
Detecting Anomalies in Financial Data Using Machine Learning Algorithms



Abstract
:1. Introduction
1.1. Research Relevance and Motivation
1.2. Problem Definition and Objectives
- Research question 1: Having GL data with journal entries of various sizes, how to use machine learning techniques to detect anomalies?
- Research question 2: How to enhance the configuration of machine learning models in detecting anomalies in the GL data?
2. Related Work
2.1. Anomaly Detection in Financial Data
2.2. Supervised and Unsupervised Machine Learning Techniques for Anomaly Detection
3. Research Methodology
3.1. Algorithms Selection Rationale
3.2. Data Mining Frameworks
- SEMMA. SEMMA data mining methodology consists of five steps that defined its acronym. Sample, Explore, Modify, Model and Assess steps form a closed cycle that iterates from the start until the goal is achieved [18]. A reduced amount of steps and simplification makes this methodology easy to understand and adopt.
- KDD. KDD stands for Knowledge Discovery in Databases. While implementing 5 steps, there are Pre KDD and Post KDD steps recognized to understand the user’s goals and lastly to incorporate a developed solution into existing user processes. Through selection, preprocessing, transformation (data mining), data mining and interpretation (evaluation), a target analytical dataset is created followed by data cleaning, transformation and an analytical part evaluated in the interpretation step. In KDD, the steps are executed iteratively and interactively.
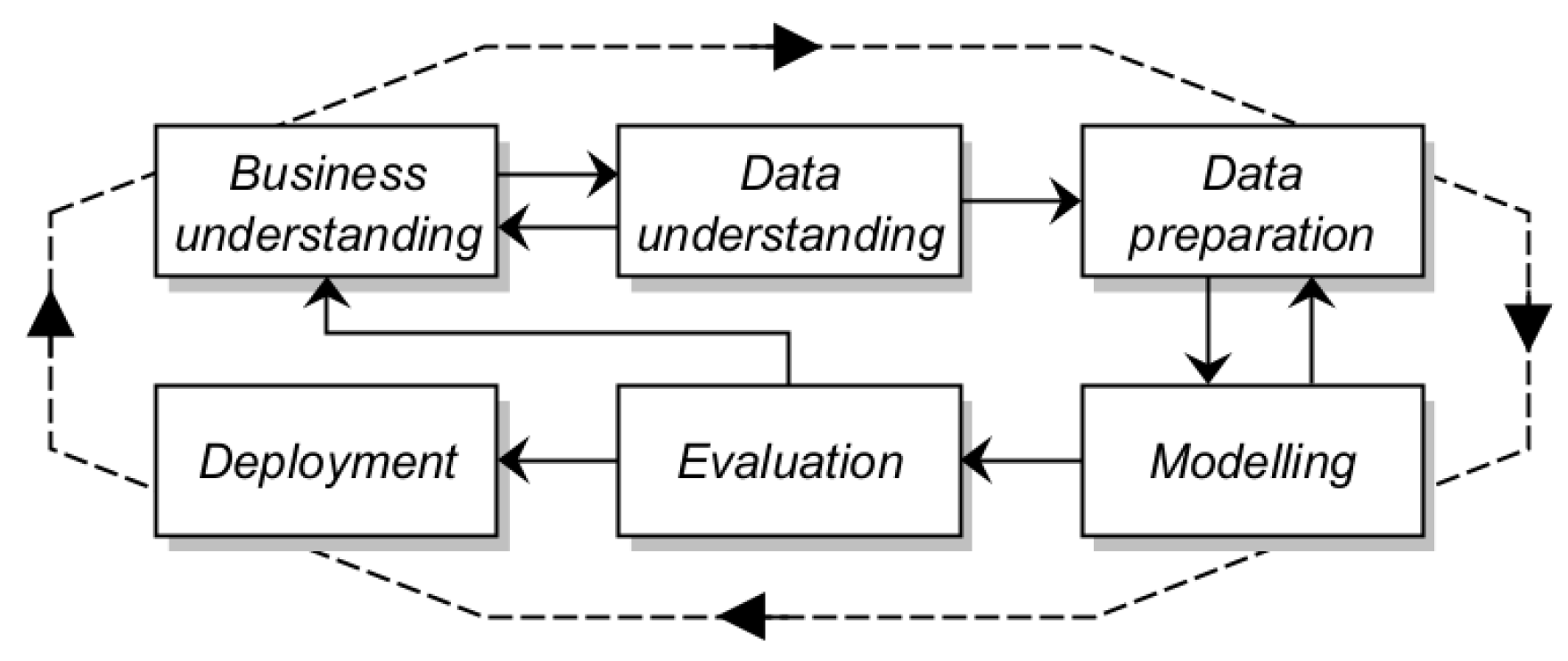
- CRISP-DM. Cross-Industry Standard Process for Data Mining (CRISP-DM) consists of 6 steps that start with business understanding and end with the deployment of a developed solution. Data-related tasks are handled in data understanding, data preparation and modeling assessed in the evaluation step. Iterations can be done throughout business understanding and until the evaluation step.
- TDSP. TDSP acronym stands for Team Data Science Process, which is Microsoft’s methodology to efficiently deliver predictive analytics and AI solutions [19]. It encompasses 5 steps, including 4 cyclic steps with bi-directional connections such as business understanding, data acquisition and understanding, modeling, deployments and the 5th customer acceptance step that signifies an end of a solution delivery cycle. In industry, along with agility of execution and teamwork in focus, it is highly beneficial to extend KDD and CRISP-DM with a customer acceptance criteria and a definite process for that.
3.3. CRISP-DM Steps
- Business understanding. Understanding the business goal is a basis of any analytical process. Being unable to connect planned activities with the actual business objective leads to failures in evaluating the results and implementation of the developed solution. When a background is known, there is a need to define the objectives and success criteria. All this is not studied in a data-agnostic manner as it is crucial to understand that data required for the project can be extracted and processed.
- Data understanding. Data-centric processes require an understanding of how the data can be collected and what these data are, while mapping this knowledge with business understanding. During this stage, we describe collected dataset(s) and perform data exploration analysis. Data quality should be assessed and reported. Further data transformations should not be included in this step.
- Data preprocessing. Before data can be used in the modeling step, there are common transformations to be performed including data selection (sampling), data cleaning, feature selection, feature engineering and algorithm-required transformations such as reformatting, encoding, scaling, class balancing and dimensionality reduction.
- Modeling. The actual algorithmic part implementation is performed in this step. Having prepared input data, it becomes possible to train machine learning models or apply other statistical methods to achieve previously defined aim. In the case of machine learning modeling, algorithms and hyperparameters selection, composing and fitting the models are performed. The models’ performance assessment and obtaining the selected metrics values follow model training.
- Evaluation. Empirical results obtained in the previous steps need to be assessed, and if multiple models were trained, compared across the modeling step. Business success criteria identified in the business understanding step is taken into account. The overall success of the modeling process is discussed and a decision is being made on model selection and further steps.
- Deployment. If a solution ended up being successful, there may be a decision made to implement it in an existing setting. For machine learning modeling, a deployment plan is being developed including actual model deployment, maintenance and documentation. The deployment step may be used to distribute the gained knowledge about the data modeling in an organized manner [16]. In this case, it is limited to the discussion of contributing value of the developed solution in achieving the business goal, comparing the previous state of the problem in question in industry or academy and the implications of the applied solution.
