
Data-Driven Strategies for Complex System Forecasts: The Role of Textual Big Data and State-Space Transformers in Decision Support

Abstract
1. Introduction
- Introducing a new state space-based Transformer model, as discussed in Section 3.3: by integrating the state space model with the Transformer, a novel prediction model has been designed, capable of effectively processing text big data and accurately describing the dynamic changes in complex systems.
- Developing a set of text preprocessing and feature extraction methods for complex systems: considering the special requirements for predicting complex systems, a new set of text preprocessing and feature extraction processes has been developed, ensuring the model can extract the most useful information from text data for prediction, as discussed in Section 3.1 and Section 3.2.
- Conducting empirical studies on multiple complex systems: empirical studies have been conducted in various fields, including legal case judgment, legal case translation, and financial data analysis, verifying the effectiveness and versatility of our model.
- Performing extensive model comparisons and analyses, as shown in Section 4: by comparing our model with existing Transformer models, BERT, and other baseline models, the performance of our model has been comprehensively evaluated, and its advantages and potential application values have been thoroughly analyzed.
2. Related Work
2.1. RNN and LSTM
2.2. Transformer
2.3. State Space Models and Mamba
3. Materials and Methods
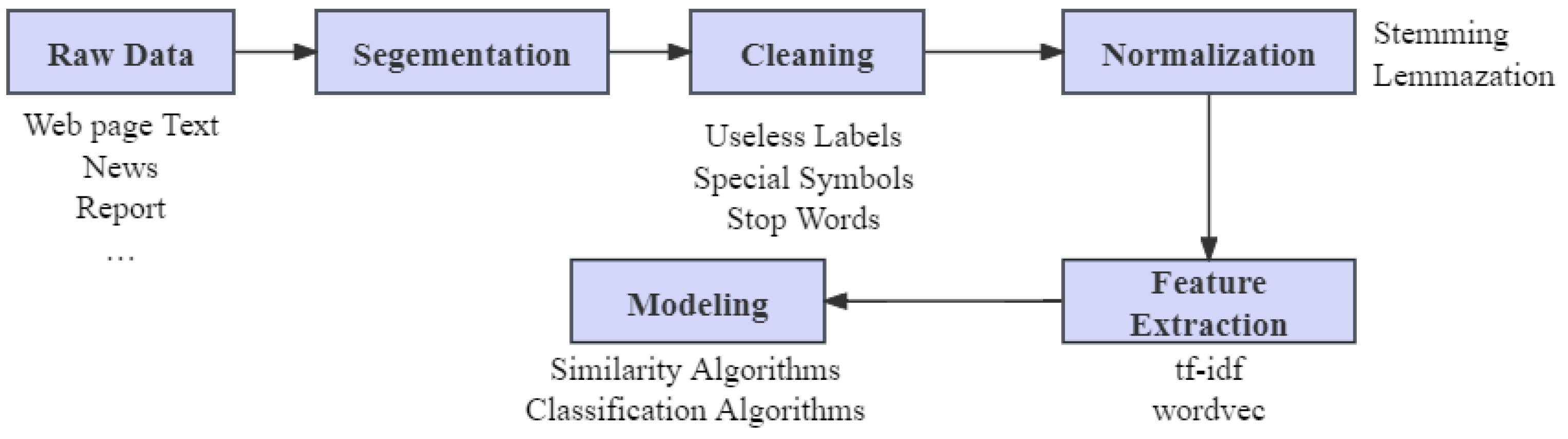
3.1. Dataset Collection
3.2. Dataset Preprocessing
3.2.1. Standard Preprocessing Methods
3.2.2. Building Knowledge Graphs
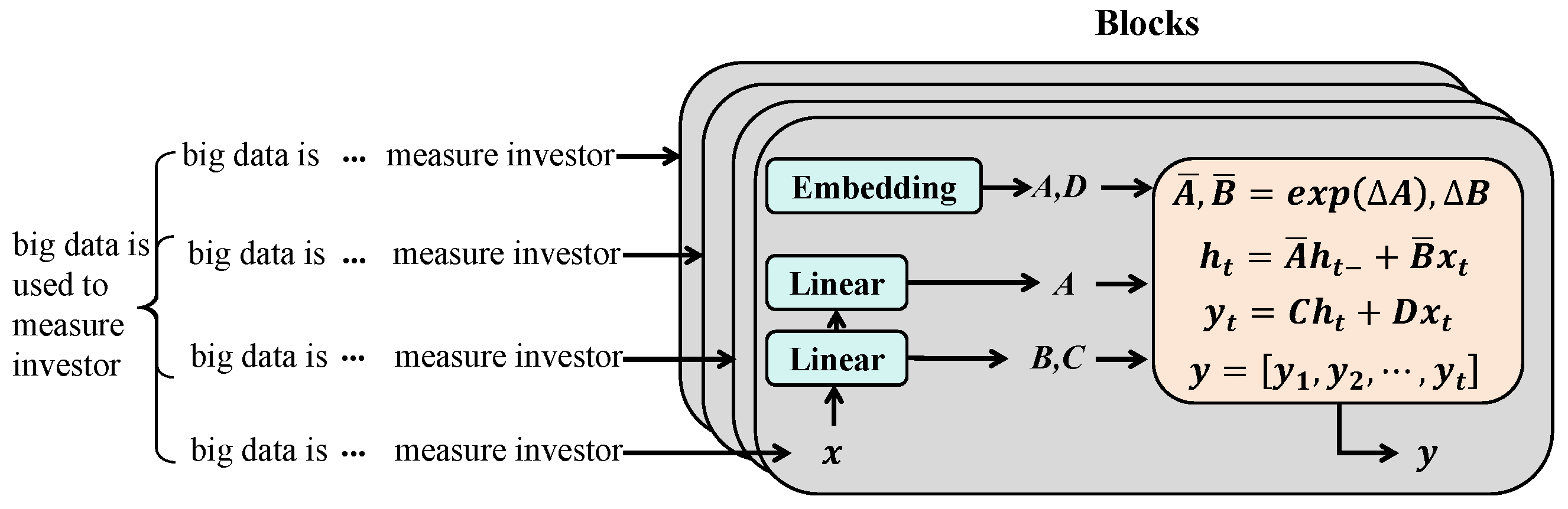
3.3. Proposed Method
3.3.1. State Space-Based Transformer Model
- Cross-attention Mechanism [75]:where Q, K, V represent the query, key, and value vectors, respectively, is the dimension of the key vectors, and A is the output of the attention mechanism.
- State Space Model Integration [76]:where and represent the current and next time step system states, respectively, and F, G, and H are state-space model parameters, with A being the output of the cross-attention.
3.3.2. State Space Transition Equation
- Enhanced temporal dynamic modeling: The state space transition equation enables the model to capture the dynamic changes in time series data more finely, improving prediction accuracy.
- Flexible parameter updates: The parameter update mechanism in the state space model allows the model to flexibly adapt to the characteristics of different complex systems, enabling targeted optimization.
- Enhanced data processing capability: The introduction of the state space model enables the model to handle data containing complex dynamics, such as financial data analysis or natural language text, often embodying implicit time series characteristics. The model can process not only static semantic information but also capture the evolution of data over time, critical for dynamic prediction.
- Optimized state change modeling: The state space transition equation provides a mathematically rigorous way to describe continuous state changes, enabling the model to predict future states more precisely in time series prediction tasks compared to conventional Transformer structures.
