
A Novel Methodology for Estimating Technology Value and Importance of Factors in Market-Based Approach


Abstract
:1. Introduction
- We propose a new technology valuation method that can be applicable when we have transaction datasets that have multiple responses, such as upfront payment and royalty rate.
- We propose methods to evaluate the relative importance of influential factors to the multivariate response.
- Also, the proposed method can identify the optimal number k of previous transaction cases to compare.
2. Related Work
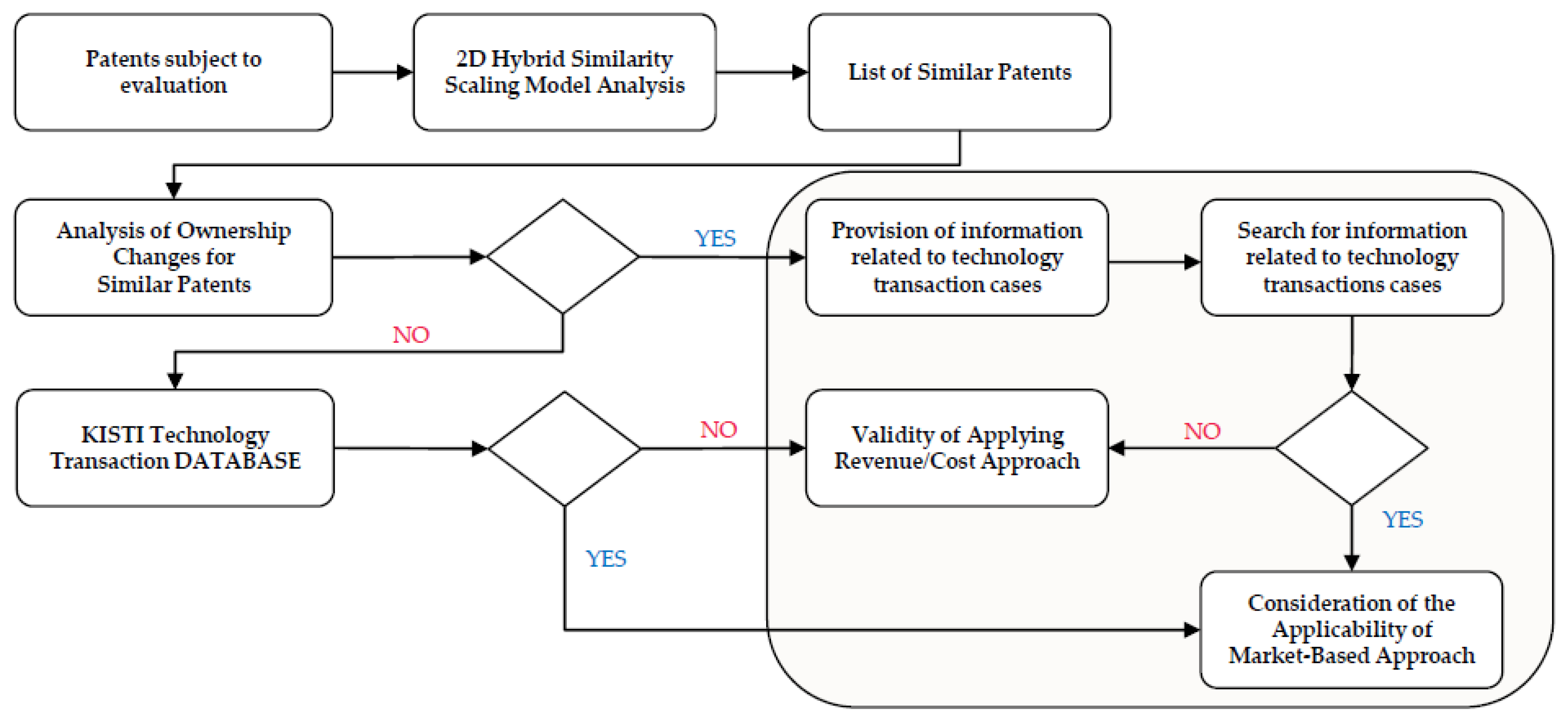
2.1. Market-Based Technology Valuation Method
2.2. Identification of Key Influential Factors in Technology Valuation
2.3. Estimation of Relative Importance of Input Variables of Regression Model
3. Analysis of the Importance of Technology Value Influential Factors Using Regression Analysis Based on k-Nearest Neighbor Method
