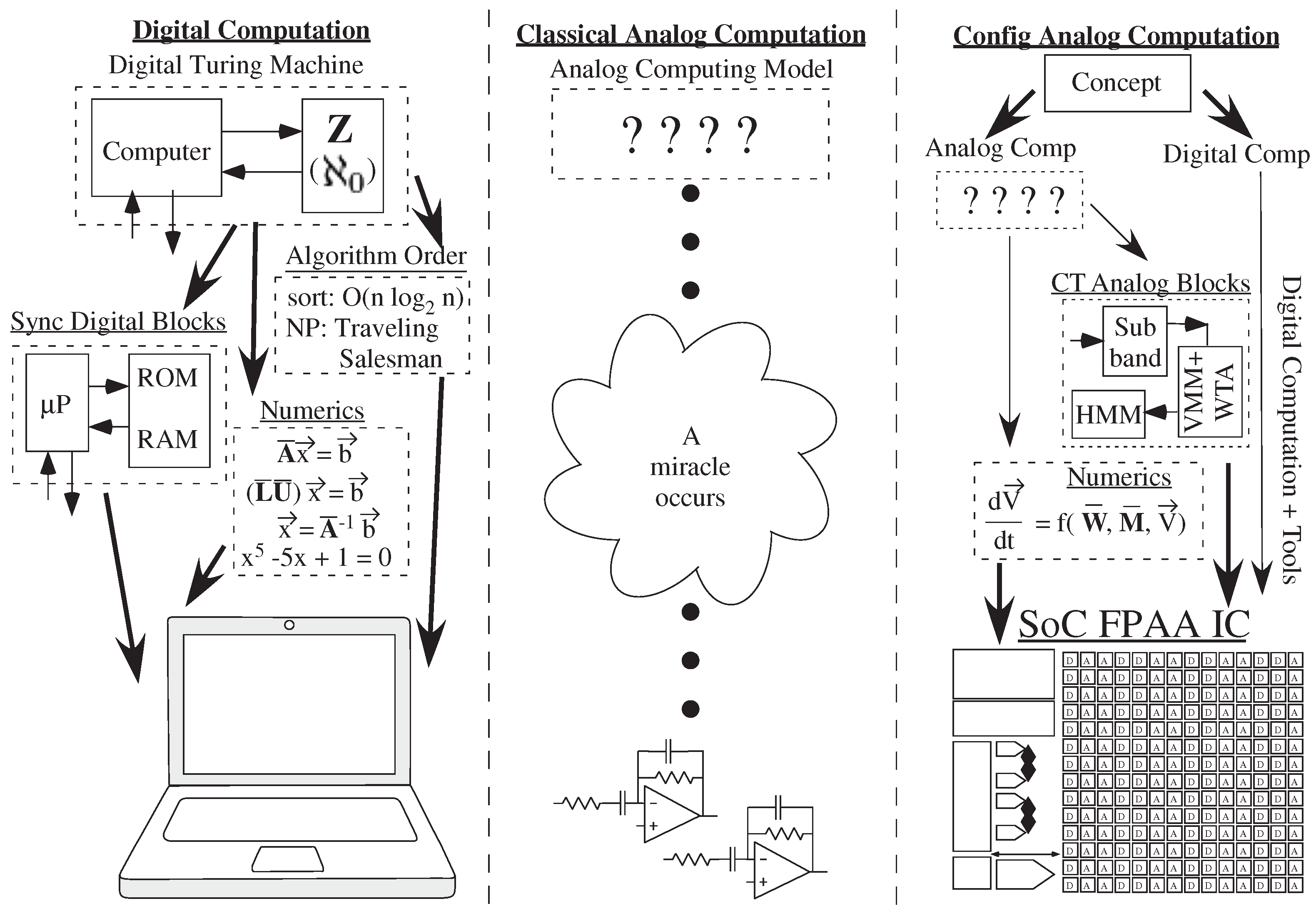
Figure 1). Often, individuals often state confidently that developing a hierarchical representation for analog circuits and systems is incredibly difficult, unlike the simple digital circuit and system representation, even those trained in analog design. Analog systems require so many different circuit combinations, with many detailed and complicated decisions. Digital systems are naturally hierarchical, composed from NAND or NOR logic gates, multiplies and addition units, and a range of processors with associated memories. Digital, as currently taught, naturally moves from device to circuit to Gate to Module to System., and analog just seems nearly impossible to make a similar story.
Are digital systems naturally hierarchical, and is analog processing nearly impossible, or are the perceptions a product of historical development? Digital required hierarchy and a computational framework (e.g., [
1]) in its early development (1940s and 1950s) to compete with existing physical (e.g., analog) computing devices, a framework that allowed it to accelerate through the Moore’s law [
2,
3] and VLSI design [
4] eras, in order to become the usual computational choice today (
Figure 2). Analog computation was less and less used or taught in education. Without significant analog implementations available, particularly those accessible to some non-analog Integrated Circuit (IC) designers, any discussion of analog computation is effectively theoretical.
Traditional analog system design and computing still resembles its roots in the 1950s and 1960s, where every problem is hand crafted by a circuit expert to create a miraculous solution (
Figure 2). The design often tends to be bottom-up, and reuse of previous solutions and approaches is not common. Such approaches don’t enable wide-spread development using these techniques, unlike the wide use of digital design techniques.
Analog computation [
5] becomes relevant with the advent of FPAA devices (
Figure 2), particularly the SoC (System on Chip) FPAA devices [
6] and resulting design tools [
7] (Figure 4). FPAA requires an analog computation framework (
Figure 2) to reach its large potential. The discussion of resolution and computational noise and computation energy has recently been addressed [
8], showing a balance between analog and digital computation, each with their own optimal regions. Analog abstraction and hierarchy, including the capability of top-down analog computing, is fundamental for practical analog computation.
The abstraction and tool framework will focus on the SoC FPAA family of devices, although the techniques would be applicable to other FPAA devices, as well as applicable to general analog implementations and other real-valued (physical) computing systems. Analog abstraction will focus on algorithmic abstraction, such as filtering, subband processing, and classification, as the analog equivalent of multiply and addition tend to be circuits requiring simply one (or a few) transistors per input vector component [
9]. These presented techniques are only the beginning of these directions.
This discussion presents the first step in analog (and mixed signal) abstraction utilized in an FPAA encoded in the open-source SciLab/Xcos based toolset. Reviewing the SoC FPAA ecosystem and energy efficiency discussions (
Section 2) provides the background for developing abstraction. This background enables developing design approaches for abstraction and resulting library blocks (
Section 3). We instantiated abstraction in tools (
Section 4) is split into system design (
Section 4.1) and circuit level design (
Section 4.2) with a transition between levels. The SoC FPAA approach is aimed primarily for system design while still enabling circuit level design. The discussion then proceeds to show the abstraction and complexity of multiple working test cases, illustrating analog abstraction capability (
Section 5). We conclude by discussing the FPAA block library (
Section 6), discussing the implications for the existing library as well as speculation on fundamental block concepts of analog computational approaches.
2. Energy Efficiency and SoC FPAA Ecosystem
This discussion will develop the start of an analog and mixed signal abstraction resulting from a number tool efforts required for system-level FPAA design. Design tools are a practical instantiation of abstraction (
Figure 1). Analog computing enables both improved computational efficiency (speed and/or larger complexity) of ×1000 or more compared to digital solutions (as predicted by [
9]), as well as potential improvements in area efficiency of ×100. Multiple analog signal processing functions are a 1000× factor more energy efficient than digital processing, such as Vector-Matrix Multiplication (VMM), frequency decomposition, adaptive filtering and classification (e.g., [
6] and references within). Biologically-inspired classifier techniques open the opportunity for configurable biologically-inspired, energy-efficient classifier approaches (1,000,000× over custom digital solutions) [
10] for context-aware applications.
