

User Sentiment Analysis of COVID-19 via Adversarial Training Based on the BERT-FGM-BiGRU Model

1
School of Maritime Economics and Management, Dalian Maritime University, Dalian 116026, China
2
School of Economics and Management, Dalian University of Technology, Dalian 116024, China
3
Southampton Business School, University of Southampton, Southampton SO17 1BJ, UK
*
Author to whom correspondence should be addressed.
Systems 2023, 11(3), 129; https://doi.org/10.3390/systems11030129
Submission received: 9 January 2023
/
Revised: 15 February 2023
/
Accepted: 25 February 2023
/
Published: 1 March 2023
(This article belongs to the Section Systems Practice in Social Science)
Abstract
:With the rapid development of social network platforms, Sina Weibo has become the main carrier for modern netizens to express public views and emotions. How to obtain the tendency of public opinion and analyze the text’s emotion more accurately and reasonably has become one of the main challenges for the government to monitor public opinion in the future. Due to the sparseness of Weibo text data and the complex semantics of Chinese, this paper proposes an emotion analysis model based on the Bidirectional Encoder Representation from Transformers pre-training model (BERT), Fast Gradient Method (FGM) and the bidirectional Gated Recurrent Unit (BiGRU), namely BERT-FGM-BiGRU model. Aiming to solve the problem of text polysemy and improve the extraction effect and classification ability of text features, this paper adopts the BERT pre-training model for word vector representation and BiGRU for text feature extraction. In order to improve the generalization ability of the model, this paper uses the FGM adversarial training algorithm to perturb the data. Therefore, a BERT-FGM-BiGRU model is constructed with the goal of sentiment analysis. This paper takes the Chinese text data from the Sina Weibo platform during COVID-19 as the research object. By comparing the BERT-FGM-BiGRU model with the traditional model, and combining the temporal and spatial characteristics, it further studies the changing trend of user sentiment. Finally, the results show that the BERT-FGM-BiGRU model has the best classification effect and the highest accuracy compared with other models, which provides a scientific method for government departments to supervise public opinion. Based on the classification results of this model and combined with the temporal and spatial characteristics, it can be found that public sentiment is spatially closely related to the severity of the pandemic. Due to the imbalance of information sources, the public showed negative emotions of fear and worry in the early and middle stages, while in the later stage, the public sentiment gradually changed from negative to positive and hopeful with the improvement of the epidemic situation.
1. Introduction
In late 2019, there was an outbreak of unexplained pneumonia in Wuhan, China, which was later named COVID-19 [1] by the World Health Organization. This public health emergency has aroused widespread concern throughout the country and the world [2]. With the gradual deterioration of the epidemic situation, people began to become afraid and anxious. Negative emotions and rumors about COVID-19 spread among the public. At the same time, the National Health Commission of the People’s Republic of China issued “Home quarantine” policy, which prohibits the public from participating in offline activities. The public had to express their views through social networking platforms such as Twitter or Sina Weibo. People publish and disseminate their views on the Internet anytime and anywhere, which generates a huge amount of real-time comment data. Information dissemination in the new media era has got rid of the restrictions of time and space, and has the characteristics of interactivity, immediacy, and sharing. Some events that attract people’s attention can be spread quickly and widely, and then generate public opinion on the Internet, which promotes the spread and diffusion of online public opinion. Analyzing these text data helps the government to explore people’s emotional tendencies and the general trend of public opinion in society. To some extent, this will avoid social unrest caused by false information and negative public opinion, and promote social stability and development [3,4,5]. Therefore, it has become a common concern of public opinion monitoring departments and academia to seek efficient sentiment analysis strategies and monitor online public opinion to avoid social risks and further maintain social stability in view of the emotional changes of users during COVID-19.
At present, the main part of the recent contribution to healthcare has been positioned in the context of COVID-19 [6]. The online public opinion research in the field of public health emergencies mostly focuses on the use of sentiment dictionaries or traditional language models for analysis, without considering the contextual characteristics of the text, nor using more scientific sentiment analysis methods to express the emotional tendency of users. Therefore, this paper proposes a BERT-FGM-BiGRU sentiment analysis model, to study the relationship between the changes in public sentiment and the development of the epidemic, under the background of COVID-19, so as to provide a scientific basis for government departments to monitor public opinion.
This paper is organized as follows: The first part introduces the research background and significance. The second part is a literature review according to the research content. The third part introduces the model and method used in this paper. The fourth part is experiment and analysis. Precision, recall rate, and F1-score are used to evaluate the performance of the model. Based on the sentiment analysis model, temporal and spatial characteristics are integrated for further analysis. The fifth part reviews the paper and puts forward the direction for future improvement.
2. Literature Review
In order to explore the research status of relevant issues, we conducted an analysis of online public opinion and public sentiment during COVID-19. The specific domestic and international research statuses are as follows:
2.1. Analysis of Online Public Opinion on COVID-19
As a public health emergency, COVID-19 poses a huge threat to public health [7], and this infection may lead to severe pneumonia and a series of diseases [8]. Countries have taken strict social isolation or keeping safe social distancing against the epidemic, which will have a serious impact on the economy, society, and psychology [9,10,11].
In the context of the COVID-19 epidemic, social interaction has shifted from offline to online, and data from social media platforms have become the main data sources for research. At present, domestic and foreign scholars have made certain research progress. Qin et al. [12] collected the search index of social media during COVID-19 and used the lag sequence of SMSI to predict the number of suspected COVID-19 cases. Li et al. [13] used the Online Ecological Recognition (OER) method to analyze the Sina Weibo posts of active Weibo users based on multiple machine learning prediction models. They calculated word frequency, emotional indicators, and cognitive indicators from the collected data to provide references for policy makers and effectively countered COVID-19 by improving the stability of public sentiment. Li et al. [14] used information monitoring methods of social media to help describe the distribution of disease and the public knowledge, attitudes, and behaviors that are critical to the early stages of an epidemic. Zhao et al. [15] collected topics related to the COVID-19 epidemic on the Sina Microblog hot search list, and used VOSviewer to implement a visual cluster analysis of hot keywords. They build a social network of public opinion content, and described the trend of public attention on topics related to COVID-19. Li et al. [16] used the BERT-BiLSTM emotional analysis model to analyze the emotional tendency of comments, and the LDA topic model to mine the topics of comments with different emotional attributes, this provided new ideas for further exploring the research of online public opinion in colleges and universities, and was conducive to preventing the crisis of campus public opinion. Wang et al. [17] used a topic modeling technique to identify the most common topics posted by users, analyzed the emotional tendencies of the topics, and performed user behavior analysis on the topics using data collected from the number of likes, comments, and retweets. Some scholars [18] have studied the characteristics of the spread of false statements and rumors during the COVID-19. It can be seen from the above literature that the monitoring and analyzing of online public opinion in public health emergencies have become a hot topic for scholars. However, most of them focus on the analysis of text content and topics or the quantitative analysis of public opinion. Few literature have included sentiment analysis and correlation of temporal and spatial characteristics into the evolution cycle of public opinion for analysis, and few scholars have used scientific sentiment analysis methods to consider both public opinion and epidemic severity.
2.2. Adversarial Training
With the development of deep learning, adversarial training has also received extensive attention. In the early days, adversarial training was mostly applied in the field of computer vision (CV). In recent years, with the growing difficulty in generating effective adversarial samples in natural language tasks and other related problems, adversarial training has been introduced in the field of natural language processing (NLP), such as domain adaptation [19], cross-language transfer learning [20], and multi-task learning [21], adversarial training enhances the robustness of the model through adversarial attacks and defenses against the model. One meaning of adversarial in deep learning refers to the generation of antagonistic networks (GAN), which represents a large class of advanced generation models. Another meaning is the field related to adversarial attacks and samples, which is related to GAN, but different. Its main concern is the robustness of the model under small disturbances.
Szegedy et al. [22] proposed the concept of adversarial samples for the first time, and formed adversarial samples by adding some subtle interference to the data set. Goodfellow et al. [23] proposed the concept of adversarial training for the first time, and designed a fast gradient sign method (FGSM), which is used to calculate the disturbance of input samples. By continuously inputting the disturbance to the model, the robustness of the model against malicious adversarial samples is improved. At the same time, as a regularization method, it can prevent overfitting and improve the generalization ability of the model. Miyato et al. [24] made some modifications in the part of FGSM to calculate the disturbance, regularized it according to the specific gradient, proposed to add the disturbance to the word vector layer, and carried out the semi-supervised text classification task and verified its effectiveness. In addition, the method based on local adversarial training by Li Jing et al. [25] not only alleviates the problem of named entity identification caused by confusion of boundary samples, but also reduces the adversarial sample redundancy caused by increased calculation in traditional adversarial training. Yasunaga et al. [26] used adversarial training in POS tasks, which not only improved the overall labeling accuracy, but also enhanced the robustness of the model. Zhou et al. [27] added disturbance to the word embedding layer, which improved the generalization ability of the named entity recognition model with low resources.
By reading the literature of the above scholars, we can find that in NLP tasks, the role of adversarial training is no longer to defend against malicious attacks based on gradient, but is more as a regularization method to improve the generalization ability of the model. Based on the above research, this study integrates adversarial training into the emotional analysis model, and generates adversarial samples by adding disturbance factors into the word embedding layer, which can enhance the anti-interference ability of the model, thus improving the robustness and prediction ability of the model.
2.3. Sentiment Analysis
Sentiment analysis aims at mining the views in the text and analyzing the emotional information contained in the text [28]. Through sentiment analysis of hot issues, it can clarify the emotional attitude conveyed by the text of users, which can help the government departments to understand the public opinion tendency and plays an auxiliary role in monitoring public opinion. Existing sentiment analysis studies mainly include sentiment dictionary methods and deep learning sentiment analysis methods.
Sentiment analysis based on the sentiment dictionary mainly depends on the construction of the sentiment dictionary, and the purpose of sentiment analysis can be achieved through the matching of the text and the dictionary, which can accurately reflect the unstructured characteristics of the text. However, most emotional dictionaries are constructed manually, which requires great labor costs. In addition, there are still some problems in sentiment analysis based on the sentiment dictionary, such as poor recognition effect of network special terms, different meanings of the same sentiment word in different contexts, and inability to consider the semantic relationship between contexts [29,30,31]. Therefore, this method is not suitable for texts in specific fields.
In recent years, due to the outstanding performance of deep learning in natural language processing, more and more researchers began to apply the concept of deep learning to the field of sentiment analysis, and the methods of sentiment analysis based on deep learning are also expanding. Compared with traditional sentiment analysis based on the sentiment dictionary, sentiment analysis based on deep learning has obvious advantages in text feature learning, which can better extract semantic information of text, thus effectively realizing sentiment analysis of the text. At present, the research on sentiment analysis based on deep learning mainly focuses on two aspects. On the one hand, it learns the feature information in the text through the deep network model, thus improving the performance of model emotion classification [32,33,34,35,36]. This method uses continuous and low-latitude vectors to represent the text, which can effectively solve the problem of sparse text, but its performance depends too much on the model structure. On the other hand, it makes full use of large-scale monolingual corpus to construct sentence-level context representation through the pre-training language model, which effectively alleviates the problem of excessive dependence on model structure in the sentiment analysis method based on deep learning [37]. However, the static word vector obtained by the traditional pre-training language model cannot solve the polysemy phenomenon well, and cannot fully obtain the semantic information. Compared with other common texts, Sina Weibo comments during COVID-19 are shorter and more colloquial, so how to extract emotional features of comment texts more accurately is of great significance for online public opinion monitoring [38].
