
A Prompt Example Construction Method Based on Clustering and Semantic Similarity


Abstract
1. Introduction
- This paper proposes a novel prompt example construction method, called the clustering-semantic similarity prompt example construction method. By innovatively combining the clustering and semantic similarity techniques, this method was compared with five other prompt example construction methods across seven datasets and six LLMs. The overall accuracy and stability of this method significantly outperform other methods, effectively improving the accuracy of LLM-generated answers.
- The paper conducts comparative testing on seven datasets, evaluating the impact of six prompt example construction methods on the answer accuracy of six LLMs. Through an in-depth analysis of the experimental results, the study summarizes key patterns regarding how different prompt example construction methods affect LLM output performance, providing important insights for selecting prompt example construction methods to enhance LLMs in practical applications:
- –
- As the parameter scale of LLMs increases, the impact of different prompt example construction methods on the accuracy of LLM-generated answers diminishes.
- –
- In comparative tests across multiple datasets and LLMs, the semantic similarity, clustering, and clustering–semantic similarity methods performed the best overall, followed by the identical and random methods, with the zero-shot method performing the worst.
- –
- The random method outperformed the identical method overall, indicating that diverse prompt examples lead to more significant improvements in the accuracy of LLM-generated answers.
2. Literature Review
2.1. Individual Features
2.1.1. Example Structure
2.1.2. Example Content
2.1.3. Example Quality
2.2. Overall Features
2.2.1. Example Order
2.2.2. Example Quantity
2.2.3. Example Distribution
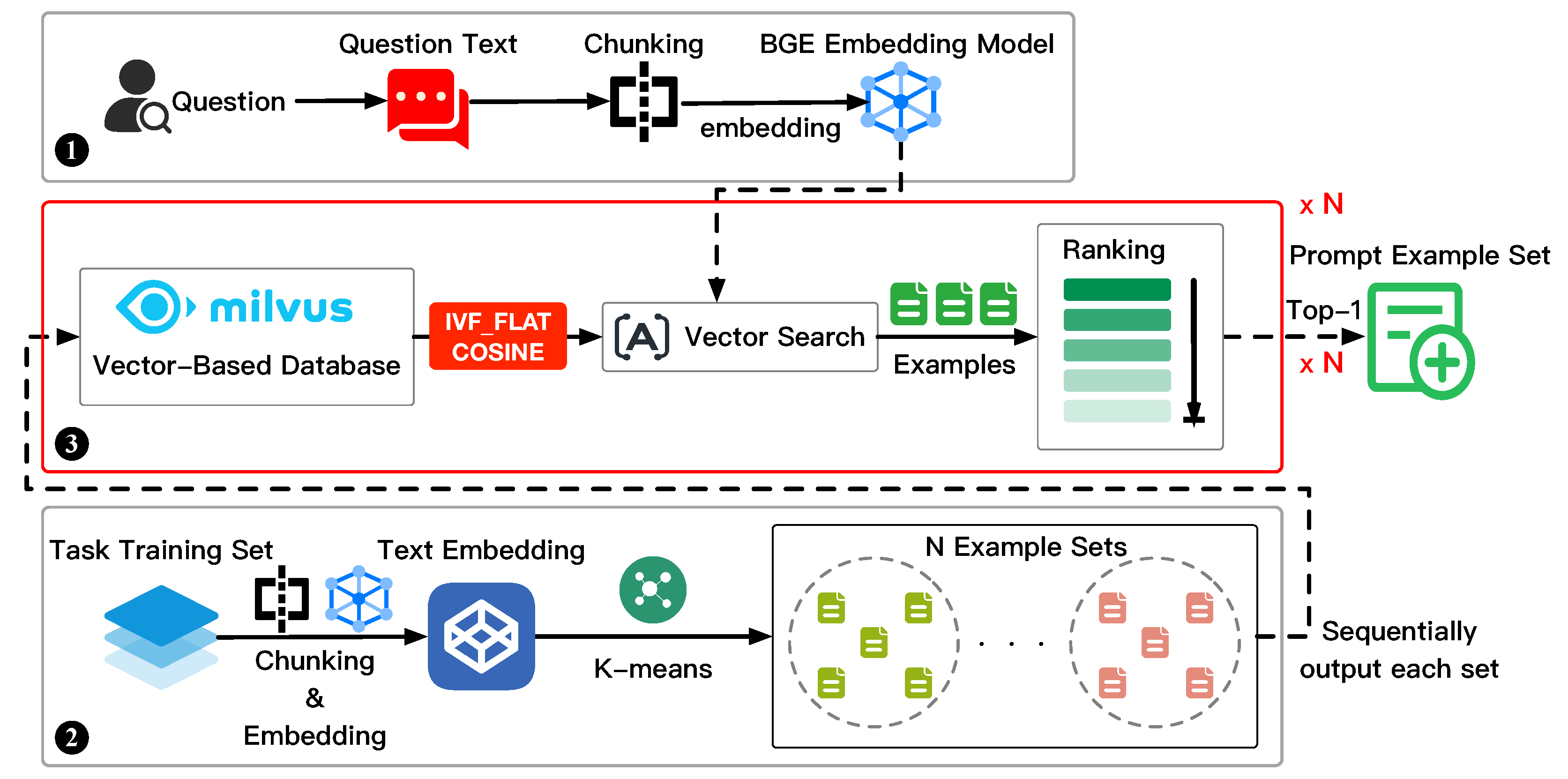
3. Method
3.1. Problem Formulation
3.2. Clustering–Semantic Similarity Prompt Example Construction Method
3.2.1. Input Question Processing
3.2.2. Sample Clustering
3.2.3. Prompt Example Retrieval
4. Experiment and Performance Analysis
4.1. Dataset Description and Preprocessing
4.2. LLMs for Comparison
4.3. Prompt Example Construction Methods for Comparison
4.4. Performance Analysis
4.4.1. LLaMA2 Chat Series Results
4.4.2. Baichuan2 Chat Series and ChatGLM3-6B Results
4.4.3. Overall Analysis
- Zero-shot method: Overall the worst performer, but it confirms that prompt examples can significantly enhance the accuracy of LLMs. These models indeed have contextual learning abilities, learning to solve similar problems and standardizing output formats from the provided examples.
- Identical and random prompt methods: Performed better than the zero-shot method, with the random method outperforming the identical method, indicating that models benefit more from diverse prompt examples. Although the identical prompt method is straightforward, its repeated use of the identical example provides insufficient information, making it less effective than the random prompt method.
- Semantic similarity, clustering, and clustering–semantic similarity methods: Performed the best, particularly the clustering–semantic similarity method, which showed more stable performance and the highest average accuracy across different datasets. These methods consider the semantic information and diversity of prompt examples, providing richer reference information and improving model performance.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
