
A Novel Air Pollutant Concentration Prediction System Based on Decomposition-Ensemble Mode and Multi-Objective Optimization for Environmental System Management



Abstract
:1. Introduction
2. Design of the APCP System
2.1. Decomposition-Ensemble Mode
2.2. Weight Search Mechanism
| Algorithm 1. Weight search mechanism |
| Input: Outputs: F—the best fitness results —the suitable weights Parameters: ITer—the iteration number —the current iteration number —the location of -th grasshopper —the number of —the dimension of ARchIvemax—the archive size ARchIvenum—the number of repositories 1: /* Initialize . */ 2: /*Set , , and ITer.*/ 3. /*Calculate F of each search agent.*/ 4. /*.*/ 5. WHILE () DO 6. /*Update coefficient .*/ 7. 8. FOR (each search agent) DO 9. /*Normalize .*/ 10. /*Update .*/ 11. 12. /*Reset if it moves beyond the boundaries.*/ 13. 14. /*Update if a better solution is produced.*/ 15. /*Calculate F of each search agent.*/ 16. /*Identify the non-dominated solutions.*/ 17. /*Extended repository based on the non-dominated solutions.*/ 18. IF DO 19. /* Start the repository maintainer to remove one repository resident.*/ 20. /*Put the new non-dominated solution into it.*/ 21. END IF 22. END FOR 23. 24. END WHILE 25. RETURN |
2.3. Framework of the APCP System
2.3.1. Time Series Reconstruction
2.3.2. Submodel Simulation
2.3.3. Weight Search
2.3.4. Integration
3. Establishment and Evaluation of Experiment
3.1. Description of Datasets
3.2. Evaluation Indexes
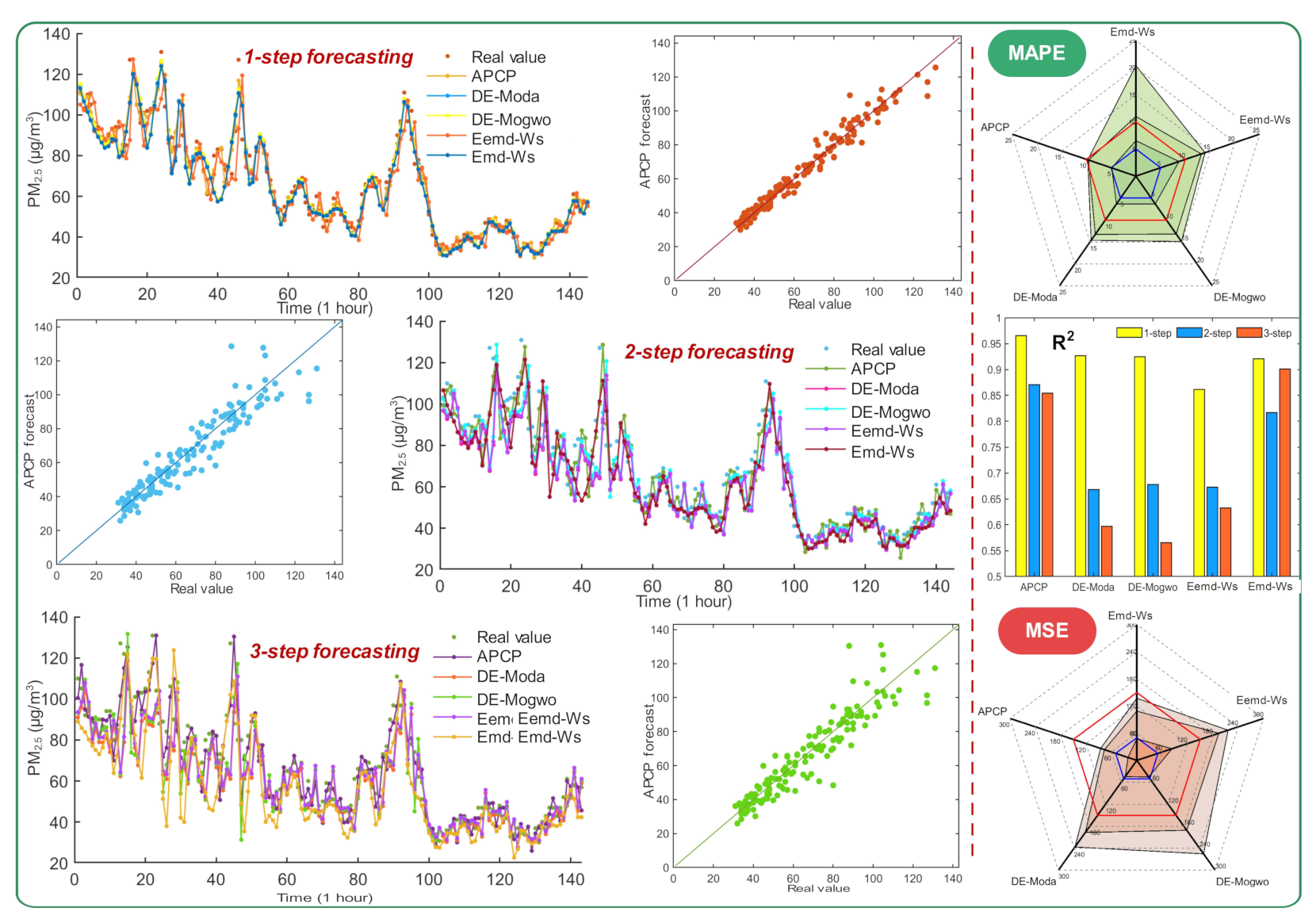
3.3. Experiment I: Comparison with the Individual Models
3.4. Experiment II: Test the Superiority of the APCP System
3.5. Experiment III: Comparison of Different Module Strategies
4. Discussions
4.1. Significance Analysis
4.2. Correlation Analysis
4.3. Sensitivity Analysis
5. Conclusions and Prospect
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, H.Y.; Dunea, D.; Iordache, S.; Pohoata, A. A Review of Airborne Particulate Matter Effects on Young Children’s Respiratory Symptoms and Diseases. Atmosphere 2018, 9, 150. [Google Scholar] [CrossRef]
- Yang, S.; Fang, D.; Chen, B. Human Health Impact and Economic Effect for PM2.5 Exposure in Typical Cities. Appl. Energy 2019, 249, 316–325. [Google Scholar] [CrossRef]
- Hao, Y.; Niu, X.; Wang, J. Impacts of Haze Pollution on China’s Tourism Industry: A System of Economic Loss Analysis. J. Environ. Manag. 2021, 295, 113051. [Google Scholar] [CrossRef] [PubMed]
- Kim, K.H.; Kabir, E.; Kabir, S. A Review on the Human Health Impact of Airborne Particulate Matter. Environ. Int. 2015, 74, 136–143. [Google Scholar] [CrossRef] [PubMed]
- Maji, K.J.; Ye, W.F.; Arora, M.; Shiva Nagendra, S.M. PM2.5-Related Health and Economic Loss Assessment for 338 Chinese Cities. Environ. Int. 2018, 121, 392–403. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Bocquet, M.; Mallet, V.; Seigneur, C.; Baklanov, A. Real-Time Air Quality Forecasting, Part I: History, Techniques, and Current Status. Atmos. Environ. 2012, 60, 632–655. [Google Scholar] [CrossRef]
- Wang, J.; Wang, R.; Li, Z. A Combined Forecasting System Based on Multi-Objective Optimization and Feature Extraction Strategy for Hourly PM2.5 Concentration. Appl. Soft Comput. 2022, 114, 108034. [Google Scholar] [CrossRef]
- Djalalova, I.; Delle Monache, L.; Wilczak, J. PM2.5 Analog Forecast and Kalman Filter Post-Processing for the Community Multiscale Air Quality (CMAQ) Model. Atmos. Environ. 2015, 108, 76–87. [Google Scholar] [CrossRef]
- Baker, K.R.; Woody, M.C.; Valin, L.; Szykman, J.; Yates, E.L.; Iraci, L.T.; Choi, H.D.; Soja, A.J.; Koplitz, S.N.; Zhou, L.; et al. Photochemical Model Evaluation of 2013 California Wild Fire Air Quality Impacts Using Surface, Aircraft, and Satellite Data. Sci. Total Environ. 2018, 637–638, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Q.; Xue, D.; Liu, X.; Gong, X.; Gao, H. Process Analysis of PM2.5 Pollution Events in a Coastal City of China Using CMAQ. J. Environ. Sci. 2019, 79, 225–238. [Google Scholar] [CrossRef]
