


Video Synopsis Algorithms and Framework: A Survey and Comparative Evaluation



Abstract
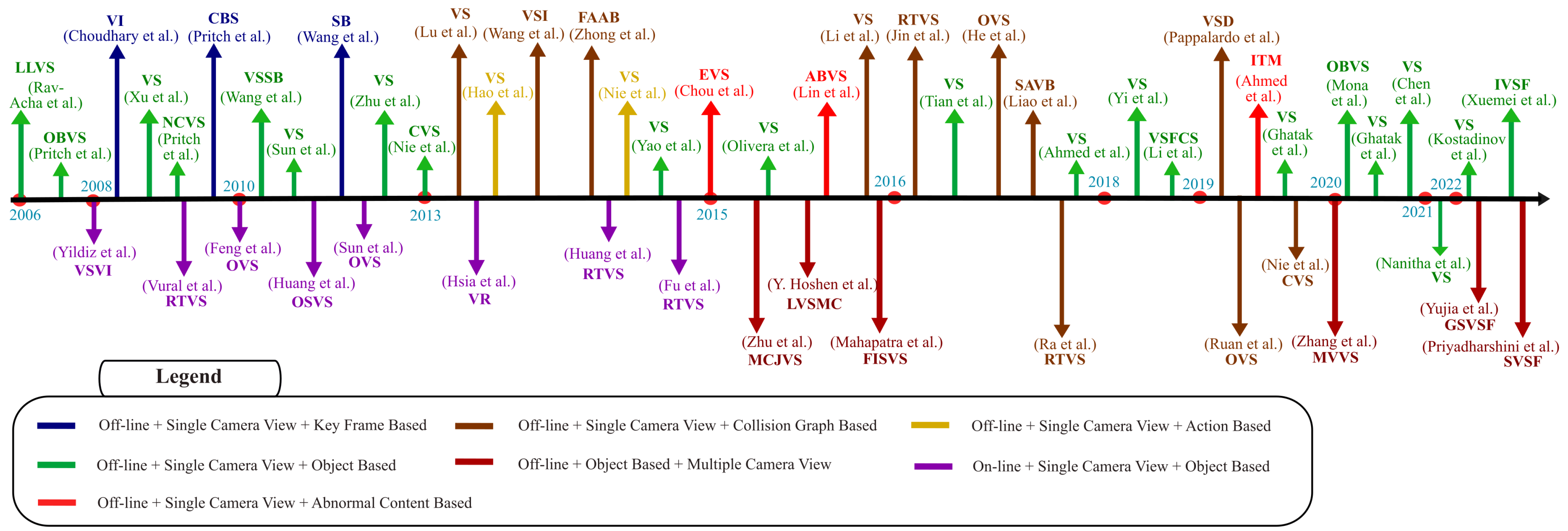
1. Introduction
- Based on video synopsis usage scenarios, we put forward three different synopsis frameworks, then present a taxonomy of video synopsis techniques along with their respective steps.
- We clearly define the lacuna and complexity of the existing studies based on a comprehensive comparison of various current techniques (i.e., object detection, object tracking, stitching algorithms), then perform an evaluation through experimentation on publicly available datasets.
- This is the first survey paper to study video synopsis in the context of distinguishing different performance methodologies. Compared with the existing reviews, in the article we focus on determining the most effective video synopsis methods, rather than on describing all types of methods.
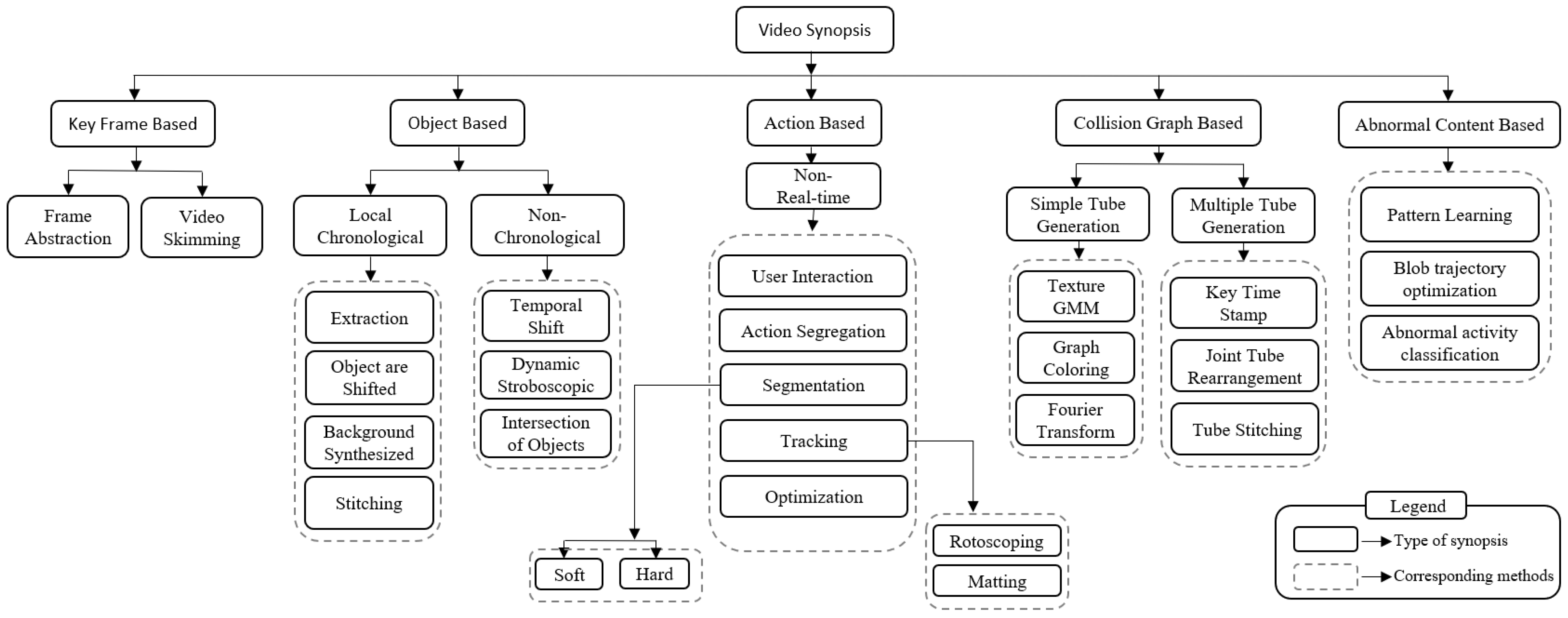
2. Classification of Video Synopsis Techniques
2.1. Keyframe-Based Synopsis
2.2. Object-Based Synopsis
2.3. Action-Based Synopsis
2.4. Collision Graph-Based Synopsis
2.5. Abnormal Content-Based Synopsis
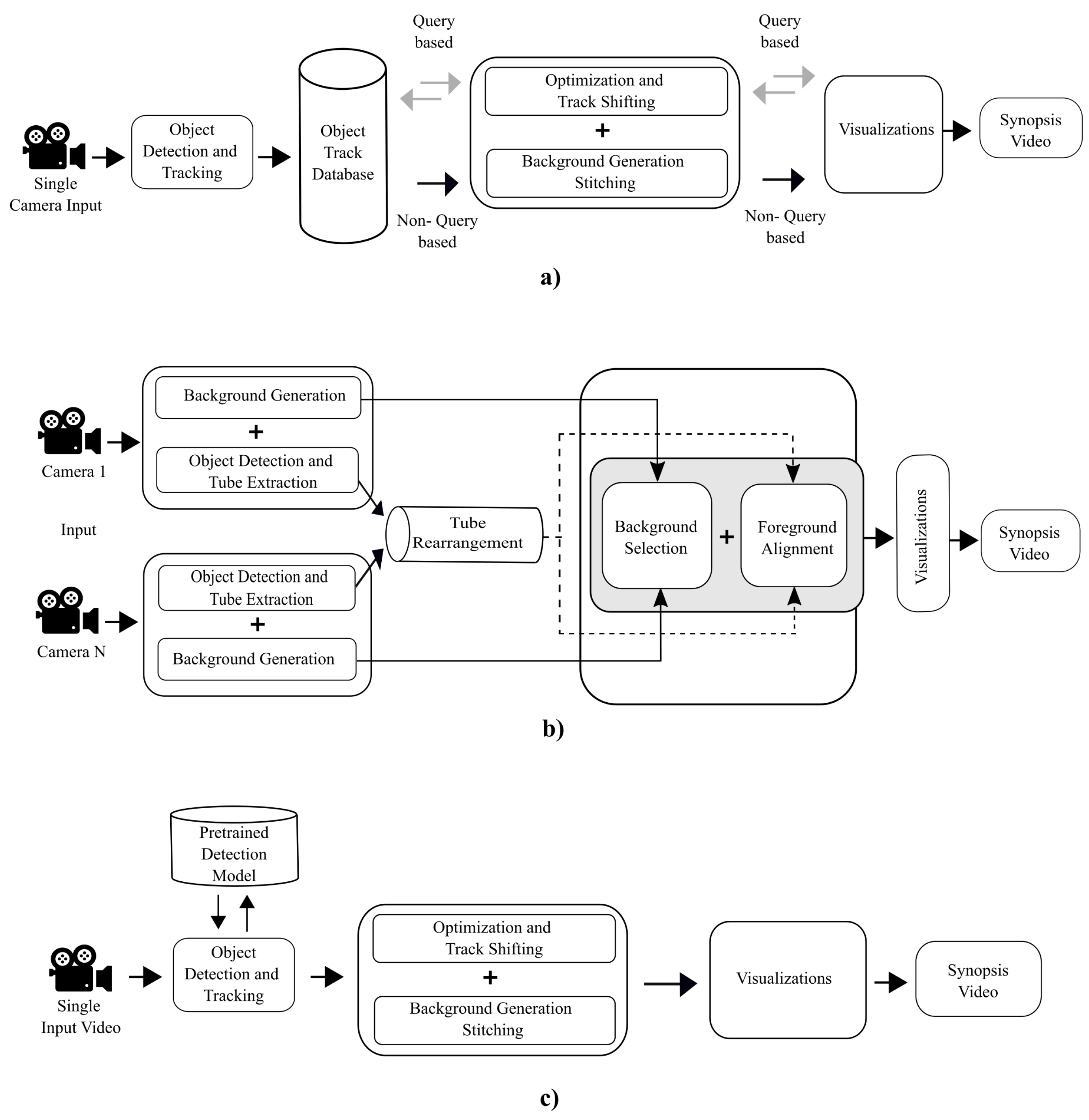
3. Video Synopsis Framework
4. Results and Discussion
4.1. Datasets and Metrics
4.1.1. Datasets
4.1.2. Evaluation Metrics
4.2. Analysis 1: Evaluation of Object Detection and Tracking
4.3. Analysis 2: Evaluation of Various Optimization Techniques
5. Challenges in Video Synopsis
- Edge-based synopsis: as next-generation surveillance cameras have slightly better computing, the summary can be accomplished on the edge device itself using technologies such as fog/cloud computing. However, state-of-the-art synopsis frameworks lack the required capabilities to create edge-based solutions.
- Multi-view video synopsis: creating a synopsis for every single camera occupies a great deal of space and time; a better real-world solution is multi-view video synopsis, as it can create a single synopsis for multiple videos. However, a major problem that occurs is selecting a common background, as the acquired videos have different view angles and locations. Thus, the resulting synopsis view is complex and challenging to understand, as the tubes are shifted against a very different background.
- Visual constituent redundancy: there have been many methods proposed for creating single-view camera summaries in past years. When a similar strategy is applied in the case of multi-view camera systems, the inter-video relations between visual content are ignored, leading to redundant content. Therefore, it is better to use a synopsis of each video and then stitch the frames to create a single summary for multi-view cameras.
- Relationship association: as there are numerous objects present the constructed video synopses, it is difficult for a video analyzer to associate summary objects with the original video objects. A better option is to create a single-camera synopsis, which is not feasible in real-world surveillance system with multiple cameras. Thus, there is a need to find a mechanism that can link the desired synopsis object with the original video cameras.
- Multi-model: as there are several components in the video synopsis framework, a multi-model learning approach can be used for better inclusion of these components. A single multitask learning model can perform segmentation, depth analysis, and background generation.
- Interactive: as synopsis generation is predefined or application based, incorporation of an interactive user mode can help to generate user-defined parameters such as type of object, duration and speed of synopsis, etc.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| ABGC | Alpha–Beta Graph Cut |