- The training set, test set, and validation set (if applicable) from the original dataset are merged, and the entire dataset is randomly shuffled before being split again to ensure uniformity.
- The columns of the original dataset are inspected, and based on their structure, columns are either merged or split to form two standardized columns: text and label_text. For example, if the original dataset separates titles and body text, they are combined into a single text column for consistency in later experiments.
- Each sample is processed by adjusting the original label values according to a designed mapping, ensuring large language models can better recognize the data. The text length is also checked, and samples with text that is too long or too short are discarded based on predefined limits.
- All valid samples are consolidated into a new dataset, from which 2000 samples are drawn as the training set and 1000 as the test set. If the processed dataset contains fewer than 3000 samples, it is split into training and test sets in a 2:1 ratio. The final dataset is saved as a JSON file at a specified path.

{kind=link}
{kind=link}
| Dataset Name | Label Range | Number of Training Samples | Number of Test Samples |
|---|---|---|---|
| SST2 | positive/negative | 2000 | 1000 |
| SST5 | very positive/positive/neutral/negative /very negative | 2000 | 1000 |
| MR | positive/negative | 2000 | 1000 |
| Amazon | positive/negative | 2000 | 1000 |
| AgNews | World/Sports/Business/Technology | 2000 | 1000 |
| TREC | Abbreviation/Entity/Description/Person/Location /Number | 1000 | 500 |
| DBPedia | Company/School/Artist/Athlete/Politician/ Transportation/Building/Nature/Village/Animal/ Plant/Album/Film/Book | 2000 | 1000 |
| Dataset | Prompt Template |
|---|---|
| SST2 | You are an expert in sentiment analysis, please classify the sentiment of the sentence into positive/negative. {examples} Please answer: {question} You only need to output the answer, no additional explanation is needed. |
| SST5 | You are an expert in sentiment analysis, please classify the sentiment of the sentence into very positive/positive/neutral/negative/very negative. {examples} Please answer: {question} You only need to output the answer, no additional explanation is needed. |
| MR | You are an expert in sentiment analysis, please classify the sentiment of the movie review into positive/negative. {examples} Please answer: {question} You only need to output the answer, no additional explanation is needed. |
| Amazon | You are an expert in sentiment analysis, please classify the sentiment of the product review into positive/negative. {examples} Please answer: {question} You only need to output the answer, no additional explanation is needed. |
| AgNews | You are an expert in topic classification, please classify the topic of the academic news article into world/sports/business/technology. {examples} Please answer: {question} You only need to output the answer, no additional explanation is needed. |
| TREC | You are an expert in topic classification, please classify the topic of the question into abbreviation/entity/description/person/location/number. {examples} Please answer: {question} You only need to output the answer, no additional explanation is needed. |
