1. Introduction
A self-driving lab (SDL) represents an innovative paradigm in modern scientific research that provides unprecedented opportunities for researchers to accelerate and automate their experimental and analytical processes. SDLs integrate robotics, artificial intelligence (AI), and machine learning (ML) to streamline workflows, including experimental design, execution, and data analysis [
1]. Using advanced robotic systems and automated equipment, SDLs facilitate complex experimental tasks and AI enhances efficiency by automating data interpretation and evaluating results. As a cutting-edge research tool, SDLs bridge the gap between futuristic innovations and practical applications, thereby enabling breakthroughs that redefine the limits of scientific exploration. In addition to combining equipment and software, SDLs function as a “pioneer” in expanding the frontiers of scientific discovery. This function represents the convergence of human curiosity and technological advancement, fostering innovation with the potential to transform human life fundamentally.
The emergence of SDLs marks a pivotal transformation in research automation. It represents an integral part of the data-driven science paradigm, which aims to process and analyze vast datasets across diverse fields to generate new knowledge. An SDL’s software (
https://www.libsdl.org/, accessed on 30 March 2025) is critical in interpreting high-dimensional datasets and solving multivariate research challenges [
2]. By effectively exploring complex variable combinations and identifying optimal experimental conditions, SDLs are powerful tools that overcome human limitations and push the boundaries of scientific discovery.
SDLs can perform experiments up to 1000 times faster than traditional methods, driving significant advancements in new material discovery, drug development, and process optimization [
3]. This unparalleled speed enables researchers to conduct large-scale experiments, rapidly collect and analyze data, and focus on high-level creative tasks [
4]. Industries such as chemistry, life sciences, and materials engineering, where high-throughput experimentation is essential, have found that SDLs are indispensable for addressing high-dimensional data challenges and accelerating innovation.
Despite their widespread application, systematic research analyzing SDL trends is limited. Previous studies have explored applications of SDLs in health and wellness or conducted bibliometric analyses in engineering fields and countries, highlighting the recent surge in SDL research [
5]. Other studies have proposed directions for the development of SDLs, including equipment design, workflow optimization, data management [
6], and effective SDL construction methods [
3,
6]. However, no comprehensive research has focused on SDL trend analysis as a primary subject, and limitations in data and methodology have raised concerns about the reliability of existing findings. This study addresses these gaps by applying a systematic analytical framework based on comprehensive and reliable data to establish strategic directions for SDL adoption across industries.
The primary goal of this research effort is to promote the adoption and utilization of SDLs by conducting an in-depth trend analysis, thereby advancing scientific research across industries. It systematically positions SDLs as a critical research tool across disciplines and offers meaningful insights into research directions and strategic approaches. This study underscores SDLs’ role as an indispensable tool in the AI-driven era, thereby providing sustainable adoption strategies tailored to various industries and laying the groundwork for future researchers by analyzing SDLs’ automation and optimization functions. Furthermore, it proposes new directions for expanding SDL applications, confirming their status as a transformative technology for scientific research.
This examination used data from the Web of Science to gather SDL-focused research papers through systematic preprocessing techniques, which included removing stop words and standardizing synonyms. This study employed trend analysis, network analysis, and topic modeling to uncover significant insights. Trend analysis identified overarching research trends, network analysis was conducted to systematically examine the relationships between keywords, and topic modeling extracted major research themes and keywords. To ensure the validity of the topic modeling results, additional analyses, including the Pearson correlation, were conducted. This comprehensive approach provides a detailed understanding of the current SDL research landscape, offering implications for future studies. Integrating diverse analytical techniques can guide strategic and efficient SDL research planning.
This analysis provides actionable insights for practical applications in various domains. For industries, it offers insights into R&D prioritization and investment strategies, identifying potential SDL applications and commercialization opportunities to prepare sustainable scientific analysis systems for market entry and enhance global competitiveness. In academia, an SDL trend analysis aids in setting research agendas and improving educational programs to train an industry’s sustainable workforce. Enhanced industry-academic collaboration can bridge the gap between research outcomes and practical applications. This study provides evidence for policymakers to shape science and technology policies supporting SDL development, fostering a sustainable and research-friendly environment and boosting national competitiveness.
The remainder of this paper is organized as follows.
Section 2 reviews the theoretical background of SDL and prior studies and sets their objectives.
Section 3 details the research methodology, including the data collection and techniques used in the SDL trend analysis.
Section 4 presents the findings of the trend analysis, network analysis, and topic modeling.
Section 5 interprets the results from academic, practical, and policy perspectives and draws implications. Finally,
Section 6 concludes with a discussion of the study’s limitations and suggestions for future research directions.
2. Literature Review
2.1. Topical Review: Self-Driving Labs
The SDL is a cutting-edge research environment designed to automate experiments and maximize efficiency. It is a scientific research system that manages and optimizes the entire experimental process using AI and robotics. SDLs integrate robotics, experimental systems, and ML models to design experiments, analyze results, and interpret outcomes, offering a revolutionary autonomous laboratory platform. Recently, data-driven experimental planning has garnered increasing attention from the scientific community [
7]. Integration of ML and innovative approaches to scientific methods has energized theoretical and computational research domains and practical applications [
2,
5]. Moreover, SDLs have significant potential to address critical societal needs, such as carbon-neutral processes, food security, sustainable agriculture, clean energy, energy storage, and drug discovery [
6]. By leveraging AI and ML algorithms to analyze datasets ranging from small to large, SDLs enable researchers to identify patterns and trends, resulting in more effective and efficient R&D processes [
8]. The following are some areas where SDLs are being utilized.
Biotechnology: SDLs provide a powerful platform for autonomously designing and engineering new biological functions, particularly in synthetic biology and genetic manipulation [
9]. For example, SDLs have shown promising results in autonomously exploring protein conformational landscapes and advancing biomedical and molecular biology research beyond traditional chemical synthesis methods [
9]. This function enables researchers to investigate the intricate interactions of living systems more efficiently. SDLs have also been applied to the development of biochemical response neural networks, referred to as Chemical Reaction Neural Networks, which autonomously design neural networks to predict chemical responses and identify experimental pathways [
10]. This application has proven instrumental in understanding and controlling the kinetics of complex chemical reactions. Additionally, advancements such as autonomous implantable devices for neural recording and stimulation in freely moving primates have demonstrated the application of SDLs in advanced biomedical research [
11].
Chemical Engineering: Traditional computational tools have limitations in accelerating chemical research [
12,
13]. SDLs address this by autonomously exploring multistage chemical pathways, enabling a rapid understanding of complex chemical systems and achieving optimized results [
14]. For instance, SDLs have been applied to electrocatalyst discovery, utilizing closed-loop approaches for nitrogen reduction reactions to efficiently explore multi-target experimental outcomes [
15]. Deep-learning-driven SDL systems have also uncovered unknown reaction pathways that have significantly contributed to understanding complex chemical systems [
10,
14]. These advancements have extended the boundaries of chemical exploration and enhanced global collaboration, thereby fostering the universalization of scientific discovery [
12].
Materials Engineering: In materials science, SDLs can address complex multi-objective problems [
16]. For instance, SDL integration into thin-film material research has significantly improved optimization processes through model-based algorithms, identifying the ideal synthesis conditions for materials with intricate electronic properties [
17]. These processes provide more accurate and consistent results than conventional methods and enhance the material performance across diverse applications. SDLs have accelerated the discovery of new battery chemicals and the development of energy storage solutions, particularly in battery research [
18,
19]. Moreover, SDLs optimize solar cell materials by autonomously refining the perovskite nano crystals [
20]. They are also employed in reverse design challenges, where deep reinforcement learning of experimental data efficiently explores design spaces to achieve optimal material properties [
21]. These capabilities enable researchers to design innovative materials quickly and precisely.
