1. Introduction
Knowledge retrieval systems in database-driven environments prioritize the delivery of query-relevant information. Within the patent domain, the integration of deep learning methods has accelerated the evolution of similar patent search capabilities. Although GPT-style decoder-only transformers demonstrate robust query responsiveness, they remain susceptible to hallucination. Retrieval-Augmented Generation (RAG) systems have emerged as a preferred solution in knowledge-based expert systems, effectively mitigating hallucination while maintaining high-quality knowledge services. These systems continue to advance, leveraging patent databases to identify query-relevant documents and generate appropriate responses based on validated source material.
For patent document retrieval systems, selecting patent document candidates relevant to queries is crucial for service quality. Traditional patent search systems focus on applying deep learning models to patent classification systems based on registration criteria. Primarily, encoding model-type deep learning methods are being applied to classification tasks for automating similar patent search processes. Patent document classification methods based on Convolutional Neural Networks (CNN), Transformer–Encoder-based patent document classification methods, and patent classification methods utilizing hierarchical structures for large-scale patent documents have been proposed. Recent deep learning methods demonstrate superior performance in patent classification due to patent documents’ typical textual document information characteristics. Despite the performance achieved through deep learning in patent classification tasks, similar patent searches still require expert knowledge for similarity evaluation tasks. RAG systems select similar document candidates through similarity evaluation. While cosine similarity is typically used for general similarity assessment, showing high similarity for content with similar structure and content, patent document similarity evaluation must consider technical relationships with prior art, which fundamentally differs from general document similarity evaluation. For example, an Apple touch interface patent (US 7,469,381) may be technically related to an older Microsoft scrolling patent (US 5,495,566) despite minimal textual overlap due to their functional equivalence, while having high textual similarity with contemporaneous Apple patents in unrelated technical domains. Although image classification methods have been proposed to reduce similarity distances between similar information for robust query handling, similarity distance learning methods are not effectively utilized in document classification due to rare significant differences in document representation similarity. Meanwhile, sematic search tasks are characterized by the difficulty of determining semantic similarity between documents based solely on document class information. Experts traditionally use ontological models like synonym dictionaries for similarity evaluation. However, ontological models present challenges in continuously expanding environments like patent information due to the ongoing expert resource update costs.
This paper proposes a novel model for selecting appropriate candidates for RAG-based patent document knowledge retrieval services. We utilize prior art relationship information, bypassing the need for expert-developed knowledge structures to reflect expert knowledge in similarity evaluations. Similar Patent Search Network using Prior Art Information (PAI-NET) is a contrastive learning-based multi-tasking model that applies similarity to prior arts in classification task models.
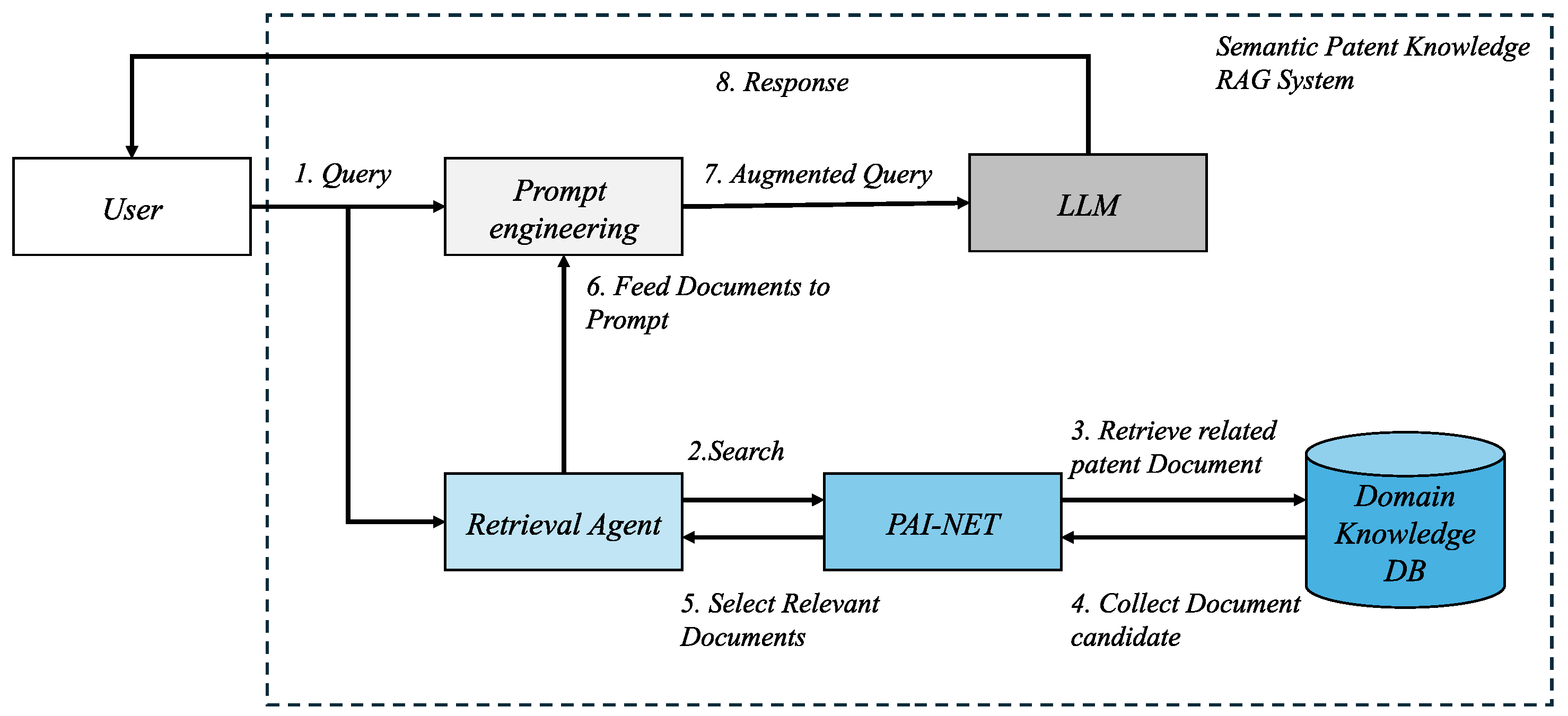
Figure 1 illustrates the architecture of our Semantic Patent Knowledge RAG (Retrieval-Augmented Generation) system, which emphasizes semantic similarity analysis between priority art documents. The system comprises a retrieval agent, PAI-NET, prompt engineering module, and Large Language Model (LLM), with a particular focus on analyzing deep relationships between prior art documents.
The core innovation lies in the interactions between steps 2–5, where the retrieval agent and PAI-NET collaborate to establish semantic relationships between prior art documents. When PAI-NET searches for prior art documents in the Domain Knowledge DB, it goes beyond simple keyword matching to understand the semantic connections between documents. Specifically, it calculates similarities by considering relationships between patent claims and specifications, citation networks, and technical field hierarchies. This approach ensures that retrieved prior art documents form an interconnected knowledge network rather than a collection of isolated documents.
