1. Introduction
Urban agglomeration is a regional form of densely populated towns that gradually develops under favorable urbanization conditions. The development of transportation systems plays a crucial role in the formation and development of urban agglomerations [
1]. The expressways in urban agglomerations are important transportation arteries connecting cities, characterized by high traffic volume, high density, and high accident rates [
2]. Therefore, in recent years, the expressway safety assessment has received increasing attention from extensive perspectives, including driving behavior [
3], accident frequency [
4], and accident severity [
5].
In general, risk assessment of road safety involves developing risk acceptance criteria based on on-site information and drawing risk assessment conclusions based on the probability and severity of identified risks [
6], and extensive research has been carried out to better quantify the safety of the road. The International Road Assessment Program (iRAP) [
7] amplifies traffic accident data collected on specific road sections into annual data based on factors such as national conditions, traffic habits, and the environment. The iRAP then uses this information to evaluate road safety levels within the area to enhance traffic safety and improve roadside facilities. British Petroleum [
8] has stipulated the scope, steps, and processes of safety risk assessment, creating road-specific risk guidelines that aim to mitigate traffic risks in accident-prone areas. New Zealand has established the Highway Safety Management System for safety assessment at all stages of highway planning, design, construction, operation, and maintenance. The system is used primarily to identify problems in highway safety at all stages, assess the identified issues, and propose improvement measures.
From the methodological perspective, various risk assessment methods have been developed [
9,
10,
11,
12,
13,
14,
15], which can be divided into three main types: quantitative [
9,
10,
11,
12], qualitative [
13,
14], and comprehensive assessment methods [
15], which combine qualitative and quantitative methods. Typical quantitative analysis methods include factor and cluster analysis, time series and regression models, equal risk maps, and decision tree methods. In contrast, typical qualitative analysis methods include factor and logical analysis, historical comparison, and the Delphi method. For example. Hu et al. [
9] constructed a coupled model of causal factors for highway traffic risk in high-altitude geological and meteorological environments using the N-K model (where N and K represent the number of risk factors and the number of interacting risk factors, respectively) and an improved coupling degree model. Zhang et al. [
10] have improved the risk assessment method from multiple perspectives by using the Decision Experiment and Evaluation Laboratory (DEMATEL) method, combined with fuzzy comprehensive evaluation and the Analytic Hierarchy Process. Martins and Garcez [
11] introduced risk theory and early warning theory into the study of road traffic safety and developed a comprehensive evaluation index system for road traffic safety. Liu et al. [
12] classified the degree of uncertainty of road traffic safety risks based on the state of global research in the field of risk-related studies. They then proposed countermeasures for controlling and managing road traffic safety risks. Different from the quantitative analysis method, Jiang et al. [
13] proposed a skewed logistic model, which belongs to the qualitative method, based on this model. They found hit-and-run crashes when the automobile overtakes the bicycle. Zhu et al. claimed that the occurrence of crashes will significantly increase in off-ramps and weaving sections [
14]. Currently, some comprehensive assessment methods have also been proposed. Xiao et al. proposed a hybrid visualization model of road safety based on knowledge mapping, which can both capture the relationship between accidents and factors and predict the probability of a crash [
15].
The formation mechanisms behind traffic accidents have also been comprehensively studied from multiple perspectives, which utilize comprehensive longitudinal and horizontal analyses across factors such as people, vehicles, roads, and the environment. The French national insurance company analyzed the direct factors that lead to road traffic accidents [
16]. After a detailed study of 1064 accidents, it was concluded that over 40% of road-related factors could explain accidents that are typically attributed to driver errors and mistakes. In the U.S., Williamson [
17] further investigated the effects of different lanes on accident formation by defining seven distinct lanes. Mao et al. [
18] segmented key factors of traffic accident information and utilized geographical information system technology to analyze the distribution patterns of accidents from temporal and spatial perspectives. Statistical analytical methods such as factor and regression analyses [
19] were employed to analyze the causal factors of drivers, road conditions, traffic conditions (like density and volume), and traffic environments in accidents. Yang et al. [
20] used Pearson’s correlation coefficient to analyze the correlation between various illegal behaviors of motor vehicle drivers that affect road traffic accidents and four indicators related to road traffic accidents.
Although issues related to road safety assessment have received extensive attention, there is still a gap in the risk assessment of the expressway. Firstly, most research only focuses on the urban road and highway, neglecting the scenarios of expressways in urban agglomerations, which may bring about heterogeneity [
21]. Considering the significance of the expressway, the risk assessment method for the expressway should also be proposed. Additionally, due to disparities in traffic facilities, regulations, and conditions between domestic and foreign contexts, many research findings from abroad are not directly applicable to China. Consequently, conducting accident analysis and prevention strategy research tailored to China’s unique traffic conditions is necessary.
Accordingly, this study aims to fill the relevant gap and investigates dynamic risk assessment methods and accident-generation mechanisms based on multi-scale information fusion at a micro level, with a focus on high-accident-prone expressways in urban agglomerations. The study explores the intrinsic characteristics and patterns of traffic accidents at the micro level and, in conjunction with advanced accident-prevention measures and methodologies, analyzes and develops scientific strategies for preventing traffic accidents on expressways in China’s urban agglomerations. The remainder of the paper is arranged as below: In
Section 2, we explained the methodology applied in this research, mainly including the adaptive neuro-fuzzy inference system (ANFIS) and decision tree analysis. In
Section 3, we discussed the data materials and the process of our experiments. The results and relevant discussions of ANFIS and the decision tree have been given in
Section 4. The conclusions of this research are displayed in
Section 5.
2. Methodology
Global researchers have analyzed the risk status and potential occurrences of accidents in road traffic settings in terms of qualitative, quantitative, and combined qualitative–quantitative perspectives. This encompasses a range of dynamic risk assessment models and methods, including logistic regression, decision trees, support vector machines, Bayesian analysis, equal risk diagram analysis, and discriminant analysis. However, due to disparities in transportation policies, traffic infrastructure, and public awareness across different countries, along with differences in the goals, scope, and principles of research, different safety risk assessment methods show major differences in terms of their applicability and utility. Therefore, this study introduces an integrated analytical method based on decision trees [
22] and an adaptive neuro-fuzzy inference system (ANFIS) [
23]. The purpose of the proposed approach is to identify the major influencing factors of dynamic risk in traffic operations using decision trees and then to perform dynamic risk assessment modeling that utilizes these main factors. The basic idea of this method is to use decision trees to identify the main influencing factors of dynamic risk in traffic operations, and then use these main influencing factors as input variables for the ANFIS model to conduct dynamic risk assessment modeling.
