
How Can Scientific Crowdsourcing Realize Value Co-Creation? A Knowledge Flow-Based Perspective


Abstract
1. Introduction
- (1)
- What are the stages of the knowledge flow process in scientific crowdsourcing?
- (2)
- How does the value co-creation process evolve in scientific crowdsourcing?
- (3)
- What is the intrinsic logical relationship between knowledge flow and value co-creation?
2. Literature Review
2.1. Scientific Crowdsourcing
2.2. Knowledge Flow
2.3. Value Co-Creation
2.4. Research Gaps and Contributions
- (1)
- The flow of knowledge is pivotal in facilitating the emergence and dissemination of innovation. While scientific crowdsourcing represents a novel and important pathway for collaborative scientific innovation, existing literature has yet to deeply analyze the evolutionary dynamics of knowledge flow in this context.
- (2)
- Value co-creation highlights the importance of participant interactions in generating value. However, existing studies on process models of value co-creation through resource integration and service exchange, along with their extended theoretical models, have not systematically elucidated the specific processes of interaction and value realization among participants. Particularly in the context of scientific crowdsourcing, the mechanisms by which users, platforms, and other entities engage in value creation remain theoretically ambiguous.
3. Research Design
3.1. Research Method
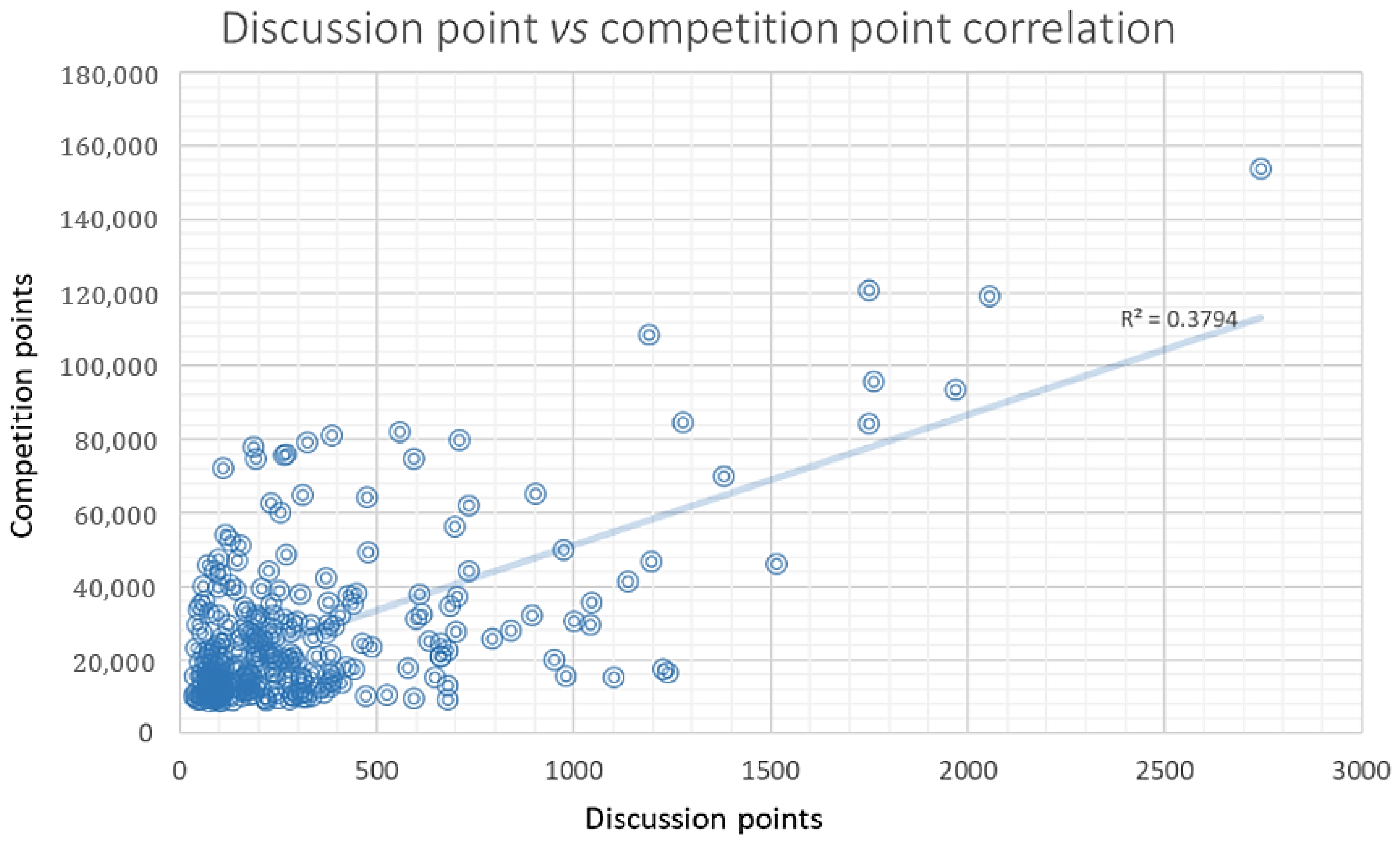
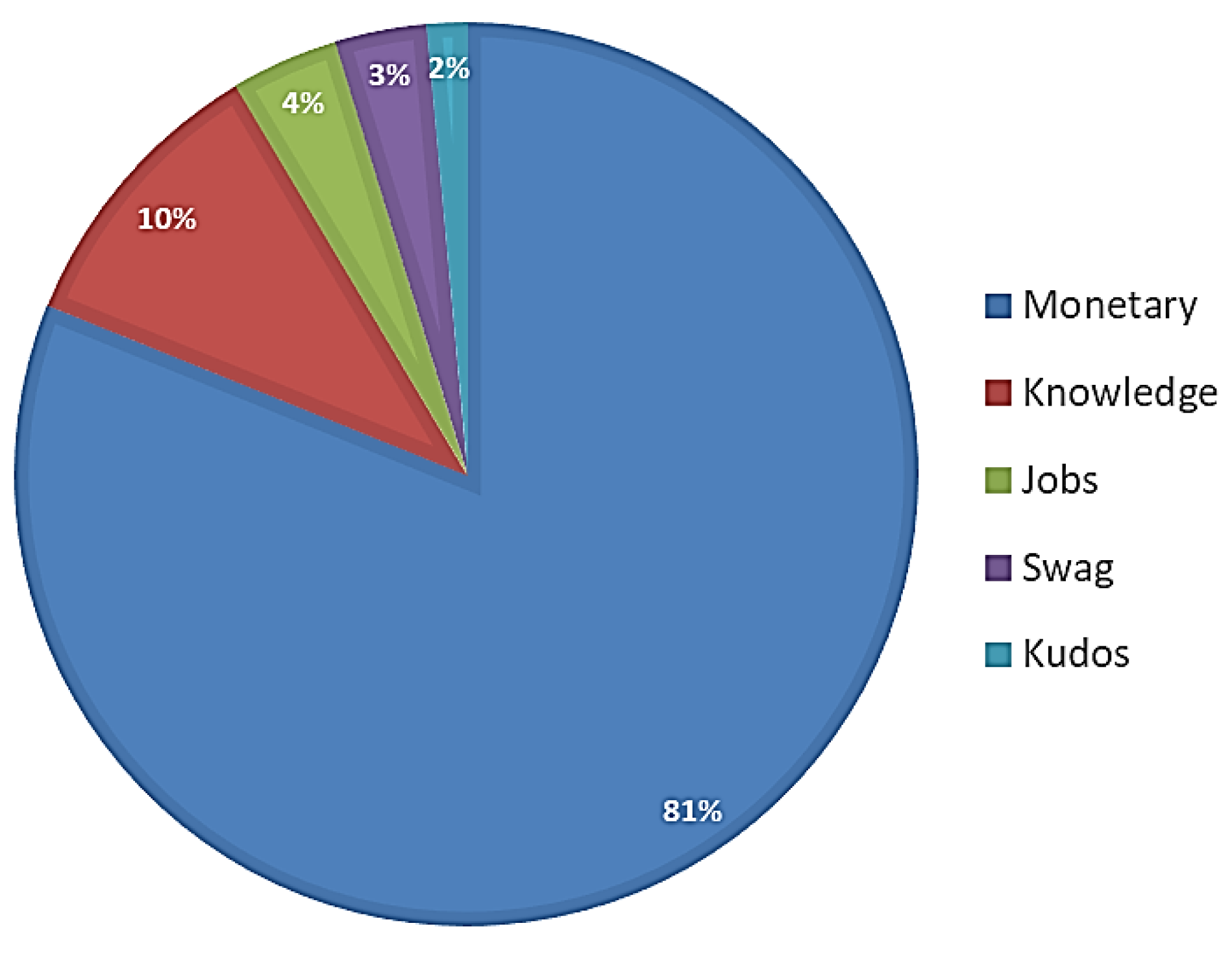
3.2. Case Selection and Data Collection
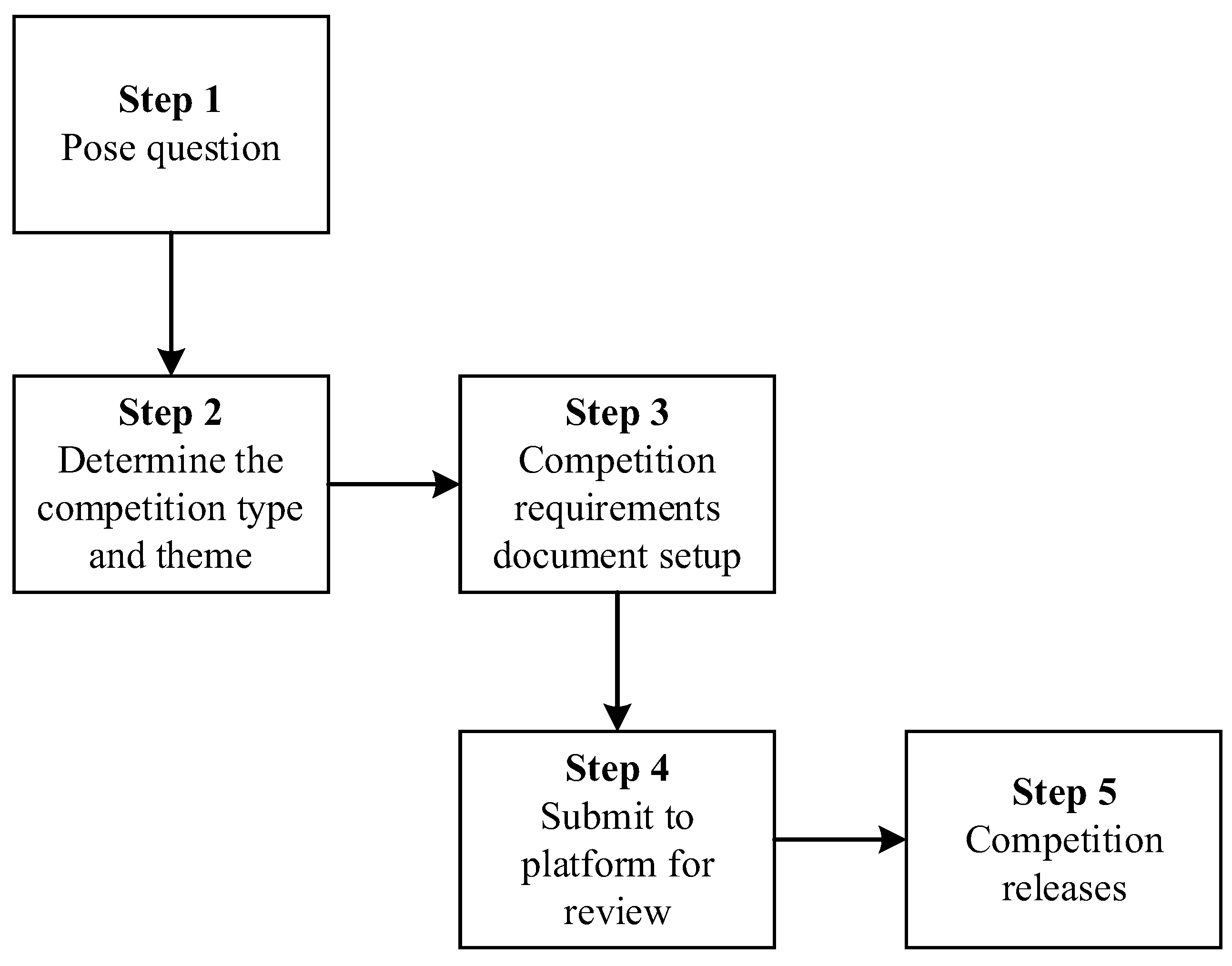
3.3. Case Introduction
- (1)
- Initiators
- (2)
- Solvers
- (3)
- Crowdsourcing Platform
4. Analysis and Discussion
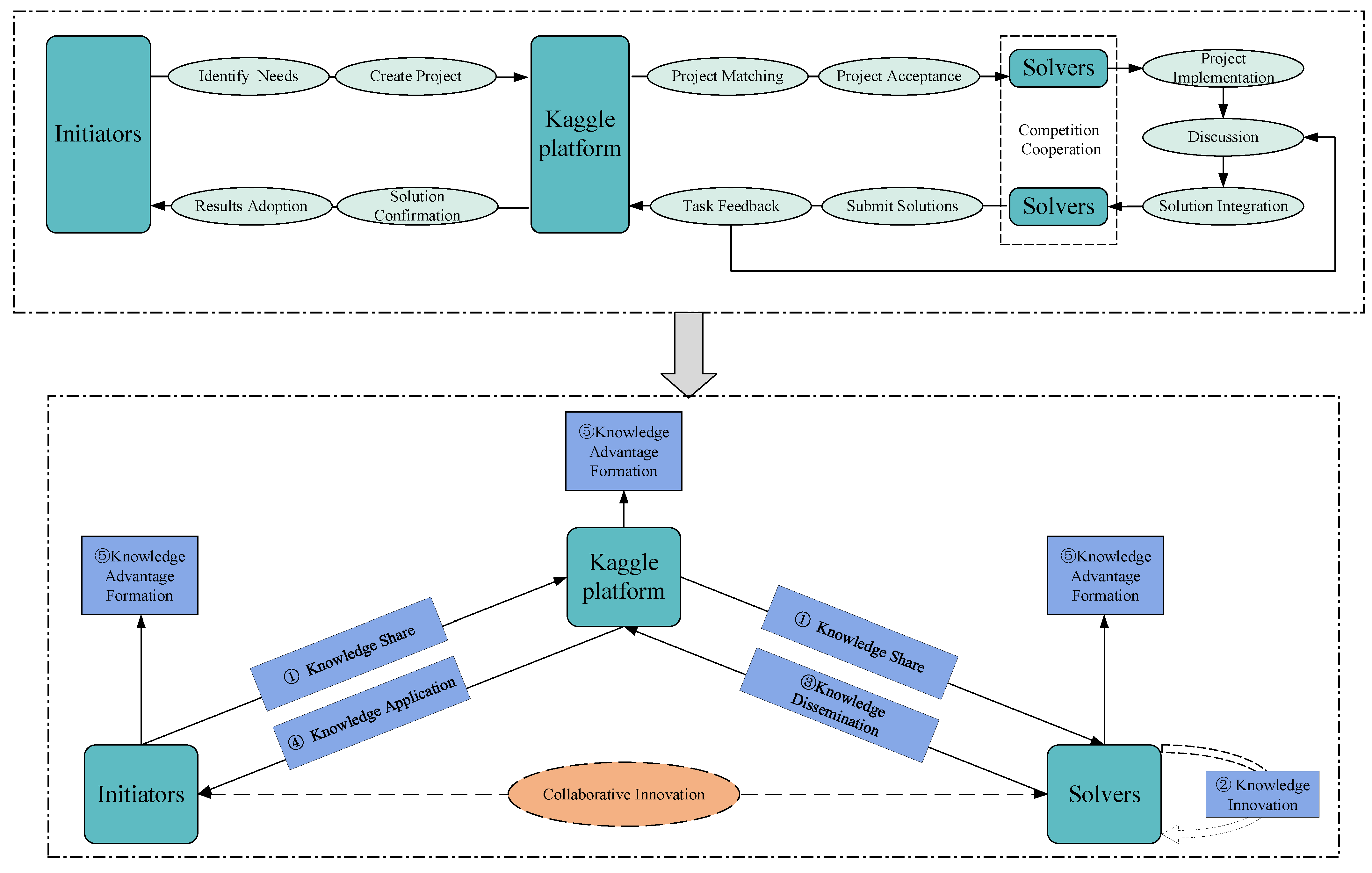
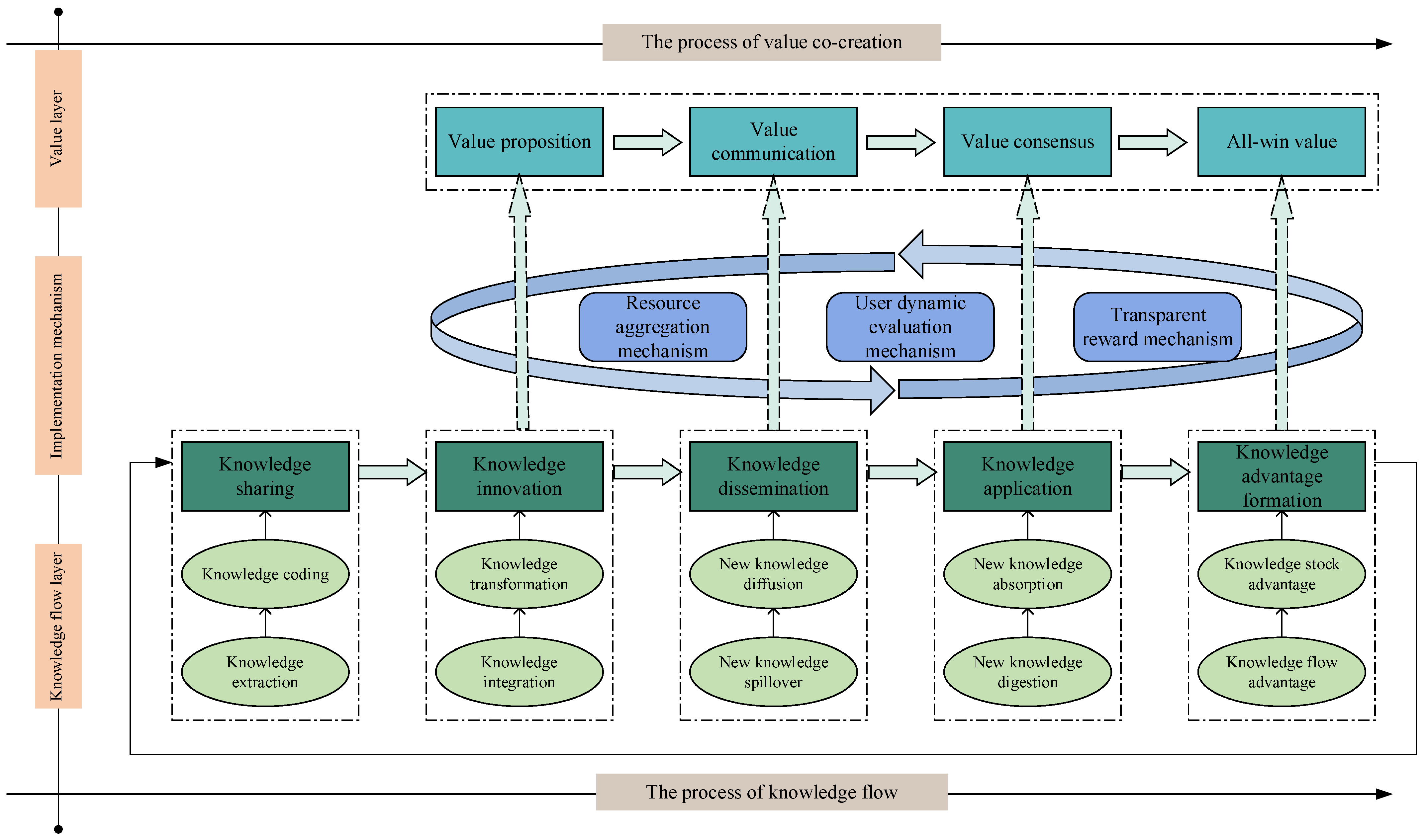
4.1. Analysis of the Operation Process of Scientific Crowdsourcing Based on Knowledge Flow
- (1)
- Knowledge sharing
- (2)
- Knowledge innovation
- (3)
- Knowledge dissemination
- (4)
- Knowledge application
- (5)
- Knowledge advantage formation
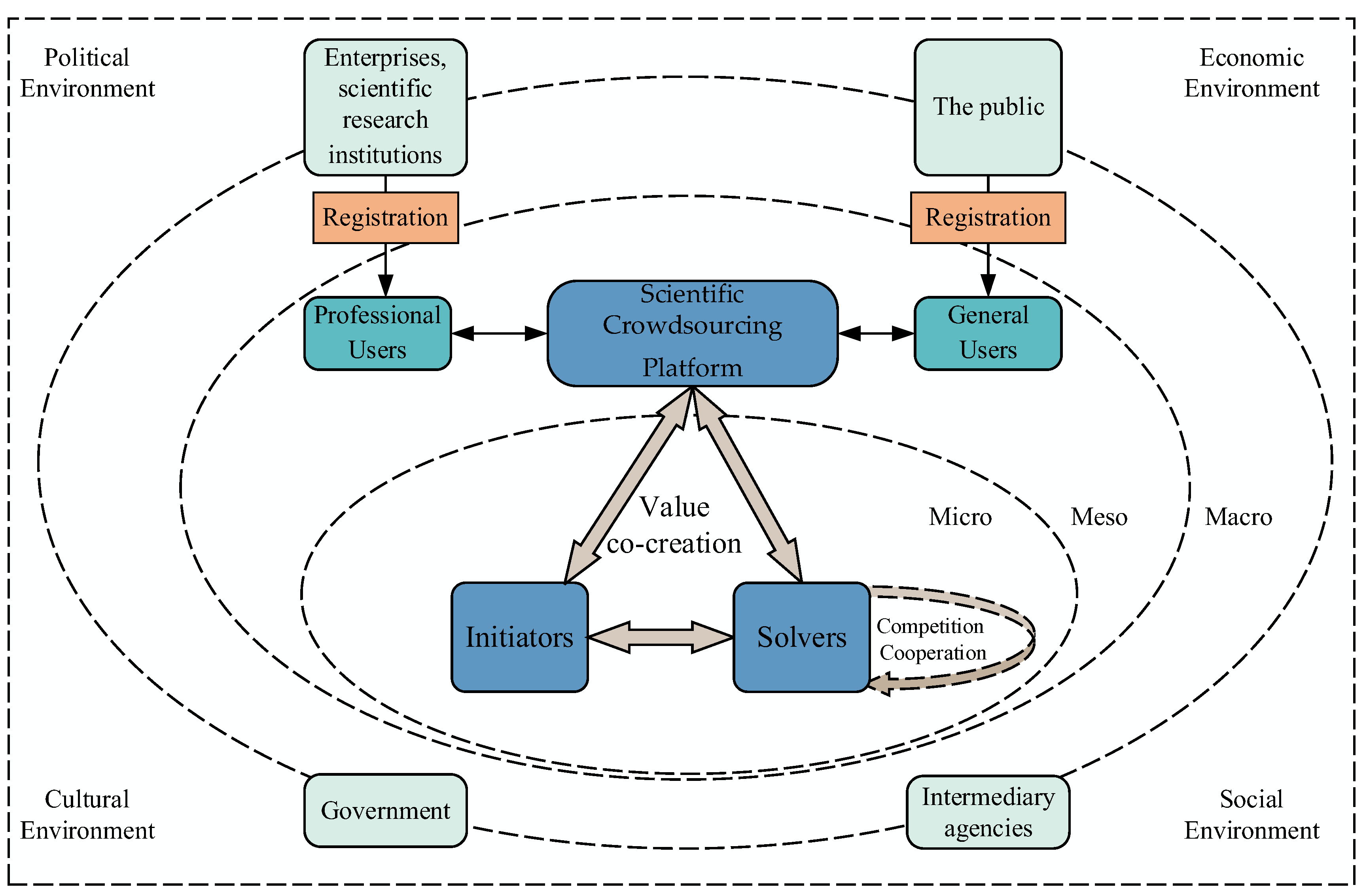
4.2. Value Co-Creation Process of Scientific Crowdsourcing Based on Knowledge Flow
- (1)
- Value proposition
- (2)
- Value communication
