
Learning to Score: A Coding System for Constructed Response Items via Interactive Clustering


Abstract
1. Introduction
- We propose a novel and practical response coding approach to obtain better scoring results for constructed response items in a large-scale assessment setting.
- State-of-the-art algorithms are integrated into the proposed ASSIST system for clustering and classifier learning. We propose an interactive clustering method that allows experts to actively review and refine the code-discovering process. We incorporate a classifier with out-of-distribution detection for learning to score while explaining clustering results.
- We conduct experiments on real-world assessment datasets. The performance and visualization results highlighted the effectiveness of the developed model, including clustering quality and automatic scoring accuracy.
2. Related Works
2.1. Automatic Response Coding System
2.2. Text Clustering
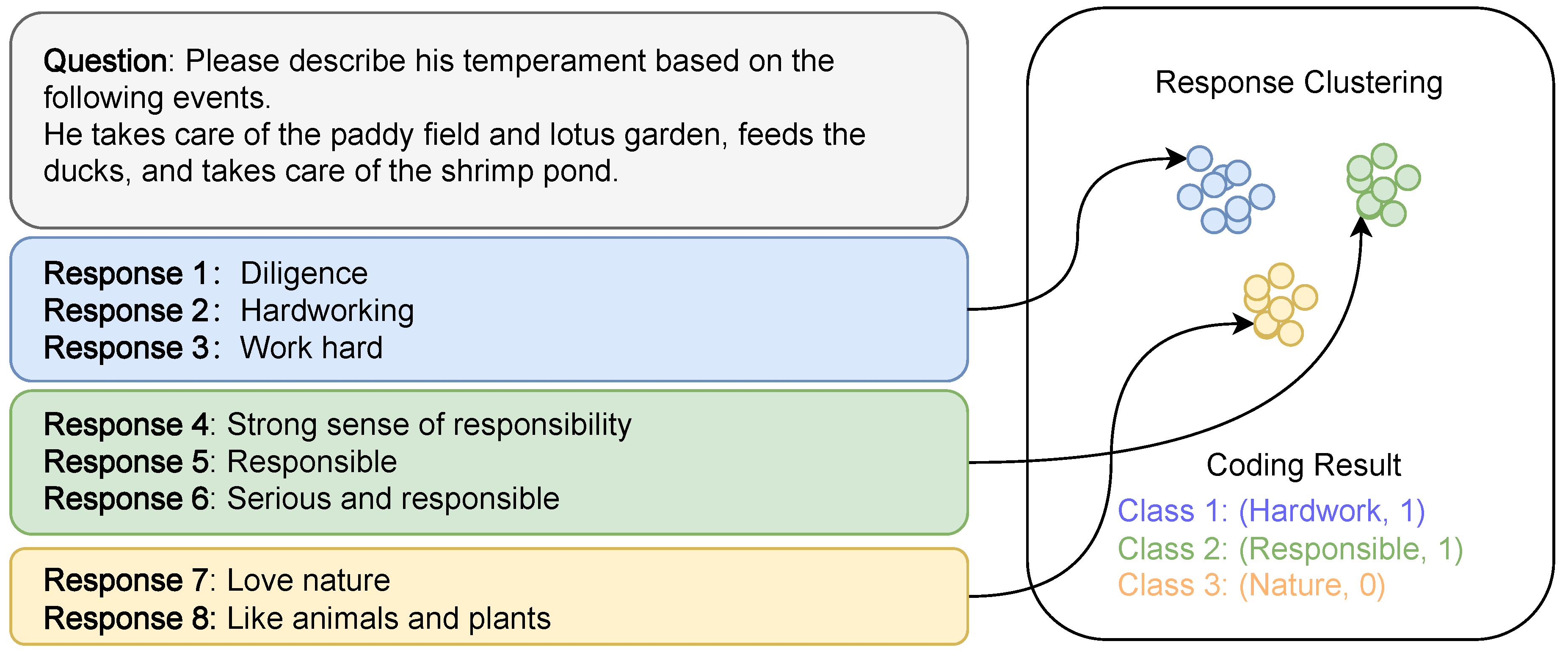
3. Methodology
3.1. Problem Definition
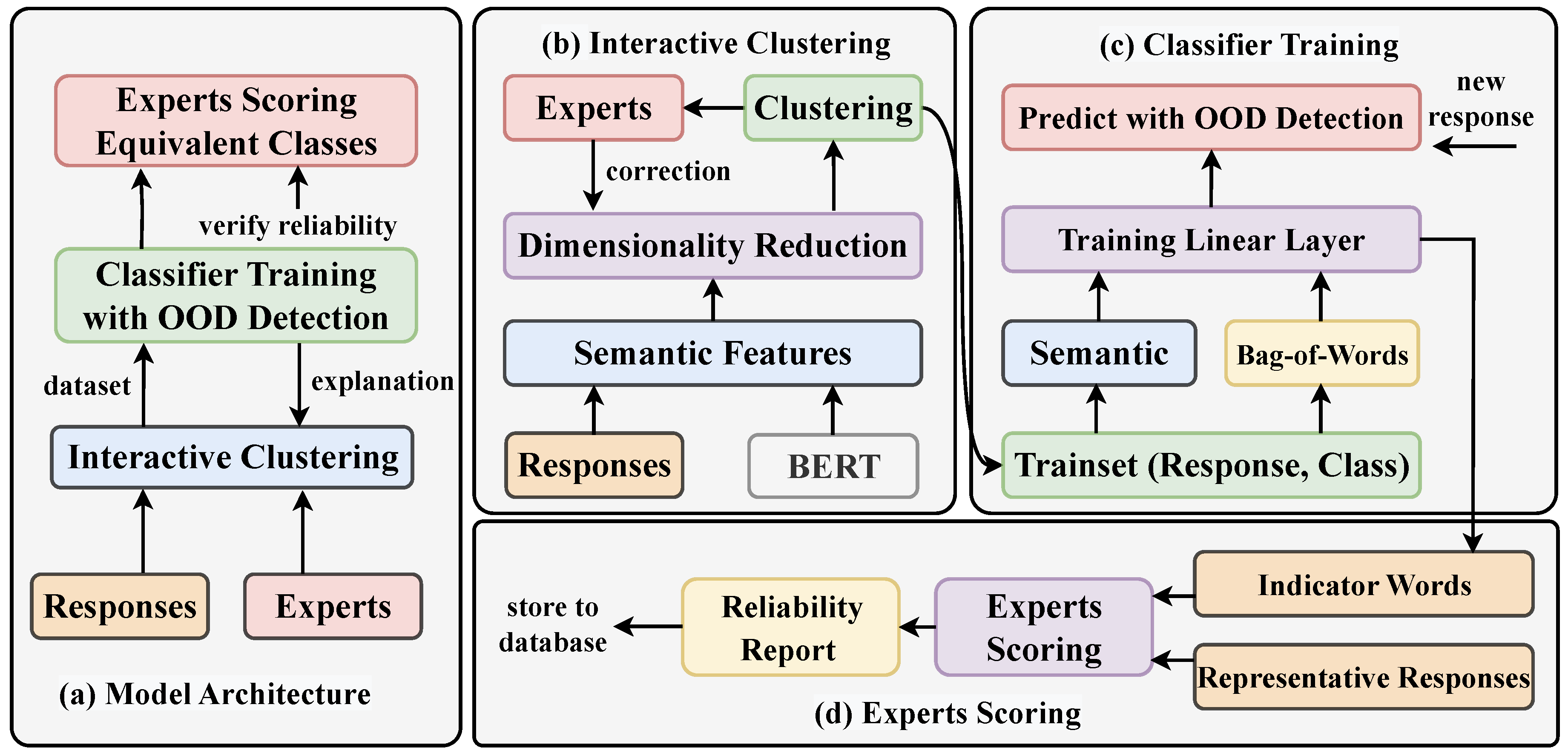
3.2. System Architecture
- Semantic Feature Extraction. After text pre-processing, word embedding and pre-trained BERT are used to extract semantic features from the raw responses. Then, to solve the distance failure phenomenon caused by the high dimensionality of the feature, dimensionality reduction is performed on the feature. For text pre-processing, see Section 4.2.
- Interactive Clustering. The dimension-reduced features are clustered, and each cluster represents an equivalent response class. Experts’ feedback helps correct individual errors; see Section 3.3.
- Classifier Training. The input of the classifier contains two parts, namely semantic features and one-hot bag-of-words vector. The BoW model is used to capture the word similarity between responses and is used to explain the clustering results. The output of the classifier is the equivalent response class; see Section 3.4. The backbone of the classifier is a linear layer. For detailed parameter settings, see Section 4.2.
- Scoring and Reliability Report. Representative responses and indicator words, which are extracted from clustering and classifier, are provided to each expert to score each equivalent response class. Then, all experts’ scoring will be jointly calculated for reliability to ensure the objectivity and consistency of the ratings, see Section 3.5.