2.1. ANFIS
Under the combined effects of multiple factors, the dynamic risk of traffic operations on a typical road section is nonlinear, and describing this behavior using a specific mathematical formula is difficult. Neural networks offer distributed parallel data processing and self-learning capabilities, enabling them to approximate arbitrary nonlinear functions [
24]. Therefore, they have been successfully used for the inference and prediction of nonlinear systems. However, neural networks cannot intuit the rules implicit in network structures. By contrast, fuzzy logic systems excel at handling uncertainties caused by influencing factors. However, when dealing with complex systems, the human mind has difficulties understanding the causal relationships in systems, which increases the difficulty of determining fuzzy inference rules. Therefore, combining neural networks and fuzzy logic opens an avenue for effectively addressing nonlinear system modeling and simulation. The ANFIS leverages the strengths of both neural networks and fuzzy systems by encompassing neural network learning mechanisms and fuzzy system inference capabilities [
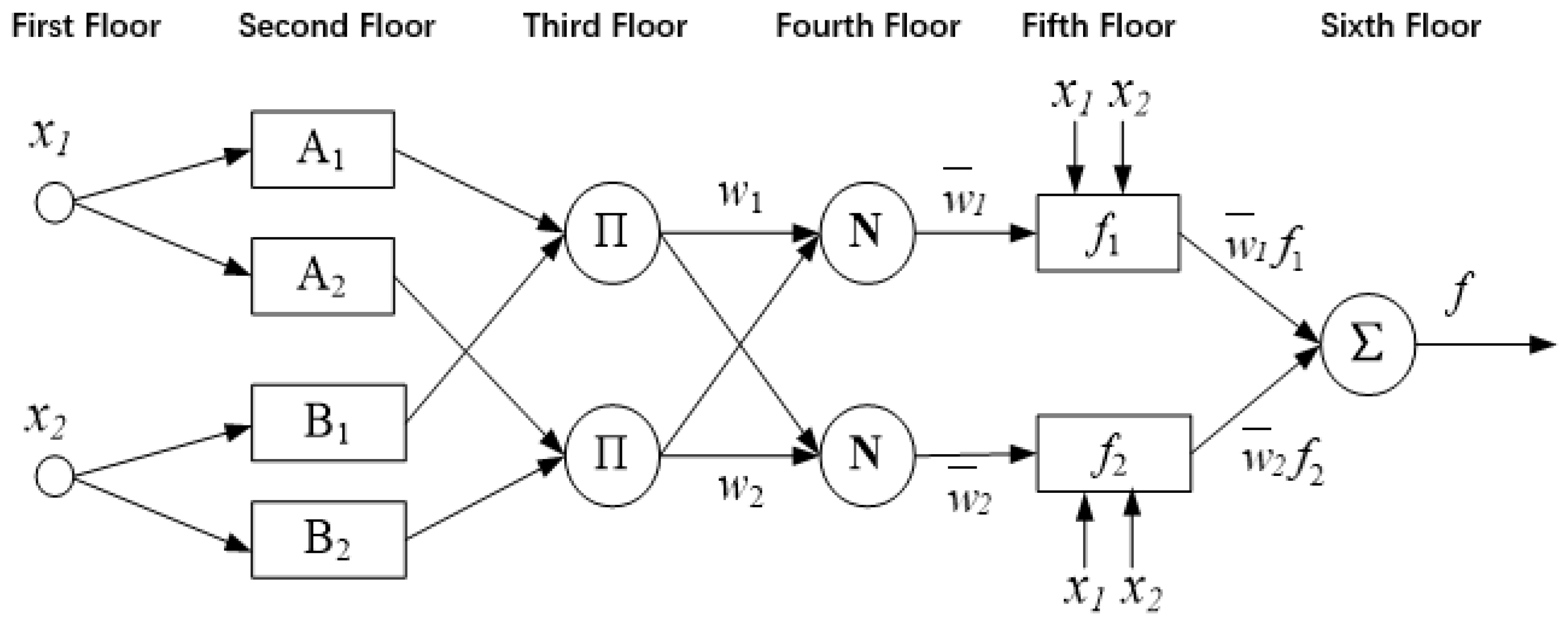
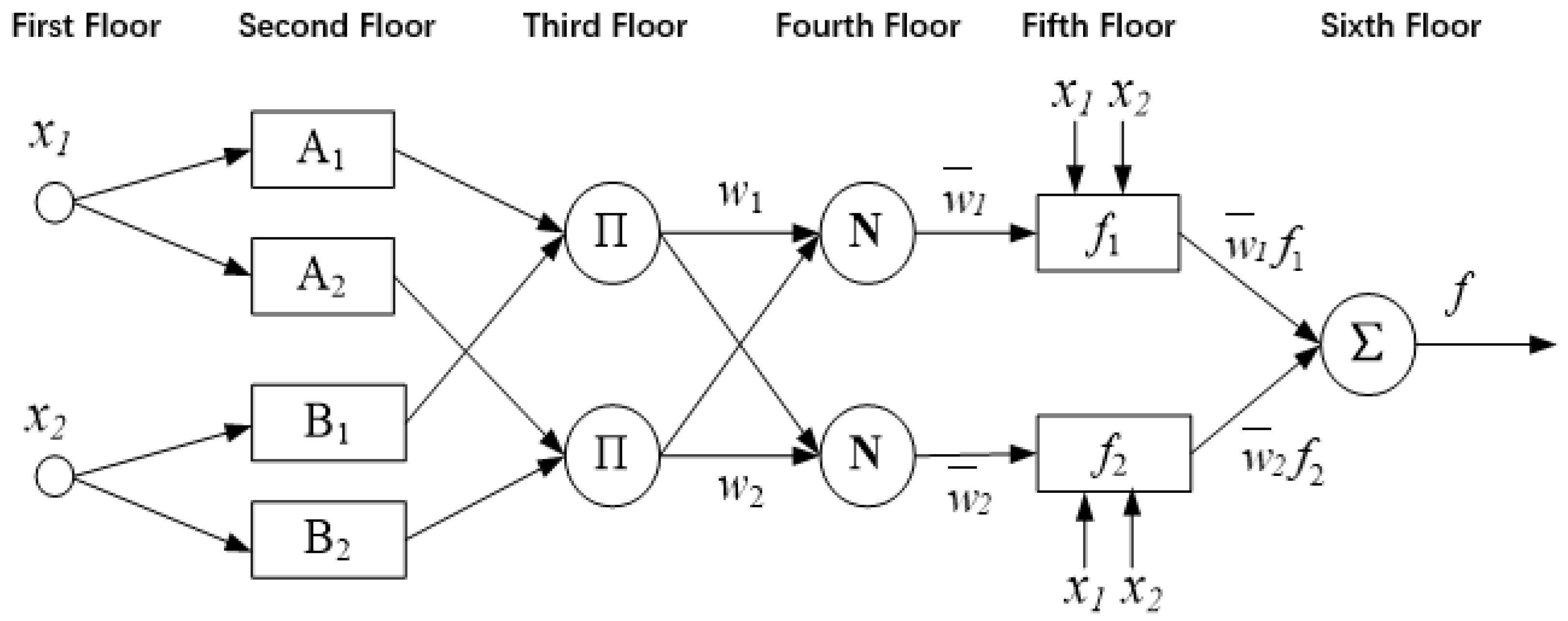
25]. This makes the ANFIS a suitable choice for modeling and analyzing the dynamic risk assessment of traffic operations on typical road sections. The ANFIS was originally proposed to facilitate the analysis of key accident characteristics and provide effective accident prevention strategies. This ANFIS is equivalent to a first-order Sugeno fuzzy model. Through training and learning, the ANFIS can quickly and precisely calculate optimal parameters for membership functions, effectively simulating real input–output relationships. The ANFIS has many advantages, such as the ability to converge rapidly, the requirement for a small sample size, and the generation of limited error. The equivalent ANFIS structure of the Sugeno fuzzy system is shown in
Figure 1.
In
Figure 1, the connecting lines between nodes depict the flow of information, and square and circular nodes represent adjustable and non-adjustable parameters, respectively. The diagram reveals that only floors 2 and 5 contain adjustable parameters. Nodes on the same floor share identical functions. With the input of the i
th node in the kth floor denoted as O
ik, the functions of each floor within the ANFIS structure are as follows [
25]:
- 2.