- Lee, K.; Yu, J.; Lee, S.; Park, M.; Hong, H.; Park, S.Y.; Choi, M.; Kim, J.; Kim, Y.; Woo, J.H.; et al. Development of Korean Air Quality Prediction System Version 1 (KAQPS v1) with Focuses on Practical Issues. Geosci. Model Dev. 2020, 13, 1055–1073. [Google Scholar] [CrossRef]
- Ryu, Y.H.; Hodzic, A.; Barre, J.; Descombes, G.; Minnis, P. Quantifying Errors in Surface Ozone Predictions Associated with Clouds over the CONUS: A WRF-Chem Modeling Study Using Satellite Cloud Retrievals. Atmos. Chem. Phys. 2018, 18, 7509–7525. [Google Scholar] [CrossRef]
- Cheng, X.; Liu, Y.; Xu, X.; You, W.; Zang, Z.; Gao, L.; Chen, Y.; Su, D.; Yan, P. Lidar Data Assimilation Method Based on CRTM and WRF-Chem Models and Its Application in PM2.5 Forecasts in Beijing. Sci. Total Environ. 2019, 682, 541–552. [Google Scholar] [CrossRef] [PubMed]
- Abdi-Oskouei, M.; Carmichael, G.; Christiansen, M.; Ferrada, G.; Roozitalab, B.; Sobhani, N.; Wade, K.; Czarnetzki, A.; Pierce, R.B.; Wagner, T.; et al. Sensitivity of Meteorological Skill to Selection of WRF-Chem Physical Parameterizations and Impact on Ozone Prediction During the Lake Michigan Ozone Study (LMOS). J. Geophys. Res. Atmos. 2020, 125, e2019JD031971. [Google Scholar] [CrossRef]
- Lopez-Restrepo, S.; Yarce, A.; Pinel, N.; Quintero, O.L.; Segers, A.; Heemink, A.W. Forecasting PM10 and PM2.5 in the Aburrá Valley (Medellín, Colombia) via EnKF Based Data Assimilation. Atmos. Environ. 2020, 232, 117507. [Google Scholar] [CrossRef]
- Wei, W.; Lv, Z.F.; Li, Y.; Wang, L.T.; Cheng, S.; Liu, H. A WRF-Chem Model Study of the Impact of VOCs Emission of a Huge Petro-Chemical Industrial Zone on the Summertime Ozone in Beijing, China. Atmos. Environ. 2018, 175, 44–53. [Google Scholar] [CrossRef]
- Chen, Q.; Taylor, D. Transboundary Atmospheric Pollution in Southeast Asia: Current Methods, Limitations and Future Developments. Crit. Rev. Environ. Sci. Technol. 2018, 48, 997–1029. [Google Scholar] [CrossRef]
- De Mattos Neto, P.S.G.; Madeiro, F.; Ferreira, T.A.E.; Cavalcanti, G.D.C. Hybrid Intelligent System for Air Quality Forecasting Using Phase Adjustment. Eng. Appl. Artif. Intell. 2014, 32, 185–191. [Google Scholar] [CrossRef]
- Baptista, M.; Sankararaman, S.; de Medeiros, I.P.; Nascimento, C.; Prendinger, H.; Henriques, E.M.P. Forecasting Fault Events for Predictive Maintenance Using Data-Driven Techniques and ARMA Modeling. Comput. Ind. Eng. 2018, 115, 41–53. [Google Scholar] [CrossRef]
- Wang, J.; Lei, C.; Guo, M. Daily Natural Gas Price Forecasting by a Weighted Hybrid Data-Driven Model. J. Pet. Sci. Eng. 2020, 192, 107240. [Google Scholar] [CrossRef]
- Aladağ, E. Forecasting of Particulate Matter with a Hybrid ARIMA Model Based on Wavelet Transformation and Seasonal Adjustment. Urban Clim. 2021, 39, 100930. [Google Scholar] [CrossRef]
- Bhatti, U.A.; Yan, Y.; Zhou, M.; Ali, S.; Hussain, A.; Qingsong, H.; Yu, Z.; Yuan, L. Time Series Analysis and Forecasting of Air Pollution Particulate Matter (PM2.5): An SARIMA and Factor Analysis Approach. IEEE Access 2021, 9, 41019–41031. [Google Scholar] [CrossRef]
- Shaziayani, W.N.; Ul-Saufie, A.Z.; Ahmat, H.; Al-Jumeily, D. Coupling of Quantile Regression into Boosted Regression Trees (BRT) Technique in Forecasting Emission Model of PM10 Concentration. Air Qual. Atmos. Health 2021, 14, 1647–1663. [Google Scholar] [CrossRef]
- Liu, T.; Lau, A.K.H.; Sandbrink, K.; Fung, J.C.H. Time Series Forecasting of Air Quality Based On Regional Numerical Modeling in Hong Kong. J. Geophys. Res. Atmos. 2018, 123, 4175–4196. [Google Scholar] [CrossRef]
- Abdullah, S.; Napi, N.N.L.M.; Ahmed, A.N.; Mansor, W.N.W.; Mansor, A.A.; Ismail, M.; Abdullah, A.M.; Ramly, Z.T.A. Development of Multiple Linear Regression for Particulate Matter (PM10) Forecasting during Episodic Transboundary Haze Event in Malaysia. Atmosphere 2020, 11, 289. [Google Scholar] [CrossRef]
- Mohd Napi, N.N.L.; Noor Mohamed, M.S.; Abdullah, S.; Mansor, A.A.; Ahmed, A.N.; Ismail, M. Multiple Linear Regression (MLR) and Principal Component Regression (PCR) for Ozone (O3) Concentrations Prediction. IOP Conf. Ser. Earth Environ. Sci. 2020, 616, 012004. [Google Scholar] [CrossRef]
