Abstract
Hidden Markov Models (HMMs) are widely used probabilistic models, particularly for annotating sequential data with an underlying hidden structure. Patterns in the annotation are often more relevant to study than the hidden structure itself. A typical HMM analysis consists of annotating the observed data using a decoding algorithm and analyzing the annotation to study patterns of interest. For example, given an HMM modeling genes in DNA sequences, the focus is on occurrences of genes in the annotation. In this paper, we define a pattern through a regular expression and present a restriction of three classical algorithms to take the number of occurrences of the pattern in the hidden sequence into account. We present a new algorithm to compute the distribution of the number of pattern occurrences, and we extend the two most widely used existing decoding algorithms to employ information from this distribution. We show experimentally that the expectation of the distribution of the number of pattern occurrences gives a highly accurate estimate, while the typical procedure can be biased in the sense that the identified number of pattern occurrences does not correspond to the true number. We furthermore show that using this distribution in the decoding algorithms improves the predictive power of the model.
1. Introduction
A Hidden Markov Model (HMM) is a probabilistic model for sequential data with an underlying hidden structure. Because of their computational and analytical tractability, they are widely used especially in speech recognition [1,2,3], image processing [4] and in several applications in bioinformatics; e.g., modeling of proteins [5,6,7], sequence alignment [8,9,10], phylogenetic analysis [11,12] and identification of coding regions in genomes [13,14].
Patterns in the hidden structure are, however, often more relevant to study than the full hidden structure itself. When modeling proteins, one might be interested in neighboring secondary structures that differ, while for sequence alignments, the pattern could capture specific characteristics, such as long indels. In phylogenetic analysis, changes in the tree along the sequence are most relevant, while when investigating coding regions of DNA data, patterns corresponding to genes are the main focus.
Counting the number of occurrences of such patterns can be approached (as in the methods based on [15]) by making inferences from the prediction of a decoding algorithm; e.g., the Viterbi algorithm or the posterior-Viterbi algorithm. As we show in our experiments, this can give consistently biased estimates for the number of pattern occurrences. A more realistic method is presented in [16], where the distribution of the number of pattern occurrences is computed by means of Markov chain embedding. To our knowledge, this is the only study of patterns in the hidden sequence of HMMs. The problem of pattern finding in random sequences generated by simple models, such as Markov chains, has been intensively studied using the embedding technique [17,18,19].
We present a fundamentally different approach to compute the distribution of the number of pattern occurrences and show how it can be used to improve the prediction of the hidden structure. We use regular expressions as patterns and employ their deterministic finite automata to keep track of occurrences. The use of automata to describe occurrences of patterns in Markov sequences has been described previously in [18,20,21]. However, analyzing pattern occurrences in the hidden structure of HMMs by means of automata has not been done before. We introduce a new version of the forward algorithm, the restricted forward algorithm, which computes the likelihood of the data under the hidden sequence containing a specific number of pattern occurrences. This algorithm can be used to compute the occurrence number distribution. We furthermore introduce new versions of the two most widely used decoding algorithms, the Viterbi algorithm and the posterior-Viterbi algorithm, where the prediction is restricted to containing a certain number of occurrences, e.g., the expectation obtained from the distribution. We have implemented and tested the new algorithms and performed experiments that show that this approach improves both the estimate of the number of pattern occurrences and the prediction of the hidden structure.
The remainder of this paper is organized as follows: we start by introducing Hidden Markov Models and automata; we continue by presenting our restricted algorithms, which we then validate experimentally.
2. Methods
2.1. Hidden Markov Models
A Hidden Markov Model (HMM) [3] is a joint probability distribution over an observed sequence y1:T = y1y2…yT ∈
 * and a hidden sequence x1:T = x1x2 … xT ∈
* and a hidden sequence x1:T = x1x2 … xT ∈
 *, where
and
are finite alphabets of observables and hidden states, respectively. The hidden sequence is a realization of a Markov process that explains the hidden properties of the observed data. We can formally define an HMM as consisting of a finite alphabet of hidden states
= {h1, h2, …, hN}, a finite alphabet of observables
= {o1,o2, …, oM}, a vector Π = (πhi)1≤i≤N, where πhi = ℙ(X1 = hi) is the probability of the hidden sequence starting in state hi, a matrix A = {ahi,hj}1≤i,j≤N, where ahi,hj = ℙ(Xt = hj | Xt−1 = hi) is the probability of a transition from state hi to state hj, and a matrix
, where bhi,oj = ℙ(Yt = oj | Xt = hi) is the probability of state hi emitting oj.
*, where
and
are finite alphabets of observables and hidden states, respectively. The hidden sequence is a realization of a Markov process that explains the hidden properties of the observed data. We can formally define an HMM as consisting of a finite alphabet of hidden states
= {h1, h2, …, hN}, a finite alphabet of observables
= {o1,o2, …, oM}, a vector Π = (πhi)1≤i≤N, where πhi = ℙ(X1 = hi) is the probability of the hidden sequence starting in state hi, a matrix A = {ahi,hj}1≤i,j≤N, where ahi,hj = ℙ(Xt = hj | Xt−1 = hi) is the probability of a transition from state hi to state hj, and a matrix
, where bhi,oj = ℙ(Yt = oj | Xt = hi) is the probability of state hi emitting oj.
* and a hidden sequence x1:T = x1x2 … xT ∈
*, where
and
are finite alphabets of observables and hidden states, respectively. The hidden sequence is a realization of a Markov process that explains the hidden properties of the observed data. We can formally define an HMM as consisting of a finite alphabet of hidden states
= {h1, h2, …, hN}, a finite alphabet of observables
= {o1,o2, …, oM}, a vector Π = (πhi)1≤i≤N, where πhi = ℙ(X1 = hi) is the probability of the hidden sequence starting in state hi, a matrix A = {ahi,hj}1≤i,j≤N, where ahi,hj = ℙ(Xt = hj | Xt−1 = hi) is the probability of a transition from state hi to state hj, and a matrix
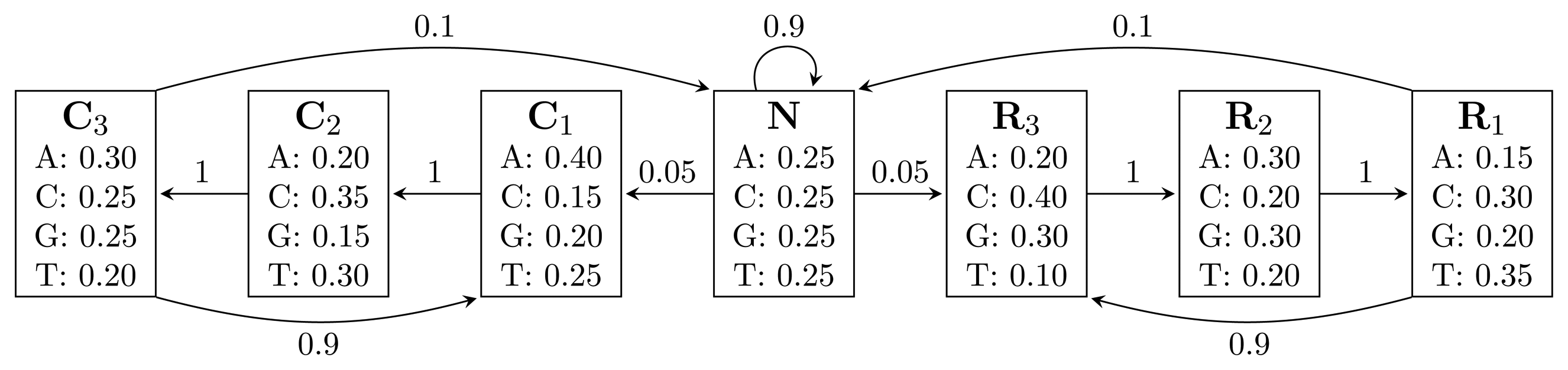
, where bhi,oj = ℙ(Yt = oj | Xt = hi) is the probability of state hi emitting oj.Figure 1 shows an HMM designed for gene finding. The observed sequence is a DNA sequence over the alphabet
= {A, C, G, T}, while the hidden states encode if a position is in a non-coding area (N) or is part of a gene on the positive strand (C) or on the negative strand (R). The model incorporates the fact that nucleotides come in multiples of three within genes, where each nucleotide triplet codes for an amino acid. The set of hidden states is
= {N} ∪ {Ci, Ri|1 ≤ i ≤ 3}. In practice, models used for gene finding are much more complex, but this model captures the essential aspects of a gene finder.