3.3. Interactive Clustering
3.4. Classifier Training
3.5. Expert Scoring for Equivalent Response Classes
| Algorithm 1 The pseudo-code of the ASSIST system. |
| Input: Raw responses Output: Trained classifier
|
4. Experiments
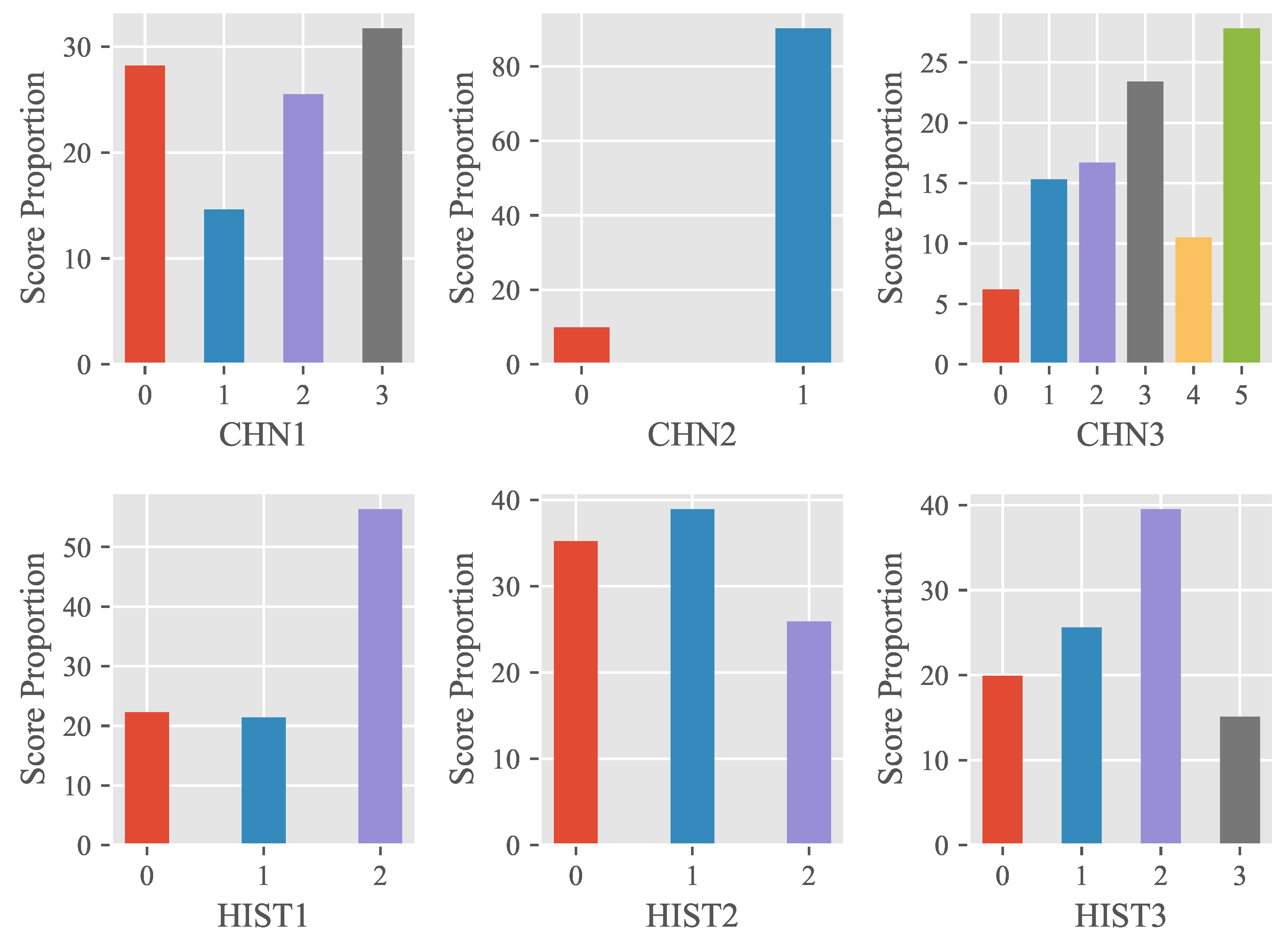
4.1. Dataset Description
4.2. Experiment Setup
4.2.1. Word Embeddings
4.2.2. Parameter Settings
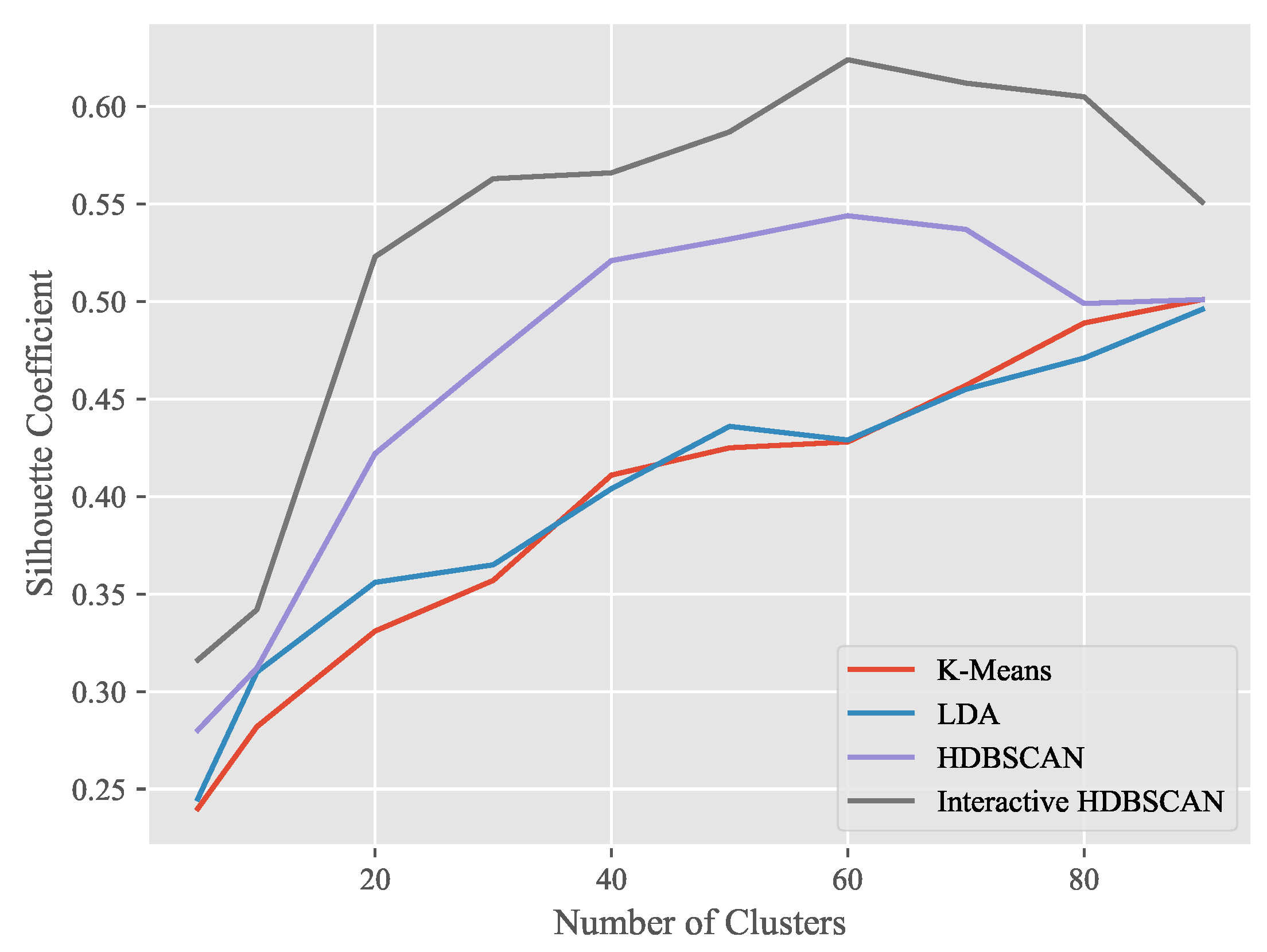
4.3. Performance on Response Clustering
4.4. Performance on Automatic Scoring
- BiLTSM and TextCNN. We take BiLSTM in the semantic feature extraction stage. BiLSTM stands for Bidirectional Long Short-Term Memory. It is a type of recurrent neural network (RNN) architecture designed to capture sequential dependencies in data. The bidirectional aspect makes them particularly effective in capturing dependency patterns in temporal sequences. TextCNN utilizes convolutional layers to capture local patterns and hierarchical representations in text. The BiLSTM and TextCNN are widely used in automatic scoring, such as the rubric-aware model [54] and the attention-based scoring model [55].
- BERT-Refine: This method adds a semantic refinement layer after the BERT backbone to refine the semantics of the BERT outputs, which consists of a Bi-LSTM network and a Capsule network with position information in parallel [6]. We reproduce the feature extractor to our pipeline but without the proposed triple-hot loss strategy because we model the automatic coding as classification instead of regression.
- SR-Combined: This method proposes a feature extractor based on InferSent and incorporates class-specific representatives obtained after clustering [8]. We use the InferSent, combined token-sentence similarity, as mentioned in this work, to generate the predicted code while keeping the clustering as our result for the sake of comparability.
- Sentence-BERT: As mentioned in Section III.C, the pre-trained sentence-BERT is used as our default feature extractor, and this model is also used in recent automatic scoring work such as [56].
- w/o Semantic and w/o bag-of-words: Based on sentence-BERT, We ablate specific modules to show the effectiveness. The w/o semantic means that we only use bag-of-words features to train the classifier, and the w/o bag-of-words means that we only use semantic features to train the classifier.
