
Advanced Dance Choreography System Using Bidirectional LSTMs



Abstract
1. Introduction
2. Related Works
2.1. Frameworks for Choreography Creation
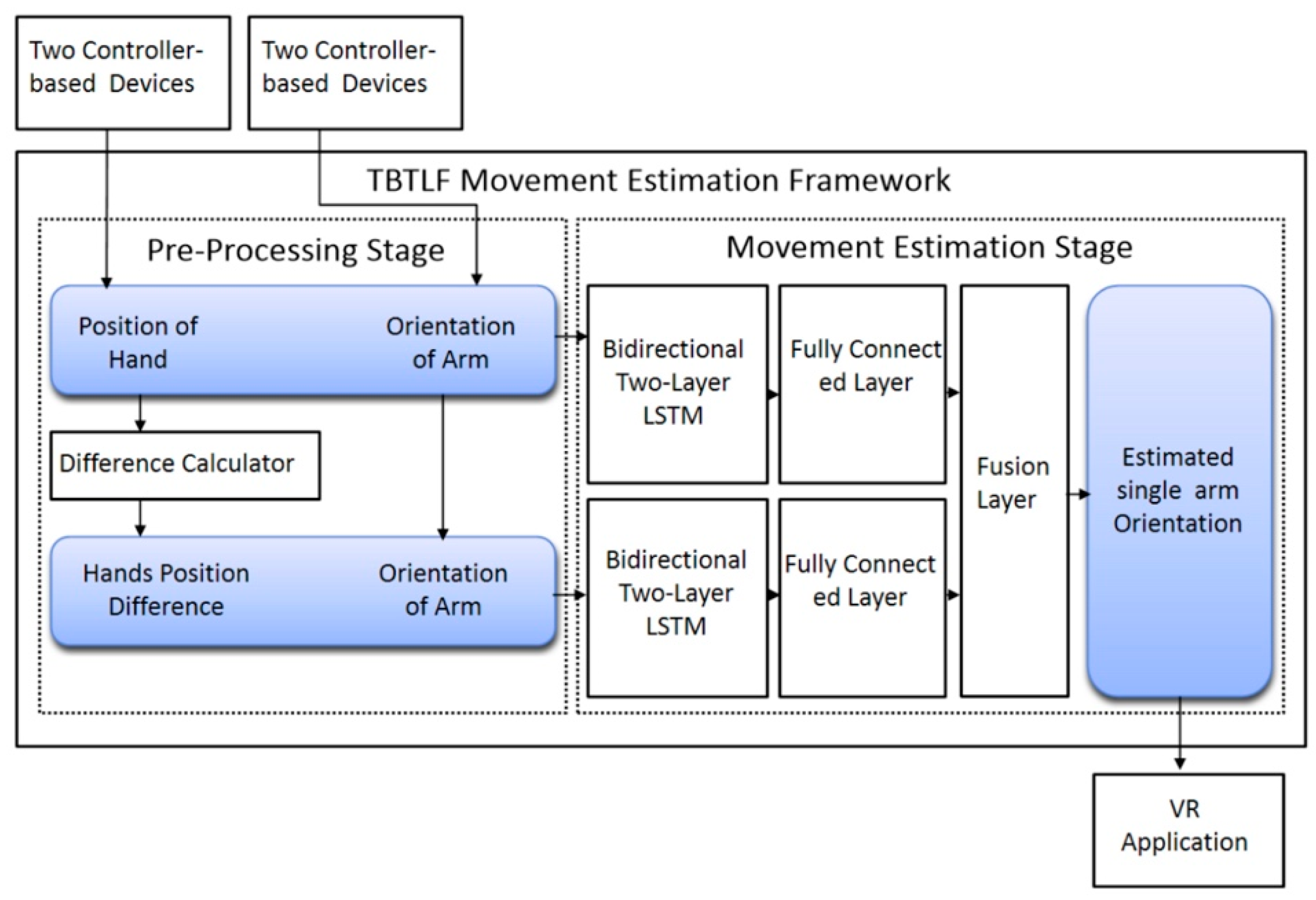
2.2. Movement Estimation Techniques
2.3. Virtual Reality
2.4. Comparison with the Proposed System
3. System for K-POP Choreography Creation
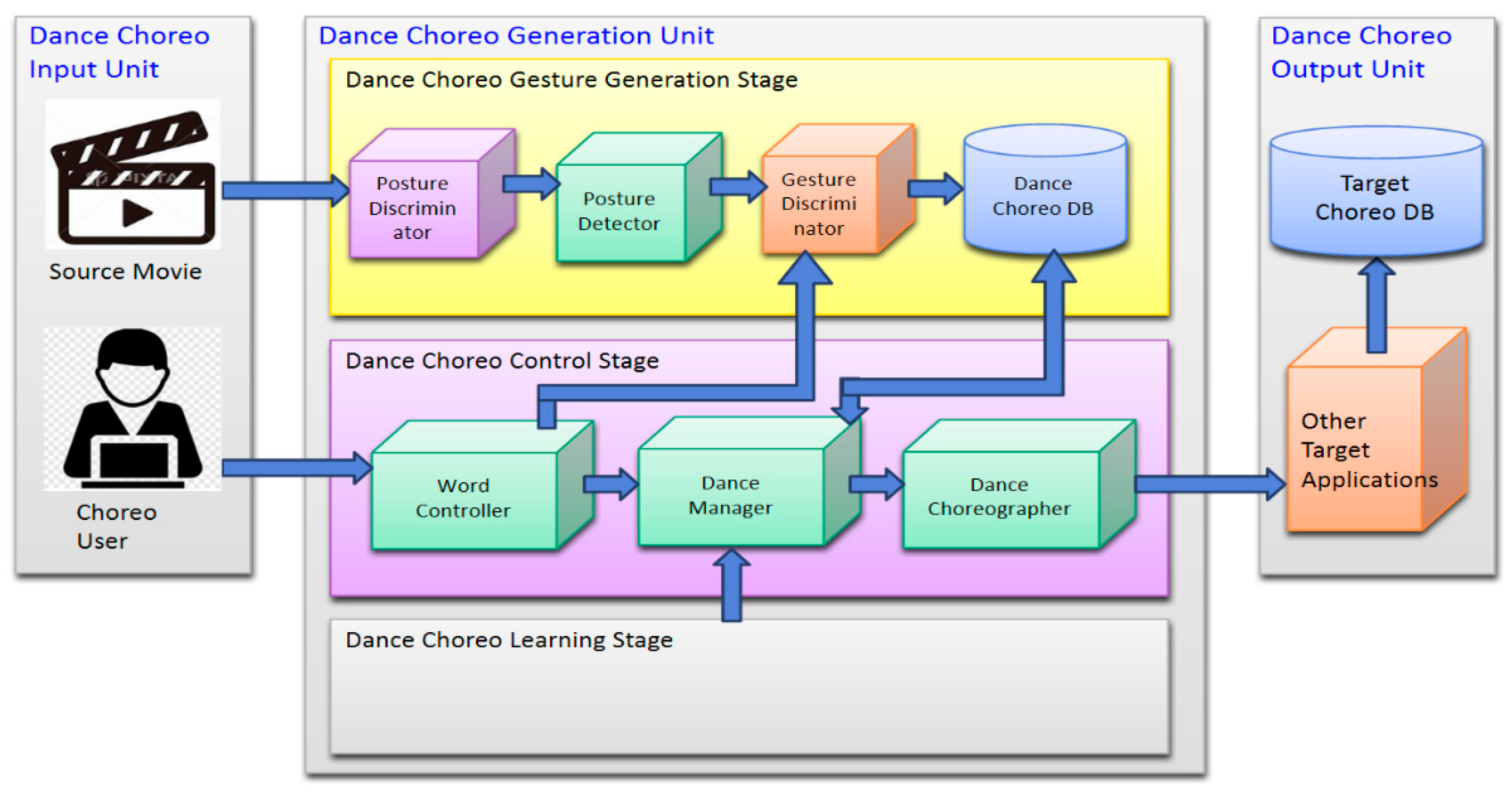
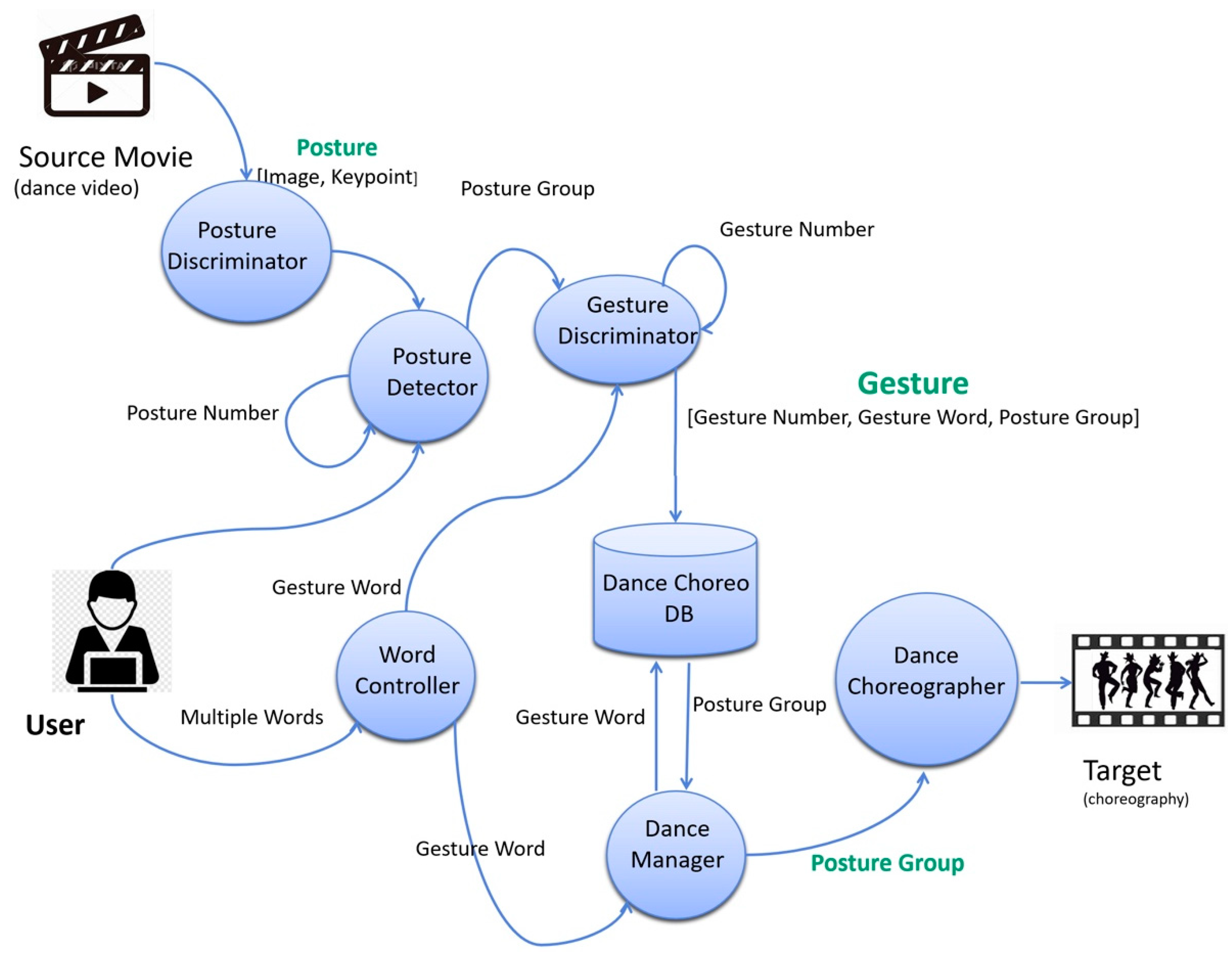
3.1. Overview
3.2. The Dance-Choreo-Gesture-Generation-Stage
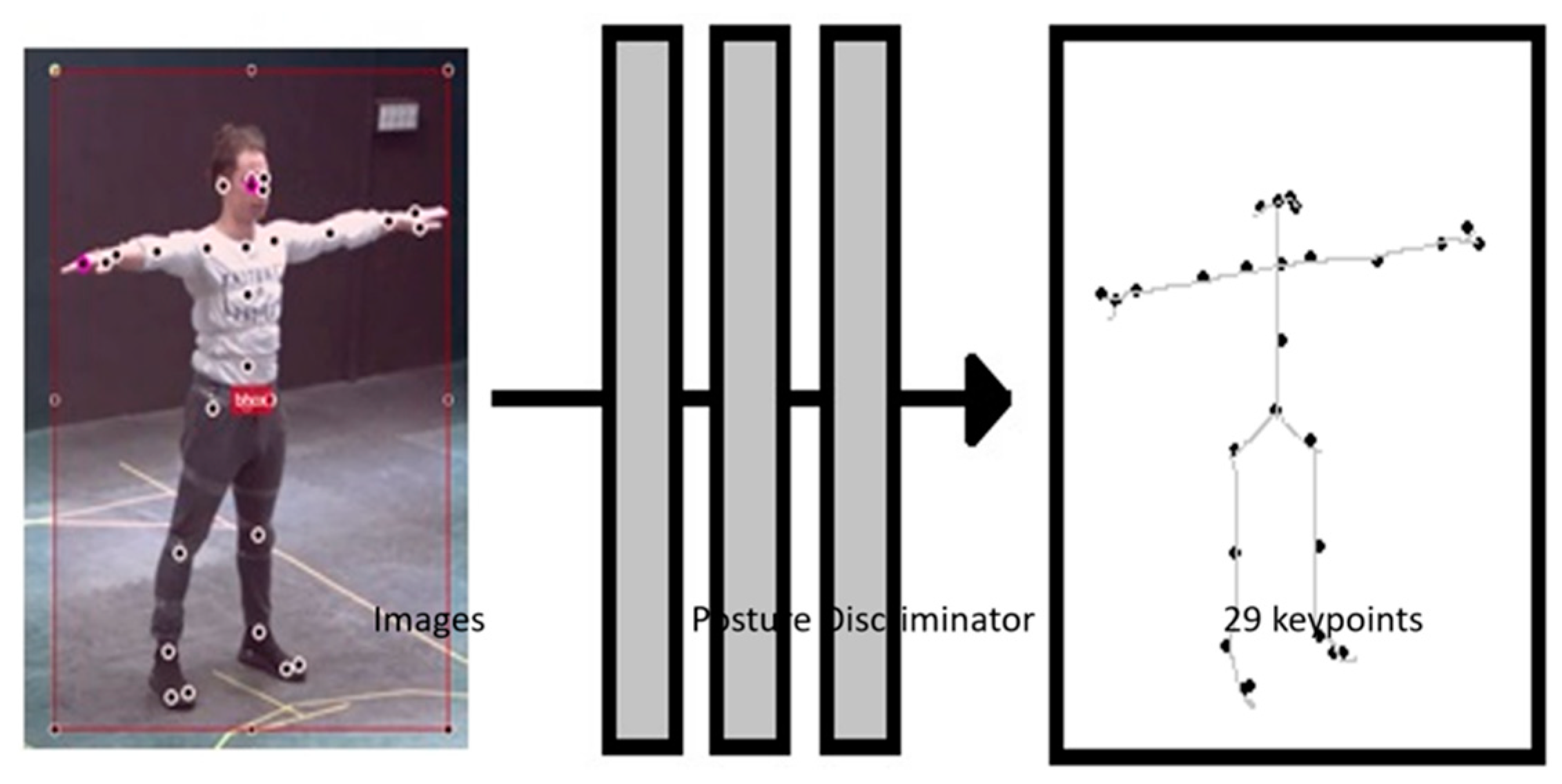
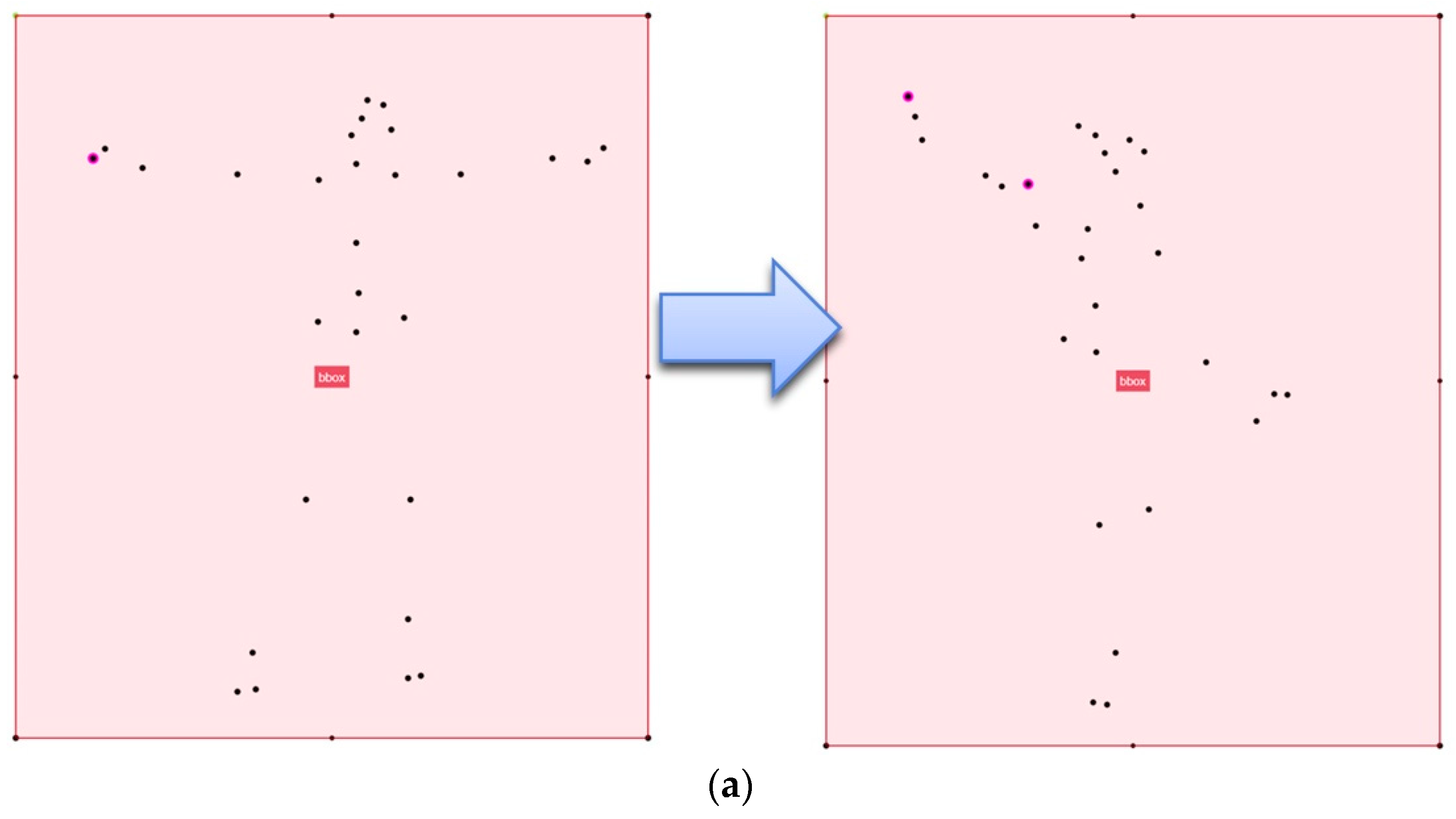
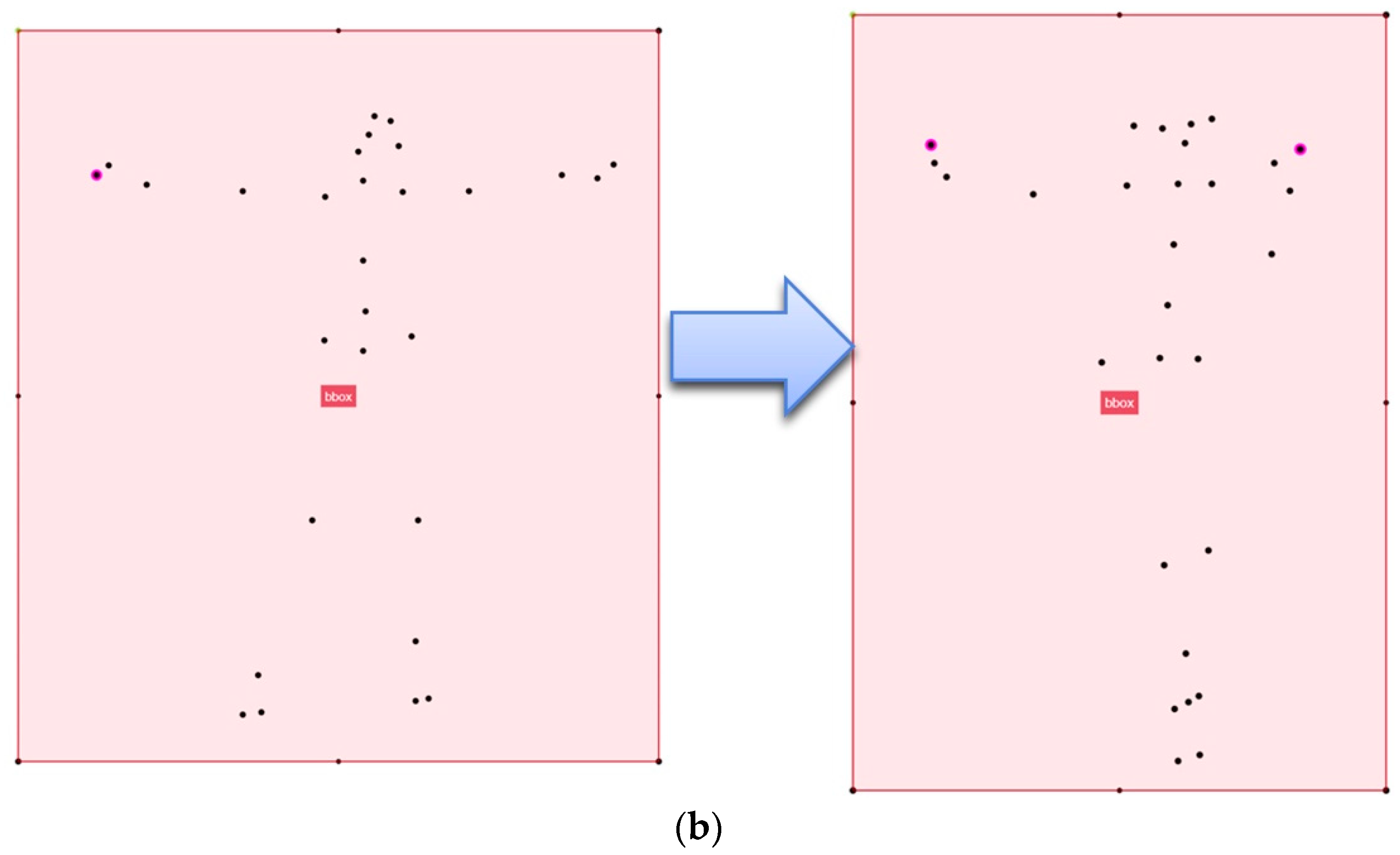
3.2.1. Posture Discriminator
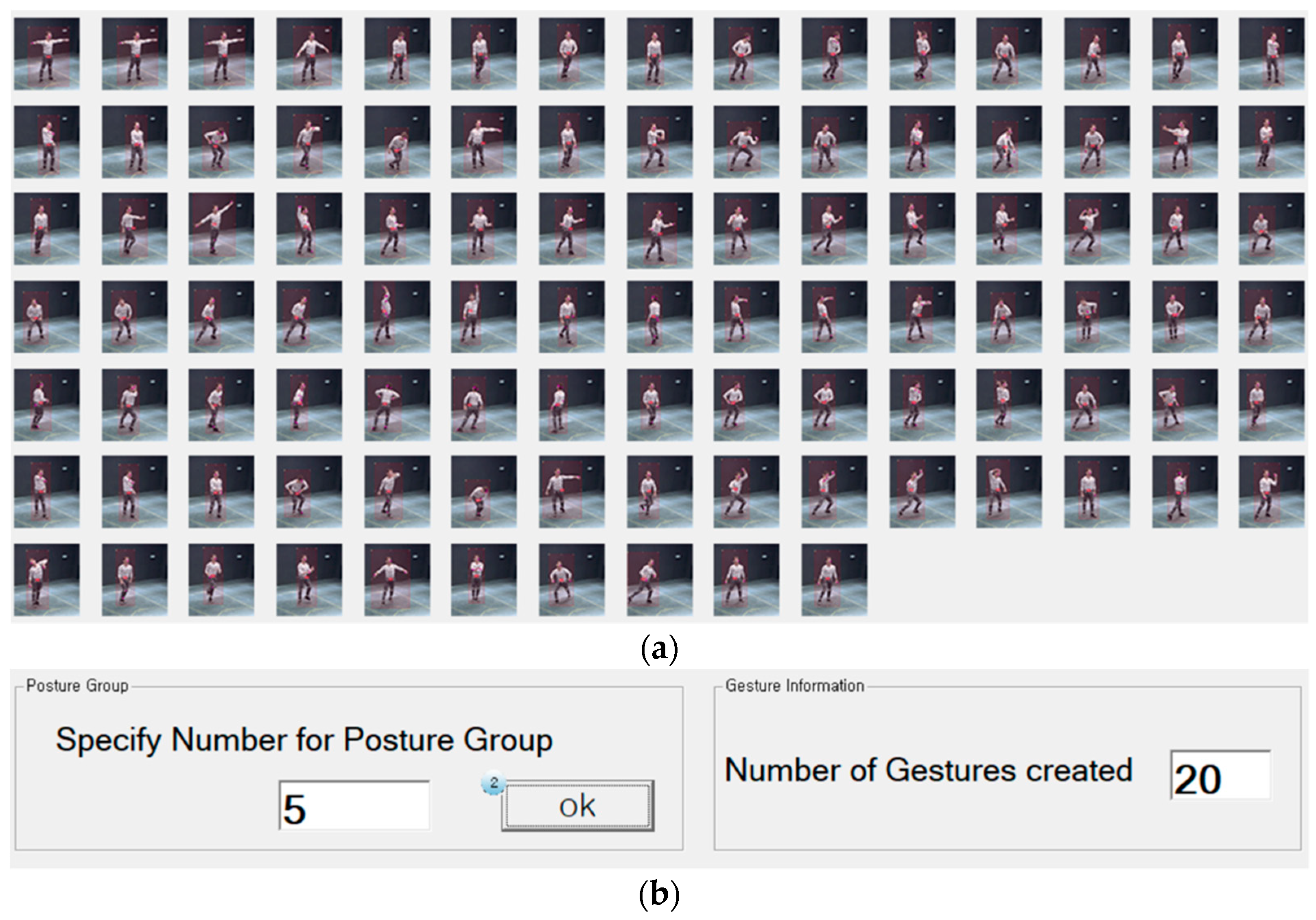
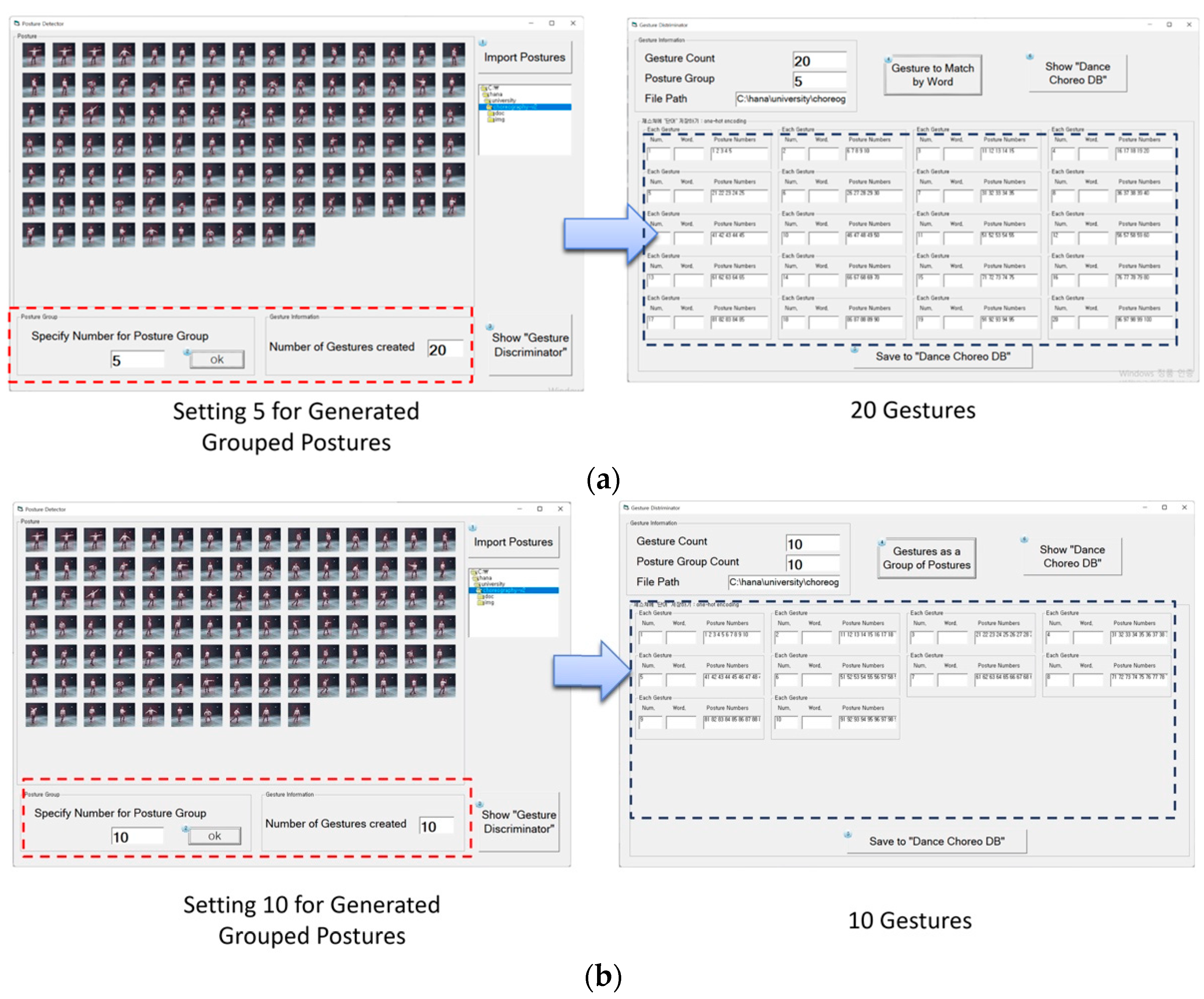
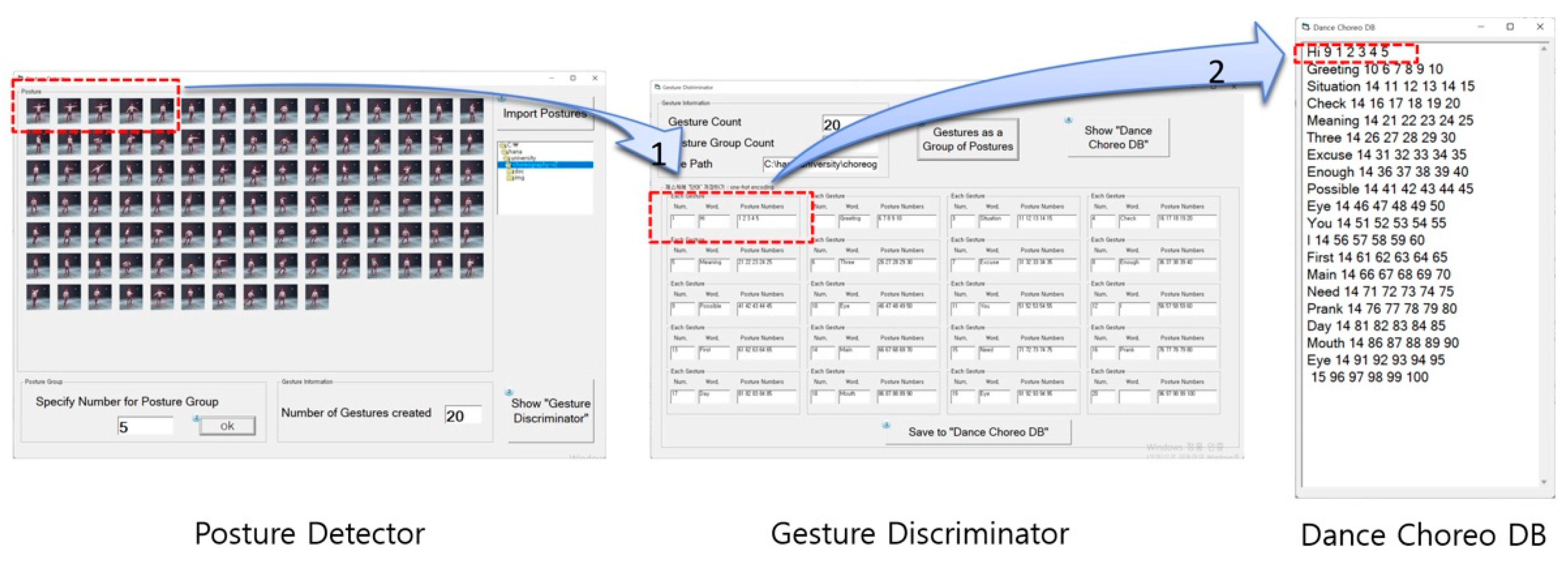
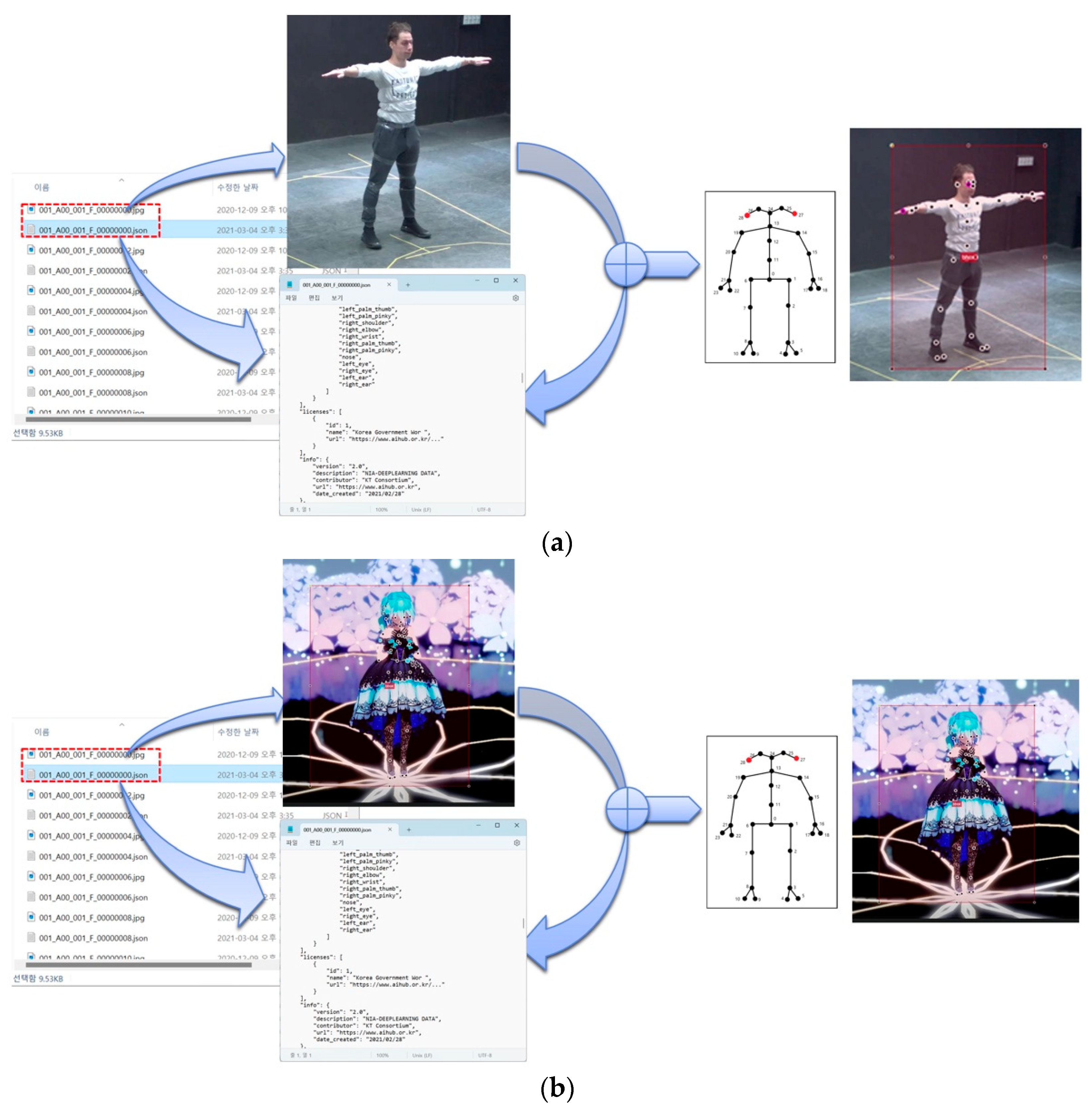
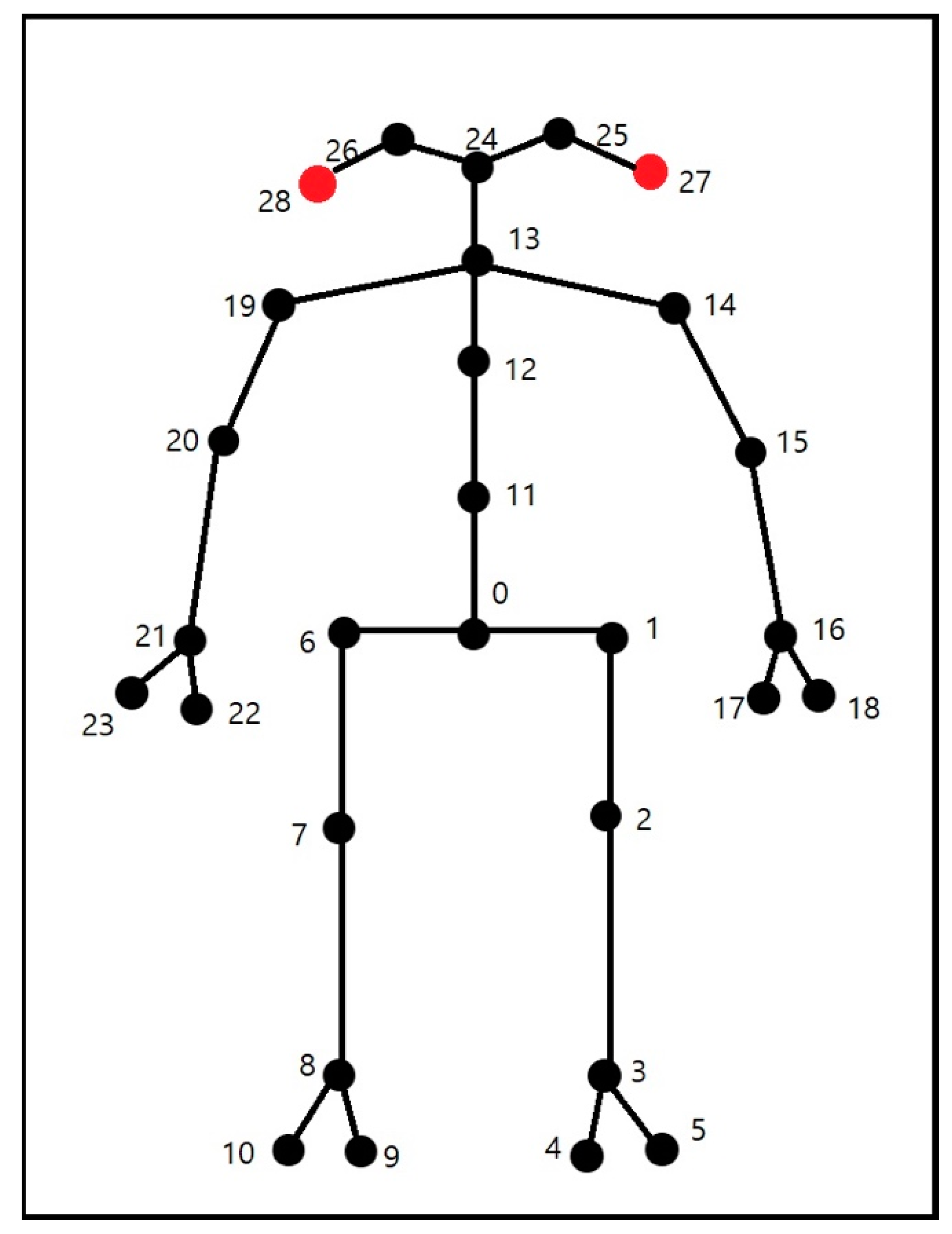
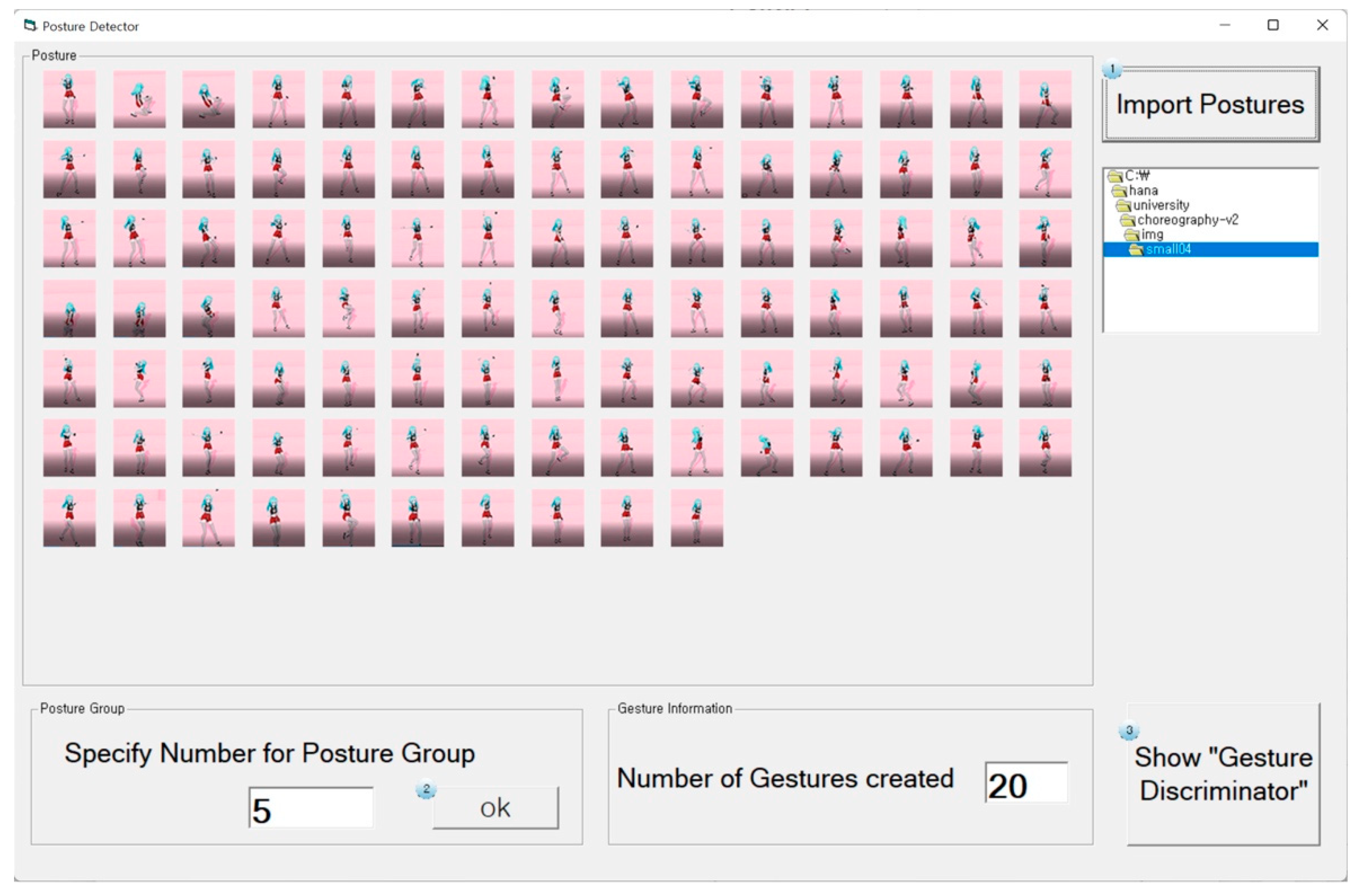
3.2.2. Posture Detector
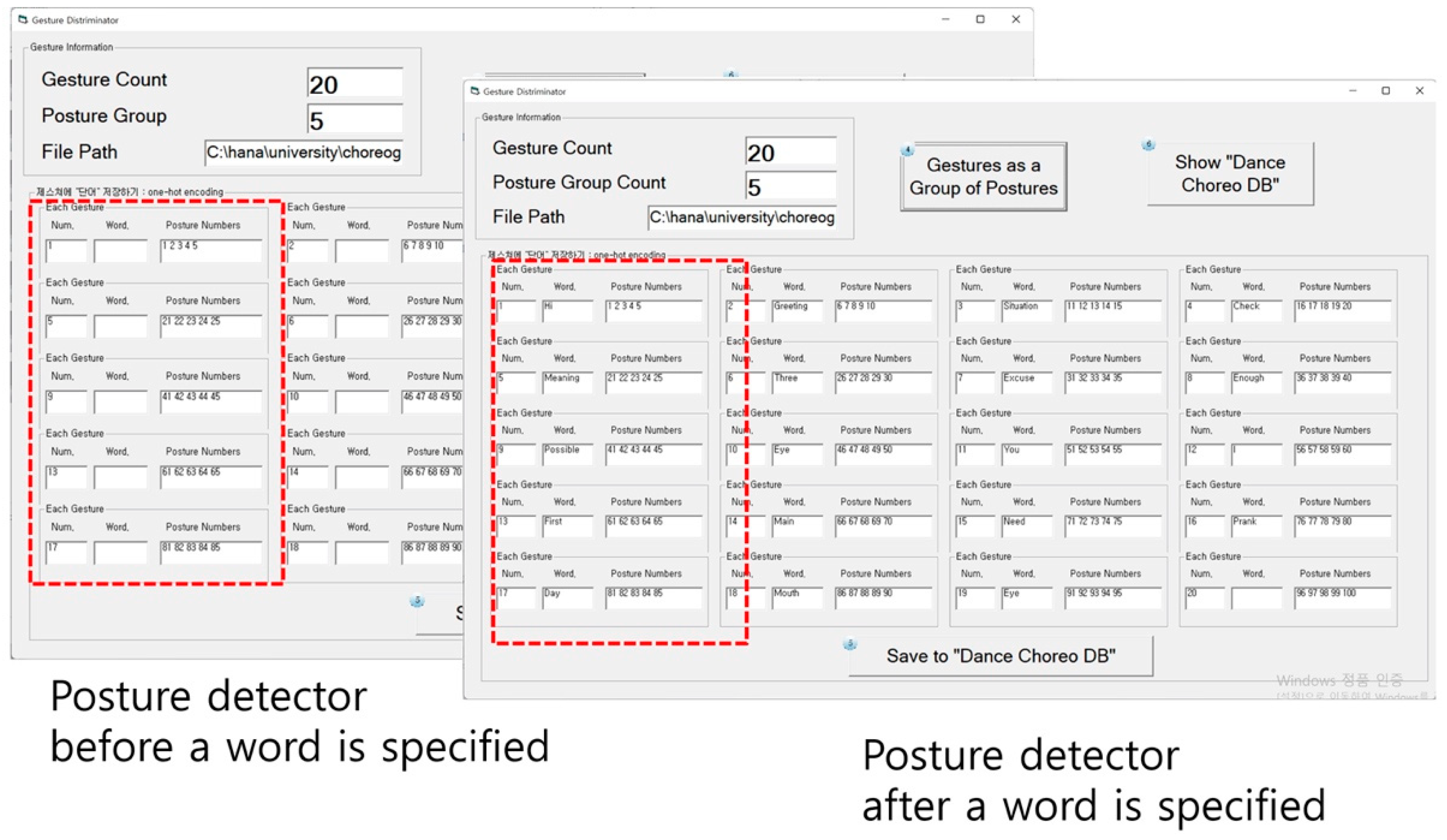
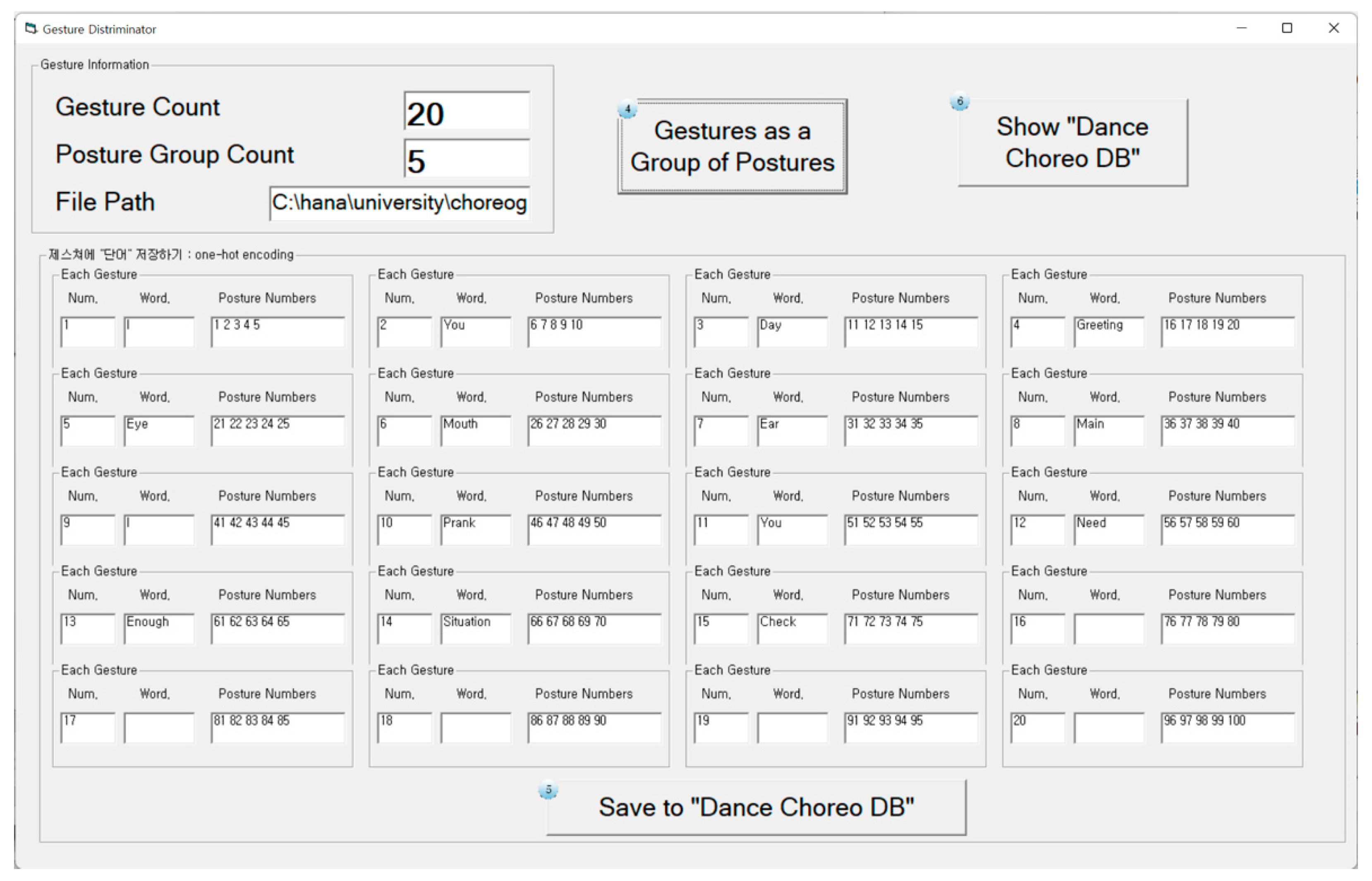
3.2.3. Gesture Discriminator
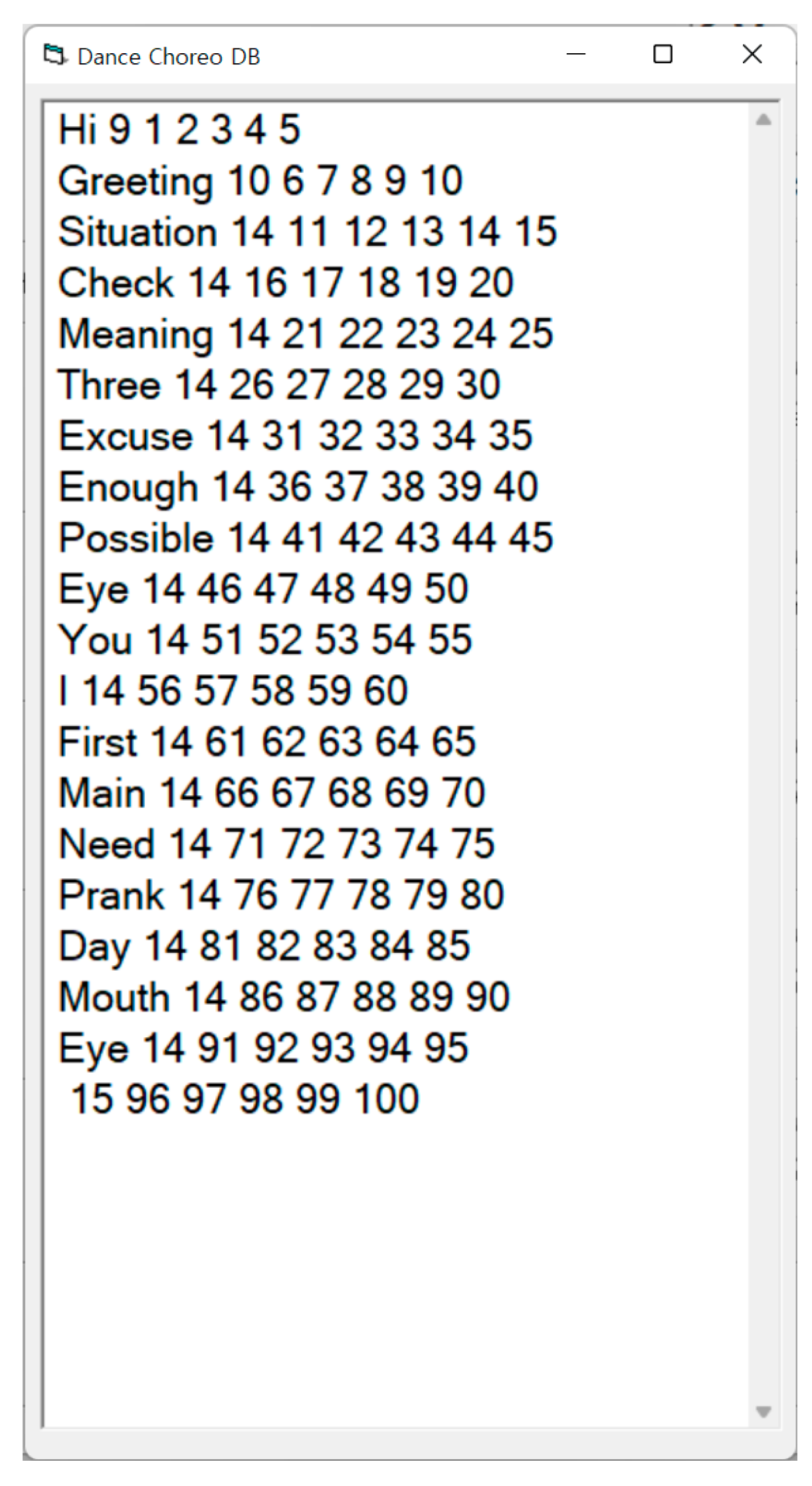
3.2.4. Dance-Choreo-DB