SDLs emphasize the integration of robotics and advanced data processing, thereby achieving research efficiencies that are unattainable with traditional methods [
12]. For example, using Bayesian experimental methods, SDLs reduce the number of experiments required to identify high-performance parametric structures by approximately 60-fold compared with grid-based exploration [
22]. Platforms such as Chem-OS provide universal access to autonomous discovery, enabling under-resourced researchers to participate in SDL technologies [
23]. This democratizes scientific discovery and extends opportunities beyond privileged research groups. SDLs have also shown promise in diagnostics, where deep probabilistic learning methods can autonomously interpret experimental data, including automating the analysis of X-ray diffraction spectra [
24]. These features enable SDLs to process large amounts of experimental data quickly and accurately, thereby maximizing research efficiency. In addition to interoperable data representation, effective data sharing and communication methods are required to realize laboratory automation [
14]. Additionally, they have been expanded through cloud-based SDL platforms, allowing researchers to conduct autonomous experiments remotely and strengthen cooperation within the global scientific community [
3].
2.2. Prior Research on Self-Driving Labs and Limitations
The introduction of SDLs has been a pivotal driving force for accelerating growth across various research domains, particularly in advancing AI-based automation [
12]. In addition, the active involvement of governments and research institutes has been identified as a major factor propelling the expansion of SDL research. For example, Da Silva analyzed the application of AI in healthcare by examining the adoption of SDLs across different years, engineering fields, and countries using bibliometric analysis. The results revealed a rapid increase in SDL-related research, particularly in the chemical and bioscience fields, highlighting SDLs’ potential to provide significant opportunities for emerging economies. These countries are likely to use SDLs to enhance their research competitiveness and reduce the use of resources and time [
5]. The growing recognition of SDLs’ importance in academia and industry is evidenced by their widespread adoption, with leading research institutes in countries such as the United States, China, and Germany at the forefront of this development [
12].
Furthermore, some studies have explored the development directions and prospects of SDLs. Hysmith emphasized the necessity of careful planning in various aspects of SDL design, such as physical configurations, data management, and workflow optimization. This study highlighted the shift from focusing on individual tools and tasks to creating and managing complex workflows, underscoring the importance of integrating human input into processes. Additionally, the role of the reward function design was identified as critical for developing efficient workflows alongside the interplay between hardware advancements, ML applications across chemical processes, and compensation systems. Hysmith envisioned a future for SDLs that merges AI’s precision, speed, and data-processing capabilities with human intuitive hypothesis formulations [
2].
Research has been conducted on the effective construction of SDLs. MacLeod stressed that SDLs must operate beyond simple automation, emphasizing their adaptability to new research areas. This study outlines the criteria for SDL design and addresses challenges such as laboratory reuse. They argued that effective SDLs should (1) operate at speeds surpassing traditional automation and (2) demonstrate the ability to quickly adapt to novel research contexts. MacLeod identified key strategies for building SDLs that could expedite the discovery of new materials, thereby emphasizing the importance of adaptability and reusability in SDL design [
6].
2.3. Methodological Review: Topic Modeling and Self-Driving Labs
Natural language processing is a field that is actively being discussed and applied as a tool in various scientific fields, including natural sciences, social sciences, and engineering [
25,
26]. Natural language processing means extracting meaningful data from unstructured data within large-scale texts; it is being developed using learning algorithms [
25,
27]. The text mining approach was developed for natural language processing and is effective for extracting information from unstructured data [
28]. Academic research on text mining studies the relationships and occurrences of behaviors through text [
29]. This is the most relevant approach for mining data in SDLs, helping discover ideas or new relationships, identify potential meanings, and establish policies or strategies [
30].
The primary methodologies of this study include network analysis and topic modeling. Network analysis contributes to identifying structural relationships by examining behavioral characteristics and enhances a researcher’s subjective judgment through the analysis of objective data [
31,
32,
33]. Topic modelling is a statistical model that infers the events or concepts a document describes [
34]. This is suitable for trend analysis of SDLs, which is being rapidly introduced across various scientific fields. In particular, it can measure the semantic similarity between words in data, making it possible to analyze the relationship between concepts and infer topics. Using Latent Dirichlet Allocation (LDA) in various sustainability fields is effective for examining overall research trends [
35]. In previous studies, topic modelling has been applied to various sustainability areas, including smart factories [
36], smart cities [
29], and logistics [
37,
38].
Previous studies have explored the application of SDLs in health and well-being or conducted bibliometric analyses in engineering domains and countries, emphasizing the growth of recent SDL research. Other studies have proposed directions for the development of SDLs, including device design, workflow optimization, data management, and effective SDL construction methods. However, no comprehensive study has conducted a trend analysis of SDLs as the main research object, and limitations in data and methodology have raised concerns about the reliability of existing research results. To bridge these gaps, this study applies a systematic analysis framework based on comprehensive and reliable data to establish strategic directions for SDL adoption across various industries.
While previous research has primarily focused on the application of SDLs in medicine and pharmaceuticals, this study conducted a quantitative analysis using text-mining techniques and extended the application of SDLs to various engineering disciplines, such as materials science, cellular and biological processes, and artificial intelligence, which helps to develop the potential of SDL applications in the industrial field.
3. Materials and Methods
The present research examines the overarching trends in SDL studies and investigates strategic approaches for their effective implementation and the sustainable advancement of related research. Trend analysis, network analysis, and topic modeling techniques were employed to achieve this. Through trend analysis, the overall research trends in SDLs were identified and text mining techniques, such as network analysis and topic modeling, were employed to extract SDL-related research topics across major scientific domains and to identify meaningful keywords for each topic.
This study, conducted in four stages as illustrated in
Figure 1, comprises a sequential process of data collection, preprocessing, trend analysis, and text mining. Data retrieved from the Web of Science database were subjected to tailored preprocessing steps to suit the specific requirements of each research method. For trend analysis, data were filtered to include only SDL-related publications prior to analysis. For text mining, such as network analysis and topic modeling, additional preprocessing steps, including stop word removal and synonym handling, were applied following the initial filtering.
3.1. Data Collection
The data collection step involves selecting the data necessary for research analysis. The data used in this study were collected from the Web of Science. Publication records related to SDLs from the Web of Science were used to ensure data reliability. The web of science provides advanced citation analysis tools and various analytical features, enabling systematic exploration of relevant trends and connections within research fields. Additionally, its rigorous peer-review process ensures the quality of the submitted reports.
For a research trend analysis, it is essential to cover a period that sufficiently reflects the emergence of new theories, technological advancements, and methodologies. Accordingly, a 20-year period (2004–2023) was selected to provide a representative dataset for examining the development of research directions and significant trends within the field. Using the same search formula as in
Table 1, data were extracted, and the SDL expressions used in previous studies were reviewed.
The document type was limited to “Article”, resulting in the extraction of 352 records. To facilitate data processing, the extraction format was designated as Excel, including fields such as Author, Title, Source, Publication Year, Source Title, Affiliations, Times Cited, Accession Number, Abstract, Keywords, Addresses, and Document Type.
The collected data were categorized based on their intended purpose, underwent appropriate preprocessing steps, and were subsequently utilized for further analysis. For trend analysis and network analysis, the dataset was filtered to include only SDL-related papers prior to analysis. For instance, fields such as Publication Year, Source Title, Affiliations, and Times Cited were employed in trend analysis. For text mining, including network analysis and topic modeling, Abstract data were first filtered and then subjected to additional preprocessing steps, such as stop word removal, meaningless keyword removal, and synonym processing. The refined abstract data were then used in the topic modeling analysis.
3.2. Data Preprocessing
The preprocessing step involves transforming the data into a format suitable for research analysis using Python (version 3.11.10) and Google Colab. From the 352 data points extracted in Step 1, abstracts containing keywords related to autonomous driving—such as “car”, “cars”, “vehicle”, “transit”, “conveyance”, “airplane”, and “ship”—were filtered out. After this filtering process, the dataset was refined to 219 data points. The refined dataset of 219 papers spans various scientific application fields, as shown in
Table 2.