| DBPedia | You are an expert in ontology classification, please classify the ontology of the sentence into company/school/artist/athlete/politician/transportation/building/nature/village/animal/plant/album/film/book. {examples} Please answer: {question} You only need to output the answer, no additional explanation is needed. |
References
- Zhao, W.X.; Zhou, K.; Li, J.; Tang, T.; Wang, X.; Hou, Y.; Min, Y.; Zhang, B.; Zhang, J.; Dong, Z.; et al. A Survey of Large Language Models. arXiv 2023, arXiv:2303.18223. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. In Proceedings of the Advances in Neural Information Processing Systems, New York, NY, USA, 6–12 December 2020; Volume 33, pp. 1877–1901. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. LLaMA: Open and Efficient Foundation Language Models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Du, Z.; Qian, Y.; Liu, X.; Ding, M.; Qiu, J.; Yang, Z.; Tang, J. GLM: General Language Model Pretraining with Autoregressive Blank Infilling. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022; Volume 1: Long Papers, pp. 320–335. [Google Scholar] [CrossRef]
- BigScience Workshop; Scao, T.L.; Fan, A.; Akiki, C.; Pavlick, E.; Ilić, S.; Hesslow, D.; Castagné, R.; Luccioni, A.S.; Yvon, F.; et al. BLOOM: A 176B-Parameter Open-Access Multilingual Language Model. arXiv 2023, arXiv:2211.05100. [Google Scholar]
- Wu, C.; Yin, S.; Qi, W.; Wang, X.; Tang, Z.; Duan, N. Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models. arXiv 2023, arXiv:2303.04671. [Google Scholar]
- Cui, J.; Ning, M.; Li, Z.; Chen, B.; Yan, Y.; Li, H.; Ling, B.; Tian, Y.; Yuan, L. Chatlaw: A Multi-Agent Collaborative Legal Assistant with Knowledge Graph Enhanced Mixture-of-Experts Large Language Model. arXiv 2024, arXiv:2306.16092. [Google Scholar]
- Wu, S.; Irsoy, O.; Lu, S.; Dabravolski, V.; Dredze, M.; Gehrmann, S.; Kambadur, P.; Rosenberg, D.; Mann, G. BloombergGPT: A Large Language Model for Finance. arXiv 2023, arXiv:2303.17564. [Google Scholar]
- Min, S.; Lyu, X.; Holtzman, A.; Artetxe, M.; Lewis, M.; Hajishirzi, H.; Zettlemoyer, L. Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP 2022, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 11048–11064. [Google Scholar] [CrossRef]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Ichter, B.; Xia, F.; Chi, E.; Le, Q.V.; Zhou, D. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022; Volume 35, pp. 24824–24837. [Google Scholar]
- Liu, J.; Shen, D.; Zhang, Y.; Dolan, B.; Carin, L.; Chen, W. What Makes Good In-Context Examples for GPT-3? In Proceedings of the Deep Learning Inside Out (DeeLIO 2022): The 3rd Workshop on Knowledge Extraction and Integration for Deep Learning Architectures, Dublin, Ireland, 27 May 2022; pp. 100–114. [Google Scholar] [CrossRef]
- Rubin, O.; Herzig, J.; Berant, J. Learning To Retrieve Prompts for In-Context Learning. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Seattle, DC, USA, 10–15 July 2022; pp. 2655–2671. [Google Scholar] [CrossRef]
- Su, H.; Kasai, J.; Wu, C.H.; Shi, W.; Wang, T.; Xin, J.; Zhang, R.; Ostendorf, M.; Zettlemoyer, L.; Smith, N.A.; et al. Selective Annotation Makes Language Models Better Few-Shot Learners. arXiv 2022, arXiv:2209.01975. [Google Scholar]
- Zhang, Z.; Zhang, A.; Li, M.; Smola, A. Automatic Chain of Thought Prompting in Large Language Models. arXiv 2022, arXiv:2210.03493. [Google Scholar]