- Customized output equation: By combining the state space model’s output equation with the Transformer’s output layer, the model’s output incorporates information determined by the current state and also considers the impact of direct inputs, offering a more comprehensive prediction.
3.3.3. State Space Loss Function
- Consistency with dynamic prediction and loss function: The state space loss function aligns closely with the goal of dynamic system prediction, focusing simultaneously on the accuracy of predictions and the smoothness of state changes during the prediction process. This is crucial for dynamic systems where state changes are often smooth over time, and any abrupt changes may indicate system anomalies or data issues. The part effectively reduces the likelihood of such abrupt changes, making the model’s predictions more credible.
- Prevention of overfitting: Traditional Transformer models might perform poorly on future data due to overfitting historical data. The smoothness loss component in the state space loss function helps improve model performance on unseen data by forcing the model to learn more generalized state change rules rather than merely memorizing patterns in the training dataset.
- Flexibility in parameter adjustment: By adjusting the values of and , researchers can flexibly control the weight of prediction loss versus smoothness loss in the total loss function. For different complex system prediction tasks, these parameters can be optimized based on the specific characteristics of the system and task requirements to achieve the best prediction performance.
- Enhanced interpretability: The state space loss function not only optimizes the model’s predictive performance but also enhances its interpretability. Since the model needs to consider the coherence of state transitions, the trends learned by the model are more aligned with the physical or logical laws of the real world, allowing researchers to explain the model’s predictive behavior by analyzing the parameters of the state space model.
- Adaptability to complex tasks: Complex systems, like financial markets or weather systems, have multifactorial and nonlinear state changes. Traditional loss functions struggle to capture this complexity. The state space loss function, by simulating changes in the state transition matrix and control matrix, better adapts to this complexity, thereby enhancing model performance in such complex tasks.
3.4. Experimental Configuration
3.4.1. Hardware and Software Configuration
- NumPy: A fundamental scientific computing library in Python, NumPy provides powerful multi-dimensional array objects and a wide range of mathematical functions for efficiently handling large volumes of data. In this study, NumPy was extensively used for data preprocessing, feature extraction, and numerical computation tasks.
- Pandas: A data analysis and manipulation library, Pandas offers user-friendly data structures and data analysis tools. By using Pandas, various formats of datasets, including CSV and Excel, could be conveniently processed and analyzed.
