
Face Mask Detection in Smart Cities Using Deep and Transfer Learning: Lessons Learned from the COVID-19 Pandemic
 , , , and
, , , and
Abstract
:1. Introduction
1.1. Preliminary
1.2. Contributions
- Identifying and systematically reviewing existing DL and TL models used to monitor social distancing in indoor and outdoor environments.
- Describing the state-of-the-art ML- and DL-based methods applied to detect mask-covered faces in the wild.
- Analyzing and discussing the performance of ML and DL models in detecting social distancing respect and face mask usage and identifying their pros and cons.
- Highlighting the open issues for the ongoing research in the field and providing insights about the research directions and applications that can attract considerable interest in the near future.
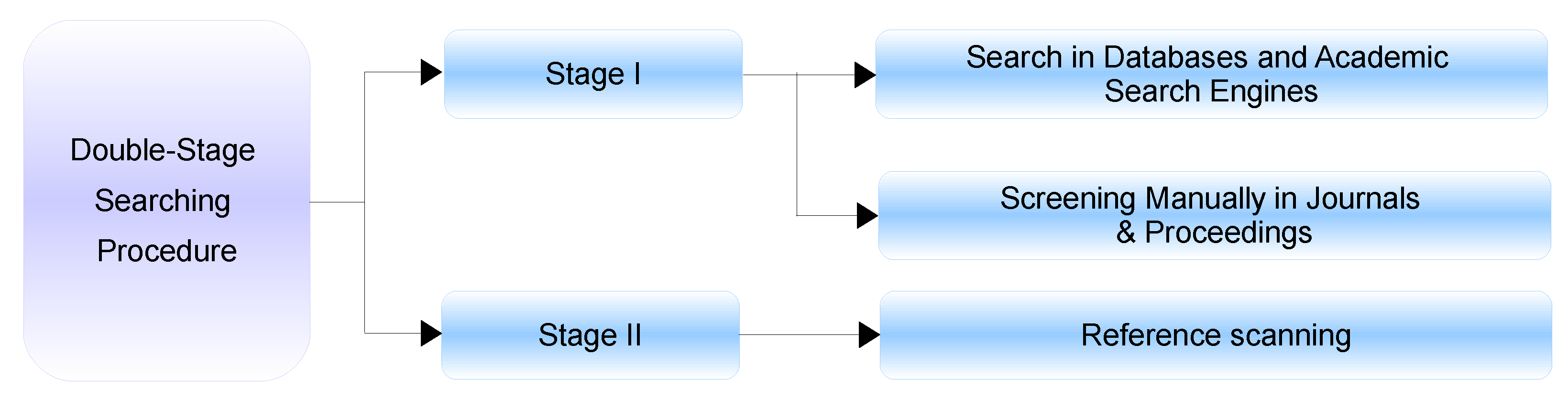
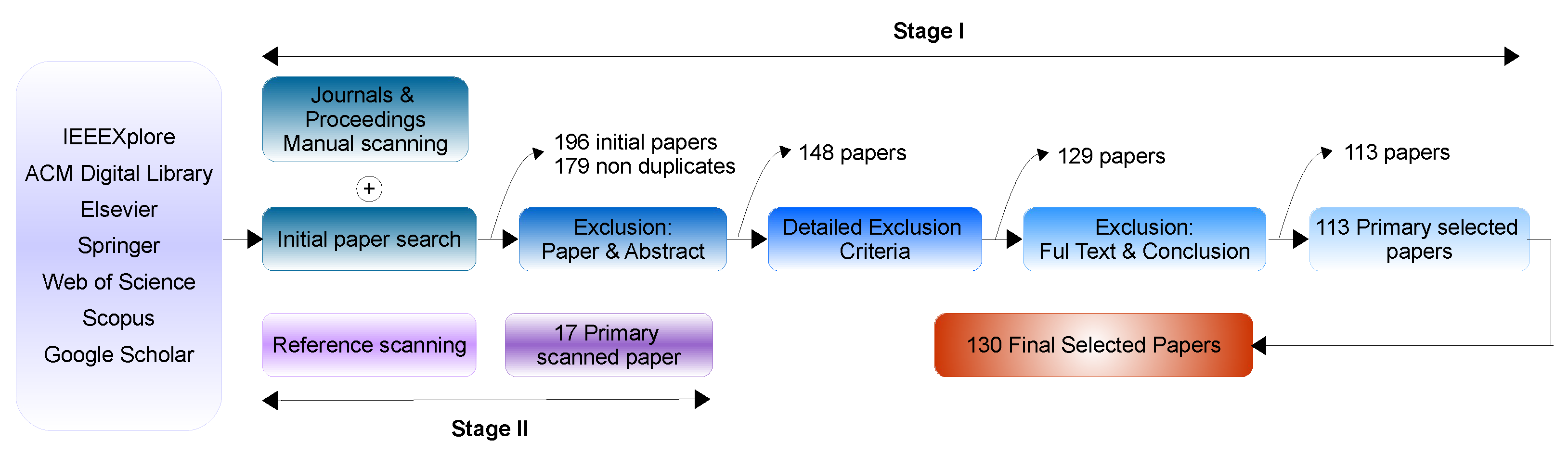
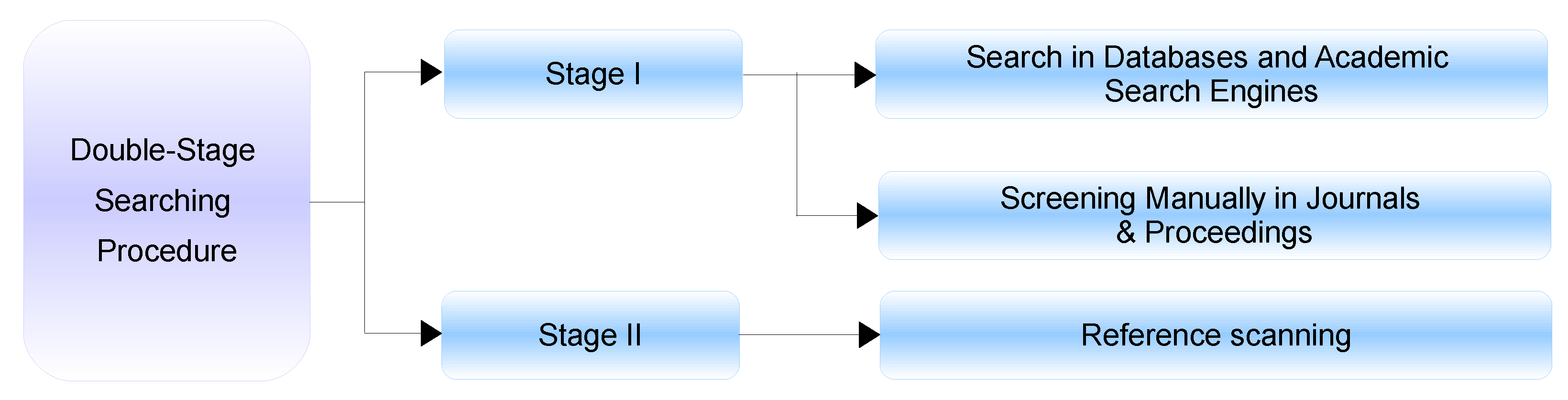
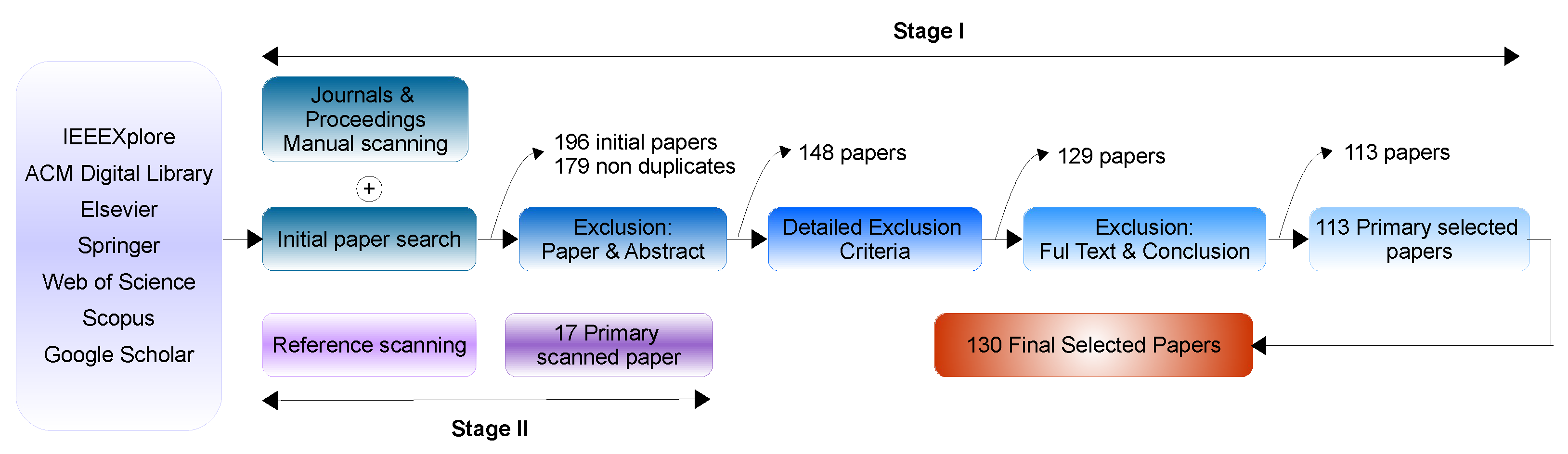
1.3. Review Methodology
2. Background
2.1. FMD Related Tasks
2.1.1. Mask Occlusion Detection
2.1.2. Incorrect Face Mask Wearing Detection
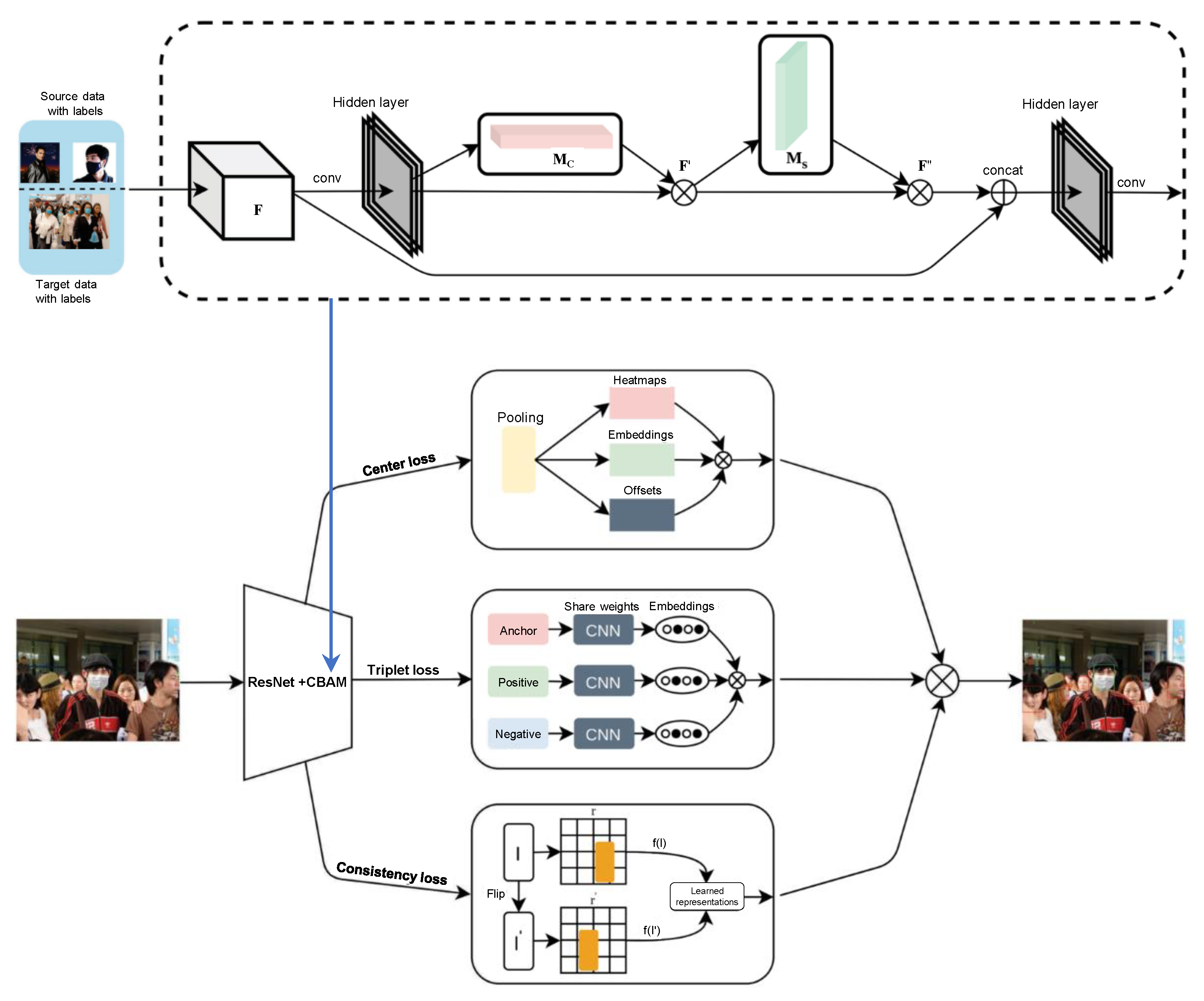
2.1.3. Masked Face Recognition (MFR)
2.1.4. Partial Face Recognition
2.2. Datasets
2.3. Evaluation Metrics
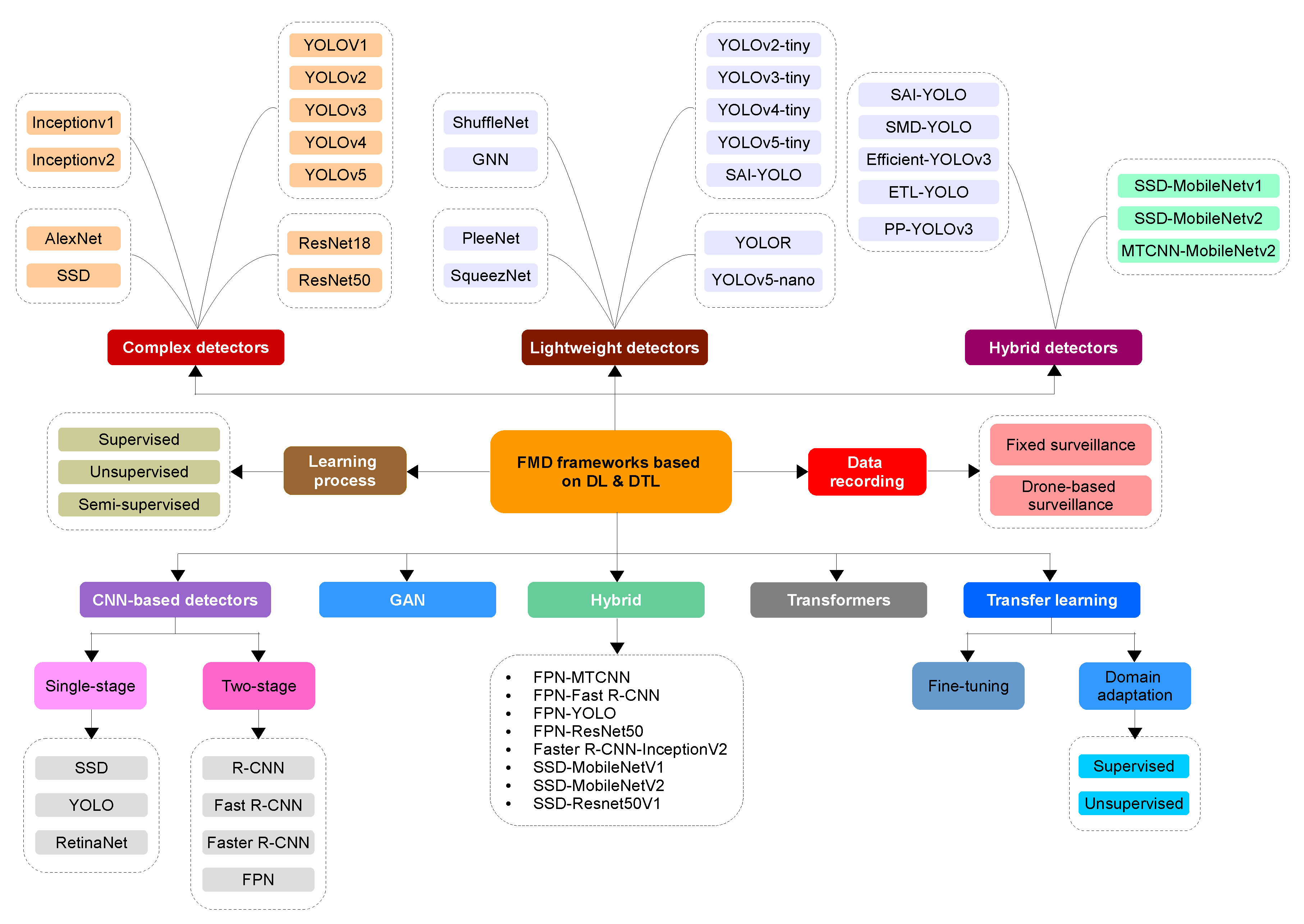
3. FMD Based on Conventional ML
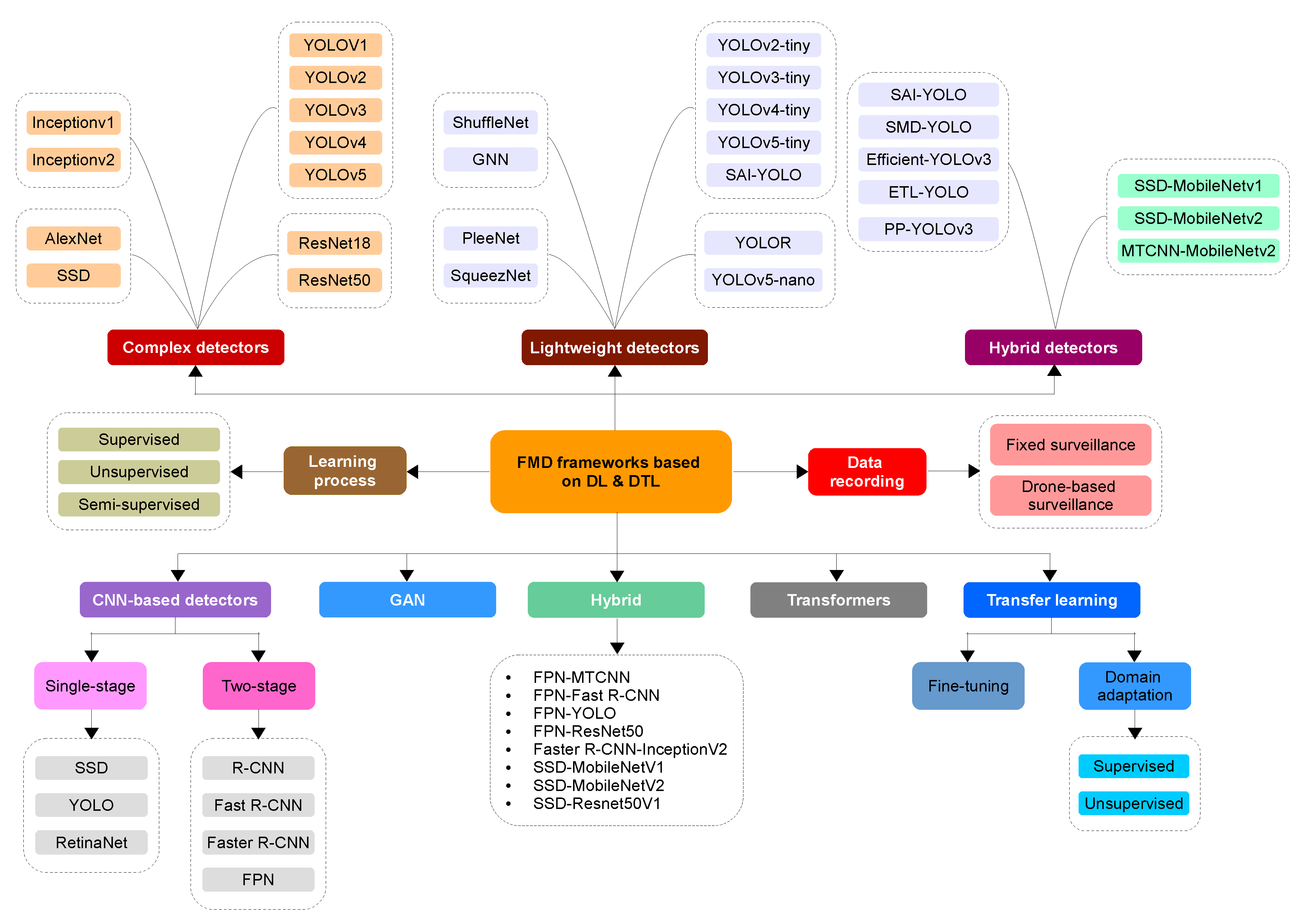
4. DL-Based FMD
4.1. Sorted by the Employed Architecture
4.1.1. Convolutional Neural Networks (CNNs)
4.1.2. Generative Adversarial Networks (GANs)
4.2. Sorted by the Number of Processing Stages
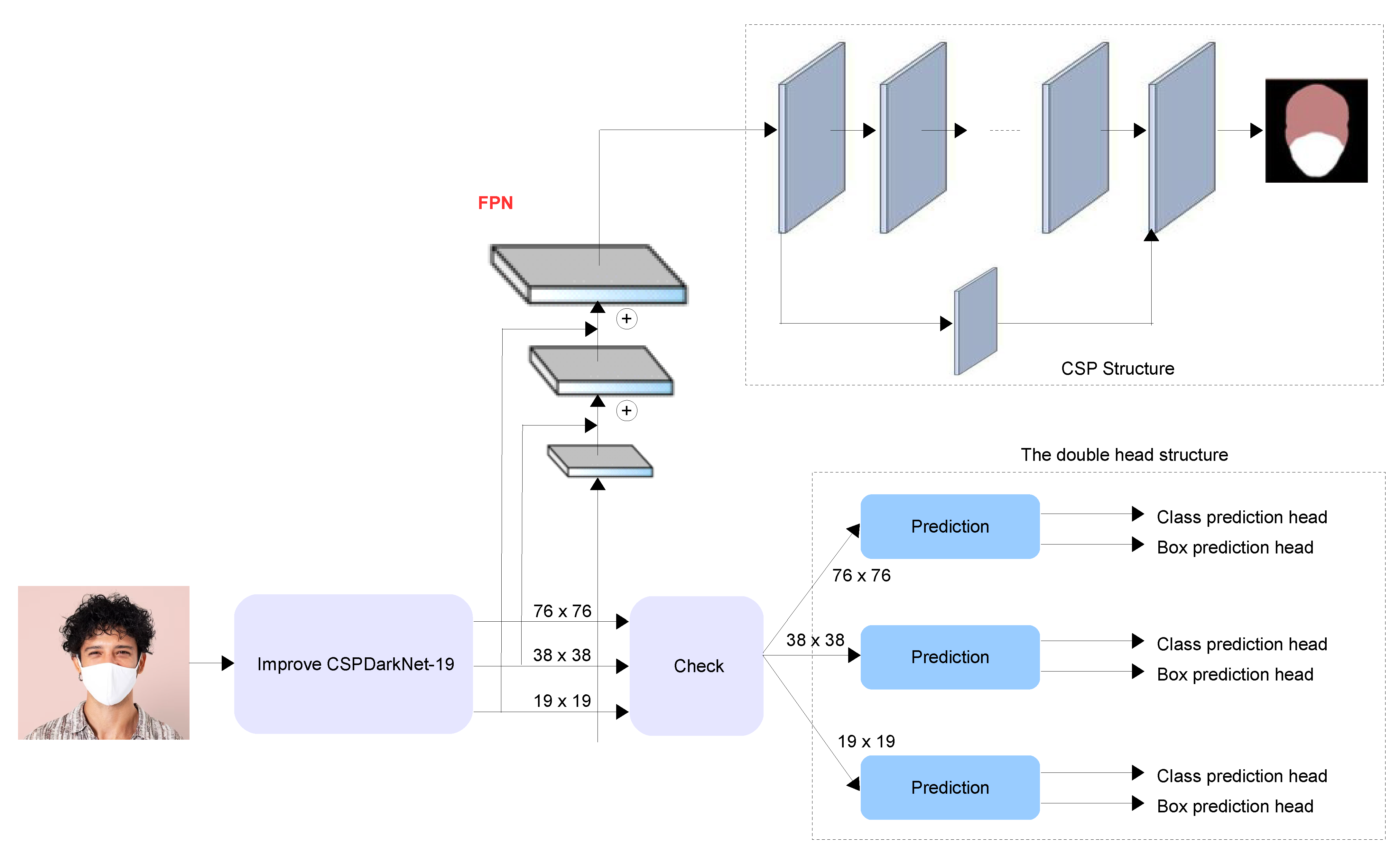
4.2.1. One-Stage FMD
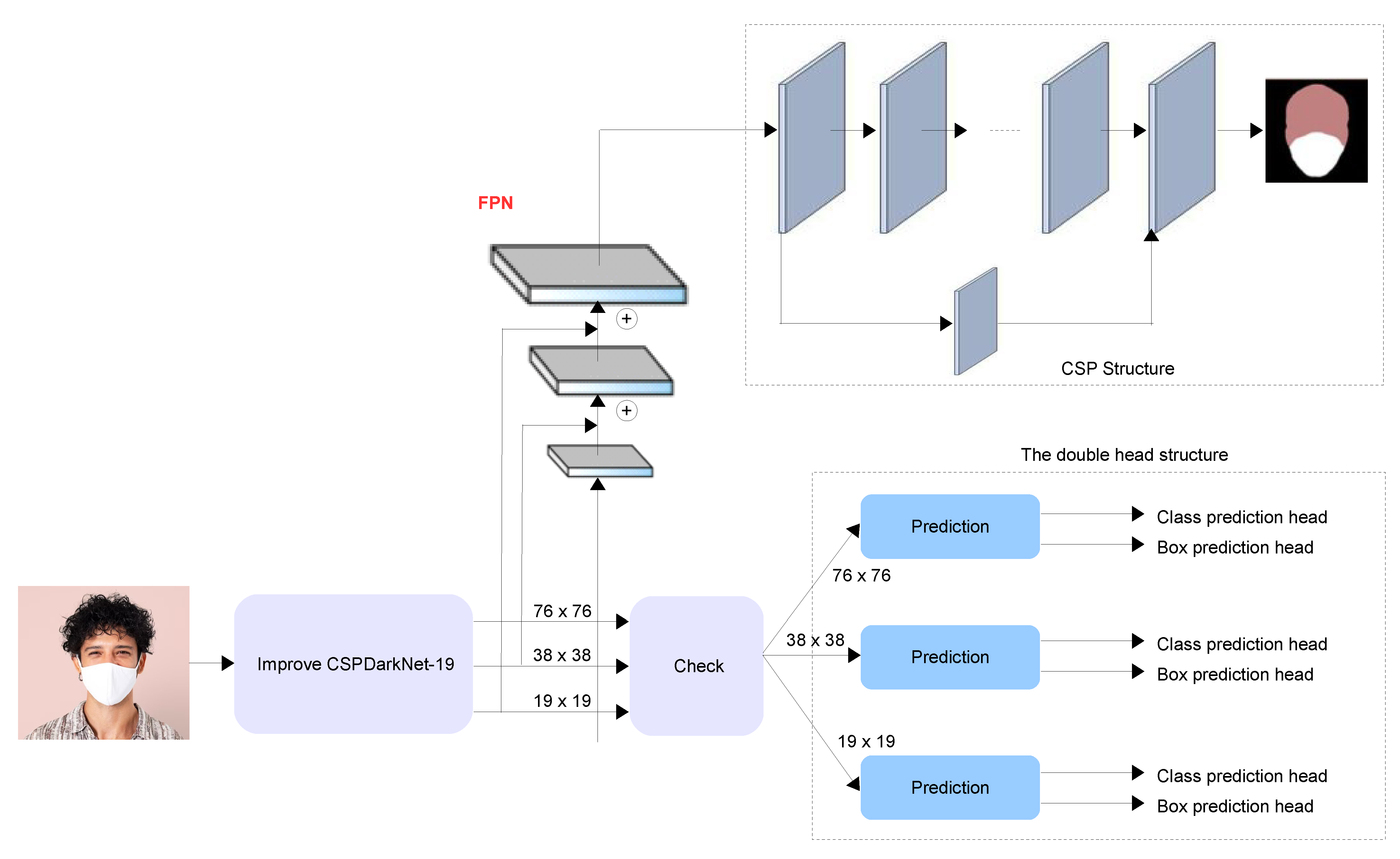
4.2.2. Two-Stage FMD
4.2.3. Discussion
4.3. Sorted by the Complexity of the Models
4.3.1. Complex Object Detectors
4.3.2. Lightweight Object Detectors

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
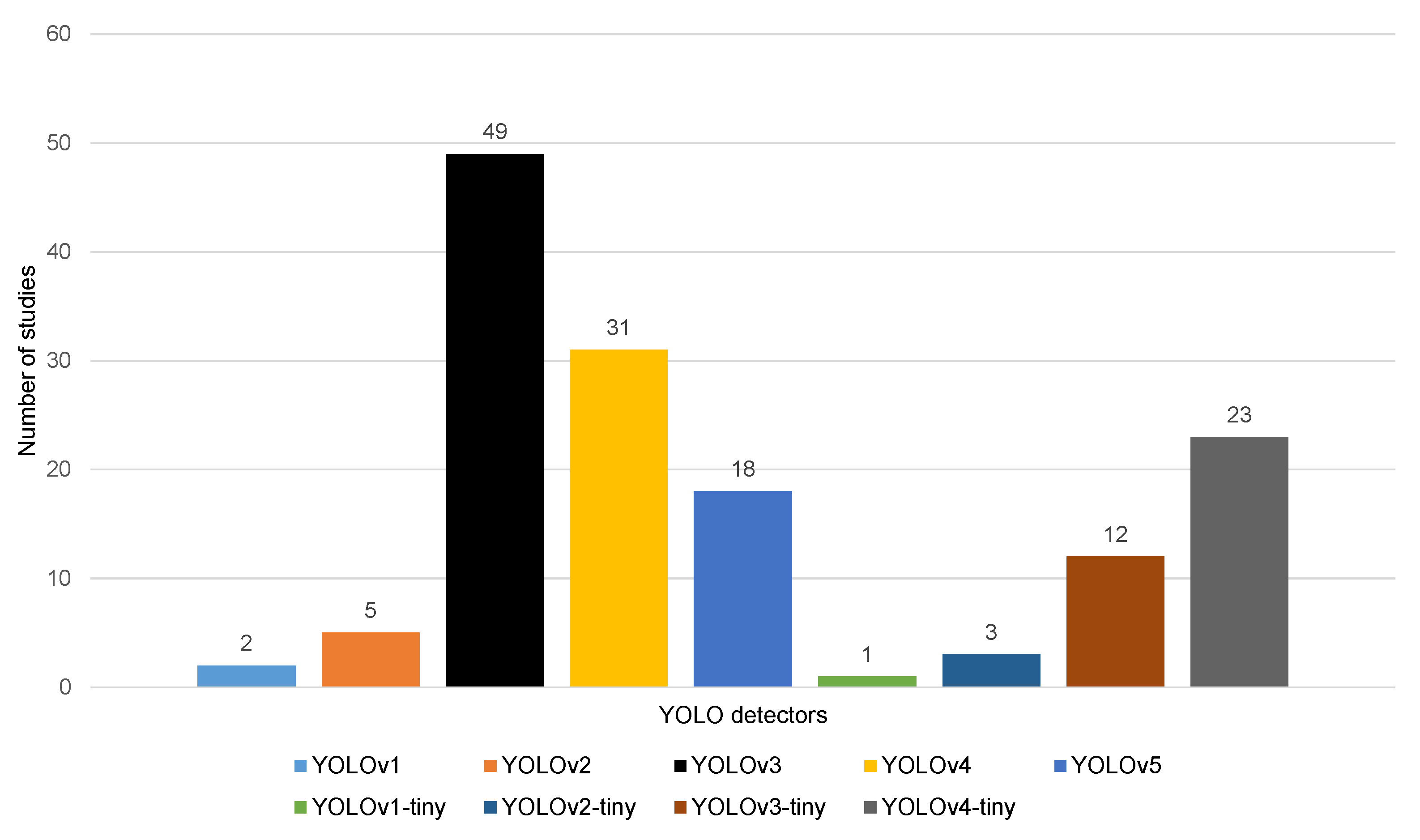{kind=link}
{kind=link}
{kind=link}
| Work | Model | Description | Dataset | Best FMD Performance | Advantage/Limitation |
|---|---|---|---|---|---|
| [19] | SRCNet | Distinguish face masks using image super-resolution and classification networks. | MedMasks | Acc = 98.70% | Validation on the small test dataset. Not robust to facemask-wearing variation (frontal orientation, posture change, etc.) |
| [171] | Inceptionv3 | FMD using InceptionV3-based TL. | SMFD | Acc = 99% | Validation on a small masked face dataset. FMD assessment in real-life video streaming is missing. |
| [172] | CNN | Detection of masked, non-masked, and properly-masked faces. | MFDD, RWFCD, SMFRD. | Acc = 98.6% | Validation on real-world masked face datasets. FMD assessment in real-life video streaming is missing. |
| [173] | CNN | 1,539 faced, and no-faced images were used to train a CNN model. | Private data | Acc = 98.7% | Offline FMD using masked face and non-masked face pictures collected using CCTV cameras. No assessment of real-world masked face datasets. |
| [126] | FMY3, YOLov3, ResNet-SSD300 | Using a DTL to reduce computational cost. | Private data | Acc = 98% | Offline FMD on a small face image dataset. No assessment of popular real-world masked face datasets. |
| [128] | R-CNN | FMD using RCNN-based object detection and comparison with SSD-MobileNetv2 and SSD-Inceptionv2 models. | COCO | Acc = 68.72% | Have an overfitting problem and Validation on datasets without assessment in real-world scenarios. |
| [27] | SSD, MobileNetv2 | Real-time FMD using SSD and MobileNetV | KMMD, PBD, RTMMD | Acc = 93% | High computational cost. |
| [133] | MTCNN, MobileNetv2 | FMD using (i) MTCNN-based face detection and (ii) MobileNetv2-based object in the masked region. | Private video data. | Acc = 81% | Low accuracy performance and FMD mainly relies on face detection. |
| [97] | YOLOv3 | FMD using YOLOv3 and Google Colab. | Private image dataset (600 images) | Acc = 96% | • Validation on a small dataset without assessment in real-world scenarios. |
| [174] | Tiny-CNN (SqueezeNet, Modified SqueezeNet) | Low computational medical FMD and comparison of the performance with SqueezeNet and Modified SqueezeNet. | Combination of FMID-12k, FMC, and private image datasets. | Acc = 99.81% | Validation on face image datasets without assessment in real-world scenarios. |
| [71] | YOLO-fastest, NCNN | Edge-based FMD using YOLO-fastest, NCNN and WebAssembly. | Combination of Wider Face, MAFA, RWMFD, MMD and SMFD | mAP = 89% (YOLOv3) | Scalable solution where other lightweight DL models can be used. Requires internet connectivity, which makes it computationally expensive. |
| [44] | YOLOv3, YOLOv3Tiny, SSD, Faster-R-CNN | FD using various CNN architectures. | Moxa3K and MMD | mAP = 63.99% (YOLOv3) | Low detection accuracy; further improvements are required by using effective object detectors. |
| [142] | CNN | FMD using posture recognition and DL. | Private real-world data. | Acc = 95.8% | Validation on a limited dataset, although they were collected from real-world environments. |
| [151] | MobileNetv2 | Low computational FMD using a lightweight CNN. | MMD, FMD | Acc = 99.75% | Validation on face image datasets without assessment in real-world scenarios. |
| [12] | CNN | FMD without generating over-fitting. | A balanced masked face dataset of 3832 images. | N/A | The CNN architecture has been trained using the balanced dataset and used in real-world scenarios, though without evaluation. |
| [150] | CNN | The CNN architecture has been made similar to MobileNetv2 for an efficient computational cost. | FMDD | Acc = 99% | MobileNetv2 has been used to classify pre-processed video frames using OpenCV. There is no comparison with other methods on the training/test splits of the FMDD dataset. |
| [129] | RCNN, Fast-RCNN, and Faster-RCNN | Real-time analysis of FMD and SDM. | Private dataset | Acc = 93% | Validation on a small dataset without assessment in real-world scenarios. |