Considering the above deficiencies, this paper uses relevant text from Sina Weibo as research samples, proposes a sentiment analysis model based on the pre-training algorithm, integrates the spatial-temporal characteristics to divide the evolution cycle of public opinion, and studies the emotional changes of public opinion in different life cycles under the background of COVID-19. It provides some theoretical support for the public opinion management of government departments.
3. Construction of the BERT-FGM-BiGRU Sentiment Analysis Model
In recent years, compared with traditional language models, deep learning models generally have the advantage of high classification accuracy, and are increasingly applied in sentiment analysis. In general, traditional language models have the limitation of ignoring the context of the text above and below. To fully explore the deep semantic information in the COVID-19 text and improve the accuracy of sentiment analysis, a BERT-FGM-BiGRU sentiment analysis model is constructed by considering the following aspects. Firstly, Since the Sina Weibo data is colloquial and the context needs to be considered, the BERT pre-training model is selected to obtain the word vector. This model can deal with the polysemy of the text and solve the problem of sparse word vector matrix obtained by the traditional language model. Secondly, considering the performance of the model and the redundancy of the data. After BERT obtained the word vector, we used the FGM adversarial training algorithm to perturb the data, to improve the generalization ability and classification performance of the model. Finally, the BiGRU model is used to further extract text features to improve the classification performance of the model.
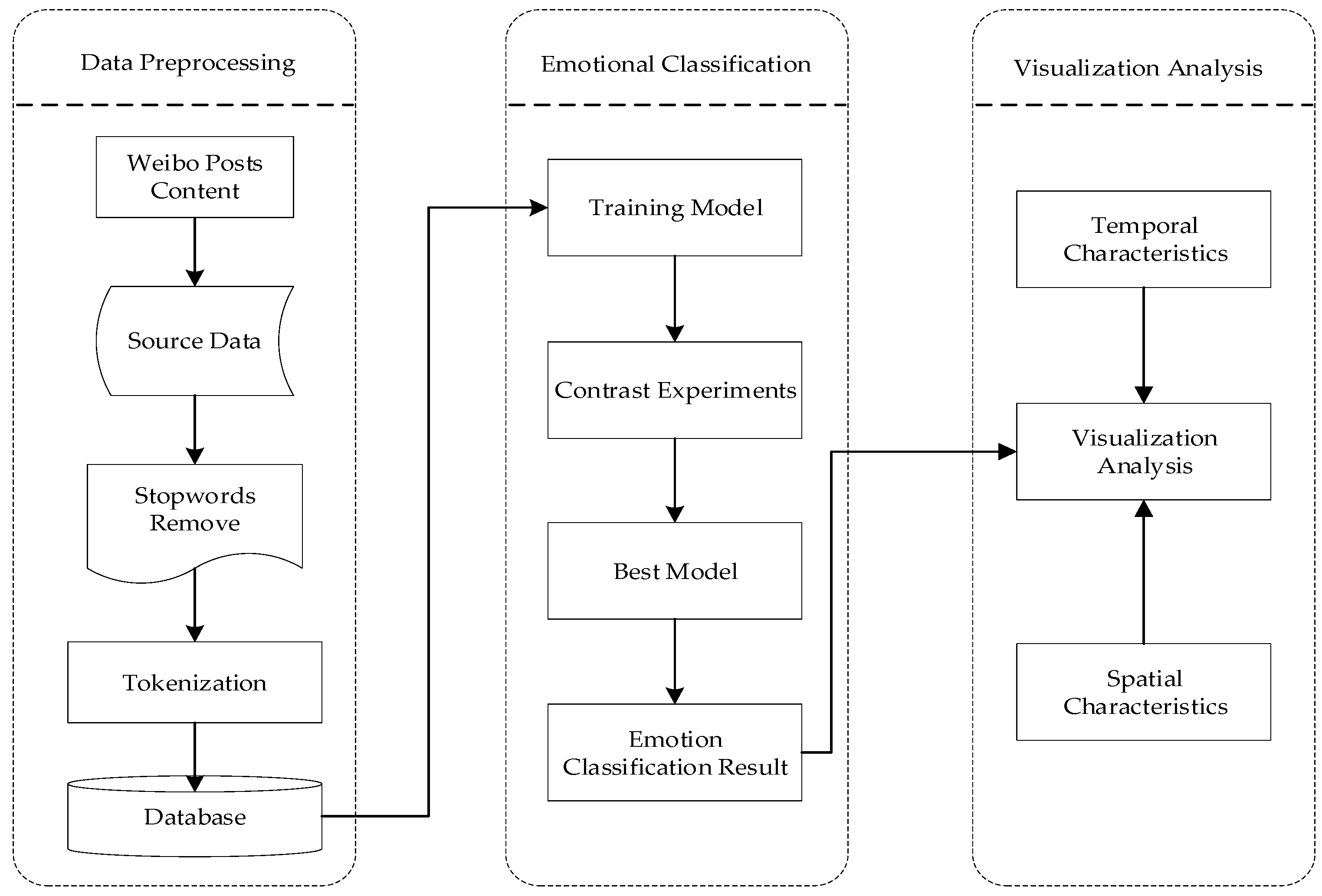
This study collects the text data related to the COVID-19 epidemic on the Sina Weibo platform, and constructs the epidemic corpus after preprocessing; then, uses the sentiment analysis technology based on the BERT pre-training model, BiGRU model, and FGM to analyze the epidemic corpus, model training, and evaluation; finally, uses the optimal sentiment analysis model to obtain the results of sentiment tendency, integrate the Spatio-temporal features and visual expression on the epidemic corpus of the social network platform from the regional scale and time scale, aiming at comprehensive analysis and displayed the emotional change trend of network public opinion, provides a certain reference for the emotional guidance of public health emergencies. The specific research framework is shown in Figure 1.
3.1. Word Vector Construction Based on the BERT Model
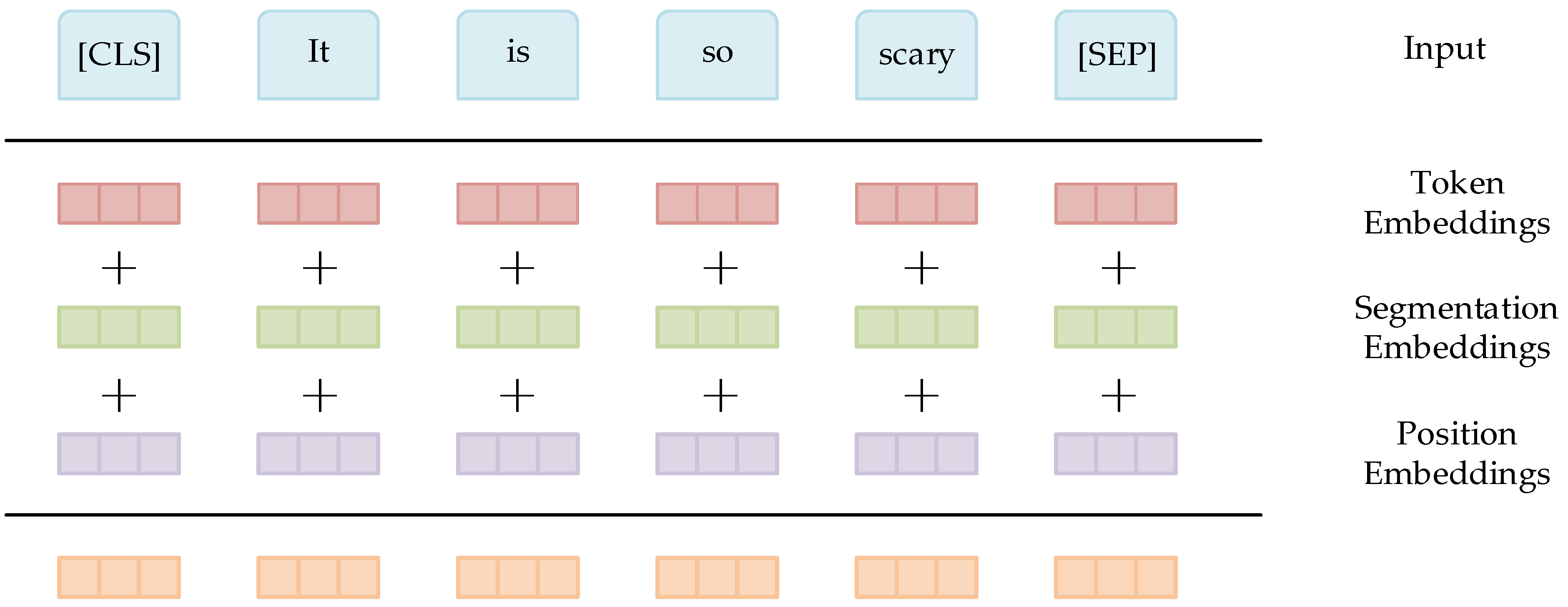
The BERT-FGM-BiGRU model is based on the BERT pre-training model [39] proposed by the Google team in 2018. We mainly used the BERT model for text feature extraction. Although the BERT model and the traditional Word2Vec model [40] are both used to represent text semantic information, the Word2Vec model has only one representation for the same token, which has certain drawbacks. The word vector matrix generated by the traditional language model is high latitude and sparse, which can not represent the text semantics well. BERT has the following improvements over the traditional language model: the encoding layer of the BERT model uses a bidirectional Transformer to extract text features. It mainly introduces the self-attention mechanism and uses the residual mechanism of the convolutional neural network for faster training and better representation. Moreover, the BERT model adopts a new masked language model MLM to better represent the bidirectional semantics language. The structure of BERT is shown in Figure 2, E1, E2, E3... En is the input vector of the BERT model, T1, T2, T3... Tn is the BERT model output vector.
The input vector of BERT includes three parts: Token Embedding, Segmentation Embedding, and Position Embedding. The output of BERT is the last Transformer output, which is also the input of the downstream task. These three vectors realize the purpose of pre-training and predicting the next sentence, and the composition structure is shown in Figure 3. The pre-training process of BERT uses two methods, namely the masked language model and next sentence prediction, for capturing word and sentence level representations, respectively. When processing a word, it can use the information of the previous word and the following word simultaneously, which is different from the traditional language model. Moreover, BERT masks some words randomly and uses all unmasked words for prediction. In short, the BERT model can better solve the polysemy problem than the Word2Vec model. Compared with the Recurrent Neural Network [41], it is more efficient, and it can capture longer-distance dependencies and real bidirectional context information. If it passes the test, we can use this model to obtain semantic information about the text.