= {A, C, G, T}, while the hidden states encode if a position is in a non-coding area (N) or is part of a gene on the positive strand (C) or on the negative strand (R). The model incorporates the fact that nucleotides come in multiples of three within genes, where each nucleotide triplet codes for an amino acid. The set of hidden states is
= {N} ∪ {Ci, Ri|1 ≤ i ≤ 3}. In practice, models used for gene finding are much more complex, but this model captures the essential aspects of a gene finder.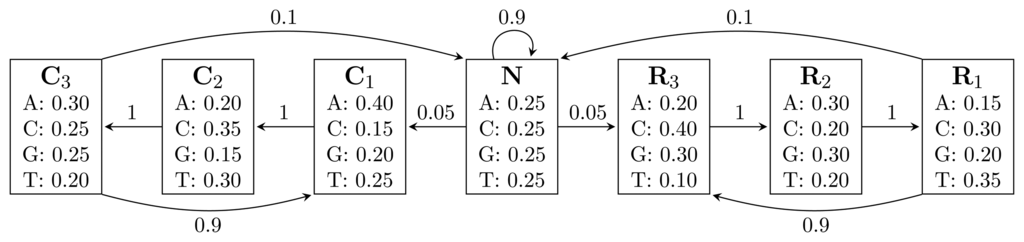
Figure 1.
A Hidden Markov Model (HMM) for gene prediction. Each box represents a hidden state, and the numbers inside are the emission probabilities of each nucleotide. Numbers on arcs are transition probabilities between hidden states.
Figure 1.
A Hidden Markov Model (HMM) for gene prediction. Each box represents a hidden state, and the numbers inside are the emission probabilities of each nucleotide. Numbers on arcs are transition probabilities between hidden states.
HMMs can be used to generate sequences of observables, but their main application is for analyzing an observed sequence, y1:T. The likelihood of a given observed sequence can be computed using the forward algorithm [3], while the Viterbi algorithm [3] and the posterior-Viterbi algorithm [22] are used for predicting a corresponding hidden sequence. All these algorithms run in
(TN2) time, using
(TN) space.
(TN2) time, using
(TN) space.2.1.1. The Forward Algorithm
The forward algorithm [3] finds the probability of observing y1:T by summing the joint probability of the observed and hidden sequences for all possible sequences, x1:T. This is given by:
where Equation (1) is the multiplication of the probabilities of transitions and emissions, which explain observing y1:T with x1:T as the hidden sequence: the HMM starts in state x1 and emits y1 from x1, and for all t = 2, …, T, it makes a transition from state xt−1 to xt and emits yt from xt.
The forward algorithm finds Equation (2) by recursively filling up a table, α, with values αt(xt) = ℙ(y1:t, xt) = Σx1:t−1 ℙ(y1:t, x1:t) being the probability of observing y1:t and being in state xt at time t. The recursion is:
and, finally, ℙ(y1:T) = Σi αT(hi).
2.1.2. The Viterbi Algorithm
The Viterbi algorithm [3] finds the sequence of hidden states, x1:T, that maximizes the joint probability of the observed and hidden sequences (1). It uses the same type of approach as the forward algorithm: a new table, ω, is defined by ωt(xt) = maxx1:t−1 {ℙ(y1:t, x1:t)}, the probability of a most likely decoding ending in xt at time t, having observed y1:t. This can be obtained as follows:
After computing ω, a most likely sequence of hidden states is retrieved by backtracking through the table, starting in entry argmaxhi {ωT(hi)}.
2.1.3. The Posterior Decoding Algorithm
The posterior deco ding [3] of an observed sequence is an alternative to the prediction given by the Viterbi algorithm. While the Viterbi algorithm computes the decoding with the highest joint probability, the posterior decoding computes a sequence of hidden states, x1:T, such that xt = argmaxhi {γt(hi)} has the highest posterior probability γt(hi) = ℙ(hi | y1:T). If we let βt(hi) = ℙ(yt+1:T | hi), we have:
The backward algorithm [3] gives βt(hi) by using a recursion similar to Equation (3). Thus, to compute the posterior decoding, we first fill out αt(hi) and βt(hi) for all t and i and then compute the decoding by xt = argmaxhi {γt(hi)}.
2.1.4. The Posterior-Viterbi Algorithm
The posterior decoding algorithm often computes decodings that are very accurate locally, but it may return syntactically incorrect decodings; i.e., decodings with transitions that have a probability of zero. The posterior-Viterbi algorithm [22] corrects for this by computing a syntactically correct decoding
with the highest posterior probability, where Ap is the set of syntactically correct decodings. To compute this, a new table, γ˜, is defined by
, the maximum posterior probability of a decoding from Ap ending in xt at time t. The table is filled using the recursion:
After computing γ˜, a decoding from Ap with the highest posterior probability is retrieved by backtracking through γ˜ from entry argmaxhi {γ˜T(hi)}. We note that, provided that the posterior decoding algorithm returns a decoding from Ap, the posterior-Viterbi algorithm will return the same decoding.
2.2. Automata
In this paper, we are interested in patterns over the hidden alphabet
= {h1, h2, …, hN} of an HMM. Let r be a regular expression over
, and let FA (r) = (Q,
, q0, A, δ) [23] be the deterministic finite automaton (DFA) that recognizes the language described by (h1 ∣ h2 ∣ … ∣ hN)*(r), where Q is the finite set of states, q0 ∈ Q is the initial state, A ⊆ Q is the set of accepting states and δ : Q ×
→ Q is the transition function. FA (r) accepts any string that has r as a suffix. We construct the DFA EA (r) = (Q,
, q0, A, δE) as an extension of FA (r), where δE is defined by:
= {h1, h2, …, hN} of an HMM. Let r be a regular expression over
, and let FA (r) = (Q,
, q0, A, δ) [23] be the deterministic finite automaton (DFA) that recognizes the language described by (h1 ∣ h2 ∣ … ∣ hN)*(r), where Q is the finite set of states, q0 ∈ Q is the initial state, A ⊆ Q is the set of accepting states and δ : Q ×
→ Q is the transition function. FA (r) accepts any string that has r as a suffix. We construct the DFA EA (r) = (Q,
, q0, A, δE) as an extension of FA (r), where δE is defined by:
Essentially, EA (r) restarts every time it reaches an accepting state. Figure 2 shows FA (r) and EA (r) for r = (NC1) ∣ (R1N) with the hidden alphabet
= {N} ∪ {Ci, Ri ∣ 1 ≤ i ≤ 3} of the HMM from Figure 2. Both automata have Q = {0, 1, 2, 3, 4}, q0 = 0, and A = {2, 4}. State 1 marks the beginning of NC1, while state 3 corresponds to the beginning of R1N. State 2 accepts NC1, and state 4 accepts R1N. As C2, C3, R2 and R3 are not part of r, using them, the automaton restarts by transitioning to state 0 from all states. We left these transitions out of the figure for clarity. The main difference between FA (r) and EA (r) is that they correspond to overlapping and non-overlapping occurrences, respectively. For example, for the input string, R1NC1, FA (r) first finds R1N using state 4, from which it transitions to state 2 and matches NC1. However, after EA (r) recognizes R1N, it transitions back to state 0, not matching NC1. The algorithms we provide are independent of which of the two automata is used, and therefore, all that remains is to switch between them when needed. In our implementation, we used an automata library for Java [24] to obtain FA (r), which we then converted to EA (r).