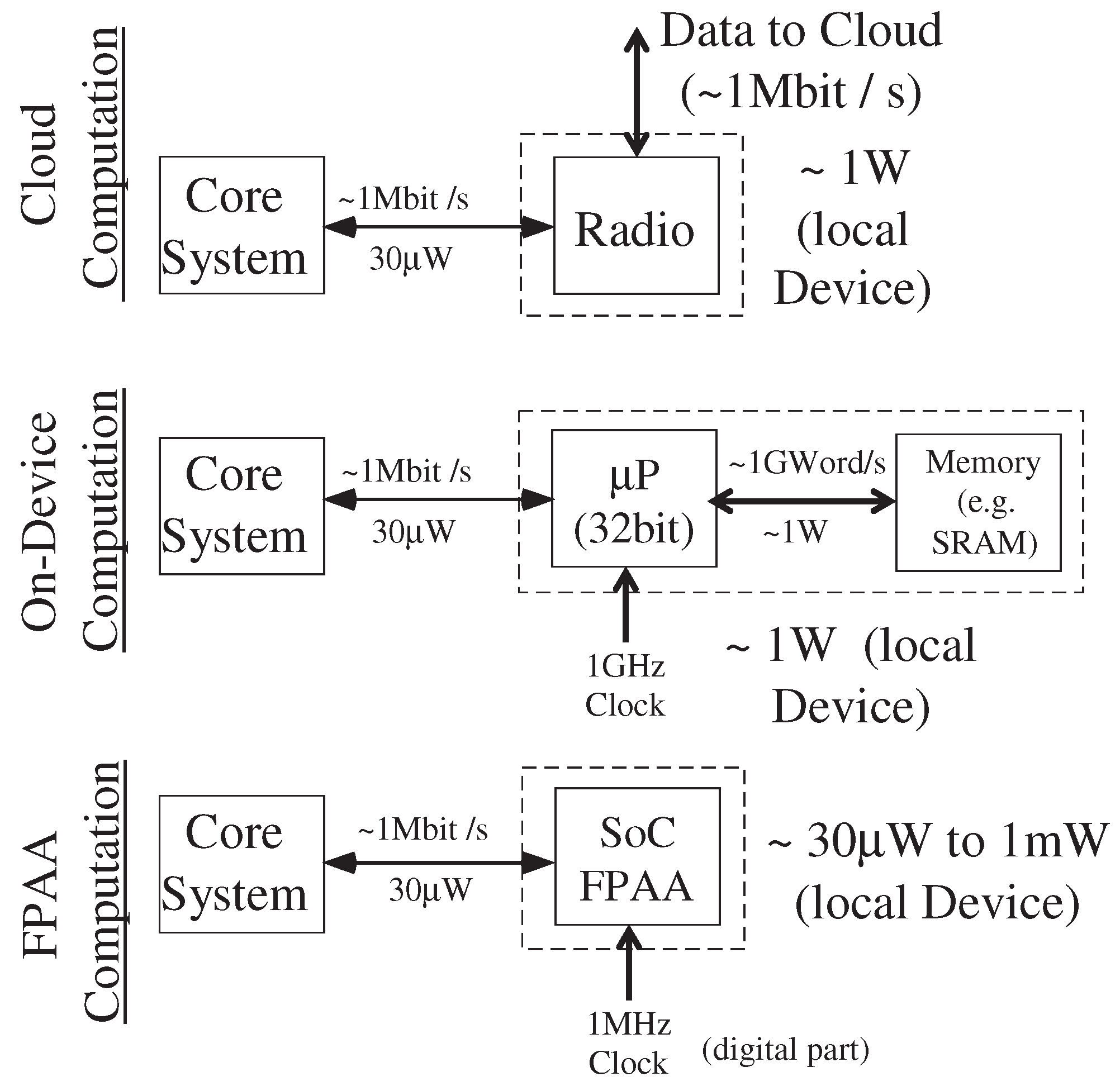
Figure 3 illustrates the energy impact for cloud computation, on-device digital computation, and FPAA assisted computation. Many portable and wearable devices are constrained by their energy-efficiency. Digital communication typically dominates the overall energy consumption [
10]. Cloud based computing removes issues of real-time embedded (e.g., fixed point arithmetic) to be done on some far away (and supposedly free) server using MATLAB-style coding, a high-level language utilizing double-precision numerics where the numerical algorithms are already developed. Computation done off of the device is not seen, and considered effectively endless, eventually resulting in energy and resulting infrastructure required still has significant impacts. The host system still must constantly transmit and receive data through its wireless communication system to perform these computations. The network connectivity must have a minimum quality at all times; otherwise, performance noticeably drops. One often assumes that the cloud is nearly free for a small number of users. As the product scales to the consumer market, these assumptions can break down. Although the local digital device computation (for a good wireless network) requires similar energy for cloud and on-device computation (at a 100MMAC(/s) level), physical computation, such as FPAA empowered devices, enables factors of 1000× improvement in the overall power requirements.
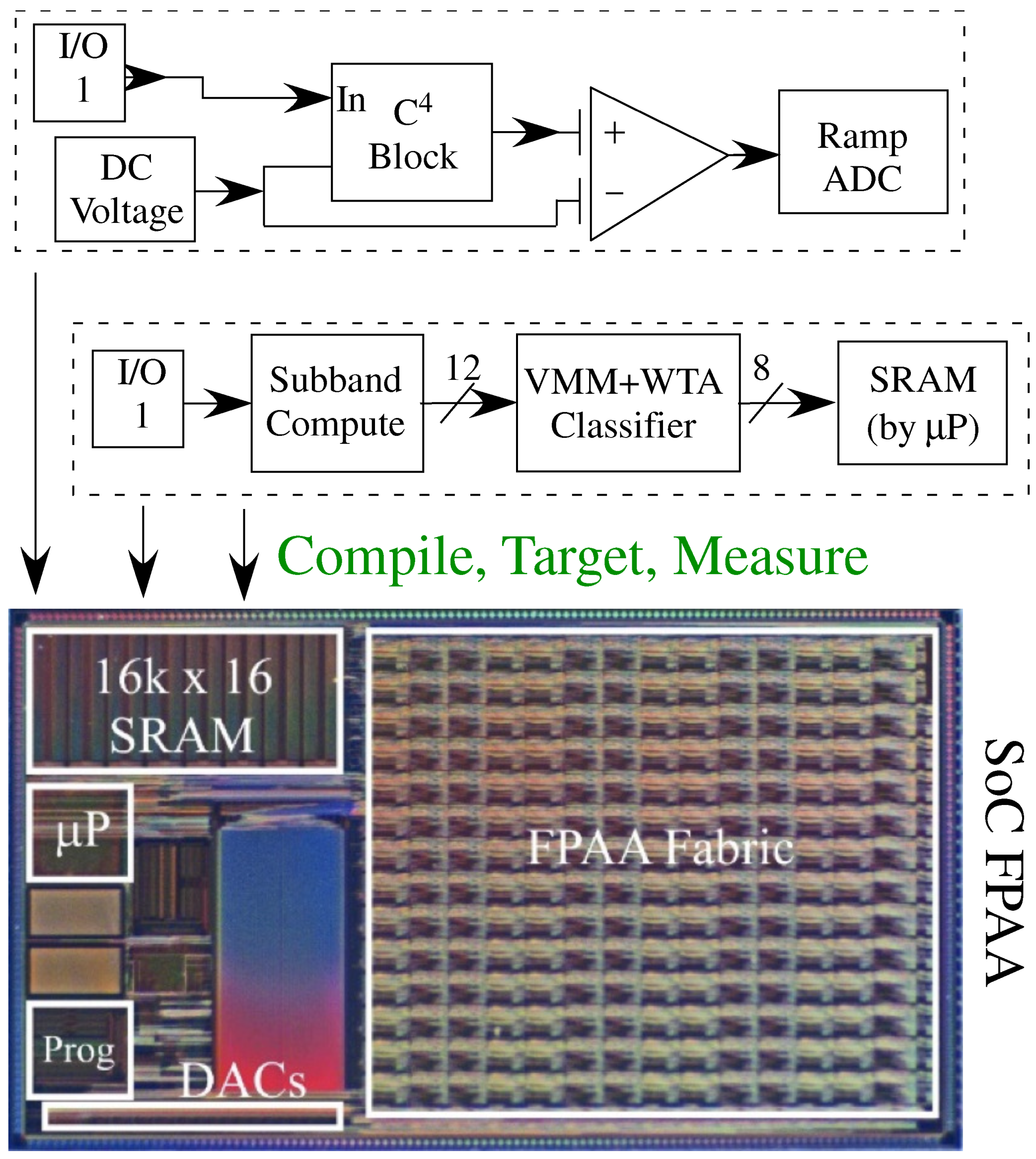
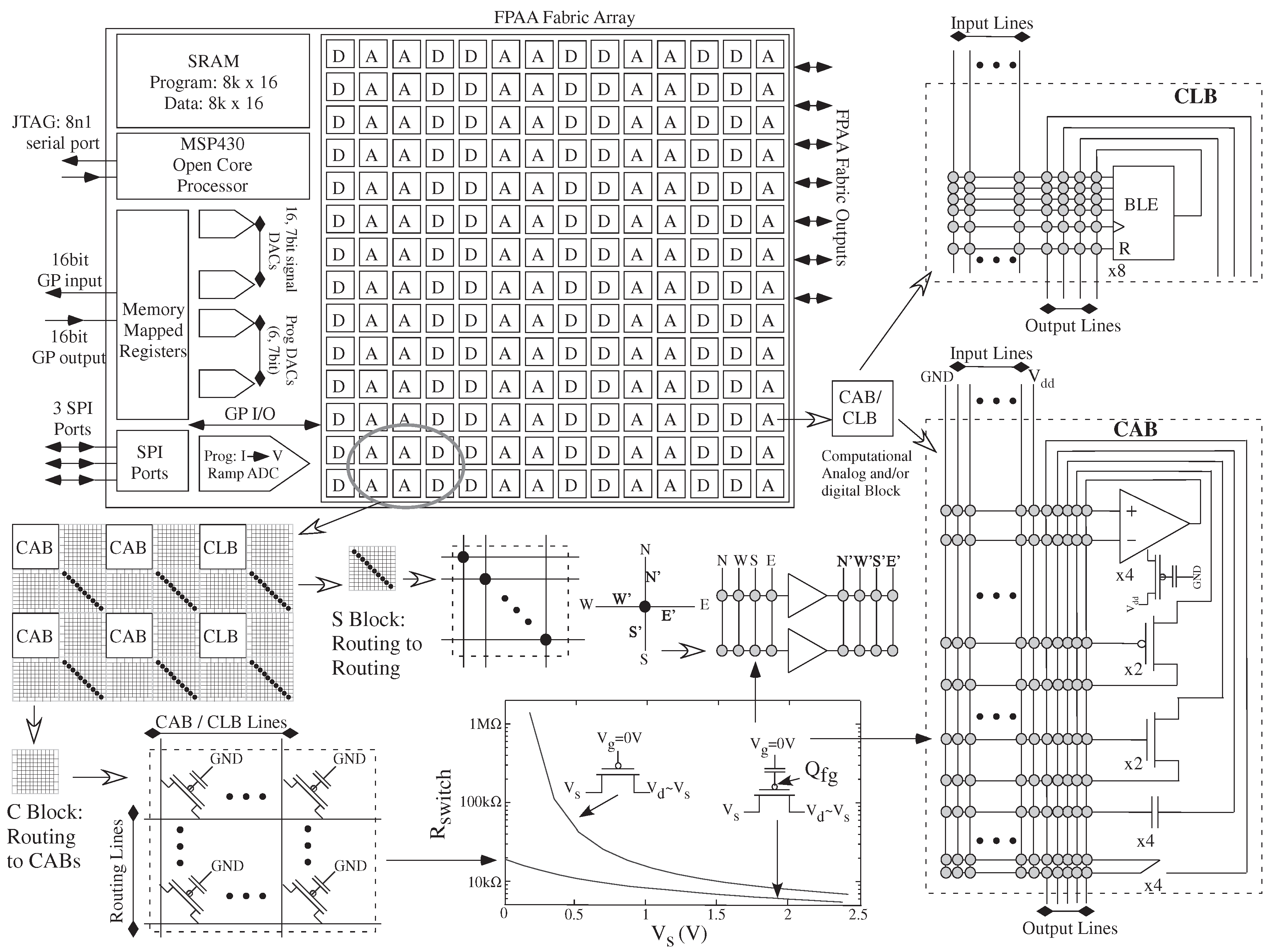
The SoC FPAA ecosystem (
Figure 4) is built around the SoC FPAA family of devices, such as [
6], providing user-friendly infrastructure for system design. The infrastructure could be utilized for the earliest of FPAA devices (e.g., [
11]). These FPAA devices use Floating-Gate (FG) devices for ubiquitous small, dense, non-volatile memory throughout the 350 nm CMOS IC. SoC FPAA devices can scale to smaller IC process nodes with improved energy efficiency, increased bandwidth/clock rates, and reduced system area, all improving quadratically with decreasing linewidth [
12] We expect future FPAA devices to be built to this standard. Early recognition of FG switches (e.g., Computational Analog Blocks (CAB) selection crossbars) as computational elements [
13] both enabled a wide range of computations (e.g., VMM [
14]), as well as brought creative energy to the routing infrastructure (history described in [
6]) and resulting system capabilities. In such architectures, the CAB components are often the boundary conditions for the computation, not the core computation.