3.2. Add Adversarial Perturbation to the Text
In order to improve the robustness of the neural network and the classification effect of the model, perturbation is added to the word vector matrix generated by the text representation model. In practical applications, adversarial training refers to adding perturbations to the model during the model training process to attack the model so as to improve the robustness and generalization ability of the model.
At present, the adversarial perturbation in text processing tasks can be divided into discrete or continuous: discrete perturbation means adding subtle perturbation at the text character level; continuous perturbation refers to adding subtle perturbation to the word vector matrix generated in the text representation model. This paper uses the continuous perturbation method.
The mathematical principle of confrontation training can be unified and abstracted into a formula, as shown in Formula (1):
The entire optimization process is carried out alternately with max and min, are model parameters, x and y represent input and label respectively, are against perturbation, and is perturbation spaces. For the external experience risk E, seek the minimum value, and for the internal loss function , seek the maximum value. The essence is to add perturbation to the input samples within the perturbation range. The purpose is to find the parameters that minimize the empirical risk.
Regarding the design of appropriate perturbation, the idea is to make the direction of perturbation along the direction of loss increase [24], that is, the direction of gradient increase. The difference between them is that the normalization method is different. FGSM uses the sign function to normalize the gradient by max, as shown in Formula (2):
Among them, ϵ is a constant, usually set to 0.25, sign is the sign function, L is the loss function, is the gradient ∆x of the loss function with respect to x, in order to prevent it from being too large, FGM will be standardized, as shown in Formula (3):
According to Formula (3), the direction of the gradient is more preserved by normalization, while the direction of max normalization is not necessarily the same as that of the original gradient. Of course, they all have a common premise, that is, the loss function L must be linear or at least locally linear, so as to ensure that the direction of gradient lifting is the optimal direction.
The algorithm of FGM is described as follows:
For x in the dataset:
(1) Calculating the forward loss and backward propagation of x to obtain a gradient;
(2) Calculate ∆x through the gradient of the embedding matrix and add it to the current embedding, and the result is equivalent to x + ∆x;
(3) Calculate the forward loss of x + ∆x, and get the gradient of confrontation by backward propagation, and add it to the gradient of (1);
(4) Restoring embedding to the value of (1), and updating the parameters according to the gradient of (3);
(5) Repeat the above process until the model training is completed.
Although the input of word sequence in NLP is discrete, the original text will be transformed into a vector representation in low-dimensional space through embedding. We regard the original text vector representation after embedding as x in the above-mentioned adversarial training model. In the process of model training, we choose the FGM adversarial training algorithm to directly perturb the parameter matrix composed of each embedded vector obtained by the BERT model and take batch data as a whole for unified normalization calculation. This way can play the role of regularization, and can easy to implement, also be called more efficient.
3.3. Introduction of GRU Model
Recurrent neural networks are widely used in natural language processing, automatic speech recognition, and other fields. Gate Recurrent Unit (GRU) [42] is a type of Recurrent Neural Network (RNN), and like Long-Short Term Memory (LSTM) [43], it belongs to the improved model of RNN. GRU can solve the problem of gradient disappearance when RNN processes sequences. Compared with the LSTM network, GRU has a simpler structure, less computation, and better effect. GRU is a very popular neural network at present. The GRU model replaces forgotten gates and input gates in the LSTM with update gates, and the cell State and hidden state ht are merged. It has only one update gate and one reset gate when calculating the current information. The specific structure is shown in Figure 4.
Among them: represents the input at time t; represents the update gate at time t; represents the reset gate at time t; represents the state of the candidate hidden layer at the previous moment; represents the Sigmoid function; represents the state of the candidate hidden layer at time t; represents the state of the hidden layer at time t. The specific calculation process is as follows:
where: is the weight matrix of the update gate; is the weight matrix of the reset gate; is the weight matrix of the output gate; is the weight matrix of the candidate hidden layer states.
As a very important model, the GRU model has many significant advantages. It performs semantic analysis by discarding some words that are of little significance to our understanding of the information. It has been successfully applied in some fields. However, the GRU model only extracts the semantic impact of the above text on the text, and cannot fully reflect the information impact of the following context on the text above. Therefore, this study uses a bidirectional gated recurrent unit for feature extraction. BiGRU consists of forward GRU and backward GRU, it can capture the forward and reverse semantic information at the same time, and combine the context to extract the emotional features contained in the text deeply. The structure is shown in Figure 5. L represents the GRU network for feature extraction from left to right, and R represents the GRU network for feature extraction from right to left. Then, the semantic information vectors extracted from the R layer and the L layer are fused and spliced to obtain the final feature extraction results of the BiGRU model.
3.4. A Sentiment Analysis Model of BERT-FGM-BiGRU
In order to solve the polysemy problem of the traditional single language model, a sentiment analysis method based on a pre-training BERT model with feature extraction using BiGRU is introduced. At the same time, to improve the model’s generalization ability and robustness, the adversarial training algorithm of the Fast Gradient Method (FGM) is used to perturb the data. Therefore, we established the BERT-FGM-BiGRU sentiment analysis model to identify user emotional characteristics, thereby improving the classification accuracy of texts in the field of COVID-19. The structure of the model is shown in Figure 6, which is divided into three parts: input coding layer, feature extraction layer, and classification output layer.
(1) Input coding layer: The text vector encoding layer, converts text data into a vector form that can be received by BiGRU. In this paper, the Input word vector Wi is obtained by cleaning and preprocessing the original data set; then, the vector representation of each word is obtained through the BERT pre-training model, and the perturbation variable di is added to the embedding layer to fight against the perturbation, where each word vector is composed of Token Embedding, Segment Embedding, and Position Embedding.
(2) Feature extraction layer: The encoded data of the input layer into the BiGRU model for deep feature extraction. BiGRU is composed of forward GRU and backward GRU, which comprehensively encodes sentences through the above and below. The calculation process is shown in Formulas (9)–(11), Among them, gets to forward information, gets the backward text information, is a feature representation from front to back, is a characteristic representation of text sequence information.
(3) Classification output layer: Use the Softmax function to classify the output of the vector by the feature extraction layer to obtain the final sentiment classification result.
4. Experiment and Results Analysis
4.1. Data Collection and Preprocessing
Due to the sudden nature of the COVID-19 epidemic, a large number of new words and hot words appeared in the web text. The general sentiment analysis data sets fall short of the model’s accuracy. Therefore, this paper constructs a data set for COVID-19 for the model training. We obtained the data of Sina Weibo through the web crawler technology and compiled the crawler program by using the requests library of python. Because Weibo search can only display 50 pages at most, we searched and crawled as many contents as possible in different periods. We collect text data related to keywords such as “COVID-19” and “pneumonia of unknown cause” on Sina Weibo from 1 January 2020, to 31 May 2020, and initially collect 1,060,000 original Weibo data. Each piece of Weibo data includes user ID, Weibo text content, release time, release location and other fields. After pre-processing the collected data by removing duplicate values, irrelevant labels, stop words, and hyperlinks, 631,342 valid data were obtained. Because the original data is not labeled with tendentiousness, we first classify the data by BosonNLP [34], then identify and label them manually, and finally get more accurate labeled corpus for model training. For model training, 10,606 pieces of data are labeled, and the data set is divided into train data, validation data, and test data in a ratio of about 6:2:2. Using labeled data for model training and model comparison, and using the best model to identify the emotional tendency of the remaining unlabeled data. Finally, the paper studies the evolution of public emotion during the COVID-19 epidemic in two dimensions of time and space. Some examples of posts with different sentiment categories are shown in Table 1.
4.2. Parameters Setting
During the experiment, the setting of parameters plays a key role in the final training model. The maximum length of the sentence we set in the model is 128. When a comment text is larger than 128 characters, it will be truncated, and when it is less than 128 characters, it will be automatically replaced with zeros to fill it up. We fine-tuned the Chinese BERT-BASE model trained by Google based on the Chinese corpus in Wikipedia with 12 layers and hidden dimension 768, the total parameter size of the model is 110 MB. According to the suggestion on hyperparameters selection by the original BERT paper [39], we set up the following parameters: epoch is 10, learning rate is 1 × 10−5, and batch size is 8. The number of hidden layer units in GRU is 128, the activation function is Relu, the optimizer is Adam [44], and the dropout [45] mechanism with a value of 0.1 is used to address the issue of overfitting. The experimental environment of this model is shown in Table 2.
4.3. Evaluation Indicators
In this paper, precision (P), recall (R), and weighted F1 value are used as the evaluation index. In the classification task, the precision rate represents the proportion of the actual positive samples in the predicted positive samples; the recall rate represents the proportion of the predicted positive samples in the actual positive samples; the F1 value represents the performance of comprehensive evaluation of accuracy rate and recall rate, and the specific formula is as follows:
In the above formula, TP is the number of positive samples that are judged as positive; FP is the number of negative samples that are misjudged as positive samples; FN is the number of positive samples that are misjudged as negative samples.
4.4. Comparative Analysis of Model’s Prediction Results
In order to verify the effectiveness of the model in this paper, we selected several sets of experiments using different models for verification:
(1) Word2Vec-BiLSTM [34]: using Jieba to segment words, initialize the word2vec model and thesaurus, and generate the vector corresponding to the whole sentence. Then using the transformed matrix to fit the BiLSTM model, so as to train the model of the data.
(2) BERT-BiLSTM [37]: using BERT to generate word vectors, BiLSTM network to extract features, and Softmax to classify emotions.
(3) GRU [43]: labeling the text corpus and dividing the words, counting the number of words, and using the GRU model in Keras to calculate the predicted value for evaluation.
(4) BiGRU: defining the model structure of bidirectional GRU, and finally using the fully connected layer to output the results through softmax.
(5) BERT [39]: The BERT used here only extracts text features from the BERT pre-training model without any processing, and then using Softmax to classify the text.
(6) TextCNN [35]: using multiple kernels with different sizes to extract key information from sentences, so as to better capture local relevance.
(7) BERT-CNN: using BERT to generate word vectors, CNN network to extract features, and Softmax to classify emotions.
(8) Word2Vec-BiGRU [36]: using Jieba to segment words, initializing word2vec model and thesaurus, and generating the vector corresponding to the whole sentence. Then using the transformed matrix to fit the BiGRU model, so as to train the model of the data.
(9) BERT-GRU: using BERT to generate word vectors, the GRU network to extract features, and Softmax to classify emotions.
(10) BERT-BiGRU: using BERT to generate word vectors, the BiGRU network to extract features, and Softmax to classify emotions.
(11) BERT-FGM-BiGRU: using BERT to generate word vectors, adding perturbation to the embedding layer, using the BiGRU network to extract features, and Softmax to classify emotions.