4.5. Discussion on Reliability and Efficiency
5. Conclusions
6. Limitations and Future Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bennett, R.E. On the meanings of constructed response. ETS Res. Rep. Ser. 1991, 1991, i-46. [Google Scholar] [CrossRef]
- Gao, R.; Merzdorf, H.E.; Anwar, S.; Hipwell, M.C.; Srinivasa, A.R. Automatic assessment of text-based responses in post-secondary education: A systematic review. Comput. Educ. Artif. Intell. 2024, 6, 100206. [Google Scholar] [CrossRef]
- Del Gobbo, E.; Guarino, A.; Cafarelli, B.; Grilli, L.; Limone, P. Automatic evaluation of open-ended questions for online learning. A systematic mapping. Stud. Educ. Eval. 2023, 77, 101258. [Google Scholar] [CrossRef]
- Wang, F.; Huang, Z.; Liu, Q.; Chen, E.; Yin, Y.; Ma, J.; Wang, S. Dynamic cognitive diagnosis: An educational priors-enhanced deep knowledge tracing perspective. IEEE Trans. Learn. Technol. 2023, 16, 306–323. [Google Scholar] [CrossRef]
- Abbas, M.; van Rosmalen, P.; Kalz, M. A data-driven approach for the identification of features for automated feedback on academic essays. IEEE Trans. Learn. Technol. 2023, 16, 914–925. [Google Scholar] [CrossRef]
- Zhu, X.; Wu, H.; Zhang, L. Automatic short-answer grading via Bert-based deep neural networks. IEEE Trans. Learn. Technol. 2022, 15, 364–375. [Google Scholar] [CrossRef]
- Zehner, F.; Sälzer, C.; Goldhammer, F. Automatic coding of short text responses via clustering in educational assessment. Educ. Psychol. Meas. 2015, 76, 280–303. [Google Scholar] [CrossRef]
- Marvaniya, S.; Saha, S.; Dhamecha, T.I.; Foltz, P.; Sindhgatta, R.; Sengupta, B. Creating scoring rubric from representative student answers for improved short answer grading. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, New York, NY, USA, 22–26 October 2018; pp. 993–1002. [Google Scholar] [CrossRef]
- Bae, J.; Helldin, T.; Riveiro, M.; Nowaczyk, S.; Bouguelia, M.R.; Falkman, G. Interactive clustering: A comprehensive review. ACM Comput. Surv. 2020, 53, 1–39. [Google Scholar] [CrossRef]
- Noorbehbahani, F.; Kardan, A. The automatic assessment of free text answers using a modified BLEU algorithm. Comput. Educ. 2011, 56, 337–345. [Google Scholar] [CrossRef]
- Ren, J.; Liu, P.J.; Fertig, E.; Snoek, J.; Poplin, R.; Depristo, M.; Dillon, J.; Lakshminarayanan, B. Likelihood ratios for out-of-distribution detection. In Proceedings of the Advances in Neural Information Processing Systems 32: NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019; pp. 1–12. [Google Scholar]
- Nelson, L.K. Computational grounded theory: A methodological framework. Sociol. Methods Res. 2020, 49, 3–42. [Google Scholar] [CrossRef]
- Burrows, S.; Gurevych, I.; Stein, B. The eras and trends of automatic short answer grading. Int. J. Artif. Intell. Educ. 2014, 25, 60–117. [Google Scholar] [CrossRef]
- Sukkarieh, J.Z.; Blackmore, J. c-rater: Automatic content scoring for short constructed responses. In Proceedings of the Twenty-Second International FLAIRS Conference, Sanibel Island, FL, USA, 19–21 March 2009; pp. 290–295. [Google Scholar]
- Sultan, M.A.; Salazar, C.; Sumner, T. Fast and easy short answer grading with high accuracy. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1070–1075. [Google Scholar] [CrossRef]
- Tan, H.; Wang, C.; Duan, Q.; Lu, Y.; Zhang, H.; Li, R. Automatic short answer grading by encoding student responses via a graph convolutional network. Interact. Learn. Environ. 2023, 31, 1636–1650. [Google Scholar] [CrossRef]
- Schneider, J.; Schenk, B.; Niklaus, C.; Vlachos, M. Towards llm-based auto-grading for short textual answers. In Proceedings of the 16th International Conference on Computer Supported Education, Angers, France, 2–4 May 2024. [Google Scholar] [CrossRef]
- Chang, L.H.; Ginter, F. Automatic short answer grading for Finnish with ChatGPT. In Proceedings of the 39th AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 23173–23181. [Google Scholar]
- Min, Q.; Zhou, Z.; Li, Z.; Wu, M. Automatic evaluation of instructional videos based on video features and student watching experience. IEEE Trans. Learn. Technol. 2024, 17, 54–62. [Google Scholar] [CrossRef]