Over a decade of consistent FPAA development and application design has roughly converged on a typical mixture of several medium level components per CAB (OTAs, FG OTAs, T-gates), along with a few low level elements (transistors, FG transistors, capacitors). Comparing the CABs of early papers [
11] to the CAB topology of recent FPAA designs (
Figure 5, adapted from Figure 2 in [
6]) shows some similar characteristics, validated by numerous circuits designed and measured in these architectures. A few CABs might be specialized for larger functions (e.g., signal-by-signal multipliers [
6], sensor interfacing [
15], neurons [
16]), showing their relative importance in these discussions. Most of these elements have at least one FG parameter that is part of the particular device used. For small to moderate CAB components, the complexity of the resulting device is roughly proportional to the number of pins available for routing. Three terminals of an nFET transistor has similar system complexity to three terminals of an FG OTA. We expect some small shifts in these components in future FPAA devices, such as dedicated current-conveyer blocks, but generally, the CAB level components are stable. The number and size of FPGAs Look Up Tables (LUT) vary from architecture to architecture; FPAA CABs vary similarly.
FG circuits enable a large potential circuit design space that can be tuned around mismatches (e.g., [
17]). All Transconductance Amplifiers (OTA) have an FG transistor to set its bias current; the bias current can be directly programmed between 50 pA and 10
A with better than 1% accuracy at all current levels [
18]. FG OTAs are chosen for programming input offsets (FG charge) as well as programming the linearity (capacitor elements) and open-loop gain of the OTA. For many applications, one considers the OTA devices as a differential-input, voltage-output amplifier.
The SoC FPAA [
6] ecosystem represents a device to system user configurable system. An SoC FPAA implemented a command-word acoustic classifier utilized hand-tuned weights demonstrating command-word recognition in less than 23
W power utilizing standard digital interfaces [
6]. Multiple analog signal processing functions are a factor of 1000× more efficient than digital processing, such as Vector-Matrix Multiplication (VMM), frequency decomposition, adaptive filtering and classification (e.g., [
6] and references within). Embedded classifiers have found initial success using this SoC FPAA device towards command-word recognition [
6], and accoustic (and biomedical) sensor classification and learning (e.g., [
19]) in 10–30
W average power consumption. Floating-Gate (FG) devices empower FPAA by providing a ubiquitous, small, dense, non-volatile memory element. The circuits compute from sensor to classified output in a single structure, handling all of the initial sensor processing and early stage signal processing. This ecosystem scales with newer ICs built to this standard, as expected by all future FPAA devices [
12]. The
P is clocked at 20 MHz, and can be clocked at least to 50 MHz, consistent with other digital computation in 350 nm CMOS; at smaller linewidth processes, the highest clock rate increases.
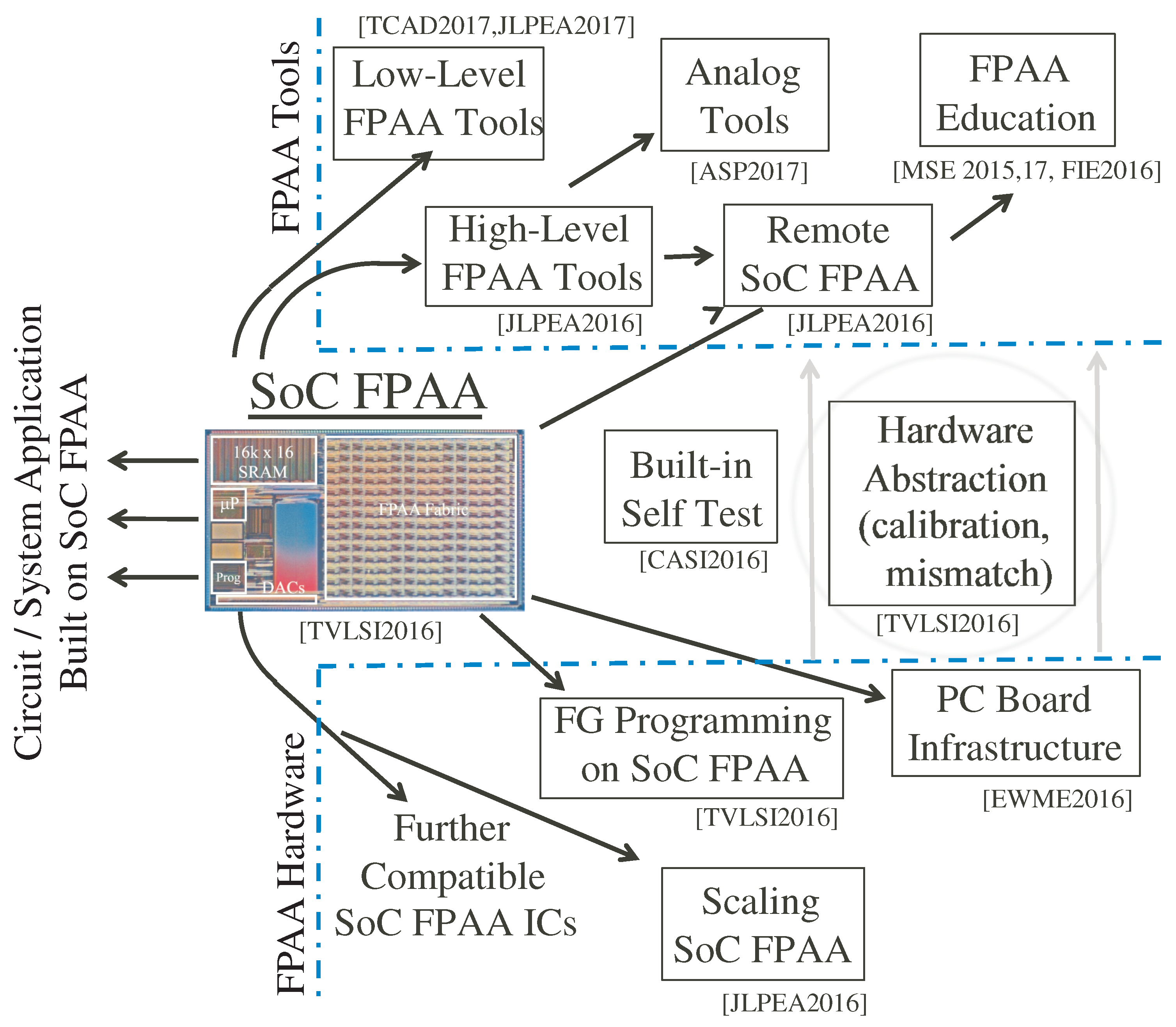
Figure 4 shows a high level view of the demonstrated infrastructure and tools for the SoC FPAA, from FG programming, device scaling, and PC board infrastructure, through system enabling technologies as calibration and built-in self test methodologies, and through high level tools for design as well as education. The current infrastructure enables a discussion of the analog block abstraction.