The primary data from 219 papers, excluding those unrelated to SDLs, were analyzed through trend analysis. The abstract data from these 219 papers underwent additional preprocessing before being used for text mining, including network analysis and topic modeling. These additional steps included stop word removal, meaningless keyword removal, and synonym grouping. These preprocessing steps were carried out with careful consideration to ensure that conceptually meaningful terms and research-relevant expressions were not inadvertently excluded or altered.
In the stop word removal step, common words, such as articles, prepositions, and conjunctions, are eliminated to reduce noise and focus on the relevant terms. In the meaningless keyword removal step, words that hold no significance for the analysis, such as “dollar” and “date”, are excluded to enhance the abstract dataset’s analytical quality. These steps ensure that the abstract dataset is refined and free from unnecessary or irrelevant terms, making it suitable for the topic modeling analysis. Representative examples of the terms removed are listed in
Table 3.
The final step in the preprocessing stage is synonym grouping. This step involves consolidating synonyms with identical meanings into single terms. Thus, the potential for noise in the data analysis is minimized, which enhances the reliability of the results. Representative examples of the grouped synonyms are presented in
Table 4.
3.3. Trend Analysis
A trend analysis was conducted on the 219 publications extracted during the preprocessing stage using Python and Google Colab. The purpose of trend analysis is to understand the changes occurring in the SDL field and to support the prediction of technological directions or the formulation of strategic decisions. Furthermore, it plays a crucial role in understanding shifts in industrial markets and technological trends, enabling stakeholders to seize opportunities, manage risks, and maintain competitiveness.
The analysis focused on three key aspects: (1) the top 10 countries with the highest number of SDL-related publications per year, (2) the top 10 journals and their corresponding citation counts, and (3) the top 10 authors and affiliations contributing to SDL research. These insights provide a comprehensive understanding of the research landscape and help identify leading contributors and influential regions.
3.4. Text Mining
In this study, various text mining analyses, including frequency analysis, TF-IDF, connection centrality, n-gram, and topic modeling, were employed to understand changes occurring in the SDL field, predict technological development directions, and support strategic decision-making. The results were then statistically validated through Pearson correlation analysis.
3.4.1. TF-IDF
The TF-IDF algorithm, which considers both the term frequency and document frequency of key terms, is a widely used method for feature weighting [
39,
40]. Additionally, TF-IDF is a text mining technique used to evaluate the significance of a term within a document relative to an entire corpus [
41,
42,
43]. It is calculated as the product of TF, which quantifies how frequently a term appears in a document, and IDF, which adjusts for the term’s prevalence across the corpus to mitigate the influence of commonly occurring words [
44,
45]. A high document frequency of a feature keyword indicates that it appears in many texts, making it less useful for distinguishing categories. Therefore, a lower weight should be assigned to such feature keywords, as shown in Equation (1).
In Equation (1), ω represents the computed weight of a specific feature keyword. The term tf denotes the word frequency, while df represents the document frequency, specifically indicating the number of texts that contain the feature keyword. Additionally, N refers to the total number of texts in the training dataset.
3.4.2. Connection Centrality
Connection Centrality is a centrality measure in network theory that evaluates how well a particular node is connected within a network [
46]. Generally, connection centrality is used not only to assess the direct connections a node has but also to analyze its role in the overall network structure and information flow between nodes. Equation (2) computes the connection centrality value.
n: the number of nodes
(): the number of routes connecting node and
3.4.3. n-Gram
This study employs an
n-gram technique, which is widely used in natural language processing (NLP) and data analysis, to analyze text patterns and extract sequences of words or characters in specific contexts. The
n-gram refers to a sequence consisting of
n consecutive words or characters, making it useful for modeling the structural characteristics of textual data [
47,
48,
49]. Furthermore, the
n-gram method contributes to improving the quality of text analysis by inferring relationships between words and predicting subsequent words. Equation (3) is the formula used for
n-gram calculation.
w: the word (or token) in a sequence
3.4.4. Topic Modeling
Topic modeling techniques were employed to automatically extract and analyze major topics from large-scale text data. Specifically, the LDA algorithm was applied to identify research focuses and field-specific topics by analyzing the patterns of recurring words in text data [
50,
51]. The topics extracted through topic modeling reflect the primary concerns of the research field and contribute to understanding the flow and trends of related studies by analyzing the topic distributions across documents [
52,
53,
54,
55,
56]. LDA has the advantage of reducing subjective bias in text analysis by employing mathematical algorithms to automatically process textual data. Latent themes are identified based on several factors, including the number of extracted topics, topic size, key terms within each topic, the distance between topics, and the λ value. A higher λ value enhances the ability to distinguish topics composed of meaningful words [
57,
58].
LDA assumes that each document consists of multiple topics and calculates the probabilistic distribution of each topic based on the occurrence of words within the document [
59]. The vector values of words can be obtained and grouped into related terms, from which topics can be inferred [
60,
61]. This allows the subject structure of the documents to be quantified, indicating the extent to which each document relates to a specific topic. The following is the formal equation of the LDA topic modeling model [
60]. Equation (4) models the joint probability distribution of observed words across topics and the distribution of latent topics within each document.
D: the total number of documents in the corpus
K: the total number of topics, set as a hyperparameter
N: the number of words in document d
: the nth observed word in document d
: the word distribution for topic k, represented as a vector over the vocabulary
: the topic proportion vector for document d
: the topic assigned to the nth word in document d
In this study, abstracts from the collected papers served as the primary text data, which underwent preprocessing steps, such as terminology removal and synonym grouping. Additionally, an optimization process was conducted to determine the ideal number of topics to ensure a balanced and meaningful topic distribution.
The number of topics is an important parameter in topic modeling [
62]. If there are too few topics, the content of one topic will be too broad. Conversely, if there are too many topics, they will be small and contain similar content. An incorrect selection of the number of topics can lead to inaccurate results and incorrect interpretations. Therefore, selecting the correct number of topics is important to obtain reliable results [
63,
64,
65]. The criteria to determine the optimal number of topics include obscurity, log-likelihood, and coherence scores [
66]. This study determines the optimal number of topic models by deriving the commonly used perplexity and coherence [
67,
68,
69]. Perplexity is an indicator of the predictive ability of a model; a lower value signifies better performance. Coherence is an indicator that measures the semantic consistency between words in a topic; a higher value indicates that the words in the topic are more closely related and that the keyword accurately describes the topic. Therefore, to perform optimal topic modeling, we selected the number of topics that yielded relatively low perplexity and high coherence scores, ensuring that the extracted topics effectively represent the underlying themes. This process calculated the optimal number of topics by applying pyLDAvis to Google CoLab [
70]. The analysis utilized a Python 3 runtime environment, with hardware acceleration restricted to a T4 GPU.
3.4.5. Pearson Correlation
Equation (5) represents the standard formula for the Pearson correlation. To validate the reliability of the topic modeling results through additional experiments, a topic correlation matrix was constructed following the extraction of key topics and keywords through topic modeling. The topic correlation matrix is based on topic weight results extracted for each document. Using weight vectors of individual topics, Pearson correlation coefficients were calculated to generate the matrix, which effectively addresses the independence and correlation between topics [
71,
72,
73]. This makes it suitable for evaluating the quality of topic modeling results. The analysis utilized a Python 3 runtime environment, with hardware acceleration restricted to a T4 GPU.