| [42] | YOLOv3, faster-RCNN | Real-time automated FMD | MAFA, Wider Face | PR = 62% | Real-time implementation is supported with YOLOv3, while its accuracy is lower than faster R-CNN. |
| [130] | Context-attention RCNN | Detection of faces without masks, with wrong masks, and with correct masks. | A new MAFA-based dataset is created | mAP = 84.1% | Evaluation on a small dataset (4672 images), and the performance needs further improvement. |
| [63] | TL-AlexNet-LSTM/BiLSTM, TL-VGG16-LSTM/BiLSTM | TL-based AlexNet and VGG16 were combined with LSTM and BiLSTM to detect the manner people use facemasks. | Private data (2000 images) | Acc = 95.66% | Face masks via real-time video recordings were not supported, and the Validation was on a small dataset. |
| [175] | Improved YOLOv4 | FMD and standard wear detection | RMFD+, MaskedFace-Net, private data | mAP = 98.3% | Insufficient feature extraction for difficult detection samples. FMD, when the light is insufficient, was not treated. |
| [176] | YOLOv3, YOLOv4-tiny | The YOLO network using Darknet applied is a state-of-the-art real-time object detection system. | A novel publicly annotated dataset | mAP = 90.69% | Applied only with surgical mask (helms or shield masks) |
| [64] | CNN (VGG-16) | FMD in real-time with an alarm system. | A new web dataset. | Acc = 98% | The prevention by creating an alarm stipulation these rules are not observed properly. |
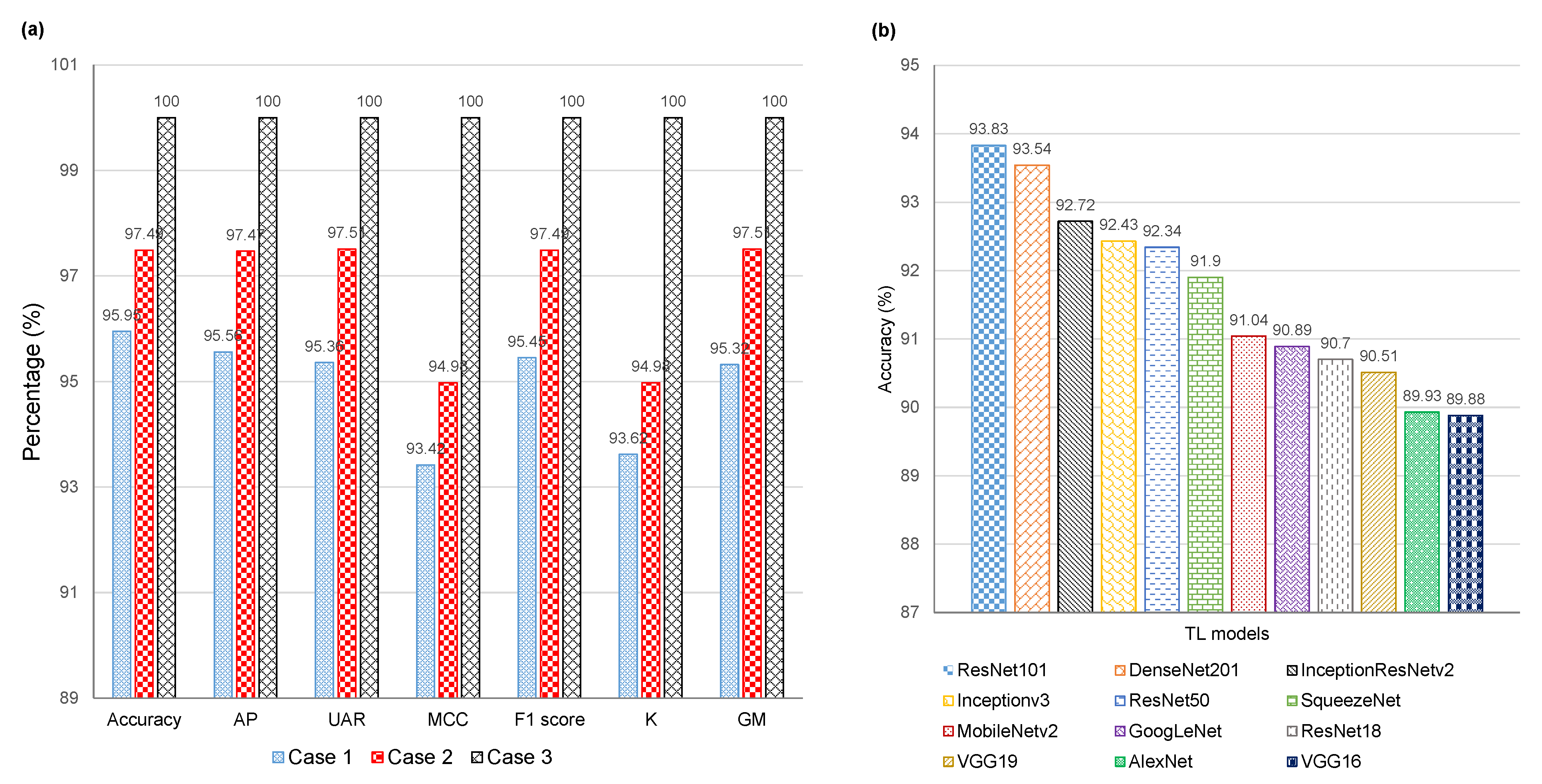
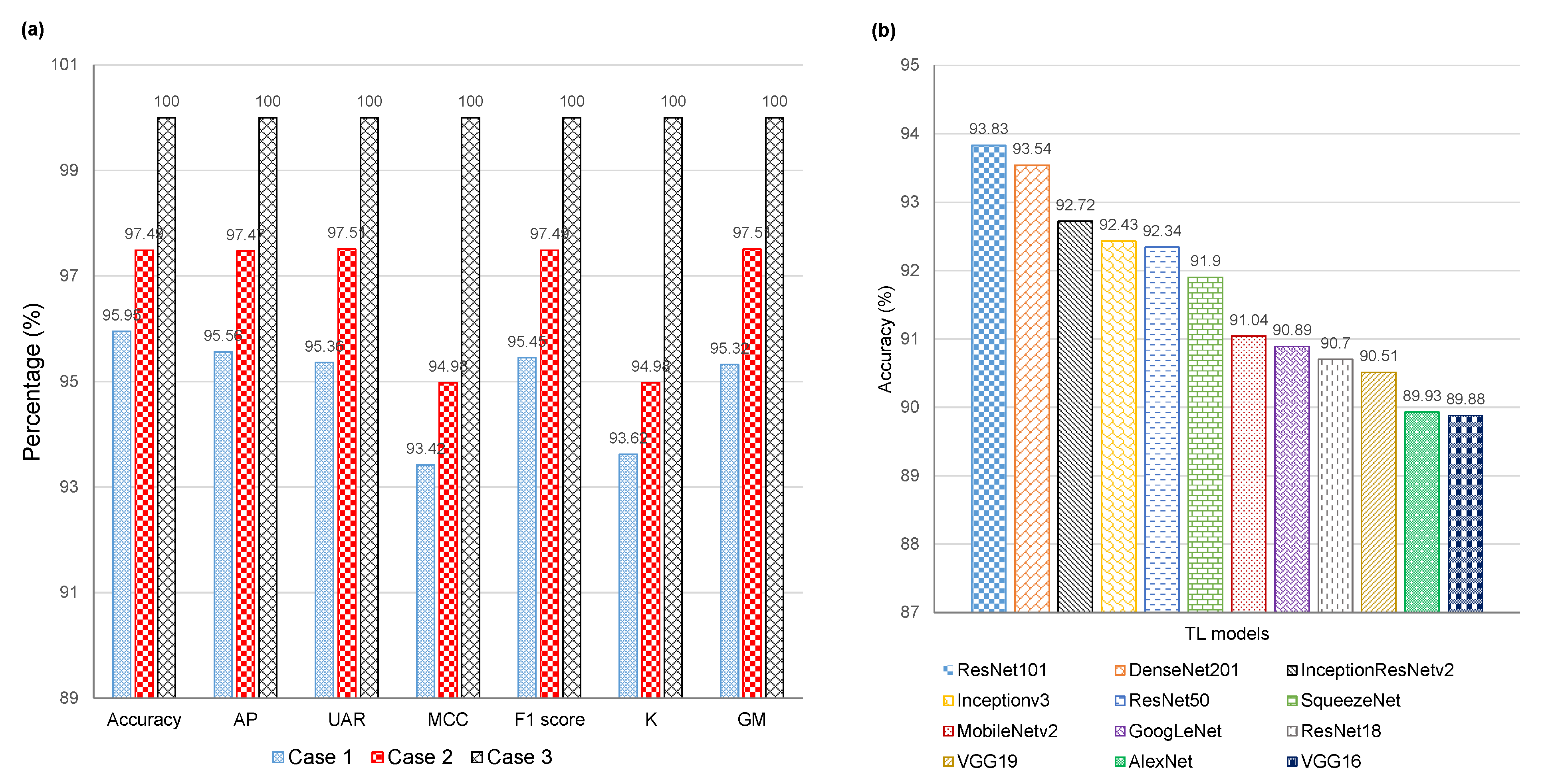
| [170] | ResNet101 | Pre-trained ResNet101 and DenseNet201 are used to generate image features, a RelieF selector is used to find discriminative features, and an SVM for classifying images. | MaskedFace-NET, a private dataset with three classes. | Acc = 99.75% | Not compared with existing solutions on the custom dataset. |
| [138] | VGG-16 and CNN | Automatic FMD system in public transportation using Raspberry Pi. | Private data | Acc = 99.4% | Not validated on public datasets, which makes it difficult to compare the performance with existing solutions. |
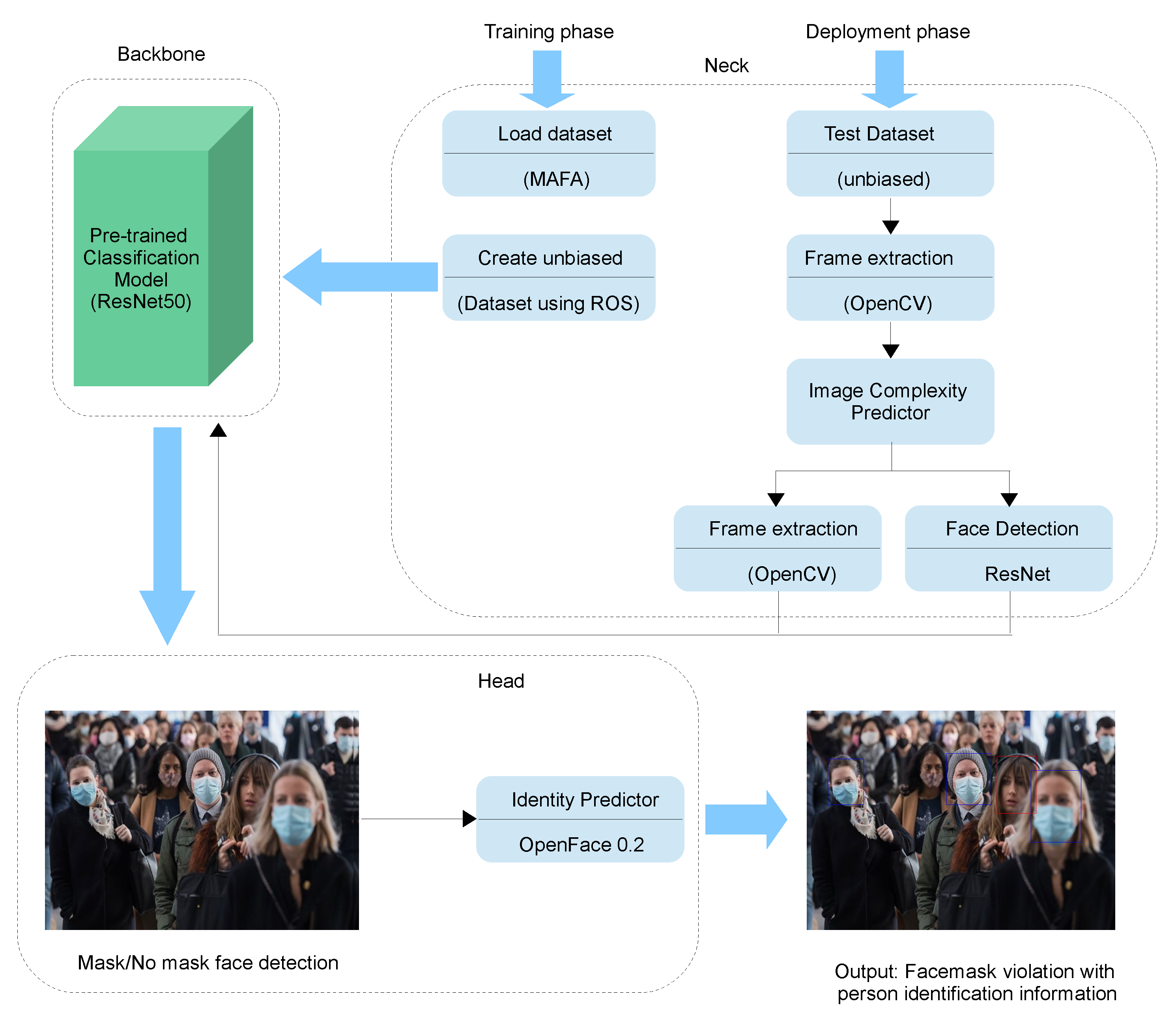
| [72] | TL-based ResNet50, YOLOv2 | Using TL-based ResNet50 for feature extraction and YOLOv2 classifier to detect medical masks. | MMD, FMD | Acc = 81% | Do not discriminate between medical and normal masks. |
| [110] | YOLOv4 | Real-time FMD using effective structures of backbone, neck, and prediction head based on YOLOv4 | MAFA, WiderFace | AP = 94% | Achieve real-time FMD and suitable for dark/night environments. |
| [121] | Mask RCNN, YOLOv4, YOLOv5, and YOLOR | FMD using different lightweight CNN models for detecting mask-wearing in videos. | ViDMASK | mAP = 97.1% (YOLOR) | The dataset and code are publicly available. Faces are shot from various angles. |
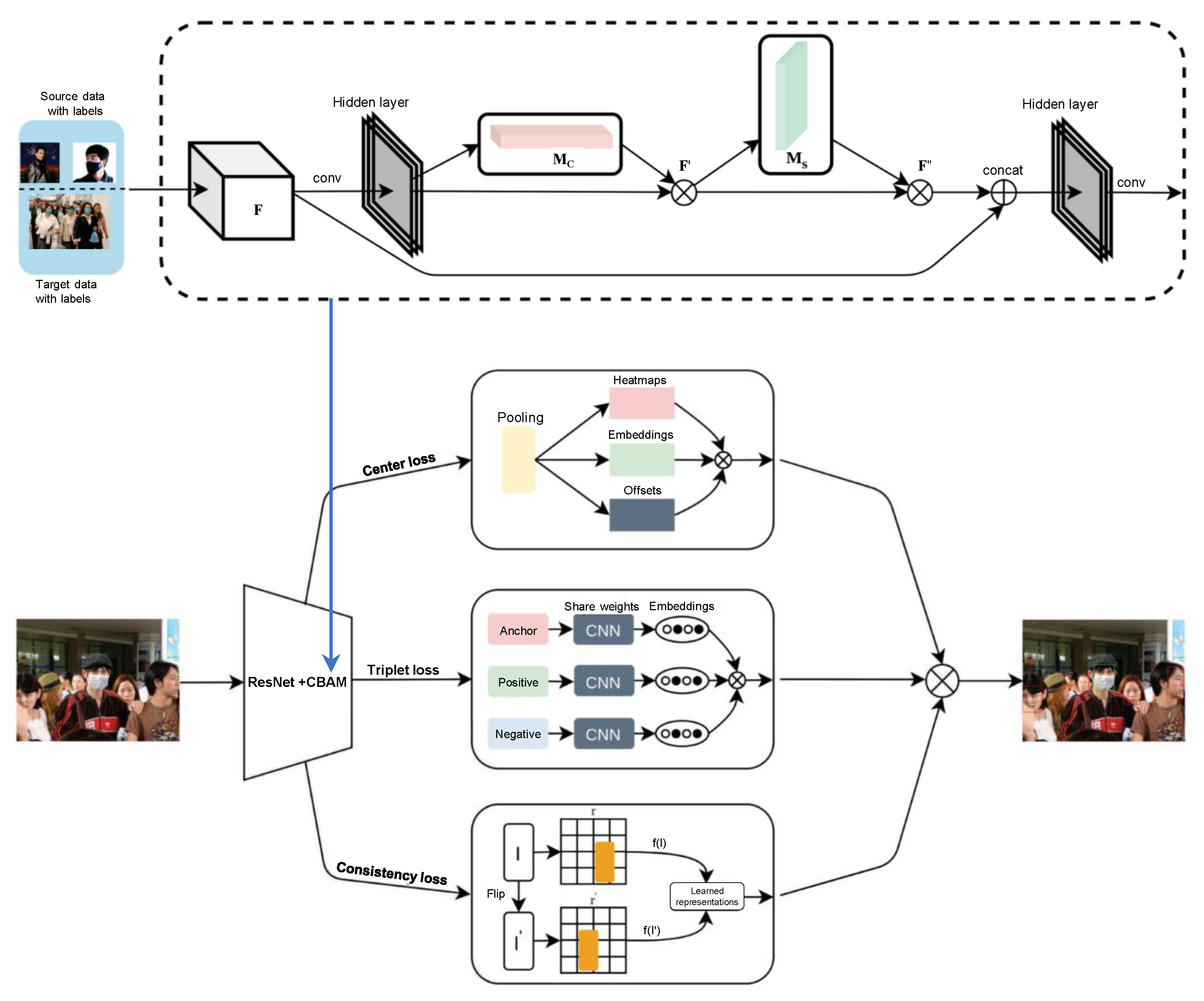
| [137] | ResNet-18 | FMD using triplet-consistency representation learning. | WiderFace, MAFA | L = 91.5% (MAFA), L = 54.1% (Wider Face) | The performance drops under noisy environments (i.e., the hard set of Wider Face), and the privacy preservation are not addressed. |
4.4. FMD Based on Deep Transfer Learning (DTL)
| Work | DTL Model | Description | Dataset | Best FMD Performance | Advantage/Limitation |
|---|---|---|---|---|---|
| [122] | TL-based ResNet50 and MobileNetv1 | FMD using ResNet or MobileNet as the backbone, FPN as the neck, and context attention modules as the heads. | MAFA + FMD | Acc = 91.9% (ResNet) | No assessment on real-world masked face datasets. |
| [195] | Transfer learning | Relies on adopting transfer learning to detect face masks in both images and video streams. | RMFD | Acc = 98% | (i) Works on a variety of devices (e.g., smartphones, etc.) and is also able to process in real-time images and video streams, (ii) the approach is not well interpretable activation since they do not use activation maps. |
| [171] | Inceptionv3-based DTL | FMD using Inceptionv3-based DTL. | SMFD | Acc = 99% | Validation on a small masked face dataset. FMD assessment in real-life video streaming is missing. |
| [18] | MobileNetv2, Xception, Inceptionv3, ResNet50, NASNet, VGG19 | Detection of incorrect face mask-wearing using CNN and DTL. | Private data | Acc = 83% | (i) Implemented via Android app that works with real scenarios, and the solution can identify mask misuse, (ii) Unable to detect incorrect lateral adjustment and glasses underneath. Moreover, the system was applied with surgical and FP2 masks. Not applied with masks that have sequins and other drawings. |
| [196] | DTL based on combining SVM and MobileNetv2 | MFD using deep feature selection and award-winning pre-trained DL models. | Collected data of 1376 images | Acc = 97.1% | Tested on a small-sized dataset. Not tested on the challenging occluded face. |
| [197] | YOLOv3 and Darknet53 | Data augmentation and DTL for FMD. | data collected from Kaggle. | Prec = | The automated system detects masks using an augmented dataset. |
| [198] | VGG-19 transfer learning DCNN | A software model that could be used in existing surveillance applications. | FMDC | Acc = 98% | (i) Implemented via live feed footage in IP cameras. (ii) Tested on the artificially created dataset. Not suitable with a web server or linkage of multiple IP cameras. |
| [189] | Improved FaceNet | FMD using residual inception networks. | M-CASIA | Acc = 99.2% | Validated on a simulated dataset; however, any unrealistic part in the simulated images might cause some inaccuracies in the recognition. |
| [191] | Faster-RCNN | Automated real-time FMD using Faster-RCNN-based DTL. | FMD | AvPrec = 81%, AvRec = 84% | The performance needs further improvement. |
| [192] | MobileNetv2 | Using DTL and fine-tuning to detect face masks. | Private data | Acc = 98.2% | Validation of public dataset is required to compare the performance with other existing FMD solutions. |
| [193] | VGG16, MobileNetv1, ResNet50 | Development of a real-time CNN-based lightweight mobile FMD system. | VGGFace2, MaskedFace-Net | Acc = 99.6% | Less computational power and resources are required using MobilNetv1. |
