
Mobile Social Recommendation Model Integrating Users’ Personality Traits and Relationship Strength under Privacy Concerns


Abstract
1. Introduction
2. Related Work
2.1. The Relationship between the Big Five Personality Traits and Users’ Online Behavior
2.2. The Strength of the User Relationship and Personality Traits in Social Networks
2.3. Recommendation Services and Privacy Protection in Social Networks
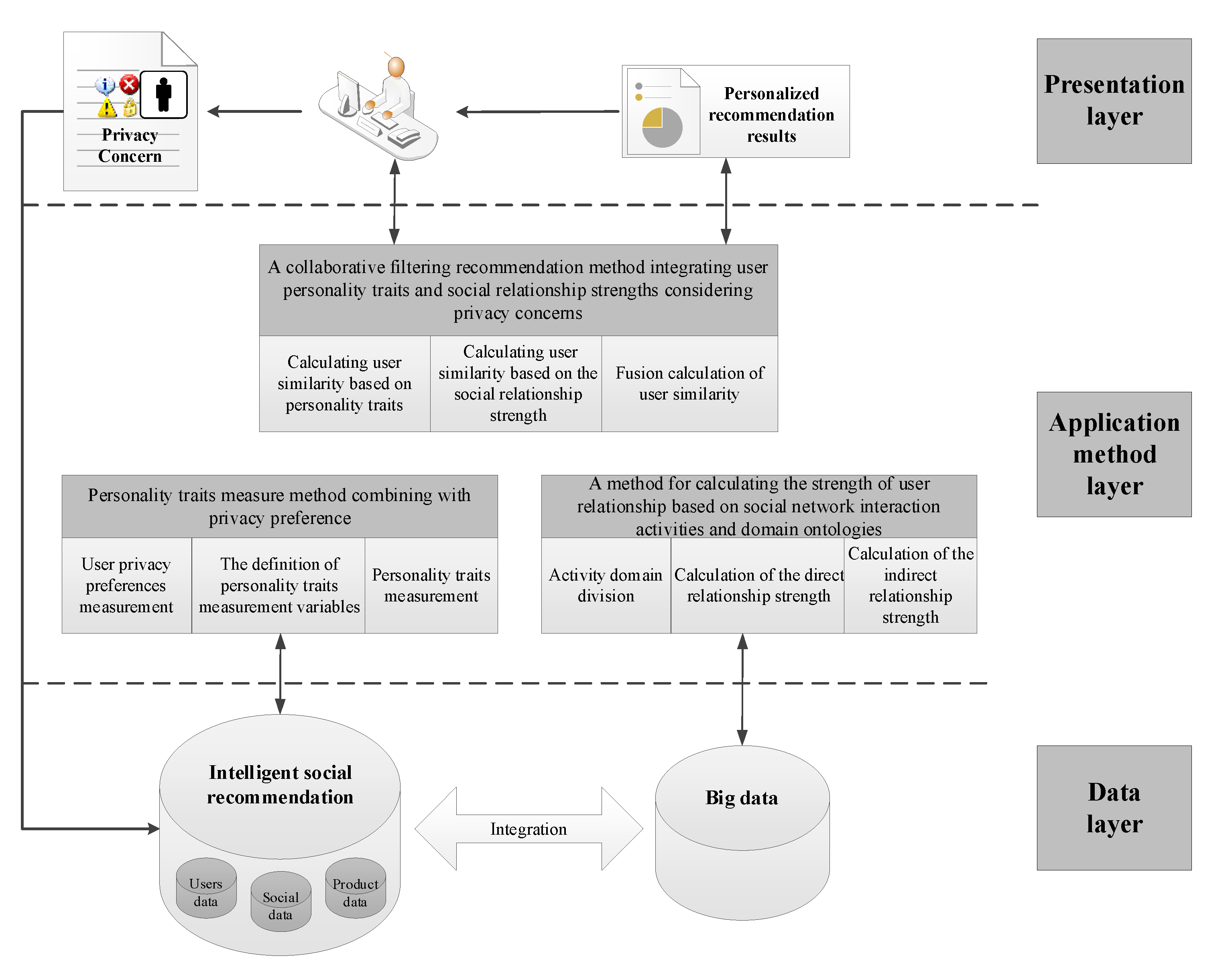
3. Methodology
3.1. The Implementation Mechanism of the Methodology
3.2. Personality Trait Measurement Method Integrating Privacy Preferences
3.2.1. User Privacy Preferences Measurement
3.2.2. Personality Traits Measurement
- , where the vector variables of , , and are calculated by a multiple linear regression model, respectively.
3.3. A Method for Calculating the Strength of a User Relationship Based on Social Network Interaction Activities and Domain Ontologies
3.3.1. Construction of the AI-URS Method
3.3.2. User Relationship Strength Measurement
- Allocation of Activity Domains
- 2
- User relationship strength measurement
- (a)
- Calculation of the direct relationship strength
- Among them, represents the weight of the relationship between and , users who are in the same activity domain, as determined by the frequency of interaction,. represents the number of interactions between and in this activity domain, and represents the total number of interactions of with other users in this activity domain. Here, l represents the count of interaction instances between two users in a specific activity domain. represents the count of instances where the source-target user in a specific activity domain interacts with all other users, and is a temporal factor, expressed as a function.
- (b)
- Calculation of the indirect relationship strength
- Among them, is the length of the relationship path and is its attenuation coefficient. is the weight of the j-th relationship path. denotes an attenuation function with a value varying continuously between 0 and 1, representing the weight coefficient of a relationship path among all paths. As the path length d increases, the value of the function will decrease. The calculation of the attenuation coefficient can reflect the phenomenon that the relationship strength between users will decrease with an increase in distance. There are often multiple relationship paths between two users. This paper assumes that the number of relationship paths between user and user is n. Pij = {P1, P2, …, Pn} is used to represent the set of relationship paths between two users, and represents the set of weights of each path.
- (c)
- Calculation of the comprehensive relationship strength
3.4. A Collaborative Filtering Recommendation Method Integrating Users’ Personality Traits and Social Relationship Strengths, Considering Privacy Concerns
3.4.1. Generation of a User Similarity Set
- Calculating user similarity based on personality traits, integrating with privacy preferences
- 2
- Calculating user similarity, based on the social relationship strength
- 3
- Fusion calculation of user similarity
3.4.2. Predicting User Preferences and Generating Recommendations
4. Experiments and Analysis
4.1. Data Collection and Evaluation Criteria
4.1.1. Data Collection
4.1.2. Evaluation Standard of Experimental Results
- Normalized Discounted Cumulative Gain (NDCG)
- 2
- P@R
- 3
- Mean Average Precision (MAP)
- represents the number of products/services recommended by the recommendation system for the i-th user; represents the ranking of the j-th product/service recommended by the system for the i-th user in the test set.
