
DVS: A Drone Video Synopsis towards Storing and Analyzing Drone Surveillance Data in Smart Cities




Abstract
1. Introduction
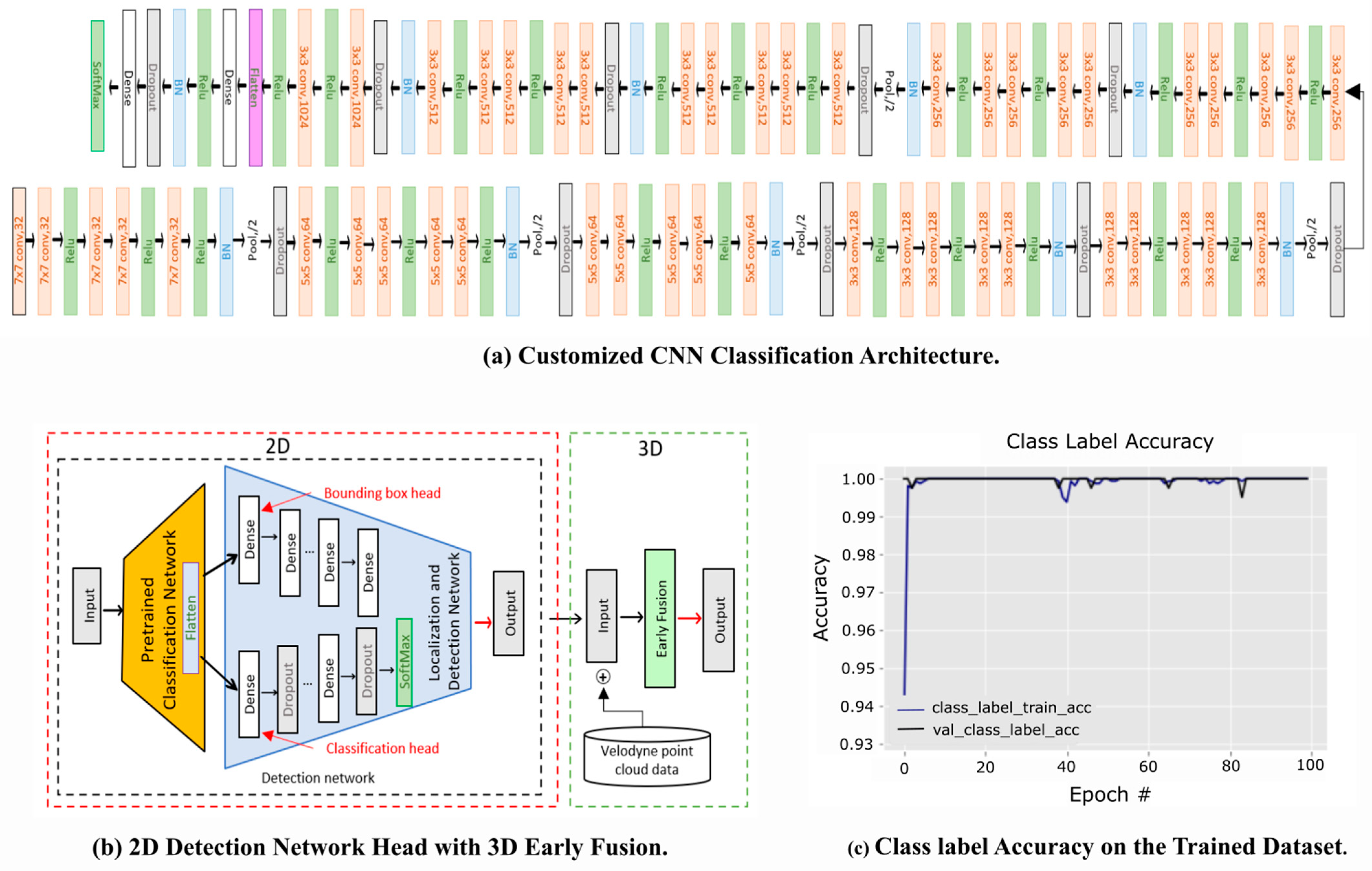
- We introduced a new customized classification CNNs model for classifying abnormal objects. In addition, we fused a lightweight detector network on top of the classification head for performing object detection and classification. Finally, the proposed model has been trained and evaluated on the benchmark dataset.