| [48] | VGG-16, MobileNetv2, Inceptionv3, ResNet50, and CNN | IoT- and DTL-based FMD scheme for rapid screening. | MAFA, Masked Face-Net, and Bing | Acc = 99.81% (VGG-16) | Validated on public datasets that mostly have artificially created and noisy face mask images. |
| [171] | Inceptionv3 | FMD using TL and image augmentation. | SMFD | Acc = 100% | Evaluation on large-scale real-world datasets is required. The type of mask cannot be detected. |
| [194] | ResNet50-based DA | MFR using DA. | Private data | F1 = 89.7% (unmasked), F1 = 44.73% (masked) | Have problems in detecting masked faces. The dataset used is unbalanced. |
5. Evaluation, Discussion and Findings
5.1. Comparative Analysis
| Work | Method | Real-Time | Dataset | Sample Size | Mask Type | Recognition Type | Validation Accuracy |
|---|---|---|---|---|---|---|---|
| [200] | PCA | No | ORL Face | 400 | Real | Masked/Unmasked | 95% |
| [33] | Latent part detection | No | CASIA-WebFace | 4,916 | Augmented | Masked/Unmasked | 97.94% |
| [65] | CNN | No | Private data | 7855 | Mix | Masked/Unmasked | 99.45% |
| [19] | CNN | No | KMMD | 3835, 134, 3030 | Real | Correct/Incorrect/Unmasked | 98.70% |
| [201] | Mixture of Gaussians | Yes | Private data | N/A | Real | Masked/Unmasked | 95% |
| [134] | ResNet50-based DTL | No | RMFD, SMFD, LFW | 10,000, 1570, 13,000 | Mix | Masked/Unmasked | 100% |
| [18] | CNN | No | Private data | 3200 | Real | Correct/Incorrect/Unmasked | 83% |
| [20] | MobileNet | No | Private data | 770, 500 | Augmented | Correct/Incorrect/Unmasked | 90% |
| [21] | Haar feature cascade | No | CMFD, IMFD | 137,016 | Mix | Correct/Incorrect/Unmasked | - |
| [171] | Inceptionv3 | No | SMFD | 1570 | Augmented | Masked/Unmasked | 99.90% |
| [193] | MobileNetv2-based DTL | Yes | VGGFace, Tailored dataset | 1,022,811, 1849 | Mix | Correct/Incorrect/Unmasked | 99.96% |
5.2. Critical Discussion
- Lack of suitable datasets: one major challenge is the Lack of datasets with a sufficient number of images of faces with masks, as well as a diverse range of mask types and wearing conditions. This can make it difficult to train and evaluate face mask detection algorithms, as the performance of these algorithms is often dependent on the quality and diversity of the training data.
- Small intra-class distance and significant inter-class distance: another challenge is the small intra-class distance and large inter-class distance between masked and non-masked faces, making it difficult to accurately distinguish between these two classes. This may require specialized algorithms or techniques that can extract distinguishing features and increase the separation between these classes.
- Noise caused by masks: the presence of masks on the face can also introduce noise that can interfere with the performance of face mask detection algorithms. This may be due to factors such as the mask’s texture, reflections or shadows, and the occlusion of facial features.
- Variability in mask appearance: face masks come in a wide variety of shapes, sizes, and colors, and they may also be worn in different ways (e.g., covering the nose and mouth, covering only the nose, or hanging around the neck). This variability can make it challenging for a model to detect masks accurately.
- Occlusions: face masks can occlude parts of the face, making it difficult for the model to identify features such as the eyes, nose, and mouth.
- Lighting and background: the model may have difficulty detecting masks in low light conditions or against cluttered or complex backgrounds.
- False positives and false negatives: the model needs to minimize false positives (incorrectly identifying a mask when none is present) and false negatives (failing to identify a mask when one is present).
- Real-time performance: there is also a need for face mask detection algorithms that are able to perform in real time, as these algorithms may be used in applications such as surveillance or event analysis, where speed is critical.
- Adversarial examples: an attacker can create "adversarial examples" (images specifically designed to fool the model) that could cause the model to make incorrect predictions.
6. Open Challenges
6.1. Lack of Annotated Datasets
6.2. Computational Cost
6.3. Security and Privacy
6.4. Difficulty in Recognizing People’s Emotions
6.5. Masked Face Attacks
7. Future Directions
7.1. Interpretability and Explainability
7.2. Further Generalization for FMD Techniques
7.3. Federated FMD
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
| 1 | https://www.kaggle.com/vtech6/medical-masks-dataset, accessed on 5 January 2022. |
References
- Hyysalo, J.; Dasanayake, S.; Hannu, J.; Schuss, C.; Rajanen, M.; Leppänen, T.; Doermann, D.; Sauvola, J. Smart mask–Wearable IoT solution for improved protection and personal health. Internet Things 2022, 18, 100511. [Google Scholar] [CrossRef]
- WHO Coronavirus (COVID-19) Dashboard. Available online: https://covid19.who.int/ (accessed on 13 January 2022).
- Himeur, Y.; Al-Maadeed, S.; Almadeed, N.; Abualsaud, K.; Mohamed, A.; Khattab, T.; Elharrouss, O. Deep visual social distancing monitoring to combat COVID-19: A comprehensive survey. Sustain. Cities Soc. 2022, 85, 104064. [Google Scholar] [CrossRef]
- Fanelli, D.; Piazza, F. Analysis and forecast of COVID-19 spreading in China, Italy and France. Chaos Solitons Fractals 2020, 134, 109761. [Google Scholar] [CrossRef] [PubMed]
- Galbadage, T.; Peterson, B.M.; Gunasekera, R.S. Does COVID-19 spread through droplets alone? Front. Public Health 2020, 8, 163. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liao, M.; Liu, H.; Wang, X.; Hu, X.; Huang, Y.; Liu, X.; Brenan, K.; Mecha, J.; Nirmalan, M.; Lu, J.R. A technical review of face mask wearing in preventing respiratory COVID-19 transmission. Curr. Opin. Colloid Interface Sci. 2021, 52, 101417. [Google Scholar] [CrossRef] [PubMed]