The core innovation lies in the interactions between steps 2–5, where the retrieval agent and PAI-NET collaborate to establish semantic relationships between prior art documents. In step 2, the retrieval agent transforms the user query into an embedding representation that captures the technical essence of the patent information being sought. During step 3, PAI-NET executes a semantic search in the Domain Knowledge DB, applying specialized embeddings that prioritize technical relationships over superficial textual similarities. In step 4, the Domain Knowledge DB returns candidate patent documents based on these specialized search parameters, providing the raw material for technical analysis. Finally, in step 5, PAI-NET evaluates and ranks the retrieved documents by computing similarity scores that specifically reflect technical relevance rather than textual similarity. This comprehensive approach ensures that retrieved prior art documents form an interconnected knowledge network rather than a collection of isolated documents.
The Domain Knowledge DB functions as a knowledge graph that encodes complex relationships between prior art documents, rather than serving as a simple document repository. PAI-NET leverages this structured information to identify the most relevant set of prior art documents for a given query. This process not only considers technical features of patents but also filing dates, citation relationships, and technological evolution patterns within the field. Before being passed to the LLM (large language model) through the prompt engineering module (steps 6–7), the retrieved documents are structured according to their semantic relevance. This enables the LLM to comprehend the complex relationships between prior art documents and generate more accurate and contextually appropriate responses (step 8).
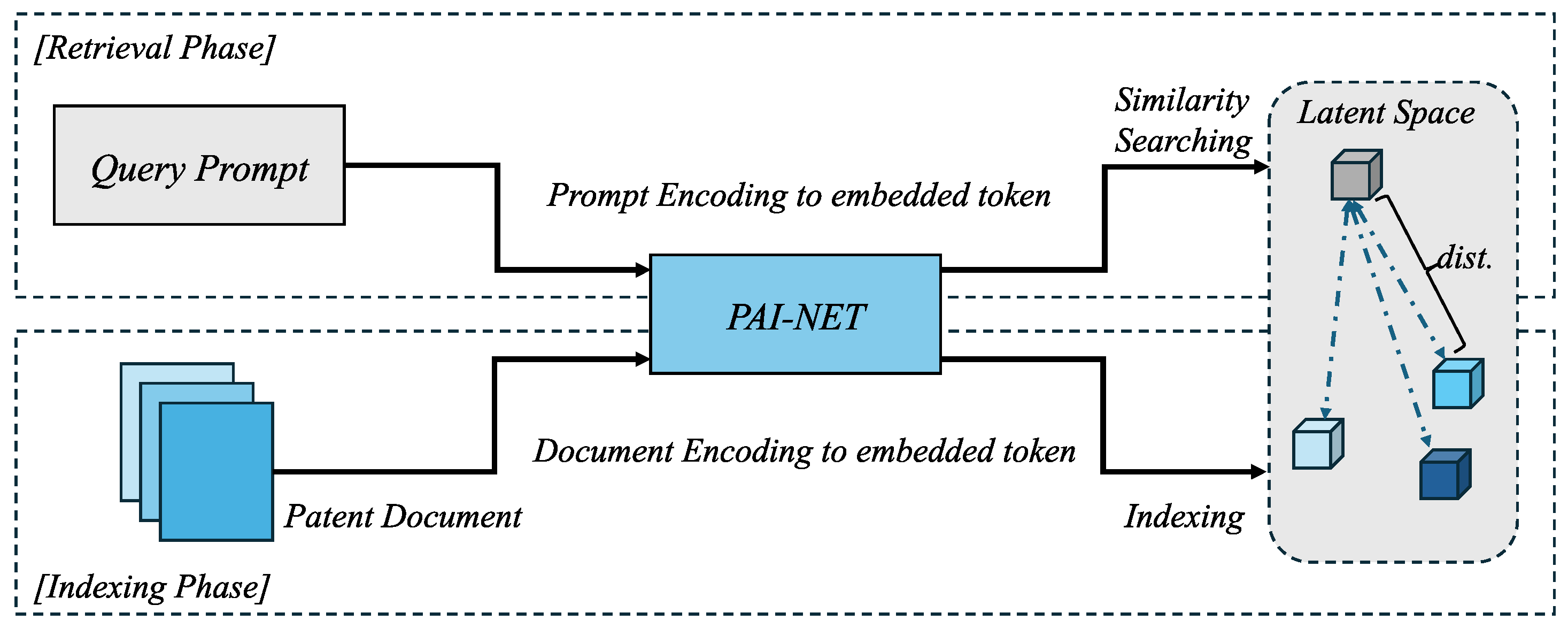
Figure 2 depicts the core components and process flow of the PAI-NET-based patent RAG system. This system is fundamentally divided into two phases: indexing and retrieval. In the indexing phase, each document from the patent document database is processed through the PAI-NET model. Documents are transformed from textual data into embedded tokens, reflecting the semantic characteristics of the documents. The converted embeddings are indexed in a latent space, where prior art relationship information is incorporated such that technically similar documents are positioned in proximity to one another. In the retrieval phase, user query prompts are converted into embeddings through the identical PAI-NET model. These generated query embeddings are utilized for similarity searching, calculating distances between the query and previously indexed document embeddings in the latent space. Rather than relying on simple document representation matching, the search is based on the distance-based technical similarity inherent in patents, with particular emphasis on similarity measurements that reflect prior art relationships. Similarity measurement in the latent space differs from conventional document similarity approaches by considering the technical relationships between patent documents and prior art information. This overcomes the limitations of ontology-based models and significantly enhances the accuracy and relevance of patent searches.
This architecture overcomes the limitations of traditional RAG systems in patent search applications. By performing sophisticated analysis of semantic similarities between prior art documents, it provides more comprehensive and accurate patent search results. Furthermore, this deep document analysis significantly contributes to the thorough identification of relevant prior art documents during patent examination processes. In this process, our model applies a method of generating similar document groups based on prior art information between patents to extract query-relevant candidates. When these similar document candidates are presented, the service is provided by inputting prompts combining queries and candidate documents into generative language models to compose appropriate responses from candidate documents.
Our main contributions are summarized as follows:
PAI-NET is a novel model for similar patent search that improves document similarity evaluation performance by incorporating expert knowledge into similarity metrics.
We demonstrate that prior art information can enhance similarity search performance without independent manual ontology construction.
PAI-NET performs both classification and similarity learning tasks while maintaining computational costs comparable to traditional classification-only models.
We analyze and evaluate PAI-NET through extensive experiments on real patent datasets, demonstrating significant performance improvements in similar patent search tasks.
3. PAI-NET: RAG Patent Network Using Prior Art Information
RAG Patent network using Prior Art Information (PAI-NET) is designed for similar patent search services. The PAI-NET framework has a multi-tasking structure that learns the similarity distance between documents and classification tasks together. To this end, PAI-NET has a conjured triple-encoder structure for multi-tasking tasks and utilizes objective functions for similarity distance learning tasks and classification tasks.