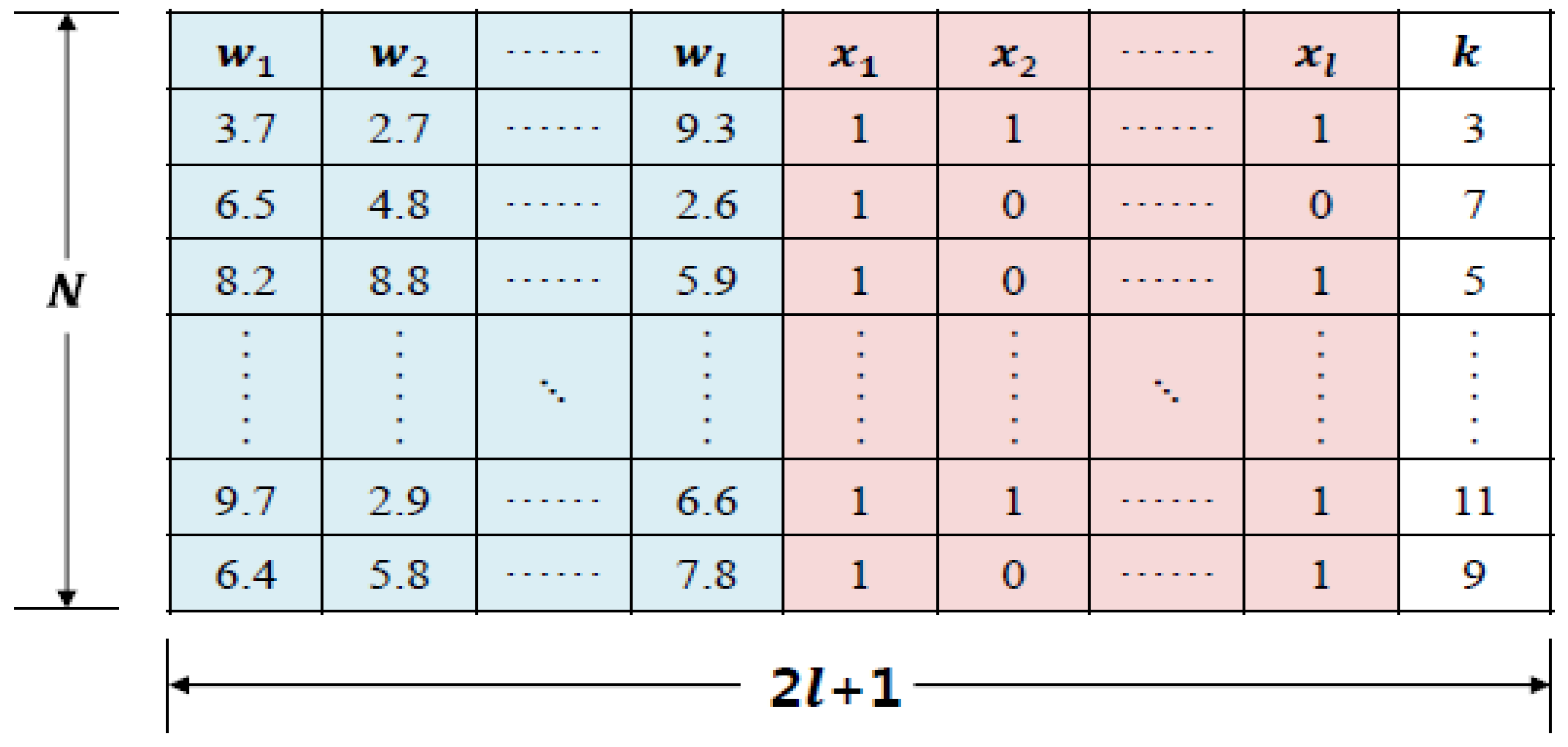
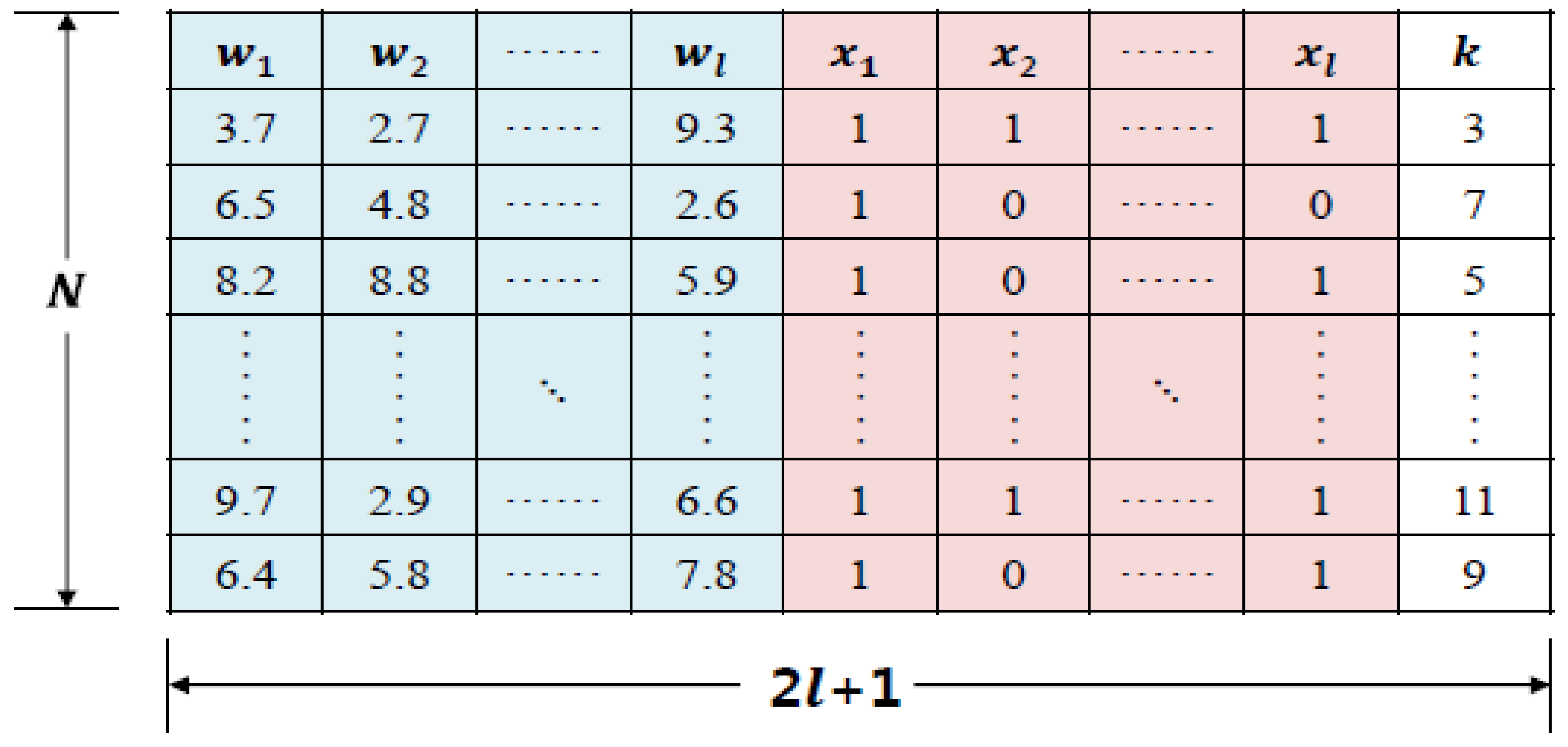
3.1. Estimating Running Royalty Using k-Nearest Neighbor Regression Analysis
3.2. Problem Definition for Estimating Importance of Key Influential Factors
3.3. Estimation of Key Influential Factor Importance
| Algorithm 1. Short-term of the Proposed Methodology | ||||
| : Solution matrix | ||||
| : Gower Similarity(using Equations (2) and (3)) | ||||
| : Weight for the -th subset | ||||
| : Neighboring outputs of the -th output | ||||
| : Target value for the -th input | ||||
| : Predicted value for the -th output | ||||
| : Total number of samples | ||||
| Begin | ||||
| 1. | Initialize and . | |||
| 2. | Repeat until convergence criteria is met: | |||
| 3. | for each output in do: | |||
| 4. | Compute using Equation (4). | |||
| 5. | for each input in do: | |||
| 6. | Compute using Equation (1). | |||
| 7. | End For | |||
| 8. | Update using Equation (1). | |||