By analyzing the prediction results of each model in Table 3, we can find that the TextCNN model has the worst precision effect. Compared with the Word2Vec-BiLSTM model, Word2Vec combined with BiGRU is the best for word vector coding when using Word2Vec to obtain word vectors, and the precision rate is 74.8%. Compared with GRU and BiGRU, the precision rate has increased by 1.68%, and each index of the BiGRU model has been improved in different degrees, which shows that it will be more advantageous to obtain text information in both directions. When using BERT pre-training to obtain word vectors, each index of the model of BERT combined with the neural network is significantly higher than the word vector representation method obtained based on Word2Vec. Among them, the accuracy of BERT is the worst, and the accuracy of BERT-CNN is 6.3% higher than that of BERT. To enhance the robustness of the model and make it more suitable for epidemic corpus in COVID-19, the word vectors should be dynamically acquired using the BERT approach, add perturbation to the embedding layer, and the features should be extracted using the BiGRU approach. The results show that the BERT-FGM-BiGRU model achieves the best results by improving the classification accuracy by 4.1% over the Word2vec-BiGRU model.
The above analysis shows that using the BERT pre-training model for dynamic word vector coding improves the accuracy of word vectors obtained by the model. The bidirectional GRU is selected for feature extraction, which enhances the feature extraction ability of the context and improves the classification performance of the model. Adding FGM can improve the performance of the final model.
In order to verify the role of each part of the model in this paper on the results, we conducted an ablation experiment. BERT is the model after ablation antagonism training and bidirectional GRU feature extraction, which is directly used for word vector coding and classification. The BERT-BiGRU model is a model after ablation antagonism training. The BERT model is used for word vector acquisition, and BiGRU is used for feature extraction to obtain a finally classification. BERT-FGM-BiGRU is the model proposed in this paper. The experimental results are shown in Table 4.
From the comparison results of the three models, we can conclude that:
The precision and F1 value of the BERT-FGM-BiGRU model is 78.90% and 0.7820, respectively, which are higher than the 77.85% and 0.7743 of the BERT-BiGRU model and the 69.55% and 0.6417 of the BERT model. The classification accuracy of the BERT-BiGRU model is 8.3% higher than that of the BERT model, which proves that the BiGRU is effective in feature extraction. On the basis of determining the use of the BERT- BiGRU model, we introduced FGM to add interference to the input samples when training the text, and it can be seen that compared with the BERT-BiGRU model, the accuracy rate has increased by 1.05%, indicating that the classification effect of the model is better after adding adversarial training, which verifies the effectiveness of adversarial training.
Through the analysis of the comparison models, the BERT-FGM-BiGRU model has the best classification effect. It can be concluded that, compared with the single BERT model, the BERT-FGM-BiGRU model avoids the polysemy phenomenon, effectively overcomes the problem of sparse word vector matrix obtained by the traditional language model, and improves the generalization ability and classification effect of the model. It also shows that the sentiment analysis model constructed in this paper has a certain significance. On the one hand, it can improve classification accuracy, on the other hand, it can facilitate the subsequent field of emotional analysis of the COVID-19 epidemic.
4.5. Sentiment Analysis Integrating Spatiotemporal Features
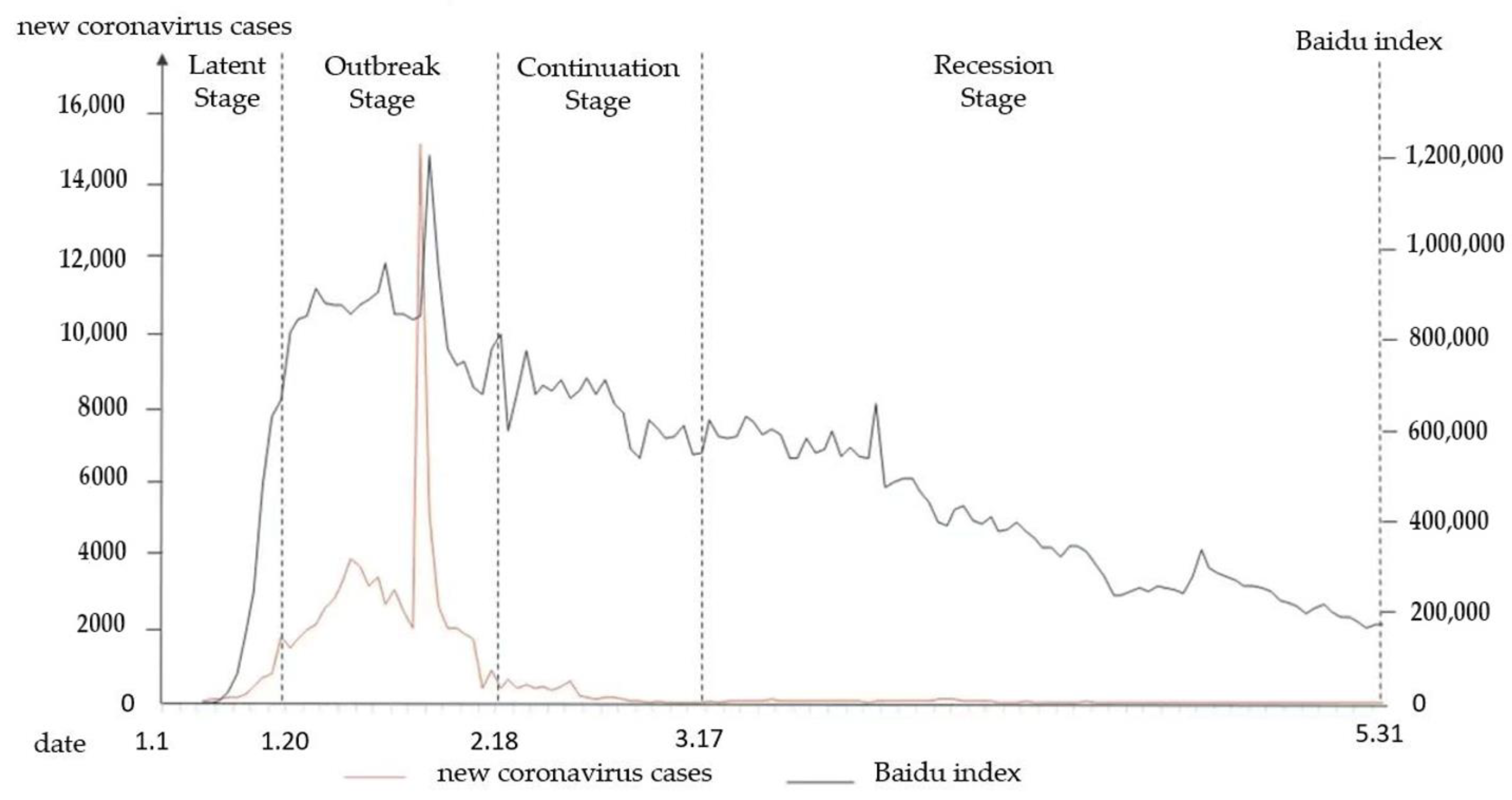
Baidu Index [48] is a data-sharing platform based on the behavioral data of the massive netizens in Baidu. It is based on the search volume of netizens and takes keywords as statistical objects. Through scientific analysis, the search frequency of each keyword in Baidu is calculated. Taking “COVID-19” as the keyword, this paper obtains the Baidu Index from 1 January 2020 to 31 May 2020. Combined with the officially announced daily number of newly confirmed cases of COVID-19. In this way, we can measure the severity of COVID-19 and the hot topics of public opinion discussion, and draw the trend of public opinion development. As can be seen from Figure 7, the trend of newly confirmed cases of COVID-19 is basically the same as that of public opinion discussion. In the theory of crisis communication, Steven Fink [49] divided the life cycle of public opinion into Prodromal, Breakout, Chronic, and Resolution. For better research on the changing trend of public sentiment in different stages, we choose 20 January, 18 February, and 17 March as the cut-off points, and divide the evolution cycle of public opinion into four stages: latent stage, outbreak stage, continuation stage, and recession stage.
There were fewer than 100 new confirmed cases between 1 January and 20 January 2020. In the early stages, there was not enough information available to the public, and the number of microblog posts related to COVID-19 was small; on 20 January, the National Commission of the People’s Republic of China held a press conference to explain the human-to-human transmission of the novel coronavirus. The most microblog postings were made and were the most popular from 21 January to 18 February, demonstrating the growing seriousness with which the public is taking COVID-19. At this stage, the number of new confirmed cases of COVID-19 in a single day also reached its peak; on February 19, the number of new cured and discharged cases in Wuhan was more significant than the number of new confirmed cases for the first time, and the number of new cases nationwide dropped significantly. From 19 February to 17 March, the number of microblog posts also declined, and the popularity index tended to decline; on March 18, there were zero reports of new confirmed cases in the country for the first time. The state has promoted the policy of resuming work and production, and public opinion on the epidemic has gradually moved to the stage of recession.
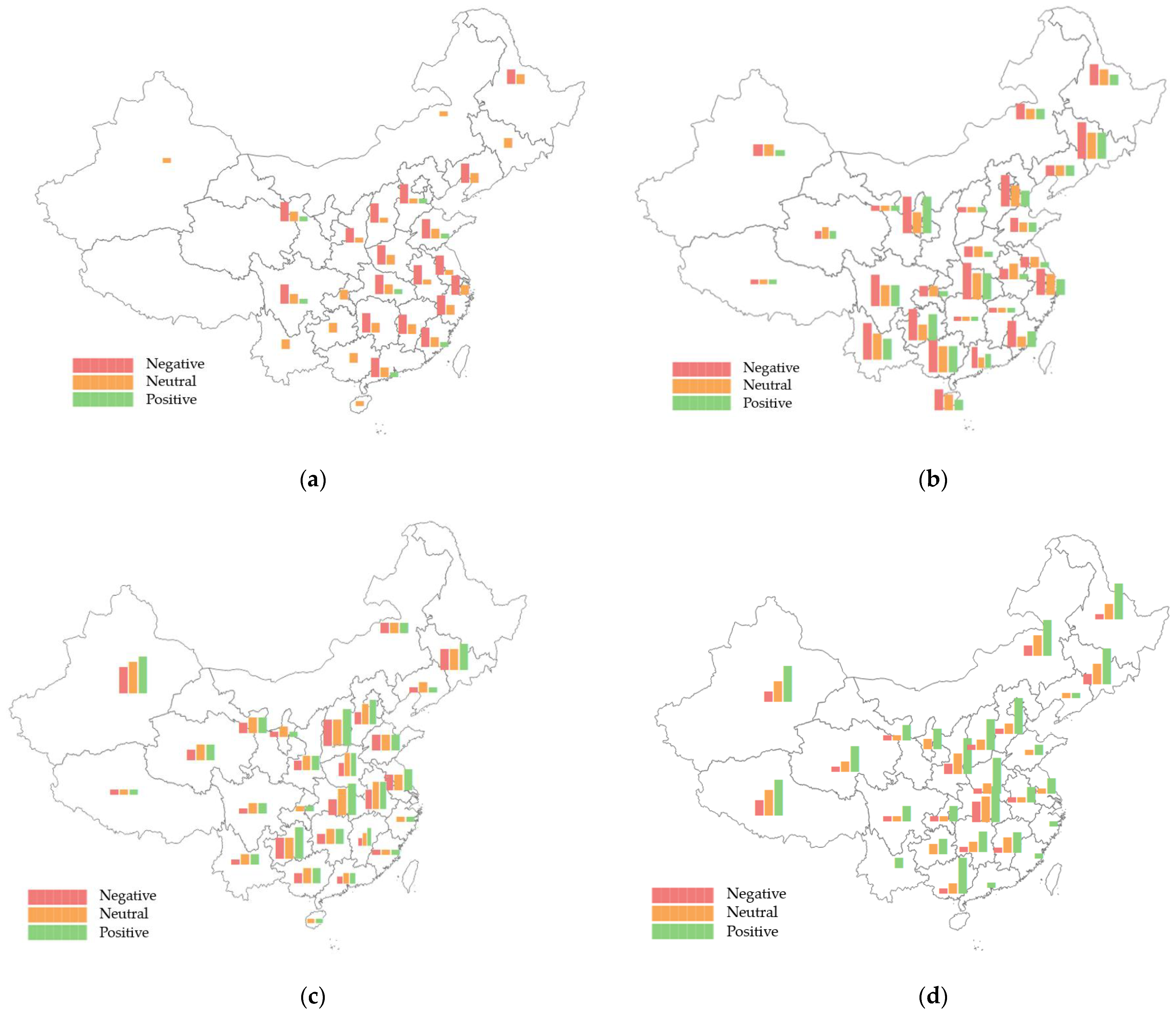
The BERT-FGM-BiGRU model constructed in the previous section is used to identify the emotion of the remaining texts, and the emotional tendency of each provincial administrative region is calculated by combining the spatial and temporal characteristics with the emotion classification. The result is shown in Figure 7. According to the results, it is possible to thoroughly study the distribution variations and evolution patterns of epidemic sentiment in various regions and periods. In addition, it can assist the government and relevant departments to formulate corresponding management guidelines and policies according to the characteristics and patterns of different regions.