Floor 2: Fuzzification floor. The role of this floor is to generate fuzzy input variables to generate the corresponding membership function. Each unit on this floor signifies a segmented fuzzy subset. The transfer function of a node can be expressed as follows:
where
is the input to the node,
is the linguistic variable associated with that node’s function (e.g., high, low), and
is the membership function of
, which indicates how well
satisfies
. Normally,
can be either a bell-shaped membership or a Gaussian membership function expressed as follows:
where
is the set of parameters for the floor. These parameters are referred to as premise or condition parameters.
- 3.
Floor 3: Fuzzy operation floor. This floor executes fuzzy set operations under certain conditions, combining various fuzzy subsets of different variables to create corresponding rules. The output represents the degree of applicability of each rule, typically calculated by the following equation:
Each node’s output indicates the incentive strength of the corresponding rule.
- 4.
Floor 4: Normalization floor. This floor normalizes the applicability of each rule. The normalized incentive strength of rule i is calculated by dividing the incentive strength of that rule by the sum of incentive strengths across all rules as follows:
- 5.
Floor 5: Conclusion floor. This floor computes the output of each rule. The transfer functions of nodes in this floor are linear functions, with inputs consisting of network input and normalized incentive strength transmitted by floor 3. Node outputs are obtained by multiplying the transfer function with the normalized incentive strength as follows:
where
is the set of parameters for the floor. These parameters are referred to as conclusion parameters.
- 6.
Floor 6: Output floor. This floor calculates the output of the fuzzy system, which is represented as the sum of the outputs of all rules as follows:
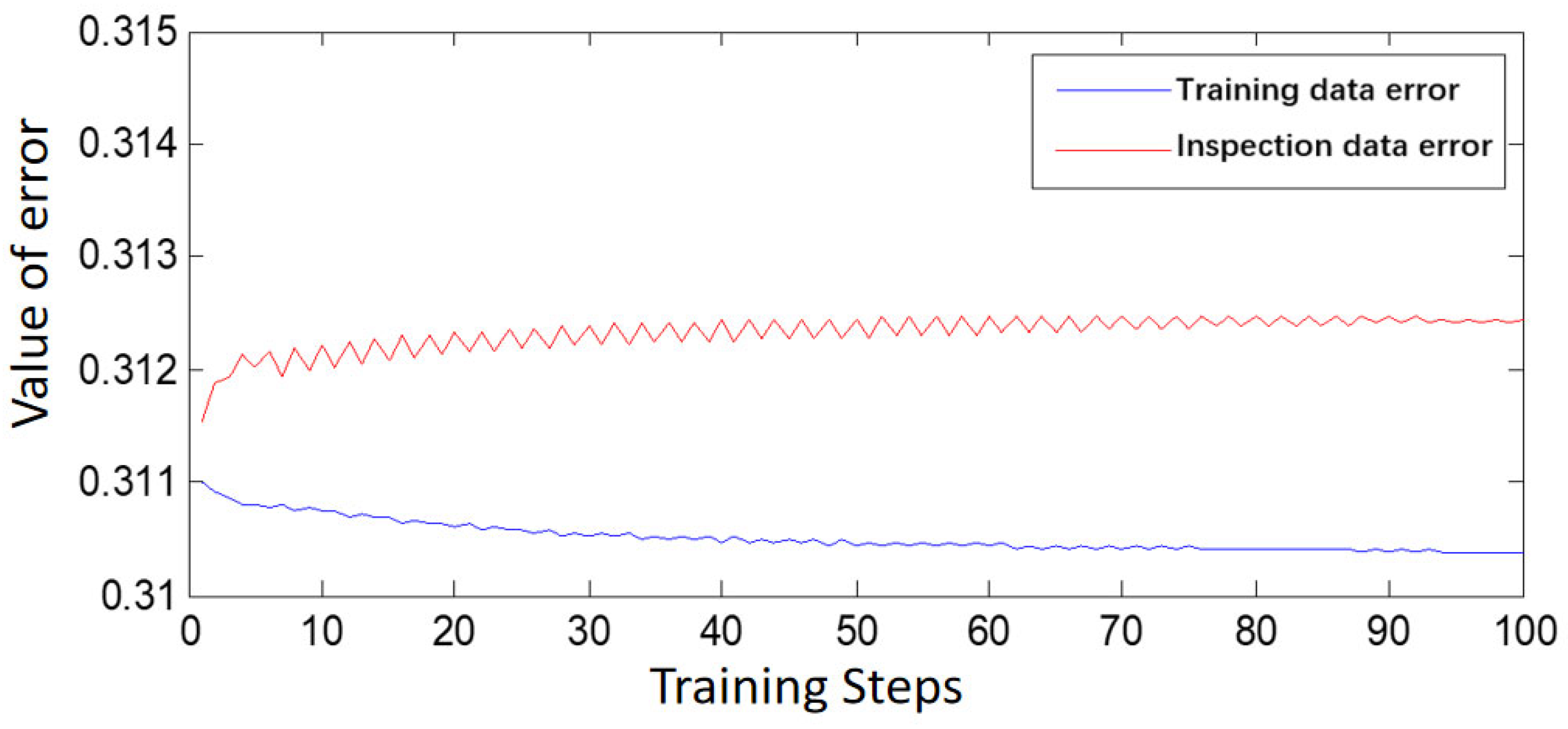
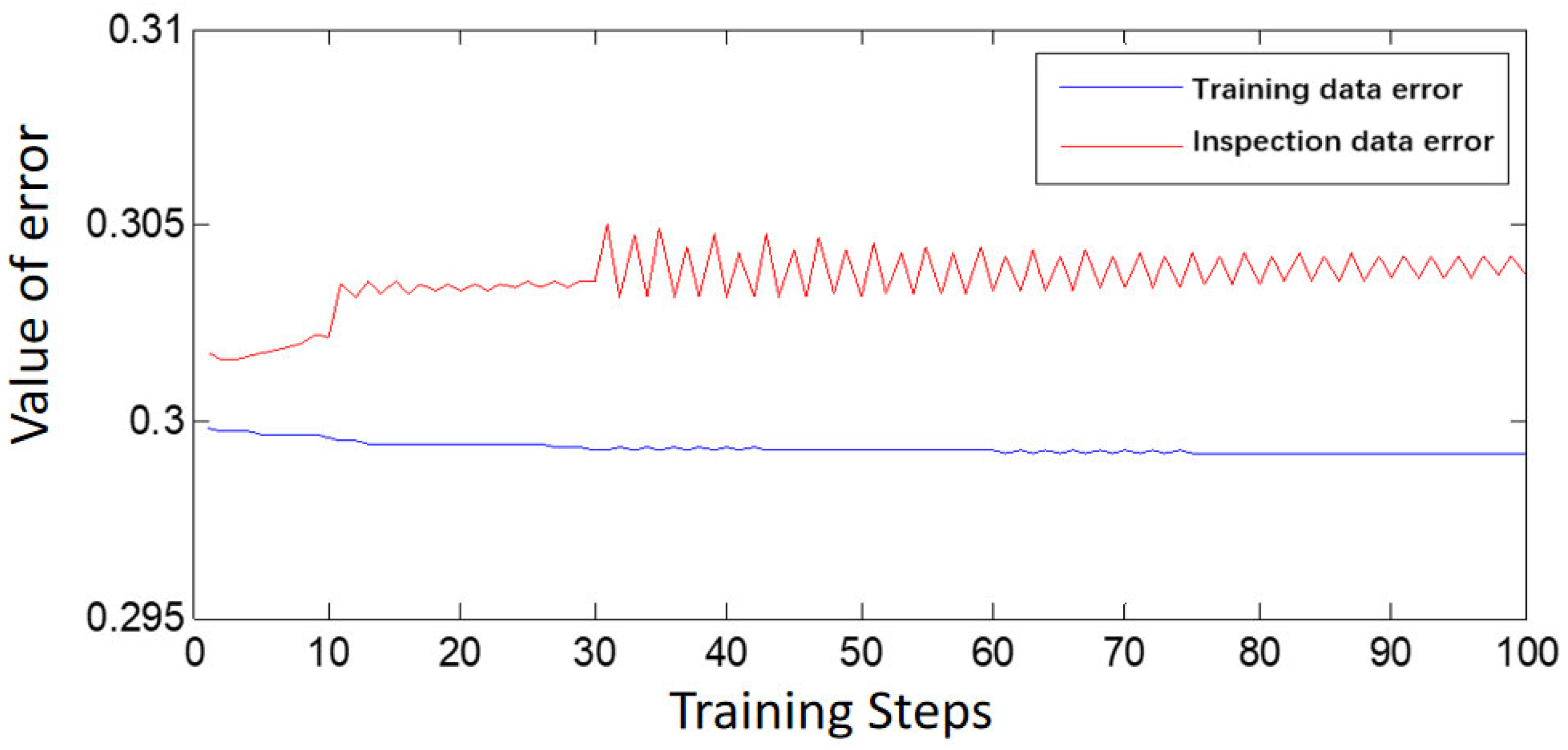
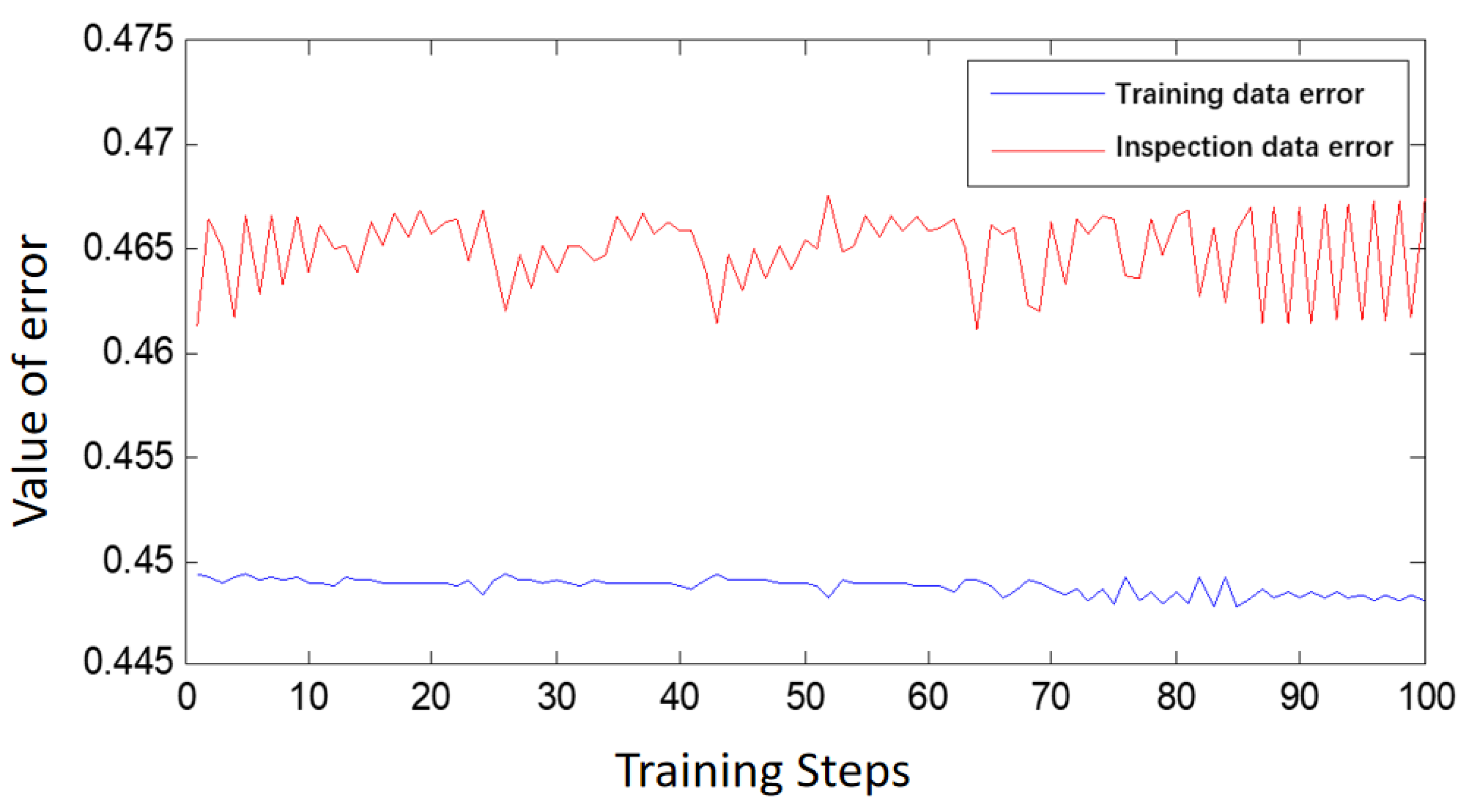
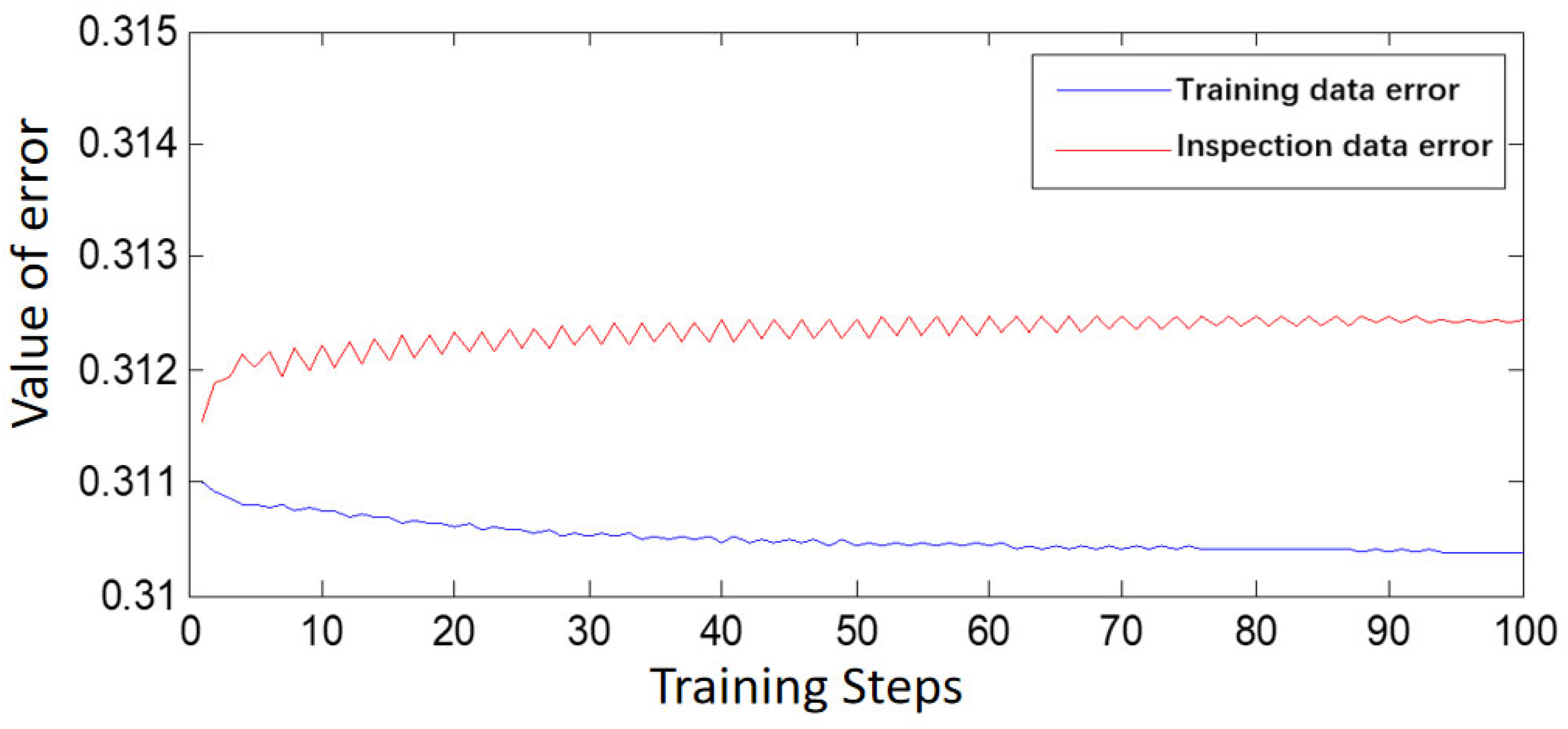