- Zesch, T.; Heilman, M.; Cahill, A. Reducing annotation efforts in supervised short answer scoring. In Proceedings of the 10th Workshop on Innovative Use of NLP for Building Educational Applications, Denver, CO, USA, 4 June 2015; pp. 124–132. [Google Scholar]
- Andersen, N.; Zehner, F.; Goldhammer, F. Semi-automatic coding of open-ended text responses in large-scale assessments. J. Comput. Assist. Learn. 2022, 39, 841–854. [Google Scholar] [CrossRef]
- Zhang, Y.; Jin, R.; Zhou, Z.H. Understanding bag-of-words model: A statistical framework. Int. J. Mach. Learn. Cybern. 2010, 1, 43–52. [Google Scholar] [CrossRef]
- Ramos, J. Using TF-IDF to determine word relevance in document queries. In Proceedings of the First Instructional Conference on Machine Learning, Piscataway, NJ, USA, 3–8 December 2003; pp. 29–48. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Conneau, A.; Kiela, D.; Schwenk, H.; Barrault, L.; Bordes, A. Supervised learning of universal sentence representations from natural language inference data. arXiv 2017, arXiv:1705.02364. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- McInnes, L.; Healy, J.; Melville, J. Umap: Uniform manifold approximation and projection for dimension reduction. arXiv 2018, arXiv:1802.03426. [Google Scholar] [CrossRef]
- Zhang, D.; Zhou, Z.H.; Chen, S. Semi-supervised dimensionality reduction. In Proceedings of the 2007 SIAM International Conference on Data Mining, Minneapolis, MN, USA, 26–28 April 2007; pp. 629–634. [Google Scholar] [CrossRef]
- Erisoglu, M.; Calis, N.; Sakallioglu, S. A new algorithm for initial cluster centers in k-means algorithm. Pattern Recognit. Lett. 2011, 32, 1701–1705. [Google Scholar] [CrossRef]
- Jelodar, H.; Wang, Y.; Yuan, C.; Feng, X.; Jiang, X.; Li, Y.; Zhao, L. Latent Dirichlet allocation (LDA) and topic modeling: Models, applications, a survey. Multimed. Tools Appl. 2019, 78, 15169–15211. [Google Scholar] [CrossRef]
- Schubert, E.; Sander, J.; Ester, M.; Kriegel, H.P.; Xu, X. DBSCAN revisited, revisited: Why and how you should (still) use DBSCAN. ACM Trans. Database Syst. 2017, 42, 1–21. [Google Scholar] [CrossRef]
- Murtagh, F.; Contreras, P. Algorithms for hierarchical clustering: An overview. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2011, 2, 86–97. [Google Scholar] [CrossRef]
- Malzer, C.; Baum, M. A hybrid approach to hierarchical density-based cluster selection. In Proceedings of the 2020 IEEE International Conference on Multisensor Fusion and Integration for Intelligent Systems (MFI), Karlsruhe, Germany, 14–16 September 2020; pp. 223–228. [Google Scholar] [CrossRef]
- Pedrycz, W. Computing and clustering in the environment of order-2 information granules. IEEE Trans. Cybern. 2023, 53, 5414–5423. [Google Scholar] [CrossRef] [PubMed]
- Pedrycz, W. Proximity-based clustering: A search for structural consistency in data with semantic blocks of features. IEEE Trans. Fuzzy Syst. 2013, 21, 978–982. [Google Scholar] [CrossRef]
- Pedrycz, W. Collaborative fuzzy clustering. Pattern Recognit. Lett. 2002, 23, 1675–1686. [Google Scholar] [CrossRef]
- Ju, W.; Yi, S.; Wang, Y.; Long, Q.; Luo, J.; Xiao, Z.; Zhang, M. A survey of data-efficient graph learning. In Proceedings of the 33rd International Joint Conference on Artificial Intelligence, Jeju, Republic of Korea, 3–9 August 2024; pp. 8104–8113. [Google Scholar]
- Ju, W.; Gu, Y.; Chen, B.; Sun, G.; Qin, Y.; Liu, X.; Luo, X.; Zhang, M. GLCC: A general framework for graph-level clustering. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 4391–4399. [Google Scholar]
- Luo, X.; Ju, W.; Qu, M.; Gu, Y.; Chen, C.; Deng, M.; Hua, X.S.; Zhang, M. CLEAR: Cluster-enhanced contrast for self-supervised graph representation learning. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 899–912. [Google Scholar] [CrossRef]
- Yi, S.; Ju, W.; Qin, Y.; Luo, X.; Liu, L.; Zhou, Y.; Zhang, M. Redundancy-free self-supervised relational learning for graph clustering. IEEE Trans. Neural Netw. Learn. Syst. 2023, 1–15. [Google Scholar] [CrossRef]