- (3)
- Value consensus
- (4)
- All-win value
4.3. Value Co-Creation Realization Mechanism of Scientific Crowdsourcing Based on Knowledge Flow
4.3.1. Resource Aggregation Mechanism
4.3.2. User Dynamic Evaluation Mechanism
4.3.3. Reasonable and Transparent Reward Mechanism
5. Research Summary
5.1. Research Conclusions
- (1)
- Due to the knowledge differentiation and complementarity between the participants in scientific crowdsourcing, knowledge flow permeates the whole process of scientific crowdsourcing. The knowledge flow process of scientific crowdsourcing is divided into five evolutionary and progressive stages: “knowledge sharing–knowledge innovation–knowledge dissemination–knowledge application–knowledge advantage formation”. Knowledge realizes level upgrades through effective flow and accumulation, and finally, promotes scientific research collaboration and innovation.
- (2)
- In the context of scientific crowdsourcing, the participants are coupled, transformed, and complementary to each other, thus forming a service ecology system of scientific crowdsourcing. Among them, the initiators, the solvers, and the crowdsourcing platform are the core elements and key actors of the system. They carry out resource integration and service exchange around the scientific crowdsourcing project and eventually create common value. Value co-creation in scientific crowdsourcing is a dynamic evolution and continuous optimization process, including value proposition, value communication, value consensus, and all-win value, within which value proposition is the premise, value communication is the foundation, value consensus is the core, and value win-win is the goal. The four links complement each other and jointly promote the realization of value co-creation.
- (3)
- Knowledge flow is the deep-level logic of value co-creation in scientific crowdsourcing, and the two have a high degree of fit. Specifically, knowledge sharing and knowledge innovation support value proposition, knowledge dissemination creates conditions for value communication, knowledge application is the internal expression of value consensus, and knowledge advantage is an important driving force for value win-win. Thus, the value co-creation activities of scientific crowdsourcing are gradually activated under the flow of knowledge.
- (4)
- The resource aggregation mechanism, user evaluation mechanism, and transparent incentive mechanism are indispensable in the implementation of scientific crowdsourcing, which can control and guide the running activities of each stage of knowledge flow, to open up the channels of knowledge flow and accelerate the realization of value co-creation.
5.2. Theoretical Contributions and Management Insights
5.2.1. Theoretical Contributions
5.2.2. Management Insights
- (1)
- It is essential to clearly define the nature of the platform and the crowdsourcing projects within it, thereby identifying the necessary steps for project implementation and eliminating redundant processes. Ensuring that each step is seamlessly integrated will minimize the waste of human, material, and financial resources, fostering tighter coupling among participants. This approach reduces the temporal and spatial distance of knowledge flow, thereby facilitating more efficient knowledge exchange and integration.