The main purpose of the ANFIS system is to employ a neural network learning mechanism to adjust the structure and parameters of the fuzzy system. Structural adjustments involve modifying the number of variables and domain division, whereas parameter adjustments concern parameters associated with membership functions, such as center and slope. When the network structure is established, ANFIS learning involves only parameter tuning. According to the literature, four main methods are used for parameter tuning. This study employs a hybrid learning algorithm consisting of gradient descent and least squares methods to adjust all parameters of the ANFIS. The advantages of the ANFIS hybrid learning algorithm include its optimization of conclusion rule parameters using the least squares method under fixed conditional parameters. In terms of operational speed, the hybrid learning algorithm outperforms gradient descent when used alone.
2.2. Decision Tree Analysis
The decision tree method is straightforward, intuitive, easy to verify, and highly efficient. A decision tree is a data analysis technique that has emerged from the fields of machine learning and data mining. It primarily employs recursive partitioning to predict and segment data. The resulting model from the decision tree method is represented as a hierarchical tree structure. Given their proficiency in handling non-numerical data and the clarity of their outcomes, decision trees have found wide-ranging applications across various domains. In the realm of transportation, decision trees have also been extensively used. Examples include the use of decision trees in studying vehicle actions (start/stop) when under a yellow light [
26], analyzing parameters that affect traffic accidents, researching driver self-feedback mechanisms, and investigating key parameters in assessing the quality of transportation system services. This study integrates the decision tree approach into the dynamic risk assessment and modeling of traffic operations in typical road sections.
Decision trees achieve data classification through a series of rules. A decision tree has a tree-like structure composed of root nodes, subnodes, and branches. Roots and subnodes represent the entire dataset and individual variables, respectively. Connections between roots and subnodes are established through branches. When a node cannot be further divided, it becomes a terminal node, representing a final set of variables; otherwise, it is referred to as an internal node. The tree structure of a decision tree can be envisioned as the sequential execution of a series of decision rules. Each decision rule constitutes a branch of the decision tree, linking the root nodes to the terminal nodes.