4. Results
4.1. Business Understanding
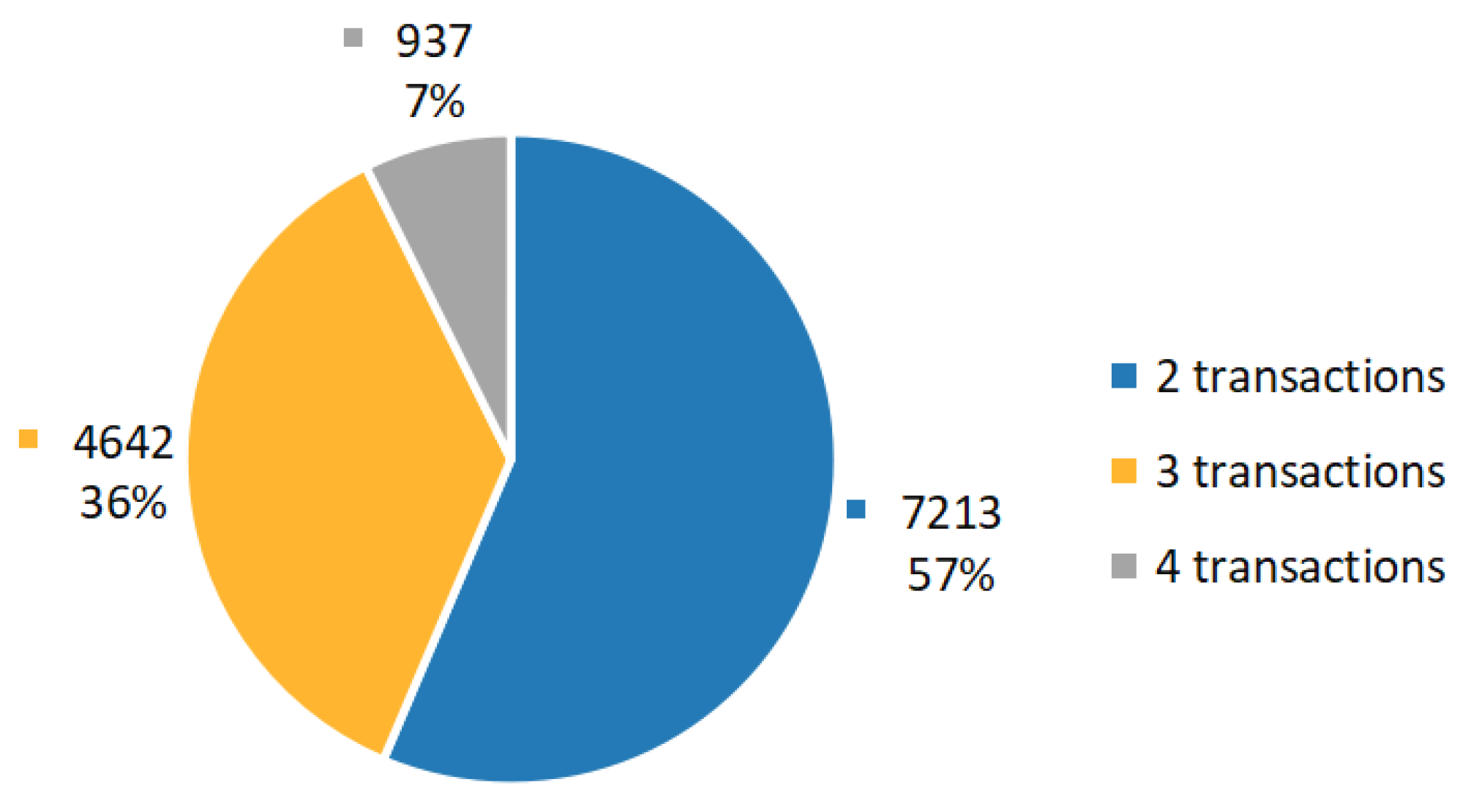
4.2. Data Understanding
4.3. Data Preprocessing
4.3.1. Data Cleaning
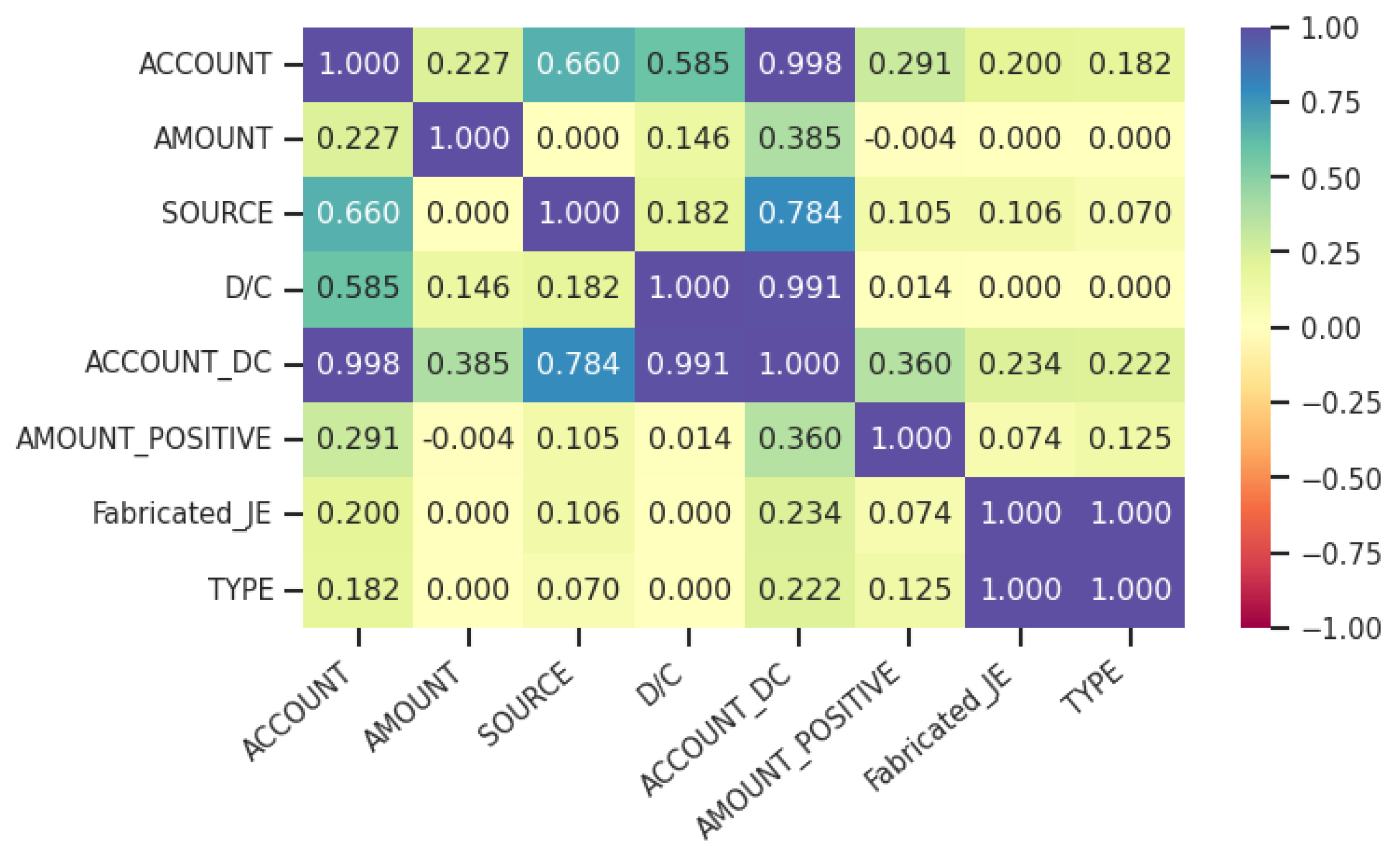
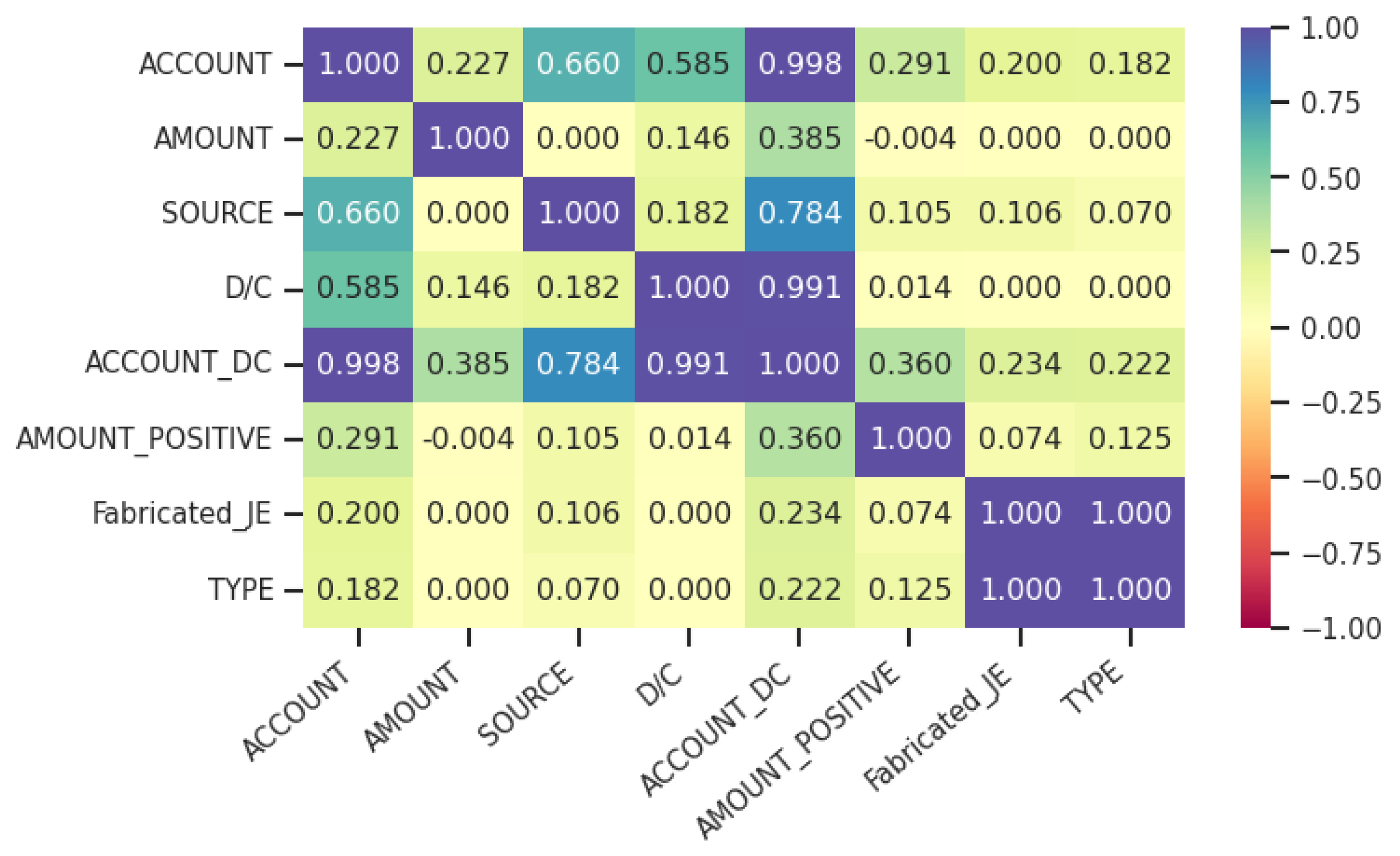
4.3.2. Feature Selection
4.3.3. Feature Engineering
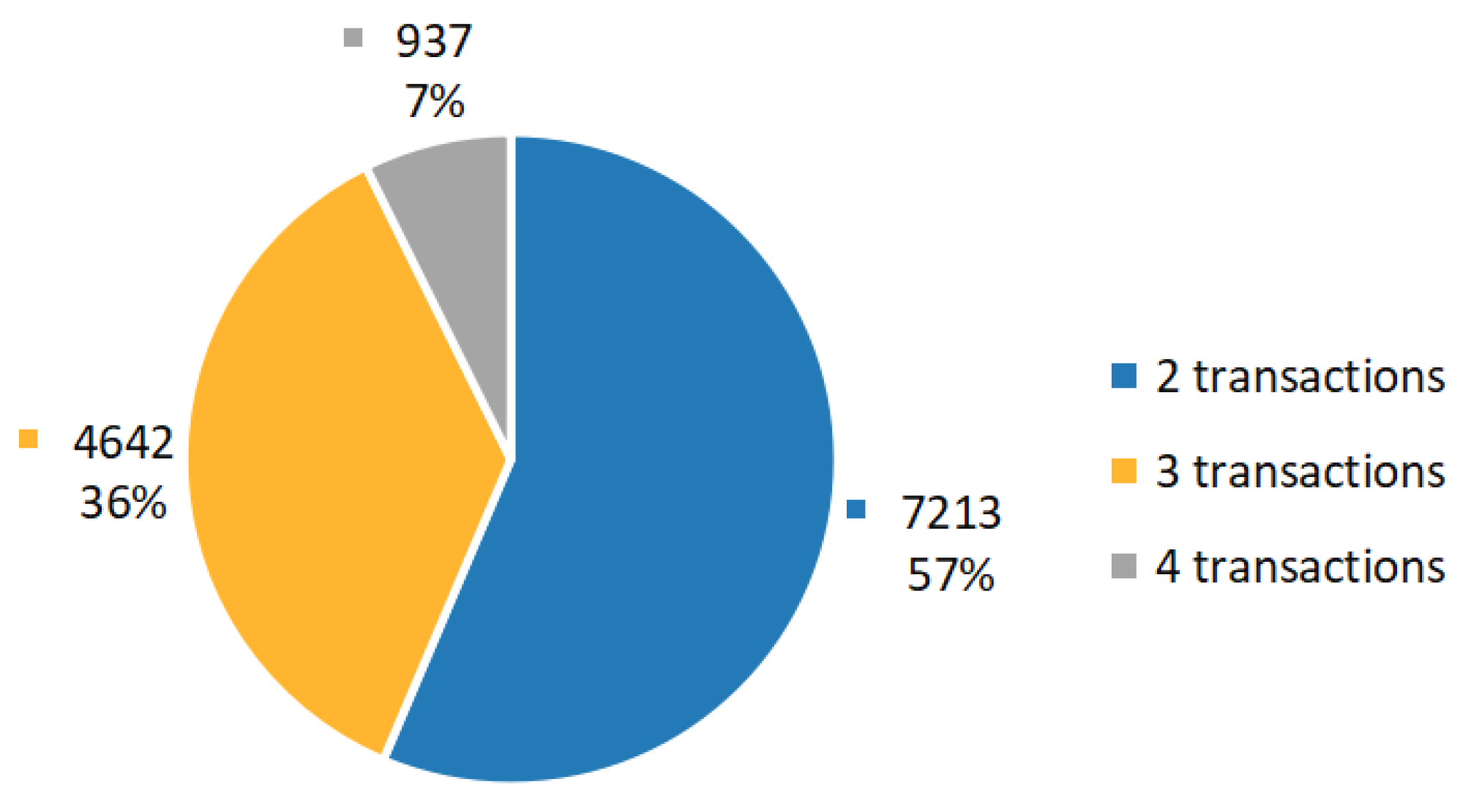
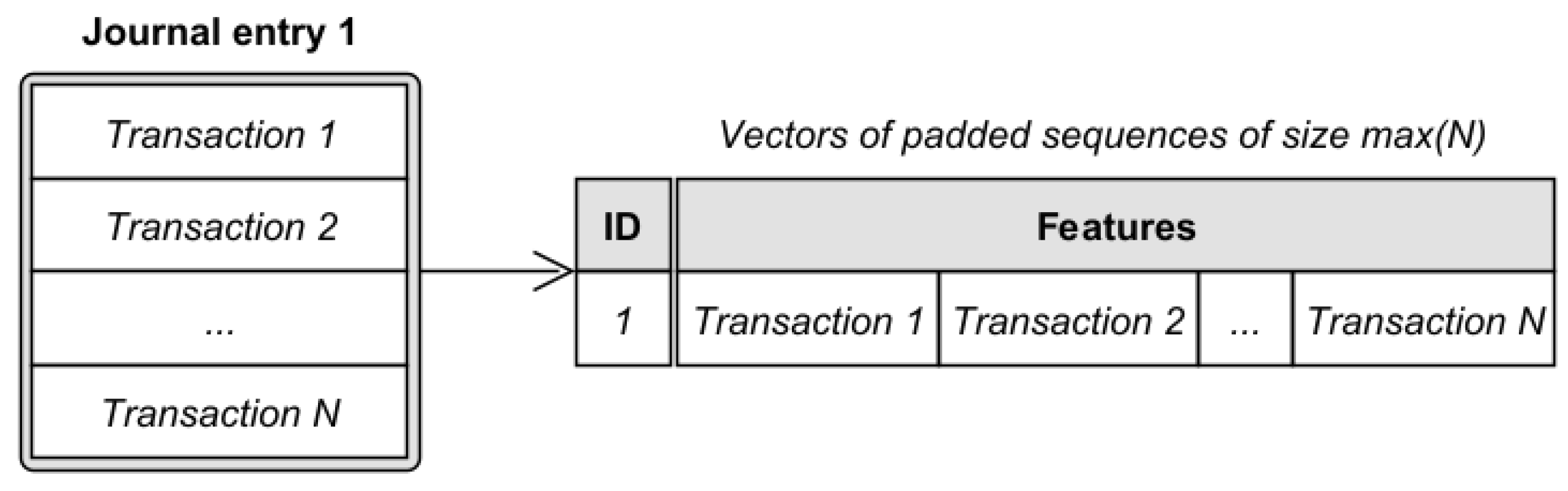
4.3.4. Journal Entry Encoding
4.3.5. Categorical Features One-Hot Encoding
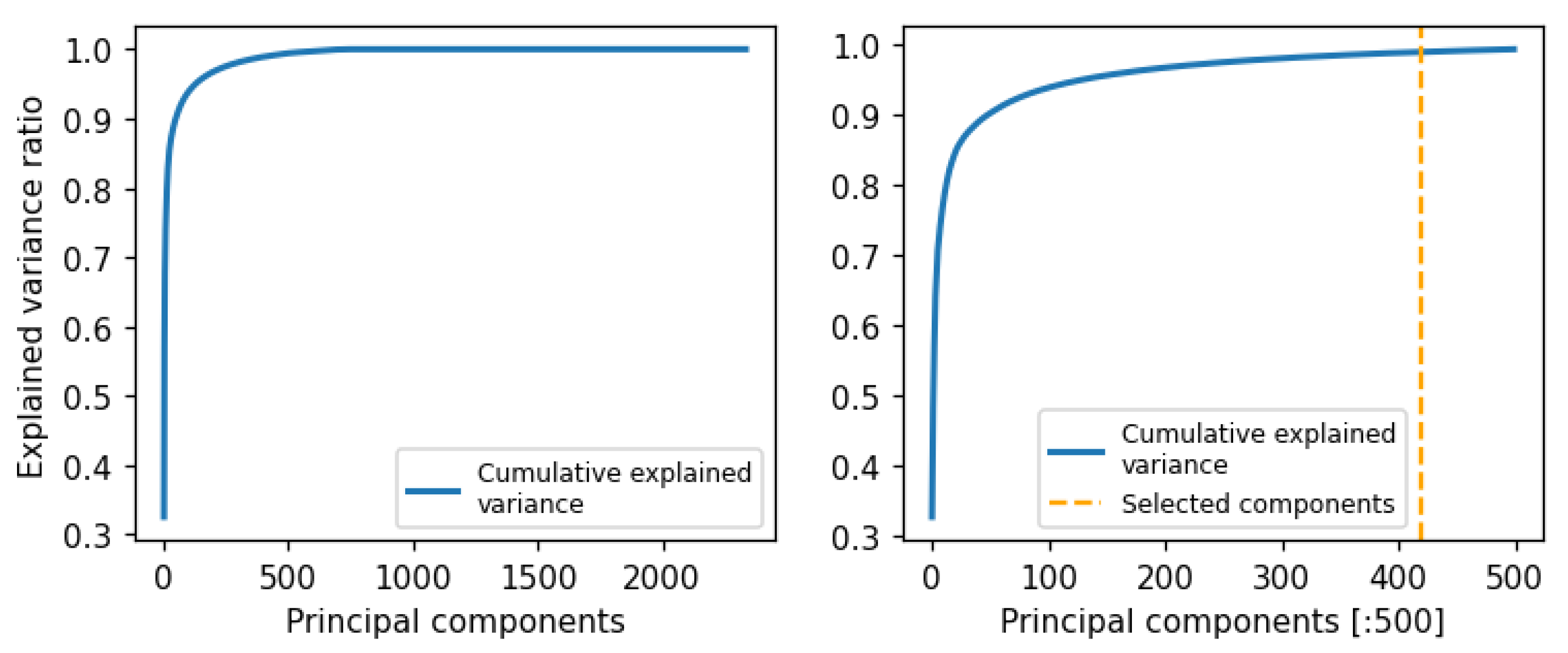
4.3.6. Dimensionality Reduction
4.3.7. Data Normalization
4.4. Modeling
4.4.1. Hyperparameters Tuning
4.4.2. Train–Test Data Split
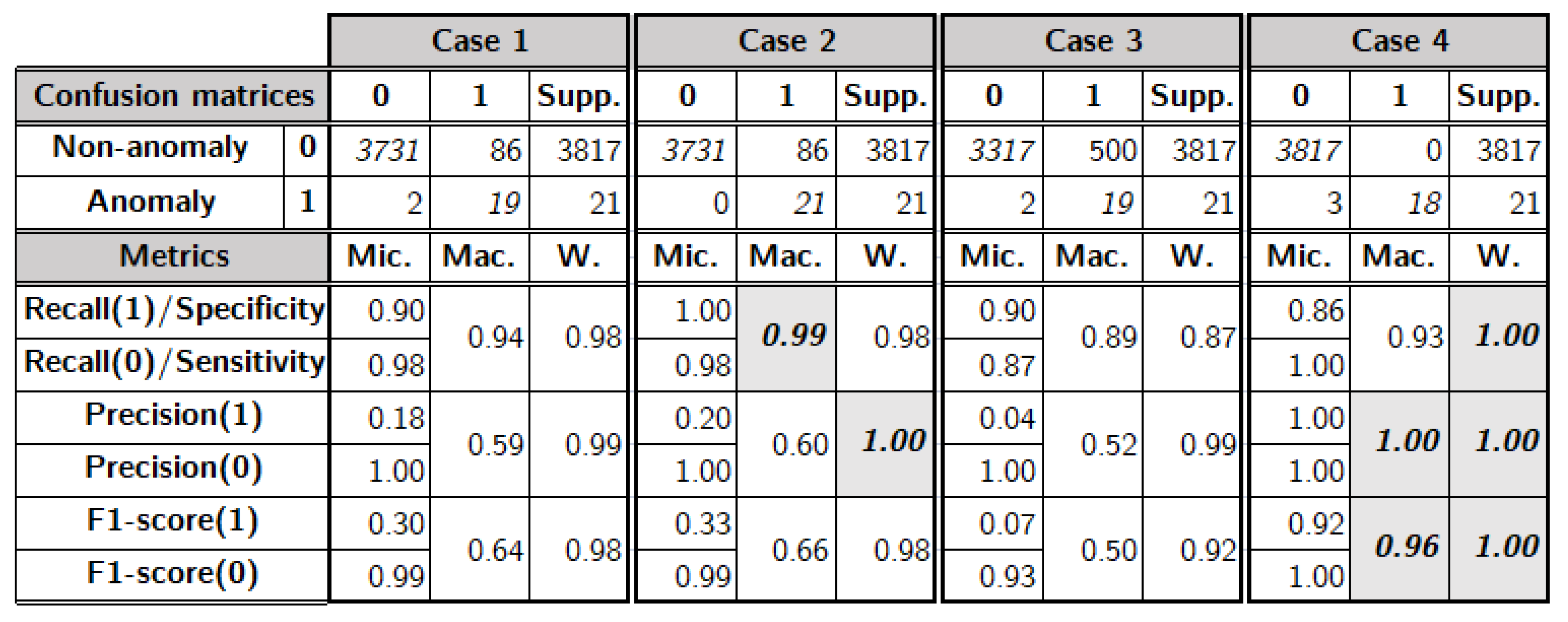
4.4.3. Models Performance Measure
- Accuracy. The accuracy metric represents the percentage of correctly predicted classes, both positive and negative. It is used for balanced datasets when true-positives and negatives are important.
- Precision. Precision is a measure of correctly identified positive or negative classes from all the predicted positive or negative cases, when we care about having the least false-positives possible. Tuning a model by this metric can cause some true positives to be missed.
- Recall. Recall estimates how many instances of the class were predicted out of all instances of that class. Tuning a model using this metric means we aim to find all class instances regardless of possible false findings. According to [1], this metric is mostly used in anomaly and fraud detection problems.
