

User Sentiment Analysis of COVID-19 via Adversarial Training Based on the BERT-FGM-BiGRU Model


Abstract
1. Introduction
2. Literature Review
2.1. Analysis of Online Public Opinion on COVID-19
2.2. Adversarial Training
2.3. Sentiment Analysis
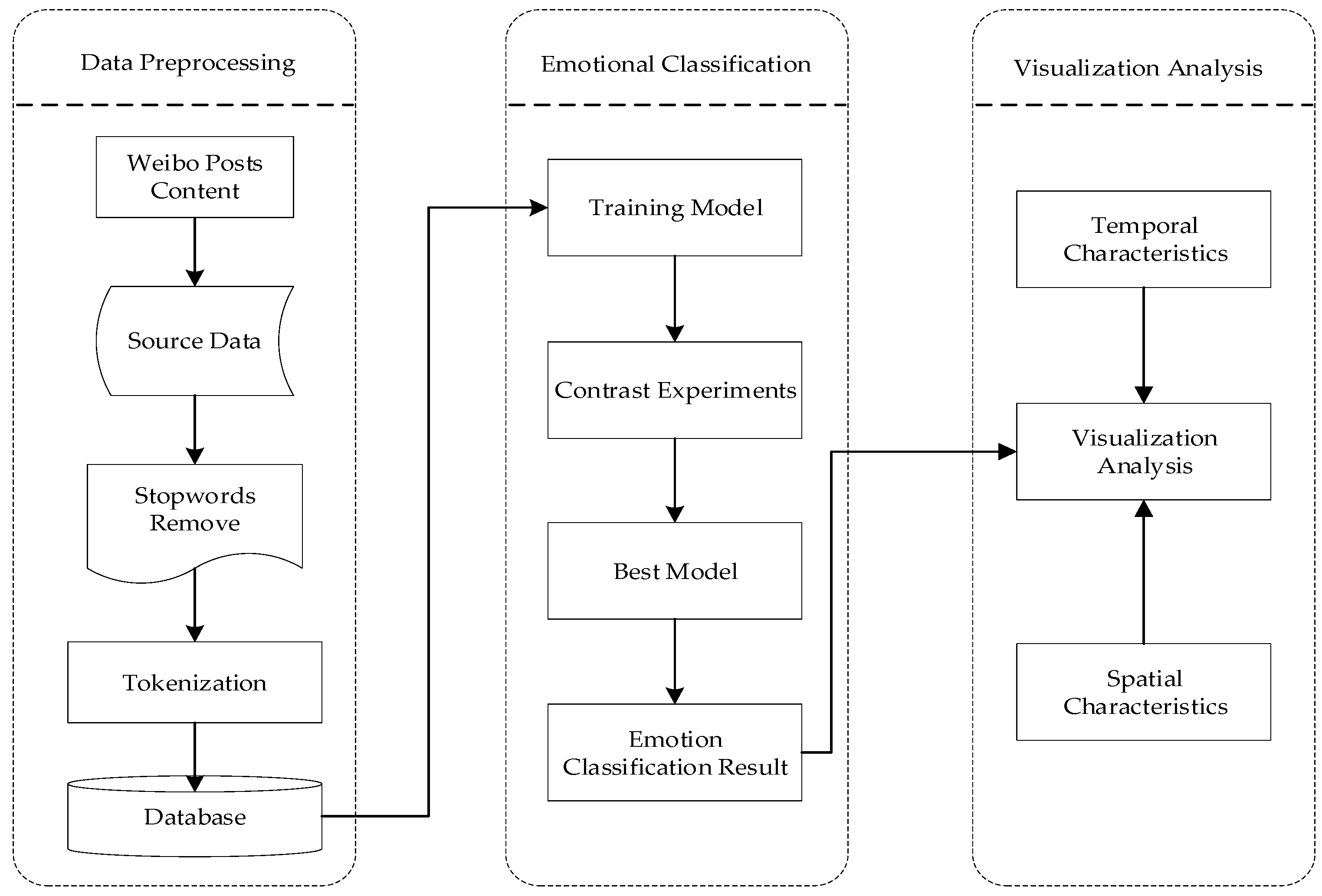
3. Construction of the BERT-FGM-BiGRU Sentiment Analysis Model
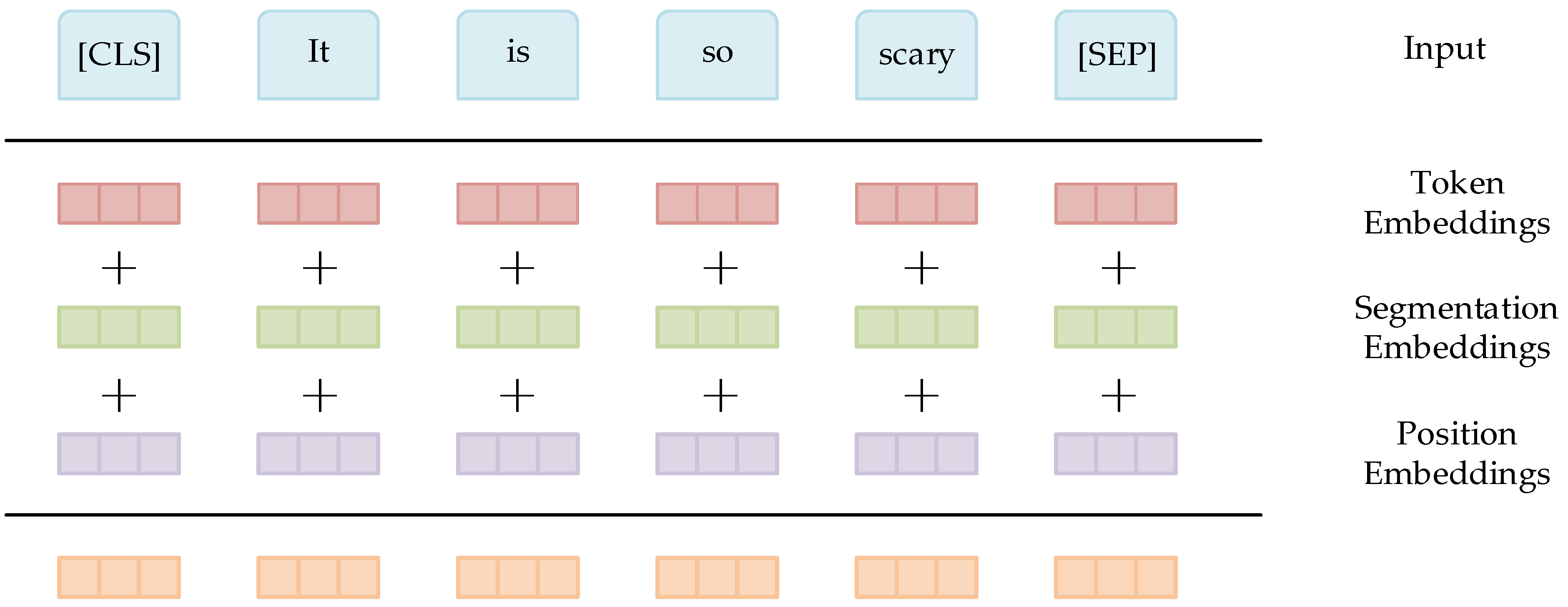