- Bai, Y.; Li, Y.; Wang, X.; Xie, J.; Li, C. Air Pollutants Concentrations Forecasting Using Back Propagation Neural Network Based on Wavelet Decomposition with Meteorological Conditions. Atmos. Pollut. Res. 2016, 7, 557–566. [Google Scholar] [CrossRef]
- Li, X.; Peng, L.; Yao, X.; Cui, S.; Hu, Y.; You, C.; Chi, T. Long Short-Term Memory Neural Network for Air Pollutant Concentration Predictions: Method Development and Evaluation. Environ. Pollut. 2017, 231, 997–1004. [Google Scholar] [CrossRef]
- Jiang, X.; Wei, P.; Luo, Y.; Li, Y. Air Pollutant Concentration Prediction Based on a CEEMDAN-FE-BiLSTM Model. Atmosphere 2021, 12, 1452. [Google Scholar] [CrossRef]
- Weihong, W.; Shuangshuang, N. The Performance of Several Combining Forecasts for Stock Index. In Proceedings of the 2008 International Seminar on Future Information Technology and Management Engineering, Leicestershire, UK, 20 November 2008; pp. 450–455. [Google Scholar] [CrossRef]
- Wang, J.; Li, J.; Li, Z. Prediction of Air Pollution Interval Based on Data Preprocessing and Multi-Objective Dragonfly Optimization Algorithm. Front. Ecol. Evol. 2022, 10, 855606. [Google Scholar] [CrossRef]
- Yang, W.; Sun, S.; Hao, Y.; Wang, S. A Novel Machine Learning-Based Electricity Price Forecasting Model Based on Optimal Model Selection Strategy. Energy 2022, 238, 121989. [Google Scholar] [CrossRef]
- Murillo-Escobar, J.; Sepulveda-Suescun, J.P.; Correa, M.A.; Orrego-Metaute, D. Forecasting Concentrations of Air Pollutants Using Support Vector Regression Improved with Particle Swarm Optimization: Case Study in Aburrá Valley, Colombia. Urban Clim. 2019, 29, 100473. [Google Scholar] [CrossRef]
- Wu, Q.; Lin, H. A Novel Optimal-Hybrid Model for Daily Air Quality Index Prediction Considering Air Pollutant Factors. Sci. Total Environ. 2019, 683, 808–821. [Google Scholar] [CrossRef] [PubMed]
- Li, G.; Chen, L.; Yang, H. Prediction of PM2.5 Concentration Based on Improved Secondary Decomposition and CSA-KELM. Atmos. Pollut. Res. 2022, 13, 101455. [Google Scholar] [CrossRef]
- Gan, R.; Guo, Q.; Chang, H.; Yi, Y. Improved Ant Colony Optimization Algorithm for the Traveling Salesman Problems. J. Syst. Eng. Electron. 2010, 21, 329–333. [Google Scholar] [CrossRef]
- Dhiman, G.; Kumar, V. Seagull Optimization Algorithm: Theory and Its Applications for Large-Scale Industrial Engineering Problems. Knowledge-Based Syst. 2019, 165, 169–196. [Google Scholar] [CrossRef]
- Zhou, Q.; Lv, Q.; Zhang, G. A Combined Forecasting System Based on Modified Multi-Objective Optimization for Short-Term Wind Speed and Wind Power Forecasting. Appl. Sci. 2021, 11, 9383. [Google Scholar] [CrossRef]
- Zhou, Y.; Wang, J.; Li, Z.; Lu, H. Short-Term Photovoltaic Power Forecasting Based on Signal Decomposition and Machine Learning Optimization. Energy Convers. Manag. 2022, 267, 115944. [Google Scholar] [CrossRef]
- Wang, J.; Gao, J.; Wei, D. Electric Load Prediction Based on a Novel Combined Interval Forecasting System. Appl. Energy 2022, 322, 119420. [Google Scholar] [CrossRef]
- Wu, Z.; Zhang, S. Study on the Spatial–Temporal Change Characteristics and Influence Factors of Fog and Haze Pollution Based on GAM. Neural Comput. Appl. 2019, 31, 1619–1631. [Google Scholar] [CrossRef]
- Zakaria, N.N.; Othman, M.; Sokkalingam, R.; Daud, H.; Abdullah, L.; Kadir, E.A. Markov Chain Model Development for Forecasting Air Pollution Index of Miri, Sarawak. Sustainability 2019, 11, 5190. [Google Scholar] [CrossRef]
- Zhou, W.; Wu, X.; Ding, S.; Cheng, Y. Predictive Analysis of the Air Quality Indicators in the Yangtze River Delta in China: An Application of a Novel Seasonal Grey Model. Sci. Total Environ. 2020, 748, 141428. [Google Scholar] [CrossRef]
- Kim, J.; Wang, X.; Kang, C.; Yu, J.; Li, P. Forecasting Air Pollutant Concentration Using a Novel Spatiotemporal Deep Learning Model Based on Clustering, Feature Selection and Empirical Wavelet Transform. Sci. Total Environ. 2021, 801, 149654. [Google Scholar] [CrossRef] [PubMed]