| CNN | Convolutional Neural Networks |
| DP | Dynamic Programming |
| FFT | Fast Fourier Transform |
| GMM | Gaussian Mixture Model |
| GSVSF | Geospatial video synopsis framework |
| SVSF | Spherical video synopsis framework |
| IVSF | Infrared video synopsis framework |
| KNN | k-nearest neighbor |
| LCRT | Low Complexity Range Tree |
| MRF | Markov Random Field |
| OD | Object Detection |
| RTVS | Real-time video synopsis framework |
| SA | Simulated Annealing |
| TA | Tube Generation |
References
- Reinsel, D.; Gantz, J.; Rydning, J. Data Age 2025: The Evolution of Data to Life-Critical. Don’t Focus on Big Data; Focus on the Data That’s Big; International Data Corporation (IDC) White Paper; 2017; Available online: https://www.import.io/wp-content/uploads/2017/04/Seagate-WP-DataAge2025-March-2017.pdf (accessed on 10 October 2022).
- Sarhan, N. Automated Video Surveillance Systems. U.S. Patent 9,313,463, 12 April 2016. [Google Scholar]
- Tsakanikas, V.; Dagiuklas, T. Video surveillance systems-current status and future trends. Comput. Electr. Eng. 2018, 70, 736–753. [Google Scholar] [CrossRef]
- Truong, B.; Venkatesh, S. Video abstraction: A systematic review and classification. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2007, 3, 3–es. [Google Scholar] [CrossRef]
- Nam, J.; Tewfik, A. Video abstract of video. In Proceedings of the 1999 IEEE Third Workshop on Multimedia Signal Processing (Cat. No. 99TH8451), Copenhagen, Denmark, 13–15 September 1999; pp. 117–122. [Google Scholar] [CrossRef]
- Schuldt, C.; Laptev, I.; Caputo, B. Recognizing human actions: A local SVM approach. In Proceedings of the 17th International Conference on Pattern Recognition, ICPR 2004, Cambridge, UK, 23–26 August 2004; Volume 3, pp. 32–36. [Google Scholar] [CrossRef]
- Gorelick, L.; Blank, M.; Shechtman, E.; Irani, M.; Basri, R. Actions as space-time shapes. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 2247–2253. [Google Scholar] [CrossRef] [PubMed]
- Sillito, R.; Fisher, R. Semi-supervised Learning for Anomalous Trajectory Detection. In Proceedings of the BMVC, Leeds, UK, 1–4 September 2008; Volume 1, pp. 1–10. [Google Scholar]
- Yang, B.; Nevatia, R. Multi-target tracking by online learning of non-linear motion patterns and robust appearance models. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1918–1925. Available online: https://www.computer.org/csdl/proceedings/cvprw/2012/12OmNANkoa6 (accessed on 18 October 2022).
- Mahalingam, T.; Subramoniam, M. ACO–MKFCM: An Optimized Object Detection and Tracking Using DNN and Gravitational Search Algorithm. Wirel. Pers. Commun. 2020, 110, 1567–1604. [Google Scholar] [CrossRef]
- Kille, B.; Hopfgartner, F.; Brodt, T.; Heintz, T. The plista dataset. In Proceedings of the 2013 International News Recommender Systems Workshop and Challenge, Hong Kong, China, 13 October 2013; pp. 16–23. [Google Scholar]
- Wang, T.; Liang, J.; Wang, X.; Wang, S. Background modeling using local binary patterns of motion vector. In Proceedings of the 2012 Visual Communications and Image Processing, San Diego, CA, USA, 27–30 November 2012; pp. 1–5. [Google Scholar]
- Baskurt, K.; Samet, R. Video synopsis: A survey. Comput. Vis. Image Underst. 2019, 181, 26–38. [Google Scholar] [CrossRef]
- Ghatak, S.; Rup, S. Single Camera Surveillance Video Synopsis: A Review and Taxonomy. In Proceedings of the 2019 International Conference on Information Technology (ICIT), Bhubaneswar, India, 19–21 December 2019; pp. 483–488. Available online: https://ieeexplore.ieee.org/xpl/conhome/9022805/proceeding (accessed on 20 November 2022).
