1. Introduction
The logistics industry is a fundamental, strategic, and leading sector that supports the development of the national economy. Reducing logistics costs and increasing efficiency are not only essential for the nation, society, and industry, but also for the enterprises themselves. For many companies, transportation costs are usually the largest portion of their logistics expenses. According to statistics from the National Development and Reform Commission, China’s total social logistics cost in 2023 reached CNY 18.2 trillion, a year-on-year increase of 2.3%, with the transportation cost amounting to CNY 9.8 trillion, increasing by 2.8%. The transportation cost still accounts for the largest share of the total social logistics cost and is one of the key expenditures for logistics companies. The high proportion of the transportation cost is largely influenced by the delivery costs of logistics companies. According to the “2021 Logistics Business Environment Survey” published by the China Federation of Logistics and Purchasing, delivery costs ranked fourth among the top nine items for which the surveyed companies reported the most significant cost increases, accounting for 35.5%. The persistently high delivery costs are closely related to the failure of many logistics companies to develop scientific, reasonable, and efficient delivery routes, which remains a pressing issue for many enterprises. Currently, the majority of delivery problems faced by enterprises can be categorized as the Vehicle Routing Problem (VRP) and its variants, for which further in-depth research is necessary.
The VRP was first introduced by Dantzig and Ramser in 1959, and was initially termed “The truck dispatching problem” [
1]. The authors extended the concept of the Traveling Salesman Problem (TSP) by introducing the constraint of multiple vehicles. Subsequently, researchers have proposed various variants of the VRP based on different scenarios encountered in reality. These include the Capacitated Vehicle Routing Problem (CVRP) [
2], Dynamic Vehicle Routing Problem (DVRP) [
3], Vehicle Routing Problem with Pickup and Delivery (VRPPD) [
4], the Heterogeneous Fleet VRP (HFVRP) [
5], among others. The Vehicle Routing Problem with Time Windows (VRPTW) [
6] is a significant variant of the VRP that is characterized by time window constraints. As a significant branch of combinatorial optimization problems, the VRPTW has attracted extensive research interest over the years.
The Vehicle Routing Problem with Soft Time Windows (VRPSTW) is an extension of the VRPTW that allows for more flexible scheduling under time window constraints. Soft time windows mean that customers can accept service outside of their specified time windows, but usually at the cost of a penalty fee. Each customer has a desired service time window, and if the vehicle arrives within this window, the service can begin normally without incurring additional costs. However, if the vehicle services the customer outside of their time window, a penalty cost is incurred. Because exceeding the time window incurs extra costs, scheduling strategies must balance timely service and cost reduction. Soft time windows provide greater scheduling flexibility compared to hard time windows, allowing vehicles to adjust their arrival and service times within certain limits to optimize the overall routes and costs. Zhang et al. [
7] noted that the feasible solution space for the VRPSTW is larger than that for the VRPHTW, providing decision-makers with more options. The VRPSTW effectively simulates many scenarios wherein the time window constraints are not strict. This model makes it suitable for situations requiring flexible scheduling, such as express delivery and maintenance services, for which customers may tolerate a certain degree of early or late service. Considering both customer experience and economic benefits, soft time windows are more applicable to real-world situations. Chiang et al. [
8] argue that the VRPSTW can effectively reduce delivery costs without significantly lowering customer satisfaction.
The Vehicle Routing Problem with Fuzzy Time Windows (VRPFTW) is an extended version of the vehicle routing problem that aims to address the uncertainty and vagueness of time windows. In practical applications, a customer may not only have a desired time window for receiving service but may also have a tolerable time window. Incorporating fuzzy logic to consider the flexibility of time windows allows the service to be delivered earlier or later within a certain range while also considering the corresponding customer satisfaction levels, an approach that better balances customer satisfaction and operational costs. Tang et al. [
9] were among the first to consider the VRPFTW. The authors used fuzzy membership functions to describe the service-level issues related to the window violations in vehicle routing problems, and thus introduced the concept of fuzzy time windows. Based on this concept, they proposed the vehicle routing problem with fuzzy time windows. The model they established is framed as a multi-objective optimization problem, with the objective functions able to minimize the total distance and maximize the overall service level.
However, both the VRPSTW and the VRPFTW have some flaws when describing real-world scenarios, as follows:
- (1)
The VRPSTW model overlooks the service levels. In some cases, violating the time windows does not directly result in any penalty costs, but customer satisfaction (the service level of the delivery side) may decrease, potentially leading to long-term profit losses.
- (2)
Furthermore, in the current literature, VRPSTW models are often used to calculate the penalty costs in the objective function by directly multiplying the amount of time violated by a predetermined penalty coefficient. However, this approach is not very realistic, as it ignores the size of the customer demand, which in practice, is often related to the calculation of penalty fees.
- (3)
In contrast, the VRPFTW model established by Tang et al. is overly simplistic. The objective function of this model only considers the minimization of the total distance and the maximization of the overall service level, and its service-level calculation neglects the characteristics of individual customers, and thus cannot accurately reflect the true service level of the delivery side.
In light of the increasing demand in the logistics and transportation sectors, scholars have proposed various algorithms to solve the VRPTW, aiming to enhance the efficiency of vehicle transportation logistics. Initially, researchers attempted to solve the VRPTW using exact algorithms; however, because the VRPTW is an NP-hard problem, using exact algorithms to solve large-scale VRPTWs is time-consuming. As a result, over time, scholars have proposed various heuristic algorithms to tackle the VRPTW, including the Genetic Algorithm (GA) [
10], Simulated Annealing (SA) [
11], Memetic Algorithm (MA) [
12], Ant Colony Optimization (ACO) [
13], Particle Swarm Optimization (PSO) [
14], Tabu Search (TS) [
15], Harmony Search (HS) [
16], Large Neighborhood Search (LNS) [
17], Variable Neighborhood Search (VNS) [
18], and other techniques.
Up to now, no heuristic or metaheuristic algorithm has been found to be superior to other algorithms in all situations, and each algorithm has its own advantages and disadvantages; therefore, researchers have attempted to combine multiple algorithms to obtain better ones. B. Yu and colleagues proposed a hybrid algorithm that combines Ant Colony Optimization (ACO) and Tabu Search (TS) [
19]. YANG SHEN and colleagues proposed a hybrid swarm intelligence algorithm that combines the Ant Colony System (ACS) and Brain Storm Optimization (BSO) algorithms [
20] to minimize the total distance for solving the VRPTW. Moreover, Qichao Wu and colleagues proposed using Neighborhood Comprehensive Learning Particle Swarm Optimization (N-CLPSO) [
21] to solve the VRPTW. The above studies indicate that a reasonable combination of two or more methods can enhance their advantages in specific situations and compensate for their disadvantages.