- Dai, H.; Huang, G.; Zeng, H.; Zhou, F. PM2.5 Volatility Prediction by XGBoost-MLP Based on GARCH Models. J. Clean. Prod. 2022, 356, 131898. [Google Scholar] [CrossRef]
- Liu, B.; Yu, X.; Chen, J.; Wang, Q. Air Pollution Concentration Forecasting Based on Wavelet Transform and Combined Weighting Forecasting Model. Atmos. Pollut. Res. 2021, 12, 101144. [Google Scholar] [CrossRef]
- Sayeed, A.; Choi, Y.; Eslami, E.; Lops, Y. Using a Deep Convolutional Neural Network to Predict 2017 Ozone Concentrations, 24 Hours in Advance. Neural Netw. 2019, 121, 396–408. [Google Scholar] [CrossRef] [PubMed]
- Mo, Y.; Li, Q.; Karimian, H.; Fang, S.; Tang, B.; Chen, G. A Novel Framework for Daily Forecasting of Ozone Mass Concentrations Based on Cycle Reservoir with Regular Jumps Neural Networks. Atmos. Environ. 2020, 220, 117072. [Google Scholar] [CrossRef]
- Chen, S.; Wang, J.; Zhang, H. A Hybrid PSO-SVM Model Based on Clustering Algorithm for Short-Term Atmospheric Pollutant Concentration Forecasting. Technol. Forecast. Soc. Chang. 2019, 146, 41–54. [Google Scholar] [CrossRef]
- Huang, G.; Li, X.; Zhang, B.; Ren, J. PM2.5 Concentration Forecasting at Surface Monitoring Sites Using GRU Neural Network Based on Empirical Mode Decomposition. Sci. Total Environ. 2021, 768, 144516. [Google Scholar] [CrossRef] [PubMed]
- Wang, B.; Jiang, Q.; Jiang, P. A Combined Forecasting Structure Based on the L 1 Norm: Application to The. J. Environ. Manag. 2019, 246, 299–313. [Google Scholar] [CrossRef]
- Saremi, S.; Mirjalili, S.; Lewis, A. Grasshopper Optimisation Algorithm: Theory and Application. Adv. Eng. Softw. 2017, 105, 30–47. [Google Scholar] [CrossRef]
- Diebold, F.X.; Mariano, R.S. Comparing Predictive Accuracy. J. Bus. Econ. Stat. 1995, 13, 253–263. [Google Scholar] [CrossRef]
- Liu, S.; Lin, Y. Introduction to Grey Systems Theory. In Understanding Complex Systems; Springer: Berlin/Heidelberg, Germany, 2010; Volume 68, pp. 1–399. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Ref. | Dataset | Conclusions | Strengths | Limitations |
|---|---|---|---|---|---|
| GAM | [41] | PM2.5 in Beijing | The lag order and climatic conditions have the most significant influence on the change in PM2.5 concentration. | The GAM model intuitively explains the reasons for the change and diffusion of PM2.5 concentration. | The prediction accuracy of this model is limited. |
| Markov chain model | [42] | API in Malaysia | Markov chain model can be used as an effective tool in haze pollution prediction. | The model is simple in structure and easy to operate. | The higher-order extended form of Markov chain is not considered. |
| SNgbn (1,1) model | [43] | AQI, PM10, PM2.5, SO2, NO2, CO, and O3 in the Yangtze River Delta | For data with seasonal periodic fluctuations, the model provides stable prediction results. | The SNgbn (1,1) model simulates the seasonal characteristics of APs to a great extent. | External factors are not added to the model. |
| 3D-CBLstm | [44] | PM2.5 in Beijing | The application of clustering analysis and feature selection strategy is conducive to the improvement of the prediction effect. | The 3D-CBLstm model not only realizes the efficient extraction of important features but also considers the long-term correlation in the sequence. | The selection of prediction model parameters is subjective. |
| XGBoost-Garch-MLP | [45] | PM2.5 in Shanxi | This model can effectively predict the fluctuation range of PM2.5 concentration, which is helpful to identify the moving direction of PM2.5. | The quality of input data is improved based on feature selection and four Garch extended models comprehensively cover the fluctuation interval of PM2.5 concentration. | The selection of input variables and prediction models needs to be further optimized. |
| CWfm | [46] | PM10, PM2.5, NO2, SO2, O3, and CO in Beijing | The CWfm model is scientific and efficient for predicting the concentration of APs. | The proposed combined model has better fitting results than its submodel. | The influencing factors considered are not comprehensive enough. |