- 4
- Degree of Agreement (DOA)
- Among them, if,, otherwise . Thus, represents the predicted position of in the recommendation list. represents the potential predictive ranking products/services, and indicates that the products/services have been rated by in the test set.
4.2. Experimental Results of Personality Traits Measurement Integrating Privacy Preferences
- Based on the stepwise multivariable linear regression model, it can be found from the results in Table 2 (the confidence interval is set to 0.05) that there is a linear regression relationship between openness (the dependent variable) and the number of likes or comments of independent variables (the regression coefficient is −0.006), the number of followers (the regression coefficient is 0.125), the number of mentions (the regression coefficient is 0.594) and the number of shares (the regression coefficient is 0.087). At the same time, by analyzing the regression coefficient, it is found that there is a positive linear relationship between openness and the number of followers, the number of mentions and the number of shares, and the number of mentions in the social platform has the greatest impact on openness (the absolute value of the regression coefficient is the largest), which is in line with common sense. Finally, the multi-correlation coefficient and the coefficient of determination of the openness dimension regression model in personality traits are and respectively, indicating that openness is positively correlated with the number of likes or comments, the number of followers, the number of mentions, and the number of shares, and the model fits the data well.
- (2)
- Based on the stepwise multivariable regression model, it can be seen from the results in Table 3 that there is a linear regression relationship between extraversion (the dependent variable) and the number of followers (the regression coefficient 0.104), the number of likes or comments (the regression coefficient is 0.876), the number of following (the regression coefficient is −0.004) and the number of posts (the regression coefficient is 0.125) of the independent variable. At the same time, the multi-correlation coefficient and the coefficient of determination of the extraversion dimension regression model in personality traits are and , respectively, indicating that the extraversion is positively correlated with the number of followers, the number of posted works, the number of likes or comments, and the number of concerns, and the model fits the data well.
- (3)
- Based on the stepwise multivariable regression model, it can be seen from the results in Table 4 that there is a linear regression relationship between agreeableness (the dependent variable) and the number of followers (the regression coefficient is 0.145), the number of shares (the regression coefficient is 0.087), the number of likes or comments (the regression coefficient is −0.008) and the number of follows (the regression coefficient 1.161) of the independent variable. At the same time, the multi-correlation coefficient and the coefficient of determination of the agreeableness dimension regression model in terms of personality traits are and respectively, indicating that the agreeableness is positively correlated with the number of followers, the number of shares, the number of likes or comments, and the number of concerns, and the model fits the data well.
- (4)
- Based onthe stepwise multivariable regression model, it can be seen from the results in Table 5 that there is a linear regression relationship between the privacy preference (the dependent variable) and “Who is allowed to personally message me?” (the regression coefficient is −0.820), “Who is allowed to comment on me?” (the regression coefficient is −0.138), and whether to allow “My