Data-Driven Business Innovation Processes: Evidence from Authorized Data Flows in China


Abstract
1. Introduction
2. Literature Review and Theoretical Framework
2.1. Literature Review
2.1.1. The Economic Value of Data
2.1.2. Data Application in the Public and Private Sectors
2.2. Theoretical Framework
3. Empirical Design
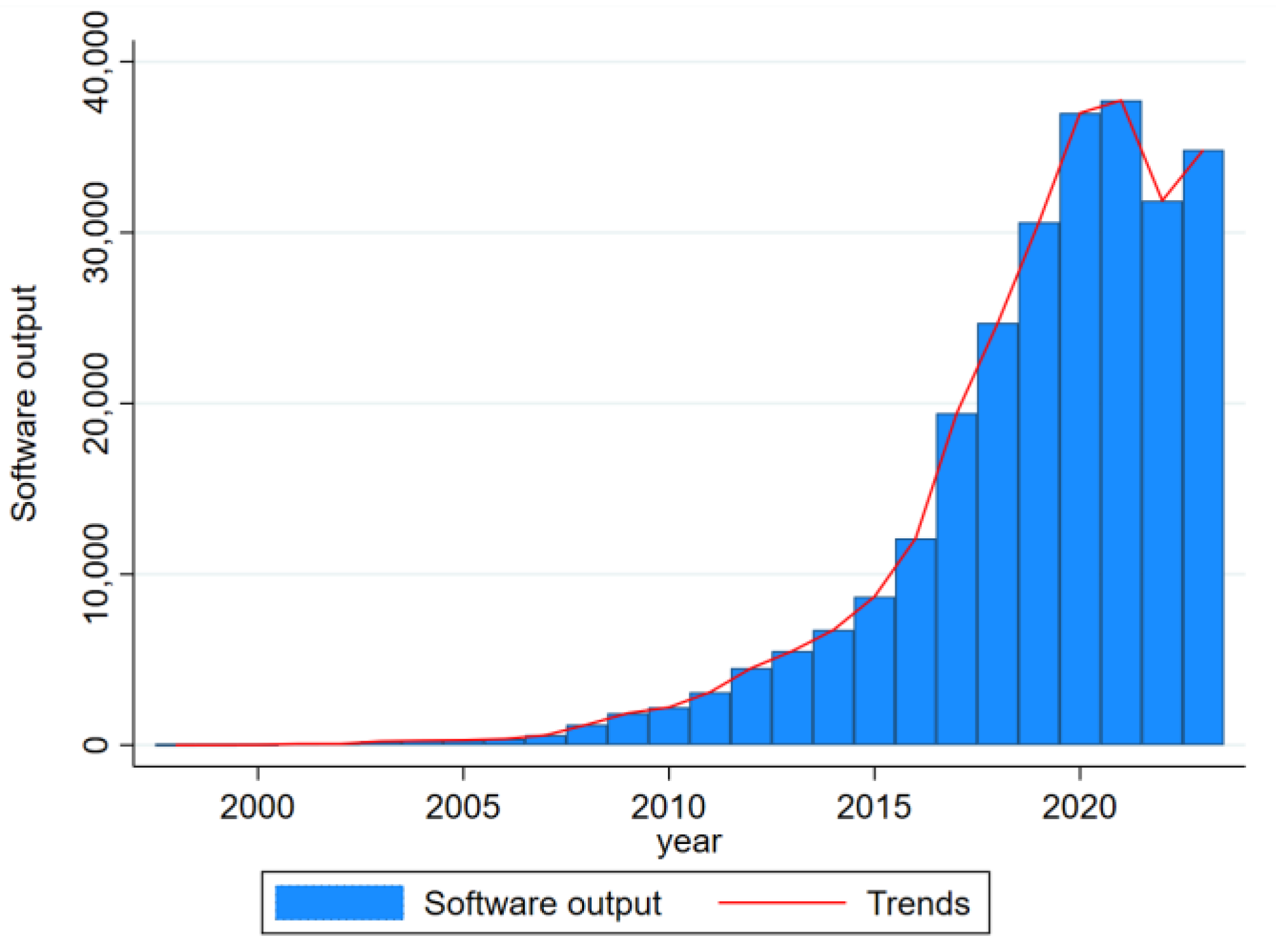
3.1. Data Sources
3.2. Empirical Strategy
4. Product Innovation Effects of Government Data Authorization
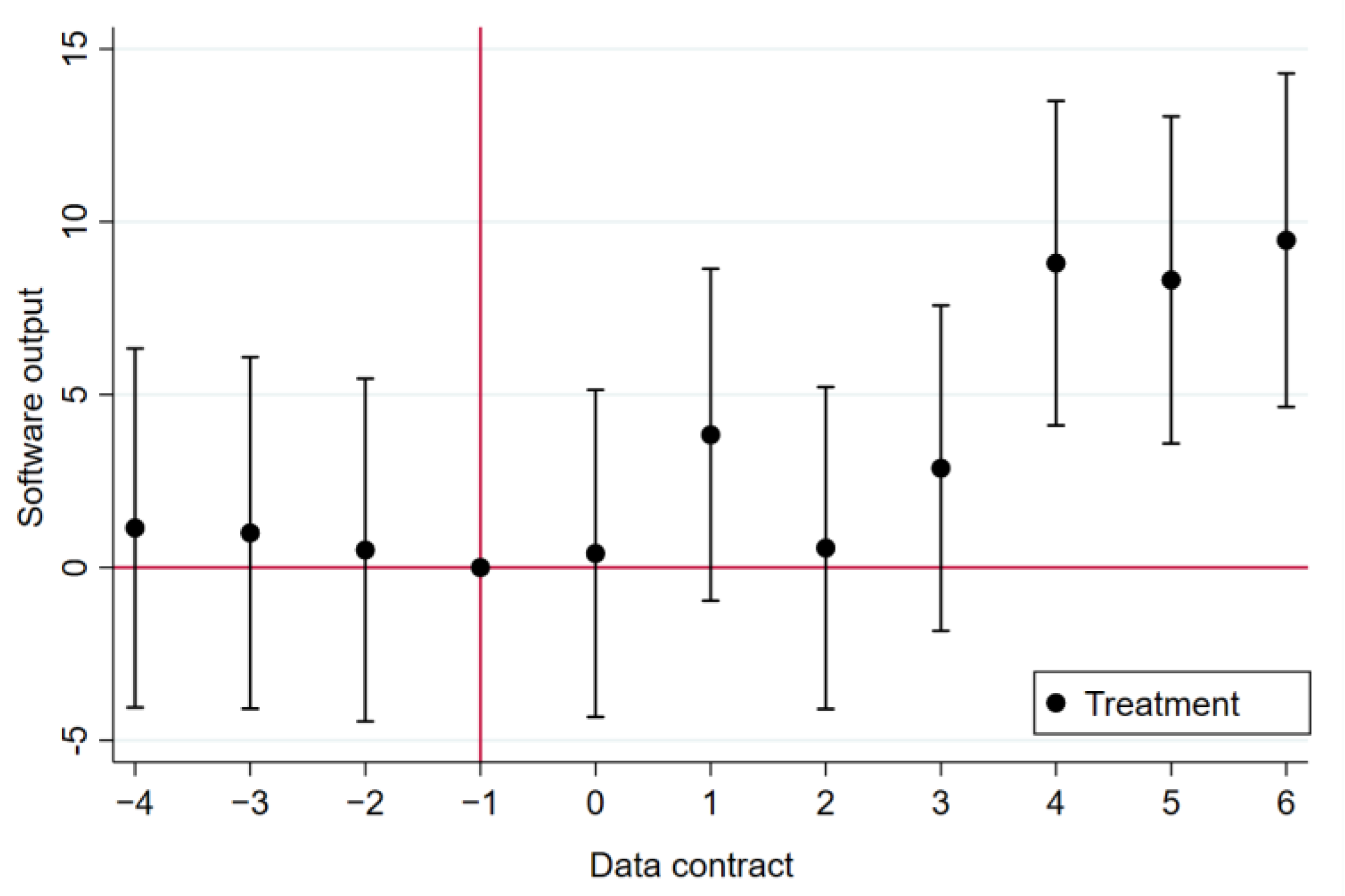
4.1. Baseline Regression
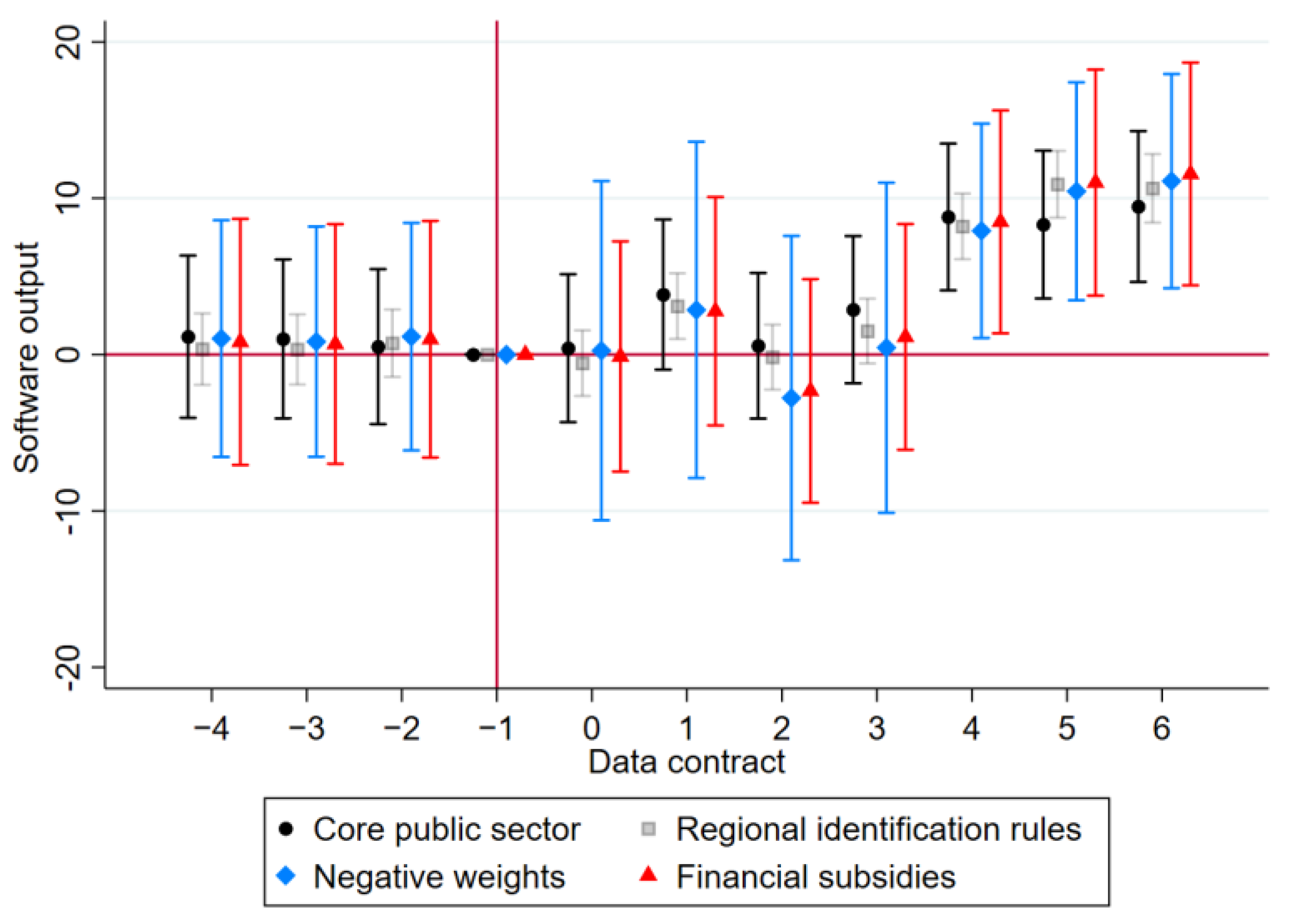
4.2. Robustness Checks
4.2.1. Changing Data Contract Identification Rules
4.2.2. Consideration of Negative Weights
4.2.3. Excluding the Effect of Financial Subsidies
5. Heterogeneity Analysis
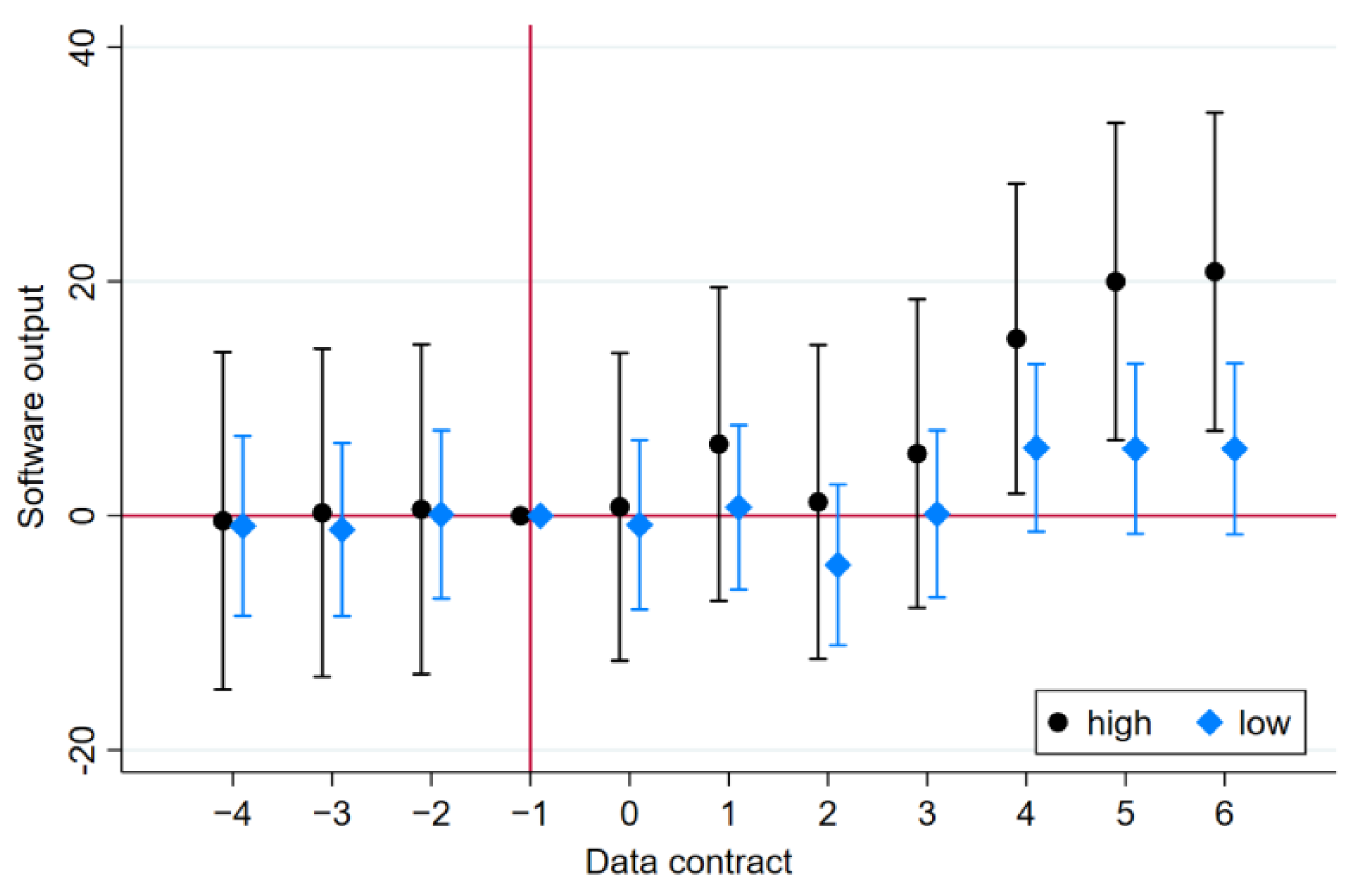