- Agarwal, C.; Kaur, I.; Yadav, S. Hybrid CNN-SVM Model for Face Mask Detector to Protect from COVID-19. In Artificial Intelligence on Medical Data; Springer: Berlin/Heidelberg, Germany, 2023; pp. 419–426. [Google Scholar]
- Elharrouss, O.; Al-Maadeed, S.; Subramanian, N.; Ottakath, N.; Almaadeed, N.; Himeur, Y. Panoptic segmentation: A review. arXiv 2021, arXiv:2111.10250. [Google Scholar]
- Liberatori, B.; Mami, C.A.; Santacatterina, G.; Zullich, M.; Pellegrino, F.A. YOLO-Based Face Mask Detection on Low-End Devices Using Pruning and Quantization. In Proceedings of the 2022 45th Jubilee International Convention on Information, Communication and Electronic Technology (MIPRO), Opatija, Croatia, 23–27 May 2022; pp. 900–905. [Google Scholar]
- Wakchaure, A.; Kanawade, P.; Jawale, M.; William, P.; Pawar, A. Face Mask Detection in Realtime Environment using Machine Learning based Google Cloud. In Proceedings of the 2022 International Conference on Applied Artificial Intelligence and Computing (ICAAIC), Salem, India, 9–11 May 2022; pp. 557–561. [Google Scholar]
- Kühl, N.; Martin, D.; Wolff, C.; Volkamer, M. “Healthy surveillance”: Designing a concept for privacy-preserving mask recognition AI in the age of pandemics. arXiv 2020, arXiv:2010.12026. [Google Scholar]
- Kaur, G.; Sinha, R.; Tiwari, P.K.; Yadav, S.K.; Pandey, P.; Raj, R.; Vashisth, A.; Rakhra, M. Face Mask Recognition System using CNN Model. Neurosci. Inform. 2021, 2, 100035. [Google Scholar] [CrossRef]
- Mohamed, M.M.; Nessiem, M.A.; Batliner, A.; Bergler, C.; Hantke, S.; Schmitt, M.; Baird, A.; Mallol-Ragolta, A.; Karas, V.; Amiriparian, S.; et al. Face mask recognition from audio: The MASC database and an overview on the mask challenge. Pattern Recognit. 2022, 122, 108361. [Google Scholar] [CrossRef]
- Mohamed, S.K.; Abdel Samee, B.E. Social Distancing Model Utilizing Machine Learning Techniques. In Advances in Data Science and Intelligent Data Communication Technologies for COVID-19; Springer: Berlin/Heidelberg, Germany, 2022; pp. 41–53. [Google Scholar]
- Selvakarthi, D.; Sivabalaselvamani, D.; Ashwath, S.; Kalaivanan, A.A.; Manikandan, K.; Pradeep, C. Experimental Analysis using Deep Learning Techniques for Safety and Riskless Transport-A Sustainable Mobility Environment for Post Covid-19. In Proceedings of the 2021 6th International Conference on Inventive Computation Technologies (ICICT), Coimbatore, India, 20–22 January 2021; pp. 980–984. [Google Scholar]
- Ray, S.; Das, S.; Sen, A. An intelligent vision system for monitoring security and surveillance of ATM. In Proceedings of the 2015 Annual IEEE India Conference (INDICON), New Delhi, India, 17–20 December 2015; pp. 1–5. [Google Scholar]
- Chen, Q.; Sang, L. Face-mask recognition for fraud prevention using Gaussian mixture model. J. Vis. Commun. Image Represent. 2018, 55, 795–801. [Google Scholar] [CrossRef]
- Tomás, J.; Rego, A.; Viciano-Tudela, S.; Lloret, J. Incorrect facemask-wearing detection using convolutional neural networks with transfer learning. Healthcare 2021, 9, 1050. [Google Scholar] [CrossRef] [PubMed]
- Qin, B.; Li, D. Identifying facemask-wearing condition using image super-resolution with classification network to prevent COVID-19. Sensors 2020, 20, 5236. [Google Scholar] [CrossRef] [PubMed]
- Rudraraju, S.R.; Suryadevara, N.K.; Negi, A. Face mask detection at the fog computing gateway. In Proceedings of the 2020 15th Conference on Computer Science and Information Systems (FedCSIS), Sofia, Bulgaria, 6–9 September 2020; pp. 521–524. [Google Scholar]
- Cabani, A.; Hammoudi, K.; Benhabiles, H.; Melkemi, M. MaskedFace-Net–A dataset of correctly/incorrectly masked face images in the context of COVID-19. Smart Health 2021, 19, 100144. [Google Scholar] [CrossRef]
- Asghar, M.Z.; Albogamy, F.R.; Al-Rakhami, M.S.; Asghar, J.; Rahmat, M.K.; Alam, M.M.; Lajis, A.; Nasir, H.M. Facial Mask Detection Using Depthwise Separable Convolutional Neural Network Model During COVID-19 Pandemic. Front. Public Health 2022, 10, 855254. [Google Scholar] [CrossRef] [PubMed]
- Jeevan, G.; Zacharias, G.C.; Nair, M.S.; Rajan, J. An empirical study of the impact of masks on face recognition. Pattern Recognit. 2022, 122, 108308. [Google Scholar] [CrossRef]
- Azeem, A.; Sharif, M.; Raza, M.; Murtaza, M. A survey: Face recognition techniques under partial occlusion. Int. Arab J. Inf. Technol. 2014, 11, 1–10. [Google Scholar]
- He, L.; Li, H.; Zhang, Q.; Sun, Z. Dynamic feature learning for partial face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7054–7063. [Google Scholar]
- Li, Y.; Guo, K.; Lu, Y.; Liu, L. Cropping and attention based approach for masked face recognition. Appl. Intell. 2021, 51, 3012–3025. [Google Scholar] [CrossRef]
- Nagrath, P.; Jain, R.; Madan, A.; Arora, R.; Kataria, P.; Hemanth, J. SSDMNV2: A real time DNN-based face mask detection system using single shot multibox detector and MobileNetV2. Sustain. Cities Soc. 2021, 66, 102692. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, G.; Huang, B.; Xiong, Z.; Hong, Q.; Wu, H.; Yi, P.; Jiang, K.; Wang, N.; Pei, Y.; et al. Masked face recognition dataset and application. arXiv 2020, arXiv:2003.09093. [Google Scholar] [CrossRef]
- Yang, S.; Luo, P.; Loy, C.C.; Tang, X. Wider face: A face detection benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5525–5533. [Google Scholar]
- Ge, S.; Li, J.; Ye, Q.; Luo, Z. Detecting masked faces in the wild with lle-cnns. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2682–2690. [Google Scholar]
- Bu, W.; Xiao, J.; Zhou, C.; Yang, M.; Peng, C. A cascade framework for masked face detection. In Proceedings of the 2017 IEEE International Conference on Cybernetics and Intelligent Systems (CIS) and IEEE Conference on Robotics, Automation and Mechatronics (RAM), Ningbo, China, 19–21 November 2017; pp. 458–462. [Google Scholar]
- Bhandary, P. Face Mask Dataset Datset (FMDS). Available online: https://www.kaggle.com/andrewmvd/face-mask-detection (accessed on 13 January 2022).