- Liu, H.; Wang, Y. Towards Informative Few-Shot Prompt with Maximum Information Gain for In-Context Learning. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, 6–10 December 2023; pp. 15825–15838. [Google Scholar] [CrossRef]
- Li, X.; Qiu, X. Finding Support Examples for In-Context Learning. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, 6–10 December 2023; pp. 6219–6235. [Google Scholar] [CrossRef]
- Yoo, K.M.; Kim, J.; Kim, H.J.; Cho, H.; Jo, H.; Lee, S.-W.; Lee, S.-G.; Kim, T. Ground-Truth Labels Matter: A Deeper Look into Input-Label Demonstrations. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP 2022, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 2422–2437. [Google Scholar] [CrossRef]
- Wei, J.; Wei, J.; Tay, Y.; Tran, D.; Webson, A.; Lu, Y.; Chen, X.; Liu, H.; Huang, D.; Zhou, D.; et al. Larger Language Models Do In-Context Learning Differently. arXiv 2023, arXiv:2303.03846. [Google Scholar]
- Pawelczyk, M.; Neel, S.; Lakkaraju, H. In-Context Unlearning: Language Models as Few Shot Unlearners. arXiv 2024, arXiv:2310.07579. [Google Scholar]
- Zhao, Z.; Wallace, E.; Feng, S.; Klein, D.; Singh, S. Calibrate Before Use: Improving Few-shot Performance of Language Models. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; PMLR, Proceedings of Machine Learning Research. Volume 139, pp. 12697–12706. [Google Scholar]
- Milios, A.; Reddy, S.; Bahdanau, D. In-Context Learning for Text Classification with Many Labels. In Proceedings of the 1st GenBench Workshop on (Benchmarking) Generalisation in NLP, Singapore, 6 December 2023; pp. 173–184. [Google Scholar] [CrossRef]
- Lu, Y.; Bartolo, M.; Moore, A.; Riedel, S.; Stenetorp, P. Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022; Volume 1: Long Papers, pp. 8086–8098. [Google Scholar] [CrossRef]
- Zhang, Y.; Feng, S.; Tan, C. Active Example Selection for In-Context Learning. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP 2022, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 9134–9148. [Google Scholar] [CrossRef]
- Wu, Z.; Wang, Y.; Ye, J.; Kong, L. Self-Adaptive In-Context Learning: An Information Compression Perspective for In-Context Example Selection and Ordering. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, Toronto, ON, Canada, 9–14 July 2023; Volume 1: Long Papers, pp. 1423–1436. [Google Scholar] [CrossRef]
- Socher, R.; Perelygin, A.; Wu, J.; Chuang, J.; Manning, C.D.; Ng, A.; Potts, C. Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, DC, USA, 18–21 October 2013; pp. 1631–1642. [Google Scholar]
- Pang, B.; Lee, L. Seeing Stars: Exploiting Class Relationships for Sentiment Categorization with Respect to Rating Scales. In Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics (ACL’05), Ann Arbor, MI, USA, 25–30 June 2005; pp. 115–124. [Google Scholar] [CrossRef]
- McAuley, J.; Leskovec, J. Hidden factors and hidden topics: Understanding rating dimensions with review text. In Proceedings of the 7th ACM Conference on Recommender Systems, New York, NY, USA, 12–16 October 2013; RecSys ’13. pp. 165–172. [Google Scholar] [CrossRef]
- Zhang, X.; Zhao, J.; LeCun, Y. Character-level Convolutional Networks for Text Classification. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Hovy, E.; Gerber, L.; Hermjakob, U.; Lin, C.Y.; Ravichandran, D. Toward semantics-based answer pinpointing. In Proceedings of the First International Conference on Human Language Technology Research, San Diego, CA, USA, 18–21 March 2001; HLT ’01. pp. 1–7. [Google Scholar] [CrossRef]