This ecosystem and abstraction allows us to talk about approaches for future FPAA devices in scaled down technologies (e.g., 130 nm and 40 nm) [
12]. Development of FPAA devices in 350 nm CMOS has enabled a powerful platform to iterate on FPAA designs, while still having several engineering applications. One expects future FPAAs in a range of processes for a range of bandwidths and clock frequencies. The development of a 40 nm SoC FPAA device [
20] showed that FG enabled analog and digital design is fairly similar to design at the 350 nm node. The FG devices eliminate most issues of threshold voltage mismatch, the primary issue in porting analog and digital designs to 40 nm and smaller device nodes. Avoiding threshold voltage mismatch by FG devices breaks the typical viewpoint that one wants large transistors for analog as opposed to using small transistors for digital operation. Smaller voltage headroom and lower transistor gain need to be considered for any design, where the drop from 2.5 V supply at 350 nm FPAA to a 1 V supply at 40 nm is a small effect, particularly for circuits operating with subthreshold bias currents. Transistors at 40 nm CMOS are mostly operating with subthreshold or near subthreshold bias currents. As a result, one expects little change in device modeling or in system abstraction scaling between 350 nm and 40 nm CMOS that likely continues when scaling to smaller process nodes. The device and circuit modeling would be similar, although the simulation parameters would likely change for a new IC process (350 nm → 40 nm). One can also utilize digital devices to assist with any analog functionality as a result of scaling, just as one can utilize more analog devices to assist with numerical computation.
The open-source toolkit is a developed Analog-Digital Hardware-Software CoDesign environment for simulating and programming reconfigurable systems [
7]. The analog (and mixed signal) abstraction is developed in this open-source toolkit used for the SoC FPAAs. This tool simulates, designs, as well as enables experimental measurements after compiling to configurable systems in the same integrated design tool framework. The simulation tool enables current-voltage and individual transistor level simulation, as well as abstracted system-level simulation. High-level software,
x2c, in Scilab/Xcos (open-source clone of MATLAB/Simulink) converts high-level block description by the user to a modified
blif ( Berkeley Logic Interface Format) format, verilog and assembly language. This tool uses modified VPR [
21] code for global place and route while utilizing its own code for local place and route functions. The resulting targetable switch list is targeted on the resulting configurable analog–digital system.
3. Tool, Abstraction, and Initial Block Library Design Approach
One might wonder if fundamental analog building blocks, both in hardware and in the software tools, can be reasonably determined in a similar way one uses look-up tables and flip-flops for FPGA designs. Digital FPGA components did not start off being obvious, starting with Programmable Array Logic (PAL) and Programmable Logic Array (PLA) approaches. The approaches used came from the same individuals who were working on look-up tables and and-or logic components. There was not a methodology, but rather a good approach that when scaled up has been effective. Today, these approaches seem sufficient for most tasks, particularly since FPGA architectures are partially hidden from their users.
Analog computation has not had a similar set of blocks because analog computation did not build up a computational framework [
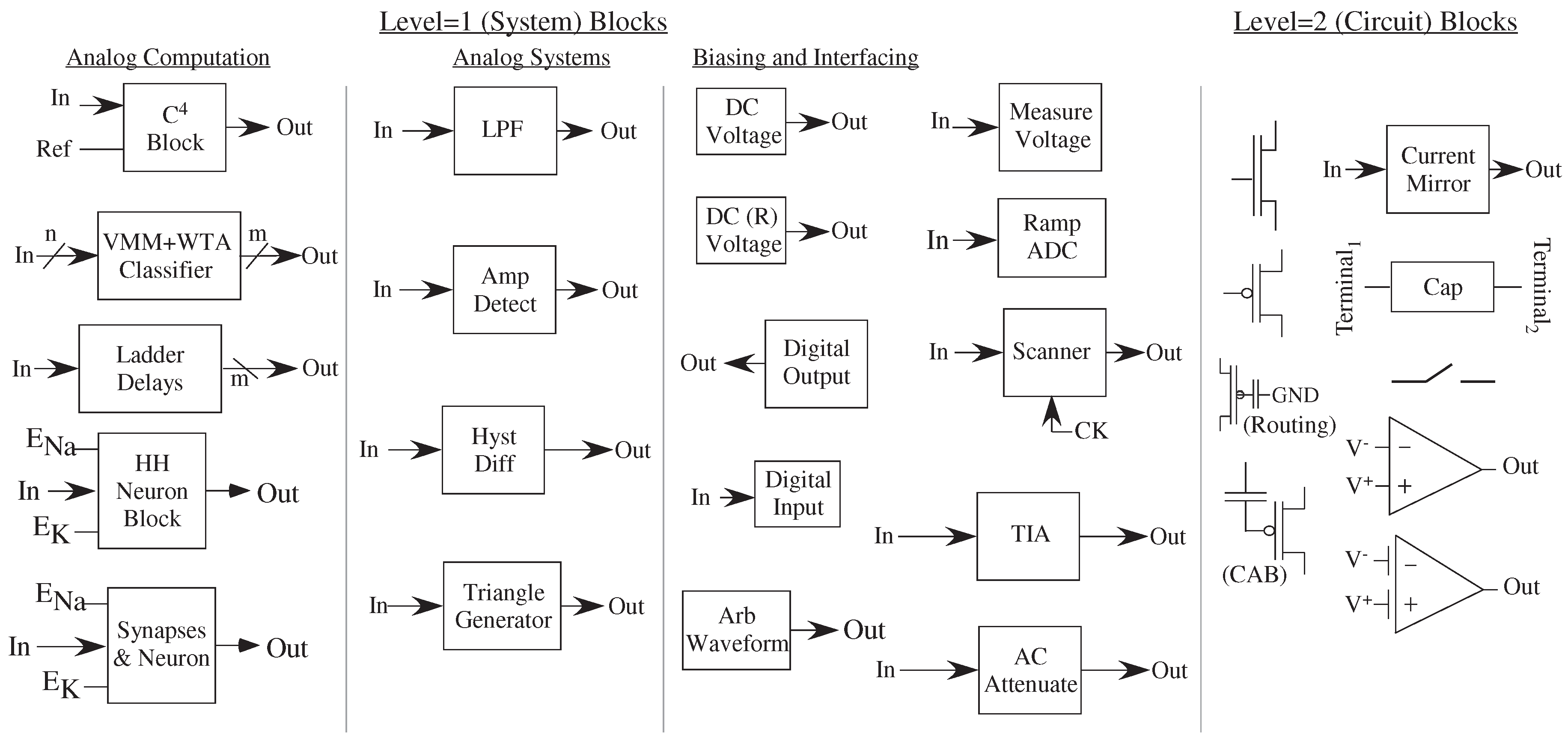
5] to enable transitioning to these higher levels. The rise of FPAA approaches has become the testbed to begin to build this framework. The tools designed to enable a non-circuits expert, like a system applications engineer, to investigate particular algorithms. Analog block library are similar to a high level software definition or library (e.g., we will show later in
Figure 6). The analog Scilab/Xcos system is a visual programming language in the same tradition as Simulink, building on aspects of visual programming languages [
22,
23], and data flow languages [
24,
25]. Graphical algorithms are popular for Graphical FPGA tools, such as the recent and independently developed open-source tool, Icestudio [
26]. Labview is a non-open-source related approach that does have some aspects to connect to physical instruments (e.g., [
27]), and with ODE-based infrastructure might be adapted to create a similar flow. The Scilab/Xcos blocks are core blocks where there are not lower level pictures of these components, although many of them are described as part of this discussion. Higher level abstraction is possible with blocks as we will see throughout this technical discussion.
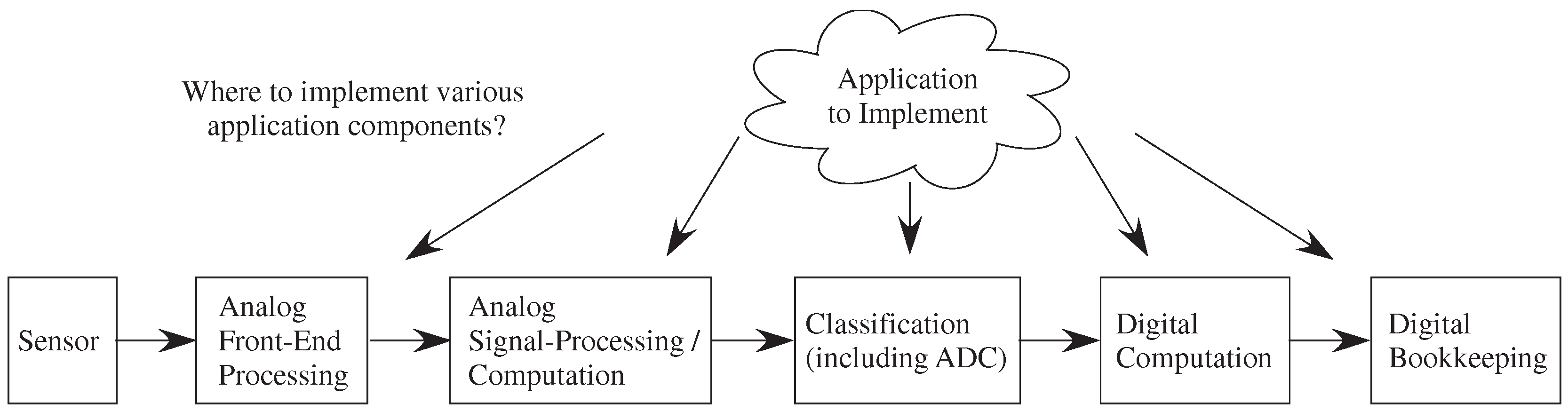
This new capability creates opportunities, but also creates design stress to address the resulting large co-design problem (
Figure 7). The designer must choose the sensors as well as where to implement algorithms between the analog front-end, analog signal processing blocks, classification (mixed signal computation) which includes symbolic (e.g., digital) representations, digital computation blocks, and resulting
P computation. Moving heavy processing to analog computation tends to have less impact on signal line and substrate coupling to neighboring elements compared to digital systems, an issue often affecting the integration of analog components with mostly digital computing systems. Often the line between digital and analog computation is blurred. For example, data-converters, or the more general case of analog classifiers, typically have digital outputs. The digital processor will be invaluable for bookkeeping functions, including interfacing, memory buffering, and related computations, as well as serial computations that are just better understood at the time of a particular design. Some heuristic concepts have been used previously, but far more research is required in building applications and the framework of these applications to enable co-design procedures in this space.
