1. Introduction
Both professional users and the community at large expect that services they use will be provided competently and reliably. Service providers draw on financial and physical assets to help meet such expectations. In some cases, service system failure may have severe consequences. In achieving its intended mission, a particular asset, such as an ICT network, a military aircraft or a power station does not operate in isolation, but is linked to other assets such as extended distribution networks, and changes in one asset might impact another. Some researchers [
1] compare this kind of behavior with that of a natural ecosystem. Others [
2] view the larger entity as a system of systems that may be both interdependent and independent to some extent. This leads to a focus on interaction and connections within both the entities themselves and within their supporting services that may be represented in system architecture descriptions. The research question explored here is
how do service support systems adapt to assure the reliability of complex assets in a dynamic environment?The physical assets of interest here are generally capital-intensive and are expected to last for a long time. However, during that time, changes in user requirements, changes in technology or changes in access to finances may result in changes in the asset and/or how it is used, which places varying demands on support services. Many of the requisite support services are knowledge-intensive, and knowledge of new technologies must be maintained in parallel with knowledge of asset legacy systems. The interplay of financial, physical and knowledge assets may influence who does what, and support system configurations are expected to change over time.
One attribute of reliable systems is that no critical incidents occur, and their background operation is transparent in the provision of reliable services. This is assured by the effective operation of a network of socio-technical support systems that continuously monitor and upgrade the physical assets as makes both operational and business sense. It has been suggested that the study of high reliability organizations is of value because it provides “a window on a distinctive set of processes that foster effectiveness under trying conditions” [
3]. In this paper, we pursue this idea and offer reliability-oriented case examples. In the context of trying conditions, we like a quotation from Rochlin, LaPorte and Roberts [
4]:
“So you want to understand an aircraft carrier? Well, just imagine that it's a busy day, and you shrink San Francisco Airport to only one short runway and one ramp and gate. Make planes take off and land at the same time, at half the present time interval, rock the runway from side to side, and require that everyone who leaves in the morning returns that same day. Make sure the equipment is so close to the edge of the envelope that it's fragile. Then turn off the radar to avoid detection, impose strict controls on radios, fuel the aircraft in place with their engines running, put an enemy in the air, and scatter live bombs and rockets around. Now wet the whole thing down with salt water and oil, and man it with 20-year-olds, half of whom have never seen an airplane close-up. Oh, and by the way, try not to kill anyone. Senior officer, Air Division”. The message from this article is that appropriate combinations of people and technology, informal and formal procedures can achieve remarkable results.
Researchers have observed that innovative value creation in service networks may be supported by cooperative efforts between customers and suppliers [
5] and numerous public–private partnerships provide examples of this [
6,
7]. In these circumstances, both customers and suppliers may take on changed roles with new interactions and interdependencies in providing support services [
8].
The paper is organized as follows. Firstly, drawing on multidisciplinary academic literature, there is a discussion of physical assets and sociotechnical systems and how they might be characterized, followed by a similar discussion of services. This leads to a view of service ecosystems as adaptive networks of actors, resources and activities. Secondly, the research methodology adopted and six case studies are described, followed by a discussion of cross-case observations and of how observations from the cases relate to ten service science components outlined by Spohrer and Kwan [
9]. Concluding remarks provide an overview of what has been learned from the study presented here from both theoretical and practical perspectives.
2. Theoretical Background
2.1. Characterising Physical Assets and Their Operation Using Systems Thinking
It has been suggested that systems thinking can be applied to the study of the holistic behavior of a collection of parts in natural, organizational and technological settings, and this involves identifying and understanding the parts and of total system and their shared purpose with an emphasis on interconnections [
10]. In a review of the application of general systems theory, Kitto [
11] identified three aspects of context to be considered: the interaction between components, the influence of the observer viewpoint, and the system interaction with the broader environment.
At the component interaction level, systems thinking has been applied using functional models to support software design [
12], project management [
13], flexible manufacturing systems development [
14], business process mapping [
15] and the management of complex assets [
16]. This brings together a focus on function and context (e.g., IDEF0 modeling identifies constraints and resources associated with each function—see
Figure 1) and supports the introduction of functional hierarchy.
Service blueprinting presents a systematic method for linking the customer perspective of an individual “service encounter” with the physical assets, staff actions and underlying information processes involved [
17]. An adaptation called Industrial Service Blueprinting has been used in supporting firms offering product–service packages [
18].
Kurpjuweit and Winter [
19] highlight the need to consider multiple stakeholder concerns and represent them as viewpoints when thinking about system architectures. Chen, Doumeingts, and Vernadat [
20] have reviewed a variety of approaches to system architecture modelling, and have noted the influence of different viewpoints—those oriented towards the design of a system, and those oriented towards the design and implementation of a collaborative enterprise or project. Barile and Polese [
21] note the need to balance internal and external viewpoints. An international standard relating to the development of system architecture descriptions [
22] suggests multiple viewpoints may inform such descriptions also considering inputs related to concerns, stakeholder needs, and representational models.
In this paper, we are taking an asset management viewpoint. In viewing a complex asset as a system, we can identify a hierarchy of subsystems that it is comprised of. For example, a power station will have a fuel management subsystem, a power conversion subsystem, electricity generation subsystem, connections with a distribution system, a control subsystem, and buildings that house various subsystems. These may be further divided into sub–sub systems, and we can consider their operation from the viewpoint of a variety of stakeholders.
High reliability assets are commonly used to provide a community service—power stations providing electricity, hospitals supporting the provision of health services, infrastructure supporting transport services, military equipment supporting national security objectives. From this point of view, the assets and the people who operate them are part of a larger service ecosystem.
2.2. Reliability Assurance
In the pursuit of reliability-by-design, a review of new challenges by Zio [
23] indicated that some old problems persisted—matters of system representation and the modeling of uncertainty—but new challenges are presented by increasing system complexity, networked systems, organizational and human factors, and the reliability of software. Zio [
23] also noted “Complex tasks need to be performed on modern systems in order to ensure their reliability throughout the life cycle”. These tasks, characterised by Zio as maintenance and life extension activities, “need to be properly represented, modelled, analysed and optimized.” The following discussion expands the list of requisite support tasks and factors to be considered in their representation.
2.2.1. Operational Reliability Considerations
Rochlin et al. [
4] observed reliability assurance practices in Aircraft Carrier flight deck operations They noted the introduction of redundancy within technical systems, and rapid availability of critical spares combined with decision/management redundancy having two aspects—firstly, internal cross-checks on decisions, even at a micro-level; and secondly, fail-safe redundancy should one management unit should fail or be put out of action. Constant multi-level communication about completed and anticipated activities was the norm, and became a familiar pattern against which anything abnormal stood out. Operating procedures represented a formal knowledge base that was supplemented by the informal knowledge base of experienced mentors working with crews that regularly changed in accordance with Navy policy. Culture was seen as a source of reliability [
24].
Schulman, Roe, van Eeten, and de Bruijne [
25] studied the management of critical infrastructures and approaches to reliability assurance during times of crisis in electric power delivery. They also noted that the emergence of distributed systems (smart electricity grids in their case) resulted in changed management control considerations. From observation of a number of potentially critical incidents, they noted the key role of experienced operators. “The quest for high reliability in tightly coupled, highly interactive critical infrastructures can be characterized briefly along two dimensions: (1) the type of knowledge brought to bear on efforts to make an operation or system reliable; and (2) the focus of attention or scope of these reliability efforts. The knowledge base from which reliability is pursued can range from formal or representational knowledge, in which key activities are understood through abstract principles and deductive models based upon these principles, to experience, based on informal or tacit understanding, generally derived from trial and error”. Similar themes are observed by Roberts and Bea [
26] in relation to the operations of other complex systems—in health management and airline operations too (e.g., briefings to share information, redundancy—two pilots flying airliners), and noted the value of failure simulation tools to help people learn how to respond to abnormal situations. Important support tasks identified from this discussion are designing for technical redundancy, establishing arrangements for rapid access to spare parts, asset-specific training, and context-specific creative problem-solving.
2.2.2. Reliability and Trust
Common themes in dictionary definitions of reliability are process consistency and trust, e.g.,
Oxford dictionary: The quality of being trustworthy or of performing consistently well. Spohrer and Khan [
9] make a related comment “
Without standardized measures, it is hard to agree and harder to trust.”
Trust and shared values are seen as important in supporting large complex systems [
27], as implied in the previous section. Cox, Jones, and Collinson [
28] studied the influence of intra-organizational trust in two high reliability organizations—a nuclear power station and an offshore oil rig. High levels of trust supported multi-level communications, enhancing knowledge sharing and continuous learning. Cooke and Rohleder [
29] stressed the importance of reporting and learning from incidents, no matter how trivial they may seem, and noted the impact of ignoring such incidents in a high reliability context.
The reliability of operations is also influenced by inter-organizational trust associated with supply chains [
30], external professional services [
31] and Internet-based services. Jøsang, Ismail, and Boyd [
32] investigated the role of reputation-building practices such as referrals and customer ratings in the implementation of on-line service business models. They noted that the relative importance of different classes of trust depended on the trust purpose: provision trust, access trust, delegation trust (trust in an agent), identity trust and context trust (which also refers to different aspects of reliability such as legal surety). They also noted that such reputation systems could be subject to manipulation.
Sako [
33] has characterized three aspects of trust in inter-organizational settings, the first two of which are essential in supporting reliable operations:
Contract-based trust (an expectation that an exchange partner will deliver as promised),
Competence-based trust (an expectation that an exchange partner can deliver as promised and is competent to carry out agreed tasks), and
Goodwill trust (confidence in the exchange partner’s open commitment to supporting an exchange relationship). This aspect of trust may also provide a foundation for future relationships.
It has been observed that trust is context-sensitive, e.g., related to competency to undertake specific tasks [
34]. Gefen, Rao, and Tractinsky [
35] reviewed literature relating to trust, risk and e-commerce, noting that high levels of trust were associated with high risk environments. However, trust is a fragile management construct, taking time to build, but possibly being quickly destroyed. On the basis that trust is a risky business (making assumptions about future behavior), it has been suggested [
36] that focusing discussion in potential risks (contract, competence and goodwill risks) and how to manage them can be more productive than talking about who and what can be trusted, which brings us back to a risk mitigation orientation. This brief discussion identifies competency maintenance, contract management, relationship management and risk management as tasks influencing trust in a high reliability setting.
2.2.3. Reliability Assurance Tools
Simulators are used to support operator training and to explore responses to potential fault conditions in many high reliability sectors (health, aviation, power generation), but these are also complex systems requiring maintenance and upgrading [
37].
Drawing on the extant literature, Hensley and Utley [
38] identified reliability tools used in service operations and categorized them in relation to subsystem reliability (failure rate analysis, control charts, failsafe techniques, standards), configuration (service blueprinting, serial/parallel flows) and system reliability (Failure Mode and Effects Analysis, Root-Cause-Analysis).
In a consumer customer context, Chuang [
39] explored the utility of combining a service blueprint model to identify potential failure points (in both front-office and back-office activities), with FMEA to prioritize critical failure modes for preventative action. The reliability focus here was not so much on safety, but on service delivery. A failure was defined as any incident where customer expectations were not met. The concept was beneficially applied in a chain of hypermarket stores, where information about observed failures was provided by some 100 managers/operators, identifying seven areas for constant attention.
Suh and Han [
40] suggested an information systems risk analysis method that considers sources of discontinuity in the enterprise business model related to the specific functions serviced and the assets involved. The outcome is a risk mitigation priority list.
The combination of drawing on accumulated experience and experimenting with future possibilities in a structured way, e.g., emerging from simulation studies or opportunities offered by emerging technologies and infrastructure seems appropriate in a high reliability environment. The foregoing discussion identifies support tasks associated with configuration management, quality management systems and information management.
2.2.4. Reliability in Knowledge-Based Services
The requisite support activities described so far each require knowledge and specific competencies, however as mentioned earlier, one attribute of reliable systems is that no significant incidents are observed, so what might be happening in the background, and how are competencies maintained. There may also be long times between major maintenance activities, which can limit learning opportunities and make it difficult to maintain a critical mass of knowledgeable people over long asset life-cycles (e.g., 25 years or more). This can result in asset owners contracting external specialists to provide support, where competency is maintained by serving a larger number of asset owners.
Quinn [
41] discussed potential management issues in deciding to access external sources of knowledge or alternatively, to generate additional business by obtaining leverage from internal knowledge (e.g., in pursuing a servitization business model). For buyers of knowledge-based services, some potential issues were evidence supporting competence-based and contract-based trust, confidentiality matters, supplier access to supplementary knowledge networks, how to measure the impact of the supplier’s contribution, and the risk of becoming over-dependent on the supplier. For sellers of knowledge-based services, some potential issues were knowing more than the buyer may cause communication problems, the buyer cannot guide by direct orders clearly specifying requirements, performance perception mismatches can emerge, and there may be concerns about losing outsourced skills. Kujala et al. [
42] have described how such situations can lead to the need to adapt both knowledge service supplier and asset owner business models. Guajardo et al. [
43] compared the impact of different forms of contracting of jet engine maintenance services, noting that one type stimulated improved engine reliability more than others.
This interplay between what makes operational sense and what makes business sense in sustaining access to requisite support knowledge highlights tasks associated with project management, boundary-spanning [
44] and knowledge management [
45].
2.2.5. Reliability Summary
One point to be made here is that support services continue to evolve in response to changes in the asset being supported, its operating environment and the people involved, building on what is progressively learned. Recurring themes from the foregoing discussion of reliability assurance are:
2.3. A Sociotechnical Systems Perspective
In the previous
Section 2.2 discussion of the combination of people and technology in assuring asset reliability identified a number of support functions to be enacted, and the need for continuous learning and adaptation in response to various sources of change. Geels [
50] considered that socio-technical systems comprised “a cluster of aligned elements, e.g., artifacts, knowledge, user practices and markets, regulation, cultural meaning, infrastructure, maintenance networks and supply networks.” He argued that transitions involve processes engaging multiple actors with different perspectives, but all acting within broader social structures and technological regimes that themselves continue to evolve. At the level of an enterprise, Li and Williams [
51] observe that during its whole lifecycle, an enterprise or a project interacts with its environment to provide a needed set of products and/or services, but at the same time will have to engage with external actors to gain access to complementary knowledge, skills and resources. They describe a reference architecture (PERA) that considers entity interaction and representation at concept, functional/definition, and design/implementation stages. Matters of context—mission, vision, values and policies—are enunciated at the concept stage. Requisite task, function and technology building blocks are identified at the definition stage. At the implementation stage, PERA refers to information and production architectures with human/organizational interfaces and functional activities linking them (see
Figure 2). These ideas frame the following discussion.