The Genetic Algorithm (GA) was first proposed by John Holland in the 1970s, and was designed based on the principles of biological evolution in nature. As a heuristic optimization algorithm, the GA has been applied to the VRPTW to find optimal delivery routes. By simulating the process of biological evolution in nature, the GA can find better solutions in large search spaces and demonstrates good robustness when dealing with complex optimization problems.
The Large Neighborhood Search (LNS) algorithm is an effective tool for solving complex combinatorial optimization problems. Paul Shaw utilized constraint programming and the LNS to address the VRPTW [
22], demonstrating high accuracy and a high local search capability. Grigorios and colleagues developed a Multi-objective Large Neighborhood Search (MOLNS) algorithm to solve the VRPTW [
23].
The model established in this paper is a multi-objective optimization model. One of the most commonly used heuristic algorithms for solving multi-objective vehicle routing problems is the Non-dominated Sorting Genetic Algorithm (NSGA), which was proposed by Srinivas and Deb in 1995 and is based on the concept of Pareto optimality. In 2000, the authors introduced an improved version called the NSGA-II, which incorporates an elitism strategy. The NSGA-II algorithm treats all the objectives as equally important when dealing with multi-objective optimization problems, without assigning priority to any single objective, and it seeks a set of Pareto optimal solutions through non-dominated sorting and the crowding distance, ensuring that all objectives are balanced and considered throughout the solution process. This approach is suitable for scenarios in which all objectives are equally important or it is difficult to clearly define the priorities.
The research on the above-mentioned solution algorithms has several shortcomings, as follows:
- (1)
The genetic algorithm has accuracy limitations when solving the VRPTW and faces challenges such as falling into local optimal solutions and a slow convergence speed in the later stages of the algorithm. In particular, the traditional genetic operators in the algorithm may become less effective as the population converges to a certain extent, rendering their performance negligible and potentially causing negative impacts by disrupting the superior individuals within the population.
- (2)
The LNS has its limitations, primarily due to its high computational resource consumption, and it can be constrained by the complexity of the search space and limitations related to computational resources, especially when dealing with large-scale problems.
- (3)
In scenarios in which certain objectives require higher priority, the standard NSGA-II may struggle to produce satisfactory solutions. In reality, most decision-makers face constraints due to limited resources and often establish priorities in multi-objective optimization. In such cases, optimizing the higher-priority objectives while also attempting to optimize the lower-priority objectives may yield results that are more valuable to decision-makers.
The research and contributions of this paper are as follows:
- (1)
The model established in this paper is a variant of the VRPTW that simultaneously considers soft and fuzzy time windows. The variant improves upon the traditional VRPSTW and VRPFTW models, creating a more comprehensive and realistic model called the VRPSFTW model.
- (2)
Considering the issues present in the related research, in this study, we address the VRPTW model by designing a Directed Mutation Genetic Algorithm (DGA) combined with a Large Neighborhood Search (LNS) algorithm (LDGA). This approach leverages the advantages of the genetic algorithm in the early stages while mitigating the slower convergence speed in the later stages, thereby improving the overall efficiency and accuracy of the algorithm, leading to better solution results.
- (3)
For the multi-objective problem, this paper employs a two-stage solution approach, designing two sets of algorithms based on the principles of “cost priority” and “service-level priority”. It moves away from traditional swarm intelligence algorithms that use the optimal solution from the last generation as the final answer, instead defining a “historical optimal solution” variable that is continuously updated during iterations to seek Pareto solutions. Additionally, a population update operator is introduced to incorporate the “historical optimal solution” into the population.
- (4)
The paper also optimizes the start service time by designing an operator to determine it.
- (5)
The simulation results demonstrate that the proposed algorithms achieve notable solution performance.
The structure of the rest of this paper is as follows:
Section 2 establishes a VRPSFTW model;
Section 3 details the specific design of the LDGA and two-stage algorithm;
Section 4 presents the relevant experimental results and their analysis;
Section 5 concludes the paper and discusses future research directions.
3. Algorithm Design
The VRPSFTW model established in this paper is a multi-objective programming model that is an extension of the VRPTW problem. The VRPTW is an NP-hard problem, and its search space grows exponentially with the increase in the problem size. Therefore, traditional exact algorithms often require significant computational resources and time to solve the VRPTW, making them both difficult and impractical. In this context, heuristic algorithms have become an effective approach for solving the VRPTW.