- Mahapatra, A.; Sa, P. Video Synopsis: A Systematic Review. In High Performance Vision Intelligence; Springer: Singapore, 2020; pp. 101–115. [Google Scholar]
- Liu, T.; Zhang, X.; Feng, J.; Lo, K. Shot reconstruction degree: A novel criterion for key frame selection. Pattern Recognit. Lett. 2004, 25, 1451–1457. [Google Scholar] [CrossRef]
- Choudhary, V.; Tiwari, A. Surveillance video synopsis. In Proceedings of the 2008 Sixth Indian Conference on Computer Vision, Graphics & Image Processing, Bhubaneswar, India, 16–19 December 2008; pp. 207–212. [Google Scholar]
- Zass, R.; Shashua, A. A unifying approach to hard and probabilistic clustering. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05), NW, Washington, DC, USA, 17–21 October 2005; Volume 1, pp. 294–301. [Google Scholar]
- Pritch, Y.; Ratovitch, S.; Hendel, A.; Peleg, S. Clustered synopsis of surveillance video. In Proceedings of the 2009 Sixth IEEE International Conference on Advanced Video and Signal Based Surveillance, Genova, Italy, 2–4 September 2009; pp. 195–200. [Google Scholar]
- Wang, S.; Yang, J.; Zhao, Y.; Cai, A.; Li, S. A surveillance video analysis and storage scheme for scalable synopsis browsing. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; pp. 1947–1954. [Google Scholar]
- Petrovic, N.; Jojic, N.; Huang, T. Adaptive video fast forward. Multimed. Tools Appl. 2005, 26, 327–344. [Google Scholar] [CrossRef]
- Smith, M.; Kanade, T. Video skimming and characterization through the combination of image and language understanding techniques. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Juan, PR, USA, 17–19 June 1997; pp. 775–781. Available online: https://ieeexplore.ieee.org/xpl/conhome/4821/proceeding (accessed on 13 November 2022).
- Pal, C.; Jojic, N. Interactive montages of sprites for indexing and summarizing security video. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 2, p. 1192. [Google Scholar]
- Wexler, Y.; Shechtman, E.; Irani, M. Space-time video completion. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2004, Washington, DC, USA, 27 June–2 July 2004; Volume 1. [Google Scholar]
- Rother, C.; Bordeaux, L.; Hamadi, Y.; Blake, A. Autocollage. ACM Trans. Graph. (TOG) 2006, 25, 847–852. [Google Scholar] [CrossRef]
- Kang, H.; Matsushita, Y.; Tang, X.; Chen, X. Space-time video montage. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 2, pp. 1331–1338. [Google Scholar]
- Rav-Acha, A.; Pritch, Y.; Peleg, S. Making a long video short: Dynamic video synopsis. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 1, pp. 435–441. [Google Scholar]
- Pritch, Y.; Rav-Acha, A.; Gutman, A.; Peleg, S. Webcam synopsis: Peeking around the world. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Rio De Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar]
- Xu, M.; Li, S.; Li, B.; Yuan, X.; Xiang, S. A set theoretical method for video synopsis. In Proceedings of the 1st ACM International Conference on Multimedia Information Retrieval, Vancouver, BC, Canada, 30–31 October 2008; pp. 366–370. [Google Scholar]
- Pritch, Y.; Rav-Acha, A.; Peleg, S. Nonchronological video synopsis and indexing. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 1971–1984. [Google Scholar] [CrossRef]
- Wang, S.; Liu, H.; Xie, D.; Zeng, B. A novel scheme to code object flags for video synopsis. In Proceedings of the 2012 Visual Communications and Image Processing, San Diego, CA, USA, 27–30 November 2012; pp. 1–5. [Google Scholar]
- Sun, H.; Cao, L.; Xie, Y.; Zhao, M. The method of video synopsis based on maximum motion power. In Proceedings of the 2011 Third Chinese Conference on Intelligent Visual Surveillance, Beijing, China, 1–2 December 2011; pp. 37–40. [Google Scholar]
- Zhu, X.; Liu, J.; Wang, J.; Lu, H. Key observation selection for effective video synopsis. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba, Japan, 11–15 November 2012; pp. 2528–2531. [Google Scholar]
- Nie, Y.; Xiao, C.; Sun, H.; Li, P. Compact video synopsis via global spatiotemporal optimization. IEEE Trans. Vis. Comput. Graph. 2012, 19, 1664–1676. [Google Scholar] [CrossRef]
- Yao, T.; Xiao, M.; Ma, C.; Shen, C.; Li, P. Object based video synopsis. In Proceedings of the 2014 IEEE Workshop on Advanced Research and Technology in Industry Applications (WARTIA), Ottawa, ON, Canada, 29–30 September 2014; pp. 1138–1141. [Google Scholar]
- Olivera, J.; Cuadra, N.; Oliva, E.; Albornoz, E.; Martinez, C. Development of an open source library for the generation of video synopsis. In Proceedings of the 2015 XVI Workshop on Information Processing and Control (RPIC), Cordoba, Argentina, 6–9 October 2015; pp. 1–4. [Google Scholar]
- Tian, Y.; Zheng, H.; Chen, Q.; Wang, D.; Lin, R. Surveillance video synopsis generation method via keeping important relationship among objects. IET Comput. Vis. 2016, 10, 868–872. [Google Scholar] [CrossRef]
- Ahmed, A.; Kar, S.; Dogra, D.; Patnaik, R.; Lee, S.; Choi, H.; Kim, I. Video synopsis generation using spatio-temporal groups. In Proceedings of the 2017 IEEE International Conference on Signal and Image Processing Applications (ICSIPA), Sarawak, Malaysia, 12–14 September 2017; pp. 512–517. [Google Scholar]
- Collins, R.; Osterdahl, K.; Shringi, A.; Corona, K.; Swears, E.; Meth, R.; Hoogs, A. Data, Algorithms, and Framework for Automated Analytics of Surveillance Camera Networks; Kitware Inc.: Clifton Park, NY, USA, 2018. [Google Scholar]
- He, Y.; Han, J.; Sang, N.; Qu, Z.; Gao, C. Chronological video synopsis via events rearrangement optimization. Chin. J. Electron. 2018, 27, 399–404. [Google Scholar] [CrossRef]
- Li, X.; Wang, Z.; Lu, X. Video synopsis in complex situations. IEEE Trans. Image Process. 2018, 27, 3798–3812. [Google Scholar] [CrossRef]
- Ghatak, S.; Rup, S.; Majhi, B.; Swamy, M. An improved surveillance video synopsis framework: A HSATLBO optimization approach. Multimed. Tools Appl. 2020, 79, 4429–4461. [Google Scholar] [CrossRef]
- Moussa, M.; Shoitan, R. Object-based video synopsis approach using particle swarm optimization. Signal Image Video Process. 2021, 15, 761–768. [Google Scholar] [CrossRef]
- Li, T.; Ma, Y.; Endoh, T. A systematic study of tiny YOLO3 inference: Toward compact brainware processor with less memory and logic gate. IEEE Access 2020, 8, 142931–142955. [Google Scholar] [CrossRef]
- Yildiz, A.; Ozgur, A.; Akgul, Y. Fast non-linear video synopsis. In Proceedings of the 2008 23rd International Symposium on Computer and Information Sciences, Istanbul, Turkey, 27–29 October 2008; pp. 1–6. [Google Scholar]
- Vural, U.; Akgul, Y. Eye-gaze based real-time surveillance video synopsis. Pattern Recognit. Lett. 2009, 30, 1151–1159. [Google Scholar] [CrossRef]
- Feng, S.; Liao, S.; Yuan, Z.; Li, S. Online principal background selection for video synopsis. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 17–20. [Google Scholar]