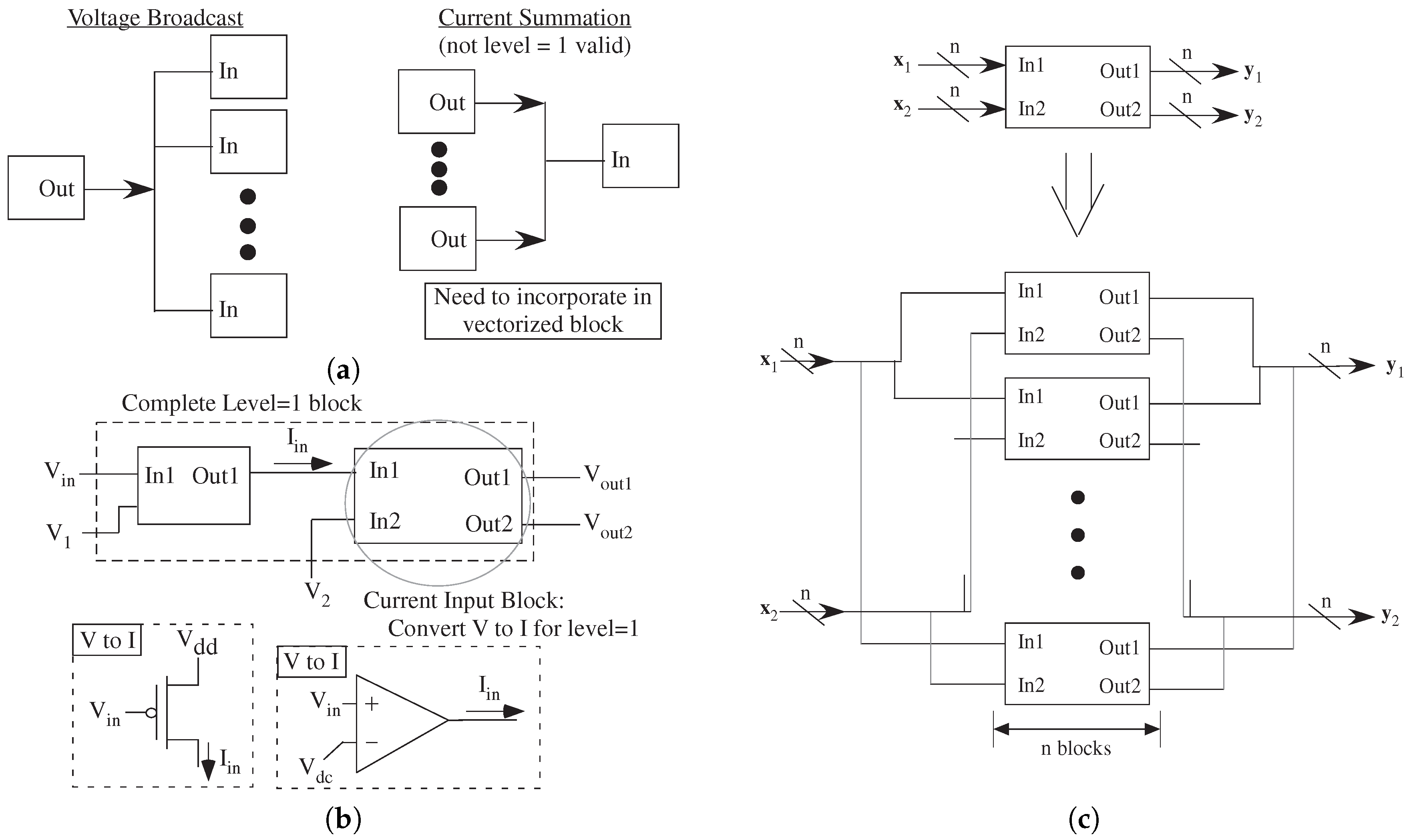
Analog computation directly implements dataflow parallelism. Analog executes as data appears. This representation allows parallel algorithms by design. Analog computation optimally merges data and computation, typical of data flow computation. The event data flow graphs fit well with neural computation/modeling, particularly for low average rate firing systems. Event (asynchronous) and clocked (synchronous) systems would be pipelined data flow systems [
25]. The
P primarily enables event driven processing as well as interfacing to outside synchronous digital world. Tool compilation will state whether enough resources are available, including computational components and data communication. The need for deep FIFOs, as in digital data flow implementations [
24], is rarely needed except for final data logging and debugging.
5. Illustration of Complexity Available for Analog Abstraction
This section shows multiple examples demonstrating the design of many levels of analog/mixed-signal abstraction, showing the new capabilities and patterns in analog abstraction. The examples start with simple circuit elements and work towards analog computation, showing the complexity as well as abstraction throughout the process. FPAA abstraction, and resulting tool implementation, must involve compilation and simulation. These concepts introduce the abstraction of a complex circuit element, both in its suprising layers of required abstraction, as well as the amount of abstraction required for instrumenting the computation. Analog signal processing using these blocks requires a higher layer of abstraction, and computation, like classification and learning, requires even high layers of abstraction. These blocks show the large number of abstraction layers, and the constant reuse of components. The block abstraction concepts and tool design developed in an ethos of FPAA experimental design and measurement experience. Most of the application circuit implementations were not envisioned until after the SoC FPAA ICs were fabricated.
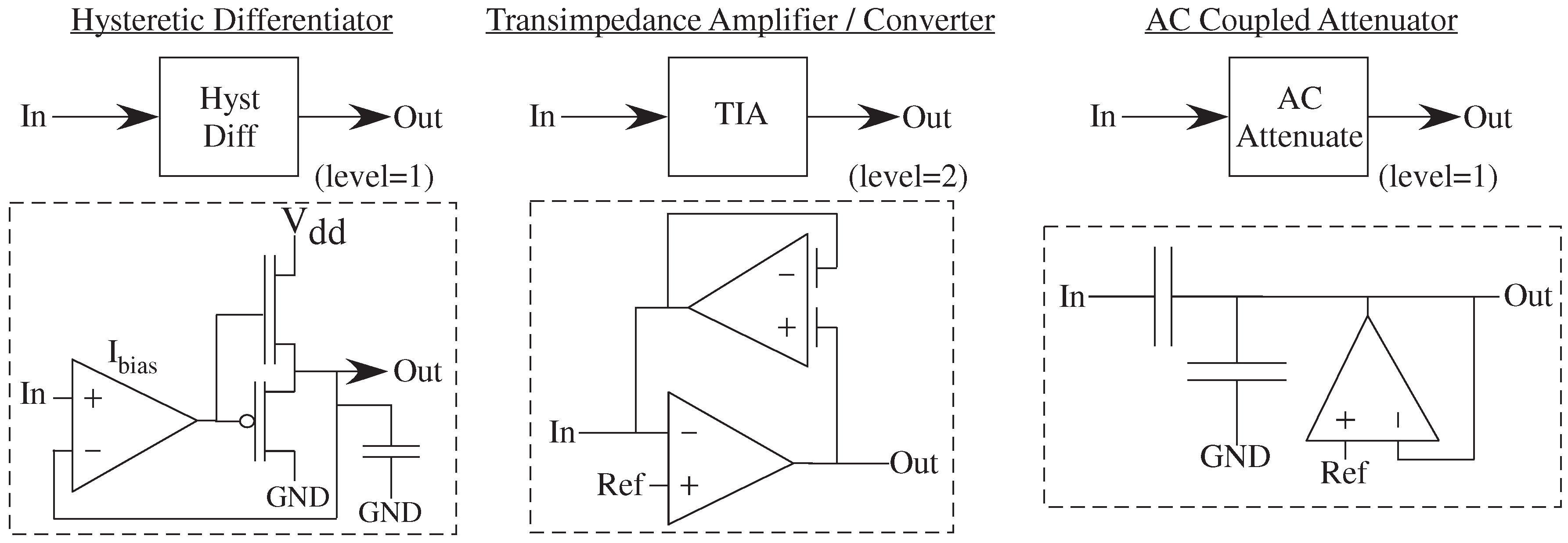
We have already seen a few representative Level = 1 blocks and their circuit representation (
Figure 9). These blocks use a small number of components for input signal interfacing (AC Coupled Attenuator), for output signal interfacing (Transimpedance Amplifier), and for a range of linear and nonlinear (Hysteretic Differentiator) functions.
FG OTAs can be used for a number of applications required in analog circuit techniques. One can use these blocks to gain a signal between 10 and 100 around a DC value. Two OTA devices can build a divide by 10 or another value around a DC potential. Analog circuits often need to tune the particular input or output signal range between components. Two OTAs are be used to build the low-pass filter second-order section block definition (e.g., [
65]). OTA blocks are important for building on music synthesis blocks [
66], including the current block, CurrentStarvedInverter.