(r) restarts every time it reaches an accepting state. Figure 2 shows FA (r) and EA (r) for r = (NC1) ∣ (R1N) with the hidden alphabet
= {N} ∪ {Ci, Ri ∣ 1 ≤ i ≤ 3} of the HMM from Figure 2. Both automata have Q = {0, 1, 2, 3, 4}, q0 = 0, and A = {2, 4}. State 1 marks the beginning of NC1, while state 3 corresponds to the beginning of R1N. State 2 accepts NC1, and state 4 accepts R1N. As C2, C3, R2 and R3 are not part of r, using them, the automaton restarts by transitioning to state 0 from all states. We left these transitions out of the figure for clarity. The main difference between FA (r) and EA (r) is that they correspond to overlapping and non-overlapping occurrences, respectively. For example, for the input string, R1NC1, FA (r) first finds R1N using state 4, from which it transitions to state 2 and matches NC1. However, after EA (r) recognizes R1N, it transitions back to state 0, not matching NC1. The algorithms we provide are independent of which of the two automata is used, and therefore, all that remains is to switch between them when needed. In our implementation, we used an automata library for Java [24] to obtain FA (r), which we then converted to EA (r).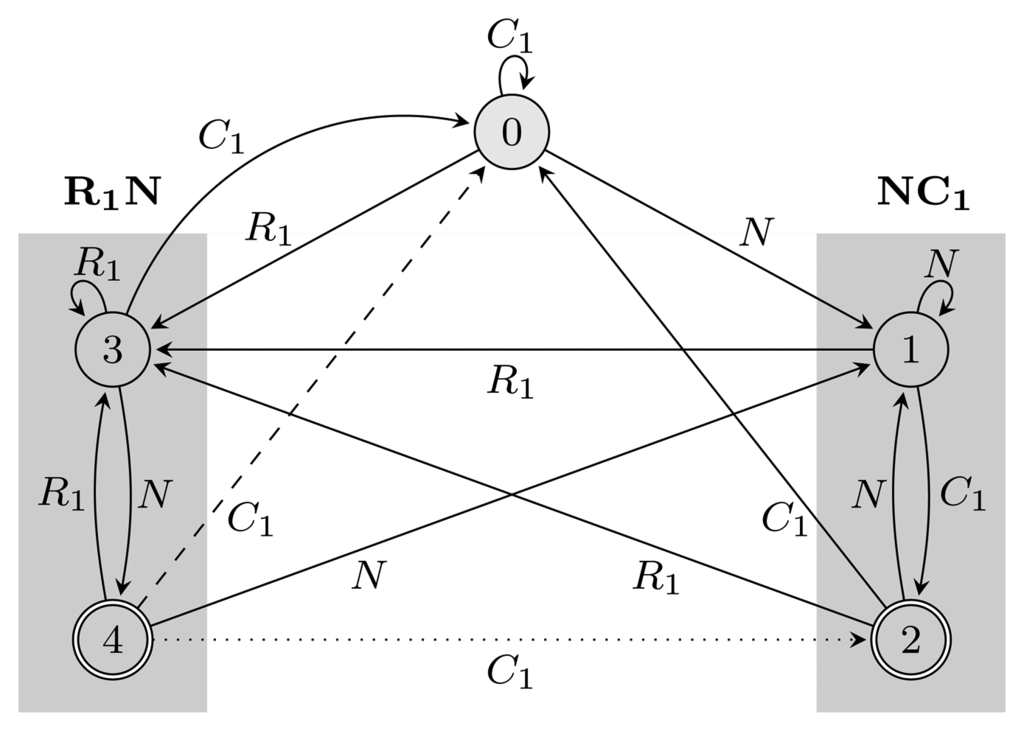
Figure 2.
Two automata, FA (r) and EA (r), for the pattern r = (NC1) ∣ (R1N),
= {N} ∪ {Ci, Ri ∣ 1 ≤ i ≤ 3}, Q = {0, 1, 2, 3, 4}, q0 = 0, and A = {2, 4}. States 1, 2 and 3, 4 are used for matching sequences ending with NC1 and R1N, respectively, as marked with gray boxes. The two automata differ only with respect to transitions from accepting states: the dotted transition belongs to FA (r) and the dashed one to EA (r). For clarity, the figure lacks transitions going from all states to state 0 using C2, C3, R2 and R3.
(r) and EA (r), for the pattern r = (NC1) ∣ (R1N),
= {N} ∪ {Ci, Ri ∣ 1 ≤ i ≤ 3}, Q = {0, 1, 2, 3, 4}, q0 = 0, and A = {2, 4}. States 1, 2 and 3, 4 are used for matching sequences ending with NC1 and R1N, respectively, as marked with gray boxes. The two automata differ only with respect to transitions from accepting states: the dotted transition belongs to FA (r) and the dashed one to EA (r). For clarity, the figure lacks transitions going from all states to state 0 using C2, C3, R2 and R3.
Figure 2.
Two automata, FA (r) and EA (r), for the pattern r = (NC1) ∣ (R1N),
= {N} ∪ {Ci, Ri ∣ 1 ≤ i ≤ 3}, Q = {0, 1, 2, 3, 4}, q0 = 0, and A = {2, 4}. States 1, 2 and 3, 4 are used for matching sequences ending with NC1 and R1N, respectively, as marked with gray boxes. The two automata differ only with respect to transitions from accepting states: the dotted transition belongs to FA (r) and the dashed one to EA (r). For clarity, the figure lacks transitions going from all states to state 0 using C2, C3, R2 and R3.