: correlation coefficient
: values of the x-variable in a sample
: mean of the values of the x-variable
: values of the y-variable in a sample
: mean of the values of the y-variable
4. Results
4.1. Trend Analysis
Analysis of SDL-related publications by year revealed significant trends. As shown in
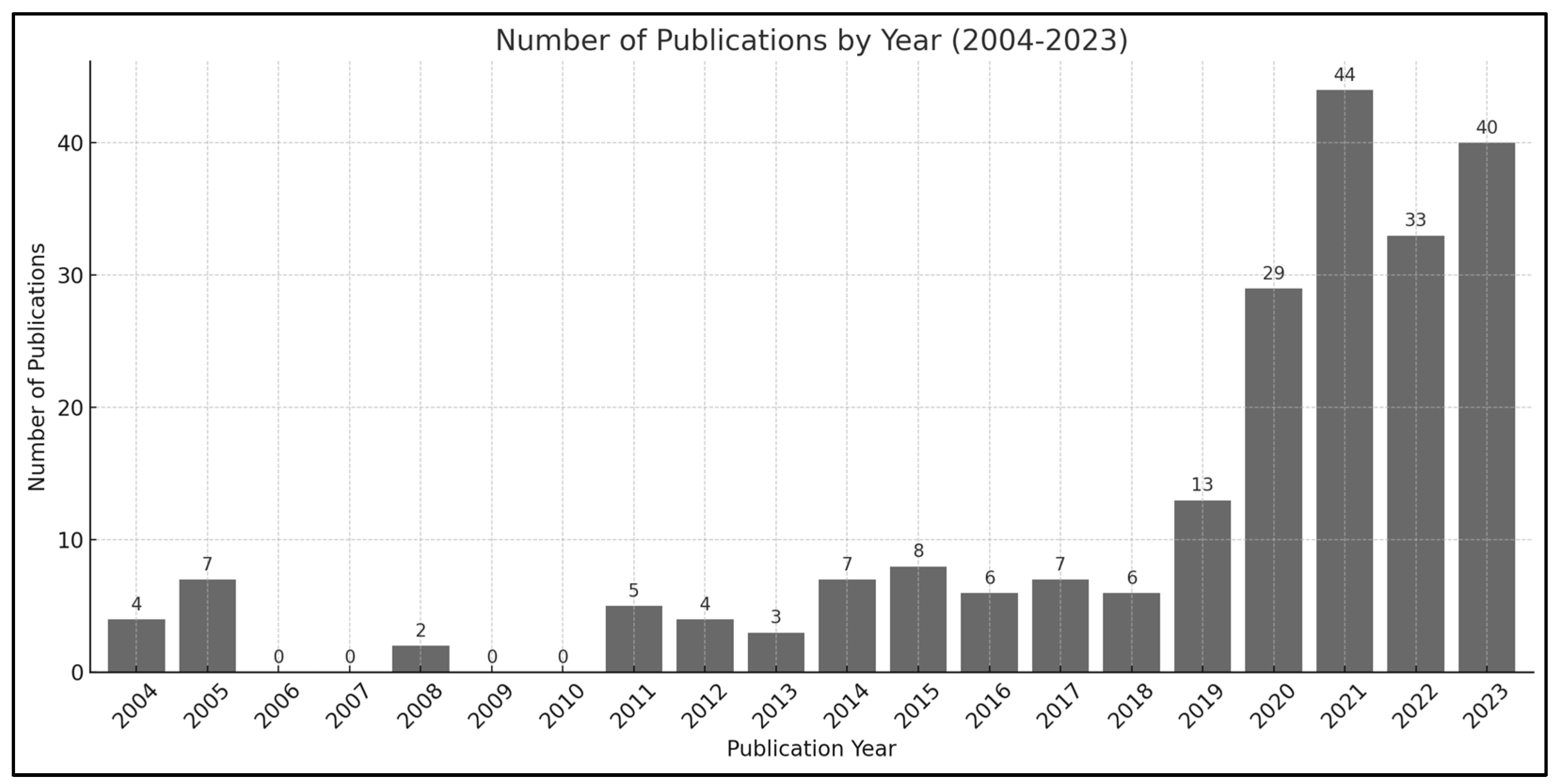
Figure 2, the number of publications between 2004 and 2018 remained relatively small and irregular. However, a sharp increase was observed in 2019, with the highest number of publications recorded in 2021. This upward trend continued in 2022 and 2023, highlighting the remarkable growth in SDL research over the past three years. These findings suggest a substantial increase in interest and activity in SDL research during this period.
A country-wise analysis of SDL-related publications provides important insights.
Figure 3 illustrates the number of publications from the top 10 countries. Among the 30 countries contributing to SDL research, the top 10 countries accounted for 186 publications, representing 85.32% of the total. This concentration indicates that SDL research is conducted predominantly in a select group of leading countries, whereas foundational research is beginning to emerge in lower- and middle-tier nations.
The United States, Germany, and China have led SDL-related publications, followed by Canada, the United Kingdom, Australia, Sweden, Switzerland, South Korea, and Spain. These countries’ strong academic and industrial infrastructures are likely to contributes to their active engagement in SDL research. Meanwhile, the emergence of SDL publications in other countries suggests a growing global interest in the field and the potential for broader participation.
Table 5 presents the number of SDL-related papers published in each country. Countries with a well-established research infrastructure, such as the top 10 contributors, are likely to invest in high-tech development. This leadership can be attributed to their robust research environments, ability to attract skilled human resources, close industry–academia connections, effective government policies, and strategic initiatives to enhance global competitiveness. These factors enable these countries to accelerate the development and commercialization of SDL technologies. Consequently, these nations have achieved innovative breakthroughs that have significantly contributed to their national economies and security.
A journal-wise analysis of SDL-related publications provides further insights into the research landscape.
Figure 4 illustrates the number of publications and citations for the top 10 journals contributing to SDL research. Among the 145 journals, the top 10 accounted for 51 publications, representing 23.39% of the total. The relatively low concentration of publications in the top 10 journals indicates that SDL research spans various disciplines, including computing science, pure science, and other interdisciplinary fields. This convergence demonstrates the close connection between SDL research and domains, such as AI, materials science, and microbiology.
Among the top journals, Digital Discovery has eight publications, but a relatively low citation count of 76, suggesting a limited overall influence. Similarly, the Journal of Laboratory Automation (JALA) has contributed six publications with 77 citations, reflecting some impact on experimental automation research without significant citation influence. Conversely, Lab on a Chip stands out as a highly influential journal, with six publications garnering 175 citations. This highlights the importance of microfluidics and small-scale experimental devices in SDL research. Similarly, NPJ Computational Materials contributed to SDL research in computational materials science with five publications and 91 citations.
Journals such as HardwareX and the Journal of Visualized Experiences (JoVE) exhibited relatively low influence, recording 56 and 12 citations, respectively. Scientific Reports, an open-access journal, has shown a particular influence, with four publications receiving 149 citations. Notably, Science Advances emerged as the most influential journal, despite publishing only four papers and achieving an impressive 461 citations. This underscores its significant contribution to SDL research and high reliability in the field. These findings highlight the varying levels of influence among journals contributing to SDL research. Given their high citation rates and impact, journals such as Science Advances and Lab on a Chip have established themselves as pivotal platforms in this domain.
An analysis of SDL-related publications identified key contributors and their affiliated research institutions. A total of 1146 authors and 317 research institutes were identified, providing insights into the main contributors to the field and the geographical distribution of SDL research.
Table 6 presents the top ten authors with the highest number of publications, along with their affiliated institutions and countries. This highlights individual researchers’ influence and SDL research’s international scope.
Among the top contributors, Aspuru-Guzik has led eight publications, establishing himself as a central figure in SDL research in Canada. Roch and Noack have published six papers each, representing significant contributions from the United States. While Roch is affiliated with Harvard University, Noack is based at the Lawrence Berkeley National Laboratory. Both of these are prominent research institutions driving SDL research in the U.S.
Jesse, Reyes, and Hickman have published five papers each, demonstrating their active involvement in the field. Jesse and Reyes are affiliated with the Oak Ridge National Laboratory and the University at Buffalo, respectively, underscoring the diversity of research institutions contributing to SDL research in the U.S. However, Hickman is a member of the University of Toronto, reaffirming Canada’s pivotal role in this domain.