| Dcnn | [47] | Meteorological and AP (NOX and O3) data in Texas | Compared with the deterministic models and linear models, the prediction results of this model are significantly improved. | Predictions can be successfully achieved even when there are fewer input dimensions. | The model has poor accuracy in estimating extreme values. |
| CEemd-CRJ-MLR model | [48] | Meteorological and AP (NO2, CO, and O3) data in Beijing | The improved CRJ model is effectively applied to the prediction of AP concentration, and the prediction performance of the hybrid model is improved. | The hybrid model also has accurate results for the long-term prediction of the concentration of APs. | The structural design of the model is complex, which reduces the universality. |
| Pso-Svm model | [49] | Meteorological and AP (AQI, PM10, PM2.5, SO2, NO2, CO, and O3) data in Beijing | The hybrid model is superior to the benchmark models in both fitting accuracy and simulation speed. | As the amount of data is reduced, the running time of the model is shortened. | The influence of holidays, seasons, and other relevant information is not included. |
| Emd-Gru model | [50] | PM2.5 in Beijing | Compared with the Gru model, the proposed combined model shows the best results in all error measurement indicators. | The problem of time lag is perfectly solved. | The fitting results of different spaces are lacking, and the regional versatility of the model is limited. |
| Combined model based on the L1 norm | [51] | PM10, PM2.5, SO2, NO2, CO, and O3 in Baoding, Tianjin, and Shijiazhuang | The proposed model can accurately evaluate future air quality and has broad application prospects. | The model parameters are adjusted based on the optimization algorithm, which enhances the scientificity and feasibility. | The model structure is complex. |
| Models | Guangzhou | Shanghai | Chengdu | Average | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MSE | MRE | MAPE | R2 | MSE | MRE | MAPE | R2 | MSE | MRE | MAPE | R2 | MSE | MRE | MAPE | R2 | |
| Cnn | 25.477 | 0.009 | 5.465% | 0.958 | 43.353 | 0.039 | 9.564% | 0.973 | 55.457 | 0.034 | 8.224% | 0.983 | 41.429 | 0.027 | 7.751% | 0.971 |
| Bilstm | 31.704 | 0.014 | 6.119% | 0.947 | 47.755 | 0.028 | 10.225% | 0.970 | 60.800 | 0.041 | 8.414% | 0.982 | 46.753 | 0.028 | 8.252% | 0.966 |
| Lssvm | 29.878 | 0.013 | 5.752% | 0.950 | 51.454 | 0.058 | 10.610% | 0.968 | 61.730 | 0.049 | 9.123% | 0.982 | 47.687 | 0.040 | 8.495% | 0.967 |
| Gp | 100.916 | 0.057 | 12.038% | 0.832 | 270.369 | 0.352 | 39.540% | 0.830 | 156.823 | 0.175 | 20.018% | 0.953 | 176.036 | 0.195 | 23.865% | 0.872 |
| Lstm | 22.180 | 0.011 | 5.043% | 0.963 | 39.016 | 0.030 | 9.876% | 0.975 | 51.518 | 0.031 | 7.970% | 0.985 | 37.571 | 0.024 | 7.630% | 0.974 |
| Gru | 34.112 | 0.029 | 7.025% | 0.943 | 68.920 | 0.120 | 17.239% | 0.957 | 145.464 | 0.132 | 17.194% | 0.957 | 82.832 | 0.094 | 13.819% | 0.952 |
| Elm | 23.160 | 0.012 | 5.282% | 0.962 | 41.545 | 0.030 | 9.563% | 0.974 | 52.633 | 0.033 | 8.117% | 0.984 | 39.113 | 0.025 | 7.654% | 0.973 |
| Enn | 23.465 | 0.012 | 5.330% | 0.961 | 41.920 | 0.035 | 9.796% | 0.974 | 53.782 | 0.036 | 8.320% | 0.984 | 39.722 | 0.028 | 7.815% | 0.973 |
| Systems | Symbol | Explanation | Value | Systems | Symbol | Explanation | Value |
|---|---|---|---|---|---|---|---|
| Bilstm | Max epochs number | 400 | Gp | Gaussian likelihood | −1 | ||
| Hidden layer node numbers | 20 | Input layer node number | 4 | ||||
| BPnn, Elm, Enn | Input layer node numbers | 4 | Lstm | Epochs of training | 500 | ||
| Output layer node numbers | 1 | Emd | Stopping rule of sifting | wave | |||
| Hidden layer node numbers | 20 | Boundary | type 5 | ||||
| Cnn | Number of kernels in convolutional layer | 3 | Eemd | Signal-to-noise ratio | 0.1 | ||
| Kernel size of the convolutional layer | 40 | DE | Maximum iteration number | 500 | |||
| Hidden layer node numbers | [384,384] | Number of noise additions | 50 | ||||
| Gru | Max epochs number | 2000 | Signal-to-noise ratio | 0.1 | |||