2.3.1. A Focus on Support Functionality
Functional support activities (services) identified in the discussion of reliability assurance were designing for technical redundancy, life extension tasks, configuration management, supply chain management including arrangements for rapid access to spare parts, maintenance, competency maintenance and asset-specific training, risk management, information management, quality management, contract management, relationship management and context-specific creative problem-solving. Drawing on the PERA architecture, each one will have its own information, technology and knowledge foundations, but will operate in a common context.
There will be linkages between the functions that may change depending on short and long-term needs, and each function will have its own external professional and knowledge connections. Whilst these functions may be clustered in a formal enterprise hierarchy, they may also be linked differently, for example to support a project. This leads to the suggestion of a more general representation of the functions identified as a network of activities that can be dynamically linked as required. Not all functions may be needed at a particular time. For example, access to design functions may only be needed occasionally after a particular asset is operational, but that situation itself raises a management issue of knowledge retention/access. Other functions such as supply chain and quality management may be more continuously employed.
2.3.2. A Focus on Interfaces and Connections
In developing a framework for an engineering asset management system, El-Akruti and Dwight [
52] noted that interactions between a number of functions had to be planned and controlled, and there was a need to integrate this system with the broader enterprise system. Taking a long-term view, their framework included asset life cycle functions (acquisition, deployment, operation/maintenance and retirement) and asset management supporting functions (technical support, HR management, Information systems, finance, accounting, inventory, handling and industrial safety). These were associated with six higher-level functions:
- -
Strategic analysis and evaluation;
- -
Strategic decision-making;
- -
Aggregate coordinating and planning;
- -
Aggregate control and reporting;
- -
Operational task control, and;
- -
Operational measurement and monitoring.
They pointed out that system effectiveness was influenced by a number of attributes: information system and technology, knowledge and experience, organization culture and incentives.
The author has applied system thinking to connections between organization functions by using an interaction matrix tool—a responsibility matrix. This simply maps requisite functions against who is responsible for each function, with the contents of the matrix indicating what services are to be provided by those responsible and what services they expect from others. In a project management environment, there is a matrix for each phase of development, e.g., what quality management activities are associated with each phase.
As observed by Porter and Millar [
53] in their work on value chains, there are functional tasks to be carried out regardless of who does them and how they are done. The responsibility matrix has to be complete following any re-organization or outsourcing initiative. In the latter case, the responsibility matrix shows what the supplier is responsible for and what linkages there are within the customer organization. The responsibility matrix concept can also be applied at different hierarchical levels.
A responsibility matrix is an example of the organization architecture referred to in the PERA enterprise model, and at the implementation level, this model also considers the nature of interfaces with two physical systems:
Information systems that facilitate coordination and planning, control and reporting, measurement and monitoring. What is to be done by manual/visual systems and what is to be done by IT systems? How should any human–computer interface be designed?
Tools that facilitate task completion. What is to be done by people and what is to be done by technology? What health and safety matters have to be considered?
The need for supporting knowledge and experience has been raised in earlier discussion (
Figure 2). What do we need to know about functions and interfaces between them? Contrast for example an artifact produced by a craftsman from a few sketches with something similar produced by 3D printing. Domain knowledge is required about the physical tools and production processes used, about requisite information and how to interpret it, about what decisions have to be made, e.g., in relation to sequencing and scheduling tasks, and about how these elements are orchestrated (architectural knowledge). In both cases, the requisite knowledge is logically the same and built on experience, but the craftsman draws on an informal knowledge base whilst 3D printing requires formalization of knowledge. In passing, it is noted that the maintenance of architectural knowledge is not always given the same attention as domain knowledge [
54].
The point to be made here is that functional interfaces are multi-dimensional having physical, information, decision system and knowledge components to be considered.
Carlile [
55] described three kinds of interface framing tools. He identified a syntactic approach (e.g., a hexadecimal zero or one as in software code) which once shared as a common language is sufficient, and the focus moves to the processing of information. A semantic approach which recognizes there may be different interpretations of syntax/language that can make communication and collaboration difficult, and brings together information and context, plus a focus on learning about sources that created this difference. Carlisle suggested a pragmatic approach, and in a new product development context, links this with the use of boundary objects (see later) that help create new knowledge from the combination of different perspectives.
2.3.3. Orchestration Challenges
Socio-technical systems implementation requires the orchestration of quite different kinds of actors, activities and resources. The orchestration analogy has been described in a variety of settings: e.g., in facilitating organizational change [
56], in considering resource orchestration within a firm as it evolves [
57] in describing a style of management that balances competing resource allocation demands in large capital projects [
58], in medical emergency management [
59], in service-oriented manufacturing processes [
60] and in the management of global software engineering projects [
61]. Utilizing the orchestration analogy in a socio-technical systems setting, Boy [
62] identified significant influence factors as firstly, situation awareness, secondly the operating environment at successive points in time, and thirdly, authority—who is in charge and who has freedom to act. His observations came from longitudinal studies of air traffic management systems, where it was observed four kinds of process supported authority allocation:
Sharing information, knowledge and resources among actors who need to have a common understanding of the situation;
Distribution of authority according to actor roles and capabilities;
Formal delegations in the sense of contract commitments (mutual understandings);
Trading—negotiation among actors in real time to deal with potentially conflicting goals, contexts and resources.
Boy saw this scenario-based configuration approach as an alternative to a traditional military-style hierarchical decomposition of functions. In passing, it is interesting to note the current military adoption of network-centric approaches to warfare [
63]. Drawing on music analogies, Boy noted some generic actor roles to be considered (composer, conductor, musician and audience) plus some generic artifacts helping to synchronize operations (music theory translating sound to print, and scores that assemble these sounds in creative ways).
Peltz [
64] described an interpretation of orchestration and choreography concepts in combining independent web services to create cross-organizational business processes where orchestration represents control from one party’s perspective, and choreography facilitates collaborative interaction. This capability required the identification of suitable exchange languages to facilitate communication between different contributors plus some structured activities to facilitate exchange.
Viewed from another perspective, a boundary-spanning entity (person, organization, agent) may be assigned responsibility for dynamically organizing connections and exchanges as appropriate to an emergent situation [
65,
66,
67,
68] with the aid of boundary objects (artifacts interpretable by disparate communities [
55,
69,
70,
71]).
A common theme here is that orchestration is a process of making connections and organizing exchanges where some generic kinds of actors (or intelligent agents) undertake specific kinds of activities (sharing, distributing authority, delegating and trading) with the aid of some knowledge resources (protocols and procedures).
Studies of services supporting high reliability assets reviewed earlier in this paper have identified three different operational scenarios: routine activities that keep everything running smoothly, project activities to enhance operations, and responding to unexpected events, each with potentially different governance and knowledge-sharing arrangements and interaction timescales.
2.3.4. Socio-Technical Systems Summary
Socio-technical systems require the orchestration of people, information and technology involving:
A focus on interfaces and connections with an appreciation of two-way flows supported by boundary-spanning functions;
A need for multiple kinds of domain knowledge plus architectural knowledge—knowing how it all works together;
Some support activities may be provided routinely, or on a project basis, or on an as-needed basis;
In an asset management context, tasks include firstly, strategic analysis/evaluation of scenarios and decision-making; secondly, tactical planning/coordinating plus control and reporting, and thirdly, operational task control plus outcome measuring/monitoring, with each adapted to different scenarios;
Tools may include architecture framework models and interface communication aids such as protocols and boundary objects.
2.4. Some Attributes of Service Systems
Some firms offer knowledge-based services such as consulting or architectural design. Some offer services drawing on knowledge of their own products, some offer services supporting a particular type of product. Some offer access to infrastructure services such as electricity or the Internet. Channeling observations about different production process, Silvestro et al. [
72] developed a characterization of services based on the frequency of customer contact and contact time:
Low contact frequency, long contact time, high levels of customization with a front office, people and process orientation were seen to be attributes of professional services such as management consultancy, field service and bank corporate operations.
Moderate levels of contact, customization and discretion with a combined front office/back office and people/equipment orientation were seen to be attributes of a services shop such as a hotel, rental service or bank retail operations.
High contact frequency, low contact times, customization and discretion with a back office and product orientation were seen as mass services such as retailers and transport services.
In the context of high reliability assets, a longitudinal study of the evolution of Rolls Royce jet engines by Smith [
73] noted the interplay between emergent technologies and business models with the dominant logic moving from product centric to customer/service centric over time. Product knowledge had to be supplemented with service delivery knowledge, then, as engine digital health monitoring systems became more sophisticated, with knowledge management capabilities. Brady, Davies and Gann [
74] examined how suppliers of capital goods are offering a combination of goods and services that deliver a business solution to customers their research indicated that both service and product firms may need to develop new capabilities as they focus on integrated customer solutions. These included:
Systems integration capabilities: to design and integrate systems composed of internally or externally developed hardware, software and services;
Operational service capabilities: to maintain, operate, upgrade and renovate a product through its operational life cycle;
Business consulting capabilities: to provide customers with advice on how to develop business plans, design and build a system and maintain and operate it;
Financing capabilities: to help customers purchase high-cost products and manage an installed base of capital assets.
Bettencourt et al. [
75] observed that in the provision of knowledge-intensive services such as business consulting, the co-creation of knowledge was a likely outcome. However, this required some particular capabilities: communication openness, a shared problem-solving attitude, and a tolerance of minor setbacks, accommodation of different perspectives, project advocacy, an involvement in project governance, and personal buy-in. Bitner, Booms and Tetreault [
76] made somewhat similar observations in a mass services context. From a study of 700 “service encounters” viewed as critical incidents, they observed the outcome may perceived as favorable or unfavorable, noting the potential influence of five independent dimensions of service quality: tangibles, reliability, responsiveness, assurance and empathy. Employee responses to customers influenced the customer view of value in response to service delivery failures, in response to meeting customer needs and requests, and in relation to unprompted/unsolicited employee actions.
Payne, Storbacka and Frow [
77] looked into the mechanics of value co-creation. Customers needed value-in-use and supplier opportunity identification competencies. Suppliers needed customer value creation, value delivery and value extraction competencies (characteristic of a business model), and a service encounter management process.
The value co-creation theme was also adopted in a service-dominant logic (SDL) view of customer–supplier interactions proposed by Vargo and Lusch [
78,
79]. An informal international network of scholars, the IMP group, evolved an interaction view of supply chains beginning in the 1990s. This group has tested the utility of an Activity-Resources-Actor model that characterizes supply chains and markets as interacting networks of actors, resources and activities. Dynamic change may be facilitated by adding new actors, resources or activities and/or by reconfiguring network connections. Ford [
80] conducted a detailed comparison the SDL and ARA models, making the following observations. They both have an interaction focus with customer–supplier interdependencies that frame resource allocation decisions. Investment in both resources and relationships is needed. Boundaries between a firm and its environment may be fuzzy—interactions outside a firm can influence the firm and vice-versa. There were differences of view about how value co-creation may be achieved—as a targeted outcome from a service encounter and as an emergent outcome from multiple encounters.
In summary, it is seen that service systems operate in a variety of contexts, which influence the nature of those systems. The dominant process is interaction.
2.5. SSMED and Notions of a Service Ecosystem
In the forgoing discussion, we have referred to service system, management, engineering and design (SSMED) literatures to consider support service influence factors in a high reliability asset context. Building on the work of other researchers, Demirkan, Spohrer and Krishna [
81] identified ten core services science concepts that frame the operating environment, and suggest hierarchical linkages between them. The primary concept, that of a service system ecology, is seen as diverse “populations of entities, changing the ways they interact”. Aldrich and Wiedenmayer [
82] describe an ecological approach to organizational studies as emphasizing foundings and disbandings of populations related to the way resources are distributed and the terms on which they are available. Sub-tier concepts identified by Demirkan, Spohrer and Krishna [
81] relate to the entities (characterized as service systems), interactions (through service networks with agreed value delivery and governance arrangements) and outcomes (delivered value that may or may not be positive).
We may link the Aldrich and Wiedenmayer [
82] ecological viewpoint to these subtier concepts as follows:
From an ecological viewpoint,
entities represent a particular population of organizations having access to particular resources supported by managerial and technical competencies. Spohrer and Kwan [
9] have described service system entities as dynamic configurations of resources with workable access rights that may be conceived in a variety of ways (e.g., as an organization or an on-line community).
From an ecological perspective,
interactions represent the founding and disbanding of populations in response to drivers of variation and selection criteria. Spohrer and Kwan [
9] describe interaction through service networks that deliver on a value proposition supported by governance arrangements. They see the value proposition as supported by relationships (access rights) and role definitions (resources) plus measures (quality, productivity, compliance, sustainable innovation) and stakeholder perceptions of value (customers, suppliers, authorities and competitors).
From an ecological perspective,
outcomes may be the retention of technical and managerial competence and the diffusion of beneficial variations. Spohrer and Kwan [
9] describe outcomes in terms of winning and losing, of knowledge co-creation, and matters of reputation.
There are operational links between the concepts. Entities establish interactions that deliver outcomes. Entities, interactions and outcomes influence, and are influenced by, the broader ecology.
In a seminal paper on the ecology of organizations (cited more than 8000 times), Hannan and Freeman [
83] raise questions about appropriate levels of organizational analysis—members, sub-units, individual organizations, populations of organizations, or communities of (of populations) organizations. They suggested the last three best aligned with a natural ecology model, and favored analysis at the level of populations. They noted that organization—environment relations are defined in terms of selected boundaries—e.g., geographical, political, market or product viewpoints. This kind of thinking has led some researchers to study specific kinds of ecosystems—a particular set of actors located within a particular boundary having access to particular kinds of supporting resources. Related examples are knowledge, business and innovation ecosystems [
84] services ecosystems [
85,
86], and web service ecosystems [
9]. Albeit in different ways, these authors also refer to the role of institutions (or “rules for the game”) in facilitating service exchanges. Interactions between these “populations” (ecosystems) are also noted.