- Huang, C.; Chen, H.; Chung, P. Online surveillance video synopsis. In Proceedings of the 2012 IEEE International Symposium on Circuits and Systems (ISCAS), Seoul, Republic of Korea, 20–23 May 2012; pp. 1843–1846. [Google Scholar]
- Huang, C.; Chung, P.; Yang, D.; Chen, H.; Huang, G. Maximum a posteriori probability estimation for online surveillance video synopsis. IEEE Trans. Circuits Syst. Video Technol. 2014, 24, 1417–1429. [Google Scholar] [CrossRef]
- Sun, L.; Xing, J.; Ai, H.; Lao, S. A tracking based fast online complete video synopsis approach. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba, Japan, 11–15 November 2012; pp. 1956–1959. [Google Scholar]
- Hsia, C.; Chiang, J.; Hsieh, C.; Hu, L. A complexity reduction method for video synopsis system. In Proceedings of the 2013 International Symposium on Intelligent Signal Processing and Communication Systems, Okinawa, Japan, 12–15 November 2013; pp. 163–168. [Google Scholar]
- Fu, W.; Wang, J.; Gui, L.; Lu, H.; Ma, S. Online video synopsis of structured motion. Neurocomputing 2014, 135, 155–162. [Google Scholar] [CrossRef]
- Ghatak, S.; Rup, S.; Majhi, B.; Swamy, M. HSAJAYA: An improved optimization scheme for consumer surveillance video synopsis generation. IEEE Trans. Consum. Electron. 2020, 66, 144–152. [Google Scholar] [CrossRef]
- Chen, S.; Liu, X.; Huang, Y.; Zhou, C.; Miao, H. Video synopsis based on attention mechanism and local transparent processing. IEEE Access 2020, 8, 92603–92614. [Google Scholar] [CrossRef]
- Namitha, K.; Narayanan, A.; Geetha, M. Interactive visualization-based surveillance video synopsis. Appl. Intell. 2022, 52, 3954–3975. [Google Scholar] [CrossRef]
- Kostadinov, G. Synopsis of video files using neural networks. In Proceedings of the International Conference on Engineering Applications of Neural Networks, Chersonisos, Crete, Greece, 17–20 June 2022; pp. 190–202. [Google Scholar]
- Li, X.; Qiu, S.; Song, Y. Dynamic Synopsis and storage algorithm based on infrared surveillance video. Infrared Phys. Technol. 2022, 124, 104213. [Google Scholar] [CrossRef]
- Zhu, J.; Liao, S.; Li, S. Multicamera joint video synopsis. IEEE Trans. Circuits Syst. Video Technol. 2015, 26, 1058–1069. [Google Scholar] [CrossRef]
- Hoshen, Y.; Peleg, S. Live video synopsis for multiple cameras. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 212–216. [Google Scholar]
- Mahapatra, A.; Sa, P.; Majhi, B.; Padhy, S. MVS: A multi-view video synopsis framework. Signal Process. Image Commun. 2016, 42, 31–44. [Google Scholar] [CrossRef]
- Zhang, Z.; Nie, Y.; Sun, H.; Zhang, Q.; Lai, Q.; Li, G.; Xiao, M. Multi-view video synopsis via simultaneous object-shifting and view-switching optimization. IEEE Trans. Image Process. 2019, 29, 971–985. [Google Scholar] [CrossRef]
- Xie, Y.; Wang, M.; Liu, X.; Wang, X.; Wu, Y.; Wang, F.; Wang, X. Multi-camera video synopsis of a geographic scene based on optimal virtual viewpoint. Trans. GIS 2022, 26, 1221–1239. [Google Scholar] [CrossRef]
- Priyadharshini, S.; Mahapatra, A. PanoSyn: Immersive video synopsis for spherical surveillance video. Sādhanā 2022, 47, 167. [Google Scholar] [CrossRef]
- Hao, L.; Cao, J.; Li, C. Research of grabcut algorithm for single camera video synopsis. In Proceedings of the 2013 Fourth International Conference on Intelligent Control and Information Processing (ICICIP), Beijing, China, 9–11 June 2013; pp. 632–637. [Google Scholar]
- Agarwala, A.; Hertzmann, A.; Salesin, D.; Seitz, S. Keyframe-based tracking for rotoscoping and animation. ACM Trans. Graph. (ToG) 2004, 23, 584–591. [Google Scholar] [CrossRef]
- Nie, Y.; Sun, H.; Li, P.; Xiao, C.; Ma, K. Object movements synopsis viaPart assembling and stitching. IEEE Trans. Vis. Comput. Graph. 2014, 20, 1303–1315. [Google Scholar] [CrossRef]
- Wang, J.; Bhat, P.; Colburn, R.; Agrawala, M.; Cohen, M. Interactive video cutout. ACM Trans. Graph. (ToG) 2005, 24, 585–594. [Google Scholar] [CrossRef]
- Bai, X.; Wang, J.; Simons, D.; Sapiro, G. Video snapcut: Robust video object cutout using localized classifiers. ACM Trans. Graph. (ToG) 2009, 28, 1–11. [Google Scholar] [CrossRef]
- Lu, M.; Wang, Y.; Pan, G. Generating fluent tubes in video synopsis. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 2292–2296. [Google Scholar]
- Wang, S.; Wang, Z.; Hu, R. Surveillance video synopsis in the compressed domain for fast video browsing. J. Vis. Commun. Image Represent. 2013, 24, 1431–1442. [Google Scholar] [CrossRef]
- Zhong, R.; Hu, R.; Wang, Z.; Wang, S. Fast synopsis for moving objects using compressed video. IEEE Signal Process. Lett. 2014, 21, 834–838. [Google Scholar] [CrossRef]
- Zhu, J.; Feng, S.; Yi, D.; Liao, S.; Lei, Z.; Li, S. High-performance video condensation system. IEEE Trans. Circuits Syst. Video Technol. 2014, 25, 1113–1124. [Google Scholar]
- Chakraborty, S.; Tickoo, O.; Iyer, R. Adaptive keyframe selection for video summarization. In Proceedings of the 2015 IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 5–9 January 2015; pp. 702–709. [Google Scholar]
- He, Y.; Qu, Z.; Gao, C.; Sang, N. Fast online video synopsis based on potential collision graph. IEEE Signal Process. Lett. 2016, 24, 22–26. [Google Scholar] [CrossRef]
- He, Y.; Gao, C.; Sang, N.; Qu, Z.; Han, J. Graph coloring based surveillance video synopsis. Neurocomputing 2017, 225, 64–79. [Google Scholar] [CrossRef]
- Liao, W.; Tu, Z.; Wang, S.; Li, Y.; Zhong, R.; Zhong, H. Compressed-domain video synopsis via 3d graph cut and blank frame deletion. In Proceedings of the on Thematic Workshops of ACM Multimedia 2017, Mountain View, CA, USA, 23–27 October 2017; pp. 253–261. [Google Scholar]
- Ra, M.; Kim, W. Parallelized tube rearrangement algorithm for online video synopsis. IEEE Signal Process. Lett. 2018, 25, 1186–1190. [Google Scholar] [CrossRef]
- Pappalardo, G.; Allegra, D.; Stanco, F.; Battiato, S. A new framework for studying tubes rearrangement strategies in surveillance video synopsis. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 664–668. [Google Scholar]
- Ruan, T.; Wei, S.; Li, J.; Zhao, Y. Rearranging online tubes for streaming video synopsis: A dynamic graph coloring approach. IEEE Trans. Image Process. 2019, 28, 3873–3884. [Google Scholar] [CrossRef]
- Li, K.; Yan, B.; Wang, W.; Gharavi, H. An effective video synopsis approach with seam carving. IEEE Signal Process. Lett. 2015, 23, 11–14. [Google Scholar] [CrossRef]
- Jin, J.; Liu, F.; Gan, Z.; Cui, Z. Online video synopsis method through simple tube projection strategy. In Proceedings of the 2016 8th International Conference on Wireless Communications & Signal Processing (WCSP), Yangzhou, China, 13–15 October 2016; pp. 1–5. [Google Scholar]