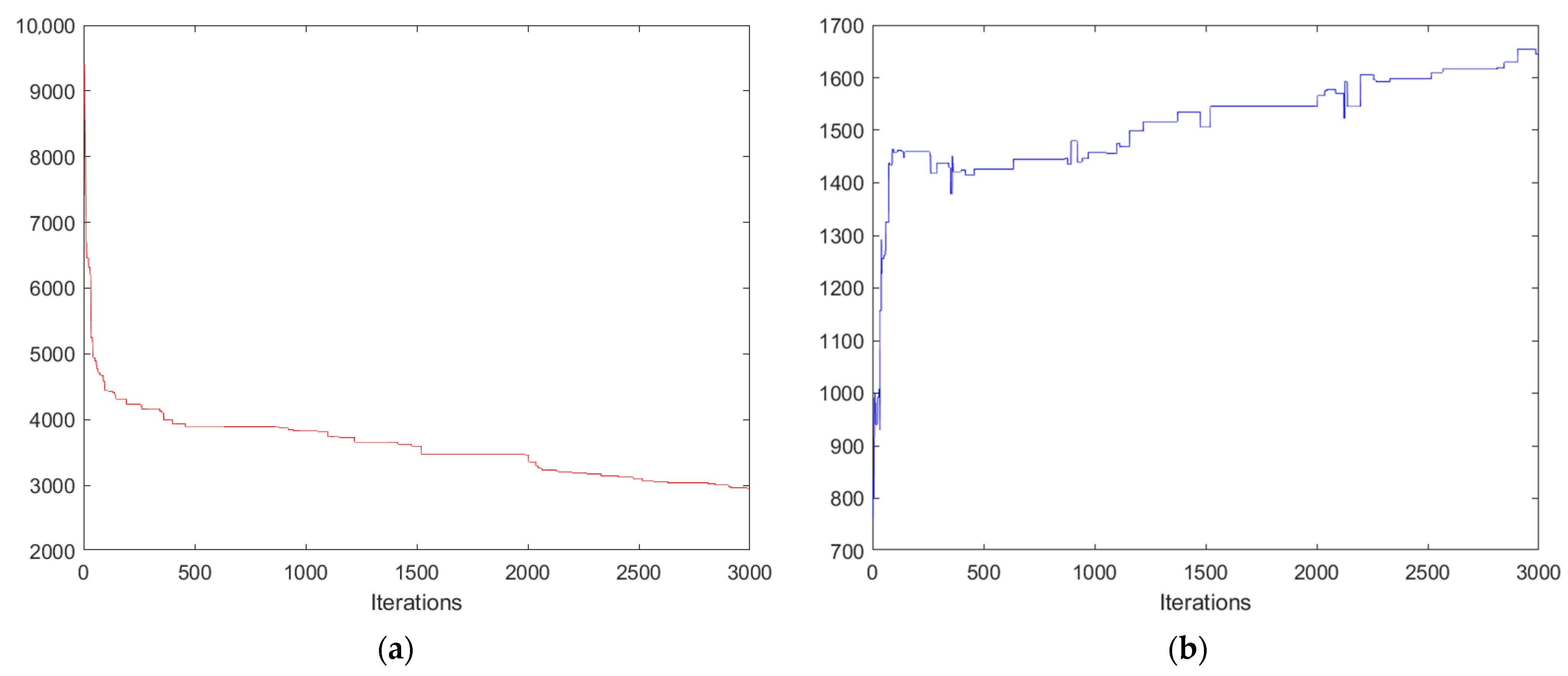
The Genetic Algorithm (GA) is a commonly used heuristic algorithm. When solving complex problems such as the VRPTW, genetic algorithms can usually find better solutions, but their search efficiencies vary at different stages. In the early stages of genetic algorithms, there are significant differences among the individuals in the population due to the vast search space and large diversity. Therefore, operations such as selection, crossover, and mutation can rapidly and effectively explore the solution space to obtain better solutions. Hence, the early-stage efficiency of genetic algorithms is relatively high. However, as the search progresses, the individuals in the population gradually become similar, reducing the diversity, and the rate of fitness improvement slows down. Consequently, the search efficiency of genetic algorithms decreases. The continuation of traditional non-directed mutation operations at this point may no longer be useful to the search for better solutions and may even have negative effects due to the lack of clear direction and the excessive randomness. Therefore, this paper proposes a Directed Mutation Genetic Algorithm (DGA) combined with Large Neighborhood Search (LNS) algorithm (LDGA). It fully utilizes the advantages of genetic algorithms in the early stages and compensates for the weaknesses of the crossover and mutation operators in the later stages. This enhancement improves the search capability in the later stages, thereby enhancing the overall efficiency and accuracy of the algorithm and ultimately achieving better solution results.
For the VRPTW with hard time windows, the time at which vehicle k starts servicing customer i is not a decision variable because when vehicle k arrives at customer point i earlier than , it must wait until time to begin service; when vehicle k arrives at customer point i within , it can start service immediately; and vehicle k is not allowed to arrive at customer point i later than . The VRPTW with hard time windows has only one objective function, which is to minimize the total distance traveled by the vehicle, which is independent of .
For the VRPSTW, when vehicle k arrives at customer i earlier than time , it can start service early, but incurs a certain penalty cost. The exact timing of the early start to the service will affect the total cost objective function value, and thus optimization is necessary. For the VRPFTW, there is a tolerable start time () () for customer i, and the vehicle can start service at any point in the range . The specific timing of the service start will impact the total service level objective function value; thus, this also requires optimization.
However, as we understand it, in most of the current studies that employ heuristic algorithms to solve the VRPSTW or VRPFTW, researchers do not discuss the optimization of the starting service time, which they often assume is the same as the arrival time, or when the arrival time is earlier than , the starting time is set to be delayed until and after that, the service starts immediately. In this study, we optimized the start of the service time and designed an operator to determine it.
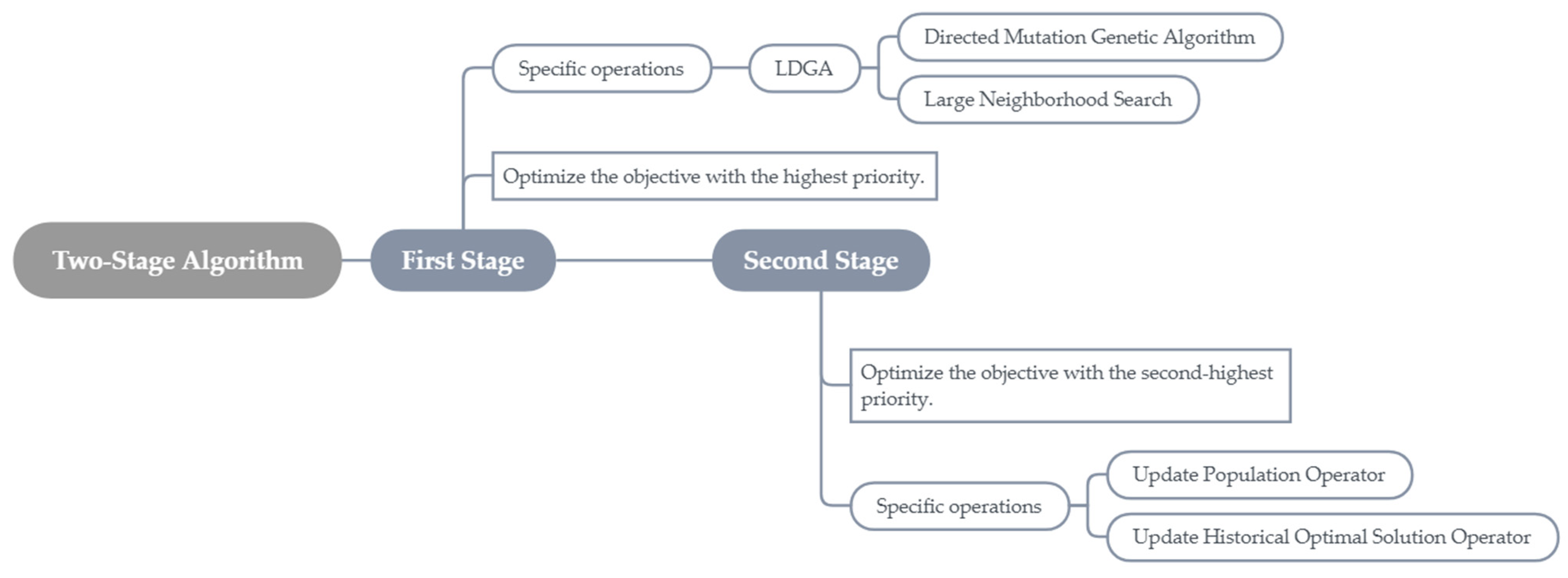
To address the multi-objective problem, this paper adopts a two-stage solution approach and discards the traditional method of using the optimal solution from the final generation of the population as the final solution in swarm intelligence algorithms. Instead, it defines a “historical optimal solution” variable and designs an algorithm that continuously updates this variable during the iteration process to seek Pareto solutions. Additionally, an updating operator for the population is designed to incorporate the “historical optimal solution”, resulting in excellent solving performance.