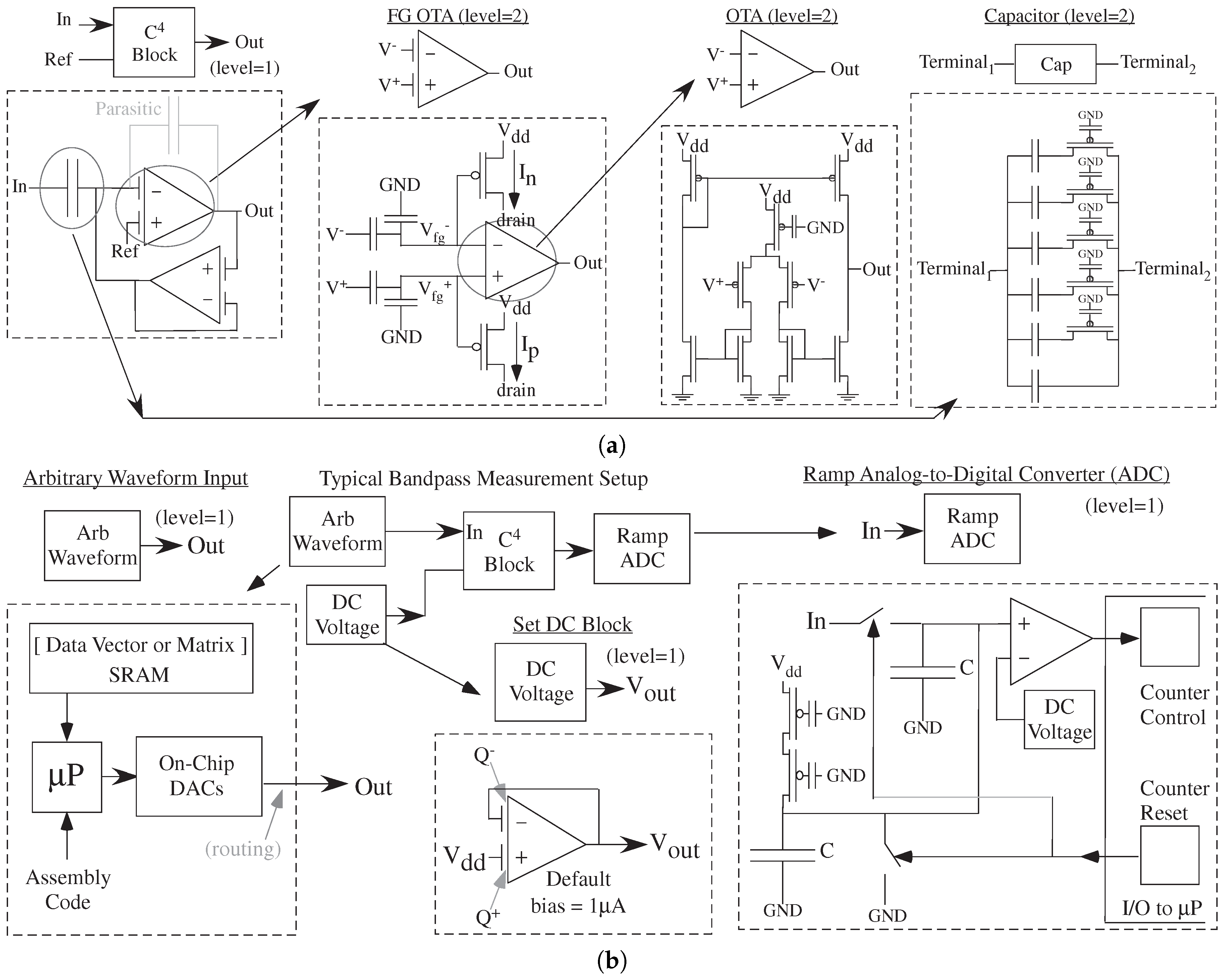
A simple second-order bandpass filter block (simulation and compilation) shows significant analog/mixed-signal abstraction (
Figure 10), providing a useful example showing the number of levels of a few fundamental components required for reusable analog elements. The multiple levels of analog abstraction is significant in a typical implementation, levels that can be abstracted from the designer who only needs to use higher level blocks ( blocks in measurement setup of
Figure 10b). The bandpass block, a G
-C C
bandpass filter topology, is deceptive because underlying the simple block are multiple levels of abstraction where FG elements are used throughout each structure, as well as tunable capacitor banks (
Figure 10a). FG elements eliminate biasing issues through programable parameters; programmable parameters are essential for any abstractible physical system. FG enables abstraction by programmable components and abstraction makes users not unnecessarily focus on these details. IC designers want to see circuit details (
Figure 10a), and are typically suprised at the detailed levels.
The blocks for testing require additional instrumentation blocks that are all part of the complete compiled system (
Figure 10b). The set of blocks is the entire system. The blocks for instrumentation to
test a component is part of the computation, illustrating the co-design trade-off in these areas. The DC voltage block is one FG OTA, set in unity gain configuration, and programmed with the required charge to set a DC voltage, eliminating the need for biasing structures (not tunable) or biasing DACs (large elements). The core structure looks like a highly sophisticated analog system design effectively built through a few blocks, simple and robust enough to be a user’s first day potential example. Typically, most analog/mixed-signal systems take a long time to build, and an even longer time to instrument. These techniques immediately show the issues and blocks to build, and eliminates the arbitrary (and unhelpful) lines between design and test.
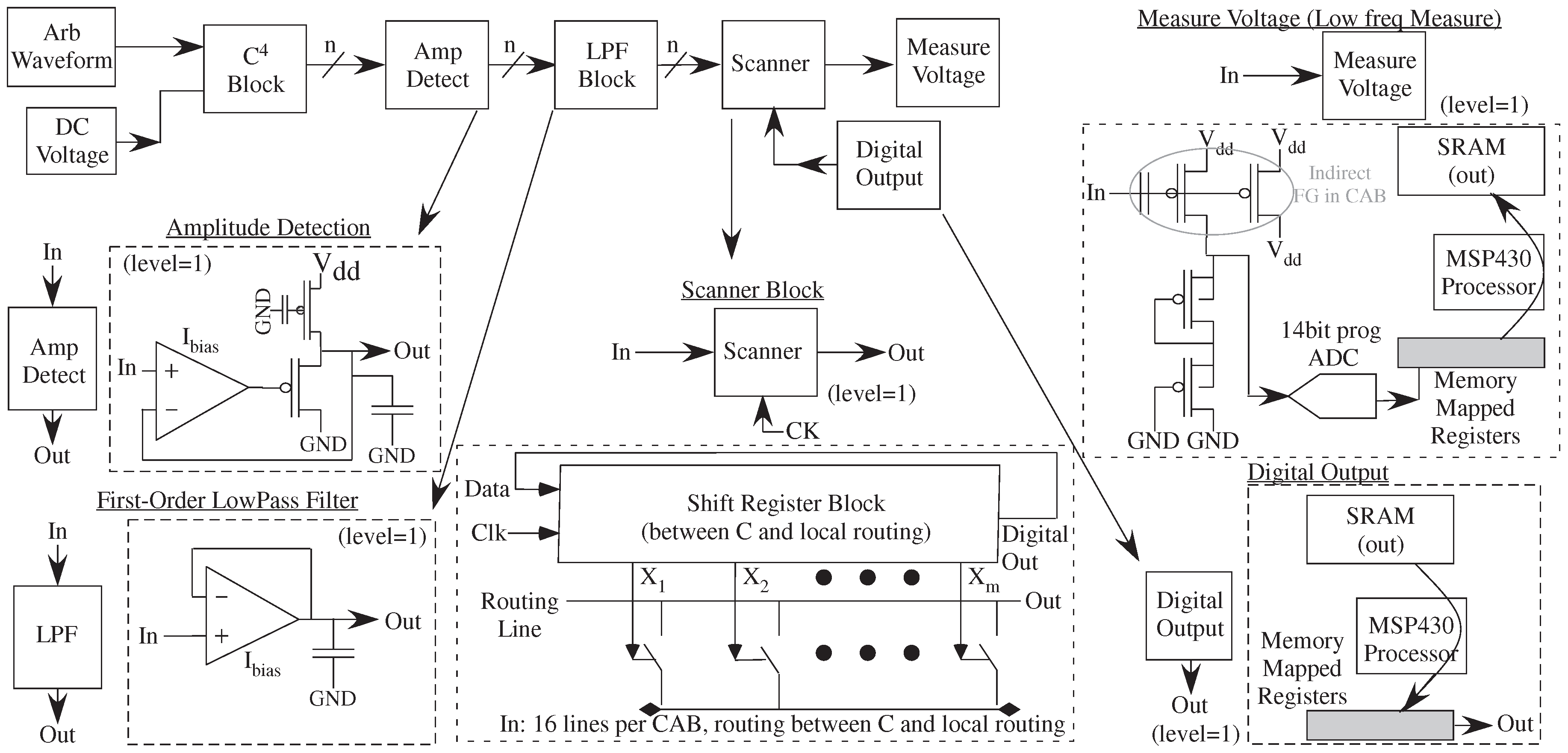
Moving to signal processing applications requires even higher levels of abstraction (
Figure 11), particularly when considering computations like frequency decomposition (e.g., continuous-time wavelet transforms). The previous bandpass filters and amplitude detection block are key components for an exponentially scaled wavelet frequency decompostion (
Figure 11). The computational chain requires a parallel bank of C
, a frequency decomposition, Amplitude Detection, or modulation to baseband, and an LPF. The core block fits into a single CAB and replicated for the number of required bands (
Figure 11). Compiling a block into a single CAB results in a modular structure with minimal internal capacitance.
Table 1 summarizes representative available SoC FPAA interfacing blocks. The particular specifications directly affect the measurements possible for the resulting computation. This measurement illustrates the measure voltage block, effectively a slow speed (200SPS), high-resolution (14-bit) voltage measurement. The structure uses the FG programming circuitry, including the 14-bit measurement ramp ADC, still available in
run mode. Measured data for this operation is shown in Figure 3 of [
6]. The particular voltage measurement location can be multiplexed through the programming selection circuitry.