location” to be marked (the regression coefficient is −0.136) of the independent variable. In addition, the regression coefficients of “Who is allowed to personally message me?”, ”Who is allowed to comment on me?” and of whether to allow “My location” to be marked are all less than 0, indicating that with the increase in the user’s allowing personal messages, allowing comments, and allowing location information, the lower the resulting privacy preferences are, which is consistent with common sense. In this model, the absolute value of the standard coefficient “Who is allowed to personally message me?” is the largest. The multi-correlation coefficient and the coefficient of determination of the privacy preference dimension regression model in personality traits are and respectively, indicating that the privacy preference is positively correlated with “Who is allowed to personally message me?”, “Who is allowed to comment on me?” and whether to allow “My location” to be marked, and the model fits the data well.
4.3. Experimental Results of the Method for Calculating the Strength of User Relationship Based on Social Network Interactive Activities and Domain Ontologies
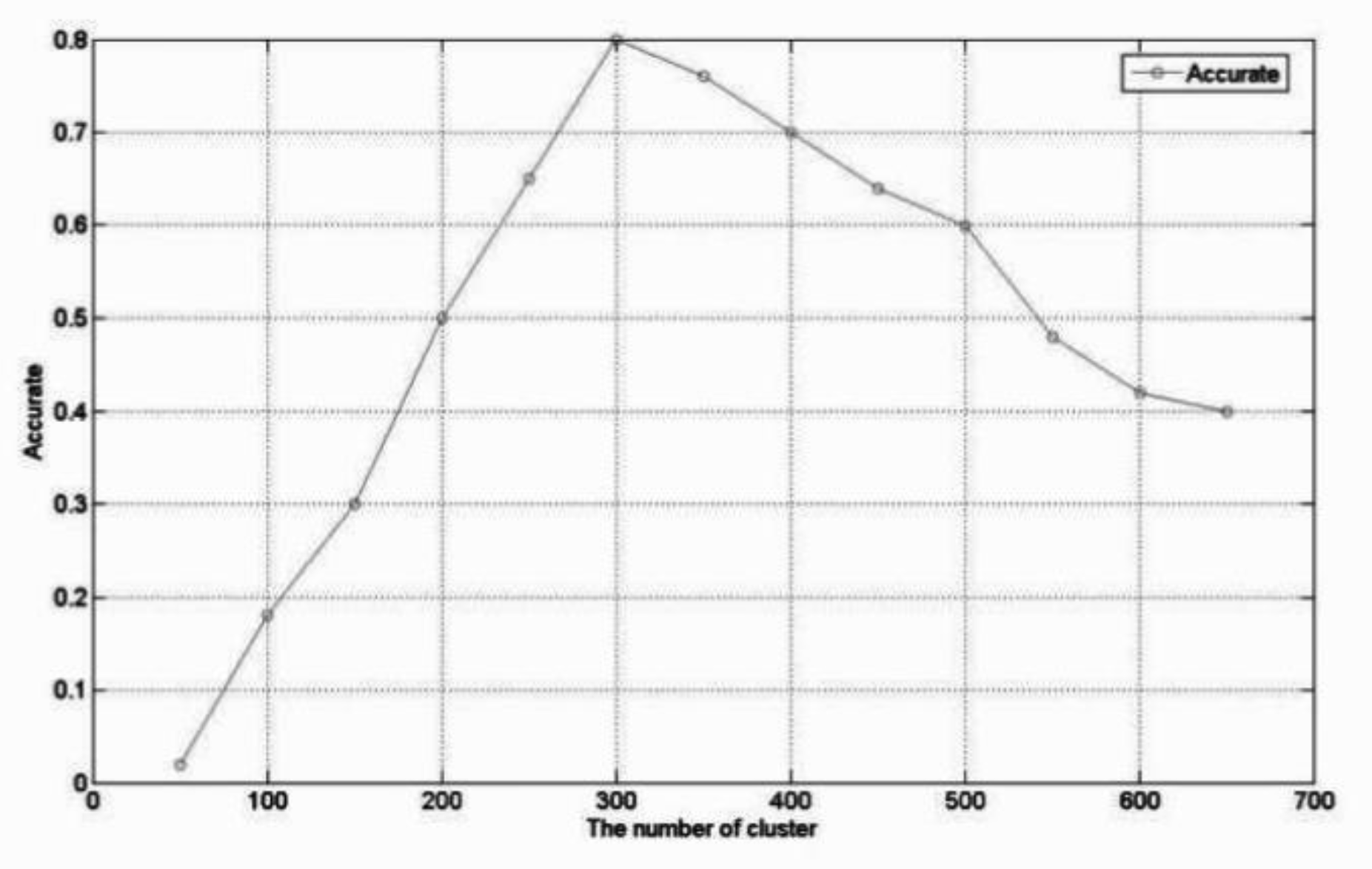
4.3.1. Evaluation Results of Activity Domains Allocation
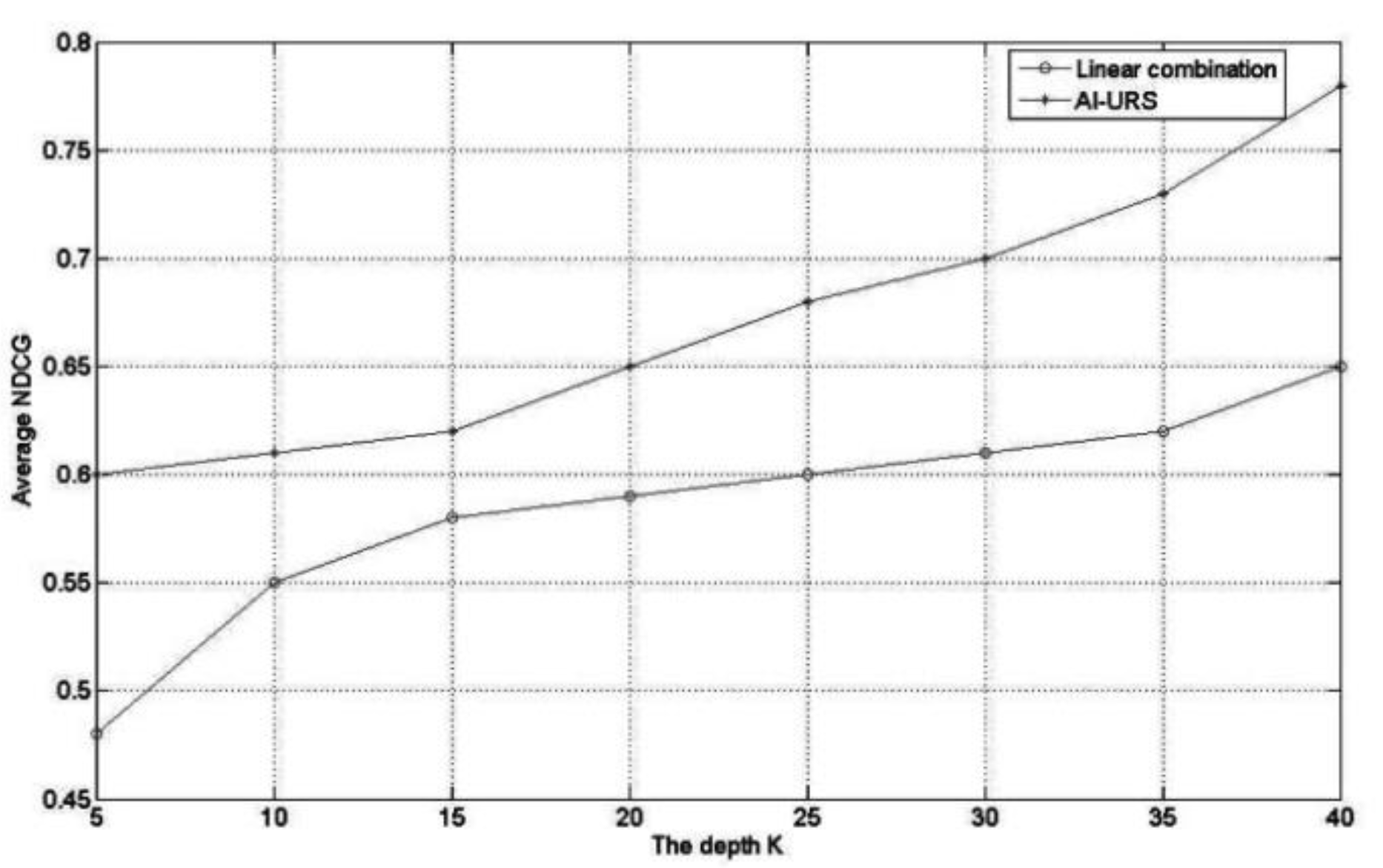
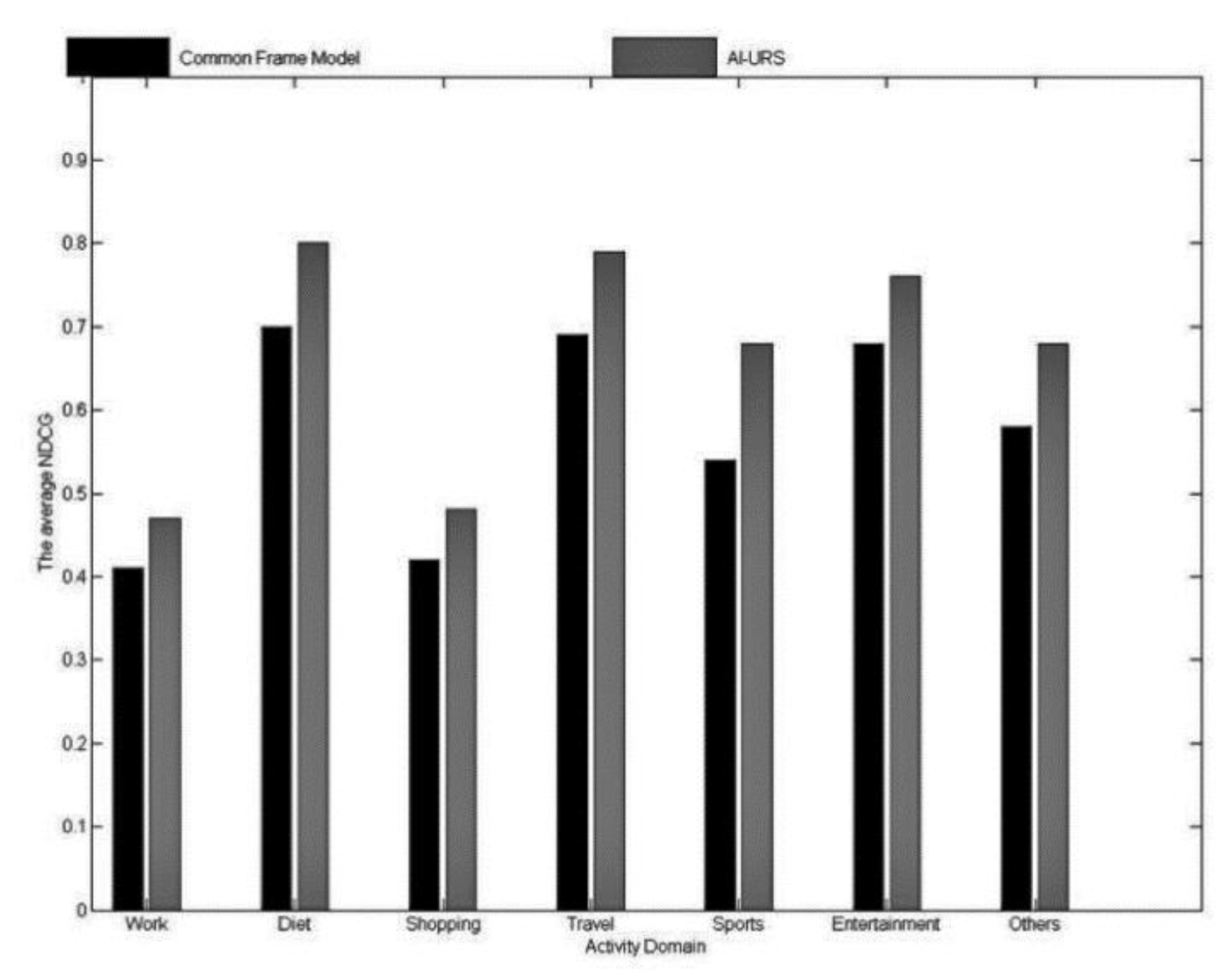
4.3.2. Evaluation Results of the Relationship Strength Calculation
- (a)
- AI-URS: The relationship strength is calculated using the method proposed in 3.3.
- (b)
- The linear combination method: This method obtains the strength of the relationship between two users in the same activity domain by calculating the personal data similarity of two users with direct connection and the linear combination of interactive activities. Compared with other methods, the biggest advantage of this method is its simple operation and low computational complexity.