As shown in Figure 8 above, we can conclude that:
(1) During the latent stage, the overall sentiment in the southeastern region is more negative than in other parts of the country. The mood in Hubei’s surrounding areas is primarily negative due to the impact of space. However, the spread of public opinion is limited due to the slow speed of information dissemination. There has not been much dissemination across the country. The public opinion under extremely negative emotions is highly dangerous. If it cannot be dealt with promptly, it will severely impact public psychology and social order. When managing public opinion, the government should pay attention to and be aware of the areas where anomalous data occurs, and timely control and grasp the trend of public opinion.
(2) During the outbreak stage, the number of new confirmed cases increased rapidly across the country, and media reports also created a sense of crisis among the public. The country is in a negative mood, but in every region, there are people who maintained a positive attitude. At this stage, the demand of the public for information is very urgent. The epidemic information should be released on time to enhance public confidence and avoid unnecessary panic caused by spreading false information.
(3) In the continuation stage, the number of information released by the public reduced significantly, and the negative sentiment also declines rapidly, with the overall sentiment being positive. At this stage, the epidemic has been somewhat controlled. In order to avoid too much negative emotional influence in the previous stage, the media actively guided it, and people of all ethnic groups in the country are also helping each other to tide over the difficulties.
(4) In the recession stage, the situation of the epidemic in China has been alleviated, emotions have improved, and normal life has gradually resumed. All localities actively responded to the “precise resumption of work and production” policy.
To sum up, the changes in public sentiment in different regions and periods reflect the characteristics of the staged spatial distribution of public opinion. When regulating, the government should consider regional factors, focus on the distribution of special emotional values in space and time, and carry out timely Guidance of public opinion to ease public sentiment in case the incident worsens.
In addition to the above analysis, according to the four stages of public opinion evolution, we also count the high-frequency vocabulary, as shown in Table 5.
It can be seen that in the latent stage, the high-frequency words include words such as “unknown cause”, “Wuhan”, “pneumonia”, and “coronavirus”, as well as emotional words such as “fear” and “worry”. The outbreak of the epidemic had just occurred in Wuhan, and the public was in a state of emotional instability. During the outbreak stage, high-frequency words included “Wuhan”, “Hope”, “persistence”, “masks”, and “prevention and control”, as the public took preventive and control measures to respond to the epidemic, and public sentiment changed from fear to hope. In the continuation stage, words such as “prevention and control”, “end” and “work” frequently appeared on Weibo, and the public began to look forward to the end of prevention and control. People believed that Wuhan could defeat the epidemic, and their emotions were positive. In the recession phase, high-frequency words such as “America”, “work”, “influence” and “country” indicate that people have started to pay attention to other things and pay less attention to COVID-19. The trend is consistent with the sentiment analysis results of the above time series.
5. Conclusions and Future Work
The Sina Weibo platform saw a spike in the production of public opinion texts during the COVID-19 pandemic. It is very important for the government to analyze and mine these texts to monitor public opinion. This paper takes the Sina Weibo text during the COVID-19 epidemic as the research object and analyzes the shortcomings of the existing COVID-19 related research and emotional analysis model. It is concluded that the traditional language models are prone to sparse matrices and polysemy when acquiring word vectors, and cannot adequately acquire contextual information during feature extraction. In order to analyze users’ emotional changes, the BERT-FGM-BiGRU emotion analysis model based on the pre-training model is proposed. The verification results show that compared with the prediction results of Word2Vec-BiLSTM, TextCNN, Word2Vec-BiGRU, GRU, BiGRU, BERT, BERT-CNN, BERT-BiLSTM, BERT-GRU, and BERT-BiGRU, the model proposed in this paper is superior in precision, recall rate, and F1 value. The experiment verifies that the BERT-FGM-BiGRU model proposed in this paper has a good classification effect, which can provide a basis for decision-making in the field of sentiment analysis of COVID-19. Then, according to the severity of the epidemic and the popularity of public opinion, the evolution stages of the epidemic are divided into the latent stage, outbreak stage, continuation stage, and recession stage. We used the BERT-FGM-BiGRU model to analyze emotions at different stages. According to the division rules of national and provincial administrative regions, combined with the spatial characteristics, we analyzed the emotional evolution of different regions in different periods. From the research results, we can see that in terms of space, the emotion of the public is consistent with the severity of the epidemic, and the emotional expression spreads from the center of Hubei Province to the surrounding areas, reflecting the regional correlation characteristics of public health events; In terms of time, public sentiment shows an overall trend of gradually improving with the passage of time, and the government gives active guidance, which makes the public sentiment change from negative to positive in the middle and late periods. Although this paper has made some progress, there are some shortcomings in this study, such as insufficient data sets and single data sources, and there is a lack of research on the correlation between the theme of online public opinion and the emotional evolution of the offline epidemic. In the following work, we will consider the relationship between the event theme and emotion, and conduct further research on public health emergencies, so as to provide some reference for relevant government departments to guide public opinion scientifically.
Author Contributions
Conceptualization, L.Z. and X.Y.; Methodology, Z.L., H.J. and W.L.; Software, X.Y.; Validation, L.Z.; Formal analysis, L.Z.; Resources, J.Z.; Data curation, L.Z., X.Y. and J.Z.; Writing—original draft, L.Z. and J.Z.; Writing—review & editing, Z.L.; Supervision, Z.L., H.J. and W.L.; Project administration, Z.L. and H.J.; Funding acquisition, W.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China, grant No. 71874022.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Naming the Coronavirus Disease (COVID-19) and the Virus that Causes It. Available online: https://www.who.int/emergencies/diseases/novel-coronavirus-2019/technical-guidance/naming-the-coronavirus-disease-(covid-2019)-and-the-virus-that-causes-it (accessed on 11 February 2020).
- Wang, C.; Pan, R.; Wan, X.; Tan, Y.; Xu, L.; Ho, C.S.; Ho, R.C. Immediate Psychological Responses and Associated Factors during the Initial Stage of the 2019 Coronavirus Disease (COVID-19) Epidemic among the General Population in China. Int. J. Environ. Res. Public Health. 2020, 17, 1729. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vosoughi, S.; Roy, D.K.; Aral, S. The spread of true and false news online. Science 2018, 359, 1146–1151. [Google Scholar] [CrossRef]
- Scheufele, D.A.; Eveland, W.P., Jr. Perceptions of ‘Public Opinion’ and ‘Public’ Opinion Expression. Int. J. Prod. Res. 2001, 13, 25–44. [Google Scholar] [CrossRef]