- Reimers, N.; Gurevych, I. Sentence-bert: Sentence embeddings using siamese bert-networks. arXiv 2019, arXiv:1908.10084. [Google Scholar] [CrossRef]
- Aggarwal, C.C.; Hinneburg, A.; Keim, D.A. On the surprising behavior of distance metrics in high dimensional space. In Proceedings of the 8th International Conference on Database Theory: ICDT 2001, London, UK, 4–6 October 2001; pp. 420–434. [Google Scholar] [CrossRef]
- Damrich, S.; Hamprecht, F.A. On UMAP’s true loss function. In Proceedings of the 35th Conference on Neural Information Processing Systems: NeurIPS 2021, Virtual Conference, 6–14 December 2021; pp. 5798–5809. [Google Scholar]
- McInnes, L.; Healy, J.; Astels, S. Hdbscan: Hierarchical density based clustering. J. Open Source Softw. 2017, 2, 205. [Google Scholar] [CrossRef]
- Guan, R.; Zhang, H.; Liang, Y.; Giunchiglia, F.; Huang, L.; Feng, X. Deep feature-based text clustering and its explanation. IEEE Trans. Knowl. Data Eng. 2022, 34, 3669–3680. [Google Scholar] [CrossRef]
- Zhang, Z.; Xiang, X. Decoupling maxlogit for out-of-distribution detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 3388–3397. [Google Scholar]
- Sun, Y.; Ming, Y.; Zhu, X.; Li, Y. Out-of-distribution detection with deep nearest neighbors. In Proceedings of the 39th International Conference on Machine Learning, PMLR 162, Baltimore, MD, USA, 17–23 July 2022; pp. 20827–20840. [Google Scholar]
- Jiao, Z.; Sun, S.; Sun, K. Chinese lexical analysis with deep Bi-GRU-CRF network. arXiv 2018, arXiv:1807.01882. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar] [CrossRef]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]
- Kim, Y. Convolutional neural networks for sentence classification. arXiv 2014, arXiv:1408.5882. [Google Scholar] [CrossRef]
- Zhou, P.; Shi, W.; Tian, J.; Qi, Z.; Li, B.; Hao, H.; Xu, B. Attention-based bidirectional long short-term memory networks for relation classification. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 207–212. [Google Scholar]
- Wang, T.; Inoue, N.; Ouchi, H.; Mizumoto, T.; Inui, K. Inject rubrics into short answer grading system. In Proceedings of the 2nd Workshop on Deep Learning Approaches for Low-Resource NLP: DeepLo 2019, Hong Kong, China, 3 November 2019; pp. 175–182. [Google Scholar]
- Qi, H.; Wang, Y.; Dai, J.; Li, J.; Di, X. Attention-based hybrid model for automatic short answer scoring. In Proceedings of the 11th International Conference on Simulation Tools and Techniques: SIMUtools 2019, Chengdu, China, 8–10 July 2019; pp. 385–394. [Google Scholar]
- Condor, A.; Litster, M.; Pardos, Z. Automatic short answer grading with SBERT on out-of-sample questions. In Proceedings of the 14th Iteration of the Conference, Educational Data Mining, Virtual Conference, 29 June 2021; pp. 1–8. [Google Scholar]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Xia, F.; Chi, E.; Le, Q.V.; Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. Adv. Neural Inf. Process. Syst. 2022, 35, 24824–24837. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Num. of Samples | Num. of Avg Word | Score | |
|---|---|---|---|
| CHN1 | 2480 | 8.42 | 0–3 |
| CHN2 | 2391 | 4.19 | 0–1 |
| CHN3 | 2579 | 15.07 | 0–5 |
| HIST1 | 892 | 4.81 | 0–2 |
| HIST2 | 876 | 3.69 | 0–2 |
| HIST3 | 904 | 7.13 | 0–3 |
| Item | Precision | Recall | micro-F1 | AUC | RMSE | |
|---|---|---|---|---|---|---|
| CHN1 | 0.723 ± 0.074 | 0.644 ± 0.066 | 0.752 ± 0.079 | 0.671 ± 0.073 | 0.136 ± 0.021 | 0.773 ± 0.087 |
| CHN2 | 0.755 ± 0.069 | 0.657 ± 0.064 | 0.741 ± 0.082 | 0.706 ± 0.068 | 0.114 ± 0.030 | 0.826 ± 0.053 |
| CHN3 | 0.724 ± 0.082 | 0.685 ± 0.076 | 0.697 ± 0.069 | 0.705 ± 0.063 | 0.152 ± 0.033 | 0.807 ± 0.059 |
| HIST1 | 0.787 ± 0.080 | 0.761 ± 0.072 | 0.740 ± 0.077 | 0.808 ± 0.049 | 0.185 ± 0.026 | 0.699 ± 0.091 |
| HIST2 | 0.749 ± 0.087 | 0.794 ± 0.068 | 0.764 ± 0.092 | 0.779 ± 0.074 | 0.172 ± 0.019 | 0.724 ± 0.072 |
| HIST3 | 0.759 ± 0.081 | 0.719 ± 0.058 | 0.803 ± 0.047 | 0.786 ± 0.078 | 0.139 ± 0.029 | 0.750 ± 0.083 |
| OOD Detection on Test Set | Inter-Rater Reliability | |||||
|---|---|---|---|---|---|---|
| Item | Precision | Recall | F1 | OOD% | ||