- Nie, Y.; Li, Z.; Zhang, Z.; Zhang, Q.; Ma, T.; Sun, H. Collision-free video synopsis incorporating object speed and size changes. IEEE Trans. Image Process. 2019, 29, 1465–1478. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Wang, Z.; Lu, X. Surveillance video synopsis via scaling down objects. IEEE Trans. Image Process. 2015, 25, 740–755. [Google Scholar] [CrossRef] [PubMed]
- Chou, C.; Lin, C.; Chiang, T.; Chen, H.; Lee, S. Coherent event-based surveillance video synopsis using trajectory clustering. In Proceedings of the 2015 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Torino, Italy, 29 June–3 July 2015; pp. 1–6. [Google Scholar]
- Lin, W.; Zhang, Y.; Lu, J.; Zhou, B.; Wang, J.; Zhou, Y. Summarizing surveillance videos with local-patch-learning-based abnormality detection, blob sequence optimization, and type-based synopsis. Neurocomputing 2015, 155, 84–98. [Google Scholar] [CrossRef]
- Ahmed, S.; Dogra, D.; Kar, S.; Patnaik, R.; Lee, S.; Choi, H.; Nam, G.; Kim, I. Query-based video synopsis for intelligent traffic monitoring applications. IEEE Trans. Intell. Transp. Syst. 2019, 21, 3457–3468. [Google Scholar] [CrossRef]
- Ingle, P.; Kim, Y. Real-Time Abnormal Object Detection for Video Surveillance in Smart Cities. Sensors 2022, 22, 3862. [Google Scholar] [CrossRef]
- Ingle, P.; Kim, Y.; Kim, Y. Dvs: A drone video synopsis towards storing and analyzing drone surveillance data in smart cities. Systems 2022, 10, 170. [Google Scholar] [CrossRef]
- Stauffer, C.; Grimson, W. Learning patterns of activity using real-time tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 747–757. [Google Scholar] [CrossRef]
- Hofmann, M.; Tiefenbacher, P.; Rigoll, G. Background segmentation with feedback: The pixel-based adaptive segmenter. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 38–43. [Google Scholar]
- St-Charles, P.; Bilodeau, G. Improving background subtraction using local binary similarity patterns. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Springs, CO, USA, 24–26 March 2014; pp. 509–515. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Finkel, R.; Bentley, J. Quad trees a data structure for retrieval on composite keys. Acta Inform. 1974, 4, 1–9. [Google Scholar] [CrossRef]
- Kolmogorov, V.; Zabin, R. What energy functions can be minimized via graph cuts? IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 147–159. [Google Scholar] [CrossRef]
- Liao, S.; Zhao, G.; Kellokumpu, V.; Pietikäinen, M.; Li, S. Modeling pixel process with scale invariant local patterns for background subtraction in complex scenes. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 1301–1306. [Google Scholar]
- Kasamwattanarote, S.; Cooharojananone, N.; Satoh, S.; Lipikorn, R. Real time tunnel based video summarization using direct shift collision detection. In Proceedings of the Pacific-Rim Conference on Multimedia, Shanghai, China, 21–24 September 2010; pp. 136–147. [Google Scholar]
- Kalman, R. A new approach to linear filtering and prediction problems. J. Basic Eng. Mar. 1960, 82, 35–45. [Google Scholar] [CrossRef]
- Emran, S.; Ye, N. Robustness of Chi-square and Canberra distance metrics for computer intrusion detection. Qual. Reliab. Eng. Int. 2002, 18, 19–28. [Google Scholar] [CrossRef]
- Bolme, D.; Beveridge, J.; Draper, B.; Lui, Y. Visual object tracking using adaptive correlation filters. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2544–2550. [Google Scholar]
- Gorin, B.; Waxman, A. Flight test capabilities for real-time multiple target detection and tracking for airborne surveillance and maritime domain awareness. Opt. Photonics Glob. Homel. Secur. IV 2008, 6945, 205–217. [Google Scholar]
- Rajab, M.; Woolfson, M.; Morgan, S. Application of region-based segmentation and neural network edge detection to skin lesions. Comput. Med. Imaging Graph. 2004, 28, 61–68. [Google Scholar] [CrossRef]
- Salvador, S.; Chan, P. Determining the number of clusters/segments in hierarchical clustering/segmentation algorithms. In Proceedings of the 16th IEEE International Conference on Tools with Artificial Intelligence, Boca Raton, FL, USA, 15–17 November 2004; pp. 576–584. [Google Scholar]
- Hafiane, A.; Chabrier, S.; Rosenberger, C.; Laurent, H. A new supervised evaluation criterion for region based segmentation methods. In Proceedings of the International Conference on Advanced Concepts for Intelligent Vision Systems, Delft, The Netherlands, 28–31 August 2007; pp. 439–448. [Google Scholar]
- Rao, R.; Savsani, V.; Vakharia, D. Teaching–learning-based optimization: A novel method for constrained mechanical design optimization problems. Comput.-Aided Des. 2011, 43, 303–315. [Google Scholar] [CrossRef]
- Kirkpatrick, S.; Gelatt, C., Jr.; Vecchi, M. Optimization by simulated annealing. Science 1983, 220, 671–680. [Google Scholar] [CrossRef]
- Boykov, Y.; Veksler, O.; Zabih, R. Fast approximate energy minimization via graph cuts. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 1222–1239. [Google Scholar] [CrossRef]
- Whitley, D. A genetic algorithm tutorial. Stat. Comput. 1994, 4, 65–85. [Google Scholar] [CrossRef]
- Peleg, S.; Rousso, B.; Rav-Acha, A.; Zomet, A. Mosaicing on adaptive manifolds. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1144–1154. [Google Scholar] [CrossRef]
- Zhi, Q.; Cooperstock, J. Toward dynamic image mosaic generation with robustness to parallax. IEEE Trans. Image Process. 2011, 21, 366–378. [Google Scholar] [CrossRef]
- Uyttendaele, M.; Eden, A.; Skeliski, R. Eliminating ghosting and exposure artifacts in image mosaics. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, Kauai, HI, USA, 8–14 December 2001; Volume 2, p. II. [Google Scholar]
- Brown, M.; Lowe, D. Automatic panoramic image stitching using invariant features. Int. J. Comput. Vis. 2007, 74, 59–73. [Google Scholar] [CrossRef]
- Lin, W.; Liu, S.; Matsushita, Y.; Ng, T.; Cheong, L. Smoothly varying affine stitching. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 345–352. [Google Scholar]
- Liu, W.; Chin, T. Correspondence insertion for as-projective-as-possible image stitching. arXiv 2016, arXiv:1608.07997. [Google Scholar]
- Chang, C.; Sato, Y.; Chuang, Y. Shape-preserving half-projective warps for image stitching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3254–3261. [Google Scholar]
- Li, N.; Xu, Y.; Wang, C. Quasi-homography warps in image stitching. IEEE Trans. Multimed. 2017, 20, 1365–1375. [Google Scholar] [CrossRef]
- Chen, Y.; Chuang, Y. Natural image stitching with the global similarity prior. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 186–201. [Google Scholar]
- Zhang, G.; He, Y.; Chen, W.; Jia, J.; Bao, H. Multi-viewpoint panorama construction with wide-baseline images. IEEE Trans. Image Process. 2016, 25, 3099–3111. [Google Scholar] [CrossRef] [PubMed]
- Xiang, T.; Xia, G.; Bai, X.; Zhang, L. Image stitching by line-guided local warping with global similarity constraint. Pattern Recognit. 2018, 83, 481–497. [Google Scholar] [CrossRef]