- Ding, F.; Peng, P.; Huang, Y.; Geng, M.; Tian, Y. Masked face recognition with latent part detection. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 2281–2289. [Google Scholar]
- Witkowski, M. Medical Masks Dataset (MMD). Available online: https://humansintheloop.org/resources/datasets/medical-mask-dataset/ (accessed on 13 January 2022).
- Jangra, A. Face Mask 12k Images Dataset. Available online: https://www.kaggle.com/datasets/ashishjangra27/face-mask-12k-images-dataset (accessed on 13 January 2022).
- Makwana, D. Face Mask Classification. Available online: https://www.kaggle.com/datasets/dhruvmak/face-mask-detection (accessed on 13 January 2022).
- Real-World Masked Face Dataset, RMFD. Available online: https://github.com/X-zhangyang/Real-World-Masked-Face-Dataset (accessed on 13 January 2022).
- Dey, S.K.; Howlader, A.; Deb, C. MobileNet mask: A multi-phase face mask detection model to prevent person-to-person transmission of SARS-CoV-2. In International Conference on Trends in Computational and Cognitive Engineering; Springer: Berlin/Heidelberg, Germany, 2021; pp. 603–613. [Google Scholar]
- Bhandary, P. Simulated Masked Face Dataset. Available online: https://github.com/prajnasb/observations (accessed on 13 January 2022).
- Queiroz, L.; Oliveira, H.; Yanushkevich, S. Thermal-mask–a dataset for facial mask detection and breathing rate measurement. In Proceedings of the 2021 International Conference on Information and Digital Technologies (IDT), Zilina, Slovakia, 22–24 June 2021; pp. 142–151. [Google Scholar]
- Ullah, N.; Javed, A.; Ghazanfar, M.A.; Alsufyani, A.; Bourouis, S. A novel DeepMaskNet model for face mask detection and masked facial recognition. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 9905–9914. [Google Scholar] [CrossRef]
- Singh, S.; Ahuja, U.; Kumar, M.; Kumar, K.; Sachdeva, M. Face mask detection using YOLOv3 and faster R-CNN models: COVID-19 environment. Multimed. Tools Appl. 2021, 80, 19753–19768. [Google Scholar] [CrossRef] [PubMed]
- Batagelj, B.; Peer, P.; Štruc, V.; Dobrišek, S. How to Correctly Detect Face-Masks for COVID-19 from Visual Information? Appl. Sci. 2021, 11, 2070. [Google Scholar] [CrossRef]
- Roy, B.; Nandy, S.; Ghosh, D.; Dutta, D.; Biswas, P.; Das, T. MOXA: A deep learning based unmanned approach for real-time monitoring of people wearing medical masks. Trans. Indian Natl. Acad. Eng. 2020, 5, 509–518. [Google Scholar] [CrossRef]
- Irem Eyiokur, F.; Kemal Ekenel, H.; Waibel, A. A Computer Vision System to Help Prevent the Transmission of COVID-19. arXiv 2021, arXiv:2103.08773. [Google Scholar]
- Wang, B.; Zhao, Y.; Chen, C.P. Hybrid transfer learning and broad learning system for wearing mask detection in the covid-19 era. IEEE Trans. Instrum. Meas. 2021, 70, 1–12. [Google Scholar] [CrossRef]
- Jiang, X.; Gao, T.; Zhu, Z.; Zhao, Y. Real-time face mask detection method based on YOLOv3. Electronics 2021, 10, 837. [Google Scholar] [CrossRef]
- Hussain, S.; Yu, Y.; Ayoub, M.; Khan, A.; Rehman, R.; Wahid, J.A.; Hou, W. IoT and deep learning based approach for rapid screening and face mask detection for infection spread control of COVID-19. Appl. Sci. 2021, 11, 3495. [Google Scholar] [CrossRef]
- Nowrin, A.; Afroz, S.; Rahman, M.S.; Mahmud, I.; Cho, Y.Z. Comprehensive review on facemask detection techniques in the context of covid-19. IEEE Access 2021, 9, 106839–106864. [Google Scholar] [CrossRef]
- Mita, T.; Kaneko, T.; Hori, O. Joint haar-like features for face detection. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05) Volume 1, Beijing, China, 17–21 October 2005; Volume 2, pp. 1619–1626. [Google Scholar]
- Jauhari, A.; Anamisa, D.; Negara, Y. Detection system of facial patterns with masks in new normal based on the Viola Jones method. J. Phys. Conf. Ser. 2021, 1836, 012035. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer society Conference on Computer Vision and Pattern Recognition, CVPR 2001, Kauai, HI, USA, 8–14 December 2001; Volume 1, p. I. [Google Scholar]
- Chelbi, S.; Mekhmoukh, A. A practical implementation of mask detection for COVID-19 using face detection and histogram of oriented gradients. Aust. J. Electr. Electron. Eng. 2022, 19, 129–136. [Google Scholar] [CrossRef]
- Yoon, S.M.; Kee, S.C. Detection of Partially Occluded Face Using Support Vector Machines. In Proceedings of the MVA, Nara, Japan, 11–13 December 2002; pp. 546–549. [Google Scholar]
- Sharifara, A.; Rahim, M.S.M.; Anisi, Y. A general review of human face detection including a study of neural networks and Haar feature-based cascade classifier in face detection. In Proceedings of the 2014 International Symposium on Biometrics and Security Technologies (ISBAST), Kuala Lumpur, Malaysia, 26–27 August 2014; pp. 73–78. [Google Scholar]
- Colombo, A.; Cusano, C.; Schettini, R. Gappy PCA classification for occlusion tolerant 3D face detection. J. Math. Imaging Vis. 2009, 35, 193–207. [Google Scholar] [CrossRef]
- Ichikawa, K.; Mita, T.; Hori, O.; Kobayashi, T. Component-based face detection method for various types of occluded faces. In Proceedings of the 2008 3rd International Symposium on Communications, Control and Signal Processing, Saint Julian’s, Malta, 12–14 March 2008; pp. 538–543. [Google Scholar]
- Thom, N.; Hand, E.M. Facial attribute recognition: A survey. In Computer Vision: A Reference Guide; Springer: Cham, Switzerland, 2020; pp. 1–13. [Google Scholar]
- Bhandari, M.; Shahi, T.B.; Siku, B.; Neupane, A. Explanatory classification of CXR images into COVID-19, Pneumonia and Tuberculosis using deep learning and XAI. Comput. Biol. Med. 2022, 150, 106156. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Jin, K.; Zhou, D.; Kubota, N.; Ju, Z. Attention mechanism-based CNN for facial expression recognition. Neurocomputing 2020, 411, 340–350. [Google Scholar] [CrossRef]
- Sayed, A.N.; Himeur, Y.; Bensaali, F. Deep and transfer learning for building occupancy detection: A review and comparative analysis. Eng. Appl. Artif. Intell. 2022, 115, 105254. [Google Scholar] [CrossRef]
- Himeur, Y.; Elnour, M.; Fadli, F.; Meskin, N.; Petri, I.; Rezgui, Y.; Bensaali, F.; Amira, A. Next-generation energy systems for sustainable smart cities: Roles of transfer learning. Sustain. Cities Soc. 2022, 85, 104059. [Google Scholar] [CrossRef]
- Koklu, M.; Cinar, I.; Taspinar, Y.S. CNN-based bi-directional and directional long-short term memory network for determination of face mask. Biomed. Signal Process. Control 2022, 71, 103216. [Google Scholar] [CrossRef]
- Militante, S.V.; Dionisio, N.V. Deep Learning Implementation of Facemask and Physical Distancing Detection with Alarm Systems. In Proceedings of the 2020 Third International Conference on Vocational Education and Electrical Engineering (ICVEE), Surabaya, Indonesia, 3–4 October 2020; pp. 1–5. [Google Scholar]
- Chavda, A.; Dsouza, J.; Badgujar, S.; Damani, A. Multi-stage cnn architecture for face mask detection. In Proceedings of the 2021 6th International Conference for Convergence in Technology (I2CT), Maharashtra, India, 2–4 April 2021; pp. 1–8. [Google Scholar]
- Din, N.U.; Javed, K.; Bae, S.; Yi, J. A novel GAN-based network for unmasking of masked face. IEEE Access 2020, 8, 44276–44287. [Google Scholar] [CrossRef]
- Geng, M.; Peng, P.; Huang, Y.; Tian, Y. Masked face recognition with generative data augmentation and domain constrained ranking. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 2246–2254. [Google Scholar]
- Ge, S.; Li, C.; Zhao, S.; Zeng, D. Occluded face recognition in the wild by identity-diversity inpainting. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 3387–3397. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Computer Vision—ECCV 2016. ECCV 2016; Lecture Notes in Computer Science; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016; Volume 9905. [Google Scholar]
- Anithadevi, N.; Abinisha, J.; Akalya, V.; Haripriya, V. An Improved SSD Object Detection Algorithm For Safe Social Distancing and Face Mask Detection In Public Areas Through Intelligent Video Analytics. In Proceedings of the 2021 12th International Conference on Computing Communication and Networking Technologies (ICCCNT), Kharagpur, India, 6–8 July 2021; pp. 1–7. [Google Scholar]
- Wang, Z.; Wang, P.; Louis, P.C.; Wheless, L.E.; Huo, Y. Wearmask: Fast in-browser face mask detection with serverless edge computing for covid-19. arXiv 2021, arXiv:2101.00784. [Google Scholar] [CrossRef]
- Loey, M.; Manogaran, G.; Taha, M.H.N.; Khalifa, N.E.M. Fighting against COVID-19: A novel deep learning model based on YOLO-v2 with ResNet-50 for medical face mask detection. Sustain. Cities Soc. 2021, 65, 102600. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Pi, Y.; Nath, N.D.; Sampathkumar, S.; Behzadan, A.H. Deep Learning for Visual Analytics of the Spread of COVID-19 Infection in Crowded Urban Environments. Nat. Hazards Rev. 2021, 22, 04021019. [Google Scholar] [CrossRef]
- Ahmed, I.; Ahmad, M.; Rodrigues, J.J.; Jeon, G.; Din, S. A deep learning-based social distance monitoring framework for COVID-19. Sustain. Cities Soc. 2021, 65, 102571. [Google Scholar] [CrossRef] [PubMed]
- Shalini, G.; Margret, M.K.; Niraimathi, M.S.; Subashree, S. Social Distancing Analyzer Using Computer Vision and Deep Learning. J. Phys. Conf. Ser. 2021, 1916, 012039. [Google Scholar] [CrossRef]
- Widiatmoko, F.; Berchmans, H.J.; Setiawan, W. Computer Vision and Deep Learning Approach for Social Distancing Detection During COVID-19 Pandemic. Ph.D. Thesis, Swiss German University, Kota Tangerang, Indonesia, 2021. [Google Scholar]
- Wu, P.; Li, H.; Zeng, N.; Li, F. FMD-Yolo: An efficient face mask detection method for COVID-19 prevention and control in public. Image Vis. Comput. 2022, 117, 104341. [Google Scholar] [CrossRef]
- Basu, A.; Ali, M.F. COVID-19 Face Mask Recognition with Advanced Face Cut Algorithm for Human Safety Measures. In Proceedings of the 2021 12th International Conference on Computing Communication and Networking Technologies (ICCCNT), Kharagpur, India, 6–8 July 2021; pp. 1–5. [Google Scholar]
- Nagaraj, P.; Phebe, G.S.; Singh, A. A Novel Technique to Classify Face Mask for Human Safety. In Proceedings of the 2021 Sixth International Conference on Image Information Processing (ICIIP), Shimla, India, 26–28 November 2021; Volume 6, pp. 235–239. [Google Scholar]
- Anthoniraj, S. Face Mask Detection with Computer Vision & Deep Learning. In Proceedings of the 2021 International Conference on Advancements in Electrical, Electronics, Communication, Computing and Automation (ICAECA), Coimbatore, India, 8–9 October 2021; pp. 1–4. [Google Scholar]
- Subhash, S.; Sneha, K.; Ullas, A.; Raj, D. A COVID-19 Safety Web Application to Monitor Social Distancing and Mask Detection. In Proceedings of the 2021 IEEE 9th Region 10 Humanitarian Technology Conference (R10-HTC), Bangalore, India, 30 September–2 October 2021; pp. 1–6. [Google Scholar]
- Setyawan, N.; Putri, T.S.N.P.; Al Fikih, M.; Kasan, N. Comparative Study of CNN and YOLOv3 in Public Health Face Mask Detection. In Proceedings of the 2021 8th International Conference on Electrical Engineering, Computer Science and Informatics (EECSI), Semarang, Indonesia, 20–21 October 2021; pp. 354–358. [Google Scholar]
- Liu, S.; Agaian, S.S. COVID-19 face mask detection in a crowd using multi-model based on YOLOv3 and hand-crafted features. In Proceedings of the Multimodal Image Exploitation and Learning 2021, Online, 12–16 April 2021; Volume 11734, p. 117340M. [Google Scholar]
- Gawde, B.B. A Fast, Automatic Risk Detector for COVID-19. In Proceedings of the 2020 IEEE Pune Section International Conference (PuneCon), Pune, India, 16–18 December 2020; pp. 146–151. [Google Scholar]
- He, J. Mask detection device based on YOLOv3 framework. In Proceedings of the 2020 5th International Conference on Mechanical, Control and Computer Engineering (ICMCCE), Harbin, China, 25–27 December 2020; pp. 268–271. [Google Scholar]
- Aswal, V.; Tupe, O.; Shaikh, S.; Charniya, N.N. Single camera masked face identification. In Proceedings of the 2020 19th IEEE International Conference on Machine Learning and Applications (ICMLA), Miami, FL, USA, 14–17 December 2020; pp. 57–60. [Google Scholar]
- Ren, X.; Liu, X. Mask wearing detection based on YOLOv3. J. Phys. Conf. Ser. 2020, 1678, 012089. [Google Scholar] [CrossRef]
- Darawsheh, A.; Siam, A.A.; Shaar, L.A.; Odeh, A. High-performance Detection and Predication Safety System using HUAWEI Atlas 200 DK AI Developer Kit. In Proceedings of the 2022 2nd International Conference on Computing and Information Technology (ICCIT), Tabuk, Saudi Arabia, 25–27 January 2022; pp. 213–216. [Google Scholar]
- Kumar, K.S.; Kumar, G.A.; Rajendra, P.P.; Gatti, R.; Kumar, S.S.; Nataraja, N. Face Mask Detection and Temperature Scanning for the Covid-19 Surveillance System. In Proceedings of the 2021 International Conference on Recent Trends on Electronics, Information, Communication & Technology (RTEICT), Bangalore, India, 27–28 August 2021; pp. 985–989. [Google Scholar]
- Rakhsith, L.; Karthik, B.; Nithish, D.A.; Kumar, V.K.; Anusha, K. Face Mask and Social Distancing Detection for Surveillance Systems. In Proceedings of the 2021 5th International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 3–5 June 2021; pp. 1056–1065. [Google Scholar]
- Prabha, P.A.; Karthikeyan, G.; Kuttralanathan, K.; Venkatesun, M.M. Intelligent Mask Detection Using Deep Learning Techniques. J. Phys. Conf. Ser. 2021, 1916, 012072. [Google Scholar] [CrossRef]
- Zhang, K.; Jia, X.; Wang, Y.; Zhang, H.; Cui, J. Detection System of Wearing Face Masks Normatively Based on Deep Learning. In Proceedings of the 2021 International Conference on Control Science and Electric Power Systems (CSEPS), Shanghai, China, 28–30 May 2021; pp. 35–39. [Google Scholar]
- Amin, P.N.; Moghe, S.S.; Prabhakar, S.N.; Nehete, C.M. Deep Learning Based Face Mask Detection and Crowd Counting. In Proceedings of the 2021 6th International Conference for Convergence in Technology (I2CT), Maharashtra, India, 2–4 April 2021; pp. 1–5. [Google Scholar]
- Xiang, Y.; Yang, H.; Hu, R.; Hsu, C.Y. Comparison of the Deep Learning Methods Applied on Human Eye Detection. In Proceedings of the 2021 IEEE International Conference on Power Electronics, Computer Applications (ICPECA), Shenyang, China, 22–24 January 2021; pp. 314–318. [Google Scholar]
- Avanzato, R.; Beritelli, F.; Russo, M.; Russo, S.; Vaccaro, M. YOLOv3-Based Mask and Face Recognition Algorithm for Individual Protection Applications. Available online: https://ceur-ws.org/Vol-2768/p7.pdf (accessed on 7 February 2023).