- Matplotlib and Seaborn: Both libraries were utilized for data visualization. Matplotlib, a plotting library, provides extensive drawing functions supporting various formats and high-quality graphic output. Seaborn, built on Matplotlib, offers a higher-level interface focused on drawing statistical graphics, making data visualization more intuitive and attractive.
- Scikit-learn: A Python library for machine learning, Scikit-learn offers simple and efficient tools for data mining and data analysis. In this study, Scikit-learn was used for model evaluation, cross-validation, and various machine-learning tasks.
- Mamba: A computational framework tailored for state space models, Mamba supports the rapid development and accurate estimation of complex models. Through Mamba, effective parameter estimation and state inference for state space models were achieved, crucial for capturing dynamic changes in complex systems.
3.4.2. Training Strategy
3.4.3. Model Evaluation Metrics
3.5. Baseline
4. Results and Discussion
4.1. Legal Case Judgment Prediction Results
4.2. Legal Case Translation Results
4.3. Financial Data Analysis Results
4.4. Discussion on Results
4.5. Different Loss Function Ablation Results
4.6. Different Transformer Attention Ablation Results
4.7. Limitations and Future Work
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kounadi, O.; Ristea, A.; Araujo, A.; Leitner, M. A systematic review on spatial crime forecasting. Crime Sci. 2020, 9, 1–22. [Google Scholar] [CrossRef] [PubMed]
- Soni, P.; Tewari, Y.; Krishnan, D. Machine Learning approaches in stock price prediction: A systematic review. J. Phys. Conf. Ser. 2022, 2161, 012065. [Google Scholar] [CrossRef]
- Islam, M.N.; Inan, T.T.; Rafi, S.; Akter, S.S.; Sarker, I.H.; Islam, A.N. A systematic review on the use of AI and ML for fighting the COVID-19 pandemic. IEEE Trans. Artif. Intell. 2020, 1, 258–270. [Google Scholar] [CrossRef]
- Ikotun, A.M.; Ezugwu, A.E.; Abualigah, L.; Abuhaija, B.; Heming, J. K-means clustering algorithms: A comprehensive review, variants analysis, and advances in the era of big data. Inf. Sci. 2023, 622, 178–210. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M.; Furht, B. Text data augmentation for deep learning. J. Big Data 2021, 8, 101. [Google Scholar] [CrossRef] [PubMed]
- Rana, S.; Kanji, R.; Jain, S. Comparison of SVM and Naive Bayes for Sentiment Classification using BERT data. In Proceedings of the 2022 5th International Conference On Multimedia, Signal Processing and Communication Technologies (IMPACT), Aligarh, India, 26–27 November 2022. [Google Scholar] [CrossRef]
- Wahba, Y.; Madhavji, N.; Steinbacher, J. A Comparison of SVM Against Pre-trained Language Models (PLMs) for Text Classification Tasks. In Proceedings of the 8th Annual International Conference on Machine Learning, Optimization and Data Science, LOD 2022, PT II, Certosa di Pontignano, Italy, 18–22 September 2022; Nicosia, G., Ojha, V., LaMalfa, E., LaMalfa, G., Pardalos, P., DiFatta, G., Giuffrida, G., Umeton, R., Eds.; Lecture Notes in Computer Science. Springer: Cham, Switzerland, 2023; Volume 13811, pp. 304–313. [Google Scholar] [CrossRef]
- Du, J.; Vong, C.M.; Chen, C.P. Novel efficient RNN and LSTM-like architectures: Recurrent and gated broad learning systems and their applications for text classification. IEEE Trans. Cybern. 2020, 51, 1586–1597. [Google Scholar] [CrossRef] [PubMed]
- Jang, B.; Kim, M.; Harerimana, G.; Kang, S.u.; Kim, J.W. Bi-LSTM model to increase accuracy in text classification: Combining Word2vec CNN and attention mechanism. Appl. Sci. 2020, 10, 5841. [Google Scholar] [CrossRef]
- Atienza, R. Vision transformer for fast and efficient scene text recognition. In Proceedings of the International Conference on Document Analysis and Recognition, Lausanne, Switzerland, 5–10 September 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 319–334. [Google Scholar]
- Sharaff, A.; Khurana, S.; Sahu, T. Quality assessment of text data using C-RNN. In Proceedings of the Sixth International Congress on Information and Communication Technology: ICICT 2021, London, UK, 25–26 February 2021; Springer: Berlin/Heidelberg, Germany, 2022; Volume 3, pp. 201–208. [Google Scholar]