- F1-Score. This metric mathematically is a harmonic mean of recall and precision that would balance out classes over or under representation to be used when false negatives and positives are important to minimize.
4.4.4. Supervised Machine Learning Modeling
Logistic Regression Model
Support Vector Machines Model
Decision Tree Model
Random Forest Model
K-Nearest Mean Model
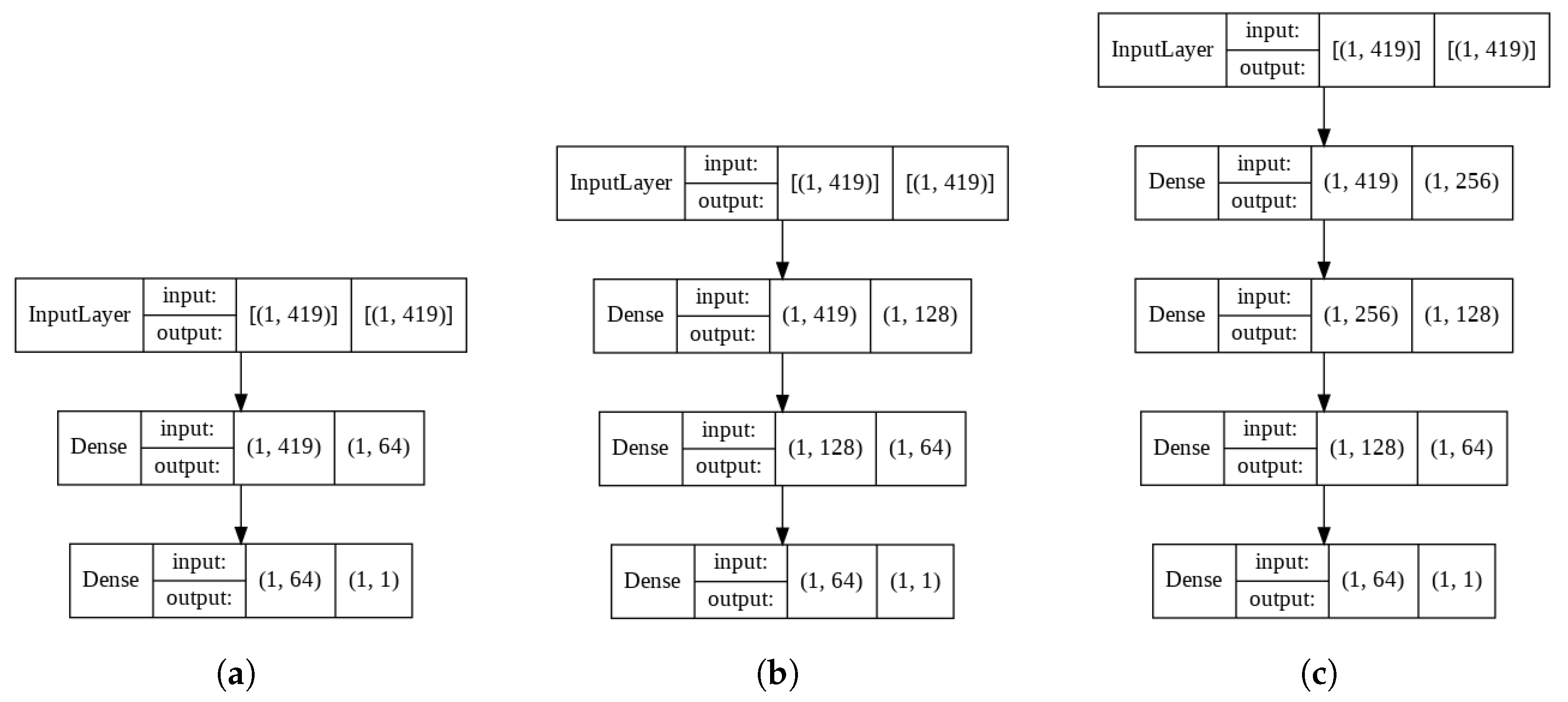
Artificial Neural Network Model
4.4.5. Unsupervised Machine Learning Modeling
Isolation Forest Model
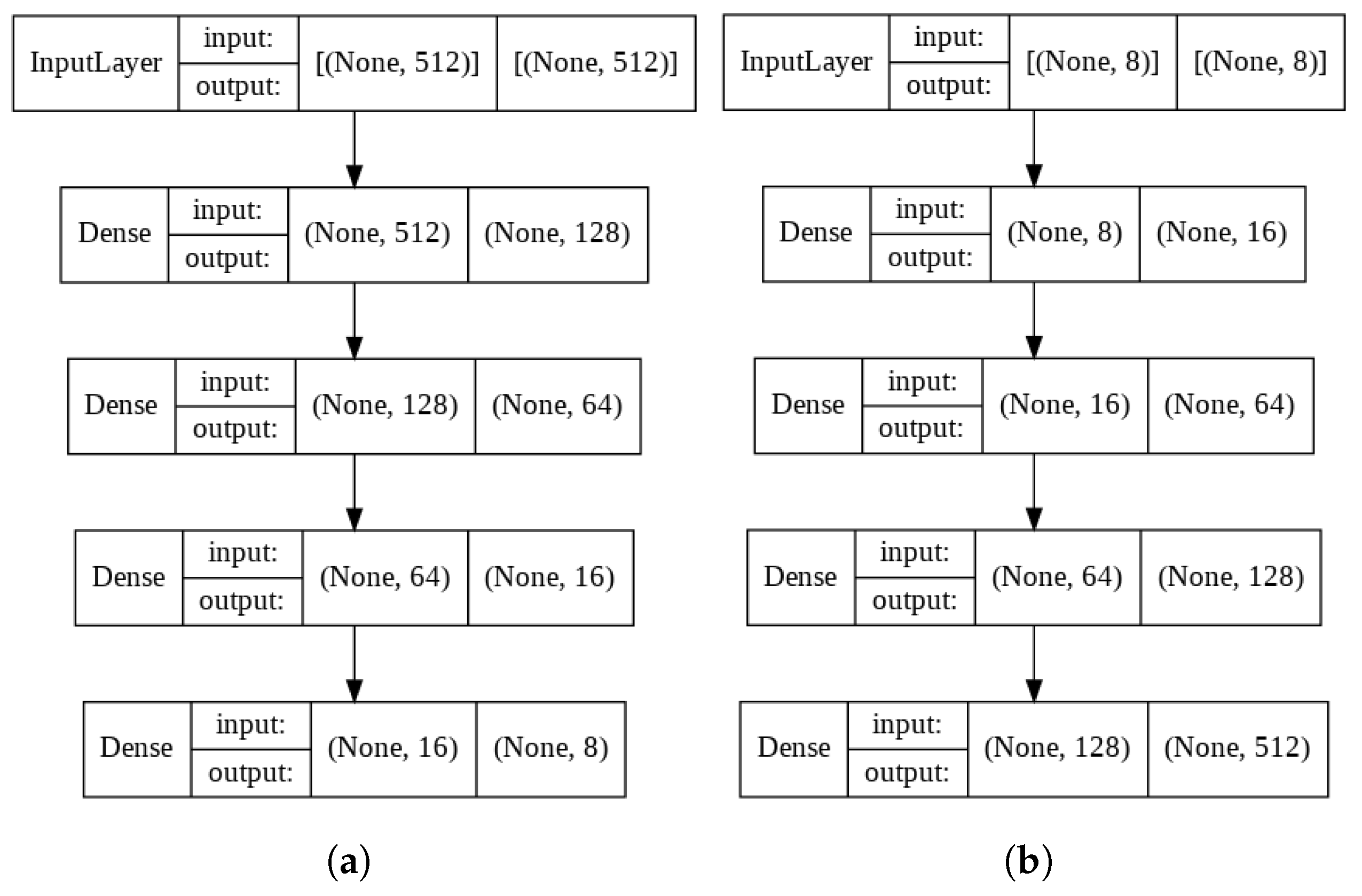
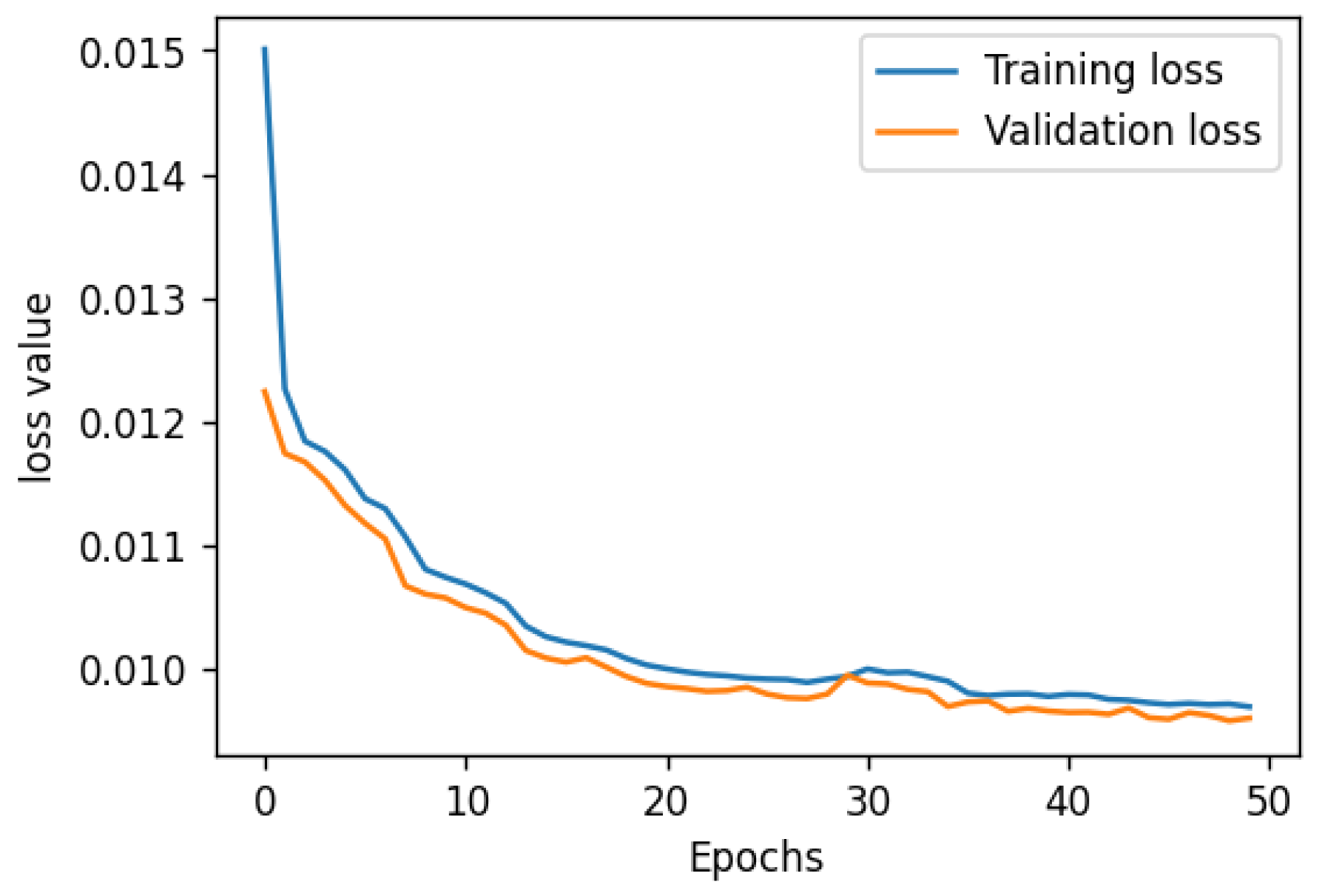
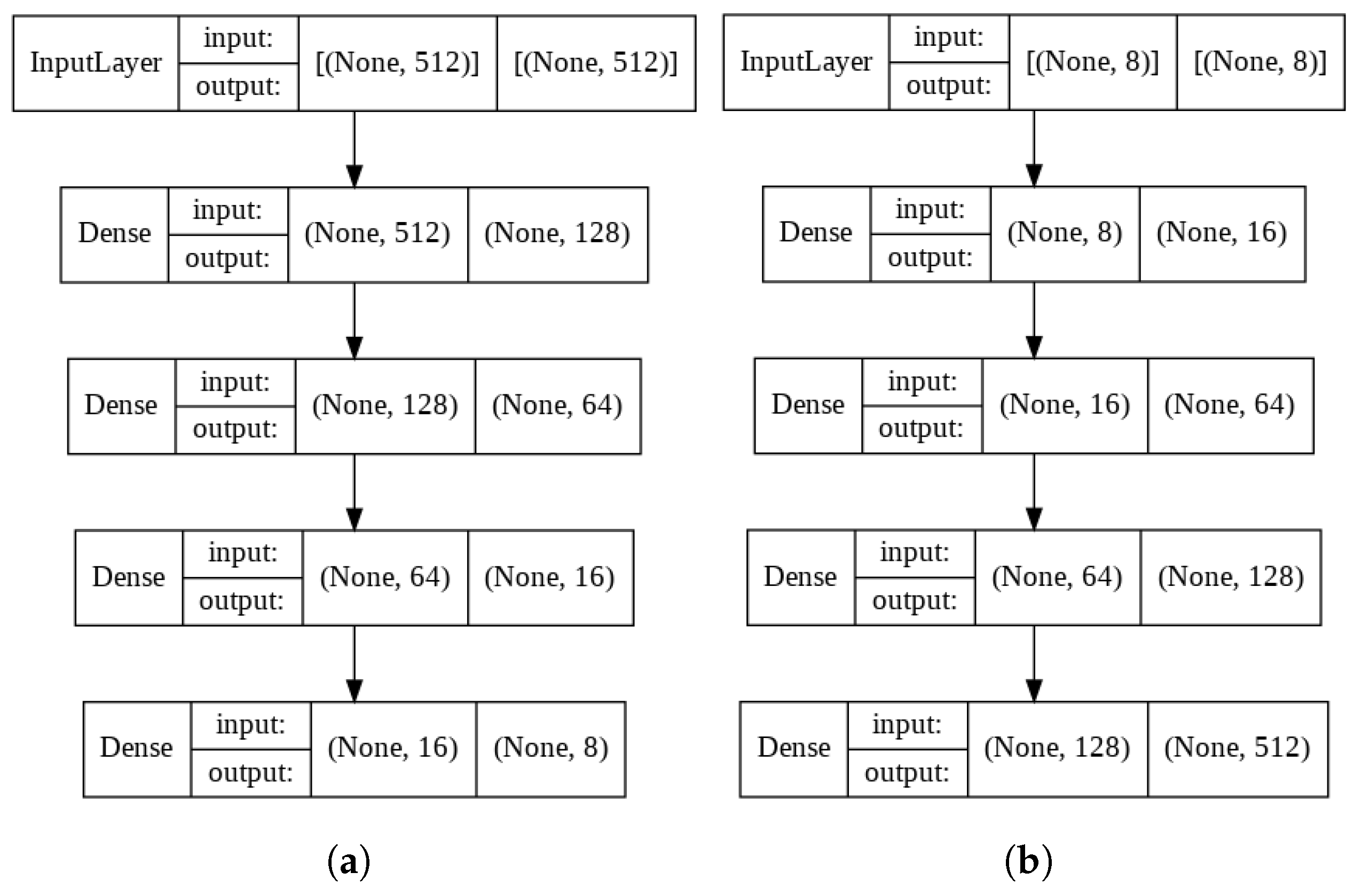
Autoencoder Model
4.5. Evaluation
4.5.1. Supervised Models Evaluation
4.5.2. Unsupervised Models Evaluation
4.6. Deployment
- Sampling risk. Manual assessment of financial statements requires random data sampling that practically amounts to less than 1 percent of the total, with high probability that undiscovered misstatements will come into a bigger non-sampled group [3]. In this work, we trained an unsupervised machine learning model using the isolation forest algorithm that is capable to discover all anomalies of each of the defined anomaly