In a service systems sense, dominant actors are customers and service providers, but these may be individuals or groups or organizations. This raises a question about the practicality of limiting an ecological view to a study of populations. There is a considerable body of literature related to the “service encounter” at the individual level, and business-to-business arrangements frequently involve individuals negotiating on behalf of the business. In a business environment, the relative power of customers and other actors (competitors, new entrants, substitutes) influence the dynamics of a particular population. There are interactions between multiple actors at multiple levels [
86].
This leads us to support an ecosystems model of a network of actors that interact in different ways for different purposes at different times, drawing on a network of resources that may be accessed and linked as needed. What determines that need is the kind of interaction taking place, represented as an activity. Discussion in previous sections of this paper has identified a large number of activities that may be components of an asset management function, and these are also linked in different ways at different times, e.g., during asset design or during asset operation.
This ecosystem representation is consistent with the IMP group view of business relationships as comprising three “layers” or “effect parameters”: activity links, resource ties and actor bonds [
87]. “
Activity links refer to the connections among operations that are carried out within and between firms in networks and how mutual adaptations in activities take place between relationship partners. Resource ties develop as companies exchange or access each other’s resources (broadly defined) in carrying out their activities, in the process often transforming and adapting existing resources and creating new resources. Actor bonds refer to the ways individual and collective (organizational) actors in a relationship perceive and respond to each other both professionally and socially. These bonds arise over time and are mutually adapted through the knowledge and experience gained in interaction. They affect the way actors view and interpret situations, as well as their identities in relation to each other and to third parties. Bonds include the closeness–distance, degree of commitment, power-dependence, degree of cooperation, and conflict and trust among relationship partners” [
88].
3. A Reliability Context Service Ecosystem Research Model
In this paper, we are exploring support system ecosystems that facilitate the reliable operation of complex assets. Preceding sections have considered some matters of context—a reliability perspective, a socio-technical systems perspective, some attributes of service systems, and some ways of representing the service systems environment.
It is observed that asset management support systems orchestrate access to a significant number of different functional subsystems that draw on internal and external knowledge, some of which may come from operation of the asset. From this perspective, there is an element of customer–supplier value co-creation. Knowledge of past incidents and theorizing about possible future events is needed to pre-empt possible disruption and assure safe operations, which involves interaction with a broadly based knowledge ecosystem. The common purpose of both access to knowledge and the provision of support services is reliability assurance, but this has to also make business sense, and there is evidence of some interplay between reliability assurance requirements, business models that deliver value and service ecosystems in the literature. Reliability also impacts reputation and trust in the utilization of complex assets, which is considered in three parts: contract, competence and goodwill based trust.
It is suggested that three factors—reliability assurance, a knowledge ecosystem, and business models—frame the context of an appropriate asset management service ecosystem, which is made up of interconnected networks of actors, resources and activities. This representation is shown in
Figure 3.
4. Research Approach and Results
The research question explored here is how do service support systems adapt to assure the reliability of complex assets in a dynamic environment?
A multiple case study approach was adopted, drawing on data from six knowledge-based support service projects, each representing a “service encounter” (a project) and the interaction of multiple actors. A case study approach is seen as appropriate when exploring context-sensitive “how” questions [
89].
De Santo et al. [
90] have suggested that service research be “on stage”, referring to practical evidence about something iterative, interactive, instrumented, interconnected, intelligent, in order to stimulate thinking about smarter concepts. Consistent with this view, all case studies used an action research methodology, assembling information and knowledge directly useful to practitioners, and encouraging them to take up and use the research findings [
91,
92,
93]. The action research collaborative process involves identifying the specific problem/research question to be explored, gathering the information to answer the question, analyzing and interpreting the information, and reflecting on the results with the participants. This cycle may be repeated, building on what has been learned (Berg [
94]; Coghlan [
95]).
Three cases having a reliability assurance tool orientation and drawing on past experience represent interventions at different operational system levels. The “service encounter” involved responding to unforeseen events. Another three having an adaptation orientation explored potential interventions at the top level in response to internal or external change. This form of “service encounter” represents a practice adopted in high reliability organizations—exploring possible scenarios and thinking about pre-emptive actions. These three cases involved customer–supplier partnerships to varying extents and all used the same analysis process, but indifferent contexts. The process modeled the operational and support status quo, then considered the impact of a change. An overview of each case follows and observations from the cases are compared in the later discussion section of the paper.
4.1. Case RA1: Supporting Safe Aircraft Life Extension
4.1.1. Context and Specific Problem/Question
This case describes a system level intervention and is presented from the perspective of an aerospace organization (which we will call AO) providing engineering support and some maintenance services to the military. When it came time to replace a military jet training aircraft, budget constraints precluded this, and the aircraft was required to operate safely for at least another ten years. The question was how could this be achieved. As part of the process, a series of other questions were asked—where could we expect to find structural “hot spots”; how does our asset usage compare with that assumed in the manufacturers test program; what tools can we use to inspect potential “hot spots”; and how can we best assure structural integrity going forward?
4.1.2. Actors Involved and Data Sources
These were:
The Department of Defence specifying the future role of the aircraft and funding life extension activities.
Air Force operational support managers responsible for investigating options, implementing an action plan and safety monitoring. These managers also provided access to aircraft maintenance records and aircraft maintenance personnel.
Department of Defence researchers responsible for independent review of technical reports produced and for developing and verifying structural inspection techniques.
The Air Force Research and Development Unit responsible for flying missions to collect aircraft structural performance data.
AO Engineering specialists having appropriate domain knowledge and access to original design and test data.
AO Manufacturing specialists who assembled the aircraft originally and who could work out how to replace structural components if needed.
The aircraft designer, who provided supplementary design and test data, and observations from experience with the aircraft by other operators around the world.
4.1.3. Data Collection and Option Identification
The focus was on hot spots and usage. Hot spot indicators from multiple sources (design, test, maintenance) were represented on post-it-notes placed on a very large drawing of the aircraft to identify candidate areas for monitoring, and actors were assembled from time to time to discuss this. Usage patterns were compared on a diagram showing the average distribution of “g” forces experienced by the aircraft. Following initial data collection activities, one aircraft was equipped with a series of smart sensors to help verify assumptions about the relationship between hot-spot stresses and usage events.
4.1.4. Reflection on Action and Emergent Issues
Analysis of the data showed that the aircraft was used in a different way from many other operators (undertaking a wider variety of roles), and that some usage patterns (such as those associated with teaching combat maneuvers) were more severe. Reliability assurance options resulted in a decision to replace some parts in all aircraft and individually collect data on every flight of every aircraft in the future, with supplementary inspections to check potential hot spots. A new Air Force Engineering group was established to collect and analyze usage information. The AO engineering specialists developed software to help interpret the field data, and ran training programs as personnel changed. These asset management activities were subsequently applied across all aircraft types in the fleet.
4.2. Case RA2: Infrequent Incident Mapping
4.2.1. Context and Specific Problem/Question
This case may be seen as promoting Service Dominant Logic within a contract manufacturing organization (which we will call HD) where a particular production team was encourage to regard the team receiving their product as the “next customer”. The focus was on delivery reliability. The case is presented from the perspective of a manufacturing engineering support group aiming to maximize delivery performance across all teams. The production team constructed large aircraft wing ribs using a semi-automated drilling and fastening process. Some sub-components assembled to form the ribs were made using less automated processes. The wing ribs had been in production for a number of years, and production processes were quite reliable. It was not uncommon for a particular type of aircraft to remain in production for fifteen years or more. Over such a period however, operators would change, and adjustments to component manufacturing and assembly practices would be made to pursue continuous cost reduction. In addition, customers were seeking higher levels of reliability in schedule performance and reduced cycle times leading to reductions in inventory. Sometimes, these changes could lead to problems that had been observed in the past, but there was no process for sharing past learnings, and this was important, as team membership was liable to change. The question was: how do we deal with this problem?
4.2.2. Actors Involved and Data Sources
Critical incidents were regarded as anything that impacted delivery, and actors were:
Current and past HD team members who contributed their tacit knowledge of incidents that had been observed at any process step in the past, and of any current concerns.
HD Area managers who could draw on past performance statistics.
HD Quality assurance staff who could draw on past quality incident reports.
The HD manufacturing engineering support team.
The HD customer contact manager.
The end customer—an international aircraft manufacturer client who specified product supply requirements.
Client production line operators who used the assembled wing ribs.
Another company that was a strategic partner in another program who shared their experience with incident mapping.
4.2.3. Data Analysis and Option Identification
Initially, collecting incident information at the work cell (team) level produced a jumble of data. Drawing on the experience of the associated company, operators and support staff were asked to associate each incident with stages on a team workflow diagram, and to reflect further on any incident that had occurred at each process step. This identified a number of additional incidents. Any clustering of incidents highlighted where pre-emptive actions might be focused and what kind of action might be needed. In addition, discussions between the company and the upstream client assembly operators who use the wing ribs led to suggestions about how the components might be optimally prepared for the next assembly step. In all cases, parts may be produced within drawing requirements, but still leave scope for improved ease of assembly at some process step. Over time however, the reasons for aiming for particular component features could be forgotten.
4.2.4. Reflection on Action and Emergent Issues
The track record of the assembly team was good, and if there was a problem, customers were made aware of this and of any corrective action being taken. This combination enhanced team reputation. Pre-emptive actions, such as the introduction of Kanban visual control systems meant that some past supply incidents were less likely to recur. However, in pursuing continuous improvement, new team members might try out ideas that had failed in the past. A modified version of the team workflow with numbered incident information was placed on the team visibility board. Team members could add a new incident to this, and new team members could be introduced to things that might go wrong as well as receiving training on requisite workflow tasks. Permanently placing the incident map and any specific client requirements on the team board meant it remained visible at daily standup meetings, reinforcing a reliability mindset.
4.3. Case RA3: Establishing Fault-Tree Libraries
4.3.1. Context and Specific Problem/Question
This case describes a system level intervention with an emphasis on delivery reliability. The company (HD) produced elevators (control surface) under contract for a large commercial aircraft and had a good track record. The case is presented from the perspective of a Quality engineering support group that had had also participated in the design of the elevator. Some combination of parts that were built within specification tolerances, or some process (e.g., painting) that had been reliable for long period would suddenly experience a transient problem. The question was, what was the real source of the problem, and what had to be done to stop it recurring?
4.3.2. Actors Involved and Data Sources
The incidents considered in this case did not have clear cause and effect relationships, and required some detective work to be undertaken.
HD Quality engineers documented case histories of each incident, and these were stored in an incident library as updated information became available.
HD manufacturing engineers investigated possible causes of process issues.
HD materials engineers investigated possible causes related to production material characteristics and their application.
HD quality laboratory technicians provided measurement and analysis reports.
HD tool maintenance and QA staff provided reports on measurement system reliability.
The HD customer contact manager.
The end customer—an international aircraft manufacturer who specified product supply requirements.
Customer design engineers who reviewed some of their assumptions about critical interfaces.
The HD IT department established a searchable on-line case library system.
4.3.3. Data Analysis and Option Identification
Whilst the problem might emerge at a particular process step, the material, current process or prior process property that led to it might not be clear. In this situation, comprehensive case histories were made as a way of retaining a “corporate memory”. Sometimes, investigations were inconclusive. However, by collecting these case histories over a period of time and clustering them according to the problem type (e.g., paint, assembly fit, build distortion), some recurring pointers could emerge.
4.3.4. Reflection on Action and Emergent Issues
In a sense, this was like an extension of the previous case using indications from a number of cases to point to a current or previous process step or material property for investigation. However, this required the application of architectural knowledge about the whole production process. The important thing here was the maintenance of case records, and the ability to cluster clues around a potential problem source. The success of any fixes put in place was judged by whether the problem re-occurred or not. This required the retention of a long-term problem log. These kinds of problems most commonly occurred at the interfaces between things and/or were related to the operating environment. The customer designers had adopted a formalized practice of identifying “key characteristics” of components or materials that had to be more closely controlled that other features, and also had a review process to add to the list or modify manufacturing requirements if needed, and the long-term resolution of some issues required customer-initiated changes. Some incidents arose when functions were automated, and experienced operators had to invest more time in “teaching” a robot the finer points of a particular process step.
4.4. Case SSA1: Transport System Support.
4.4.1. Context and Specific Problem/Question
This case involved a small team of four practitioners and university researchers utilizing a systems thinking methodology to explore the impact of change in complex socio-technical support systems. Both operational and business impacts were investigated with the aid of models. Working in small teams with support from academics, industry practitioners with at least 15 years’ experience supporting complex assets in some way characterized the system architecture of an as-is situation. They were then asked to consider potential drivers of change, select one to evaluate, developing a to-be proposal and assessing the issues and risks associated with its implementation. The research team did not meet face-to-face for the first six weeks and posted data in an on-line wiki with different pages for different viewpoints then met full time over four days in a workshop to consolidate what they learned and explore a change proposal.
The asset studied in this case was a government owned regional rail–bus system (which we shall call VL) operating in a highly regulated environment with customer expectations of high reliability. VL has a strategic alliance with an enterprise responsible for rail track installation and maintenance, who provides the same service to other users, and with some rail–car manufacturers.
4.4.2. Actors Involved and Data Sources
The research team was tasked with identifying actors, activities and resources in the case study operation drawing on data from publications and the internet supplemented with interviews with rail industry practitioners from their extended social network. They considered generic actors as follows:
Strategy creators—political and senior management actors that set policy, budget and transport system development plans.
Competing actors seeking to access the same resources (e.g., other rail track users such as freight companies).
External supporting actors—supply chain actors, e.g., providing fuel, ticketing systems, maintenance providers including suppliers of proprietary spare parts, specialist inspection and refurbishment contractors.
Internal supporting actors responsible for stations, catering services, cleaning services.
Deciding actors—who could authorize change.
VL customers.
4.4.3. Data Analysis and Option Identification
The research team was asked to take multiple views of the case study organization:
Review the services provided by VL, the financial and physical resources needed to support each service, and associated support activities.
Review the operational, support and decision-making knowledge base needed.
Identify information needed to operate VL services.
Review business model(s) adopted by VL, including their value proposition(s) and revenue streams.