(r) and EA (r), for the pattern r = (NC1) ∣ (R1N),
= {N} ∪ {Ci, Ri ∣ 1 ≤ i ≤ 3}, Q = {0, 1, 2, 3, 4}, q0 = 0, and A = {2, 4}. States 1, 2 and 3, 4 are used for matching sequences ending with NC1 and R1N, respectively, as marked with gray boxes. The two automata differ only with respect to transitions from accepting states: the dotted transition belongs to FA (r) and the dashed one to EA (r). For clarity, the figure lacks transitions going from all states to state 0 using C2, C3, R2 and R3.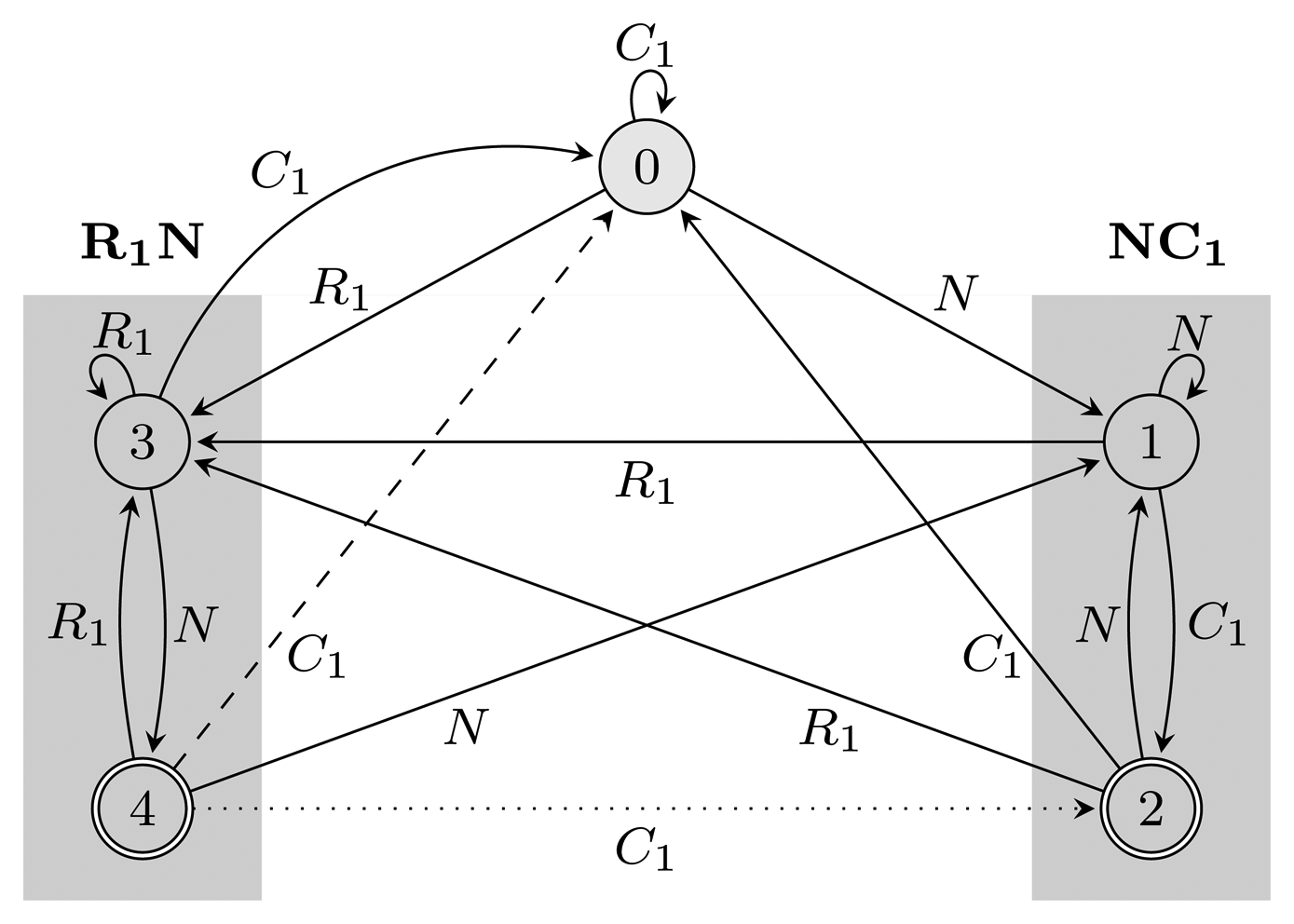
3. Results and Discussion
Consider an HMM as defined previously, and let r be a regular expression over the alphabet of hidden states,
. We present a modified version of the forward algorithm to compute the distribution of the number of occurrences of r, which we then use in an adaptation of the Viterbi algorithm and the posterior-Viterbi algorithm to obtain an improved prediction.
. We present a modified version of the forward algorithm to compute the distribution of the number of occurrences of r, which we then use in an adaptation of the Viterbi algorithm and the posterior-Viterbi algorithm to obtain an improved prediction.3.1. The Restricted Forward Algorithm
Let Or(x1:T) be the number of matches of r in x1:T. We wish to estimate Or by using its probability distribution. We do this by running the HMM and FA (r) in parallel. Let FA (r)t be the state in which the automaton is after t transitions, and define α̂t(xt, k, q) = Σ{x1:t−1:Or(x1:t) =k} ℙ(y1:t, x1:t, FA (r)t = q) to be the entries of a new table, α̂, where k = 0, …, m and m ≤ T is the maximum number of pattern occurrences in a hidden sequence of length T. The table entries are the probabilities of having observed y1:t, being in hidden state xt and automaton state q at time t and having seen k occurrences of the pattern, corresponding to having visited accepting states k times. Letting δ−1(q, hi) = {q′ ∣ δ(q′, hi) = q} be the automaton states from which a transition to q exists, using hidden state hi and
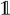 being the indicator function, mapping a Boolean expression to one if it is satisfied and to zero otherwise, we have that:
being the indicator function, mapping a Boolean expression to one if it is satisfied and to zero otherwise, we have that:
(r) in parallel. Let FA (r)t be the state in which the automaton is after t transitions, and define α̂t(xt, k, q) = Σ{x1:t−1:Or(x1:t) =k} ℙ(y1:t, x1:t, FA (r)t = q) to be the entries of a new table, α̂, where k = 0, …, m and m ≤ T is the maximum number of pattern occurrences in a hidden sequence of length T. The table entries are the probabilities of having observed y1:t, being in hidden state xt and automaton state q at time t and having seen k occurrences of the pattern, corresponding to having visited accepting states k times. Letting δ−1(q, hi) = {q′ ∣ δ(q′, hi) = q} be the automaton states from which a transition to q exists, using hidden state hi and
being the indicator function, mapping a Boolean expression to one if it is satisfied and to zero otherwise, we have that:
These probabilities now allow for the evaluation of the distribution of the number of occurrences, conditioned on the observed data:
from which the expectation can be computed. The likelihood of the data can be obtained from either the forward or restricted forward algorithm, ℙ(y1:T) = Σi α(hi) = Σi,k,qα̂T(hi, k, q).
The α̂ table has T · N · m · |Q| entries, and the computation of each requires
(N|Q|), leading to a
(TN2m|Q|2) running time and a space consumption of
(TNm|Q|). In practice, both time and space consumption can be reduced. The restricted forward algorithm can be run for values of k that are gradually increasing up to kmax for which ℙ(at most kmax occurrences of r ∣ y1:T) is greater than, e.g., 99.99%. This kmax is generally significantly less than m, while the expectation of the number of matches of r can be reliably calculated from this truncated distribution. The space consumption can be reduced to
(N|Q|), because the calculation at time t for a specific value, k, depends only on the results at time t − 1 for k and k − 1.
(N|Q|), leading to a
(TN2m|Q|2) running time and a space consumption of
(TNm|Q|). In practice, both time and space consumption can be reduced. The restricted forward algorithm can be run for values of k that are gradually increasing up to kmax for which ℙ(at most kmax occurrences of r ∣ y1:T) is greater than, e.g., 99.99%. This kmax is generally significantly less than m, while the expectation of the number of matches of r can be reliably calculated from this truncated distribution. The space consumption can be reduced to
(N|Q|), because the calculation at time t for a specific value, k, depends only on the results at time t − 1 for k and k − 1.3.2. Restricted Decoding Algorithms
The aim of the restricted decoding algorithms is to obtain a sequence of hidden states, x1:T, for which Or(x1:T) ∈ [l, u], where l and u are set to, for example, the expected number of occurrences, which can be calculated from the distribution. The restricted decoding algorithms are built in the same way as the restricted forward was obtained: a new table is defined, which is filled using a simple recursion. The evaluation of the table is followed by backtracking to obtain a sequence of hidden states, which contains between l and u occurrences of the pattern. The two restricted decoding algorithms use
(TNu|Q|) space and
(TN2u|Q|2) time.