Other notable contributors include Vasudevan, Abolhasani, and Brown, who have published four papers. Vasudevan is affiliated with the Oak Ridge National Laboratory, Abolhasani with North Carolina State University, and Brown with Boston University, reflecting the strong presence of SDL research across various U.S. universities and research centers. Kalinin has contributed three papers and continues to play an active role in SDL research at the Oak Ridge National Laboratory.
The findings highlight that SDL research is concentrated in major research institutes such as the Oak Ridge National Laboratory, Lawrence Berkeley National Laboratory, and Harvard University in the United States, and the University of Toronto in Canada. These institutions and their researchers have made significant contributions to SDL research by emphasizing the central role of North America in this field.
4.2. Word Frequency
A word frequency analysis was conducted using the abstract data extracted from 219 research papers after a preprocessing phase. The top 40 most frequently occurring keywords in the abstracts are presented in
Table 7. The results indicate that the most frequently appearing keywords are “data” (1902), “material” (1630), and “cell” (1248). This finding highlights the significance of data in SDL-related research and suggests that materials science and cell-based studies constitute core research themes in this field. Furthermore, the prominence of “optimization” (1241) and “synthesis” (1070) suggests an active focus on optimizing experimental processes and synthesizing new materials or compounds through SDLs. Additionally, the presence of “laboratory” (1029), “chemical” (941), and “measurement” (848) underscores the crucial role of experimental techniques and chemical analysis in contemporary research.
Keywords related to artificial intelligence (AI) and computational methodologies also account for a significant portion of the extracted data. The occurrence of “machine” (915), “software” (907), “algorithms” (706), “intelligence” (665), and “AI” (486) indicates the increasing utilization of AI-based tools in SDL research. Notably, the presence of “prediction” (435) and “Bayesian” (412) suggests that probabilistic modeling and machine-learning-driven predictive analysis are emerging as key components in the adoption of SDLs.
The relevance of SDLs in the life sciences and chemistry domains is also evident from the analysis. Keywords such as “DNA” (789), “chemistry” (741), “chemical” (941), and “biological” (0.30%) highlight the active research in genetics, synthetic biology, and organic chemistry. Additionally, the keywords “blood” (433) and “antimicrobial” (394) indicate ongoing research in diagnostics and pharmaceutical science, particularly in drug discovery and medical applications.
Experimental techniques and analytical methodologies are also integral components of SDL research. The frequent occurrence of “measurement” (848), “microfluidic” (722), “microscopy” (468), and “sensor” (594) emphasizes the critical role of precision analysis tools in scientific discoveries. In particular, the relatively high frequency of “microfluidic” and “microscopy” suggests that nanotechnology and imaging techniques are gaining increasing importance in life sciences and materials science research.
4.3. TF-IDF
Table 8 presents the top 40 keywords identified through TF-IDF analysis. TF-IDF analysis was conducted to complement the limitations of word frequency analysis. While frequency analysis is useful for identifying how often a specific word appears in a document, it does not account for whether the word is commonly used across multiple documents or holds relative importance within a particular document. To address this limitation, TF-IDF was applied to assess the relative importance of words across different documents. Since TF-IDF values increase as the number of documents containing a specific word decrease, this method is particularly useful for identifying key insights that may not be easily detected through simple frequency analysis.
The results indicate that documents containing the keywords “data”, “algorithms”, “artificial”, “chemical”, “microfluidic”, “strategy”, “polymer”, “machine”, “software”, and “measurement” were prevalent. A comparison between the top 40 results from TF-IDF analysis and the top 40 most frequent words revealed slight differences in ranking. Notably, “algorithms”, “chemical”, “microfluidic”, “strategy”, and “Bayesian” ranked higher in TF-IDF than in simple frequency analysis. Additionally, words such as “artificial”, “polymer”, “extraction”, “accelerate”, “enzyme”, “atomic”, “nanocrystals”, “resistance”, “fabrication”, and “database” were newly identified in the TF-IDF results, despite not appearing in the top frequency rankings. In contrast, terms like “cell”, “laboratory”, “chemistry”, “liquid”, “reactions”, “techniques”, “exploration”, “physical”, and “architecture” were present in the frequency analysis results but did not appear in the top 40 TF-IDF rankings.
4.4. Connection Centrality
The results of the network centrality analysis are presented in
Table 9. Network centrality analysis was conducted to examine the most significant concepts and their interconnections within the research domain. The centrality metric quantifies the importance of a specific term in the overall research landscape by measuring its connectivity with other nodes, providing insights into keyword significance. Degree centrality increases as the number of connected nodes rises. The results of the centrality analysis showed differences in rankings compared to word frequency and TF-IDF analysis.
The most central term was “data” (0.359), emphasizing the fundamental role of data across various research fields. The high centrality values of “material” (0.343) and “laboratory” (0.340) suggest that materials science and laboratory-based research are integral components of modern scientific advancements. Furthermore, the strong centrality of “optimization” (0.313) highlights the importance of optimizing experimental processes and improving efficiency, which are key research objectives in multiple scientific and engineering disciplines.
4.5. n-Gram
n-gram analysis is a method used to predict which words are likely to follow a given word within a sentence, playing a crucial role in analyzing word relationships within sentence structures. By examining sequential word occurrence patterns, this technique helps identify tendencies in which specific words frequently appear together. Such relationships are analyzed based on frequency distributions, allowing for a systematic examination of how particular word combinations are utilized within a document.
Table 10 presents the sequential occurrences of highly correlated words, providing a clearer understanding of the contexts in which specific terms appear together. In this study,
n-gram analysis was employed to extract word co-occurrence patterns, aiming to uncover meaningful associations within the text. This approach enables a more refined understanding of structural relationships between words within sentences, extending beyond simple word frequency analysis.
The n-gram analysis revealed that artificial intelligence and computational techniques play a crucial role in scientific research. The most frequently occurring combination, “intelligence—AI”, along with “Bayesian—optimization”, “AI—software”, and “machine—artificial”, highlights the widespread use of machine learning, probabilistic modeling, and AI-driven computational methods across various research domains. Additionally, the high frequency of “neural—networks” and “convolutional—neural” suggests that deep neural networks have become essential tools for data analysis, predictive modeling, and experimental automation. As AI applications expand, combinations such as “Bayesian—experiments” indicate that data-driven methodologies are increasingly contributing to the design and optimization of experiments.
Significant n-gram patterns were also identified in materials science and chemistry research. The frequent occurrence of “material—synthesis” and “material—chemical” underscores the importance of novel material synthesis and chemical processing in contemporary research. Additionally, the high frequency of “material—laboratory” and “material—acceleration” suggests that laboratory-based materials research is being accelerated through AI and automation technologies. The prominence of “organic—chemistry” further indicates the continued significance of organic synthesis, pharmaceutical development, and biomaterials research. The occurrence of “quantum—dots” highlights the growing impact of quantum dot research in nanotechnology, optoelectronics, and next-generation semiconductor technologies.
Furthermore, the increasing integration of robotics in laboratory settings was observed. The frequent appearance of “laboratory—robotic”, along with “robotic—material” and “robotic—machine”, suggests that experimental automation and smart manufacturing technologies are being actively incorporated into scientific research. The combinations “laboratory—equipment” and “equipment—experiments” indicate that advanced experimental instruments and automated systems play a key role in enhancing experimental efficiency and precision.
In the life sciences and genomics domains, interesting patterns also emerged. The frequent n-gram occurrences of “Escherichia—coli”, “DNA—amplification”, and “DNA—extraction” indicate that genome analysis, synthetic biology, and microbiological research are actively progressing. Notably, the combinations “DNA—cell” and “neural—cell” suggest a potential convergence between genomics and neuroscience. Additionally, the frequent appearance of “electron—Escherichia” implies that electron microscopy is a crucial tool in microbiology and cellular research.