This multiple viewpoint approach frequently produced apparently similar data, but in reviewing these instances it was found that the different views helped provide a richer representation of VL operations. A system architecture description standard (ISO 42010) was used to provide a framework for assembling this data. That standard also suggests that stakeholder concerns be identified, and a short list was compiled drawing on data from different VL actors. A PESTEL analysis (Yüksel [
96]) was done to identify possible future concerns. These related primarily to aging systems and demands from population increases.
4.4.4. Reflection on Action and Emergent Issues
Each team member was asked to reflect on, and to document, what they had learned from both the case study and the analysis tools used. A typical comment was concern about how to represent and visualize such a complex system. Mapping network connections produced something that looked like a bowl of spaghetti. There was a suggestion to develop a representation that only considered high level subsystems and their connections, and then have similar views within each subsystem. Adopting a service perspective, the actor network was made the primary viewpoint, with lists of activities undertaken and resources used by each actor, and with notes about associated input and output links. Another tool that was highly valued was an interaction matrix. All of the actors, activities and resources identified were listed and represented in a very large matrix. This included interactions between resources such as knowledge, finances, technology and infrastructure. This showed for example that the older style rail track infrastructure would limit the speed of new, faster trains, if reliable operations were to be sustained. When considering the impact of a changed situation, the interaction matrix could be inspected to assess which elements might be impacted, then consider how to manage that impact.
4.5. Case SSA2: Health System Support
4.5.1. Context and Specific Problem/Question
As in the previous case, this case involved a small team of practitioners and university researchers utilizing a systems thinking methodology to explore the impact of change in complex socio-technical support systems. Both operation and business impacts were investigated with the aid of models.
The asset studied in this case was health services infrastructure. The case study firm, which we shall call AX was formed by a group of health experts from the public and private sectors, who shared the vision of an organization that could work effectively across both sectors to improve access to quality healthcare for patients in developing countries. A not-for profit Division aimed to improve access to quality healthcare through engagement with local stakeholders. A for-profit consulting Division supported private sector health care expansion opportunities.
4.5.2. Actors Involved and Data Sources
The research team was tasked with identifying actors in the case study operation drawing on data from publications and the Internet supplemented with interviews with health system practitioners from their extended social network. Actors identified were:
Government policy makers and health system administrators at multiple levels of government.
International development agencies (United Nations, World Health Organisation).
Financial institutions.
National training agencies.
Public health care providers.
Private health-care providers.
Partner institutions (e.g., research organizations) that focus on specific local health problems.
Logistics partners.
Corporate pharmaceutical supply partners.
Patients.
4.5.3. Data Analysis and Option Identification
AX has a global network of over 400 institutions in many countries, providing them with a comprehensive database and access to local knowledge. It was noted that the two AX Divisions had very different business model, but AX has identified synergistic links between them. The company has a proven health system assessment methodology, which helped identify local priority areas. It includes both affordability and economic models. AX operated its own distribution warehouses in some countries where there was limited logistics infrastructure, and this also gave it good purchasing power. Challenges facing some clients include increasing populations; shortages of food and water that impact patient health; outbreaks of particular diseases (e.g., aids, ebola); some cultural and patient education challenges (e.g., patients do not want come in contact with other sick people or give blood), and local conflict zones that make field access difficult. There were so many challenges that the problem was deciding where to start.
4.5.4. Reflection on Action and Emergent Issues
The team used the same actor network and interaction matrix views described in
Section 4.4.4 of this paper, and made similar comments. Stakeholder interaction was very complex in this case, and a change somewhere seemed to impact the majority of actors. The research team reflected that the process of looking at concepts related to system interaction provided a broader view than might be taken in an engineering solution-seeking environment. The ways the generic actors interacted could be quite different in different countries. The not-for profit and for-profit linkages enable good value to be obtained from donations on one hand, and on the other hand encouraged large pharmaceutical companies to buy-in and make donations of product. Managing relationships and client education were important support system functions to support the introduction of more sophisticated technological systems.
4.6. Case SSA3: Agriculture Product–Service System Support
4.6.1. Context and Specific Problem/Question
As in the previous case, the research team characterized the system architecture of an as-is situation. They were then asked to consider potential drivers of change, select one to evaluate, developing a to-be proposal and assessing the issues and risks associated with its implementation.
This case had a client solution orientation—providing both products and services where intelligent devices added to the product could change the way assets were used. The case study firm, which we shall call DE, traditionally provided farm machinery, and had realized that it had a large dealer and client base it could leverage by embracing smart systems and cloud-based technologies. This expanded the scope of support systems needed by the firm.
4.6.2. Actors Involved and Data Sources
The research team was tasked with identifying actors in the case study operation drawing on data from publications and the Internet supplemented with interviews with agriculture practitioners from their extended social network. The DE focus was on local regions. Actors identified were:
The DE manufacturing operation and global spare parts supply chain.
The DE local dealer.
Smart system integration partners—hardware and software developers.
Private of public sector agriculture industry consultants.
ICT network providers that provide linkages between farmers, DE and agricultural consultants.
Corporate agrochemical supply partners.
Financial institutions.
Farmers/farm managers.
Farmer industry groups.
Each stakeholder group had produced “white papers” of some sort reporting on the experience of farm automation lead users suggesting future directions, and in some cases issues to be managed.
4.6.3. Data Analysis and Option Identification
DE planned to provide customized farm solutions in conjunction with its partner network and the deployment of smart sensors on the farm (e.g., soil moisture sensors). It offered autonomous machines that can be programmed in conjunction with GPS systems and local wireless networks. On-board machine health sensors could facilitate timely machine maintenance. In theory, a farm could be managed from a “control room” and data collected analyzed to refine farm management strategies. In response to increased capital requirements, innovative business models were being developed in conjunction with financial institution partners to help offer sustainable value propositions. The research team identified more than 40 activities that had to be managed in supporting a total farm management system. Actor education was a significant task. Collaborations with agrichemical suppliers could facilitate custom formulation of chemicals based on smart device data collected. However, limited Internet access in some regions meant that a variety of implementation arrangements had to be developed in conjunction with local dealers. The more smart devices that were added to the network, the more individual component reliability became critical. Farmers were also concerned about their ability to manage system elements combined on-farm daily requirements if something went wrong. The research team noted that farmers had to also confront environmental challenges such as climate change.
4.6.4. Reflection on Action and Emergent Issues
The team used the same kinds of actor network and interaction matrix views described in
Section 4.4.4 of this paper, and made similar comments. Food security (where does food come from and how is it produced), cultural preferences (e.g., Halal practices), environmental issues and economic sustainability were seen as challenges for farmers. How the sophisticated systems offered by DE and its partners could help confront these issues was a topic of active research team discussion, but use of the interaction matrix to identify potential touch-points. The research team found this matrix helpful in considering implementation risks arising from the interactions to be managed. The team observed that the implementation of smart technologies increased the farmer’s reliance on a different mix of suppliers, and the team chose to investigate an incentivized profit-sharing scheme. Whilst the scheme could reduce some kinds of risks, it introduced others and redistributed risk between the actors.
5. Discussion
Each complex asset considered in the previous section could be described as providing a service if viewed from a Service-Dominant Logic (SDL) viewpoint [
86]. In case RA1, a military jet trainer is utilized in providing a pilot training service supporting a government enterprise. Production facilities are used in providing a private sector manufacturing service in cases RA2 and RA3. Case SSA1 is about the provision of public sector transport services, case SSA2 is about facilitating both public and private sector health services, and case SSA 3 is about providing services to individual farmers. The focus of the paper is on the provision of high reliability asset management support services. Multiple viewpoints are needed to understand the nature of the “service encounters” involved from both customer and supplier perspectives.
This discussion starts with some cross-case observations, then considers observations from the cases in the context of a service science framework described by Spohrer and Maglio [
9]: services ecology concepts, service entities supporting service interactions that deliver service outcomes.
5.1. Cross-Case Observations
Some patterns were evident from the cases presented. There were a number of actors involved in the provision of support services, and they could take on different roles at different times, which begs the question who is the customer? Within each case there were a number of different “service encounters”—can a set of individual interactions be considered as one service encounter at the level of the case? This paper is about the pursuit of absolute reliability, but that may mean different things to different stakeholders, who may also have different perceptions about delivered value. A variety of methodological tools were exercised in the cases—what utility did they provide? Each of these topics will be discussed in turn.
5.1.1. Who is the Customer?
Observation 1: Suppliers of support services may deal with other suppliers of complementary services to deliver an outcome sought by an asset owner. From this perspective, one supplier may then be a customer of another, depending on the activity being undertaken.
In the cases previously presented, some of the actors played different roles at different times. Akaka, Vargo and Lusch [
86] describe a service ecosystem perspective, observing that customers and suppliers are embedded in social and institutional networks and interactions are associated with “value in context”. Interactions at a macro-level influence interactions at a meso-level, which influence interactions at a micro-level. Whilst dominant actors at the micro-level are customers and suppliers, context arises from meso- and macro-level interaction between two other types of actor: resource integrators (aligning and coordinating resources provided by other actors) and institutions (influencing norms and rules for the game).
Using this way of viewing our cases proved helpful in thinking about relationships between actors. In the simplest case (
Section 4.2—manufacturing aerospace components) the shop team could be regarded as the customer of the manufacturing engineer, who in turn could be regarded as a resource integrator, bringing together knowledge from multiple sources. The shop team could be regarded as a supplier to the client production line. The client acted as both the ultimate customer and an institutional actor, flowing down airworthiness requirements and contract ‘rules’ regarding continuous improvement initiatives. From another perspective, individual consumers may be regarded as customers (e.g., transport system
Section 2.4 or health system
Section 4.5 customers).
If we were to take an activity perspective and consider the activity of contracting, then in manufacturing services case
Section 4.2, there would be a negotiation between functional representatives of the customer and the supplier that would establish price, delivery and quality expectations. In the transport system case
Section 4.4, interaction would be via the ticketing system. In thinking about the connected actors, as well as asking who is the customer and who is the supplier, one might ask about any resource integration and institutional representation each one is associated with. This brings a sharper focus on types of interactions (activities) associated a particular ecosystem and the kind of value delivered. It is consistent with a systems thinking viewpoint that considers context, as illustrated in
Figure 1 (IDEF(0) function modeling).
5.1.2. Framing the Service Encounter
Observation 2: The service encounter concept tends to focus on some attributes associated with a single event (e.g., value co-creation, perceived quality and impact on reputation), but in our cases there were multiple service encounters to be considered.
The service encounter perspective tends to focus on some attributes associated with a single event (value co-creation, perceived quality, impact on reputation). In all of our cases, there were multiple actors that interacted in different ways at different times in the operation of a complex asset. In describing the process of service blueprinting, Bitner, Ostrom and Morgan [
17] used the example of a hotel overnight stay, where a number of encounters—at reception, in luggage handling, in food service, lead to an overall impression of the visit. In a similar way, each of our cases could be regarded as a “service encounter”, as could individual activities within them. We chose projects intended to enhance the operation of complex assets as our unit of study, and project outcomes were achieved by completing a succession of tasks (activities). Some had to be completed sequentially, some could be completed in parallel (e.g., in
Section 4.1, the tasks of hot-spot mapping and usage mapping). Some could not be started before a preceding one was completed. Sometimes, iteration was needed, depending on what had been learned and whether external conditions had changed.
Project management techniques such as PERT show how a network of activities are enacted over time, and estimate timelines for the activities. In our case studies, viewing requisite activities as “service encounters” highlighted who required the deliverable, what resources both customers and suppliers had to contribute to co-create value, with the timing aspect informing expectations about delivery reliability. This viewpoint—how the relative success of a high level service encounter might be conditioned by experience from a multitude of lower level service encounters—would seem to complement the contention of Akaka, Vargo and Lusch [
86], where service encounter conditions are influenced by meso and macro-level actor networks.
5.1.3. Matters of Reliability and Trust
Observation 3: The reliability assurance concept has multiple dimensions with some being associated with different aspects of trust.
Reliability is one of five key dimensions of service quality identified in prior research. Other dimensions were responsiveness, assurance (that includes an ability to inspire trust and confidence), empathy and tangibles that may be delivered or may condition the environment where service is delivered (e.g., in the hotel visit service blueprint mentioned earlier). This paper is focused on asset management services, and the measure of performance is not so much on the delivery of the service, but on the performance of the asset being supported. In all of our cases, there was an orientation towards reliable delivery, but in some, there was a stronger emphasis on safety as an important aspect of reliability where extremely low failure rates are targeted. One was about safely extending the operating life of an aircraft (
Section 4.1). Public transport and health systems must operate safely (
Section 4.4 and
Section 4.5). In the farm automation case (
Section 4.6), economic viability, environmental considerations and the operation of autonomous vehicles could all be seen from a safety perspective. Process reliability was a requirement from an occupational health and safety point of view, and reliability was a dominant mindset in the people involved (all cases).
As noted earlier, a dictionary definition of reliability is “The quality of being trustworthy or of performing consistently well” (Oxford Dictionary). In an e-commerce context, this also includes trust in data security and in identity—is it safe to trust this service provider [
32]. The quality service dimensions of responsiveness and assurance are assessed in one or multiple service encounters, where competency and goodwill are demonstrated, particularly if something goes wrong. From this point of view, recording and mapping critical incidents is seen to be an essential aspect of service quality assurance.
5.1.4. Perceptions of Value
Observation 4: A value proposition may need to support a number of stakeholder expectations.
Service encounters proceed when both customers and suppliers see some value in doing so, and whilst value is a net outcome where the benefits exceed the cost/effort of participation, the benefits or the costs are not always simply financial. In our cases—services supporting high reliability assets—customers realize value in use, helping to earn revenue, with optimal rather than minimal costs as high reliability minimizes disruption costs and enhances reputation. Here, optimal represents a tradeoff, because as noted in the literature survey, some redundancy may be needed to assure both short-term and long term reliability. The three pre-emptive study cases (
Section 4.4,
Section 4.5 and
Section 4.6) represent an investment in future scenarios that may never happen. For suppliers, value is in delivery, maintaining a revenue/cost balance, maintaining a reputation that supports access to future opportunities, with service activities and knowledge-sharing helping to maintain competencies.