This paper designs two sets of algorithms to solve the VRPSFTW based on the principles of “cost priority” and “service-level priority”, respectively.
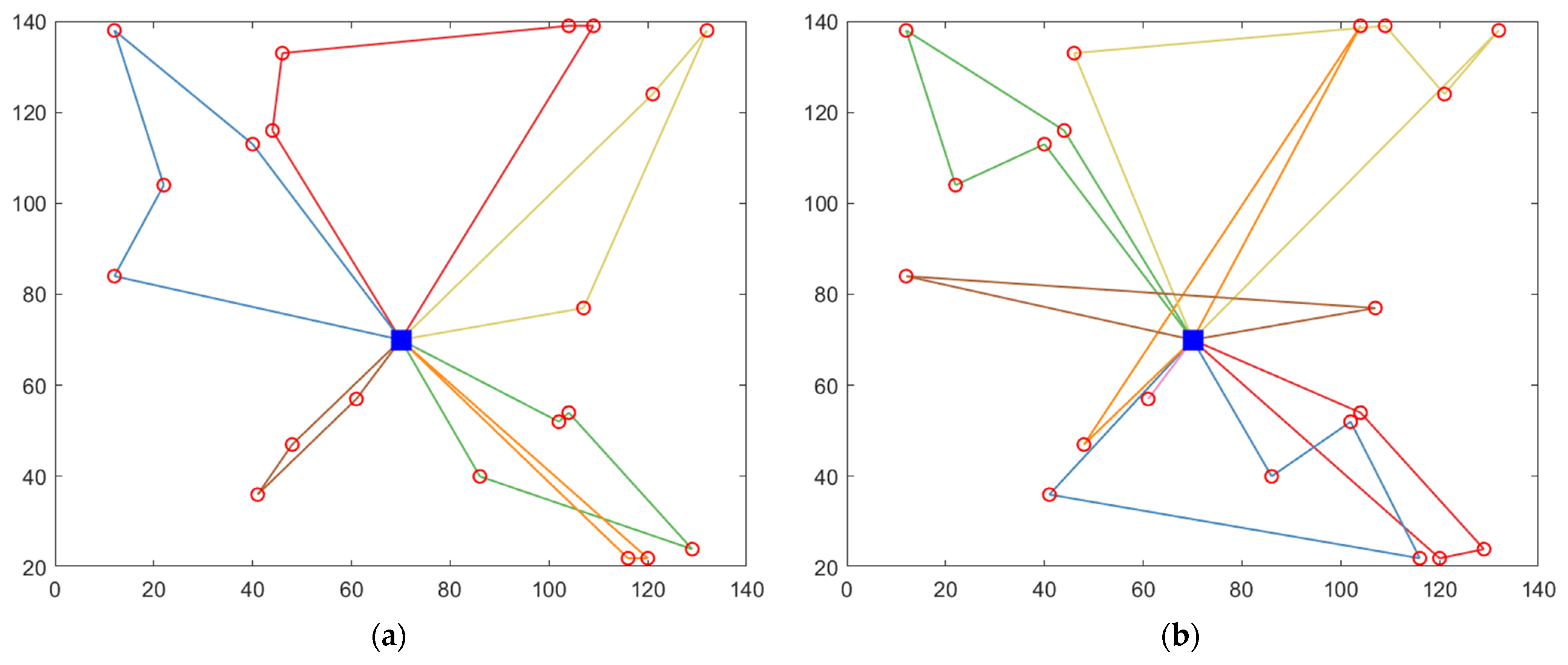
The general concept of the algorithm designed in this paper is illustrated in
Figure 1.
3.1. Directed Mutation Genetic Algorithm
Below is a detailed introduction to the algorithm, including its chromosome encoding, initial population construction, fitness evaluation, chromosome selection, crossover, traditional mutation, and directed mutation.
3.1.1. Chromosome Encoding
In genetic algorithms, chromosome encoding is a way to represent the solutions to a problem as chromosomes. Each chromosome represents an individual (that is, a feasible solution). A chromosome is composed of a set of genes, and the population consists of a set of chromosomes.
The coding method adopted in this study treats the customer index numbers as the elements that constitute individuals (1, 2, 3, …, N), using a sequence of arranged customer index numbers to represent the customers served by a vehicle in order. The paths of all the vehicles in an overall delivery plan are concatenated to form a single individual code, and the index numbers of all the available vehicles are increased by N, resulting in a set, z = {1 + N, 2 + N, 3 + N, …, K + N}. The elements of set z are inserted sequentially between every two vehicle paths to indicate the vehicles’ return to the distribution center and to facilitate the distinction between different vehicle paths. If the length of the individual code has not reached N + K − 1, then elements from set z that have not been inserted between the two vehicle paths will continue to be added to the end of the code. When the length of the individual code reaches N + K − 1, the addition will stop.
For example, if the number of customers is 6, the customer index numbers are 1, 2, 3, 4, 5, 6, the maximum number of vehicles is 4, and the vehicle index numbers are 1, 2, 3, 4, then
z = {1 + 6, 2 + 6, 3 + 6, 4 + 6} = {7, 8, 9, 10}. A feasible individual encoding can be represented as 127348569, where 7 and 8 indicate that a vehicle has completed its delivery and returned to the depot. The encoding is divided into three parts corresponding to the delivery routes of three vehicles, with 0 representing the depot, as follows:
Because 9 is not inserted between the two vehicle paths, it is added to the end of the three routes. At this point, the length of the individual encoding has reached N + K − 1; thus, 10 is no longer added.