Experimental optimization and data utilization have also emerged as significant research directions. The frequent combinations “optimization—strategy” and “exploration—optimization” highlight the increasing importance of optimization techniques in research design and experimental procedures. Moreover, the high occurrence of “historical—data” suggests a widespread adoption of data-driven approaches that leverage existing research data for experiment design and outcome prediction. This trend is expected to drive further advancements in AI-powered experimental automation, high-speed data analysis, and improved research efficiency.
4.6. Topic Modeling
Prior to conducting the topic modeling analysis, the optimal number of topics was determined through a preliminary evaluation process.
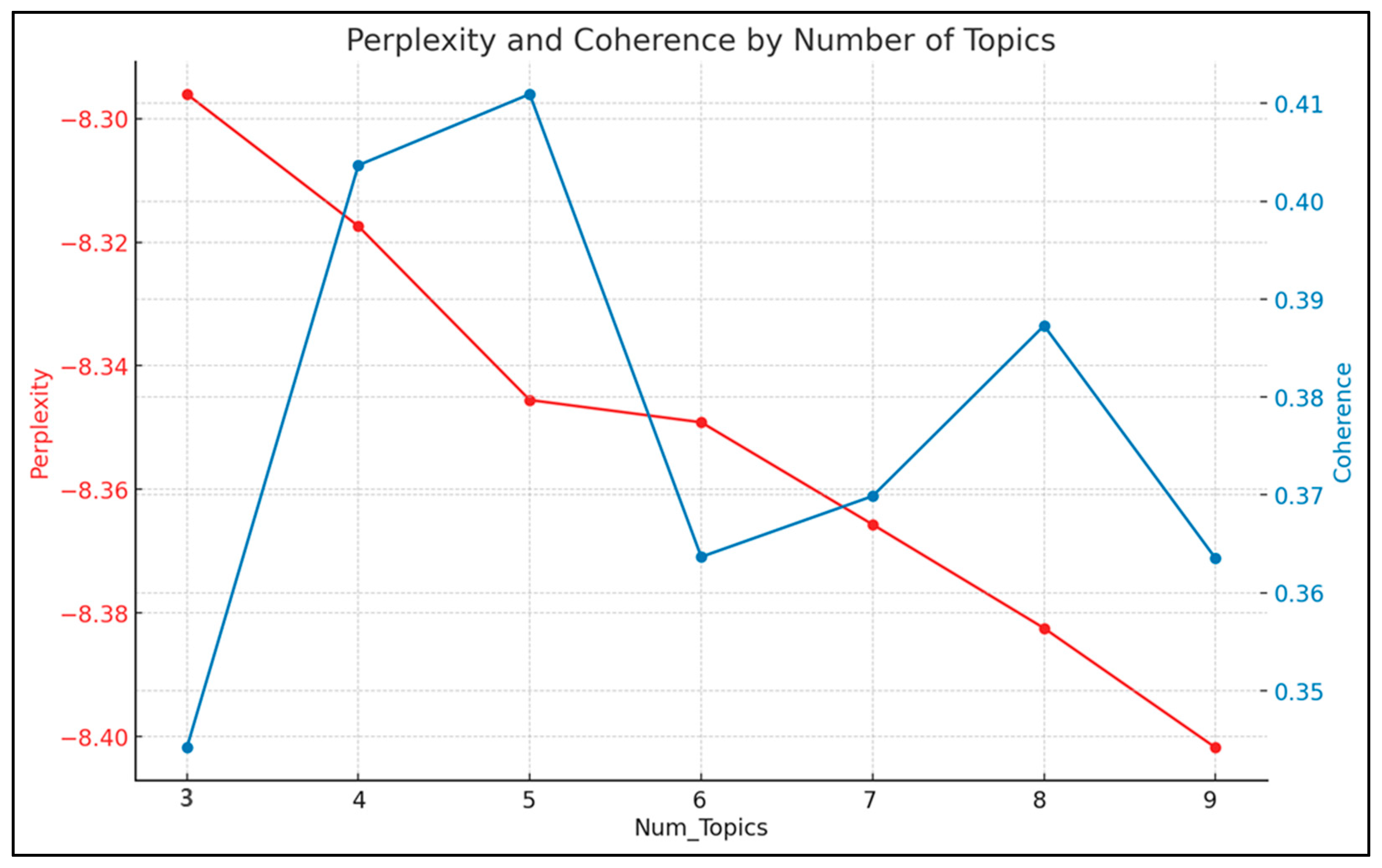
Figure 5 illustrates the calculation results for selecting the optimal topic model and balancing the perplexity and coherence scores. Considering the balance between perplexity and coherence, the most suitable number of topics is likely five, where coherence is high, and perplexity remains relatively stable. The analysis identified five topics with the best performance as follows: high coherence score and a relatively low perplexity score. Coherence measures the semantic consistency between words within a topic, with higher values indicating better interpretability. Conversely, the perplexity evaluates a model’s predictive performance, with lower values indicating improved reliability. In this study, the five-topic model demonstrated a strong balance between these metrics, achieving relatively high coherence and low perplexity, signifying optimal model performance. Based on these findings, five topics were selected for the subsequent analysis.
Table 11 presents the keyword weights assigned to each topic derived from the topic modeling analysis. The weight of each keyword reflects its importance within a specific topic and provides a quantitative understanding of the terms that define each theme. These weights serve as crucial indicators for characterizing topics, distinguishing between themes, and analyzing the centrality of concepts within the dataset. By examining the weights in
Table 10, researchers can numerically compare and interpret distinct topic compositions; this aids in identifying significant terms and their relevance to specific research themes. This numerical representation facilitates a clearer understanding of topic modeling results, enhancing the ability to interpret and utilize insights for future research planning.