| 9. | End For | |||
| 10. | Compute RMSE and Penalty using Equation (5). | |||
| 11. | Compute the objective function using and . | |||
| 12. | Update using a suitable optimization algorithm to minimize . | |||
| 13. | End Repeat. | |||
| End | ||||
4. Experiment
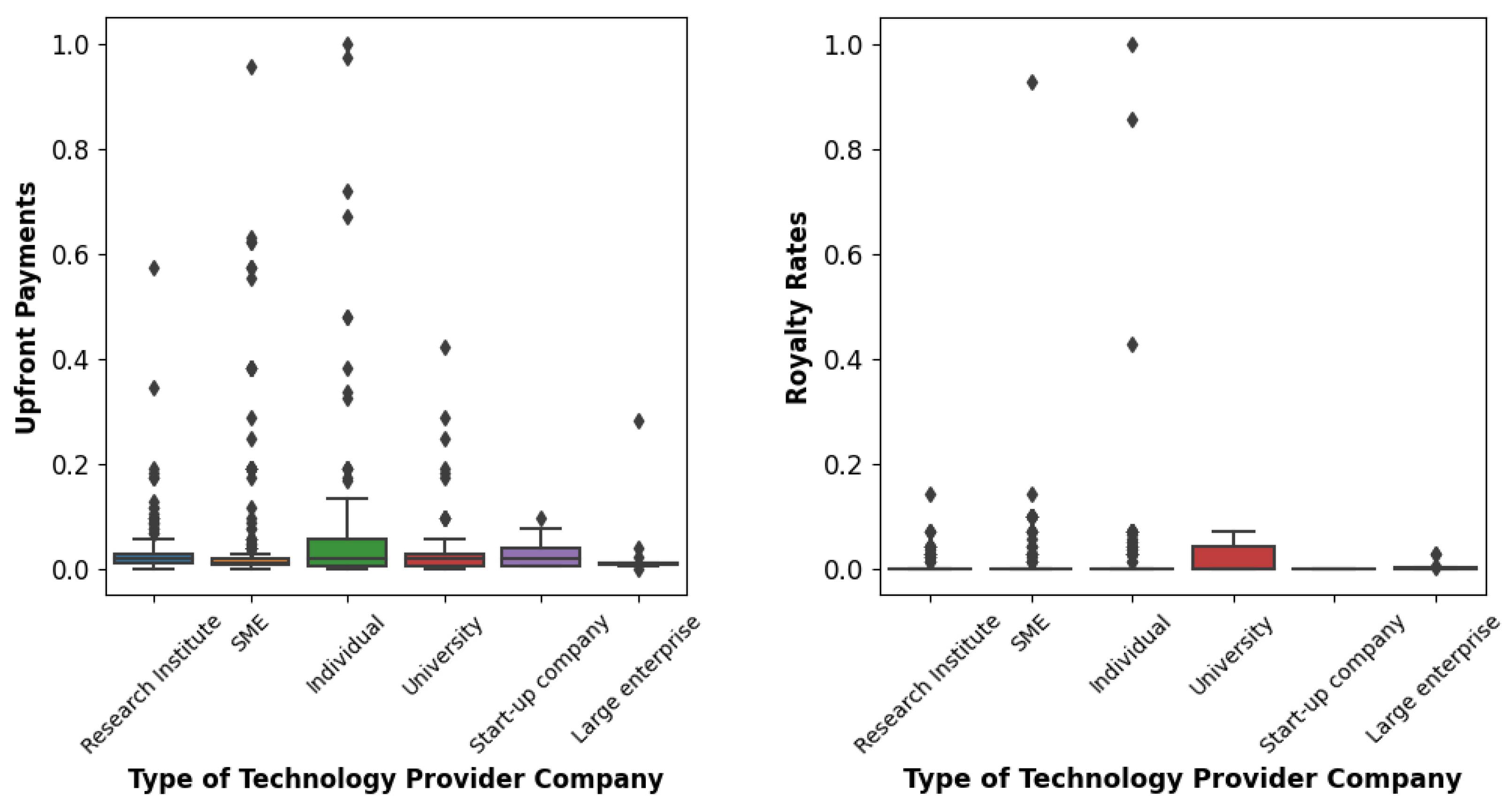
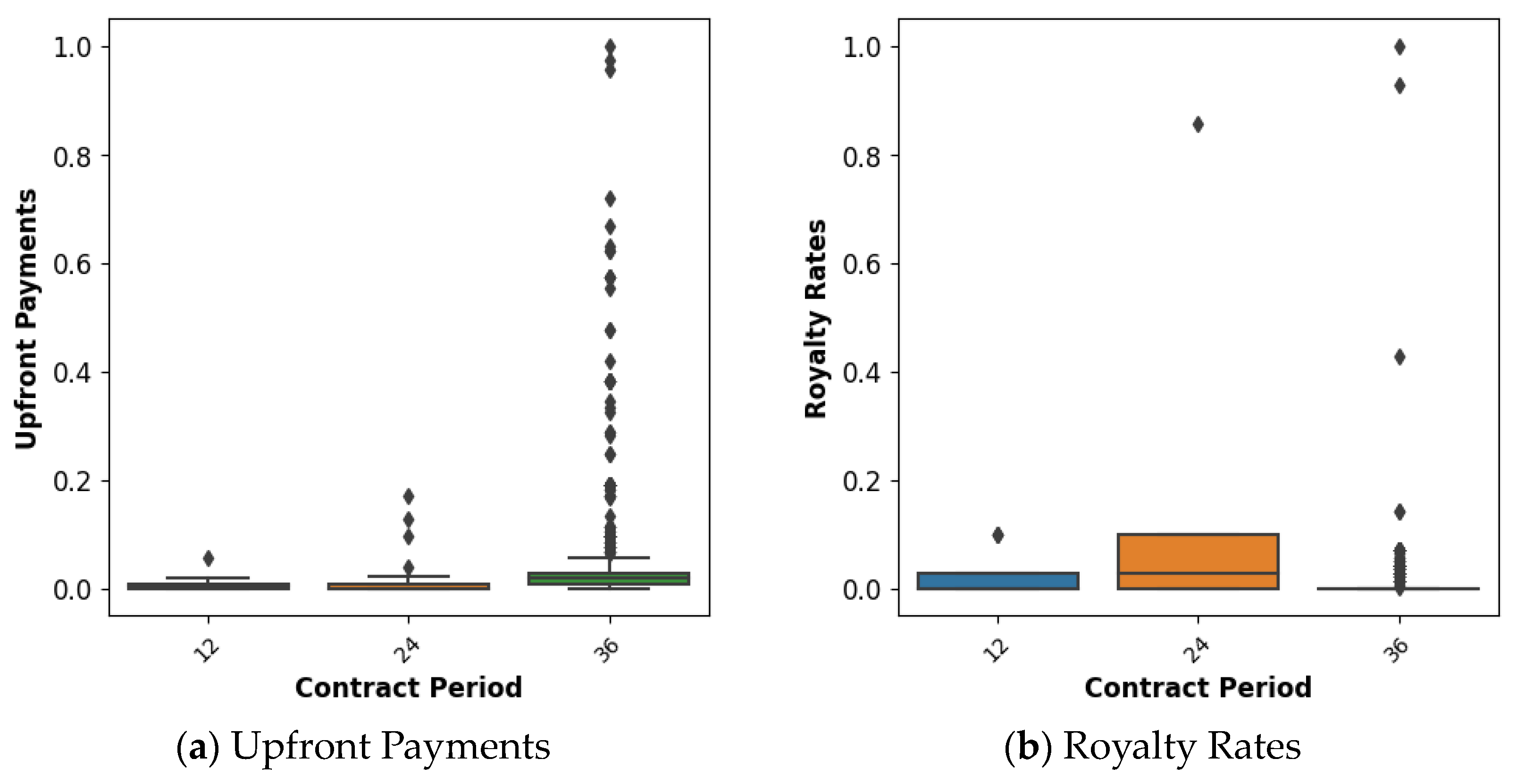
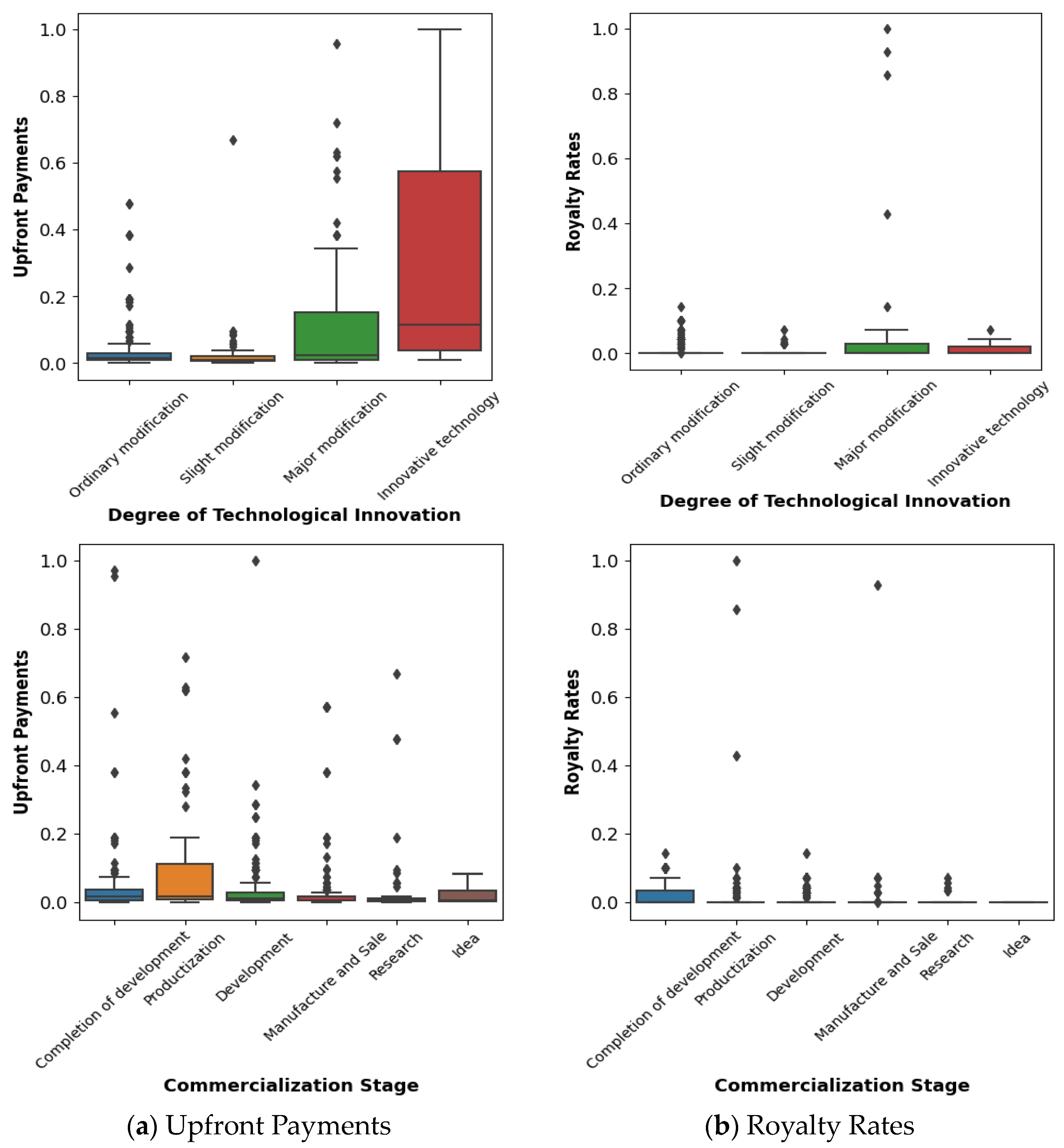
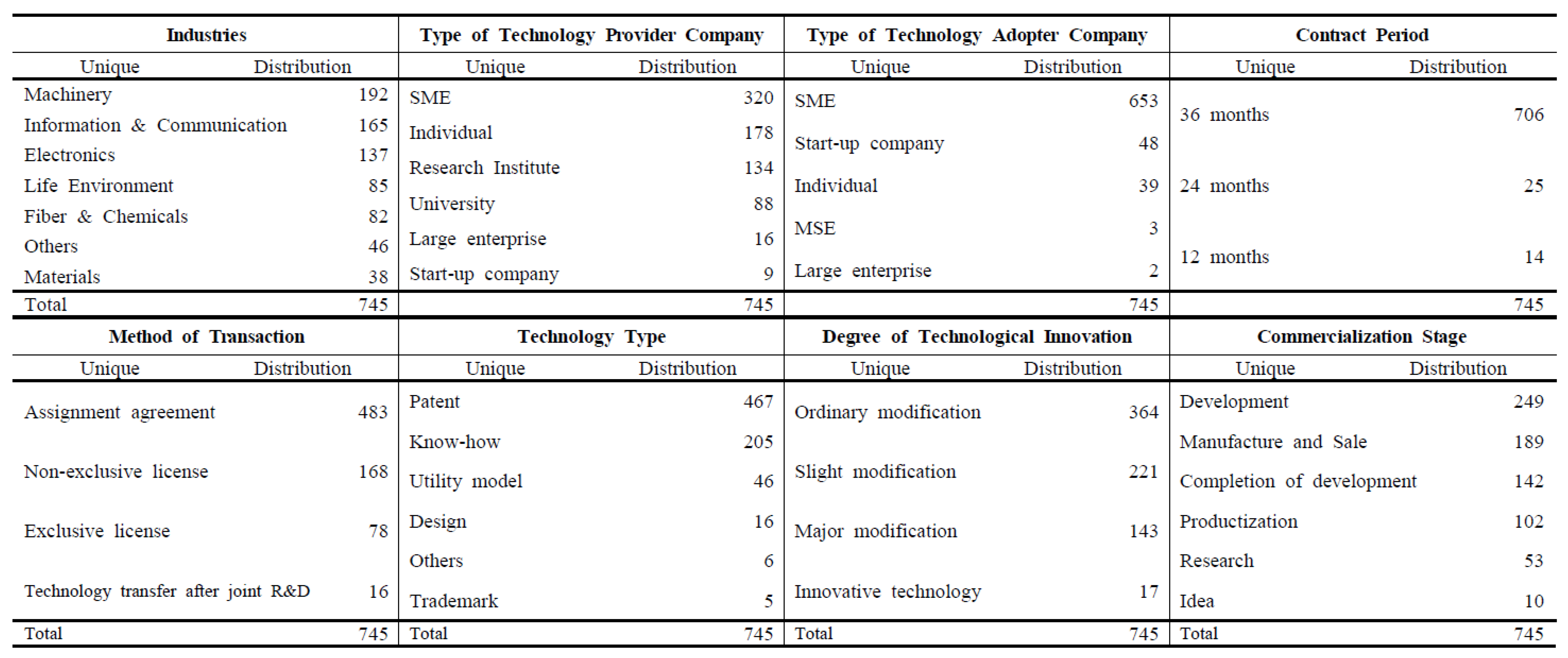
4.1. Data Description
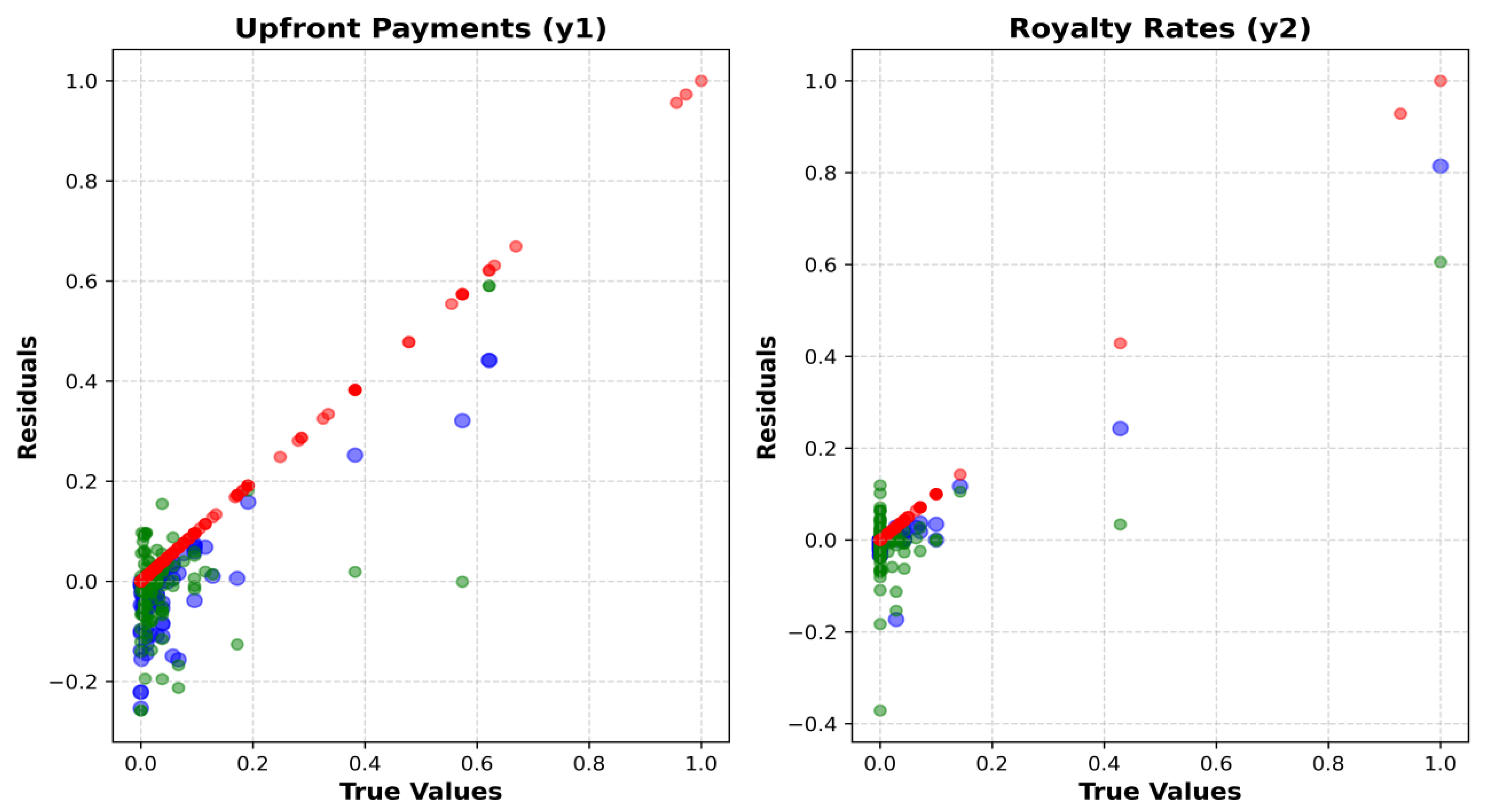
4.2. Estimated Importance of Key Influential Factors
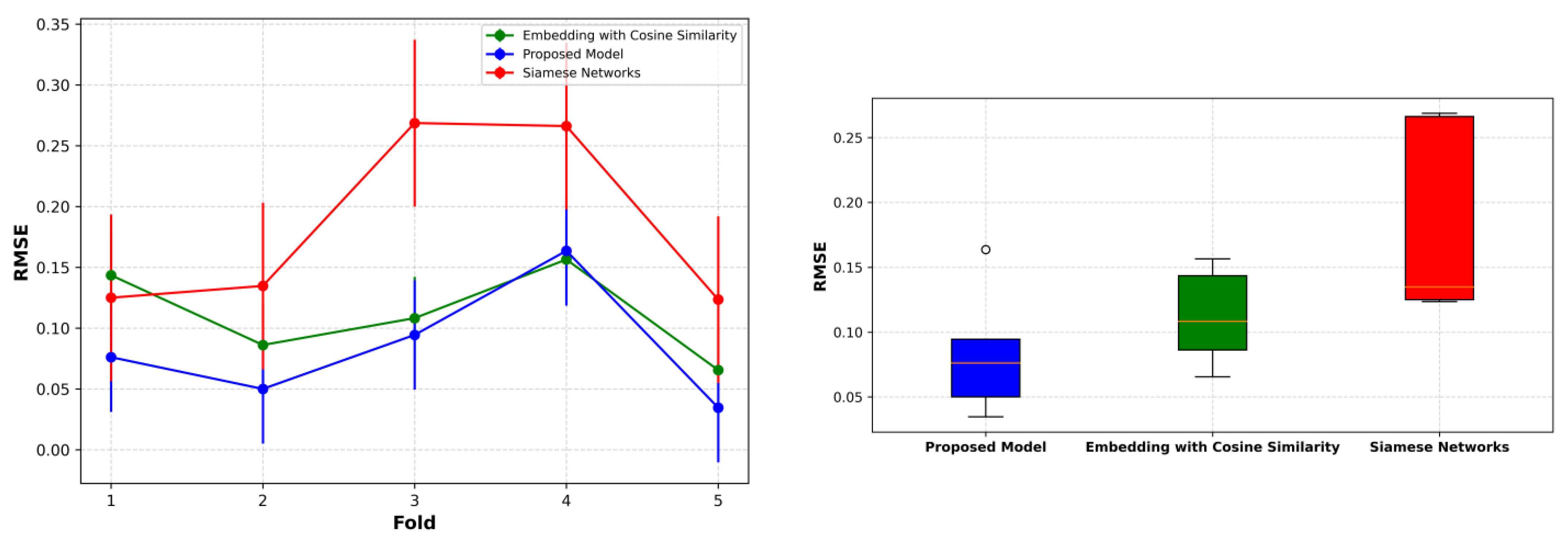
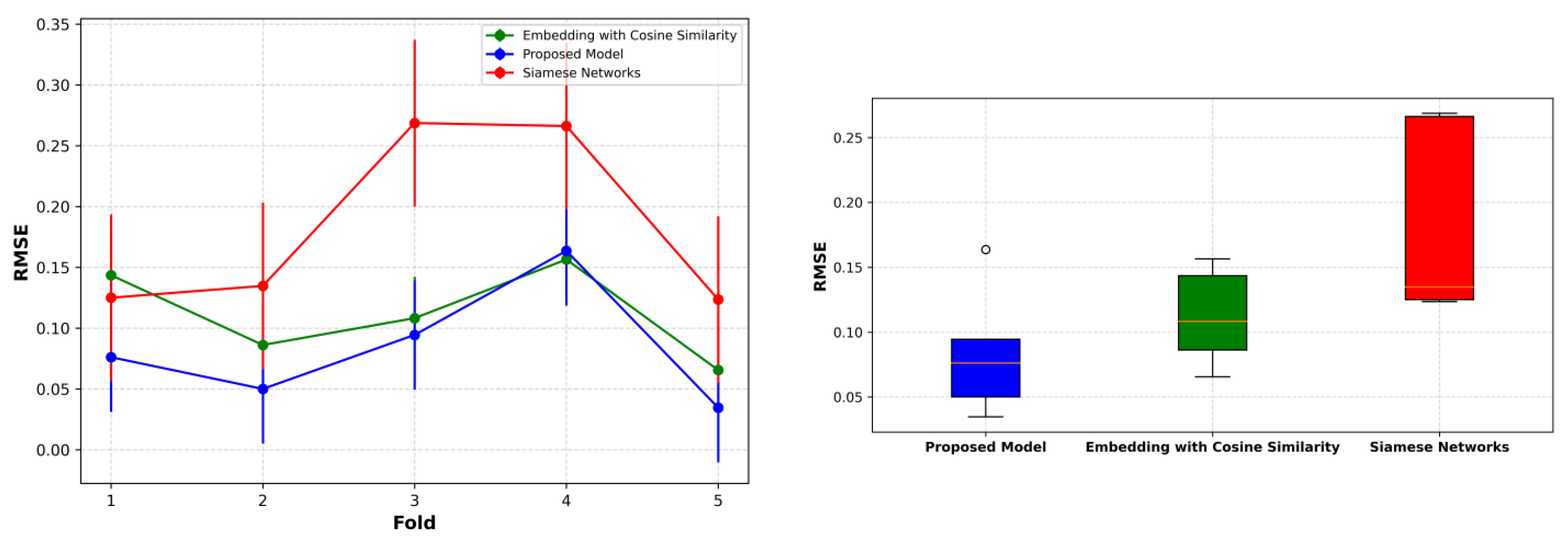
4.3. Benchmarking with State-of-the-Art Methods
4.4. Case Study
5. Conclusions
5.1. Discussion
5.2. Contributions
- We propose a new technology valuation method that can be applicable when we have transaction datasets that have multiple responses, such as upfront payment and royalty rate.