- (c)
- The common framework model method. The strength of the direct relationship between users in the same interest activity domain is calculated by using the personal information of users and the interaction activity information between users.
4.4. Experimental Results of a Collaborative Filtering Recommendation Method Integrating User Personality Traits and Social Relationship Strengths, Considering Privacy Concerns
- (a)
- Comparison of the influence of different values on the hybrid collaborative filtering method based on user similarity fusion
- (b)
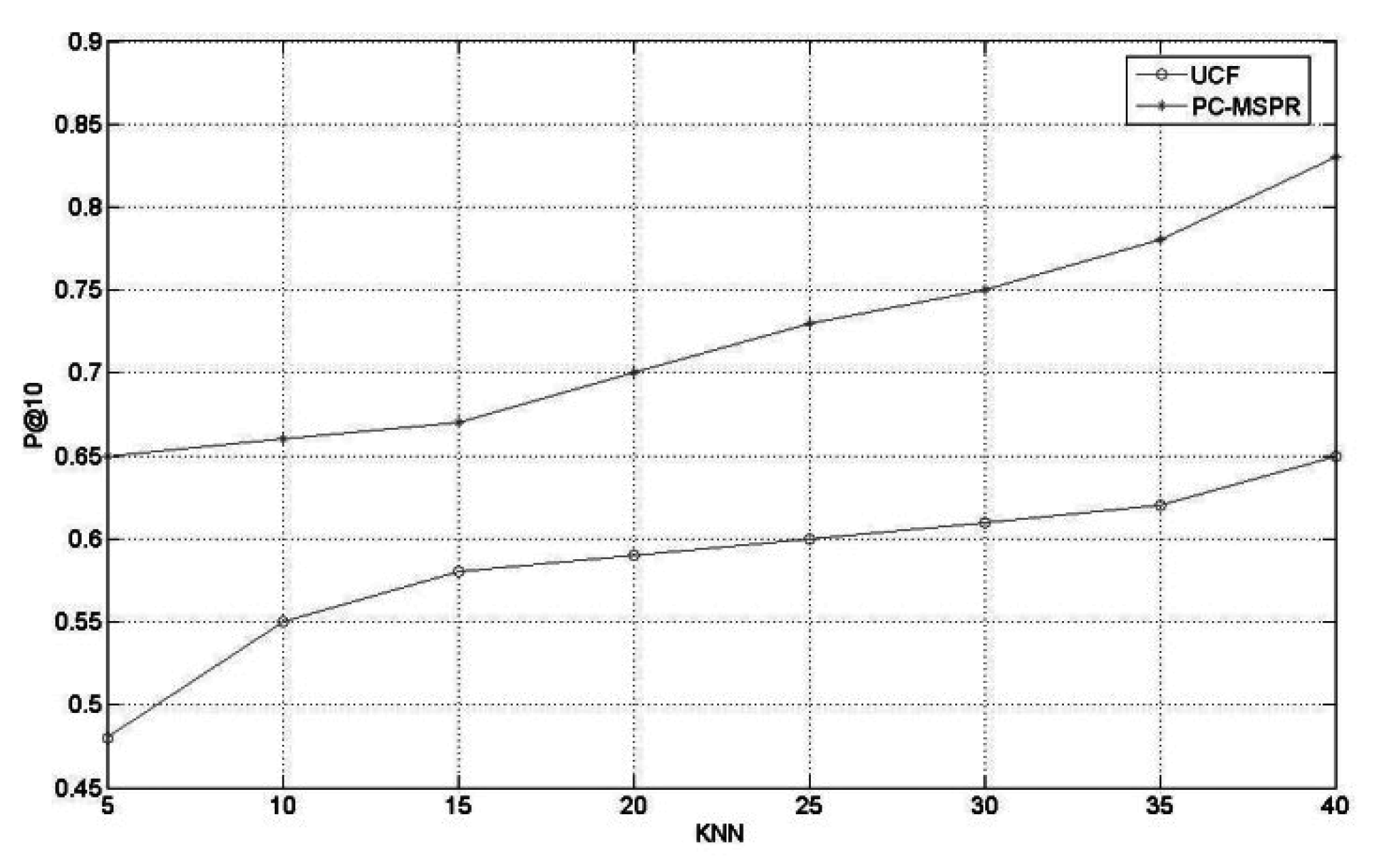
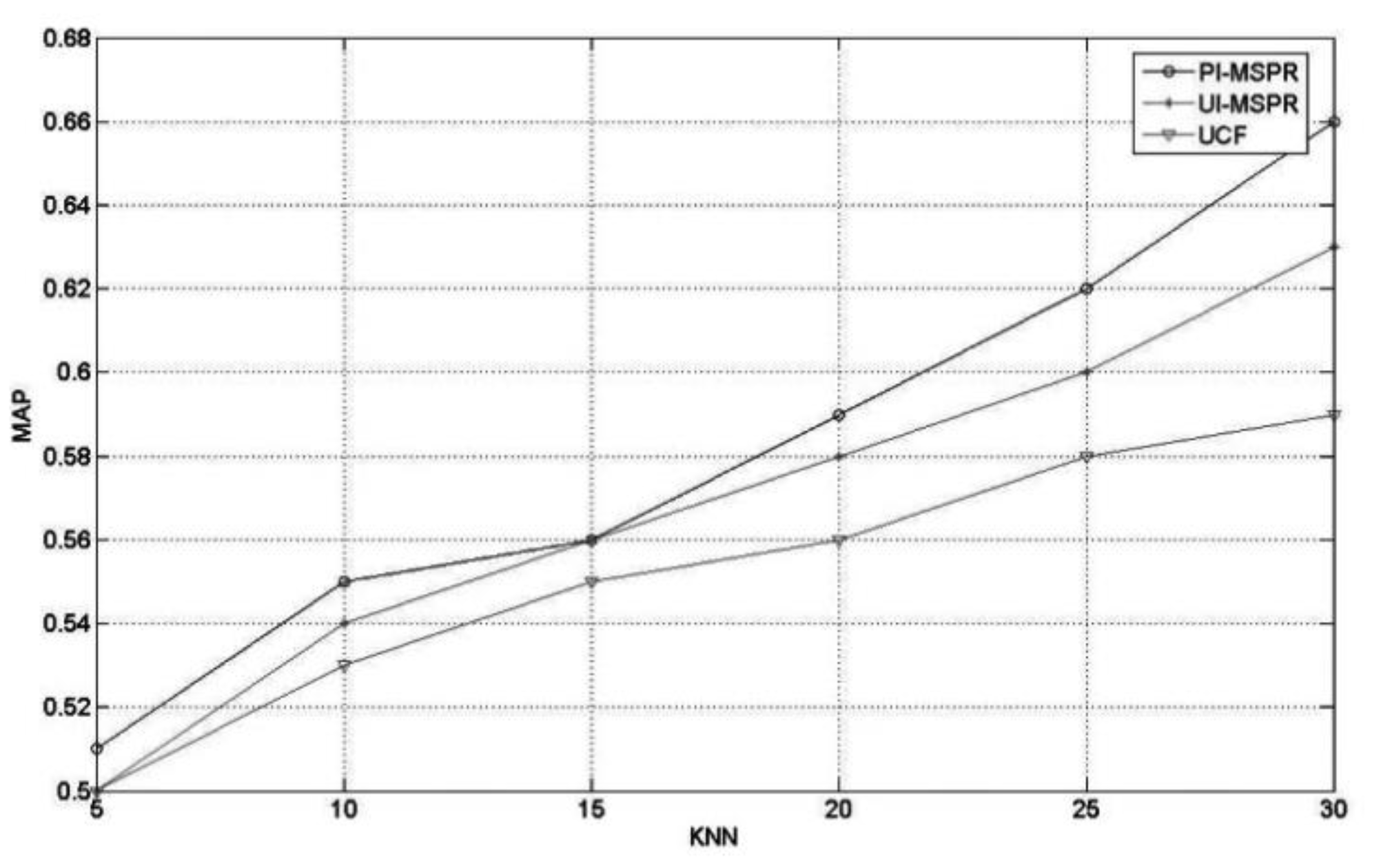
- Performance comparison between the different collaborative filtering methods
4.5. Discussion
5. Conclusions and Future Work
- This paper offers the rationality of personality traits for user preference mining and focuses on the analysis of the influence of openness, extraversion, and agreeableness on mobile users’ online behavior, innovatively integrating privacy concerns into the individual personality traits calculation model. The four influencing factors are quantified, and a personality trait calculation method integrating privacy concerns, i.e., PP-PTM, is proposed.
- A method for calculating user relationship strength, AI-URS, based on social network interactive activities and domain ontologies is proposed. AI-URS divides interactive activities into activity domains and calculates the strength of relationships between users belonging to the same activity domain. At the same time, the comprehensive relationship strength of users in the same domain is calculated based on interactive activity documents, including direct and indirect relationships, which overcomes the limitation of previous studies that could only calculate the strength of the relationship for directly related users and improves the accuracy of the calculation results.