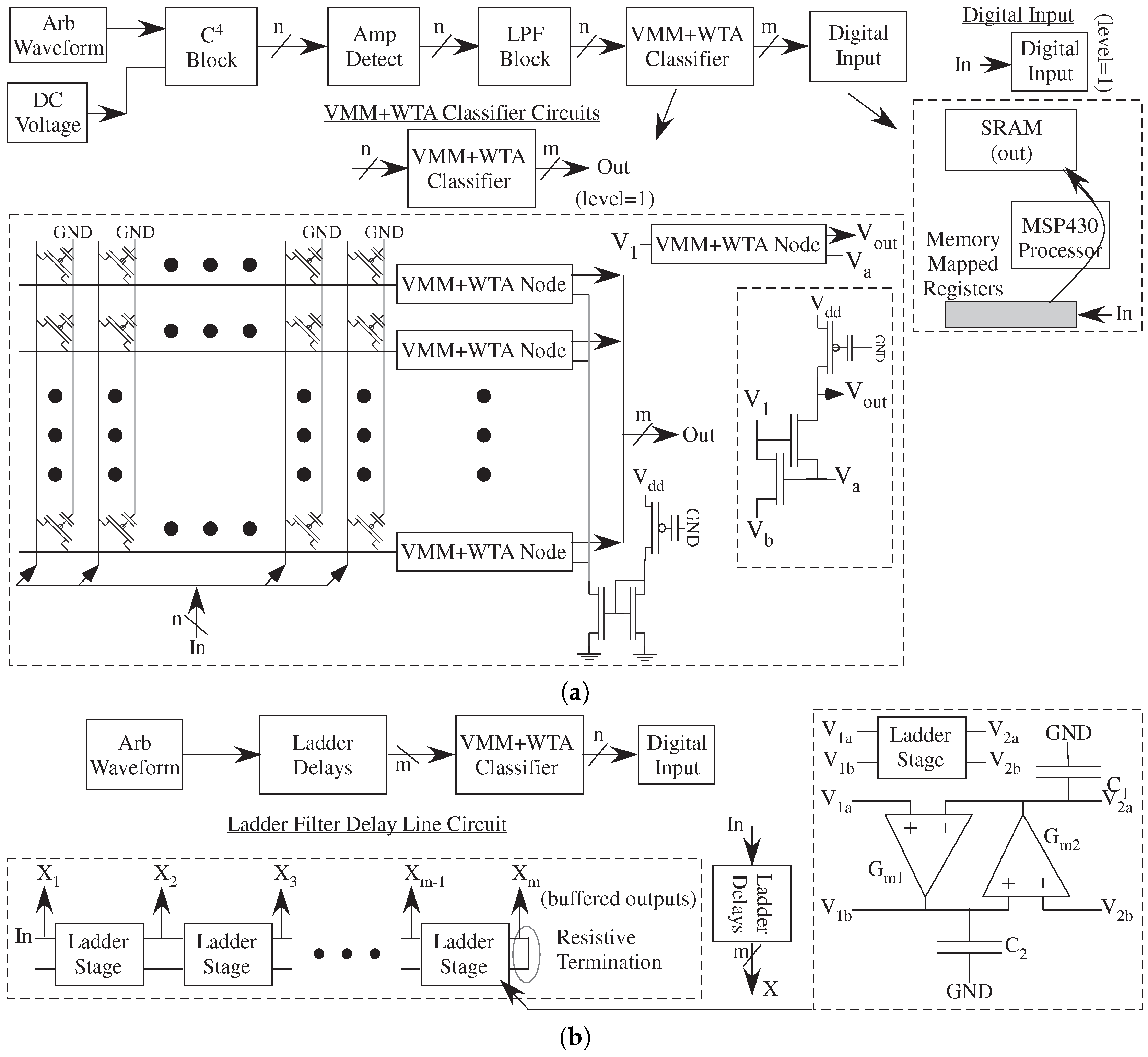
The step towards analog/mixed-signal computation, such as a classifier or learning classifier, requires more additional abstraction levels comprised of multiple modular components (
Figure 12). Modular components are essential results for compiling these circuits into an FPAA structure. Six to either abstraction levels, typical of digital computation, are common for implementing this level of computation. These systems allow for sensors to classified symbolic data, a significant challenge for any system and interface design utilizing popular neural network accelerator hardware solutions. The front-end to the classifier stage could be chosen to the front-end frequency decomposition (
Figure 11 abstracted into
Figure 12a), or a continuous-time delay line approximation (
Figure 12b). The choice of a front-end stage can be dependent on the signal classification algorithm as well as other nontechnical factors. The ladder filter basis function uses a number of coupled G
-C components with a similar complexity per output as the bandpass filter frequency decomposition.
Both approaches (
Figure 12a,b) perform the final classification using a VMM+WTA classifier structure. The VMM items are FG local routing transistors. Unlike traditional FPGA architectures, which have optimized architectures for multipliers (and adds) and memory access to the computation, VMM in FG enabled FPAA devices is simply routing to the next computation with the non-volatile values locally stored. The structure used a digital input block to move the data from the circuit output into the
P SRAM. Recent results show that this VMM+WTA classifier is capable of learning, utilizing additional analog circuit, interfacing, and
P control (more assembly code), in a similar structure [
67].
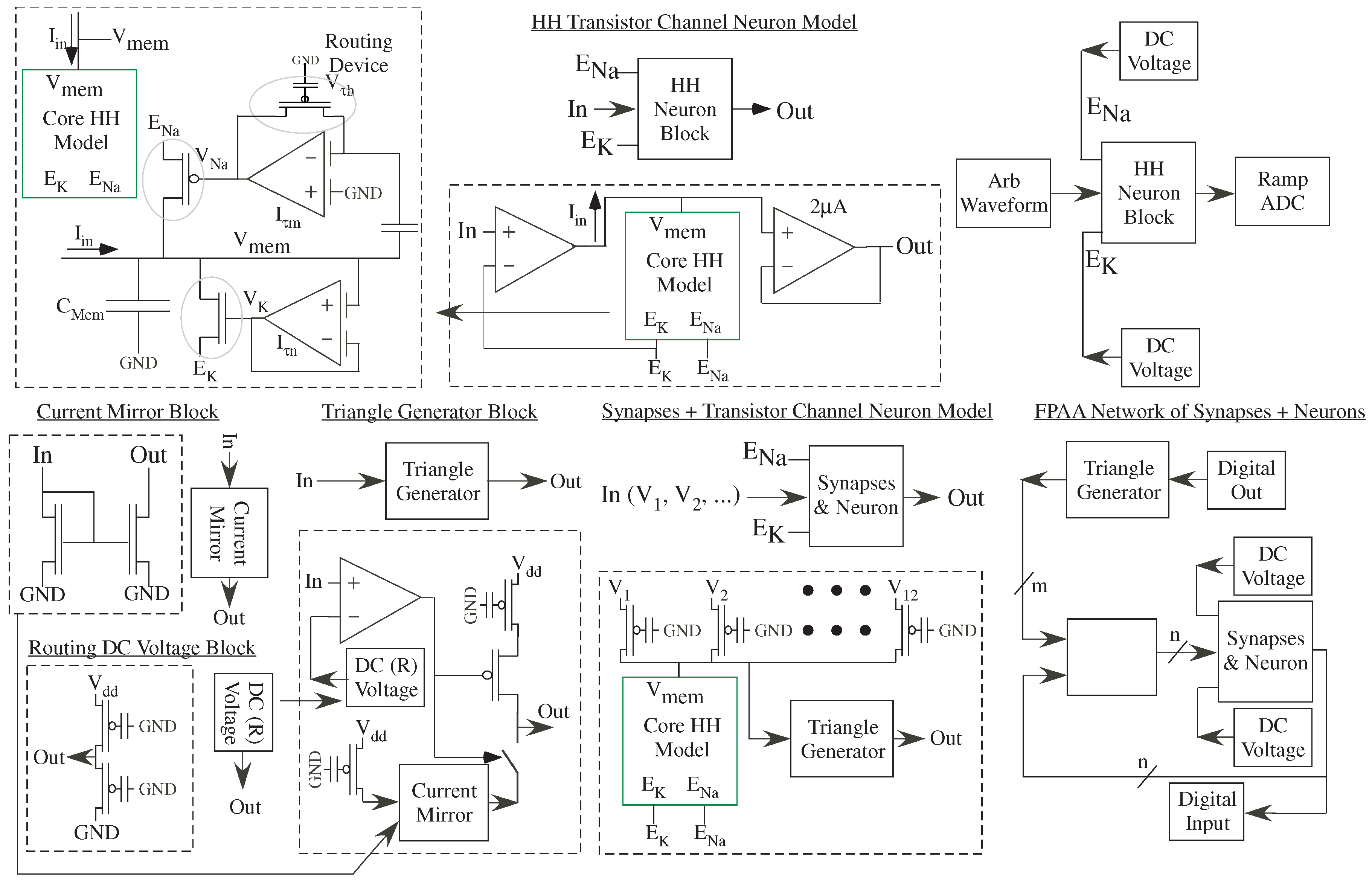
As another Classification and Learning example, abstraction techniques for analog classification can be extended to neuromorphically inspired approaches. The measurement structure shows a full layer of synaptically connected neurons, similar to the dynamics shown in custom ICs [
68], with Level = 1 abstraction of neural blocks using the transistor channel model definitions (
Figure 13). This block could specify the SoC FPAA [
6] compilation of a network of 92 biologically modeled neurons each with 12–14 synaptic inputs and 10–12 network inputs. Learning techniques from the VMM + WTA classifier could be adapted for this network [
67]. One could create a software interface to directly utilize the PyNN [
69] neural representation for simulation or compilation. PyNN shows promise as a tool to unify multiple groups through an open community type tool used by multiple academics. The approach would extend to other neural network applications and approaches in a straightforward manner.