3.1. Word Vector Construction Based on the BERT Model
3.2. Add Adversarial Perturbation to the Text
3.3. Introduction of GRU Model
3.4. A Sentiment Analysis Model of BERT-FGM-BiGRU
4. Experiment and Results Analysis
4.1. Data Collection and Preprocessing
4.2. Parameters Setting
4.3. Evaluation Indicators
4.4. Comparative Analysis of Model’s Prediction Results
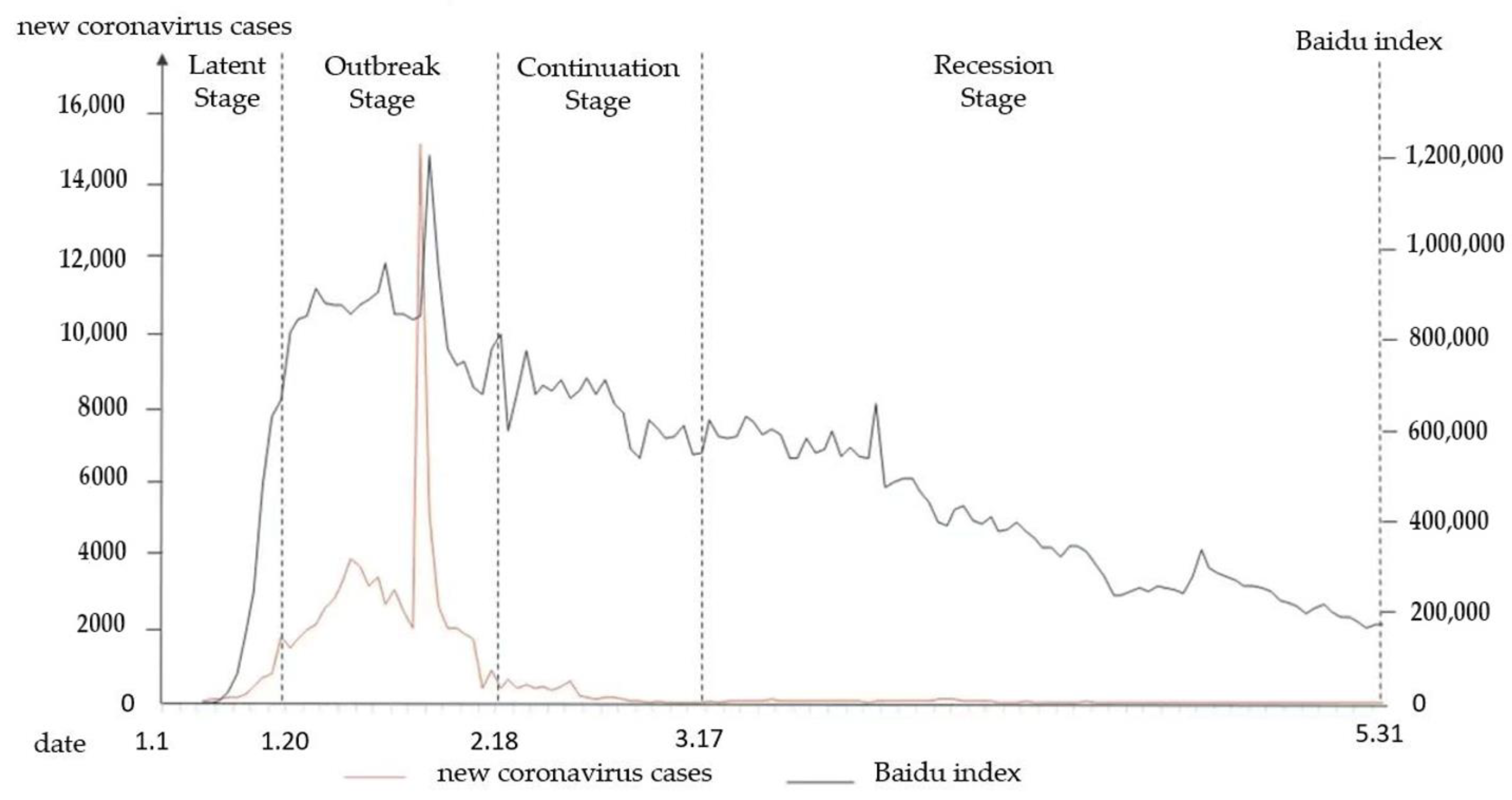
4.5. Sentiment Analysis Integrating Spatiotemporal Features
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Naming the Coronavirus Disease (COVID-19) and the Virus that Causes It. Available online: https://www.who.int/emergencies/diseases/novel-coronavirus-2019/technical-guidance/naming-the-coronavirus-disease-(covid-2019)-and-the-virus-that-causes-it (accessed on 11 February 2020).