- Casillas, C.J.; Enns, P.K.; Wohlfarth, P.C. How Public Opinion Constrains the U.S. Supreme Court. Am. J. Political Sci. 2011, 55, 74–88. [Google Scholar] [CrossRef]
- Elbattah, M.; Arnaud, É.; Gignon, M.; Dequen, G. The Role of Text Analytics in Healthcare: A Review of Recent Developments and Applications. In Proceedings of the International Conference on Health Informatics, Victoria, BC, Canada, 3–7 October 2021. [Google Scholar]
- Huang, C.-L.; Wang, Y.-M.; Li, X.-W. Clinical features of patients infected with 2019 novel coronavirus in Wuhan, China. Lancet 2020, 395, 497–506. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhao, D.; Yao, F.; Wang, L.; Zheng, L.; Gao, Y.; Ye, J.; Guo, F.; Zhao, H.; Gao, R. A Comparative Study on the Clinical Features of Coronavirus 2019 (COVID-19) Pneumonia With Other Pneumonias. Clin. Infect. Dis. 2020, 71, 756–761. [Google Scholar] [CrossRef] [Green Version]
- Baker, S.R.; Bloom, N.; Davis, S.J.; Kost, K.J.; Sammon, M.; Viratyosin, T. The Unprecedented Stock Market Reaction to COVID-19. Rev. Asset Pricing Stud. 2020, 10, 742–758. [Google Scholar] [CrossRef]
- del Rio-Chanona, R.M.; Mealy, P.; Pichler, A.; Lafond, F.; Farmer, J.D. Supply and demand shocks in the COVID-19 pandemic: An industry and occupation perspective. Oxford Rev. Econ. Policy. 2020, 36 (Suppl. S1), S94–S137. [Google Scholar] [CrossRef]
- Son, C.; Hegde, S.; Smith, A.; Wang, X.; Sasangohar, F. Effects of COVID-19 on College Students’ Mental Health in the United States: Interview Survey Study. J. Med. Internet Res. 2020, 22, e21279. [Google Scholar] [CrossRef]
- Qin, L.; Sun, Q.; Wang, Y.; Wu, K.-F.; Chen, M.; Shia, B.-C.; Wu, S.-Y. Prediction of Number of Cases of 2019 Novel Coronavirus (COVID-19) Using Social Media Search Index. Int. J. Environ. Res. Public Health. 2020, 17, 2365. [Google Scholar] [CrossRef] [Green Version]
- Li, S.; Wang, Y.; Xue, J.; Zhao, N.; Zhu, T. The Impact of COVID-19 Epidemic Declaration on Psychological Consequences: A Study on Active Weibo Users. Int. J. Environ. Res. Public Health. 2020, 17, 2032. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, J.; Xu, Q.; Cuomo, R.; Purushothaman, V.; Mackey, T. Data Mining and Content Analysis of the Chinese Social Media Platform Weibo During the Early COVID-19 Outbreak: Retrospective Observational Infoveillance Study. JMIR Public Health Surveill 2020, 6, e18700. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhao, Y.; Cheng, S.; Yu, X.; Xu, H. Chinese Public’s Attention to the COVID-19 Epidemic on Social Media: Observational Descriptive Study. J. Med. Internet Res. 2020, 22, e18825. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Li, Z.; Tian, Y. Sentimental Knowledge Graph Analysis of the COVID-19 Pandemic Based on the Official Account of Chinese Universities. Electronics 2021, 10, 2921. [Google Scholar] [CrossRef]
- Wang, J.; Zhou, Y.; Zhang, W.; Evans, R.; Zhu, C. Concerns Expressed by Chinese Social Media Users During the COVID-19 Pandemic: Content Analysis of Sina Weibo Microblogging Data. J. Med. Internet Res. 2020, 22, e22152. [Google Scholar] [CrossRef]
- Depoux, A.; Martin, S.; Karafillakis, E.; Preet, R.; Wilder-Smith, A.; Larson, H. The pandemic of social media panic travels faster than the COVID-19 outbreak. J. Travel Med. 2020, 27, 31. [Google Scholar] [CrossRef] [Green Version]
- Chen, X.-L.; Sun, Y.; Athiwaratkun, B.; Cardie, C.; Weinberger, K. Adversarial Deep Averaging Networks for Cross-Lingual Sentiment Classification. Trans. Assoc. Comput. Linguist. 2018, 6, 557–570. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Zhang, M.; Chen, W.; Zhang, W.; Wang, H.; Zhang, M. Adversarial Learning for Chinese NER from Crowd Annotations. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Shui, L.-C.; Liu, W.-Z.; Feng, Z.-M. Automatic image annotation based on generative confrontation network. Int. J. Comput. 2019, 39, 2129–2133. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.J.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Goodfellow, I.-J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Miyato, T.; Andrew, M.-D.; Goodfellow, I. Adversarial training methods for semi-supervised text classification. arXiv 2017, arXiv:1605.07725. [Google Scholar]
- Li, J.; Cheng, P.S.; Xu, L.D.; Liu, J.Y. Name entity recognition based on local adversarial training. J. Sichuan Univ. (Nat. Sci. Ed.) 2021, 58, 113–120. [Google Scholar]
- Yasunaga, M.; Kasai, J.; Radev, D. Robust Multilingual Part-of-Speech Tagging via Adversarial Training. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; Volume 1 (Long Papers), pp. 976–986. [Google Scholar]
- Zhou, J.-T.; Zhang, H.; Jin, D.; Zhu, H.-Y.; Fang, M.; Goh, B.-S.-M.; Kwok, K. Dual Adversarial Neural Transfer for Low-Resource Named Entity Recognition. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 3461–3471. [Google Scholar]
- Brauwers, G.; Frasincar, F. A Survey on Aspect-Based Sentiment Classification. ACM Comput. Surv. 2021, 55, 65. [Google Scholar] [CrossRef]
- Ahmed, M.; Chen, Q.; Li, Z. Constructing domain-dependent sentiment dictionary for sentiment analysis. Neural Comput. Appl. 2020, 32, 14719–14732. [Google Scholar] [CrossRef]
- Mujahid, M.; Lee, E.; Rustam, F.; Washington, P.B.; Ullah, S.; Reshi, A.A.; Ashraf, I. Sentiment Analysis and Topic Modeling on Tweets about Online Education during COVID-19. Appl. Sci. 2021, 11, 8438. [Google Scholar] [CrossRef]
- Wang, Z.; Qin, Y. The Impact of Shanghai Epidemic, China, 2022 on Public Psychology: A Sentiment Analysis of Microblog Users by Data Mining. Sustain Sci. 2022, 14, 9649. [Google Scholar] [CrossRef]
- Wang, W.; Sun, Y.; Qi, Q.; Meng, X. Text sentiment classification model based on BiGRU-attention neural network. Appl. Res. Comput. 2019, 36, 3558–3564. [Google Scholar]
- Gui, X.-Q.; Gao, Z.; Li, L. Text sentiment analysis during epidemic using TCN and BiLSTM+Attention models. J. Xi’an Univ. Technol. 2021, 1, 113–121. (In Chinese) [Google Scholar]
- Zhou, J.; Lu, Y.; Dai, H.; Wang, H.; Xiao, H. Sentiment Analysis of Chinese Microblog Based on Stacked Bidirectional LSTM. IEEE Access 2019, 7, 38856–38866. [Google Scholar] [CrossRef]
- Liu, C.L.; Wu, J.Q.; Tan, Y.N. Polarity discrimination of user comments based on TextCNN. Electron. World 2019, 48, 50. (In Chinese) [Google Scholar]
- Elnagar, A.; Al-Debsi, R.; Einea, O. Arabic text classification using deep learning models. Inf. Process. Manag. 2019, 57, 102121. [Google Scholar] [CrossRef]
- Colón-Ruiz, C.; Segura-Bedmar, I. Comparing deep learning architectures for sentiment analysis on drug reviews. J. Biomed. Infor. 2022, 110, 103539. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.-Q.; Li, X.; Han, X.; Song, D.-D.; Liao, L.-J. Multi-category sentiment analysis method of microblog based on bilingual dictionary. Acta Electron. Sin. 2016, 9, 2068–2073. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Zaremba, W.; Sutskever, I.; Vinyals, O. Recurrent Neural Network Regularization. arXiv 2014, arXiv:1409.2329. [Google Scholar]
- Cho, K.; Merrienboer, B.V.; Gülçehre, Ç.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; Volume D14-1179, pp. 1724–1734. [Google Scholar]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to forget: Continual prediction with LSTM. Neural Comput. 2000, 12, 2451–2471. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A system for large-scale machine learning. Osdi 2016, 16, 265–283. [Google Scholar]
- Chollet, F.; Keras. GitHub Repository. 2015. Available online: https://github.com/fchollet/keras (accessed on 15 November 2022).
- Lu, L.; Zou, Y.-q.; Peng, Y.-S.; Li, K.-L.; Jiang, T.-J. Comparative analysis of Baidu index and microindex in influenza surveillance in China. Comput. Appl. Res. 2016, 2, 392–395. (In Chinese) [Google Scholar]
- STEVENF. Crisis Management: Planning for the Inevitable; American Management Association: New York, NY, USA, 1986. [Google Scholar]
Figure 1.
Flow chart of the research framework.
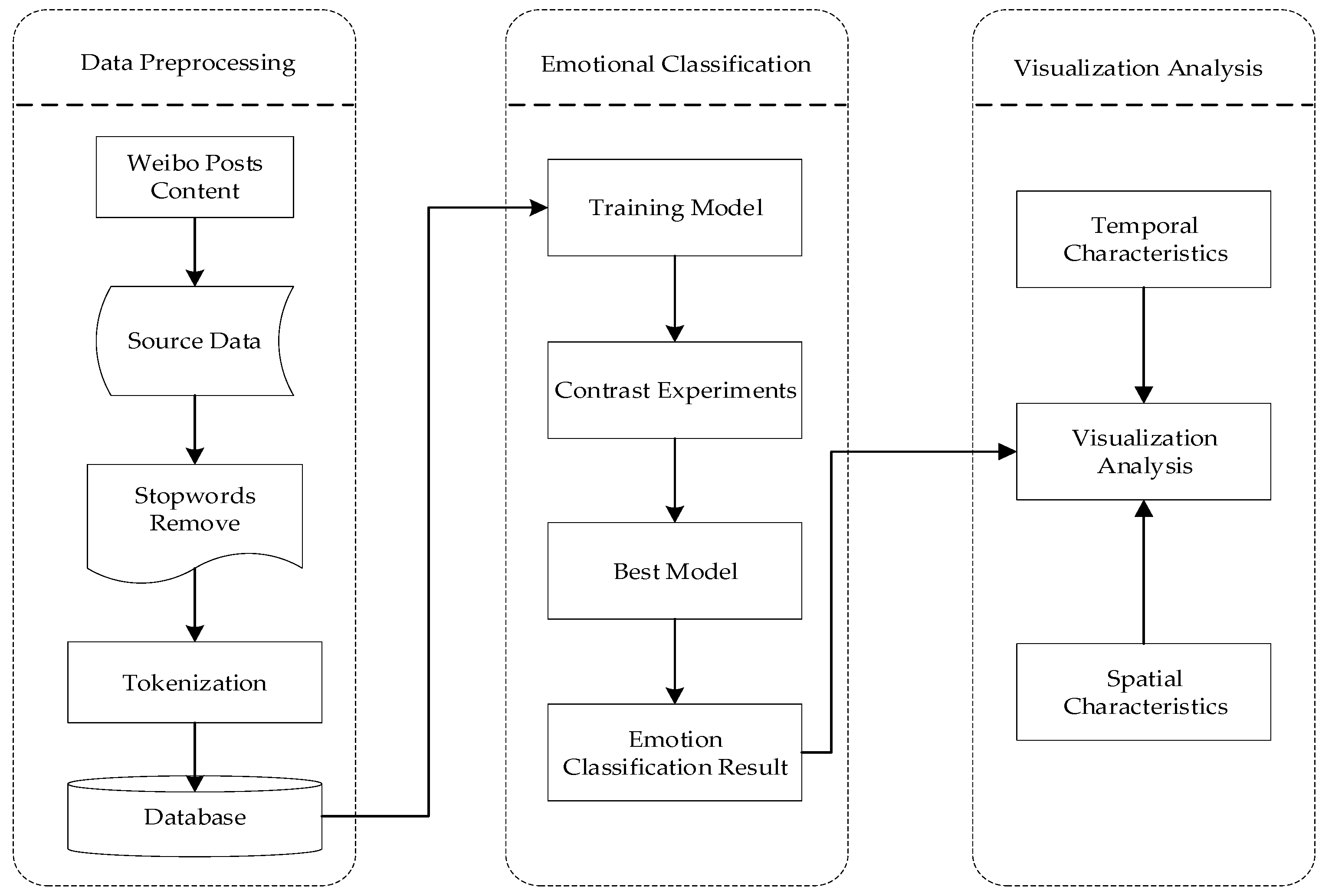
Figure 2.
Structure diagram of the BERT model.