- In the collaborative filtering recommendation process, user similarity is calculated by combining personality traits and user relationship strength according to privacy concerns. This paper uses simulated datasets and public datasets to conduct experiments to verify the superiority of the model. The experimental results show that the model proposed in this paper can help alleviate the cold-start and data sparsity problems in recommendations. In addition, this model can reduce the negative impact of current privacy issues on users’ adoption of mobile personalized intelligent recommendation services from the user’s subjective perspective.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, X.; Wang, H.; Zhang, C. A Literature Review of Social Commerce Research from a Systems Thinking Perspective. Systems 2022, 10, 56. [Google Scholar] [CrossRef]
- Nawaz, Z.; Zhao, C.H.; Nawaz, F.; Safeer, A.A.; Irshad, W. Role of Artificial Neural Networks Techniques in Development of Market Intelligence: A Study of Sentiment Analysis of eWOM of a Women’s Clothing Company. J. Theor. Appl. Electron. Commer. Res. 2021, 16, 1862–1876. [Google Scholar] [CrossRef]
- García-Sánchez, F.; Colomo-Palacios, R.; Valencia-García, R. A social-semantic recommender system for advertisements. Inf. Process. Manag. 2020, 57, 1–16. [Google Scholar] [CrossRef]
- Guo, F.P.; Zhou, W.; Lu, Q.B.; Zhang, C. Path extension similarity link prediction method based on matrix algebra in directed networks. Comput. Commun. 2022, 187, 83–92. [Google Scholar] [CrossRef]
- Song, C.Y.; Ge, Y.; Ge, T.J.; Wu, H.X.; Lin, Z.T.; Kang, H.; Yuan, X.J. Similar but Foreign: Link Recommendation Across Communities. Inf. Sci. 2021, 552, 142–166. [Google Scholar] [CrossRef]
- Zhao, Y.L.; Tarus, S.K.; Yang, L.T.; Sun, J.Y.; Ge, Y.F.; Wang, J.K. Privacy-preserving Clustering for Big Data in Cyber-physical-social Systems: Survey and Perspectives. Inf. Sci. 2020, 515, 132–155. [Google Scholar] [CrossRef]
- Lin, X.L.; Sarker, S.; Featherman, M. Users’ Psychological Perceptions of Information Sharing in the Context of Social Media: A Comprehensive Model. Int. J. Electron. Commer. 2019, 23, 453–491. [Google Scholar] [CrossRef]
- Al-Natour, S.; Cavusoglu, H.; Benbasat, I.; Aleem, U. An Empirical Investigation of the Antecedents and Consequences of Privacy Uncertainty in the Context of Mobile Apps. Inf. Syst. Res. 2020, 31, 1037–1063. [Google Scholar] [CrossRef]
- Wang, H.F.; Zuo, Y.; Li, H.; Wu, J.J. Cross-domain recommendation with user personality. Knowl. Based Syst. 2021, 213, 106664. [Google Scholar] [CrossRef]
- Power, R.A.; Pluess, M. Heritability estimates of the Big Five personality traits based on common genetic variants. Transl. Psychiatry 2015, 5, e604. [Google Scholar] [CrossRef] [PubMed]
- Taddicken, M. The Privacy Paradox in the Social Web: The Impact of Privacy Concerns, Individual Characteristics, and the Perceived Social Relevance on Different Forms of Self-disclosure. J. Comput. Mediat. Commun. 2014, 19, 248–273. [Google Scholar] [CrossRef]
- Goldberg, L.R. The structure of phenotypic personality traits. Am. Psychol. 1993, 48, 26–34. [Google Scholar] [CrossRef]
- McCrae, R.R.; John, O.P. An introduction to the five-factor model and its applications. J. Pers. 1992, 60, 175–215. [Google Scholar] [CrossRef]
- Kwantes, P.J.; Derbentseva, N.; Lam, Q.; Vartainian, O.; Marmurek, H.H.C. Assessing the big five personality traits with latent semantic analysis. Pers. Individ. Differ. 2016, 102, 229–233. [Google Scholar] [CrossRef]
- Moreno, J.L. Who Shall Survive?: A New Approach to the Problem of Human Interrelations; Nervous and Mental Disease Publishing Co.: Washington, DC, USA, 1934. [Google Scholar]
- Selfhout, M.; Burk, W.; Branje, S.; Denissen, J.J.A.; van Aken, M.; Meeus, M. Emerging late adolescent friendship networks and big five personality traits: A social network approach. J. Person. 2010, 78, 509–538. [Google Scholar] [CrossRef] [PubMed]
- Lu, Y.B.; Zhao, L.; Wang, B. From virtual community members to C2C e-commerce buyers: Trust in virtual communities and its effect on consumers’ purchase intention. Electro. Commer. Res. Appl. 2010, 9, 346–360. [Google Scholar] [CrossRef]
- Quercia, D.; Lambiotte, R.; Stillwell, D.; Kosinski, M.; Crowcroft, J. The personality of popular facebook users. In Proceedings of the ACM 2012 Conference on Computer Supported Cooperative Work, Seattle, WA, USA, 11–15 February 2013; pp. 955–964. [Google Scholar]
- Golbeck, J.; Robles, C.; Turner, K. Predicting personality with social media. In Proceedings of the International Conference on Human Factors in Computing Systems, Vancouver, BC, Canada, 7–12 May 2011; pp. 7–12. [Google Scholar]
- Zhao, Y.L.; Li, Y.B. Research on forecasting personality traits and relationship strngth of social network users. In Proceedings of the 7th (2012) China Management Annual Conference on Business Intelligence (Selected), Tianjin, China, 13–14 October 2012; pp. 4–13. [Google Scholar]
- Shi, G.H. Behaviors of Weibo Use Predict the Big-Five Personality Traits. Master’s Thesis, Huazhong Normal University, Wuhan, China, 2014. [Google Scholar]
- Lin, L.; Li, A.; Hao, B.; Guan, Z.; Zhu, T. Predicting Active Users’ Personality Based on Micro-Blogging Behaviors. PLoS ONE 2014, 9, e84997. [Google Scholar]