5.1. Regional Data Quality
5.2. Scarcity of Data
6. Dynamics of Knowledge Accumulation
6.1. Learning from Data
6.2. Quality Upgrading Effect
6.3. Data Diffusion Effects
7. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, M.; Sinha, A.; Hu, K.; Shah, M.I. Impact of Technological Innovation on Energy Efficiency in Industry 4.0 Era: Moderation of Shadow Economy in Sustainable Development. Technol. Forecast. Soc. Chang. 2021, 164, 120521. [Google Scholar] [CrossRef]
- Veile, J.W.; Schmidt, M.C.; Voigt, K.I. Toward a New Era of Cooperation: How Industrial Digital Platforms Transform Business Models in Industry 4.0. J. Bus. Res. 2022, 143, 387–405. [Google Scholar] [CrossRef]
- Wang, S.; Wan, J.; Zhang, D.; Li, D.; Zhang, C. Towards Smart Factory for Industry 4.0: A Self-Organized Multi-Agent System with Big Data Based Feedback and Coordination. Comput. Netw. 2016, 101, 158–168. [Google Scholar] [CrossRef]
- Baden-Fuller, C.; Haefliger, S. Business Models and Technological Innovation. Long Range Plann. 2013, 46, 419–426. [Google Scholar] [CrossRef]
- Schaefer, D.; Walker, J.; Flynn, J. A Data-Driven Business Model Framework for Value Capture in Industry 4.0. In Advances in Manufacturing Technology; IOS Press: Amsterdam, The Netherlands, 2017; Volume XXXI, pp. 245–250. [Google Scholar]
- Foss, N.J.; Saebi, T. Fifteen Years of Research on Business Model Innovation: How Far Have We Come, and Where Should We Go? J. Manag. 2017, 43, 200–227. [Google Scholar] [CrossRef]
- Shet, S.V.; Pereira, V. Proposed Managerial Competencies for Industry 4.0—Implications for Social Sustainability. Technol. Forecast. Soc. Chang. 2021, 173, 121080. [Google Scholar] [CrossRef]