3.1.2. Initial Population Construction
In the genetic algorithm, the construction of the initial population directly impacts the convergence speed of the algorithm and its final optimization results. A good initial population can help the algorithm quickly find the global optimal solution, while a poor initial population is more likely to cause the algorithm to converge to a local optimal solution, or even fail to converge at all.
If the individuals in the initial population are somewhat close to the optimal solution, this will be more favorable for accelerating the convergence process. Therefore, the initial population construction method used in this study differs from the commonly used completely random construction. Instead, a heuristic method is employed, utilizing time window and vehicle load constraints to construct an initial population that satisfies these constraints as much as possible. The method is as follows:
Randomly generate a sequence that can traverse all customers, where each element represents the customer index (i {1, 2, 3, …, N}). Traverse each customer according to sequence and add them to the paths. The specific principles are as follows:
Initialize a path, with the load of goods currently loaded by the vehicle on this path set as ;
The current customer index being traversed is , the corresponding customer demand is , and the maximum load capacity of each vehicle is ;
Determine whether inserting this customer into the current path satisfies the load constraint;
When , compare the start time () of the service window to find a suitable position to add the customer to the current path, for which there are three possible cases:
If the current path is empty, then simply add the customer to it;
If there is only one customer () in the current path, compare the start time of the service windows ( and ):
- a)
If is earlier than the start time of customer ’s service window (), then insert customer before ;
- b)
If is later than the start time of customer ’s service window (), then insert customer after ;
If there are multiple customers in the current path, then traverse their start times of their service windows:
- a)
If is earlier than the start time of the first customer in the path, then insert customer at the beginning;
- b)
If the interval between the start times of two adjacent customers in the path can accommodate , then insert customer between them;
- c)
If is later than the start time of the last customer in the path, then insert customer at the end;
When , create a new path and insert customer into it;
Following the above steps, traverse from customer to to generate an initial solution;
Repeat the above steps until initial solutions that meet the population size are generated.
3.1.3. Fitness Evaluation
In the “cost priority” algorithm, the fitness is the inverse of the cost function value, as follows:
In the “service-level priority” algorithm, the fitness is the overall service-level function value, as follows:
The fitness defined in this paper is primarily used for optimizing the solution of the first-priority objective in the first stage of a two-stage algorithm. The specific details of the two stages will be explained in more detail later.
3.1.4. Chromosome Selection
The roulette wheel selection method is employed in this study. In the genetic algorithm, roulette wheel selection is a commonly used selection strategy. Its basic idea is similar to selecting individuals on a rotating wheel, where the probability of each individual being selected is proportional to its fitness value. The advantage of this method is that it effectively preserves individuals with higher fitness, granting them a greater chance of survival, while it also considers individuals with lower fitness, thereby reducing the likelihood of falling into local optima to some extent.
3.1.5. Crossover
The crossover operator in the genetic algorithm simulates the gene exchange process in biological reproduction and evolution. Through the crossover operator, information between different individuals can be exchanged, resulting in new individuals. Specifically, the crossover operator exchanges part of the chromosome information (gene sequences) between two parent individuals to produce new offspring individuals. This way, there is a chance to combine the excellent characteristics of different individuals, resulting in better offspring.
The crossover method employed in this study is as follows: If two individuals, A and B, undergo a crossover operation, two crossover points are randomly selected, and the chromosome segments between these points form the crossover interval. The elements within the crossover interval are separately placed in front of the other individuals, resulting in new individuals, A’ and B’. Then, the new individuals are traversed from front to back for processing purposes; if duplicate elements are encountered, the second element is removed, leaving only the first one, which ensures that each element appears only once. Once these operations are complete, the crossover operation for individuals A and B is finished.
3.1.6. Traditional Mutation
The traditional mutation operation used in this study involves randomly selecting two genes on a chromosome and exchanging their positions.
3.1.7. Directed Mutation
This paper designs a directed mutation operator based on the traditional mutation operator, and the specific operation is as follows:
Firstly, create a duplicate (b) of chromosome a.
Perform the traditional mutation operation on duplicate b, generating b’.
Compare the fitness levels of a and b’. If the fitness of b’ is better than that of a, replace a with b’; otherwise, retain a.
Unlike traditional mutation, the mutation rate of the directed mutation operator should be set higher. In this paper, it is set to 100%, meaning that all the individuals selected by the selection operator participate in the directed mutation.
3.2. Large Neighborhood Search
Large Neighborhood Search (LNS) is a heuristic search algorithm that is primarily used to solve combinatorial optimization problems (COPs). LNS explores the solution space by destroying and repairing parts of a solution, aiming to find better solutions.
The algorithm used in this study primarily applies the concept of destruction and repair from the LNS algorithm. Specifically, it involves removing a portion of the customers from the path and then re-inserting them.
3.2.1. Removal Operator
Randomly select a customer from the path and remove it, then place it in the set μ.
Randomly select a customer c from set μ.
Calculate the relevance between the remaining customers in the path and customer
c, then arrange these customers in temporary set
α in descending order of their relevance to customer
c. The function used to calculate the relevance is as follows:
where
represents the normalized value of
, with a range of [0, 1].
represents whether i and j are on the same vehicle’s delivery route. If they are,
= 0; otherwise,
= 1.
In order to avoid a situation wherein similar sets of visits are constantly selected based on relevance alone, a random element is added:
where
RemoveIndex represents the index of the next customer to be removed in set
α;
Remain represents the number of customers in set
α; Rand represents a random number between 0 and 1; and
P is the parameter controlling the determinism. When
P = 1, relevance is ignored, and customers are randomly selected for removal from set
α. When
P = ∞, it approaches selecting the customer in set
α with the highest rank (i.e., the customer most relevant to customer
c) for removal.
The removed customers are stored in set μ.
Repeat steps B to E until the desired number of removed customers is met.
3.2.2. Re-Insertion Operator
The approach combines the farthest insertion heuristic with branch and bound.
Take out an element from set μ, which is composed of removed customers.
Find all the insertion points where inserting the element into the route satisfies the vehicle load constraint. If no such points exist, then create a new route and place the element into it.