- Xiao, L.; Guo, F.P.; Lu, Q.B. Mobile Personalized Service Recommender Model Based on Sentiment Analysis and Privacy Concern. Mobile Inf. Syst. 2018, 2018, 8071251. [Google Scholar] [CrossRef]
- Xiao, L.; Lu, Q.B.; Guo, F.P. Mobile personalized recommendation model based on privacy concerns and context analysis for the sustainable development of M-commerce. Sustainability 2020, 12, 3036. [Google Scholar] [CrossRef]
- Xiang, R.; Neville, J.; Rogati, M. Modeling relationship strength in online social networks. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 981–990. [Google Scholar]
- Viswanath, B.; Mislove, A.; Cha, M.; Gummadi, P.K. On the evolution of user interaction in facebook. In Proceedings of the 2nd ACM Workshop on Online Social Networks, Barcelona, Spain, 17 August 2009; pp. 37–42. [Google Scholar]
- Lin, X.; Shang, T.; Liu, J.W. An estimation method for relationship strength in weighted social network graphs. J. Comput. Commun. 2014, 2, 82–89. [Google Scholar] [CrossRef]
- Feng, J.; Yang, L.T.; Gati, N.J.; Xie, X.; Gavuna, B.S. Privacy-preserving Computation in Cyber-physical-social Systems: A Survey of the State-of-the-art and Perspectives. Inf. Sci. 2020, 527, 341–355. [Google Scholar] [CrossRef]
- Zhao, X.J.; Yuan, J.; Li, G.D.; Chen, X.M.; Li, Z.J. Relationship strength estimation for online social networks with the study on Facebook. Neurocomputing 2012, 95, 89–97. [Google Scholar] [CrossRef]
- Su, Z.; Zheng, X.L.; Ai, J.; Shen, Y.M.; Zhang, X.X. Link prediction in recommender systems based on vector similarity. Phys. A Stat. Mech. Appl. 2020, 560, 125154. [Google Scholar] [CrossRef]
- Singla, P.; Richardson, M. Yes, there is a correlation: From social networks to personal behavior on the web. Environ. Geol. 2008, 58, 1627–1628. [Google Scholar] [CrossRef]
- Anusic, I.; Schimmack, U. Stability and change of personality traits, self-esteem, and well-being: Introducing the meta-analytic stability and change model of retest correlations. J. Person. Soc. Psychol. 2016, 110, 766–781. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Ma, X.; Wan, S.H.; Abbas, H.; Guizani, M. CrossRec: Cross-Domain Recommendations Based on Social Big Data and Cognitive Computing. Mob. Netw. Appl. 2018, 23, 1610–1623. [Google Scholar] [CrossRef]
- Lu, Q.B.; Guo, F.P. Personalized information recommendation model based on context contribution and item correlation. Measurement 2019, 142, 30–39. [Google Scholar] [CrossRef]
- Yang, G.L.; Yang, Q.; Jin, H.X. A novel trust recommendation model for mobile social network based on user motivation. Electron. Commer. Res. 2021, 21, 809–830. [Google Scholar] [CrossRef]
- He, J.N.; Fang, X.; Liu, H.Y.; Li, X.D. Mobile App Recommendation: An Involvement-Enhanced Approach. MIS Q. 2019, 43, 827–849. [Google Scholar] [CrossRef]
- Do, Q.; Liu, W.; Fan, J.; Tao, D.C. Unveiling Hidden Implicit Similarities for Cross-Domain Recommendation. IEEE Trans. Knowl. Data Eng. 2021, 33, 302–315. [Google Scholar] [CrossRef]
- Guo, F.P.; Lu, Q.B. Contextual Collaborative Filtering Recommendation Model Integrated with Drift Characteristics of User Interest. Hum. Cent. Comput. Inf. Sci. 2021, 11, 1–18. [Google Scholar] [CrossRef]
- Wang, T.; Manogaran, G.; Wang, M.H. Framework for social tag recommendation using Lion Optimization Algorithm and collaborative filtering technique. Clust. Comput. 2020, 23, 2009–2019. [Google Scholar] [CrossRef]
- Ma, H.; Zhou, D.Y.; Liu, C.; Lyu, M.R.; King, I. Recommender systems with social regularization. In Proceedings of the Fourth International Conference on Web Search and Web Data Mining, WSDM, Hong Kong, China, 9–12 February 2011; pp. 287–296. [Google Scholar]
- Fernández-Tobías, I.; Cantador, I.; Tomeo, P.; Anelli, V.W.; Di Noia, T. Addressing the User Cold Start with Cross-domain Collaborative Filtering: Exploiting Item Metadata in Matrix Factorization. User Model. User Adapt. Interact. 2019, 29, 443–486. [Google Scholar] [CrossRef]
- Guy, I.; Zwerdling, N.; Carmel, D.; Ronen, I.; Uziel, E.; Yogev, S.; Ofek-Koifman, S. Personalized recommendation of social software items based on social relations. In Proceedings of the Third ACM Conference on Recommender Systems, New York, NY, USA, 23–25 October 2009; pp. 53–60. [Google Scholar]
- Massa, P.; Avesani, P. Trust-aware recommender systems. In Proceedings of the 2007 ACM Conference on Recommender Systems, Minneapolis, MN, USA, 19–20 October 2007; pp. 17–24. [Google Scholar] [CrossRef]
- Sahu, A.K.; Dwivedi, P. Knowledge Transfer by Domain-independent User Latent Factor for Cross-domain Recommender Systems. Future Gener. Comput. Syst. 2020, 108, 320–333. [Google Scholar] [CrossRef]
- Tang, W.J.; Zhang, K.; Ren, J.; Zhang, Y.X.; Shen, X.M. Privacy-preserving Task Recommendation with Win-win Incentives for Mobile Crowdsourcing. Inf. Sci. 2020, 527, 477–492. [Google Scholar] [CrossRef]
- Zhao, C.; Yang, S.S.; Mccann, J.A. On the Data Quality in Privacy-Preserving Mobile Crowdsensing Systems with Untruthful Reporting. IEEE Trans. Mob. Comput. 2021, 20, 647–661. [Google Scholar] [CrossRef]
- Mousavi, R.; Chen, R.; Kim, D.J.; Chen, K.C. Effectiveness of Privacy Assurance Mechanisms in Users’ Privacy Protection on Social Networking Sites from the Perspective of Protection Motivation Theory. Decis. Support Syst. 2020, 135, 113323. [Google Scholar] [CrossRef]