- We performed early fusion on the gimble camera 2D data and 3D point cloud LiDAR data to locate the abnormal object using customized CNN. We tracked the fused abnormal object tube for constructing a synchronized smooth synopsis. Furthermore, the model was tested on lightweight drones such as Tello, Parrot Mambo, Mavic 2, Mavic 3, and Anafi Parrot
- Extensive experiments exhibit supercilious execution of our model on different lightweight drones. Calibrating the frames to extract the background and align the foreground abnormal object network has significantly reduced the flickering effect. Finally, stitching was performed on the foreground and respective background, thus creating a compact drone video synopsis.
2. Related Work
2.1. Traditional Video Synopsis Methodologies
2.2. Object Detection in Drones
2.3. Problem Definition
- Background synthesis: Generating the chronological ordering of objects synced with the background is inconsistent. While stitching the foreground objects creates a collision and merging of the entities. It is a time and memory-intensive task; thus, these methods are insufficient for a longer dynamic video sequence [23].
- Dense video inputs: It isn’t easy to recognize the faster-moving objects in crowded scenarios, and the distinguished relationship among them is relatively slow. Thus, the synopsis obtained is not redundant; understanding the visual content is confusing and distorted [25].
- Demand-based synopsis: Most of the constructed video synopsis is not flexible to view as it does not meet the observer’s demands. A synopsis framework should provide a platform to build a synopsis based on the observer parameters. It will create an additional task to view only important objects based on an observer’s demand, thus creating a collision [26].
- Wider baseline and large parallax: Stitching is one of the major components of video surveillance systems. The wider baseline angle can cause irregular artifacts and distortion as the surveillance cameras are distributed in the stitched video. Mainly parallax contributes to the ghosting and the blurring in the stitched frames. These problems can be dealt with using deep learning-based semantic matching and optimization based on seam and mesh [26].
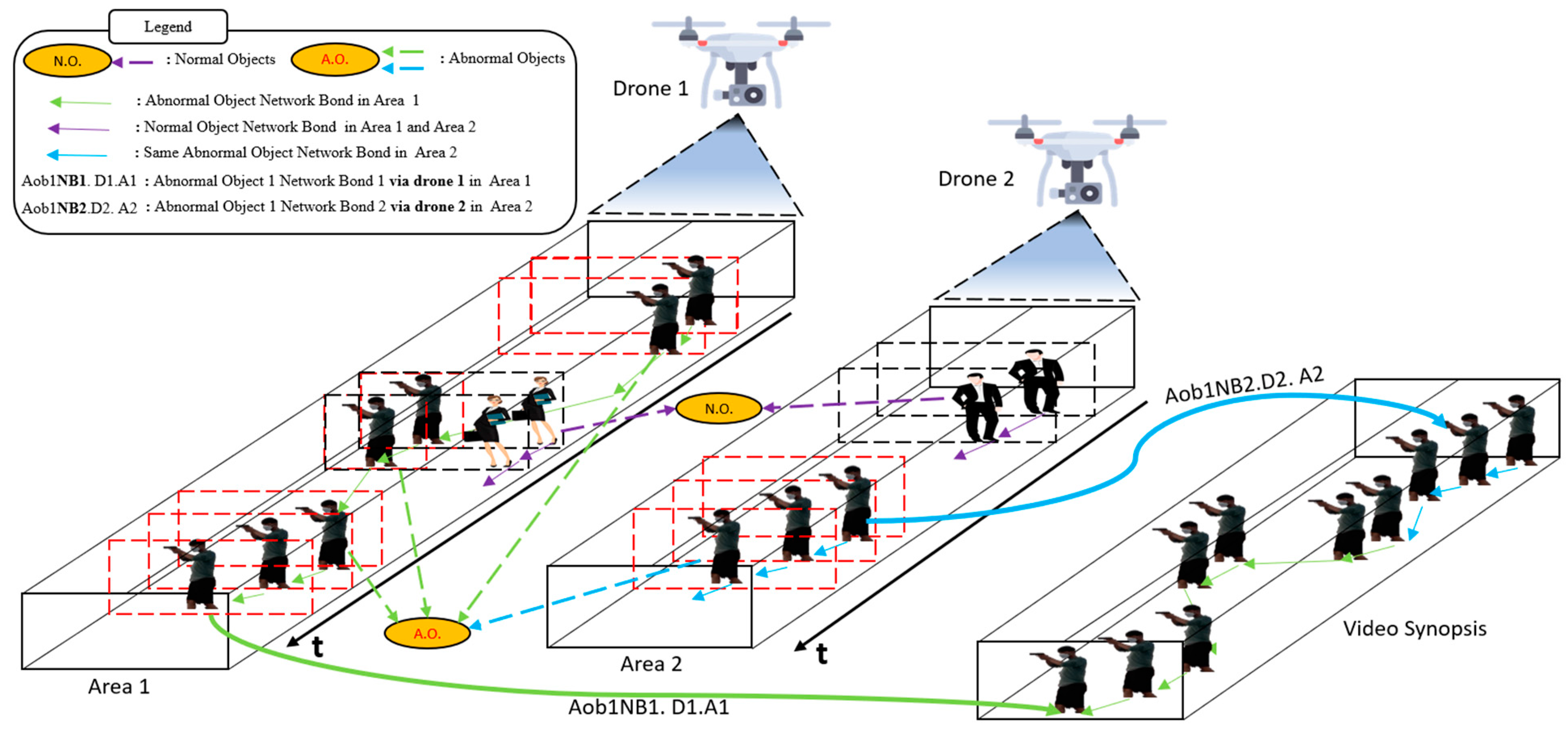
3. DVS Framework
3.1. System View of DVS
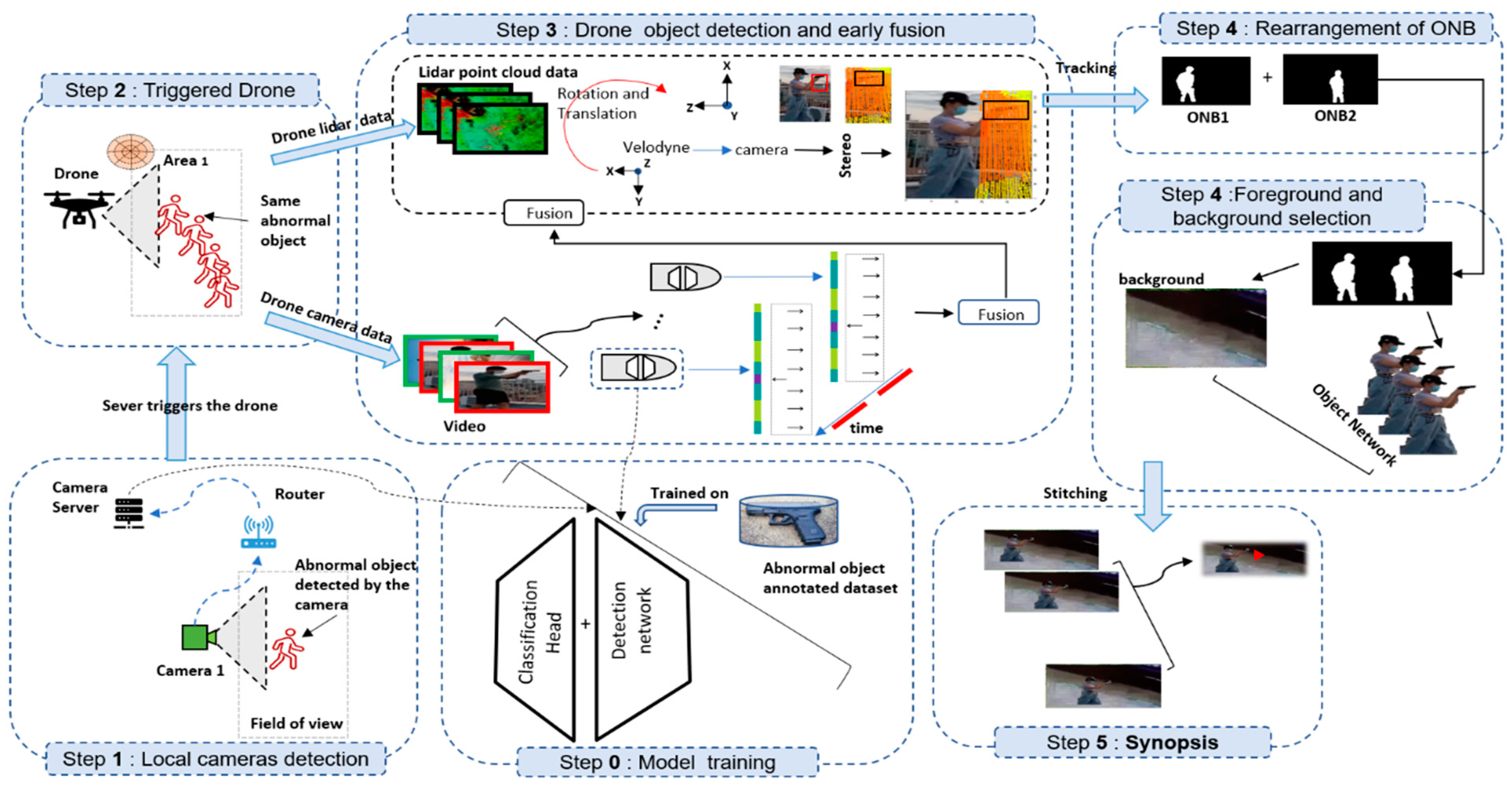
3.2. Process View of DVS
3.2.1. Model Training
3.2.2. Local Camera Detection
3.2.3. Triggered Drone
3.2.4. Drone Object Detection and Early Fusion
3.2.5. Rearrangement and Selection of Foreground and Background
3.2.6. Synopsis
4. Experimental Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Parrott, E.; Panter, H.; Morrissey, J.; Bezombes, F. A low cost approach to disturbed soil detection using low altitude digital imagery from an unmanned aerial vehicle. Drones 2019, 3, 50. [Google Scholar] [CrossRef]