| CHN1 | 0.727 | 0.667 | 0.696 | 4.84% | 0.815 | 0.127 |
| CHN2 | 0.588 | 0.909 | 0.714 | 4.60% | 0.793 | 0.218 |
| CHN3 | 0.625 | 0.769 | 0.689 | 5.04% | 0.921 | 0.262 |
| HIST1 | 0.714 | 0.833 | 0.769 | 6.74% | 0.672 | 0.301 |
| HIST2 | 0.571 | 0.800 | 0.667 | 5.68% | 0.843 | 0.179 |
| HIST3 | 0.545 | 0.750 | 0.632 | 8.89% | 0.758 | 0.245 |
| CHN | HIST | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | Precision | Recall | micro-F1 | AUC | RMSE | Precision | Recall | micro-F1 | AUC | RMSE | ||
| BiLSTM | 0.687 | 0.635 | 0.697 | 0.643 | 0.132 | 0.791 | 0.723 | 0.704 | 0.749 | 0.703 | 0.145 | 0.679 |
| w/o interact | 0.663 | 0.475 | 0.594 | 0.617 | - | - | 0.618 | 0.488 | 0.538 | 0.544 | - | - |
| TextCNN | 0.701 | 0.646 | 0.721 | 0.656 | 0.117 | 0.748 | 0.741 | 0.732 | 0.748 | 0.695 | 0.127 | 0.694 |
| w/o interact | 0.571 | 0.463 | 0.618 | 0.536 | - | - | 0.611 | 0.564 | 0.572 | 0.471 | - | - |
| BERT-Refine [6] | 0.735 | 0.656 | 0.725 | 0.707 | 0.171 | 0.804 | 0.753 | 0.769 | 0.762 | 0.750 | 0.183 | 0.742 |
| w/o interact | 0.436 | 0.378 | 0.461 | 0.533 | - | - | 0.485 | 0.558 | 0.506 | 0.524 | - | - |
| SR-Combined [8] | 0.719 | 0.655 | 0.738 | 0.680 | 0.153 | 0.810 | 0.745 | 0.732 | 0.772 | 0.764 | 0.153 | 0.706 |
| w/o interact | 0.738 | 0.844 | 0.639 | 0.513 | - | - | 0.742 | 0.581 | 0.696 | 0.650 | - | - |
| Sentence-BERT | 0.734 | 0.662 | 0.730 | 0.694 | 0.134 | 0.802 | 0.765 | 0.758 | 0.769 | 0.791 | 0.165 | 0.724 |
| w/o interact | 0.721 | 0.723 | 0.679 | 0.683 | - | - | 0.699 | 0.651 | 0.870 | 0.784 | - | - |
| w/o semantic | 0.711 | 0.617 | 0.703 | 0.657 | 0.182 | 0.663 | 0.752 | 0.733 | 0.752 | 0.827 | 0.123 | 0.676 |
| w/o bag-of-words | 0.679 | 0.625 | 0.669 | 0.641 | 0.126 | 0.775 | 0.676 | 0.711 | 0.934 | 0.787 | 0.141 | 0.768 |
| Before Correction | After Correction | |||||||
|---|---|---|---|---|---|---|---|---|
| Item | Score | #Cluster | mean (#Resp.) | max (#Resp.) | #Clusters | mean (#Resp.) | max (#Resp.) | Diff. |
| 0 | - | - | - | 21 | 26.64 | 38 | - | |
| 1 | - | - | - | 16 | 18.10 | 51 | - | |
| CHN1 | 2 | - | - | - | 17 | 29.76 | 59 | - |
| 3 | - | - | - | 9 | 69.88 | 106 | - | |
| All | 61 | 32.52 | 114 | 63 | 31.49 | 106 | 67 | |
| 0 | - | - | - | 19 | 9.96 | 14 | - | |
| CHN2 | 1 | - | - | - | 26 | 66.29 | 105 | - |
| All | 47 | 40.70 | 94 | 45 | 42.51 | 105 | 53 | |
| 0 | - | - | - | 13 | 9.85 | 15 | - | |
| 1 | - | - | - | 18 | 17.55 | 28 | - | |
| 2 | - | - | - | 14 | 24.64 | 33 | - | |
| CHN3 | 3 | - | - | - | 23 | 21.01 | 30 | - |
| 4 | - | - | - | 9 | 24.09 | 47 | - | |
| 5 | - | - | - | 10 | 57.41 | 98 | - | |
| All | 87 | 23.71 | 103 | 87 | 23.71 | 98 | 185 | |
| 0 | - | - | - | 15 | 10.61 | 27 | - | |
| HIST1 | 1 | - | - | - | 13 | 11.75 | 23 | - |
| 2 | - | - | - | 26 | 15.45 | 31 | - | |
| All | 55 | 12.97 | 31 | 54 | 13.21 | 31 | 92 | |
| 0 | - | - | - | 18 | 5.65 | 14 | - | |
| HIST2 | 1 | - | - | - | 22 | 16.34 | 29 | - |
| 2 | - | - | - | 13 | 18.42 | 27 | - | |
| All | 54 | 12.98 | 30 | 53 | 13.22 | 29 | 64 | |
| 0 | - | - | - | 17 | 8.46 | 17 | - | |
| 1 | - | - | - | 25 | 7.40 | 18 | - | |
| HIST3 | 2 | - | - | - | 19 | 15.02 | 26 | - |
| 3 | - | - | - | 6 | 18.18 | 35 | - | |
| All | 64 | 11.30 | 36 | 67 | 10.79 | 35 | 89 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, L.; Yang, H.; Li, Z.; Pedrycz, W. Learning to Score: A Coding System for Constructed Response Items via Interactive Clustering. Systems 2024, 12, 380. https://doi.org/10.3390/systems12090380
Luo L, Yang H, Li Z, Pedrycz W. Learning to Score: A Coding System for Constructed Response Items via Interactive Clustering. Systems. 2024; 12(9):380. https://doi.org/10.3390/systems12090380
Chicago/Turabian StyleLuo, Lingjing, Hang Yang, Zhiwu Li, and Witold Pedrycz. 2024. "Learning to Score: A Coding System for Constructed Response Items via Interactive Clustering" Systems 12, no. 9: 380. https://doi.org/10.3390/systems12090380
APA StyleLuo, L., Yang, H., Li, Z., & Pedrycz, W. (2024). Learning to Score: A Coding System for Constructed Response Items via Interactive Clustering. Systems, 12(9), 380. https://doi.org/10.3390/systems12090380