Design Science Research: Evaluation in the Lens of Big Data Analytics



{kind=link}
Abstract
1. Introduction
- -
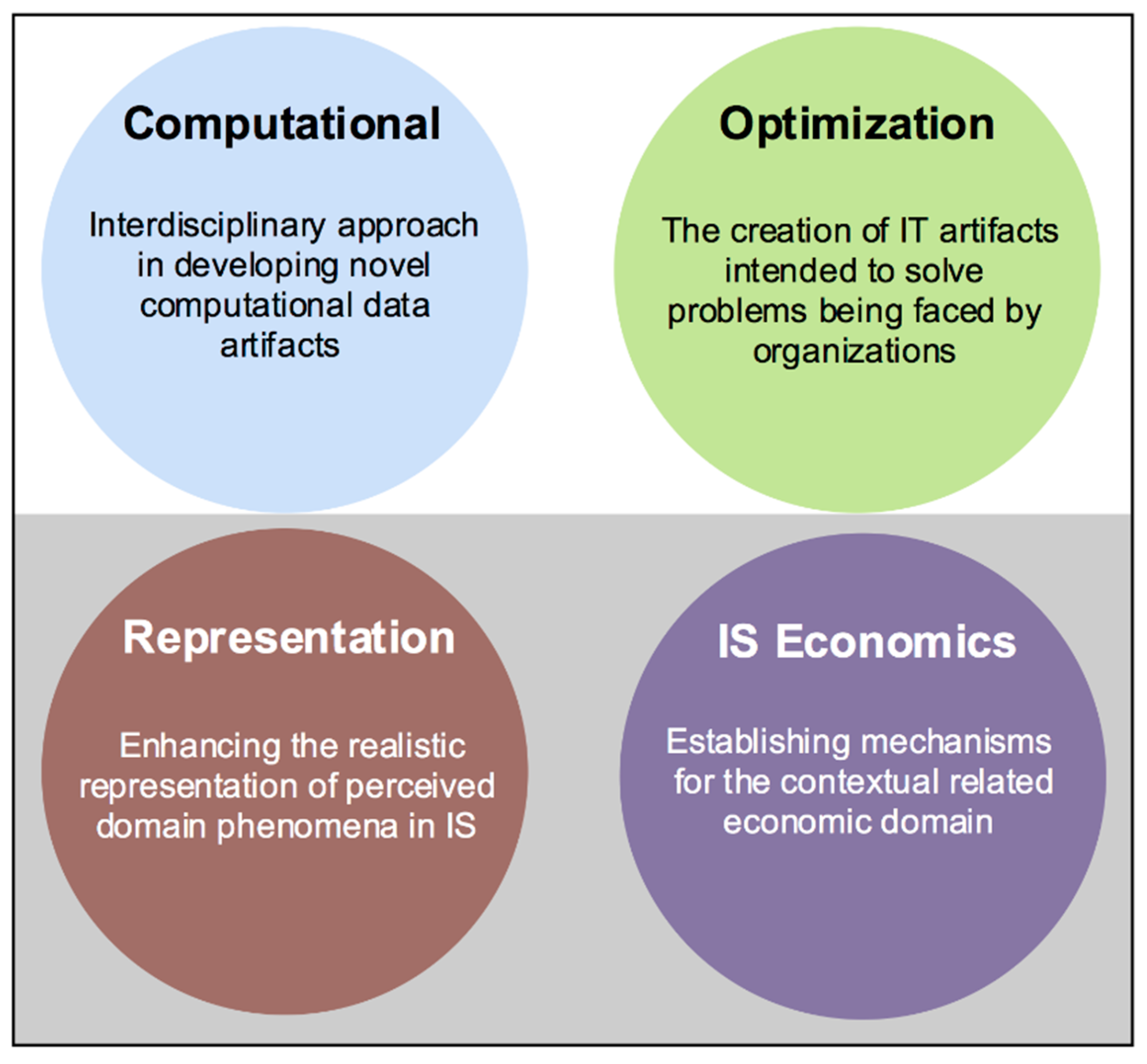
- Computational Genre:
- ◦
- This class of DSR research stresses an interdisciplinary approach in developing artifacts such as data representations, algorithms e.g., machine learning algorithms, analytics methods, and human–computer interaction (HCI) innovations.
- -
- Optimization Genre:
- ◦
- This class of DSR research looks at the creation of IT artifacts that are intended to solve organizational problems such as: maximizing profits, utilities, welfare, etc. Additionally, it falls under the optimization of supply chain activities, internal operations, customer relationship management activities (e.g., the effective use of personalization technologies), and pricing decisions (e.g., price discrimination strategies enabled by analytics).