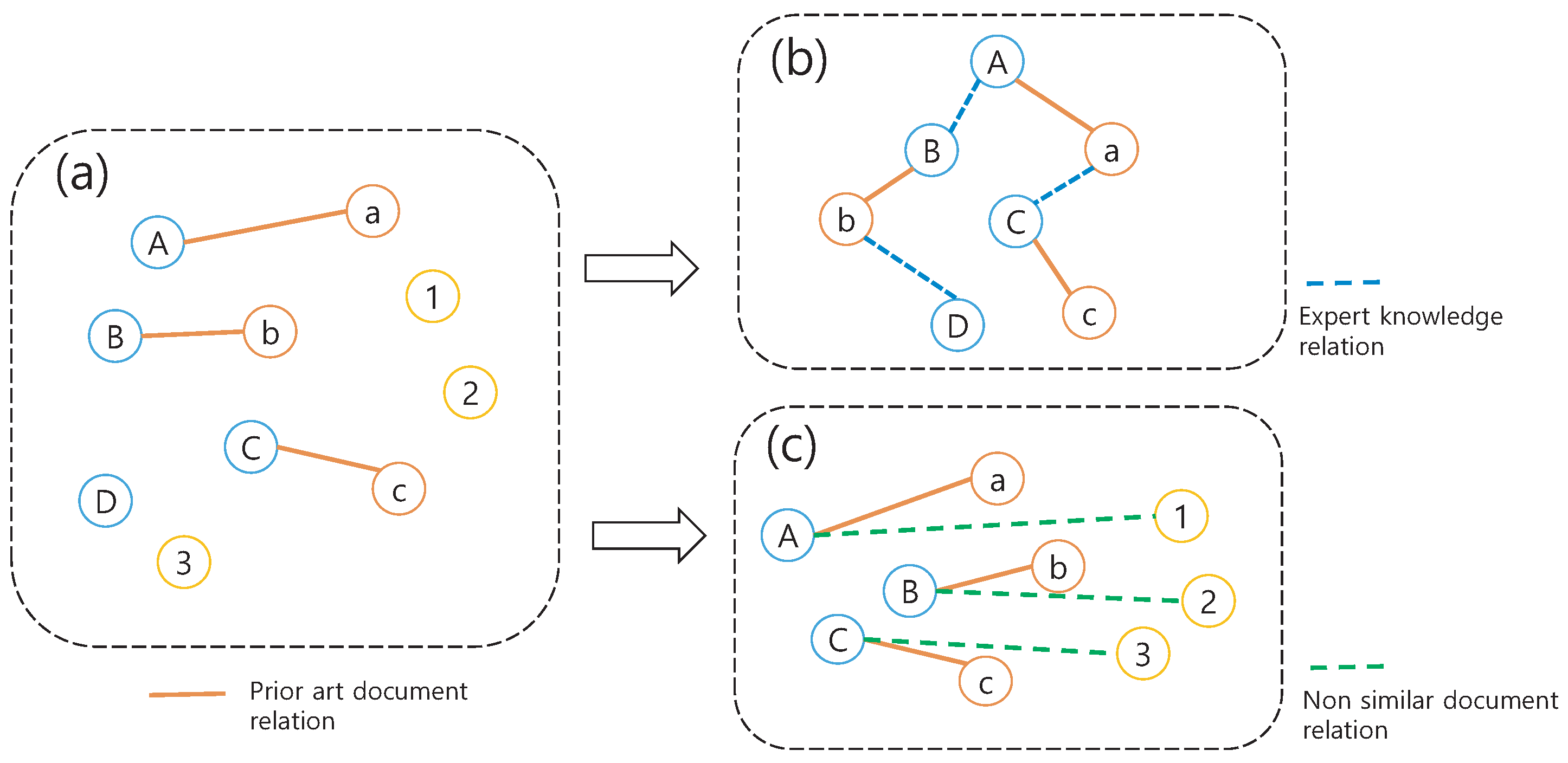
Figure 3 shows how the proposed method utilizes prior art information.
Figure 3a shows the relationship between the prior art document and the claimed patent (target document) as domain knowledge, the most technically similar relationship with 1 to 1 matching. Meanwhile,
Figure 3b shows how to generate traditional ontological structures. In
Figure 3b, in addition to prior art relationships, patent experts leverage domain knowledge to further apply the linkages between each document to generate a searchable graph structure. On the other hand, in
Figure 3c, the proposed method combines non-similar patent document information with the prior art pair. It uses it to consider the similarity distance between the prior art and the target patent document relatively in the learning task.
This approach can be illustrated through a real-world example involving Apple’s “bounce-back” effect patent (US 7,469,381), its family patent US 7,864,163 (covering double-tap zoom functionality), and its prior art, Microsoft’s scrolling patent (US 5,495,566). As shown in
Figure 3c, PAI-NET does not simply learn the relationship between a target patent (A) and its prior art patent (P); it also takes non-prior art patent documents (N) into consideration. This represents a significant innovation in learning patent document similarities. Family patents US 7,469,381 and US 7,864,163 share the same priority application (January 2007) and use similar terminology and expressions, thus showing high similarity even in text-based similarity measurements. In contrast, Apple’s patent and Microsoft’s prior art patent both concern scrolling functionality, but due to their more than 10-year difference in filing dates and different writing styles, they would be evaluated as distant based on text-based similarity metrics. PAI-NET accurately reflects the technical relevance of prior art in the embedding space despite these differences in document representation. PAI-NET’s contrastive learning approach simultaneously considers three document relationships, as depicted in
Figure 3c. It learns prior art relationships (A-P) as positive pairs while ensuring distance from non-prior art patent documents (N). This approach relatively evaluates the similarity distance between patents A and P, enabling effective patent similarity learning without the complex expert knowledge graphs required by traditional ontological structures (
Figure 3b). By leveraging prior art relationships directly, PAI-NET offers a solution to the cost challenges associated with constructing and maintaining comprehensive ontological structures, which typically require significant expert resources and continuous updates to remain relevant in the evolving patent landscape.