- We propose methods to evaluate the relative importance of influential factors to the multivariate response.
- Also, the proposed method can identify the optimal number k of previous transaction cases to compare.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kang, P.; Geum, Y.J.; Park, H.W.; Kim, S.K.; Sung, T.E.; Lee, H.Y. A market substitution cost approach for technology valuation. J. Korean Inst. Ind. Eng. 2015, 41, 150–161. [Google Scholar]
- Kim, K.H.; Shim, W.; Kang, J.S.; Park, H.W.; Moon, Y.H. Analyzing the observation of technical transaction information for the application of market access approach. In Proceedings of the Korea Society for Technology Innovation Annual Conference, 2012; pp. 54–62. [Google Scholar]
- Kang, J.; Lee, H.J.; Moon, Y.H. Systematic monitoring of competitors’ patents using 2-dimensional hybrid similarity method. In Proceedings of the 2011 ACM Symposium on Research in Applied Computation, Miami, FL, USA, 2–5 November 2011; pp. 252–254. [Google Scholar]
- Lim, S.M.; Kim, S.K.; Park, H.W. A Study on a Conceptual Model for Technology Valuation Based on Market Approach. J. Korea Soc. Innov. Technol. Manag. 2015, 18, 204–231. [Google Scholar]
- Sung, T.E.; Kim, D.S.; Jang, J.M.; Park, H.W. An Empirical Analysis on Determinant Factors of Patent Valuation Technology Transaction Prices. J. Korea Soc. Innov. Technol. Manag. 2016, 19, 254–279. [Google Scholar]
- Kim, S.K.; Lee, H.; Park, H.W. Application of Market Approach Based on Technology Transfer Case Information. In Proceedings of the Korea Technology Innovation Society Conference, 2012; pp. 323–340. [Google Scholar]
- Gower, J.C. A general coefficient of similarity some of its properties. Biometrics 1971, 27, 857–871. [Google Scholar] [CrossRef]
- Kim, Y.G.; Park, S.T.; Lee, S.J. A Study On Valuation Factors of Patent. Soc. Digit. Policy Manag. 2009, 7, 63–70. [Google Scholar]
- Meng, Y.; Li, W.J.; Shan, J.; Jing, C.; Chang, Q.; Glyn, J.; Frewer, L.J. Precision pesticide technology adoption influencing factors among farmers: Evidence from apple producing regions in China. Integr. Agric. J. 2023, 22, 292–305. [Google Scholar]
- Park, S. Analysis of the Relative Importance of Patent Valuation Criteria for Product Categories. Ph.D. Thesis, Chungbuk National University, Cheongju-si, Republic of Korea, 2010. [Google Scholar]
- Kim, Y.G.; Park, S.T.; Lee, S.J. Selection of important factors for Patent Valuation using Delphi Method. Entrue J. Inf. Technol. 2010, 9, 7–17. [Google Scholar]
- Park, W.G.; Smita, W. Index of Patent Rights. In Economic Freedom of the World: 2002 Annual Report; 2002; pp. 33–43. Available online: https://www.fraserinstitute.org/research/economic-freedom-of-the-world-2002-annual-report (accessed on 20 August 2023).