- Kumar, A. A study: Hate speech and offensive language detection in textual data by using RNN, CNN, LSTM and Bert model. In Proceedings of the 2022 6th International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 25–27 May 2022; pp. 1–6. [Google Scholar]
- Lee, H.; Kang, Y. Mining tourists’ destinations and preferences through LSTM-based text classification and spatial clustering using Flickr data. Spat. Inf. Res. 2021, 29, 825–839. [Google Scholar] [CrossRef]
- Hasib, K.M.; Azam, S.; Karim, A.; Marouf, A.A.; Shamrat, F.M.J.M.; Montaha, S.; Yeo, K.C.; Jonkman, M.; Alhajj, R.; Rokne, J.G. MCNN-LSTM: Combining CNN and LSTM to Classify Multi-Class Text in Imbalanced News Data. IEEE Access 2023, 11, 93048–93063. [Google Scholar] [CrossRef]
- Kumar, V.; Choudhary, A.; Cho, E. Data augmentation using pre-trained transformer models. arXiv 2020, arXiv:2003.02245. [Google Scholar]
- Phan, L.N.; Anibal, J.T.; Tran, H.; Chanana, S.; Bahadroglu, E.; Peltekian, A.; Altan-Bonnet, G. Scifive: A text-to-text transformer model for biomedical literature. arXiv 2021, arXiv:2106.03598. [Google Scholar]
- Acheampong, F.A.; Nunoo-Mensah, H.; Chen, W. Transformer models for text-based emotion detection: A review of BERT-based approaches. Artif. Intell. Rev. 2021, 54, 5789–5829. [Google Scholar] [CrossRef]
- Koutnik, J.; Greff, K.; Gomez, F.; Schmidhuber, J. A clockwork rnn. In Proceedings of the International Conference on Machine Learning, PMLR, Beijing, China, 21–26 June 2014; pp. 1863–1871. [Google Scholar]
- Xin, J.; Zhou, C.; Jiang, Y.; Tang, Q.; Yang, X.; Zhou, J. A signal recovery method for bridge monitoring system using TVFEMD and encoder-decoder aided LSTM. Measurement 2023, 214, 112797. [Google Scholar] [CrossRef]
- Zaheer, S.; Anjum, N.; Hussain, S.; Algarni, A.D.; Iqbal, J.; Bourouis, S.; Ullah, S.S. A multi parameter forecasting for stock time series data using LSTM and deep learning model. Mathematics 2023, 11, 590. [Google Scholar] [CrossRef]
- Aseeri, A.O. Effective RNN-based forecasting methodology design for improving short-term power load forecasts: Application to large-scale power-grid time series. J. Comput. Sci. 2023, 68, 101984. [Google Scholar] [CrossRef]
- Dudukcu, H.V.; Taskiran, M.; Taskiran, Z.G.C.; Yildirim, T. Temporal Convolutional Networks with RNN approach for chaotic time series prediction. Appl. Soft Comput. 2023, 133, 109945. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, Y.; Shi, H. A convolutional recurrent neural-network-based machine learning for scene text recognition application. Symmetry 2023, 15, 849. [Google Scholar] [CrossRef]
- Shiri, F.M.; Perumal, T.; Mustapha, N.; Mohamed, R. A comprehensive overview and comparative analysis on deep learning models: CNN, RNN, LSTM, GRU. arXiv 2023, arXiv:2305.17473. [Google Scholar]
- Sherstinsky, A. Fundamentals of recurrent neural network (RNN) and long short-term memory (LSTM) network. Phys. D Nonlinear Phenom. 2020, 404, 132306. [Google Scholar] [CrossRef]
- Zhao, J.; Huang, F.; Lv, J.; Duan, Y.; Qin, Z.; Li, G.; Tian, G. Do RNN and LSTM have long memory? In Proceedings of the International Conference on Machine Learning, PMLR, Virtual Event, 13–18 July 2020; pp. 11365–11375. Available online: https://proceedings.mlr.press/v119/zhao20c.html (accessed on 1 May 2024).
- Lu, M.; Xu, X. TRNN: An efficient time-series recurrent neural network for stock price prediction. Inf. Sci. 2024, 657, 119951. [Google Scholar] [CrossRef]
- Gülmez, B. Stock price prediction with optimized deep LSTM network with artificial rabbits optimization algorithm. Expert Syst. Appl. 2023, 227, 120346. [Google Scholar] [CrossRef]
- Moghar, A.; Hamiche, M. Stock market prediction using LSTM recurrent neural network. Procedia Comput. Sci. 2020, 170, 1168–1173. [Google Scholar] [CrossRef]
- Li, K.; Huang, W.; Hu, G.; Li, J. Ultra-short term power load forecasting based on CEEMDAN-SE and LSTM neural network. Energy Build. 2023, 279, 112666. [Google Scholar] [CrossRef]