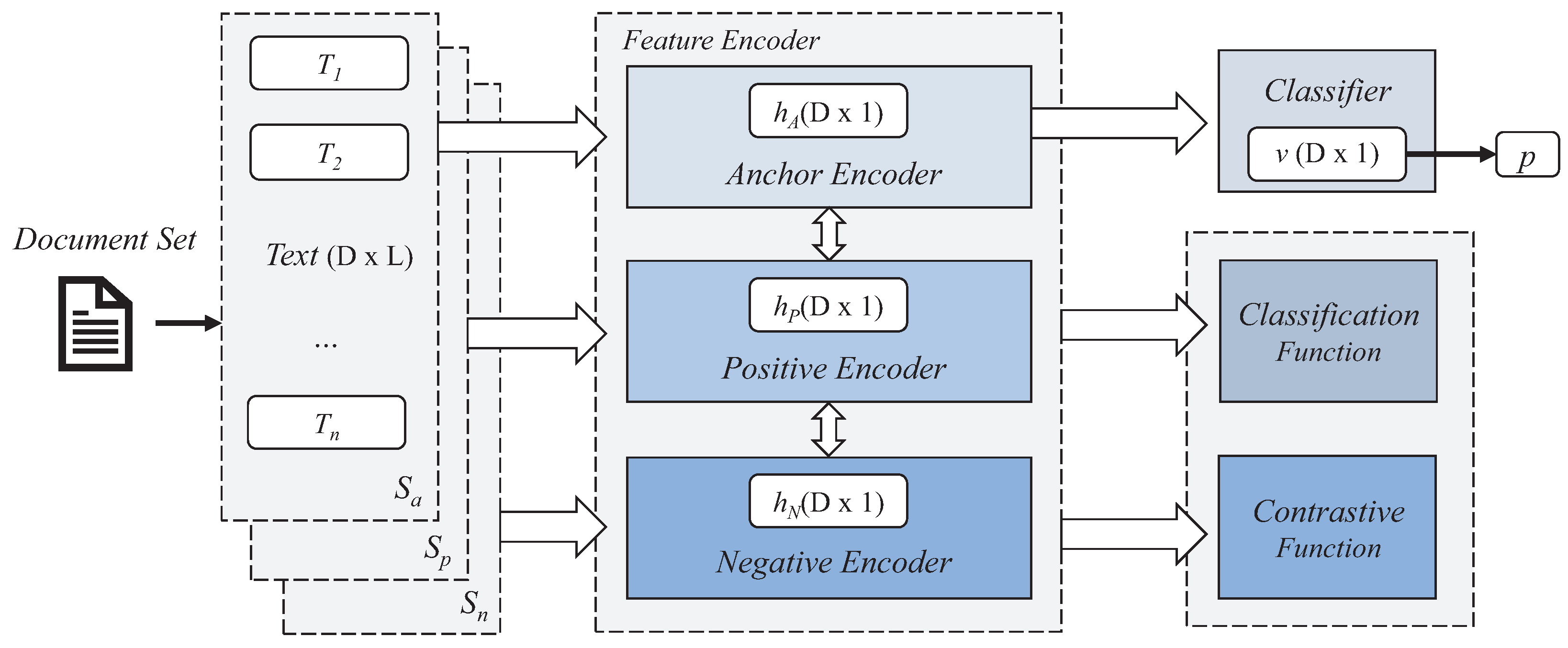
Our framework uses the set
S of three different documents in parallel in one input step. The three document inputs are used as anchors
, positives
, and negatives
, respectively. Each document is transformed into a set of embedding tokens through an embedding process [
10]. The encoder
uses three conjured Transformer encoders that share weights, and the embedded document set
entered is converted into document feature set
of
through the encoder corresponding to each location. Each transformed document feature
is used for classification tasks and similarity distance learning tasks. Document features that pass through the anchor encoder are used as inputs to the classifier
for classification objective function computing. The anchor document feature
is also used for similarity distance learning, where it is used for objective function computation with the positive document feature
and the negative document feature
. We design our framework without increasing computational time cost compared to existing single classification tasks using a parallel encoder batch process and share the weights of each encoder so that the encoders can focus on achieving the goal of the objective function.
Figure 4 and the following equations represent the overall process:
We describe how to combine pairs of documents in the preprocessing step and the embedding process in
Section 3.1. The document embeddings after the preprocessing process are used as input to the encoder. Equation (
1) shows the feature encoding process for the multi-tasking process described in
Section 3.2. Equation (
2) presents the classification task in
Section 3.3, and the description of the objective function for multi-tasking is covered in
Section 3.2. Lastly, the aggregated features pass through a final fully connected layer and softmax for label prediction learning in Equation (
3) while being utilized in parallel as features for document similarity evaluation, as shown in Algorithm 1.
| Algorithm 1 Pseudo-code of PAI-NET |
| Input: Document Set S = [, , ] |
| Output: Document feature |
| Initialization: initialize shared weight w of document encoders , , and set value |
| ∘ Training phase |
- 1:
= target Document set (anchor) - 2:
= the prior art document pair set of (positive) - 3:
= non relevant document set of (negative) {⊳process mini-batch size learning} - 4:
for each batch size s of S do - 5:
= () - 6:
= () - 7:
= () {⊳each v encoded by parallel process of } - 8:
= ( ) by ( 8) - 9:
= ( , , ) by ( 9) - 10:
= + · - 11:
w = w + ∇ {⊳update shared w of document encoders} - 12:
end for ∘ Similar search phase {⊳find similar candidate documents with target } - 13:
= () - 14:
for all Candidate Set do - 15:
= () - 16:
get Top-K of MAX() - 17:
end for - 18:
return Candidate by using index of
|
3.1. Preprocessing
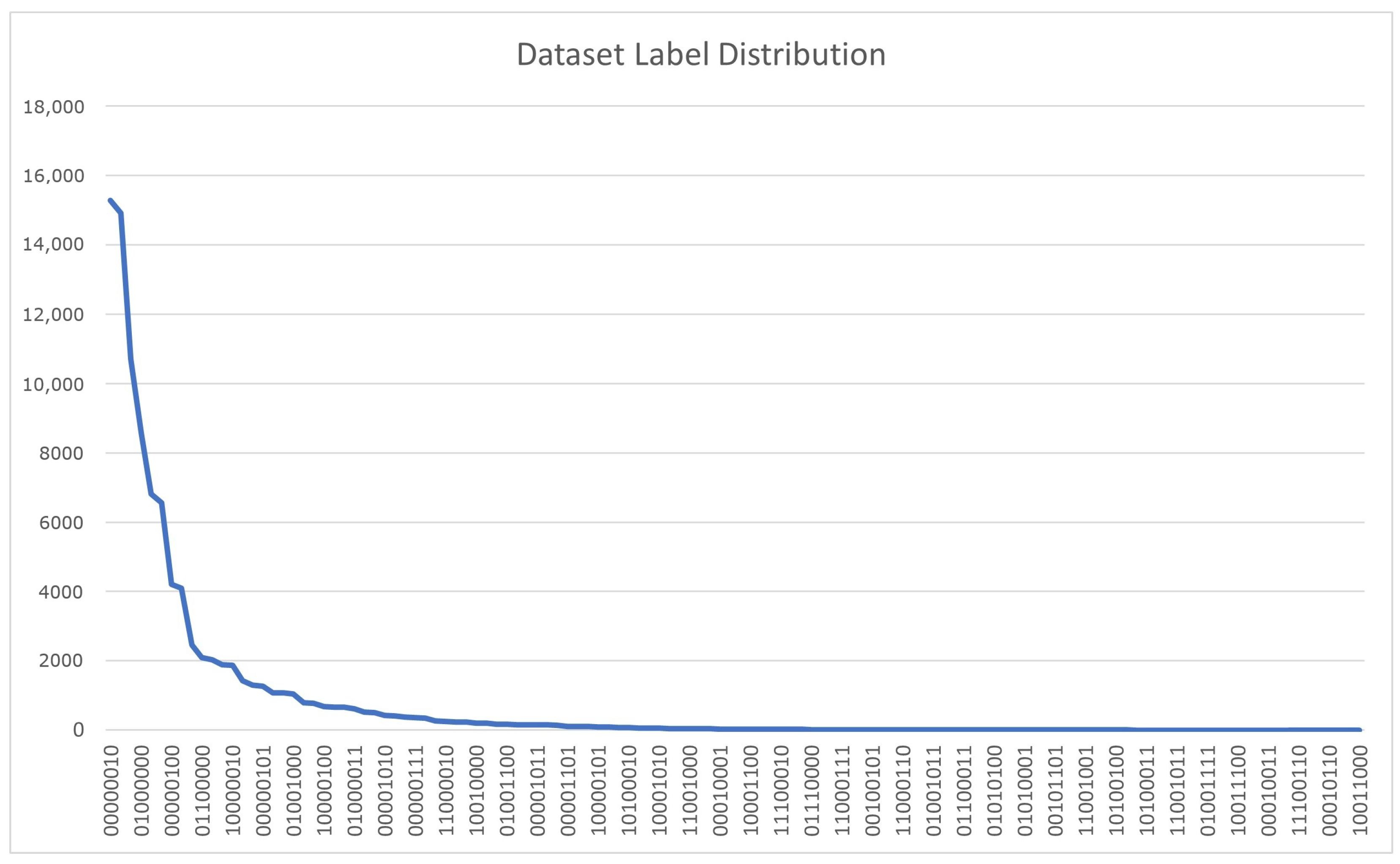
Patent documents have hierarchical classification labels. Patent documents are organized using the Cooperative Patent Classification (CPC) system, which has a five-level hierarchical structure: section (e.g., G—Physics), class (e.g., G06—Computing), subclass (G06F—Electric Digital Data Processing), group (G06F3—Input/Output arrangements), and subgroup (G06F3/0488—Interaction with touch-sensitive screens). As classification specificity increases from section to subgroup, patents sharing deeper-level classifications typically exhibit greater technical similarity. However, classification alone is insufficient for determining technical relevance, as patents with identical classifications may implement fundamentally different technical approaches. In general, patent documents with the same classification label have higher similarity as the classification level becomes deeper. However, having the same label does not mean they are similar, because each patent document has different technical claims, even if it has the same classification category. We take this into account and utilize the records of prior art information that experts consider most similar to the target patent document in the patent registration or prior art investigation process. We design a method to compute the relative similarity distance of document features closely by using document information and classification information from each patent document to learn the model, and we use leading literature similar to the target document as input. Also, while patent document collections can be classified into multiple overlapping classes in a multi-class format, as shown in
Figure 5, they have a highly skewed distribution, making it difficult to select similar documents based solely on similar classification attributes.
In our setting, we construct a triple-input document dataset by adding non-similar documents to consider the similarity between the prior art document and the target document in classification task learning. Given the challenges of quantitatively evaluating the technical similarity between patent documents, a method that considers relative similarity distances in learning is a detour, yet it is reasonable method for searching similar documents.
Let
and
be the set of documents
S and their labels. We use a triple-pair dataset of inputs:
In Equation (
4), we group the target document as
(anchor), the prior art document as
(positive), and documents that are not similar to the target document as
(negative) into one input pair.