- Doherty, P.; Rudol, P. A UAV search and rescue scenario with human body detection and geolocalization. In Proceedings of the Australasian Joint Conference on Artificial Intelligence, Gold Coast, Australia, 2–6 December 2007; pp. 1–13. [Google Scholar]
- Sa, I.; Hrabar, S.; Corke, P. Outdoor flight testing of a pole inspection UAV incorporating high-speed vision. In Field and Service Robotics; Springer: Cham, Switzerland, 2015; pp. 107–121. [Google Scholar]
- Gleason, J.; Nefian, A.V.; Bouyssounousse, X.; Fong, T.; Bebis, G. Vehicle detection from aerial imagery. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 2065–2070. [Google Scholar]
- Tang, T.; Deng, Z.; Zhou, S.; Lei, L.; Zou, H. Fast vehicle detection in UAV images. In Proceedings of the 2017 International Workshop on Remote Sensing with Intelligent Processing (RSIP), Shanghai, China, 18–21 May 2017; pp. 1–5. [Google Scholar]
- Kim, S.J.; Lim, G.J.; Cho, J. Drone flight scheduling under uncertainty on battery duration and air temperature. Comput. Ind. Eng. 2018, 117, 291–302. [Google Scholar] [CrossRef]
- Dogru, S.; Marques, L. Drone Detection Using Sparse Lidar Measurements. IEEE Robot. Autom. Lett. 2022, 7, 3062–3069. [Google Scholar] [CrossRef]
- United Nations Office on Drugs and Crime (UNODC). Global Study on Homicide 2019. Data: UNODC Homicide Statistics 2019. Available online: https://www.unodc.org/documents/data-and-analysis/gsh/Booklet_5.pdf (accessed on 1 March 2022).