| Mini batch size | 256 | Ws, Moda, Mogwo | Maximum iteration number | 500 | |||
| Lssvm | Kernel function parameter | 5 | Archive size | 400 | |||
| Penalty parameter | 5 | Chameleon number | 60 |
| Datasets | No. | Max. | Min. | Mean | Std. | Mlye |
|---|---|---|---|---|---|---|
| Guangzhou | ||||||
| Total | 744 | 176 | 8 | 34.16 | 69.61 | 0.23 |
| Train | 595 | 176 | 8 | 35.79 | 69.79 | 0.17 |
| Test | 149 | 142 | 31 | 26.77 | 68.89 | 0.37 |
| Shanghai | ||||||
| Total | 744 | 255 | 11 | 55.56 | 84.04 | 0.31 |
| Train | 595 | 255 | 11 | 55.99 | 90.41 | 0.28 |
| Test | 149 | 203 | 13 | 45.86 | 58.60 | 0.04 |
| Chengdu | ||||||
| Total | 744 | 335 | 15 | 64.71 | 141.84 | 0.27 |
| Train | 595 | 335 | 15 | 59.47 | 154.84 | 0.28 |
| Test | 149 | 233 | 23 | 58.59 | 89.91 | 0.14 |
| Metrics | Mathematical Formula |
|---|---|
| Mean Absolute Percentage Error | |
| Mean Relative Error | |
| Mean Squared Error | |
| R-squared score |
| Models | City | Guangzhou | Shanghai | Chengdu | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MSE | MRE | MAPE | R2 | MSE | MRE | MAPE | R2 | MSE | MRE | MAPE | R2 | ||
| APCP | 1-step | 20.861 | 0.000 | 4.883% | 0.965 | 38.445 | 0.006 | 9.139% | 0.976 | 49.914 | 0.012 | 7.560% | 0.985 |
| 2-step | 76.568 | −0.014 | 9.552% | 0.871 | 143.385 | −0.025 | 15.477% | 0.903 | 157.888 | 0.021 | 13.515% | 0.953 | |
| 3-step | 85.532 | −0.014 | 9.710% | 0.854 | 147.137 | −0.028 | 14.994% | 0.894 | 158.789 | 0.027 | 13.810% | 0.952 | |
| Bilstm | 1-step | 31.704 | 0.014 | 6.119% | 0.947 | 47.755 | 0.028 | 10.225% | 0.970 | 60.800 | 0.041 | 8.414% | 0.982 |
| 2-step | 97.906 | 0.031 | 10.704% | 0.835 | 183.587 | 0.078 | 20.620% | 0.876 | 203.926 | 0.110 | 16.432% | 0.939 | |
| 3-step | 209.020 | 0.060 | 16.410% | 0.644 | 416.976 | 0.156 | 31.115% | 0.699 | 487.225 | 0.217 | 27.335% | 0.853 | |
| Gru | 1-step | 34.112 | 0.029 | 7.025% | 0.943 | 68.920 | 0.120 | 17.239% | 0.957 | 145.464 | 0.132 | 17.194% | 0.957 |
| 2-step | 88.941 | 0.046 | 11.036% | 0.850 | 222.910 | 0.277 | 34.932% | 0.849 | 520.354 | 0.300 | 34.546% | 0.844 | |
| 3-step | 364.031 | 0.064 | 19.808% | 0.381 | 585.365 | 0.511 | 59.411% | 0.577 | 1425.353 | 0.570 | 61.621% | 0.571 | |
| Gp | 1-step | 100.916 | 0.057 | 12.038% | 0.832 | 270.369 | 0.352 | 39.540% | 0.830 | 156.823 | 0.175 | 20.018% | 0.953 |
| 2-step | 158.148 | 0.078 | 15.547% | 0.733 | 465.399 | 0.489 | 54.192% | 0.685 | 368.929 | 0.278 | 31.152% | 0.889 | |
| 3-step | 205.923 | 0.098 | 18.482% | 0.650 | 681.216 | 0.632 | 69.090% | 0.508 | 640.693 | 0.373 | 41.128% | 0.807 | |
| Lssvm | 1-step | 29.878 | 0.013 | 5.752% | 0.950 | 51.454 | 0.058 | 10.610% | 0.968 | 61.730 | 0.049 | 9.123% | 0.982 |
| 2-step | 101.226 | 0.031 | 10.821% | 0.829 | 185.359 | 0.131 | 20.207% | 0.874 | 183.649 | 0.101 | 16.178% | 0.945 | |
| 3-step | 209.427 | 0.058 | 16.510% | 0.644 | 408.764 | 0.219 | 29.946% | 0.705 | 371.823 | 0.160 | 23.578% | 0.888 | |
| Cnn | 1-step | 25.477 | 0.009 | 5.465% | 0.958 | 43.353 | 0.039 | 9.564% | 0.973 | 55.457 | 0.034 | 8.224% | 0.983 |
| 2-step | 95.182 | 0.022 | 10.614% | 0.839 | 165.475 | 0.091 | 17.971% | 0.888 | 173.737 | 0.092 | 15.444% | 0.948 | |
| 3-step | 94.856 | 0.023 | 10.537% | 0.839 | 160.774 | 0.081 | 18.188% | 0.884 | 166.672 | 0.062 | 14.993% | 0.950 | |
| Lstm | 1-step | 22.180 | 0.011 | 5.043% | 0.963 | 39.016 | 0.030 | 9.876% | 0.975 | 51.518 | 0.031 | 7.970% | 0.985 |
| 2-step | 92.552 | 0.019 | 10.346% | 0.844 | 179.377 | 0.066 | 23.206% | 0.878 | 180.829 | 0.071 | 15.373% | 0.946 | |
| 3-step | 94.432 | 0.020 | 10.303% | 0.839 | 175.869 | 0.069 | 22.962% | 0.873 | 181.508 | 0.066 | 15.209% | 0.945 | |
| Elm | 1-step | 23.160 | 0.012 | 5.282% | 0.962 | 41.545 | 0.030 | 9.563% | 0.974 | 52.633 | 0.033 | 8.117% | 0.984 |
| 2-step | 86.027 | 0.029 | 10.312% | 0.855 | 159.395 | 0.081 | 18.464% | 0.892 | 166.130 | 0.087 | 15.212% | 0.950 | |
| 3-step | 92.910 | 0.018 | 10.404% | 0.842 | 165.485 | 0.061 | 19.901% | 0.880 | 176.767 | 0.064 | 15.206% | 0.947 | |
| Enn | 1-step | 23.465 | 0.012 | 5.330% | 0.961 | 41.920 | 0.035 | 9.796% | 0.974 | 53.782 | 0.036 | 8.320% | 0.984 |