A decision tree is constructed in two steps. In the first step, an initial split is determined to identify the optimal attribute domain for classification. The second step involves establishing decision tree branches based on distinct values of recorded fields. The difficulty of the decision tree algorithm is in selecting suitable branch values. The quality of branch values not only affects the growth rate of the decision tree but significantly affects its structure.
Currently, three primary classification algorithms are used for decision trees: iterative dichotomies, classification and regression trees (CART), and supervised learning. The CART algorithm can prevent excessive pruning of the decision tree and automatically prune the tree to its smallest size. In addition, the resulting tree structure can be evaluated using cross-validation. Thus, this study employs the CART algorithm for decision tree analysis.
Assuming X and Y are input and output variables, respectively, and Y is a continuous variable, given a training dataset of D = {(x
1, y
1), (x
2, y
2), …, (x
N, y
N)}, where x
i = (x
i(1), x
i(2), …, x
i(n)) is the input instance (feature vector), n is the number of features, and i = 1, 2, N, where N is the sample size. We use heuristic methods to partition the feature space, examining all the values of all features in the current set one by one during each partition and selecting the optimal one as the segmentation point based on the minimum squared error criterion. For the j-th feature variable x
j and its value s in the training set, as the segmentation variable and segmentation point, and defining two regions
R1(
s,
j)
= {
x|
x(j) <
s} and
R2(
s,
j)
= {
x|
x(j) >
s}, to find the optimal j and s, solve the following equation:
That is, to find the j and s that minimize the sum of squared errors between the two regions to be divided. Among them, c
1 and c
2 are fixed output values in the two regions after division, and these two optimal output values are the mean of Y in their respective regions. Therefore, the above equation can be written as:
Here, , .