In our contrastive learning framework, we structure each training instance as a triplet of patent documents. The target document serves as the reference patent. The prior art document is selected from specific prior art patents cited within the target document itself, representing expert-validated technical relationships. These citations, formally documented during patent registration, provide reliable technical similarity information. The non-relevant document is chosen from patents that may share the same classification category but have no direct technical relevance to the target. This approach leverages existing expert knowledge embedded in citation relationships without requiring additional human annotation, enabling our model to distinguish between superficial category-based similarities and meaningful technical relationships.
Before feeding the data, we split each document into word tokenizing with a fixed-size word length l, and all words are embedded to D dimensional features as . We add a classification token to the front of the token array of each embedded document. Using a classification token for classification tasks is an easy way to summarize the features of a document as a single length dimension.
We design a triplet-conjured encoder as an encoding task method that extracts document features for document classification and similarity learning tasks. Each encoder uses a stacked encoder such as a Transformer mechanism [
9], which extracts the document feature as follows:
where
Q,
K, and
V indicate the query, key, and value for the Transformer encoder, respectively. These feature vectors are also embedded by concatenating the
token and
as
. Here,
denotes concatenation.
L is the total number of stacked encoders, and
l is the index of the stacked encoder.
L and
t determine how many encoder layers are used to summarize paragraph
. Considering the efficiency of learning, we use the contextualized word embedding method [
34] and a pre-trained language model, as used by the encoding Transformer [
10].
Each encoder receives input from the anchor
, positive
, and negative
embedded document and outputs summarized document features as
,
, and
. The summarized document features are computed from the objective function and used for learning similarity distancing. Meanwhile, the anchor document feature
is used for classification tasks. Each encoder performs operations independently and in parallel. However, the three encoders share the same weight, which is inspired by a relevant study [
35]. In the encoding process of PAI-NET, the anchor encoder can consider the learning experience of each encoder in regulating the similarity distance between documents.
3.2. Objective Function
3.2.1. Total Loss
We use a sum of functions for classification tasks and functions for similarity distance computing to perform multi-tasking tasks. Recent studies [
36,
37] have used the sum of classification and margin losses for the robustness of classification queries. Inspired by these parts, we use them for the robustness of similar document search queries. Total loss is expressed in a way that adds a percentage of margin losses to classification losses as follows:
This multi-task learning approach can be demonstrated using our patent document example. Consider the embedding space shown in
Figure 4, where we have Apple’s “bounce-back” patent (US 7,469,381) as our anchor document (A), Microsoft’s scrolling patent (US 5,495,566) as the prior art positive example (P), and Apple’s zoom functionality patent (US 7,864,163) as a patent within the same classification but not technically related as the negative example (N). Initially, the embedding distances between these documents have the following relationships:
Prior art distance:
(technically related but textually different)
Similar classification patent distance:
(close due to similar representation and classification)
Here, the initial distance relationship is often
because patents in the same classification typically share vocabulary and structure. During training, PAI-NET applies the total loss function to adjust these distances. The classification loss (
) works to ensure documents are correctly classified into their respective patent categories. Meanwhile, the margin loss (
) specifically focuses on reducing the distance between the anchor and positive prior art document while increasing the distance to negative examples according to Equation (
9). Using the optimal
value, the model balances these objectives. After training, remarkably, the distance between Apple’s patent and its prior art decreases substantially despite their textual differences, resulting in the final relationship
. This demonstrates how PAI-NET can learn similarity based on actual technical relevance beyond simple textual similarity or classification-based similarity.
3.2.2. Classification Loss
The classification task of patent documents is a multi-class multi-label problem, so we use the BCEWithLogitsLoss function for this as follows:
where target
x and predicted label
y are for coordinate training loss.
3.2.3. Margin Loss
We use triplet loss to bring the similarity distance between the target document and the prior art document close. Triple loss controls the distance between the prior art and non-similar documents as follows:
where
,
, and
indicate the target document (anchor), prior art document (positive), and non-similar document (negative), respectively. The
is a constant factor to control the distance between positive and negative features. If the margin value increases, the robustness of the similar search query is enhanced. However, the size of the latent feature space is limited, and we need to determine the range of a margin factor to determine the query performance. In (
10), the distance function uses the euclidean distance.
3.3. Document Classification
The end of the network is the single fully connected (FC) network for document classification. The output of the anchor encoder is fed into an 8-way function, which produces the distribution over the size of the section category (CPC).