- Bhuiyan, M.R.; Khushbu, S.A.; Islam, M.S. A deep learning based assistive system to classify COVID-19 face mask for human safety with YOLOv3. In Proceedings of the 2020 11th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kharagpur, India, 1–3 July 2020; pp. 1–5. [Google Scholar]
- Li, C.; Cao, J.; Zhang, X. Robust deep learning method to detect face masks. In Proceedings of the 2nd International Conference on Artificial Intelligence and Advanced Manufacture, Manchester, UK, 15–17 October 2020; pp. 74–77. [Google Scholar]
- Vinh, T.Q.; Anh, N.T.N. Real-Time Face Mask Detector Using YOLOv3 Algorithm and Haar Cascade Classifier. In Proceedings of the 2020 International Conference on Advanced Computing and Applications (ACOMP), Quy Nhon, Vietnam, 25–27 November 2020; pp. 146–149. [Google Scholar]
- Głowacka, N.; Rumiński, J. Face with Mask Detection in Thermal Images Using Deep Neural Networks. Sensors 2021, 21, 6387. [Google Scholar] [CrossRef]
- Mahurkar, R.R.; Gadge, N.G. Real-time COVID-19 Face Mask Detection with YOLOv4. In Proceedings of the 2021 Second International Conference on Electronics and Sustainable Communication Systems (ICESC), Coimbatore, India, 4–6 August 2021; pp. 1250–1255. [Google Scholar]
- Protik, A.A.; Rafi, A.H.; Siddique, S. Real-time Personal Protective Equipment (PPE) Detection Using YOLOv4 and TensorFlow. In Proceedings of the 2021 IEEE Region 10 Symposium (TENSYMP), Jeju, Republic of Korea, 23–25 August 2021; pp. 1–6. [Google Scholar]
- Prasad, P.; Chawla, A.; Mohana. Facemask Detection to Prevent COVID-19 Using YOLOv4 Deep Learning Model. In Proceedings of the 2022 Second International Conference on Artificial Intelligence and Smart Energy (ICAIS), Coimbatore, India, 23–25 February 2022; pp. 382–388. [Google Scholar] [CrossRef]
- Qin, Z.; Guo, Z.; Lin, Y. An Implementation of Face Mask Detection System Based on YOLOv4 Architecture. In Proceedings of the 2022 14th International Conference on Computer Research and Development (ICCRD), Shenzhen, China, 7–9 January 2022; pp. 207–213. [Google Scholar] [CrossRef]
- Gupta, A.; Thapar, D.; Deb, S. Smart Camera for Enforcing Social Distancing. In Proceedings of the 2021 IEEE International Symposium on Smart Electronic Systems (iSES) (Formerly iNiS), Jaipur, India, 18–22 December 2021; pp. 349–354. [Google Scholar]
- Ubaid, M.T.; Khan, M.Z.; Rumaan, M.; Arshed, M.A.; Khan, M.U.G.; Darboe, A. COVID-19 SOP’s Violations Detection in Terms of Face Mask Using Deep Learning. In Proceedings of the 2021 International Conference on Innovative Computing (ICIC), Lahore, Pakistan, 9–10 November 20212021; pp. 1–8. [Google Scholar]
- Vella, S.; Scerri, D. Vision-based Health Protocol Observance System for Small Rooms. In Proceedings of the 2021 IEEE 11th International Conference on Consumer Electronics (ICCE-Berlin), Berlin, Germany, 15–18 November 2021; pp. 1–6. [Google Scholar]
- Mokeddem, M.L.; Belahcene, M.; Bourennane, S. Yolov4FaceMask: COVID-19 Mask Detector. In Proceedings of the 2021 1st International Conference On Cyber Management And Engineering (CyMaEn), Virtual, 26–28 May 2021; pp. 1–6. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Cao, Z.; Shao, M.; Xu, L.; Mu, S.; Qu, H. MaskHunter: Real-time object detection of face masks during the COVID-19 pandemic. IET Image Process. 2020, 14, 4359–4367. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Rahim, A.; Maqbool, A.; Rana, T. Monitoring social distancing under various low light conditions with deep learning and a single motionless time of flight camera. PLoS ONE 2021, 16, e0247440. [Google Scholar] [CrossRef] [PubMed]
- Rodriguez, C.R.; Luque, D.; La Rosa, C.; Esenarro, D.; Pandey, B. Deep learning applied to capacity control in commercial establishments in times of COVID-19. In Proceedings of the 2020 12th International Conference on Computational Intelligence and Communication Networks (CICN), Bhimtal, India, 25–26 September 2020; pp. 423–428. [Google Scholar]
- Pandya, S.; Sur, A.; Solke, N. COVIDSAVIOR: A Novel Sensor-Fusion and Deep Learning Based Framework for Virus Outbreaks. Front. Public Health 2021, 9, 797808. [Google Scholar] [CrossRef] [PubMed]
- Gola, A.; Panesar, S.; Sharma, A.; Ananthakrishnan, G.; Singal, G.; Mukhopadhyay, D. MaskNet: Detecting Different Kinds of Face Mask for Indian Ethnicity. In Proceedings of the International Advanced Computing Conference; Springer: Berlin/Heidelberg, Germany, 2020; pp. 492–503. [Google Scholar]
- Kumar, A.; Kalia, A.; Verma, K.; Sharma, A.; Kaushal, M. Scaling up face masks detection with YOLO on a novel dataset. Optik 2021, 239, 166744. [Google Scholar] [CrossRef]
- Jocher, G.; Stoken, A.; Borovec, J.; Changyu, L.; Hogan, A.; Diaconu, L.; Ingham, F.; Poznanski, J.; Fang, J.; Yu, L.; et al. ultralytics/yolov5: v3. 1-Bug Fixes and Performance Improvements. Version v3. 2020; Volume 1. Available online: https://zenodo.org/record/4154370#.Y-8cJR9Bw2w (accessed on 7 February 2023).
- Yap, M.H.; Hachiuma, R.; Alavi, A.; Brüngel, R.; Cassidy, B.; Goyal, M.; Zhu, H.; Rückert, J.; Olshansky, M.; Huang, X.; et al. Deep learning in diabetic foot ulcers detection: A comprehensive evaluation. Comput. Biol. Med. 2021, 135, 104596. [Google Scholar] [CrossRef] [PubMed]
- Walia, I.S.; Kumar, D.; Sharma, K.; Hemanth, J.D.; Popescu, D.E. An Integrated Approach for Monitoring Social Distancing and Face Mask Detection Using Stacked ResNet-50 and YOLOv5. Electronics 2021, 10, 2996. [Google Scholar] [CrossRef]
- Ottakath, N.; Elharrouss, O.; Almaadeed, N.; Al-Maadeed, S.; Mohamed, A.; Khattab, T.; Abualsaud, K. ViDMASK dataset for face mask detection with social distance measurement. Displays 2022, 73, 102235. [Google Scholar] [CrossRef]
- Jiang, M.; Fan, X.; Yan, H. Retinamask: A face mask detector. arXiv 2020, arXiv:2005.03950. [Google Scholar]
- Deng, J.; Guo, J.; Ververas, E.; Kotsia, I.; Zafeiriou, S. Retinaface: Single-shot multi-level face localisation in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 5203–5212. [Google Scholar]
- Zhu, R.; Yin, K.; Xiong, H.; Tang, H.; Yin, G. Masked Face Detection Algorithm in the Dense Crowd Based on Federated Learning. Wirel. Commun. Mob. Comput. 2021, 2021, 8586016. [Google Scholar] [CrossRef]
- Nguyen Quoc, H.; Truong Hoang, V. Real-time human ear detection based on the joint of yolo and retinaface. Complexity 2021, 2021, 7918165. [Google Scholar] [CrossRef]
- Addagarla, S.K.; Chakravarthi, G.K.; Anitha, P. Real time multi-scale facial mask detection and classification using deep transfer learning techniques. Int. J. Adv. Trends Comput. Sci. Eng. 2020, 9, 4402–4408. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Gathani, J.; Shah, K. Detecting masked faces using region-based convolutional neural network. In Proceedings of the 2020 IEEE 15th International Conference on Industrial and Information Systems (ICIIS), Rupnagar, India, 26–28 November 2020; pp. 156–161. [Google Scholar]
- Meivel, S.; Devi, K.I.; Maheswari, S.U.; Menaka, J.V. Real time data analysis of face mask detection and social distance measurement using Matlab. Mater. Today Proc. 2021. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Han, F.; Chun, Y.; Chen, W. A novel detection framework about conditions of wearing face mask for helping control the spread of covid-19. IEEE Access 2021, 9, 42975–42984. [Google Scholar] [CrossRef] [PubMed]
- Sahraoui, Y.; Kerrache, C.A.; Korichi, A.; Nour, B.; Adnane, A.; Hussain, R. DeepDist: A Deep-Learning-Based IoV Framework for Real-Time Objects and Distance Violation Detection. IEEE Internet Things Mag. 2020, 3, 30–34. [Google Scholar] [CrossRef]
- Gupta, P.; Sharma, V.; Varma, S. A novel algorithm for mask detection and recognizing actions of human. Expert Syst. Appl. 2022, 198, 116823. [Google Scholar] [CrossRef] [PubMed]
- Joshi, A.S.; Joshi, S.S.; Kanahasabai, G.; Kapil, R.; Gupta, S. Deep learning framework to detect face masks from video footage. In Proceedings of the 2020 12th International Conference on Computational Intelligence and Communication Networks (CICN), Bhimtal, India, 25–26 September 2020; pp. 435–440. [Google Scholar]
- Loey, M.; Manogaran, G.; Taha, M.H.N.; Khalifa, N.E.M. A hybrid deep transfer learning model with machine learning methods for face mask detection in the era of the COVID-19 pandemic. Measurement 2021, 167, 108288. [Google Scholar] [CrossRef] [PubMed]
- Sethi, S.; Kathuria, M.; Kaushik, T. Face mask detection using deep learning: An approach to reduce risk of Coronavirus spread. J. Biomed. Inform. 2021, 120, 103848. [Google Scholar] [CrossRef]
- Snyder, S.E.; Husari, G. Thor: A Deep Learning Approach for Face Mask Detection to Prevent the COVID-19 Pandemic. In Proceedings of the SoutheastCon 2021, Atlanta, GA, USA, 10–13 March 2021; pp. 1–8. [Google Scholar]
- Yang, C.W.; Phung, T.H.; Shuai, H.H.; Cheng, W.H. Mask or Non-Mask? Robust Face Mask Detector via Triplet-Consistency Representation Learning. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2022, 18, 1–20. [Google Scholar] [CrossRef]
- Kumar, T.A.; Rajmohan, R.; Pavithra, M.; Ajagbe, S.A.; Hodhod, R.; Gaber, T. Automatic face mask detection system in public transportation in smart cities using IoT and deep learning. Electronics 2022, 11, 904. [Google Scholar] [CrossRef]
- Bansal, A.; Dhayal, S.; Mishra, J.; Grover, J. COVID-19 Outbreak: Detecting face mask types in real time. J. Inf. Optim. Sci. 2022, 43, 357–370. [Google Scholar] [CrossRef]
- Gupta, S.; Sreenivasu, S.; Chouhan, K.; Shrivastava, A.; Sahu, B.; Potdar, R.M. Novel face mask detection technique using machine learning to control COVID’19 pandemic. Mater. Today Proc. 2021. [Google Scholar] [CrossRef]
- Mundial, I.Q.; Hassan, M.S.U.; Tiwana, M.I.; Qureshi, W.S.; Alanazi, E. Towards facial recognition problem in COVID-19 pandemic. In Proceedings of the 2020 4rd International Conference on Electrical, Telecommunication and Computer Engineering (ELTICOM), Medan, Indonesia, 3–4 September 2020; pp. 210–214. [Google Scholar]
- Lin, H.; Tse, R.; Tang, S.K.; Chen, Y.; Ke, W.; Pau, G. Near-realtime face mask wearing recognition based on deep learning. In Proceedings of the 2021 IEEE 18th Annual Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 9–12 January 2021; pp. 1–7. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7291–7299. [Google Scholar]
- Asif, S.; Wenhui, Y.; Tao, Y.; Jinhai, S.; Amjad, K. Real Time Face Mask Detection System using Transfer Learning with Machine Learning Method in the Era of Covid-19 Pandemic. In Proceedings of the 2021 4th International Conference on Artificial Intelligence and Big Data (ICAIBD), Chengdu, China, 28–31 May 2021; pp. 70–75. [Google Scholar]
- Habib, S.; Alsanea, M.; Aloraini, M.; Al-Rawashdeh, H.S.; Islam, M.; Khan, S. An Efficient and Effective Deep Learning-Based Model for Real-Time Face Mask Detection. Sensors 2022, 22, 2602. [Google Scholar] [CrossRef] [PubMed]