From a literature review on perceptions of customer value, Sánchez-Fernández and Iniesta-Bonillo [
97] noted a range of possibilities (which are related to our cases):
A value proposition is associated with a particular business model, and in our cases reliability was a significant element of such propositions. However, if the business model changed, so might perceptions of value. By way of example, in the aircraft life extension case (
Section 2.1), the Department of Defence could consider an option of leasing an alternative aircraft or sending pilots to another country for specific kinds of training instead of extending the life of the current aircraft. This would have resulted in different roles (or no role) for a particular actor.
5.1.5. Tools Supporting Multiple Viewpoints
Observation 5: Methodologies developed in a management, engineering or design context may be useful in a service systems context.
In the cases described here, the practitioners involved utilized tools from different disciplines—management, engineering and design to help understand and deliver asset management services. A discussion of the tools used follows.
The first two cases (
Section 4.1 and
Section 4.2) mapped actual or anticipated critical service incidents and used a form of failure mode and effects analysis (FMEA) that has also been used in assessing service reliability [
38,
98]. One considered the reliability of a resource (an aircraft structure) and the other the reliability of an activity (component manufacturing). The third case (
Section 4.3.) used a form of fault-tree analysis that has also been used in a software services reliability context [
99].
A business model representation (see
Figure 4) was used to provide one view of services that linked to a value proposition in cases
Section 4.4,
Section 4.5 and
Section 4.6. There are many business model representations cited in the literature. A representation often used by practitioners is the “business model canvas” described by Osterwalder and Pigneur [
100] having four primary elements: a value proposition, customer interface aspects (customer segment, relationships and channels), infrastructure management aspects (key activity, key resources, key partner), and financial aspects (revenue stream, cost structure). In the model shown in
Figure 4, there is a slightly different representation of a business model that draws attention to front office and back office aspects commonly considered in framing service operations [
101,
102], and refers to a target beneficiary rather than a customer. For example, in the health system case (
Section 4.5), the direct customer was an enterprise (government or health service), but the target beneficiary was the patient. This term is also used by Vargo and Lusch [
79] in their SDL foundation proposition 10—“Value is always uniquely and phenomenologically determined by the beneficiary”.
Other viewpoints were also used to assemble a picture of service operations in these three cases (
Section 4.4,
Section 4.5 and
Section 4.6)—who are key actors, what resources do they need, and what activities do they undertake? What domain and architectural knowledge is needed to operate this system? An operational system viewpoint was assembled using an architecture standard originally intended to help characterize software systems—ISO 42010 (see
Figure 5). This standard recommended that complex systems be studied from multiple viewpoints, and suggested some reference architecture models might help facilitate this. Business and operational viewpoints were merged using their respective dominant themes: business value proposition and architecture rationale; beneficiaries and stakeholders; business infrastructure and system architecture.
One way of rationalizing data from the multiple viewpoints was to adopt an entity (actor) viewpoint, associating a value proposition, primary activity, resources, inputs required and value delivered with a particular entity, then considering the impact of some kind of change. In addition, an interaction viewpoint was adopted using a large “to-from” interaction matrix that listed all actors, resources and activities. This kind of tool is commonly used in natural ecology research [
103]. Each cell was initially color coded to indicate the nature any interactions (e.g., primary interactions or supporting interactions—left blank for no interactions). When a change was considered in one component, then the interactions that had to be considered were evident.
As well as suggesting methods for studying operations and attributes that might characterize them, associated artifacts acted as “boundary objects”. Different practitioners placed post-it notes on a very large drawing of an aircraft (
Section 4.1), on a workflow diagram (
Section 4.2), an evolving fault-tree diagram (
Section 4.3). Discussion of each element of the ISO 42010 diagram (
Figure 5) and each element of the business model diagram (
Figure 4) drew from different viewpoints in the pre-emptive studies (
Section 4.4,
Section 4.5 and
Section 4.6). Working with an interaction matrix helped discuss possible impacts of changing some aspect of the ecosystem.
5.2. A Services Ecology Perspective
Spohrer and Maglio [
104] had suggested components of a suggested services science framework, and a services ecology is one component.
In the following sections of this paper, an extract from this framework is presented followed by some discussion related to the subject of the paper. “
At the highest level, service system ecology is the population of all types of service system entities that interact over time to create outcomes. Types of service system entities include individuals (people) and collectives (organizations). History is the trace of all outcomes over time for all entities that interact.” [
104].
Ecological studies of the natural world include studies of all living things (plants and animals) and interactions between such things and their non-living environment, which provide resources (air, water, energy etc.). Studies may be undertaken at different levels—e.g., in the context of a particular geographical domain or relating to a particular species of plant or animal [
105]. In this paper, we are concerned with a particular service domain—that of asset management services, which is thus viewed as a service ecosystem. There are interactions with both tangible assets (e.g., transport equipment), and intangible assets (e.g., health-care practices), and the supported assets are used as part of a socio-technical system in delivering services to individuals, groups or enterprises. We observe overlaps between a goods producing ecology and a services ecology, and there is a growing business literature on bundling products and services in customer offerings (product–service systems). By way of example, in our health systems case study (
Section 4.5), the AX enterprise utilized two business models—one offering consulting services and the other (not-for-profit) supporting both physical system operations and the flow of medical goods. Resources drawn on may be characterized as knowledge, information, financial, physical, technology and infrastructure.
The notion of interactions between ecosystems has been explored by Valkokari [
84] in relation to business, innovation and knowledge ecosystems using attributes of goal/rationale, relationships/connectivity, actors/roles, and the “logic of action” (which we interpret as matters of network configuration) to compare them. In the operational context model shown in
Figure 3, it is indicated that a knowledge ecosystem and a service interact to achieve two goals—absolute reliability and value delivery. In our case studies where the primary goal is absolute reliability, there are internal and external connections related to specific functional activities undertaken, and actors include individuals, teams, enterprises and policy-makers. System configurations are adapted for specific purposes—to solve a problem, to support routine activities, or to develop plans for pre-emptive action before a problem occurs. It is the author’s observation that, as in natural ecosystems, the networks of actors, generic activities undertaken by them and kinds of resources available do not change very fast, but variations in the multiple connections between actors, activities and resources may lead to what is seen as a significant change (e.g., bundle asset production and ongoing maintenance).
5.3. An Entity Perspective
Spohrer and Maglio [
104] see a second component of a services science framework as follows. Service system entities are dynamic configurations of resources. They see “
resources as people, organizations, shared information, and technology that can be combined in many ways, depending on access rights”. This fits with a socio-technical perspective (see
Figure 2) taken in our case studies. They refer to formal and informal entities—“
Formal service system entities are named entities, often with legal rights (such as a corporation), and ultimately the focal resource must be a person or group of people in some authoritative or formal role relative to the other resources (such as the chief executive officer and board of directors). Informal service systems may not have legal rights, and the focal resource may simply be a person or group of people with an idea (shared information), such as the tentative name and purpose of a new company”.
The kind of entity we are studying in this paper is a formal asset management function, which commonly has two goals—maintaining the value and utility of the asset, and assuring its reliable operation. The focus of this paper is on reliability assurance, which involves being able to rapidly respond to a critical incident, and being able to anticipate potential critical incidents and take pre-emptive action. From a service-dominant-logic viewpoint, the assets of interest are components of a socio-technical system that delivers services to end-users. This implies a need to support information, organizational, technological and knowledge assets (see
Figure 2). Tacit knowledge is held by the people involved, and codified knowledge may be embedded in information systems, in organizational procedures or in applied technology, but there is always an element of associated tacit knowledge—people have to understand the embedded knowledge in order to make system changes.
Our literature survey identified a significant number of activities that are associated with asset management. How does each function relate to each asset and what might be the coordination mechanism. By way of example, how does a configuration management function relate to information, organizational and knowledge assets and to other activities such as maintenance? There are a lot of potential interactions and they could be considered using an N2 chart [
106] but this is beyond the scope of this paper. The literature also indicated that the efforts of heterogeneous action were aligned by a common culture—the adoption of an absolute reliability mindset.
The notion of dynamic configurations sits well with our case study observations. In the aircraft life extension case (
Section 4.1), a virtual team was established drawing on resources within and outside of the DoD. In the manufacturing service case studies (
Section 4.2 and
Section 4.3), a subset of company functional specialists worked along with some external contributors). In the transport (
Section 4.4) and health (
Section 4.5) systems cases, both internal and external resources were called on, and particularly in the farm automation case (
Section 4.6), the customer was an import contributor.
5.4. An Interaction Perspective
Spohrer and Maglio [
104] suggest that “
Patterns of interaction give rise to service system networks. The interactions occur between and among a set of service system entities over time. Recognizable patterns of interactions (networks) are commonly known as business models. The simplest service system network is a customer and a provider connected by a single value proposition. More complex service system networks include multiple stakeholders, including a provider, and one or more customers, competitors, and authorities, as well as all the value propositions that connect these entities and other satellite stakeholders (criminals, victims, etc.)”.
In our cases, a business model view was considered or implied, and had the business model changed, the nature of interactions would change. By way of example, in the aircraft life extension case (
Section 4.1), the customer was the DoD, and the value proposition explored was to extend the operating life of a training aircraft. However, the DoD was also a supplier of national security services to the government and if this value proposition should not look attractive, then others could be considered—e.g., rent alternative aircraft or send pilots elsewhere for this aspect of training. In the health systems case (
Section 4.2), two synergistic business models were operated in parallel.
Patterns of interaction do not appear randomly, but emerge from consideration of which interactions deliver (or are likely to deliver) value and the establishment of suitable governance arrangements. In the simplest case, this might be terms of purchase, but these terms may be influenced by external factors such as consumer protection laws. Akaka, Vargo and Lusch [
86] present a service ecosystem perspective where a provider may represent or be connected with a network of specialist providers, and where an institutional actor sets or influences rules for the game, influencing patterns of interaction. Co-operative venture governance is a topic of research in its own right, and will not be considered further here. We will now consider governance-based and value-based interaction in more detail.
5.4.1. Governance Mechanism Interactions
This is framed as “
The governance of the system directs the system towards a final goal by transforming static structural relationships into dynamic interactions with other systems. Governance mechanisms reduce the uncertainty in these situations by prescribing, in advance, a mutually agreed process for resolving any disputes that might arise. The ability to organise relationships determines the efficiency and viability of the system. It also determines the equilibrium of the system from the internal perspective, and the satisfaction of other systems from the external perspective” [
21].
All of our case study systems had the common goal of reliably providing a service, and the respective support systems had a common goal of economically assuring reliability goals were met. We observed several types of governance arrangements:
Authoritarian—directed arrangements where an entity in a position of power mandates action in pursuit of a goal. For example, in our first case (
Section 4.1), the DoD directed its Air Force Engineering function to work out how to extend the operating life of an aircraft, and that office directed other DoD staff to undertake tasks as required.
Negotiated—where customers, service providers and other collaborators agree mutually compatible goals and the terms of engagement, normally involving a formal or informal contract. This was evident in some aspect of the support arrangements in all cases.
Voluntary—people volunteer to pursue a common goal, generally with negotiated codes of behavior (e.g., as in open-source software development). This was observed in the health system case (
Section 4.5).
Hybrid—(a) some blend of authoritarian and negotiated arrangements may occur when a buyer or seller is in a dominant position. This was not observed in the cases reported here, but has been noted in other cases; (b) some blend of authoritarian and voluntary arrangements where a seller mandates that some resources will be provided on a voluntary basis. This was also observed in the health system case (
Section 4.2) where pharmaceutical companies provided some supplies free of charge; and (c) some blend of negotiated and voluntary arrangement that may result in form of a memorandum of agreement. This was observed in the agriculture automation case (
Section 4.6) where a farmer might agree to be a beta tester/lead user.
5.4.2. Value Delivery Mechanisms
Spohrer and Maglio [
104] suggest that “
Individual entities try to interact with other entities via value propositions. Normatively, service system entities interact to maximize short-term and long-term value-cocreation. They do this by communicating and agreeing to value propositions, which they reason about and refine through trial-and-error and other mechanisms. For example, informal promises between people, contracts between businesses, and treaties or trade agreements between nations are all examples of value proposition based interactions. Value determination is entity-dependent, history-dependent, and context-dependent”.
What is to be delivered aligns with stakeholder needs/wants and how their expectations are measured. The value delivery mechanism is contingent on the resources available and their accessibility. As noted earlier, we see this encapsulated in a business model. Spohrer and Maglio [
104] offer the following observations about aspects of a value proposition to be considered:
Stakeholders: “All service system entities can view themselves and be viewed by others from multiple stakeholder perspectives. There are four main types of stakeholder perspectives: customer, provider, authority, and competitor. From a provider’s perspective, a good value proposition is one that is in-demand (customers need or want it, and do not prefer self service), unique (only the provider can perform it), legal (no disputes with authority, and will pass all audits), superior (once competitors know about it, they cannot propose anything better, but may try to copy it, given enough time).” It was evident from our case study descriptions that there were multiple stakeholders in all cases, but there was little reference to competitors. In broad terms, this was because our unit of study—projects started with an as-is situation.
Measures: “The four types of measures include: quality (customer determines), productivity (provider determines), compliance (authority determines), and sustainable innovation (competitor determines). Service system entities often have associated KPIs that must be improved to create value.” Our case study focus on absolute reliability (an aspect of service quality) makes business sense—from an economic viewpoint (e.g., see the results of six sigma initiatives), from a social perspective reliable infrastructure minimizes safety concerns, and environmental benefits accrue from the avoidance of disasters such as oil spills in the ocean, plus longer lasting goods reduces the impact on natural resources.
Resources: “Every named thing is a resource. For our purposes, there are four types of resources: physical-with-rights (people), physical-with-no-rights (technology, environment), non-physical-with-rights (businesses, nations, universities), non-physical-with-no-rights (information). All resources have a lifecycle: a beginning, middle, and end. All non-physical resources exist as localized or distributed patterns in the physical states of physical resources, and are subject to coding errors (imperfect patterns or interpretations).” From a business model perspective, resources are needed to create and deliver value, and as noted earlier, in our cases, knowledge and finances were regarded as key resources.
Access Rights: “Resources have associated access rights. A resource can be owned-outright (such as a car that is paid for), leased–contracted (such as limousine and driver), shared-access (such as the language we speak), and privileged access (such as one’s own thoughts).” In all of our cases, access rights were associated with the governance arrangements established.