types, sampling less than 10% of the most deviated data out of total. The anomaly score threshold can be adjusted, while in this work we set it using a statistical method. A ‘sampling assistant’ application can be created based on this model.
- Patterns complexity. According to the auditors, there exists a high complexity of patterns in the financial data. Different systems that generate these data and different individual account plans contribute to that problem. Besides, multiple transaction types are grouped into a single journal entry of different sizes. Leveraging size variability with data encoding, we trained a random forest machine learning classifier model that efficiently learns data patterns using labeled anomalies. The model is able to discover all anomalies of known types from the unseen test data, while tagging just 1.48% false-positives out of total data amount. Productionization of a high-performing supervised machine learning model allows automatic discovering of data instances of known anomaly types in the multivariate data.
- Data amount and time efficiency. Increasingly large data amounts make laborious manual auditing work more costly. Adopting machine learning solutions that help the auditing process can much decrease data-processing time and accordingly reduce associated costs. A deployed supervised anomaly detection model that we trained, depending on the system compute power, can make large batch predictions for the transformed data instantaneously that could help auditors to detect misstatements in record time. An unsupervised anomaly detection model would take comparably longer time scanning through the whole dataset, still providing results in a highly efficient manner compared to conventional methods.
- Imperceptibly concealed fraud. Each year, a typical legal entity loses 5% of its revenue because of fraud [1]. Evolving fraudulent financial misstatements are carefully organized, aiming to dissolve in the usual day-to-day financial activities. Conventional auditing methods inevitably create high risks of missing financial misstatements when the majority of missed misstatements are fraudulent [4]. The isolation forest unsupervised model that we implemented in this work is capable of discovering unknown patterns that deviate from normality of the data. Looking into high-risk data samples could more efficiently reveal concealed fraud.
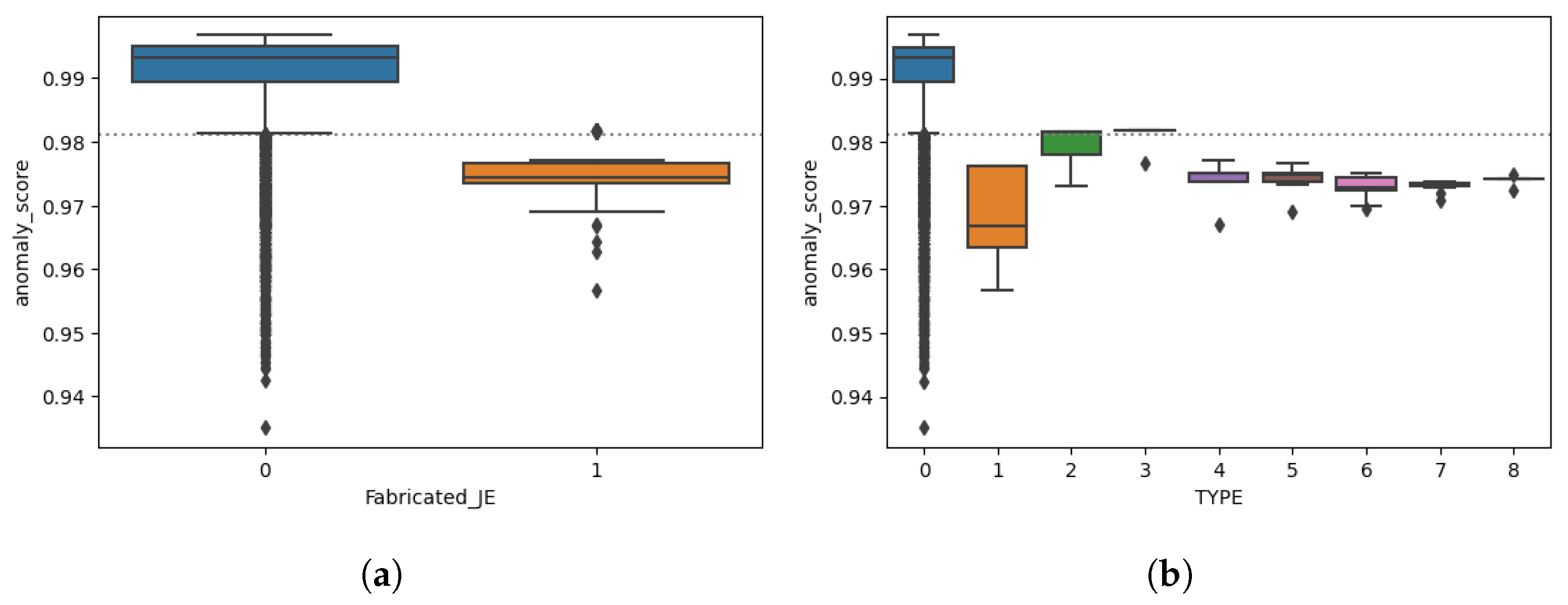
- Deviation report. Accounting data deviation report can be based on multiple data science solutions. Provided that we trained an unsupervised anomaly detection model that scans through all journal entries, it is possible to show which