- Agostini, L.; Nosella, A. Industry 4.0 and Business Models: A Bibliometric Literature Review. Bus. Process Manag. J. 2021, 27, 1633–1655. [Google Scholar] [CrossRef]
- Farboodi, M.; Veldkamp, L. Long-run growth of financial data technology. Am. Econ. Rev. 2020, 110, 2485–2523. [Google Scholar] [CrossRef]
- Kraus, S.; Durst, S.; Ferreira, J.J.; Veiga, P.; Kailer, N.; Weinmann, A. Digital Transformation in Business and Management Research: An Overview of the Current Status Quo. Int. J. Inf. Manag. 2022, 63, 102466. [Google Scholar] [CrossRef]
- Arrieta-Ibarra, I.; Goff, L.; Jiménez-Hernández, D.; Lanier, J.; Weyl, E.G. Should we treat data as labor? Moving beyond “free”. In aea Papers and Proceedings. In AEA Papers and Proceedings; American Economic Association: Nashville, TN, USA, 2018; Volume 108, pp. 38–42. [Google Scholar]
- Cong, L.; Li, B.W.; Zhang, Q.T. Alternative data in fintech and business intelligence. In The Palgrave Handbook of FinTech and Blockchain; Palgrave Macmillan: Cham, Switzerland, 2021; pp. 217–242. [Google Scholar]
- Acquisti, A.; Taylor, C.; Wagman, L. The economics of privacy. J. Econ. Lit. 2016, 54, 442–492. [Google Scholar] [CrossRef]
- Veldkamp, L.; Chung, C. Data and the aggregate economy. J. Econ. Lit. 2024, 62, 458–484. [Google Scholar] [CrossRef]
- Schaefer, M.; Sapi, G. Learning from data and network effects: The example of internet search. SSRN Electron. J. 2020. DIW Berlin Discussion Paper No. 1894. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3688819 (accessed on 3 May 2022).