3. Data Acquisition and Experimental Setup
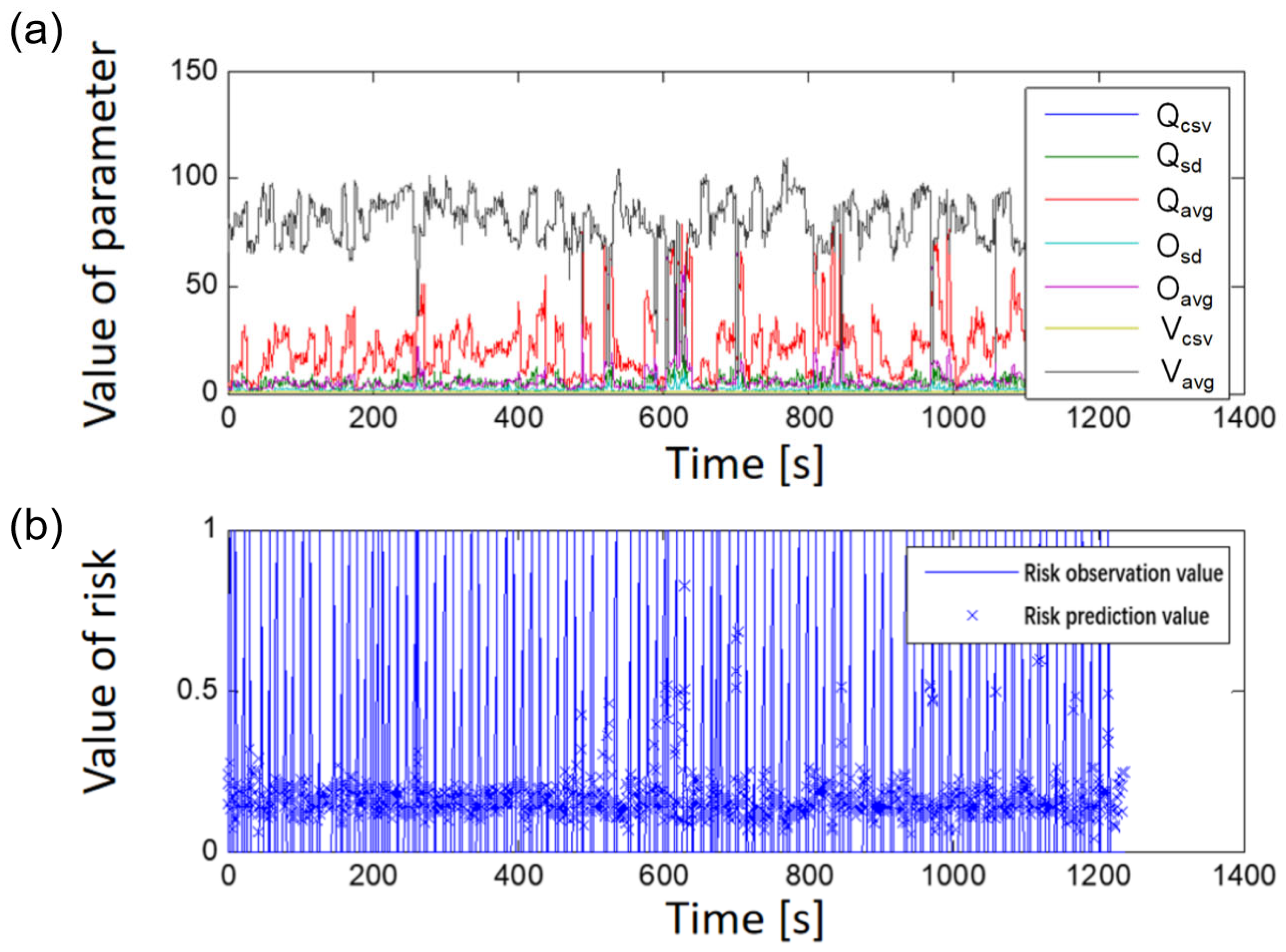
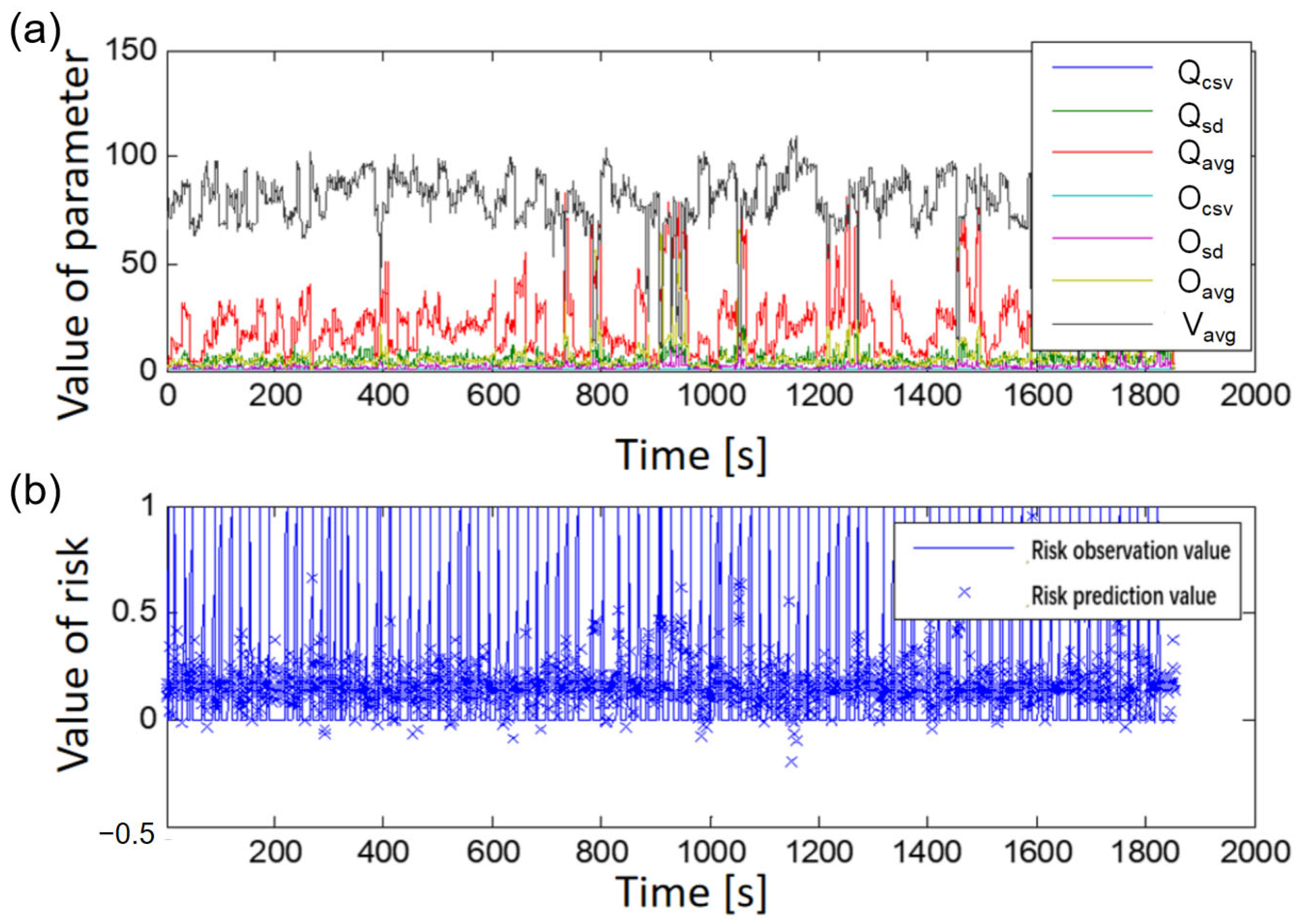
The dynamic risk of highway traffic operation is influenced by various factors, including road alignment, weather, traffic flow operation, and driver behavior. These factors interact with each other and, together, affect the dynamic risk level of transportation operations. In practice, it is impossible to investigate and collect all factors separately. Given the difficulty in obtaining information related to immediate changes in weather, road alignment, and driver behavior, coupled with changes in traffic flow and accidents, it best represents the dynamic risk state of road traffic operations. This study focuses on collecting traffic flow data and accident information captured by microwave coils and videos for modeling and analysis of dynamic risk assessment in traffic operations. Accident data includes detailed information such as time, location, type, and cause. The traffic flow data includes parameters such as speed, flow, and occupancy rate for each 30 s detection cycle of dividing lanes.
To obtain an accurate analysis of the characteristics of dynamic risk changes in traffic operations and to explore the relationship between dynamic risk and traffic accidents, traffic flow and accident data must be screened and processed. Crash and traffic flow data derived from external factors such as weather, road alignment, and individual driver behavior were excluded from the data cases whenever possible. In addition, because the relationship between single-vehicle accidents and traffic operations is not strong at high service levels, accident samples were selected with a preference for multi-vehicle accidents occurring at higher traffic volumes (i.e., below the level of Service C according to the HCM2010 [
27]). To enhance data analysis accuracy and reliability, this study also conducted calibration and processing of traffic flow data. This involved identifying outliers using spatio-temporal graph methods and statistical techniques, while correcting outliers using linear interpolation and filtering. This enabled us to select detector data of better quality for traffic flow parameters such as time mean speed, coefficient of variation of speed, flow rate, and occupancy. Suitable cases for modeling and validation analysis of dynamic risk assessment for traffic operations could then be selected by matching detector data with accident data.