data instances are deviating from normality based on the selected anomaly score threshold. Moreover, each data point is assigned with the anomaly score, so there exist a possibility to group journal entries by risk levels.
5. Discussion
Research Questions Re-Visited
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Baesens, B.; Van Vlasselaer, V.; Verbeke, W. Fraud Analytics Using Descriptive, Predictive, and Social Network Techniques: A Guide to Data Science for Fraud Detection; Wiley: New York, NY, USA, 2015. [Google Scholar]
- Zemankova, A. Artificial Intelligence in Audit and Accounting: Development, Current Trends, Opportunities and Threats-Literature Review. In Proceedings of the 2019 International Conference on Control, Artificial Intelligence, Robotics & Optimization (ICCAIRO), Athens, Greece, 8–10 December 2019; pp. 148–154. [Google Scholar]
- Nonnenmacher, J.; Gómez, J.M. Unsupervised anomaly detection for internal auditing: Literature review and research agenda. Int. J. Digit. Account. Res. 2021, 21, 1–22. [Google Scholar] [CrossRef]
- IFAC. International Standards on Auditing 240, The Auditor’s Responsibilities Relating to Fraud in an Audit of Financial Statements. 2009. Available online: https://www.ifac.org/system/files/downloads/a012-2010-iaasb-handbook-isa-240.pdf (accessed on 18 April 2022).