3.3. Dance-Choreo-Control-Stage
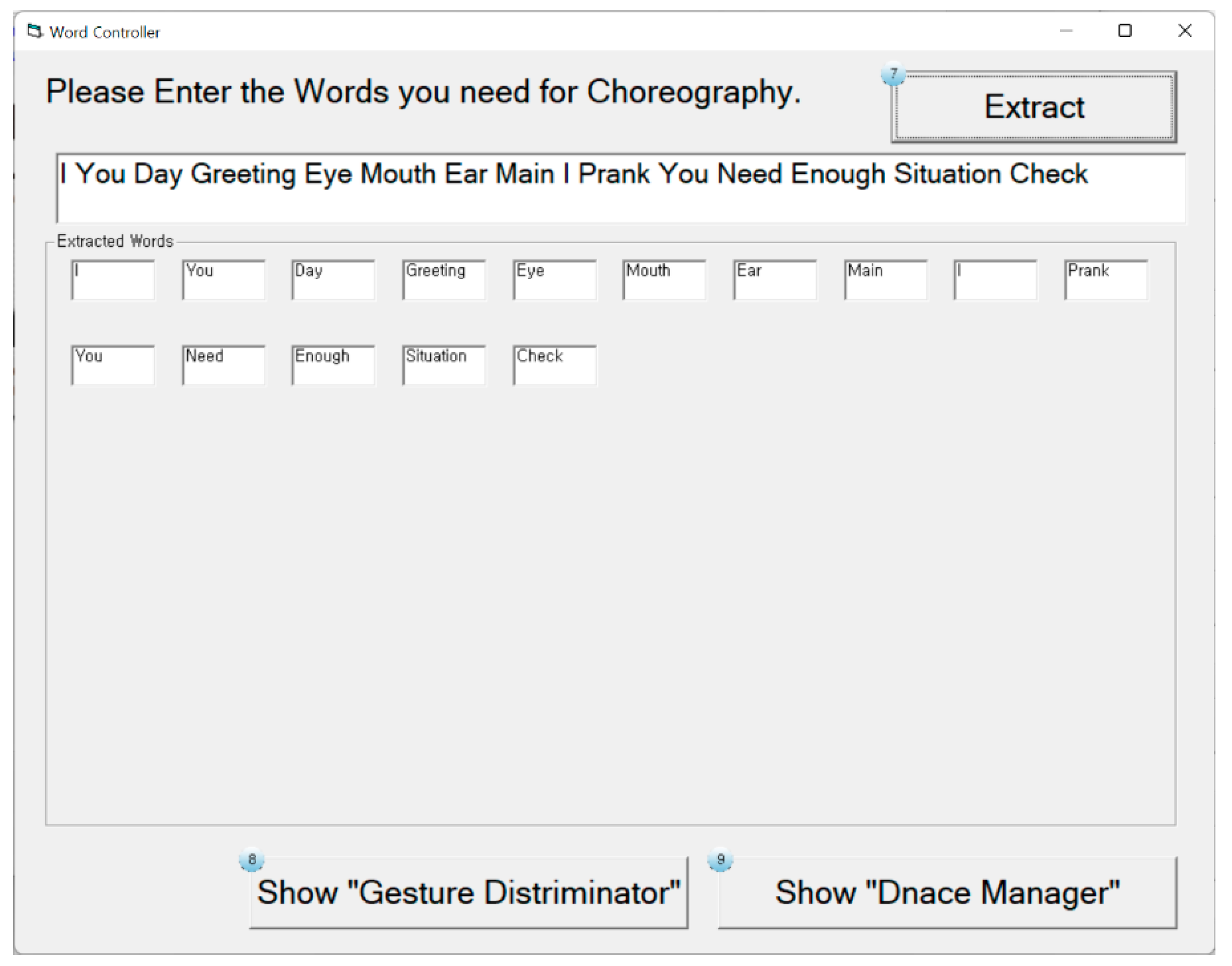
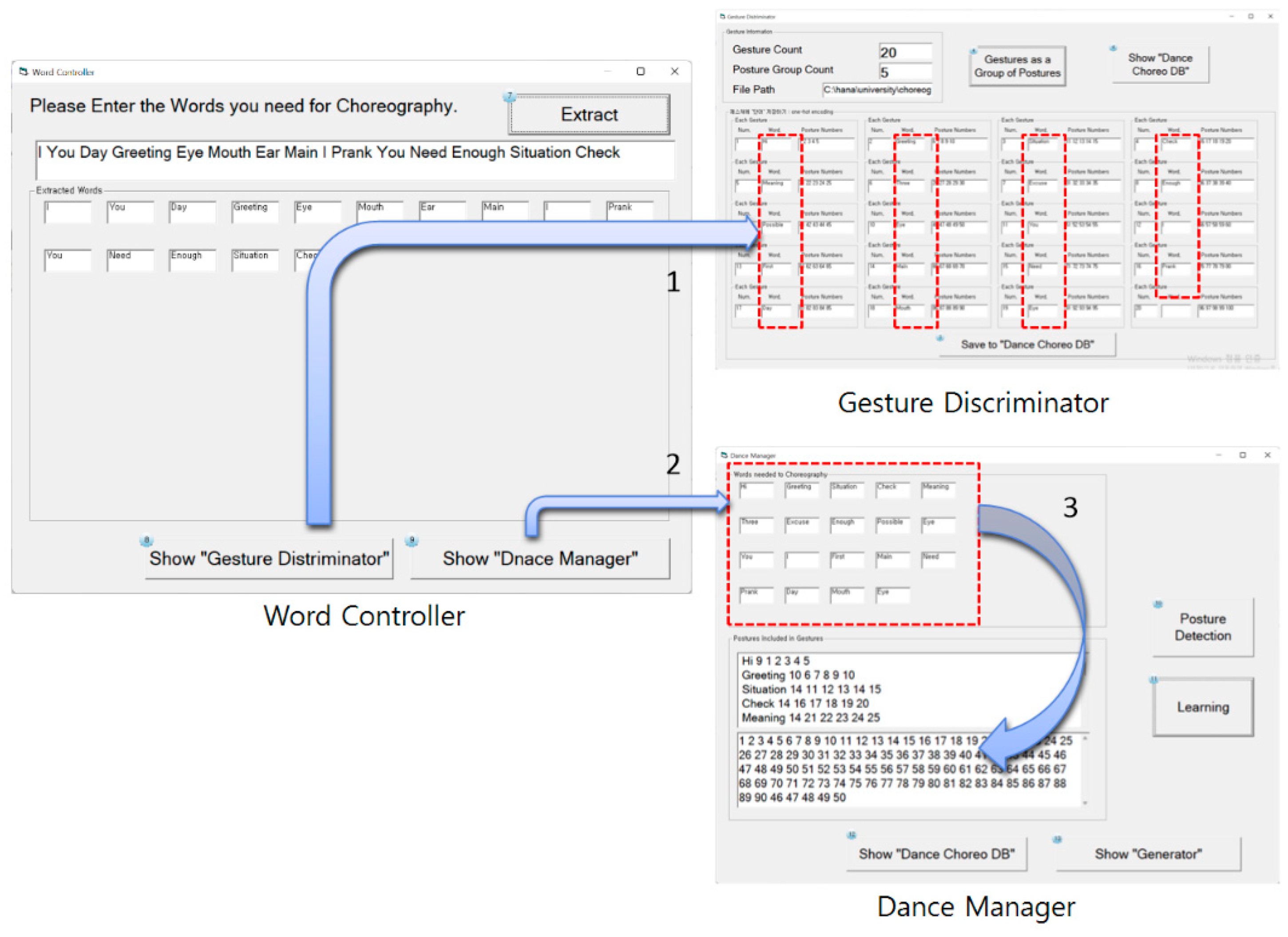
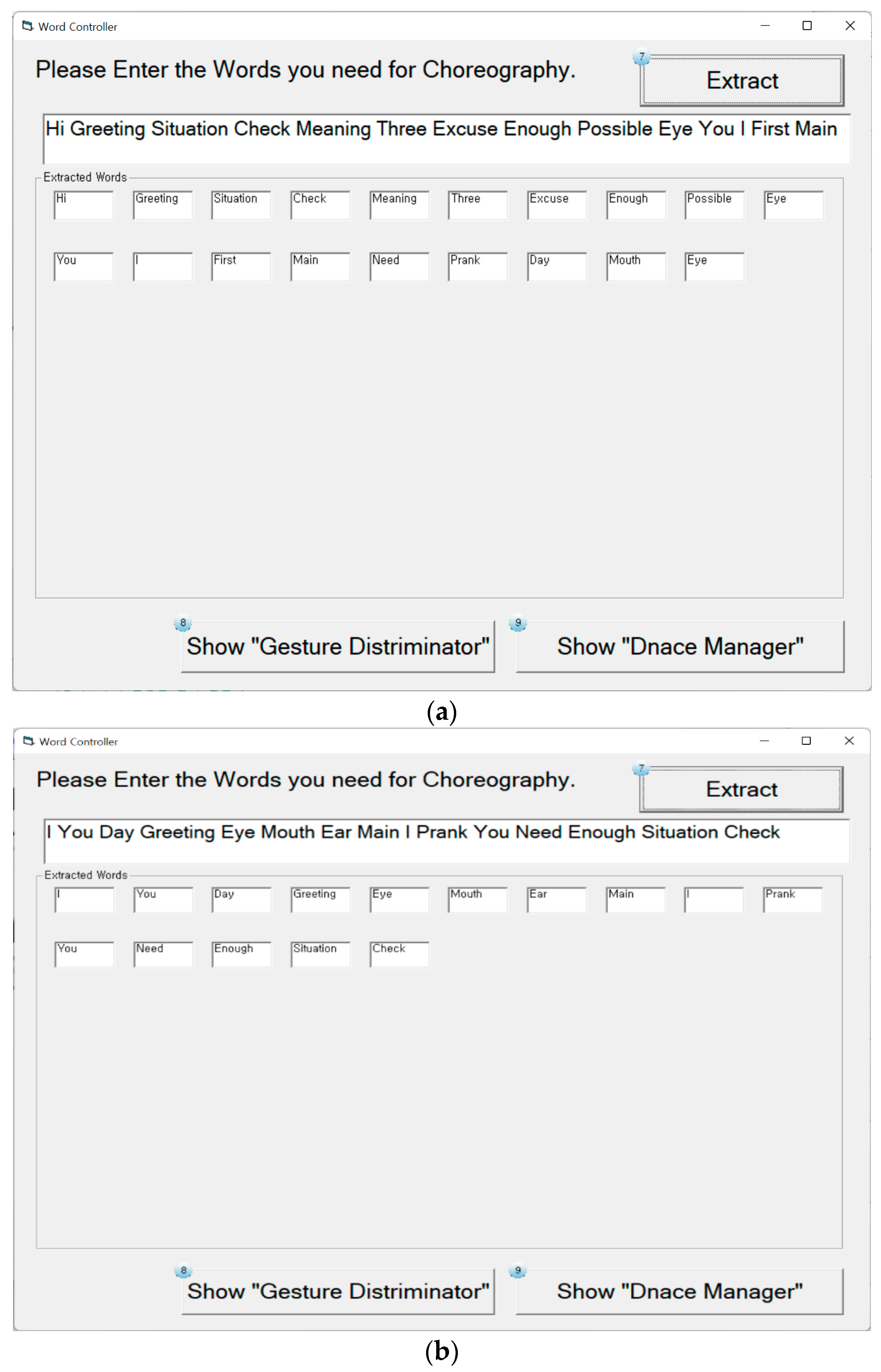
3.3.1. Word Controller
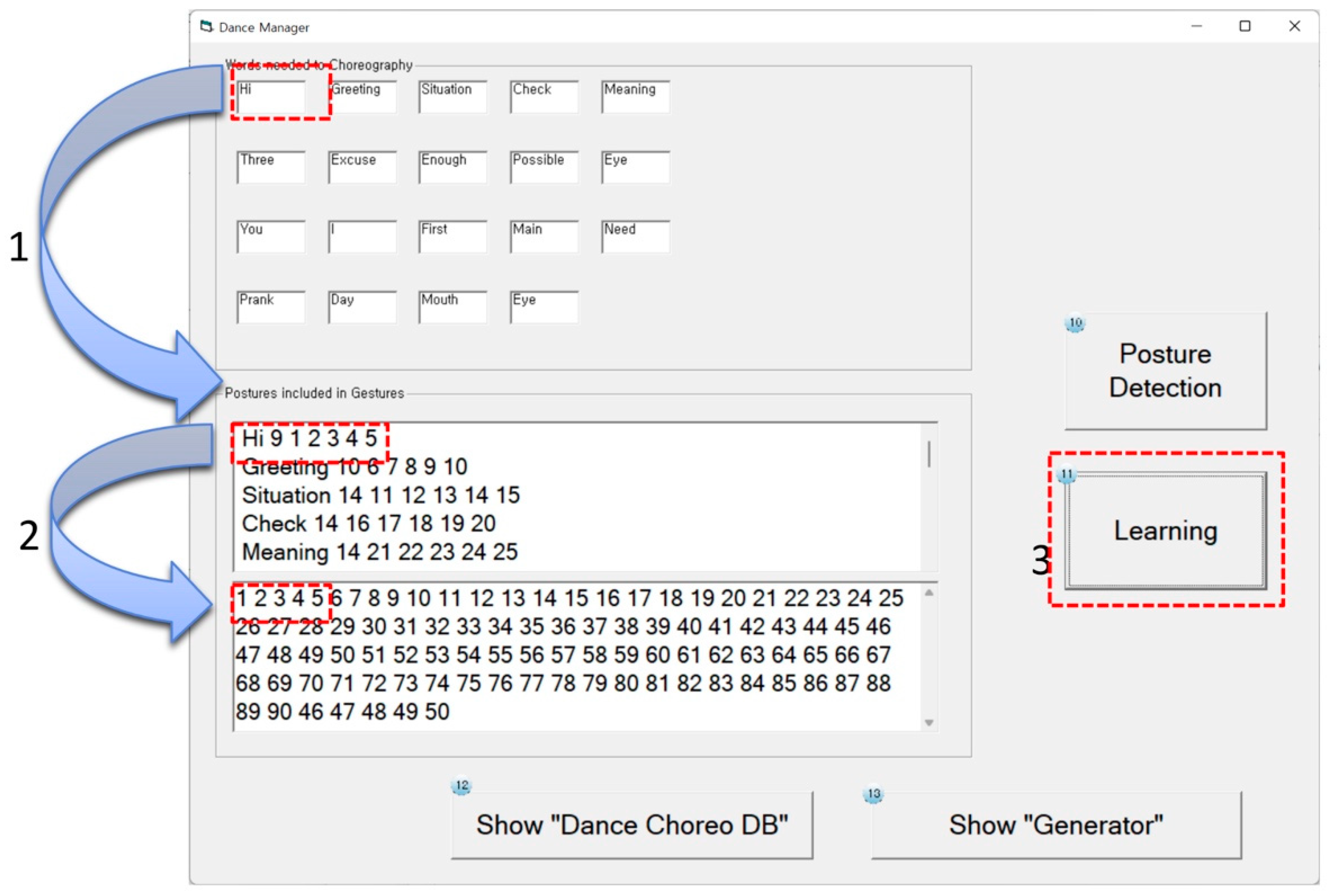
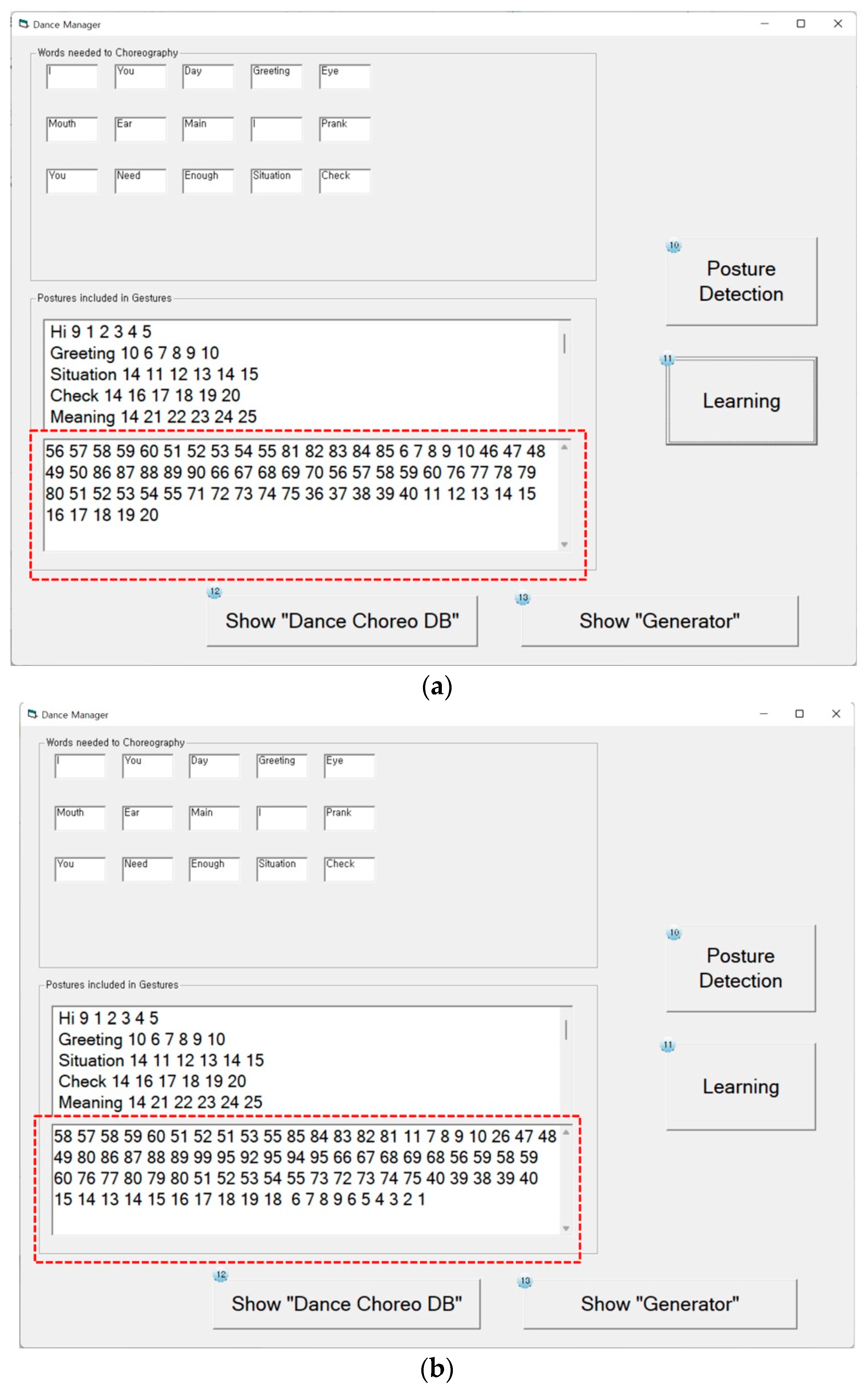
3.3.2. Dance Manager
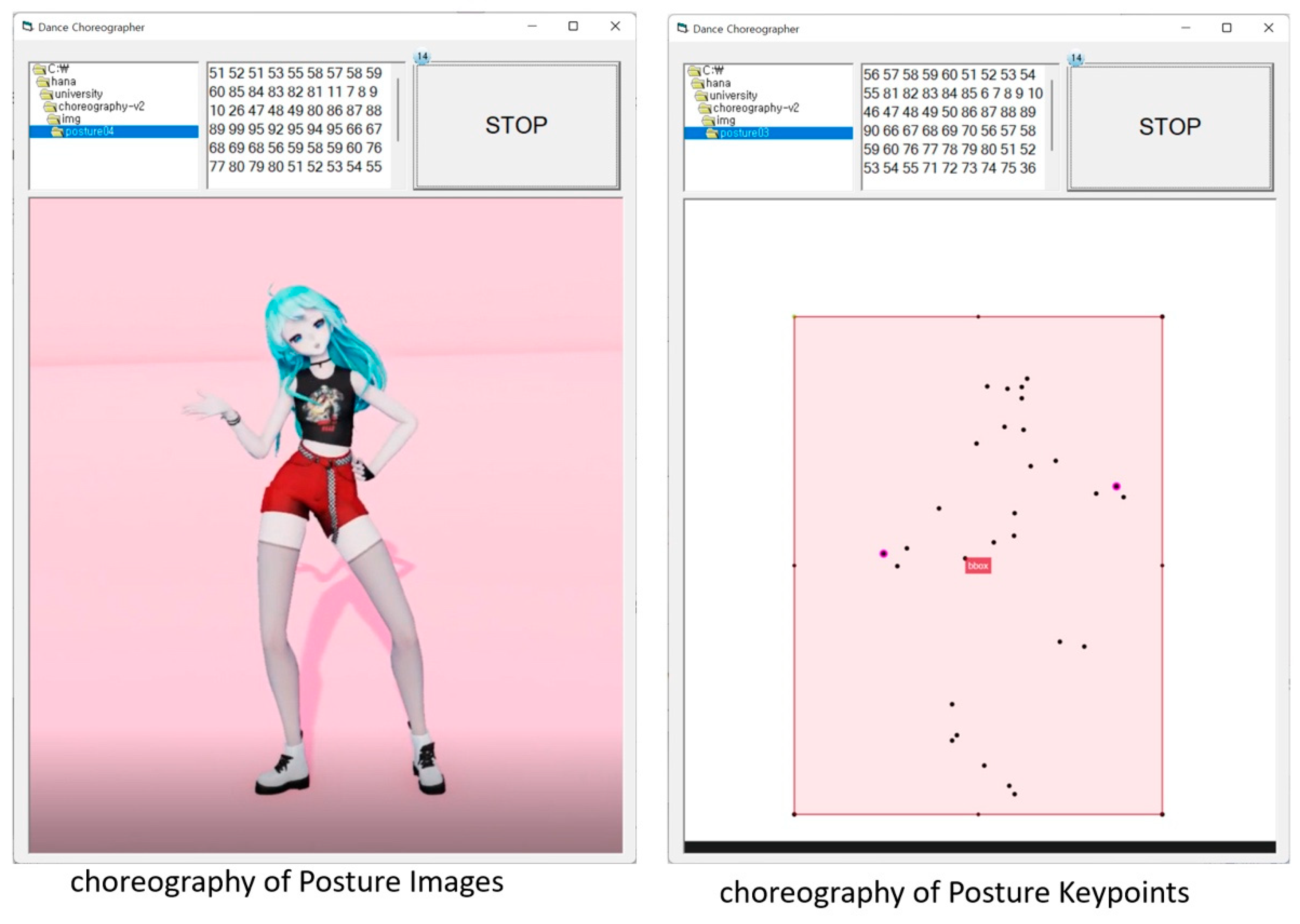
3.3.3. Dance Choreographer
3.4. Dance-Choreo-Learning-Stage
3.5. Flow Chart of Creative Choreography Data
4. Experiments and Results
4.1. Experimental Environment
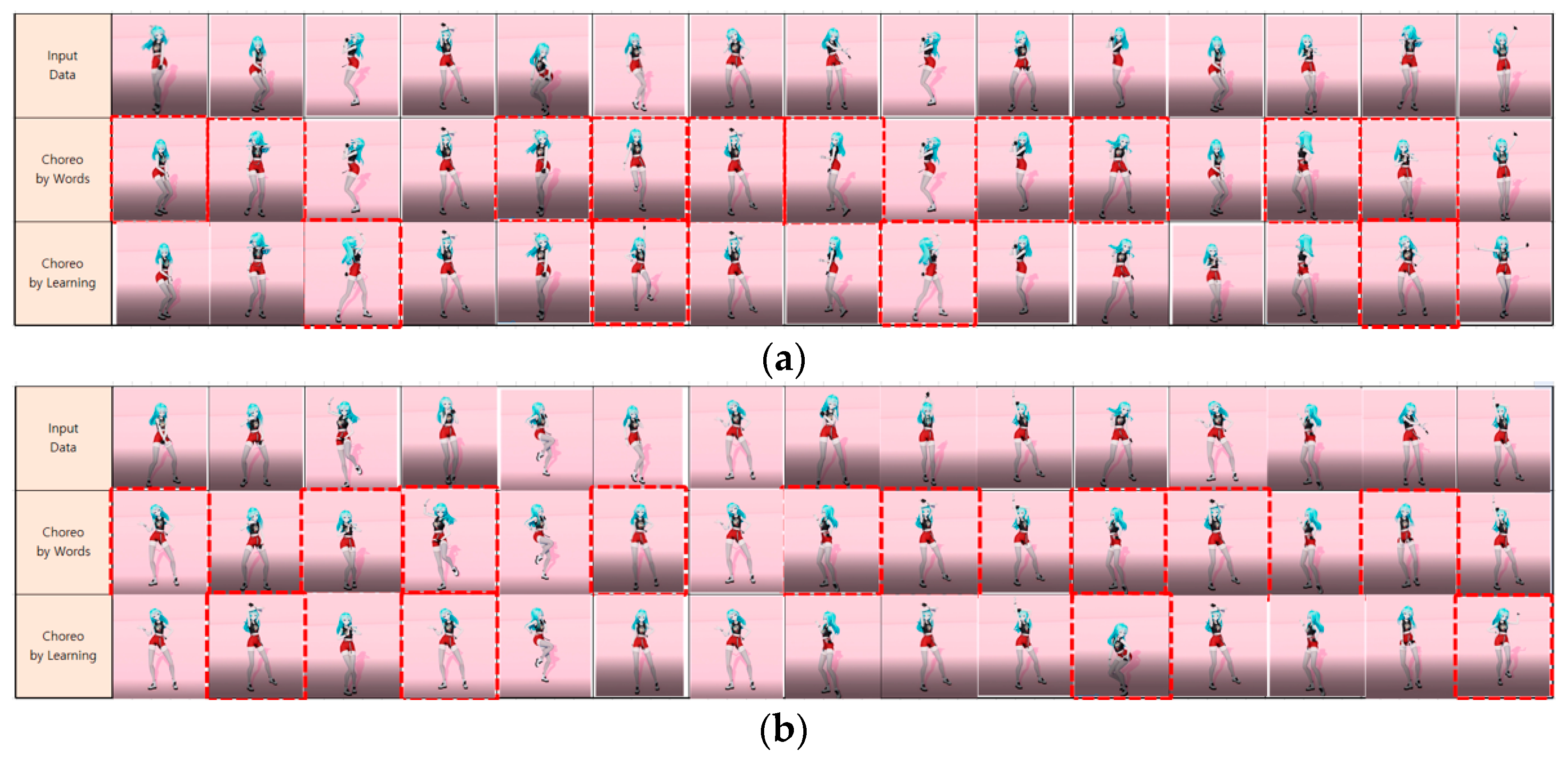
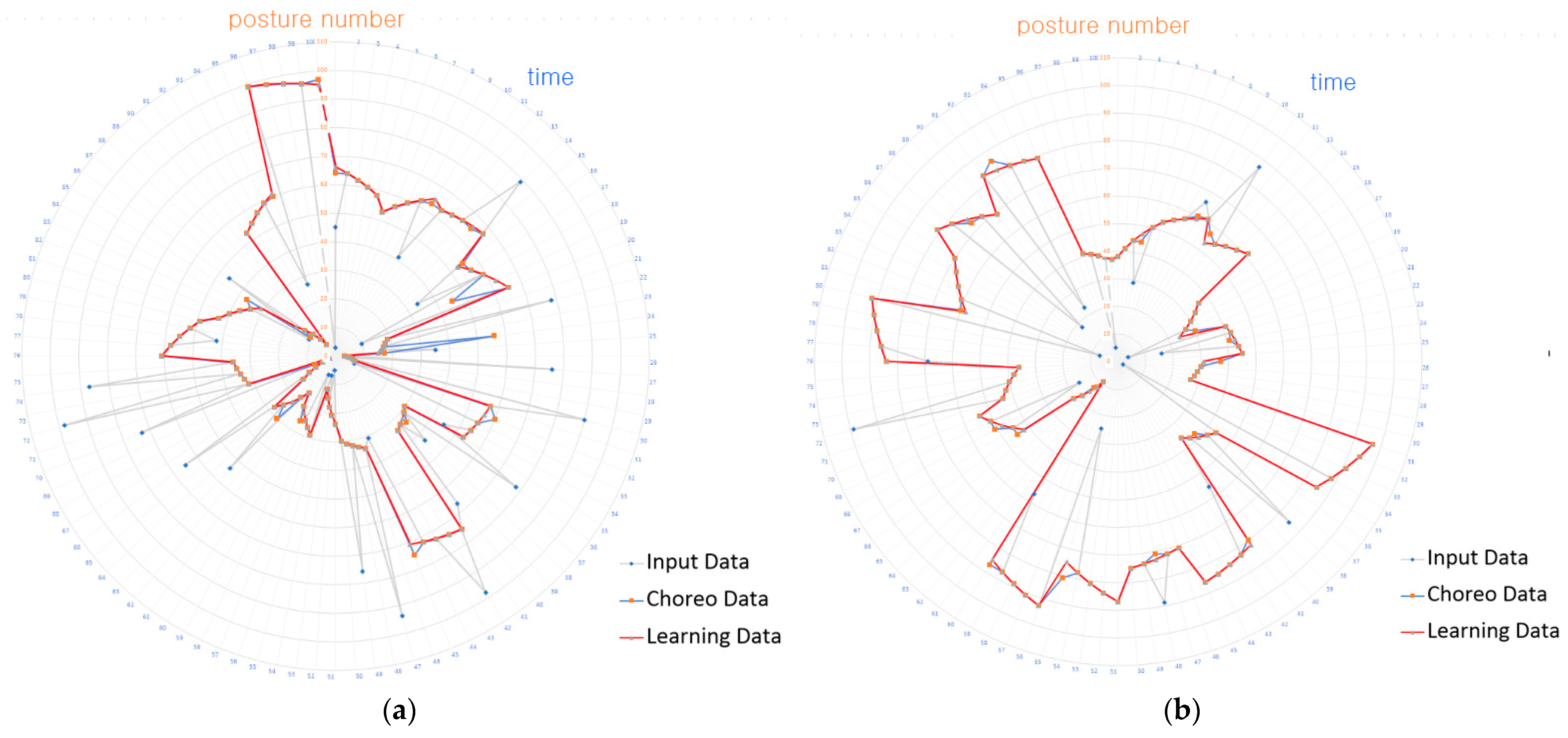
4.2. Experimental Results
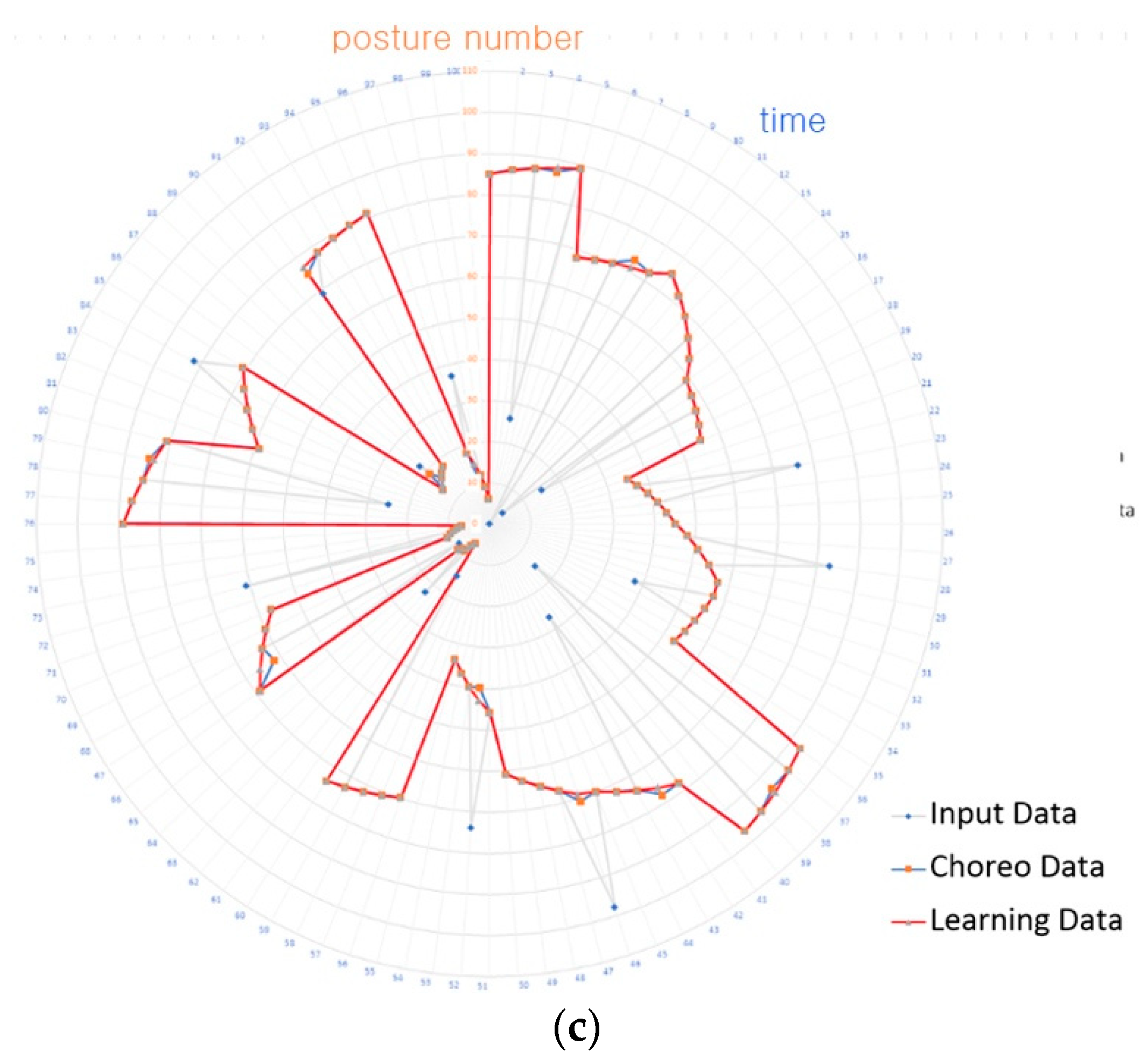
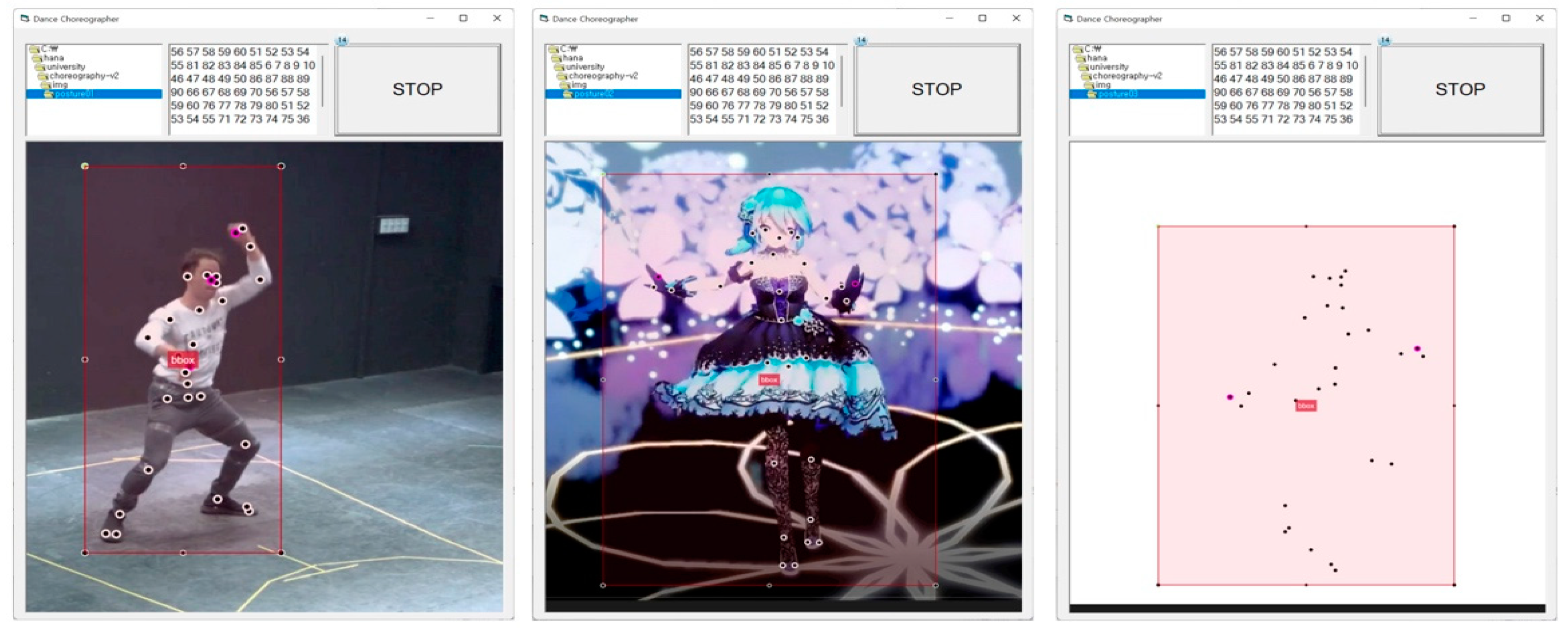
4.3. Experimental Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Joonhee, K. Analysis of Research Trends on K-pop—Focused on Research Papers from 2011 to 2018. Cult. Converg. 2019, 41, 461–490. [Google Scholar]
- Sol, K.; Jun, K. Exploring the Changes and Prospects of the Street Dance Environment caused by COVID-19. J. Korean Soc. Sport. Sci. 2021, 30, 257–272. [Google Scholar]