Calculate the increase in the distance that each feasible insertion scheme for the customer would bring to the total route, and identify the smallest increase in the distance among them.
Perform the above operations for each element in the set μ. Find the element with the maximum “minimum distance increment” and insert it into the path according to the scheme with the smallest distance increment. Then, remove this element from the set μ.
Repeat steps A to D until all the elements in the set μ are re-inserted into the route.
3.2.3. Acceptance Criterion
If the fitness value of the new solution is greater than that of the solution before the destruction and repair process, then accept the new solution as the current solution.
3.3. Directed Mutation Genetic Algorithm Combined with Large Neighborhood Search
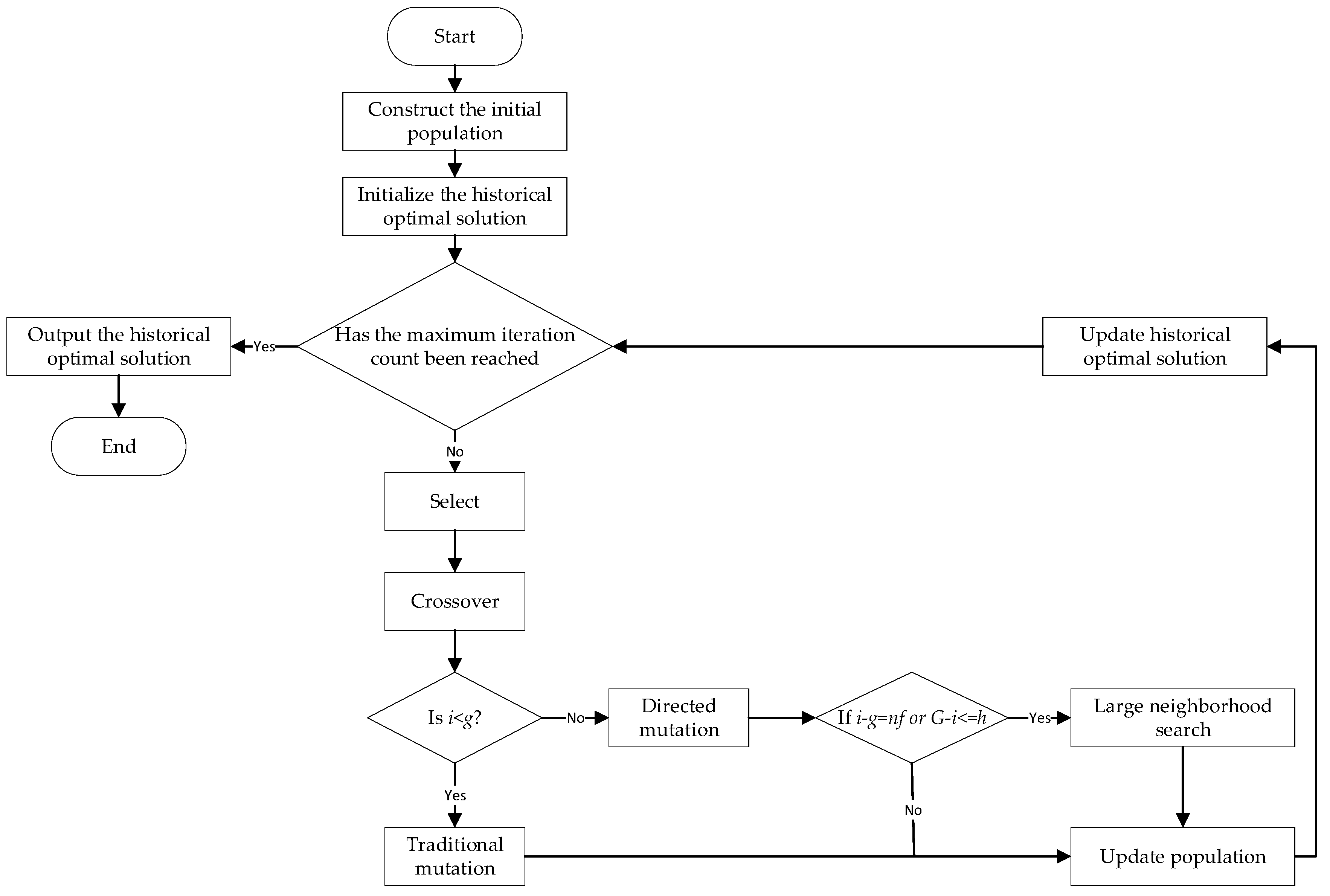
To address the issue of high efficiency in the early stages but low efficiency in the later stages of the genetic algorithm, this paper proposes an algorithm that fully leverages the advantages of the genetic algorithm in the early stages while enhancing the search capability in the later stages. The specific combination approach of the algorithm is outlined as follows:
In the early stage of the algorithm, only the traditional operations of the genetic algorithm are performed, adopting traditional mutation;
When the algorithm iterates to the g-th generation, the population converges to a certain extent, and the speed of exploring the optimal solution slows down. At this point, directed mutation begins to replace traditional mutation;
At the same time, a large neighborhood search removal operator and a re-insertion operator are added after the directed mutation operator;
Starting from the g-th generation, the removal and re-insertion operations are performed every f generations. Finally, the removal and re-insertion operations are performed in every generation of the last h generations.
The parameters
g,
f, and
h need to be reasonably set according to specific circumstances. The main consideration is the complexity of the problem, and the main factors that affect it are the number of points and their degree of clustering. If the problem is not very complex and requires fewer iterations to converge the population to a certain level, then
g and
f can be set smaller. If the problem is very complex, with a huge solution space, and requires more iterations to ensure that the algorithm has enough opportunities to explore the solution space, then
g should correspondingly be set larger. It is an empirical summary that for datasets with around 100 points, when the number of iterations
G is large (several thousand generations), balancing computational efficiency and effectiveness can be achieved by satisfying the following constraint:
This constraint actually limits the number of executions of the removal and re-insertion operators used in the LDGA for solving datasets containing approximately 100 points. The reason is that these operators are effective but require a long execution time. When the number of executions is less than 20, their effectiveness is not fully realized and when the number of executions exceeds 150, the execution time becomes excessively long, and the marginal benefits decrease significantly in the later stages. Therefore, based on the experience gained from our experiments, we recommend limiting the number of executions to the range of [20, 150].