- Jones, C.I.; Tonetti, C. Nonrivalry and the Economics of Data. Am. Econ. Rev. 2020, 110, 2819–2858. [Google Scholar] [CrossRef]
- Agrawal, A.; McHale, J.; Oettl, A. Finding needles in haystacks: Artificial intelligence and recombinant growth. In The Economics of Artificial Intelligence: An Agenda; University of Chicago Press: Chicago, IL, USA, 2018; pp. 149–174. [Google Scholar]
- Acciarini, C.; Cappa, F.; Boccardelli, P.; Oriani, R. How can organizations leverage big data to innovate their business models? A systematic literature review. Technovation 2023, 123, 102713. [Google Scholar] [CrossRef]
- Farboodi, M.; Veldkamp, L. A Model of the Data Economy (No. w28427); National Bureau of Economic Research: Cambridge, MA, USA, 2021. [Google Scholar]
- Garicano, L.; Rossi-Hansberg, E. Organizing Growth. J. Econ. Theory 2012, 147, 623–656. [Google Scholar] [CrossRef]
- Kitchens, B.; Dobolyi, D.; Li, J.; Abbasi, A. Advanced Customer Analytics: Strategic Value through Integration of Relationship-Oriented Big Data. J. Manag. Inf. Syst. 2018, 35, 540–574. [Google Scholar] [CrossRef]
- Veldkamp, L.L. Slow boom, sudden crash. J. Econ. Theory 2005, 124, 230–257. [Google Scholar] [CrossRef]
- Ianni, M.; Masciari, E.; Sperlí, G. A Survey of Big Data Dimensions vs Social Networks Analysis. J. Intell. Inf. Syst. 2021, 57, 73–100. [Google Scholar] [CrossRef]
- Etzion, D.; Aragon-Correa, J.A. Big Data, Management, and Sustainability: Strategic Opportunities Ahead. Organ. Environ. 2016, 29, 147–155. [Google Scholar] [CrossRef]
- Lamba, K.; Singh, S.P. Dynamic Supplier Selection and Lot-Sizing Problem Considering Carbon Emissions in a Big Data Environment. Technol. Forecast. Soc. Chang. 2019, 144, 573–584. [Google Scholar] [CrossRef]
- Begenau, J.; Farboodi, M.; Veldkamp, L. Big Data in Finance and the Growth of Large Firms. J. Monet. Econ. 2018, 97, 71–87. [Google Scholar] [CrossRef]
- Sorescu, A. Data-Driven Business Model Innovation: Business Model Innovation. J. Prod. Innov. Manag. 2017, 34, 691–696. [Google Scholar] [CrossRef]
- Xie, D.; Zhang, L. A Generalized Model of Growth in the Data Economy. SSRN 2022. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4033576 (accessed on 13 February 2022).
- Hou, Y.; Huang, J.; Xie, D.; Zhou, W. The Limits to Growth in the Data Economy: Storage Constraint and “Data Productivity Paradox”. SSRN 2022. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4099544 (accessed on 3 May 2022).
- Jovanovic, B.; Nyarko, Y. Learning by Doing and the Choice of Technology; National Bureau of Economic Research: Cambridge, MA, USA, 1994. [Google Scholar]
- Atkeson, A.; Kehoe, P.J. Modeling and measuring organization capital. J. Polit. Econ. 2005, 113, 1026–1053. [Google Scholar] [CrossRef]
- Oberfield, E.; Venkateswaran, V. Expertise and firm dynamics. In 2018 Meeting Papers; No. 1132; Society for Economic Dynamics: New York, NY, USA, 2018. [Google Scholar]
- Cong, L.W.; Xie, D.; Zhang, L. Knowledge accumulation, privacy, and growth in a data economy. Manag. Sci. 2021, 67, 6480–6492. [Google Scholar] [CrossRef]
- Schaefer, M.; Sapi, G. Complementarities in learning from data: Insights from general search. Inf. Econ. Policy 2023, 65, 101063. [Google Scholar] [CrossRef]
- Agrawal, A.; Gans, J.; Goldfarb, A. Prediction, judgment, and complexity: A theory of decision-making and artificial intelligence. In The Economics of Artificial Intelligence: An Agenda; University of Chicago Press: Chicago, IL, USA, 2018; pp. 89–110. [Google Scholar]
- Bajari, P.; Chernozhukov, V.; Hortaçsu, A.; Suzuki, J. The impact of big data on firm performance: An empirical investigation. In AEA Papers and Proceedings; American Economic Association: Nashville, TN, USA, 2019; Volume 109, pp. 33–37. [Google Scholar]