(TNu|Q|) space and
(TN2u|Q|2) time.The entries in the table for the restricted Viterbi algorithm contain the probability of a most likely decoding containing k pattern occurrences, ending in state xt and automaton state q at time t and having observed y1:t, ω̂t(xt, k, q) = max{x1:t−1:Or(x1:t) =k} {ℙ(y1:t, x1:t, FA (r)t = q)} with k = 0, …, u. The corresponding recursion is:
and the backtracking starts in entry argmaxi,k∈[l,u],q {ω̂T(hi, k, q)}.
(r)t = q)} with k = 0, …, u. The corresponding recursion is:
For the restricted posterior-Viterbi algorithm, we compute the highest posterior probability of a decoding from Ap containing k pattern occurrences, ending in state xt and automaton state q at time t and having observed y1:t, γ̂t(xt, k, q) = max{x1:t−1:Or(x1:t) =k} {ℙ(x1:t, FA (r)t = q ∣ y1:T)}. We have:
(r)t = q ∣ y1:T)}. We have:
The backtracking starts in entry argmaxi,k∈[l,u],q {γ̂T(hi, k, q)}.
3.3. Experimental Results on Simulated Data
We implemented the algorithms in Java, validated and evaluated their performance experimentally as follows: We first generated a test set consisting of 500 pairs of observed and hidden sequences for each length L = 500, 525, …, 1,500 from the gene finder in Figure 2. As the HMM is used for finding genes, an obvious choice of pattern is r = (NC1) ∣ (R1N), corresponding to the start of a gene. For each of the sequences, we estimated the number of overlapping pattern occurrences with the expected number of pattern occurrences, computed using the restricted forward algorithm, which we then used to run the restricted decoding algorithms. We also computed the prediction given by the two unrestricted decoding algorithms for comparison.
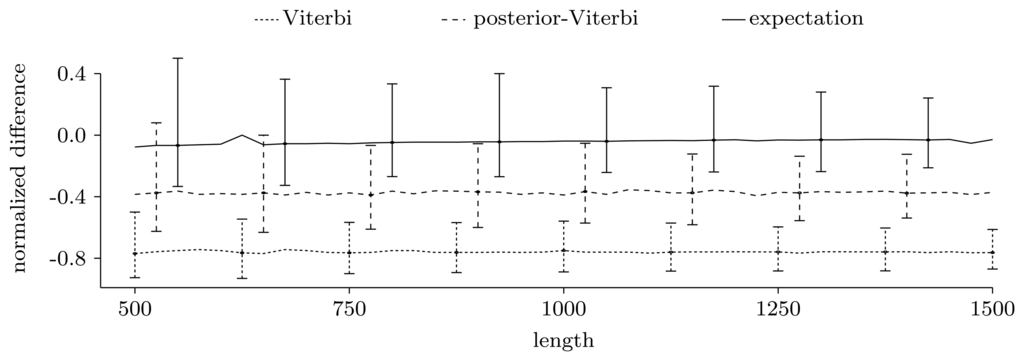
Figure 3.
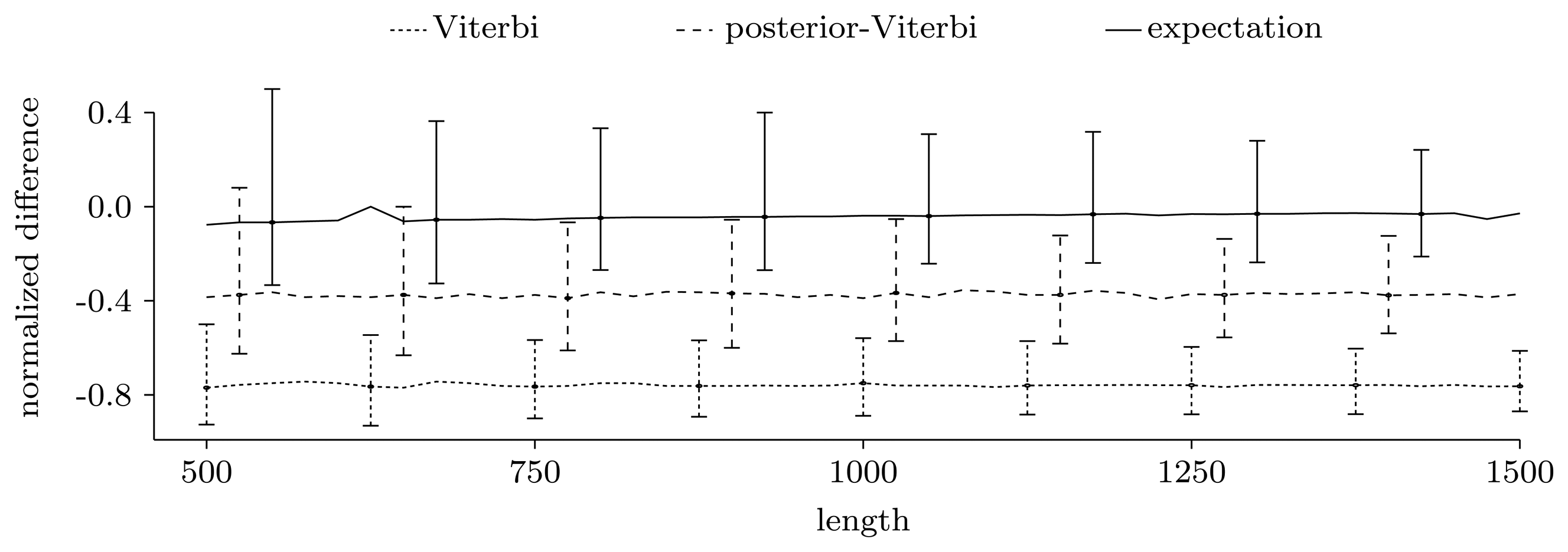
Normalized difference,
, between the true number of pattern occurrences, the number given by the two unrestricted decoding algorithms and the expected number of pattern occurrences computed using the restricted forward algorithm. For each sequence length, we show the median of the normalized differences in the 500 experiments, together with the 0.025 and 0.975 quantiles, given as error bars.
Figure 3.
Normalized difference,
, between the true number of pattern occurrences, the number given by the two unrestricted decoding algorithms and the expected number of pattern occurrences computed using the restricted forward algorithm. For each sequence length, we show the median of the normalized differences in the 500 experiments, together with the 0.025 and 0.975 quantiles, given as error bars.
3.3.1. Counting Pattern Occurrences
Figure 3 shows the power of the restricted forward algorithm and the two unrestricted decoding algorithms to recover the true number of pattern occurrences. For each given length, we computed the normalized difference,
, and plotted the median over the 500 sequences together with the 0.025 and 0.975 quantiles, given as error bars. As Figure 3 shows, the expectation gives a very good estimate. The decoding algorithms' performances are significantly lower, and they always give underestimates. This may be partly due to the model structure, where transitions to and from coding regions have low probability, leading to few, but long, genes.
3.3.2. Quality of Predictions
We compared the predictive power of the two decoding algorithms in the original and restricted versions, using the expectation for the number of pattern occurrences. For each length in the test set, we measured the quality of each method, both at the nucleotide and gene level, following the analysis in [25]. Because the measures we use require binary data, we first converted the true hidden sequence and decoding to binary data containing non-coding areas and genes, by first considering the genes on the reverse strand as non-coding and calculating the measures for the genes on the direct strand, and vice versa. The final plotted measures are the averages obtained from the two conversions.