- Rav-Acha, A.; Pritch, Y.; Lischinski, D.; Peleg, S. Dynamosaics: Video mosaics with non-chronological time. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 58–65. [Google Scholar]
- Su, T.; Nie, Y.; Zhang, Z.; Sun, H.; Li, G. Video stitching for handheld inputs via combined video stabilization. In Proceedings of the SIGGRAPH ASIA 2016 Technical Briefs, Macao, China, 5–8 December 2016; pp. 1–4. [Google Scholar]
- Nie, Y.; Su, T.; Zhang, Z.; Sun, H.; Li, G. Dynamic video stitching via shakiness removing. IEEE Trans. Image Process. 2017, 27, 164–178. [Google Scholar] [CrossRef]
- Lin, K.; Liu, S.; Cheong, L.; Zeng, B. Seamless video stitching from hand-held camera inputs. Comput. Graph. Forum 2016, 35, 479–487. [Google Scholar] [CrossRef]
- Panda, D.; Meher, S. A new Wronskian change detection model based codebook background subtraction for visual surveillance applications. J. Vis. Commun. Image Represent. 2018, 56, 52–72. [Google Scholar] [CrossRef]
- Lee, D. Effective Gaussian mixture learning for video background subtraction. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 827–832. [Google Scholar]
- St-Charles, P.; Bilodeau, G.; Bergevin, R. Flexible background subtraction with self-balanced local sensitivity. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 408–413. [Google Scholar]
- Yao, J.; Odobez, J. Multi-layer background subtraction based on color and texture. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Rao, R.; Saroj, A. Constrained economic optimization of shell-and-tube heat exchangers using elitist-Jaya algorithm. Energy 2017, 128, 785–800. [Google Scholar] [CrossRef]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef]
- Mirjalili, S.; Mirjalili, S.; Lewis, A. Grey wolf optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef]
- Wang, W.; Chung, P.; Huang, C.; Huang, W. Event based surveillance video synopsis using trajectory kinematics descriptors. In Proceedings of the 2017 Fifteenth IAPR International Conference on Machine Vision Applications (MVA), Nagoya, Japan, 8–12 May 2017; pp. 250–253. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Existing Studies | Deployment | Viewpoint | Analysis | Methods | Lacuna | Time Complexity | Application | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Non-Real Time | Real Time | Single Camera | Multiple Camera | No of Summary | Visualization | Best View Selection | |||||
| Choudhary et al., 2008 [17] | ✔ | ✔ | 1 | S | Stroboscopic, Background Subtraction | Unable to deal with illumination and clutter effects. | Video Indexing | ||||
| Pritch et al., 2009 [19] | ✔ | ✔ | 1 | S | ✔ | K-Nearest Neighbors, Temporal Shifting | Substantial number of frames get dropped causing flickering effect. | Non-Chronological | |||
| Wang et al., 2011 [20] | ✔ | ✔ | 1 | S | Simulated Annealing (SA) | Method suffers from occlusion and memory inefficient. | Video Browsing | ||||
| Existing Studies | Deployment | Viewpoint | Analysis | Methods | Lacuna | Time Complexity | Application | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Non-Real Time | Real Time | Single Camera | Multiple Camera | No of Summary | Visualization | Best View Selection | |||||
| Rav-Acha et al., 2006 [27] | ✔ | ✔ | 1 | S | Markov Random Field (MRF), Graph Cut | For long time video synopsis, occlusion of objects is observed. | Low level Synopsis | ||||
| Pritch et al., 2007 [28] | ✔ | ✔ | 1 | S | SA | This framework fails to compute synopsis for moving cameras. | Query based Synopsis | ||||
| Yildiz et al., 2008 [28] | ✔ | ✔ | 1 | S | Nonlinear Image, Dynamic Programming (DP) | Computationally expensive (CE) and space complexity is more. | Real-time Synopsis | ||||
| Xu et al., 2008 [29] | ✔ | ✔ | 1 | S | Mean Shift Algorithm | Spatial dimension has not been considered while designing the framework. | Video Synopsis | ||||
| Pritch et al., 2008 [30] | ✔ | ✔ | 1 | S/D | ObjectDetection (OD), Tube Generation (TG) | This technique is not applicable to a video with dense activity. | Video Indexing | ||||
| Vural et al., 2009 [46] | ✔ | ✔ | 1 | S | Frequency Background Subtraction, DP | Information loss 3D to 2D projection, mount eye-glaze camera challenging. | Real-time Synopsis | ||||
| Feng et al., 2010 [47] | ✔ | ✔ | n | S | Background Subtraction | This study is not applicable for crowded scenario and is CE. | Online Synopsis | ||||
| Wang et al., 2012 [31] | ✔ | ✔ | 1 | S/D | Object Region Flag | Method suffers from occlusion and memory inefficient. | Scalable Browsing | ||||
| Sun et al., 2011 [32] | ✔ | ✔ | 1 | S | Maximum Motion Power | Cannot work with motion cameras. Also, illumination and cluttering effect not minimized. | Video Synopsis | ||||
| Huang et al., 2012 [48] | ✔ | ✔ | 1 | S | Object Tracking, Table Driven Approach | Flickering effect and occlusion can be majorly observed. | Online Synopsis | ||||
| Sun et al., 2012 [50] | ✔ | ✔ | 1 | S | Map-Based Optimization | The obtained synopsis is densely condensed creating confusion. | Online Synopsis | ||||
| Zhu et al., 2012 [33] | ✔ | ✔ | 1 | S | Key observation | Problem of occlusion arises since spatial dimension is neglected. | Video Synopsis | ||||
| Nie et al., 2013 [34] | ✔ | ✔ | n | S | ✔ | Alpha-Beta Graph Cut (ABGC) | Incapable to work with moving cameras. | Compact Synopsis | |||
| Hsia et al., 2013 [51] | ✔ | ✔ | 1 | S | Low Complexity Range Tree (LCRT) | Computationally expensive as well as occlusion can be noticed. | Retrieval | ||||
| Huang et al., 2014 [49] | ✔ | ✔ | n | S/D | Maximum Posteriori Estimation | Space complexity and occlusion is highly noted. | Real-time Synopsis | ||||
| Yao et al., 2014 [35] | ✔ | ✔ | 1 | S | OD, Object Tracking, Genetic Algorithm | Cannot detect and track continuously moving object. Thus, frames droped. | Video Synopsis | ||||
| Fu et al., 2014 [52] | ✔ | ✔ | n | S | Motion Structure, Hierarchical optimization | CE and does not support crowded videos. | Real-Time Synopsis | ||||
| Zhu et al., 2015 [58] | ✔ | ✔ | ✔ | n | D | ✔ | Joint Tube Generation | Obtained video is confusing and redundant. | Joint Synopsis | ||
| Olivera et al., 2015 [36] | ✔ | ✔ | 1 | S | Open source library | The resultant output suffers from jittering, flickering effects. | Video Synopsis | ||||
| Hoshen et al., 2015 [59] | ✔ | ✔ | ✔ | n | D | TG, SA | Occlusion and jittering effect is observed. Moreover, frame drop. | Live Video Synopsis | |||
| Mahapatra et al., 2015 [60] | ✔ | ✔ | n | D | Clustered Track, Collision Detection | CE and chronology of objects is not maintained. | Multiview Synopsis | ||||
| Tian et al., 2016 [37] | ✔ | ✔ | 1 | S | Genetic Algorithm | Occurance of illumination and cluttering effect and CS. | Video Synopsis | ||||