| 2-step | 87.895 | 0.031 | 10.345% | 0.852 | 162.584 | 0.096 | 19.111% | 0.890 | 167.932 | 0.094 | 15.414% | 0.950 | |
| 3-step | 93.483 | 0.019 | 10.452% | 0.841 | 169.585 | 0.069 | 20.610% | 0.877 | 180.407 | 0.066 | 15.460% | 0.946 | |
| City | Guangzhou | Shanghai | Chengdu | Average | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| APCP vs. Bilstm | 1-step | 34.20% | 98.40% | 20.20% | 19.50% | 79.32% | 10.62% | 17.90% | 71.02% | 10.16% | 23.87% | 82.91% | 13.66% |
| 2-step | 21.79% | 55.72% | 10.77% | 21.90% | 67.66% | 24.94% | 22.58% | 80.96% | 17.75% | 22.09% | 68.11% | 17.82% | |
| 3-step | 59.08% | 76.97% | 40.83% | 64.71% | 81.84% | 51.81% | 67.41% | 87.61% | 49.48% | 63.73% | 82.14% | 47.37% | |
| APCP vs. Gru | 1-step | 38.85% | 99.23% | 30.49% | 44.22% | 95.16% | 46.99% | 65.69% | 90.98% | 56.03% | 49.58% | 95.12% | 44.50% |
| 2-step | 13.91% | 69.42% | 13.45% | 35.68% | 90.90% | 55.69% | 69.66% | 92.99% | 60.88% | 39.75% | 84.44% | 43.34% | |
| 3-step | 76.50% | 78.41% | 50.98% | 74.86% | 94.44% | 74.76% | 88.86% | 95.28% | 77.59% | 80.08% | 89.38% | 67.78% | |
| APCP vs. Gp | 1-step | 79.33% | 99.62% | 59.44% | 85.78% | 98.35% | 76.89% | 68.17% | 93.18% | 62.24% | 77.76% | 97.05% | 66.19% |
| 2-step | 51.58% | 82.07% | 38.56% | 69.19% | 94.85% | 71.44% | 57.20% | 92.43% | 56.62% | 59.33% | 89.78% | 55.54% | |
| 3-step | 58.46% | 86.04% | 47.46% | 78.40% | 95.51% | 78.30% | 75.22% | 92.79% | 66.42% | 70.69% | 91.45% | 64.06% | |
| APCP vs. Lssvm | 1-step | 30.18% | 98.38% | 15.11% | 25.28% | 90.04% | 13.87% | 19.14% | 75.60% | 17.14% | 24.87% | 88.01% | 15.37% |
| 2-step | 24.36% | 55.64% | 11.73% | 22.64% | 80.69% | 23.41% | 14.03% | 79.16% | 16.46% | 20.34% | 71.83% | 17.20% | |
| 3-step | 59.16% | 76.44% | 41.19% | 64.00% | 87.06% | 49.93% | 57.29% | 83.17% | 41.43% | 60.15% | 82.22% | 44.18% | |
| Models | City | Guangzhou | Shanghai | Chengdu | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MSE | MRE | MAPE | R2 | MSE | MRE | MAPE | R2 | MSE | MRE | MAPE | R2 | ||
| APCP | 1-step | 20.861 | 0.000 | 4.883% | 0.965 | 38.445 | 0.006 | 9.139% | 0.976 | 49.914 | 0.012 | 7.560% | 0.985 |
| 2-step | 76.568 | −0.014 | 9.552% | 0.871 | 143.385 | −0.025 | 15.477% | 0.903 | 157.888 | 0.021 | 13.515% | 0.953 | |
| 3-step | 85.532 | −0.014 | 9.710% | 0.854 | 147.137 | −0.028 | 14.994% | 0.894 | 158.789 | 0.027 | 13.810% | 0.952 | |
| DE-Moda | 1-step | 44.299 | −0.018 | 6.346% | 0.926 | 78.536 | −0.016 | 12.558% | 0.951 | 138.789 | 0.055 | 12.368% | 0.959 |
| 2-step | 196.907 | −0.062 | 13.260% | 0.668 | 291.930 | −0.040 | 20.260% | 0.802 | 324.790 | 0.022 | 16.480% | 0.902 | |
| 3-step | 236.687 | −0.083 | 14.610% | 0.597 | 322.913 | −0.071 | 20.461% | 0.767 | 388.779 | 0.179 | 23.553% | 0.883 | |
| DE-Mogwo | 1-step | 45.530 | −0.008 | 6.333% | 0.924 | 80.208 | 0.007 | 12.356% | 0.949 | 144.490 | 0.048 | 12.091% | 0.957 |
| 2-step | 190.901 | −0.029 | 13.188% | 0.678 | 303.205 | 0.005 | 19.997% | 0.795 | 312.185 | 0.101 | 18.881% | 0.906 | |
| 3-step | 255.447 | −0.060 | 14.885% | 0.565 | 316.368 | −0.023 | 19.873% | 0.771 | 478.242 | 0.007 | 17.896% | 0.856 | |
| Eemd-Ws | 1-step | 83.250 | −0.020 | 8.714% | 0.862 | 125.311 | −0.006 | 13.821% | 0.921 | 135.219 | 0.048 | 11.996% | 0.960 |
| 2-step | 194.027 | −0.054 | 13.224% | 0.673 | 292.060 | −0.042 | 20.282% | 0.802 | 309.633 | 0.071 | 17.753% | 0.907 | |
| 3-step | 215.869 | −0.052 | 13.967% | 0.633 | 311.389 | −0.043 | 19.927% | 0.775 | 381.970 | 0.144 | 21.816% | 0.885 | |
| Emd-Ws | 1-step | 47.653 | −0.026 | 6.535% | 0.921 | 79.500 | 0.010 | 12.204% | 0.950 | 76.215 | −0.088 | 10.261% | 0.977 |
| 2-step | 108.801 | −0.067 | 10.993% | 0.816 | 116.014 | −0.009 | 16.138% | 0.921 | 879.255 | −0.381 | 39.738% | 0.736 | |
| 3-step | 137.224 | 0.123 | 20.357% | 0.901 | 162.807 | 0.011 | 17.037% | 0.882 | 294.961 | −0.132 | 18.134% | 0.911 | |
| Models | Guangzhou | Shanghai | Chengdu | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 1-Step | 2-Step | 3-Step | 1-Step | 2-Step | 3-Step | 1-Step | 2-Step | 3-Step | |