- (2)
- It is imperative to accelerate the development of a competitive integrated platform service architecture, providing user-friendly and convenient project support tools. These tools should cater to all stages of scientific crowdsourcing projects, from creation, publication, matching, management, and maintenance to completion. This approach will stimulate the proactivity of participants, enhancing their willingness to share knowledge at each stage, especially the transfer of tacit knowledge.
- (3)
- It is necessary to establish sound matching mechanisms, incentive mechanisms, and regulatory mechanisms to foster a fair and trustworthy crowdsourcing competition environment. These mechanisms effectively control and guide knowledge activities, better eliminating barriers to knowledge flow. Promoting cooperative, shared, and mutually beneficial relationships among participants reduces free-riding behavior and prevents the destruction of value.
- (4)
- As the value co-creation in scientific crowdsourcing is a dynamic, evolving process that encompasses numerous value activities and continuous optimization, it is crucial to focus on the status of key nodes in each value activity. Effectively leveraging the impact output of value co-creation, enhancing publicity, and attracting user participation are essential to increase the user base. This approach fosters continuous value co-creation, thereby maintaining the platform’s vitality and sustainability.
5.3. Future Prospects and Limitations
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lenart-gansiniec, R.; Czakon, W.; Sułkowski, Ł. Understanding crowdsourcing in science. Rev. Manag. Sci. 2023, 17, 2797–2830. [Google Scholar] [CrossRef]
- Kit, C.W.; Zolkepli, I.A. Crowdsourcing and service-dominant logic: The interaction effect of brand familiarity, customer experience and loyalty on value co-creation. Asia Pac. J. Adv. Bus. Soc. Stud. 2018, 4, 154–162. [Google Scholar]
- Xue, X.; Zhao, Y.X.; Zhu, Q.H.; Ying, J.; Hao, S.B. Construction of open data service ecosystem for major public health events based on public science model. Libr. Inf. Work. 2022, 66, 33–44. [Google Scholar] [CrossRef]
- Mishra, D.; Maheshwari, N. Crowdsourcing a wellspring of value co-creation: An integration of social capital and organizational learning mechanisms. Kybernetes 2024, 53, 424–450. [Google Scholar] [CrossRef]
- Vargo, S.L.; Lusch, R.F. From Repeat Patronage to Value Co-creation in Service Ecosystems: A Transcending Conceptualization of Relationship. J. Bus. Mark. Manag. 2010, 4, 169–179. [Google Scholar] [CrossRef]
- Vargo, S.L.; Lusch, R.F. Institutions and axioms: An extension and update of service-dominant logic. J. Acad. Mark. Sci. 2016, 44, 5–23. [Google Scholar] [CrossRef]
- Zhao, D.H.; Zhang, C.N.; Sun, X.B. A case study of collaborative incentive mechanism among creative class crowdsourcing participants. Technol. Econ. 2021, 40, 133–145. [Google Scholar]
- Al-kumaim, N.H.; Alhazmi, A.K.; Ramayah, T.; Shabbir, M.S.; Gazem, N.A. Sustaining continuous engagement in value co-creation among individuals in universities using online platforms: Role of knowledge self-efficacy, commitment and perceived benefits. Front. Psychol. 2021, 12, 637808. [Google Scholar] [CrossRef]
- Reypens, C.; Lievens, A.; Blazevic, V. Leveraging value in multi-stakeholder innovation networks: A process framework for value co-creation and capture. Ind. Mark. Manag. 2016, 56, 40–50. [Google Scholar] [CrossRef]
- Liu, Q.; Zhao, X.; Sun, B. Value co-creation mechanisms of enterprises and users under crowdsource-based open innovation. Int. J. Crowd Sci. 2018, 2, 2–17. [Google Scholar] [CrossRef]
- Meng, Q.L.; Hang, Y.; Chen, X.J. Value co-creation mechanisms of multi-agent participation in crowdsourcing innovation: A grounded theory study. J. Intell. Fuzzy Syst. 2021, 41, 4995–5006. [Google Scholar]
- Galateanu, E.; Avasilcai, S. Value co–creation through crowdsourcing: The case of Squadhelp competition platform. In MATEC Web of Conferences. EDP Sci. 2018, 184, 04011. [Google Scholar]
- Beck, S.; Brasseur, T.M.; Poetz, M.; Sauermann, H. Crowdsourcing research questions in science. Res. Policy 2022, 51, 104491. [Google Scholar] [CrossRef]
- Wang, G.H.; Yu, L.Y. Differential game analysis of scientific crowdsourcing on knowledge transfer. Sustainability 2019, 11, 2735. [Google Scholar] [CrossRef]
- Xu, W.; Duan, H.; Chen, X. Blockchain-based multi-skill mobile crowdsourcing services. EURASIP J. Wirel. Commun. Netw. 2022, 2022, 55. [Google Scholar] [CrossRef]
- Wang, H.; Liu, W.; Liu, A.; Wang, T.; Song, H.; Zhang, S. SQCS: A sustainable quality control system for spatial crowdsourcing via three-party evolutionary game: Theory and practice. Expert Syst. Appl. 2024, 238, 122132. [Google Scholar] [CrossRef]