- Li, X.; Roth, D. Learning question classifiers. In Proceedings of the 19th International Conference on Computational Linguistics, Taipei, Taiwan, 26–30 August 2002; COLING ’02. Volume 1, pp. 1–7. [Google Scholar] [CrossRef]
- Lehmann, J.; Isele, R.; Jakob, M.; Jentzsch, A.; Kontokostas, D.; Mendes, P.N.; Hellmann, S.; Morsey, M.; van Kleef, P.; Auer, S.; et al. DBpedia—A large-scale, multilingual knowledge base extracted from Wikipedia. Semant. Web 2015, 6, 167–195. [Google Scholar] [CrossRef]
- Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; et al. Llama 2: Open Foundation and Fine-Tuned Chat Models. arXiv 2023, arXiv:2307.09288. [Google Scholar]
- Yang, A.; Xiao, B.; Wang, B.; Zhang, B.; Bian, C.; Yin, C.; Lv, C.; Pan, D.; Wang, D.; Yan, D.; et al. Baichuan 2: Open Large-scale Language Models. arXiv 2023, arXiv:2309.10305. [Google Scholar]
- Zeng, A.; Liu, X.; Du, Z.; Wang, Z.; Lai, H.; Ding, M.; Yang, Z.; Xu, Y.; Zheng, W.; Xia, X.; et al. GLM-130B: An Open Bilingual Pre-trained Model. arXiv 2023, arXiv:2210.02414. [Google Scholar]

| Dataset Name | Task Type | Number of Classes | Training Set Size | Validation Set Size |
|---|---|---|---|---|
| SST2 | Text Sentiment Classification | 2 | 6920 | 872 |
| SST5 | Text Sentiment Classification | 5 | 8544 | 1101 |
| MR | Movie Review Classification | 2 | 10,662 | - |
| Amazon | Product Review Classification | 2 | 3,600,000 | 400,000 |
| AgNews | News Topic Classification | 4 | 120,000 | 7600 |
| TREC | Question Text Classification | 6 | 5452 | 500 |
| DBPedia | Text Ontology Classification | 14 | 560,000 | 70,000 |
| Model Name | Parameter | Type | Development Organization | Release Date |
|---|---|---|---|---|
| LLaMA2-70B-Chat | 70B | Chat | Meta Platform Inc. | July 2023 |
| LLaMA2-13B-Chat | 13B | Chat | Meta Platform Inc. | July 2023 |
| LLaMA2-7B-Chat | 7B | Chat | Meta Platform Inc. | July 2023 |
| Baichuan2-13B-Chat | 13B | Chat | Baichuan Intelligence Inc. | September 2023 |
| Baichuan2-7B-Chat | 7B | Chat | Baichuan Intelligence Inc. | September 2023 |
| ChatGLM3-6B | 6B | Chat | Beijing Knowledge Atlas Technology Co., Ltd. | October 2023 |
| Construction Method | SST2 | SST5 | MR | Amazon | AgNews | TREC | DBPedia | AVG |
|---|---|---|---|---|---|---|---|---|
| Zero-Shot | 50.36% | - | 33.76% | 58.31% | 45.41% | 15.67% | 63.78% | 44.55% |
| Identical | 71.01% | - | 55.66% | - | 31.24% | 42.12% | 29.24% | 45.85% |
| Random | 80.20% | - | - | - | 26.32% | 36.99% | - | 47.84% |
| Semantic Similarity | 86.30% | - | 78.13% | - | 57.49% | 54.14% | - | 69.01% |
| Clustering | 84.11% | - | 86.90% | - | 26.42% | 49.21% | - | 61.66% |
| Clustering–Semantic Similarity | 87.87% | - | 78.24% | - | 57.27% | 52.98% | - | 69.09% |
| Construction Method | SST2 | SST5 | MR | Amazon | AgNews | TREC | DBPedia | AVG |
|---|---|---|---|---|---|---|---|---|
| Zero-Shot | 93.77% | 34.55% | 88.75% | 96.67% | 57.98% | 52.39% | 76.05% | 71.45% |
| Identical | 89.39% | 39.80% | 87.54% | 94.14% | 53.24% | 62.74% | 77.26% | 72.02% |
| Random | 94.04% | 43.12% | 92.25% | 95.86% | 48.40% | 57.89% | 85.65% | 73.89% |
| Semantic Similarity | 92.95% | 42.94% | 88.34% | 96.54% | 64.95% | 71.74% | 87.95% | 77.92% |
| Clustering | 92.64% | 48.27% | 89.64% | 88.37% | 69.02% | 62.90% | 77.57% | 75.49% |
| Clustering–Semantic Similarity | 93.84% | 49.87% | 89.99% | 96.43% | 81.98% | 71.28% | 94.96% | 82.62% |