- -
- Representation Genre:
- ◦
- This class of DSR research contributes by evaluating and refining existing modeling grammar or methods, the design of new modeling grammar or methods, the development of software artifacts to support or instantiate such work, or the evaluation of these efforts using analytical methods. Such contributions face challenges from philosophy, linguistics, and psychology that unavoidably occur when experimenting representations.
- -
- IS Economics Genre:
- ◦
- This class of DSR research contributes by developing and refining models and algorithms that focus on the role of IS to solve problems related to the conduct of economic activities and attainment of objectives of an economic system. Additionally, the discovery and characterization of behaviors of economic participants. The instantiation of models and algorithms into software, technology platforms, and other artifacts. Lastly, the evaluation of the validity of causal mechanisms and the utility of solutions. This class mainly focuses on unfolding the relationship between IS and the design of economic systems.
2. Design Science Research
3. Evaluation
- -
- If the DSR aims to develop design theories, then hypotheses proposed could be tested via experiments, conceptually, or instantiated-oriented;
- -
- In case DSR aims to design an artefact, system, or method, then demonstration is an acceptable evaluation mechanism;
- -
- Design oriented research could utilize lab experiments, pilot testing, simulations, expert reviews, and field experiments;
- -
- Explanatory design, on the other hand, could be evaluated via hypothesis testing and experimental setup;
- -
- Actions design research views design and evaluation as sequential. That is, they look at one process where organizational intervention and evaluation are required.
4. Big Data Analytics
5. Evaluation in the Lens of BDA
- What kind of data [or datasets] about the world are available to a data scientist or researcher?
- How can these data [sets] be represented?
- What rules govern conclusions to be drawn from these datasets?
- How to interpret such a conclusion?
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Baskerville, R.; Baiyere, A.; Gregor, S.; Hevner, A.; Rossi, M. Design science research contributions: Finding a balance between artifact and theory. J. Assoc. Inf. Syst. 2018, 19, 358–376. [Google Scholar] [CrossRef]
- Rai, A. Editor’s Comments: Diversity of Design Science Research. Manag. Inf. Syst. Q. 2017, 41, iii–xviii. [Google Scholar]
- Elragal, A.; Klischewski, R. Theory-driven or process-driven prediction? Epistemological challenges of big data analytics. J. Big Data 2017, 4, 19. [Google Scholar] [CrossRef]
- Haddara, M.; Su, K.L.; Alkayid, K.; Ali, M. Applications of Big Data Analytics in Financial Auditing-A Study on The Big Four. In Proceedings of the Americas Conference on Information Systems (AMCIS), New Orleans, Louisiana, USA, 16–18 August 2018. [Google Scholar]
- Wang, Y.; Kung, L.; Byrd, T.A. Big data analytics: Understanding its capabilities and potential benefits for healthcare organizations. Technol. Forecast. Soc. Chang. 2018, 126, 3–13. [Google Scholar] [CrossRef]
- Wang, G.; Gunasekaran, A.; Ngai, E.W.; Papadopoulos, T. Big data analytics in logistics and supply chain management: Certain investigations for research and applications. Int. J. Prod. Econ. 2016, 176, 98–110. [Google Scholar] [CrossRef]
- Gregor, S.; Hevner, A.R. Positioning and presenting design science research for maximum impact. MIS Q. 2013, 37, 337–355. [Google Scholar] [CrossRef]
- Peffers, K.; Tuunanen, T.; Niehaves, B. Design science research genres: introduction to the special issue on exemplars and criteria for applicable design science research. Eur. J. Inf. Syst. 2018, 27, 129–139. [Google Scholar] [CrossRef]
- Von Alan, R.H.; March, S.T.; Park, J.; Ram, S. Design science in information systems research. MIS Q. 2004, 28, 75–105. [Google Scholar]
- Baskerville, R. What Design Science Is Not; Springer: Berlin, Germany, 2008. [Google Scholar]
- March, S.T.; Smith, G.F. Design and natural science research on information technology. Decis. Support Syst. 1995, 15, 251–266. [Google Scholar] [CrossRef]
- Chatterjee, S. Writing My next Design Science Research Master-piece: But How Do I Make a Theoretical Contribution to DSR ? In Proceedings of the 23rd European Conference on Information Systems (ECIS 2015), Munster, Germany, 26–29 May 2015. [Google Scholar]
- Kuechler, B.; Vaishnavi, V. Design Science Research in Information Systems. 2004. Available online: http://www.desrist.org/design-research-in-information-systems (accessed on 22 May 2019).