- Ghasemaghaei, M.; Turel, O. Possible Negative Effects of Big Data on Decision Quality in Firms: The Role of Knowledge Hiding Behaviours. Inf. Syst. J. 2020, 31, 268–293. [Google Scholar] [CrossRef]
- Arthur, K.N.A.; Owen, R. A Micro-Ethnographic Study of Big Data-Based Innovation in the Financial Services Sector: Governance, Ethics and Organizational Practices. J. Bus. Ethics 2019, 160, 363–375. [Google Scholar] [CrossRef]
- Nguyen Dang Tuan, M.; Nguyen Thanh, N.; Le Tuan, L. Applying a Mindfulness-Based Reliability Strategy to the Internet of Things in Healthcare—A Business Model in the Vietnamese Market. Technol. Forecast. Soc. Chang. 2019, 140, 54–68. [Google Scholar] [CrossRef]
- Mariani, M.M.; Fosso Wamba, S. Exploring How Consumer Goods Companies Innovate in the Digital Age: The Role of Big Data Analytics Companies. J. Bus. Res. 2020, 121, 338–352. [Google Scholar] [CrossRef]
- Dubey, R.; Gunasekaran, A.; Childe, S.J.; Bryde, D.J.; Giannakis, M.; Foropon, C.; Roubaud, D.; Hazen, B.T. Big Data Analytics and Artificial Intelligence Pathway to Operational Performance under the Effects of Entrepreneurial Orientation and Environmental Dynamism: A Study of Manufacturing Organisations. Int. J. Prod. Econ. 2020, 226, 107599. [Google Scholar] [CrossRef]
- Mikalef, P.; Boura, M.; Lekakos, G.; Krogstie, J. The Role of Information Governance in Big Data Analytics Driven Innovation. Inf. Manag. 2020, 57, 103361. [Google Scholar] [CrossRef]
- Janssen, M.; Charalabidis, Y.; Zuiderwijk, A. Benefits, adoption barriers and myths of open data and open government. Inf. Syst. Manag. 2012, 29, 258–268. [Google Scholar] [CrossRef]
- Moon, M.J. Shifting from old open government to new open government: Four critical dimensions and case illustrations. Public Perform. Manag. Rev. 2020, 43, 535–559. [Google Scholar] [CrossRef]
- Zuiderwijk, A.; Janssen, M.; Choenni, S.; Meijer, R.; Alibaks, R.S. Socio-technical impediments of open data. Electr. J. e-Gov. 2012, 10, 156–172. [Google Scholar]
- Zhao, Y.; Fan, B. Effect of an agency’s resources on the implementation of open government data. Inf. Manag. 2021, 58, 103465. [Google Scholar] [CrossRef]
- Hopp, W.J.; Li, J.; Wang, G. Big Data and the Precision Medicine Revolution. Prod. Oper. Manag. 2018, 27, 1647–1664. [Google Scholar] [CrossRef]
- Chen, P.-T. Medical Big Data Applications: Intertwined Effects and Effective Resource Allocation Strategies Identified through IRA-NRM Analysis. Technol. Forecast. Soc. Chang. 2018, 130, 150–164. [Google Scholar] [CrossRef]
- Heimstädt, M.; Saunderson, F.; Heath, T. From toddler to teen: Growth of an open data ecosystem. JeDEM-eJournal eDemocracy Open Gov. 2014, 6, 123–135. [Google Scholar] [CrossRef]
- Jetzek, T.; Avital, M.; Bjørn-Andersen, N. The sustainable value of open government data. J. Assoc. Inf. Syst. 2019, 20, 702–734. [Google Scholar] [CrossRef]
- Wang, H.J.; Lo, J. Adoption of open government data among government agencies. Gov. Inf. Q. 2016, 33, 80–88. [Google Scholar] [CrossRef]
- Fang, J.; Zhao, L.; Li, S. Exploring open government data ecosystems across data, information, and business. Gov. Inf. Q. 2024, 41, 101934. [Google Scholar] [CrossRef]
- Yang, T.M.; Lo, J.; Shiang, J. To open or not to open? Determinants of open government data. J. Inf. Sci. 2015, 41, 596–612. [Google Scholar] [CrossRef]
- Liu, Z.G.; Li, X.Y.; Zhu, X.H. Scenario Modeling for Government Big Data Governance Decision-Making: Chinese Experience with Public Safety Services. Inf. Manag. 2022, 59, 103622. [Google Scholar] [CrossRef]
- Safarov, I.; Meijer, A.; Grimmelikhuijsen, S. Utilization of open government data: A systematic literature review of types, conditions, effects and users. Inf. Polity 2017, 22, 1–24. [Google Scholar] [CrossRef]
- Jetzek, T.; Avital, M.; Bjorn-Andersen, N. Data-driven innovation through open government data. J. Theor. Appl. Electron. Commer. Res. 2014, 9, 100–120. [Google Scholar] [CrossRef]