- Uhlmann, E.L.; Ebersole, C.R.; Chartier, C.R. Scientific utopia III: Crowdsourcing science. Perspect. Psychol. Sci. 2019, 14, 711–733. [Google Scholar] [CrossRef] [PubMed]
- Saez-Rodriguez, J.; Costello, J.C.; Friend, S.H. Crowdsourcing biomedical research: Leveraging communities as innovation engines. Nat. Rev. Genet. 2016, 17, 470–486. [Google Scholar] [CrossRef]
- Zahay, D.; Hajli, N.; Sihi, D. Managerial perspectives on crowdsourcing in the new product development process. Ind. Mark. Manag. 2018, 17, 41–53. [Google Scholar] [CrossRef]
- Kou, L.L.; Zhu, Z.M.; Bai, L.L. Research on the collaboration model of scientific crowdsourcing projects—Crowd Research as an example. Libr. Intell. Work 2018, 62, 146–152. [Google Scholar] [CrossRef]
- Lenart-Gansiniec, R. Towards a typology development of crowdsourcing in science. J. Inf. Sci. 2022, 0, 01655515221118045. [Google Scholar] [CrossRef]
- Qin, S.F.; Van der Velde, D.; Chatzakis, E.; McStea, T.; Smith, N. Exploring barriers and opportunities in adopting crowdsourcing based new product development in manufacturing SMEs. Chin. J. Mech. Eng. 2016, 29, 1052–1066. [Google Scholar] [CrossRef]
- Bassi, H.; Lee, C.J.; Misener, L. Exploring the characteristics of crowdsourcing: An online observational study. J. Inf. Sci. 2020, 46, 291–312. [Google Scholar] [CrossRef]
- Gao, L.; Gan, Y.; Zhou, B. A user-knowledge crowdsourcing task assignment model and heuristic algorithm for expert knowledge recommendation systems. Eng. Appl. Artif. Intell. 2020, 96, 103959. [Google Scholar] [CrossRef]
- Tang, J.; Zhou, X.; Zhao, Y. How the type and valence of feedback information influence volunteers’ knowledge contribution in citizen science projects. Inf. Process. Manag. 2021, 58, 102633. [Google Scholar] [CrossRef]
- Djelassi, S.; Cambier, F. Creative crowdsourcing: Understanding participation barriers and levers from a heterogeneous crowd perspective. J. Mark. Manag. 2023, 39, 585–614. [Google Scholar] [CrossRef]
- Che, Z.; Wu, C.; Qu, W. How does multidimensional interaction of knowledge transfer affect digital innovation capability? Knowl. Manag. Res. Pract. 2023, 21, 1–13. [Google Scholar] [CrossRef]
- Fu, L.; Liu, Z.; Zhou, Z. Can open innovation improve firm performance? An investigation of financial information in the biopharmaceutical industry. Technol. Anal. Strateg. Manag. 2019, 31, 776–790. [Google Scholar] [CrossRef]
- Chiu, M.L.; Cheng, T.S.; Lin, C.N. Driving open innovation capability through new knowledge diffusion of integrating intrinsic and extrinsic motivations in organizations: Moderator of individual absorptive capacity. J. Knowl. Econ. 2023, 15, 3685–3717. [Google Scholar] [CrossRef]
- Hai, Z. Knowledge flow network planning and simulation. Decis. Support Syst. 2006, 42, 571–592. [Google Scholar] [CrossRef]
- Szulanski, G. Exploring internal stickiness: Impediments to the transfer of best practice within the firm. Strateg. Manag. J. 1996, 17, 27–43. [Google Scholar] [CrossRef]
- Kong, J.; Zhang, J.; Deng, S. Knowledge convergence of science and technology in patent inventions. J. Informetr. 2023, 17, 101435. [Google Scholar] [CrossRef]
- Aliasghar, O.; Haar, J. Open innovation: Are absorptive and desorptive capabilities complementary? Int. Bus. Rev. 2021, 32, 101865. [Google Scholar] [CrossRef]
- West, J.; Bogers, M. Leveraging external sources of innovation: A review of research on open innovation. J. Prod. Innov. Manag. 2014, 31, 814–831. [Google Scholar] [CrossRef]
- Zhang, S.; Wang, X.; Zhang, B. Innovation ability of universities and the efficiency of university–industry knowledge flow: The moderating effect of provincial innovative agglomeration. Chin. Manag. Stud. 2022, 16, 446–465. [Google Scholar] [CrossRef]
- Nonaka, I. The knowledge-creating company. In The economic Impact of Knowledge; Routledge: London, UK, 2009; pp. 175–187. [Google Scholar]
- Wang, L.; You, Z.J. Simulation study on the value evolution of innovation ecosystem based on knowledge flow. Chin. Sci. Technol. Forum 2019, 6, 48–55. [Google Scholar] [CrossRef]
- Chu, J.W.; Li, J.X. Research on knowledge evolution and wisdom creation in knowledge ecosystem--a case study of Zhihu community. Intell. Theory Pract. 2022, 45, 51–58. [Google Scholar] [CrossRef]
- Ranjan, K.R.; Read, S. Value co-creation: Concept and measurement. J. Acad. Mark. Sci. 2016, 44, 290–315. [Google Scholar] [CrossRef]
- Prahalad, C.K.; Ramaswamy, V. Co-opting customer competence. Harv. Bus. Rev. 2000, 78, 79–90. [Google Scholar]
- Vargo, S.L.; Lusch, R.F. Evolving to a new dominant logic for marketing. J. Mark. 2004, 68, 1–17. [Google Scholar] [CrossRef]
- Prahalad, C.K.; Ramaswamy, V. Co-creation experiences: The next practice in value creation. J. Interact. Mark. 2004, 18, 5–14. [Google Scholar] [CrossRef]