- Lee, K. A Study on the Technology Value Evaluation Based on Patent Information. Master’s Thesis, Ajou University, Suwon, Republic of Korea, 2013. [Google Scholar]
- Park, H.W. An Empirical Study of Determinants of Technology Value in Korea. J. Korea Technol. Innov. Soc. 2005, 8, 623–649. [Google Scholar]
- Reitzig, M. What determines patent value? Insights from the semiconductor industry. Res. Policy 2003, 32, 13–26. [Google Scholar] [CrossRef]
- Azen, R.; Budescu, D.V. The dominance analysis approach for comparing predictors in multiple regression. Psychol. Methods 2003, 8, 129. [Google Scholar] [CrossRef]
- Eriksson, L.; Johansson, E.; Kettaneh-Wold, N.; Wold, S. Multi-and Megavariate Data Analysis; Umetrics Academy: Umeå, Sweden, 2001; p. 43. [Google Scholar]
- Johnson, J.W. A heuristic method for estimating the relative weight of predictor variables in multiple regression. Multivar. Behav. Res. 2000, 35, 1–19. [Google Scholar] [CrossRef] [PubMed]
- Chiu, C. A case-based customer classification approach for direct marketing. Expert Syst. Appl. 2002, 22, 163–168. [Google Scholar] [CrossRef]
- Burkhard, H.D. Similarity distance in case-based reasoning. Fundam. Inform. 2001, 47, 201–215. [Google Scholar]
- Roh, T.H.; Yoo, M.H.; Han, I.G. Integration rough set theory case-based reasoning for the corporate credit evaluation. J. Inf. Syst. 2005, 14, 41–65. [Google Scholar]
- Doğan, S.Z.; Arditi, D.; Murat Günaydin, H. Using decision trees for determining attribute weights in a case-based model of early cost prediction. J. Constr. Eng. Manag. 2008, 134, 146–152. [Google Scholar] [CrossRef]
- Park, M.; Sung, K.; Lee, H.; Ji, S.; Kim, S. Schematic Cost Estimation Method using Case-Based Reasoning: Focusing on Determining Attribute Weight. Korean J. Constr. Eng. Manag. 2010, 11, 22–31. [Google Scholar] [CrossRef]
- Ji, S.H.; Park, M.; Lee, H.S. Cost estimation model for building projects using case-based reasoning. Can. J. Civ. Eng. 2011, 38, 570–581. [Google Scholar] [CrossRef]
- Chiu, C.; Chang, P.C.; Chiu, N.H. A case-based expert support system for due-date assignment in a wafer fabrication factory. J. Intell. Manuf. 2003, 14, 287. [Google Scholar] [CrossRef]
- Shin, K.S.; Han, I. Case-based reasoning supported by genetic algorithms for corporate bond rating. Expert Syst. Appl. 1999, 16, 85–95. [Google Scholar] [CrossRef]
- Kuo, R.J.; Kuo, Y.P.; Chen, K.Y. Developing a diagnostic system through integration of fuzzy case-based reasoning fuzzy ant colony system. Expert Syst. Appl. 2005, 28, 783–797. [Google Scholar] [CrossRef]
- Hall, M.A. Correlation-based feature selection of discrete numeric class machine learning. In Proceedings of the Seventeenth International Conference on Machine Learning, San Francisco, CA, USA, 29 June–2 July 2000; pp. 359–366. [Google Scholar]
- Park, J.S.; Heo, K. Optimal k-Nearest Neighbor Classifier Using Genetic Algorithm. Commun. Stat. Appl. Methods (CSAM) 2010, 17, 17–27. [Google Scholar]
- Tahir, M.A.; Bouridane, A.; Kurugollu, F. Simultaneous feature selection feature weighting using Hybrid Tabu Search/k-nearest neighbor classifier. Pattern Recognit. Lett. 2007, 28, 438–446. [Google Scholar] [CrossRef]
- Punch, W.F., III; Goodman, E.D.; Pei, M.; Chia-Shun, L.; Hovl, P.D.; Enbody, R.J. Further Research on Feature Selection Classification Using Genetic Algorithms. In Proceedings of the International Conference on Genetic Algorithms (ICGA), San Francisco, CA, USA, 15–19 July 1993; pp. 557–564. [Google Scholar]
- Lee, Y.; Lee, C.-L. A Study on Antecedents Outcome Variables of Switching Costs: Focusing on the Moderating Effect of Service Contract Type. Mark. Res. 2005, 20, 1–28. [Google Scholar]
- Yoojae, L.; Cheongrim, L. Antecedents consequences of switching costs: The moderating role of service subscription types. Korean J. Mark. 2005, 20, 1–28. [Google Scholar]
- Lee, J.H.; Kim, E.; Sung, T.E.; Shin, K. Factors affecting pricing in patent licensing contracts in the biopharmaceutical industry. Sustainability 2018, 10, 3143. [Google Scholar] [CrossRef]
- Zhou, K.; Ethayarajh, K.; Card, D.; Jurafsky, D. Problems with cosine as a measure of embedding similarity for high frequency words. arXiv 2022, arXiv:2205.05092. [Google Scholar]
- Habibi, M.; Starlinger, J.; Leser, U. Tabsim: A siamese neural network for accurate estimation of table similarity. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 930–937. [Google Scholar]
- Kim, M.S.; Lee, C.H.; Choi, J.H.; Jang, Y.J.; Lee, J.H.; Lee, J.; Sung, T.E. A study on intelligent technology valuation system: Introduction of kibo patent appraisal system ii. Sustainability 2021, 13, 12666. [Google Scholar] [CrossRef]
- Kim, B.; Gazzola, G.; Yang, J.; Lee, J.M.; Coh, B.Y.; Jeong, M.K.; Jeong, Y.S. Two-phase edge outlier detection method for technology opportunity discovery. Scientometrics 2017, 113, 1–16. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable Separation | Variable Initials | Variable Type |
|---|---|---|
| Technology Influential Factors | x1 | Categorical variable |
| x2 | Nominal variable | |
| ⋮ | ⋮ | |
| xl | Ordinal variable | |
| Technical Fee | y1 | Continuous variable |
| y2 | Continuous variable |
| Variable Separation | Variable Initials | Variable Type and Description |
|---|---|---|
| Technology Influential Factors | Industry | Nominal variables (Machinery, Materials, Life Environment, Fiber and Chemicals, Electronics, Information and Communication, Others) |