- Wan, A.; Chang, Q.; Khalil, A.B.; He, J. Short-term power load forecasting for combined heat and power using CNN-LSTM enhanced by attention mechanism. Energy 2023, 282, 128274. [Google Scholar] [CrossRef]
- Jailani, N.L.M.; Dhanasegaran, J.K.; Alkawsi, G.; Alkahtani, A.A.; Phing, C.C.; Baashar, Y.; Capretz, L.F.; Al-Shetwi, A.Q.; Tiong, S.K. Investigating the power of LSTM-based models in solar energy forecasting. Processes 2023, 11, 1382. [Google Scholar] [CrossRef]
- Abou Houran, M.; Bukhari, S.M.S.; Zafar, M.H.; Mansoor, M.; Chen, W. COA-CNN-LSTM: Coati optimization algorithm-based hybrid deep learning model for PV/wind power forecasting in smart grid applications. Appl. Energy 2023, 349, 121638. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, L.; Shi, W. Seismic control of adaptive variable stiffness intelligent structures using fuzzy control strategy combined with LSTM. J. Build. Eng. 2023, 78, 107549. [Google Scholar] [CrossRef]
- Redhu, P.; Kumar, K. Short-term traffic flow prediction based on optimized deep learning neural network: PSO-Bi-LSTM. Phys. A Stat. Mech. Its Appl. 2023, 625, 129001. [Google Scholar]
- Osama, O.M.; Alakkari, K.; Abotaleb, M.; El-Kenawy, E.S.M. Forecasting Global Monkeypox Infections Using LSTM: A Non-Stationary Time Series Analysis. In Proceedings of the 2023 3rd International Conference on Electronic Engineering (ICEEM), Menouf, Egypt, 7–8 October 2023; pp. 1–7. [Google Scholar]
- Wang, J.; Ozbayoglu, E.; Baldino, S.; Liu, Y.; Zheng, D. Time Series Data Analysis with Recurrent Neural Network for Early Kick Detection. In Proceedings of the Offshore Technology Conference, OTC, Houston, TX, USA, 1–4 May 2023; p. D021S020R002. [Google Scholar]
- Md, A.Q.; Kapoor, S.; AV, C.J.; Sivaraman, A.K.; Tee, K.F.; Sabireen, H.; Janakiraman, N. Novel optimization approach for stock price forecasting using multi-layered sequential LSTM. Appl. Soft Comput. 2023, 134, 109830. [Google Scholar] [CrossRef]
- Wijanarko, B.D.; Heryadi, Y.; Murad, D.F.; Tho, C.; Hashimoto, K. Recurrent Neural Network-based Models as Bahasa Indonesia-Sundanese Language Neural Machine Translator. In Proceedings of the 2023 International Conference on Computer Science, Information Technology and Engineering (ICCoSITE), Jakarta, Indonesia, 16 February 2023; pp. 951–956. [Google Scholar]
- Durga, P.; Godavarthi, D. Deep-Sentiment: An Effective Deep Sentiment Analysis Using a Decision-Based Recurrent Neural Network (D-RNN). IEEE Access 2023, 11, 108433–108447. [Google Scholar] [CrossRef]
- Tang, J.; Yang, R.; Dai, Q.; Yuan, G.; Mao, Y. Research on feature extraction of meteorological disaster emergency response capability based on an RNN Autoencoder. Appl. Sci. 2023, 13, 5153. [Google Scholar] [CrossRef]
- Pulvirenti, L.; Rolando, L.; Millo, F. Energy management system optimization based on an LSTM deep learning model using vehicle speed prediction. Transp. Eng. 2023, 11, 100160. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Bello, A.; Ng, S.C.; Leung, M.F. A BERT framework to sentiment analysis of tweets. Sensors 2023, 23, 506. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhang, J.; Zong, C. Transformer: A general framework from machine translation to others. Mach. Intell. Res. 2023, 20, 514–538. [Google Scholar] [CrossRef]
- Friedman, D.; Wettig, A.; Chen, D. Learning transformer programs. In Proceedings of the Neural Information Processing Systems 36 (NeurIPS 2023), New Orleans, LA, USA, 10–16 December 2023. [Google Scholar]
- Kazemnejad, A.; Padhi, I.; Natesan Ramamurthy, K.; Das, P.; Reddy, S. The impact of positional encoding on length generalization in transformers. In Proceedings of the Neural Information Processing Systems 36 (NeurIPS 2023), New Orleans, LA, USA, 10–16 December 2023. [Google Scholar]
- Huangliang, K.; Li, X.; Yin, T.; Peng, B.; Zhang, H. Self-adapted positional encoding in the transformer encoder for named entity recognition. In Proceedings of the International Conference on Artificial Neural Networks, Crete, Greece, 26–29 September 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 538–549. [Google Scholar]
- Mian, T.S. Evaluation of Stock Closing Prices using Transformer Learning. Eng. Technol. Appl. Sci. Res. 2023, 13, 11635–11642. [Google Scholar] [CrossRef]