- Mirzaeinia, A.; Hassanalian, M. Minimum-cost drone–nest matching through the kuhn–munkres algorithm in smart cities: Energy management and efficiency enhancement. Aerospace 2019, 6, 125. [Google Scholar] [CrossRef]
- Sharma, V.; You, I.; Pau, G.; Collotta, M.; Lim, J.D.; Kim, J.N. LoRaWAN-based energy-efficient surveillance by drones for intelligent transportation systems. Energies 2018, 11, 573. [Google Scholar] [CrossRef]
- Baskurt, K.B.; Samet, R. Video synopsis: A survey. Comput. Vis. Image Underst. 2019, 181, 26–38. [Google Scholar] [CrossRef]
- Gong, Y.; Liu, X. Video summarization with minimal visual content redundancies. In Proceedings of the 2001 International Conference on Image Processing (Cat. No. 01CH37205), Thessaloniki, Greece, 7–10 October 2001; pp. 362–365. [Google Scholar]
- Rav-Acha, A.; Pritch, Y.; Peleg, S. Making a long video short: Dynamic video synopsis. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; pp. 435–441. [Google Scholar]
- Pritch, Y.; Rav-Acha, A.; Gutman, A.; Peleg, S. Webcam synopsis: Peeking around the world. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar]
- Pritch, Y.; Rav-Acha, A.; Peleg, S. Nonchronological video synopsis and indexing. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 1971–1984. [Google Scholar] [CrossRef]
- Wang, S.; Liu, H.; Xie, D.; Zeng, B. A novel scheme to code object flags for video synopsis. In Proceedings of the 2012 Visual Communications and Image Processing, San Diego, CA, USA, 27–30 November 2012; pp. 1–5. [Google Scholar]
- Nie, Y.; Xiao, C.; Sun, H.; Li, P. Compact video synopsis via global spatiotemporal optimization. IEEE Trans. Vis. Comput. Graph. 2012, 19, 1664–1676. [Google Scholar] [CrossRef]
- Li, K.; Yan, B.; Wang, W.; Gharavi, H. An effective video synopsis approach with seam carving. IEEE Signal Process. Lett. 2015, 23, 11–14. [Google Scholar] [CrossRef]
- Moussa, M.M.; Shoitan, R. Object-based video synopsis approach using particle swarm optimization. Signal Image Video Process. 2021, 15, 761–768. [Google Scholar] [CrossRef]
- Vural, U.; Akgul, Y.S. Eye-gaze based real-time surveillance video synopsis. Pattern Recognit. Lett. 2009, 30, 1151–1159. [Google Scholar] [CrossRef]
- Feng, S.; Liao, S.; Yuan, Z.; Li, S.Z. Online principal background selection for video synopsis. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 17–20. [Google Scholar]
- Huang, C.-R.; Chung, P.-C.J.; Yang, D.-K.; Chen, H.-C.; Huang, G.-J. Maximum a posteriori probability estimation for online surveillance video synopsis. IEEE Trans. Circuits Syst. Video Technol. 2014, 24, 1417–1429. [Google Scholar] [CrossRef]
- Chou, C.-L.; Lin, C.-H.; Chiang, T.-H.; Chen, H.-T.; Lee, S.-Y. Coherent event-based surveillance video synopsis using trajectory clustering. In Proceedings of the 2015 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Turin, Italy, 29 June–3 July 2015; pp. 1–6. [Google Scholar]
- Lin, W.; Zhang, Y.; Lu, J.; Zhou, B.; Wang, J.; Zhou, Y. Summarizing surveillance videos with local-patch-learning-based abnormality detection, blob sequence optimization, and type-based synopsis. Neurocomputing 2015, 155, 84–98. [Google Scholar] [CrossRef]