- Wang, C.; Pan, R.; Wan, X.; Tan, Y.; Xu, L.; Ho, C.S.; Ho, R.C. Immediate Psychological Responses and Associated Factors during the Initial Stage of the 2019 Coronavirus Disease (COVID-19) Epidemic among the General Population in China. Int. J. Environ. Res. Public Health. 2020, 17, 1729. [Google Scholar] [CrossRef] [PubMed]
- Vosoughi, S.; Roy, D.K.; Aral, S. The spread of true and false news online. Science 2018, 359, 1146–1151. [Google Scholar] [CrossRef]
- Scheufele, D.A.; Eveland, W.P., Jr. Perceptions of ‘Public Opinion’ and ‘Public’ Opinion Expression. Int. J. Prod. Res. 2001, 13, 25–44. [Google Scholar] [CrossRef]
- Casillas, C.J.; Enns, P.K.; Wohlfarth, P.C. How Public Opinion Constrains the U.S. Supreme Court. Am. J. Political Sci. 2011, 55, 74–88. [Google Scholar] [CrossRef]
- Elbattah, M.; Arnaud, É.; Gignon, M.; Dequen, G. The Role of Text Analytics in Healthcare: A Review of Recent Developments and Applications. In Proceedings of the International Conference on Health Informatics, Victoria, BC, Canada, 3–7 October 2021. [Google Scholar]
- Huang, C.-L.; Wang, Y.-M.; Li, X.-W. Clinical features of patients infected with 2019 novel coronavirus in Wuhan, China. Lancet 2020, 395, 497–506. [Google Scholar] [CrossRef] [PubMed]
- Zhao, D.; Yao, F.; Wang, L.; Zheng, L.; Gao, Y.; Ye, J.; Guo, F.; Zhao, H.; Gao, R. A Comparative Study on the Clinical Features of Coronavirus 2019 (COVID-19) Pneumonia With Other Pneumonias. Clin. Infect. Dis. 2020, 71, 756–761. [Google Scholar] [CrossRef]
- Baker, S.R.; Bloom, N.; Davis, S.J.; Kost, K.J.; Sammon, M.; Viratyosin, T. The Unprecedented Stock Market Reaction to COVID-19. Rev. Asset Pricing Stud. 2020, 10, 742–758. [Google Scholar] [CrossRef]
- del Rio-Chanona, R.M.; Mealy, P.; Pichler, A.; Lafond, F.; Farmer, J.D. Supply and demand shocks in the COVID-19 pandemic: An industry and occupation perspective. Oxford Rev. Econ. Policy. 2020, 36 (Suppl. S1), S94–S137. [Google Scholar] [CrossRef]
- Son, C.; Hegde, S.; Smith, A.; Wang, X.; Sasangohar, F. Effects of COVID-19 on College Students’ Mental Health in the United States: Interview Survey Study. J. Med. Internet Res. 2020, 22, e21279. [Google Scholar] [CrossRef]
- Qin, L.; Sun, Q.; Wang, Y.; Wu, K.-F.; Chen, M.; Shia, B.-C.; Wu, S.-Y. Prediction of Number of Cases of 2019 Novel Coronavirus (COVID-19) Using Social Media Search Index. Int. J. Environ. Res. Public Health. 2020, 17, 2365. [Google Scholar] [CrossRef]
- Li, S.; Wang, Y.; Xue, J.; Zhao, N.; Zhu, T. The Impact of COVID-19 Epidemic Declaration on Psychological Consequences: A Study on Active Weibo Users. Int. J. Environ. Res. Public Health. 2020, 17, 2032. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Xu, Q.; Cuomo, R.; Purushothaman, V.; Mackey, T. Data Mining and Content Analysis of the Chinese Social Media Platform Weibo During the Early COVID-19 Outbreak: Retrospective Observational Infoveillance Study. JMIR Public Health Surveill 2020, 6, e18700. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Y.; Cheng, S.; Yu, X.; Xu, H. Chinese Public’s Attention to the COVID-19 Epidemic on Social Media: Observational Descriptive Study. J. Med. Internet Res. 2020, 22, e18825. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Li, Z.; Tian, Y. Sentimental Knowledge Graph Analysis of the COVID-19 Pandemic Based on the Official Account of Chinese Universities. Electronics 2021, 10, 2921. [Google Scholar] [CrossRef]
- Wang, J.; Zhou, Y.; Zhang, W.; Evans, R.; Zhu, C. Concerns Expressed by Chinese Social Media Users During the COVID-19 Pandemic: Content Analysis of Sina Weibo Microblogging Data. J. Med. Internet Res. 2020, 22, e22152. [Google Scholar] [CrossRef]
- Depoux, A.; Martin, S.; Karafillakis, E.; Preet, R.; Wilder-Smith, A.; Larson, H. The pandemic of social media panic travels faster than the COVID-19 outbreak. J. Travel Med. 2020, 27, 31. [Google Scholar] [CrossRef]
- Chen, X.-L.; Sun, Y.; Athiwaratkun, B.; Cardie, C.; Weinberger, K. Adversarial Deep Averaging Networks for Cross-Lingual Sentiment Classification. Trans. Assoc. Comput. Linguist. 2018, 6, 557–570. [Google Scholar] [CrossRef]