5.5. An Outcomes Perspective
Spohrer and Maglio [
104] suggest that “
from game theory, two player games have four possible outcomes: win–win, lose–lose, win–lose, and lose–win. Win–win, or more correctly benefit–benefit, is the desired outcome of service system interactions. Taking a broader service science perspective, we proposed ten possible outcomes via the Interact-Service-Propose-Agree-Realize (ISPAR) model, based in part on the four-stakeholder view: customer, provider, authority, and competitor”. In a later article, this is framed in the context of value changes—an interaction may or may not deliver a value change, which may be perceived as positive or negative.
The ISPAR model represents a life-cycle view of a service encounter, identifying potential failure points at each process step. The reliability mindset referred to in this paper includes learning from failures, and
Table 2 shows an FMEA representation of generic ISPAR failure modes where what might be learned from each failure is indicated in the analysis column.
We would like to make a comment in passing about the win–lose combinations referred to earlier, drawing on our broader experience. We have observed the following:
In some cultures, a perceived lose–lose outcome of contract negotiations is favored as it means that both parties had to accept significant compromises to realize a mutually compatible goal. This may be also observed in some political negotiations.
A win–lose situation can result when there is a successful service encounter, and the customer received what was asked for, but the customer had failed to understand what they really needed or just what they were buying into (e.g., when one firm buys another one).
We have observed a lose–win situation in contract research where the researchers were not able to solve the client’s problem, but learned something that helped solve another problem.
Outcomes influence buyer reputation with suppliers and supplier reputation with buyers. We saw reliability as a significant contributor to reputation in all of our case studies, which in turn influenced trust when making a decision to enter a service encounter. Reputation is regarded as a significant (complex) intangible asset by many firms, and like other kinds of assets, its establishment and maintenance requires operation of a number of generic activities: understanding your reputation, alignment with stakeholder expectations, meeting expectations, complaint handling, using complaints data, preparing for the worst, training and rehearsal, and keeping it relevant [
107].
6. Conclusions
The research question explored here is how do service support systems adapt to assure the reliability of complex assets in a dynamic environment? In exploring this question, we had to learn something about adaptable service support systems, something about high reliability complex assets and something about dynamic environments. Curiously, the measure of success is that nothing happens, or at least there are no critical incidents. This poses a potential knowledge management problem—we have to look for subtle indicators of potential failure in masses of information, and we have to learn as much as we can from few and infrequent incidents. The case studies presented illustrate two adaptation modes. At an operational level, the first involves continuous mapping and investigation of critical incidents from any source that may be related to the asset being supported, plus associated corrective action. A knowledge base is retained for future reference. At a strategic level, the second involves understanding the status quo and any current issues plus reviewing sources of change and their potential impact to identify possible pre-emptive actions.
The view presented here is that a service support system can be represented by a particular configuration of linked networks of actors, resources and activities. These linkages may rapidly change, and draw on other elements of a broader services ecosystem where there are different configurations for different purposes. Associated business models define value propositions and value delivery pathways that may favor particular configurations. Operational assets are considered as socio-technical systems. How reliable are requisite information systems, organizational systems, technical systems and sources of knowledge? Are the views of multiple stakeholders considered, how might reliability assurance actors and resources be dynamically connected? How do service science core concepts such as the “service encounter” and supplier–customer value co-creation help us to understand a given situation?