- Ahmed, S.A.; Dogra, D.P.; Kar, S.; Patnaik, R.; Lee, S.-C.; Choi, H.; Nam, G.P.; Kim, I.-J. Query-based video synopsis for intelligent traffic monitoring applications. IEEE Trans. Intell. Transp. Syst. 2019, 21, 3457–3468. [Google Scholar] [CrossRef]
- Mahapatra, A.; Sa, P.K. Video Synopsis: A Systematic Review. In High Performance Vision Intelligence; Springer: Singapore, 2020; pp. 101–115. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Everingham, M.; Eslami, S.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Breckon, T.P.; Barnes, S.E.; Eichner, M.L.; Wahren, K. Autonomous real-time vehicle detection from a medium-level UAV. In Proceedings of the 24th International Conference on Unmanned Air Vehicle Systems, Bristol, UK, 30 March–1 April 2009; pp. 29.21–29.29. [Google Scholar]
- Razakarivony, S.; Jurie, F. Vehicle detection in aerial imagery: A small target detection benchmark. J. Vis. Commun. Image Represent. 2016, 34, 187–203. [Google Scholar] [CrossRef]
- Leira, F.S.; Johansen, T.A.; Fossen, T.I. Automatic detection, classification and tracking of objects in the ocean surface from UAVs using a thermal camera. In Proceedings of the 2015 IEEE Aerospace Conference, Big Sky, MT, USA, 7–14 March 2015; pp. 1–10. [Google Scholar]
- Lee, J.; Wang, J.; Crandall, D.; Šabanović, S.; Fox, G. Real-time, cloud-based object detection for unmanned aerial vehicles. In Proceedings of the 2017 First IEEE International Conference on Robotic Computing (IRC), Taichung, Taiwan, 10–12 April 2017; pp. 36–43. [Google Scholar]
- Snoek, C.G.; Worring, M.; Smeulders, A.W. Early versus late fusion in semantic video analysis. In Proceedings of the 13th Annual ACM International Conference on Multimedia, Singapore, 6–11 November 2005; pp. 399–402. [Google Scholar]
- Griffin, G.; Holub, A.; Perona, P. Caltech-256 Object Category Dataset. Pietro 2007. Available online: https://authors.library.caltech.edu/7694/?ref=https://githubhelp.com (accessed on 13 August 2022).
- Panda, D.K.; Meher, S. A new Wronskian change detection model based codebook background subtraction for visual surveillance applications. J. Vis. Commun. Image Represent. 2018, 56, 52–72. [Google Scholar] [CrossRef]
- Zhao, Z.-Q.; Zheng, P.; Xu, S.-t.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Jensen, O.B. Drone city–power, design and aerial mobility in the age of “smart cities”. Geogr. Helv. 2016, 71, 67–75. [Google Scholar] [CrossRef]
- Nguyen, D.D.; Rohacs, J.; Rohacs, D. Autonomous flight trajectory control system for drones in smart city traffic management. ISPRS Int. J. Geo-Inf. 2021, 10, 338. [Google Scholar] [CrossRef]
- Ismail, A.; Bagula, B.A.; Tuyishimire, E. Internet-of-things in motion: A uav coalition model for remote sensing in smart cities. Sensors 2018, 18, 2184. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Trained | Aeroplane | Bike | Bus | Estate Car | Person | Army Tank | Police Van | Racing Car | Revolver | Rifle | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R-CNN (alex) [42] | 07++In | 68.1 | 72.8 | 66.3 | 74.2 | 58.7 | 62.3 | 53.4 | 58.6 | 27.6 | 33.8 | 57.58 |
| R-CNN(VGG16) [42] | 07++In | 73.4 | 77.0 | 75.1 | 78.1 | 73.1 | 68.8 | 57.7 | 60.1 | 38.4 | 35.9 | 63.76 |