- Singleton, T.W.; Singleton, A.J. Fraud Auditing and Forensic Accounting, 4th ed.; Wiley: New York, NY, USA, 2010. [Google Scholar]
- Amani, F.A.; Fadlalla, A.M. Data mining applications in accounting: A review of the literature and organizing framework. Int. J. Account. Inf. Syst. 2017, 24, 32–58. [Google Scholar] [CrossRef]
- Lahann, J.; Scheid, M.; Fettke, P. Utilizing Machine Learning Techniques to Reveal VAT Compliance Violations in Accounting Data. In Proceedings of the 2019 IEEE 21st Conference on Business Informatics (CBI), Moscow, Russia, 15–17 July 2019; pp. 1–10. [Google Scholar]
- Becirovic, S.; Zunic, E.; Donko, D. A Case Study of Cluster-based and Histogram-based Multivariate Anomaly Detection Approach in General Ledgers. In Proceedings of the 2020 19th International Symposium INFOTEH-JAHORINA (INFOTEH), East Sarajevo, Bosnia and Herzegovina, 18–20 March 2020. [Google Scholar]
- EY. How an AI Application Can Help Auditors Detect Fraud. Available online: https://www.ey.com/en_gl/better-begins-with-you/how-an-ai-application-can-help-auditors-detect-fraud (accessed on 22 April 2022).
- PwC. GL.ai, PwC’s Anomaly Detection for the General Ledger. Available online: https://www.pwc.com/m1/en/events/socpa-2020/documents/gl-ai-brochure.pdf (accessed on 22 April 2022).
- Schreyer, M.; Sattarov, T.; Schulze, C.; Reimer, B.; Borth, D. Detection of Accounting Anomalies in the Latent Space using Adversarial Autoencoder Neural Networks. In Proceedings of the 2nd KDD Workshop on Anomaly Detection in Finance, Anchorage, AK, USA, 5 August 2019. [Google Scholar]
- Schultz, M.; Tropmann-Frick, M. Autoencoder Neural Networks versus External Auditors: Detecting Unusual Journal Entries in Financial Statement Audits. In Proceedings of the 53rd Hawaii International Conference on System Sciences, Maui, HI, USA, 7–10 January 2020. [Google Scholar]
- Župan, M.; Letinić, S.; Budimir, V. Journal entries with deep learning model. Int. J. Adv. Comput. Eng. Netw. IJACEN 2018, 6, 55–58. [Google Scholar]
- Ayodele, T. Types of machine learning algorithms. New advances in machine learning. New Adv. Mach. Learn. 2010, 3, 19–48. [Google Scholar]
- Sarker, I.H. Machine Learning: Algorithms, Real-World Applications and Research Directions. SN Comput. Sci. 2021, 2, 160. [Google Scholar] [CrossRef] [PubMed]
- Plotnikova, V.; Dumas, M.; Milani, F. Adaptations of data mining methodologies: A systematic literature review. PeerJ Comput. Sci. 2020, 6, e267. [Google Scholar] [CrossRef] [PubMed]
- Foroughi, F.; Luksch, P. Data Science Methodology for Cybersecurity Projects. Comput. Sci. Inf. Technol. 2018, 01–14. [Google Scholar]
- Azevedo, A.; Santos, M. KDD, semma and CRISP-DM: A parallel overview. In Proceedings of the IADIS European Conference on Data Mining, Amsterdam, The Netherlands, 24–26 July 2008; pp. 182–185. [Google Scholar]
- Microsoft. What Is the Team Data Science Process? Available online: https://docs.microsoft.com/en-us/azure/architecture/data-science-process/overview (accessed on 23 May 2022).
- BAS. General Information about the Accounting Plan. Available online: https://www.bas.se/english/general-information-about-the-accounting-plan (accessed on 12 April 2022).
- Salem, N.; Hussein, S. Data dimensional reduction and principal components analysis. Procedia Comput. Sci. 2019, 163, 292–299. [Google Scholar] [CrossRef]
- Databrics. How (Not) to Tune Your Model with Hyperopt. 2021. Available online: https://databricks.com/blog/2021/04/15/how-not-to-tune-your-model-with-hyperopt.html (accessed on 26 April 2022).
- Gholamy, A.; Kreinovich, V.; Kosheleva, O. Why 70/30 or 80/20 Relation between Training and Testing Sets: A Pedagogical Explanation. 2018. Available online: https://scholarworks.utep.edu/cs_techrep/1209 (accessed on 19 April 2022).
- Peng, C.Y.J.; Lee, K.L.; Ingersoll, G.M. An Introduction to Logistic Regression Analysis and Reporting. J. Educ. Res. 2002, 96, 3–14. [Google Scholar] [CrossRef]
- Evgeniou, T.; Pontil, M. Support Vector Machines: Theory and Applications. Mach. Learn. Its Appl. Adv. Lect. 2001, 2049, 249–257. [Google Scholar]
- Jijo, B.T.; Abdulazeez, A.M. Classification Based on Decision Tree Algorithm for Machine Learning. J. Appl. Sci. Technol. Trends 2021, 2, 20–28. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Cunningham, P.; Delany, S.J. k-Nearest Neighbour Classifiers: 2nd Edition (with Python examples). arXiv 2020, arXiv:2004.04523. [Google Scholar]
- Rish, I. An Empirical Study of the Naïve Bayes Classifier. In Proceedings of the IJCAI 2001 Work Empir Methods Artif Intell, Seattle, WA, USA, 4–10 August 2001; Volume 3. [Google Scholar]
- Dastres, R.; Soori, M. Artificial Neural Network Systems. Int. J. Imaging Robot. 2021, 21, 13–25. [Google Scholar]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation Forest. In Proceedings of the ICDM ’08, Eighth IEEE International Conference on Data Mining, Beijing, China, 8–11 November 2019. [Google Scholar]
- Xu, Y.; Dong, H.; Zhou, M.; Xing, J.; Li, X.; Yu, J. Improved Isolation Forest Algorithm for Anomaly Test Data Detection. J. Comput. Commun. 2021, 9, 48–60. [Google Scholar] [CrossRef]
- Pang, G.; Shen, C.; Cao, L.; Hengel, A.V.D. Deep Learning for Anomaly Detection: A Review. ACM Comput. Surv. 2020, 54, 1–38. [Google Scholar] [CrossRef]
- Bank, D.; Koenigstein, N.; Giryes, R. Autoencoders. arXiv 2020, arXiv:2003.05991. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| JE_NO | EFF_DATE | ACCOUNT | AMOUNT | SOURCE | COMPANY | FY | Fabricated_JE | TYPE |
|---|---|---|---|---|---|---|---|---|