- Li, R.; Yang, S.; Ross, D.A.; Kanazawa, A. Ai choreographer: Music Conditioned 3D Dance Generation with AIST++. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 10–17 October 2021; pp. 13401–13412. [Google Scholar]
- Wang, Q.; Li, B.; Xiao, T.; Zhu, J.; Li, C.; Wong, D.F.; Chao, L.S. Learning deep transformer models for machine translation. arXiv 2019, arXiv:1906.01787. [Google Scholar]
- Umino, B.; Soga, A. Automatic Composition Software for Three Genres of Dance Using 3D Motion Data. In Proceedings of the 17th Generative Art Conference, Rome, Italy, 17–19 December 2014; pp. 79–90. [Google Scholar]
- Chan, C.; Ginosar, S.; Zhou, T.; Efros, A. Everybody Dance Now. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5933–5942. [Google Scholar]
- Jordan, B.; Devasia, N.; Hong, J.; Williams, R.; Breazeal, C. A Toolkit for Creating (and Dancing) with AI. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 15551–15559. [Google Scholar]
- Sminchisescu, C. 3D Human Motion Analysis in Monocular Video: Techniques and Challenges. In Human Motion; Springer: Dordrecht, The Netherlands, 2008; pp. 185–211. [Google Scholar]
- Guo, H.; Sung, Y. Movement Estimation using Soft Sensors based on Bi-LSTM and Two-Layer LSTM for Human Motion Capture. Sensors 2020, 20, 1801. [Google Scholar] [CrossRef] [PubMed]
- Yim, S. Suggestions for the Independent Body in the era of Artificial Intelligence Choreography. Trans- 2022, 12, 1–19. [Google Scholar]
- Pan, Z.; Yu, W.; Yi, X.; Khan, A.; Yuan, F.; Zheng, Y. Recent Progress on Generative Adversarial Networks (GANs): A survey. IEEE Access 2019, 7, 36322–36333. [Google Scholar] [CrossRef]
- Huang, Y.; Kaufmann, M.; Aksan, E.; Black, M.J.; Hilliges, O.; Pons-Moll, G. Deep Inertial Poser: Learning to Reconstruct Human Pose from Sparse Inertial Measurements in Real Time. ACM Trans. Graph. (TOG) 2018, 37, 1–15. [Google Scholar] [CrossRef]
- Iashin, V.; Rahtu, E. Multi-modal Dense Video Captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 958–959. [Google Scholar]