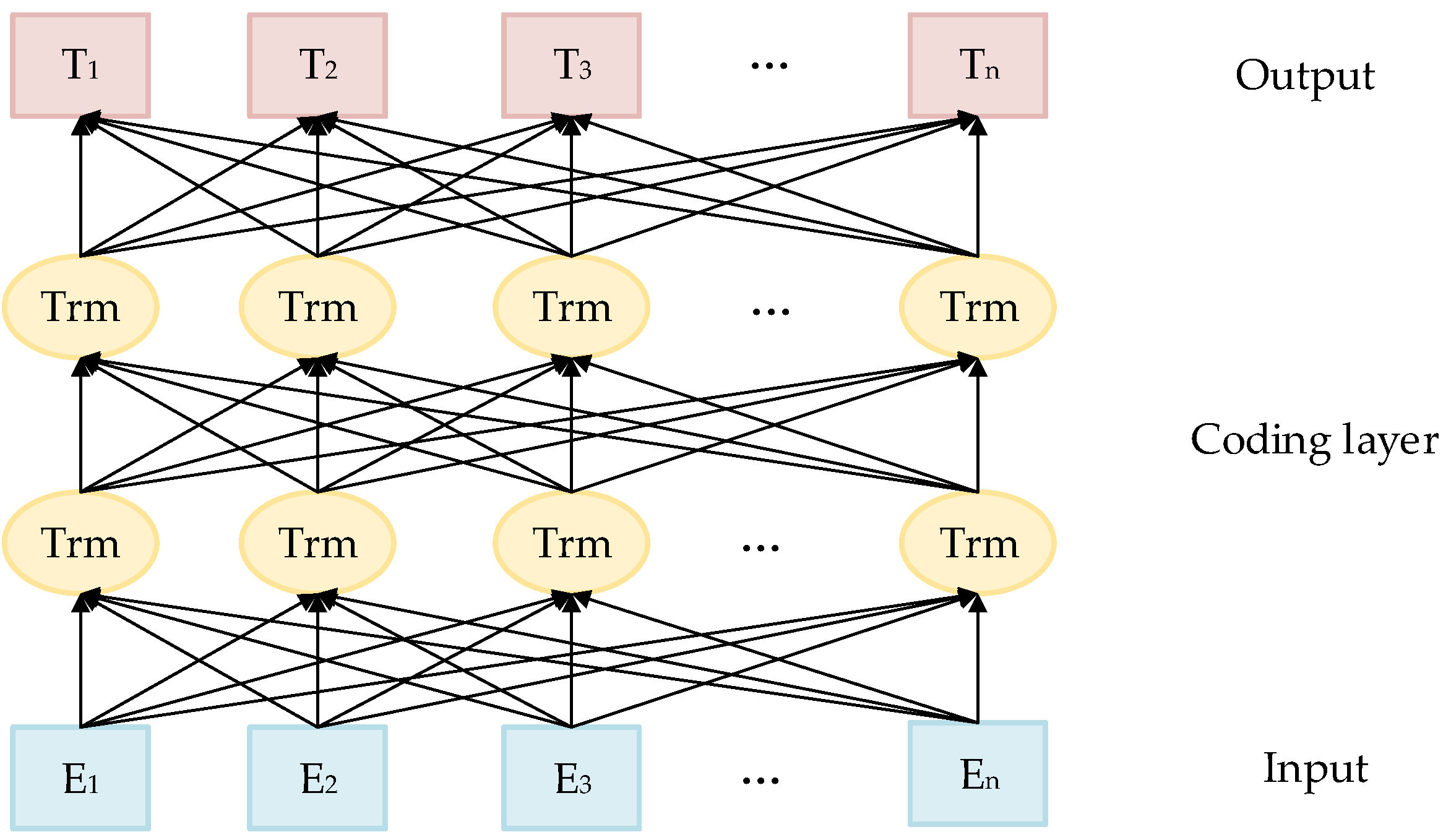
Figure 3.
The input vector of the BERT.
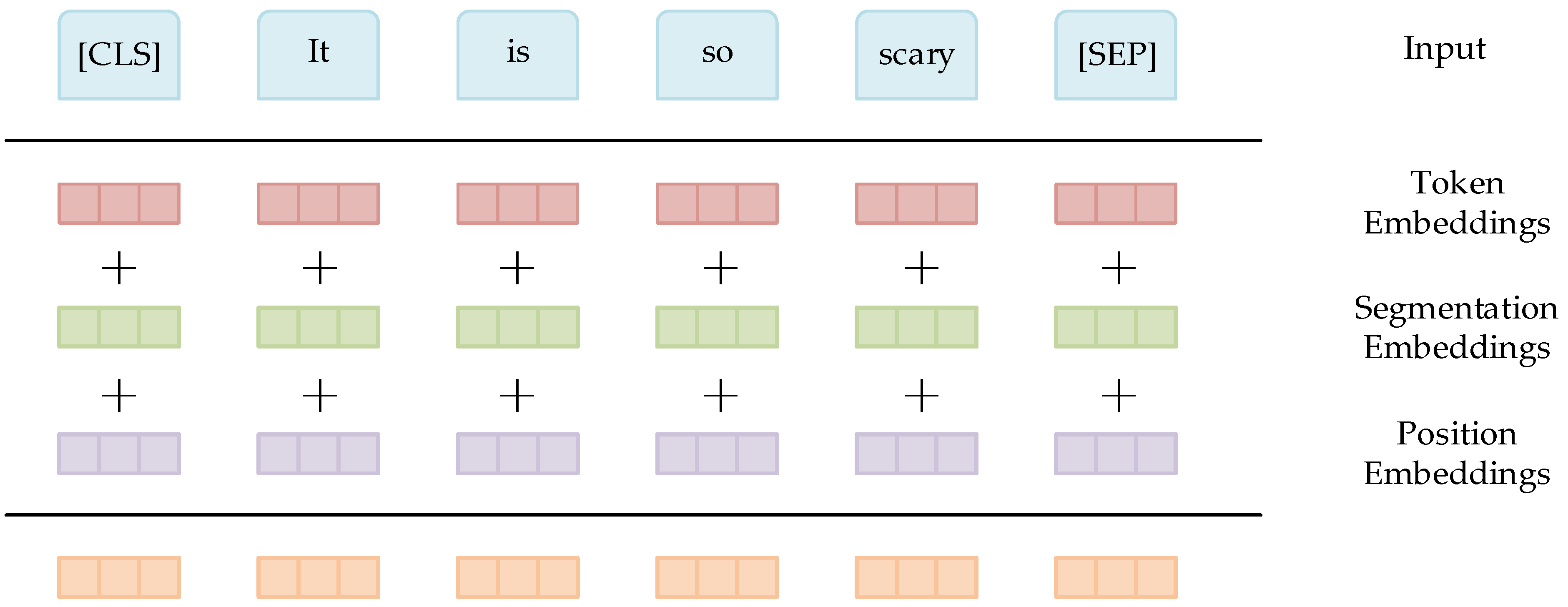
Figure 4.
Structure of the GRU model.
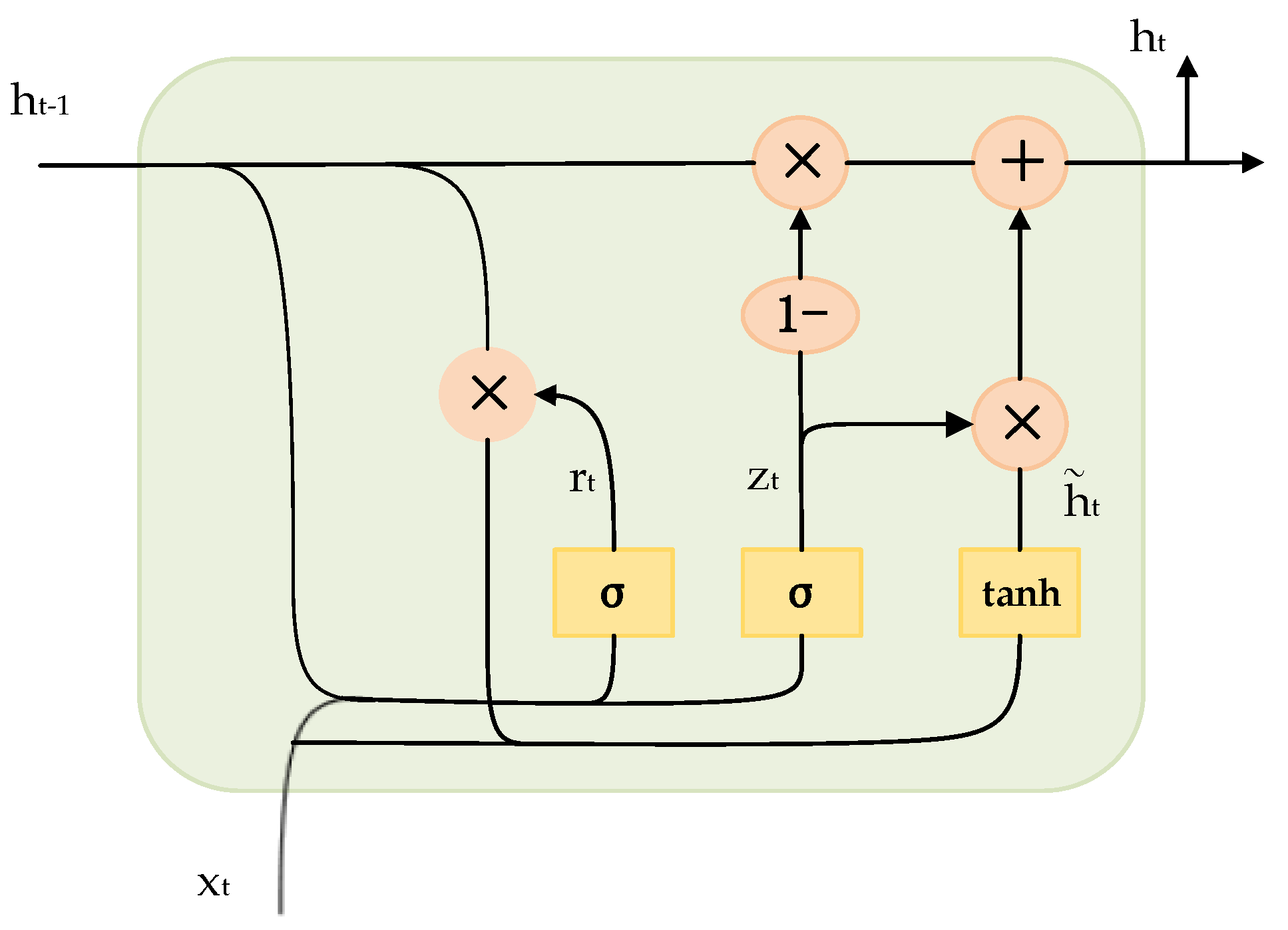
Figure 5.
Structure diagram of the BiGRU model.

Figure 6.
Structure diagram of the BERT-FGM-BiGRU model.