| A-111 | 2019-07-07 | 1930 | 10,512.00 | C | 44 | 2018-09-01–2019-08-31 | 0 | 0 |
| A-111 | 2019-07-07 | 1510 | −10,512.00 | C | 44 | 2018-09-01–2019-08-31 | 0 | 0 |
| B-111 | 2019-06-10 | 2330 | −2374.00 | E | 55 | 2018-07-01–2019-06-30 | 0 | 0 |
| B-111 | 2019-06-10 | 2440 | 2374.00 | E | 55 | 2018-07-01–2019-06-30 | 0 | 0 |
| N | Column Name | Column Type |
|---|---|---|
| 0 | JE_NO | string |
| 1 | EFF_DATE | datetime |
| 2 | ACCOUNT | string |
| 3 | AMOUNT | float |
| 4 | SOURCE | string |
| 5 | COMPANY | string |
| 6 | FY | string |
| 7 | Fabricated_JE | string |
| 8 | TYPE | string |
| Label | Count |
|---|---|
| Normal data | 31,952 |
| Anomaly type 1 | 22 |
| Anomaly type 7 | 20 |
| Anomaly type 3 | 20 |
| Anomaly type 4 | 18 |
| Anomaly type 6 | 18 |
| Anomaly type 5 | 18 |
| Anomaly type 8 | 18 |
| Anomaly type 2 | 14 |
| Label | Count |
|---|---|
| Normal data | 31,952 |
| Anomaly | 148 |
| No. | Description |
|---|---|
| 1 | Classic mistake. Account that should not be combined with VAT. |
| 2 | Withdrawal cash to your private account and finance it by getting VAT back. Zero game for company, win for yourself. |
| 3 | Invoice with only VAT. Insurance which should be cost only (no VAT) has been recorded as only VAT. |
| 4 | Decreasing cost and getting VAT back. Improves margins and provides cash. |
| 5 | Increasing revenue and getting VAT back. Improve top line, margins and provides cash. |
| 6 | Inflating revenue, recording manual revenue and cost. |
| 7 | Fake revenue followed by clearing the invoice against account 4010 to make it look as if the invoice were paid, using the client payment process. |
| 8 | Double entry of supplier invoice, followed by recording it as being paid by creating revenue instead of reversing the invoice. |
| Column Name | Unique Count |
|---|---|
| JE_NO | 5105 |
| EFF_DATE | 1558 |
| ACCOUNT | 426 |
| SOURCE | 7 |
| COMPANY | 9 |
| FY | 18 |
| Fabricated_JE | 2 |
| TYPE | 9 |
| ACCOUNT | AMOUNT | SOURCE | D/C | ACCOUNT_DC | AMOUNT_POSITIVE |
|---|---|---|---|---|---|
| ✓ | ✓ |
| Precision | Recall | F1-Score | Support | |
|---|---|---|---|---|
| 0 | 1.00 | 0.98 | 0.99 | 3817 |
| 1 | 0.21 | 0.90 | 0.35 | 21 |
| accuracy | 0.98 | 3838 | ||
| macro avg | 0.61 | 0.94 | 0.67 | 3838 |
| weighted avg | 1.00 | 0.98 | 0.99 | 3838 |
| ID | Fabricated_JE | TYPE | y_Pred |
|---|---|---|---|
| 11410 | 1 | 8 | 0 |
| 11704 | 1 | 8 | 0 |
| Precision | Recall | F1-Score | Support | |
|---|---|---|---|---|
| 0 | 1.00 | 0.98 | 0.99 | 3817 |
| 1 | 0.19 | 0.95 | 0.32 | 21 |
| accuracy | 0.98 | 3838 | ||
| macro avg | 0.60 | 0.97 | 0.65 | 3838 |
| weighted avg | 1.00 | 0.98 | 0.98 | 3838 |
| ID | Fabricated_JE | TYPE | y_Pred |
|---|---|---|---|
| 11410 | 1 | 8 | 0 |
| Precision | Recall | F1-Score | Support | |
|---|---|---|---|---|
| 0 | 1.00 | 0.97 | 0.99 | 3817 |
| 1 | 0.16 | 1.00 | 0.28 | 21 |
| accuracy | 0.97 | 3838 | ||
| macro avg | 0.58 | 0.99 | 0.63 | 3838 |
| weighted avg | 1.00 | 0.97 | 0.98 | 3838 |
| Precision | Recall | F1-Score | Support | |
|---|---|---|---|---|
| 0 | 1.00 | 0.99 | 0.99 | 3817 |
| 1 | 0.27 | 1.00 | 0.42 | 21 |
| accuracy | 0.99 | 3838 | ||
| macro avg | 0.63 | 0.99 | 0.71 | 3838 |
| weighted avg | 1.00 | 0.99 | 0.99 | 3838 |
| Precision | Recall | F1-Score | Support | |
|---|---|---|---|---|
| 0 | 1.00 | 1.00 | 1.00 | 3817 |
| 1 | 0.83 | 0.71 | 0.77 | 21 |
| accuracy | 1.00 | 3838 | ||
| macro avg | 0.92 | 0.86 | 0.88 | 3838 |
| weighted avg | 1.00 | 1.00 | 1.00 | 3838 |
| ID | Fabricated_JE | TYPE | y_Pred |
|---|---|---|---|
| 517 | 1 | 6 | 0 |
| 867 | 1 | 6 | 0 |
| 11410 | 1 | 8 | 0 |
| 11704 | 1 | 8 | 0 |
| 9494 | 1 | 8 | 0 |
| 603 | 1 | 1 | 0 |
| Precision | Recall | F1-Score | Support | |
|---|---|---|---|---|
| 0 | 1.00 | 1.00 | 1.00 | 3817 |
| 1 | 1.00 | 0.19 | 0.32 | 21 |
| accuracy | 1.00 | 3838 | ||
| macro avg | 1.00 | 0.60 | 0.66 | 3838 |
| weighted avg | 1.00 | 1.00 | 0.99 | 3838 |
| Model No. | Model | No. of Hidden Layers | Recall Avg Macro |
|---|---|---|---|
| 1 (a) | Vanilla ANN | 1 | 0.9043 |
| 2 (b) | DNN1 | 2 | 0.9041 |
| 3 (c) | DNN2 | 3 | 0.9277 |
| No. | Algorithm | TN | FN | FP | TP | Recall Avg Macro |
|---|---|---|---|---|---|---|
| 1 | Logistic Regression | 3747 | 2 | 70 | 19 | 0.9432 |
| 2 | Support Vector Machines | 3732 | 1 | 85 | 20 | 0.9650 |
| 3 | Decision Tree | 3710 | 0 | 107 | 21 | 0.9859 |
| 4 | Random Forest | 3760 | 0 | 57 | 21 | 0.9925 |
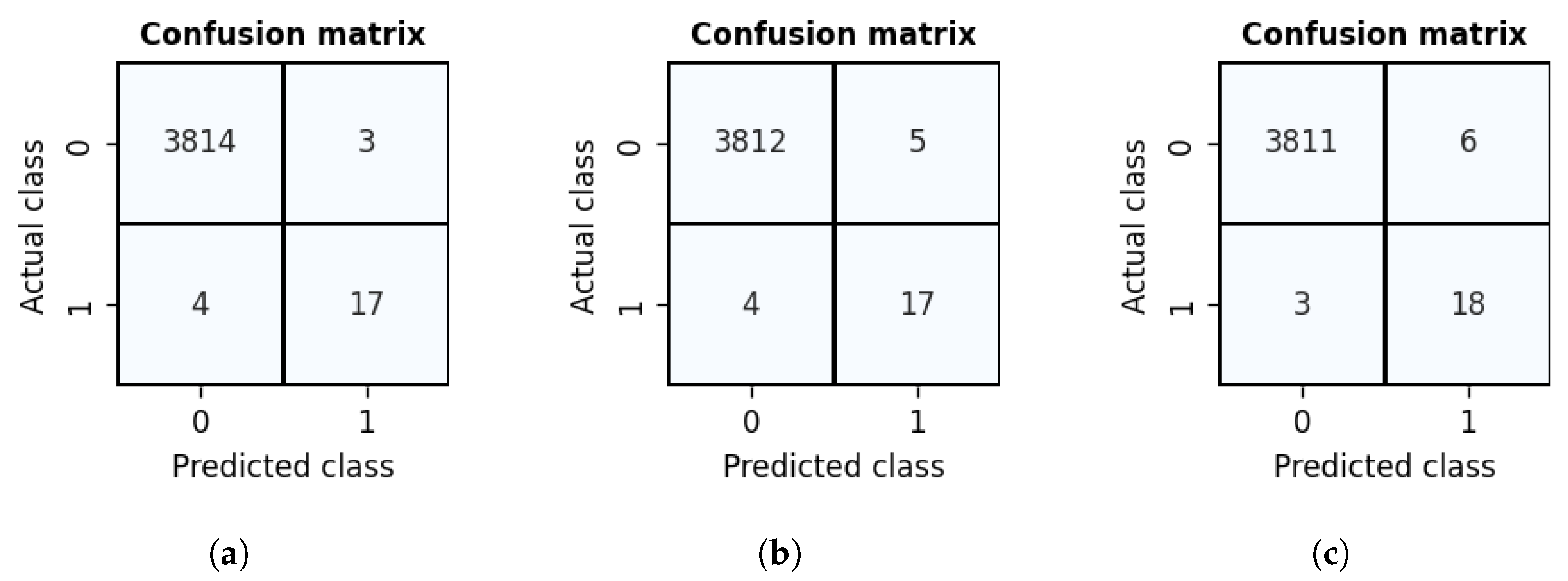
| 5 | K-Nearest Neighbour | 3814 | 6 | 3 | 15 | 0.8567 |
| 6 | Naïve Bayes | 3817 | 17 | 0 | 4 | 0.5952 |
| 7 | Deep Neural Network | 3811 | 3 | 6 | 18 | 0.9277 |
| No. | Algorithm | TN | FN | FP | TP | Recall Avg Macro | Anom.% |
|---|---|---|---|---|---|---|---|
| 1 | Isolation Forest | 11,592 | 0 | 1130 | 70 | 0.9555 | 9.38 |
| 2 | Autoencoder | 11,301 | 0 | 1421 | 70 | 0.9441 | 11.65 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bakumenko, A.; Elragal, A. Detecting Anomalies in Financial Data Using Machine Learning Algorithms. Systems 2022, 10, 130. https://doi.org/10.3390/systems10050130
Bakumenko A, Elragal A. Detecting Anomalies in Financial Data Using Machine Learning Algorithms. Systems. 2022; 10(5):130. https://doi.org/10.3390/systems10050130
Chicago/Turabian StyleBakumenko, Alexander, and Ahmed Elragal. 2022. "Detecting Anomalies in Financial Data Using Machine Learning Algorithms" Systems 10, no. 5: 130. https://doi.org/10.3390/systems10050130
APA StyleBakumenko, A., & Elragal, A. (2022). Detecting Anomalies in Financial Data Using Machine Learning Algorithms. Systems, 10(5), 130. https://doi.org/10.3390/systems10050130