| Ahmed et al., 2017 [38] | ✔ | ✔ | 1 | S | TG | Computationally expensive and the output is confussing. | Video Synopsis | ||||
| Yi et al., 2018 [40] | ✔ | ✔ | 1 | S | Spatio temporal | Computationally expensive and cannot handle illumination. | Video Synopsis | ||||
| Li et al., 2018 [41] | ✔ | ✔ | 1 | S | ✔ | Group Partition, Greedy Approach | CE and does not support moving cameras. | Video Complex Synopsis | |||
| Ghatak et al., 2019 [42] | ✔ | ✔ | 1 | S | HSATLBO | Framework dissents moving cameras and several frames are lost. | Video Synopsis | ||||
| Zhang et al., 2020 [61] | ✔ | ✔ | n | S/D | Spatio-Temporal, Dynamic Programming | Browsing is not scalable and merging of objects can be seen. | Multiview Synopsis | ||||
| Mona et al., 2020 [43] | ✔ | ✔ | 1 | S | ✔ | Yolo3, Swarm Algorithm | High memory consumption and numerous frames are dropped. | Video Synopsis | |||
| Ghatak et al., 2020 [53] | ✔ | ✔ | 1 | S | HSAJAYA | Quality of the video is compromised. | Video Synopsis | ||||
| Chen et al., 2020 [54] | ✔ | ✔ | n | S | Attention-RetinaNet, Local Transparency | Computationally expensive and time consuming. | Video Synopsis | ||||
| Nanitha et al., 2021 [55] | ✔ | ✔ | n | S/D | ✔ | Joint Tube Generation | High memory consumption and occlusion of object is observed. | Video Synopsis | |||
| Kostadinov et al., 2022 [56] | ✔ | ✔ | n | S | ✔ | Object localization, Object tracking, reidentification | Resource intensive task thus consume large memory, flickering. | Video Synopsis | |||
| Xie et al., 2022 [62] | ✔ | ✔ | n | S/D | Video Spatialization, Spatiotemporal pipeline | CS as it deals with locating the camera position. | Geospatial Synopsis | ||||
| Li et al., 2022 [57] | ✔ | ✔ | S/D | Fourier Transform, Object tracking | Occlusion and jittering effect is observed. | Infrared Video synopsis | |||||
| Priyadharshini. 2022 [63] | ✔ | ✔ | n | S/D | ✔ | Action recognition module, Tracking | High memory consumption and occlusion of object is observed. | Spherical video Synopsis | |||
| Existing Studies | Deployment | Viewpoint | Analysis | Methods | Lacuna | Time Complexity | Application | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Non-Real Time | Real-Time | Single Camera | Multiple Camera | No of Summary | Visualization | Best View Selection | |||||
| Hao et al., 2013 [64] | ✔ | ✔ | 1 | S | Grab Cut, Object Segmentation | Does not support multi-camera view and the quality is low. | Video Synopsis | ||||
| Nie et al., 2014 [66] | ✔ | ✔ | 1 | S | MRF | Technique cannot be applied on moving cameras. | Video Synopsis | ||||
| Existing Studies | Deployment | Viewpoint | Analysis | Methods | Lacuna | Time Complexity | Application | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Non-Real Time | Real-Time | Single Camera | Multiple Camera | No of Summary | Visualization | Best View Selection | |||||
| Lu et al., 2013 [69] | ✔ | ✔ | 1 | S | Gaussian Mixture Model (GMM), TG | Synchronization and alignment of the tube is not seen. | Video Synopsis | ||||
| Wang et al., 2013 [70] | ✔ | ✔ | 1 | S | Flag-Based, SA | Computationally expensive and loss of pixels. | Video Indexing | ||||
| Zhong et al., 2014 [71] | ✔ | ✔ | 1 | S | ✔ | Graph Cut, SA | Cannot work with regular vidoes, movie and TV video. | Fast Analysis | |||
| Li et al., 2016 [80] | ✔ | ✔ | 1 | S | TG, Greedy Approach | Chronology is not maintained and performance drop can be observed. | Effective Synopsis | ||||
| Li et al., 2016 [83] | ✔ | ✔ | 1 | S | Temporal Domain, SA | Spatial domain is compromised giving rise to occlusion and frames are dropped. | Video Synopsis | ||||
| Jin et al., 2016 [81] | ✔ | ✔ | 1 | S | ✔ | Projection Matrix | Quality is not up to mark and time consuming. | Real-Time Synopsis | |||
| He et al., 2017 [74] | ✔ | ✔ | 1 | S | Collision Graph | Computationally expensive and loss of frames. | Online Video Synopsis | ||||
| He et al., 2017 [75] | ✔ | ✔ | 1 | S | Graph Coloring | Chronological order, motion structure, activity preserving are compromised. | Video Synopsis | ||||
| Liao et al., 2017 [76] | ✔ | ✔ | 1 | S | 3D Graph Cut | Computationally expensive and data lost can be seen. | Synopsis Browsing | ||||
| Ra et al., 2018 [77] | ✔ | ✔ | 1 | S | Fast Fourier Transform (FFT) | Computationally expensive and slow. | Real-Time Synopsis | ||||
| Pappalardo et al., 2019 [78] | ✔ | ✔ | 1 | S | Graph Coloring | Object tracking and detection are not considered. | Video Synopsis Dataset | ||||
| Ruan et al., 2019 [79] | ✔ | ✔ | 1 | S/D | Dynamic Graph Coloring | Computationally expensive and time consuming. | Online Video Synopsis | ||||
| Existing Studies | Deployment | Viewpoint | Analysis | Methods | Lacuna | Time Complexity | Application | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Non-Real Time | Real Time | Single Camera | Multiple Camera | No of Summary | Visualization | Best View Selection | |||||
| Chou et al., 2015 [84] | ✔ | ✔ | n | D | OD, Object tracking | Loss of frame. Object detection and tracking are left out. | Event Synopsis | ||||
| Lin et al., 2015 [85] | ✔ | ✔ | 1 | S | ✔ | Local Patch Learning Based Abnormality Detection | Is not applicable to moving cameras and output is not accurate. | Activity Synopsis | |||
| Ahmed et al., 2019 [86] | ✔ | ✔ | N | S/D | ✔ | TG | Does not support crowded data and moving cameras. | Intelligent Traffic | |||
| Method | Synopsis | Name and Reference | Technique | View Point | Distinguished | Computational Cost | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Class | Type | Single Camera | Multiple Camera | Pros | Cons | L | M | H | |||
| Pixel Based | Frame | Off-line | Peleg et al. [108] | Optical flow | ✔ | Fast | Low accuracy | ✔ | |||
| Object / Action | Zhi Q et al. [109] | Depth and color | ✔ | Degree of depth | Complicated calculation | ✔ | |||||
| Uyttendale et al. [110] | Graph structutre | ✔ | ✔ | Eliminate ghosting | Complicated calculation | ✔ | |||||
| Feature Based | Frame | Brown et al. [111] | Sparse matching | ✔ | Automated | Limited plane | ✔ | ||||
| Lin et al. [112] | Varying affine | ✔ | Address parallax | Single affine | ✔ | ||||||
| Liu et al. [113] | Insertion view | ✔ | Degree of parallax | Complicated calculation | ✔ | ||||||
| Chang et al. [114] | Tranformation | ✔ | ✔ | Overlapping Region | Limited to parallel | ✔ | |||||
| Object / Action | Li et al. [115] | Homography | ✔ | ✔ | Reduce distortion | Limited to parallel | ✔ | ||||
| Chen et al. [116] | Coarse fine | ✔ | Rotation correction | Local distortion | ✔ | ||||||
| Zhang et al. [117] | Prior constraints | ✔ | Wide baseline | Complicated calculation | ✔ | ||||||
| Xiang et al. [118] | Level Feature | ✔ | ✔ | Degree of texture | Local distortion | ✔ | |||||
| Object / Action / Collision | On-line | Rav-Ach et al. [119] | Embed the object | ✔ | Accurate alignment | Limited to camera | ✔ | ||||