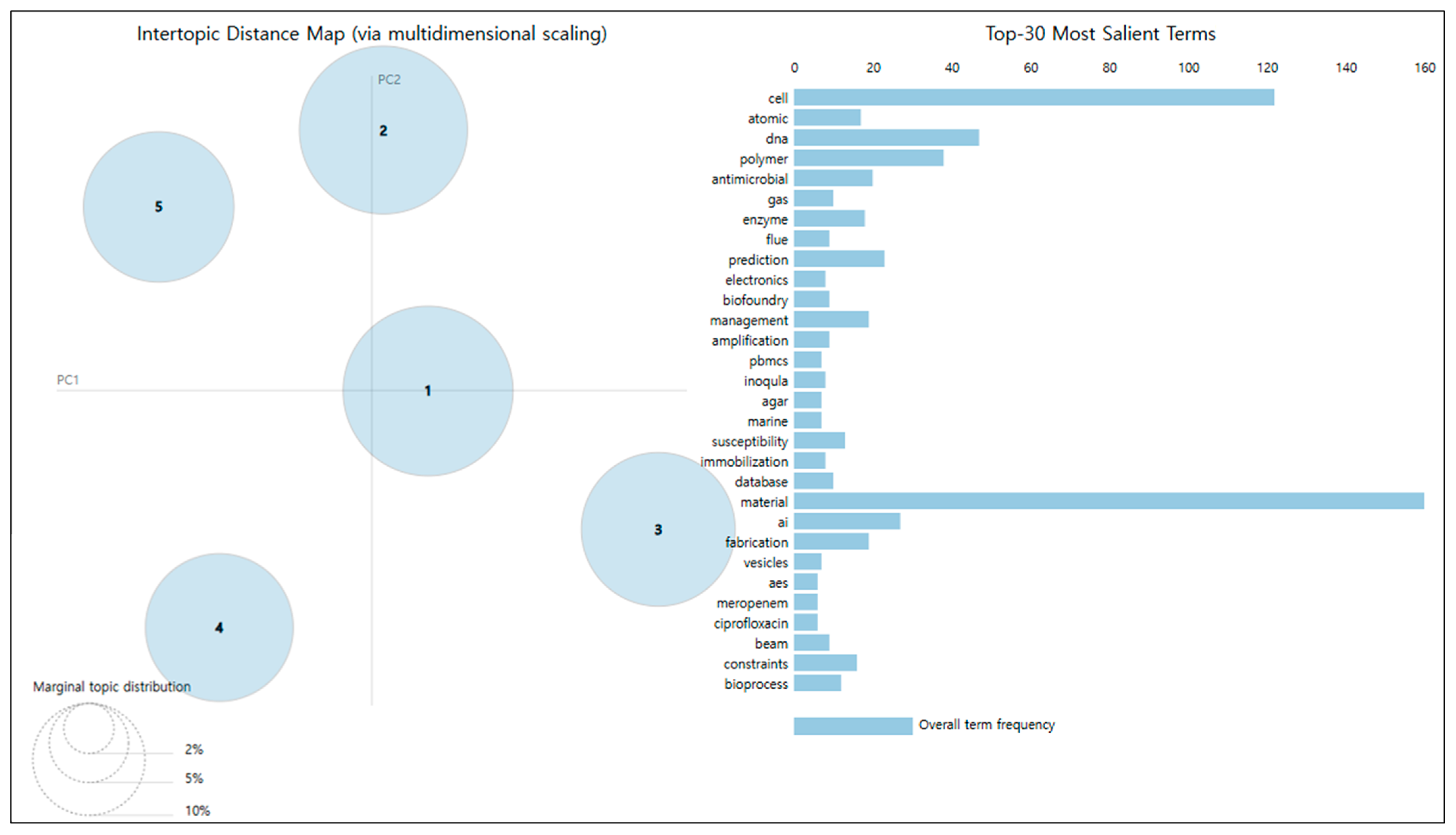
Figure 6 presents the results of the topic model Intertopic Distance Map (IDM), which illustrates the distribution of the five main themes in a two-dimensional space derived through multidimensional reduction. Each theme is positioned along the PC1 and PC2 axes to provide insights into their relationships and characteristics. Topic 1 is centrally located with high interconnectivity with other topics, suggesting its role as a central theme encompassing common elements shared across the dataset. Conversely, Topic 2 is positioned at the top of the PC2 axis, relatively independent of other topics, and represents a distinct concept with a focused theme. Topics 3 and 4 are distributed in opposite directions along the PC1 axis, each indicating a specific and unique attribute. Finally, Topic 5 is located at the lower left of the map, exhibiting a low correlation with other topics, implying a relatively independent character.
The Top 30 Most Salient Terms graph lists the key terms associated with each topic, highlighting their unique characteristics. Common terms such as “material” and “cell” are the most frequent across the dataset, underscoring their centrality in the research data. These terms suggest that materials and cellular concepts are the foundational elements of SDL-related research. The topic-specific terms further define the unique attributes of each theme. For example, “atomic”, “dna”, and “polymer” are closely associated with Topic 2, emphasizing its focus on biological and chemical concepts. Topic 3 is characterized by terms such as “database” and “ai”, indicating its strong connection to technical and computational elements. Additional terms like “biofoundry”, “immobilization”, and “vesicles” further differentiate the topics, highlighting their specialized content.
The IDM analysis reveals significant patterns in topic distribution. Topics centrally located, such as Topic 1, are highly correlated with other themes, suggesting the potential for multidisciplinary research and the need for a multidimensional approach. Conversely, topics positioned independently, such as Topics 2 and 5, display low relevance to other themes. This indicates the need for an in-depth exploration of specific specialized fields. These findings provide a visual and analytical framework for understanding the subject structure of SDL research, offering valuable insights for identifying hidden relationships and setting future research directions.
4.6.1. Topic 1
This topic centers on optimizing various chemical and biological materials, representing 40.07% of the total data. The key terms associated with this topic include material, optimization, synthesis, and chemical, reflecting the focus on enhancing material properties and synthesis processes. Based on the interconnectedness of keywords, the primary focus is to improve the material properties and optimize the synthesis processes. Optimization techniques are applied in specific fields, such as polymers and bioprocesses. Furthermore, keywords related to atoms and gases are associated with detailed topics concerning the control of synthesis processes. This indicates a strong correlation between SDLs and the optimization of synthesis and material property enhancement. SDLs play a critical role in regulating chemical reactions and synthesizing new materials. Thus, the keywords in Topic 1 suggest that SDLs are actively employed in the optimization and synthesis of materials, improving chemical performance and driving the development of high-performance materials.
4.6.2. Topic 2
This topic focuses on cells and biological systems and examines various biological processes at the cellular level. It accounts for 19.08% of the total data, with key terms including cell, enzyme, bioprocess, and extraction. This demonstrates the applicability of SDLs in various biological fields, including those involving cells. It specifically addresses enzyme actions and purification processes at the cellular level, highlighting the strong correlation between SDLs and the production and improvement of biological materials. Notably, this topic emphasizes the complex intracellular reactions, and the biological techniques used to regulate them. In conclusion, the keywords for Topic 2 explore methodologies for producing and purifying biological materials through SDLs, suggesting potential applications in drug development and the production of biological therapeutics.
4.6.3. Topic 3
This topic focuses on leveraging AI and predictive algorithms to analyze and optimize the properties of materials and chemical reactions. It accounts for 15.73% of the total data, with key terms including AI, algorithms, and predictions. Artificial intelligence and predictive algorithms have become essential components across all industries, making it difficult to assign Topic 3 to a specific industrial field. The keywords in Topic 3 suggest that artificial intelligence, algorithms, and prediction are integrated and implemented in research areas through the SDL system. Furthermore, the keywords Bayesian and neural networks indicate exploring methods to reduce uncertainty in predictions.
4.6.4. Topic 4
This topic explores the integration of microfluidic technology and robotics to enhance the efficiency of biological and chemical research. It accounts for 13.27% of the total data, with key terms including microfluidic, robotic, fabrication, and modules. Microfluidic technology is a technique used for the precise control of small volumes of liquids. It has been critically utilized in detailed robotic experiments, demonstrating that SDLs are being incorporated and applied in precise and repetitive experimental processes conducted through robotics.
4.6.5. Topic 5
This topic focuses on measuring and analyzing the properties of materials and biological processes, accounting for 11.86% of the total data. The key terms include measurement, architecture, engineering, reproducibility, and reliability. To date, ensuring reproducibility has been an essential condition for obtaining reliable data in scientific experiments. SDLs demonstrate high relevance and utility in this process by improving the accuracy and reproducibility of the experiments, thereby facilitating the acquisition of trustworthy data.
Figure 7 presents the topic correlation matrix, which quantitatively analyzes the relationships between various topics within the dataset. This matrix provides critical insights into the independence and thematic structure of the topics. The diagonal values of the matrix indicate a perfect positive correlation for each topic with itself, with a correlation coefficient of 1.0. This reflects the strong internal consistency of each topic. On the other hand, all off-diagonal values are negative, with correlation coefficients ranging from approximately −0.22 to −0.31. These negative correlations suggest that the topics are independent and non-redundant, with minimal thematic overlap. Notably, Topic 4 exhibits the lowest correlation (−0.31) with other topics, indicating that it possesses the most distinct characteristics within the dataset.
These results demonstrate that the topic modeling process has effectively achieved clear differentiation among the topics. The observed negative correlations emphasize that the topics are independently structured and contribute to capturing diverse perspectives within the dataset. A more in-depth examination of the keywords or content associated with each topic could further clarify their unique characteristics and the underlying reasons for the negative correlations. Additionally, the matrix validates the distinct separation between topics, supporting the reliability and interpretability of the results.