- Christian, F.L.; Wong, S.F.; Chang, Y.; Bravo, E.R. The Effect of Fair Information Practices and Data Collection Methods on Privacy-Related Behaviors: A Study of Mobile Apps. Inf. Manag. 2021, 58, 103284. [Google Scholar] [CrossRef]
- Goldberg, D.; Nichols, D.; Oki, B.; Terry, D. Using collaborative filtering to weave an information tapestry. Commun. ACM 1992, 35, 61–70. [Google Scholar] [CrossRef]
- Henson, B.; Reyns, B.W.; Fisher, B.S. Security in the 21st Century: Examining the link between online social network activity, privacy, and interpersonal victimization. Crim. Justice Rev. 2011, 36, 253–268. [Google Scholar] [CrossRef]
- Hellriegel, D.; Slocum, J.W.; Woodman, R.W. Organizational Behavior, 9th ed.; East China Normal University Press: Shanghai, China, 2001. [Google Scholar]
- Abu-Salih, B.; Chan, K.Y.; Al-Kadi, O.; Al-Tawil, M.; Wongthongtham, P.; Issa, T.; Saadeh, H.; Al-Hassan, M.; Bremie, B.; Albahlal, A. Time-aware domain-based social influence prediction. J. Big Data 2020, 7, 1–37. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Users | Items | Ratings | Density |
|---|---|---|---|---|
| Amazon-Movie | 9870 | 41,058 | 232,110 | 0.057% |
| Amazon-Book | 12,137 | 40,232 | 314,409 | 0.064% |
| Variables | Regression Coefficient b | Standard Coefficient r | t-Test | Degree of Significance p |
|---|---|---|---|---|
| The number of followers | 0.125 | 0.806 | 11.104 | 0.000 |
| The number of shares | 0.087 | 0.121 | 2.489 | 0.014 |
| The number of likes or comments | −0.006 | −0.144 | −2.457 | 0.013 |
| The number of mentions | 0.594 | 0.918 | 2.162 | 0.030 |
| Variables | Regression Coefficient b | Standard Coefficient r | t-Test | Degree of Significance p |
|---|---|---|---|---|
| The number of followers | 0.104 | 0.654 | 11.941 | 0.000 |
| The number of posts | 0.125 | 0.166 | 3.747 | 0.000 |
| The number of likes or comments | 0.876 | 0.170 | 3.398 | 0.001 |
| The number of follows | −0.004 | −0.134 | −2.658 | 0.026 |
| Variables | Regression Coefficient b | Standard Coefficient r | t-Test | Degree of Significance p |
|---|---|---|---|---|
| The number of followers | 0.145 | 0.777 | 10.571 | 0.000 |
| The number of shares | 0.087 | 0.098 | 2.003 | 0.045 |
| The number of likes or comments | −0.008 | −0.170 | −2.877 | 0.003 |
| The number of follows | 1.161 | 0.193 | 3.471 | 0.001 |
| Variables | Regression Coefficient b | Standard Coefficient r | t-Test | Degree of Significance p |
|---|---|---|---|---|
| Who is allowed to personally message me | −0.820 | −0.653 | −11.942 | 0.000 |
| Who is allowed to comment on me | −0.138 | −0.165 | −3.746 | 0.030 |
| Whether to allow “My location” to be marked | −0.136 | −0.171 | −3.398 | 0.021 |
| Method | Extraversion | Openness | Agreeableness |
|---|---|---|---|
| A (Amazon-movie) | 0.73 | 0.77 | 0.71 |
| B (Amazon-movie) | 0.86 | 0.86 | 0.85 |
| A (Amazon-Book) | 0.72 | 0.78 | 0.70 |
| B (Amazon-Book) | 0.85 | 0.86 | 0.85 |
| The Hybrid Collaborative Filtering Method Based on User Similarity Fusion | P@5 (k = 10,20,30,50) | P@10 (k = 10,20,30,50) | ||||||
|---|---|---|---|---|---|---|---|---|
| 10 | 20 | 30 | 50 | 10 | 20 | 30 | 50 | |
| 0.0 | 0.47 | 0.52 | 0.54 | 0.57 | 0.45 | 0.48 | 0.52 | 0.53 |
| 0.2 | 0.49 | 0.55 | 0.56 | 0.58 | 0.48 | 0.51 | 0.53 | 0.55 |
| 0.4 | 0.51 | 0.56 | 0.57 | 0.58 | 0.50 | 0.53 | 0.54 | 0.56 |
| 0.6 (Demarcation point) | 0.53 | 0.57 | 0.58 | 0.59 | 0.51 | 0.54 | 0.55 | 0.57 |
| 0.8 | 0.52 | 0.55 | 0.57 | 0.58 | 0.49 | 0.53 | 0.54 | 0.55 |
| 1.0 | 0.48 | 0.52 | 0.54 | 0.57 | 0.47 | 0.51 | 0.52 | 0.54 |
| The Hybrid Collaborative Filtering Method Based on User Similarity Fusion | MAP (k = 10,20,30,50) | DOA (n = 2–8,3–7,4–6,5–5) | ||||||
|---|---|---|---|---|---|---|---|---|
| 10 | 20 | 30 | 50 | 80%-20% | 70%-30% | 60%-40% | 50%-50% | |
| 0.0 | 0.51 | 0.55 | 0.58 | 0.60 | 0.77 | 0.80 | 0.82 | 0.83 |
| 0.2 | 0.54 | 0.57 | 0.60 | 0.61 | 0.79 | 0.82 | 0.84 | 0.84 |
| 0.4 | 0.55 | 0.58 | 0.61 | 0.62 | 0.80 | 0.83 | 0.85 | 0.85 |
| 0.6 (Demarcation point) | 0.56 | 0.59 | 0.62 | 0.63 | 0.81 | 0.83 | 0.85 | 0.86 |
| 0.8 | 0.54 | 0.58 | 0.60 | 0.62 | 0.80 | 0.82 | 0.84 | 0.85 |
| 1.0 | 0.52 | 0.56 | 0.59 | 0.61 | 0.78 | 0.81 | 0.83 | 0.85 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, Q.; Guo, F.; Zhou, W.; Wang, Z.; Ji, S. Mobile Social Recommendation Model Integrating Users’ Personality Traits and Relationship Strength under Privacy Concerns. Systems 2022, 10, 198. https://doi.org/10.3390/systems10060198
Lu Q, Guo F, Zhou W, Wang Z, Ji S. Mobile Social Recommendation Model Integrating Users’ Personality Traits and Relationship Strength under Privacy Concerns. Systems. 2022; 10(6):198. https://doi.org/10.3390/systems10060198
Chicago/Turabian StyleLu, Qibei, Feipeng Guo, Wei Zhou, Zifan Wang, and Shaobo Ji. 2022. "Mobile Social Recommendation Model Integrating Users’ Personality Traits and Relationship Strength under Privacy Concerns" Systems 10, no. 6: 198. https://doi.org/10.3390/systems10060198
APA StyleLu, Q., Guo, F., Zhou, W., Wang, Z., & Ji, S. (2022). Mobile Social Recommendation Model Integrating Users’ Personality Traits and Relationship Strength under Privacy Concerns. Systems, 10(6), 198. https://doi.org/10.3390/systems10060198