Nucleotide level
To investigate the quality at the nucleotide level, we compared the decoding and the true hidden state position by position. Each position can be classified as a true positive (predicted as part of a gene when it was part of a gene), true negative (predicted as non-coding when it was non-coding), false positive (predicted as part of a gene when it was non-coding) and false negative (predicted as non-coding when it was part of a gene). Using the total number of true positives (tp), true negatives (tn), false positives (fp) and false negatives (fn), we calculated the sensitivity, specificity and Matthew's correlation coefficient (MCC):
Sensitivity and specificity are always between zero and one and relate to how well the algorithms are able to find genes (true positives) and non-coding regions (true negatives), respectively. MCC reflects the overall correctness and lies between −1 and 1, where 1 represents perfect prediction.
Gene level
When looking at the decoding position by position, genes that are predicted correctly do not contribute to the measures in an equal manner, but rather, the longer the gene, the more contribution it brings. However, it is interesting how well the genes are recovered, independent of how long they are. To measure this, we consider a predicted gene as one true positive if it overlaps by at least 50% of a true gene and as one false positive if there is no true gene with which it overlaps by at least 50%. Each true gene for which there is no predicted gene that overlaps by at least 50% counts as one false negative; see Figure 4. In this context, true negatives, i.e., the areas where there was no gene and no gene was predicted, are not considered, as they are not informative. The final measures are the recall, precision and F-score:
They are all between zero and one and reflect how well the true genes have been recovered. The recall gives the fraction of true genes that have been found, while the precision gives the fraction of the predicted genes that are true genes. The F-score is the harmonic mean of the two.

Figure 4.
Error types at the gene level. A predicted gene is considered one true positive if it overlaps with at least 50% of a true gene and one false positive if there is no true gene with which it overlaps by at least 50%. Each true gene for which there is no predicted gene that overlaps by at least 50% counts as one false negative. True genes that are covered more than 50% by predicted genes, but for which there is no single predicted gene that covers a minimum of 50% are disregarded.
Figure 4.
Error types at the gene level. A predicted gene is considered one true positive if it overlaps with at least 50% of a true gene and one false positive if there is no true gene with which it overlaps by at least 50%. Each true gene for which there is no predicted gene that overlaps by at least 50% counts as one false negative. True genes that are covered more than 50% by predicted genes, but for which there is no single predicted gene that covers a minimum of 50% are disregarded.

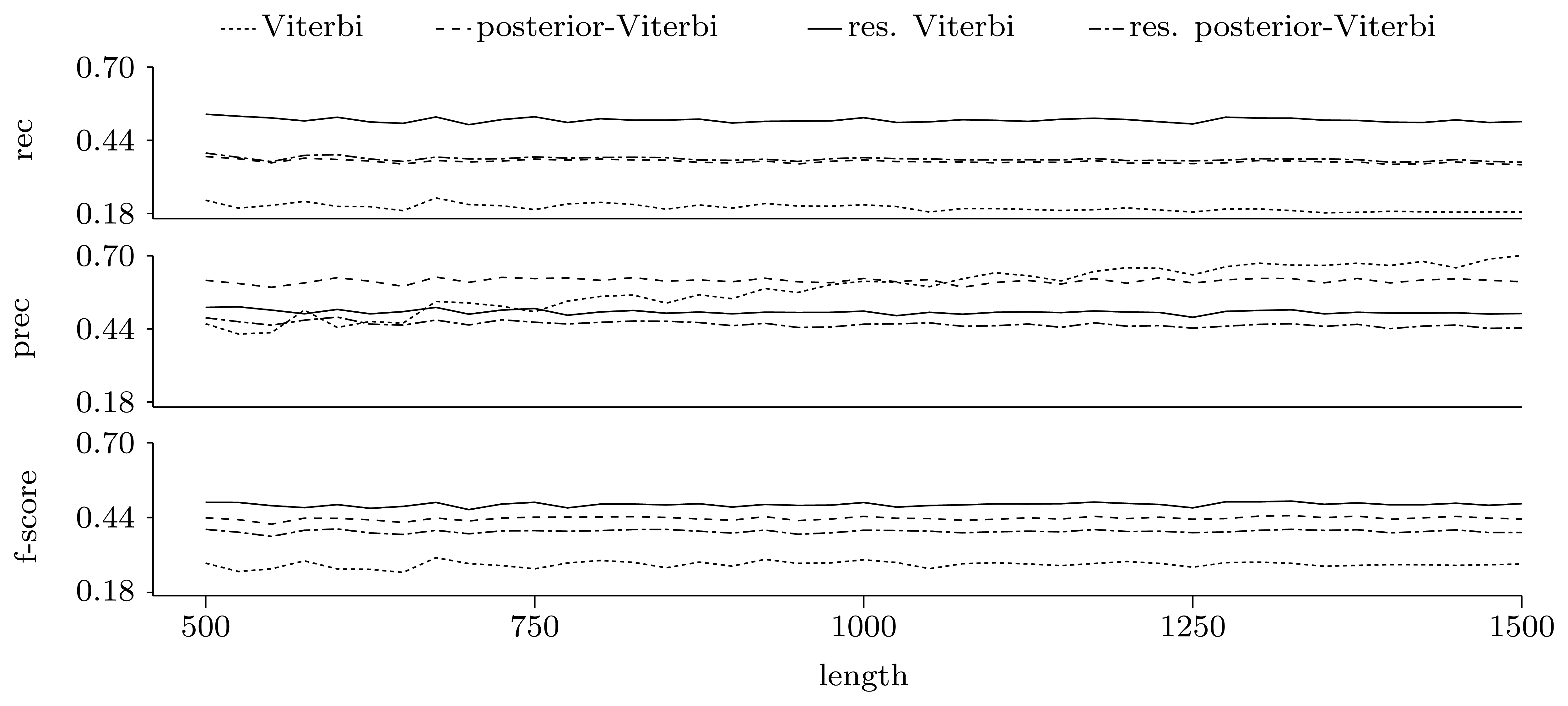
Figures 5 and 6 show the quality of predictions at the nucleotide and gene level, respectively. When comparing the Viterbi algorithm with the restricted Viterbi algorithm, it is clear that the restriction brings a great improvement to the prediction, as the restricted version has an increased power in all measures considered, with the exception of precision, where the Viterbi algorithm shows a tendency of increased precision with sequence length. However, when comparing the posterior-Viterbi algorithm with its restricted version, it is apparent that the restricted version does as good at the nucleotide level, but it performs worse at the gene level. By inspecting the predictions of the two methods, it was clear that the restricted posterior-Viterbi obtained an increased number of genes dictated by the expectation by just fractioning the genes predicted by the posterior-Viterbi. We believe this happens because the posterior-Viterbi algorithm finds the best local decoding, and therefore, adding global information, such as the total number of genes in the prediction, does not aid in the decoding. On the other hand, as the Viterbi algorithm finds the best global decoding, using the extra information results in a significant improvement of the prediction. Overall, at the nucleotide level, the posterior-Viterbi shows the best performance, while at the gene level, the restricted Viterbi has the highest quality. One might expect this, given the nature of the algorithms.
Apart from these experiments, we also ran the algorithms on the annotated E. coli genome (GenBank accession number U00096). In this set of experiments, we split the genome into sequences of a length of approximately 10,000, for which we ran the algorithms as previously described. We found the same trends as in the performance for simulated data (results not shown). When using the E. coli data, we also recorded the running time of the algorithms, and we found that the restricted algorithms are about 45 times slower than the standard algorithms, which is faster than the worst case scenario, which would lead to a k · |Q|2 = 7 · 52 = 175 slowdown, as the average expectation of the number of patterns per sequence was k = 7.