- Jain, A.; Tompson, J.; LeCun, Y.; Bregler, C. MoDeep: A Deep Learning Framework Using Motion Features for Human Pose Estimation. In Proceedings of the Computer Vision–ACCV 2014: 12th Asian Conference on Computer Vision, Singapore, 1–5 November 2014; Revised Selected Papers, Part II 12. Springer International Publishing: Berlin/Heidelberg, Germany, 2014; pp. 302–315. [Google Scholar]
- Ionescu, C.; Papava, D.; Olaru, V.; Sminchisescu, C. Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 1325–1339. [Google Scholar] [CrossRef] [PubMed]
- Jain, A.; Zamir, A.R.; Savarese, S.; Saxena, A. Deep Learning on Spatio-temporal Graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5308–5317. [Google Scholar]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A dataset of 101 human actions classes from videos in the wild. arXiv 2012, arXiv:1212.0402. [Google Scholar]
- Jia, Y.; Johnson, M.; Macherey, W.; Weiss, R.J.; Cao, Y.; Chiu, C.C.; Wu, Y. Leveraging Weakly Supervised Data to Improve end-to-end Speech-to-text Translation. In Proceedings of the ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 7180–7184. [Google Scholar]
- Khan, N.; Muhammad, K.; Hussain, T.; Nasir, M.; Munsif, M.; Imran, A.S.; Sajjad, M. An Adaptive Game-Based Learning Strategy for Children Road Safety Education and Practice in Virtual Space. Sensors 2021, 21, 3661. [Google Scholar] [CrossRef] [PubMed]
- Tsuchida, S.; Fukayama, S.; Hamasaki, M.; Goto, M. AIST Dance Video Database: Multi-Genre, Multi-Dancer, and Multi-Camera Database for Dance Information Processing. Int. Soc. Music Inf. 2019, 1, 6. [Google Scholar]
- Zhang, J.; Chen, Z.; Tao, D. Towards high performance human keypoint detection. Int. J. Comput. Vis. 2021, 129, 2639–2662. [Google Scholar] [CrossRef]








































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| sequence_length | 5 | This is the length of the input sequences that the network will operate on. In other words, if the network is processing text data, it will work with sequences of 5 words at a time. |
| number_class | 100 | This is the number of classes that the network is attempting to classify the input into. For example, if the network is trying to classify images, there might be 100 different types of objects that the network is trying to identify. |