The core Hodgkin-Huxley (HH) model circuit (Level = 2) is an FPAA adaptation of the original channel neuron circuit [
70]. Different applications result in different methods to supply the input current from input voltage(s) creating different blocks. For both cases, all components are chosen to embed the structure in a single CAB, macroblocking the design. One case uses an OTA to transform between voltage input to a single, direct current input into the neuron element(s). The membrane voltage (V
) is buffered to the output. The measurement structure requires similar complexity to other circuits with an input, output, and two DC voltage biases (E
, E
) for all circuit instances. E
and E
are the same biological supply for all neurons and therefore shared between blocks.
Synaptic elements to combine synaptic and neuron activity utilize the local routing FG transistors, adding another level of complexity that is abstracted through the high-level tool framework. The outputs are a triangle ramp that pre-computes the modeled charge concentration reaching the post-synaptic terminal. The number of synapses is limited, in this approach, by the number of local input routing lines. The inputs require a triangle ramp processing from their initial digital events. The ramp element can integrate directly on the line capacitance or can be buffered depending on the resulting synaptic current consumption. The routing DC Voltage block sets DC voltages using only routing fabric, using an FG pFET voltage follower, enabling dense setting of DC voltages. By characterizing one element, one gets a nearly ubiquitous voltage supply circuit that can be routed on any local line. Each CAB has local routing to Vdd and GND lines, so this component is always available with nearly no cost.
6. Collection of FPAA Blocks → Analog Computational Benchmarks
The FPAA block list (
Figure 6) opens the discussion of fundamental block concepts of analog computational approaches. The current list of blocks in the Xcos/Scilab FPAA infrastructure (
Figure 6) are fundamental circuits and blocks at two levels of depth (Level = 1 and 2).
Table 2 summarizes the names of these blocks. Mead’s initial analog VLSI work already mentioned many of these core elements [
65]. The addition of analog programmability and configurability enables both system level design as well as realistic systematic building up of these concepts. The block library shown allows for core analog circuit design through high-level applications, including acoustic, speech, and vision processing, as well as computation using networks of neurons which includes applications in optimal path planning.
Reuse of analog blocks (e.g.,
Figure 6) should reach a way similar to digital blocks, whether in custom circuits or in configurable (e.g., FPGA) platforms. Analog designers are known to be artistic in their craft and in the way they approach their craft. A master painter rarely reuses a part of another artist’s work, but rather the painter will add their artistic skill (e.g., optimizations) to the effort. Many companies (e.g., [
71]) have tried to automate the analog design process, but failed because the solution was aimed for analog IC designers. A configurable analog/mixed-signal system-level platform, instead of relying on custom analog design, would create a demand for analog abstraction and automation. Abstracting analog design for system designers increases the chance of automation to be utilized. Reuse of analog blocks, similar to use in digital Verilog or
C libraries, is both an opportunity for rapid growth of analog computing systems, as well as essential to the growth of the field. The FPAA system utilizes a number of blocks (
Table 1 shows some representatives).
The blocks available give some insight on what we see for abstraction of analog functionality. The block library in
Figure 6 is still a subset of blocks currently used. It would be hard to write down every digital algorithm, but both sets of computations usually arrive from a subset of fundamental primitives; specialized applications will always exist.
Table 3 illustrates some of the resulting compiled FPAA computations, and some values of their resulting utilization on an SoC FPAA device. Related computations in telecommunications, such as VMM for beamforming and DCT computation, Viterbi and HMM classification, and computation of PDE solutions provide a fairly complete coverage of computations, particularly sensor computations. A computing approach based on large number of coupled ODEs [
8] has tremendous potential. The capability for vectorized computations and representations enables system thinking. VMM is a fundamental operation in both analog and digital computation, providing a conceptual bridge between the approaches. Analog VMM implementation in routing fabric results in a huge advantage for analog computing opportunities.
The block library in
Figure 6 is still a subset of blocks currently used because new blocks are being generated. Users of these tools have their own creative directions when solving application challenges, resulting in new innovations. These tools enable a similar case to a software library definition, enabling these capabilities for analog and mixed-signal design. The tools support these new innovations, and the authors encourage building up shared library spaces. An open FPAA infrastructure potentially fulfills the possibility of an open configurable architecture, unlike most commercial FPGA devices (e.g., [
76,
77]). A number of blocks are still not finished, and one expects a list is never completely finished. One expects eventually to have a complete set of ADC blocks, such as successive approximation, algoithmic, and pipeline architectures, a number of image processing blocks, communication circuits, and mixed signal computation such as distributed arithmatic linear phase computation [
78].
Benchmark circuits are a way to codify what one means by computing. Defining an analog block library sets the stage to set up benchmarks circuits. The fundamental computation levels show potential parameterized set of benchmark circuits:
VMM + WTA acoustic classifier,
Neuron + moderate number of Synapses,
Analog filter with approximately linear phase constraints,
Biomedical signal regression and/or classification,
Image convolutions and/or classification,
Dendritic Classiciation,
Spatio-Temporal PDE solution, such as Path planning of a given network size.
A settled set of benchmark circuits enables both the characterization of existing configurable devices, as well as opening up research into optimal FPAA architectures. Analog benchmark circuits illustrates the meaning of computing.
7. Analog Abstraction: Summary and Implications
We see the first step in analog (and mixed signal) abstraction utilized in FPAA, encoded in the open-source SciLab/Xcos based toolset. The analog (and mixed signal) abstraction developed for the open-source toolkit used for the SoC FPAAs. Abstraction of Blocks in the FPAA block library makes the SoC FPAA ecosystem accessible to system-level designers while still enabling circuit designers the freedom to build at a low level. The test cases in the previous sections show various levels of complexity illustrating the analog abstraction capability. Abstract analog blocks, with digital components, into higher level abstractions enabled by the Scilab/Xcos toolset illuminates the higher-level representations for analog computation.
Although many aspects of analog abstraction are still yet to be discovered, they have hopefully shattered the view that analog devices, circuits, and systems are not abstractable. This abstraction is explicitly implemented in tools that enable CAD design, simulation, and compilable physical design. In no way have we made all of the blocks ever needed, but the framework is established to be evolved with new discoveries. Having any opportunity of a wide-scale utilization of ultra-low power technology both requires programmability/reconfigurability as well as abstractable tools. Abstraction is essential both make systems rapidly, as well as reduce the barrier for a number of users to use ultra-low power physical computing techniques.
In practice, two views are likely for analog computing, first, that analog device, circuits, and systems are just not abstractable like digital systems, and, second, that analog abstraction is incredibly difficult because one can not abstract analog functionality and computation in a similar way to digital computation. As mentioned earlier, sometimes macromodeling is used in larger analog projects to make simulation tractable and related uses, so some level of analog abstraction is considered by a few in the larger design community. Effectively, these two views are two sides of the same viewpoint since the effective perceived difference between these two viewpoints is between nearly impossible and not possible. This work challenges these viewpoints by explicitly demonstrating multiple layers of analog abstraction. These demonstrations lead to developing initial computing blocks libraries that compose a large number of analog signal processing and computation. Designing FPAA applications highly encourages creating reusable abstractable libraries.
The lowest level of analog abstraction occurs at a higher level than the lowest digital abstraction. Digital is built by simple operations, and yet it is constrained by these few operations—typically delays, arithmatic operations, and comparisons in a sampled time environment. Multiply-accumulate is a significant digital structure compared to a 1–10 transistor analog circuit. Analog circuits have a richer set of functions, starting from some common digital functions, as well as additional dynamic components (e.g., low-pass filters). Dataflow architectures become a useful framework for users to utilize these concepts. guiding the user’s intellectual framework, similar to early MATLAB guiding users towards developing vectorized code for higher performance.
Analog/mixed signal can have abstraction built similarly to digital computation, since there are no fundamental limitations of analog abstraction to digital abstraction. Some aspects will be more advantageous than others. Nothing fundamentally constrains analog approaches. Achieving these goals requires wide use of these techniques with a number of component libraries. Abstraction challenges center around developing a community of users developing various analog system level libraries. Growing a community requires effort and time, as well as resources to demonstrate a range of competitive applications. A commercial source of SoC FPAA devices would accelerate the development of these communities. As these libraries develop, code management techniques for the physical modules/routines will need to be developed. We expect that there will be specialized libraries where individuals require these techniques. A larger library helps refine the fundamental components while classifying particular blocks as needed. The abstraction is clear for the 100 s of digital standard cell library elements.
Analog/Mixed signal abstraction development could result in multiple new opportunities. Abstraction would potentially allow for topological optimization (e.g., Genetic Algorithms) to optimize a design for a particular application if appropriate system metrics can be described for the optimization. One can visualize extending these concepts outside of SoC FPAA compilation, or any FPAA compilation, to custom IC design approaches. One could extend the toolset from targeting FPAA devices to generating from the same high-level blocks, as either IC layout or the required files for IC layout, or directly generating IC layout. These correct by design concepts could open up translating FPAA solutions to custom IC solutions utilizing analog and digital standard cells, decreasing the transition cost between these solutions.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}