3.4. Evaluation Metrics
To quantitatively assess the model’s ability to rank similar documents highly, we employ the Mean Reciprocal Rank (MRR) metric. MRR effectively measures how well the model positions pre-defined relevant documents at higher ranks in a retrieval task. For a set of queries
Q, MRR is formally defined as follows:
where
is the number of queries, and
is the position of the first relevant document for the
i-th query. The reciprocal rank
assigns higher scores when relevant documents appear at higher positions (e.g., 1.0 for the first position, 0.5 for the second position, etc.).
Additionally, we employ the Jaccard Index as a supplementary metric to maintain classification performance. The Jaccard Index measures the overlap between two document multi-label classification term sets and is formulated as follows:
where
A and
B represent the term sets of two documents,
denotes the number of common terms, and
represents the total number of unique terms. This metric produces values between 0 and 1 and is used to optimize document similarity without compromising the primary classification objective.
In our evaluation framework, each query document is paired with one known similar document (positive) and multiple dissimilar documents (negatives). The MRR score reflects the model’s ability to consistently rank the positive document above the negative documents. A higher MRR value indicates better performance, with a perfect score of 1.0 indicating that the model always ranks the similar document in the first position. This metric is particularly suitable for our task, as it directly quantifies the model’s effectiveness in identifying and prioritizing semantically similar patent documents in a retrieval context.
3.5. Implementation Details
To establish our experimental environment, we prepared two datasets. First, we randomly selected 100,000 domestic and international patent documents (patent registrations only, excluding utility models) registered in the Republic of Korea (KPRIS,
https://plus.kipris.or.kr, accessed on 2 April 2025) from 2020 to 2023 for training, and 20,000 for testing. This dataset was used for performance comparison with other models.
Figure 5 shows the distribution of multi-labels across eight sections based on the CPC classification system for this dataset. To validate performance in a specific domain environment, we also utilized the Artificial Intelligence Patent Dataset (AIPD,
https://www.uspto.gov/ip-policy/economic-research/research-datasets/artificial-intelligence-patent-dataset, accessed on 2 April 2025) provided by the USPTO. For the AIPD, we randomly selected 10,000 documents from approximately 1 million documents in the seed group and split them in an 8:2 ratio for training and testing as anchor document data. This dataset was employed in
Section 3.9 to evaluate how the proposed technique’s training affected the similarity distance adjustment compared to the pre-trained model environment.
Table 1 shows the AI classification descriptions and their proportions in this dataset, where multiple classifications can overlap for a single patent due to the multi-label attribute of the data. For contrastive learning, each dataset was structured as triplets consisting of a reference patent, a registered patent explicitly cited as prior art for that patent, and a non-prior art patent document.
We trained the networks for 10 epochs with an initial learning rate set to 0.001 and divided by 0.1 every 10 epoch. The datatset consisted of 100,000 training and 20,000 validation documents. In our experiments, we used 768 dimensions of embedding vector size
D for each word, and we set the input size to
l to 100 words. We used a fine-tuning method with a pre-trained Bert model [
10] for efficient learning.
We evaluated PAI-NET 10 times with difference random seeds, then we reported the average performances. We used the Adam optimizer [
38] and applied the early stopping method based on the EM score. We used a
AMD CPU, 192 GB of RAM, and RTX-4090 24GB GPU RAM and A100 cloud system for the implementation.
3.6. Ablation Studies
In this work, we have taken steps to determine the degree of margin distance and the ratio of margin loss values to combine classification and margin functions. To this end, we first use a method to determine the margin distance with low losses for classification tasks and then determine the ratio sequentially.
3.6.1. Margin Distance
When a document feature is projected into a latent region, the larger the distance between the classification sets of each document feature, the more robust the model can be seen. Thus, theoretically, the greater the margin distance, the greater the degree of robustness. However, since the margin distance cannot be increased indefinitely within a limited area, the experimental margin distance between the classification sets must be maintained appropriately, and the closer the margin distance between similar documents. In this regard,
Table 2 demonstrates the rationale for selecting appropriate coefficients for the margin distance based on the classification performance of the document. Evaluation of the classification performance of documents is not used when training margin distances. The negative values for
(e.g., −0.009 at margin = 5) represent positioning in the embedding space where negative examples are placed in the opposite direction from anchor documents relative to the origin. This arrangement creates greater distances between similar and dissimilar patents, with larger absolute values of
reflecting increased separation in the vector space. However, it is reasonable to select margin distances that have the most negligible impact on the classification results performance and combine them with classification tasks in a multi-task environment. Therefore, in this work, we compute the margin distance based on the label classification performance and choose ‘3’ as the coefficient.
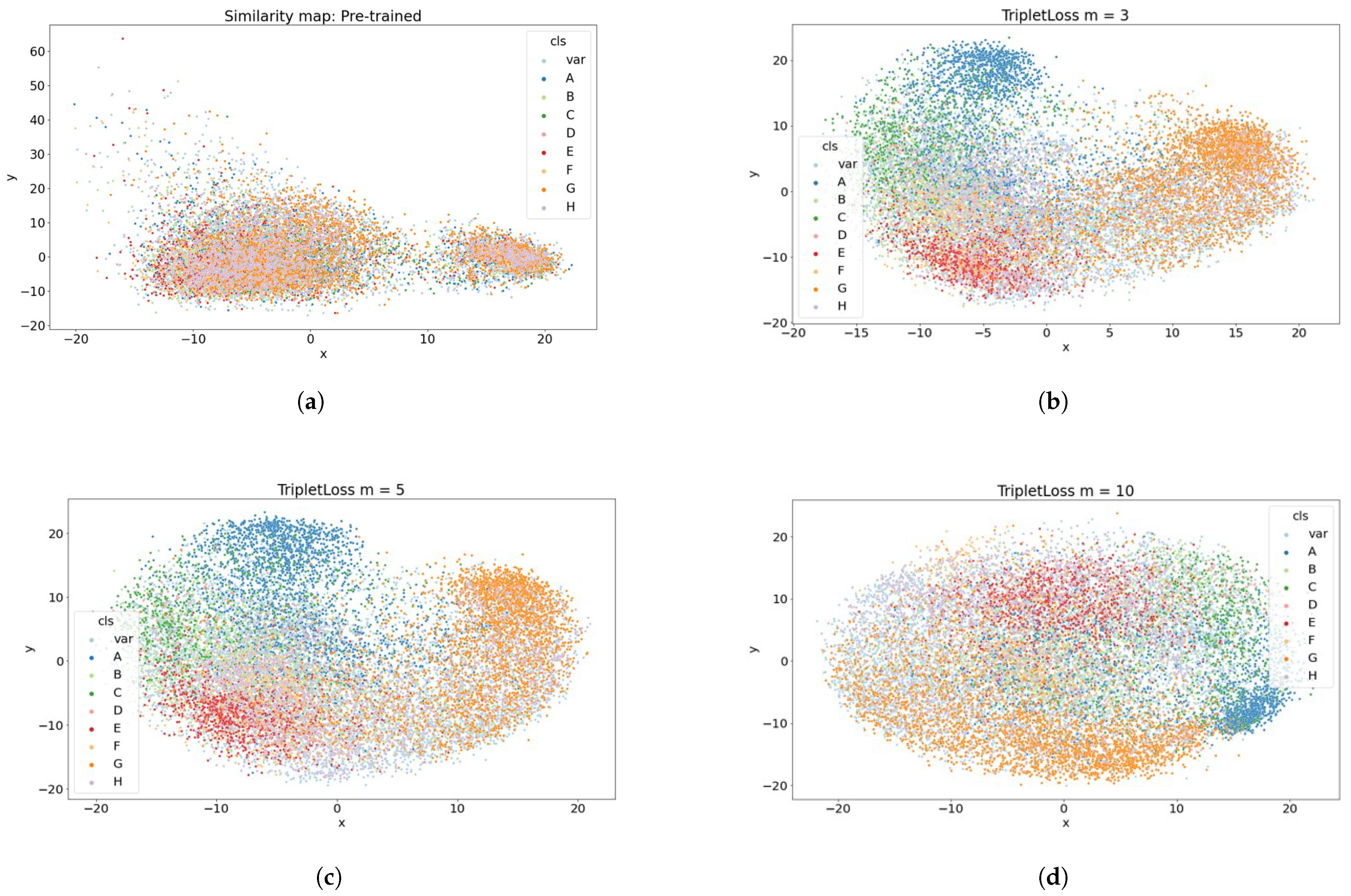
Meanwhile, visualizing the dispersion of document features over margin distances in
Figure 6, as previously described, the degree of overlap of the features is high, making it challenging to evaluate the similarity or classification criteria between documents. On the other hand, if the margin distance is 10, it can be seen that document features are spread evenly throughout the area. However, there is a problem of poor cohesion according to the classification boundary.