| hidden_size | 512 | This is the number of neurons in each hidden layer of the network. The higher the hidden size, the more complex the network can be. |
| number_layer | 2 | This is the number of layers in the network. The more layers, the more complex the network can be. |
| batch_size | 128 | This is the number of samples that the network processes at a time during training. A higher batch size can lead to more efficient training. |
| dropout | 0.1 | This is the dropout rate, which is the probability that each neuron will be randomly dropped out during training. Dropout is a regularization technique that can prevent overfitting. |
| Lr | 1 × 10−4 | This is the learning rate, which determines how quickly the network will adjust its weights during training. A higher learning rate can lead to faster training, but can also cause the network to overshoot optimal weights. |
| adam_weight_decay | 0.01 | This is the weight decay parameter used by the Adam optimizer. Weight decay is another regularization technique that can prevent overfitting. |
| adam_beta1 | 0.9 | This is the beta1 parameter used by the Adam optimizer. It determines the decay rate for the moving average of the gradient. |
| adam_beta2 | 0.98 | This is the beta2 parameter used by the Adam optimizer. It determines the decay rate for the moving average of the squared gradient. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yoo, H.; Sung, Y. Advanced Dance Choreography System Using Bidirectional LSTMs. Systems 2023, 11, 175. https://doi.org/10.3390/systems11040175
Yoo H, Sung Y. Advanced Dance Choreography System Using Bidirectional LSTMs. Systems. 2023; 11(4):175. https://doi.org/10.3390/systems11040175
Chicago/Turabian StyleYoo, Hanha, and Yunsick Sung. 2023. "Advanced Dance Choreography System Using Bidirectional LSTMs" Systems 11, no. 4: 175. https://doi.org/10.3390/systems11040175
APA StyleYoo, H., & Sung, Y. (2023). Advanced Dance Choreography System Using Bidirectional LSTMs. Systems, 11(4), 175. https://doi.org/10.3390/systems11040175