- Magalhaes, G.; Roseira, C. Open Government Data and the Private Sector: An Empirical View on Business Models and Value Creation. Gov. Inf. Q. 2020, 37, 101248. [Google Scholar] [CrossRef]
- Trabucchi, D.; Buganza, T.; Pellizzoni, E. Give Away Your Digital Services: Leveraging Big Data to Capture Value New models that capture the value embedded in the data generated by digital services may make it viable for companies to offer those services for free. Res. Technol. Manag. 2017, 60, 43–52. [Google Scholar] [CrossRef]
- Minatogawa, V.L.F.; Franco, M.M.V.; Rampasso, I.S.; Anholon, R.; Quadros, R.; Durán, O.; Batocchio, A. Operationalizing Business Model Innovation through Big Data Analytics for Sustainable Organizations. Sustainability 2019, 12, 277. [Google Scholar] [CrossRef]
- Akter, S.; Wamba, S.F.; Gunasekaran, A.; Dubey, R.; Childe, S.J. How to improve firm performance using big data analytics capability and business strategy alignment? Int. J. Prod. Econ. 2016, 182, 113–131. [Google Scholar] [CrossRef]
- Erevelles, S.; Fukawa, N.; Swayne, L. Big Data consumer analytics and the transformation of marketing. J. Bus. Res. 2016, 69, 897–904. [Google Scholar] [CrossRef]
- Wu, L.; Hitt, L.; Lou, B. Data analytics, innovation, and firm productivity. Manag. Sci. 2020, 66, 2017–2039. [Google Scholar] [CrossRef]
- Story, V.; O’Malley, L.; Hart, S. Roles, role performance, and radical innovation competencies. Ind. Mark. Manag. 2011, 40, 952–966. [Google Scholar] [CrossRef]
- Callaway, B.; Sant’Anna, P.H. Difference-in-differences with multiple time periods. J. Econom. 2021, 225, 200–230. [Google Scholar] [CrossRef]
- Beraja, M.; Yang, D.Y.; Yuchtman, N. Data-intensive innovation and the state: Evidence from AI firms in China. Rev. Econ. Stud. 2023, 90, 1701–1723. [Google Scholar] [CrossRef]
- Sun, L.; Abraham, S. Estimating dynamic treatment effects in event studies with heterogeneous treatment effects. J. Econom. 2021, 225, 175–199. [Google Scholar] [CrossRef]
- Frank, A.G.; Dalenogare, L.S.; Ayala, N.F. Industry 4.0 technologies: Implementation patterns in manufacturing companies. Int. J. Prod. Econ. 2019, 210, 15–26. [Google Scholar] [CrossRef]
- Jha, A.K.; Agi, M.A.N.; Ngai, E.W.T. A note on big data analytics capability development in supply chain. Decis. Support Syst. 2020, 138, 113382. [Google Scholar] [CrossRef]
- Jetzek, T.; Avital, M.; Bjørn-Andersen, N. The Value of Open Government Data: A Strategic Analysis Framework. In Proceedings of the 2012 Pre-ICIS Workshop: Open Data and Open Innovation in eGovernment, Orlando, FL, USA, 15 December 2012. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Substantial Data | Little Data | |
|---|---|---|
| Variables | (1) | (2) |
| Total product innovation | 15.4 | 10.6 |
| (37.2) | (44.8) | |
| Minor version | 5.0 | 2.9 |
| (16.2) | (21.0) | |
| 371.5 | 148.7 | |
| (1676.5) | (931.0) | |
| 56.7 | 9.5 | |
| (869.8) | (58.0) | |
| Duration of the company | 38.4 | 31.4 |
| (13.1) | (13.0) | |
| Operation capital | 55.6 | 8.5 |
| (893.5) | (57.2) | |
| N | 14,884 | 8316 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, X.; Feng, H. Data-Driven Business Innovation Processes: Evidence from Authorized Data Flows in China. Systems 2024, 12, 280. https://doi.org/10.3390/systems12080280
Gao X, Feng H. Data-Driven Business Innovation Processes: Evidence from Authorized Data Flows in China. Systems. 2024; 12(8):280. https://doi.org/10.3390/systems12080280
Chicago/Turabian StyleGao, Xueyuan, and Hua Feng. 2024. "Data-Driven Business Innovation Processes: Evidence from Authorized Data Flows in China" Systems 12, no. 8: 280. https://doi.org/10.3390/systems12080280
APA StyleGao, X., & Feng, H. (2024). Data-Driven Business Innovation Processes: Evidence from Authorized Data Flows in China. Systems, 12(8), 280. https://doi.org/10.3390/systems12080280