| Type of Technology Provider Company | Nominal variables (Large enterprise, University, Small and Medium-sized Enterprises (SME), Start-up company, Research Institute, Individual) | |
| Type of Technology Adopter Company | Nominal variables (Individual, Start-up company, SME, Medium-sized enterprise (MSE), Large enterprise) | |
| Contract Period | Continuous variables (12, 24, 34 (months)) | |
| Method of Transaction | Nominal variables (Assignment agreement, Exclusive license, Non-exclusive license, Technology transfer after joint R&D) | |
| Technology Type | Nominal variables (Patent, Utility model, Design, Trademark, know-how, Others) | |
| Degree of Technological Innovation | Ordinal variables (Slight modification, Ordinary modification, Major modification, Innovative technology) | |
| Commercialization Stage | Ordinal variables (Idea, Research, Development, Completion of development, Productization, Manufacture and Sale) | |
| Running Royalty Method | Upfront Payments | Continuous variables (0 KRW to 523,000,000 KRW) |
| Royalty Rates | Continuous variables (0–70%) |
| Key Influential Factors | Importance | Transaction Case k |
|---|---|---|
| Type of Technology Provider Company | 0.515 | 5 |
| Contract Period | 0.485 |
| Model | Embedding with Cosine Similarity | Siamese Networks |
|---|---|---|
| Input layer | - Nominal: One-hot encoded - Ordinal: Label Encoded - Continuous: Min–Max Scaled | - Anchor: Reference instance - Positive: Similar to the anchor - Negative: Dissimilar to the anchor |
| Hidden layer | - Dense layer with 128 neurons - ReLU loss function - Adam optimizer | - Four Dense layers with 128, 64, 32, and 16 neurons - Triplet loss function - Adam optimizer |
| Output layer | - Upfront payments (y1) node - Royalty rates (y2) node | - Embedding representation for each of the input instances |
| Fold | Proposed Model | Embedding with Cosine Similarity | Siamese Networks |
|---|---|---|---|
| #1 | 0.0701 | 0.0854 | 0.0989 |
| #2 | 0.0893 | 0.0998 | 0.1443 |
| #3 | 0.0784 | 0.0941 | 0.1308 |
| #4 | 0.0617 | 0.0834 | 0.0989 |
| #5 | 0.0781 | 0.0831 | 0.1305 |
| Mean | 0.0755 | 0.0892 | 0.1207 |
| STD | 0.0103 | 0.0074 | 0.0206 |
| Hyperparameters | Embedding with Cosine Similarity | Siamese Networks | ||
|---|---|---|---|---|
| Range | Best | Range | Best | |
| Learning Rate | (0.001, 0.01, 0.1) | 0.01 | (0.001, 0.01, 0.1) | 0.001 |
| Batch Size | (16, 32, 64) | 16 | (16, 32, 64) | 32 |
| Hidden Unit | (64, 128, 256) | 256 | (32, 64, 128) | 128 |
| Hidden layers | - | (1, 2, 3) | 3 | |
| RMSE | 0.0648 | 0.0986 | ||
| Model | Proposed Model | Fine-Tuned Embedding with Cosine Similarity | Fine-Tuned Siamese Networks |
|---|---|---|---|
| #1 | 0.0480 | 0.0698 | 0.0990 |
| #2 | 0.0237 | 0.0802 | 0.1067 |
| #3 | 0.0982 | 0.0719 | 0.0989 |
| #4 | 0.0515 | 0.0585 | 0.0991 |
| #5 | 0.1509 | 0.0685 | 0.1037 |
| Mean | 0.0745 | 0.0698 | 0.1015 |
| STD | 0.0505 | 0.0078 | 0.0036 |
| Fold | Reduced Model | ||||
|---|---|---|---|---|---|
| #1 | 0.108 | 0.109 | 0.109 | 0.108 | 0.108 |
| #2 | 0.074 | 0.073 | 0.073 | 0.073 | 0.073 |
| #3 | 0.096 | 0.096 | 0.096 | 0.096 | 0.096 |
| #4 | 0.085 | 0.085 | 0.085 | 0.085 | 0.085 |
| #5 | 0.109 | 0.109 | 0.109 | 0.109 | 0.109 |
| Mean | 0.094 | 0.094 | 0.094 | 0.094 | 0.094 |
| STD | 0.015 | 0.016 | 0.016 | 0.015 | 0.015 |
| Fold | Weighted Model | ||||
| #1 | 0.106 | 0.103 | 0.104 | 0.105 | 0.105 |
| #2 | 0.071 | 0.068 | 0.068 | 0.069 | 0.070 |
| #3 | 0.094 | 0.091 | 0.091 | 0.092 | 0.092 |
| #4 | 0.084 | 0.085 | 0.085 | 0.085 | 0.085 |
| #5 | 0.105 | 0.104 | 0.105 | 0.106 | 0.106 |
| Mean | 0.092 | 0.090 | 0.091 | 0.091 | 0.092 |
| STD | 0.015 | 0.015 | 0.015 | 0.015 | 0.015 |
| k | t-Statistic | p-Value |
|---|---|---|
| 3 | 4.70679 | 0.00926 |
| 5 | 3.93366 | 0.01705 |
| 7 | 3.9194 | 0.01726 |
| 9 | 3.81032 | 0.01893 |
| 11 | 3.83349 | 0.01856 |
| Model | Proposed Model | Embedding Wit Cosine Similarity | Siamese Networks |
|---|---|---|---|
| #1 | 0.0701 | 0.0855 | 0.0989 |
| #2 | 0.0893 | 0.1026 | 0.1655 |
| #3 | 0.0784 | 0.1003 | 0.0989 |
| #4 | 0.0617 | 0.0755 | 0.1280 |
| #5 | 0.0781 | 0.0855 | 0.0989 |
| Mean | 0.0755 | 0.0899 | 0.1180 |
| STD | 0.0103 | 0.0114 | 0.0294 |
| Model | Proposed Model | Embedding with Cosine Similarity | Siamese Networks |
|---|---|---|---|
| #1 | 0.0761 | 0.1435 | 0.1250 |
| #2 | 0.0500 | 0.0862 | 0.1347 |
| #3 | 0.0944 | 0.1082 | 0.2686 |
| #4 | 0.1636 | 0.1564 | 0.2661 |
| #5 | 0.0346 | 0.06556 | 0.1235 |
| Mean | 0.0837 | 0.1120 | 0.1836 |
| STD | 0.0503 | 0.0381 | 0.0766 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yoon, J.; Bose, A.; Park, H.; Lee, J.; Kim, B. A Novel Methodology for Estimating Technology Value and Importance of Factors in Market-Based Approach. Systems 2023, 11, 439. https://doi.org/10.3390/systems11090439
Yoon J, Bose A, Park H, Lee J, Kim B. A Novel Methodology for Estimating Technology Value and Importance of Factors in Market-Based Approach. Systems. 2023; 11(9):439. https://doi.org/10.3390/systems11090439
Chicago/Turabian StyleYoon, Juho, Aparajita Bose, Hun Park, Jongtaik Lee, and Byunghoon Kim. 2023. "A Novel Methodology for Estimating Technology Value and Importance of Factors in Market-Based Approach" Systems 11, no. 9: 439. https://doi.org/10.3390/systems11090439
APA StyleYoon, J., Bose, A., Park, H., Lee, J., & Kim, B. (2023). A Novel Methodology for Estimating Technology Value and Importance of Factors in Market-Based Approach. Systems, 11(9), 439. https://doi.org/10.3390/systems11090439