| Construction Method | SST2 | SST5 | MR | Amazon | AgNews | TREC | DBPedia | AVG |
|---|---|---|---|---|---|---|---|---|
| Zero-Shot | 94.87% | 53.50% | 90.11% | 97.33% | 74.25% | 63.70% | 85.31% | 79.87% |
| Identical | 93.75% | 51.96% | 90.63% | 94.77% | 72.20% | 62.42% | 87.28% | 79.00% |
| Random | 95.86% | 51.03% | 91.70% | 94.72% | 74.93% | 67.53% | 89.95% | 80.82% |
| Semantic Similarity | 95.67% | 50.10% | 90.85% | 96.65% | 84.47% | 85.04% | 97.19% | 85.71% |
| Clustering | 95.60% | 52.85% | 91.89% | 96.86% | 74.93% | 76.29% | 81.69% | 81.44% |
| Clustering–Semantic Similarity | 95.20% | 50.13% | 91.37% | 96.46% | 86.40% | 83.40% | 93.96% | 85.27% |
| Construction Method | SST2 | SST5 | MR | Amazon | AgNews | TREC | DBPedia | AVG |
|---|---|---|---|---|---|---|---|---|
| Zero-Shot | 78.17% | 36.64% | 79.03% | 80.61% | - | - | - | 68.61% |
| Identical | 75.81% | 41.38% | 69.95% | 79.07% | 41.30% | - | - | 61.50% |
| Random | 70.40% | 45.08% | 79.04% | 87.60% | 72.78% | 50.28% | - | 67.53% |
| Semantic Similarity | 90.12% | 46.58% | 79.78% | 93.22% | 87.64% | 61.27% | 92.97% | 78.80% |
| Clustering | 93.32% | 46.77% | 85.61% | 92.69% | 66.87% | 45.42% | 43.60% | 67.76% |
| Clustering–Semantic Similarity | 90.91% | 48.33% | 83.46% | 92.65% | 86.05% | 62.58% | 91.10% | 79.30% |
| Construction Method | SST2 | SST5 | MR | Amazon | AgNews | TREC | DBPedia | AVG |
|---|---|---|---|---|---|---|---|---|
| Zero-Shot | 80.91% | 34.05% | 69.60% | 88.23% | 39.42% | 15.19% | 72.32% | 57.10% |
| Identical | 78.67% | 39.32% | 71.59% | 86.70% | - | 40.67% | 78.19% | 65.86% |
| Random | 65.34% | 29.75% | 70.42% | 92.35% | 38.63% | 38.12% | 84.73% | 59.90% |
| Semantic Similarity | 79.20% | 36.77% | 71.90% | 92.10% | 74.07% | 48.14% | 89.95% | 70.31% |
| Clustering | 86.78% | 30.94% | 86.43% | 90.46% | 64.11% | 22.78% | 77.94% | 65.64% |
| Clustering–Semantic Similarity | 83.20% | 38.12% | 77.72% | 92.33% | 80.80% | 40.91% | 88.83% | 71.70% |
| Construction Method | SST2 | SST5 | MR | Amazon | AgNews | TREC | DBPedia | AVG |
|---|---|---|---|---|---|---|---|---|
| Zero-Shot | 81.22% | 40.23% | 68.02% | 83.18% | 33.21% | 42.71% | 53.00% | 57.37% |
| Identical | 91.46% | 45.27% | 84.69% | 92.79% | 69.68% | 63.32% | 84.54% | 75.96% |
| Random | 94.27% | 48.19% | 89.60% | 96.60% | 67.83% | 58.73% | 83.92% | 77.02% |
| Semantic Similarity | 92.07% | 47.26% | 87.40% | 95.19% | 76.09% | 81.10% | 92.98% | 81.73% |
| Clustering | 95.47% | 50.23% | 89.80% | 97.06% | 78.49% | 72.25% | 82.87% | 80.88% |
| Clustering–Semantic Similarity | 94.67% | 49.63% | 89.00% | 95.47% | 82.96% | 83.41% | 93.67% | 84.11% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, D.; Wang, J. A Prompt Example Construction Method Based on Clustering and Semantic Similarity. Systems 2024, 12, 410. https://doi.org/10.3390/systems12100410
Chen D, Wang J. A Prompt Example Construction Method Based on Clustering and Semantic Similarity. Systems. 2024; 12(10):410. https://doi.org/10.3390/systems12100410
Chicago/Turabian StyleChen, Ding, and Jun Wang. 2024. "A Prompt Example Construction Method Based on Clustering and Semantic Similarity" Systems 12, no. 10: 410. https://doi.org/10.3390/systems12100410
APA StyleChen, D., & Wang, J. (2024). A Prompt Example Construction Method Based on Clustering and Semantic Similarity. Systems, 12(10), 410. https://doi.org/10.3390/systems12100410