As previously mentioned, this study mainly leveraged traffic flow data and accident data to assess the dynamic risks of traffic operations. The studied road segment was the Beijing section of the Beijing–Harbin Expressway, which has a length of approximately 39.7 km. The study deployed 20 microwave detectors to detect traffic flow data in both directions and 16 video vehicle detectors to detect data in a single direction.
Given that traffic police tend to record only the cross-section stake information when noting accident locations, the traffic flow data of the respective cross-sections was chosen as the primary parameter for analyzing the relationship between traffic flow and accident generation. The following data conversion formulas for transforming divided-lane traffic flow data into cross-sectional traffic flow data were applied.
where
,
, and
are the traffic volume, occupancy, and speed of the divided lane, respectively, and
is the total number of lanes.
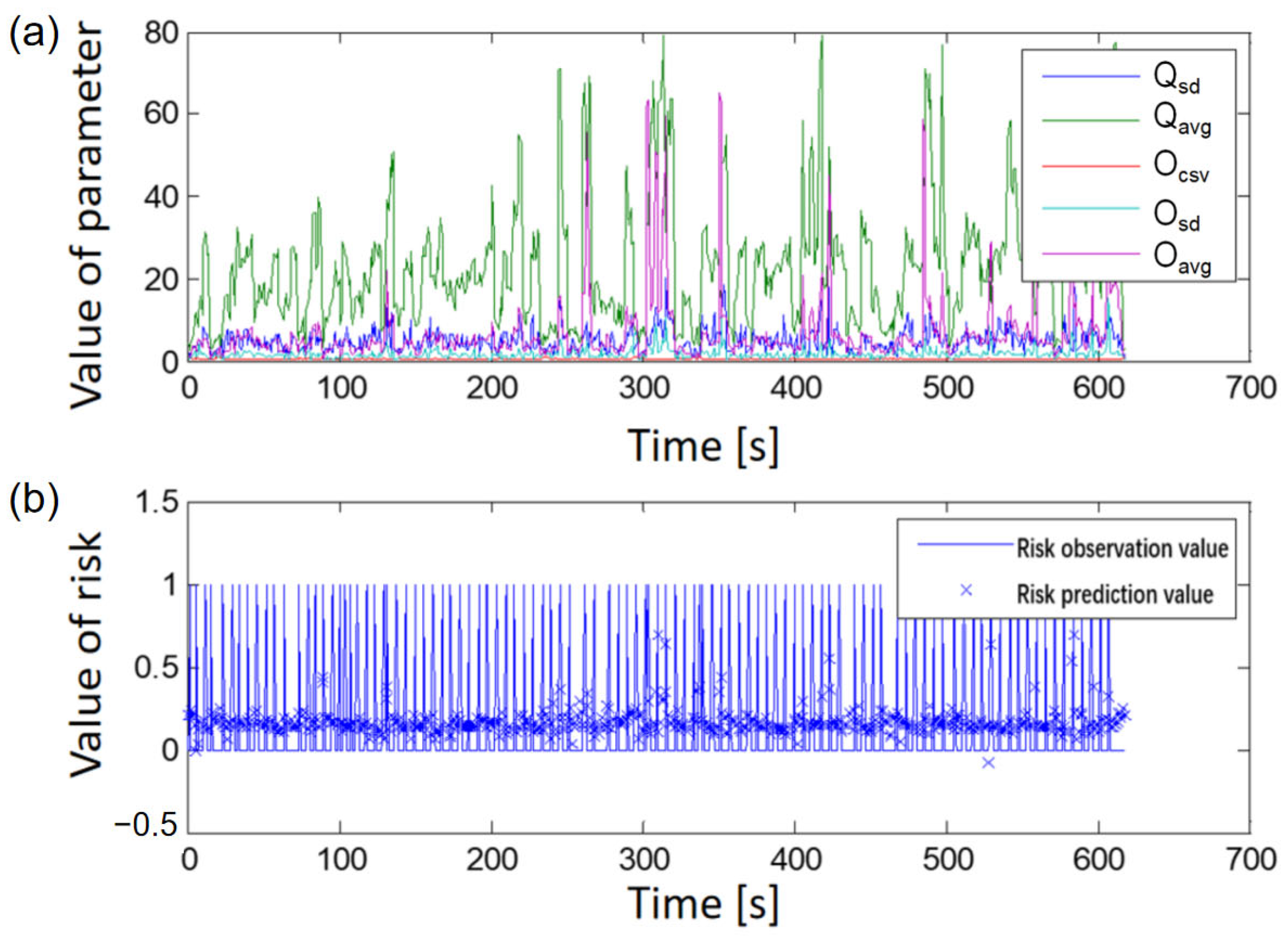
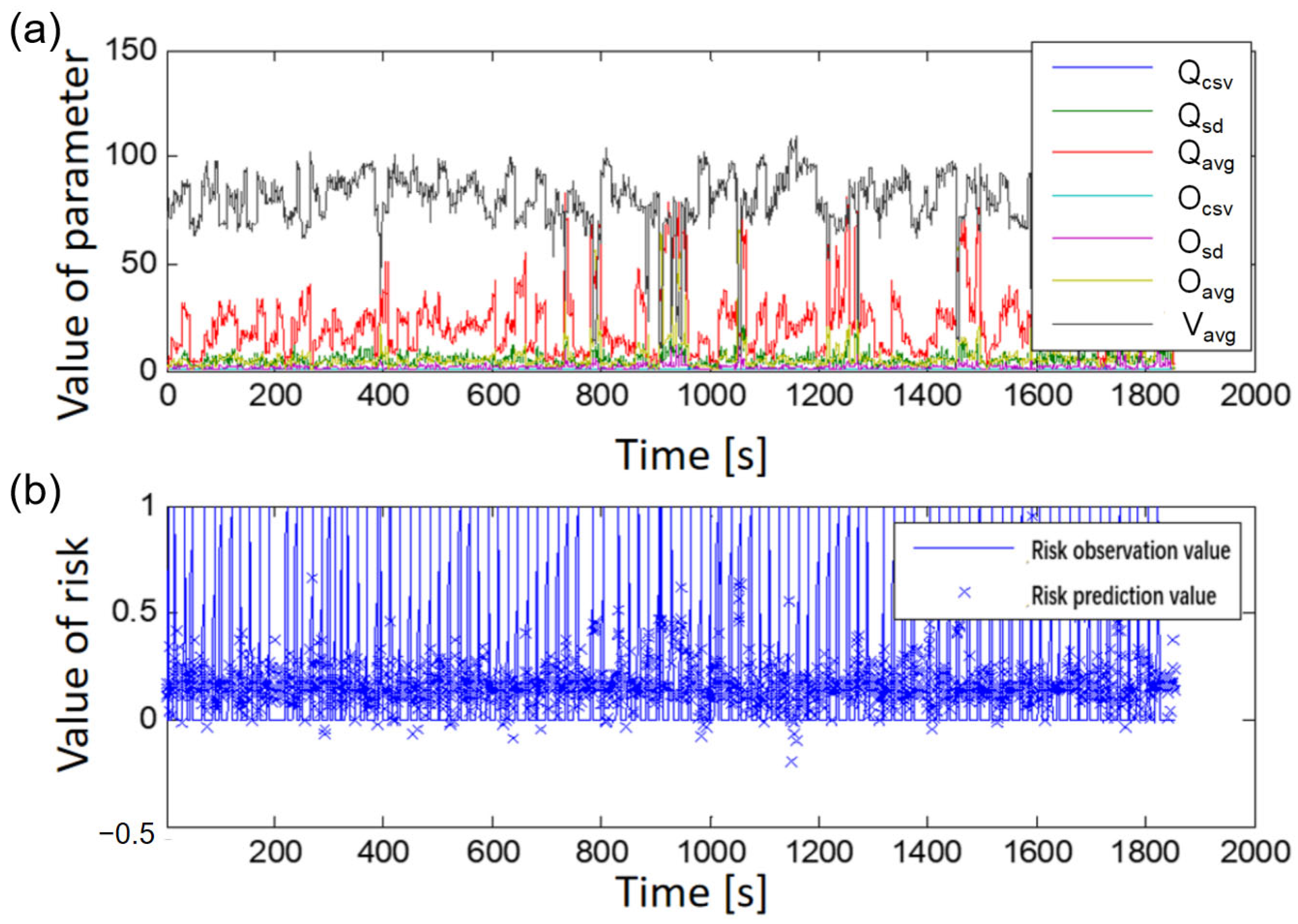
For dynamic risk assessment, another important issue is identifying the right periods and intervals for data collection and modeling analysis. Referring to relevant literature, this study used traffic flow data for each traffic accident derived from the upstream detector section at every 10-min interval within a 30-min period prior to the accident’s occurrence. The study also used traffic flow data for the respective accident control groups. The selection criteria for the control group were as follows: (1) the control group’s date differs from the corresponding accident date; (2) the control group’s date coincides with the accident’s occurrence time; (3) the control group’s date matches the location of the accident; and (4) the control group’s date corresponds to a day when no accidents occurred at that location. In addition, to mitigate the potential impact of different traffic characteristics on weekends and weekdays on the risk assessment model, as the control group, this study independently chose traffic flow data from the same 30-min period of the upstream detector section on the seventh and 14th days prior to the accident. By aligning detector data with accident records, this study ultimately selected 123 samples with accident data and 246 samples from the control group without accident occurrences. The samples were used for dynamic analysis, modeling evaluation, and validation analysis. The collected traffic flow parameters are listed in
Table 1.