- Yang, Y.; Zhang, M.; Chen, W.; Zhang, W.; Wang, H.; Zhang, M. Adversarial Learning for Chinese NER from Crowd Annotations. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Shui, L.-C.; Liu, W.-Z.; Feng, Z.-M. Automatic image annotation based on generative confrontation network. Int. J. Comput. 2019, 39, 2129–2133. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.J.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Goodfellow, I.-J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Miyato, T.; Andrew, M.-D.; Goodfellow, I. Adversarial training methods for semi-supervised text classification. arXiv 2017, arXiv:1605.07725. [Google Scholar]
- Li, J.; Cheng, P.S.; Xu, L.D.; Liu, J.Y. Name entity recognition based on local adversarial training. J. Sichuan Univ. (Nat. Sci. Ed.) 2021, 58, 113–120. [Google Scholar]
- Yasunaga, M.; Kasai, J.; Radev, D. Robust Multilingual Part-of-Speech Tagging via Adversarial Training. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; Volume 1 (Long Papers), pp. 976–986. [Google Scholar]
- Zhou, J.-T.; Zhang, H.; Jin, D.; Zhu, H.-Y.; Fang, M.; Goh, B.-S.-M.; Kwok, K. Dual Adversarial Neural Transfer for Low-Resource Named Entity Recognition. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 3461–3471. [Google Scholar]
- Brauwers, G.; Frasincar, F. A Survey on Aspect-Based Sentiment Classification. ACM Comput. Surv. 2021, 55, 65. [Google Scholar] [CrossRef]
- Ahmed, M.; Chen, Q.; Li, Z. Constructing domain-dependent sentiment dictionary for sentiment analysis. Neural Comput. Appl. 2020, 32, 14719–14732. [Google Scholar] [CrossRef]
- Mujahid, M.; Lee, E.; Rustam, F.; Washington, P.B.; Ullah, S.; Reshi, A.A.; Ashraf, I. Sentiment Analysis and Topic Modeling on Tweets about Online Education during COVID-19. Appl. Sci. 2021, 11, 8438. [Google Scholar] [CrossRef]
- Wang, Z.; Qin, Y. The Impact of Shanghai Epidemic, China, 2022 on Public Psychology: A Sentiment Analysis of Microblog Users by Data Mining. Sustain Sci. 2022, 14, 9649. [Google Scholar] [CrossRef]
- Wang, W.; Sun, Y.; Qi, Q.; Meng, X. Text sentiment classification model based on BiGRU-attention neural network. Appl. Res. Comput. 2019, 36, 3558–3564. [Google Scholar]
- Gui, X.-Q.; Gao, Z.; Li, L. Text sentiment analysis during epidemic using TCN and BiLSTM+Attention models. J. Xi’an Univ. Technol. 2021, 1, 113–121. (In Chinese) [Google Scholar]
- Zhou, J.; Lu, Y.; Dai, H.; Wang, H.; Xiao, H. Sentiment Analysis of Chinese Microblog Based on Stacked Bidirectional LSTM. IEEE Access 2019, 7, 38856–38866. [Google Scholar] [CrossRef]
- Liu, C.L.; Wu, J.Q.; Tan, Y.N. Polarity discrimination of user comments based on TextCNN. Electron. World 2019, 48, 50. (In Chinese) [Google Scholar]
- Elnagar, A.; Al-Debsi, R.; Einea, O. Arabic text classification using deep learning models. Inf. Process. Manag. 2019, 57, 102121. [Google Scholar] [CrossRef]
- Colón-Ruiz, C.; Segura-Bedmar, I. Comparing deep learning architectures for sentiment analysis on drug reviews. J. Biomed. Infor. 2022, 110, 103539. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.-Q.; Li, X.; Han, X.; Song, D.-D.; Liao, L.-J. Multi-category sentiment analysis method of microblog based on bilingual dictionary. Acta Electron. Sin. 2016, 9, 2068–2073. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Zaremba, W.; Sutskever, I.; Vinyals, O. Recurrent Neural Network Regularization. arXiv 2014, arXiv:1409.2329. [Google Scholar]
- Cho, K.; Merrienboer, B.V.; Gülçehre, Ç.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; Volume D14-1179, pp. 1724–1734. [Google Scholar]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to forget: Continual prediction with LSTM. Neural Comput. 2000, 12, 2451–2471. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A system for large-scale machine learning. Osdi 2016, 16, 265–283. [Google Scholar]
- Chollet, F.; Keras. GitHub Repository. 2015. Available online: https://github.com/fchollet/keras (accessed on 15 November 2022).