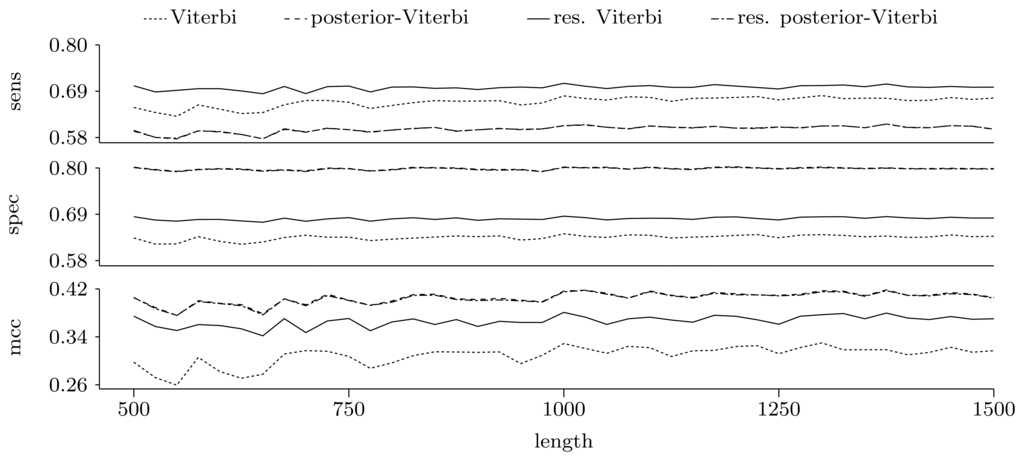
Figure 5.
Prediction quality at the nucleotide level given by average sensitivity, specificity and Matthew's correlation coefficient (MCC) for the decoding algorithms. We ran the restricted decoding algorithms using the expectation calculated from the distribution returned by the restricted forward algorithm. The plots show a zoom-in of the three measures. As both sensitivity and specificity are between zero and one, the Y-axes in these two plots have the same scale.
Figure 5.
Prediction quality at the nucleotide level given by average sensitivity, specificity and Matthew's correlation coefficient (MCC) for the decoding algorithms. We ran the restricted decoding algorithms using the expectation calculated from the distribution returned by the restricted forward algorithm. The plots show a zoom-in of the three measures. As both sensitivity and specificity are between zero and one, the Y-axes in these two plots have the same scale.
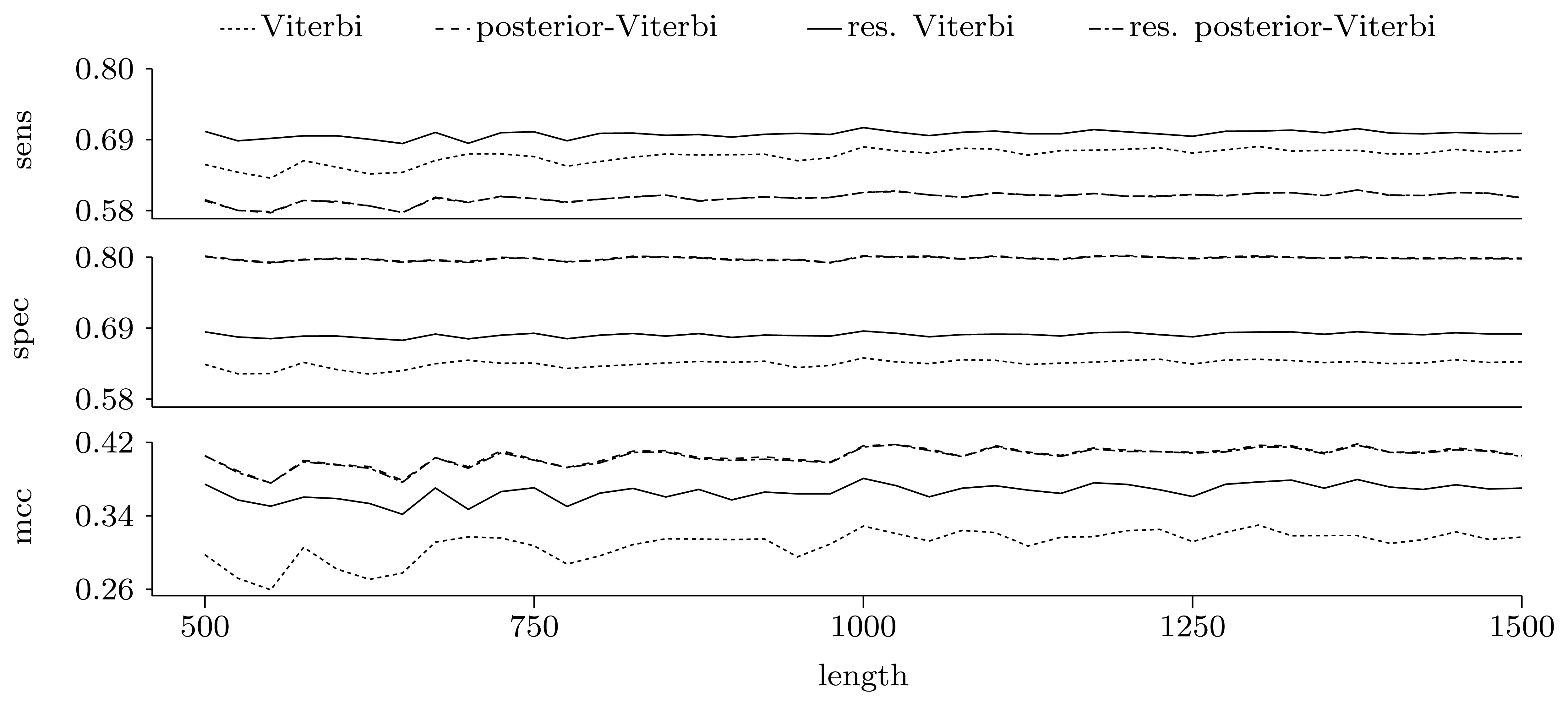
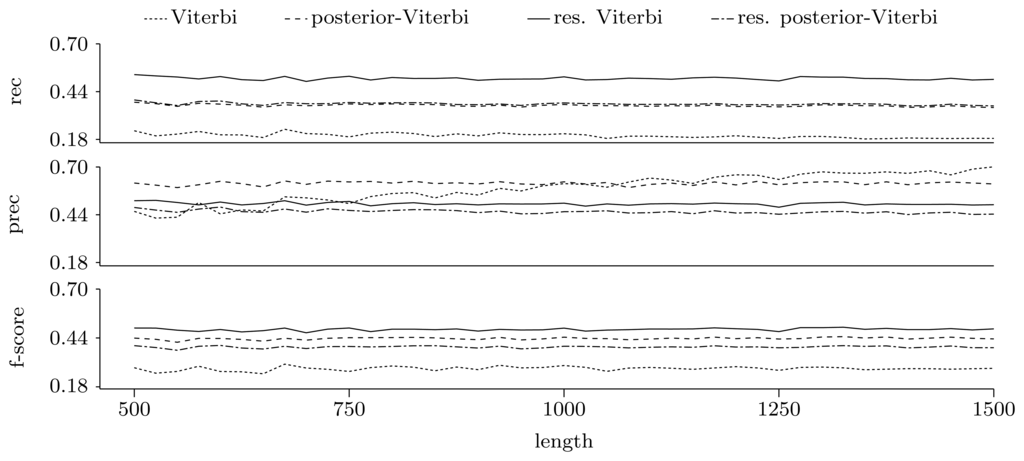
Figure 6.
Prediction quality at the gene level given by average recall, precision and F-score for the decoding algorithms. We ran the restricted decoding algorithms using the expectation calculated from the distribution returned by the restricted forward algorithm. The plots show a zoom-in of the three measures with the same scale on the Y axes.
Figure 6.
Prediction quality at the gene level given by average recall, precision and F-score for the decoding algorithms. We ran the restricted decoding algorithms using the expectation calculated from the distribution returned by the restricted forward algorithm. The plots show a zoom-in of the three measures with the same scale on the Y axes.