- Shishehgarkhaneh, M.B.; Moehler, R.C.; Fang, Y.; Hijazi, A.A.; Aboutorab, H. Transformer-based Named Entity Recognition in Construction Supply Chain Risk Management in Australia. arXiv 2023, arXiv:2311.13755. [Google Scholar] [CrossRef]
- Li, R.; Zhang, Z.; Liu, P. COVID-19 Epidemic Prediction Based on Deep Learning. J. Nonlinear Model. Anal. 2023, 5, 354. [Google Scholar]
- Du, H.; Du, S.; Li, W. Probabilistic time series forecasting with deep non-linear state space models. CAAI Trans. Intell. Technol. 2023, 8, 3–13. [Google Scholar] [CrossRef]
- Shi, Z. MambaStock: Selective state space model for stock prediction. arXiv 2024, arXiv:2402.18959. [Google Scholar]
- Benozzo, D.; Baggio, G.; Baron, G.; Chiuso, A.; Zampieri, S.; Bertoldo, A. Analyzing asymmetry in brain hierarchies with a linear state-space model of resting-state fMRI data. bioRxiv 2023. [Google Scholar] [CrossRef]
- Afandizadeh, S.; Bigdeli Rad, H. Estimation of parameters affecting traffic accidents using state space models. J. Transp. Res. 2023. [Google Scholar] [CrossRef]
- Gu, A.; Dao, T. Mamba: Linear-time sequence modeling with selective state spaces. arXiv 2023, arXiv:2312.00752. [Google Scholar]
- Saon, G.; Gupta, A.; Cui, X. Diagonal state space augmented transformers for speech recognition. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Gu, A.; Goel, K.; Ré, C. Efficiently modeling long sequences with structured state spaces. arXiv 2021, arXiv:2111.00396. [Google Scholar]
- Yuan, Q.; Shen, H.; Li, T.; Li, Z.; Li, S.; Jiang, Y.; Xu, H.; Tan, W.; Yang, Q.; Wang, J.; et al. Deep learning in environmental remote sensing: Achievements and challenges. Remote Sens. Environ. 2020, 241, 111716. [Google Scholar] [CrossRef]
- Tian, H.; Qin, P.; Li, K.; Zhao, Z. A review of the state of health for lithium-ion batteries: Research status and suggestions. J. Clean. Prod. 2020, 261, 120813. [Google Scholar] [CrossRef]
- Yu, Y.; Wang, C.; Fu, Q.; Kou, R.; Huang, F.; Yang, B.; Yang, T.; Gao, M. Techniques and challenges of image segmentation: A review. Electronics 2023, 12, 1199. [Google Scholar] [CrossRef]
- Chai, C.P. Comparison of text preprocessing methods. Nat. Lang. Eng. 2023, 29, 509–553. [Google Scholar] [CrossRef]
- Arisha, A.O.; Wabula, Y. Text Preprocessing Approaches in CNN for Disaster Reports Dataset. In Proceedings of the 2023 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Bali, Indonesia, 20–23 February 2023; pp. 216–220. [Google Scholar]
- Yu, L.; Liu, B.; Lin, Q.; Zhao, X.; Che, C. Semantic Similarity Matching for Patent Documents Using Ensemble BERT-related Model and Novel Text Processing Method. arXiv 2024, arXiv:2401.06782. [Google Scholar]
- Gomes, L.; da Silva Torres, R.; Côrtes, M.L. BERT-and TF-IDF-based feature extraction for long-lived bug prediction in FLOSS: A comparative study. Inf. Softw. Technol. 2023, 160, 107217. [Google Scholar] [CrossRef]
- Zhang, C.; Wang, X.; Zhang, H.; Zhang, J.; Zhang, H.; Liu, C.; Han, P. LayerLog: Log sequence anomaly detection based on hierarchical semantics. Appl. Soft Comput. 2023, 132, 109860. [Google Scholar] [CrossRef]
- Kabra, B.; Nagar, C. Convolutional neural network based sentiment analysis with tf-idf based vectorization. J. Integr. Sci. Technol. 2023, 11, 503. [Google Scholar]
- Zhou, M.; Tan, J.; Yang, S.; Wang, H.; Wang, L.; Xiao, Z. Ensemble transfer learning on augmented domain resources for oncological named entity recognition in Chinese clinical records. IEEE Access 2023, 11, 80416–80428. [Google Scholar] [CrossRef]
- Zaeem, J.M.; Garg, V.; Aggarwal, K.; Arora, A. An Intelligent Article Knowledge Graph Formation Framework Using BM25 Probabilistic Retrieval Model. In Proceedings of the Iberoamerican Knowledge Graphs and Semantic Web Conference, Zaragoza, Spain, 13–15 November 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 32–43. [Google Scholar]
- Nicholson, D.N.; Greene, C.S. Constructing knowledge graphs and their biomedical applications. Comput. Struct. Biotechnol. J. 2020, 18, 1414–1428. [Google Scholar] [CrossRef]
- Yilahun, H.; Hamdulla, A. Entity extraction based on the combination of information entropy and TF-IDF. Int. J. Reason.-Based Intell. Syst. 2023, 15, 71–78. [Google Scholar]