- Pera, R.; Occhiocupo, N.; Clarke, J. Motives and resources for value co-creation in a multi-stakeholder ecosystem: A managerial perspective. J. Bus. Res. 2016, 69, 4033–4041. [Google Scholar] [CrossRef]
- Gummesson, E.; Mele, C. Marketing as value co-creation through network interaction and resource integration. J. Bus. Mark. Manag. 2010, 4, 181–198. [Google Scholar] [CrossRef]
- Ramaswamy, V.; Gouillart, F. Building the co-creative enterprise. Harv. Bus. Rev. 2010, 88, 100–109. [Google Scholar] [PubMed]
- Aarikka, S.L.; Jaakkola, E. Value co-creation in knowledge intensive business services: A dyadic perspective on the joint problem-solving process. Ind. Mark. Manag. 2012, 41, 15–26. [Google Scholar] [CrossRef]
- Zhou, W.H.; Cao, Y.; Zhou, Y.F. Consensus, co-production and win-win: A process model of value co-creation. Sci. Res. Manag. 2015, 36, 129–135. [Google Scholar] [CrossRef]
- Eisenhardt, K.M.; Graebner, M.E. Theory building from cases: Opportunities and challenges. Acad. Manag. J. 2007, 50, 25–32. [Google Scholar] [CrossRef]
- Bojer, C.S.; Meldgaard, J.P. Kaggle forecasting competitions: An overlooked learning opportunity. Int. J. Forecast. 2021, 37, 587–603. [Google Scholar] [CrossRef]
- Chen, Y.Q.; Zhao, Y.X.; Zhu, Q.H. Research on task matching model for public science projects from the perspective of scientific crowdsourcing. Libr. Intell. Knowl. 2018, 3, 4–15. [Google Scholar] [CrossRef]
- Acar, O.A. Motivations and solution appropriateness in crowdsourcing challenges for Innovation. Res. Policy 2019, 48, 103716. [Google Scholar] [CrossRef]
- Dissanayake, I.; Zhang, J.; Yasar, M.; Nerur, S.P. Strategic effort allocation in online innovation tournaments. Inf. Manag. 2018, 55, 396–406. [Google Scholar] [CrossRef]
- Tu, Z.Z.; Gu, X. Research on the collaborative innovation process of industry-university-research based on knowledge flow. Sci. Technol. Res. 2013, 31, 1381–1390. [Google Scholar] [CrossRef]
- Chandler, J.D.; Vargo, S.L. Contextualization and value-in-context: How context frames exchange. Mark. Theory 2011, 11, 35–49. [Google Scholar] [CrossRef]
- Beirão, G.; Patrício, L.; Fisk, R.P. Value cocreation in service ecosystems: Investigating health care at the micro, meso, and macro levels. J. Serv. Manag. 2017, 28, 227–249. [Google Scholar] [CrossRef]
- Ren, R.; Yan, B.; Jian, L. Show me your expertise before teaming up: Sharing online profiles predicts success in open innovation. Internet Res. 2020, 30, 845–868. [Google Scholar] [CrossRef]
- Wang, X.; Khasraghi, H.J.; Schneider, H. Towards an understanding of participants’ sustained participation in crowdsourcing contests. Inf. Syst. Manag. 2020, 37, 213–226. [Google Scholar] [CrossRef]
- Javadi, K.H.; Hirschheim, R. Collaboration in crowdsourcing contests: How different levels of collaboration affect team performance. Behav. Inf. Technol. 2022, 41, 1566–1582. [Google Scholar] [CrossRef]
- Javadi, K.H.; Vaghefi, I.; Hirschheim, R. Contribution to team and community in crowdsourcing contests: A qualitative investigation. Inf. Technol. People 2024, 37, 223–250. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Initiators | Number of Competitions | Total Number of Solvers |
|---|---|---|
| Kaggle | 63 | 53,480 |
| Google Research | 10 | 4855 |
| Google Cloud | 9 | 4943 |
| 9 | 15,663 | |
| Fine-Grained Visual Categorization | 9 | 3060 |
| Booz Allen Hamilton | 6 | 10,522 |
| 5 | 3087 | |
| Avito | 4 | 3114 |
| Banco Santander | 4 | 20,173 |
| Google Brain | 4 | 1577 |
| Jigsaw/Conversation AI | 3 | 9336 |
| The National Football League | 3 | 2038 |
| Two Sigma | 3 | 7473 |
| Allstate Insurance | 3 | 4712 |
| Walmart | 3 | 2215 |
| TalkingData | 2 | 5626 |
| Radiological Society of North America | 2 | 2844 |
| Quora | 2 | 7341 |
| Microsoft | 2 | 2803 |
| University of Nicosia | 2 | 6467 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiu, R.; Wang, G.; Yu, L.; Xing, Y.; Yang, H. How Can Scientific Crowdsourcing Realize Value Co-Creation? A Knowledge Flow-Based Perspective. Systems 2024, 12, 295. https://doi.org/10.3390/systems12080295
Qiu R, Wang G, Yu L, Xing Y, Yang H. How Can Scientific Crowdsourcing Realize Value Co-Creation? A Knowledge Flow-Based Perspective. Systems. 2024; 12(8):295. https://doi.org/10.3390/systems12080295
Chicago/Turabian StyleQiu, Ran, Guohao Wang, Liying Yu, Yuanzhi Xing, and Hui Yang. 2024. "How Can Scientific Crowdsourcing Realize Value Co-Creation? A Knowledge Flow-Based Perspective" Systems 12, no. 8: 295. https://doi.org/10.3390/systems12080295
APA StyleQiu, R., Wang, G., Yu, L., Xing, Y., & Yang, H. (2024). How Can Scientific Crowdsourcing Realize Value Co-Creation? A Knowledge Flow-Based Perspective. Systems, 12(8), 295. https://doi.org/10.3390/systems12080295