4. Conclusions
We have introduced three novel algorithms that efficiently combine the theory of Hidden Markov Models with automata and pattern matching to recover pattern occurrences in the hidden sequence. First, we computed the distribution of the number of pattern occurrences by using an algorithm similar to the forward algorithm. This problem has been treated in [16] by means of Markov chain embedding, using simple finite sets of strings as patterns. Our method is, however, more general, as it allows the use of regular expressions.
From the occurrence number distribution, we calculated the expected number of pattern matches, which estimated the true number of occurrences with high precision. We then used the distribution to alter the prediction given by the two most widely used decoding algorithms: the Viterbi algorithm and the posterior-Viterbi algorithm. We have shown that in the case of the Viterbi algorithm, which finds the best global prediction, using the expected number of pattern occurrences greatly improves the prediction, both at the nucleotide and gene level. However, in the case of the posterior-Viterbi algorithm, which finds the best local prediction, such an addition only fragments the predicted genes, leading to a poorer prediction. Overall, deciding which algorithm is best depends on the final measure used, but as our focus was on finding genes, we conclude that the restricted Viterbi algorithm showed the best result.
As the distribution obtained from the restricted forward algorithm facilitates the calculation of the distribution of the waiting time until the occurrence of the kth pattern match, the restricted Viterbi algorithm could potentially be further extended to incorporate this distribution while calculating the joint probability of observed and hidden sequences. Weighted transducers [26] are sequence modeling tools similar to HMMs, and analyzing patterns in the hidden sequence can potentially also be done by composition of the transducers, which describe the HMM and the automaton.
Our method can presumably be used with already existing HMMs to improve their prediction, by using patterns that reflect the problems studied using the HMMs. For example, in [13], an HMM is used for finding frameshifts in coding regions. In this situation, the pattern would capture the sequence of hidden states that corresponds to a frameshift. In HMMs used for phylogenetic analysis [11,12], the hidden states represent trees, and an event of interest is a shift in the tree. A pattern capturing a change in the hidden state could thus aid in improving the prediction. In HMMs built for probabilistic alignments [10], the pattern could capture the start of an indel, and our method could potentially aid in finding a more accurate indel rate estimate. There is therefore a substantial potential in the presented method to successfully improve the power of HMMs.
Acknowledgments
We are grateful to Jens Ledet Jensen for useful discussions in the initial phase of this study.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Chong, J.; Yi, Y.; Faria, A.; Satish, N.; Keutzer, K. Data-parallel Large Vocabulary Continuous Speech Recognition on Graphics Processors. Proceedings of the 1st Annual Workshop on Emerging Applications and Many Core Architecture, Beijing, China, June 2008; pp. 23–35.
- Gales, M.; Young, S. The application of hidden Markov models in speech recognition. Found. Trends Signal Process. 2007, 1, 195–304. [Google Scholar]
- Rabiner, L. A tutorial on hidden Markov models and selected applications in speech recognition. Proc. IEEE 1989, 77, 257–286. [Google Scholar]
- Li, J.; Gray, R. Image Segmentation and Compression Using Hidden Markov Models; Springer: Berlin/Heidelberg, Germany, 2000; Volume 571. [Google Scholar]
- Karplus, K.; Barrett, C.; Cline, M.; Diekhans, M.; Grate, L.; Hughey, R. Predicting protein structure using only sequence information. Proteins Struct. Funct. Bioinformatics 1999, 37, 121–125. [Google Scholar]
- Krogh, A.; Brown, M.; Mian, I.; Sjolander, K.; Haussler, D. Hidden Markov models in computational biology: Applications to protein modeling. J. Mol. Biol. 1994, 235, 1501–1531. [Google Scholar]
- Krogh, A.; Larsson, B.; von Heijne, G.; Sonnhammer, E. Predicting transmembrane protein topology with a hidden Markov model: Application to complete genomes. J. Mol. Biol. 2001, 305, 567–580. [Google Scholar]
- Eddy, S. Multiple Alignment Using Hidden Markov Models. Proceedings of the Third International Conference on Intelligent Systems for Molecular Biology, Cambridge, UK, 16–19 July 1995; Volume 3, pp. 114–120.
- Eddy, S. Profile hidden Markov models. Bioinformatics 1998, 14, 755–763. [Google Scholar]
- Lunter, G. Probabilistic whole-genome alignments reveal high indel rates in the human and mouse genomes. Bioinformatics 2007, 23, i289–i296. [Google Scholar]
- Mailund, T.; Dutheil, J.Y.; Hobolth, A.; Lunter, G.; Schierup, M.H. Estimating divergence time and ancestral effective population size of bornean and sumatran orangutan subspecies using a coalescent hidden Markov model. PLoS Genet. 2011, 7, e1001319. [Google Scholar]
- Siepel, A.; Haussler, D. Phylogenetic Hidden Markov Models. In Statistical Methods in Molecular Evolution; Nielsen, R., Ed.; Springer: New York, NY, USA, 2005; pp. 325–351. [Google Scholar]
- Antonov, I.; Borodovsky, M. GeneTack: Frameshift identification in protein-coding sequences by the Viterbi algorithm. J. Bioinforma. Comput. Biol. 2010, 8, 535–551. [Google Scholar]
- Lukashin, A.; Borodovsky, M. GeneMark.hmm: New solutions for gene finding. Nucleic Acids Res. 1998, 26, 1107–1115. [Google Scholar]
- Krogh, A.; Mian, I.S.; Haussler, D. A hidden Markov model that finds genes in E.coli DNA. Nucleic Acids Res. 1994, 22, 4768–4778. [Google Scholar]
- Aston, J.A.D.; Martin, D.E.K. Distributions associated with general runs and patterns in hidden Markov models. Ann. Appl. Stat. 2007, 1, 585–611. [Google Scholar]
- Fu, J.; Koutras, M. Distribution theory of runs: A Markov chain approach. J. Am. Stat. Appl. 1994, 89, 1050–1058. [Google Scholar]
- Nuel, G. Pattern Markov chains: Optimal Markov chain embedding through deterministic finite automata. J. Appl. Probab. 2008, 45, 226–243. [Google Scholar]
- Wu, T.L. On finite Markov chain imbedding and its applications. Methodol. Comput. Appl. Probab. 2011, 15, 453–465. [Google Scholar]
- Lladser, M.; Betterton, M.; Knight, R. Multiple pattern matching: A Markov chain approach. J. Math. Biol. 2008, 56, 51–92. [Google Scholar]
- Nicodeme, P.; Salvy, B.; Flajolet, P. Motif statistics. Theor. Comput. Sci. 2002, 287, 593–617. [Google Scholar]
- Fariselli, P.; Martelli, P.L.; Casadio, R. A new decoding algorithm for hidden Markov models improves the prediction of the topology of all-beta membrane proteins. BMC Bioinformatics 2005, 6. [Google Scholar] [CrossRef]
- Thompson, K. Programming techniques: Regular expression search algorithm. Commun. ACM 1968, 11, 419–422. [Google Scholar]
- Møller, A. dk.brics.automaton—Finite-State Automata and Regular Expressions for Java. 2010. Available online: http://www.brics.dk/automaton/ (accessed on 16 January 2012).
- Burset, M.; Guigo, R. Evaluation of gene structure prediction programs. Genomics 1996, 34, 353–367. [Google Scholar]
- Mohri, M. Weighted Automata Algorithms. In Handbook of Weighted Automata; Springer: Berlin/Heidelberg, Germany, 2009; pp. 213–254. [Google Scholar]
© 2013 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).