- Pan, J.Z.; Razniewski, S.; Kalo, J.C.; Singhania, S.; Chen, J.; Dietze, S.; Jabeen, H.; Omeliyanenko, J.; Zhang, W.; Lissandrini, M.; et al. Large language models and knowledge graphs: Opportunities and challenges. arXiv 2023, arXiv:2308.06374. [Google Scholar]
- Cao, J.; Fang, J.; Meng, Z.; Liang, S. Knowledge graph embedding: A survey from the perspective of representation spaces. ACM Comput. Surv. 2024, 56, 1–42. [Google Scholar] [CrossRef]
- Wu, K.; Fan, J.; Ye, P.; Zhu, M. Hyperspectral image classification using spectral–spatial token enhanced transformer with hash-based positional embedding. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–16. [Google Scholar] [CrossRef]
- Ge, C.; Song, S.; Huang, G. Causal intervention for human trajectory prediction with cross attention mechanism. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 658–666. [Google Scholar]
- Newman, K.; King, R.; Elvira, V.; de Valpine, P.; McCrea, R.S.; Morgan, B.J. State-space models for ecological time-series data: Practical model-fitting. Methods Ecol. Evol. 2023, 14, 26–42. [Google Scholar] [CrossRef]
- Shen, Y.; Dong, Y.; Han, X.; Wu, J.; Xue, K.; Jin, M.; Xie, G.; Xu, X. Prediction model for methanation reaction conditions based on a state transition simulated annealing algorithm optimized extreme learning machine. Int. J. Hydrogen Energy 2023, 48, 24560–24573. [Google Scholar] [CrossRef]
- Shi, J.; Chen, X.; Xie, Y.; Zhang, H.; Sun, Y. Population-based discrete state transition algorithm with decomposition and knowledge guidance applied to electrolytic cell maintenance decision. Appl. Soft Comput. 2023, 135, 109996. [Google Scholar] [CrossRef]
- Ai, C.; He, S.; Fan, X. Parameter estimation of fractional-order chaotic power system based on lens imaging learning strategy state transition algorithm. IEEE Access 2023, 11, 13724–13737. [Google Scholar] [CrossRef]
- Xu, X.; Zhou, X. Deep Learning Based Feature Selection and Ensemble Learning for Sintering State Recognition. Sensors 2023, 23, 9217. [Google Scholar] [CrossRef] [PubMed]
- Dehghan, A.; Razzaghi, P.; Abbasi, K.; Gharaghani, S. TripletMultiDTI: Multimodal representation learning in drug-target interaction prediction with triplet loss function. Expert Syst. Appl. 2023, 232, 120754. [Google Scholar] [CrossRef]
- Jin, H.; Montúfar, G. Implicit bias of gradient descent for mean squared error regression with two-layer wide neural networks. J. Mach. Learn. Res. 2023, 24, 1–97. [Google Scholar]
- Yu, S.; Zhou, Z.; Chen, B.; Cao, L. Generalized temporal similarity-based nonnegative tensor decomposition for modeling transition matrix of dynamic collaborative filtering. Inf. Sci. 2023, 632, 340–357. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Han, K.; Xiao, A.; Wu, E.; Guo, J.; Xu, C.; Wang, Y. Transformer in transformer. Adv. Neural Inf. Process. Syst. 2021, 34, 15908–15919. [Google Scholar]
- Laborde, D.; Martin, W.; Vos, R. Impacts of COVID-19 on global poverty, food security, and diets: Insights from global model scenario analysis. Agric. Econ. 2021, 52, 375–390. [Google Scholar] [CrossRef] [PubMed]
- Zhou, M.; Kong, Y.; Lin, J. Financial Topic Modeling Based on the BERT-LDA Embedding. In Proceedings of the 2022 IEEE 20th International Conference on Industrial Informatics (INDIN), Perth, Australia, 25–28 July 2022; pp. 495–500. [Google Scholar]
- Zhou, B.; Jiang, H.B. Application of PLC in the Control System of Fins-former. Adv. Mater. Res. 2013, 712, 2840–2843. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Kryeziu, L.; Shehu, V. Pre-Training MLM Using Bert for the Albanian Language. SEEU Rev. 2023, 18, 52–62. [Google Scholar] [CrossRef]
- Liang, X.; Zhou, Z.; Huang, H.; Wu, S.; Xiao, T.; Yang, M.; Li, Z.; Bian, C. Character, Word, or Both? Revisiting the Segmentation Granularity for Chinese Pre-trained Language Models. arXiv 2023, arXiv:2303.10893. [Google Scholar]
- An, H.; Ma, R.; Yan, Y.; Chen, T.; Zhao, Y.; Li, P.; Li, J.; Wang, X.; Fan, D.; Lv, C. Finsformer: A Novel Approach to Detecting Financial Attacks Using Transformer and Cluster-Attention. Appl. Sci. 2024, 14, 460. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Quantity | Collection Method | Source | Time Period |