3.6.2. Margin Loss Ratio
Margin loss functions require expert similarity assessments within the training data to effectively learn similarity relationships. In patent datasets with imbalanced label distributions, relying solely on similarity learning would necessitate extensive training data for each classification label. To address this challenge, we combine margin loss with classification functions to achieve learning efficiency. We conducted experiments varying the margin loss ratio
from 0 to 0.5, with the results presented in
Table 3. In
Table 3, the EM score (Exact Match score) represents the percentage of test cases where all predicted classification labels exactly match the ground truth labels. As a strict evaluation metric for multi-label classification, it only considers a prediction correct when there is 100% agreement across all possible labels, with no partial credit for partially correct predictions.
The selection of an appropriate value requires balancing multiple performance objectives. At = 0.0 (baseline classification-only model), we observe the highest Exact Match (EM) score of 60.935% but the poorest retrieval performance (MRR = 0.5856), with minimal differentiation between similar and dissimilar documents (). Conversely, at = 0.5, the model achieves the highest (0.8124) and maximum separation between positive and negative examples (), but at the cost of substantially reduced classification accuracy (EM = 56.735%).
Our analysis identified = 0.2 as the optimal value, representing a strategic balance point where classification performance remains robust (EM = 60.545%, just 0.39% below the baseline), the Jaccard index reaches its maximum value (75.389%), retrieval performance shows significant improvement (MRR = 0.7417, a 26.7% increase over baseline), and a sufficient margin between similar and dissimilar documents is maintained. When exceeds 0.2, both the Jaccard index and EM scores decline more rapidly, indicating that higher weights on the margin loss begin to introduce noise into the classification task as, similarity pairs are constructed independently of classification criteria. The empirical evidence demonstrates that = 0.2 provides the optimal trade-off: maintaining high-quality classification while significantly enhancing the model’s ability to recognize technical relationships between patent documents.
3.7. Using Cosine Distance for Loss Function
The choice of distance metric in margin loss calculations significantly impacts model performance. While document similarity is traditionally measured using cosine distance in information retrieval, we investigated whether euclidean distance might be more effective for patent document relationships in our contrastive learning framework. In
Table 4, we compare four different distance metric configurations: pure euclidean distance, pure cosine distance, a combination of both (Euc + Cos), and a hybrid approach that uses euclidean distance globally while applying cosine distance specifically to anchor-positive pairs
. The results reveal distinct performance patterns across these configurations. The highest Mean Reciprocal Rank (MRR) of 0.7627 was achieved using the hybrid approach
, which applies cosine distance specifically to anchor-positive document pairs while using euclidean distance elsewhere. Pure cosine distance achieves the largest separation between positive and negative document pairs
, indicating its superior discriminative power in embedding space. However, this comes at the cost of reduced MRR (0.6865), suggesting that while it creates clearer boundaries between similar and dissimilar documents, it may not align optimally with the ranked retrieval task. These findings demonstrate that euclidean distance is more effective for maintaining classification performance in our multi-task learning framework, likely because it better preserves the geometric relationships needed for classification boundaries. Meanwhile, cosine distance excels at capturing semantic similarity between technically related documents, particularly between anchor patents and their prior art. The hybrid approach
successfully balances these complementary strengths, resulting in the best overall retrieval performance.
3.8. Episodic Training
We evaluated performance as a way to regulate the learning dataset. In this regard,
Table 5 compares PAI-NET with PAI-NET using the underlying dataset, a set of documents with only the same label compared to the baseline document, and PAI-NET
n with the same label without considering similarity. We reveal that pairs of similar document sets with only the same label have lower classification performance or similarity than baseline datasets. They were insufficient to be written as appropriate learning sets for pairs of similar document sets with different labels.
On the other hand, the classification performance was best when using different datasets with the same label without considering similarity, which can be seen as reflected in the classification feature even if it is not classified as data written in the existing self-supervision method.
3.9. Comparisons with Pretrained Model
To evaluate the performance enhancement of our proposed model, we conducted comprehensive experiments comparing PAI-NET with its pretrained baseline model through cosine similarity distances and Mean Reciprocal Rank (MRR) analysis. Our experimental findings demonstrate substantial improvements achieved by PAI-NET.