5. Conclusions
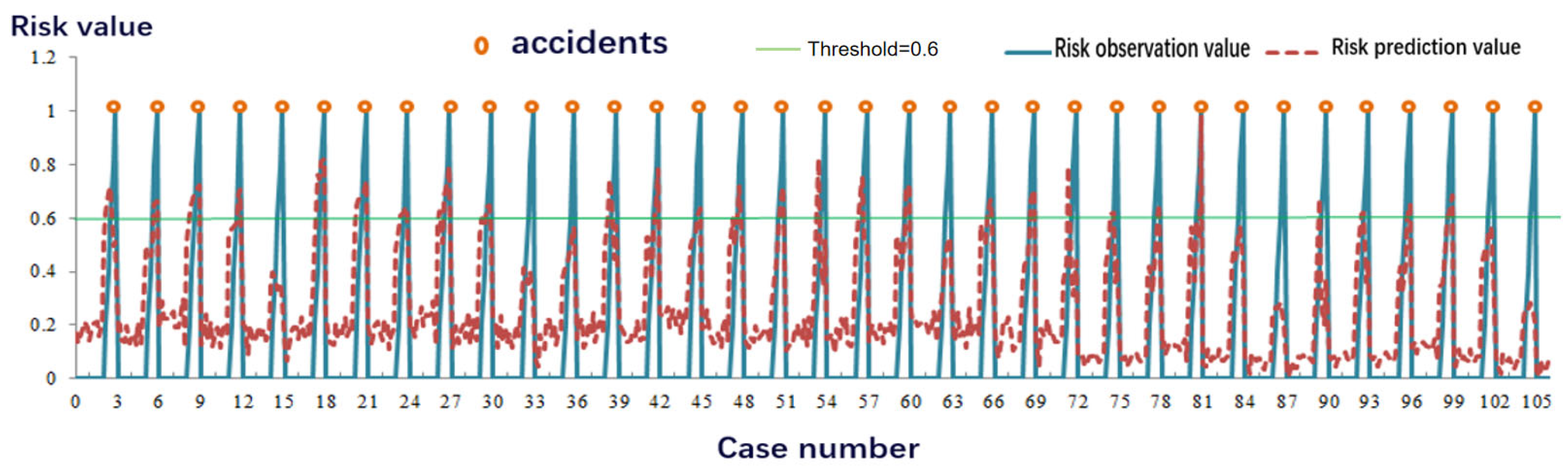
This study established a technological system for dynamic risk assessment on expressways based on the Beijing–Harbin Expressway, used as a representative road section in China. The system consists of finely grained models that operate on a minute-level dimension. For periods in which accidents are of high risk, a fine-grained risk assessment is performed at the minute level. Following analysis of accident and traffic flow data, input parameters for the dynamic risk assessment model were derived. Data within the 5-, 10-, 20-, and 30-min periods prior to the occurrence of accidents were used to determine suitable data collection and model-training time frames, define risk values, and conduct dynamic risk assessment modeling. Error analysis showed that selecting data from the first 30 min prior to the occurrence of accidents as well as data from the first 30 min of the corresponding control group for the dynamic risk assessment modeling based on decision trees and ANFIS resulted in the smallest model errors and a high accuracy in accident prediction. Specifically, decision trees were employed to identify the primary influencing factors of dynamic traffic operation risk, and these were then used for ANFIS modeling. Therefore, for the dynamic risk assessment of traffic operations on an expressway section in an urban agglomeration, employing data from the 30 min prior to accidents for training and simulation of a dynamic risk assessment model is recommended. The trained model can be used for a real-time assessment of traffic operation risk within each time interval. Effective control measures such as the issuance of risk warnings, accident forecasts, lane management, and speed control can be employed if risk values are greater than 0.6.
Overall, this study shifted the focus from ex-post risk evaluation to ex-ante risk analysis. This marks a departure from the traditional approach of relying solely on statistical and historical data for road risk analysis. The findings can be applied to real-time monitoring of traffic operation risk levels on roads and serve as the basis for developing targeted accident alerts and traffic control measures. This approach enhances the technology and efficiency of traffic safety management to ensure road traffic safety. The main significance of this study is reflected in the following aspects:
(1) For a certain scenario, we can conduct safety assessments in advance based on its traffic flow characteristic data, transforming post-evaluation into pre-evaluation.
(2) This study used data from China and focused on expressions in urban agglomerations. It can be directly applied to expressions in Chinese agglomerations, filling the gap in related fields.
In this article, we mainly considered the characteristics of traffic flow and conducted a dynamic risk assessment model. However, this study still has the following shortcomings:
Firstly, we only considered some relatively simple traffic flow characteristics. In order to better model, some complex features should also be considered, such as the distribution of speeds on different lanes and the correlation coefficient between the speeds of front and rear vehicles [
19].
Secondly, we did not consider static risk assessment factors [
28] and environmental characteristics (such as weather characteristics [
29]). Considering that traffic safety is a complex system, incomplete feature inputs may introduce heterogeneity and bias [
21].
Our further research will be focused on assessment models with more comprehensive factors. Through intelligent description and factor analysis of a large amount of traffic flow data, traffic environment, road facilities, and traffic accident data, we will extract indicator parameters that can reflect the dynamic and static risk levels of road traffic safety, further eliminate heterogeneity, and provide a more reliable model for the safety assessment of Chinese expressways.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}