|---|---|---|---|---|
| Legal Case Judgment —English | 3987 | Web Crawling, Open Source Download | US Courts Website, UK Courts and Tribunals Website | 2018.5–2023.5 |
| Legal Case Judgment —Chinese | 3712 | Web Crawling, Open Source Download | China Judgments Online | 2010.7–2023.7 |
| Legal Case Translation —English | 15,980 | Open Source Download | European Parliament Proceedings, OpenSubtitles, Tatoeba | 2020.8–2023.8 |
| Legal Case Translation —Chinese | 21,746 | Web Crawling | Tatoeba | 2020.9–2023.9 |
| Financial Analysis —English | 142,764 | Web Crawling | Yahoo Finance | 2003.11–2023.1 |
| Financial Analysis —Chinese | 187,156 | Web Crawling | Flush Finance | 2003.12–2023.1 |
| Model | Precision | Recall | Accuracy |
|---|---|---|---|
| Transformer [85] | 0.80 | 0.77 | 0.79 |
| BERT [86] | 0.83 | 0.80 | 0.82 |
| wwm-BERT [87] | 0.86 | 0.83 | 0.85 |
| Finsformer [88] | 0.89 | 0.86 | 0.88 |
| Proposed Method | 0.93 | 0.90 | 0.91 |
| Model | Precision | Recall | Accuracy |
|---|---|---|---|
| Transformer [85] | 0.84 | 0.82 | 0.83 |
| BERT [86] | 0.86 | 0.84 | 0.85 |
| wwm-BERT [87] | 0.89 | 0.86 | 0.88 |
| Finsformer [88] | 0.92 | 0.88 | 0.90 |
| Proposed Method | 0.95 | 0.91 | 0.93 |
| Model | Precision | Recall | Accuracy |
|---|---|---|---|
| Transformer [85] | 0.82 | 0.80 | 0.81 |
| BERT [86] | 0.85 | 0.82 | 0.83 |
| wwm-BERT [87] | 0.88 | 0.85 | 0.86 |
| Finsformer [88] | 0.91 | 0.87 | 0.89 |
| Proposed Method | 0.94 | 0.90 | 0.92 |
| Model | Precision | Recall | Accuracy |
|---|---|---|---|
| Legal Case Judgment—Cross-Entropy Loss | 0.82 | 0.80 | 0.81 |
| Legal Case Judgment—Focal Loss | 0.87 | 0.83 | 0.85 |
| Legal Case Judgment—State Space Loss | 0.93 | 0.90 | 0.91 |
| Legal Case Translation—Cross-Entropy Loss | 0.84 | 0.81 | 0.83 |
| Legal Case Translation—Focal Loss | 0.88 | 0.84 | 0.86 |
| Legal Case Translation—State Space Loss | 0.95 | 0.91 | 0.93 |
| Financial Data Analysis—Cross-Entropy Loss | 0.83 | 0.81 | 0.82 |
| Financial Data Analysis—Focal Loss | 0.87 | 0.85 | 0.86 |
| Financial Data Analysis—State Space Loss | 0.94 | 0.90 | 0.92 |
| Model | Precision | Recall | Accuracy |
|---|---|---|---|
| Legal Case Judgment—Multi-head Attention | 0.78 | 0.73 | 0.76 |
| Legal Case Judgment—Sparse Attention | 0.85 | 0.81 | 0.83 |
| Legal Case Judgment—State Space-based Transformer | 0.93 | 0.90 | 0.91 |
| Legal Case Translation—Multi-head Attention | 0.77 | 0.75 | 0.76 |
| Legal Case Translation—Sparse Attention | 0.86 | 0.83 | 0.85 |
| Legal Case Translation—State Space-based Transformer | 0.95 | 0.91 | 0.93 |
| Financial Data Analysis—Multi-head Attention | 0.78 | 0.72 | 0.74 |
| Financial Data Analysis—Sparse Attention | 0.85 | 0.80 | 0.82 |
| Financial Data Analysis—State Space-based Transformer | 0.94 | 0.90 | 0.92 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huo, H.; Guo, W.; Yang, R.; Liu, X.; Xue, J.; Peng, Q.; Deng, Y.; Sun, X.; Lv, C. Data-Driven Strategies for Complex System Forecasts: The Role of Textual Big Data and State-Space Transformers in Decision Support. Systems 2024, 12, 171. https://doi.org/10.3390/systems12050171
Huo H, Guo W, Yang R, Liu X, Xue J, Peng Q, Deng Y, Sun X, Lv C. Data-Driven Strategies for Complex System Forecasts: The Role of Textual Big Data and State-Space Transformers in Decision Support. Systems. 2024; 12(5):171. https://doi.org/10.3390/systems12050171
Chicago/Turabian StyleHuo, Huairong, Wanxin Guo, Ruining Yang, Xuran Liu, Jingyi Xue, Qingmiao Peng, Yiwei Deng, Xinyi Sun, and Chunli Lv. 2024. "Data-Driven Strategies for Complex System Forecasts: The Role of Textual Big Data and State-Space Transformers in Decision Support" Systems 12, no. 5: 171. https://doi.org/10.3390/systems12050171
APA StyleHuo, H., Guo, W., Yang, R., Liu, X., Xue, J., Peng, Q., Deng, Y., Sun, X., & Lv, C. (2024). Data-Driven Strategies for Complex System Forecasts: The Role of Textual Big Data and State-Space Transformers in Decision Support. Systems, 12(5), 171. https://doi.org/10.3390/systems12050171