| GCNN [42] | 07++In | 68.3 | 77.3 | 78.5 | 79.5 | 66.6 | 52.4 | 68.57 | 64.8 | 34.8 | 40.6 | 63.13 |
| SubCNN [42] | 07++In | 70.2 | 80.5 | 79.0 | 78.7 | 70.2 | 60.5 | 47.9 | 72.6 | 38.2 | 45.9 | 64.37 |
| HyperNet [42] | 07++In | 77.4 | 83.3 | 83.1 | 87.4 | 79.1 | 70.5 | 62.4 | 76.3 | 51.6 | 50.1 | 72.12 |
| Faster R-CNN [42] | 07++12++In | 84.9 | 79.8 | 77.5 | 75.9 | 79.6 | 74.9 | 70.8 | 79.2 | 40.5 | 52.3 | 71.54 |
| YOLO [42] | 07++12++In | 77.0 | 67.2 | 55.9 | 63.5 | 63.5 | 60.4 | 57.8 | 60.3 | 24.5 | 38.9 | 56.9 |
| YOLOv2 [42] | 07++12++In | 79.0 | 75.0 | 78.2 | 79.3 | 75.6 | 73.5 | 63.4 | 61.6 | 30.8 | 45.6 | 66.2 |
| SSD300 [42] | 07++12++In | 85.1 | 82.5 | 79.1 | 84.0 | 83.7 | 79.5 | 74.6 | 81.2 | 72.9 | 51.6 | 77.42 |
| Proposed | In | - | - | - | - | - | 80 | 70.0 | 62 | 81 | 55.0 | 69.6 |
| Proposed | 07++12 | 78.5 | 79.5 | 79.3 | 82.2 | 81.2 | - | - | - | - | - | 80.14 |
| Proposed | 07++In | 81.2 | 82.7 | 83.3 | 80.0 | 84.2 | 82 | 74 | 75 | 83 | 60.1 | 78.55 |
| Proposed (V.S) | 07++In++Cal | 87.2 | 88.7 | - | - | - | - | 80 | - | 88 | - | 85.97 |
| Sr. | Drone Type | Camera View (Degree) | Camera Dimension | Mobile Net | Tiny-Yolo | Proposed | |||
|---|---|---|---|---|---|---|---|---|---|
| Loading | Inference | Loading | Inference | Loading | Inference | ||||
| 1 | Tello | Fixed Front View (80) | 2592 × 1936 | 0.023 | 0.038 | 0.019 | 0.035 | 0.09 | 0.021 |
| 2 | Parrot Mambo | Fixed Down View | 1280 × 720 | 0.021 | 0.032 | 0.017 | 0.028 | 0.08 | 0.019 |
| 3 | Mavic 2 | 135 to 100 | 1920 × 1080 | 0.019 | 0.025 | 0.016 | 0.022 | 0.07 | 0.016 |
| 4 | Mavic 3 | 135 to 100 | 1920 × 1080 | 0.014 | 0.021 | 0.013 | 0.018 | 0.06 | 0.014 |
| 5 | Anafi Parrot | 180 | 2704 × 1520 | 0.09 | 0.016 | 0.012 | 0.014 | 0.04 | 0.012 |
| Video | Original Video (t) | Frame Rate (fps) | Video Length (#Frame) | Number of Object | Number of Abnormal Object | Drone Video Synopsis |
|---|---|---|---|---|---|---|
| v1 | 3.24 min | 24 | 4665 | 3 | 2 | 0.55 s |
| v2 | 2.20 min | 25 | 3300 | 2 | 1 | 0.49 s |
| v3 | 1.23 min | 23 | 1690 | 1 | 1 | 0.34 s |
| v4 | 5.24 min | 23 | 7231 | 2 | 1 | 1.58 s |
| v5 | 3.70 min | 23 | 5106 | 2 | 1 | 1.07 s |
| v6 | 6.38 min | 23 | 8786 | 2 | 1 | 2.13 s |
| v7 | 8.24 min | 23 | 11,362 | 2 | 1 | 2.20 s |
| v8 | 7.32 min | 23 | 10,097 | 2 | 1 | 1.15 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ingle, P.Y.; Kim, Y.; Kim, Y.-G. DVS: A Drone Video Synopsis towards Storing and Analyzing Drone Surveillance Data in Smart Cities. Systems 2022, 10, 170. https://doi.org/10.3390/systems10050170
Ingle PY, Kim Y, Kim Y-G. DVS: A Drone Video Synopsis towards Storing and Analyzing Drone Surveillance Data in Smart Cities. Systems. 2022; 10(5):170. https://doi.org/10.3390/systems10050170
Chicago/Turabian StyleIngle, Palash Yuvraj, Yujun Kim, and Young-Gab Kim. 2022. "DVS: A Drone Video Synopsis towards Storing and Analyzing Drone Surveillance Data in Smart Cities" Systems 10, no. 5: 170. https://doi.org/10.3390/systems10050170
APA StyleIngle, P. Y., Kim, Y., & Kim, Y.-G. (2022). DVS: A Drone Video Synopsis towards Storing and Analyzing Drone Surveillance Data in Smart Cities. Systems, 10(5), 170. https://doi.org/10.3390/systems10050170