- Sen, S.; Sawant, K. Face mask detection for covid_19 pandemic using pytorch in deep learning. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1070, 012061. [Google Scholar] [CrossRef]
- Sanjaya, S.A.; Rakhmawan, S.A. Face Mask Detection Using MobileNetV2 in The Era of COVID-19 Pandemic. In Proceedings of the 2020 International Conference on Data Analytics for Business and Industry: Way Towards a Sustainable Economy (ICDABI), Sakheer, Bahrain, 26–27 October 2020; pp. 1–5. [Google Scholar]
- Boulila, W.; Alzahem, A.; Almoudi, A.; Afifi, M.; Alturki, I.; Driss, M. A Deep Learning-based Approach for Real-time Facemask Detection. arXiv 2021, arXiv:2110.08732. [Google Scholar]
- Lad, A.M.; Mishra, A.; Rajagopalan, A. Comparative Analysis of Convolutional Neural Network Architectures for Real Time COVID-19 Facial Mask Detection. J. Phys. Conf. Ser. 2021, 1969, 012037. [Google Scholar] [CrossRef]
- Nayak, R.; Manohar, N. Computer-Vision based Face Mask Detection using CNN. In Proceedings of the 2021 6th International Conference on Communication and Electronics Systems (ICCES), Coimbatre, India, 8–10 July 2021; pp. 1780–1786. [Google Scholar]
- Taneja, S.; Nayyar, A.; Nagrath, P. Face Mask Detection Using Deep Learning During COVID-19. In Second International Conference on Computing, Communications, and Cyber-Security; Springer: Berlin/Heidelberg, Germany, 2021; pp. 39–51. [Google Scholar]
- Kayali, D.; Dimililer, K.; Sekeroglu, B. Face Mask Detection and Classification for COVID-19 using Deep Learning. In Proceedings of the 2021 International Conference on INnovations in Intelligent SysTems and Applications (INISTA), Kocaeli, Turkey, 25–27 August 2021; pp. 1–6. [Google Scholar]
- Singh, R.; Singh, I.; Kapoor, A.; Chawla, A.; Gupta, A. Co-Yudh: A Convolutional Neural Network (CNN)-Inspired Platform for COVID Handling and Awareness. Sn Comput. Sci. 2022, 3, 241. [Google Scholar] [CrossRef] [PubMed]
- Aadithya, V.; Balakumar, S.; Bavishprasath, M.; Raghul, M.; Malathi, P. Comparative Study Between MobilNet Face-Mask Detector and YOLOv3 Face-Mask Detector. In Sustainable Communication Networks and Application; Springer: Berlin/Heidelberg, Germany, 2022; pp. 801–809. [Google Scholar]
- Talahua, J.S.; Buele, J.; Calvopiña, P.; Varela-Aldás, J. Facial recognition system for people with and without face mask in times of the covid-19 pandemic. Sustainability 2021, 13, 6900. [Google Scholar] [CrossRef]
- Kumar, A. A cascaded deep-learning-based model for face mask detection. Data Technol. Appl. in press. 2022. [Google Scholar] [CrossRef]
- Al-Hamid, A.A.; Kim, T.; Park, T.; Kim, H. Optimization of Object Detection CNN With Weight Quantization and Scale Factor Consolidation. In Proceedings of the 2021 IEEE International Conference on Consumer Electronics-Asia (ICCE-Asia), Gangwon, Republic of Korea, 1–3 November 2021; pp. 1–5. [Google Scholar]
- Bharathi, S.; Hari, K.; Senthilarasi, M.; Sudhakar, R. An Automatic Real-Time Face Mask Detection using CNN. In Proceedings of the 2021 Smart Technologies, Communication and Robotics (STCR), Sathyamangalam, India, 9–10 October 2021; pp. 1–5. [Google Scholar]
- Jaisharma, K.; Nithin, A. A Deep Learning Based Approach for Detection of Face Mask Wearing using YOLO V3-tiny Over CNN with Improved Accuracy. In Proceedings of the 2022 International Conference on Business Analytics for Technology and Security (ICBATS), Dubai, United Arab Emirates, 16–17 February 2022; pp. 1–5. [Google Scholar]
- Liu, G.; Zhang, Q. Mask Wearing Detection Algorithm Based on Improved Tiny YOLOv3. Int. J. Pattern Recognit. Artif. Intell. 2021, 35, 2155007. [Google Scholar] [CrossRef]
- Jiang, X.; Xiang, F.; Lv, M.; Wang, W.; Zhang, Z.; Yu, Y. YOLOv3-Slim for Face Mask Recognition. J. Phys. Conf. Ser. 2021, 1771, 1–9. [Google Scholar] [CrossRef]
- Sathyamurthy, K.V.; Rajmohan, A.S.; Tejaswar, A.R.; Kavitha, V.; Manimala, G. Realtime Face Mask Detection Using TINY-YOLO V4. In Proceedings of the 2021 4th International Conference on Computing and Communications Technologies (ICCCT), Chennai, India, 16–17 December 2021; pp. 169–174. [Google Scholar]
- Zhao, Z.; Hao, K.; Ma, X.; Liu, X.; Zheng, T.; Xu, J.; Cui, S. SAI-YOLO: A Lightweight Network for Real-Time Detection of Driver Mask-Wearing Specification on Resource-Constrained Devices. Comput. Intell. Neurosci. 2021, 2021, 4529107. [Google Scholar] [CrossRef]
- Han, Z.; Huang, H.; Fan, Q.; Li, Y.; Li, Y.; Chen, X. SMD-YOLO: An efficient and lightweight detection method for mask wearing status during the COVID-19 pandemic. Comput. Methods Programs Biomed. 2022, 221, 106888. [Google Scholar] [CrossRef] [PubMed]
- Anand, R.; Das, J.; Sarkar, P. Comparative Analysis of YOLOv4 and YOLOv4-tiny Techniques towards Face Mask Detection. In Proceedings of the 2021 International Conference on Computational Performance Evaluation (ComPE), Shillong, India, 1–3 December 2021; pp. 803–809. [Google Scholar]
- Kumar, A.; Kalia, A.; Kalia, A. ETL-YOLO v4: A face mask detection algorithm in era of COVID-19 pandemic. Optik 2022, 259, 169051. [Google Scholar] [CrossRef]
- Hraybi, S.; Rizk, M. Examining YOLO for Real-Time Face-Mask Detection. In Proceedings of the 4th Smart Cities Symposium (SCS 2021), Online, 21–23 November 2021. [Google Scholar]
- Zhu, J.; Wang, J.; Wang, B. Lightweight mask detection algorithm based on improved YOLOv4-tiny. Chin. J. Liq. Cryst. Disp. 2021, 36, 1525–1534. [Google Scholar] [CrossRef]
- Farman, H.; Khan, T.; Khan, Z.; Habib, S.; Islam, M.; Ammar, A. Real-Time Face Mask Detection to Ensure COVID-19 Precautionary Measures in the Developing Countries. Appl. Sci. 2022, 12, 3879. [Google Scholar] [CrossRef]
- Aydemir, E.; Yalcinkaya, M.A.; Barua, P.D.; Baygin, M.; Faust, O.; Dogan, S.; Chakraborty, S.; Tuncer, T.; Acharya, U.R. Hybrid deep feature generation for appropriate face mask use detection. Int. J. Environ. Res. Public Health 2022, 19, 1939. [Google Scholar] [CrossRef] [PubMed]
- Chowdary, G.J.; Punn, N.S.; Sonbhadra, S.K.; Agarwal, S. Face mask detection using transfer learning of inceptionv3. In Proceedings of the International Conference on Big Data Analytics, Sonepat, India, 15–18 December 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 81–90. [Google Scholar]
- Inamdar, M.; Mehendale, N. Real-Time Face Mask Identification Using Facemasknet Deep Learning Network. 2020. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3663305 (accessed on 7 February 2023).
- Rahman, M.M.; Manik, M.M.H.; Islam, M.M.; Mahmud, S.; Kim, J.H. An automated system to limit COVID-19 using facial mask detection in smart city network. In Proceedings of the 2020 IEEE International IOT, Electronics and Mechatronics Conference (IEMTRONICS), Vancouver, BC, Canada, 9–12 September 2020; pp. 1–5. [Google Scholar]
- Mohan, P.; Paul, A.J.; Chirania, A. A tiny CNN architecture for medical face mask detection for resource-constrained endpoints. In Innovations in Electrical and Electronic Engineering; Springer: Berlin/Heidelberg, Germany, 2021; pp. 657–670. [Google Scholar]
- Yu, J.; Zhang, W. Face mask wearing detection algorithm based on improved YOLO-v4. Sensors 2021, 21, 3263. [Google Scholar] [CrossRef] [PubMed]
- Vrigkas, M.; Kourfalidou, E.A.; Plissiti, M.E.; Nikou, C. FaceMask: A New Image Dataset for the Automated Identification of People Wearing Masks in the Wild. Sensors 2022, 22, 896. [Google Scholar] [CrossRef]
- Kumar, B.A.; Bansal, M. Face Mask Detection on Photo and Real-Time Video Images Using Caffe-MobileNetV2 Transfer Learning. Appl. Sci. 2023, 13, 935. [Google Scholar] [CrossRef]
- Al-Kababji, A.; Bensaali, F.; Dakua, S.P.; Himeur, Y. Automated liver tissues delineation techniques: A systematic survey on machine learning current trends and future orientations. Eng. Appl. Artif. Intell. 2023, 117, 105532. [Google Scholar] [CrossRef]
- Himeur, Y.; Al-Maadeed, S.; Kheddar, H.; Al-Maadeed, N.; Abualsaud, K.; Mohamed, A.; Khattab, T. Video surveillance using deep transfer learning and deep domain adaptation: Towards better generalization. Eng. Appl. Artif. Intell. 2023, 119, 105698. [Google Scholar] [CrossRef]
- Su, X.; Gao, M.; Ren, J.; Li, Y.; Dong, M.; Liu, X. Face mask detection and classification via deep transfer learning. Multimed. Tools Appl. 2022, 81, 4475–4494. [Google Scholar] [CrossRef] [PubMed]
- Sevilla, R.V.; Alon, A.S.; Melegrito, M.P.; Reyes, R.C.; Bastes, B.M.; Cimagala, R.P. Mask-Vision: A Machine Vision-Based Inference System of Face Mask Detection for Monitoring Health Protocol Safety. In Proceedings of the 2021 IEEE International Conference on Artificial Intelligence in Engineering and Technology (IICAIET), Kinabalu, Malaysia, 13–15 September 2021; pp. 1–5. [Google Scholar]
- Jian, W.; Lang, L. Face mask detection based on Transfer learning and PP-YOLO. In Proceedings of the 2021 IEEE 2nd International Conference on Big Data, Artificial Intelligence and Internet of Things Engineering (ICBAIE), Nanchang, China, 26–28 March 2021; pp. 106–109. [Google Scholar]
- Watcharabutsarakham, S.; Marukatat, S.; Suntiwichaya, S.; Junlouchai, C. Partial Facial Identification using Transfer Learning Technique. In Proceedings of the 2021 16th International Joint Symposium on Artificial Intelligence and Natural Language Processing (iSAI-NLP), Phra Nakhon Si Ayutthaya, Thailand, 22–23 December 2021; pp. 1–4. [Google Scholar]
- Mbunge, E.; Simelane, S.; Fashoto, S.G.; Akinnuwesi, B.; Metfula, A.S. Application of deep learning and machine learning models to detect COVID-19 face masks-A review. Sustain. Oper. Comput. 2021, 2, 235–245. [Google Scholar] [CrossRef]
- Teboulbi, S.; Messaoud, S.; Hajjaji, M.A.; Mtibaa, A. Real-Time Implementation of AI-Based Face Mask Detection and Social Distancing Measuring System for COVID-19 Prevention. Sci. Program. 2021, 2021, 8340779. [Google Scholar] [CrossRef]
- Fan, X.; Jiang, M.; Yan, H. A deep learning based light-weight face mask detector with residual context attention and Gaussian heatmap to fight against COVID-19. IEEE Access 2021, 9, 96964–96974. [Google Scholar] [CrossRef]
- Song, Z.; Nguyen, K.; Nguyen, T.; Cho, C.; Gao, J. Spartan Face Mask Detection and Facial Recognition System. Healthcare 2022, 10, 87. [Google Scholar] [CrossRef]
- Razavi, M.; Alikhani, H.; Janfaza, V.; Sadeghi, B.; Alikhani, E. An automatic system to monitor the physical distance and face mask wearing of construction workers in COVID-19 pandemic. SN Comput. Sci. 2022, 3, 27. [Google Scholar] [CrossRef] [PubMed]
- Moungsouy, W.; Tawanbunjerd, T.; Liamsomboon, N.; Kusakunniran, W. Face recognition under mask-wearing based on residual inception networks. Appl. Comput. Inform. 2022. [Google Scholar] [CrossRef]
- M-CASIA: CASIA-WebFace+Masks. Available online: https://paperswithcode.com/dataset/casia-webface-masks (accessed on 22 January 2022).