A literature review covered a number of topics: applying systems thinking to characterize a complex asset and its operation, some matters of reliability assurance, considering a socio-technical systems perspective and some attributes of service systems. A large number of requisite functional support activities were identified. Combined with SSMED and notions of a service ecosystem, a reliability context service system model was proposed. At the core is a broad-based services ecosystem. As with natural ecosystems, the particulars are shaped by a local context, and in this case, reliability assurance practices, business models that optimize both service delivery and economic needs. These were combined with a knowledge ecosystem providing access to asset domain knowledge, knowledge of historical “critical incidents”, and knowledge of reliability assurance tools.
Six case studies were presented:
One (
Section 4.1) considered the support arrangements for safely extending the operating life of a military aircraft used to provide pilot training services.
Two (
Section 4.2 and
Section 4.3) considered support arrangements to maximize the reliability of production systems used to provide contract manufacturing services.
Others considered the operations of a regional transport service (
Section 4.4), an international health systems support service (
Section 4.5) and a farm automation service (
Section 4.6), including reflection on how they might be reconfigured in response to possible externally driven changes.
Cross-case comparisons resulted in five service-oriented observations:
Who is the customer? Asset owners are customers, and they too have customers. The asset manager is both a supplier and a customer. Suppliers of support services may deal with other suppliers of complementary services to deliver an outcome sought by an asset owner. From this perspective, one supplier may then be a customer of another. Actors may change roles depending on the current context.
Framing the service encounter. The service encounter concept tends to focus on some attributes associated with a single event (e.g., value co-creation, perceived quality and impact on reputation), but in our cases there were multiple service encounters between a significant number of actors to be considered. At a macro-level, each case could be considered a service encounter that is described as a project. Within each project, there are multiple activities (service encounters) to be orchestrated.
Matters of reliability and trust. The reliability assurance concept has multiple dimensions, e.g., safety assurance, delivery assurance, several aspects of trust—e.g., trust in information and trust in organizations.
A value proposition. A value proposition may need to support a number of stakeholder expectations, and this may be best represented in a business model that also includes value creation and value delivery mechanisms
Tools supporting a reliability focus. Methodologies developed in a management, engineering or design contexts may be useful in a service systems context, e.g., Failure mode and effects analysis (FMEA).
6.1. Contributions to Theory
It has been suggested that “
Service is in fact becoming the lens through which many disparate areas of study can be viewed within a common framework” [
9]. Such areas of study include service sciences, management, engineering and design (SSMED). A suggested framework brings together ten concepts that may be viewed in a hierarchical way, organized from the top as an ecology where service entities interact to deliver outcomes. Outcomes impact reputation. Interactions create value through a combination of governance mechanisms and arrangement supporting a particular value proposition. Such arrangements consider stakeholders, resources, access rights and measures of success.
In this context, our first contribution is that whilst study of a service delivery ecology may be necessary, it is not sufficient. Viewing all aspects of our case studies through a service lens provided useful insights, but it was also noted there is an increasing interest in bundled product (goods)—service value propositions. Interactions between goods-producing and service-delivery populations require an understanding of a parallel goods-producing ecology. This would be analogous to the study of plants, animals and their interaction in nature.
Our second contribution moves down the ecology levels of analysis to consider an ecosystem viewpoint, where interactions in a particular context are considered. This level of analysis is popular with many researchers, e.g., with papers on service, business, knowledge, digital and software ecosystems being cited in the academic literature. This paper presents a reliability ecosystem contribution (