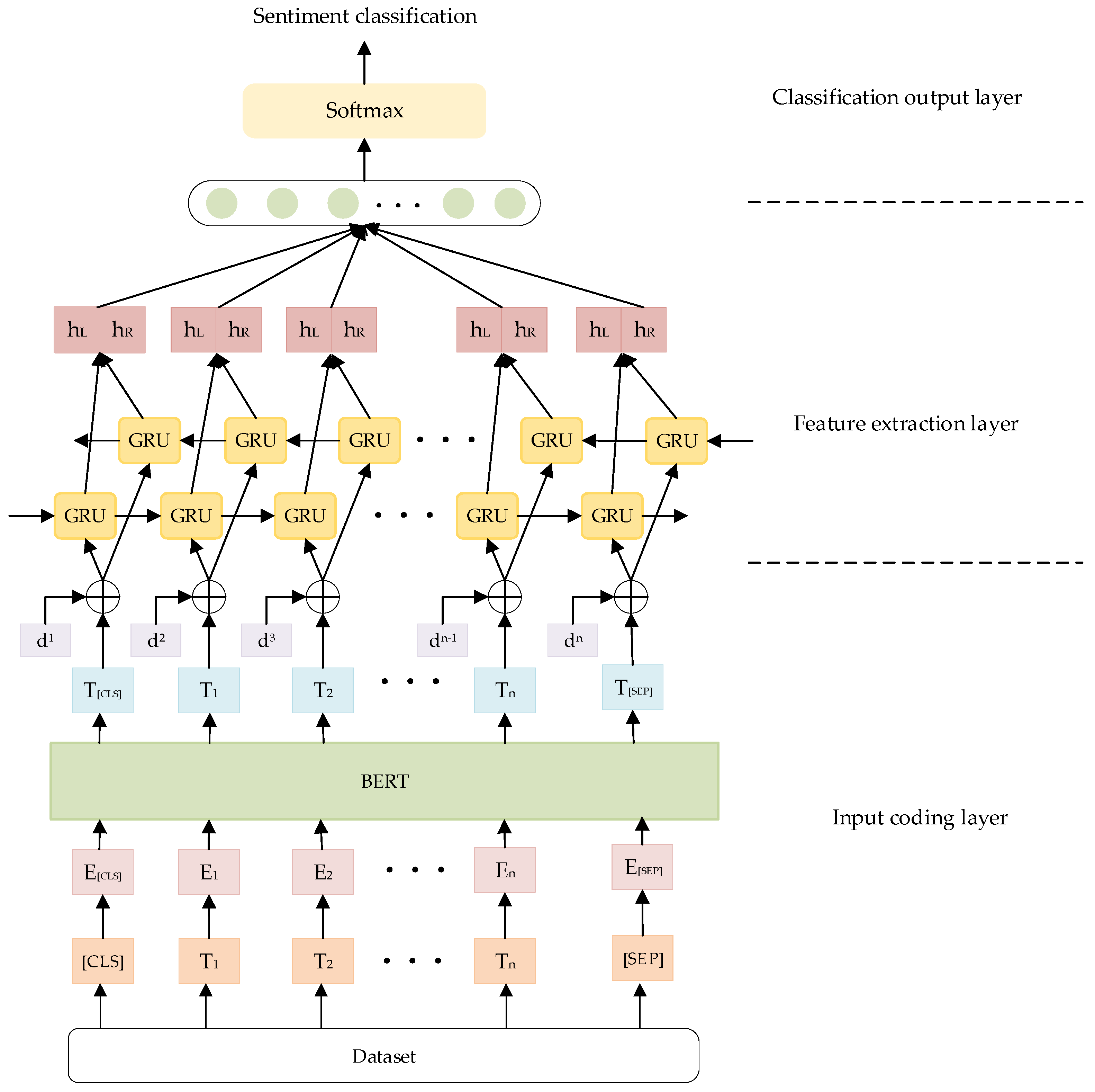
Figure 7.
Stages of Public Opinion Evolution.
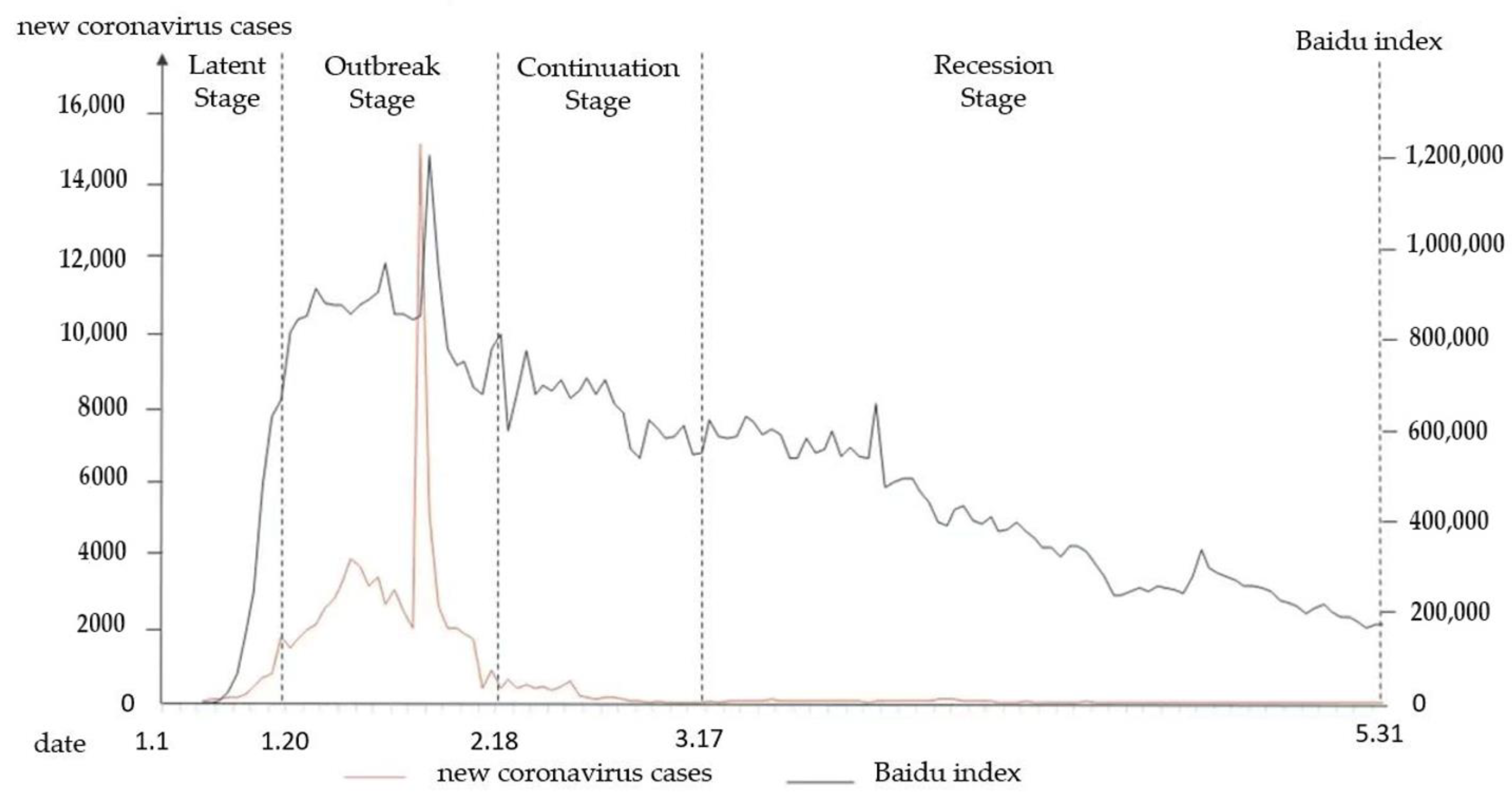
Figure 8.
Different spatiotemporal emotion distribution maps. (a) Public emotional distribution in the latent stage; (b) Public emotional distribution in the outbreak stage; (c) Public emotional distribution in the continuation stage; (d) Public emotional distribution in the recession stage.
Figure 8.
Different spatiotemporal emotion distribution maps. (a) Public emotional distribution in the latent stage; (b) Public emotional distribution in the outbreak stage; (c) Public emotional distribution in the continuation stage; (d) Public emotional distribution in the recession stage.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Examples of posts with different sentiment categories.
| Sentiment | Text Data |
|---|---|
| positive | May everyone be safe and healthy. # Tribute to the medical staff on the frontline of the epidemic # May everyone be healthy and safe. |
| neutral | Debunking rumors, look at this, pneumonia of unknown cause was renamed COVID-19 by the World Health Organization. |
| negative | Can’t accept it, save Wuhan, can’t stand the tears, a group of children puts on adult clothes to learn to save people. In the face of this symptom, those who are not sick are afraid. |
Table 2.
Experimental environment.
| Development Environment | Parameter |
|---|---|
| CPU | Intel(R)Core(TM)[email protected] GHZ |
| graphics card | NVIDIA GeForce RTX 2060 |
| operating system | Win10 64 |
| Programming Tools | Pycharm |
| Programming language | Python |
| Development Framework | Tensorflow [46] + keras [47] |
Table 3.
Compare the basic model’s experimental results.
| Model | P/% | R/% | F1 |
|---|---|---|---|
| Word2Vec-BiLSTM | 71.99% | 70.15% | 0.7070 |
| BERT-BiLSTM | 77.35% | 77.35% | 0.7700 |
| GRU | 64.71% | 64.77% | 0.6431 |
| BiGRU | 66.39% | 66.39% | 0.6525 |
| BERT | 69.55% | 64.17% | 0.6675 |
| TextCNN | 57.21% | 57.21% | 0.5094 |
| BERT-CNN | 75.85% | 75.35% | 0.756 |
| Word2Vec-BiGRU | 74.80% | 71.89% | 0.7305 |
| BERT-GRU | 77.80% | 77.80% | 0.7739 |
| BERT-FGM-BiGRU | 78.90% | 78.90% | 0.7820 |
Table 4.
Ablation model experiment results.
| Model | P/% | R/% | F1 |
|---|---|---|---|
| BERT | 69.55% | 69.55% | 0.6417 |
| BERT-BiGRU | 77.85% | 77.85% | 0.7743 |
| BERT-FGM-BiGRU | 78.90% | 78.90% | 0.7820 |
Table 5.
High frequency vocabulary.
| Epidemic Development Stages | High-Frequency Vocabulary |
|---|---|
| latent stage | unknown cause, Wuhan, pneumonia, coronavirus, virus, case, epidemic, worry, fear, afraid |
| outbreak stage | Wuhan, persistence, hope, masks, prevention and control, frontline, at home, safety, home, infection, health |
| continuation stage | hope, prevention and control, end, work, cheer, life, country, enterprise, economy, influence. |
| recession stage | America, work, influence, country, prevention and control, ending, health, economy, children, domestic, development |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Li, Z.; Zhou, L.; Yang, X.; Jia, H.; Li, W.; Zhang, J. User Sentiment Analysis of COVID-19 via Adversarial Training Based on the BERT-FGM-BiGRU Model. Systems 2023, 11, 129. https://doi.org/10.3390/systems11030129
AMA Style
Li Z, Zhou L, Yang X, Jia H, Li W, Zhang J. User Sentiment Analysis of COVID-19 via Adversarial Training Based on the BERT-FGM-BiGRU Model. Systems. 2023; 11(3):129. https://doi.org/10.3390/systems11030129
Chicago/Turabian StyleLi, Zhaohui, Luli Zhou, Xueru Yang, Hongyu Jia, Wenli Li, and Jiehan Zhang. 2023. "User Sentiment Analysis of COVID-19 via Adversarial Training Based on the BERT-FGM-BiGRU Model" Systems 11, no. 3: 129. https://doi.org/10.3390/systems11030129
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.