3.4. Operator for Determining the Start of the Service Time
According to the encoding method adopted in this study, a chromosome represents a delivery plan that can be decoded into multiple vehicle delivery routes. In this study, the planning of the start service time is carried out for each distribution route.
represents the arrival time of vehicle k at customer i, and represents the time at which vehicle k starts serving customer i. represents the index of the i-th customer in the path among all the customers, where is the desired start time of the service window for that customer, and is the acceptable start time of the service window that the customer can tolerate.
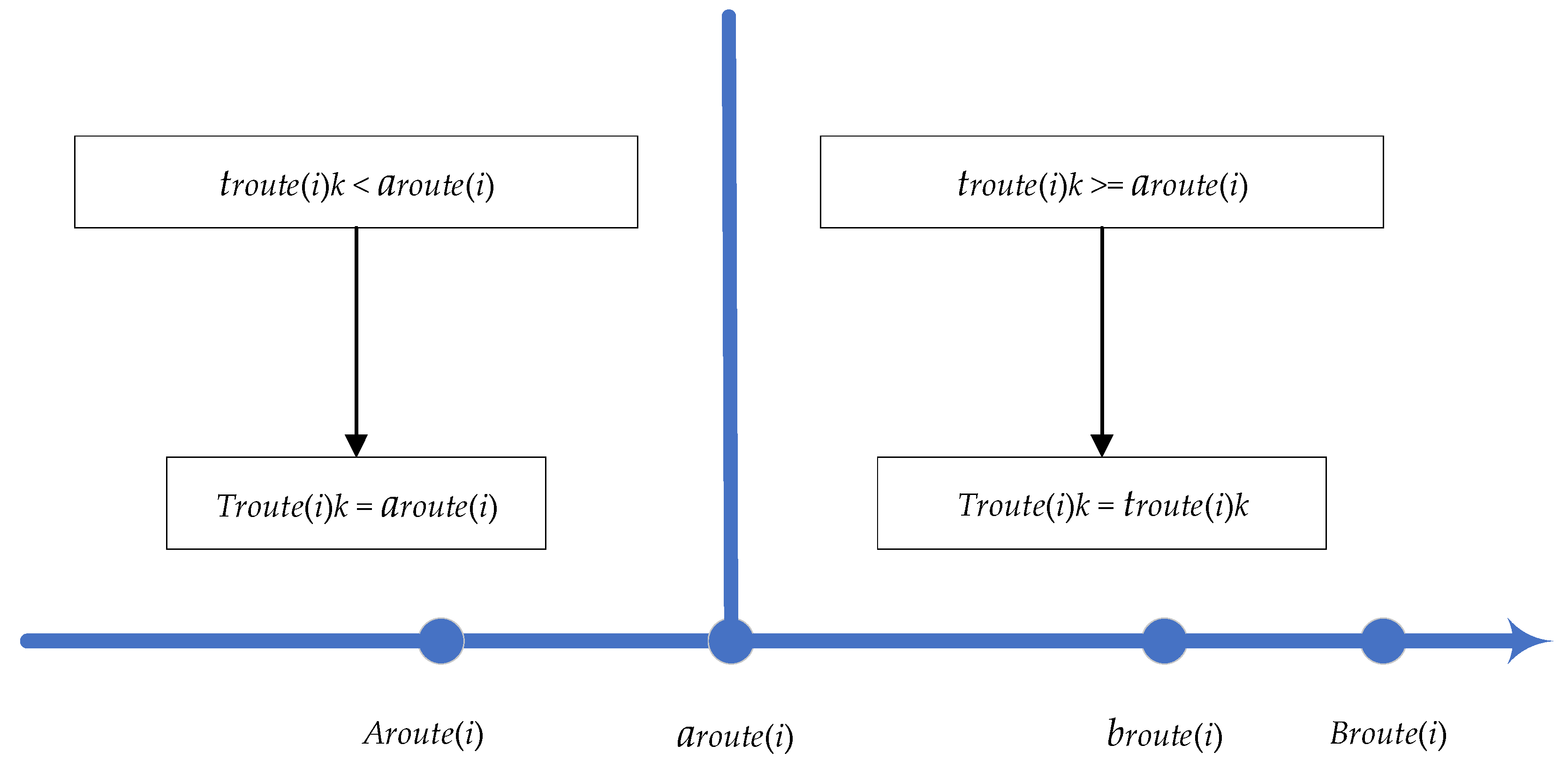
In the “cost priority” algorithm, the method for determining the start service time is as follows:
Starting from the first customer served by vehicle k, calculate the arrival time () of vehicle k at that customer;
If < , then execute the following operations:
Calculate the compensation cost of providing service to the customer in advance by one unit of time , where represents the demand of the i-th customer in that route;
is the waiting cost per unit time. Determine the relationship between and :
- a)
If , then ;
- b)
If , then determine which value is larger or smaller between and :
If , then ;
If , then .
If , then .
Repeat the process from A to C until all customers served by vehicle k have been traversed.
The idea behind the above operator is visually demonstrated in
Figure 2.
In the “service-level priority” algorithm, the method for determining the start service time is as follows:
Starting from the first customer served by vehicle k, calculate the arrival time () of vehicle k at the location of that customer;
If , then ;
If , then ;
Repeat the process from A to C until all customers served by vehicle k have been traversed.
The idea behind the above operator is visually demonstrated in
Figure 3.
3.5. Update Historical Optimal Solution Operator
The previous operations mainly utilized the fitness function to screen and accept new solutions. In our algorithm, the “fitness function” is defined as “the objective function prioritized for optimization within the multi-objective function”. Therefore, the main role of the various operators in the preceding stage is to complete the optimization of the first phase in the two-stage algorithm. Updating the historical optimal solution is the core operation of the second stage of the two-stage algorithm and a key step in seeking Pareto solutions. This paper describes the specific operations of this operator in the two algorithms: “cost priority” and “service-level priority”.
The premise for updating the historical optimal solution is that a historical optimal solution is currently available. The operation for initializing the historical optimal solution follows immediately after the population initialization and before the iterative optimization. Taking “cost priority” as an example, it is first necessary to filter out the subset of individuals in the initial population with the minimum total cost. Then, from , the subset with the highest overall service level should be selected. Finally, we randomly choose one individual from as the initial historical optimal solution. The “service-level priority” follows a similar approach: It is first necessary to filter out the subset of individuals with the highest overall service level. Then, from this subset, those with the minimum total cost should be selected. Finally, we randomly choose one individual from this group as the initial historical optimal solution.