Figure 3), and whilst there have been some related studies in a natural ecosystem context [
108] there are few in a systems reliability context.
Our third contribution draws on the work of others [
88], observing an ecosystem from a network viewpoint. Networks of actors and networks of resources interact, and networks of activities interact with both. Some generic actor roles have been identified in the services literature—customer, service provider, integrator and instrumental, and in each of our case studies we have identified a significant number of actors that could be categorized in this way. A significant number of functional activities supporting reliability assurance have been identified in this paper, along with some generic kinds of resources (including knowledge, financial, technological, ICT, and logistics), each of which could also be considered as an ecosystem. We observe that new actors, activities or resources may emerge to change the dynamics of the ecosystem, but faster changes are made through the reconfiguration of linkages. In our case studies, a particular actor may be called on for a particular service encounter but not for other service encounters, and a particular actor may play different roles in different service encounters.
Our fourth contribution also draws on the contributions of others and an interaction viewpoint—how to represent and work with a multiplicity of interactions. Interaction matrices (N2 matrices) have been utilized for a variety of purposes, e.g., in the natural sciences, in management studies, in engineering, and in design. In a support services ecosystem context, we map touch points between actors, activities and resources in a particular instance, which helps us both understand the nature of interactions and evaluate the potential impact of some change.
Our fifth contribution, also drawing on the work of others and an interaction viewpoint relates to the concept of “boundary objects”—artifacts that help stimulate and consolidate observations and interpretations of reality by actors with different world-views. The artifacts utilized in our case studies could be broadly described as models—a very large drawing of an aircraft, production workflow diagrams, a business model, and a systems architecture framework. Clustering information around components of the model helps reveal potential “hot spots” where pre-emptive action may be appropriate, or where any flow-on effects of pre-emptive action may be considered.
6.2. Some Practical Implications
The utilization requirements of a complex asset may change over time (e.g.,
Section 4.1), and the adoption of new technologies may change historical practices (e.g.,
Section 4.6). Such changes may introduce new actors and/or new activities and/or new resources to be integrated in providing asset management support services.
Viewing complex asset operations as a socio-technical system (see
Figure 2) has the following implications:
We need to adopt practices that assure the reliability of information systems and understand the knowledge embedded in such systems. This may require validity checks on input data.
Ensuring the reliable operation of organizational systems may involve the formalization of some procedures, learning about what to do and what not to do and introducing some redundancy through cross-checking practices and multiskilling.
Ensuring the reliability of technical systems involves the use of techniques such as mistake-proofing (e.g., mechanical components can only be assembled one way) and loose subsystem coupling with strong interface control at the design stage, the introduction of some redundancy (parallel functions), smart system monitoring and looking for clues. Maintaining a knowledge base about various generations of technology can be a problem.
Maintaining architectural knowledge about how everything works together and sharing information across functional boundaries. Being able to compare issues observed in comparable systems, being the keeper of the reliability mindset ethic, undertaking pre-emptive studies—strategic, tactical and operational integration.

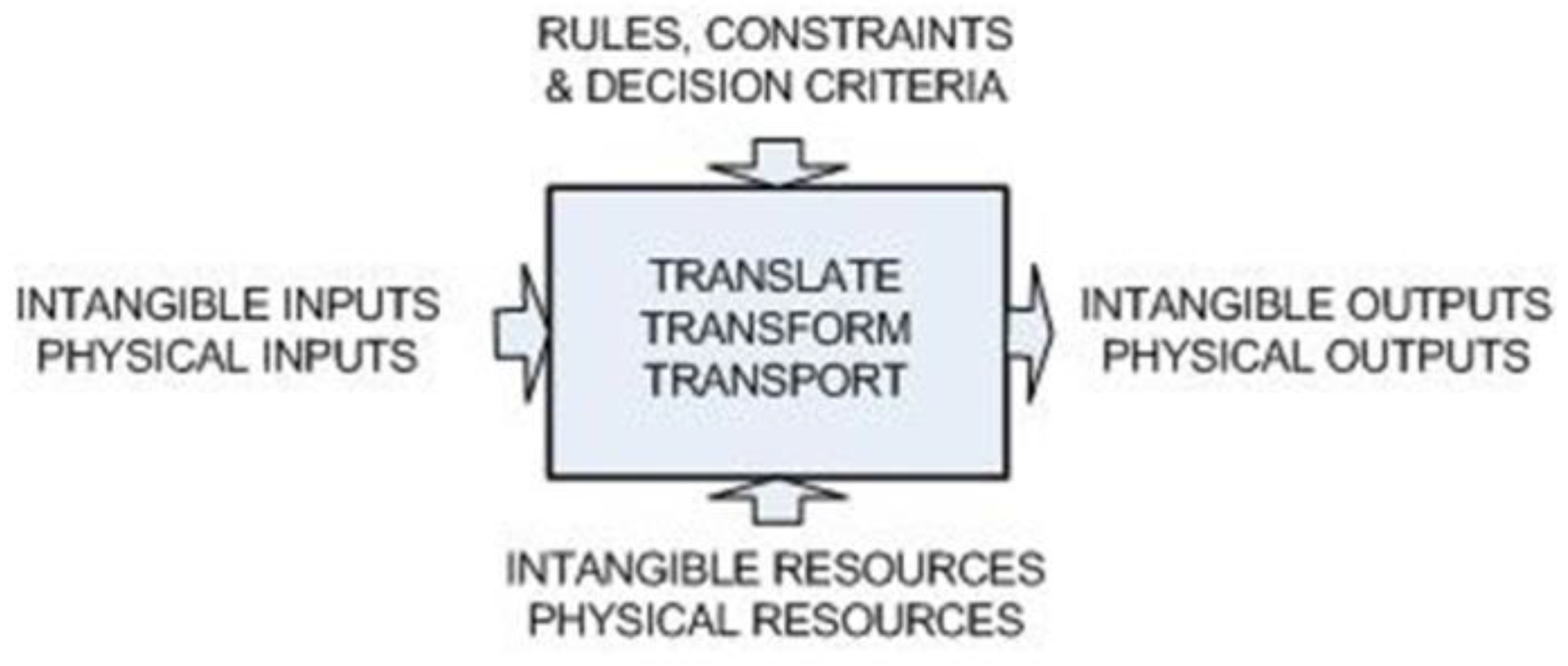
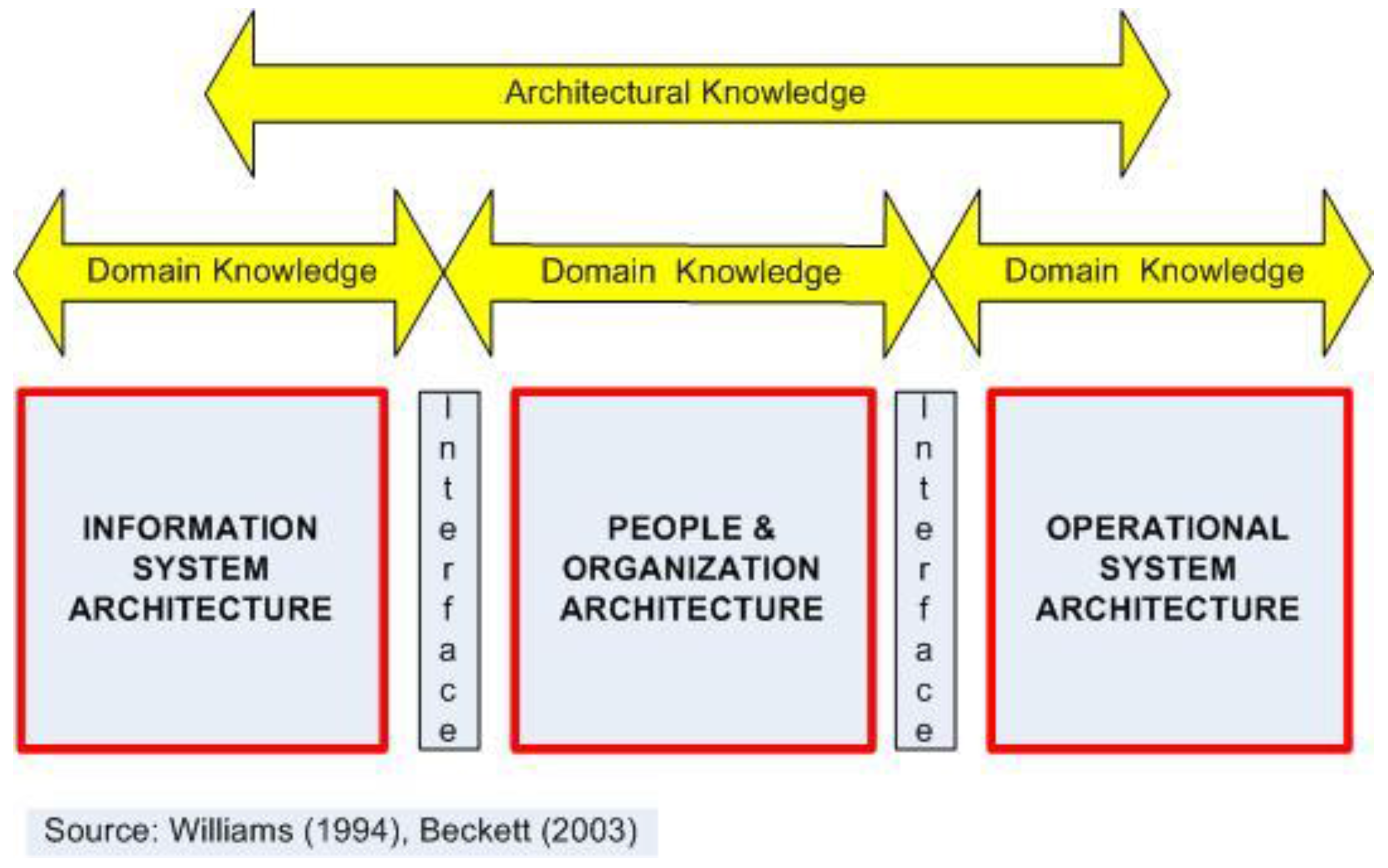
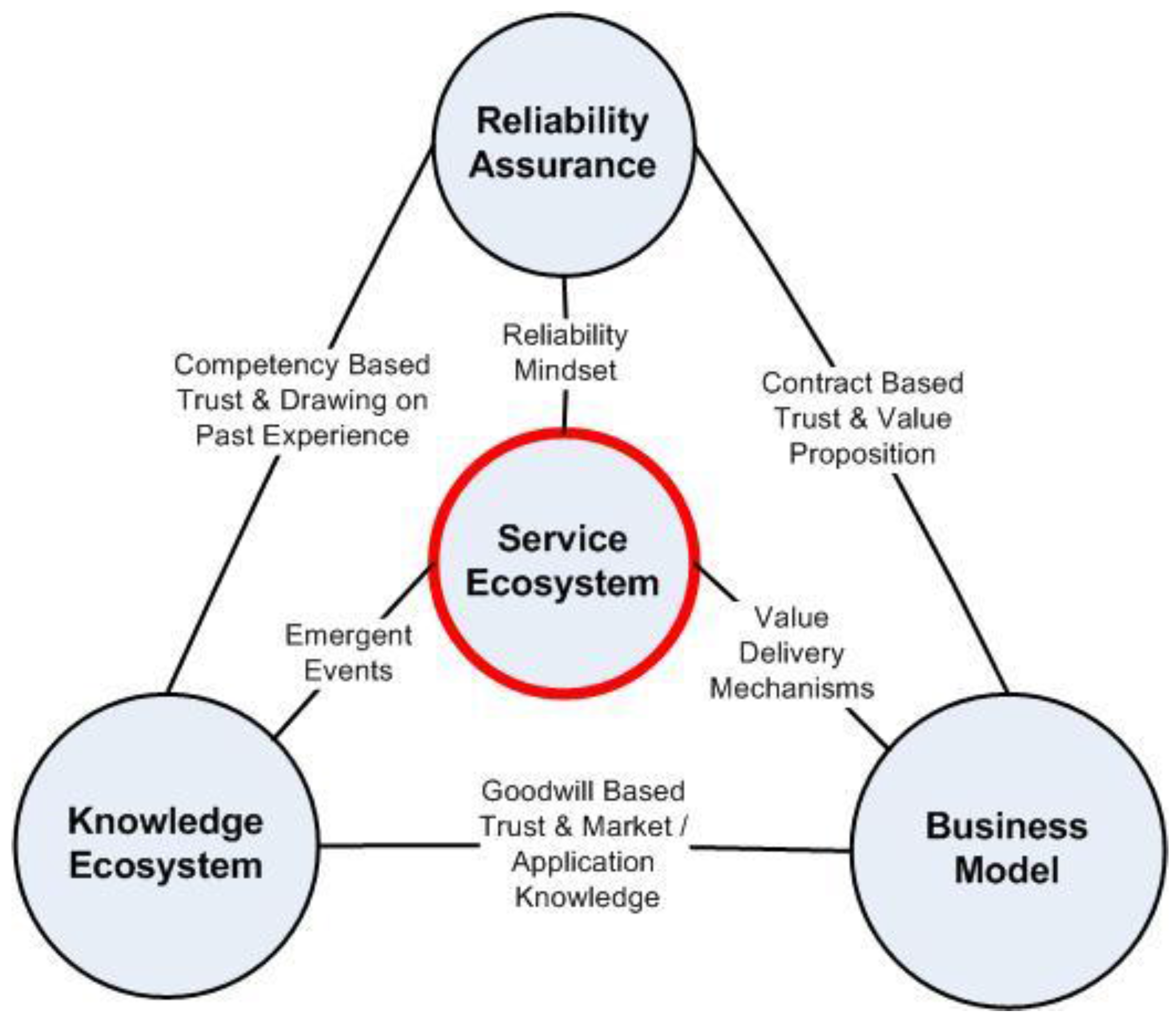
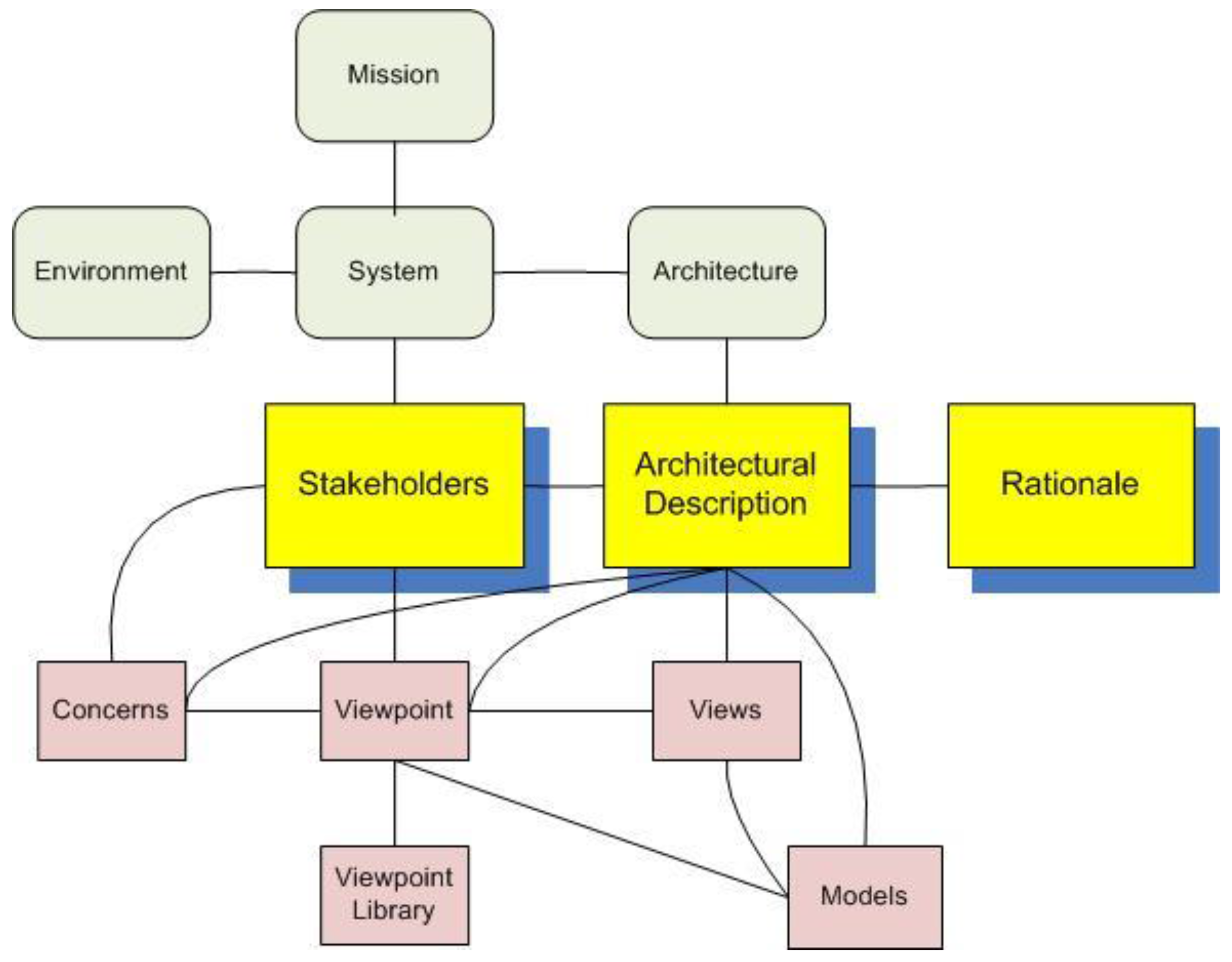

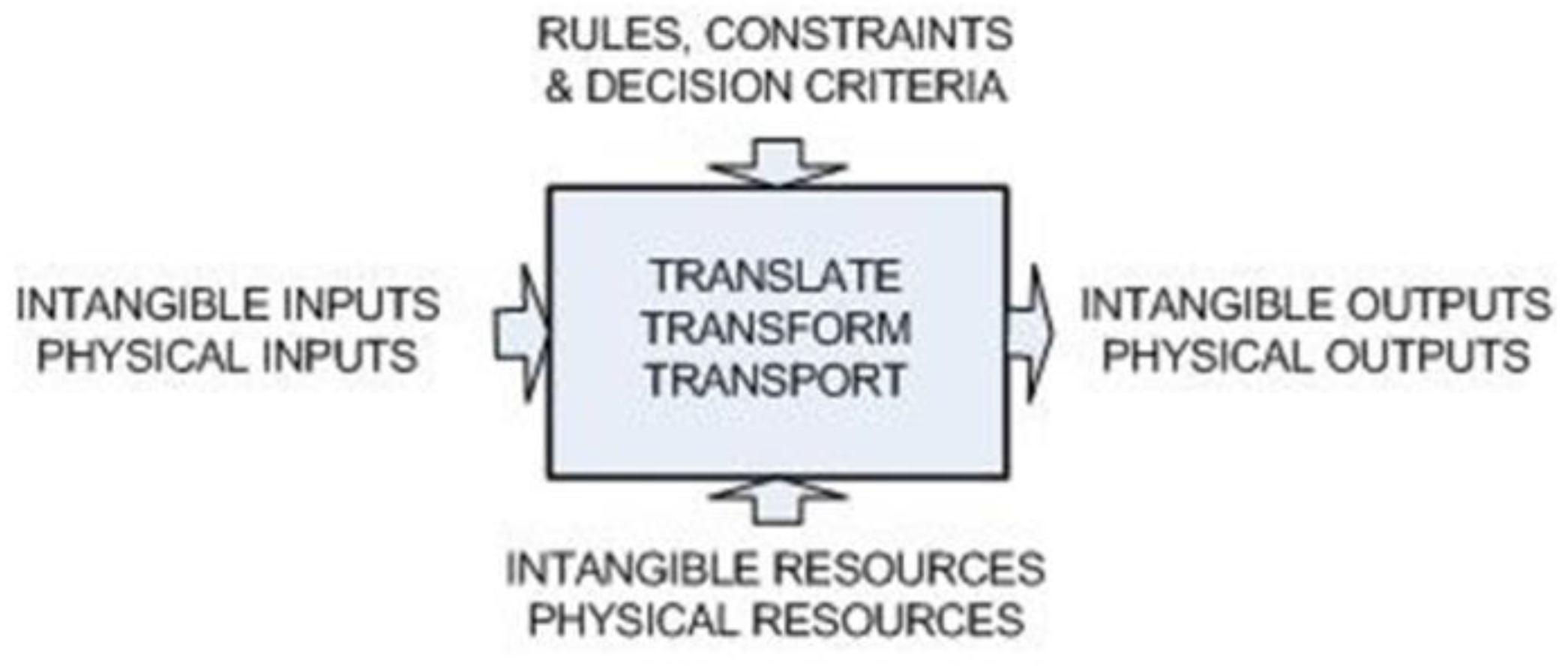{kind=link}
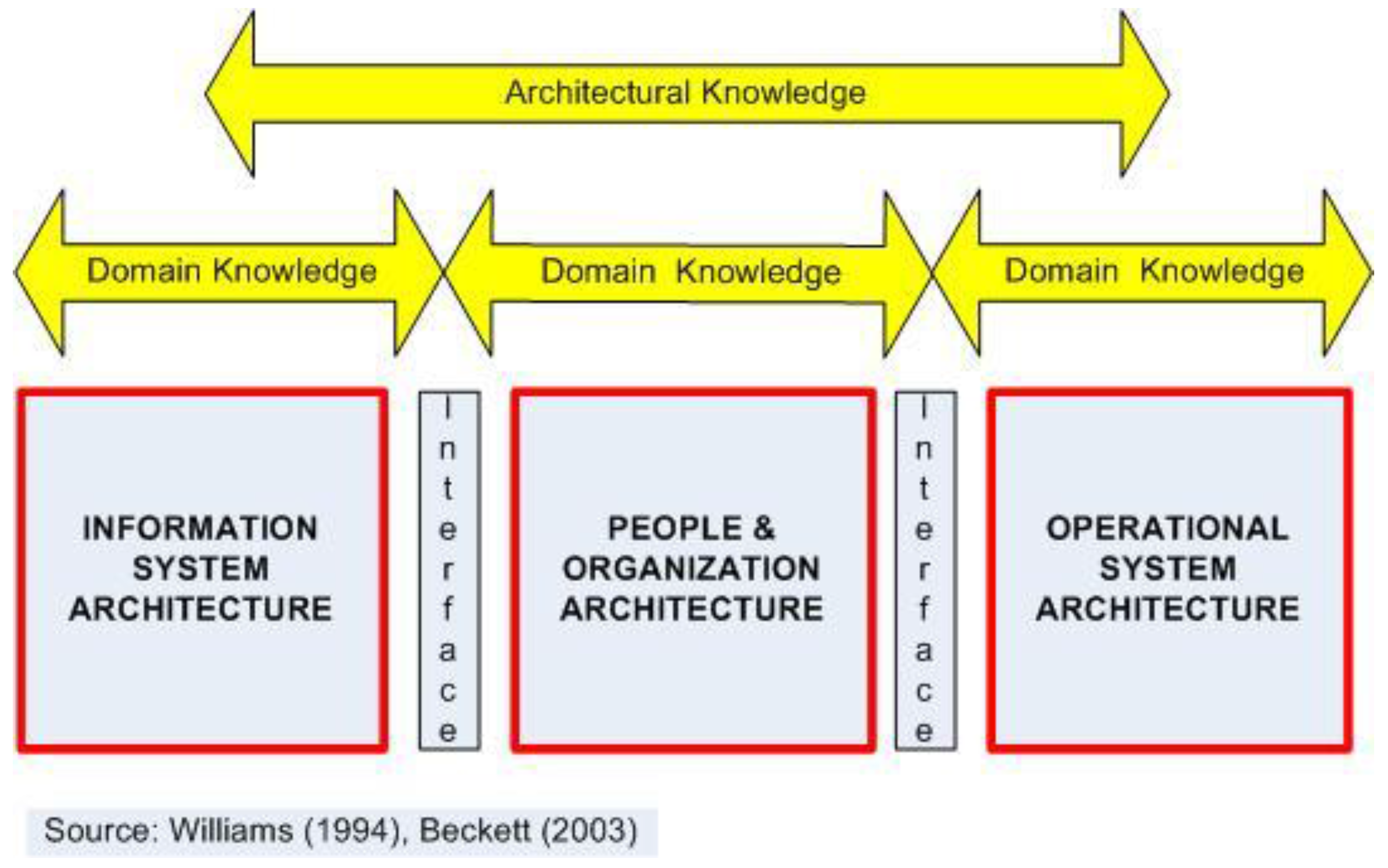{kind=link}
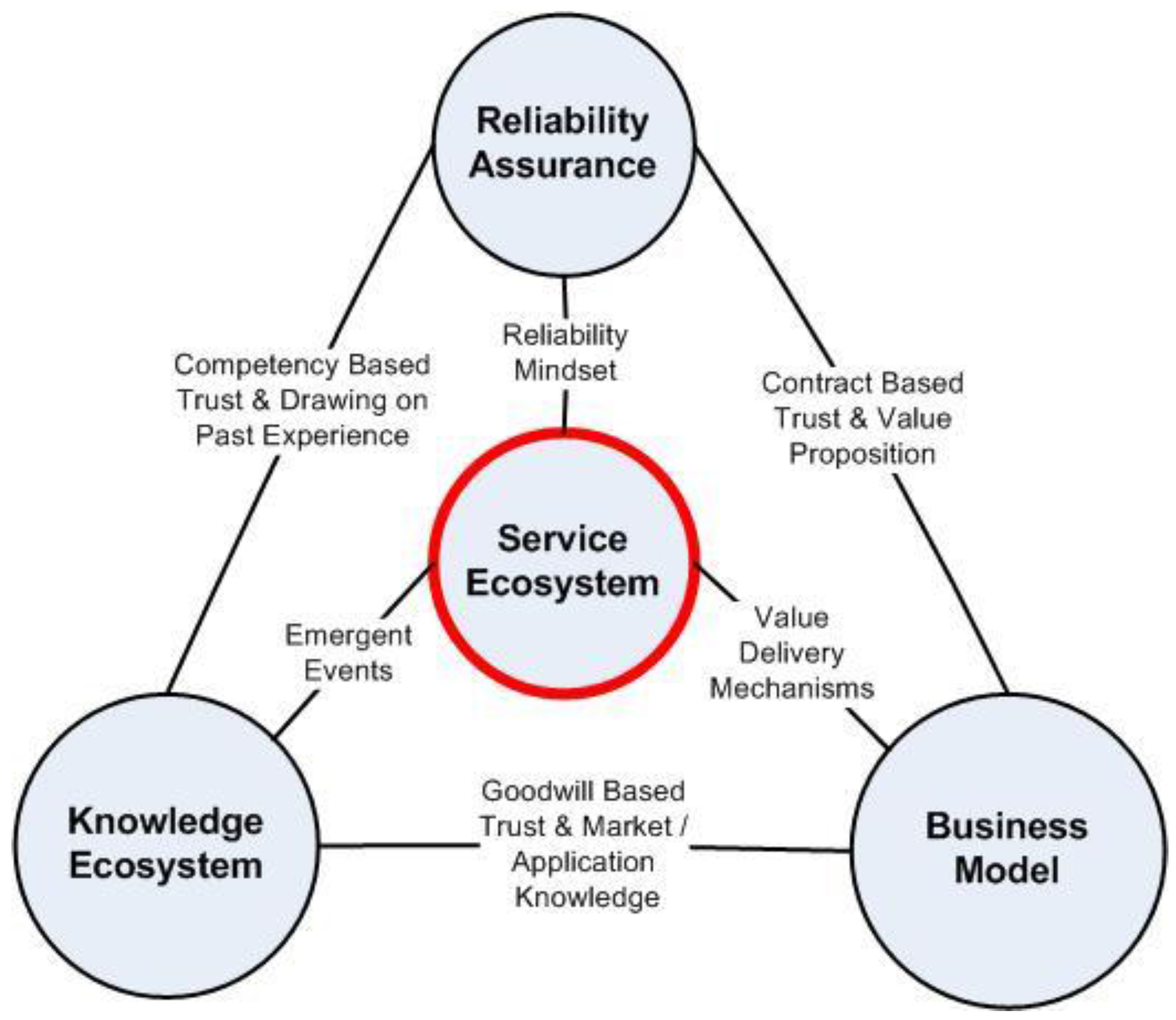{kind=link}
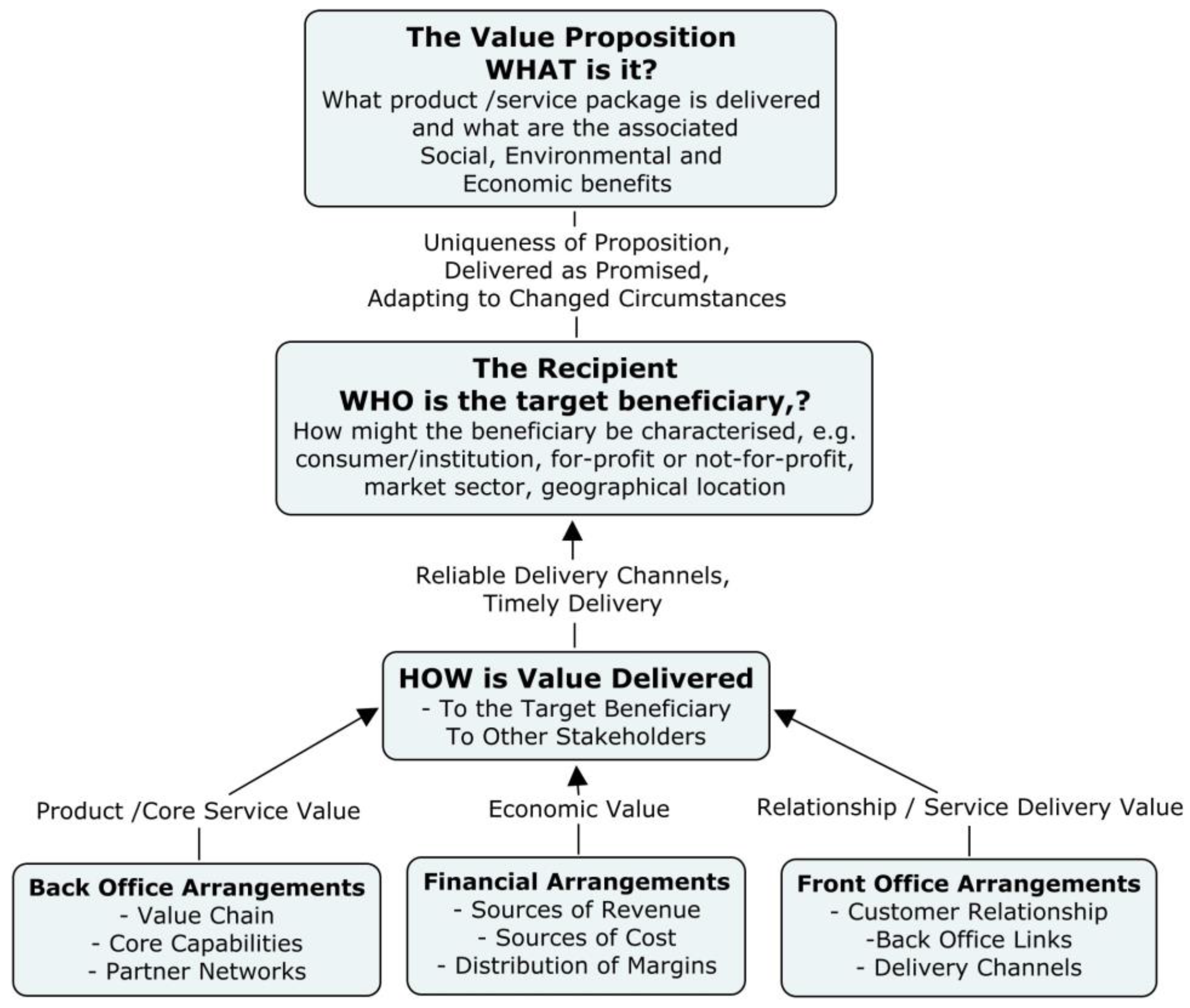{kind=link}
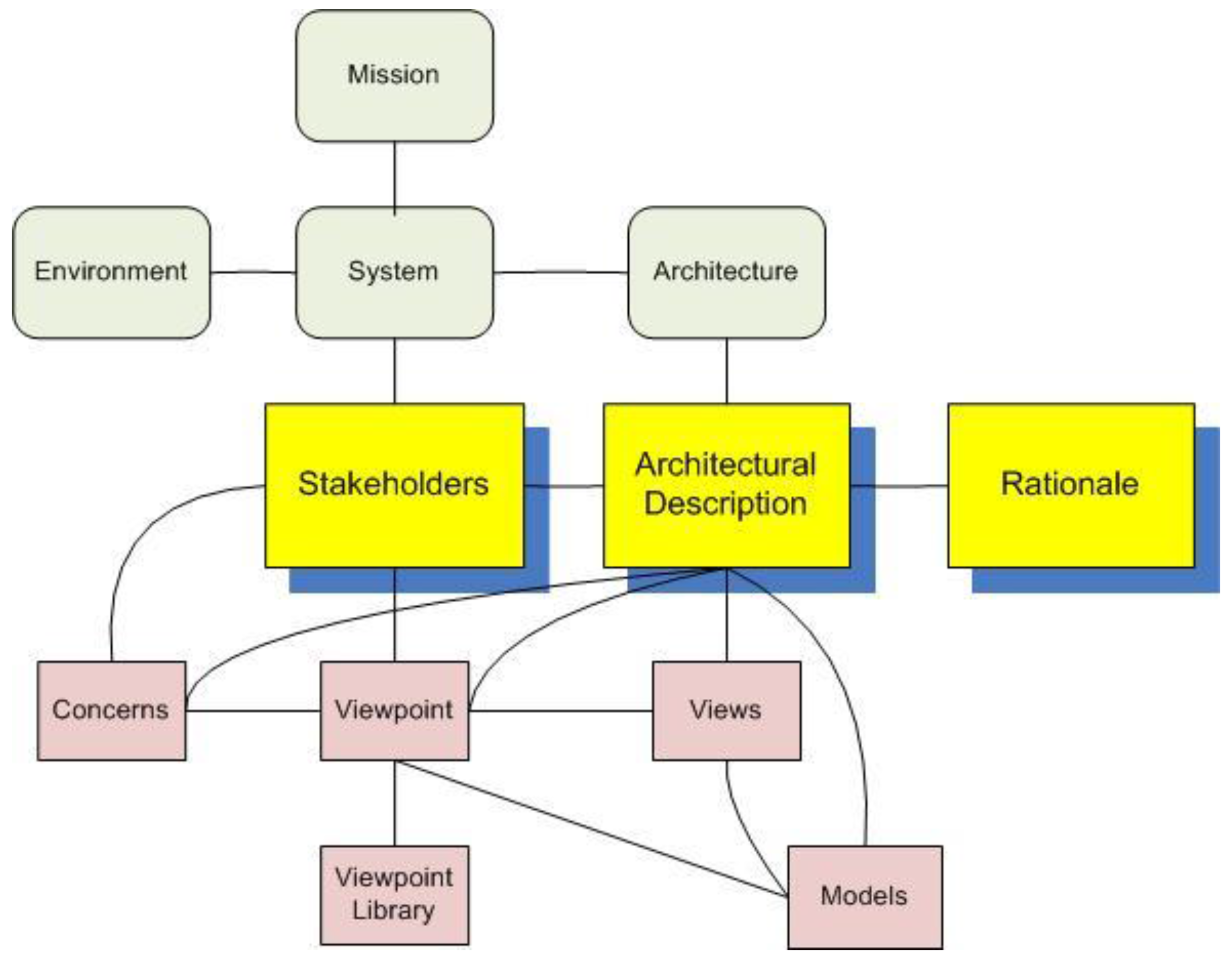{kind=link}