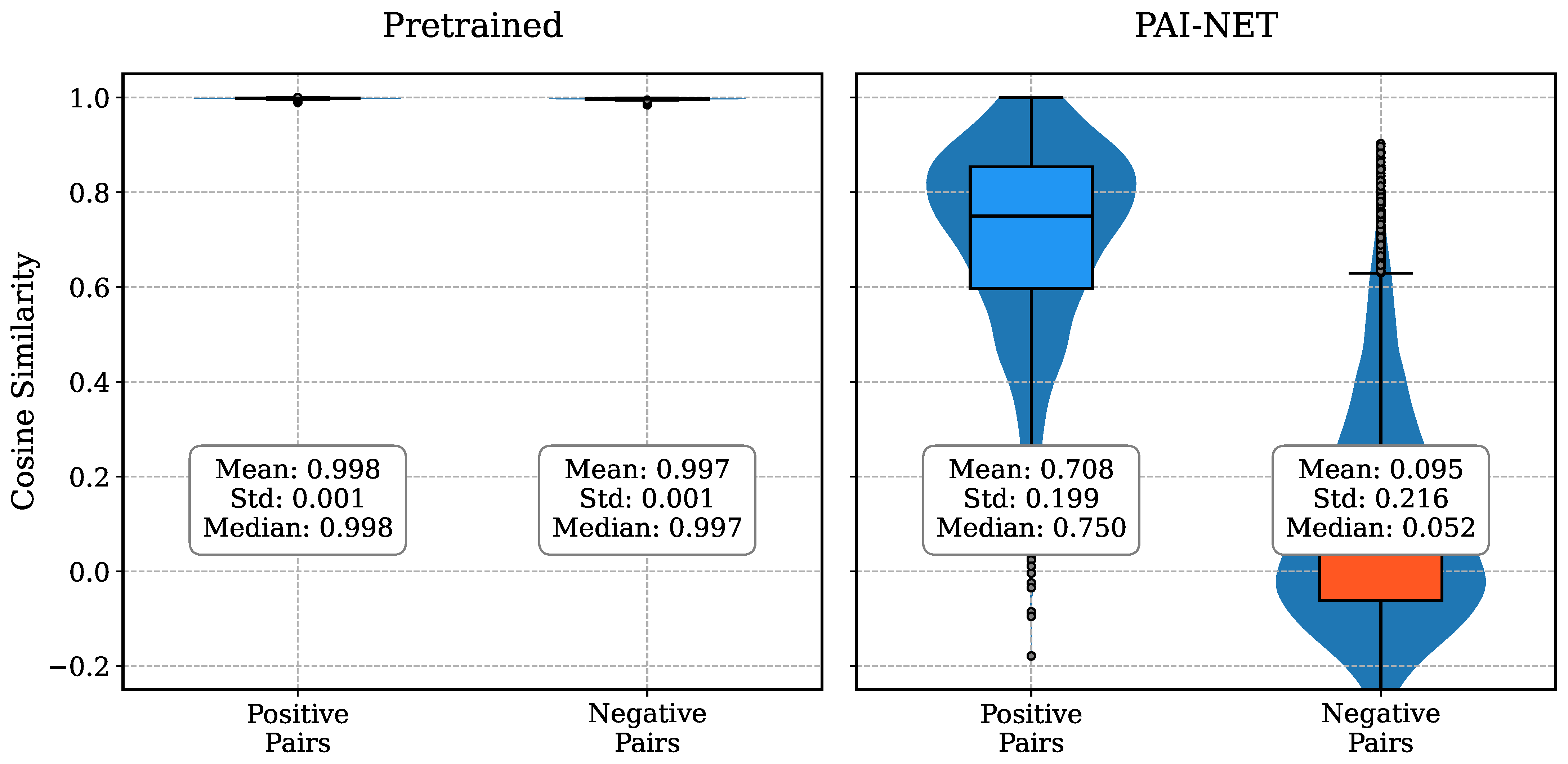
Specifically examining the cosine similarity distributions shown in
Figure 7, the pretrained model exhibits minimal discriminative capability, with nearly indistinguishable similarity scores between positive (0.998 ± 0.001) and negative document pairs (0.997 ± 0.001). In contrast, PAI-NET demonstrates significantly enhanced discriminative power by establishing a clear demarcation between positive pairs (0.708 ± 0.199) and negative pairs (0.095 ± 0.216). This pronounced separation in similarity metrics indicates PAI-NET’s superior ability to effectively differentiate between semantically similar and dissimilar patent documents.
The quantitative assessment through MRR metrics, as presented in
Table 6, further validates PAI-NET’s enhanced performance. Our model achieves an MRR score of 0.954, representing a 9.8% improvement over the pretrained model’s score of 0.869. This improvement in MRR metrics substantiates PAI-NET’s enhanced capability in accurately positioning relevant documents at higher ranks during retrieval operations, thereby delivering more precise and reliable search results.
This analysis is particularly relevant to domains with limited prior art information, as it demonstrates a key advantage of our approach. Unlike legacy ontology-based systems that require comprehensive knowledge structures covering all possible technical relationships, PAI-NET’s contrastive learning method enables the model to learn generalizable patterns of technical similarity from a limited set of examples. Our deep learning encoder, trained on existing prior art relationships, develops the ability to recognize technical relevance patterns that extend beyond the specific documents used in training. This allows PAI-NET to effectively handle novel documents or queries without established prior art connections. The model can flexibly apply learned similarity principles to emerging technical domains where explicit citations are sparse and traditional ontological frameworks would be impractical to maintain. This adaptability represents a significant advancement in making patent retrieval systems more resilient and scalable in real-world applications where complete knowledge structures are often unavailable.
3.10. Comparisons with State-of-the-Art
We measure classification performance and cosine similarity distances together with recent studies showing good performances [
20,
30,
31] (SOTA, state-of-the-art). Evaluating the degree to which the patent document classification and similarity distance performance are satisfied simultaneously, the performance of this study, as observed in
Table 7, shows superior results compared to existing studies. Among the relevant studies, CL+SCL [
31] adds sampling considering distribution at the dataset stage because the model is constructed on the premise of being self-supervised, which makes it challenging to create a suitable candidate group for classification labels within batch sizes. In PAI-NET, using triple-pair document datasets that did not consider label values, the similarity distance between similar and non-similar documents was the highest, indicating that the distance from similar documents became relatively close. We observed that our proposed method showed more than 15% improvement in MRR performance over the related SOTA methods.
4. Conclusions
We have presented PAI-NET, a novel framework for improving similarity search performance in Retrieval-Augmented Generation (RAG) systems for patent knowledge management. Our approach effectively addresses the unique challenges of patent document similarity search and makes several significant contributions to patent information systems and knowledge management.
The core strength of PAI-NET lies in its ability to incorporate expert domain knowledge through prior art relationships, resulting in superior document recommendation performance. Our experimental results demonstrate a 15% improvement in similarity-based retrieval performance compared to state-of-the-art methods in the patent domain. This substantial enhancement in retrieval accuracy provides particular value for prior art search processes where identifying relevant patent information is crucial.
A key innovation of our approach is the novel solution to knowledge representation in expert systems through the leveraging of prior art information rather than traditional ontological structures. This approach not only provides superior performance but also significantly reduces the costs associated with maintaining expert knowledge bases. This framework demonstrates sophisticated capabilities in understanding and utilizing complex relationships between patent documents, enabling more nuanced and accurate knowledge retrieval. The computational efficiency of PAI-NET’s architecture is noteworthy, as it handles similarity learning tasks through fine-tuning without significant overhead. This efficiency is particularly valuable in practical applications, enabling robust service deployment even in environments with continuously accumulating patent document information. The implications of this work extend beyond patent systems to the broader field of expert knowledge systems. The methodology we have developed for incorporating domain expertise through document relationships shows promise for adaptation to other specialized fields where similar expert-verified relationships exist. This approach represents a significant step forward in reducing the human effort required for constructing and maintaining domain-specific knowledge bases.
Looking ahead, our research opens several promising avenues for future investigation. These include the potential adaptation of our framework to general knowledge management systems and the development of more flexible neural network architectures capable of accommodating evolving domain knowledge. Furthermore, we envision extending our approach to other types of expert systems where document relationships play a crucial role in knowledge organization and retrieval.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}