- Gregor, S.; Jones, D. The anatomy of a design theory. J. Assoc. Inf. Syst. 2007, 8, 312. [Google Scholar]
- Venable, J.; Pries-Heje, J.; Baskerville, R. A comprehensive framework for evaluation in design science research. In Proceedings of the International Conference on Design Science Research in Information Systems, Las Vegas, NV, USA, 14–15 May 2012; pp. 423–438. [Google Scholar]
- Hevner, A.; Chatterjee, S. Design science research in information systems. In Design Research in Information Systems; Springer: Boston, MA, USA, 2010; pp. 9–22. [Google Scholar]
- Markus, M.L.; Majchrzak, A.; Gasser, L. A design theory for systems that support emergent knowledge processes. MIS Q. 2002, 179–212. [Google Scholar]
- Pries-Heje, J.; Baskerville, R.; Venable, J.R. Strategies for Design Science Research Evaluation. In Proceedings of the ECIS, Galway, Ireland, 9–11 June 2008; pp. 255–266. [Google Scholar]
- Hilbert, M. Big data for development: A review of promises and challenges. Dev. Policy Rev. 2016, 34, 135–174. [Google Scholar] [CrossRef]
- Elragal, A.; Haddara, M. Big Data Analytics: A text mining-based literature analysis. In Proceedings of the Norsk Konferanse for Organisasjoners Bruk AV IT, Fredrikstad, Norway, 17–19 November 2014. [Google Scholar]
- Berman, S.; Korsten, P. Embracing connectedness: Insights from the IBM 2012 CEO study. Strategy Leadersh. 2013, 41, 46–57. [Google Scholar] [CrossRef]
- Brynjolfsson, E.; Hitt, L.M.; Kim, H.H. Strength in Numbers: How Does Data-Driven Decisionmaking Affect Firm Performance? Available online: https://ssrn.com/abstract=1819486 (accessed on 22 May 2019).
- Haddara, M.; Larsson, A.O. Big Data. How to find relevant decision-making information in large amounts of data? In Metodebok for Kreative Fag; Næss, H.E.P., Lene, Eds.; Universitetsforlaget: Oslo, Norway, 2017. [Google Scholar]
- Kitchin, R. Big Data, new epistemologies and paradigm shifts. Big Data Soc. 2014, 1. [Google Scholar] [CrossRef]
- Seni, G.; Elder, J.F. Ensemble methods in data mining: improving accuracy through combining predictions. Synth. Lect. Data Min. Knowl. Discov. 2010, 2, 1–126. [Google Scholar] [CrossRef]
- Siegel, E. Predictive Analytics: The Power to Predict Who Will Click, Buy, Lie, or Die; John Wiley & Sons: Hoboken, NJ, USA, 2013; ISBN 1-118-35685-3. [Google Scholar]
- Dhar, V. Data science and prediction. Commun. ACM 2013, 56, 64–73. [Google Scholar] [CrossRef]
- O’Leary, D.E. Embedding AI and crowdsourcing in the big data lake. IEEE Intell. Syst. 2014, 29, 70–73. [Google Scholar] [CrossRef]
- Rai, A. Editor’s Comments: Avoiding Type III Errors: Formulating IS Research Problems that Matter. Manag. Inf. Syst. Q. 2017, 41, iii–vii. [Google Scholar]
- Bichler, M.; Heinzl, A.; van der Aalst, W.M. Business analytics and data science: Once again? Bus. Inf. Syst. Eng. 2017, 57, 77–79. [Google Scholar] [CrossRef]
- Shim, J.P.; French, A.M.; Guo, C.; Jablonski, J. Big Data and Analytics: Issues, Solutions, and ROI. CAIS 2015, 37, 39. [Google Scholar] [CrossRef]
- Myers, M.D.; Venable, J.R. A set of ethical principles for design science research in information systems. Inf. Manag. 2014, 51, 801–809. [Google Scholar] [CrossRef]

© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Elragal, A.; Haddara, M. Design Science Research: Evaluation in the Lens of Big Data Analytics. Systems 2019, 7, 27. https://doi.org/10.3390/systems7020027
Elragal A, Haddara M. Design Science Research: Evaluation in the Lens of Big Data Analytics. Systems. 2019; 7(2):27. https://doi.org/10.3390/systems7020027
Chicago/Turabian StyleElragal, Ahmed, and Moutaz Haddara. 2019. "Design Science Research: Evaluation in the Lens of Big Data Analytics" Systems 7, no. 2: 27. https://doi.org/10.3390/systems7020027
APA StyleElragal, A., & Haddara, M. (2019). Design Science Research: Evaluation in the Lens of Big Data Analytics. Systems, 7(2), 27. https://doi.org/10.3390/systems7020027