In the “cost priority” algorithm, the method for updating the historical optimal solution is as follows:
Calculate the cost function value of the current historical optimal solution () and the overall service-level function value of the current historical optimal solution ();
Select the individuals with the minimum cost function values from the current population to form the set , and let their cost function values be ;
If :
If :
- a)
Select all individuals from with an overall service level greater than to form the set ;
- b)
If is non-empty:
Calculate the difference between the overall service level of each individual in set and , and identify all individuals with the largest difference to form the set ;
Select any individual from set as the new historical optimal solution;
- c)
If is empty, then retain the current historical optimal solution;
If :
- a)
Select any individual from set to temporarily replace the historical optimal solution;
- b)
Calculate the cost function value of the current historical optimal solution () and the overall service-level function value of the current historical optimal solution ();
- c)
Select all individuals from with an overall service level greater than to form the set ;
- d)
If is non-empty, complete the following steps:
Calculate the difference between the overall service level of each individual in set and , and identify the individual with the largest difference to form the set ;
Select any individual from set as the new historical optimal solution;
- e)
If is empty, then retain the current historical optimal solution;
If , then retain the current historical optimal solution.
In the “service-level priority” algorithm, the method for updating the historical optimal solution is as follows:
Calculate the cost function value of the current historical optimal solution () and the overall service-level function value of the current historical optimal solution ();
Select the individuals with the maximum overall service-level function values from the current population to form the set , and let their overall service-level function values be ;
If :
If :
- a)
Select all individuals from set with cost function values less than to form the set ;
- b)
If is non-empty, complete the following steps:
Calculate the difference between and the cost function value of each individual in set and identify all individuals with the largest difference to form the set ;
Select any individual from set as the new historical optimal solution;
- c)
If is empty, then retain the current historical optimal solution.
If :
- a)
Select any individual from set to temporarily replace the historical optimal solution;
- b)
Calculate the cost function value of the current historical optimal solution () and the overall service-level function value of the current historical optimal solution ();
- c)
Select all individuals from set whose cost function value is less than to form set ;
- d)
If is non-empty, complete the following steps:
Calculate the difference between and the cost function value of each individual in set and identify all individuals with the largest difference to form set ;
Select any individual from set as the new historical optimal solution;
- e)
If is empty, then retain the current historical optimal solution.
If , then retain the current historical optimal solution.
3.6. Update Population Operator
In order to fully leverage the value of the superior individuals generated during the iteration process while ensuring the diversity of the population and avoiding local optimal solutions, the new population is composed of three parts: the current historical optimal solution, the new set of individuals generated during this iteration from the individuals selected by the selection operator, and a portion of the population from before this iteration. Firstly, the first two sets are added to the new population. Then, the individuals from the previous population are sorted in descending order based on their fitness values. Finally, a batch of individuals is selected from the sorted list and added to the new population until the number of individuals in the new population meets the specified criteria.
3.7. Two-Stage Algorithm
The first phase of the two-stage algorithm is primarily based on the Directed Mutation Genetic Algorithm combined with Large Neighborhood Search (LDGA), while the second phase focuses on the operator for updating the historical optimal solution.
Figure 4 presents a flowchart of the algorithm.
5. Conclusions
This paper established a vehicle routing problem with soft time windows and fuzzy time windows (VRPSFTW) and designs a two-stage heuristic algorithm to solve the VRPSFTW.
The VRPSFTW established in this study represents a synthesis and extension of the VRPSTW and VRPFTW, incorporating the strengths of both models while addressing their shortcomings.
This paper has improved the mutation operation of traditional genetic algorithm in the LDGA by proposing a directed mutation operator, while also integrating a large neighborhood search algorithm, enhancing the search capability of the algorithm in the later stages. The overall algorithm design fully utilizes the advantages of the genetic algorithm in the early stages. In the middle and later stages, directed mutation is used instead of traditional mutation, and removal and re-insertion operators are introduced to compensate for the weakness of the genetic algorithm in the later stages, thereby improving its overall efficiency and accuracy. The experimental results indicate that the LDGA is significantly competitive in exploring the solution space among the selected state-of-the-art algorithms recently published.
For multi-objective problems, the two-stage algorithm designed in this paper significantly outperforms the NSGA-II in handling priorities among objectives. Under conditions of limited resources and clearly defined primary goals, the algorithm can effectively optimize the key objectives while also addressing the secondary objectives within feasible limits. This mechanism makes the algorithm more aligned with the demands of practical applications.
The implications of this paper for relevant business managers in reality are as follows:
- (1)
The VRPSFTW model is more effective at describing the real-world scenarios faced by managers who have access to customer-related information. This model simultaneously considers two objective functions: total cost and total service level. This not only enables managers to optimize both the company’s short-term and long-term profits when designing delivery plans, but also helps improve customer satisfaction, achieving a win–win situation for both the company and its clients. Moreover, the model provides a more accurate and reasonable characterization of total cost and total service level, allowing managers to better understand the actual impact of the related delivery plans and thus make more informed vehicle routing decisions.
- (2)
The LDGA provides a valuable tool that management decision-makers in relevant enterprises can consider for optimizing vehicle routing arrangements.
- (3)
In reality, management decision-makers often have limited resources and typically have clear priority optimization goals during specific periods. Therefore, they can use the two-stage algorithm and flexibly choose solution strategies based on their actual needs to better achieve their objectives:
- 1)
When the company is in a phase that requires prioritizing cost savings, decision-makers can use the two-stage algorithm with the cost priority strategy for vehicle routing. This approach aims to minimize cost while also optimizing the service level to a certain extent, thereby avoiding any neglect of the service level due to a sole focus on cost reduction.
- 2)
When the company is in a phase that requires prioritizing customer satisfaction, decision-makers can use the two-stage algorithm with the service-level priority strategy for vehicle routing. This approach aims to maximize the service level while also optimizing cost to some extent, thereby avoiding any neglect of cost control that could lead to resource waste due to a sole focus on the service level.
Although the algorithm designed in this study demonstrates excellent performance, there is still room for further improvement. In our algorithm structure, the timing and frequency of the use of various operators are derived from empirical summaries based on multiple experiments. We hope to establish more standardized rules or develop adaptive rules that can be adjusted according to the population conditions in future research, which could potentially enhance the overall performance of the algorithm. Furthermore, the operator we designed to determine the starting service time employs a greedy strategy, which may not guarantee an optimal solution, which warrants further investigation.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}