| Bilstm | 2.62 ** | 1.76 * | 4.21 ** | 1.87 * | 1.77 * | 3.70 ** | 1.96 ** | 1.66 * | 5.04 ** |
| Gru | 1.68 * | 0.30 | 3.48 ** | 3.22 ** | 2.33 ** | 6.42 ** | 7.50 ** | 8.29 ** | 11.90 ** |
| Gp | 5.15 ** | 3.45 ** | 3.88 ** | 6.99 ** | 5.90 ** | 6.96 ** | 8.98 ** | 6.22 ** | 8.20 ** |
| LSsvm | 2.83 ** | 2.02 ** | 4.22 ** | 2.02 ** | 1.59 | 3.32 ** | 2.52 ** | 1.22 | 4.71 ** |
| DE-Moda | 3.35 ** | 3.28 ** | 3.87 ** | 2.72 ** | 3.57 ** | 2.72 ** | 4.68 ** | 4.22 ** | 5.04 ** |
| DE-Mogwo | 3.39 ** | 3.26 ** | 3.92 ** | 2.64 ** | 3.19 ** | 3.07 ** | 4.64 ** | 4.63 ** | 3.57 ** |
| Eemd-Ws | 4.49 ** | 3.22 ** | 3.11 ** | 3.75 ** | 3.60 ** | 2.96 ** | 4.62 ** | 4.50 ** | 4.54 ** |
| Emd-Ws | 3.41 ** | 1.93 ** | 4.45 ** | 2.71 ** | −1.04 | −0.52 | 3.60 ** | 12.53 ** | 3.05 ** |
| Models | Guangzhou | Shanghai | Chengdu | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 1-Step | 2-Step | 3-Step | 1-Step | 2-Step | 3-Step | 1-Step | 2-Step | 3-Step | |
| APCP | 0.875 | 0.847 | 0.883 | 0.888 | 0.857 | 0.876 | 0.840 | 0.807 | 0.850 |
| Bilstm | 0.857 | 0.835 | 0.826 | 0.876 | 0.831 | 0.802 | 0.825 | 0.791 | 0.768 |
| Gru | 0.862 | 0.845 | 0.801 | 0.857 | 0.791 | 0.725 | 0.762 | 0.702 | 0.633 |
| Gp | 0.757 | 0.794 | 0.821 | 0.711 | 0.711 | 0.699 | 0.721 | 0.712 | 0.723 |
| LSsvm | 0.856 | 0.833 | 0.822 | 0.876 | 0.838 | 0.809 | 0.820 | 0.799 | 0.793 |
| DE-Moda | 0.839 | 0.799 | 0.831 | 0.857 | 0.817 | 0.836 | 0.777 | 0.782 | 0.786 |
| DE-Mogwo | 0.839 | 0.806 | 0.831 | 0.860 | 0.820 | 0.842 | 0.776 | 0.776 | 0.810 |
| Eemd-Ws | 0.799 | 0.802 | 0.839 | 0.834 | 0.817 | 0.840 | 0.778 | 0.782 | 0.805 |
| Emd-Ws | 0.837 | 0.825 | 0.816 | 0.859 | 0.861 | 0.867 | 0.794 | 0.621 | 0.818 |
| City | Guangzhou | Shanghai | Chengdu | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 1-Step | 2-Step | 3-Step | 1-Step | 2-Step | 3-Step | 1-Step | 2-Step | 3-Step | |
| MSE | 0.066 | 1.632 | 3.202 | 0.609 | 1.856 | 0.420 | 0.111 | 4.351 | 1.818 |
| MRE | 0.000 | 0.001 | 0.002 | 0.002 | 0.003 | 0.001 | 0.001 | 0.001 | 0.001 |
| MAPE | 0.015 | 0.057 | 0.167 | 0.176 | 0.344 | 0.075 | 0.054 | 0.126 | 0.118 |
| R2 | 0.000 | 0.003 | 0.005 | 0.000 | 0.001 | 0.000 | 0.000 | 0.001 | 0.001 |
| MSE | 0.070 | 1.422 | 3.138 | 0.461 | 1.342 | 0.413 | 0.322 | 6.765 | 2.122 |
| MRE | 0.000 | 0.001 | 0.002 | 0.001 | 0.003 | 0.001 | 0.000 | 0.003 | 0.001 |
| MAPE | 0.010 | 0.079 | 0.189 | 0.135 | 0.315 | 0.132 | 0.046 | 0.265 | 0.119 |
| R2 | 0.000 | 0.002 | 0.005 | 0.000 | 0.001 | 0.000 | 0.000 | 0.002 | 0.001 |
| MSE | 0.036 | 1.839 | 3.587 | 0.660 | 1.678 | 1.045 | 0.816 | 6.412 | 1.671 |
| MRE | 0.000 | 0.001 | 0.002 | 0.001 | 0.003 | 0.001 | 0.000 | 0.003 | 0.001 |
| MAPE | 0.009 | 0.092 | 0.174 | 0.140 | 0.282 | 0.111 | 0.048 | 0.300 | 0.062 |
| R2 | 0.000 | 0.003 | 0.006 | 0.000 | 0.001 | 0.001 | 0.000 | 0.002 | 0.001 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hao, Y.; Zhou, Y.; Gao, J.; Wang, J. A Novel Air Pollutant Concentration Prediction System Based on Decomposition-Ensemble Mode and Multi-Objective Optimization for Environmental System Management. Systems 2022, 10, 139. https://doi.org/10.3390/systems10050139
Hao Y, Zhou Y, Gao J, Wang J. A Novel Air Pollutant Concentration Prediction System Based on Decomposition-Ensemble Mode and Multi-Objective Optimization for Environmental System Management. Systems. 2022; 10(5):139. https://doi.org/10.3390/systems10050139
Chicago/Turabian StyleHao, Yan, Yilin Zhou, Jialu Gao, and Jianzhou Wang. 2022. "A Novel Air Pollutant Concentration Prediction System Based on Decomposition-Ensemble Mode and Multi-Objective Optimization for Environmental System Management" Systems 10, no. 5: 139. https://doi.org/10.3390/systems10050139
APA StyleHao, Y., Zhou, Y., Gao, J., & Wang, J. (2022). A Novel Air Pollutant Concentration Prediction System Based on Decomposition-Ensemble Mode and Multi-Objective Optimization for Environmental System Management. Systems, 10(5), 139. https://doi.org/10.3390/systems10050139