- Sabir, M.F.S.; Mehmood, I.; Alsaggaf, W.A.; Khairullah, E.F.; Alhuraiji, S.; Alghamdi, A.S.; El-Latif, A. An automated real-time face mask detection system using transfer learning with faster-rcnn in the era of the COVID-19 pandemic. Comput. Mater. Contin. 2022, 71, 4151–4166. [Google Scholar]
- Palani, S.S.; Dev, M.; Mogili, G.; Relan, D.; Dey, R. Face Mask Detector using Deep Transfer Learning and Fine-Tuning. In Proceedings of the 2021 8th International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 17–19 March 2021; pp. 695–698. [Google Scholar]
- Kocacinar, B.; Tas, B.; Akbulut, F.P.; Catal, C.; Mishra, D. A Real-Time CNN-based Lightweight Mobile Masked Face Recognition System. IEEE Access 2022, 10, 63496–63507. [Google Scholar] [CrossRef]
- Mandal, B.; Okeukwu, A.; Theis, Y. Masked face recognition using resnet-50. arXiv 2021, arXiv:2104.08997. [Google Scholar]
- Mercaldo, F.; Santone, A. Transfer learning for mobile real-time face mask detection and localization. J. Am. Med. Inform. Assoc. 2021, 28, 1548–1554. [Google Scholar] [CrossRef] [PubMed]
- Oumina, A.; El Makhfi, N.; Hamdi, M. Control the covid-19 pandemic: Face mask detection using transfer learning. In Proceedings of the 2020 IEEE 2nd International Conference on Electronics, Control, Optimization and Computer Science (ICECOCS), Kenitra, Morocco, 2–3 December 2020; pp. 1–5. [Google Scholar]
- Prusty, M.R.; Tripathi, V.; Dubey, A. A novel data augmentation approach for mask detection using deep transfer learning. Intell.-Based Med. 2021, 5, 100037. [Google Scholar] [CrossRef] [PubMed]
- Zhang, E. A Real-Time Deep Transfer Learning Model for Facial Mask Detection. In Proceedings of the 2021 Integrated Communications Navigation and Surveillance Conference (ICNS), Dulles, VA, USA, 19–23 April 2021; pp. 1–7. [Google Scholar]
- Alganci, U.; Soydas, M.; Sertel, E. Comparative research on deep learning approaches for airplane detection from very high-resolution satellite images. Remote Sens. 2020, 12, 458. [Google Scholar] [CrossRef] [Green Version]
- Ejaz, M.S.; Islam, M.R.; Sifatullah, M.; Sarker, A. Implementation of principal component analysis on masked and non-masked face recognition. In Proceedings of the 2019 1st International Conference on Advances in Science, Engineering and Robotics Technology (ICASERT), Dhaka, Bangladesh, 3–5 May 2019; pp. 1–5. [Google Scholar]
- Nieto-Rodriguez, A.; Mucientes, M.; Brea, V.M. System for medical mask detection in the operating room through facial attributes. In Proceedings of the Iberian Conference on Pattern Recognition and Image Analysis; Springer: Berlin/Heidelberg, Germany, 2015; pp. 138–145. [Google Scholar]
- Fasfous, N.; Vemparala, M.R.; Frickenstein, A.; Frickenstein, L.; Badawy, M.; Stechele, W. Binarycop: Binary neural network-based covid-19 face-mask wear and positioning predictor on edge devices. In Proceedings of the 2021 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), Portland, OR, USA, 17–21 June 2021; pp. 108–115. [Google Scholar]
- Petrović, N.; Kocić, Đ. Iot-based system for COVID-19 indoor safety monitoring. In Proceedings of the IcETRAN, Belgrade, Serbia, 8 October 2020. [Google Scholar]
- Quiñonez, F.; Torres, R. Evaluation of AIoT performance in Cloud and Edge computational models for mask detection. Ingenius 2022, 27, 1–19. [Google Scholar]
- Kong, X.; Wang, K.; Wang, S.; Wang, X.; Jiang, X.; Guo, Y.; Shen, G.; Chen, X.; Ni, Q. Real-time mask identification for COVID-19: An edge computing-based deep learning framework. IEEE Internet Things J. 2021, 8, 15929–15938. [Google Scholar] [CrossRef]
- Magherini, R.; Mussi, E.; Servi, M.; Volpe, Y. Emotion recognition in the times of COVID19: Coping with face masks. Intell. Syst. Appl. 2022, 15, 200094. [Google Scholar] [CrossRef]
- Fang, M.; Damer, N.; Kirchbuchner, F.; Kuijper, A. Real masks and spoof faces: On the masked face presentation attack detection. Pattern Recognit. 2022, 123, 108398. [Google Scholar] [CrossRef]
- Zolfi, A.; Avidan, S.; Elovici, Y.; Shabtai, A. Adversarial Mask: Real-World Adversarial Attack Against Face Recognition Models. arXiv 2021, arXiv:2111.10759. [Google Scholar]
- Tjoa, E.; Guan, C. A survey on explainable artificial intelligence (xai): Toward medical xai. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4793–4813. [Google Scholar] [CrossRef]
- Minh, D.; Wang, H.X.; Li, Y.F.; Nguyen, T.N. Explainable artificial intelligence: A comprehensive review. Artif. Intell. Rev. 2022, 55, 3503–3568. [Google Scholar] [CrossRef]
- Hossain, M.S.; Muhammad, G.; Guizani, N. Explainable AI and mass surveillance system-based healthcare framework to combat COVID-I9 like pandemics. IEEE Netw. 2020, 34, 126–132. [Google Scholar] [CrossRef]
- Yin, B.; Tran, L.; Li, H.; Shen, X.; Liu, X. Towards interpretable face recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9348–9357. [Google Scholar]
- Zhang, J.; Yu, H. Improving the Facial Expression Recognition and Its Interpretability via Generating Expression Pattern-map. Pattern Recognit. 2022, 129, 108737. [Google Scholar] [CrossRef]
- Williford, J.R.; May, B.B.; Byrne, J. Explainable face recognition. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 248–263. [Google Scholar]
- Mery, D.; Morris, B. On Black-Box Explanation for Face Verification. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–8 January 2022; pp. 3418–3427. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Izhar, F.; Ali, S.; Ponum, M.; Mahmood, M.T.; Ilyas, H.; Iqbal, A. Detection & recognition of veiled and unveiled human face on the basis of eyes using transfer learning. Multimed. Tools Appl. 2022, 82, 4257–4287. [Google Scholar] [PubMed]
- Holkar, A.; Walambe, R.; Kotecha, K. Few-Shot learning for face recognition in the presence of image discrepancies for limited multi-class datasets. Image Vis. Comput. 2022, 120, 104420. [Google Scholar] [CrossRef]
- Jin, B.; Cruz, L.; Gonçalves, N. Deep facial diagnosis: Deep transfer learning from face recognition to facial diagnosis. IEEE Access 2020, 8, 123649–123661. [Google Scholar] [CrossRef]
- Venkateswarlu, I.B.; Kakarla, J.; Prakash, S. Face mask detection using mobilenet and global pooling block. In Proceedings of the 2020 IEEE 4th Conference on Information & Communication Technology (CICT), Chennai, India, 3–5 December 2020; pp. 1–5. [Google Scholar]
- Lanchantin, J.; Wang, T.; Ordonez, V.; Qi, Y. General multi-label image classification with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 16478–16488. [Google Scholar]
- Chen, H.; Wang, Y.; Guo, T.; Xu, C.; Deng, Y.; Liu, Z.; Ma, S.; Xu, C.; Xu, C.; Gao, W. Pre-trained image processing transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12299–12310. [Google Scholar]
- Aziz, M.N.A.; Mutalib, S.; Aliman, S. Comparison of Face Coverings Detection Methods using Deep Learning. In Proceedings of the 2021 2nd International Conference on Artificial Intelligence and Data Sciences (AiDAS), IPOH, Malaysia, 8–9 September 2021; pp. 1–6. [Google Scholar]
- Nguyen, D.C.; Pham, Q.V.; Pathirana, P.N.; Ding, M.; Seneviratne, A.; Lin, Z.; Dobre, O.; Hwang, W.J. Federated learning for smart healthcare: A survey. Acm Comput. Surv. (CSUR) 2022, 55, 1–37. [Google Scholar] [CrossRef]
- Umuroglu, Y.; Fraser, N.J.; Gambardella, G.; Blott, M.; Leong, P.; Jahre, M.; Vissers, K. Finn: A framework for fast, scalable binarized neural network inference. In Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 22–24 February 2017; pp. 65–74. [Google Scholar]
- Fang, T.; Huang, X.; Saniie, J. Design flow for real-time face mask detection using PYNQ system-on-chip platform. In Proceedings of the 2021 IEEE International Conference on Electro Information Technology (EIT), Mt. Pleasant, MI, USA, 14–15 May 2021; pp. 1–5. [Google Scholar]
- Fourati, L.C.; Samiha, A. Federated learning toward data preprocessing: COVID-19 context. In Proceedings of the 2021 IEEE International Conference on Communications Workshops (ICC Workshops), Montreal, QC, Canada, 14–23 June 2021; pp. 1–6. [Google Scholar]
- Peyvandi, A.; Majidi, B.; Peyvandi, S.; Patra, J.C.; Moshiri, B. Location-aware hazardous litter management for smart emergency governance in urban eco-cyber-physical systems. Multimed. Tools Appl. 2022, 81, 22185–22214. [Google Scholar] [CrossRef]
- Kim, J.; Park, T.; Kim, H.; Kim, S. Federated Learning for Face Recognition. In Proceedings of the 2021 IEEE International Conference on Consumer Electronics (ICCE), Penghu, Taiwan, 16–18 June 2021; pp. 1–2. [Google Scholar] [CrossRef]
- Niu, Y.; Deng, W. Federated learning for face recognition with gradient correction. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2022; Volume 36, pp. 1999–2007. [Google Scholar]
- Meng, Q.; Zhou, F.; Ren, H.; Feng, T.; Liu, G.; Lin, Y. Improving federated learning face recognition via privacy-agnostic clusters. arXiv 2022, arXiv:2201.12467. [Google Scholar]
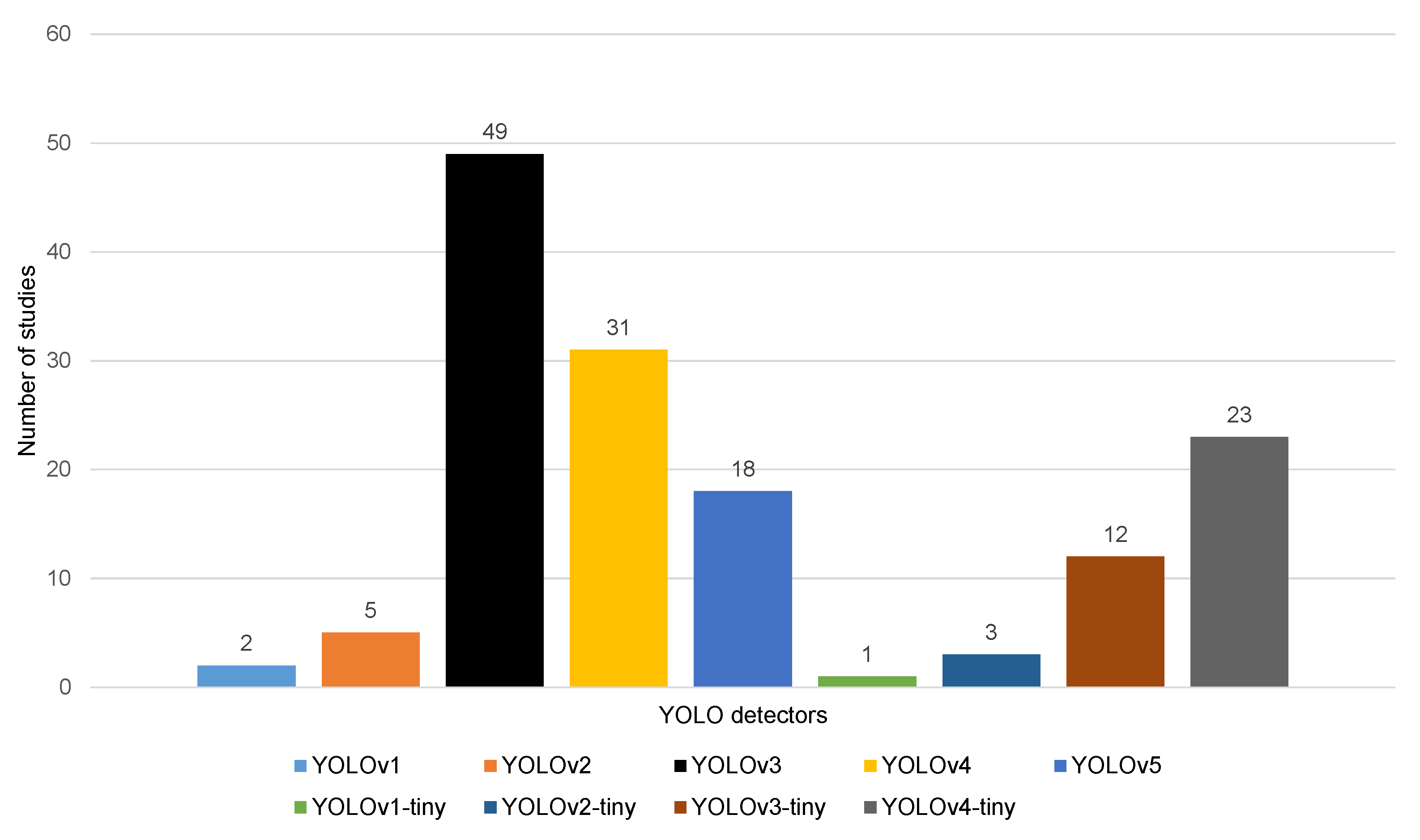
| Dataset | # Images/Faces | # Classes | # Masked/Unmasked Faces | Environment | Head Pose | Description |
|---|---|---|---|---|---|---|
| MFDS [31] | 200 | 1 | 200/0 | Real | Various | • Real masked faces applied to track and identify criminals or terrorists. |
| MAFA [30] | 30,811/35,806 | 1 | 35,806/0 | Real | Various | • Images collected from the Internet. Six attributes are manually annotated for each face region |
| Masked-LFW | 13,097 | 1 | 13,097/0 | Real | Various | • Faces from the original LFW dataset were masked using software. |
| SMFD [39] | 1570 | 2 | 785/785 | Simulated | Frontal to Profile | • All the images are web scrapped. |
| RMFD [37] | 95,000 | 2 | 5000/90,000 | Real | Various | • Part of the dataset is collected from other research datasets and another part is crawled from the Internet. |
| MMD [34] | 6000 | 20 | N/A | Real | Various | • Images acquired from the public domain with extreme attention to diversity. |
| MaskedFace-Net [21] | 137,016 | 2 | 67,049/66,734 | Real | Frontal | • Face images collected from FFHQ. |
| FMDS [32] | 853 | 3 | 717/3232 (+123 incorrect) | Real | Various | • Images collected from the Internet, used to train two-class models. |
| MFV-MFI [33] | 400 (verification) 4916 (identification) | 10 | 200/200 (verification), 2458/2458 (identification) | Real | Various | • A dataset for the MFR task. |
| MFDD [28] | 24,771 | 1 | 24,771 | Real | Various | • Images from the Internet and images of people wearing COVID-19 masks. |
| SMFRD [28] | 500,000 | 1 | 500,000/0 | Simulated | Various | • Generated using mask-wearing software based on the Dlib library. |
| Singh’s Dataset [42] | 7500 | 2 | N/A | Real | Various | • Combination of MAFA, Wider Face and captured images by surfing various sources. |
| FIDS1 [38] | 3835 | 2 | 1916/1919 | Real | Frontal to profile | • Combination of Kaggle datasets, RMFD dataset and Bing search API. |
| FIDS2 [38] | 1376 | 2 | 690/686 | Simulated | Frontal to profile | • Created based on SMFD. |
| AIZOO-Tech | 7971 | 2 | 12,620/4034 | Real | Various | • Designed by modifying the wrong annotations from datasets of Wider Face and MAFA. |
| FMLD [43] | 41,934/63,072 | 3 | 29,532/32,012 (+1528 incorrect) | Real | Various | • Combination of MAFA and Wider Face datasets. |
| Moxa3K [44] | 3000/12,176 | 2 | 9161/3015 | Real | Various | • Combination of Kaggle datasets recorded from Russia, Italy, China and India during the ongoing pandemic. |
| UFMD [45] | 21,316 | 3 | 10,698/10,618 (+500 incorrect masked faces) | Real | Frontal to Profile | • Combination of FFHQ, CelebA, LFW, YouTube videos, and the Internet. |
| WMD [46] | 7804/26,403 | 1 | 26,403/0 | Real | Various | • Collected from real scenarios of fighting against CoVID-19 covering many long-distance scenes. |
| PWMFD [47] | 9205/18,532 | 3 | 10,471/7695 (+366 incorrect masked faces) | Real | Frontal to Profile | • Combination of images from WIDER Face, MAFA, RWMFD. |
| Thermal-mask [40] | 75,908 | 2 | 42,460/33,448 | Real | Various | • The images are in both spectra (visual+thermal) with 18 variations of face mask patterns. |
| Bing dataset [48] | 4039 (tr.:3232/test.:807) | 2 | N/A | Simulated | Various | • The images are collected from Bing using the bing-images library available in Python. |
| MedMasks [19] | 3835 | 3 | 3030/671 (+134 incorrect masked faces) | Real | Various | • Images in uncontrolled environments are pre-processed. |
| Metric | Description | Formula |
|---|---|---|
| Relative error (RE) | The ratio of the absolute error of a variable to its value | |
| Mean absolute error/ difference (MAE or MAD) | Calculate the difference between the predicted and actual values for a given phenomenon. | |
| Validation loss (L) | It is determined by evaluating the model on a validation set, which is obtained by dividing the data into training, validation, and test sets using cross-validation. | |
| Kappa coefficient (K) | Assess the model’s prediction accuracy on a test dataset by comparing the predicted values to the true values. | |
| Mean squared error/difference (MSE or MSD) | Calculate the average of the differences between the predicted and actual values. | |
| Root mean squared error/ difference (RMSE or RMSD) | The square root of the MSE is taken to express the error in the same units as the original variable. | |
| Root mean square percentage error (RMSPE) | Represents the RMSE expressed in percentage. | |
| Normalized root mean squared error (NRMSE) | A standardized version of the RMSD that allows for comparison between variables that have different scales. | |
| R-squared (R) | The fitness of a regression model to the data. It measures the proportion of variance in the dependent variable that can be explained by the independent variable(s). | |
| Theil U1 index | Quantify the difference between the observed and predicted values, with a higher value indicating a better fit and more accurate predictions. | |
| Theil U2 index | Measures the quality of the predicted results. | |
| Accuracy (ACC) | Measure how closely the predicted values match the target values. | |
| Error rate (ERR) | Calculate the percentage of incorrect predictions made by the model out of the total number of predictions. | |
| Precision (PPV) | The closeness of predicted results to the true values. | |
| Recall or True positive rate (TPR) | The ratio of true positive (TP) predictions that are correctly identified. | |
| False-positive rate (FPR) | The ratio of false positive (FP) predictions among all predictions in the true negative (TN) class. | |
| True-negative rate (TNR) | Determine the percentage of true negative (TN) predictions correctly identified among all predictions in the true negative (TN) class. | |
| False-negative rate (FNR) | Measures the proportion of false negative (FN) predictions in the true positive class. | |
| F1-score | Calculate the percentage of false negative (FN) predictions among all predictions in the true positive class. | |
| Matthews correlation coefficient (MCC) | Assess the quality of a binary classification. | |
| Average precision | ||
| Mean average precision (mAP) | ||
| IoU | Intersection over union | |
| Precision recall curve (PRC) | Illustrate the balance between precision and recall as the threshold for classification varies. | - |
| Receiver operating characteristic curve (ROC) | Illustrate the balance between FPR and TPR as the threshold for classification is varied. | - |
| Area under the ROC (AUROC) | Determine the area under the ROC curve, where a higher value indicates a better classification performance. | - |
| Cross-validation (CV) | Evaluate the performance of an AI model on unseen data by testing its ability to make predictions and generalize based on a sample of training data. | - |
| Confusion matrix | A summary of the classification results of an algorithm, typically presented in a table format. | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Himeur, Y.; Al-Maadeed, S.; Varlamis, I.; Al-Maadeed, N.; Abualsaud, K.; Mohamed, A. Face Mask Detection in Smart Cities Using Deep and Transfer Learning: Lessons Learned from the COVID-19 Pandemic. Systems 2023, 11, 107. https://doi.org/10.3390/systems11020107
Himeur Y, Al-Maadeed S, Varlamis I, Al-Maadeed N, Abualsaud K, Mohamed A. Face Mask Detection in Smart Cities Using Deep and Transfer Learning: Lessons Learned from the COVID-19 Pandemic. Systems. 2023; 11(2):107. https://doi.org/10.3390/systems11020107
Chicago/Turabian StyleHimeur, Yassine, Somaya Al-Maadeed, Iraklis Varlamis, Noor Al-Maadeed, Khalid Abualsaud, and Amr Mohamed. 2023. "Face Mask Detection in Smart Cities Using Deep and Transfer Learning: Lessons Learned from the COVID-19 Pandemic" Systems 11, no. 2: 107. https://doi.org/10.3390/systems11020107