| Su et al. [120] | Optimization function | ✔ | Balance stabilization | Complicated calculation | ✔ | ||||||
| Nie et al. [121] | Background foreground | ✔ | ✔ | Improved matching | Complicated calculation | ✔ | ✔ | ||||
| Lin et al. [122] | Estimate parameter | ✔ | 3D path | Limited to depth | ✔ | ||||||
| Dataset | Year | View Type | Scenes | No. of Views | Application |
|---|---|---|---|---|---|
| PETS | 2000 | Single/multi | In/Outdoor | 1, 2 | activity monitoring, tracking, segmentation |
| WEIZMANN | 2001 | Single-view | Outdoor | 1 | detection, temporal segmentation |
| KTH | 2004 | Single-view | In/Outdoor | 1 | feature extraction, synopsis |
| CAVIAR | 2007 | Multi-view | In/Outdoor | 1, 2 | activity monitoring, tracking, segmentation, clustering |
| Hall Monitor | 2014 | Single-view | Indoor | 1 | object detection, tracking, segmentation, synopsis |
| Day-Time | 2014 | Single-view | Indoor | 1 | object detection, tracking, segmentation, synopsis |
| F-Building | 2014 | Single-view | In/Outdoor | 1 | object detection, tracking, segmentation, synopsis |
| Dataset | Methods | Precision | Recall | F1 | Time of Execution (s) |
|---|---|---|---|---|---|
| Hall Monitor Video-1 | GMM | 0.55 | 0.60 | 0.59 | 356.12 |
| MAP Based | 0.66 | 0.69 | 0.71 | 214.89 | |
| LCRT Algorithm | 0.46 | 0.52 | 0.61 | 180.79 | |
| LOBSTERBGS | 0.54 | 0.66 | 0.60 | 269.01 | |
| Object Flag | 0.59 | 0.62 | 0.65 | 174.41 | |
| SuBSENSE | 0.69 | 0.75 | 0.61 | 266.32 | |
| 3D Graph Cut and Pixel Domain | 0.67 | 0.72 | 0.69 | 140.25 | |
| Graph Cut Algorithm | 0.57 | 0.63 | 0.64 | 251.45 | |
| GMC and VQ | 0.60 | 0.64 | 0.61 | 154.38 | |
| MLBSA | 0.75 | 0.76 | 0.72 | 284.03 | |
| Hall Monitor Video-2 | GMM | 0.48 | 0.55 | 0.47 | 557.12 |
| MAP Based | 0.61 | 0.66 | 0.52 | 348.25 | |
| LCRT Algorithm | 0.54 | 0.64 | 0.59 | 373.89 | |
| LOBSTERBGS | 0.64 | 0.66 | 0.60 | 545.43 | |
| Object Flag | 0.57 | 0.58 | 0.51 | 398.93 | |
| SuBSENSE | 0.59 | 0.60 | 0.55 | 436.25 | |
| 3D Graph Cut and Pixel Domain | 0.69 | 0.75 | 0.72 | 311.71 | |
| Graph Cut Algorithm | 0.61 | 0.67 | 0.52 | 342.55 | |
| GMC and VQ | 0.59 | 0.60 | 0.54 | 243.32 | |
| MLBSA | 0.62 | 0.63 | 0.56 | 634.01 | |
| Hall Monitor Video-3 | GMM | 0.67 | 0.74 | 0.65 | 388.26 |
| MAP Based | 0.78 | 0.83 | 0.77 | 247.03 | |
| LCRT Algorithm | 0.58 | 0.66 | 0.67 | 212.93 | |
| LOBSTERBGS | 0.66 | 0.80 | 0.66 | 301.15 | |
| Object Flag | 0.71 | 0.76 | 0.71 | 206.55 | |
| SuBSENSE | 0.81 | 0.89 | 0.67 | 298.46 | |
| 3D Graph Cut and Pixel Domain | 0.79 | 0.86 | 0.75 | 172.39 | |
| Graph Cut Algorithm | 0.69 | 0.77 | 0.7 | 283.59 | |
| GMC and VQ | 0.72 | 0.78 | 0.67 | 186.52 | |
| MLBSA | 0.87 | 0.90 | 0.78 | 316.17 | |
| Hall Monitor Video-4 | GMM | 0.64 | 0.70 | 0.67 | 398.59 |
| MAP Based | 0.75 | 0.79 | 0.79 | 257.36 | |
| LCRT Algorithm | 0.55 | 0.62 | 0.69 | 223.26 | |
| LOBSTERBGS | 0.63 | 0.76 | 0.68 | 311.48 | |
| Object Flag | 0.68 | 0.72 | 0.73 | 216.88 | |
| SuBSENSE | 0.78 | 0.85 | 0.69 | 308.79 | |
| 3D Graph Cut and Pixel Domain | 0.76 | 0.82 | 0.77 | 182.72 | |
| Graph Cut Algorithm | 0.66 | 0.73 | 0.72 | 293.92 | |
| GMC and VQ | 0.69 | 0.74 | 0.69 | 196.85 | |
| MLBSA | 0.84 | 0.86 | 0.80 | 326.50 | |
| Hall Monitor Video-5 | GMM | 0.58 | 0.66 | 0.60 | 369.98 |
| MAP Based | 0.69 | 0.75 | 0.72 | 228.75 | |
| LCRT Algorithm | 0.49 | 0.58 | 0.62 | 194.65 | |
| LOBSTERBGS | 0.57 | 0.72 | 0.61 | 282.87 | |
| Object Flag | 0.62 | 0.68 | 0.66 | 188.27 | |
| SuBSENSE | 0.72 | 0.81 | 0.62 | 280.18 | |
| 3D Graph Cut and Pixel Domain | 0.70 | 0.78 | 0.70 | 154.11 | |
| Graph Cut Algorithm | 0.60 | 0.69 | 0.65 | 265.31 | |
| GMC and VQ | 0.63 | 0.70 | 0.62 | 168.24 | |
| MLBSA | 0.78 | 0.82 | 0.73 | 297.89 |
| Optimization Technique | Activity Cost | Collision Cost () | Temporal Consistency Cost | Time of Execution (s) | |
|---|---|---|---|---|---|
| Video-1 | SA | 0 | 16.21 | 11.2 | 356.12 |
| TLBO | 0 | 16.01 | 11.5 | 214.89 | |
| Graph Coloring | 0 | 20.28 | 15.7 | 180.79 | |
| Greedy Approach | 0 | 18.05 | 13.1 | 269.01 | |
| Elitist-JAYA | 0 | 15.78 | 11.6 | 174.41 | |
| ABSGCut | 0 | 18.01 | 14.7 | 266.32 | |
| NSGA-II | 0 | 15.65 | 11.4 | 140.25 | |
| Table-driven | 0 | 17.47 | 12.3 | 251.45 | |
| GWO | 0 | 16.23 | 12.4 | 154.38 | |
| HSTLBO | 0 | 14.03 | 10.8 | 284.03 | |
| Video-2 | SA | 0 | 145.36 | 55.8 | 557.12 |
| TLBO | 0 | 137.32 | 49.4 | 348.25 | |
| Graph Coloring | 0 | 190.01 | 70.3 | 373.89 | |
| Greedy Approach | 0 | 158.74 | 65.5 | 545.43 | |
| Elitist-JAYA | 0 | 150.21 | 61.7 | 398.93 | |
| ABSGCut | 0 | 159.65 | 72.3 | 436.25 | |
| NSGA-II | 0 | 148.47 | 54.4 | 311.71 | |
| Table-driven | 0 | 162.55 | 70.6 | 342.55 | |
| GWO | 0 | 151.17 | 67.8 | 243.32 | |
| HSTLBO | 0 | 146.87 | 58.7 | 634.01 | |
| Video-3 | SA | 0 | 18.34 | 12.6 | 388.26 |
| TLBO | 0 | 18.14 | 12.9 | 247.03 | |
| Graph Coloring | 0 | 22.41 | 17.1 | 212.93 | |
| Greedy Approach | 0 | 20.18 | 14.5 | 301.15 | |
| Elitist-JAYA | 0 | 17.91 | 13.1 | 206.55 | |
| ABSGCut | 0 | 20.14 | 16.1 | 298.46 | |
| NSGA-II | 0 | 17.78 | 12.8 | 172.39 | |
| Table-driven | 0 | 19.60 | 13.7 | 283.59 | |
| GWO | 0 | 18.36 | 13.8 | 186.52 | |
| HSTLBO | 0 | 16.16 | 12.2 | 316.17 | |
| Video-4 | SA | 0 | 20.47 | 13.9 | 398.59 |
| TLBO | 0 | 20.27 | 14.2 | 257.36 | |
| Graph Coloring | 0 | 24.54 | 18.4 | 223.26 | |
| Greedy Approach | 0 | 22.31 | 15.8 | 311.48 | |
| Elitist-JAYA | 0 | 20.04 | 14.3 | 216.88 | |
| ABSGCut | 0 | 22.27 | 17.4 | 308.79 | |
| NSGA-II | 0 | 19.91 | 14.1 | 182.72 | |
| Table-driven | 0 | 21.73 | 15.1 | 293.92 | |
| GWO | 0 | 20.49 | 15.1 | 196.85 | |
| HSTLBO | 0 | 18.29 | 13.5 | 326.50 | |
| Video-5 | SA | 0 | 17.35 | 20.3 | 369.98 |
| TLBO | 0 | 17.15 | 20.6 | 228.75 | |
| Graph Coloring | 0 | 21.42 | 24.8 | 194.65 | |
| Greedy Approach | 0 | 19.19 | 22.2 | 282.87 | |
| Elitist-JAYA | 0 | 16.92 | 20.7 | 188.27 | |
| ABSGCut | 0 | 19.15 | 23.8 | 280.18 | |
| NSGA-II | 0 | 16.79 | 20.5 | 154.11 | |
| Table-driven | 0 | 18.61 | 21.4 | 265.31 | |
| GWO | 0 | 17.37 | 21.5 | 168.24 | |
| HSTLBO | 0 | 15.17 | 19.9 | 297.89 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ingle, P.Y.; Kim, Y.-G. Video Synopsis Algorithms and Framework: A Survey and Comparative Evaluation. Systems 2023, 11, 108. https://doi.org/10.3390/systems11020108
Ingle PY, Kim Y-G. Video Synopsis Algorithms and Framework: A Survey and Comparative Evaluation. Systems. 2023; 11(2):108. https://doi.org/10.3390/systems11020108
Chicago/Turabian StyleIngle, Palash Yuvraj, and Young-Gab Kim. 2023. "Video Synopsis Algorithms and Framework: A Survey and Comparative Evaluation" Systems 11, no. 2: 108. https://doi.org/10.3390/systems11020108
APA StyleIngle, P. Y., & Kim, Y.-G. (2023). Video Synopsis Algorithms and Framework: A Survey and Comparative Evaluation. Systems, 11(2), 108. https://doi.org/10.3390/systems11020108