- Lu, L.; Zou, Y.-q.; Peng, Y.-S.; Li, K.-L.; Jiang, T.-J. Comparative analysis of Baidu index and microindex in influenza surveillance in China. Comput. Appl. Res. 2016, 2, 392–395. (In Chinese) [Google Scholar]
- STEVENF. Crisis Management: Planning for the Inevitable; American Management Association: New York, NY, USA, 1986. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sentiment | Text Data |
|---|---|
| positive | May everyone be safe and healthy. # Tribute to the medical staff on the frontline of the epidemic # May everyone be healthy and safe. |
| neutral | Debunking rumors, look at this, pneumonia of unknown cause was renamed COVID-19 by the World Health Organization. |
| negative | Can’t accept it, save Wuhan, can’t stand the tears, a group of children puts on adult clothes to learn to save people. In the face of this symptom, those who are not sick are afraid. |
| Development Environment | Parameter |
|---|---|
| CPU | Intel(R)Core(TM)i7-11700F@2.50 GHZ |
| graphics card | NVIDIA GeForce RTX 2060 |
| operating system | Win10 64 |
| Programming Tools | Pycharm |
| Programming language | Python |
| Development Framework | Tensorflow [46] + keras [47] |
| Model | P/% | R/% | F1 |
|---|---|---|---|
| Word2Vec-BiLSTM | 71.99% | 70.15% | 0.7070 |
| BERT-BiLSTM | 77.35% | 77.35% | 0.7700 |
| GRU | 64.71% | 64.77% | 0.6431 |
| BiGRU | 66.39% | 66.39% | 0.6525 |
| BERT | 69.55% | 64.17% | 0.6675 |
| TextCNN | 57.21% | 57.21% | 0.5094 |
| BERT-CNN | 75.85% | 75.35% | 0.756 |
| Word2Vec-BiGRU | 74.80% | 71.89% | 0.7305 |
| BERT-GRU | 77.80% | 77.80% | 0.7739 |
| BERT-FGM-BiGRU | 78.90% | 78.90% | 0.7820 |
| Model | P/% | R/% | F1 |
|---|---|---|---|
| BERT | 69.55% | 69.55% | 0.6417 |
| BERT-BiGRU | 77.85% | 77.85% | 0.7743 |
| BERT-FGM-BiGRU | 78.90% | 78.90% | 0.7820 |
| Epidemic Development Stages | High-Frequency Vocabulary |
|---|---|
| latent stage | unknown cause, Wuhan, pneumonia, coronavirus, virus, case, epidemic, worry, fear, afraid |
| outbreak stage | Wuhan, persistence, hope, masks, prevention and control, frontline, at home, safety, home, infection, health |
| continuation stage | hope, prevention and control, end, work, cheer, life, country, enterprise, economy, influence. |
| recession stage | America, work, influence, country, prevention and control, ending, health, economy, children, domestic, development |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Zhou, L.; Yang, X.; Jia, H.; Li, W.; Zhang, J. User Sentiment Analysis of COVID-19 via Adversarial Training Based on the BERT-FGM-BiGRU Model. Systems 2023, 11, 129. https://doi.org/10.3390/systems11030129
Li Z, Zhou L, Yang X, Jia H, Li W, Zhang J. User Sentiment Analysis of COVID-19 via Adversarial Training Based on the BERT-FGM-BiGRU Model. Systems. 2023; 11(3):129. https://doi.org/10.3390/systems11030129
Chicago/Turabian StyleLi, Zhaohui, Luli Zhou, Xueru Yang, Hongyu Jia, Wenli Li, and Jiehan Zhang. 2023. "User Sentiment Analysis of COVID-19 via Adversarial Training Based on the BERT-FGM-BiGRU Model" Systems 11, no. 3: 129. https://doi.org/10.3390/systems11030129
APA StyleLi, Z., Zhou, L., Yang, X., Jia, H., Li, W., & Zhang, J. (2023). User Sentiment Analysis of COVID-19 via Adversarial Training Based on the BERT-FGM-BiGRU Model. Systems, 11(3), 129. https://doi.org/10.3390/systems11030129