5. Discussions
An analysis of SDL research trends over the past 20 years (2004–2023) was conducted using the abstract data from 352 SDL-related publications. By employing trend analysis, network analysis, and LDA topic modeling techniques, this study identified key trends in SDLs, including annual publication growth rate, country-specific research concentration, journal publication patterns, author-specific contributions, and topic-specific research tendencies. The findings and implications are summarized as follows:
First, SDL research has increased rapidly since 2019, with the highest number of publications recorded in 2020 and 2021. This surge is attributed to the increasing demand for remote research environments during the pandemic and advancements in AI technology, highlighting the necessity for SDLs. These findings underscore the importance of SDLs as a tool to improve efficiency in various industries and academic disciplines.
Second, SDL-related publications are predominantly concentrated in the top 10 countries, including the United States, Germany, and China, collectively accounting for over 85% of all publications. This demonstrates that SDL research is primarily conducted in countries with well-established research infrastructures. The prioritization of SDLs in these nations reflects its perceived importance in national competitiveness and the development of advanced technologies.
Third, the results of the network centrality analysis indicate that modern scientific research is centered on interdisciplinary convergence, data-driven approaches, artificial intelligence (AI) integration, materials science, and experimental optimization. In particular, AI and computational techniques are becoming deeply embedded in research, while materials science and biotechnology are emerging as key areas in experimental and applied research. Additionally, advancements in automation and experimental technologies are accelerating, with an increasing focus on strategic management to enhance research efficiency.
Fourth, the findings from the n-gram analysis highlight key trends in contemporary scientific research, including the increasing adoption of AI and computational methods, the automation and optimization of experiments, advancements in materials science and life sciences, and the widespread implementation of data-driven research methodologies. Notably, AI and robotics technologies play a critical role in laboratory automation and data analysis, enhancing research efficiency and accuracy. Furthermore, the integration of AI and high-throughput experimental techniques with novel materials research and genomic analysis is expected to drive groundbreaking scientific discoveries.
Finally, topic modeling identified key research themes, including material optimization and synthesis, cellular and biological processes, AI and predictive algorithms, microfluidics and robotics, and measurement and experimental techniques. Active research is being conducted in material synthesis, biological process optimization, and AI-driven prediction. SDL research is inherently interdisciplinary, integrating fields such as computing, biology, materials science, and AI. Notably, publications on SDLs appear not only in computer science journals but also in pure science and applied technology journals, highlighting their cross-disciplinary nature. This finding suggests that SDLs enhance research efficiency and introduce innovative methodologies across various domains. AI and predictive algorithms play a crucial role in automating experiments and improving research accuracy. These trends underscore SDLs’ potential to enhance research efficiency and applicability across diverse fields, demonstrating their transformative impact on scientific research.
Previous studies have emphasized the integration of SDLs into medical and pharmaceutical research [
5]. This study expands on prior research by confirming the active adoption of SDLs in the medical and pharmaceutical fields and in various engineering disciplines. Furthermore, it highlighted the efficiency and potential of SDLs, particularly their rapid implementation in fields such as chemistry and materials science. Significant research and development have also been observed in the theoretical and conceptual foundations of automated laboratories. By identifying detailed topic-specific trends, this study contributes to understanding the potential applications of SDLs in various industrial domains.
6. Conclusions
The research actively applied SDLs across various industries to facilitate the adoption and utilization of SDLs while providing foundational data for enhancing scientific research. An analysis of SDL research trends over 20 years (2004–2023) based on 352 abstracts utilized trend analysis, network analysis, and LDA topic modeling to uncover key insights. These insights include the annual growth rate of SDL-related publications, country-specific research focuses, journal-specific publication patterns, author collaboration, and topic-specific research trends.
The major findings of this study are as follows: First, SDL research has grown rapidly since 2019, with the highest number of publications recorded in 2020 and 2021. This growth is largely attributable to the demand for remote research environments during the pandemic and advancements in AI technology, underscoring SDLs’ emergence as an essential tool for enhancing research efficiency across disciplines. Second, SDL-related publications are highly concentrated in leading countries such as the United States, Germany, and China, which account for over 85% of the total research output. This indicates that countries with advanced research infrastructures strategically focus on SDLs to enhance their global competitiveness and technological leadership. Third, SDL research is characterized by its interdisciplinary nature and integrates fields such as material optimization, biological processes, and AI-based predictive algorithms. The integration of AI has played a pivotal role in automating experiments and improving research efficiency, emphasizing SDLs’ potential to drive innovation and expanding their application scope across various fields. Fourth, the n-gram analysis highlights modern scientific research trends, including the growing use of AI and computational methods, experimental automation, and data-driven approaches. AI and robotics enhance laboratory efficiency and accuracy, while their integration with high-throughput techniques in materials science and genomics is driving innovation. Finally, SDLs have been shown to transform scientific research paradigms by combining automation and optimization, positioning itself as a critical methodology in the AI era. Furthermore, the increasing adoption of SDLs across cutting-edge scientific disciplines underscores their potential to drive the development of a sustainable and innovative scientific research environment by enhancing resource efficiency, reducing experimental costs, fostering interdisciplinary collaboration, and accelerating scientific discovery.
This study highlights SDLs’ transformative potential and their role in sustainable scientific systems in academia, industry, and policymaking. In the industrial sector, SDL adoption enables the reassessment of R&D priorities and investment strategies. By leveraging SDLs, industries can gain strategic insights to adapt rapidly to evolving research trends, thereby contributing to sustainable industrial growth. Furthermore, SDLs facilitate the identification of emerging technologies and commercialization opportunities, enabling companies to prepare for new product development and market expansion. These capabilities allow businesses to seize market opportunities proactively, respond flexibly to volatility, and enhance global competitiveness. In academia, an SDL trend analysis is a foundation for shaping research directions and refining educational programs. Integrating knowledge and technologies aligned with current and future research trends in curricula fosters the development of industry-ready talent. This contributes to sustainable collaboration between academia and industry while enhancing the practical applicability of research outcomes. Moreover, SDL-driven educational advancements strengthen academia–industry partnerships, ensuring a more sustainable and effective translation of research into industrial innovation. From a policy perspective, this study provides critical evidence for science and technology policies. SDL trend analysis offers insights into sustainable strategic investment priorities and regulatory frameworks that bolster national competitiveness in science and technology. Moreover, aligning regulations and support programs with SDL advancements plays a pivotal role in creating an environment conducive to scientific research and innovation at the national level.
This study has several limitations that may affect the interpretation of the results and should be addressed in future research. First, this study primarily focused on three fields—biotechnology, chemical engineering, and materials engineering—where SDLs have been widely applied. While these fields offer valuable insights, this narrow scope limits the ability to evaluate SDLs’ broader potential applications. As a result, the findings may not fully capture SDLs’ applicability across diverse scientific disciplines. To overcome this limitation, future research should expand the investigation of SDLs to include additional fields, such as computer science, environmental science, and medicine. This broader focus would enable more comprehensive analyses and foster a holistic understanding of SDLs’ potential across the scientific landscape.
Second, this study focused on papers from the early stages of SDL adoption, which may not fully capture the innovative aspects and diverse applications that could emerge as SDLs continue to mature. These temporal limitations suggest that the interpretation of results may reflect only initial patterns, which could evolve. To address this, subsequent research should include studies from a broader temporal range, encompassing both early-stage and mature implementations of SDLs. This approach would provide deeper insights into SDLs’ developmental trajectory, uncovering dynamic changes and long-term impacts as they become more widely adopted. By addressing these limitations, future research can provide a more nuanced understanding of SDLs’ applications, reliability, and evolution, ultimately advancing the field in a more comprehensive and meaningful way.
Future research can significantly contribute to the effective implementation and dissemination of SDLs by addressing these limitations and broadening the scope of investigation. A multidisciplinary approach that explores diverse scientific and industrial domains will be instrumental in maximizing SDLs’ impact and fostering a sustainable and effective scientific research ecosystem.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}